Abstract
Human Activity Recognition (HAR) systems aim to understand human behavior and assign a label to each action, attracting significant attention in computer vision due to their wide range of applications. HAR can leverage various data modalities, such as RGB images and video, skeleton, depth, infrared, point cloud, event stream, audio, acceleration, and radar signals. Each modality provides unique and complementary information suited to different application scenarios. Consequently, numerous studies have investigated diverse approaches for HAR using these modalities. This survey includes only peer-reviewed research papers published in English to ensure linguistic consistency and academic integrity. This paper presents a comprehensive survey of the latest advancements in HAR from 2014 to 2025, focusing on Machine Learning (ML) and Deep Learning (DL) approaches categorized by input data modalities. We review both single-modality and multi-modality techniques, highlighting fusion-based and co-learning frameworks. Additionally, we cover advancements in hand-crafted action features, methods for recognizing human–object interactions, and activity detection. Our survey includes a detailed dataset description for each modality, as well as a summary of the latest HAR systems, accompanied by a mathematical derivation for evaluating the deep learning model for each modality, and it also provides comparative results on benchmark datasets. Finally, we provide insightful observations and propose effective future research directions in HAR.
1. Introduction
Human Activity Recognition (HAR) has been a very active research topic for the past two decades in the field of computer vision and Artificial Intelligence (AI) that focuses on the automated analysis and understanding of human actions and recognition based on the movements and poses of the entire body.
1.1. Rationale
HAR plays an important role in various applications such as surveillance, healthcare [1,2,3], remote monitoring, intelligent human–machine interfaces, entertainment, storage video and retrieval [4,5], and human–computer interaction [6].
HAR is very important in computer vision and covers many research topics, including HAR in video, human tracking, and analysis and understanding in videos captured with a moving camera, where motion patterns exist due to video objects and the moving camera as well [7]. In such a scenario, it becomes ambiguous to recognize objects. The HAR methods were categorized into three distinct tiers: human action detection, human action tracking, and behavior understanding methods. In recent years, the investigation of interaction [8,9] and human action detection [10,11,12] has emerged as a prominent area of research. Many state-of-the-art techniques deal with action recognition using action frames as images and are only able to detect the presence of an object in them. They cannot properly recognize the object in an image or video. By properly recognizing an action in a video, it is possible to recognize the class of action more accurately. To perform action recognition, there has been an increased interest in this field in recent years due to the increased availability of computing resources as well as new advances in ML [13] and DL. Robust human action modelling and feature representation are essential components for achieving effective HAR. The main issue of representing and selecting features is a well-established problem within the fields of computer vision and ML [13]. Unlike the representation of features in an image domain, the representation of features of human actions in a video not only depicts the visual attributes of the human being(s) within the image domain but must also perform the extraction of alterations in visual attributes and pose. The problem of representation of features has been expanded from a 2D space to a 3D spatio-temporal context. In the past few years, many types of action representation techniques have been proposed. These techniques include various approaches, such as local and global features that rely on temporal and spatial alterations [14,15,16], trajectory features that are based on key point tracking [17], motion changes that are derived from depth information [18,19], and action features that are derived from human pose changes [20,21]. With the performance and successful application of DL to activity recognition and classification, many researchers have used DL for HAR. This facilitates the automatically learned features from the video dataset [22,23]. However, the aforementioned review articles have only examined certain specific facets, such as the Spatial Temporal Interest Point (STIP) and Histogram of Optical Flow (HOF)-found techniques for HAR, as well as approaches for analyzing human walking and DL-based techniques. Numerous novel approaches have been recently developed, primarily regarding the utilization of depth learning techniques for feature learning. Hence, a comprehensive examination of these fresh approaches for recognizing human actions is of significant interest. Additionally, HAR has critical applications in security and surveillance; this survey focuses on general-purpose recognition methods and does not cover security-specific techniques in depth.
1.2. Objective
Many researchers have been working to survey the HAR system article, which is mainly based on ML and DL techniques, with diverse feature extraction techniques. Such HAR literature was summarized by [24] within the framework of three key areas: sensor modality, deep models, and application. Vrigkas et al. [25] also reviewed HAR using RGB static images, covering both single-mode and multi-mode approaches. Vishwakarma et al. [26] summarized classical HAR methods, categorizing them into hierarchical and non-hierarchical methods based on feature representation. The survey by Ke et al. [27] provided a comprehensive overview of handcrafted methods in HAR. Additionally, surveys [28,29,30,31] extensively discuss the strengths and weaknesses of handcrafted versus DL methods, emphasizing the advantages of DL-based approaches. Xing et al. [32] focused on HAR development using 3D skeleton data, reviewing various DL-based techniques and comparing their performance across different dimensions. Presti et al. [33] presented HAR techniques based on 3D skeleton data. Methods for HAR using depth and skeleton data have been thoroughly reviewed by Ye et al. [19]; they also present HAR techniques using depth data.
Although certain review articles discuss data fusion methods, they offer a limited overview of HAR approaches to particular data types. Similarly, Subetha et al. [34] presented the same strategy to review action recognition methods. However, in distinction to those studies, we categorize HAR into five distinct categories: action recognition RGB and handcrafted features, action recognition RGB and DL, action recognition skeleton and handcrafted features, action recognition skeleton-based and DL, action recognition sensor-based methods, and action recognition using a multimodal dataset. The crucial element of the analysis regarding the literature on HAR is that most surveys have focused on the representations of human action features. The data of the image sequences that have been processed are typically well-segmented and consist solely of a single action event. More recently, many researchers have been working to conduct HAR survey studies with a specific point of view. For example, some researchers have surveyed Graph Convolutional Networks (GCNs) structures and data modalities for HAR and the application of GCNs in HAR [35,36]. Gupta et al. [37] explored current and future directions in skeleton-based HAR and introduced the skeleton-152 dataset, marking a significant advancement in the field. Meanwhile, Song et al. [38] reviewed advancements in human pose estimation and its applications in HAR, emphasizing its importance. Additionally, Shaikh et al. [39] focused on data integration and recognition approaches within a visual framework, specifically from an RGB-D perspective. Majumder et al. [40] and Wang et al. [41] provided reviews of popular methods using vision and inertial sensors for HAR. More recently, Wang et al. [42] surveyed HAR by performing two modalities of RGB-based and skeleton-based HAR techniques. Similarly, Sun et al. [43] surveyed HAR with various multi-modality methods.
1.2.1. Research Gaps and New Research Challenges
Also, each survey paper can give us an overall summary of the existing work in this domain. Still, there is a lack of comparative studies of the various modalities, such as RGB, skeleton, sensor, and fusion-based and diverse modality-based HAR systems of recent technologies. From a data perspective, most reviews on HAR are limited to methodologies based on specific data, such as RGB, depth, and fusion data modalities. Moreover, we did not find a HAR survey paper that included diverse modality-based HAR, including their benchmark dataset and latest performance accuracy for 2014–2025. The studies of [8,42] inspired us to complete a survey study with current research trends for HAR.
1.2.2. Our Contribution
Figure 1 demonstrates the proposed methodology flowchart. In this study, we survey state-of-the-art methods for HAR, addressing their challenges and future directions across vision-, sensor-, and fusion-based data modalities. We also summarize the current two-dimensions and three-dimensions pose estimation algorithms before discussing skeleton-based feature representation methods. Additionally, we categorize action recognition techniques into handcrafted feature-based ML and end-to-end DL-based methods. Our main contributions are as follows:
- Comprehensive Review with Diverse Modality: We conduct a thorough survey of RGB-based, skeleton-based, sensor-based, and fusion HAR-based methods, focusing on the evolution of data acquisition, environments, and human activity portrayals from 2014 to 2025.
- Dataset Description: We provide a detailed overview of benchmark public datasets for RGB, skeleton, sensor, and fusion data, highlighting their latest performance accuracy with references.
- Unique Process: Our study covers feature representation methods, common datasets, challenges, and future directions, emphasizing the extraction of distinguishable action features from video data despite environmental and hardware limitations. We also included the mathematical derivation for the evaluation of the deep learning model for each modality, such as from 3D CNN to Multi-View Transformer and GCN to EMS-TAGCN for pixel video and sequence of the skeleton dataset, respectively.
- Identification of Gaps and Future Directions: We identify significant gaps in the current research and propose future research directions supported by the latest performance data for each modality.
- Evaluation of System Efficacy: We assess existing HAR systems by analyzing their recognition accuracy and providing benchmark datasets for future development.
- Guidance for Practitioners: Our review offers practical guidance for developing robust and accurate HAR systems, providing insights into current techniques, highlighting challenges, and suggesting future research directions to advance HAR system development.
1.2.3. Research Questions
This research addresses the following major questions:
- What are the main difficulties faced in human activity recognition?
- What are the major open challenges faced in human activity recognition?
- What are the major algorithms involved in human activity recognition?
1.3. Organization of the Work
The paper is categorized as follows. The benchmark datasets are provided in Section 3.1. The action recognition RGB-data modality methods and skeleton data modality-based methods are discussed in Section 3 and Section 4, respectively. In Section 5, Section 6 and Section 7, we introduce sensor modality-based HAR, multimodal fusion modality-based, and current challenges, including four data modalities, respectively. We discuss future research trends and direction in Section 8. Finally, in Section 9, we summarized the conclusions. The detailed structure of this paper is shown in Figure 1.
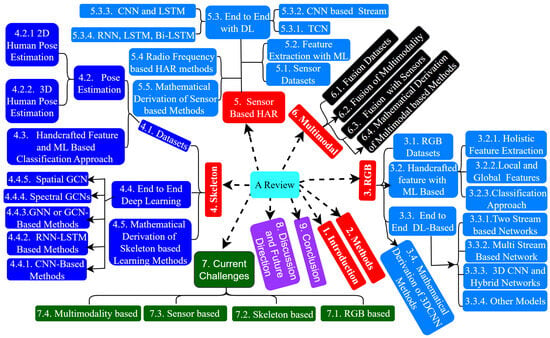
Figure 1.
Diverse modality, including the structure of this paper.
Figure 1.
Diverse modality, including the structure of this paper.
2. Methods
This section outlines the methodology for conducting a comprehensive review of HAR research, focusing on studies published between 2014 and 2025 across diverse data modalities. The methodology comprises the article search protocol, eligibility criteria, article selection, quality appraisal, and data charting strategy.
2.1. Article Search Protocol
We performed an extensive search using databases such as IEEE Xplore, Scopus, Web of Science, SpringerLink, and ACM Digital Library. Boolean keyword combinations included the following:
- “Human Activity Recognition” OR “Human Action Recognition”
- “Computer Vision”, “RGB”, “Skeleton”, “Sensor”, “Multimodal”, “Deep Learning”, “Machine Learning”
2.2. Eligibility Criteria
To refine and ensure relevance in our initial search results, we applied the following criteria:
Inclusion Criteria:
- Publications from 2014 to 2025;
- Peer-reviewed journals, conference papers, book chapters, and lecture notes;
- Focus on HAR using RGB, skeleton, sensor, fusion HAR methods, or multimodal;
- Emphasis on the evolution of data acquisition, environments, and human activity portrayals.
Exclusion Criteria:
- Exclusion of studies lacking in-depth information about their experimental procedures;
- Exclusion of research articles where the complete text is not accessible, both in physical and digital formats;
- Exclusion of research articles that include opinions, keynote speeches, discussions, editorials, tutorials, remarks, introductions, viewpoints, and slide presentations.
2.3. Article Selection Process
The literature was screened through a multi-step process: title screening, abstract review, and full-text evaluation. We prioritized articles published in prestigious journals and conferences such as:
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI);
- IEEE Transactions on Image Processing (TIP);
- International Conference on Computer Vision and Pattern Recognition (CVPR);
- IEEE International Conference on Computer Vision (ICCV);
- Springer, ELSEVIER, MDPI, Frontier, etc.
Figure 2 depicts the article selection process, while Figure 3 demonstrates the percentage of journals, conferences, and other ratios. Figure 4 shows the distribution of the year-wise number of references.
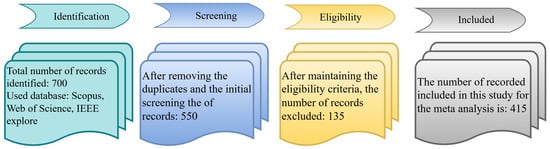
Figure 2.
Article selection process block diagram.
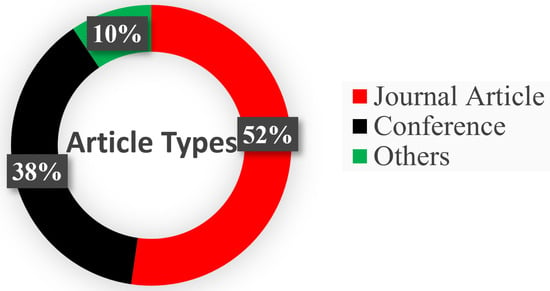
Figure 3.
Distribution of article types across journal publications, conference proceedings, and other sources.
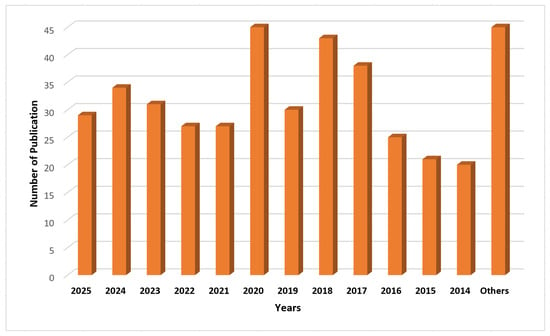
Figure 4.
Year-wise distribution of selected HAR publications (2014–2025).
2.4. Critical Appraisal of Individual Sources
We reviewed each article through a structured process involving the following:
- Abstract review;
- Methodology analysis;
- Result evaluations;
- Discussion and conclusions.
We extracted key attributes from the selected studies using a structured data charting form. The extracted data included the following:
- Bibliographic information (author(s), publication year, and venue);
- Dataset characteristics and associated HAR modality (e.g., RGB, skeleton, sensor, fusion);
- Feature extraction techniques and classification models employed;
- Evaluation metrics and reported benchmark performance.
These data were synthesized and analyzed comparatively across modalities to identify trends, strengths, and methodological gaps in the literature.
3. RGB-Data Modality-Based Action Recognition Methods
Figure 5 demonstrates a common workflow diagram of the RGB-based action recognition methods. The early stages of research regarding HAR were conducted based on the RGB data, and initially feature extraction mostly depended on manual annotation [44,45]. These annotations often relied on existing knowledge and prior assumptions. After this, DL-based architectures were developed to extract the most effective features and the best performance. The following sections describe the dataset, the methodological review of RGB-based handcrafted features with ML, and various ideas for DL-based approaches. Moreover, Table 1 lists detailed information about the RGB data modality, including the datasets, feature extraction methods, classifier, years, and performance accuracy.

Figure 5.
Workflow of RGB-based action recognition methods utilizing handcrafted features.

Table 1.
RGB and deep learning-based existing techniques for action recognition.
3.1. RGB-Based Datasets of HAR
We provided the most popular benchmark HAR datasets, which come from the RGB skeleton, which is demonstrated in Table 2. The dataset table demonstrated the details of the datasets, including modalities, creation year, number of classes, number of subjects who participated in recording the dataset, number of samples, and the latest performance accuracy of the dataset with citations.
The RGB dataset encompasses several prominent benchmarks for HAR. Notably, the Activity Net dataset, introduced in 2015, comprises 203 activity classes and an extensive 27,208 samples, achieving an impressive accuracy of 94.7% in recent evaluations [67,68]. The Kinetics-400 and Kinetics-700 datasets, from 2017 and 2019, respectively, include 400 and 700 classes with approximately 306,245 and 650,317 samples. These datasets are notable for their high accuracy rates of 92.1% and 85.9% [69,70,71]. The AVA dataset, also from 2017, contains 80 classes and 437 samples, with a recorded accuracy of 83.0% [72,73]. Datasets such as Kinetics and AVA are collected from YouTube videos. These datasets are affected by content availability issues due to reliance on external links, which may expire over time. The EPIC Kitchen 55 dataset from 2018 offers a comprehensive view with 149 classes and 39,596 samples. The Moments in Time dataset, released in 2019, is one of the largest, with 339 classes and around 1,000,000 samples, although it has a relatively lower accuracy of 51.2% [71,74]. Each dataset is instrumental for training and evaluating HAR models, providing diverse scenarios and activities.
Table 2.
Benchmark datasets for HAR RGB and Skeleton.
Table 2.
Benchmark datasets for HAR RGB and Skeleton.
| Dataset | Data Set Modalities | Year | Class | Subject | Sample | Latest Accuracy |
|---|---|---|---|---|---|---|
| UPCV [75] | Skeleton | 2014 | 10 | 20 | 400 | 99.20% [76] |
| Activity Net [67] | RGB | 2015 | 203 | - | 27,208 | 94.7% [68] |
| Kinetics-400 [69] | RGB | 2017 | 400 | - | 306,245 | 92.1% [71] |
| AVA [72] | RGB | 2017 | 80 | - | 437 | 83.0% [73] |
| EPIC Kitchen 55 [77] | RGB | 2018 | 149 | 32 | 39,596 | - |
| AVE [78] | RGB | 2018 | 28 | - | 4143 | - |
| Moments in Times [74] | RGB | 2019 | 339 | - | 1,000,000 | 51.2% [71] |
| Kinetics-700 [70] | RGB | 2019 | 700 | - | 650,317 | 85.9% [71] |
| RareAct [79] | RGB | 2020 | 122 | 905 | 2024 | 60.80% [80] |
| HiEve [81] | RGB, Skeleton | 2020 | - | - | - | 95.5% [82] |
| MSRDaily Activity3D [83] | RGB, Skeleton | 2012 | 16 | 10 | 320 | 97.50% [84] |
| N-UCLA [85] | RGB, Skeleton | 2014 | 10 | 10 | 1475 | 99.10% [86] |
| Multi-View TJU [87] | RGB, Skeleton | 2014 | 20 | 22 | 7040 | - |
| UTD-MHAD [88] | RGB, Skeleton | 2015 | 27 | 8 | 861 | 95.0% [89] |
| UWA3D Multiview II [90] | RGB, Skeleton | 2015 | 30 | 10 | 1075 | - |
| NTU RGB+D 60 [91] | RGB, Skeleton | 2016 | 60 | 40 | 56,880 | 97.40% [86] |
| PKU-MMD [92] | RGB, Skeleton | 2017 | 51 | 66 | 10,076 | 94.40% [93] |
| NEU-UB [94] | RGB | 2017 | 6 | 20 | 600 | - |
| Kinetics-600 [95] | RGB, Skeleton | 2018 | 600 | - | 595,445 | 91.90% [71] |
| RGB-D Varing-View [96] | RGB, Skeleton | 2018 | 40 | 118 | 25,600 | - |
| NTU RGB+D 120 [97] | RGB, Skeleton | 2019 | 120 | 106 | 114,480 | 95.60% [86] |
| Drive&Act [98] | RGB, Skeleton | 2019 | 83 | 15 | - | 77.61% [99] |
| MMAct [100] | RGB, Skeleton | 2019 | 37 | 20 | 36,764 | 98.60% [101] |
| Toyota-SH [102] | RGB, Skeleton | 2019 | 31 | 18 | 16,115 | - |
| IKEA ASM [103] | RGB, Skeleton | 2020 | 33 | 48 | 16,764 | - |
| ETRI-Activity3D [104] | RGB, Skeleton | 2020 | 55 | 100 | 112,620 | 95.09% [105] |
| UAV-Human [106] | RGB, Skeleton | 2021 | 155 | 119 | 27,428 | 55.00% [107] |
3.2. Handcrafted Features with ML-Based Approach
Researchers employed handcrafted feature extraction with ML-based systems at an early age to develop HAR systems [108]. In the action representation step, the RGB data are utilized to transform into the feature vector, and these feature vectors are fed into the classifier [109,110] to obtain the desired results of the action classification step. Table 3 shows the analysis of the handcrafted-based approach, including the datasets, methods of feature extraction, classifier, years, and performance accuracy. Handcrafted features are designed to capture the physical motions performed by humans and the spatial and temporal variations depicted in videos that portray actions. These variations include methods that utilize the spatio-temporal volume-based representation of actions, methods based on Spatio-temporal Interest Points (STIPs), methods that rely on the trajectory of skeleton joints for action representation, and methods that utilize human image sequences for action representation. Chen et al. [111] demonstrate this by employing Depth Motion Map (DMM)-based gestures for motion information extraction, while Local Binary Pattern (LBP) feature encoding enhances discriminative power for action recognition. Meanwhile, Patel et al. [108] fuse various features, including Histogram of Oriented Gradients (HOG) and LBP, to improve network performance in recognizing human activities. The handcrafted features can be categorized as below:
Table 3.
Action recognition methods based on handcrafted feature extraction techniques.
3.2.1. Holistic Feature Extraction
Holistic representation aims to capture the motion information of the entire human subject. Spatio-temporal action recognition often uses template-matching techniques, with key methods focusing on creating effective action templates. Bobick et al. introduced two approaches, Motion Energy Image (MEI) and Motion History Image (MHI), to perform action representation [126]. Meanwhile, Zhang et al. utilized polar coordinates in MHI and developed a Motion Context Descriptor (MCD) based on the Scale-Invariant Feature Transform (SIFT) [127]. Somasundaram et al. applied sparse representation and dictionary learning to calculate video self-similarity in both time and space [128]. In scenarios with a stationary camera, these approaches effectively capture shape-related information like human silhouettes and contours through background subtraction. However, accurately capturing silhouettes and contours in complex scenes or with camera movements remains challenging, especially when the human body is partially obscured. Many methods employ a sliding window approach to detect multiple actions within the same scene, which can be computationally expensive. These approaches transform dynamic human motion into a holistic representation in a single image. While they capture relevant foreground information, they are sensitive to background noise, including irrelevant information.
3.2.2. Local and Global Representation
Holistic feature extraction techniques for HAR face several limitations, including sensitivity to background noise, reliance on stationary cameras, difficulty in complex scenes, occlusion issues, high computational cost, limited robustness to variations, and neglect of contextual information, making them less effective in dynamic, real-world scenarios.
Combining local and global representations can effectively address HAR’s holistic feature extraction limitations. Local features reduce background noise sensitivity and handle occlusions, while global features ensure comprehensive activity recognition. This combination enhances robustness to variations, manages complex scenes, and optimizes computational efficiency, improving HAR accuracy and reliability. The local presentation means identifying a specific region, while the global representation means identifying the whole region with significant motion information. These methods [14,15,16] contain local and global features based on spatial–temporal change trajectory attributes that are founded on key point tracking [17,129], motion changes that are derived from depth information [18,19], and action-based features that are predicated on human pose changes [20,21]. The HoG and HON4D [130] is one of the feature-based techniques that calculates features on the base orientation of gradients in an image or video sequence. The HoG features are then used to encode local and global texture information, aiming to recognize different actions. Some of the presented approaches exploit the HoG in action recognition, including [131,132,133,134], in various ways. HOF is a feature extraction method used in action recognition [135,136]. It involves building histograms to present different actions over the spatio-temporal domain in a video. However, in this method, the number of bins needs to be set in advance. The challenge addresses cluttered backgrounds and camera movement by performing a physical feature-driven approach to HOF.
3.2.3. Classification Approach
Once we have the feature representation, we feed it into classifiers such as Support Vector Machine (SVM) [121], Random Forest, and K-Nearest Neighbor (KNN) [137,138] to predict the activity label. Some classification methods, such as Hidden Markov Models (HMMs), Condition Random Fields (CRFs) [139,140,141], Structured Support Vector Machine (SSVM) [110,142,143], and Global Gaussian Mixture Models (GGMMs) [7], perform sequentially for classification tasks. Additionally, Luo et al. utilized the features of fusion-based methods, Maximum Margin Distance Learning (MMDL) [144], and Multi-task Spare Learning Model (MTSLM) [145]. These methods perform the classification task based on combining various characteristics to enhance the classification task.
3.3. End-to-End Deep Learning Approach
The holistic, local, and global features reported promising results in the HAR task, but these handcrafted features need much specific knowledge to define relevant parameters. Additionally, they do not generalize sizable datasets well. In recent years, significant focus has been placed on utilizing DL in computer vision. Numerous approaches have used deep neural network-based methods to recognize human activity [22,23,47,146,147,148,149,150,151,152].
For example, Donahue et al. explored Long Short-Term Memory (LSTM) and developed Long-Term Recurrent Convolutional Networks (LRCNs) [153] to model CNN-generated spatial features across temporal sequences. Another significant HAR technique involves the use of LSTM with Convolution Neural Networks (CNNs) [154,155]. Ng et al. [155] introduced a Recurrent Neural Network (RNN) model to identify and classify the action, which performs a connection between the LSTM cell and the output of the underlying CNN. Donahue et al. [153] proposed a method of using long-term RNNs to map video frames of varying lengths to outputs of varying lengths, such as action descriptive text, rather than simply assigning them to a specific action category. Song et al. [156] introduced a model using RNNs with LSTM that employed multiple attention levels to discern key joints in the skeleton across each input frame.
Recently, researchers have utilized different ideas for spatio-temporal feature extraction, divided into four categories: two-stream networks, multi-stream networks, 3D CNN, and Hybrid Networks.
3.3.1. Two Stream-Based Network
The motion of an object can be represented based on the optical flow [157]. Simonyan et al. proposed a two-stream convolutional network to recognize human activity [22], as depicted in Figure 6. In a convolutional network with two streams, the optical flow information is computed from the sequence of images. Two separate CNNs process image and optical flow sequences as inputs during model training. Fusion of these inputs occurs at the final classification layer. The two-stream network handles a single-frame image and a stack of optical flow frames using 2D convolution. In contrast, a 3D convolutional network treats the video as a space–time structure and employs 3D convolution to capture human action features.
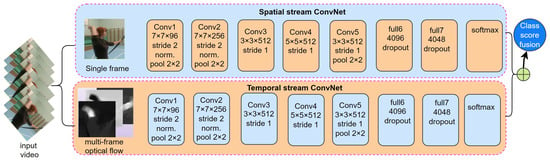
Figure 6.
RGB-based two-stream architecture HAR [22].
Numerous research endeavors have been conducted to enhance the efficacy of these two network architectures. Noteworthy advancements in the two-stream CNNs have been made by Zhang et al. [151], who substituted the optical flow sequence with the motion vector in the video stream. This substitution resulted in improved calculation speed and facilitated real-time implementation of the aforementioned HAR technique. The process of merging spatial and temporal information has been modified by Feichtenhofer et al. [50], shifting it from the initial final classification layer to an intermediate position within the network. As a result, the accuracy of action recognition has been further enhanced [51]. Moreover, an additional enhancement to the performance of the two-stream convolutional network was introduced through the proposal of a Temporal Segment Network (TSN). Moreover, the recognition results of TSN were further improved by the contributions of both Lan et al. [158] and Zhou et al. [159].
3.3.2. Multi-Stream Based Network
RGB data paired with CNNs offers powerful action recognition capabilities. Liu et al. [160] leverage a multi-stream convolutional network to enhance recognition performance by incorporating manually crafted skeleton joint information with CNN-derived features. Shi et al. [53] employ transfer learning techniques in a three-stream network, incorporating dense trajectories to characterize long-term motion effectively. Attention mechanisms with RGB data focus on relevant regions for better action recognition. Shah et al. [66] propose a Generative Adversarial Network (GAN)-based knowledge distillation framework combining spatial attention-augmented EfficientNetB7 and multi-layer Gated Recurrent Units (GRUs) with handcrafted hybrid LBP features for robust HAR, while acknowledging limitations in model generalization and noise sensitivity in complex real-world environments.
3.3.3. 3D CNN and Hybrid Networks
Traditional two-stream techniques often separate spatial and temporal information, which can render them less suitable for real-time deployment. These 3D approaches aim to address the limitations of the earlier two-stream networks. For example, Ji et al. [46] utilized the 3D CNN model for the action recognition task. This model extracts features from both the spatial and the temporal dimensions. Tran et al. [23] used C3D to extract spatio-temporal features for a large dataset to train the model, which is the extension of the 3DCNN model [46]. Carreira et al. [154] developed I3D, extending the network to extract spatio-temporal features along with the temporal dimension. They proposed image classification models to create 3D CNNs by transferring weights from 2D models pre-trained on ImageNet to align with the weights in the 3D model. P3D [161] and R(2+1)D [162] streamlined 3D network training using factorization, combining 2D spatial convolutions (1 × 3) with 1D temporal convolutions (3 × 1 × 1) instead of traditional 3D convolutions (3 × 3). For improved motion analysis, trajectory convolution [163] employed deformable convolutions in the temporal domain. Other approaches simplify 3D CNNs by integrating 2D and 3D convolutions within single networks to enhance feature maps, exemplified by models like MiCTNet [56], ARTNet [164], and S3D [165]. To enhance the performance of 3DCNN, CSN [166] has demonstrated the effectiveness of decomposing 3D convolution by separating channel interactions from spatio-temporal interactions, leading to state-of-the-art performance improvements. This technique can achieve speeds that are two to three times faster than previous methods. Feichtenhofer et al. developed the X3D method [167] that included both spatial and temporal dimensions with enhanced spatial, input resolution, and channel dimensions. Yang et al. [168] proposed that morphologically similar actions like walking, jogging, and running require discrimination assisted by visual speed. They proposed a Temporal Pyramid Network (TPN) similar to X3D. This approach enables the extraction of effective features at various temporal rates, reducing computational complexity while enhancing efficiency performances. Zhang et al. [169] proposed a 4D CNN with 4D convolution to capture the evolution of distant spatio-temporal representations.
Similarly, numerous researchers have made efforts to expand various 2D CNNs to 3D spatio-temporal structures to acquire knowledge about and identify human action features. Carreira et al. [154] expanded the network architecture of inception-V1 to incorporate 3D and introduced the two-stream inflated 3D ConvNet for HAR. Qin et al. [170] propose a fusion scheme combining classical descriptors with 3D CNN-learned features, achieving robustness against geometric and optical deformations. Diba et al. [171] extended DenseNet and introduced a temporal 3D ConvNet for HAR. Zhu et al. [172] expanded pooling operations across spatial and temporal dimensions, transforming the two-stream convolution network into a three-dimensional structure. Carreira et al. [154] conducted a comparison of five architectures: LSTM with CNN, 3D ConvNet, two-stream network, two-stream inflated 3D ConvNet, and 3D-fused two-stream network. In essence, 3D CNNs establish relationships between temporal and spatial features in various ways, complementing rather than replacing two-stream networks.
3.3.4. Other Models
Hassan et al. [64] created a deep bidirectional LSTM model, which effectively integrates the advantages of temporal effective features extraction through Bi-LSTM and spatial feature extraction via CNN. Use of the LSTM architecture is not feasible for supporting parallel computing, which can limit its efficiency. To overcome this problem, the transformer architecture [173] has become popular in DL to address this limitation. Girdhar et al. [174] used the transformer-based architecture to add context features and developed an attention mechanism to improve performance. Khan et al. [65] present two end-to-end DL models—ConvLSTM and LRCN—for HAR from raw video inputs, leveraging time distributed layers for spatio-temporal encoding, while facing limitations in computational efficiency and real-time deployment on resource-constrained devices.
3.4. Mathematical Derivation of the Benchmark RGB-Based 3DCNN Method
In RGB-based HAR, each dataset sample can be represented as:
where is the i-th video example and is its corresponding ground truth label. Each video is typically represented as a tensor with dimensions , where f is the number of frames per video, h and w denote the height and width of each frame, and is the number of color channels. CNNs are commonly used to process RGB data. They apply multiple convolutional layers to extract features from the input tensor. The feature at spatial location in the k-th feature map at the l-th layer is calculated as [175]:
where is the learned convolutional kernel for the k-th feature map at layer l, is the input patch at position in layer l, is the bias term for the k-th feature map at layer l, and is the pre-activation value at position in the k-th feature map. An activation function introduces non-linearity as flow:
where is the activated feature value at position in the k-th feature map at layer l and is typically a ReLU, tanh, or sigmoid function. Pooling layers then reduce the resolution of the feature maps, enhancing shift-invariance and robustness as follows:
where is the pooled feature at position in the k-th feature map at layer l, denotes the local pooling region around position , and is typically a max or average pooling operation. After stacking several convolutional and pooling layers, fully connected layers are added to perform higher-level reasoning. The final output is often passed through a Softmax operator to produce class probabilities. The CNN model is trained by minimizing a task-specific loss function that measures the difference between predicted and true labels. Given N training samples , where , the overall loss function is given by [175]:
where denotes the chosen loss function (e.g., cross-entropy), represents all learnable model parameters (weights and biases), and is the model’s output prediction for the n-th sample. Training on the RGB modality can be expressed as:
where is the CNN-based feature extractor for modality m with parameters , is the classifier network with parameters , denotes the loss function (e.g., cross-entropy), and is the ground truth label for the i-th sample.
3.4.1. Three-Dimensional CNN
The 3D CNN processes spatio-temporal features by applying 3D convolutions across both spatial (height, width) and temporal (frames) dimensions. For a 3D convolution operation at a certain location in the feature map [46] and also C3D [23] and P3D [161], we have:
where is the 3D convolutional kernel; are the spatial and temporal filter sizes; is the input feature map from the previous layer; and is the bias term.
3.4.2. C3D [23]
C3D, also called a deep 3D ConvNet model, is similar to the VGG model [176], which is constructed with eight convolution layers, five max-pooling layers, and two fully connected layers, where all 3D convolution kernels are and have a stride of 1 for both domains: spatial and temporal, whereas most pooling kernes are and pooling 1 layers are . According to the experiment using the UCF101 test split-1 with different kernels for the temporal depth setting, 3D ConvNet achieves high accuracy, with kernels, compared to the 2D ConvNet [23]. C3D achieved 85.2%, 85.2%, 78.3%, 98.1%, 87.7%, and 22.3% accuracy for the Sport1M, UCF101, ASLAN, YUPENN, UMD, and Object datasets, respectively [23].
3.4.3. I3D (Inflated 3D ConvNet)
It is difficult to identify good video architectures due to the small video benchmarks (UCF101, HMDB51), and most methods obtain similar performance on this dataset. They then proposed the Kinetics Dataset and proposed I3D models. The I3D architecture followed the InceptionV1 (GoogleNet) architecture. I3D inflates 2D filters from a pre-trained 2D CNN (e.g., from ImageNet) into 3D convolutions to capture temporal relationships. For the convolution at position , the equation is:
where is the inflated 3D kernel and represents the input features across the spatial and temporal dimensions. The model design is based on Inception V1, so that when training I3D, the I3D weights can be initialized with the InceptionV1 weights, which are pretrained in ImageNet [154].
3.4.4. S3D
The S3D model was developed to overcome the computational challenges of I3D. While I3D delivers strong performance, it is very computationally expensive. This leads to some important questions: Is 3D convolution truly necessary? If so, which layers should use 3D convolution, and which could use 2D convolution instead? These choices might depend on the nature of the dataset and the specific task. Additionally, is it crucial to apply convolution over both time and space together, or would it be enough to handle these dimensions separately? To address these issues, Xie et al. introduced the S3D model [165]. This model replaces traditional 3D convolutions with spatial and temporal separable convolutions, helping reduce computational costs while still effectively capturing both spatial and temporal features in video data. The convolution at position in S3D is given by the following equation:
where represents the 3D kernel and is the input feature map from the previous layer. This method improves efficiency, accuracy, and speed by reducing unnecessary computation.
3.4.5. R3D, R(2+1)D
Despite ResNet152 having only a 2D convolutional layer, it outperforms C3D on the video dataset. The development of a very deep 3D CNN from scratch results in expensive computational cost and memory demand. Three-dimensional convolution vs. (2+1)D convolution, which one is better? It is difficult to say, but we can explain as follows. Full 3D convolution used filter size , where d represents the height and width of the RGB image and t represents the temporal extent. On the other hand, (2+1)D splits the total operation into two sections, 2D convolution and 1D convolution, to reduce the computational complexity. R(2+1)D [162] uses a factorized 3D convolution: 2D convolutions in the spatial domain and 1D convolutions in the temporal domain. The update rule is:
where is the 2D spatial kernel and is the 1D temporal kernel.
3.4.6. P3D ResNet
Qiu et al. [161] proposed a novel architectural design termed Pseudo-3D ResNet (P3D ResNet), wherein each block is assembled in a distinct ResNet configuration. P3D is a pseudo 3D Convolutional Neural Network (3DCNN) constructed by combining C3D and ResNet architectures. For the Sports-1M dataset, P3D-ResNet achieves a performance accuracy of 66.4%, outperforming individual ResNet and C3D models, which achieve accuracies of 64.6% and 61.1%, respectively [161]. P3D can be categorized into three versions: P3D-A, which feeds spatial features into the temporal module and then concatenates with the residual unit. P3D-B is constructed by parallel concatenation of spatial, temporal, and residual units. P3D-C, which concatenates spatial, spatial–temporal, and residual units.
3.4.7. SlowFast Networks
SlowFast Networks use two streams, where a slow stream processes fewer frames per second (capturing long-term dependencies) and a fast stream processes more frames per second (capturing fast motion). The model was proposed by the Facebook AI Research Team and published in 2019 [177]. This model is inspired by biological studies on retinal ganglion cells. The outputs from both streams are fused. This network addresses low frame rate issues, where the slow pathway has low temporal resolution, and the fast pathway has high frame rate and temporal resolution. However, the fast pathway remains lightweight in terms of computational complexity due to the use of or of the channels, and it fuses the latest connections. The equations for the combined feature map are:
where and are the weights for slow and fast streams and is the input feature map. The slow and fast streams are then fused together to generate the final output. The Slow pathway uses a large temporal stride on input frames to focus on spatial information. It captures fine details and spatial patterns, similar to the parvocellular (P cell) function in retinal ganglion cells. This helps understand long-term data structure. The Fast pathway, with a smaller temporal stride, focuses on capturing temporal information. It has lower channel capacity compared to the Slow pathway and resembles the magnocellular (M cell) function in retinal ganglion cells. It specializes in detecting rapid visual changes, making it ideal for processing fast motion. What sets the Fast pathway apart is its ability to maintain good accuracy with a much lower channel capacity, making it efficient and lightweight in the SlowFast model.
3.4.8. X3D
This model was also proposed by Facebook AI Research and published in 2020 [167]. The basic network architecture is designed according to the ResNet and Fast pathway design for SlowFast networks. They have six expansion factors: , , , , , and . X-Fast increases the temporal activation size, , and frame-rate, , to improve temporal resolution while keeping the clip duration constant. X-Temporal extends both the duration and temporal resolution by sampling longer clips and increasing the frame-rate, . X-Spatial enhances the spatial resolution, , by improving the spatial sampling resolution of the input video. X-Depth increases the network’s depth by adding more layers per residual stage by . X-Width expands the number of channels uniformly across all layers using a global width factor, . Lastly, X-Bottleneck increases the inner channel width, , of the center convolutional filter in each residual block to improve processing efficiency. This paper presents X3D, a family of efficient video networks that progressively expand a tiny 2D image classification architecture along multiple network axes, in space, time, width, and depth. X3D [167] is a scalable architecture for video recognition. It adjusts the depth, width, and resolution of the 3D convolutions based on the computational resources. To expand the Basis Network to X3D, the model’s complexity, C, is first determined, where represents the initial complexity and denotes the desired increase. Each parameter (for ) is incrementally expanded until the model reaches the target complexity , defined as:
Six models, , are created, corresponding to each expanded parameter. The models are trained, and their performance is evaluated using a performance metric . The best-performing model, , is selected:
This best model, , becomes the new basis network, and the process can be repeated if further refinement is needed [167].
3.4.9. Vision Transformer (ViT)
Vision Transformer (ViT) is one of the crucial models designed for image classification tasks, utilizing a Transformer architecture originally developed for Natural Language Processing (NLP) [178]. ViT processes images by dividing them into non-overlapping patches and treating these patches as input tokens for a Transformer model, similar to how words are treated in text. Given that we are processing a batch of 100 videos, each with 32 frames, the input tensor V will have the shape:
where H and W are the height and width of each frame and C is the number of channels (e.g., 3 for RGB). For each video, V, we will extract patches from each frame. For each frame , we need to divide it into N non-overlapping patches, and we embed them into a patch embedding space:
Each patch is linearly projected to a fixed-dimensional vector using a convolutional layer:
Now, for each frame t, the patch embeddings will result in:
The full video sequence V now becomes a sequence of spatial tokens, with patches from all 32 frames:
Thus, the shape of the final tokenized video sequence will be:
where D is the dimensionality of each patch embedding. Then, multi-head self-attention is applied to the tokenized sequence of video frames. The attention mechanism computes the output sequence of tokens by considering the relationships between the tokens across both time and space:
where are the query, key, and value matrices, and is the dimension of the key vectors. After the self-attention operation, the model aggregates the output tokens (using global pooling, class token, or other aggregation methods) and projects it into the final class prediction:
where z is the final token representation after the Transformer encoder layers and W is the classification weight matrix.
3.4.10. Video Vision Transformer (ViViT)
ViViT [179] adapts the Vision Transformer (ViT) architecture for video data by extracting N non-overlapping spatio-temporal “tubes” from the input video, denoted as . Here, N is determined by the following expression:
where T, H, and W represent the temporal and spatial dimensions (time, height, and width) of the video and t, h, and w are the corresponding dimensions of each tube.
Each tube is then transformed into a token by a linear mapping operator E, as follows:
These tokens are concatenated together to form a sequence. A learnable class token, , is prepended to this sequence. Since transformers are permutation-invariant, a positional embedding is added to the sequence. Consequently, the tokenization process can be represented as:
Here, represent the token where z can be the sequence of the tokents, represent the learnable class token, x is the input data with position and E represent the mapping operator, and p represent the positional embedding. It is important to note that the linear projection E can be interpreted as a 3D convolution with a kernel size of and a stride of in the time, height, and width dimensions, respectively.
The resulting sequence of tokens, z, is then passed through a transformer encoder consisting of L layers. At each layer ℓ, the following operations are applied sequentially:
where MSA represents multi-head self-attention [173], LN refers to layer normalization, and MLP consists of two linear layers with a GeLU non-linearity in between.
Finally, a linear classifier, , maps the output of the encoded classification token, , to one of C possible classes.
The experimental results demonstrate the effectiveness of ViViT, with the ViViT-B model backbone and a tubelet size of 16 × 216 × 2 achieving high performance. The model is evaluated on two well-known benchmarks: Top-1 accuracy on Kinetics 400 (K400) and action accuracy on Epic Kitchens (EK). The runtime is measured during inference on a TPU-v3, showcasing the model’s efficiency and scalability [179].
3.4.11. Multiview Transformers for Video Recognition (MVT)
MVT [180] introduces a novel approach to video recognition by applying transformers to multiple views of the same video. By leveraging information from different perspectives, MVT improves recognition performance and robustness across various viewpoints. This approach enhances the model’s ability to capture diverse spatial and temporal patterns, making it particularly effective in complex video recognition tasks. MVT combines the strengths of two well-established models: SlowFast and ViViT. The SlowFast model, known for its ability to handle both fast and slow motions in video data, is integrated with ViViT, a transformer-based model that efficiently captures spatial and temporal dependencies in video. The MVT for video recognition based on the scenario in Equation (15) extracts multiple sets of tokens, , from the input video, where V is the number of views. Each view’s tokens are processed independently by separate transformer encoders with lateral connections for cross-view fusion. The tokens from all views are concatenated to form a unified sequence:
Due to the prohibitive computational cost of performing self-attention on all tokens from all views, a more efficient method is introduced by fusing tokens between adjacent views using Cross-View Attention (CVA). This is performed by applying attention where queries come from the larger view and keys and values from the smaller view, after projecting them to the same dimension [180]:
The attention is computed as [180]:
3.4.12. UniFormer-Based 3DCNN
UniFormer [181] is a new model that combines the advantages of CNNs and Vision Transformers (ViTs) to solve the challenges of learning representations from images and videos. CNNs reduce local redundancy but struggle to capture global dependencies due to their limited receptive fields. ViTs, on the other hand, capture long-range dependencies but suffer from high redundancy from comparing all tokens. UniFormer solves this by introducing a unique block structure with local and global token affinity, addressing both redundancy and dependency. A UniFormer block consists of three modules: Dynamic Position Embedding (DPE), Multi-Head Relation Aggregator (MHRA), and Feed Forward Network (FFN). This design allows UniFormer to handle both image and video inputs efficiently. UniFormer is highly versatile, working well for various vision tasks, from image classification to video understanding. It achieves state-of-the-art results across several benchmarks and outperforms traditional models like 3D CNNs without needing extra training data. UniFormer achieves 86.3% top-1 accuracy on ImageNet-1K classification and demonstrates state-of-the-art performance in various tasks, including 82.9%/84.8% top-1 accuracy on Kinetics-400/600, 60.9%/71.2% top-1 accuracy on Sth-Sth V1/V2, 53.8 box AP and 46.4 mask AP on COCO object detection, 50.8 mIoU on ADE20K semantic segmentation, and 77.4 AP on COCO pose estimation.
3.4.13. VideoMAE Based 3DCNN
VideoMAE (Video Masked Autoencoders) [182] is a self-supervised pre-training method designed to learn video representations efficiently, particularly on small datasets. Inspired by ImageMAE, VideoMAE uses a high masking ratio (90–95%) for video tube masking, which makes the reconstruction task more challenging. This higher masking ratio is possible due to the temporally redundant nature of videos, allowing VideoMAE to learn effective representations by focusing on the most informative content. VideoMAE shows that it can achieve impressive performance with a small number of training videos (around 3–4 k) without relying on additional data, unlike traditional models that require large-scale datasets. The model also demonstrates that the quality of data is more important than the quantity when it comes to self-supervised video pre-training. With this approach, VideoMAE achieves remarkable results on benchmarks like Kinetics-400 (87.4%), Something-Something V2 (75.4%), and UCF101 (91.3%) without any extra data.
3.4.14. InternVideo 3DCNN Model
InternVideo [183] is a general video foundation model that combines generative and discriminative self-supervised learning to improve video understanding. It utilizes two main pretraining objectives: masked video modeling and video-language contrastive learning. By selectively coordinating these complementary frameworks, InternVideo efficiently learns video representations that boost performance in various video applications. This approach allows InternVideo to achieve state-of-the-art results across 39 video datasets, covering tasks like action recognition, video-language alignment, and open-world video tasks. Notably, it achieves impressive top-1 accuracies of 91.1% on Kinetics-400 and 77.2% on Something-Something V2, demonstrating its effectiveness and general applicability for video understanding.
4. Skeleton Data Modality-Based Action Recognition Method
The main challenges of the RGB-based data modality-based HAR system are redundant background and computational complexity issues, and the skeleton-based data modality helps us overcome these challenges. In addition, coupling with joint coordinate estimation algorithms such as OpenPose and SDK [184] has improved the performance of accuracy and reliability of the skeleton data. Skeleton data obtained from the joint position offer several benefits over the RGB data, such as illumination variations, viewing angles, and background occlusions, making it less susceptible to noise interference. The research prefers to perform HAR by using skeleton data because they provide more focused information and reduce redundancy. Based on the feature extraction methods for HAR, the skeleton data can be divided into DL-based methods, relying on learned features, and ML-based methods, which use handcrafted features. In addition, the skeleton data depend on the precise joint position and pose estimation techniques.
Figure 7 shows the framework of skeleton-based approaches. Table 4 describes key information regarding the skeleton-based data modality on the existing model, including datasets, classification methods, years, and performance accuracy. We describe the well-known pose estimation algorithms in the following section.

Figure 7.
Workflow of skeleton-based action recognition.
4.1. Skeleton-Based HAR Dataset
We provided the most popular benchmark HAR datasets, which come from the skeleton, which is demonstrated in Table 2. The dataset table demonstrates details of the datasets, including modalities, creation year, number of classes, number of subjects who participated in recording the dataset, number of samples, and the latest performance accuracy of the dataset with citations. The Skeleton dataset includes a variety of notable benchmarks essential for HAR. The UPCV dataset from 2014 features 10 classes, 20 subjects, and 400 samples, achieving an outstanding accuracy of 99.2% [75,76]. The NTU RGB+D dataset, introduced in 2016 and expanded in 2019, is one of the most comprehensive, with 60 and 120 classes, 40 and 106 subjects, and 56,880 and 114,480 samples, respectively, both versions recording an accuracy of 97.4% [86,91,97]. The MSRDailyActivity3D dataset from 2012 includes 16 classes, 10 subjects, and 320 samples, with an accuracy of 97.5% [83,84]. The PKU-MMD dataset from 2017 contains 51 classes, 66 subjects, and 10,076 samples, with a notable accuracy of 94.4% [92,93]. The Multi-View TJU dataset from 2014 offers 20 classes, 22 subjects, and 7040 samples. These datasets are crucial for training and testing HAR models, offering diverse activities and scenarios to enhance model robustness and accuracy.
4.2. Pose Estimation
We can extract human joint skeleton points from the RGB video using media pipe, openpose, AlphaPose [185,186], MMPose, etc. Using a media pipe, Figure 8 demonstrates the 33 joint skeleton points for the whole body. Human limb trunk reconstruction includes estimating human pose by detecting joint positions in the skeleton and establishing their connections. Traditional methods, relying on manual feature labeling and regression for joint coordinate retrieval, suffer from low accuracy and are highly sensitive to occlusion. DL-based methods, including 2D and 3D pose estimation, have become pivotal in this research domain.
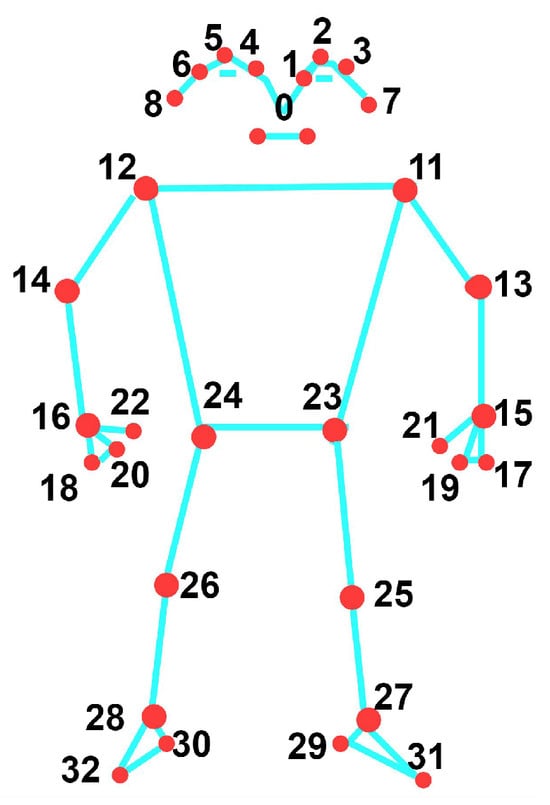
Figure 8.
Positions of the 33 key landmarks on the human body. (0) Nose, (1) Left eye inner, (2) Left eye, (3) Left eye outer, (4) Right eye inner, (5) Right eye, (6) Right eye outer, (7) Left ear, (8) Right ear, (9) Mouth left, (10) Mouth right, (11) Left shoulder, (12) Right shoulder, (13) Left elbow, (14) Right elbow, (15) Left wrist, (16) Right wrist, (17) Left pinky, (18) Right pinky, (19) Left index, (20) Right index, (21) Left thumb, (22) Right thumb, (23) Left hip, (24) Right hip, (25) Left knee, (26) Right knee, (27) Left ankle, (28) Right ankle, (29) Left heel, (30) Right heel, (31) Left foot index, (32) Right foot index.
4.2.1. Two-Dimensional Human Pose Estimation-Based Methods
The objective of 2D human pose estimation is to identify significant body parts in an image and connect them sequentially to form a human skeleton graph. Research commonly addresses the classification of single and multiple human subjects. In single-person pose estimation, the goal is to detect a solitary individual in an image. This involves first recognizing all joints of the person’s body and subsequently generating a bounding box around them. Two main categories of models exist for single-person pose estimation. The first utilizes a direct regression approach, where key points are directly predicted from extracted features. In 2D pose estimation, one can employ deformable part models to recognize the object by matching a set of templates. Nevertheless, these deformable part models exhibit limited expressiveness and fail to consider the global context. Yan et al. [187] proposed a pose-based approach and performed two main methods: detection-based and regression-based approaches. Detection-based methods utilize powerful part detectors based on CNNs, which can be integrated using graphical models, as described by Yuille et al. [188]. For solving the detection problem, pose estimation can be represented as a heat map where each pixel indicates the detection confidence of a joint, as outlined by Bulat et al. [189]. However, detection approaches do not directly provide joint coordinates. A post-processing step is applied to recover poses where (x, y) coordinates are obtained by utilizing the max function. Toshev et al. [190] proposed a cascade of regressor methods to estimate poses; they employ the regression-based approach with a nonlinear function that maps the joint coordinates and refines pose estimates. Carreira et al. [191] proposed the Iterative Error Feedback (IEF) approach, where iterative prediction is performed to correct the current estimates. Instead of predicting outputs in a single step, a self-correcting model is employed, which modifies an initial solution by incorporating error predictions, also called IEF. However, the sub-optimal nature of the regression function leads to lower performance than detection-based techniques.
4.2.2. Three-Dimensional Human Pose Estimation-Based Methods
Conversely, when presented with an image containing an individual, the objective of 3D pose estimation is to generate a 3D pose that accurately aligns with the spatial location of the person depicted. The accurate reconstruction of 3D poses from real-life images holds significant potential in various fields of HAR, such as entertainment and human–computer interaction, particularly indoors and outdoors. Earlier approaches relied on feature engineering techniques, whereas the most advanced techniques are based on deep neural networks, as proposed by Zhou et al. [192] Three-dimensional pose estimation is acknowledged to be more complex than its 2D handle due to its management of a larger 3D pose space and an increased number of ambiguities. Nunes et al. [193] presented skeleton extraction through depth images, wherein skeleton joints are inferred frame by frame. A manually selected set of 15 skeleton joints, as determined by Gan et al. [112], are used to form an APJ3D representation, which is based on relative positions and local spherical angles. These 15 joints, which have been deliberately selected, play a crucial role in the development of a concise representation of human posture. Spatial features are encoded using diverse metrics, including joint distances, orientations, vectors, distances between joints and lines, and angles between lines. These measures collectively contribute to a comprehensive texture feature set, as suggested by Chen et al. [194]. Additionally, a CNN-based network is trained to recognize corresponding actions.
Table 4.
Skeleton-based action recognition methods using handcrafted and deep learning approaches.
Table 4.
Skeleton-based action recognition methods using handcrafted and deep learning approaches.
| Author | Year | Dataset Name | Modality | Method | Classifier | Accuracy [%] |
|---|---|---|---|---|---|---|
| Veeriah et al. [195] | 2015 | MSRAction3D KTH-1 (CV) KTH-2 (CV) | Skeleton | Differential RNN | Softmax |
92.03 93.96, 92.12 |
| Xu et al. [116] | 2016 | MSRAction3D UTKinect Florence3D action | Skeleton | SVM with PSO | SVM | 93.75 97.45, 91.20 |
| Zhu et al. [196] | 2016 | SBU Kinect HDM05, CMU | Skeleton | Stacked LSTM | Softmax | 90.41 97.25, 81.04 |
| Li et al. [197] | 2017 | UTD-MHAD NTU-RGBD (CV) NTU-RGBD (CS) | Skeleton | CNN | Maximum Score | 88.10 82.3 76.2 |
| Soo et al. [198] | 2017 | NTU-RGBD (CV) NTU-RGBD (CS) | Skeleton | Temporal CNN | Softmax | 83.1 74.3 |
| Liu et al. [160] | 2017 | NTU-RGBD (CS) NTU-RGBD (CV) MSRC-12 (CS) Northwestern-UCLA | Skeleton | Multi-stream CNN | Softmax | 80.03, 87.21 96.62, 92.61 |
| Das et al. [199] | 2018 | MSRDailyActivity3D NTU-RGBD (CS) CAD-60 | Skeleton | Stacked LSTM | Softmax | 91.56 64.49, 67.64 |
| Si et al. [200] | 2019 | NTU-RGBD (CS) NTU-RGBD (CV) UCLA | Skeleton | AGCN-LSTM | Sigmoid | 89.2, 95.0 93.3 |
| Shi et al. [201] | 2019 | NTU-RGBD (CS) NTU-RGBD (CV) Kinetics | Skeleton | AGCN | Softmax | 88.5 95.1 58.7 |
| Trelinski et al. [202] | 2019 | UTD-MHAD MSR-Action3D | Skeleton | CNN-based | Softmax | 95.8, 77.44 80.36 |
| Li et al. [203] | 2019 | NTU-RGBD (CS) Kinetics (CV) | Skeleton | Actional graph based CNN | Softmax | 86.8 56.5 |
| Huynh et al. [204] | 2019 | MSRAction3D UTKinect-3D SBU-Kinect Interaction | Skeleton | ConvNets | Softmax | 97.9 98.5, 96.2 |
| Huynh et al. [205] | 2020 | NTU-RGB+D UTKinect-Action3D | Skeleton | PoT2I with CNN | Softmax | 83.85, 98.5 |
| Naveenkumar et al. [206] | 2020 | UTKinect-Action3D NTU-RGB+D | Skeleton | Deep ensemble | Softmax | 98.9, 84.2 |
| Plizzari et al. [207] | 2021 | NTU-RGBD 60 NTU-RGBD 120 Kinetics Skeleton-400 | Skeleton | ST-GCN | Softmax | 96.3, 87.1 60.5 |
| Snoun et al. [208] | 2021 | RGBD-HuDact, KTH | Skeleton | VGG16 | Softmax | 95.7, 93.5 |
| Duan et al. [209] | 2022 | NTU-RGBD UCF101 | Skeleton | PYSKL | - | 97.4, 86.9 |
| Song et al. [210] | 2022 | NTU-RGBD | Skeleton | GCN | Softmax | 96.1 |
| Zhu et al. [211] | 2023 | UESTC NTU-60 (CS) | Skeleton | RSA-Net | Softmax | 93.9, 91.8 |
| Zhang et al. [212] | 2023 | NTU-RGBD Kinetics-Skeleton | Skeleton | Multilayer LSTM | Softmax | 83.3 27.8 (Top-1) 50.2 (Top-5) |
| Liu et al. [213] | 2023 | NTU-RGBD 60 (CV)NTU-RGBD 120 (CS) | Skeleton | LKJ-GSN | Softmax | 96.1 86.3 |
| Liang et al. [214] | 2024 | NTU-RGBD (CV) NTU-RGBD 120 (CS) FineGYM | Skeleton | MTCF | Softmax | 96.9, 86.6 94.1 |
| Karthika et al. [215] | 2025 | NTU-RGBD 60 NTU-RGBD 120 Kinetics-700 Micro- Action-52 | Skeleton | Stacked Ensemble | Logistic Regression |
97.87 98.0 97.50 95.20 |
| Sun et al. [216] | 2025 | Self collected KTH UTD-MHAD | Skeleton | Multi channel fussion | Logistic Regression | 98.16 92.85 84.98 |
| Mehmood et al. [217] | 2025 | NTU-RGB+D (CS/CV) Kinetics UCF-101 HMDB-51 | Skeleton | EMS-TAGCN | Logistic Regression | 91.3/97.5 62.3 51.24 72.7 |
4.3. Handcrafted Feature and ML-Based Classification Approach
Researchers determine handcrafted features using statistical features extracted from action data. These features describe the dynamics or statistical properties of the action analyzed. Yang et al. [18] proposed a method to extract the super vector features to determine the action based on the depth information. Shao et al. [218] combined shape and motion information for HAR through temporal segmentation, utilizing MHI and Predicted Gradients (PCOG) as feature descriptors. Yang et al. [219] introduced the Depth Motion Map (DMM) technique, which allows for the projection and compression of the spatio-temporal depth structure from different viewpoints, including the side, front, and upper views. This process results in the formation of three distinct motion history maps. To represent these motion history maps, the authors employed the HOG feature. Instead of using HOG, Chen et al. [111] employed local features to describe human activities based on Dynamic Motion Models (DMMs). Additionally, Chen et al. [220] introduced a spatio-temporal depth layout across frontal, lateral, and upper orientations. Departing from depth compression methods, they extracted motion trajectory shapes and boundary histogram features from spatio-temporal interest points, leveraging dense sampling and joint points in each perspective to depict actions. Moreover, Miao et al. [221] applied the discrete cosine variation technique for the effective compression of depth maps. Simultaneously, they generated action features by utilizing transform coefficients. From the available depth data, it is possible to estimate the structure of the human skeleton promptly and precisely. Shotton et al. [222] proposed a method for the real-time estimation of body postures from depth images, thereby facilitating the rapid segmentation of humans based on depth. Within this context, the problem of detecting joints has been simplified to a per-pixel classification task. Additionally, there is ongoing research in the field of HAR that employs depth data and focuses on methods utilizing the human skeleton. These approaches analyze changes in the joint points of the human body across consecutive video frames to characterize actions, encompassing alterations in both the position and appearance of the joint points. Xia et al. [223] proposed a three-dimensional joint point histogram as a means to depict the human pose and subsequently formulated the action using a discrete hidden Markov model. Keceli et al. [224] captured depth and human skeleton information via employment of the Kinect sensor, and subsequently derived human action features by assessing angle and displacement information regarding the skeleton joint points. Similarly, Yang et al. [21] developed a method based on the EigenJoints, which leverages an Accumulative Motion Energy (AME) function to identify video frames and joint points that offer richer information for action modeling. Pazhoumand et al. [225] utilized the longest common subsequence method to select distinctive features with high discriminatory power from the skeleton’s relative motion trajectories, thereby providing a comprehensive description of the corresponding action.
Handcrafted features offer high interpretability and simplicity and are straight-forward to use. However, the handcrafted feature-based method requires prior knowledge, which is difficult to generalize.
4.4. End-to-End Deep Learning-Based Approach
Recently, there has been a growing acknowledgment in HAR of the advantages of integrating skeleton data with DL-based techniques. The handcrafted features have reduced discriminative capability for HAR; conversely, to extract features efficiently, the utilization of methods based on DL necessitates a substantial quantity of training data. Figure 9 demonstrates the year-wise end-to-end DL-based method developed by various researchers for RGB and skeleton-based HAR systems. As shown, several notable models leveraging Recurrent Neural Networks (RNNs), CNN, and GCN have been developed.
4.4.1. CNN-Based Methods
Skeleton data combined with ML methods provide efficient action recognition capabilities. Zhang et al. [226] utilized the Kinect sensor to capture skeletal representations, enabling the recognition of actions based on body part movements. Skeleton data paired with CNNs offer robust action recognition. As a result, in the work of Wang et al. [47], an advantage is found in combining handcrafted and DL-based features through the use of an enhanced trajectory. Additionally, the Trajectory-pooled Deep-Convolutional Descriptor (TpDD), also referred to as Two-stream ConvNets, is employed. The construction of an effective descriptor is achieved through the learning of multi-scale convolutional feature maps within a deep architecture. Ding et al. [227] developed a CNN-based model to extract high-level effective semantic features from RGB textured images obtained from using skeletal data. However, these methodologies have a significant amount of preprocessing steps and a chance to miss some effective information. Caetano et al. suggested SkeleMotion [228], which offers a novel skeleton image representation as an alternative input for neural networks to address these issues. Researchers have explored solutions to the challenge of long-time dependence, especially considering that CNNs do not extract long-distance motion information. To overcome this issue, Liu et al. [229] suggested a Subsequence Attention Network (SSAN) to improve the capture of long-term features. This network, combined with 3DCNN, uses skeleton data to record long-term features more effectively. Sun et al. [216] proposed a network for encoding 3D skeletal joint data into grayscale images and classifying human activities using a three-channel ResNet34-based fusion network, while noting potential limitations in handling occlusions and multi-person scenarios due to reliance on unobstructed single-person video inputs.
4.4.2. RNN-LSTM-Based Methods
Approaches relying on Recurrent Neural Networks (RNNs) with LSTM [230,231] have garnered considerable popularity as a predominant DL methodology for skeleton-based action recognition. Moreover, these approaches have demonstrated exceptional proficiency in accomplishing video-based action recognition tasks [91,149,195,196,232,233]. The spatio-temporal patterns of skeletons exhibit temporal evolutions. Consequently, these patterns can be effectively represented by memory cells within the structure of RNN-LSTM models, as proposed by [230]. In a similar way, Du et al. [232] introduced a hierarchical RNN approach to capture the long-term contextual information of skeletal data. This involved dividing the human skeleton into five distinct parts based on its physical structure. Subsequently, each lower-level part was represented using an RNN, and these representations were then integrated to form the final representation of higher-level parts, which facilitated action classification. The problem related to gradient explosion and vanishing gradients occurs if the sequences are too long for actual training. To overcome this issue, Li et al. [234] suggested an Independent Recurrent Neural Network (IndRNN) to regulate gradient backpropagation over time, allowing the network to capture long-term dependencies. Shahroudy et al. [91] introduced a model for human action learning using a part-aware LSTM. This model involves splitting the long-term memory of the entire motion into part-based cells and independently learning the long-term context of each body part. The network’s output is then formed by combining the independent body part context information. Liu et al. [149] presented a spatio-temporal LSTM network named ST-LSTM, aimed at 3D action recognition from skeletal data. They proposed a technique called skeleton-based tree traversal to feed the structure of the skeletal data into a sequential LSTM network and improved the performance of ST-LSTM by incorporating additional trust gates. In their recent work, Liu et al. [233] directed their attention towards the selection of the most informative joints in the skeleton by employing a novel type of LSTM network called Global Context-Aware Attention (GCA-LSTM) to recognize actions based on 3D skeleton data. Two layers of LSTM were utilized in his study. The initial layer encoded the input sequences and produced a global context memory for these sequences. Simultaneously, the second layer carried out attention mechanisms over the input sequences with the support of the acquired global context memory. The resulting attention representation was subsequently employed to refine the global context. Numerous iterations of attention mechanisms were conducted, and the final global contextual information was employed in the task of action classification. Compared to the methodologies based on hand-crafted designed local features, the RNN-LSTM methodologies and their variations have demonstrated superior performance in the recognition of actions. Nevertheless, these methodologies tend to excessively emphasize the temporal information while neglecting the spatial information of skeletons [91,149,195,215,232,233]. RNN-LSTM methodologies continue to face difficulties in dealing with the intricate spatio-temporal variations of skeletal movements due to multiple issues, such as jitters and variability in movement speed. Another drawback of the RNN-LSTM networks [230,231] is their sole focus on modeling the overall temporal dynamics of actions, disregarding the detailed temporal dynamics. To address these limitations, in this investigation a CNN-based methodology can extract discriminative characteristics of actions and model the various temporal dynamics of skeleton sequences via the suggested Enhanced-SPMF representation, encompassing short-term, medium-term, and long-term actions.
4.4.3. GNN or GCN-Based Methods
Graph Convolutional Neural Networks (GCNNs) are powerful DL-based methods designed to perform with non-Euclidean data. Unlike traditional CNNs and RNNs, which perform well with Euclidean data (such as images, text, and speech), they are unable to perform with non-Euclidean data [235,236,237,238,239,240]. The GCN was first introduced by Gori et al. [241] in 2005 to handle graph data. GCNNs with skeleton data enable spatial dependencies to be captured for accurate action recognition. The human skeleton data, consisting of joint points and skeletal lines, can be viewed as non-Euclidean graph data. Therefore, GCNs are particularly suited for learning from such data. There are two main branches of GCNs: Spectral GCN and Spatial GCN.
4.4.4. Spectral GCN-Based Methods
Using and leveraging both eigenvalues and eigenvectors of the Graph Laplacian Matrix (GLM) to convert graph data from the temporal to the spatial domain [242], this model is not computationally efficient. To address this issue, Kipf et al. [243] enhanced the spectral GCN approach by allowing the filter operation of only one neighbor node to reduce the computational cost. While spectral GCNs have shown effectiveness in HAR tasks, their computational cost poses challenges when dealing with graphs.
4.4.5. Spatial GCN-Based Methods
Spatial GCN-based methods are more efficient in terms of computational than spectral GCNs. Therefore, spatial GCNs have become the main focus in many GCN-based HAR approaches due to efficiency. Yan et al. [244] developed the concept of ST-GCN, a model specifically designed for spatio-temporal data. As depicted in Figure 10, the ST-GCN, bodily joints (such as joints in a human skeleton) serve as the vertices in the graph while the edges denote the connection between the bodily bones within the same frame. Shi et al. [201] developed two-stream adaptive GCN models to improve the flexibility of graph networks. This model allows for the use of the end-to-end approach to learning the graph’s topology within the model. By adopting a data-driven methodology, the 2S-AGCN model becomes more adaptable to diverse data samples, increasing flexibility. Additionally, an attention mechanism is included to improve the robustness of the 2sAGCN model. For a further improvement to explore the enhancement of HAR methods, Shiraki et al. [245] proposed the spatio-temporal attentional graph (STA)-GCN to determine the challenge of varying the importance of joints across different human actions. Unlike traditional GCNs, STA-GCN takes into account both the significance and interrelationship of joints within the graph. Researchers have drawn inspiration from STA-GCN to further enhance GCN models [246,247]. For instance, the shift-GCN [248] model introduces the innovative shift-graph method to enhance the flexibility of the Spatio-Temporal Graph’s (STG) receptive domain. Additionally, the lightweight dot convolution technique is utilized to reduce the number of feature channels and make the model more efficient. Song et al. [249] present the residual-based GCN model to improve the performance of the model in terms of accuracy and computational efficiency for HAR. Similarly, Thakkar et al. [250] and Li et al. [251] presented methods to divide the human skeleton into separate body parts, and they developed the Partial-Based Graph Convolutional Network (PB-GCN) [250], which learns four subgraphs of the skeleton data. Li et al. [251] developed the Spatio-Temporal Graph Routing (STGR) scheme to better determine the connections between joints. Mehmood et al. [217] proposed EMS-TAGCN, a multi-stream adaptive GCN with spatial–temporal-channel attention for skeleton-based HAR, achieving good results across multiple datasets while recognizing increased model complexity and limited scalability without additional optimization. These methods help improve the segmentation of body parts for HAR. Table 5 summarizes the key comparative analysis of GCN variants in the skeleton-based HAR method, including findings and limitations.
Table 5.
Comparison of prominent GCN-based models used in HAR.
4.5. Mathematical Derivation of the Skeleton-Based Learning Methods
For skeleton-based HAR, the given dataset is defined as:
where is the i-th training example representing a skeleton sequence and is the true label of the corresponding . Each skeleton training example is represented as a spatio-temporal graph:
where is the set of nodes, is the set of nodes (keypoints), and E is the set of edges (spatial and temporal connections). Each node represents a keypoint in the t-th frame, and each node has a feature vector (e.g., 3D coordinates with or without confidence scores) [175]. The notation refers to the feature vector for a node , which is a keypoint in the spatio-temporal graph for HAR. Each node represents a keypoint (joint) in the skeleton sequence, and contains the characteristics describing that keypoint. Typically, these features include the 3D coordinates of the keypoint, , making . If confidence scores are included, , and additional features increase the dimensionality c accordingly.
4.5.1. GCN
Let G be a graph representing the skeleton of a human body in each frame, and where . In addition, given the adjacency matrix A, which defines the spatial (intra-body) and temporal (inter-frame) relationships between nodes, the GCN layer update rule is:
where is the feature matrix at layer l with N nodes and features, is the normalized adjacency matrix, is the learnable weight matrix at layer l, is the activation function (e.g., ReLU), and is the updated feature matrix. We can also write it as a GCN feature .
4.5.2. ST-GCN
To improve the efficiency of the feature, Yan et al. applied the ST-GCN model as a spatio-temporal graph, applying graph convolutions to learn both spatial and temporal relationships. The convolution is defined in [244] as ST-GCN; the convolution is applied over a spatio-temporal graph, where both the adjacency matrix (spatial relationships) and the temporal connections (connections between the same keypoints across time) are considered. So, the update rule for the ST-GCN layer becomes [244]:
We can define the equation as below to understand the spatial–temporal GCN rules.
Here is the normalized adjacency matrix, is the learnable weight matrix at layer l, is the activation function (e.g., ReLU). In addition in the GCN equation corresponds to adding self-loops to the adjacency matrix to ensure that each node can aggregate information from itself. The degree matrix D normalizes the adjacency matrix to prevent nodes with high degrees from dominating the aggregation. To link the spatial–temporal convolution from ST-GCN [244] with the GCN update rule, Equation (33), we adapt the updated equation to consider both spatial and temporal dependencies, similar to the GCN framework. The spatial convolution within each frame is modeled by the adjacency matrix A and its normalization, whereas the temporal information is captured by connecting keypoints across frames. This can be done by modifying the adjacency matrix to include temporal connections (i.e., edges that link the same keypoints from consecutive frames). The final GCN-like update rule for ST-GCN, combining spatial and temporal dependencies, is:
where captures the spatial relationships between keypoints within each frame, captures the temporal relationships, linking the same keypoints across frames (i.e., between frame t and frame ), I is the identity matrix, ensuring that each node aggregates information from itself (self-loops), and m is the activation function (if needed, but you can omit it for a linear GCN).
4.5.3. STA-GCN
STA-GCN enhances feature learning by adding spatial and temporal attention mechanisms. Spatial attention is applied as [245]:
where is the feature matrix of the graph nodes, is the sigmoid activation function, is the spatial attention weight matrix, is the feature vector at time step t, and is the temporal attention weight matrix. STA-GCN improves the feature learning process of the HAR by introducing attention mechanisms, which allow the model to focus on more relevant spatial and temporal features. This is particularly useful when certain key points or time steps have more significance than others in the HAR task, leading to better performance and robustness in dynamic environments.
4.5.4. Shift-GCN
Shi et al. [201] introduces a simple shift operation to capture temporal dynamics efficiently:
where is the shifted feature of node , is the input feature of node at time , and is the temporal shift offset. Shift-GCN offers a simple and computationally efficient way to capture temporal dynamics by shifting the node features in time. Unlike more complex models such as RNNs or LSTMs, Shift-GCN directly leverages prior time step information.
4.5.5. InfoGCN
InfoGCN applies an information bottleneck to encourage compact, discriminative features. The loss is defined as [252]:
where is the variational distribution of features given skeleton graph S, is the loss function (e.g., cross-entropy), is the classifier with parameters , y is the ground truth label, is the trade-off weight for the mutual information term, and is the mutual information between input graph S and features f. InfoGCN uses an information bottleneck to encourage the model to learn compact and discriminative features. It balances the loss function with a mutual information term to optimize for compactness and relevance of features while retaining the ability to make accurate predictions.
4.5.6. EMS-TAGCN
EMS-TAGCN adds an edge-motion stream that explicitly models joint-to-joint dynamics [253]:
where is the relative motion feature between nodes i and j and is the feature vectors of nodes i and j. EMS-TAGCN introduces an edge-motion stream that explicitly models joint-to-joint dynamics, improving the model’s ability to capture the motion between pairs of joints over time. This helps in understanding the relative motion between body parts in HAR. This survey explores the evolution of skeleton-based HAR models, examining various Graph Convolutional Networks (GCNs) such as GCN, ST-GCN, STA-GCN, Shift-GCN, InfoGCN, and EMS-TAGCN. Each model applies mathematical principles to learn spatial and temporal dependencies, enhance feature learning, and capture motion dynamics. For example, GCN applies capturing graph-based joint relationships between keypoints in each frame, as seen in Equation (33), while ST-GCN extends this to a spatio-temporal graph, incorporating both spatial adjacency and temporal connections (Equation (34)). The STA-GCN model introduces attention mechanisms (Equation (37)) to focus on relevant spatial and temporal features, improving performance in dynamic environments. Meanwhile, Shift-GCN simplifies temporal dynamics by shifting features over time (Equation (38)), improving computational efficiency. InfoGCN applies an information bottleneck (Equation (39)) to learn compact, discriminative features, while EMS-TAGCN models joint-to-joint dynamics by adding an edge-motion stream (Equation (40)) to capture relative motion between keypoints. Together, these models demonstrate how the field has evolved to tackle key challenges in skeleton-based HAR, such as learning adaptable structures, focusing on relevant features, and modeling subtle joint dynamics while acknowledging trade-offs like computational cost and sensitivity to noise.
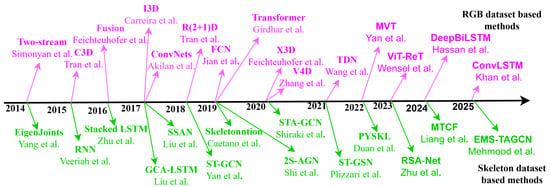
Figure 9.
Milestone approaches for HAR: RGB-based milestone methods are in pink font [22,23,50,52,57,61,63,64,65,154,162,167,169,174,180] while skeleton-based milestone methods are in green font [21,160,195,196,201,207,209,211,214,217,228,233,244,245].
Figure 9.
Milestone approaches for HAR: RGB-based milestone methods are in pink font [22,23,50,52,57,61,63,64,65,154,162,167,169,174,180] while skeleton-based milestone methods are in green font [21,160,195,196,201,207,209,211,214,217,228,233,244,245].
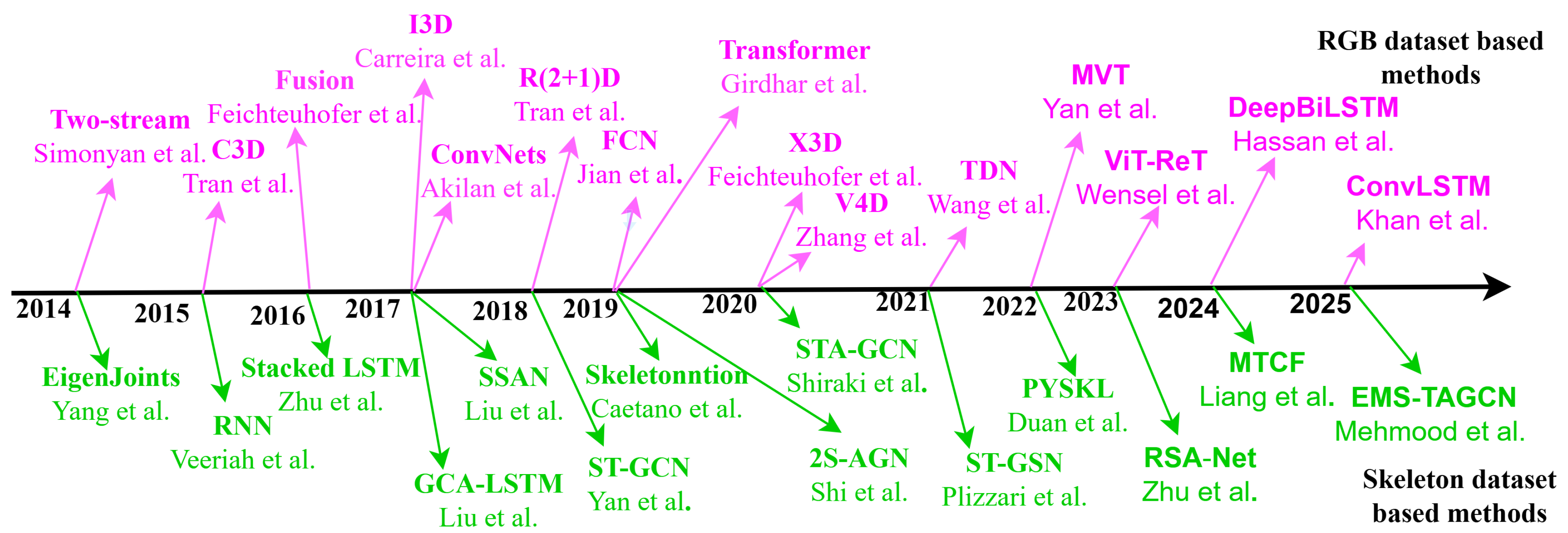
Figure 10.
Skeleton-based HAR using ST-GCN [244].
Figure 10.
Skeleton-based HAR using ST-GCN [244].
5. Sensor-Based HAR
We summarize several publicly available datasets in Table 6, including year, sensor modalities, number of sensors, number of participants, number of activities, activity categories, and latest performance accuracy. Sensor-based HAR has gained significant attention due to the advancements in wearable technology and its applications in various domains. These include health monitoring, industrial safety, sports training, and more [254]. Unlike computer vision-based or Wi-Fi-based HAR, wearable sensors offer advantages such as privacy, user acceptance, and independence from environmental factors [255]. Challenges in sensor-based HAR include diverse data collection, handling missing values, and complex activity recognition. Wearable devices use sensors like accelerometers and gyroscopes to identify human activities, but both feature extraction and model training remain challenging. The challenges with machine learning approaches rely on manual feature extraction [256], while the DL approaches now enable automatic feature extraction from raw sensor data, leading to superior results [255]. Overall, sensor-based HAR holds promise for improving healthcare and safety [257,258].
Table 7 summarizes various existing works based on sensor modality for HAR using traditional ML and DL techniques, including the author name, year, datasets, modality sensor names, methods, classifier, and performance accuracy [259]. As mentioned in the table, researchers have enhanced HAR classification performance by improving ML feature engineering, and some researchers have developed advanced DL models like CNN and LSTM for automatic feature extraction. Most studies utilized datasets from multiple sensor types placed at different body positions.
Table 6.
Databases for sensor modality.
Table 6.
Databases for sensor modality.
| Dataset Names | Year | Sensor Modalities | No. of Sensors | No. of People | No. of Activities | Activity Categories | Latest Performances |
|---|---|---|---|---|---|---|---|
| HHAR [260] | 2015 | Accelerometer, Gyroscope | 36 | 9 | 6 | Daily living activity, Sports fitness activity | 99.99% [261] |
| MHEALTH [262] | 2014 | Accelerometer, Gyroscope, Magnetometer, Electrocardiogram | 3 | 10 | 12 | Atomic activity, Daily living activity, Sports fitness activity | 97.83% [263] |
| OPPT [264] | 2013 | Acceleration, Rate of Turn Magnetic field, Reed switches | 40 | 4 | 17 | Daily living activity, Composite activity | 100% [265] |
| WISDM [266] | 2011 | Accelerometer, Gyroscopes | 1 | 33 | 6 | Daily living activity, Sports fitness activity | 97.8% [267] |
| UCIHAR [268] | 2013 | Accelerometer, Gyroscope | 1 | 30 | 6 | Daily living activity | |
| PAMAP2 [269] | 2012 | Accelerometer, Gyroscope, Magnetometer, Temperature | 4 | 9 | 18 | Daily living activity, Sports fitness activity, Composite activity | 94.72% [270] 82.12% [265] 90.27% [267] |
| DSADS [271] | 2010 | Accelerometer, Gyroscope Magnetometer | 45 | 8 | 19 | Daily living activity, Sports fitness activity | 99.48% [272] |
| RealWorld [273] | 2016 | Acceleration | 7 | 15 | 8 | Daily living activity, Sports fitness activity | 95% [274] |
| Exer. Activity [275] | 2013 | Accelerometer, Gyroscope | 3 | 20 | 10 | Sports fitness activity | - |
| UTD-MHAD [88] | 2015 | Accelerometer, Gyroscope RGB camera, depth camera | 3 | 8 | 27 | Daily living activity, Sports fitness activity Composite activity Atomic activity | 76.35% [276] |
| Shoaib [277] | 2014 | Accelerometer, Gyroscope | 5 | 10 | 7 | Daily living activity, Sports fitness activity | 99.86% [278] |
| TUD [279] | 2008 | Accelerometer | 2 | 1 | 34 | Daily living activity, Sports fitness Composite activity | - |
| SHAR [280] | 2017 | Accelerometer | 2 | 30 | 17 | Daily living activity, Sports fitness activity Atomic activity | 82.79% [281] |
| USC-HAD [282] | 2012 | Accelerometer, Gyroscope | 1 | 14 | 12 | Daily living activity, Sports fitness activity activity | 97.25% [281] |
| Mobi-Act [283] | 2016 | Accelerometer, Gyroscope orientation sensors | 1 | 50 | 13 | Daily living activity, Atomic activity activity | 75.87% [284] |
| Motion Sense [285] | 2018 | Accelerometer, Gyroscope | 1 | 24 | 6 | Daily living activity | 95.35% [286] |
| van Kasteren [287] | 2011 | switches, contacts passive infrared (PIR) | 14 | 1 | 10 | Daily living activity Composite activity activity | - |
| CASAS [288] | 2012 | Temperature Infrared motion/light sensor | 52 | 1 | 7 | Daily living activity Composite activity activity | 88.4% [289] |
| Skoda [290] | 2008 | Accelerometer | 19 | 1 | 10 | Daily living activity Composite activity activity | 97% [291] |
| Widar3.0 [253] | 2019 | Wi-Fi | 7 | 1 | 6 | Atomic activity | 82.18% [292] |
| UCI [268] | 2013 | Accelerometer, Gyroscope | 2 | 30 | 6 | Human activity | 95.90% [270] |
| HAPT [293] | 2016 | Accelerometer, Gyroscope | 1 | 30 | 12 | Human activity | 92.14% [270] 98.73% [278] |
Table 7.
Sensor data modality-based HAR models and performance.
Table 7.
Sensor data modality-based HAR models and performance.
| Author | Year | Dataset Name | Modality Sensor Name | Methods | Classifier | Accuracy % |
|---|---|---|---|---|---|---|
| Jain et al. [294] | 2017 | UCI HAR | IMU Sensor | Fusion based | SVM, KNN | 97.12 |
| Ignatov et al. [295] | 2018 | WISDM UCI HAR | IMU Sensor | CNN | Softmax | 93.32 97.63 |
| Chen et al. [296] | 2019 | MHEALTH PAMAP2 UCI HAR | IMU | CNN | Softmax | 94.05, 83.42 81.32 |
| kavuncuouglu et al. [297] | 2021 | Fall and ADLs | Accelerometer Gyroscope Magnetometer | ML | SVM K-NN | 99.96 95.27 |
| Lu et al. [298] | 2022 | WISDM, PAMAP2 UCI-HAR | IMUs Accelerometers | CNN-GRU | Softmax | 96.41 96.25 96.67 |
| Kim et al. [299] | 2022 | WISDM USC-HAR | IMUs | CNN-BiGRU | Softmax | 99.49 88.31 |
| Lin et al. [300] | 2020 | Smartwach | Accelerometer gyroscope | Dilated CNN | Softmax | 95.49 |
| Nadeem et al. [301] | 2021 | WISDM PAMAP2 USC-HAD | IMU | HMM | Softmax | 91.28 91.73 90.19 |
| Zhang et al. [302] | 2020 | WiFi CSI | WiFi signal | Dense-LSTM | Softmax | 90.0 |
| Alawneh et al. [303] | 2020 | UniMib Shar WISDM | Accelerometer IMU Sensor | Bi-LSTM | Softmax | 99.25 98.11 |
| Wei et al. [304] | 2024 | WISDM PAMAP2 USC-HAD | IMU | TCN-Attention | Softmax | 99.03 98.35 96.32 |
| Yao et al. [281] | 2024 | PAMAP2 USC-HAD, UniMiB-SHAR OPPORTUNITY | IMUs Accelerometers | ELK ResNet | Softmax | 95.53 97.25 82.79 87.96 |
| El-Adawi et al. [263] | 2024 | MHEALTH | IMU | GAF+ DenseNet169 | Softmax | 97.83 |
| Sarkar et al. [305] | 2023 | UCI-HAR WISDM, MHEALTH PAMAP2 HHAR | IMUs Accelerometers | CNN with GA | SVM | 98.74 98.34 99.72 97.55 96.87 |
| Semwal et al. [306] | 2023 | WISDM PAMAP2 USC-HAD | IMUs | CNN and LSTM | Softmax | 95.76 94.64 89.83 |
| Zhang et al. [278] | 2024 | DSADS HAPT | IMU | Multi-STMT | Softmax | 99.86 98.73 |
| Saha et al. [286] | 2024 | UCI HAR Motion-Sense | IMU | FusionActNet | Softmax | 97.35 95.35 |
| Liu et al. [307] | 2025 | UCI-HAR WISDM | Accelerometer Gyroscope | UC Fusion | Softmax | 96.84 98.85 |
| Khan et al. [308] | 2025 | HAPT Human activities | AAccelerometer Gyroscope | 1D-CNN + LSTM | Softmax | 97.84 99.04 |
| sarakon et al. [309] | 2025 | WISDM DaLiAc MotionSense PAMAP2 | Accelerometer | MLP | Softmax | 95.83 97.00 94.65 98.54 |
| Yao et al. [310] | 2025 | PAMAP2 WISDM USC-HAD | Accelerometer Gyroscope Magnetometer | MLKD | Softmax | 92.66 98.22 95.42 |
| Thakur et al. [311] | 2025 | UCI-HAR WISDM OPPORTUNITY HAR | Accelerometer Gyroscope Magnetometer GPS | CNN + RNN | Softmax | 96 95 93 95 |
| Hu et al. [312] | 2025 | UCI-HAR HAPT RHAR | Accelerometer Gyroscope Magnetometer GPS | AResGAT-LDA | Softmax | 96.62 94.56 85.08 |
| Yu et al. [313] | 2025 | UCI-HAR USC-HAD WISDM DSADS | Accelerometer Gyroscope Magnetometer GPS | ASK-HAR | Softmax | 97.25 89.40 98.46 89.42 |
| Muralidharan et al. [314] | 2025 | MobiAct | Accelerometer Gyroscope Orientation sensors | CNN-RNN | Softmax | 94.69 |
| Yang et al. [315] | 2025 | UCI-HAR RealWorld MotionSense | Accelerometer Gyroscope | Semi-supervised | Softmax | 97.5 95.6 94.2 |
| Ye et al. [265] | 2024 | OPPT, PAMAP2 | IMU | CVAE-USM | GMM | 100 82.12 |
| Kaya et al. [267] | 2024 | UCI-HAPT WISDM, PAMAP2 | IMU | Deep CNN | Softmax | 98 97.8 90.27 |
| Zhang et al. [272] | 2024 | Shoaib, SisFall HCIHAR, KU-HAR | IMU | 1DCNN-Att -BiLSTM | SVM | 99.48 91.85 96.67 97.99 |
| Sharen et al. [316] | 2024 | WISDM UCI-HAR KU-HAR | Accelerometer Gyroscope | WISNet | Softmax | 96.41 95.66 94.01 |
| Teng et al. [317] | 2025 | UCI-HAR PAMAP2 UNIMIB-SHAR USC-HAD | Accelerometer Gyroscope Magnetometer | CNN-TSFDU-LW | Softmax | 97.90 94.34 78.90 94.71 |
| Dahal et al. [318] | 2025 | mHealth UCI-HAR WISDM | Accelerometer Gyroscope Magnetometer | Stack-HAR | Gradient Boosting | 99.49 96.87 90.00 |
| Pitombeira-Neto et al. [319] | 2025 | PAMAP2 USC-HAD | Accelerometer Gyroscope Magnetometer | BDLM | Bayesian updating | 96.00 |
5.1. Preprocessing of the Sensor Dataset
Preprocessing sensor data is crucial for reliable analysis and effective maintenance. Consequently, data collected from sensing devices must be preprocessed before being utilized for any analysis. Poor data quality, including missing values, outliers, and spikes, can impact the performance results. Preprocessing steps like imputing missing data, noise reduction, and normalization are significant. A fast, scalable module is needed for real-time data preprocessing, especially in predictive maintenance systems [320]. After preprocessing the sensor data, the second step is feature engineering, which involves creating new characteristics from existing data. Its main goals are to improve connections between input and output variables in forecasting models and to select the most useful features, enhancing model quality and efficiency. Finally, a proper model must be designed and implemented.
5.2. Sensor Data Modality Based HAR System Using Feature Extraction with Machine Learning
Previous studies on sensor-based HAR have involved manually extracting features from raw sensor data and using conventional ML techniques like SVM, Random Forest, KNN, Decision Tree, and NB [321,322,323]. Kavuncuoglu et al. [297], by combining accelerometer and magnetometer data with SVM, improved fall and activity classification. Feature-level fusion has outperformed fraction-level fusion with multiclass SVM and KNN classifiers on UCI HAR and physical activity sensor datasets. Using EEG data, models like RF and GB demonstrated excellent performance [294], with Local Interpretable Model-agnostic Explanations (LIMEs) providing insights into significant EEG features [324]. Introducing new activity classifications and novel feature engineering with models like Random Forest, KNN, and SVM has enhanced activity recognition accuracy. However, these traditional methods depend heavily on the quality of feature engineering, requiring domain-specific expertise to extract and select relevant features, which may not generalize across all activities [325]. Yang et al. [315] developed a semi-supervised learning framework for HAR that employs Difference Alignment Contrastive Loss (DAC Loss) to align individual differences in data, improving model performance while recognizing challenges in generalization across various sensor configurations and environments. Dahal et al. [318] proposed the Stack-HAR framework, an ensemble learning approach that improves HAR by stacking multiple models and using a metalearner. The framework’s performance on the WISDM dataset was slightly lower due to the reliance on accelerometer data alone, which limits the granularity needed for dynamic activities like walking. Pitombeira-Neto et al. [319] presented an ensemble Bayesian Dynamic Linear Model (BDLM) for HAR, which is efficient, requires minimal data preprocessing, and operates online. The approach is demonstrated to perform competitively with other benchmark methods, using two real-world datasets, PAMAP2 and USC-HAD. Their method’s performance can be impacted by a large number of users in the ensemble, leading to high computational times.
5.3. Sensor Data Modality-Based HAR System Using a Deep Learning Approach
Recently, many researchers have developed DL-based methods for HAR using sensor-based datasets, such as CNNs and RNNs, which automatically learn complex features from raw sensor data without manual feature extraction. These models achieve state-of-the-art results in HAR. However, CNNs may not capture time-domain characteristics effectively. Recently, Hu et al. [312] introduced AResGAT-LDA, a residual graph attention network integrating linear discriminant analysis and adversarial learning for semi-supervised HAR, addressing label scarcity and robustness, though it requires significant computational power for training on high-dimensional data.
5.3.1. Background of the Deep Learning-Based Temporal Modeling TCN
Recently, many studies have revolved around advancements in HAR using ambient sensors. It highlights the integration of various types of sensors—user-driven, environment-driven, and object-driven—into HAR systems [289]. Recent progress in HAR involves leveraging DL-based techniques, including Transformer models with multi-head attention mechanisms, to effectively capture temporal dependencies in activity data [24]. Additionally, the importance of sensor frequency information and the analysis of time and frequency domains in understanding sensor-driven time series data are emphasized [326]. The previous approach aims to address challenges such as adapting HAR systems to new activities in dynamic environments [255]. Kim et al. [289] developed a contrastive learning-based novelty detection (CLAN) method for HAR from sensor data. They addressed challenges like temporal and frequency features, complex activity dynamics, and sensor modality variations by leveraging diverse negative pairs through data augmentation. The two-tower model extracts invariant representations of known activities, enhancing recognition of new activities, even with shared features. Wei et al. [304] presented a Time Convolution Network with Attention Mechanism (TCN-Attention-HAR) model designed to enhance HAR using wearable sensor data. Addressing challenges such as effective temporal feature extraction and gradient issues in deep networks, the model optimizes feature extraction with appropriate temporal convolution sizes and prioritizes important information using attention mechanisms. Zhang et al. [272] presented Multi-STMT, a multilevel model for HAR using wearable sensors that integrate spatio-temporal attention and multiscale temporal embedding; the model combines CNN and BiGRU modules with attention mechanisms to capture nuanced differences in activities. Yu et al. [313] introduced ASK-HAR, a DL method using attention-based multi-core selective kernel convolution and CBAM to capture multiscale sensor data features for accurate HAR, though it faces challenges with stationary activity recognition and deployment in complex environments. In a recent study, ref. [327] presented a DL-based domain adaptation framework specifically designed for time-series sensor data in cross-user HAR. Teng et al. [317] proposed the CNN-TSFDU-LW, a novel model designed for sensor-based HAR, integrating the dual-decoupling of temporal and spatial features along with layer-wise training, which enhances computational efficiency due to the increased Memory Access Cost (MAC) with the layer-wise approach.
5.3.2. CNN-Based Various Stream for HAR
Ignatov et al. [295] utilized a DL-based approach for real-time HAR with mobile sensor data. They employed a CNN for local feature extraction and integrated simple statistical features to capture global time series patterns. The experimental evaluations of the WISDM and UCI datasets demonstrate high accuracy across various users and datasets, highlighting their effectiveness in the DL-based method without needing complex computational resources or manual feature engineering. Chen et al. [296] developed a semi-supervised DL-based model for imbalanced HAR that utilized multimodal wearable sensory data. Addressing challenges such as limited labeled data and class imbalance, the model employs a pattern-balanced framework to extract diverse activity patterns. They used recurrent convolutional attention networks to identify salient features across modalities. Kaya et al. [267] presented a 1D-CNN-based approach for accurate HAR from sensor data. They evaluated their model using raw accelerometer and gyroscope sensor data from three public datasets: UCI-HAPT, WISDM, and PAMAP2. Zhang et al. [291] presented a method, HAR, using a sensor data modality called ConvTransformer. They combined CNN, Transformer, and attention mechanisms to handle the challenge of extracting both detailed and overall features from sensor data. Liu et al. [307] proposed UC Fusion, a DL method for HAR that combines unique and common features from multiple wearable sensors, achieving superior accuracy on the UCI HAR and WISDM datasets compared to existing methods. Sarakon et al. [309] proposed a multisource data fusion approach for HAR using a Multi-Layer Perceptron (MLP), achieving high accuracy across diverse datasets while recognizing limitations in generalization due to sensor placement variability and insufficient evaluation in resource-constrained or real-time environments. Yao et al. [310] proposed a novel multi-teacher knowledge distillation framework, MLKD, using long-kernel CNNs to transfer rich spatio-temporal knowledge to compact student networks for sensor-based HAR, while noting limitations in automatic kernel size selection and privacy concerns in real-world deployments. Park et al. [328] proposed HT-AggNet, a novel deep neural architecture with hierarchical temporal aggregation and near-zero-cost layer stacking for efficient HAR, achieving results across diverse datasets while noting potential challenges in optimal depth tuning and broader deployment on constrained devices. Sharen et al. [316] proposed a novel deep learning model, WISNet, leveraging a custom 1D-CNN architecture with specialized blocks like channel attention for enhanced HAR.
5.3.3. RNN, LSTM, Bi-LSTM for HAR
In most of the recent work, including RNNs [329] plays a crucial role in handling temporal dependencies in sensor data for HAR. To address challenges like gradient issues, LSTM networks were developed [330]. Researchers [272,302,303,331] have also explored attention-based BiLSTM models, achieving the best performance compared to other DL-based methods. The experimental evaluations on various datasets shown in Table 7 demonstrate high accuracy across various users and datasets, highlighting their effectiveness in the DL-based method without needing complex computational resources or manual feature engineering. Saha et al. [286] presented Fusion ActNet, an advanced method for HAR using sensor data. It features dedicated residual networks to capture static and dynamic actions separately, alongside a guidance module for decision-making, through a two-stage training process and evaluations on benchmark datasets. The authors [314] proposed a hybrid CNN Bi-LSTM model for HAR using sensor data, achieving high classification accuracy while acknowledging challenges in differentiating similar fall-related activities. Murad et al. [330] used Deep Recurrent Neural Networks (DRNNs) in HAR, highlighting their ability to capture long-range dependencies in variable-length input sequences from body-worn sensors. Unlike traditional approaches that overlook temporal correlations, DRNNs, including unidirectional, bidirectional, and cascaded LSTM frameworks, perform well on diverse benchmark datasets. They perform the comparison of conventional machine learning approaches like SVM and KNN, as well as other deep learning techniques such as DBNs and CNNs, demonstrating their effectiveness in activity recognition tasks.
5.3.4. Integration of CNN and LSTM-Based Technique
Several studies have developed hybrid models that utilize and combine different DL architectures and can report high-performance accuracy in HAR. For instance, a hybrid CNN-LSTM model [152,306,332] improved sleep–wake detection using heterogeneous sensors. Additionally, designs like TCCSNet [333] and CSNet leverage temporal and channel dependencies to enhance human behavior detection. Ordonez et al. [329] developed a model for HAR using CNN and LSTM recurrent units. They extract features from raw sensor data, support multimodal sensor fusion, and model complex temporal dynamics without manual feature design. Evaluation of benchmark datasets, such as Opportunity and Skoda, shows significant performance improvements over traditional methods, highlighting their effectiveness in HAR applications. Zhang et al. [334] developed a multi-channel DL-based network called a hybrid model (1DCNN-Att-BiLSTM) for improved recognition performance, evaluation using publicly accessible datasets, and comparison with ML and DL models. El-adawi et al. [263] developed a HAR model within a Wireless Body Area Network (WBAN). The model leverages the Gramian Angular Field (GAF) and DenseNet. By converting time series data into 2D images using GAF and integrating them with DenseNet, they achieved good performance accuracy. Khan et al. [308] proposed an ensemble 1D-CNN and LSTM model for transition-aware HAR using wearable sensor data, demonstrating high accuracy across both postural and dynamic activities, but recognizing limitations in model simplification for deployment on resource-constrained microdevices. Cemiloglu et al. [335] presented a compact hybrid LSTM-CNN model for HAR using wearable sensor data, effectively mitigating data heterogeneity across devices and environments, though it was constrained by challenges in layer configuration, sensor variability, and cloud-based deployment limitations. Thakur et al. [311] proposed a hybrid CNN–RNN model optimized with a GWO–WOA feature selection method for sensor-based HAR, achieving good results across benchmark datasets while facing limitations in scalability, high training complexity, and limited activity diversity.
5.4. Radio Frequency (RF)-Based HAR Techniques
Figure 11 presents a structured knowledge map of RF-based HAR. It outlines the key components of the system pipeline and categorizes the associated research challenges and applications. In the following subsection, we provide a detailed description of RF-based HAR techniques, including RF-based data preprocessing, filtering, denoising, and feature extraction methods, as well as classification techniques.

Figure 11.
Taxonomy of RF-based HAR.
5.4.1. RF Dataset and Signal Acquisition
HAR with RF signals typically begins with data from devices like Wi-Fi Network Interface Cards (NICs) (e.g., Intel 5300), USRP software-defined radios, or radar systems. These provide raw measurements including Channel State Information (CSI), Received Signal Strength Indicator (RSSI), and sometimes phase or frequency shift data [336]. CSI, the most widely used, captures amplitude and phase variations across antennas and subcarriers, enabling detailed human motion analysis [336,337].
5.4.2. Filtering, Denoising, and Segmenting the Signal
RF signals are inherently noisy due to multipath fading and hardware imperfections. Common denoising methods include Hampel filters for outlier removal [337,338], Butterworth filters for high-frequency noise [339], Kalman filters for motion estimation, and wavelet thresholding for time-frequency denoising, along with segmentation methods like amplitude variance, energy thresholds, Doppler spectrogram peaks, and LOF identify activity boundaries [337].
5.4.3. Multipath Effects and Mitigation Techniques
Multipath propagation remains a persistent and fundamental challenge in RF-based HAR, particularly within indoor environments. When radio signals encounter obstacles such as walls, furniture, or human bodies, they reflect, scatter, and diffract, creating multiple propagation paths that interfere constructively and destructively at the receiver. This results in distortion of the CSI, particularly in the amplitude and phase domains, which in turn complicates the extraction of stable and discriminative features for activity classification [340,341]. Several mitigation strategies have been proposed in the recent literature to improve signal fidelity and model robustness:
- Angle-of-Arrival (AoA) and Angle-of-Departure (AoD) Estimation: Methods such as MUSIC and ESPRIT leverage antenna array processing to spatially resolve signal paths, helping isolate the Line-of-Sight (LoS) component from multipath reflections [340].
- Time-Frequency Analysis: Doppler spectrograms and Short-Time Fourier Transform (STFT) techniques decompose CSI into time-varying frequency components, making it easier to detect motion-induced frequency shifts associated with human activities [341].
- Graph-Based Path Modeling: By jointly estimating parameters like AoA, Time-of-Flight (ToF), and Doppler shifts, recent approaches construct graph-based signal representations to maintain spatial–temporal consistency in dynamic scenarios.
- Phase Unwrapping and CSI Denoising: Techniques including Hilbert transforms, wavelet filtering, and statistical smoothing are applied to reduce high-frequency noise and unwrap distorted phase responses, enhancing the usability of CSI features.
- Domain Adaptation: DL models trained in one environment often fail to generalize to others due to the environmental sensitivity of RF signals. Adversarial domain adaptation methods (e.g., DANN, GAN-based transfer learning) have shown promise in aligning latent representations across domains [340].
Despite these advances, accurately modeling and compensating for multipath effects in real-time and across varying conditions remains an open research problem. Real-world systems such as SiFall [341] demonstrate that combining denoising, unsupervised learning, and anomaly detection can yield effective results, but general-purpose, environment-agnostic solutions are still lacking.
5.4.4. RF Feature Extraction
Feature extraction plays a crucial role in RF-based HAR by transforming raw signal data into meaningful representations. These features are typically grouped into four categories [337]. Time-domain features, such as mean, standard deviation, interquartile range, and energy, are simple to compute and commonly used in many systems. Frequency-domain features are used to analyze periodic patterns using the Fast Fourier Transform (FFT), from which dominant frequencies, power spectral density, and spectral entropy can be extracted—these are especially effective for detecting repetitive activities like walking or running. Time-frequency features provide a joint representation of temporal and spectral changes using methods like Discrete Wavelet Transform (DWT) and Hilbert–Huang Transform (HHT), allowing accurate recognition of dynamic or fast-changing gestures. Finally, spatial features such as Angle of Arrival (AoA) and Time of Flight (ToF) are used in systems equipped with antenna arrays or radar sensors; they enable motion tracking and localization by estimating direction and distance of movement. These categories of features offer different perspectives on human motion and are chosen based on the hardware setup and the nature of the activity being monitored.
5.4.5. Classification
After preprocessing the RF signals, the extracted features are classified into human activity labels using different methods [337]. The main approaches include template matching, ML, and DL. ML techniques like SVM and KNN require training with labeled data and are effective for recognizing multiple activities across different environments. DL approaches, including CNNs and LSTM networks, automatically learn feature representations from data and can handle complex patterns with high accuracy. Still, they require larger datasets and longer training times. The choice of classification method depends on factors like activity complexity, training data availability, and system requirements.
5.4.6. ML and DL Methods for RF-Based Datasets
Recent RF-based HAR approaches leverage diverse modeling techniques, including CSI temporal dynamics, Doppler spectrograms, and domain adaptation, to enhance motion and activity recognition [342,343,344,345]. For example, Uysal et al. [346] achieved over 99% accuracy with variance features and Decision Trees; Li et al. [343] integrated Doppler spectrograms with LSTM models (91.3%); Zhao et al. [342] used RFID with GCNs (92.8%); and Saeed et al. [347] achieved up to 97% with USRP-based tree classifiers. Generative models like RF-AIGC [348], as well as CNN-based approaches such as HAR-SAnet [349] and TARF [350], address domain adaptation and modality variation challenges. Multimodal fusion (e.g., Wi-Fi CSI with IMU [351] or Doppler with audio [352]) further improves robustness. Exploratory work on OTFS waveforms at 60GHz mmWave [345] shows potential but lacks quantitative metrics. Overall, ML models like SVMs and Random Forests require carefully engineered features to remain robust, while DL models (CNNs, LSTMs) excel at learning complex patterns but require large labeled datasets and face domain shift challenges [337].
5.5. Mathematical Derivation of the Sensor-Based Learning Method
In the case of sensor-based HAR, suppose the given dataset is defined as:
where is the i-th training example representing a time-series sequence of sensor readings and is the true label of the corresponding . Each training example can be represented as a matrix with dimensions , where T is the number of time steps or sensor samples and s is the number of sensor channels or modalities (e.g., accelerometer axes, gyroscope, etc.). Training on a single modality for sensor data can be written as the following equation:
where is a deep neural network feature extractor designed for time-series sensor data (such as a 1D-CNN, RNN, or Transformer) with parameters . C is a classifier with parameters . L is the loss function measuring the discrepancy between the predicted label and the true label . This formulation allows sensor-based HAR models to effectively capture temporal dependencies in human motion signals by processing the time-series data. State-of-the-art models extend this framework by incorporating techniques such as temporal convolutions, recurrent architectures, and attention mechanisms to enhance learning from noisy and multimodal sensor inputs.
6. Multimodal Fusion Modality-Based Action Recognition
Action recognition through the utilization of a dataset that consists of multiple modalities necessitates the act of discerning and categorizing human actions or activities. This dataset encompasses various forms of information, including visual, audio, and sensor data. Integrating diverse sources of information within multimodal datasets affords a better comprehension of actions. From the perspective of the input data’s modality, DL techniques can acquire human action characteristics through a diverse range of modal data. Similarly, the ML-based algorithm aims to process the information from multiple modalities. By using the strengths of various data types, multimodal ML can often perform more accurate HAR tasks. There are several types of multi-modality learning methods, including fusion-based methods such as RGB with skeleton and depth-based modalities. Generally, fusion refers to combining the information of two or more modalities to train the model and provide accurate results of HAR. There are two main approaches widely utilized in multi-modality fusion schemes, namely, score fusion and feature fusion. The fusion-based approach combines scores obtained from various sources, including weight averaging [353] or learning a score fusion [354] model, while the feature fusion [355] focuses on integrating features extracted from different modalities. Ramani et al. [356] developed an algorithm that combines depth image and 3D joint position data using local spatio-temporal features and dominant skeleton movements and trains a Random Decision Forest (RDF). Researchers have increasingly explored DL techniques to extract action-effective features utilizing RGB, depth, and skeleton data. These methods facilitate multimodal feature learning from deep networks [22,23,47,149,357], encompassing appearance image information such as optical flow sequences, depth sequences, and skeleton sequences. DL networks are proficient at learning human action effective features by performing single-modal data or multimodal fusion data [185,358,359]. Note that score fusion and feature fusion are important in advancing HAR technology to provide accurate results. A recent study [360] presents a robust tri-modal DL architecture combining CNNs and attention mechanisms, significantly enhancing HAR for home-based rehabilitation using RGB and skeleton-based data and Continuous Wavelet Transform representations. One study [361] introduces a multi-input CNN framework that enhances HAR by fusing spectrograms, recurrence plots, and multi-channel plots from accelerometer data, achieving high accuracy without complex preprocessing. CIR-DFENet [362] fuses time-series and image-based representations from tri-axial accelerometer data using a dual-stream DL network with attention mechanisms, achieving 99.4% accuracy in classifying complex gymnastic activities. Additionally, we provided the most popular benchmark HAR datasets, which come from the multimodal fusion dataset, which is demonstrated in Table 8. The dataset table presents details of the datasets, including modalities, creation year, number of classes, number of subjects who participated in recording the dataset, number of samples, and the latest performance accuracy of the dataset with citation.
Table 8.
Multi-modalitydata fusion-based HAR system models and their performance metrics.
6.1. Multimodal Fusion-Based HAR Dataset
Figure 12 demonstrates the year-wise end-to-end deep learning method developed by various researchers for sensor and multimodal fusion-based HAR systems. Liu et al. [373] proposed SAM-Net, a semantic-assisted multimodal network that integrates skeleton, RGB video, and text modalities for superior action recognition performance on RGB-D videos. Xefteris et al. [374] proposed a novel multimodal fusion method for 3D human pose estimation, combining visual data from a single RGB camera with sensor data from six IMUs, using a hybrid LSTM-Random Forest network, and reported good accuracy. Table 9 presents a comprehensive overview of benchmark datasets for HAR using various modalities. The datasets include combinations of RGB, skeleton, depth, infrared, acceleration, and gyroscope data, providing rich and diverse sources for model training and evaluation. For instance, the MSRDailyActivity3D dataset, introduced in 2012, includes RGB, skeleton, and depth data, featuring 16 classes, 10 subjects, and 320 samples with a notable accuracy of 97.50% [83,84].
These datasets are crucial for advancing HAR research, offering extensive and varied data for developing robust and accurate models.
Table 9.
Multi-modality fusion-based HAR benchmark datasets.
Table 9.
Multi-modality fusion-based HAR benchmark datasets.
| Dataset | Data Set Modalities | Year | Class | Subject | Sample | Latest Accuracy |
|---|---|---|---|---|---|---|
| MSRDaily Activity3D [83] | RGB, Skeleton, Depth | 2012 | 16 | 10 | 320 | 97.50% [84] |
| N-UCLA [85] | RGB, Skeleton, Depth | 2014 | 10 | 10 | 1475 | 99.10% [86] |
| Multi-View TJU [87] | RGB, Skeleton, Depth | 2014 | 20 | 22 | 7040 | - |
| UTD-MHAD [88] | RGB, Skeleton, Depth, Acceleration, Gyroscope | 2015 | 27 | 8 | 861 | 95.0% [89] |
| UWA3D Multiview II [90] | RGB, Skeleton, Depth | 2015 | 30 | 10 | 1075 | - |
| NTU RGB+D [91] | RGB, Skeleton, Depth, Infrared | 2016 | 60 | 40 | 56,880 | 97.40% [86] |
| PKU-MMD [92] | RGB, Skeleton, Depth, Infrared | 2017 | 51 | 66 | 10,076 | 94.40% [93] |
| NEU-UB [94] | RGB, Depth | 2017 | 6 | 20 | 600 | - |
| Kinetics-600 [95] | RGB, Skeleton, Depth, Infrared | 2018 | 600 | - | 595,445 | 91.90% [71] |
| RGB-D Varing-View [96] | RGB, Skeleton, Depth | 2018 | 40 | 118 | 25,600 | - |
| Drive&Act [98] | RGB, Skeleton, Depth | 2019 | 83 | 15 | - | 77.61% [99] |
| MMAct [100] | RGB, Skeleton, Acceleration, Gyroscope | 2019 | 37 | 20 | 36,764 | 98.60% [101] |
| Toyota-SH [102] | RGB, Skeleton, Depth | 2019 | 31 | 18 | 16,115 | - |
| IKEA ASM [103] | RGB, Skeleton, Depth | 2020 | 33 | 48 | 16,764 | - |
| ETRI-Activity3D [104] | RGB, Skeleton, Depth | 2020 | 55 | 100 | 112,620 | 95.09% [105] |
| UAV-Human [106] | RGB, Skeleton, Depth | 2021 | 155 | 119 | 27,428 | 55.00% [107] |
6.2. Fusion of RGB, Skeleton, and Depth Modalities
Recently, several hand-crafted feature-based approaches [94,375] have been developed to explore multi-modalities such as RGB, skeleton, and depth to improve the performance of the action recognition tasks, while the DL-based approaches [84,376,377,378] have been proposed due to them providing good performance. Shahoudy et al. [84] studied and explored the concept of correlation analysis between the different modalities and factorized them into desired independent components. They used a structured sparse classifier for the HAR task. Hu et al. [376] analyzed the time-varying information across the fusion of multi-modality, such as RGB, skeleton, and depth-based. They extracted temporal features from each modality and then concatenated them along the desired modality dimension. These multimodal temporal features were then input into the model. Khaire et al. [377] developed a CNN network with five streams. These streams take inputs from MHI [126], DMM [219], and skeleton images generated from RGB, depth, and skeleton sequences. Each CNN stream was trained separately, and the final classification scores were obtained by combining the output scores of all five CNN streams by utilizing a weighted product model. Similarly, Khair et al. [379] used a fusion of three methods to merge skeletal, RGB, and depth modalities. Cardenas et al. [378] utilized three distinct optical spectra channels from skeleton data [380] and dynamic images from RGB and depth videos. These features were fed into a pre-trained CNN to extract multimodal features. Finally, Hou et al. [380] used a feature aggregation module for classification tasks. Table 10 compares HAR performance across different modalities on unified datasets. Results consistently show that single-modality methods (e.g., skeleton, RGB, or depth) achieve lower accuracy (e.g., 69.90% to 80.30% on NTU RGB+D) compared to multimodal fusion methods, which reach significantly higher accuracies (e.g., up to 95.82% on NTU RGB+D). This highlights the benefit of integrating multiple modalities for improved recognition performance. For instance, Liu et al. [381] reported high performance using skeleton and RGB data on NTU-60, PKU-MMD, and N-UCLA datasets (98.0%, 98.0%, and 90.8%, respectively). Liu et al. [373] further improved performance by integrating text data (e.g., action labels or semantic information) alongside skeleton and RGB, achieving 98.5%, 98.4%, and 92.3%, respectively. This demonstrates that adding semantic information to visual and skeletal modalities can further enhance recognition in challenging scenarios.
Table 10.
Modality-based unified dataset comparison for the multimodal dataset work.
6.3. Fusion of Signal and Visual Modalities
Signal data complements visual data by providing additional information. Various DL-based approaches have been proposed to merge these modalities for HAR. Wang et al. [385] proposed three-stream CNN models to extract features from multi-modalities. They evaluated the performance of both feature fusion and score fusion, with feature fusion showing superior performance. TSN [51] showed improved performance and Kazakos et al. [386] introduced the Temporal Binding Network (TBN) for egocentric HAR, integrating audio, RGB, and optical flow inputs. TBN utilized a three-stream CNN to merge these inputs within each Temporal Binding Window, enhancing classification through temporal aggregation. Their findings demonstrated TBN’s superiority over TSN [51] in audio–visual HAR tasks. Additionally, Gao et al. [387] utilized audio data to minimize temporal redundancies in videos, employing knowledge distillation from a teacher network trained on video clips to a student network trained on image–audio pairs for efficient HAR. Xiao et al. [177] developed a novel framework combining audio and visual information, incorporating slow and fast visual pathways alongside a faster audio pathway across multiple layers. They employed two training strategies: randomly dropping the audio pathway and hierarchical audio–visual synchronization, facilitating the training of audio-video integration. In addition, in multimodal HAR-based approaches such as Bruce et al. [367], a multimodal network (MMNet) fuses skeleton and RGB data using a spatio-temporal GNN to transfer attention weights, significantly improving HAR accuracy, while Venkatachalam et al. [388] proposed a hybrid 1D CNN with an LSTM classifier for HAR. Yu et al. [389] introduced DANet, a dual-attention-enabled DL model for cognitive workload recognition using multimodal EEG and eye-tracking data. Overall, the objective of data fusion methods is to capitalize on the benefits of integrating various datasets to achieve a more robust and comprehensive feature representation. Consequently, the central issue that arises in the development of most data-fusion-based techniques revolves around determining the most efficient manner in which to combine disparate data types. This is typically addressed by employing conventional early and late fusion strategies. The initial fusion occurs at the feature level, involving feature concatenation as the input to the recognition model. In contrast, the latter scenario performs fusion at the score level, integrating the output scores of the recognition model with diverse data types. The multimodal data fusion methods generally yield better recognition results than single-data approaches. However, the multimodal data fusion methods approach requires processing larger datasets and dealing with higher feature dimensions, thereby increasing the computational complexity of action recognition algorithms.
Figure 12.
Milestone approaches for HAR. The pink font is the multi-modality-based methods [51,84,111,177,298,356,362,363,364,365,367,370,371,373,377,378,380,386] and the black font is the sensor-based methods [267,295,296,299,300,301,302,304,305,306,317,318,329,330,331].
Figure 12.
Milestone approaches for HAR. The pink font is the multi-modality-based methods [51,84,111,177,298,356,362,363,364,365,367,370,371,373,377,378,380,386] and the black font is the sensor-based methods [267,295,296,299,300,301,302,304,305,306,317,318,329,330,331].
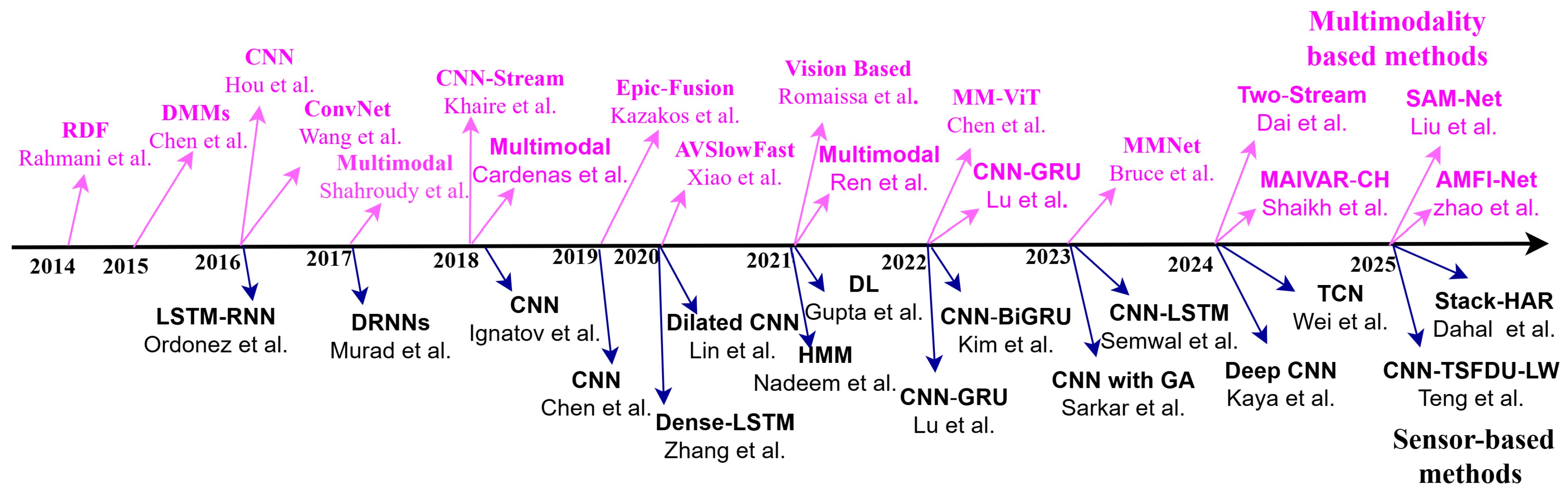
6.4. Mathematical Derivation of the Multimodal Learning Methods
In multimodal learning, multiple types of data (modalities) are combined to improve model performance. Let denote the i-th training sample from modality m, where . Each modality has its own deep neural network feature extractor:
where represents the CNN-based (or Transformer-based) encoder for modality m. For single-modality training (e.g., RGB), the learning objective can be defined as:
where denotes the loss function (e.g., cross-entropy), is the classifier network that maps extracted features to predicted labels, and is the ground truth label for sample i. When dealing with multiple modalities, the features from these modalities can be fused using an operator ⊕ (such as concatenation or weighted sum) [175]:
where and are the extracted features from the audio and video modalities, respectively. For generalized multimodal learning, the extracted features from all M modalities can be fused:
where represents the fusion operation (e.g., concatenation, weighted sum, or attention) that combines features from all modalities. Inspired by recent work [373,381], fusion strategies can also include additive fusion mechanisms:
where is the combined prediction from all modalities, processes skeleton joints J and RGB frames B with parameters , processes video frames V with parameters , and processes text data T with parameters . A classifier maps the fused features to the final prediction:
The per-sample loss is defined as:
where is the multimodal input for sample i, is the fusion operator applied to extracted features, is the classifier, and is the corresponding ground-truth label.
During training, the average loss over all training samples is computed as:
where denotes the overall training loss computed over the dataset, n is the total number of training samples, denotes the input data from all modalities for sample i, and is the corresponding ground truth label. Recent studies, such as AMFI-Net [372], have proposed advanced attention-based fusion techniques to enhance multimodal integration. AMFI-Net utilizes RGB and skeleton modalities and employs a multi-step fusion strategy.
First, they extracted features from RGB () and skeleton () modalities are concatenated:
where is the feature vector from the RGB modality extracted via ResNet3D-18, is the feature vector from the skeleton modality extracted via AGCN, and is the concatenated feature representation combining both modalities. A nonlocal feature association module then captures long-range spatio-temporal dependencies:
where is the feature vector at position i in , and are 1×1 convolution operations computing feature affinities, is a transformation function (1×1 convolution) applied at position j, is a learned weight matrix projecting the aggregated nonlocal response, and is the enhanced feature vector after applying nonlocal feature association. A channel attention mechanism assigns importance weights to different feature channels:
where is the stacked nonlocal feature-enhanced representation for all positions, is the learnable weight matrix for the 1D convolution, is the 1D convolution operation along the channel dimension, denotes the sigmoid activation function, and is the channel attention weight vector that dynamically emphasizes important features. A dynamic confidence gate for the skeleton modality is defined as:
where is the skeleton modality feature vector, W is a learned weight matrix in the fully connected layer, denotes the fully connected layer operation, and is the dynamic confidence gate output, indicating the importance of the skeleton modality. The final fused features are adaptively weighted:
where is the RGB modality feature vector, ⊙ denotes element-wise multiplication, and is the final adaptively fused feature vector combining both modalities. The overall loss combines classification loss and gating consistency loss:
where is the classification loss (e.g., cross-entropy), is the gating consistency loss enforcing smooth confidence transitions, and is the weighting factor balancing the two loss terms. The AMFI-Net model demonstrates superior performance on the NTU RGB+D dataset, achieving a reported accuracy of 95.82% in the multimodal setting (RGB+Skeleton), compared to 93.24% using the skeleton modality alone [372]. This highlights the effectiveness of attention-based multimodal fusion strategies for improving action recognition tasks. Both [381] and [373] highlight the importance of multi-level fusion strategies: weighted ST-ROI enhances key skeleton joints within RGB images, and STDR image construction combines skeleton joints with RGB frames to create dynamic region representations. These strategies improve feature learning by capturing intra- and inter-modal relationships. Different fusion strategies for include early fusion (input-level concatenation, but can struggle with temporal misalignment), late fusion (decision-level combination, offering modularity but limited feature interactions), hybrid fusion (integrates early and late fusion, balancing flexibility and complexity) [175,381], and attention-based fusion (dynamic weighting, capturing complex dependencies but requiring careful design to avoid overfitting) [373]. Practical challenges include temporal alignment, data imbalance, and increased computational demands. Incorporating semantic information, as in SAM-Net’s semantic assistance module [373], can further improve multimodal learning by enriching feature representations and reducing domain gaps. Additionally, multimodal fusion remains central to advancing HAR performance across complex environments. Table 11 provides a concise comparative analysis, highlighting their integration stages, key advantages, and inherent limitations.
Table 11.
Comparison of multimodal fusion strategies in HAR.
7. Current Challenges
Although notable progress has been made in HAR utilising four data modalities, several challenges persist due to the intricate nature of the various aspects of this task.
7.1. RGB Data Modality Based Current Challenges
The researcher explores the challenges specific to RGB-based methods in HAR. RGB data, which represents color information from regular images or videos, is widely used for determining human actions. In the following section, we describe the key challenges associated with RGB-based HAR:
7.1.1. Efficient Action Recognition Analysis
The good performance of numerous HAR approaches often comes with the cost of high computational complexity. However, an efficient HAR system is vital for many real-world applications. Therefore, it is essential to explore ways to minimise computational costs (such as CPU, GPU, and energy usage) to perform efficient and fast HAR. These limitations led to a notable impact on the computation efficiency of the network. Additionally, the process of accurately and efficiently labeling video data incurs substantial labor and time expenses due to the diversity and scale of the data.
7.1.2. Complexity Within the Environment
Certain HAR techniques perform strongly in controlled environments but tend to underperform in uncontrolled outdoor settings. This is mostly caused by motion vector noise, which can drastically degrade resolution. Extracting effective features from complex images is an extremely tough task. For example, the rapid movement of the camera complicates the extraction of effective action features. Accurate feature extraction will also affect environmental issues such as poor lighting, dynamic background, etc.
7.1.3. Large Memory of the Dataset and Limitations
The dataset exhibits both intra-class variation and inter-class similarity. Many people perform the same action in diverse manners, and even a single person may execute it in multiple ways. Additionally, different actions might have similar presentations. Furthermore, many existing datasets include unfiltered sequences, potentially compromising the timeliness and reducing the HAR accuracy of the model. The dataset’s large memory requirements pose significant limitations, particularly in terms of storage and processing capabilities. Handling massive amounts of data necessitates robust computational resources, including high-capacity storage solutions and powerful processing units. Additionally, working with large datasets may lead to challenges related to data transfer speeds, memory management, and computational efficiency. These limitations can impact the scalability, accessibility, and usability of the dataset, potentially hindering its widespread adoption and utilization in research and applications. Therefore, addressing the constraints posed by the dataset’s large memory footprint is crucial for maximizing its utility and effectiveness in various domains.
7.2. Skeleton Data Modality-Based Challenges
The challenges are specific to skeleton-based approaches in HAR. Skeleton data, which obtain joint positions and movements, are a valuable modality for understanding human actions. In the following section, some key challenges are described.
7.2.1. Pose Preparation and Analysis
Depending on depth cameras and sensors, skeleton data acquisition can be affected by environmental complexity, capture duration, and equipment exposure conditions. Another common challenge in daily-life scenarios is occlusion, caused by surrounding objects or human interaction, which contributes to detection errors. This issue is also discussed in Section 4.2 (Pose Estimation), where occlusion affects the accurate extraction of skeleton points using methods such as MediaPipe, OpenPose, and AlphaPose (see Figure 8). Despite advances in DL-based 2D and 3D pose estimation, occlusion remains a significant challenge in HAR.
7.2.2. Viewpoint Variation
Accurately distinguishing skeleton features from different perspectives poses a significant challenge, as certain features may be lost during changes in viewpoint. Meanwhile, modern RGBD cameras [390,391,392,393] can normalize 3D human skeletons [21,225] from various angles to a single pose with viewpoint invariance, utilizing pose estimation transformation matrices. However, in this process, there is a risk of losing some of the relative motion between the original skeletons. This loss of relative motion can impact the accuracy and completeness of the skeleton data, highlighting the need for careful consideration and validation of viewpoint normalization techniques in skeleton feature extraction.
7.2.3. Single Scale Data Analysis
As several skeleton-based datasets mostly provide information based on the scale of body joints, numerous techniques focus solely on extracting features related to the human joint scale. However, this technique often leads to the loss of fine joint features. Moreover, certain actions, such as shaving, tooth brushing, and applying lipstick, exhibit similar joint interactions. Therefore, there is a critical need to enhance local feature extraction while maintaining the effectiveness of holistic feature extraction techniques [394,395,396,397]. This improvement is crucial for achieving more accurate action recognition and understanding subtle variations in human movements. Even though DL methods yield superior recognition performance compared to handcrafted action features, certain challenges persist in recognizing human actions based on DL, particularly in the fusion of multimodal data in DL methods. Most of the aforementioned DL-based approaches concentrate on learning action features from diverse modality data; however, only a few studies address the fusion of multimodal data. Effective fusion based on multimodal data (RGB, optical flow, depth, and skeleton data) remains a significant unresolved challenge in HAR and DL. This area also represents a prominent research focus within HAR.
7.3. Sensor-Based HAR; Current Challenges and Possible Solution
In sensor-based HAR, different activities with similar characteristics (like walking and running) pose a challenge for feature extraction. Creating unique features to represent each activity becomes difficult due to the inter-activity similarity. Another challenge is annotation scarcity due to expensive data collection and class imbalance, particularly for rare or unexpected activities. In sensor-based HAR, three critical factors—users, time, and sensors—contribute to distribution discrepancies between training and test data. These factors include person-dependent activity patterns, evolving activity concepts over time, and diverse sensor configurations. When designing a HAR system, two key considerations are resource efficiency for portable devices and addressing privacy risks associated with continuous life recording. When dealing with sensory data, accurate recognition solutions must address interpretability and understand which parts of the data contribute to recognition and which parts introduce noise. Additionally, we describe radio frequency (RF)-based data for HAR below.
Challenges in RF-Based HAR
Despite recent advancements, RF-based HAR continues to face several fundamental challenges due to the complex nature of wireless signal propagation and the absence of structured spatial features typical in vision data:
- Modality Fusion and Latency: Fusing RF signals with data from other modalities (e.g., vision or inertial sensors) introduces challenges such as sampling rate mismatch, latency, and temporal misalignment. Achieving real-time, low-latency fusion while preserving cross-modal synchronization remains an open problem, particularly in mobile or dynamic environments [351,398].
- Representation Learning for RF Signals: Unlike images or video, RF signals lack regular grid-based spatial structure, making direct application of standard deep learning techniques less effective. Developing transferable, domain-invariant representations from complex inputs like CSI, RSSI, or Doppler spectrograms remains a growing area of research [348,399].
- Cross-Domain Generalization: RF-based models often perform poorly when transferred across different environments, hardware setups, or users due to the high sensitivity of wireless signals to ambient changes. While domain adaptation techniques such as adversarial learning and few-shot adaptation have been proposed, robust generalization remains limited relative to vision-based HAR [348,350].
- Multipath Propagation: As discussed in Section 5.4.3, multipath effects arise when signals reflect off surfaces and objects, causing interference patterns that distort amplitude and phase. These distortions degrade the quality of extracted features and the reliability of classification. While mitigation techniques such as Angle-of-Arrival (AoA) estimation, Doppler analysis, and deep domain adaptation have shown promise [340,341], real-time multipath-resilient modelling across diverse spaces remains an unsolved problem.
These open challenges highlight that RF-based HAR is not merely an extension of other modalities but is a distinct and evolving paradigm. It offers compelling advantages such as privacy preservation and through-wall sensing, yet demands novel approaches to signal modelling, robust learning, and scalable deployment.
7.4. Multimodal-Based Challenges
In the field of HAR, researchers have explored many multimodal approaches, including fusion-based systems and cross-modality transfer learning. While multimodal fusion can significantly improve HAR performance by leveraging complementary information, several key technical challenges still limit deployment in real-world applications:
7.4.1. Temporal Misalignment
Asynchronous data streams from different sensors can cause misalignment between modalities, complicating effective fusion.
7.4.2. Missing Modalities
In practice, some sensor modalities may be unavailable or corrupted, challenging the robustness of fusion models.
7.4.3. High Computational Cost
Fusion architectures, particularly attention-based or deep-learning models, often demand significant computational resources, limiting real-time or embedded applications.
7.4.4. Overfitting and Heterogeneous Data
Overfitting can occur when models struggle to generalize to new environments. Additionally, different modalities often have heterogeneous formats and temporal scales, complicating integration. These challenges must be addressed to develop more effective and deployable multimodal HAR systems.
8. Discussion and Future Direction
In this section, we describe several potential directions for future research by combining the current state of affairs and addressing the methodological and application-related challenges in RGB-based, skeleton-based, sensor modality-based, and multimodal-based HAR. We provide specific implementation pathways and technical considerations to guide researchers toward impactful contributions.
8.1. Development of the New Large Scale Datasets
Data are as essential to DL as model construction. However, existing datasets pose challenges when it comes to generalizing to realistic scenes. Factors like realistic surroundings and dataset size play an important role in this complexity. Additionally, most of the datasets are mainly focused on spatial representation [400]. Unfortunately, there is a scarcity of long-term modeling datasets. A notable issue arises due to regional constraints and privacy concerns. As discussed in Section 3.1 (RGB-Based Datasets of HAR), many benchmark datasets such as Kinetics-400 and Kinetics-700 are sourced from YouTube. However, YouTube dataset managers commonly provide only video IDs or links for download rather than the actual video content, resulting in approximately 5% of videos becoming inaccessible annually [28]. To address these limitations, researchers are actively developing new datasets that integrate RGB, depth, and skeleton data to capture multimodal information. These efforts emphasize the need for synchronized data collection, diverse environments, and robust privacy protection measures. Incorporating occlusion scenarios, variable lighting conditions, and long-term temporal sequences is crucial for building realistic and comprehensive benchmarks. Such datasets are expected to contribute significantly to advancing DL research and improving model performance in the future.
8.2. Data Augmentation Techniques
Deep neural networks exhibit exceptional performance when trained on diverse datasets. However, limited data availability remains a challenge. To overcome this issue, data augmentation plays an important role. In the domain of image recognition, various augmentation techniques have been proposed, spanning both DL-based techniques and simple image-processing approaches. These approaches include random erasing [401], Generative Adversarial Networks (GANs) [402], kernel filters [403], feature space augmentation [404], adversarial training [405], and meta-learning [406]. For HAR, typical data augmentation techniques involve horizontal flipping, subclip extraction, and video merging [407]. However, these generated videos often lack realism. To overcome this limitation, Zhang et al. [408] used GANs to generate new data samples and implemented a ‘self-paced selection’ strategy during training. Meanwhile, Gowda et al. [409] introduced Learn2Augment, which synthesizes videos from foreground and background sources as a method for data augmentation, resulting in diverse and realistic samples. By implementing these specific recommendations, future research can build more robust data augmentation pipelines that directly address the challenges faced in real-world HAR scenarios.
8.3. Advancements in Models Performances
HAR research predominantly revolves around DL-based models, much like other advancements in computer vision. Presently, ongoing progress in deep architectures is important for HAR, including the RGB-based, skeleton-based, and multimodal-based approaches to perform the action recognition task. These advancements typically focus on the following key areas of model improvement:
- Long-term Dependency Analysis: Long-term correlations refer to the sequence of actions that unfold over extended periods, akin to how memories are stored in our brains. In action recognition, it is essential to integrate both spatial and temporal modeling to capture these dependencies. To implement this, future research should consider transformer-based temporal attention models (e.g., Video Swin Transformers), TCNs, and hierarchical recurrent architectures that explicitly model variable-length sequences.
- Multimodal Modeling: This involves integrating data from multiple devices, such as RGB, skeleton, and audio sensors, to build more robust HAR systems. Implementation can leverage cross-modal attention mechanisms (e.g., co-attention modules) to dynamically weight modalities based on scene context. Techniques like cross-modal contrastive learning and domain adaptation can further enhance multimodal fusion performance, addressing occlusion and domain shift issues identified earlier.
- Enhancing Video Representations: Multimodal data (such as depth, skeleton, and RGB) is essential for improving video representations [410,411]. Future research should focus on implementing multi-stream networks, where each stream processes a different modality and shares temporal context through feature fusion layers. Additionally, self-supervised pretraining on unlabeled multimodal videos can improve generalization to unseen environments and handle missing modalities.
- Efficient Modeling Analysis: Creating an efficient network architecture is crucial due to the challenges posed by existing models, including model complexity, excessive parameters, and real-time performance limitations. To address these issues, techniques like distributed training [412], mobile networks [413], hybrid precision training, model compression, quantization, and pruning can be explored. These approaches can enhance both efficiency and effectiveness in image classification tasks.
- Semi-supervised and Unsupervised Learning Approaches: Supervised learning approaches, especially those based on deep learning, typically require large, expensive labeled datasets for model training. In contrast, unsupervised and semi-supervised learning techniques [414] can utilize unlabeled data to train models, thereby reducing the need for extensive labeled datasets. Given that unlabeled action samples are often easier to collect, unsupervised and semi-supervised approaches to HAR represent a crucial research direction deserving further exploration.
By adopting these targeted approaches, future research can systematically address key challenges such as temporal consistency, data scarcity, domain adaptation, and model efficiency, leading to more generalizable and deployable HAR systems.
8.4. Video Lengths in Human Action Recognition
The action prediction tasks can be broadly categorized into short-term and long-term predictions. Short-term prediction involves predicting action labels from partially observed actions, typically seen in short videos lasting a few seconds. In contrast, long-term prediction assumes that current actions influence future actions and focuses on longer videos spanning several minutes, simulating changes in actions over time. Formally, given an action video , which may depict either a complete or incomplete action sequence, the objective is to predict the subsequent action . These actions, and , are independent yet semantically significant, with a temporal relationship [415]. To advance action prediction research, it is essential to discover and model temporal correlations within vast datasets. Future work should focus on transformer-based and temporal convolutional models to capture long-term dependencies and variable-length sequences. Multimodal fusion of RGB, skeleton, and depth data via cross-modal attention can improve prediction robustness in occluded or cluttered scenes. Additionally, self-supervised learning on unlabelled videos—using temporal consistency regularization and contrastive objectives—can reduce annotation costs and enhance generalization. Finally, interpretability techniques such as temporal attention visualization can help identify the most informative video segments, supporting model transparency and trustworthiness.
Limitations
This study focused on research papers published between 2014 and 2025, exclusively in English, and excluded relevant studies in other languages. We exclusively considered studies that utilised visual data, including HAR feature ML-based and DL-based methods involving different data types, including RGB handcrafted features and DL-based action recognition, RGB and skeleton-based methods for multimodal datasets such as RGB, depth, and skeleton, excluding EMG-based data. Furthermore, the diverse input methods and dataset variations across reviewed studies hindered direct result comparisons. Notably, some articles lacked statistical confidence intervals, making it challenging to compare their findings.
9. Conclusions
HAR is an important task among multiple domains within the field of computer vision, including human–computer interaction, robotics, surveillance, and security. In the past decades, it has necessitated the proficient comprehension and interpretation of human actions with various data modalities. Researchers still find the HAR task challenging in real scenes due to various complicating factors in different data modalities, including various body positions, motions, and complex background occlusion. In the study, we presented a comprehensive survey of HAR methods, including advancements across various data modalities. We briefly reviewed human action recognition techniques, including hand-crafted features in RGB, skeleton, sensor, and multi-modality fusion with conventional and end-to-end DL-based action representation techniques. Moreover, we have also reviewed the most popular benchmark datasets of the RGB, skeleton, sensor, and fusion-based modalities with the latest performance accuracy. It is worth noting that, although HAR methods have implications in security domains, this survey excludes a focused review on security-related applications. After providing an overview of the literature about each research direction in HAR, the primary effective techniques were presented to familiarize researchers with the relevant research domains. The fundamental findings of this investigation on the study of human action recognition are summarized to help researchers, especially in the field of HAR.
Author Contributions
Conceptualization, J.S., N.H., A.S.M.M. and S.N.; Methodology, J.S., N.H. and A.S.M.M.; Software, N.H. and A.S.M.M.; Validation, J.S. and N.H.; Formal analysis, J.S., N.H., A.S.M.M. and S.N.; Investigation, J.S., N.H., A.S.M.M. and S.N.; Resources, J.S.; Data curation, J.S., N.H., A.S.M.M. and S.N.; Writing—original draft, J.S., N.H. and A.S.M.M.; Writing—review & editing, J.S., N.H. and A.S.M.M.; Visualization, J.S., N.H. and S.N.; Supervision, J.S.; Project administration, J.S.; Funding acquisition, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Competitive Research Fund of The University of Aizu, Japan.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| HAR | Human Activity Recognitions |
| HOF | Histogram of Optical Flow |
| STIP | Spatio-Temporal Interest Point |
| GCN | Graph Convolutional Network |
| MEI | Motion Energy Image |
| SVM | Support Vector Machine |
| TSN | Temporal Segment Network |
| RF | Radio Frequency |
| ML | Machine learning |
| KNN | K-Nearest-Neighbor |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| LSTM | Long Short Term Memory |
| DNNs | Deep Neural Networks |
References
- Papadopoulos, G.T.; Axenopoulos, A.; Daras, P. Real-time skeleton-tracking-based human action recognition using kinect data. In Proceedings of the MultiMedia Modeling: 20th Anniversary International Conference (MMM 2014), Dublin, Ireland, 6–10 January 2014; Proceedings, Part I 20. Springer: Cham, Switzerland, 2014; pp. 473–483. [Google Scholar]
- Islam, M.N.; Jahangir, R.; Mohim, N.S.; Wasif-Ul-Islam, M.; Ashraf, A.; Khan, N.I.; Mahjabin, M.R.; Miah, A.S.M.; Shin, J. A multilingual handwriting learning system for visually impaired people. IEEE Access 2024, 12, 10521–10534. [Google Scholar] [CrossRef]
- Rahim, M.A.; Miah, A.S.M.; Sayeed, A.; Shin, J. Hand gesture recognition based on optimal segmentation in human-computer interaction. In Proceedings of the 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), Kaohsiung, Taiwan, 21–23 August 2020; pp. 163–166. [Google Scholar]
- Van Gemert, J.C.; Jain, M.; Gati, E.; Snoek, C.G. APT: Action localization proposals from dense trajectories. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; Volume 2, p. 4. [Google Scholar]
- Zhu, H.; Vial, R.; Lu, S. Tornado: A spatio-temporal convolutional regression network for video action proposal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5813–5821. [Google Scholar]
- Ziaeefard, M.; Bergevin, R. Semantic human activity recognition: A literature review. Pattern Recognit. 2015, 48, 2329–2345. [Google Scholar] [CrossRef]
- Wu, S.; Oreifej, O.; Shah, M. Action recognition in videos acquired by a moving camera using motion decomposition of lagrangian particle trajectories. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1419–1426. [Google Scholar]
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Chao, Y.W.; Wang, Z.; He, Y.; Wang, J.; Deng, J. Hico: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1017–1025. [Google Scholar]
- Peng, X.; Schmid, C. Multi-region two-stream R-CNN for action detection. In Proceedings of the ECCV 2016: 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Cham, Switzerland, 2016; pp. 744–759. [Google Scholar]
- Liu, J.; Li, Y.; Song, S.; Xing, J.; Lan, C.; Zeng, W. Multi-modality multi-task recurrent neural network for online action detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2667–2682. [Google Scholar] [CrossRef]
- Patrona, F.; Chatzitofis, A.; Zarpalas, D.; Daras, P. Motion analysis: Action detection, recognition and evaluation based on motion capture data. Pattern Recognit. 2018, 76, 612–622. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Das Dawn, D.; Shaikh, S.H. A comprehensive survey of human action recognition with spatio-temporal interest point (STIP) detector. Vis. Comput. 2016, 32, 289–306. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Song, Z.; Yan, S. STAP: Spatial-temporal attention-aware pooling for action recognition. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 77–86. [Google Scholar] [CrossRef]
- Shao, L.; Zhen, X.; Tao, D.; Li, X. Spatio-temporal Laplacian pyramid coding for action recognition. IEEE Trans. Cybern. 2013, 44, 817–827. [Google Scholar] [CrossRef]
- Burghouts, G.; Schutte, K.; ten Hove, R.J.M.; van den Broek, S.; Baan, J.; Rajadell, O.; van Huis, J.; van Rest, J.; Hanckmann, P.; Bouma, H.; et al. Instantaneous threat detection based on a semantic representation of activities, zones and trajectories. Signal Image Video Process. 2014, 8, 191–200. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 804–811. [Google Scholar]
- Ye, M.; Zhang, Q.; Wang, L.; Zhu, J.; Yang, R.; Gall, J. A survey on human motion analysis from depth data. In Time-of-Flight and Depth Imaging, Sensors, Algorithms, and Applications: Dagstuhl 2012 Seminar on Time-of-Flight Imaging and GCPR 2013 Workshop on Imaging New Modalities, Schloss Dagstuhl; Springer: Berlin/Heidelberg, Germany, 2013; pp. 149–187. [Google Scholar]
- Li, M.; Leung, H.; Shum, H.P. Human action recognition via skeletal and depth based feature fusion. In Proceedings of the 9th International Conference on Motion in Games, Burlingame, CA, USA, 10–12 October 2016; pp. 123–132. [Google Scholar]
- Yang, X.; Tian, Y. Effective 3D action recognition using eigenjoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef]
- Vishwakarma, S.; Agrawal, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Ke, S.R.; Thuc, H.L.U.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, X.; Liu, C.; Zolfaghari, M.; Xiong, Y.; Wu, C.; Zhang, Z.; Tighe, J.; Manmatha, R.; Li, M. A comprehensive study of deep video action recognition. arXiv 2020, arXiv:2012.06567. [Google Scholar]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Ma, N.; Wu, Z.; Cheung, Y.m.; Guo, Y.; Gao, Y.; Li, J.; Jiang, B. A survey of human action recognition and posture prediction. Tsinghua Sci. Technol. 2022, 27, 973–1001. [Google Scholar] [CrossRef]
- Xing, Y.; Zhu, J. Deep learning-based action recognition with 3D skeleton: A survey. CAAI Trans. Intell. Technol. 2021, 6, 80–92. [Google Scholar] [CrossRef]
- Presti, L.L.; La Cascia, M. 3D skeleton-based human action classification: A survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Subetha, T.; Chitrakala, S. A survey on human activity recognition from videos. In Proceedings of the 2016 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 25–26 February 2016; IEEE: New York, NY, USA, 2016; pp. 1–7. [Google Scholar]
- Feng, M.; Meunier, J. Skeleton graph-neural-network-based human action recognition: A survey. Sensors 2022, 22, 2091. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, Y.; Zhao, W.; Tang, J. A comparative review of graph convolutional networks for human skeleton-based action recognition. Artif. Intell. Rev. 2022, 55, 4275–4305. [Google Scholar] [CrossRef]
- Gupta, P.; Thatipelli, A.; Aggarwal, A.; Maheshwari, S.; Trivedi, N.; Das, S.; Sarvadevabhatla, R.K. Quo vadis, skeleton action recognition? Int. J. Comput. Vis. 2021, 129, 2097–2112. [Google Scholar] [CrossRef]
- Song, L.; Yu, G.; Yuan, J.; Liu, Z. Human pose estimation and its application to action recognition: A survey. J. Vis. Commun. Image Represent. 2021, 76, 103055. [Google Scholar] [CrossRef]
- Shaikh, M.B.; Chai, D. RGB-D data-based action recognition: A review. Sensors 2021, 21, 4246. [Google Scholar] [CrossRef] [PubMed]
- Majumder, S.; Kehtarnavaz, N. Vision and inertial sensing fusion for human action recognition: A review. IEEE Sens. J. 2020, 21, 2454–2467. [Google Scholar] [CrossRef]
- Wang, L.; Huynh, D.Q.; Koniusz, P. A comparative review of recent kinect-based action recognition algorithms. IEEE Trans. Image Process. 2019, 29, 15–28. [Google Scholar] [CrossRef]
- Wang, C.; Yan, J. A comprehensive survey of rgb-based and skeleton-based human action recognition. IEEE Access 2023, 11, 53880–53898. [Google Scholar] [CrossRef]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Action recognition using optimized deep autoencoder and CNN for surveillance data streams of non-stationary environments. Future Gener. Comput. Syst. 2019, 96, 386–397. [Google Scholar] [CrossRef]
- Lan, Z.; Lin, M.; Li, X.; Hauptmann, A.G.; Raj, B. Beyond gaussian pyramid: Multi-skip feature stacking for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 204–212. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Sharma, S.; Kiros, R.; Salakhutdinov, R. Action recognition using visual attention. arXiv 2015, arXiv:1511.04119. [Google Scholar]
- Ijjina, E.P.; Chalavadi, K.M. Human action recognition using genetic algorithms and convolutional neural networks. Pattern Recognit. 2016, 59, 199–212. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Akilan, T.; Wu, Q.J.; Safaei, A.; Jiang, W. A late fusion approach for harnessing multi-CNN model high-level features. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 566–571. [Google Scholar]
- Shi, Y.; Tian, Y.; Wang, Y.; Huang, T. Sequential deep trajectory descriptor for action recognition with three-stream CNN. IEEE Trans. Multimed. 2017, 19, 1510–1520. [Google Scholar] [CrossRef]
- Ahsan, U.; Sun, C.; Essa, I. Discrimnet: Semi-supervised action recognition from videos using generative adversarial networks. arXiv 2018, arXiv:1801.07230. [Google Scholar]
- Tu, Z.; Xie, W.; Qin, Q.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. Multi-stream CNN: Learning representations based on human-related regions for action recognition. Pattern Recognit. 2018, 79, 32–43. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, X.; Zha, Z.J.; Zeng, W. Mict: Mixed 3d/2d convolutional tube for human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 449–458. [Google Scholar]
- Jian, M.; Zhang, S.; Wu, L.; Zhang, S.; Wang, X.; He, Y. Deep key frame extraction for sport training. Neurocomputing 2019, 328, 147–156. [Google Scholar] [CrossRef]
- Gowda, S.; Rohrbach, M.; Sevilla-Lara, L. Smart frame selection for action recognition. arXiv 2020, arXiv:2012.10671. [Google Scholar] [CrossRef]
- Khan, M.A.; Javed, K.; Khan, S.A.; Saba, T.; Habib, U.; Khan, J.A.; Abbasi, A.A. Human action recognition using fusion of multiview and deep features: An application to video surveillance. Multimed. Tools Appl. 2020, 79, 27973–27995. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20 June 2021; pp. 1895–1904. [Google Scholar]
- Wang, X.; Zhang, S.; Qing, Z.; Tang, M.; Zuo, Z.; Gao, C.; Jin, R.; Sang, N. Hybrid relation guided set matching for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19948–19957. [Google Scholar]
- Wensel, J.; Ullah, H.; Munir, A. Vit-ret: Vision and recurrent transformer neural networks for human activity recognition in videos. IEEE Access 2023, 11, 72227–72249. [Google Scholar] [CrossRef]
- Hassan, N.; Miah, A.S.M.; Shin, J. A Deep Bidirectional LSTM Model Enhanced by Transfer-Learning-Based Feature Extraction for Dynamic Human Activity Recognition. Appl. Sci. 2024, 14, 603. [Google Scholar] [CrossRef]
- Khan, M.H.; Javed, M.A.; Farid, M.S. Deep-learning-based ConvLSTM and LRCN networks for human activity recognition. J. Vis. Commun. Image Represent. 2025, 110, 104469. [Google Scholar] [CrossRef]
- Shah, H.; Holia, M.S. Hybrid Feature Extraction and Knowledge Distillation Based Deep Learning Model for Human Activity Recognition System. Signal Process. Image Commun. 2025, 137, 117308. [Google Scholar] [CrossRef]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; pp. 961–970. [Google Scholar]
- Li, K.; Wang, Y.; He, Y.; Li, Y.; Wang, Y.; Wang, L.; Qiao, Y. Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer. arXiv 2022, arXiv:2211.09552. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Wang, Y.; Li, K.; Li, X.; Yu, J.; He, Y.; Chen, G.; Pei, B.; Zheng, R.; Xu, J.; Wang, Z.; et al. Internvideo2: Scaling video foundation models for multimodal video understanding. arXiv 2024, arXiv:2403.15377. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 6047–6056. [Google Scholar]
- Sheng, K.; Dong, W.; Ma, C.; Mei, X.; Huang, F.; Hu, B.G. Attention-based multi-patch aggregation for image aesthetic assessment. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 879–886. [Google Scholar]
- Monfort, M.; Andonian, A.; Zhou, B.; Ramakrishnan, K.; Bargal, S.A.; Yan, T.; Brown, L.; Fan, Q.; Gutfreund, D.; Vondrick, C.; et al. Moments in time dataset: One million videos for event understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 502–508. [Google Scholar] [CrossRef]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. Pose-based human action recognition via sparse representation in dissimilarity space. J. Vis. Commun. Image Represent. 2014, 25, 12–23. [Google Scholar] [CrossRef]
- Zhou, Q.; Rasol, J.; Xu, Y.; Zhang, Z.; Hu, L. A high-performance gait recognition method based on n-fold Bernoulli theory. IEEE Access 2022, 10, 115744–115757. [Google Scholar] [CrossRef]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 720–736. [Google Scholar]
- Tian, Y.; Shi, J.; Li, B.; Duan, Z.; Xu, C. Audio-visual event localization in unconstrained videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 247–263. [Google Scholar]
- Miech, A.; Alayrac, J.B.; Laptev, I.; Sivic, J.; Zisserman, A. Rareact: A video dataset of unusual interactions. arXiv 2020, arXiv:2008.01018. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Lin, W.; Liu, H.; Liu, S.; Li, Y.; Qian, R.; Wang, T.; Xu, N.; Xiong, H.; Qi, G.J.; Sebe, N. Human in events: A large-scale benchmark for human-centric video analysis in complex events. arXiv 2020, arXiv:2005.04490. [Google Scholar]
- Duan, X. Abnormal Behavior Recognition for Human Motion Based on Improved Deep Reinforcement Learning. Int. J. Image Graph. 2024, 24, 2550029. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Shahroudy, A.; Ng, T.T.; Gong, Y.; Wang, G. Deep multimodal feature analysis for action recognition in rgb+ d videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1045–1058. [Google Scholar] [CrossRef]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Cheng, Q.; Cheng, J.; Liu, Z.; Ren, Z.; Liu, J. A Dense-Sparse Complementary Network for Human Action Recognition based on RGB and Skeleton Modalities. Expert Syst. Appl. 2024, 244, 123061. [Google Scholar] [CrossRef]
- Liu, A.A.; Su, Y.T.; Jia, P.P.; Gao, Z.; Hao, T.; Yang, Z.X. Multiple/single-view human action recognition via part-induced multitask structural learning. IEEE Trans. Cybern. 2014, 45, 1194–1208. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QUC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Liu, M.; Yuan, J. Recognizing human actions as the evolution of pose estimation maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1159–1168. [Google Scholar]
- Rahmani, H.; Mahmood, A.; Huynh, D.; Mian, A. Histogram of oriented principal components for cross-view action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2430–2443. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1010–1019. [Google Scholar]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding. arXiv 2017, arXiv:1703.07475. [Google Scholar]
- Li, T.; Fan, L.; Zhao, M.; Liu, Y.; Katabi, D. Making the invisible visible: Action recognition through walls and occlusions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 872–881. [Google Scholar]
- Kong, Y.; Fu, Y. Max-margin heterogeneous information machine for RGB-D action recognition. Int. J. Comput. Vis. 2017, 123, 350–371. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A short note about kinetics-600. arXiv 2018, arXiv:1808.01340. [Google Scholar]
- Ji, Y.; Xu, F.; Yang, Y.; Shen, F.; Shen, H.T.; Zheng, W.S. A large-scale RGB-D database for arbitrary-view human action recognition. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1510–1518. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Martin, M.; Roitberg, A.; Haurilet, M.; Horne, M.; Reiß, S.; Voit, M.; Stiefelhagen, R. Drive&act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2801–2810. [Google Scholar]
- Lin, D.; Lee, P.H.Y.; Li, Y.; Wang, R.; Yap, K.H.; Li, B.; Ngim, Y.S. Multi-modality action recognition based on dual feature shift in vehicle cabin monitoring. arXiv 2024, arXiv:2401.14838. [Google Scholar]
- Kong, Q.; Wu, Z.; Deng, Z.; Klinkigt, M.; Tong, B.; Murakami, T. Mmact: A large-scale dataset for cross modal human action understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8658–8667. [Google Scholar]
- Liu, Y.; Wang, K.; Li, G.; Lin, L. Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition. IEEE Trans. Image Process. 2021, 30, 5573–5588. [Google Scholar] [CrossRef]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota smarthome: Real-world activities of daily living. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 27–2 November 2019; pp. 833–842. [Google Scholar]
- Ben-Shabat, Y.; Yu, X.; Saleh, F.; Campbell, D.; Rodriguez-Opazo, C.; Li, H.; Gould, S. The ikea asm dataset: Understanding people assembling furniture through actions, objects and pose. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 847–859. [Google Scholar]
- Jang, J.; Kim, D.; Park, C.; Jang, M.; Lee, J.; Kim, J. ETRI-activity3D: A large-scale RGB-D dataset for robots to recognize daily activities of the elderly. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10990–10997. [Google Scholar]
- Dokkar, R.R.; Chaieb, F.; Drira, H.; Aberkane, A. ConViViT–A Deep Neural Network Combining Convolutions and Factorized Self-Attention for Human Activity Recognition. arXiv 2023, arXiv:2310.14416. [Google Scholar]
- Li, T.; Liu, J.; Zhang, W.; Ni, Y.; Wang, W.; Li, Z. Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16266–16275. [Google Scholar]
- Xian, R.; Wang, X.; Kothandaraman, D.; Manocha, D. PMI Sampler: Patch similarity guided frame selection for Aerial Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 6982–6991. [Google Scholar]
- Patel, C.I.; Garg, S.; Zaveri, T.; Banerjee, A.; Patel, R. Human action recognition using fusion of features for unconstrained video sequences. Comput. Electr. Eng. 2018, 70, 284–301. [Google Scholar] [CrossRef]
- Liu, J.; Kuipers, B.; Savarese, S. Recognizing human actions by attributes. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 3337–3344. [Google Scholar]
- Shi, Q.; Cheng, L.; Wang, L.; Smola, A. Human action segmentation and recognition using discriminative semi-markov models. Int. J. Comput. Vis. 2011, 93, 22–32. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 1092–1099. [Google Scholar]
- Gan, L.; Chen, F. Human Action Recognition Using APJ3D and Random Forests. J. Softw. 2013, 8, 2238–2245. [Google Scholar] [CrossRef]
- Everts, I.; Van Gemert, J.C.; Gevers, T. Evaluation of color spatio-temporal interest points for human action recognition. IEEE Trans. Image Process. 2014, 23, 1569–1580. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Chen, W.; Guo, G. Evaluating spatiotemporal interest point features for depth-based action recognition. Image Vis. Comput. 2014, 32, 453–464. [Google Scholar] [CrossRef]
- Liu, L.; Shao, L.; Li, X.; Lu, K. Learning spatio-temporal representations for action recognition: A genetic programming approach. IEEE Trans. Cybern. 2015, 46, 158–170. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Xiao, X.; Wang, X.; Wang, J. Human action recognition based on Kinect and PSO-SVM by representing 3D skeletons as points in lie group. In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 568–573. [Google Scholar]
- Vishwakarma, D.K.; Kapoor, R.; Dhiman, A. A proposed unified framework for the recognition of human activity by exploiting the characteristics of action dynamics. Robot. Auton. Syst. 2016, 77, 25–38. [Google Scholar] [CrossRef]
- Singh, D.; Mohan, C.K. Graph formulation of video activities for abnormal activity recognition. Pattern Recognit. 2017, 65, 265–272. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Nazir, S.; Yousaf, M.H.; Velastin, S.A. Evaluating a bag-of-visual features approach using spatio-temporal features for action recognition. Comput. Electr. Eng. 2018, 72, 660–669. [Google Scholar] [CrossRef]
- Ullah, S.; Bhatti, N.; Qasim, T.; Hassan, N.; Zia, M. Weakly-supervised action localization based on seed superpixels. Multimed. Tools Appl. 2021, 80, 6203–6220. [Google Scholar] [CrossRef]
- Al-Obaidi, S.; Al-Khafaji, H.; Abhayaratne, C. Making sense of neuromorphic event data for human action recognition. IEEE Access 2021, 9, 82686–82700. [Google Scholar] [CrossRef]
- Hejazi, S.M.; Abhayaratne, C. Handcrafted localized phase features for human action recognition. Image Vis. Comput. 2022, 123, 104465. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Xu, Z.; Huang, J.; Lu, J. Hybrid handcrafted and learned feature framework for human action recognition. Appl. Intell. 2022, 52, 12771–12787. [Google Scholar] [CrossRef]
- Fatima, T.; Rahman, H.; Jalal, A. A novel framework for human action recognition based on features fusion and decision tree. In Proceedings of the 2023 4th International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 20–22 February 2023; Volume 53. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Zhang, Z.; Hu, Y.; Chan, S.; Chia, L.T. Motion context: A new representation for human action recognition. In Computer Vision–ECCV 2008, Proceedings of the10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Proceedings, Part IV 10; Springer: Berlin/Heidelberg, Germany, 2008; pp. 817–829. [Google Scholar]
- Somasundaram, G.; Cherian, A.; Morellas, V.; Papanikolopoulos, N. Action recognition using global spatio-temporal features derived from sparse representations. Comput. Vis. Image Underst. 2014, 123, 1–13. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Patel, C.I.; Labana, D.; Pandya, S.; Modi, K.; Ghayvat, H.; Awais, M. Histogram of oriented gradient-based fusion of features for human action recognition in action video sequences. Sensors 2020, 20, 7299. [Google Scholar] [CrossRef]
- Tan, P.S.; Lim, K.M.; Lee, C.P. Human action recognition with sparse autoencoder and histogram of oriented gradients. In Proceedings of the 2020 IEEE 2nd International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Sabah, 26–27 September 2020; pp. 1–5. [Google Scholar]
- Wattanapanich, C.; Wei, H.; Xu, W. Analysis of Histogram of Oriented Gradients on Gait Recognition. In Proceedings of the 4th Mediterranean Conference on Pattern Recognition and Artificial Intelligence, MedPRAI 2020, Hammamet, Tunisia, 20–22 December 2020; Proceedings 4. Springer: Cham, Switzerland, 2021; pp. 86–97. [Google Scholar]
- Zuo, Z.; Yang, L.; Liu, Y.; Chao, F.; Song, R.; Qu, Y. Histogram of fuzzy local spatio-temporal descriptors for video action recognition. IEEE Trans. Ind. Inform. 2019, 16, 4059–4067. [Google Scholar] [CrossRef]
- Wang, H. Enhanced forest microexpression recognition based on optical flow direction histogram and deep multiview network. Math. Probl. Eng. 2020, 2020, 5675914. [Google Scholar] [CrossRef]
- Ullah, S.; Hassan, N.; Bhatti, N. Temporal Superpixels based Human Action Localization. In Proceedings of the 2018 14th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 21–22 November 2018; pp. 1–6. [Google Scholar]
- Laptev, I.; Pérez, P. Retrieving actions in movies. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- Tran, D.; Sorokin, A. Human activity recognition with metric learning. In Proceedings of the Computer Vision–ECCV 2008, 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2008; pp. 548–561. [Google Scholar]
- Morency, L.P.; Quattoni, A.; Darrell, T. Latent-dynamic discriminative models for continuous gesture recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Wang, S.B.; Quattoni, A.; Morency, L.P.; Demirdjian, D.; Darrell, T. Hidden conditional random fields for gesture recognition. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1521–1527. [Google Scholar]
- Wang, L.; Suter, D. Recognizing human activities from silhouettes: Motion subspace and factorial discriminative graphical model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Tang, K.; Fei-Fei, L.; Koller, D. Learning latent temporal structure for complex event detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1250–1257. [Google Scholar]
- Wang, Z.; Wang, J.; Xiao, J.; Lin, K.H.; Huang, T. Substructure and boundary modeling for continuous action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1330–1337. [Google Scholar]
- Luo, G.; Yang, S.; Tian, G.; Yuan, C.; Hu, W.; Maybank, S.J. Learning Depth from Monocular Videos using Deep Neural Networks. J. Comput. Vis. 2014, 10, 1–10. [Google Scholar]
- Yuan, C.; Hu, W.; Tian, G.; Yang, S.; Wang, H. Multi-task sparse learning with beta process prior for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 423–429. [Google Scholar]
- Kar, A.; Rai, N.; Sikka, K.; Sharma, G. Adascan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4768–4777. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14; Springer: Cham, Switzerland, 2016; pp. 816–833. [Google Scholar]
- Shin, J.; Miah, A.S.M.; Akiba, Y.; Hirooka, K.; Hassan, N.; Hwang, Y.S. Korean sign language alphabet recognition through the integration of handcrafted and deep learning-based two-stream feature extraction approach. IEEE Access 2024, 12, 68303–68318. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-time action recognition with deeply transferred motion vector cnns. IEEE Trans. Image Process. 2018, 27, 2326–2339. [Google Scholar] [CrossRef]
- Hassan, N.; Miah, A.S.M.; Shin, J. Enhancing human action recognition in videos through dense-level features extraction and optimized long short-term memory. In Proceedings of the 2024 7th International Conference on Electronics, Communications, and Control Engineering (ICECC), Kuala Lumpur, Malaysia, 22–24 March 2024; pp. 19–23. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. arXiv 2017, arXiv:1705.07750. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.J.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. arXiv 2015, arXiv:1503.08909. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Spatio-temporal attention-based LSTM networks for 3D action recognition and detection. IEEE Trans. Image Process. 2018, 27, 3459–3471. [Google Scholar] [CrossRef] [PubMed]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Lan, Z.; Zhu, Y.; Hauptmann, A.G.; Newsam, S. Deep local video feature for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–7. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 803–818. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. arXiv 2017, arXiv:1711.10305. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Lin, D. Trajectory convolution for action recognition. Adv. Neural Inf. Process. Syst. 2018, 31, 2208–2219. [Google Scholar]
- Wang, L.; Li, W.; Li, W.; Van Gool, L. Appearance-and-relation networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1430–1439. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 27–2 November 2019; pp. 5552–5561. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Yang, C.; Xu, Y.; Shi, J.; Dai, B.; Zhou, B. Temporal pyramid network for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 591–600. [Google Scholar]
- Zhang, S.; Guo, S.; Huang, W.; Scott, M.R.; Wang, L. V4d: 4d convolutional neural networks for video-level representation learning. arXiv 2020, arXiv:2002.07442. [Google Scholar]
- Qin, Y.; Mo, L.; Xie, B. Feature fusion for human action recognition based on classical descriptors and 3D convolutional networks. In Proceedings of the 2017 Eleventh International Conference on Sensing Technology (ICST), Auckland, New Zealand, 28–30 November 2017; pp. 1–5. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Zhu, J.; Zhu, Z.; Zou, W. End-to-end video-level representation learning for action recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 645–650. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS’17: 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 244–253. [Google Scholar]
- Shaikh, M.B.; Chai, D.; Islam, S.M.S.; Akhtar, N. From CNNs to transformers in multimodal human action recognition: A survey. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 260. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xiao, F.; Lee, Y.J.; Grauman, K.; Malik, J.; Feichtenhofer, C. Audiovisual slowfast networks for video recognition. arXiv 2020, arXiv:2001.08740. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QUC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Yan, S.; Xiong, X.; Arnab, A.; Lu, Z.; Zhang, M.; Sun, C.; Schmid, C. Multiview transformers for video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and PATTERN Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 3333–3343. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 10078–10093. [Google Scholar]
- Wang, Y.; Li, K.; Li, Y.; He, Y.; Huang, B.; Zhao, Z.; Zhang, H.; Xu, J.; Liu, Y.; Wang, Z.; et al. Internvideo: General video foundation models via generative and discriminative learning. arXiv 2022, arXiv:2212.03191. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Xiu, Y.; Li, J.; Wang, H.; Fang, Y.; Lu, C. Pose Flow: Efficient online pose tracking. arXiv 2018, arXiv:1802.00977. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2878–2890. [Google Scholar] [CrossRef]
- Chen, X.; Yuille, A.L. Articulated pose estimation by a graphical model with image dependent pairwise relations. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Human pose estimation via convolutional part heatmap regression. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14; Springer: Cham, Switzerland, 2016; pp. 717–732. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Zhou, X.; Zhu, M.; Pavlakos, G.; Leonardos, S.; Derpanis, K.G.; Daniilidis, K. Monocap: Monocular human motion capture using a cnn coupled with a geometric prior. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 901–914. [Google Scholar] [CrossRef]
- Nunes, U.M.; Faria, D.R.; Peixoto, P. A human activity recognition framework using max-min features and key poses with differential evolution random forests classifier. Pattern Recognit. Lett. 2017, 99, 21–31. [Google Scholar] [CrossRef]
- Chen, Y. Reduced basis decomposition: A certified and fast lossy data compression algorithm. Comput. Math. Appl. 2015, 70, 2566–2574. [Google Scholar] [CrossRef]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Joint distance maps based action recognition with convolutional neural networks. IEEE Signal Process. Lett. 2017, 24, 624–628. [Google Scholar] [CrossRef]
- Soo Kim, T.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21 July 2017; pp. 20–28. [Google Scholar]
- Das, S.; Koperski, M.; Bremond, F.; Francesca, G. Deep-temporal lstm for daily living action recognition. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1227–1236. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Trelinski, J.; Kwolek, B. Ensemble of classifiers using CNN and hand-crafted features for depth-based action recognition. In Artificial Intelligence and Soft Computing: Proceedings of the 18th International Conference, ICAISC 2019, Zakopane, Poland, 16–20 June 2019; Proceedings, Part II 18; Springer: Cham, Switzerland, 2019; pp. 91–103. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Huynh-The, T.; Hua, C.H.; Kim, D.S. Encoding pose features to images with data augmentation for 3-D action recognition. IEEE Trans. Ind. Inform. 2019, 16, 3100–3111. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Ngo, T.T.; Kim, D.S. Image representation of pose-transition feature for 3D skeleton-based action recognition. Inf. Sci. 2020, 513, 112–126. [Google Scholar] [CrossRef]
- Naveenkumar, M.; Domnic, S. Deep ensemble network using distance maps and body part features for skeleton based action recognition. Pattern Recognit. 2020, 100, 107125. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208, 103219. [Google Scholar] [CrossRef]
- Snoun, A.; Jlidi, N.; Bouchrika, T.; Jemai, O.; Zaied, M. Towards a deep human activity recognition approach based on video to image transformation with skeleton data. Multimed. Tools Appl. 2021, 80, 29675–29698. [Google Scholar] [CrossRef]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. Pyskl: Towards good practices for skeleton action recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 7351–7354. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef]
- Zhu, G.; Wan, C.; Cao, L.; Wang, X. Relation-mining self-attention network for skeleton-based human action recognition. Pattern Recognit. 2023, 135, 109098. [Google Scholar] [CrossRef]
- Zhang, G.; Wen, S.; Li, J.; Che, H. Fast 3D-graph convolutional networks for skeleton-based action recognition. Appl. Soft Comput. 2023, 145, 110575. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Li, Y.; He, K.; Xu, D. Skeleton-based human action recognition via large-kernel attention graph convolutional network. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2575–2585. [Google Scholar] [CrossRef]
- Liang, C.; Yang, J.; Du, R.; Hu, W.; Hou, N. Temporal-Channel Attention and Convolution Fusion for Skeleton-Based Human Action Recognition. IEEE Access 2024, 12, 64937–64949. [Google Scholar] [CrossRef]
- Karthika, S.; Nancy Jane, Y.; Khanna Nehemiah, H. Spatio-temporal 3D skeleton kinematic joint point classification model for human activity recognition. J. Vis. Commun. Image Represent. 2025, 110, 104471. [Google Scholar] [CrossRef]
- Sun, T.; Lian, C.; Dong, F.; Shao, J.; Zhang, X.; Xiao, Q.; Ju, Z.; Zhao, Y. Skeletal joint image-based multi-channel fusion network for human activity recognition. Knowl.-Based Syst. 2025, 315, 113232. [Google Scholar] [CrossRef]
- Mehmood, F.; Guo, X.; Chen, E.; Akbar, M.A.; Khan, A.A.; Ullah, S. Extended multi-stream temporal-attention module for skeleton-based human action recognition (HAR). Comput. Hum. Behav. 2025, 163, 108482. [Google Scholar] [CrossRef]
- Shao, L.; Ji, L.; Liu, Y.; Zhang, J. Human action segmentation and recognition via motion and shape analysis. Pattern Recognit. Lett. 2012, 33, 438–445. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Chen, W.; Guo, G. TriViews: A general framework to use 3D depth data effectively for action recognition. J. Vis. Commun. Image Represent. 2015, 26, 182–191. [Google Scholar] [CrossRef]
- Miao, J.; Jia, X.; Mathew, R.; Xu, X.; Taubman, D.; Qing, C. Efficient action recognition from compressed depth maps. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 16–20. [Google Scholar]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3d joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Keceli, A.S.; Can, A.B. Recognition of basic human actions using depth information. Int. J. Pattern Recognit. Artif. Intell. 2014, 28, 1450004. [Google Scholar] [CrossRef]
- Pazhoumand-Dar, H.; Lam, C.P.; Masek, M. Joint movement similarities for robust 3D action recognition using skeletal data. J. Vis. Commun. Image Represent. 2015, 30, 10–21. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Ding, Z.; Wang, P.; Ogunbona, P.O.; Li, W. Investigation of different skeleton features for cnn-based 3D action recognition. In Proceedings of the 2017 IEEE International Conference on Multimedia & ExpoWorkshops (ICMEW), Hong Kong, China, 10–14 July, 2017; pp. 617–622. [Google Scholar]
- Caetano, C.; Sena, J.; Brémond, F.; Dos Santos, J.A.; Schwartz, W.R. Skelemotion: A new representation of skeleton joint sequences based on motion information for 3d action recognition. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Liu, H.; Tu, J.; Liu, M. Two-stream 3d convolutional neural network for skeleton-based action recognition. arXiv 2017, arXiv:1705.08106. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ogiela, M.R.; Jain, L.C. Computational Intelligence Paradigms in Advanced Pattern Classification; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 386. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5457–5466. [Google Scholar]
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J. Dynamic Hand Gesture Recognition using Multi-Branch Attention Based Graph and General Deep Learning Model. IEEE Access 2023, 11, 4703–4716. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Suzuki, K.; Hirooka, K.; Hasan, M.A.M. Dynamic Korean Sign Language Recognition Using Pose Estimation Based and Attention-Based Neural Network. IEEE Access 2023, 11, 143501–143513. [Google Scholar] [CrossRef]
- Shin, J.; Kaneko, Y.; Miah, A.S.M.; Hassan, N.; Nishimura, S. Anomaly Detection in Weakly Supervised Videos Using Multistage Graphs and General Deep Learning Based Spatial-Temporal Feature Enhancement. IEEE Access 2024, 12, 65213–65227. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Egawa, R.; Hassan, N.; Hirooka, K.; Tomioka, Y. Multimodal Fall Detection Using Spatial–Temporal Attention and Bi-LSTM-Based Feature Fusion. Future Internet 2025, 17, 173. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Nishimura, S.; Shin, J. Sign Language Recognition using Graph and General Deep Neural Network Based on Large Scale Dataset. IEEE Access 2024, 12, 34553–34569. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Hasan, M.A.M.; Jang, S.W.; Lee, H.S.; Shin, J. Multi-Stream General and Graph-Based Deep Neural Networks for Skeleton-Based Sign Language Recognition. Electronics 2023, 12, 2841. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QUC, Canada, 31 July 31–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Li, R.; Tapaswi, M.; Liao, R.; Jia, J.; Urtasun, R.; Fidler, S. Situation recognition with graph neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4173–4182. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shiraki, K.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Spatial temporal attention graph convolutional networks with mechanics-stream for skeleton-based action recognition. In Proceedings of the Asian Conference on Computer Vision, Virtual, 30 November–4 December 2020. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Huang, Z.; Xiang, X.; Gong, X.; Zhang, B. Long-short graph memory network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 7–10 January 2020; pp. 645–652. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 183–192. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, faster and more explainable: A graph convolutional baseline for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1625–1633. [Google Scholar]
- Thakkar, K.; Narayanan, P. Part-based graph convolutional network for action recognition. arXiv 2018, arXiv:1809.04983. [Google Scholar]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-temporal graph routing for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8561–8568. [Google Scholar]
- Chi, H.g.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. Infogcn: Representation learning for human skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 20186–20196. [Google Scholar]
- Zheng, Y.; Zhang, Y.; Qian, K.; Zhang, G.; Liu, Y.; Wu, C.; Yang, Z. Zero-effort cross-domain gesture recognition with Wi-Fi. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Republic of Korea, 17–21 June 2019; pp. 313–325. [Google Scholar]
- Sanhudo, L.; Calvetti, D.; Martins, J.P.; Ramos, N.M.; Meda, P.; Goncalves, M.C.; Sousa, H. Activity classification using accelerometers and machine learning for complex construction worker activities. J. Build. Eng. 2021, 35, 102001. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Huan, R.; Jiang, C.; Ge, L.; Shu, J.; Zhan, Z.; Chen, P.; Chi, K.; Liang, R. Human complex activity recognition with sensor data using multiple features. IEEE Sens. J. 2021, 22, 757–775. [Google Scholar] [CrossRef]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-based human activity recognition with spatio-temporal deep learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Kabir, M.H.; Mahmood, S.; Al Shiam, A.; Musa Miah, A.S.; Shin, J.; Molla, M.K.I. Investigating Feature Selection Techniques to Enhance the Performance of EEG-Based Motor Imagery Tasks Classification. Mathematics 2023, 11, 1921. [Google Scholar] [CrossRef]
- Al Farid, F.; Bari, A.; Mansor, S.; Uddin, J.; Kumaresan, S.P. A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living. J. Imaging 2025, 11, 182. [Google Scholar] [CrossRef]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republic of Korea, 1–4 November 2015; pp. 127–140. [Google Scholar]
- Abbas, S.; Alsubai, S.; Sampedro, G.A.; ul Haque, M.I.; Almadhor, A.; Al Hejaili, A.; Ivanochko, I. Active Machine Learning for Heterogeneity Activity Recognition Through Smartwatch Sensors. IEEE Access 2024, 12, 22595–22607. [Google Scholar] [CrossRef]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In Proceedings of the International Workshop on Ambient Assisted Living, Belfast, UK, 2–5 December 2014; pp. 2–5. [Google Scholar]
- El-Adawi, E.; Essa, E.; Handosa, M.; Elmougy, S. Wireless body area sensor networks based human activity recognition using deep learning. Sci. Rep. 2024, 14, 2702. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.d.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Ye, X.; Wang, K.I.K. Deep Generative Domain Adaptation with Temporal Relation Knowledge for Cross-User Activity Recognition. arXiv 2024, arXiv:2403.14682. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM Sigkdd Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Kaya, Y.; Topuz, E.K. Human activity recognition from multiple sensors data using deep CNNs. Multimed. Tools Appl. 2024, 83, 10815–10838. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN, Bruges, Belgium, 24–26 April 2013; Volume 3, p. 3. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Zhu, Y.; Luo, H.; Chen, R.; Zhao, F. DiamondNet: A Neural-Network-Based Heterogeneous Sensor Attentive Fusion for Human Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 15321–15331. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B.; Tunçel, O. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognit. 2010, 43, 3605–3620. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, L. Multi-STMT: Multi-level network for human activity recognition based on wearable sensors. IEEE Trans. Instrum. Meas. 2024, 73, 2508612. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar]
- Khan, D.; Al Mudawi, N.; Abdelhaq, M.; Alazeb, A.; Alotaibi, S.S.; Algarni, A.; Jalal, A. A wearable inertial sensor approach for locomotion and localization recognition on physical activity. Sensors 2024, 24, 735. [Google Scholar] [CrossRef]
- Cheng, H.T.; Sun, F.T.; Griss, M.; Davis, P.; Li, J.; You, D. Nuactiv: Recognizing unseen new activities using semantic attribute-based learning. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 361–374. [Google Scholar]
- Zolfaghari, P.; Rey, V.F.; Ray, L.; Kim, H.; Suh, S.; Lukowicz, P. Sensor Data Augmentation from Skeleton Pose Sequences for Improving Human Activity Recognition. arXiv 2024, arXiv:2406.16886. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Zhang, L.; Yu, J.; Gao, Z.; Ni, Q. A multi-channel hybrid deep learning framework for multi-sensor fusion enabled human activity recognition. Alex. Eng. J. 2024, 91, 472–485. [Google Scholar] [CrossRef]
- Huynh, T.; Fritz, M.; Schiele, B. Discovery of activity patterns using topic models. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; pp. 10–19. [Google Scholar]
- Micucci, D.; Mobilio, M.; Napoletano, P. Unimib shar: A dataset for human activity recognition using acceleration data from smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef]
- Yao, M.; Zhang, L.; Cheng, D.; Qin, L.; Liu, X.; Fu, Z.; Wu, H.; Song, A. Revisiting Large-Kernel CNN Design via Structural Re-Parameterization for Sensor-Based Human Activity Recognition. IEEE Sens. J. 2024, 24, 12863–12876. [Google Scholar] [CrossRef]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 1036–1043. [Google Scholar]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The mobiact dataset: Recognition of activities of daily living using smartphones. In Proceedings of the International Conference on Information and Communication Technologies for Ageing Well and E-Health, Rome, Italy, 21–22 April 2016; SciTePress: Porto, Portugal, 2016; Volume 2, pp. 143–151. [Google Scholar]
- Khaertdinov, B.; Asteriadis, S. Explaining, Analyzing, and Probing Representations of Self-Supervised Learning Models for Sensor-based Human Activity Recognition. In Proceedings of the 2023 IEEE International Joint Conference on Biometrics (IJCB), Ljubljana, Slovenia, 25–28 September 2023; pp. 1–10. [Google Scholar]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting sensory data against sensitive inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems, Porto, Portugal, 23–26 April 2018; pp. 1–6. [Google Scholar]
- Saha, U.; Saha, S.; Kabir, M.T.; Fattah, S.A.; Saquib, M. Decoding human activities: Analyzing wearable accelerometer and gyroscope data for activity recognition. IEEE Sens. Lett. 2024, 8, 7003904. [Google Scholar] [CrossRef]
- van Kasteren, T.L.; Englebienne, G.; Kröse, B.J. Human activity recognition from wireless sensor network data: Benchmark and software. In Activity Recognition in Pervasive Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2011; pp. 165–186. [Google Scholar]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A smart home in a box. Computer 2012, 46, 62–69. [Google Scholar] [CrossRef]
- Kim, H.; Lee, D. CLAN: A Contrastive Learning based Novelty Detection Framework for Human Activity Recognition. arXiv 2024, arXiv:2401.10288. [Google Scholar]
- Zappi, P.; Lombriser, C.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, L.; Tröster, G. Activity recognition from on-body sensors: Accuracy-power trade-off by dynamic sensor selection. In Wireless Sensor Networks, Proceedings of the 5th European Conference, EWSN 2008, Bologna, Italy, 30 January–1 February 2008; Proceedings; Springer: Berlin/Heidelberg, Germany, 2008; pp. 17–33. [Google Scholar]
- Zhang, Z.; Wang, W.; An, A.; Qin, Y.; Yang, F. A human activity recognition method using wearable sensors based on convtransformer model. Evol. Syst. 2023, 14, 939–955. [Google Scholar] [CrossRef]
- Chen, J.; Xu, X.; Wang, T.; Jeon, G.; Camacho, D. An AIoT Framework With Multi-modal Frequency Fusion for WiFi-Based Coarse and Fine Activity Recognition. IEEE Internet Things J. 2024, 11, 39020–39029. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Jain, A.; Kanhangad, V. Human activity classification in smartphones using accelerometer and gyroscope sensors. IEEE Sens. J. 2017, 18, 1169–1177. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using convolutional neural networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef] [PubMed]
- Kavuncuoğlu, E.; Uzunhisarcıklı, E.; Barshan, B.; Özdemir, A.T. Investigating the performance of wearable motion sensors on recognizing falls and daily activities via machine learning. Digit. Signal Process. 2022, 126, 103365. [Google Scholar] [CrossRef]
- Lu, L.; Zhang, C.; Cao, K.; Deng, T.; Yang, Q. A multichannel CNN-GRU model for human activity recognition. IEEE Access 2022, 10, 66797–66810. [Google Scholar] [CrossRef]
- Kim, Y.W.; Cho, W.H.; Kim, K.S.; Lee, S. Oversampling technique-based data augmentation and 1D-CNN and bidirectional GRU ensemble model for human activity recognition. J. Mech. Med. Biol. 2022, 22, 2240048. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, J. A novel multichannel dilated convolution neural network for human activity recognition. Math. Probl. Eng. 2020, 2020, 5426532. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy markov model. Multimed. Tools Appl. 2021, 80, 21465–21498. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data augmentation and dense-LSTM for human activity recognition using WiFi signal. IEEE Internet Things J. 2020, 8, 4628–4641. [Google Scholar] [CrossRef]
- Alawneh, L.; Mohsen, B.; Al-Zinati, M.; Shatnawi, A.; Al-Ayyoub, M. A comparison of unidirectional and bidirectional lstm networks for human activity recognition. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020; pp. 1–6. [Google Scholar]
- Wei, X.; Wang, Z. TCN-attention-HAR: Human activity recognition based on attention mechanism time convolutional network. Sci. Rep. 2024, 14, 7414. [Google Scholar] [CrossRef]
- Sarkar, A.; Hossain, S.S.; Sarkar, R. Human activity recognition from sensor data using spatial attention-aided CNN with genetic algorithm. Neural Comput. Appl. 2023, 35, 5165–5191. [Google Scholar] [CrossRef]
- Semwal, V.B.; Jain, R.; Maheshwari, P.; Khatwani, S. Gait reference trajectory generation at different walking speeds using LSTM and CNN. Multimed. Tools Appl. 2023, 82, 33401–33419. [Google Scholar] [CrossRef]
- Liu, K.; Gao, C.; Li, B.; Liu, W. Human activity recognition through deep learning: Leveraging unique and common feature fusion in wearable multi-sensor systems. Appl. Soft Comput. 2024, 151, 111146. [Google Scholar] [CrossRef]
- Khan, S.I.; Dawood, H.; Khan, M.; Issa, G.F.; Hussain, A.; Alnfiai, M.M.; Adnan, K.M. Transition-aware human activity recognition using an ensemble deep learning framework. Comput. Hum. Behav. 2025, 162, 108435. [Google Scholar] [CrossRef]
- Sarakon, S.; Massagram, W.; Tamee, K. Multisource Data Fusion Using MLP for Human Activity Recognition. Comput. Mater. Contin. (CMC) 2025, 82, 2110–2136. [Google Scholar] [CrossRef]
- Yao, M.; Cheng, D.; Zhang, L.; Wang, L.; Wu, H.; Song, A. Long kernel distillation in human activity recognition. Knowl.-Based Syst. 2025, 316, 113397. [Google Scholar] [CrossRef]
- Thakur, D.; Dangi, S.; Lalwani, P. A novel hybrid deep learning approach with GWO–WOA optimization technique for human activity recognition. Biomed. Signal Process. Control 2025, 99, 106870. [Google Scholar] [CrossRef]
- Hu, L.; Zhao, K.; Ling, B.W.K.; Liang, S.; Wei, Y. Improving human activity recognition via graph attention network with linear discriminant analysis and residual learning. Biomed. Signal Process. Control 2025, 100, 107053. [Google Scholar] [CrossRef]
- Yu, X.; Al-qaness, M.A. ASK-HAR: Attention-Based Multi-Core Selective Kernel Convolution Network for Human Activity Recognition. Measurement 2025, 242, 115981. [Google Scholar] [CrossRef]
- Muralidharan, A.; Mahfuz, S. Human Activity Recognition Using Hybrid CNN-RNN Architecture. Procedia Comput. Sci. 2025, 257, 336–343. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, S.; Wei, Z.; Zhang, Y.; Zhang, L.; Li, H. Semi-supervised Human Activity Recognition with Individual Difference Alignment. Expert Syst. Appl. 2025, 275, 126976. [Google Scholar] [CrossRef]
- Sharen, H.; Anbarasi, L.J.; Rukmani, P.; Gandomi, A.H.; Neeraja, R.; Narendra, M. WISNet: A deep neural network based human activity recognition system. Expert Syst. Appl. 2024, 258, 124999. [Google Scholar] [CrossRef]
- Teng, Q.; Li, W.; Hu, G.; Shu, Y.; Liu, Y. Innovative Dual-Decoupling CNN With Layer-Wise Temporal-Spatial Attention for Sensor-Based Human Activity Recognition. IEEE J. Biomed. Health Inform. 2025, 29, 1035–1047. [Google Scholar] [CrossRef] [PubMed]
- Dahal, A.; Moulik, S.; Mukherjee, R. Stack-HAR: Complex Human Activity Recognition With Stacking-Based Ensemble Learning Framework. IEEE Sens. J. 2025, 25, 16373–16380. [Google Scholar] [CrossRef]
- Pitombeira-Neto, A.R.; de França, D.S.; Cruz, L.A.; da Silva, T.L.C.; de Macedo, J.A.F. An Ensemble Bayesian Dynamic Linear Model for Human Activity Recognition. IEEE Access 2025, 13, 30316–30333. [Google Scholar] [CrossRef]
- Latyshev, E. Sensor Data Preprocessing, Feature Engineering and Equipment Remaining Lifetime Forecasting for Predictive Maintenance. In Proceedings of the DAMDID/RCDL, Moscow, Russia, 9–12 October 2018; pp. 226–231. [Google Scholar]
- Joy, M.M.H.; Hasan, M.; Miah, A.S.M.; Ahmed, A.; Tohfa, S.A.; Bhuaiyan, M.F.I.; Zannat, A.; Rashid, M.M. Multiclass mi-task classification using logistic regression and filter bank common spatial patterns. In Proceedings of the International Conference on Computing Science, Communication and Security, Gandhingar, India, 26–27 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 160–170. [Google Scholar]
- Miah, A.S.M.; Rahim, M.A.; Shin, J. Motor-imagery classification using riemannian geometry with median absolute deviation. Electronics 2020, 9, 1584. [Google Scholar] [CrossRef]
- Zobaed, T.; Ahmed, S.R.A.; Miah, A.S.M.; Binta, S.M.; Ahmed, M.R.A.; Rashid, M. Real time sleep onset detection from single channel EEG signal using block sample entropy. In Proceedings of the IOP Conference Series: Materials Science and Engineering, IOP Publishing, Dhaka, Bangladesh, 27–28 August 2020; Volume 928, p. 032021. [Google Scholar]
- Hussain, I.; Jany, R.; Boyer, R.; Azad, A.; Alyami, S.A.; Park, S.J.; Hasan, M.M.; Hossain, M.A. An explainable EEG-based human activity recognition model using machine-learning approach and LIME. Sensors 2023, 23, 7452. [Google Scholar] [CrossRef]
- Thakur, D.; Biswas, S.; Ho, E.S.; Chattopadhyay, S. Convae-lstm: Convolutional autoencoder long short-term memory network for smartphone-based human activity recognition. IEEE Access 2022, 10, 4137–4156. [Google Scholar] [CrossRef]
- Madsen, H. Time Series Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2007. [Google Scholar]
- Ye, X.; Wang, K.I.K. Cross-User Activity Recognition Using Deep Domain Adaptation With Temporal Dependency Information. IEEE Trans. Instrum. Meas. 2025, 74, 2520415. [Google Scholar] [CrossRef]
- Park, J.; Kim, D.W.; Lee, J. HT-AggNet: Hierarchical temporal aggregation network with near-zero-cost layer stacking for human activity recognition. Eng. Appl. Artif. Intell. 2025, 149, 110465. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Gupta, S. Deep learning based human activity recognition (HAR) using wearable sensor data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Cui, W.; Liu, C.; Li, X. An attention based CNN-LSTM approach for sleep-wake detection with heterogeneous sensors. IEEE J. Biomed. Health Inform. 2020, 25, 3270–3277. [Google Scholar] [CrossRef]
- Essa, E.; Abdelmaksoud, I.R. Temporal-channel convolution with self-attention network for human activity recognition using wearable sensors. Knowl.-Based Syst. 2023, 278, 110867. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Shi, H.; Li, C.; Li, P. Multi-instance multi-label action recognition and localization based on spatio-temporal pre-trimming for untrimmed videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12886–12893. [Google Scholar]
- Cemiloglu, A.; Akay, B. Handling heterogeneity in Human Activity Recognition data by a compact Long Short Term Memory based deep learning approach. Eng. Appl. Artif. Intell. 2025, 153, 110788. [Google Scholar] [CrossRef]
- Di Domenico, S.; De Sanctis, M.; Cianca, E.; Bianchi, G. A trained-once crowd counting method using differential wifi channel state information. In Proceedings of the 3rd International on Workshop on Physical Analytics, Singapore, 26 June 2016; pp. 37–42. [Google Scholar]
- Liu, J.; Teng, G.; Hong, F. Human activity sensing with wireless signals: A survey. Sensors 2020, 20, 1210. [Google Scholar] [CrossRef]
- Jiang, W.; Miao, C.; Ma, F.; Yao, S.; Wang, Y.; Yuan, Y.; Xue, H.; Song, C.; Ma, X.; Koutsonikolas, D.; et al. Towards environment independent device free human activity recognition. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 289–304. [Google Scholar]
- Arshad, S.; Feng, C.; Liu, Y.; Hu, Y.; Yu, R.; Zhou, S.; Li, H. Wi-chase: A WiFi based human activity recognition system for sensorless environments. In Proceedings of the 2017 IEEE 18th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, China, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Li, C.; Cao, Z.; Liu, Y. Deep AI enabled ubiquitous wireless sensing: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Ji, S.; Xie, Y.; Li, M. SiFall: Practical online fall detection with RF sensing. In Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, Boston, MA, USA, 6–9 November 2022; pp. 563–577. [Google Scholar]
- Zhao, C.; Wang, L.; Xiong, F.; Chen, S.; Su, J.; Xu, H. RFID-Based Human Action Recognition Through Spatiotemporal Graph Convolutional Neural Network. IEEE Internet Things J. 2023, 10, 19898–19912. [Google Scholar] [CrossRef]
- Li, W.; Vishwakarma, S.; Tang, C.; Woodbridge, K.; Piechocki, R.J.; Chetty, C. Using RF Transmissions from IoT Devices for Occupancy Detection and Activity Recognition. IEEE Sens. J. 2022, 22, 2484–2495. [Google Scholar] [CrossRef]
- Muaaz, M.; Waqar, S.; Pätzold, M. Orientation-Independent Human Activity Recognition Using Complementary Radio Frequency Sensing. Sensors 2023, 23, 5810. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.; Marsalek, R. The Human Activity Recognition Using Radio Frequency Signals. In Proceedings of the 2023 33rd International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 19–20 April 2023. [Google Scholar] [CrossRef]
- Uysal, C.; Filik, T. A New RF Sensing Framework for Human Detection Through the Wall. IEEE Trans. Veh. Technol. 2023, 72, 3600–3610. [Google Scholar] [CrossRef]
- Saeed, U.; Shah, S.A.; Khan, M.Z.; Alotaibi, A.A.; Althobaiti, T.; Ramzan, N.; Imran, M.A.; Abbasi, Q.H. Software-Defined Radio-Based Contactless Localization for Diverse Human Activity Recognition. IEEE Sens. J. 2023, 23, 12041–12048. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, C.; Mao, S. AIGC for RF-Based Human Activity Sensing. IEEE Internet Things J. 2025, 12, 3991–4005. [Google Scholar] [CrossRef]
- Chen, Z.; Cai, C.; Zheng, T.; Luo, J.; Xiong, J.; Wang, X. RF-Based Human Activity Recognition Using Signal Adapted Convolutional Neural Network. arXiv 2023, arXiv:2110.14307. [Google Scholar] [CrossRef]
- Yang, C.; Wang, X.; Mao, S. TARF: Technology-Agnostic RF Sensing for Human Activity Recognition. IEEE J. Biomed. Health Inform. 2023, 27, 636–647. [Google Scholar] [CrossRef]
- Guo, W.; Yamagishi, S.; Jing, L. Human Activity Recognition via Wi-Fi and Inertial Sensors With Machine Learning. IEEE Access 2024, 12, 18821–18836. [Google Scholar] [CrossRef]
- Mohtadifar, M.; Cheffena, M.; Pourafzal, A. Acoustic- and Radio-Frequency-Based Human Activity Recognition. Sensors 2022, 22, 3125. [Google Scholar] [CrossRef]
- Rani, S.S.; Naidu, G.A.; Shree, V.U. Kinematic joint descriptor and depth motion descriptor with convolutional neural networks for human action recognition. Mater. Today Proc. 2021, 37, 3164–3173. [Google Scholar] [CrossRef]
- Dhiman, C.; Vishwakarma, D.K. View-invariant deep architecture for human action recognition using two-stream motion and shape temporal dynamics. IEEE Trans. Image Process. 2020, 29, 3835–3844. [Google Scholar] [CrossRef]
- Wang, L.; Ding, Z.; Tao, Z.; Liu, Y.; Fu, Y. Generative multi-view human action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6212–6221. [Google Scholar]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A. Real time action recognition using histograms of depth gradients and random decision forests. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 626–633. [Google Scholar]
- Shin, J.; Miah, A.S.M.; Kaneko, Y.; Hassan, N.; Lee, H.S.; Jang, S.W. Multimodal Attention-Enhanced Feature Fusion-Based Weakly Supervised Anomaly Violence Detection. IEEE Open J. Comput. Soc. 2024, 6, 129–140. [Google Scholar] [CrossRef]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7297–7306. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Zaher, M.; Ghoneim, A.S.; Abdelhamid, L.; Atia, A. Fusing CNNs and attention-mechanisms to improve real-time indoor Human Activity Recognition for classifying home-based physical rehabilitation exercises. Comput. Biol. Med. 2025, 184, 109399. [Google Scholar] [CrossRef]
- Ko, J.E.; Kim, S.; Sul, J.H.; Kim, S.M. Data Reconstruction Methods in Multi-Feature Fusion CNN Model for Enhanced Human Activity Recognition. Sensors 2025, 25, 1184. [Google Scholar] [CrossRef]
- Zhao, Y.; Shao, J.; Lin, X.; Sun, T.; Li, J.; Lian, C.; Lyu, X.; Si, B.; Zhan, Z. CIR-DFENet: Incorporating cross-modal image representation and dual-stream feature enhanced network for activity recognition. Expert Syst. Appl. 2025, 266, 125912. [Google Scholar] [CrossRef]
- Romaissa, B.D.; Mourad, O.; Brahim, N. Vision-based multi-modal framework for action recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5859–5866. [Google Scholar]
- Ren, Z.; Zhang, Q.; Gao, X.; Hao, P.; Cheng, J. Multi-modality learning for human action recognition. Multimed. Tools Appl. 2021, 80, 16185–16203. [Google Scholar] [CrossRef]
- Chen, J.; Ho, C.M. MM-ViT: Multi-modal video transformer for compressed video action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 1910–1921. [Google Scholar]
- Khatun, M.A.; Yousuf, M.A.; Ahmed, S.; Uddin, M.Z.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Khan, A.; Azad, A.; Moni, M.A. Deep CNN-LSTM with self-attention model for human activity recognition using wearable sensor. IEEE J. Transl. Eng. Health Med. 2022, 10, 1–16. [Google Scholar] [CrossRef]
- Bruce, X.; Liu, Y.; Zhang, X.; Zhong, S.H.; Chan, K.C. Mmnet: A model-based multimodal network for human action recognition in rgb-d videos. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3522–3538. [Google Scholar]
- Wang, L.; Koniusz, P. 3mformer: Multi-order multi-mode transformer for skeletal action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5620–5631. [Google Scholar]
- Xu, H.; Gao, Y.; Hui, Z.; Li, J.; Gao, X. Language knowledge-assisted representation learning for skeleton-based action recognition. arXiv 2023, arXiv:2305.12398. [Google Scholar] [CrossRef]
- Shaikh, M.B.; Chai, D.; Islam, S.M.S.; Akhtar, N. Multimodal fusion for audio-image and video action recognition. Neural Comput. Appl. 2024, 36, 5499–5513. [Google Scholar] [CrossRef]
- Dai, C.; Lu, S.; Liu, C.; Guo, B. A light-weight skeleton human action recognition model with knowledge distillation for edge intelligent surveillance applications. Appl. Soft Comput. 2024, 151, 111166. [Google Scholar] [CrossRef]
- Zhao, X.; Tang, C.; Hu, H.; Wang, W.; Qiao, S.; Tong, A. Attention mechanism based multimodal feature fusion network for human action recognition. J. Vis. Commun. Image Represent. 2025, 110, 104459. [Google Scholar] [CrossRef]
- Liu, D.; Meng, F.; Mi, J.; Ye, M.; Li, Q.; Zhang, J. SAM-Net: Semantic-assisted multimodal network for action recognition in RGB-D videos. Pattern Recognit. 2025, 168, 111725. [Google Scholar] [CrossRef]
- Xefteris, V.R.; Syropoulou, A.C.; Pistola, T.; Kasnesis, P.; Poulios, I.; Tsanousa, A.; Symeonidis, S.; Diplaris, S.; Goulianas, K.; Chatzimisios, P.; et al. Multimodal fusion of inertial sensors and single RGB camera data for 3D human pose estimation based on a hybrid LSTM-Random forest fusion network. Internet Things 2025, 29, 101465. [Google Scholar] [CrossRef]
- Hu, J.F.; Zheng, W.S.; Lai, J.; Zhang, J. Jointly learning heterogeneous features for RGB-D activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5344–5352. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Pan, J.; Lai, J.; Zhang, J. Deep bilinear learning for rgb-d action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Khaire, P.; Kumar, P.; Imran, J. Combining CNN streams of RGB-D and skeletal data for human activity recognition. Pattern Recognit. Lett. 2018, 115, 107–116. [Google Scholar] [CrossRef]
- Cardenas, E.E.; Chavez, G.C. Multimodal human action recognition based on a fusion of dynamic images using cnn descriptors. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Paraná, Brazil, 29 October–1 November 2018; pp. 95–102. [Google Scholar]
- Khaire, P.; Imran, J.; Kumar, P. Human activity recognition by fusion of rgb, depth, and skeletal data. In Proceedings of the 2nd International Conference on Computer Vision & Image Processing (CVIP 2017), Roorkee, India, 9–12 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1, pp. 409–421. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 807–811. [Google Scholar] [CrossRef]
- Liu, D.; Meng, F.; Xia, Q.; Ma, Z.; Mi, J.; Gan, Y.; Ye, M.; Zhang, J. Temporal cues enhanced multimodal learning for action recognition in RGB-D videos. Neurocomputing 2024, 594, 127882. [Google Scholar] [CrossRef]
- Franco, A.; Magnani, A.; Maio, D. A multimodal approach for human activity recognition based on skeleton and RGB data. Pattern Recognit. Lett. 2020, 131, 293–299. [Google Scholar] [CrossRef]
- Shah, K.; Shah, A.; Lau, C.P.; de Melo, C.M.; Chellappa, R. Multi-view action recognition using contrastive learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HA, USA, 3–7 January 2023; pp. 3381–3391. [Google Scholar]
- Wu, Z.; Ding, Y.; Wan, L.; Li, T.; Nian, F. Local and global self-attention enhanced graph convolutional network for skeleton-based action recognition. Pattern Recognit. 2025, 159, 111106. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Meinel, C. Exploring multimodal video representation for action recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1924–1931. [Google Scholar]
- Kazakos, E.; Nagrani, A.; Zisserman, A.; Damen, D. Epic-fusion: Audio-visual temporal binding for egocentric action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5492–5501. [Google Scholar]
- Gao, R.; Oh, T.H.; Grauman, K.; Torresani, L. Listen to look: Action recognition by previewing audio. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10457–10467. [Google Scholar]
- Venkatachalam, K.; Yang, Z.; Trojovskỳ, P.; Bacanin, N.; Deveci, M.; Ding, W. Bimodal HAR-An efficient approach to human activity analysis and recognition using bimodal hybrid classifiers. Inf. Sci. 2023, 628, 542–557. [Google Scholar] [CrossRef]
- Yu, X.; Yang, H.; Chen, C.H. Human operators’ cognitive workload recognition with a dual attention-enabled multimodal fusion framework. Expert Syst. Appl. 2025, 280, 127418. [Google Scholar] [CrossRef]
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A. Intel realsense stereoscopic depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Drouin, M.A.; Seoud, L. Consumer-grade RGB-D cameras. In 3D Imaging, Analysis and Applications; Springer: London, UK, 2020; pp. 215–264. [Google Scholar]
- Grunnet-Jepsen, A.; Sweetser, J.N.; Woodfill, J. Best-Known-Methods for Tuning Intel® Realsense™ d400 Depth Cameras for Best Performance; Intel Corporation: Satan Clara, CA, USA, 2018; Volume 1. [Google Scholar]
- Zabatani, A.; Surazhsky, V.; Sperling, E.; Moshe, S.B.; Menashe, O.; Silver, D.H.; Karni, Z.; Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Intel® realsense™ sr300 coded light depth camera. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2333–2345. [Google Scholar] [CrossRef]
- Li, T.; Zhang, R.; Li, Q. Multi scale temporal graph networks for skeleton-based action recognition. arXiv 2020, arXiv:2012.02970. [Google Scholar]
- Parsa, B.; Narayanan, A.; Dariush, B. Spatio-temporal pyramid graph convolutions for human action recognition and postural assessment. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Aspen, CO, USA, 1–5 March 2020; pp. 1080–1090. [Google Scholar]
- Zhu, G.; Zhang, L.; Li, H.; Shen, P.; Shah, S.A.A.; Bennamoun, M. Topology-learnable graph convolution for skeleton-based action recognition. Pattern Recognit. Lett. 2020, 135, 286–292. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Symbiotic graph neural networks for 3d skeleton-based human action recognition and motion prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3316–3333. [Google Scholar] [CrossRef] [PubMed]
- Weng, Y.; Wu, G.; Zheng, T.; Yang, Y.; Luo, J. Large Model for Small Data: Foundation Model for Cross-Modal RF Human Activity Recognition. In Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems (SenSys 2024), Hangzhou, China, 4–7 November 2024. [Google Scholar]
- Khan, M.Z.; Bilal, M.; Abbas, H.; Imran, M.; Abbasi, Q.H. A Novel Multimodal LLM-Driven RF Sensing Method for Human Activity Recognition. In Proceedings of the 2025 2nd International Conference on Microwave, Antennas & Circuits (ICMAC), Islamabad, Pakistan, 17–18 April 2025. [Google Scholar]
- Li, Y.; Li, Y.; Vasconcelos, N. Resound: Towards action recognition without representation bias. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, German, 10–13 September 2018; pp. 513–528. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. Gan augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Kang, G.; Dong, X.; Zheng, L.; Yang, Y. Patchshuffle regularization. arXiv 2017, arXiv:1707.07103. [Google Scholar]
- DeVries, T.; Taylor, G.W. Dataset augmentation in feature space. arXiv 2017, arXiv:1702.05538. [Google Scholar]
- Li, S.; Chen, Y.; Peng, Y.; Bai, L. Learning more robust features with adversarial training. arXiv 2018, arXiv:1804.07757. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-scale evolution of image classifiers. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2902–2911. [Google Scholar]
- Zou, Y.; Choi, J.; Wang, Q.; Huang, J.B. Learning representational invariances for data-efficient action recognition. Comput. Vis. Image Underst. 2023, 227, 103597. [Google Scholar] [CrossRef]
- Zhang, Y.; Jia, G.; Chen, L.; Zhang, M.; Yong, J. Self-paced video data augmentation by generative adversarial networks with insufficient samples. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1652–1660. [Google Scholar]
- Gowda, S.N.; Rohrbach, M.; Keller, F.; Sevilla-Lara, L. Learn2augment: Learning to composite videos for data augmentation in action recognition. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 242–259. [Google Scholar]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-modal transformer for video retrieval. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16; Springer: Cham, Switzerland, 2020; pp. 214–229. [Google Scholar]
- Piergiovanni, A.; Ryoo, M. Learning multimodal representations for unseen activities. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 517–526. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Training kinetics in 15 minutes: Large-scale distributed training on videos. arXiv 2019, arXiv:1910.00932. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Singh, A.; Chakraborty, O.; Varshney, A.; Panda, R.; Feris, R.; Saenko, K.; Das, A. Semi-supervised action recognition with temporal contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10389–10399. [Google Scholar]
- Yu, K.; Yun, F. Human Action Recognition and Prediction: A Survey. arXiv 2018, arXiv:1806.11230. [Google Scholar]
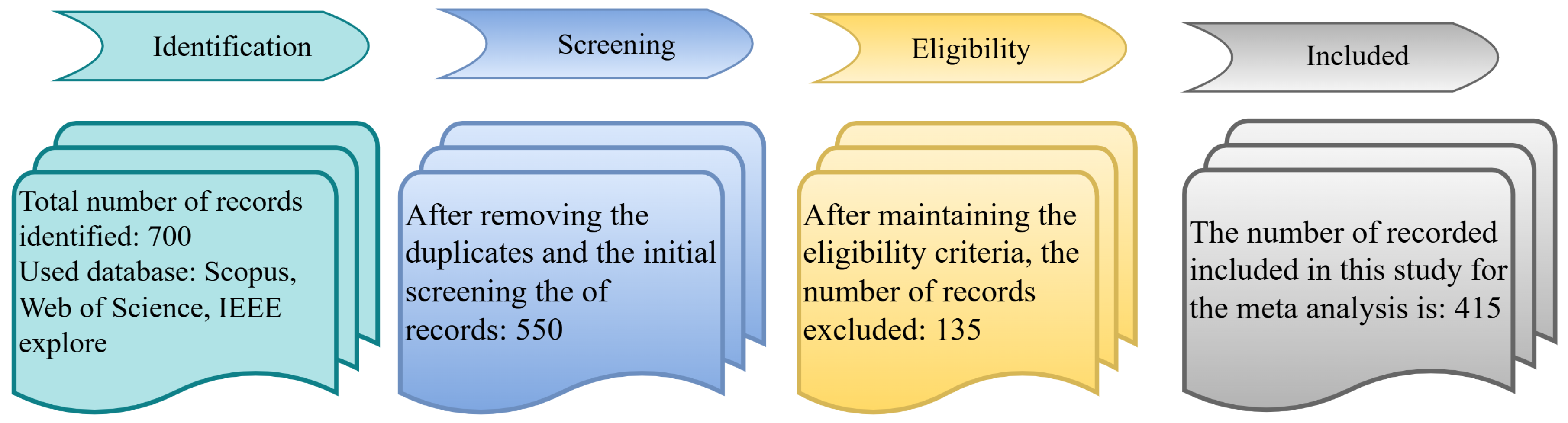
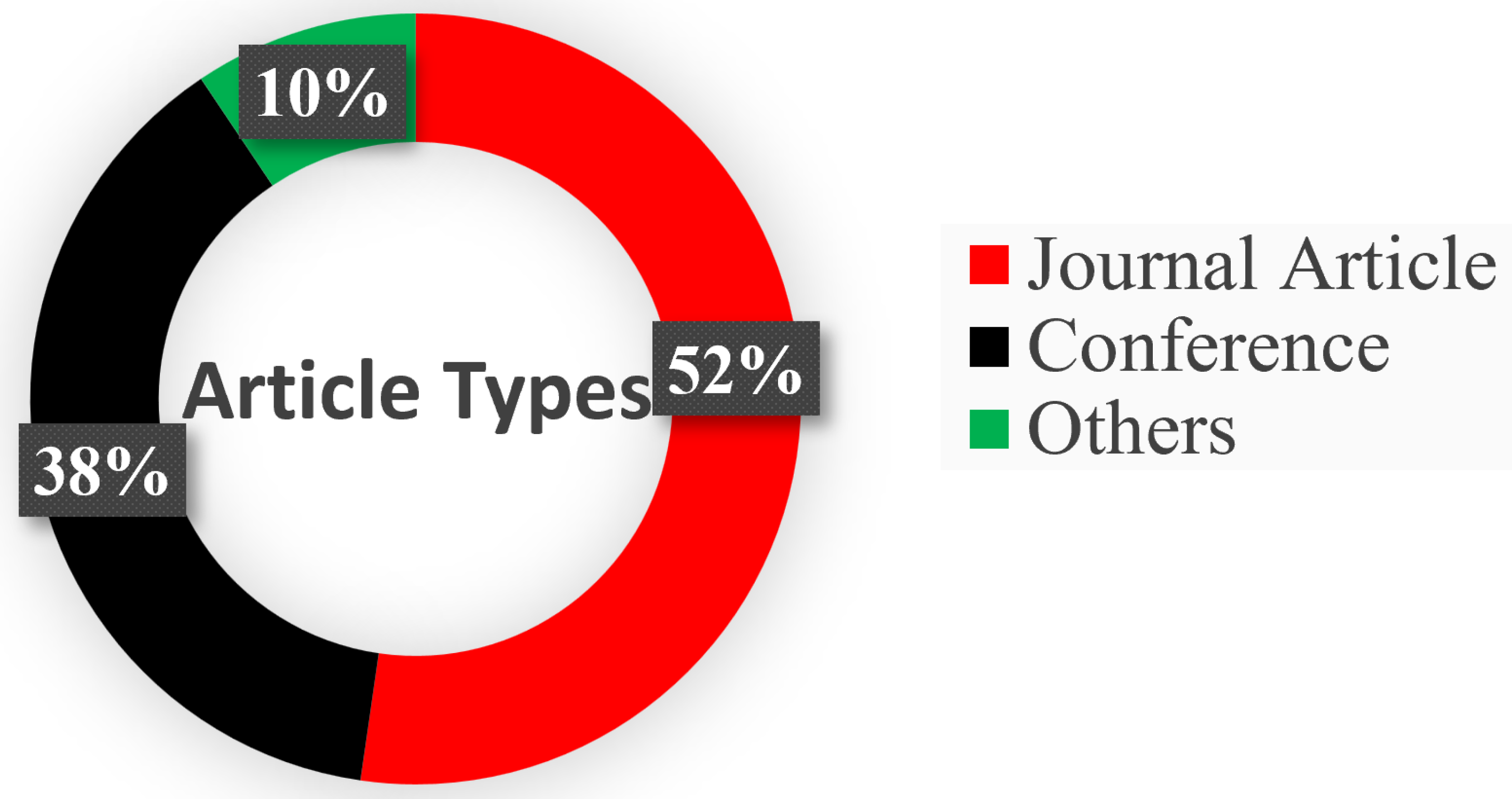
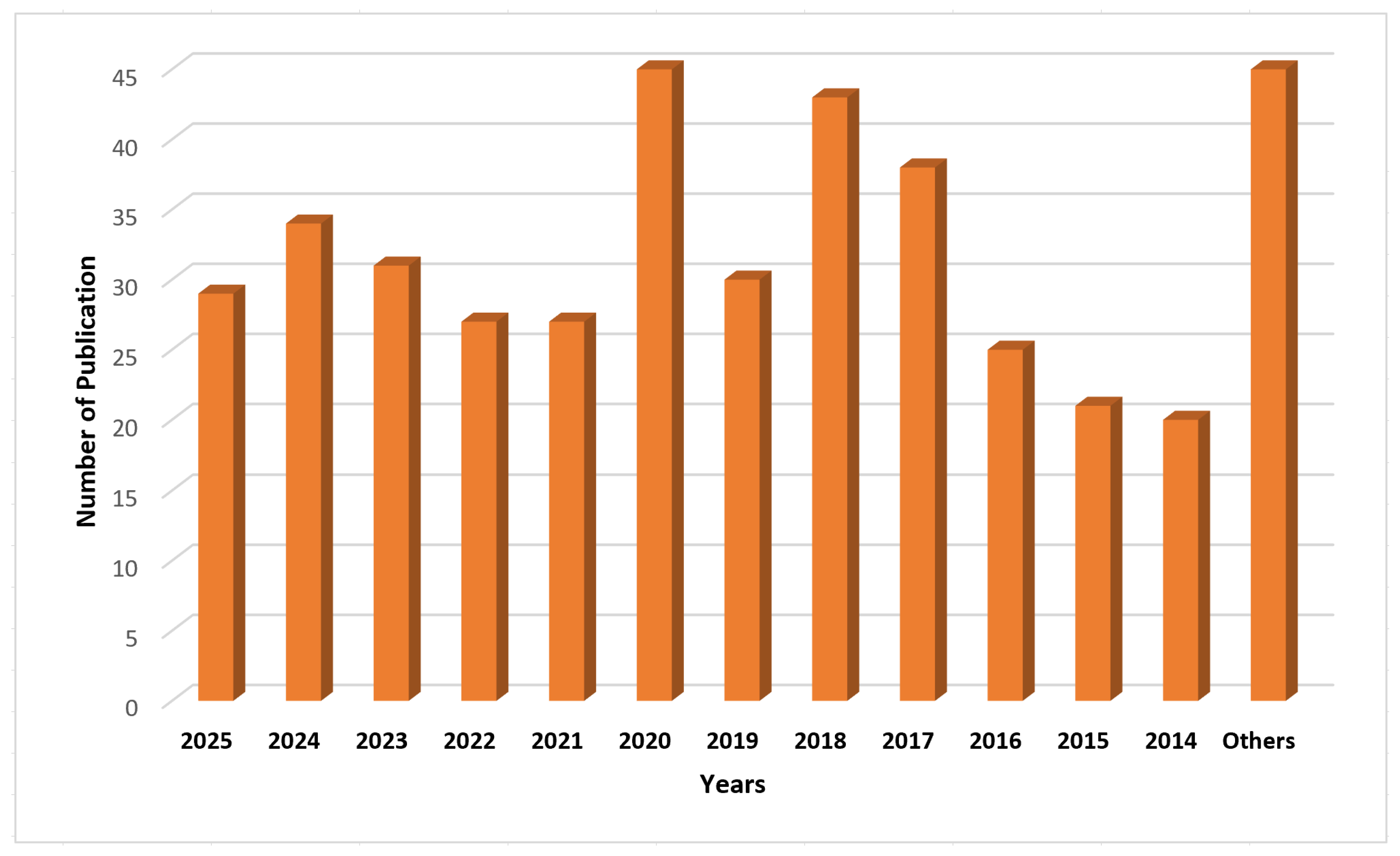

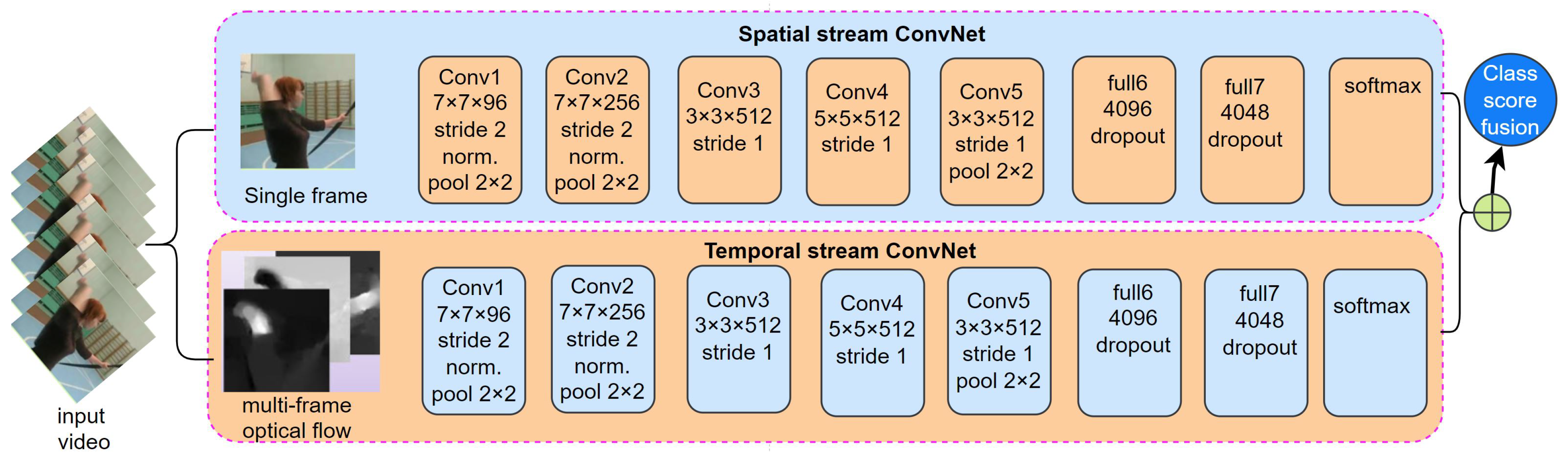

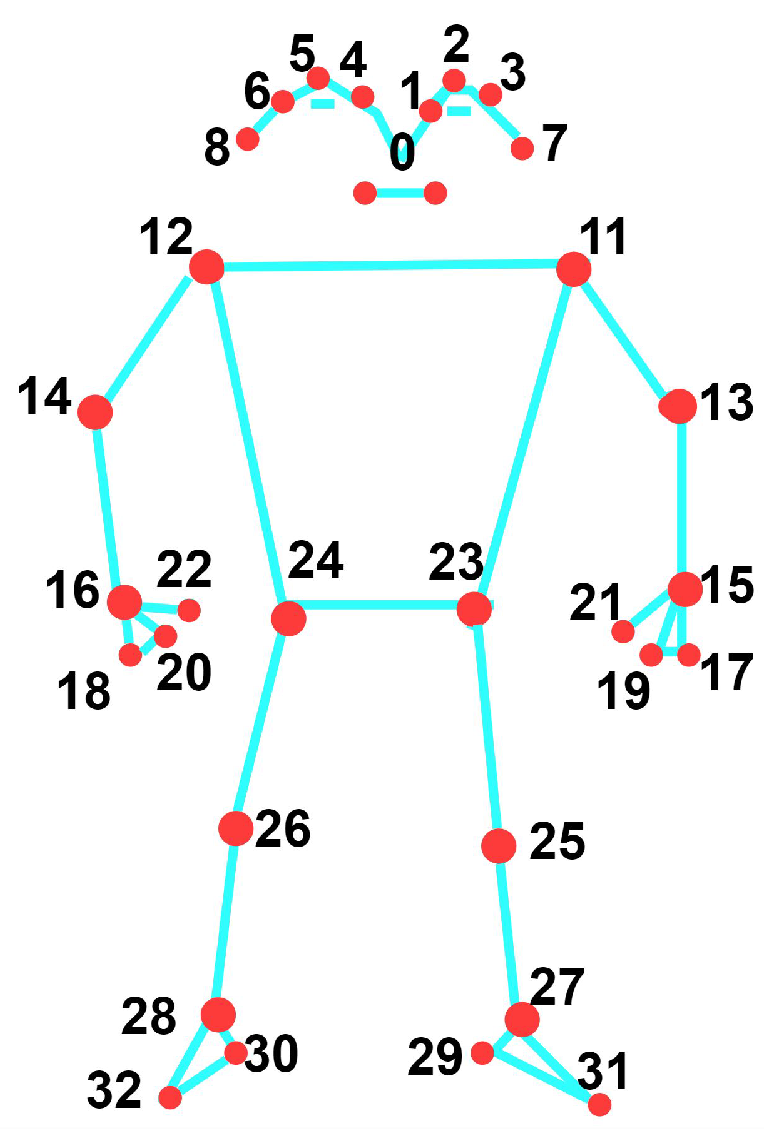

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).