5.1. Results Comparison
Table 5 shows the precision, recall and accuracy for testing and validation datasets. As a reminder, the data for the validation dataset was collected from real pumps that were different from those used for training. Therefore, the results present the model’s performance against the unseen validation and testing datasets.
Table 6 shows that the ResNet-34 model performed the best at a higher sampling frequency (i.e., 4500 Hz) for both faulty and non-faulty pumps, despite not being trained on that frequency. However, it was also observed that non-faulty pumps had comparatively worse accuracy than the faulty pumps.
For a further demonstration of the model’s performance, the following metrics were used: precision, recall, accuracy and F1-score, as can be seen in
Table 5. The datasets’ sampling frequency for these experiments can be found in
Section 4.3. These metrics are defined as follows: Precision = TP/(TP + FP), Recall = TP/(TP + FN), Accuracy = (TP + TN)/(TP + TN + FP + FN) and F1-score = 2TP/(2TP + FP + FN). These metrics can demonstrate the model’s robustness against overfitting. With the higher than 80% F1-score, we believe our model was capable enough to produce reliable decisions.
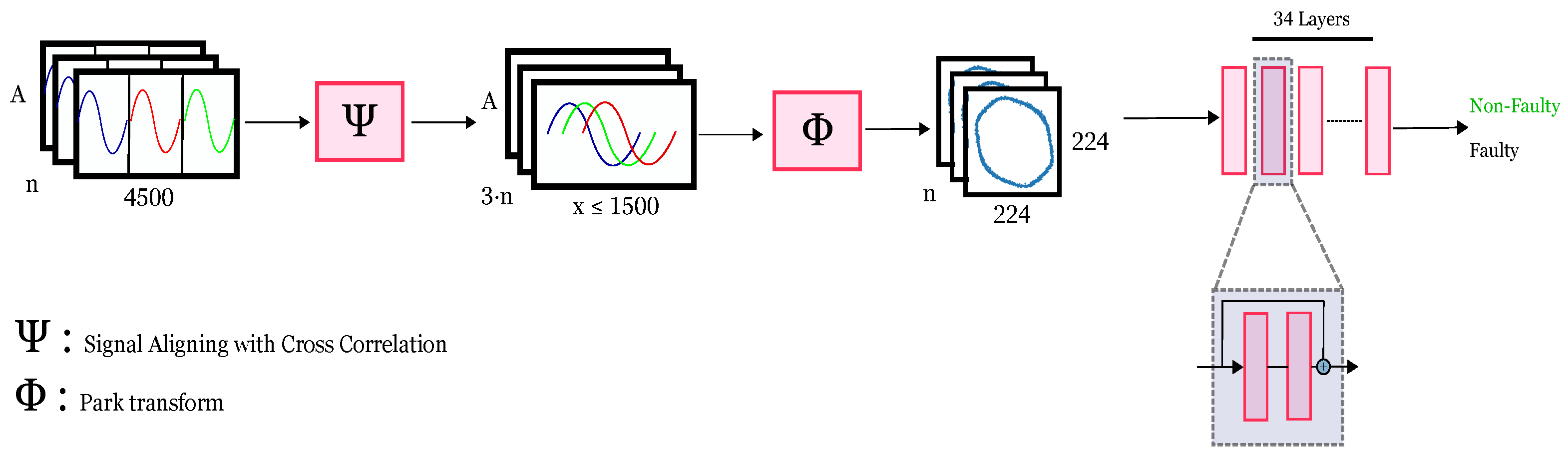
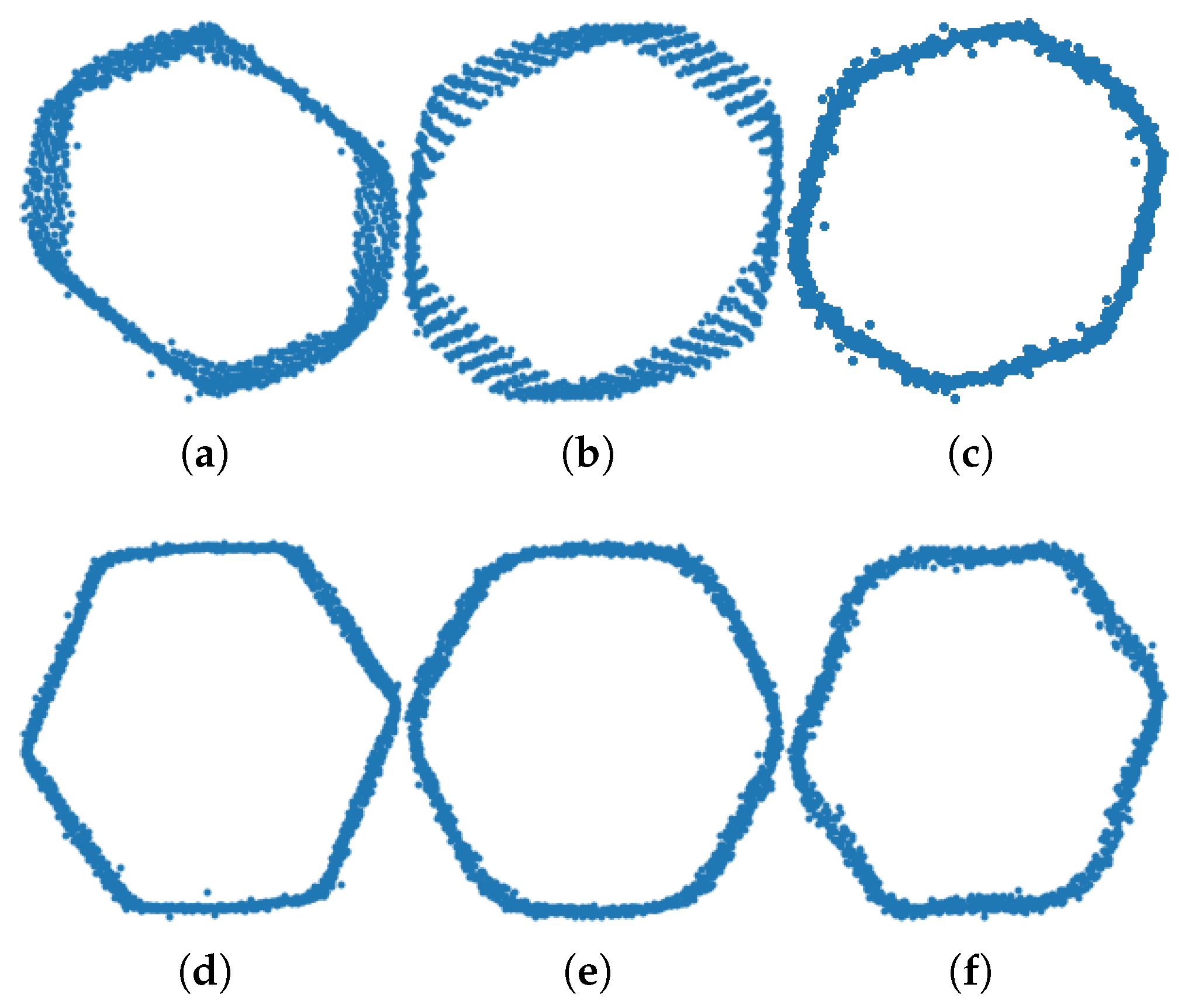
Figure 3 shows the DQ patterns for the faulty and non-faulty pumps. It can be seen that the faulty pump signatures used in our experiments were characterised by irregular and distorted shapes compared with the non-faulty pumps.
Table 7 shows the confusion matrices for 1500 Hz, 3000 Hz and 4500 Hz data.
5.2. Discussion and Lessons Learned
The authors believe that the application of a convolutional neural network model to a non-conventional signal data type is a novel and relatively unique method. Despite its unorthodoxy, the model obtained decent results on both the validation dataset and the testing datasets. Furthermore, its relative performance on varying sampling rates also shows that it is a robust technique. The accuracy seems consistent with the reported fault detection accuracies in prior work [
5,
6,
14], which ranged from 83.2% to 100%.
Although this study focuses on the machine learning aspect, the most significant challenges were faced in building, deploying and maintaining the infrastructure to collect the data. First, collecting faulty signatures from real pumps requires solving not only technical but also business dilemmas. Collecting faulty signatures requires a faulty pump or pump that is going to develop a fault soon, and thus, contradicts the customers’ needs for continuous and non-faulty operation of their systems. The early replacements of these pumps is desirable to ensure smooth operation but can reduce the number of collected faulty signatures. Obtaining a sufficient number of faulty signatures to train the machine learning algorithm to correctly identify and label the faults has indeed been one of the major challenges. This is because modern pumps may operate for many years, and even after developing some faulty condition, may run under workable conditions for a long time. In addition, pumps can have multiple faults at the same time, which may complicate correct labelling and classification. To some extent, this could be mitigated by deploying data loggers on older pumps, which are more likely to fail, based on the maintenance engineer’s knowledge.
A more reliable way to understand whether those motors/pumps are faulty or not is to intentionally damage the motor/pump to create the condition or investigate the pump/motor itself to look out for faults. While intentionally damaging the system is neither profitable nor exactly close to real life conditions, the close-up investigation of the system can render the pump/motor useless and create downtime for working systems. This is why we took extra care to limit such possibilities by using only pumps with known labels (faults), old unused pumps and intentionally damaging a small number of pumps. In the end, we obtained a very diverse dataset that contained a combination of real customer data and some intentionally damaged pumps from test benches.
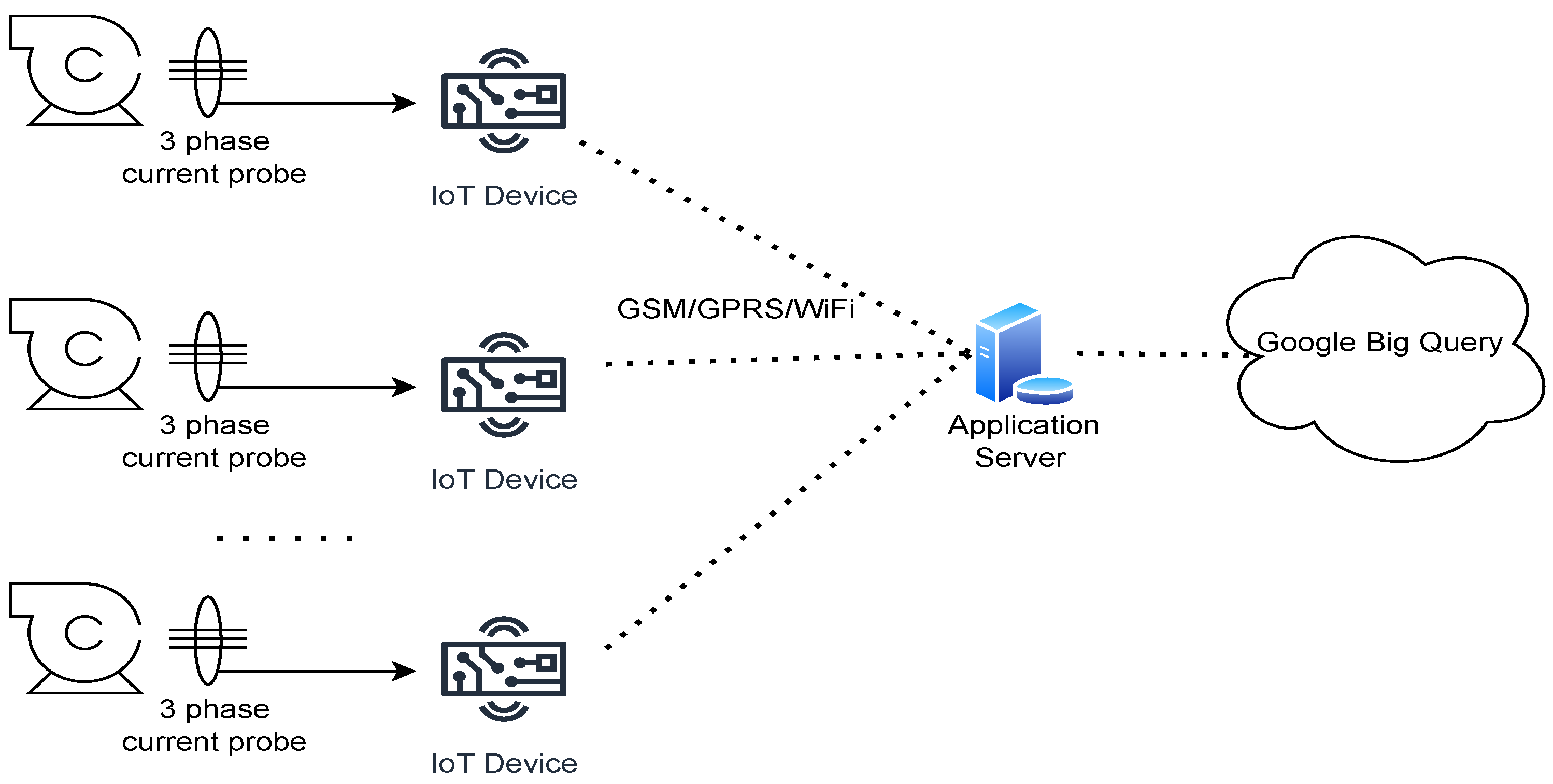
At the hardware level, developing a system that reliably collected data 24/7 with minimal downtime is a challenging task. The hardware can be down, collect incorrect data or produce noisy readings. A system that works on a lab bench may become unreliable on site, and troubleshooting hardware and firmware issues can be time and resource consuming. From the design point of view, the hardware platform selection is determined by the cost, reliability and machine learning algorithm performance, which, in turn, requires a sufficient amount of data to be collected to design and tune correctly, resulting in a circular problem. This, to some extent, has been addressed in our project by an architectural decision of using lightweight IoT devices for collecting raw data and performing all processing, including machine learning and data storage remotely on the server. In the future, it may be interesting to experiment with distributed processing, where the fault detection is made locally by the device to minimise the reliance on the centralised server and connectivity problems.
Finally, at the machine learning level, the limited dataset size and the fact that data are unbalanced towards the non-faulty signatures may lead to bias and overfitting. Therefore, it is important to test the model under diverse scenarios, ensuring the model generalises well for new data. The only reliable way to achieve this is testing the model with more data, which requires maintaining and operating the sensing infrastructure for an extended period of time, long enough for a sufficient number of pumps to fail to obtain the faulty signatures. Considering the relatively long lifespan of modern pumps, this may require several more years of data collection across several sites. This presents an immense practical and financial difficulty and is perhaps the main reason behind the scarcity of prior work involving real pump data. The contribution of this study is the development of such an infrastructure and offering an insight into the ML performance with real rather than simulated data.
Furthermore, given that the non-faulty pump/motor can become faulty over-time, the data that are used to train the model needs to be regularly checked to maintain the correctness. We also realized that the way the DQ images are resized, center cropped, etc., or the format they were saved/plotted vastly affected the model’s performance. Therefore, it needs to be noted that the training on saved images vs. detecting on images on buffer needs to be configured as equally as possible.







{kind=link}
{kind=link}
{kind=link}