
Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition



Abstract
:
1. Introduction
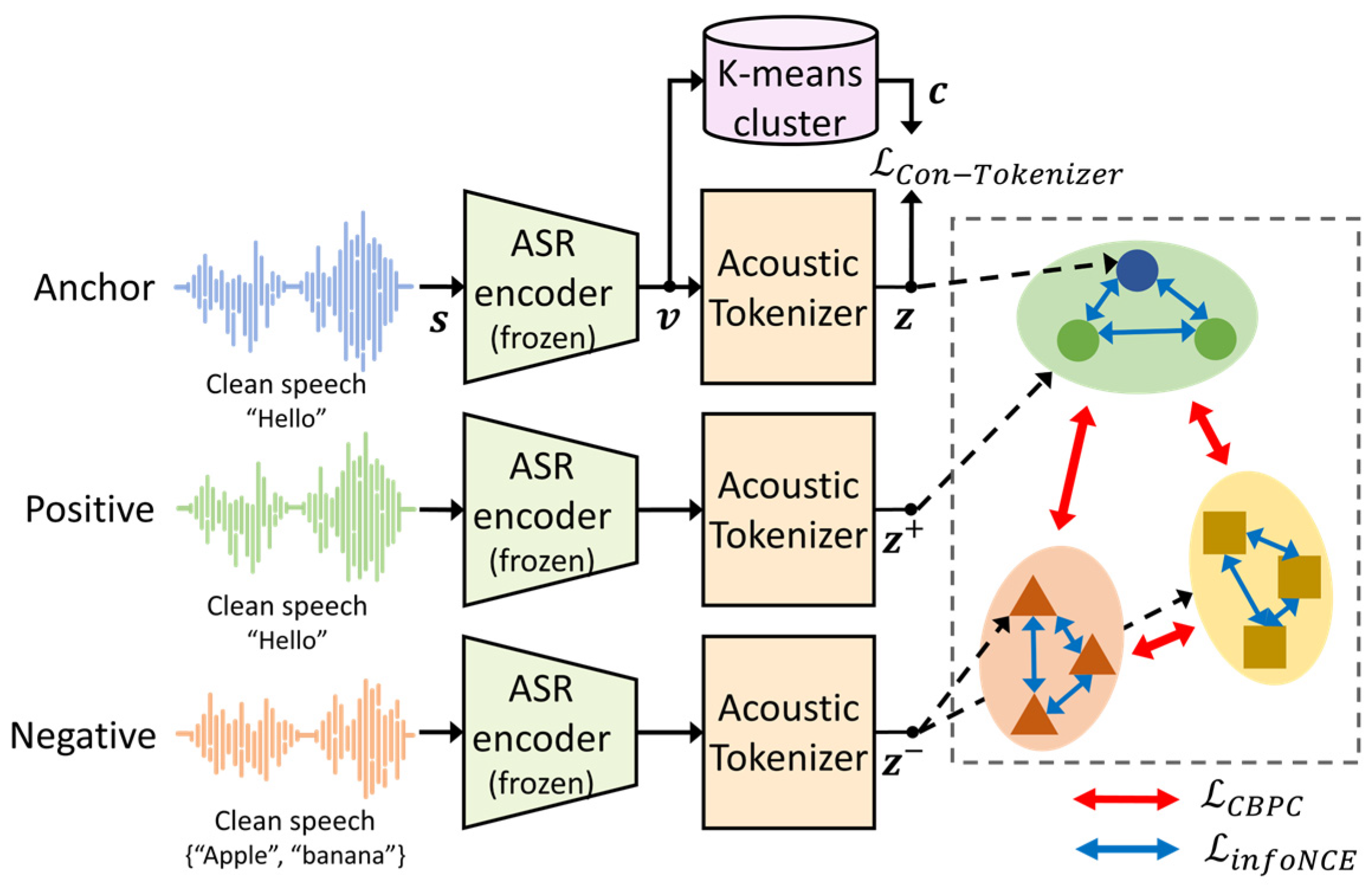
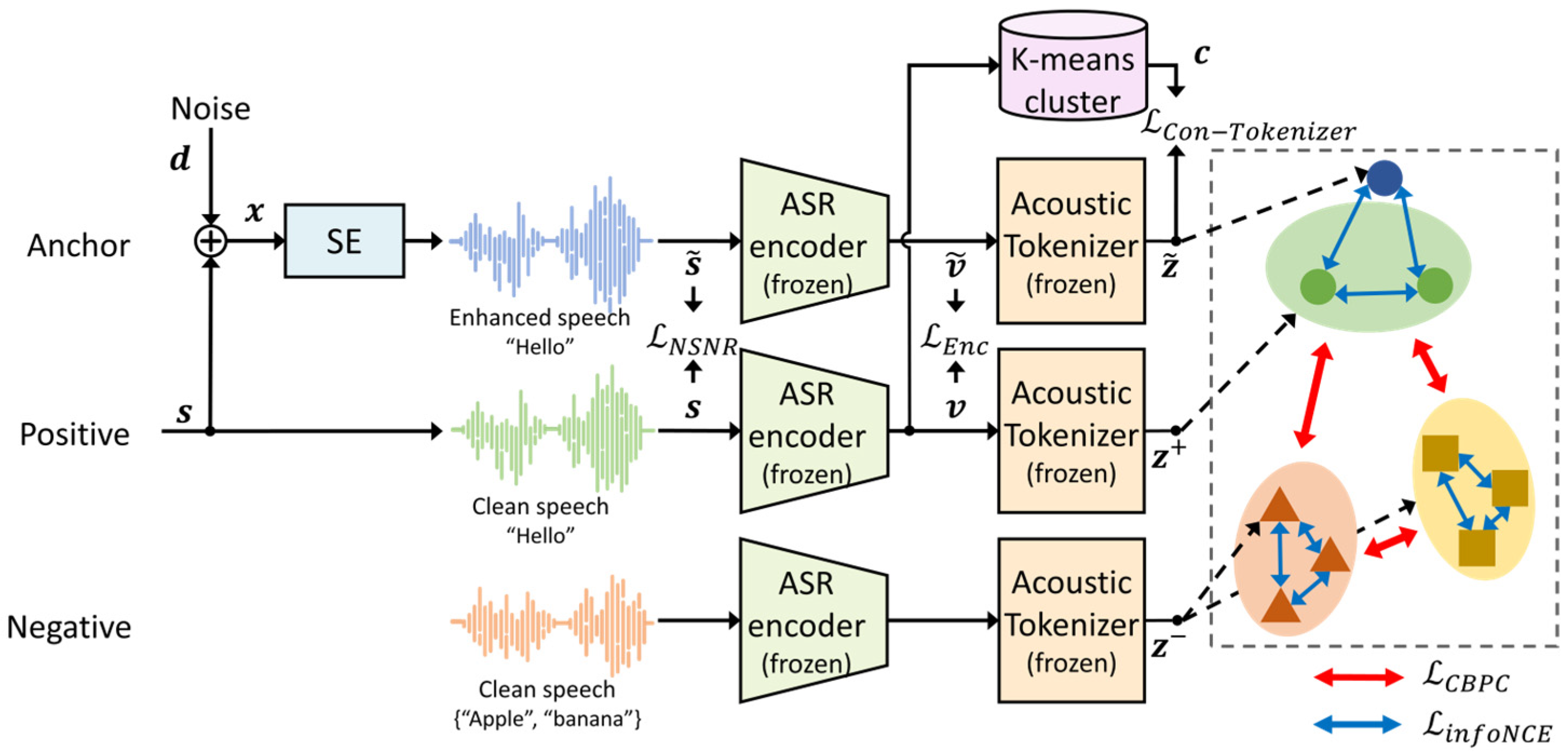
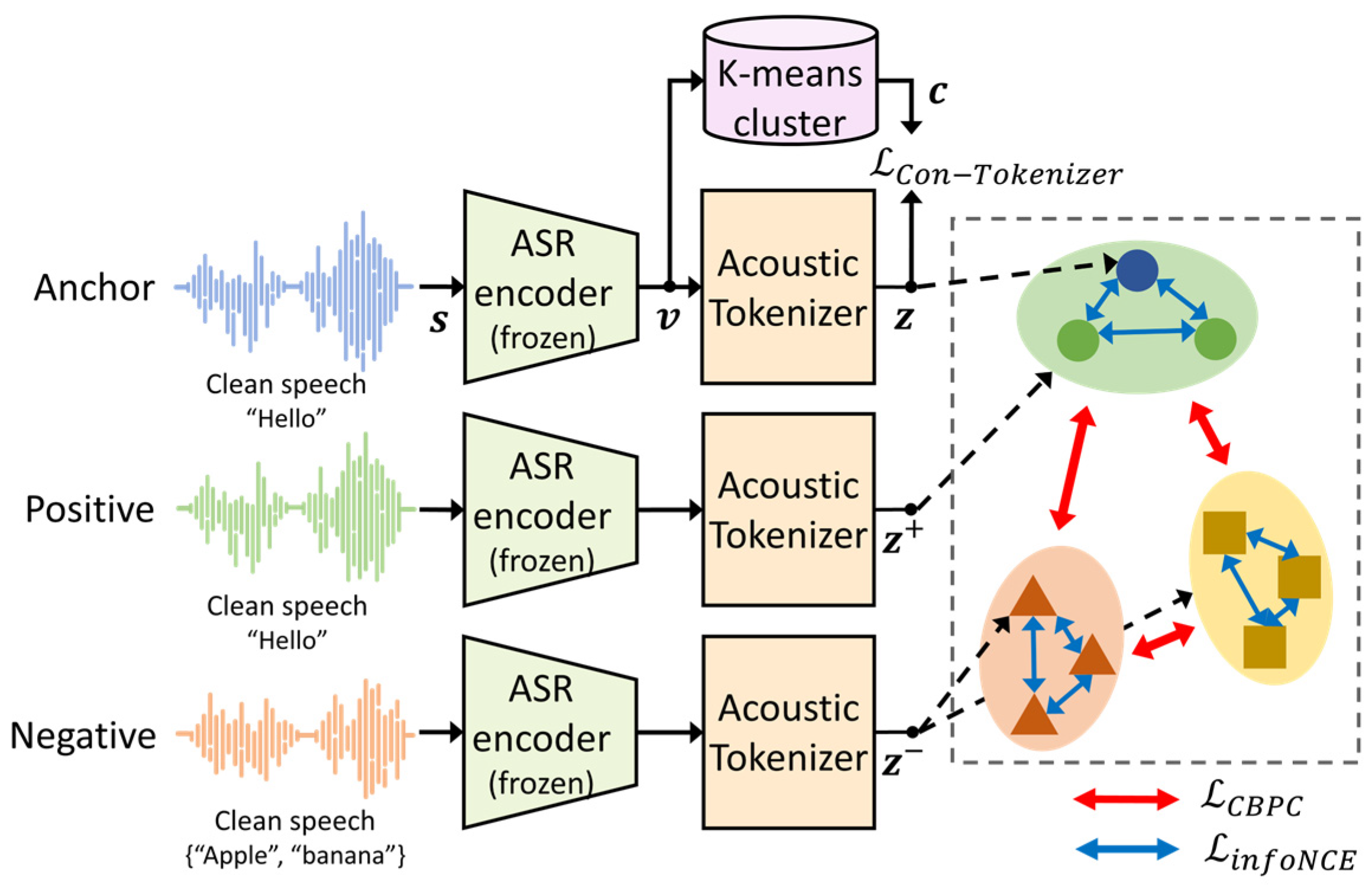
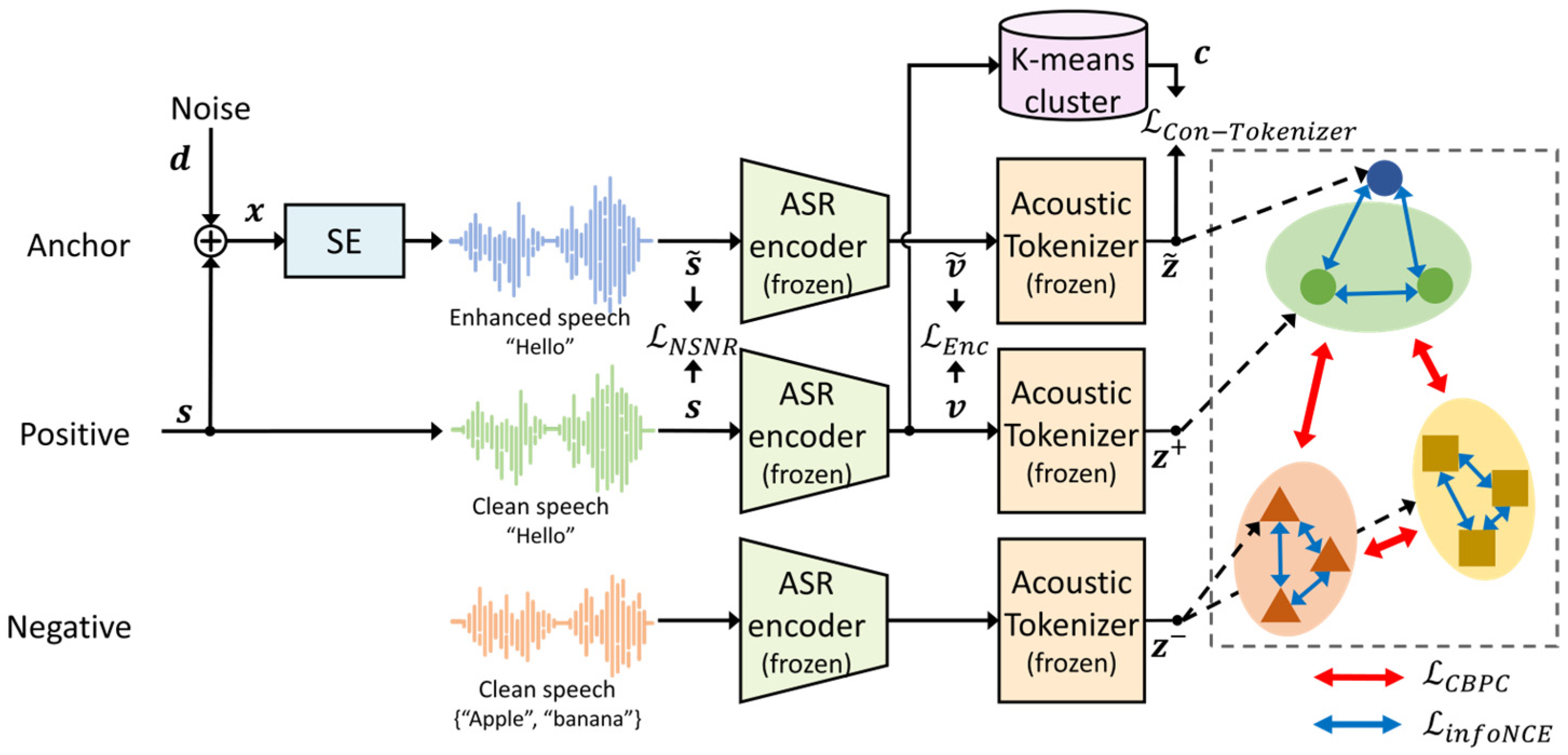
- The CBPC loss function is proposed to leverage the linguistic information for the SE model by extending the SupCon loss to a self-supervised version. Replacing the CE loss, the proposed CBPC loss is used to train the pipeline with pseudo-labels. Accordingly, the proposed CBPC loss contributes to preventing the SE model from overfitting to the outlier samples in each cluster, resulting in an improved ASR performance compared to that of the CE loss.
- To further improve the ASR performance, the proposed CBPC loss is combined with the information noise contrastive estimation (infoNCE) loss [29] to train the SE model to represent the intra-cluster pronunciation variability. This is because the proposed CBPC loss function focuses on increasing the inter-cluster representation ability. Therefore, the combined loss also contributes to retaining the contextual information among the utterances with the same pseudo-label.
- An ablation study is conducted to examine the contributions of different combinations of loss functions to the SE and ASR performance.
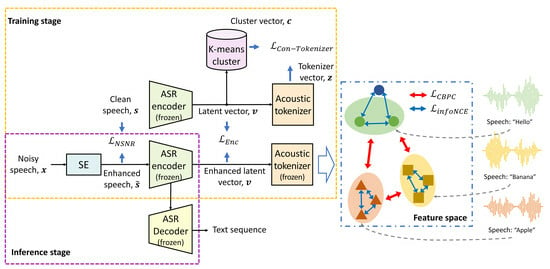
2. Pipeline Comprising SE and ASR for Noise-Robust ASR
3. Proposed Cluster-Based Pairwise Contrastive Loss Function for Joint Training
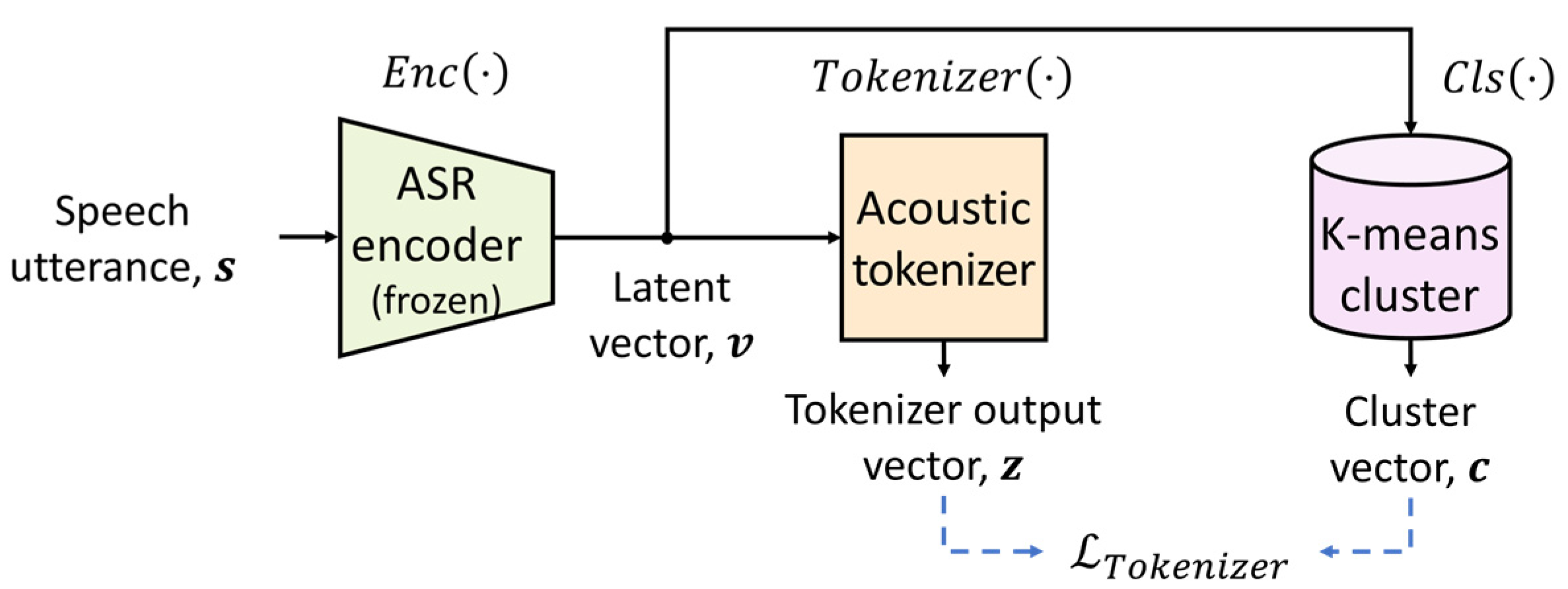
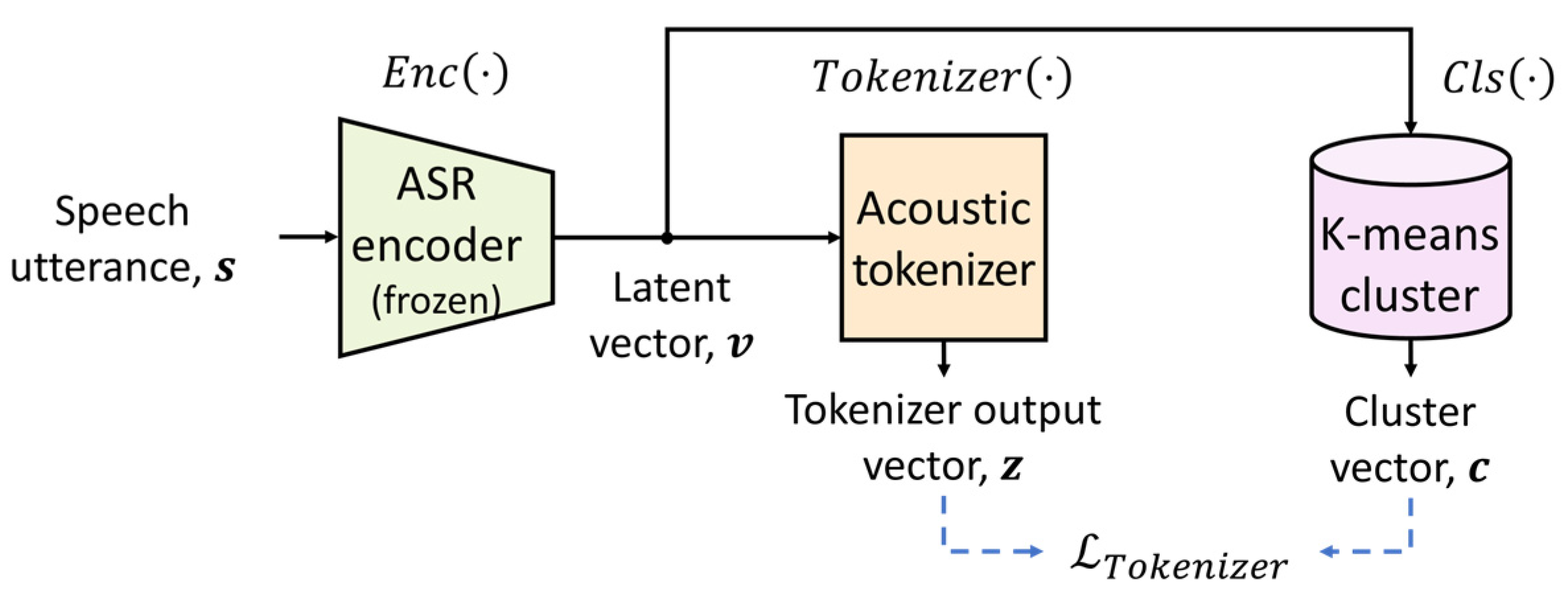
3.1. Acoustic Tokenizer
3.2. Contrastive Learning for Acoustic Tokenizer
3.3. SE Model Training
4. Experimental Setup
4.1. Dataset
4.2. Hyperparameters
4.2.1. Model Architecture
4.2.2. Training Details and Implementation
5. Performance Evaluation and Discussion
5.1. Results and Discussion of ASR Performance
5.2. Results and Discussion of SE Performance
5.3. Discussion of Performance Contribution According to Different Losses
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Nossier, S.A.; Wall, J.; Moniri, M.; Glackin, C.; Cannings, N. An experimental analysis of deep learning architectures for supervised speech enhancement. Electronics 2021, 10, 17. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2023; pp. 28492–28518. Available online: https://proceedings.mlr.press/v202/radford23a/radford23a.pdf (accessed on 5 March 2024).
- Caldarini, G.; Jaf, S.; McGarry, K. A literature survey of recent advances in chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Bingol, M.C.; Aydogmus, O. Performing predefined tasks using the human–robot interaction on speech recognition for an industrial robot. Eng. Appl. Artif. Intell. 2020, 95, 103903. [Google Scholar] [CrossRef]
- Iio, T.; Yoshikawa, Y.; Chiba, M.; Asami, T.; Isoda, Y.; Ishiguro, H. Twin-robot dialogue system with robustness against speech recognition failure in human-robot dialogue with elderly people. Appl. Sci. 2020, 10, 1522. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef]
- Droppo, J.; Acero, A. Joint discriminative front end and backend training for improved speech recognition accuracy. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toulouse, France, 14–19 May 2006; pp. 281–284. [Google Scholar] [CrossRef]
- Li, L.; Kang, Y.; Shi, Y.; Kürzinger, L.; Watzel, T.; Rigoll, G. Adversarial joint training with self-attention mechanism for robust end-to-end speech recognition. EURASIP J. Audio Speech Music Process. 2021, 26, 26. [Google Scholar] [CrossRef]
- Seltzer, M.L.; Yu, D.; Wang, Y. An investigation of deep neural networks for noise robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7398–7402. [Google Scholar] [CrossRef]
- Kinoshita, K.; Ochiai, T.; Delcroix, M.; Nakatani, T. Improving noise robust automatic speech recognition with single-channel time-domain enhancement network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7009–7013. [Google Scholar] [CrossRef]
- Wang, Z.-Q.; Wang, P.; Wang, D. Complex spectral mapping for single-and multi-channel speech enhancement and robust ASR. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1778–1787. [Google Scholar] [CrossRef] [PubMed]
- Shimada, K.; Bando, Y.; Mimura, M.; Itoyama, K.; Yoshii, K.; Kawahara, T. Unsupervised speech enhancement based on multichannel NMF-informed beamforming for noise-robust automatic speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 960–971. [Google Scholar] [CrossRef]
- Schuller, B.; Weninger, F.; Wöllmer, M.; Sun, Y.; Rigoll, G. Non-negative matrix factorization as noise-robust feature extractor for speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4562–4565. [Google Scholar] [CrossRef]
- Ma, D.; Hou, N.; Xu, H.; Chng, E.S. Multitask-based joint learning approach to robust ASR for radio communication speech. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 497–502. Available online: https://ieeexplore.ieee.org/abstract/document/9689671 (accessed on 5 March 2024).
- Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; Finn, C. Gradient surgery for multi-task learning. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 5824–5836. Available online: https://proceedings.neurips.cc/paper/2020/file/3fe78a8acf5fda99de95303940a2420c-Paper.pdf (accessed on 5 March 2024).
- Guangyuan, S.H.I.; Li, Q.; Zhang, W.; Chen, J.; Wu, X.M. Recon: Reducing conflicting gradients from the root for multi-task learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022; Available online: https://openreview.net/forum?id=ivwZO-HnzG_ (accessed on 5 March 2024).
- Lee, G.W.; Kim, H.K. Two-step joint optimization with auxiliary loss function for noise-robust speech recognition. Sensors 2022, 22, 5381. [Google Scholar] [CrossRef]
- Pandey, A.; Liu, C.; Wang, Y.; Saraf, Y. Dual application of speech enhancement for automatic speech recognition. In Proceedings of the IEEE Spoken Language Technology (SLT) Workshop, Shenzhen, China, 19–22 January 2021; pp. 223–228. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, C.; Li, R.; Zhu, Q.; Chng, E.S. Gradient remedy for multi-task learning in end-to-end noise-robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Lee, C.C.; Tsao, Y.; Wang, H.M.; Chen, C.S. D4AM: A general denoising framework for downstream acoustic models. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023; Available online: https://openreview.net/forum?id=5fvXH49wk2 (accessed on 5 March 2024).
- Lee, G.W.; Kim, H.K. Knowledge distillation-based training of speech enhancement for noise-robust automatic speech recognition. IEEE Access, 2024; under revision. [Google Scholar]
- Chai, L.; Du, J.; Liu, Q.F.; Lee, C.H. A cross-entropy-guided measure (CEGM) for assessing speech recognition performance and optimizing DNN-based speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 106–117. [Google Scholar] [CrossRef]
- Zhu, Q.S.; Zhang, J.; Zhang, Z.Q.; Dai, L.R. A joint speech enhancement and self-supervised representation learning framework for noise-robust speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 1927–1939. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. Wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 12449–12460. Available online: https://proceedings.neurips.cc/paper/2020/hash/92d1e1eb1cd6f9fba3227870bb6d7f07-Abstract.html (accessed on 5 March 2024).
- Feng, L.; Shu, S.; Lin, Z.; Lv, F.; Li, L.; An, B. Can cross entropy loss be robust to label noise? In Proceedings of the International Conference on International Joint Conferences on Artificial Intelligence (IJCAI), Virtual, 19–26 August 2021; pp. 2206–2212. [Google Scholar] [CrossRef]
- Boudiaf, M.; Rony, J.; Ziko, I.M.; Granger, E.; Pedersoli, M.; Piantanida, P.; Ayed, I.B. A unifying mutual information view of metric learning: Cross-entropy vs. pairwise losses. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 548–564. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Virtual conference, 6–12 December 2020; pp. 18661–18673. Available online: https://proceedings.neurips.cc/paper/2020/hash/d89a66c7c80a29b1bdbab0f2a1a94af8-Abstract.html (accessed on 5 March 2024).
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 2472–2476. [Google Scholar] [CrossRef]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Pang, R. Conformer: Convolution-augmented transformer for speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. Available online: https://jmlr.org/papers/v12/pedregosa11a.html (accessed on 5 March 2024).
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar] [CrossRef]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 1857–1865. Available online: https://dl.acm.org/doi/10.5555/3157096.3157304 (accessed on 5 March 2024).
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 9729–9738. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent-a new approach to self-supervised learning. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 21271–21284. Available online: https://papers.nips.cc/paper/2020/hash/f3ada80d5c4ee70142b17b8192b2958e-Abstract.html (accessed on 5 March 2024).
- Chen, M.; Fu, D.Y.; Narayan, A.; Zhang, M.; Song, Z.; Fatahalian, K.; Ré, C. Perfectly balanced: Improving transfer and robustness of supervised contrastive learning. In Proceedings of the International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2023; pp. 3090–3122. Available online: https://proceedings.mlr.press/v162/chen22d (accessed on 5 March 2024).
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. LibriSpeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Reddy, C.K.; Gopal, V.; Cutler, R.; Beyrami, E.; Cheng, R.; Dubey, H.; Gehrke, J. The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 2492–2496. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP), Brussels, Belgium, 2–4 November 2018; pp. 66–71. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Zheng, X. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. Available online: https://dl.acm.org/doi/10.5555/3026877.3026899 (accessed on 5 March 2024).
- ITU-T Recommendation P.862. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs. 2005. Available online: https://www.itu.int/rec/T-REC-P.862 (accessed on 3 March 2024).
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2007, 16, 229–238. [Google Scholar] [CrossRef]
- Yamada, T.; Kumakura, M.; Kitawaki, N. Performance estimation of speech recognition system under noise conditions using objective quality measures and artificial voice. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 2006–2013. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–15 October 2016; pp. 499–515. [Google Scholar] [CrossRef]
- Kim, S.; Kim, D.; Cho, M.; Kwak, S. Proxy anchor loss for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 July 2022; pp. 3238–3247. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Approach | Dev | Test | Average | ||
|---|---|---|---|---|---|
| Clean | Other | Clean | Other | ||
| MCT-noisy | 22.77 | 23.18 | 22.95 | 23.41 | 23.08 |
| +standalone-SE | 28.94 | 29.03 | 29.38 | 29.14 | 29.12 |
| MCT-all | 22.61 | 22.74 | 22.68 | 22.82 | 22.71 |
| Joint-Straight | 22.39 | 22.51 | 22.40 | 22.64 | 22.49 |
| Joint-ASO | 22.31 | 22.42 | 22.37 | 22.58 | 22.42 |
| Joint-Grad | 20.11 | 20.89 | 20.88 | 20.98 | 20.72 |
| Joint-Token | 19.86 | 20.40 | 20.28 | 20.67 | 20.30 |
| Proposed | 19.14 | 19.85 | 19.48 | 19.63 | 19.53 |
| Training Approach | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|
| Noisy | 1.7256 | 0.6967 | 1.8457 | 1.1615 | 1.3937 |
| +standalone-SE | 2.6512 | 0.8277 | 2.9671 | 2.5482 | 2.3410 |
| Joint-Straight | 2.4872 | 0.7504 | 2.8081 | 2.1950 | 2.1725 |
| Joint-ASO | 2.5871 | 0.7888 | 2.8213 | 2.3119 | 2.2647 |
| Joint-Grad | 2.5531 | 0.7719 | 2.8001 | 2.2964 | 2.2581 |
| Joint-Token | 2.6653 | 0.8311 | 3.1204 | 2.5684 | 2.4509 |
| Proposed | 2.6802 | 0.8311 | 3.1275 | 2.5653 | 2.4507 |
| Training Approach | Loss Function | Dev | Test | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Clean | Other | Clean | Other | |||||||
| Joint-Grad | 20.11 | 20.89 | 20.88 | 20.98 | 20.72 | |||||
| Proposed training | √ | √ | 22.58 | 22.78 | 22.74 | 23.15 | 22.81 | |||
| √ | √ | √ | 19.86 | 20.40 | 20.28 | 20.67 | 20.30 | |||
| √ | √ | √ | √ | 19.26 | 20.04 | 19.85 | 20.10 | 19.81 | ||
| √ | √ | √ | √ | √ | 19.14 | 19.85 | 19.48 | 19.63 | 19.53 | |
| Training Approach | Loss Function | PESQ | STOI | CSIG | CBAK | COVL | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | 1.7256 | 0.6967 | 1.8547 | 1.1615 | 1.3937 | |||||
| standalone-SE | 2.6512 | 0.8277 | 2.9671 | 2.5482 | 2.3410 | |||||
| Proposed training | √ | √ | 2.6500 | 0.8221 | 2.9595 | 2.5410 | 2.3387 | |||
| √ | √ | √ | 2.6653 | 0.8311 | 3.1204 | 2.5684 | 2.4509 | |||
| √ | √ | √ | √ | 2.6638 | 0.8302 | 3.1192 | 2.5651 | 2.4472 | ||
| √ | √ | √ | √ | √ | 2.6802 | 0.8311 | 3.1275 | 2.5653 | 2.4507 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.W.; Kim, H.K. Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition. Sensors 2024, 24, 2573. https://doi.org/10.3390/s24082573
Lee GW, Kim HK. Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition. Sensors. 2024; 24(8):2573. https://doi.org/10.3390/s24082573
Chicago/Turabian StyleLee, Geon Woo, and Hong Kook Kim. 2024. "Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition" Sensors 24, no. 8: 2573. https://doi.org/10.3390/s24082573
APA StyleLee, G. W., & Kim, H. K. (2024). Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition. Sensors, 24(8), 2573. https://doi.org/10.3390/s24082573