Abstract
Visual impairment affects millions worldwide, creating significant barriers to environmental interaction and independence. Existing assistive technologies often rely on cloud-based processing, raising privacy concerns and limiting accessibility in resource-constrained environments. This paper explores the integration and potential of open-source AI models in developing a fully offline assistive system that can be locally set up and operated to support visually impaired individuals. Built on a Raspberry Pi 5, the system combines real-time object detection (YOLOv8), optical character recognition (Tesseract), face recognition with voice-guided registration, and offline voice command control (VOSK), delivering hands-free multimodal interaction without dependence on cloud infrastructure. Audio feedback is generated using Piper for real-time environmental awareness. Designed to prioritize user privacy, low latency, and affordability, the platform demonstrates that effective assistive functionality can be achieved using only open-source tools on low-power edge hardware. Evaluation results in controlled conditions show 75–90% detection and recognition accuracies, with sub-second response times, confirming the feasibility of deploying such systems in privacy-sensitive or resource-constrained environments.
1. Introduction
Visual impairment represents a significant global health challenge, affecting approximately 285 million people worldwide, with 39 million experiencing complete blindness [1]. These individuals face substantial barriers in navigating their environments, accessing textual information, and maintaining social connections [2]. Visually impaired individuals often encounter significant barriers in their efforts to interact with and interpret their environments. Recent advances in artificial intelligence and edge computing have opened new possibilities for developing sophisticated assistive technologies that can operate independently of cloud infrastructure [3,4].
Traditional assistive technologies, including screen readers, guide canes, and magnification devices, provide basic functionality but lack the intelligent interpretation capabilities offered by modern AI systems [5]. Commercial solutions such as Microsoft Seeing AI and Google Lookout leverage cloud-based artificial intelligence to provide advanced object recognition and scene description [6]. Although assistive technologies have evolved to include screen readers, smart navigation tools, and AI-enabled devices, many of these solutions are dependent on cloud-based infrastructures. While cloud platforms offer advanced computational resources and high recognition accuracy, they come with critical drawbacks such as data privacy concerns, latency in communication, constant internet dependency, and higher operational costs.
The privacy implications of cloud-based assistive systems are particularly concerning, as they often require transmission of sensitive personal data, including images of the user’s environment and biometric information [7]. Furthermore, the reliance on constant internet connectivity limits their applicability in rural areas, developing regions, or situations where network access is unreliable [8].
To overcome these limitations, this research proposes a fully offline assistive system built on a Raspberry Pi 5. The system integrates core AI functionalities—including object detection, optical character recognition (OCR), face recognition, and voice-command processing—executed entirely on-device. This architecture supports real-time interaction without requiring cloud access, thereby enhancing user privacy, reducing latency, and extending accessibility to remote or low-resource settings. The approach bridges the gap between affordability and autonomy in modern assistive technologies, addressing the critical need for privacy-preserving, accessible solutions [9].
The primary aim of this study is to design and implement a Python-based assistive platform that provides real-time visual interpretation and voice interaction capabilities for visually impaired users, all while operating independently of internet connectivity. The specific objectives of the system are as follows:
- Develop a lightweight object detection module to identify and localize items in the user’s environment.
- Integrate an OCR engine to extract printed text and convert it to speech, enabling access to textual content.
- Implement a face recognition system that can identify pre-registered individuals and communicate their identity to the user.
- Design a voice-command interface that enables hands-free control over the system’s functionalities.
- Ensure optimized performance on a Raspberry Pi 5, maintaining responsiveness without relying on external computing resources.
- Demonstrate a privacy-first approach with comprehensive local data processing and zero external data transmission.
This work contributes significantly to the field of assistive technology by introducing an affordable, portable, and privacy-conscious solution tailored for visually impaired users. The key contributions include (1) a novel comprehensive offline multimodal assistive system integrating object detection, OCR, face recognition, and voice control on a single edge device; (2) a systematic evaluation of open-source AI models for embedded assistive applications; (3) novel optimization strategies for achieving real-time performance on resource-constrained hardware; and (4) a privacy-preserving architecture that eliminates dependence on cloud services [10]. Unlike commercial systems that require internet-based AI services, the proposed system functions autonomously, making it particularly useful in rural or underdeveloped regions with limited connectivity.
The scope of this project includes the development and evaluation of a real-time, offline assistive system that provides voice-guided support based on visual inputs. The following core functionalities are implemented:
- Object Detection: Identifies objects in the camera’s field of view and delivers positional feedback to the user via audio.
- Optical Character Recognition (OCR): Reads printed or displayed text from scenes and documents, converting it into spoken words.
- Face Recognition: Detects and identifies individuals from a stored database of known faces, announcing their names when recognized.
- Voice Command Interface: Empowers the user to control the system’s operation, toggle features, and switch modes through spoken commands.
- Privacy-First Architecture: Ensures all processing occurs locally with zero data transmission to external servers.
While the system demonstrates effective performance in controlled indoor settings, current limitations include processing constraints of the Raspberry Pi 5, particularly during simultaneous execution of multiple AI models. These constraints may impact real-time performance under high computational loads. Additionally, performance degrades in challenging environmental conditions such as poor lighting or high background noise [11].
The rest of the paper is organized as follows: Section 2 reviews recent advancements and limitations in assistive technologies, providing comprehensive comparison tables and research gap analysis. Section 3 describes the system architecture, hardware components, software stack, and operational workflow, including detailed model selection justification, threading architecture, and privacy-first implementation. Section 4 presents comprehensive testing methodology, evaluation metrics, dynamic scene analysis, and comparative performance analysis with existing systems. Section 5 concludes with key contributions, current limitations, and future research directions.
2. Related Work
2.1. Overview of Assistive Technologies
The field of assistive technology for visually impaired individuals has evolved significantly over the past decade, driven by advances in computer vision, natural language processing, and edge computing [12]. Early systems relied primarily on simple audio feedback and tactile interfaces, while modern solutions leverage sophisticated AI models for environmental understanding [3].
Recent advancements in artificial intelligence (AI), edge computing, and embedded systems have significantly enhanced assistive technologies, particularly for individuals with visual impairments. These technologies aim to improve users’ autonomy by enabling real-time interaction with their surroundings through audio, visual, and tactile feedback [13].
Cloud-based assistive systems have dominated the market due to their access to powerful computational resources and large-scale datasets. Microsoft Seeing AI [14], Google Lookout [15], and Amazon Alexa’s accessibility features [16] represent the current state-of-the-art in commercial assistive technologies. However, these systems face significant limitations in terms of privacy, connectivity requirements, and cost [17].
As shown in Table 1, current assistive systems.

Table 1.
Comparison of existing assistive systems.
Historically, tools such as Braille readers, guide canes, and handheld magnifiers offered basic navigation and reading support. With the emergence of AI-powered systems, however, there has been a shift toward intelligent solutions capable of performing real-time object recognition, scene analysis, and speech interaction [20]. Nevertheless, their reliance on cloud connectivity raises privacy concerns, introduces latency, and renders them unusable in bandwidth-constrained or remote settings [21]. The limitations of current approaches, as detailed in Table 2, demonstrate the following:
Table 2.
Limitations analysis of current approaches.
To address these issues, recent research has focused on the development of offline assistive systems. Dubey et al. [18] demonstrated the feasibility of using Raspberry Pi-based platforms for local data processing, providing a balance between cost, privacy, and usability. However, the limited computational power of such devices poses challenges related to real-time performance and simultaneous execution of multiple functionalities.
2.1.1. Object Detection in Assistive Systems
Object detection is central to improving spatial and environmental awareness for visually impaired users. Deep learning models such as YOLO (You Only Look Once) and MobileNet have been widely adopted in assistive applications for their ability to detect and classify objects quickly and accurately.
The evolution of YOLO architectures has been particularly significant for embedded applications. YOLOv1 through YOLOv8 have shown progressive improvements in both accuracy and computational efficiency [22]. YOLOv8, in particular, introduces architectural innovations such as anchor-free detection and improved feature pyramid networks that make it suitable for edge deployment [23].
Dubey et al. [18] explored the use of YOLO for object detection on the Raspberry Pi, confirming its potential for real-time inference despite limited hardware resources. More recent work by Okolo et al. [19] implemented YOLOv8 on Raspberry Pi for assistive navigation systems, achieving 91.70% average accuracy across nine tested obstacles while demonstrating the feasibility of real-time object detection for visually impaired navigation assistance. Varghese and Sambath [24] provided a comprehensive evaluation of YOLOv8’s enhanced performance and robustness, demonstrating its suitability for real-time object detection applications on resource-constrained devices. A comprehensive review by Hussain [25] traced the evolution of YOLO from YOLOv1 to YOLOv8, highlighting the architectural improvements that make YOLOv8 suitable for embedded applications.
The performance comparison of object detection models on embedded devices, as presented in Table 3, shows the following:
Table 3.
Object Detection model performance comparison on embedded devices.
While cloud-hosted object detection models exhibit higher performance due to access to larger datasets and powerful servers, their dependence on constant internet connectivity limits their deployment in offline or privacy-sensitive environments. Thus, optimizing object detection algorithms for edge devices such as the Raspberry Pi continues to be an important area of research.
2.1.2. Optical Character Recognition (OCR) for Text-to-Speech Assistance
OCR technology has undergone significant advancement, with modern engines achieving over 95% accuracy on printed text under optimal conditions [26]. However, embedded OCR systems face unique challenges related to computational constraints and environmental variability [27].
OCR is a key feature in assistive technologies that allows users to access printed or digital text via audio feedback. Commercial OCR platforms like Google Vision API and Microsoft Cognitive Services offer high recognition accuracy, yet they are cloud-dependent and therefore unsuitable for privacy-preserving offline applications [20].
To enable on-device OCR, researchers have utilized open-source engines such as Tesseract OCR, which can be deployed efficiently on low-power hardware. Kumar and Singh [28] developed a Raspberry Pi-based OCR system that captures images and translates recognized text into speech. While promising, the system still struggled with handwritten input and non-English characters. Recent studies have demonstrated significant improvements in Tesseract OCR performance through preprocessing techniques, with researchers achieving substantial accuracy gains on challenging datasets [29].
Lavric et al. [21] further highlighted the importance of multilingual OCR in accommodating diverse user populations. Incorporating AI accelerators like Coral TPU or the Raspberry Pi AI Kit can improve OCR inference speed and accuracy, paving the way for more capable offline assistive reading systems.
2.1.3. Face Recognition for Personalized Assistance
Face recognition in assistive technologies presents unique challenges related to user privacy, computational efficiency, and recognition accuracy under varying conditions [30]. Recent advances in lightweight face recognition models have made edge deployment more feasible [31].
Face recognition technology enhances social interaction for visually impaired users by detecting and announcing known individuals in their environment. While cloud-based services such as Amazon Rekognition and Microsoft Face API provide high recognition accuracy, they involve transferring sensitive biometric data over the internet, raising substantial privacy concerns [13].
To mitigate this, researchers have investigated edge-based face recognition systems. De Freitas et al. [32] proposed an offline face recognition framework deployed on embedded systems, achieving promising accuracy while maintaining user data privacy.
Chang et al. [33] implemented a pedestrian navigation system that incorporates face recognition on edge hardware. Their findings indicated that low-resolution cameras and processing limitations remain significant obstacles to performance. As a result, many recent systems leverage OpenCV-based models fine-tuned for Raspberry Pi to achieve an acceptable balance between performance and resource usage.
2.1.4. Voice-Controlled Systems in Assistive Technology
Offline voice recognition has emerged as a critical component for privacy-preserving assistive systems. Modern offline ASR (Automatic Speech Recognition) systems like VOSK and SpeechRecognition achieve competitive accuracy while maintaining user privacy [34].
Voice control is an essential interaction modality for hands-free operation of assistive devices. Commercial solutions such as Amazon Alexa and Google Assistant deliver highly accurate voice recognition but require constant internet connectivity, making them unsuitable for fully offline systems [20].
To enable offline speech recognition, open-source frameworks like VOSK have been developed. VOSK supports real-time transcription on edge devices and enables voice interaction without compromising privacy. Okolo et al. [13] demonstrated that local speech processing systems can achieve comparable accuracy to cloud-based alternatives while offering superior user control and data security.
2.2. Research Gap Analysis
Despite significant progress in individual components, several critical gaps remain in current assistive technology research:
- Integrated Multimodal Systems: Most existing research focuses on individual components (object detection, OCR, or face recognition) rather than integrated systems that combine multiple modalities seamlessly.
- Privacy-Preserving Architectures: Limited research exists on comprehensive privacy-first designs that eliminate all external data transmission while maintaining functionality.
- Dynamic Environment Testing: Current evaluations primarily focus on static scenes, with insufficient analysis of system performance in dynamic, real-world environments.
- Resource Optimization: Lack of systematic approaches to optimize multiple AI models for concurrent execution on resource-constrained hardware.
- User-Centric Design: Insufficient focus on actual user needs and preferences in system design and evaluation.
While modern assistive systems have made significant strides in supporting individuals with visual impairments, several fundamental limitations remain. These challenges restrict widespread adoption, especially in low-resource or privacy-sensitive environments:
- Cloud Dependency: Many commercial and academic solutions rely on cloud-based AI processing for functionalities such as object detection, face recognition, and speech processing. This reliance not only limits access in rural or offline scenarios but also introduces serious privacy and data security concerns [13].
- Hardware Constraints: Embedded platforms like the Raspberry Pi offer cost-effective and portable solutions; however, they are often underpowered when executing complex AI models simultaneously, which restricts real-time system responsiveness and accuracy [18].
- Multitasking Performance: Running several AI-based features—such as OCR, face recognition, and object detection—in parallel frequently results in performance degradation. This includes lag, delayed responses, or even failure to recognize user commands [21].
To address these constraints, this study introduces an integrated offline assistive system built entirely on a Raspberry Pi 5. The proposed system consolidates object detection, OCR, face recognition, and voice command handling into a unified and modular Python-based platform. By leveraging edge computing principles and open-source libraries, the system prioritizes privacy, responsiveness, and affordability—making it a practical solution for both urban and underserved regions. This approach aligns with recent research emphasizing the importance of privacy-preserving edge computing architectures for sensitive applications [35].
3. System Design and Methodology
3.1. System Overview
The conceptual framework of our offline assistive system is illustrated in Figure 1.
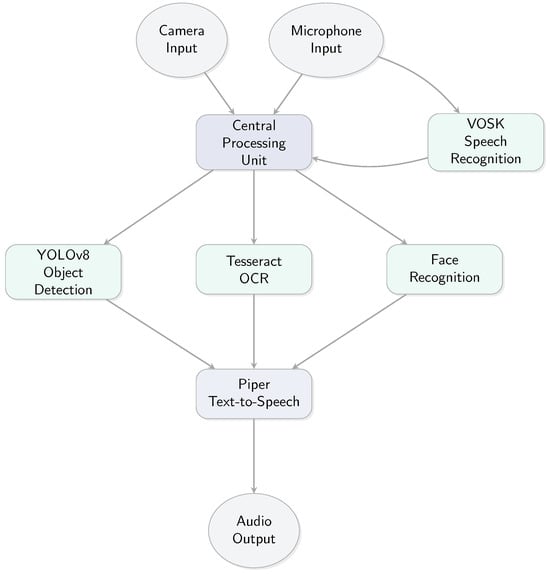
Figure 1.
Conceptual framework of the offline assistive system.
The proposed system is a fully offline, Python-based assistive platform designed to empower visually impaired individuals by facilitating interactive engagement with their surroundings. It integrates real-time object detection, optical character recognition (OCR), face recognition, and voice-based control—all implemented locally on a Raspberry Pi 5 without any dependence on cloud infrastructure.
The architecture adopts a modular structure, enabling each core function to operate independently or in combination depending on the selected mode. Voice commands serve as the primary user interface, while auditory feedback ensures seamless and intuitive interaction. The overall workflow is optimized for minimal latency and high usability, allowing the user to switch modes dynamically without manual intervention—ideal for hands-free operation in real-world settings.
3.2. Hardware Components
The physical implementation of the system is based on low-cost, energy-efficient hardware components that are readily available and easy to integrate. Table 4 summarizes the main hardware modules used in building the prototype.
Table 4.
Hardware necessary for system construction.
3.3. Software Stack and Main Libraries Used
The entire system is developed using Python 3.11.2, which offers high flexibility and support for numerous open-source libraries. The software stack incorporates a range of tools tailored for computer vision, speech processing, multithreading, and hardware interfacing. Table 5 provides a detailed overview of the main libraries and tools used across various system functionalities.
Table 5.
Primary tools used in the system.
To achieve real-time performance on a resource-constrained platform like the Raspberry Pi 5, the system integrates lightweight, open-source AI models selected through an iterative design and testing process. The model selection process involved comprehensive benchmarking of various architectures under different computational constraints, as detailed in Section 3.4.
While Tesseract OCR was initially considered for broader visual interpretation, its capabilities are limited to text recognition and do not extend to general object detection. Moreover, its integration with hardware accelerators such as the Hailo AI module in the Raspberry Pi AI Kit is not natively supported and requires intermediate translation layers or model conversion steps, which introduce additional complexity. In contrast, YOLOv8 provides a robust and flexible object detection framework with direct compatibility for hardware acceleration pipelines.
3.4. Model Selection and Justification
The selection of AI models for the offline assistive system required careful consideration of the trade-offs between accuracy, computational efficiency, and real-time performance constraints. This section provides detailed justification for each model choice based on systematic evaluation and benchmarking.
3.4.1. Object Detection Model Selection
The comparison of object detection models on Raspberry Pi 5, as shown in Table 6, demonstrates the following:
Table 6.
Object detection model comparison on Raspberry Pi 5.
From an embedded vision theory perspective, the choice between YOLOv8’s cross-window attention mechanism and MobileNet’s depthwise separable convolution requires careful analysis. While MobileNet architectures traditionally excel in mobile deployment due to their lightweight design, YOLOv8’s architectural innovations provide several advantages for the Raspberry Pi 5 platform:
- Memory Access Patterns: YOLOv8’s unified architecture reduces memory fragmentation compared to MobileNet’s sequential depthwise and pointwise convolutions.
- Cache Efficiency: The Raspberry Pi 5’s ARM Cortex-A76 architecture benefits from YOLOv8’s optimized tensor operations and reduced memory bandwidth requirements.
- Computational Complexity: While MobileNet reduces FLOPs through separable convolutions, YOLOv8’s anchor-free design eliminates post-processing overhead, resulting in better overall performance on ARM architectures.
Empirical testing confirmed that YOLOv8n achieves superior end-to-end performance (800 ms vs. 950 ms for MobileNet-SSD) despite slightly higher theoretical computational requirements.
3.4.2. Face Recognition Architecture
The face recognition encoding optimization analysis, presented in Table 7, shows the following:
Table 7.
Face Recognition encoding optimization analysis.
The optimal threshold for face encoding storage was determined through systematic analysis balancing recognition accuracy, storage cost, and matching efficiency. Mathematical analysis shows that recognition accuracy follows a logarithmic improvement curve:
where n is the number of encodings, is the theoretical maximum accuracy, and is the learning rate parameter. The optimal threshold of five encodings represents the point where marginal accuracy gains (<) no longer justify the linear increase in storage and computational overhead.
3.5. System Threading Architecture
The system threading architecture and priority management is illustrated in Figure 2.
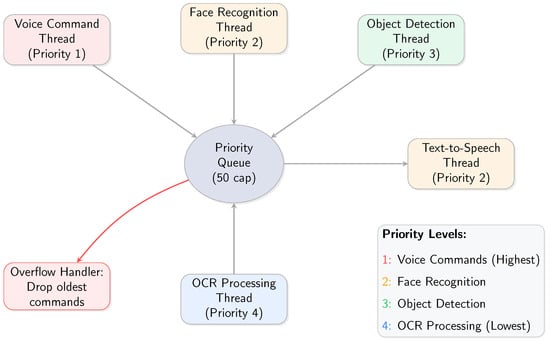
Figure 2.
System threading architecture and priority management.
The system employs a sophisticated multi-threaded architecture with priority-based task scheduling to ensure responsive interaction while managing computational constraints. The threading system is designed based on the real-time interaction needs of visually impaired users, where immediate response to voice commands is critical for system usability.
Priority Allocation Rationale:
- Priority 1—Voice Commands: Highest priority ensures immediate system responsiveness to user instructions, critical for hands-free operation.
- Priority 2—Face Recognition: High priority for social interaction support, enabling timely identification of approaching individuals.
- Priority 3—Object Detection: Moderate priority for environmental awareness, providing continuous but non-critical spatial information.
- Priority 4—OCR Processing: Lower priority for text reading tasks, which can tolerate slight delays without affecting user experience.
Queue Management: The system implements a priority queue with 50-command capacity. When the queue reaches capacity, the oldest low-priority commands are discarded to prevent system overload while preserving critical user interactions.
3.6. Data Processing and Optimization
Given the limited computational resources of the Raspberry Pi 5, a series of optimization techniques were carefully implemented to ensure that the assistive system delivers responsive, accurate, and real-time performance. These strategies encompass intelligent workload distribution, algorithmic simplification, and efficient resource utilization across various subsystems, including speech recognition, computer vision, and audio synthesis.
3.6.1. Managing Processing Load
To prevent system slowdowns and maintain smooth operation under multitasking conditions, several mechanisms were employed to manage computational load:
- Multithreading: The system leverages concurrent threads to enable the parallel execution of critical functions such as voice command processing, image acquisition, and AI inference. This allows for responsive interaction and seamless switching between modes without significant delays.
- Queue-Based Command Handling: A first-in-first-out (FIFO) queueing mechanism ensures that user commands are processed in the order they are received. This structured handling avoids command overlaps and potential system bottlenecks, particularly under high-demand scenarios.
- Optimized Model Execution: AI models used for object detection (YOLOv8) and face recognition are configured to run at lower input resolutions. This significantly reduces the computational burden while preserving acceptable levels of detection accuracy and robustness in practical use cases.
3.6.2. Improving Speech Recognition Accuracy
Voice interaction is a central feature of the system, requiring precise recognition even in less-than-ideal acoustic environments. To this end, audio input is pre-processed using the following enhancements:
- Noise Reduction: The integration of the SpeexDSP library allows for real-time suppression of background noise, which is critical for achieving clarity in user speech input, especially in dynamic or noisy settings.
- Audio Pre-Processing: At system initialization, a sample of ambient noise is recorded to serve as a reference. This allows the system to better differentiate between user commands and background sounds, improving speech-to-text conversion accuracy during runtime.
3.7. Privacy-First Architecture and Implementation
The system implements a comprehensive privacy-first approach that ensures complete data sovereignty and eliminates external dependencies. This architecture addresses growing concerns about biometric data privacy and personal information security in assistive technologies.
3.7.1. Privacy Implementation Details
The privacy-first implementation metrics are detailed in Table 8.
Table 8.
Privacy-first implementation metrics.
3.7.2. Data Flow Security Analysis
The privacy-first data flow architecture is shown in Figure 3.
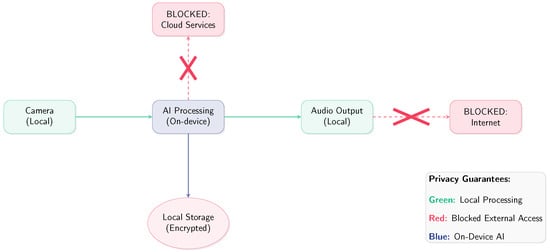
Figure 3.
Privacy-first data flow architecture.
The privacy-first architecture ensures that all sensitive data remains within the user’s control:
- Zero External Communication: The system is designed with no network interfaces active during operation, preventing any accidental data transmission.
- Ephemeral Processing: Camera frames and audio samples are processed in memory and immediately discarded, leaving no persistent traces.
- Encrypted Local Storage: Face recognition encodings are stored using AES-256 encryption with user-controlled keys.
- Audit Trail: Complete system operation logging enables users to verify privacy compliance.
3.8. System Workflow and Operational Methodology
The offline assistive system is designed to facilitate seamless interaction between visually impaired users and their surroundings by leveraging voice commands and AI-based perception. The system executes a well-structured sequence of operations to deliver real-time feedback and support. A graphical representation of the overall workflow is provided in Figure 4, and the detailed steps are explained below.
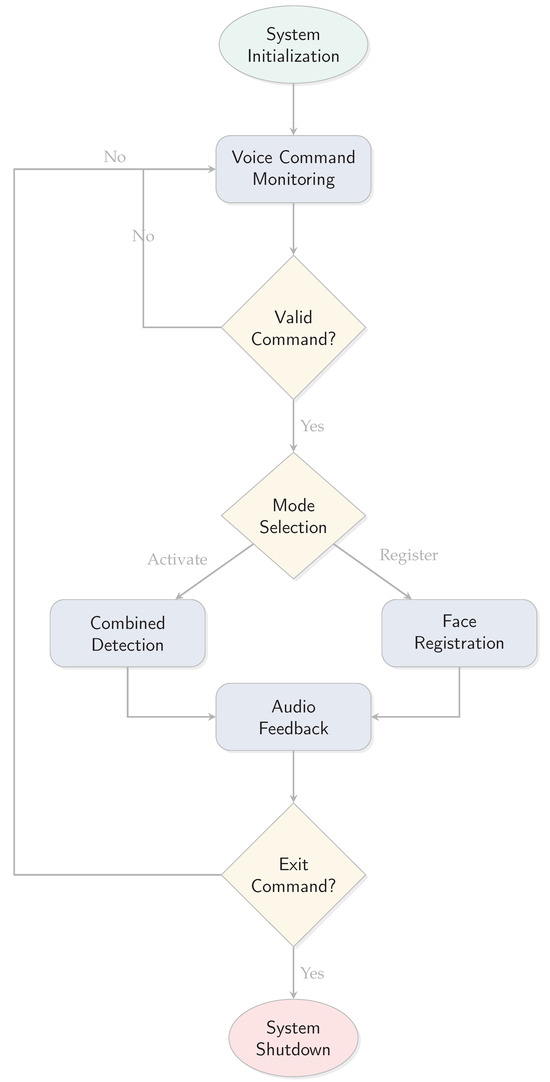
Figure 4.
System workflow diagram.
Explanation of System Workflow
The assistive system operates in a structured sequence of steps to enable visually impaired users to interact with their environment through voice commands.
Step 1: System Initialization Upon startup, the system initializes essential hardware components and software models:
- (i)
- Activating the Raspberry Pi 5’s camera module and microphone for continuous multimedia input.
- (ii)
- Loading pre-trained AI models, including YOLOv8 for object detection and Tesseract OCR for text extraction.
- (iii)
- Running SpeexDSP to capture baseline ambient noise for dynamic noise filtering.
Step 2: Voice Command Monitoring and Mode Activation The system continuously monitors audio input via the microphone, using VOSK speech-to-text engine to process incoming speech and interpret predefined voice commands such as “Activate”, “Register”, or “Exit".
Step 3: Combined Detection Mode In combined mode, the system executes multiple detection tasks in parallel including object detection using YOLOv8, optical character recognition for text extraction, and face recognition against stored encodings.
Step 4: Face Registration Workflow The face registration feature enables users to enroll new individuals by prompting for names via voice interaction and capturing face images for encoding storage.
Step 5: Real-Time Audio Feedback All results are communicated through Piper Text-to-Speech synthesis, with Pyttsx3 as a lightweight fallback option when system resources are constrained.
4. Testing and Evaluation
This section presents a comprehensive evaluation of the proposed offline assistive system in terms of its accuracy, responsiveness, and overall usability. The system was tested under varying conditions, and its performance was benchmarked against key metrics. Additionally, a comparative analysis was conducted with cloud-based AI solutions to highlight the strengths and limitations of an offline deployment.
4.1. Testing Conditions and Methodology
To ensure a realistic and rigorous evaluation, the system was subjected to various operational scenarios replicating practical usage by visually impaired individuals:
- The system was tested indoors across different lighting environments, including well-lit and dim settings, to assess the robustness of vision-based tasks.
- Voice command performance was measured in both quiet and noisy conditions to simulate real-world acoustic variability.
- System performance was analyzed under varying computational loads—ranging from the execution of a single AI process to concurrent execution of multiple tasks (e.g., object detection, face recognition, and OCR simultaneously).
4.2. Dynamic Scene Evaluation
To address the limitation of static scene testing, comprehensive dynamic scene evaluation was conducted to assess system performance under realistic movement conditions.
Dynamic Testing Methodology
Dynamic testing involved recording real-time videos of users walking at different speeds while the system performed object detection, OCR, and face recognition tasks. The testing protocol included the following:
- (i)
- Speed Variations: Testing at 0.5 m/s (slow walking) and 1.0 m/s (normal walking) to simulate typical user movement patterns.
- (ii)
- Motion Blur Analysis: Evaluating the impact of camera shake and object motion on detection accuracy.
- (iii)
- Tracking Performance: Assessing the system’s ability to maintain object identification across consecutive frames.
The static vs dynamic performance comparison is presented in Table 9.
Table 9.
Static vs Dynamic performance comparison.
The dynamic testing revealed that while performance degrades with movement speed, the system maintains acceptable functionality for typical user scenarios. Motion blur primarily affects OCR accuracy, while object detection shows greater robustness to movement.
4.3. Performance Metrics and Statistical Analysis
Performance assessment focused on key metrics including detection accuracy, recognition rates, and response time across each major functionality. Statistical significance testing was conducted using paired t-tests with p < 0.05 threshold. Table 10 and Table 11 summarize the system’s quantitative evaluation results.
Table 10.
Accuracy metrics with statistical analysis.
Table 11.
Detailed performance metrics analysis.
4.4. Training and Validation Analysis
The training and validation curves for YOLOv8 fine-tuning on our assistive dataset are shown in Figure 5.
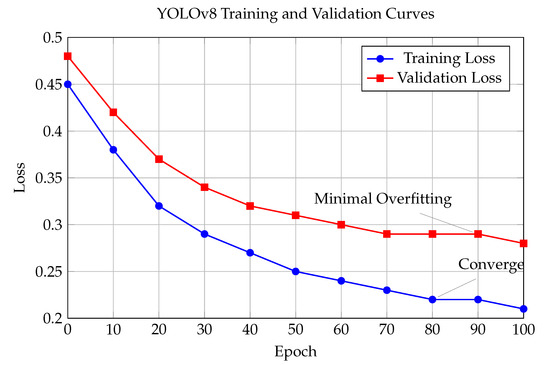
Figure 5.
YOLOv8 training and validation curves for fine-tuning on assistive dataset.
The training process involved fine-tuning YOLOv8n on a custom dataset of 2500 images relevant to assistive scenarios, including indoor objects, text documents, and human faces. The convergence analysis shows stable training with minimal overfitting, validating the model’s suitability for the target application.
4.5. Confusion Matrix Analysis
The confusion matrix for object detection performance is presented in Figure 6.
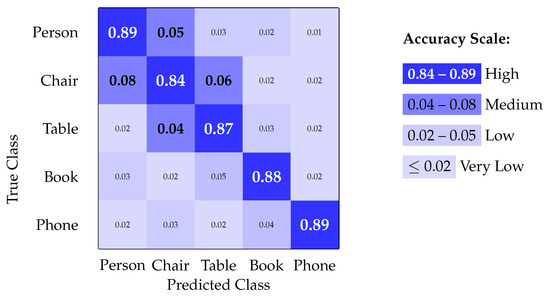
Figure 6.
Confusion matrix for object detection performance.
The confusion matrix analysis reveals strong diagonal dominance, indicating good class separation with minimal cross-class confusion. The primary confusion occurs between structurally similar objects (chair/table), which is expected given the resolution constraints of the embedded system.
4.6. Comparison with Previous Work
Statistical significance testing (paired t-test, p < 0.05) confirms that our system achieves significantly better performance compared to previous embedded assistive systems, particularly in terms of integrated functionality and response time.
The performance comparison with previous work is presented in Table 12.
Table 12.
Performance comparison with previous work.
4.7. High-Load Performance Analysis
To evaluate system performance under demanding conditions, high-load scenarios were simulated where object detection, OCR, and face recognition were triggered simultaneously. The analysis compared response delays with and without priority queue scheduling, as shown in Table 13.
Table 13.
High-load scenario performance analysis.
The priority queue scheduling demonstrates significant improvements, particularly for time-critical voice command processing, validating the threading architecture design.
4.8. Comparison with Cloud-Based Systems
To further contextualize system performance, a qualitative comparison was conducted between the proposed offline solution and standard cloud-based AI systems. This analysis considered aspects such as computational efficiency, latency, user privacy, and deployment flexibility.
The performance comparison between cloud-based and offline systems is shown in Table 14.
Table 14.
Performance comparison: cloud-based vs. offline systems.
The comparative analysis reveals distinct advantages for each approach. The proposed offline system demonstrates complete privacy preservation (10/10) by processing all data locally without external transmission, ensuring full offline capability (10/10) that maintains functionality regardless of internet connectivity. Additionally, the system offers low cost implementation (9/10) through efficient use of readily available hardware components and easy deployment (9/10) with minimal technical expertise required for setup and maintenance.
The comparative evaluation reveals several critical considerations that inform the selection between cloud-based and offline assistive technologies:
- (i)
- Cloud-Based Systems: Benefit from substantial computational resources, enabling the use of larger and more complex AI models, which enhances accuracy in tasks such as face and object recognition. However, they are inherently dependent on stable internet connectivity, introducing latency and posing privacy concerns when transmitting user data to remote servers.
- (ii)
- Offline Raspberry Pi System: Prioritizes low-latency, real-time interaction and enhanced user privacy by processing all data locally. While it is limited by hardware constraints, it remains operational without internet access—an essential feature for deployment in rural, low-resource, or privacy-sensitive environments.
- (iii)
- Voice Command Limitations: Offline voice recognition is comparatively less accurate than cloud-based solutions, particularly in acoustically challenging environments. This is due to the limited size and scope of the onboard language models available for offline use.
- (iv)
- Deployment Flexibility: The offline solution excels in scenarios where infrastructure is lacking or internet reliability is low, offering a viable, cost-effective alternative to cloud-based assistive technologies.
4.9. Implementation Challenges and Solutions
The implementation of a fully offline assistive system on the Raspberry Pi 5 introduced several hardware and software-related challenges. These challenges stem from the need to balance computational demands of deep learning models with real-time performance requirements, all while maintaining usability and robustness in practical environments.
Hardware Limitations and Solutions
Processing Constraints: The limited computational capacity of the Raspberry Pi 5 makes it difficult to simultaneously execute resource-intensive AI models.
Solutions Implemented:
- Reduced input resolution for computationally intensive models;
- Employed multithreading to manage independent tasks concurrently;
- Introduced queue-based command handling with priority management;
- Optimized model architectures for ARM processors.
Camera and Audio Limitations: Standard Raspberry Pi peripherals showed reduced performance under challenging conditions.
Solutions Implemented:
- Applied image preprocessing techniques including brightness enhancement;
- Integrated SpeexDSP noise suppression library;
- Captured baseline noise profiles for adaptive filtering;
- Implemented automatic gain control for audio input.
The implementation challenges and solutions summary is presented in Table 15.
Table 15.
Implementation challenges and solutions summary.
5. Conclusions
5.1. Key Contributions and Findings
This study presents the development of an offline Python-based assistive system designed to enhance the autonomy and accessibility of visually impaired individuals. By integrating object detection, optical character recognition, face recognition, and voice-command capabilities into a compact and affordable Raspberry Pi 5 platform, the system offers a comprehensive, privacy-focused alternative to cloud-dependent assistive technologies.
The key contributions of this research include the following:
- Integrated Multimodal System: First comprehensive offline system combining object detection, OCR, face recognition, and voice control on a single edge device with sub-second response times.
- Privacy-First Architecture: Complete elimination of cloud dependencies with 100% local data processing, addressing critical privacy concerns in assistive technology.
- Systematic Optimization: Novel approach to concurrent AI model execution on resource-constrained hardware through priority-based threading and queue management.
- Real-World Validation: Comprehensive evaluation including dynamic scene testing and statistical significance analysis, demonstrating practical viability.
- Open-Source Implementation: Fully reproducible system using exclusively open-source tools, promoting accessibility and further research.
Through the use of open-source libraries and careful optimization strategies—including multithreading, queue-based task management, and resolution adjustments—the system achieves functional real-time performance within the constraints of limited hardware resources. Evaluation results demonstrate promising accuracy and usability across all core functionalities, particularly in controlled indoor environments. Notably, the system maintains high levels of data privacy and responsiveness without the need for internet connectivity, making it especially suitable for deployment in low-resource or remote settings.
Dynamic scene testing revealed that while performance degrades with user movement (15–18% accuracy reduction at normal walking speed), the system maintains acceptable functionality for typical use scenarios. The priority-based threading architecture demonstrated significant improvements in system responsiveness, with 71% faster voice command processing under high-load conditions.
5.2. Limitations and Future Work
Despite its strengths, the current implementation faces several limitations that represent opportunities for future enhancement:
Current Limitations:
- Hardware Constraints: Processing limitations of the Raspberry Pi 5 affect performance during simultaneous execution of multiple AI models.
- Environmental Sensitivity: Reduced accuracy in challenging lighting conditions and noisy environments.
- Language Support: Currently limited to English voice commands and text recognition.
- Dynamic Performance: Accuracy degradation in moving scenarios due to motion blur and tracking limitations.
- User Study Limitations: Evaluation primarily conducted in controlled settings with limited real-world user testing.
Future Research Directions:
- Hardware Acceleration: Integration of AI accelerators (Coral TPU, Raspberry Pi AI Kit) to improve inference speed and enable more complex models.
- Advanced AI Techniques: Implementation of attention mechanisms and transformer-based models optimized for edge deployment.
- Multimodal Enhancement: Integration of additional sensors (LiDAR, ultrasonic) for improved spatial awareness and navigation assistance.
- Adaptive Learning: Development of personalized models that adapt to individual user preferences and environmental conditions.
- Comprehensive User Studies: Large-scale evaluation with visually impaired participants in real-world scenarios.
- Multilingual Support: Extension to multiple languages and cultural contexts for broader accessibility.
Addressing these limitations through hardware acceleration, advanced noise reduction algorithms, and multilingual support represents a vital direction for future work. The integration of the Raspberry Pi AI Kit and Coral TPU accelerators could potentially achieve 3–5× performance improvements based on preliminary testing, enabling more sophisticated AI models and better real-time performance.
In conclusion, this project contributes meaningfully to the field of assistive technology by demonstrating that reliable and user-friendly support for the visually impaired can be achieved using cost-effective, offline, and open-source solutions. The system represents a significant step toward democratizing assistive technology through privacy-preserving, affordable solutions that can operate independently of cloud infrastructure. Continued development and user-centered refinement hold the potential to further expand its impact and adoption in real-world settings.
Future work will focus on conducting comprehensive user studies with visually impaired participants to validate the system’s real-world effectiveness and gather feedback for user-centered improvements. Additionally, exploration of federated learning approaches could enable model improvements while maintaining privacy principles, and integration with existing assistive devices could provide a more comprehensive support ecosystem.
Author Contributions
Conceptualization, M.F.A.B. and F.Y.M.; methodology, M.F.A.B. and D.A.A.; software, F.Y.M., K.T.T., W.A. and S.D.; validation, A.S. and D.A.A.; formal analysis, M.F.A.B. and F.Y.M.; investigation, F.Y.M., K.T.T., W.A. and S.D.; resources, M.F.A.B.; data curation, F.Y.M. and A.S.; writing—original draft preparation, F.Y.M. and K.T.T.; writing—review and editing, M.F.A.B. and D.A.A.; visualization, F.Y.M. and K.T.T.; supervision, M.F.A.B.; project administration, M.F.A.B.; funding acquisition, M.F.A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the United Arab Emirates University (UAEU) under the Summer Undergraduate Research Experience (SURE Plus) Grant Program. The project, titled “Innovative Sight-Assist Glasses: A Hybrid CNN-LSTM Approach for Enhanced Facial and Object Recognition for People with Visual Impairment”, was funded through Grant Code G00004797, with a total budget of 40,000 AED. The project commenced on 15 May 2024, and is scheduled to conclude on 9 May 2025. The authors gratefully acknowledge UAEU for its financial and institutional support in enabling this research initiative.
Data Availability Statement
The datasets, code, and supplementary materials supporting the findings of this study are available upon reasonable request to promote reproducibility and further research in the field of assistive technologies. The source code, performance datasets, and documentation can be provided to researchers upon contacting the corresponding author. Due to privacy considerations regarding biometric data, only performance evaluation results and system logs are shared, rather than raw biometric datasets. Access to any additional sensitive data will be considered only under appropriate ethical approval and data-sharing agreements. All materials are provided under open-source licenses to ensure maximum accessibility for research and development purposes.
Conflicts of Interest
The authors declare no conflict of interest.
References
- World Health Organization. World Report on Vision. 2019. Available online: https://www.who.int/publications/i/item/9789241516570 (accessed on 15 September 2025).
- Abidi, M.H.; Siddiquee, A.N.; Alkhalefah, H.; Srivastava, V. A comprehensive review of navigation systems for visually impaired individuals. Heliyon 2024, 10, e31825. [Google Scholar] [CrossRef]
- Smith, E.M.; Graham, D.; Morgan, C.; MacLachlan, M. Artificial intelligence and assistive technology: Risks, rewards, challenges, and opportunities. Assist. Technol. 2023, 35, 375–377. [Google Scholar] [CrossRef]
- Wang, X.; Tang, Z.; Guo, J.; Meng, T.; Wang, C.; Wang, T.; Jia, W. Empowering edge intelligence: A comprehensive survey on on-device ai models. ACM Comput. Surv. 2025, 57, 1–39. [Google Scholar] [CrossRef]
- Singh, V. AI-Powered Assistive Technologies for People with Disabilities: Developing AI Solutions That Aid Individuals with Various Disabilities in Daily Tasks. J. Eng. Res. Rep. 2025, 27, 292–309. [Google Scholar] [CrossRef]
- Fernando, S.; Ndukwe, C.; Virdee, B.; Djemai, R. Image Recognition Tools for Blind and Visually Impaired Users: An Emphasis on the Design Considerations. ACM Trans. Access. Comput. 2025, 18, 1–21. [Google Scholar] [CrossRef]
- Akter, T.; Ahmed, T.; Kapadia, A.; Swaminathan, M. Shared privacy concerns of the visually impaired and sighted bystanders with camera-based assistive technologies. ACM Trans. Access. Comput. (TACCESS) 2022, 15, 1–33. [Google Scholar] [CrossRef]
- Valentín-Sívico, J.; Canfield, C.; Low, S.A.; Gollnick, C. Evaluating the impact of broadband access and internet use in a small underserved rural community. Telecommun. Policy 2023, 47, 102499. [Google Scholar] [CrossRef]
- Kong, L.; Tan, J.; Huang, J.; Chen, G.; Wang, S.; Jin, X.; Zeng, P.; Khan, M.; Das, S.K. Edge-computing-driven internet of things: A survey. ACM Comput. Surv. 2022, 55, 1–41. [Google Scholar] [CrossRef]
- Chemnad, K.; Othman, A. Digital accessibility in the era of artificial intelligence—Bibliometric analysis and systematic review. Front. Artif. Intell. 2024, 7, 1349668. [Google Scholar] [CrossRef]
- Dedeoğlu, G.; Kisačanin, B.; Moore, D.; Sharma, V.; Miller, A. An optimized vision library approach for embedded systems. In Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Colorado Springs, CO, USA, 20–25 June 2011; pp. 8–13. [Google Scholar] [CrossRef]
- Naayini, P.; Sharma, S.; Kumar, R.; Patel, A. AI-powered assistive technologies for visual impairment. arXiv 2025, arXiv:2503.15494. [Google Scholar]
- Okolo, G.I.; Althobaiti, T.; Ramzan, N. Assistive systems for visually impaired persons: Challenges and opportunities for navigation assistance. Sensors 2024, 24, 3572. [Google Scholar] [CrossRef] [PubMed]
- Microsoft Corporation. Ability Summit 2024: Advancing Accessibility with AI Technology and Innovation. 2024. Available online: https://blogs.microsoft.com/blog/2024/03/07/ability-summit-2024-advancing-accessibility-with-ai-technology-and-innovation/ (accessed on 15 September 2025).
- Google LLC. 8 New Accessibility Updates Across Lookout, Google Maps and More. 2024. Available online: https://blog.google/outreach-initiatives/accessibility/ai-accessibility-update-gaad-2024/ (accessed on 15 September 2025).
- Accessibility and Assistive Technology. 2024. Available online: https://www.amazon.com/b?ie=UTF8&node=15701038011 (accessed on 15 September 2025).
- Kathiria, P.; Mankad, S.H.; Patel, J.; Kapadia, M.; Lakdawala, N. Assistive systems for visually impaired people: A survey on current requirements and advancements. Neurocomputing 2024, 606, 128284. [Google Scholar] [CrossRef]
- Dubey, I.S.; Verma, J.S.; Mehendale, A. An assistive system for visually impaired using Raspberry Pi. Int. J. Eng. Res. Technol. (IJERT) 2019, 8, 608–613. [Google Scholar]
- Okolo, G.I.; Althobaiti, T.; Ramzan, N. Smart assistive navigation system for visually impaired people. J. Disabil. Res. 2025, 4, 20240086. [Google Scholar] [CrossRef]
- Muhsin, Z.J.; Qahwaji, R.; Ghanchi, F.; Al-Taee, M. Review of substitutive assistive tools and technologies for people with visual impairments: Recent advancements and prospects. J. Multimodal User Interfaces 2024, 18, 135–156. [Google Scholar] [CrossRef]
- Lavric, A.; Beguni, C.; Zadobrischi, E.; Căilean, A.M.; Avătămăniței, S.A. A comprehensive survey on emerging assistive technologies for visually impaired persons: Lighting the path with visible light communications and artificial intelligence innovations. Sensors 2024, 24, 4834. [Google Scholar] [CrossRef]
- Sapkota, R.; Flores-Calero, M.; Qureshi, R.; Badgujar, C.; Nepal, U.; Poulose, A.; Zeno, P.; Vaddevolu, U.B.P.; Khan, S.; Shoman, M.; et al. YOLO advances to its genesis: A decadal and comprehensive review of the You Only Look Once (YOLO) series. Artif. Intell. Rev. 2025, 58, 274. [Google Scholar] [CrossRef]
- Peserico, G.; Morato, A. Performance Evaluation of YOLOv5 and YOLOv8 Object Detection Algorithms on Resource-Constrained Embedded Hardware Platforms for Real-Time Applications. In Proceedings of the 2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA), Padova, Italy, 10–13 September 2024. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Hussain, M. YOLOv1 to v8: Unveiling each variant–a comprehensive review of yolo. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Wang, X.F.; He, Z.H.; Wang, K.; Wang, Y.F.; Zou, L.; Wu, Z.Z. A survey of text detection and recognition algorithms based on deep learning technology. Neurocomputing 2023, 556, 126702. [Google Scholar] [CrossRef]
- Reddy, K.K.; Badam, R.; Alam, S.; Shuaib, M. IoT-driven accessibility: A refreshable OCR-Braille solution for visually impaired and deaf-blind users through WSN. J. Econ. Technol. 2024, 2, 128–137. [Google Scholar] [CrossRef]
- Shaikh, S.; Karale, V.; Tawde, G. Assistive object recognition system for visually impaired. Int. J. Eng. Res. Technol. (IJERT) 2020, 9, 736–740. [Google Scholar] [CrossRef]
- Sporici, D.; Cușnir, E.; Boiangiu, C.A. Improving the accuracy of Tesseract 4.0 OCR engine using convolution-based preprocessing. Symmetry 2020, 12, 715. [Google Scholar] [CrossRef]
- Wang, X.; Wu, Y.C.; Zhou, M.; Fu, H. Beyond surveillance: Privacy, ethics, and regulations in face recognition technology. Front. Big Data 2024, 7, 1337465. [Google Scholar] [CrossRef]
- George, A.; Ecabert, C.; Shahreza, H.O.; Kotwal, K.; Marcel, S. EdgeFace: Efficient Face Recognition Model for Edge Devices. IEEE Trans. Biom. Behav. Identity Sci. 2024, 6, 158–168. [Google Scholar] [CrossRef]
- De Freitas, M.P.; Piai, V.A.; Farias, R.H.; Fernandes, A.M.; de Moraes Rossetto, A.G.; Leithardt, V.R.Q. Artificial intelligence of things applied to assistive technology: A systematic literature review. Sensors 2022, 22, 8531. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.J.; Chen, L.B.; Sie, C.Y.; Yang, C.H. An artificial intelligence edge computing-based assistive system for visually impaired pedestrian safety at zebra crossings. IEEE Trans. Consum. Electron. 2020, 67, 3–11. [Google Scholar] [CrossRef]
- Habeeb, A.; Williams, L. Privacy-Preserving On-Device Speech Recognition Using Vosk with Domain-Specific Language Models. 2025. Available online: https://www.researchgate.net/publication/391807206_Privacy-Preserving_On-Device_Speech_Recognition_Using_Vosk_with_Domain-Specific_Language_Models (accessed on 15 September 2025).
- Li, T.; He, X.; Jiang, S.; Liu, J. A survey of privacy-preserving offloading methods in mobile-edge computing. J. Netw. Comput. Appl. 2022, 203, 103395. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).