
Research on Binary Mixed VOCs Gas Identification Method Based on Multi-Task Learning




Abstract
Highlights
- A multi-task residual network (MRCA) which generates dynamic feature depending on the cross-fusion module was invented to perform VOCs gas component identification and concentration prediction.
- The dynamic weighted loss function, which can dynamically adjust the weight according to the training progress of each task.
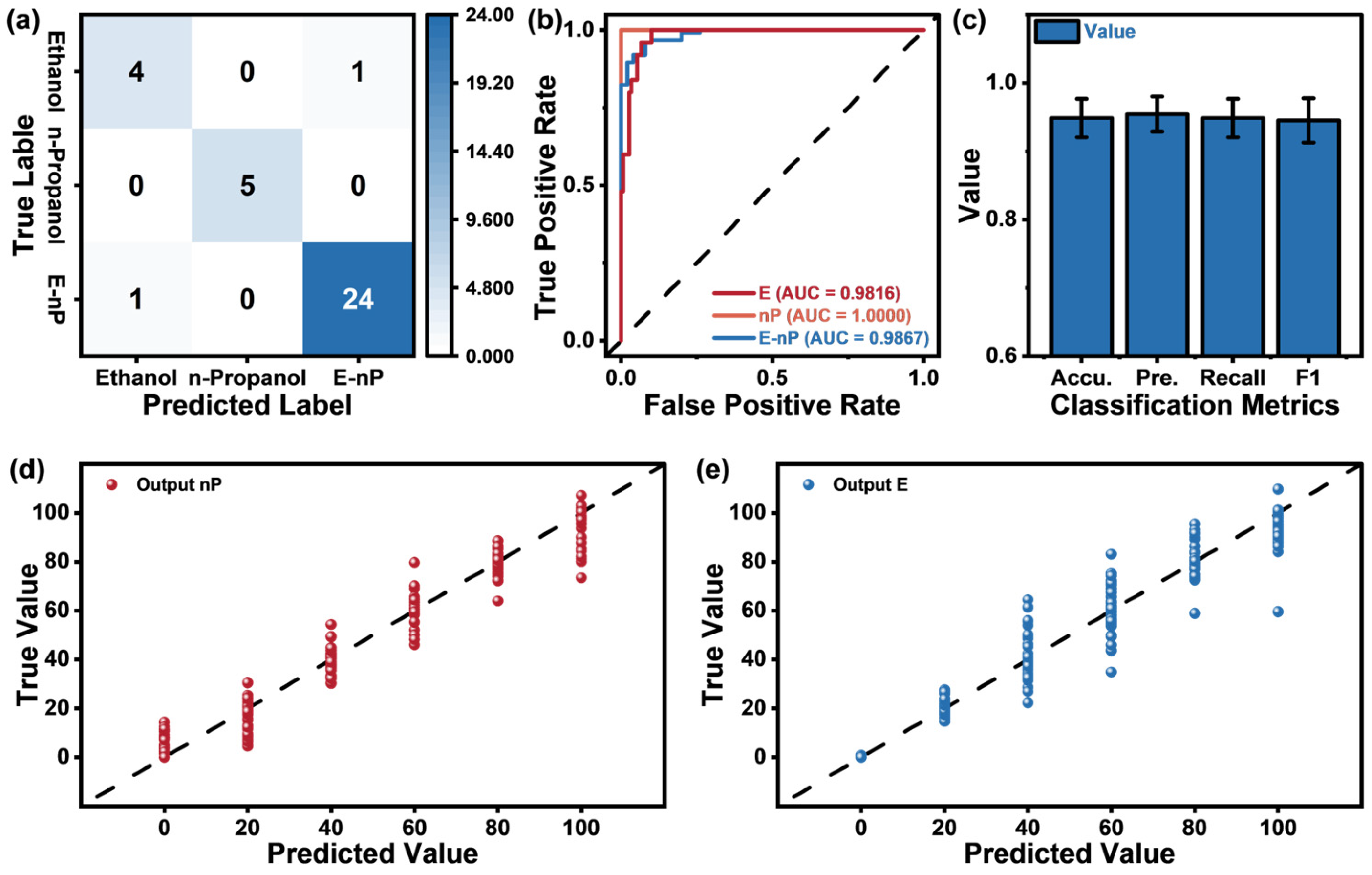
- The MRCA model showed a high classification accuracy of 94.86%, as well as achieving an R2 score up to 0.95.
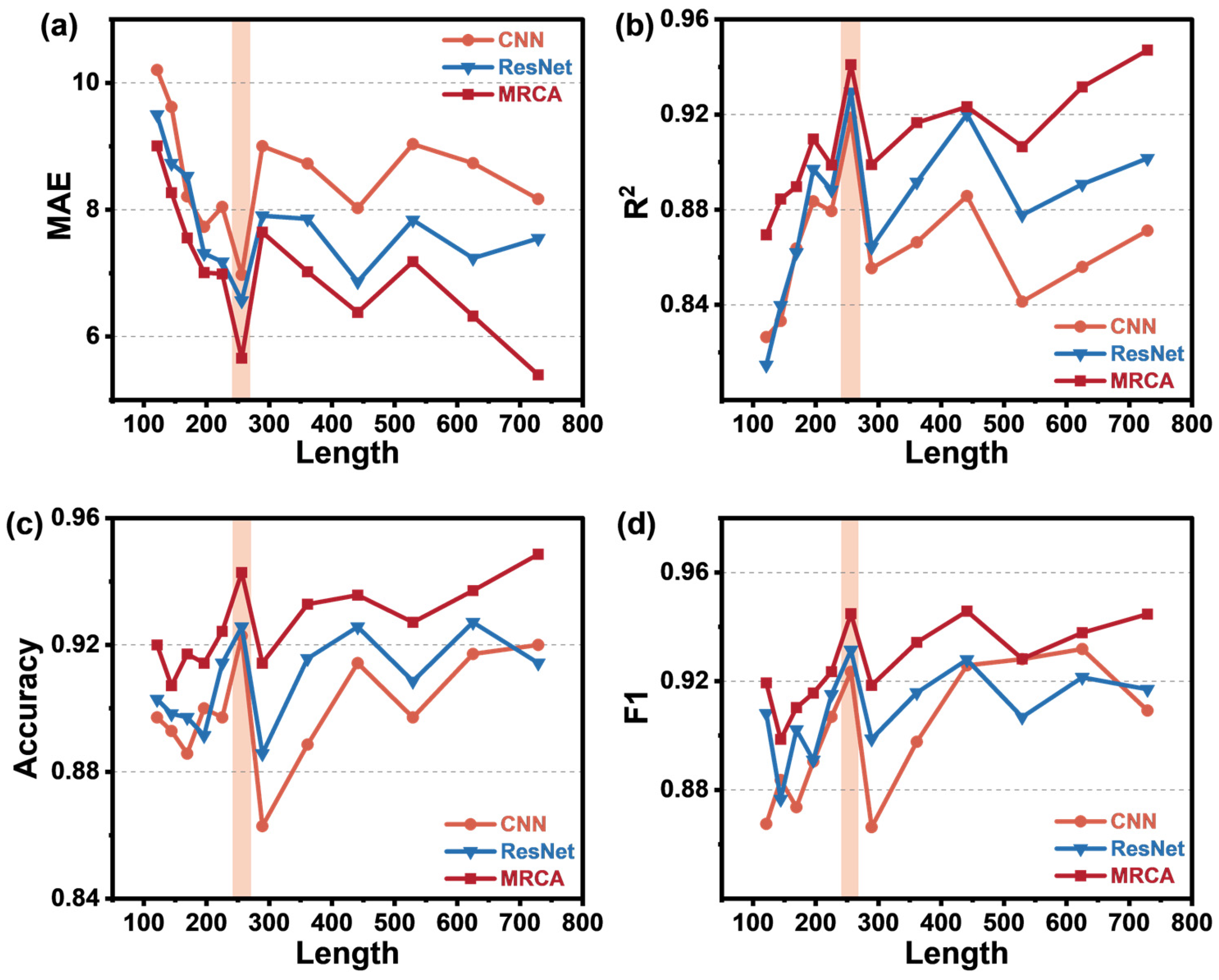
- Using only 35% of the total data length as input data leads to excellent identification performance.
Abstract
1. Introduction
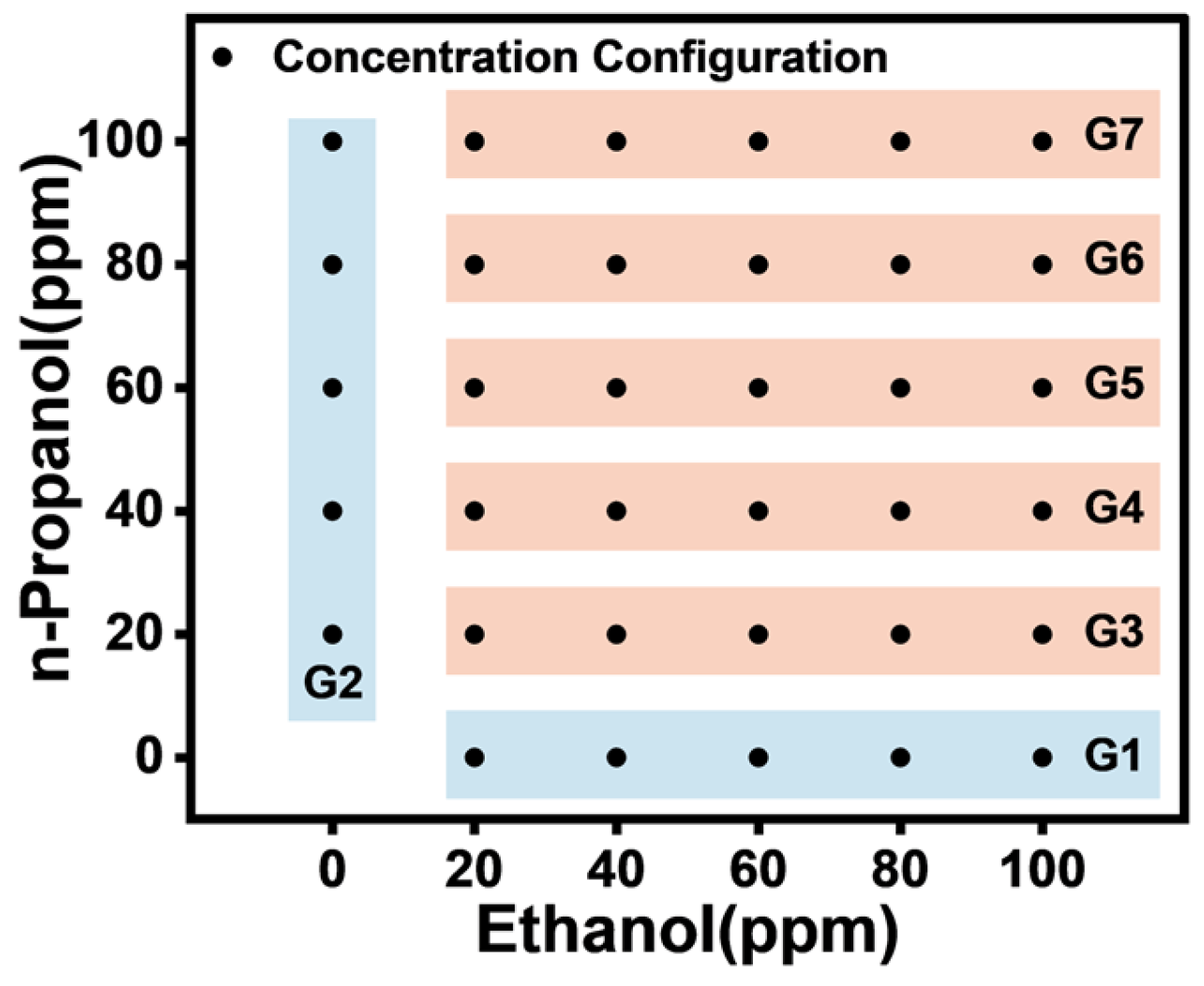
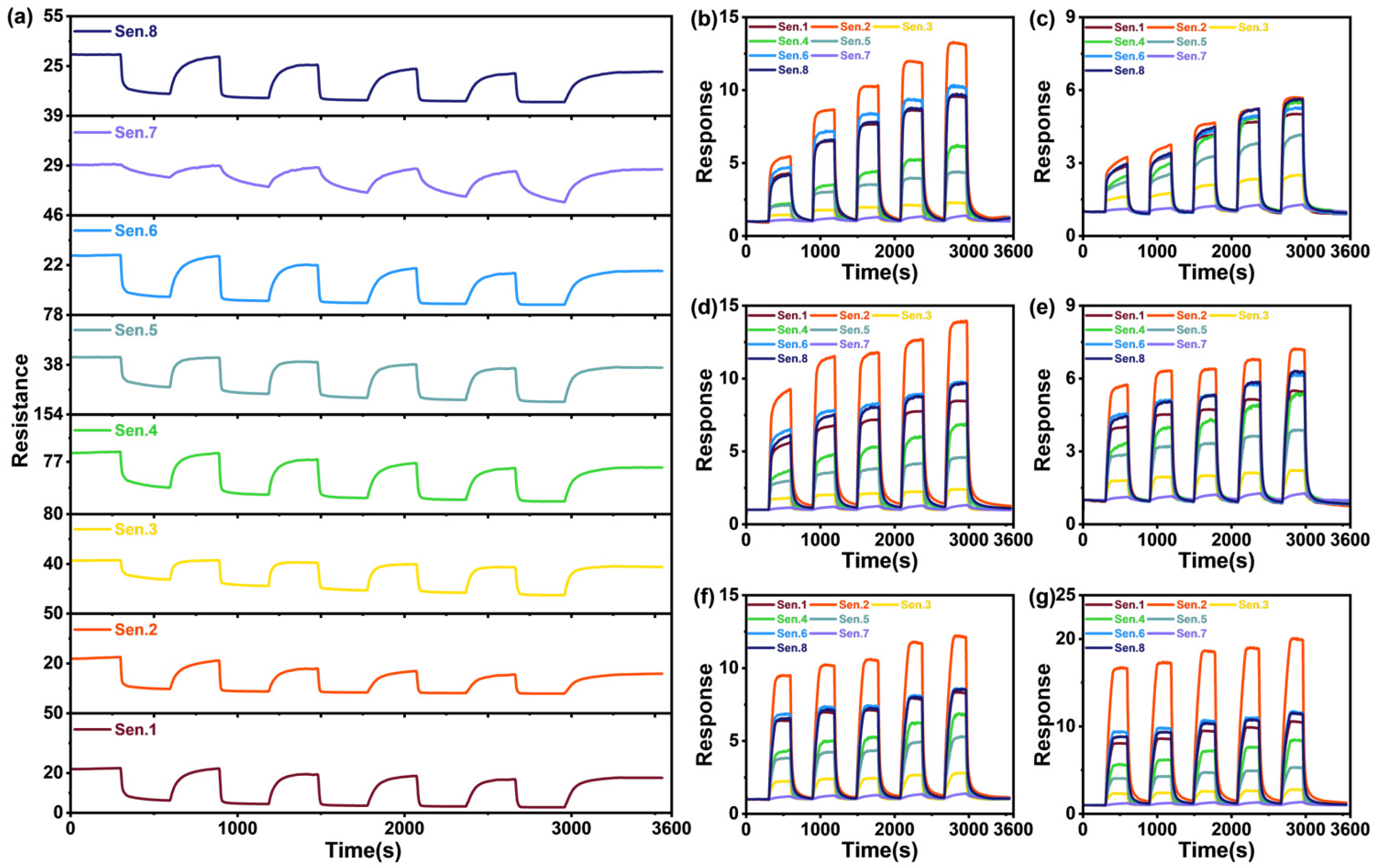
2. Gas Experiment
3. Method
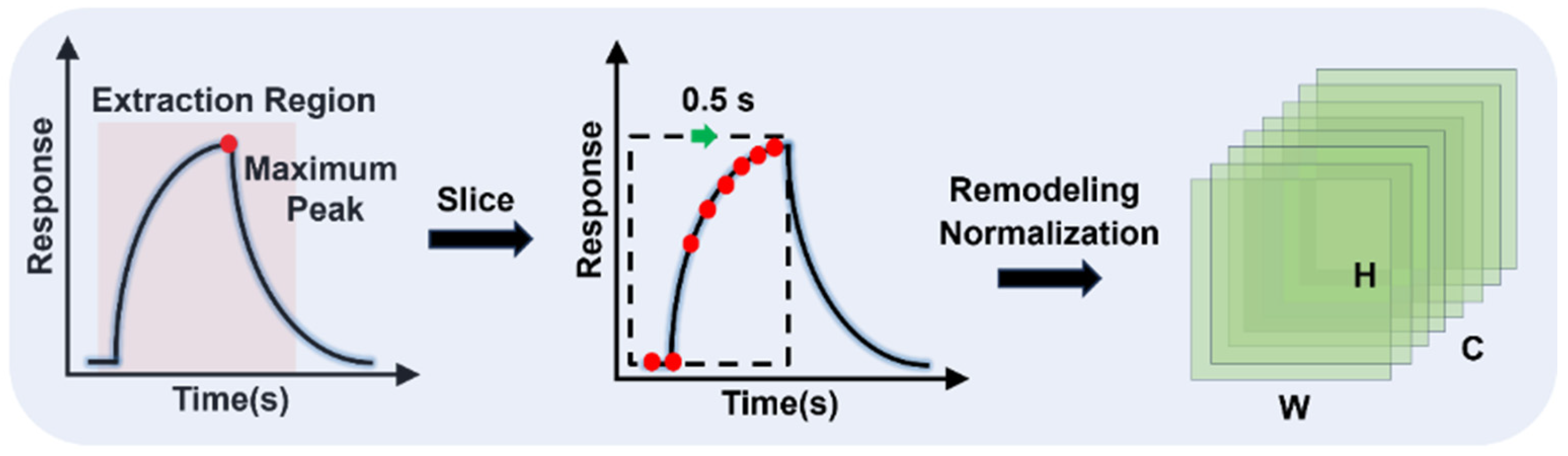
3.1. Data Preprocessing
3.1.1. Response Fragment Segmentation
3.1.2. Feature Selection
3.1.3. Feature Matrix Normalization and Reshaping
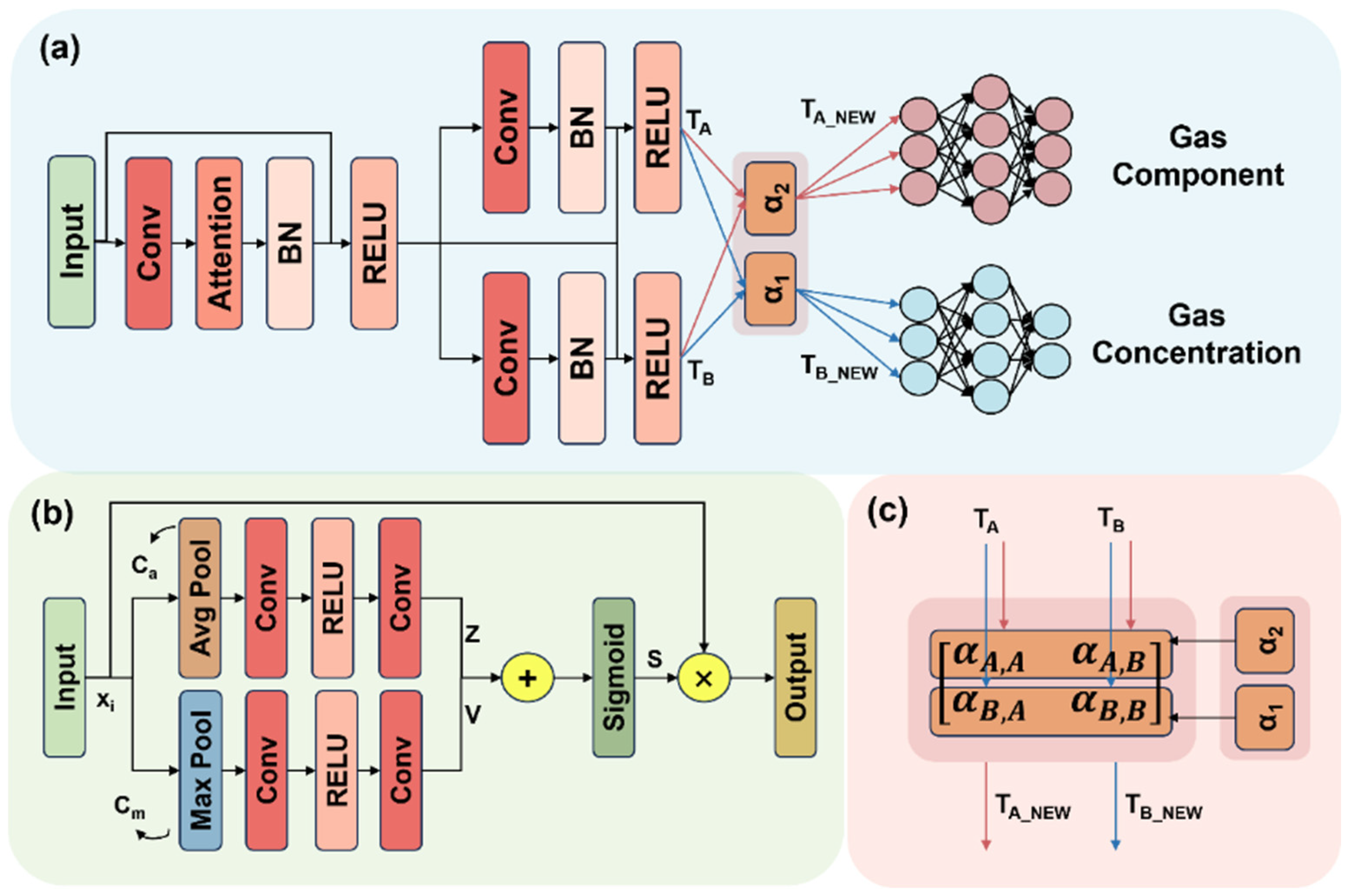
3.2. Multi-Task Learning Model
3.2.1. Channel Attention Mechanism
3.2.2. Cross-Fusion Module
3.2.3. Multi-Task Residual Network
- Input Layer: After preprocessing, the shape of the gas response data is 8 × × (where = ). The number eight represents the number of input feature maps corresponding to the number of gas sensors in the array, and × refers to the height and width of the feature maps.
- Convolutional Layer: In the backbone structure of the multi-task residual network, the convolution kernel is set to the common 3 × 3 size. To avoid information loss at the edges of the feature map due to convolution, the padding size is set to two, ensuring that edge regions fully participate in feature extraction. The main purpose of convolution is to extract deeper features, so after each convolution operation, the number of channels doubles compared to the previous layer. For example, after the second convolution, the number of channels increases to 32, gradually enhancing the network’s expressive power.
- Batch Normalization and Activation Function: To accelerate model convergence, batch normalization is applied after each convolution operation to standardize intermediate feature distributions. Since the length of the gas response data samples is relatively short, pooling and dropout operations are omitted, but batch normalization helps reduce overfitting. The activation function is chosen to improve the model’s non-linear representation and reduce computational complexity.
- Fully Connected Layer: After completing feature extraction and fusion for tasks A and B, the feature maps are flattened and passed through three fully connected layers for transformation. These layers gradually compress and map the high-dimensional feature space, enhancing the model’s ability to represent the target task. Finally, task A outputs gas component recognition results using the Softmax function to calculate the probability distribution for each category, while task B predicts the concentrations of the two gases.
4. Experimental Results and Analysis
4.1. Hyperparameter Settings
4.2. Model Training and Validation
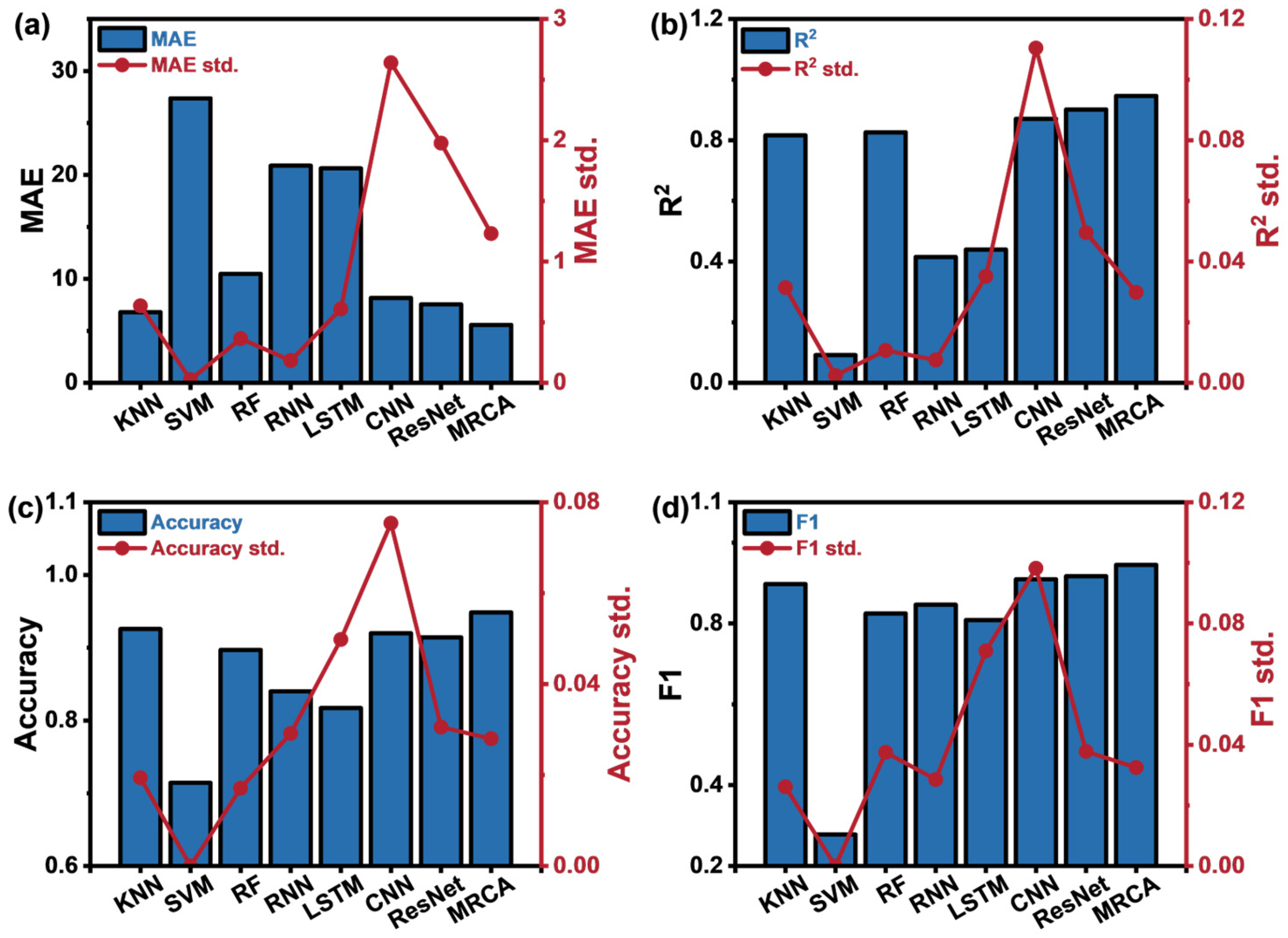
4.3. Model Performance
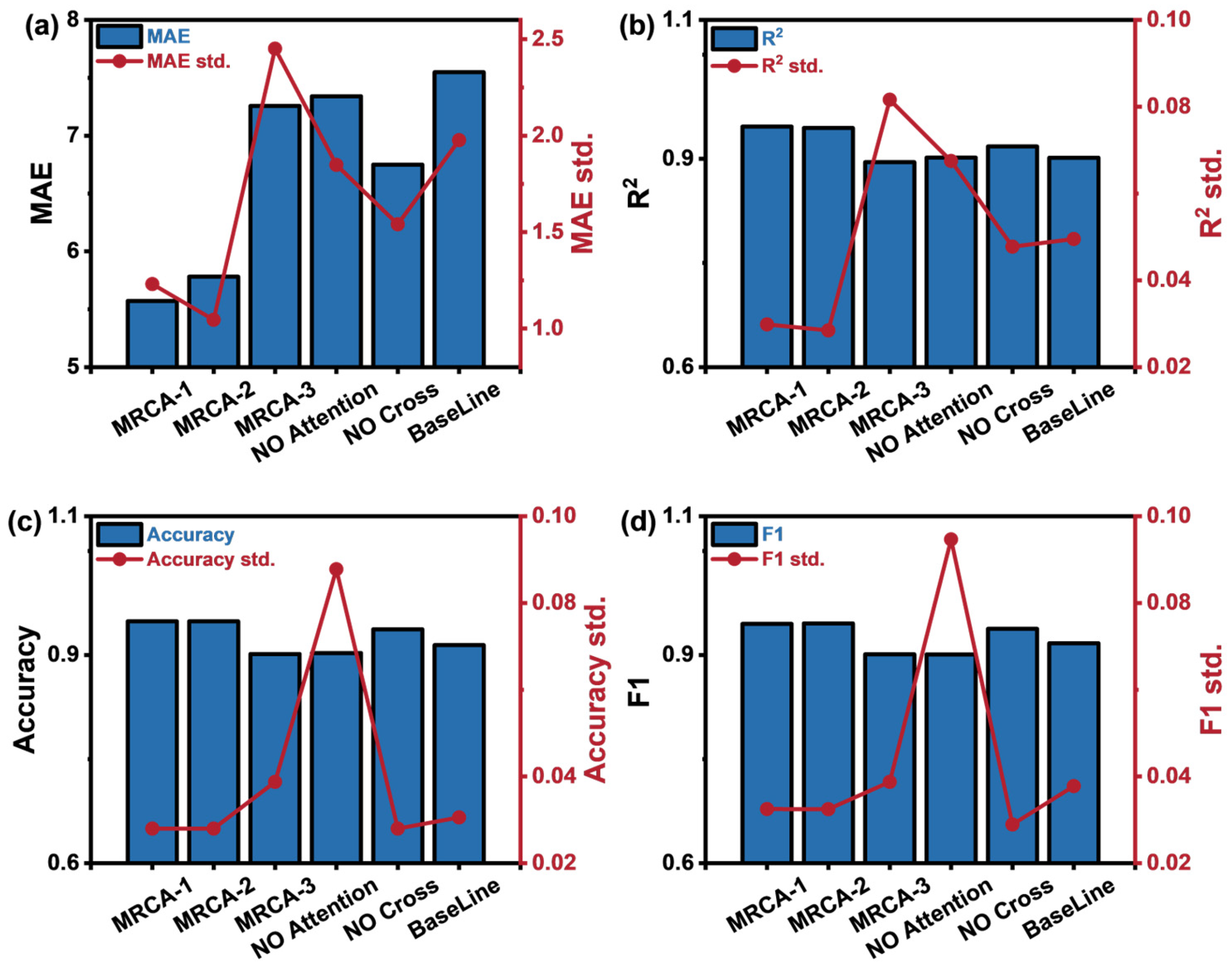
4.4. Ablation Experiment
- MRCA-1: The dynamic weighted loss function’s weight parameter σ is initialized based on experience to evaluate the impact of weight initialization on model performance.
- MRCA-2: The dynamic weighted loss function’s weight parameter σ is not initialized, aiming to evaluate the impact of not initializing the weights on model performance.
- MRCA-3: The total loss is calculated by directly adding the individual losses to evaluate the impact of the dynamic weighted loss function on model performance.
- NO Attention: The channel attention mechanism module is removed to evaluate its impact on model performance.
- NO Cross: The cross-fusion module is removed to evaluate its contribution.
- BaseLine: The baseline model, which removes both the channel attention mechanism and the cross-fusion module.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Wang, C.; Li, L.; Zheng, T. Bioaerosols and VOC emissions from landfill leachate treatment processes: Regional differences and health risks. J. Hazard. Mater. 2024, 480, 136232. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.J.; Lee, S.J.; Hong, Y.; Choi, S.D. Investigation of priority anthropogenic VOCs in the large industrial city of ulsan, south korea, focusing on their levels, risks, and secondary formation potential. Atmos. Environ. 2024, 343, 120982. [Google Scholar] [CrossRef]
- Miao, G.; Wang, Y.; Wang, B.; Yu, H.; Liu, J.; Pan, R.; Zhou, C.; Ning, J.; Zheng, Y.; Zhang, R.; et al. Multi-omics analysis reveals hepatic lipid metabolism profiles and serum lipid biomarkers upon indoor relevant VOC exposure. Environ. Int. 2023, 180, 108221. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, R.; Kong, H.; Wang, K.; Sun, L.; Yu, X.; Zhao, J.; Xiong, J.; Tran, P.T.M. Balasubramanian. long-term emission characteristics of VOCs from building materials. J. Hazard. Mater. 2024, 480, 136337. [Google Scholar] [CrossRef]
- Zhou, L.; Huang, C.; Lu, R.; Wang, X.; Sun, C.; Zou, Z. Associations between VOCs and childhood asthma in Shanghai, China: Impacts of daily behaviors. Atmos. Pollut. Res. 2024, 16, 102359. [Google Scholar] [CrossRef]
- Hussain, M.S.; Gupta, G.; Mishra, R.; Patel, N.; Gupta, S.; Alzarea, S.I.; Kazmi, I.; Kumbhar, P.; Disouza, J.; Dureja, H.; et al. Unlocking the secrets: Volatile organic compounds (VOCs) and their devastating effects on lung cancer. Pathol.-Res. Pract. 2024, 255, 155157. [Google Scholar] [CrossRef]
- Peng, J.; Mei, H.; Yang, R.; Meng, K.; Shi, L.; Zhao, J.; Zhang, B.; Xuan, F.; Wang, T.; Zhang, T. Olfactory diagnosis model for lung health evaluation based on pyramid pooling and shap-based dual encoders. ACS Sens. 2024, 9, 4934–4946. [Google Scholar] [CrossRef]
- Song, J.; Li, R.; Yu, R.; Zhu, Q.; Li, C.; He, W.; Liu, J. Detection of VOCs in exhaled breath for lung cancer diagnosis. Microchem. J. 2024, 199, 110051. [Google Scholar] [CrossRef]
- Liu, H.; Fang, C.; Zhao, J.; Zhou, Q.; Dong, Y.; Lin, L. The detection of acetone in exhaled breath using gas pre-concentrator by modified metal-organic framework nanoparticles. Chem. Eng. J. 2024, 498, 155309. [Google Scholar] [CrossRef]
- Lv, E.; Wang, T.; Yue, X.; Wang, H.; Zeng, J.; Shu, X.; Wang, J. Wearable SERS sensor based on bionic sea urchin-cavity structure for dual in-situ detection of metabolites and VOCs gas. Chem. Eng. J. 2024, 499, 156020. [Google Scholar] [CrossRef]
- Mei, H.; Peng, J.; Wang, T.; Zhou, T.; Zhao, H.; Zhang, T.; Yang, Z. Overcoming the limits of cross-sensitivity:pattern recognition methods for chemiresistive gas sensor array. Nano-Micro Lett. 2024, 16, 285–341. [Google Scholar]
- Raina, S.; Bharti, A.; Singh, H.M.; Kothari, R.; Tyagi, V.V.; Pathania, D.; Buddhi, D. Chapter 1—Applications of gas and VOC sensors for industry and environmental monitoring: Current trends and future implications. In Complex and Composite Metal Oxides for Gas, VOC, and Humidity Sensors; Yadav, B.C., Kumar, P., Eds.; Elsevier: Amsterdam, The Netherlands, 2024; pp. 3–26. [Google Scholar] [CrossRef]
- Fan, H.; Wang, P.; Zhang, H.; Hu, M.; Zhu, C.; Wang, Q. Zero-absorption-assisted multitask learning for simultaneous measurement of acetylene concentration and gas pressure from overlap-deformed spectra. Opt. Laser Technol. 2024, 176, 110968. [Google Scholar] [CrossRef]
- Gong, Z.; Fan, Y.; Guan, Y.; Wu, G.; Mei, L. Empirical Modal Decomposition Combined with Deep Learning for Photoacoustic Spectroscopy Detection of Mixture Gas Concentrations. Anal. Chem. 2024, 96, 18528–18536. [Google Scholar]
- Hou, J.; Liu, X.; Sun, H.; He, Y.; Qiao, S.; Zhao, W.; Zhou, S.; Ma, Y. Dual-Component Gas Sensor Based on Light-Induced Thermoelastic Spectroscopy and Deep Learning. Anal. Chem. 2025, 97, 5200–5208. [Google Scholar]
- Kan, Z.; Zhang, Y.; Luo, L.; Cao, Y. Ultraviolet absorption spectrometry with symmetrized dot patterns and deep learning for quantitative analysis of SO2, H2S, CS2 mixed gases. Eng. Appl. Artif. Intell. 2024, 133, 108366. [Google Scholar] [CrossRef]
- Kistenev, Y.V.; Skiba, V.E.; Prischepa, V.V.; Borisov, A.V.; Vrazhnov, D.A. Gas-mixture IR absorption spectra denoising using deep learning. J. Quant. Spectrosc. Radiat. Transf. 2024, 313, 108825. [Google Scholar] [CrossRef]
- Zhou, Y.; Jiang, M.; Dou, W.; Meng, D.; Wang, C.; Wang, J.; Wang, X.; Sun, L.; Jiang, S.; Chen, F.; et al. Narrow-band multi-component gas analysis based on photothermal spectroscopy and partial least squares regression method. Sens. Actuators B Chem. 2023, 377, 133029. [Google Scholar]
- Chakraborty, P.; Borras, E.; Rajapakse, M.Y.; McCartney, M.M.; Bustamante, M.; Mitcham, E.J.; Davis, C.E. Non-destructive method to classify walnut kernel freshness from volatile organic compound (VOC) emissions using gas chromatography-differential mobility spectrometry (GC-DMS) and machine learning analysis. Appl. Food Res. 2023, 3, 100308. [Google Scholar] [CrossRef]
- Dwyer, D.B.; Niedziela, J.L.; Miskowiec, A. Tandem pyrolysis evolved gas–gas chromatography–mass spectrometry. J. Anal. Appl. Pyrolysis 2025, 186, 106904. [Google Scholar]
- Rahmani, N.; Mani-Varnosfaderani, A. Profiling volatile organic compounds of different grape seed oil genotypes using gas chromatography-mass spectrometry and chemometric methods. Ind. Crops Prod. 2024, 222, 119928. [Google Scholar]
- Zhang, Z.; Zhang, Q.; Xi, Y.; Zhou, Y.; Zhan, M. Establishment of a headspace-thermal desorption and gas chromatography-mass spectrometry method (HS-TD-GC-MS) for simultaneous detection of 51 volatile organic compounds in human urine: Application in occupational exposure assessment. J. Chromatogr. A 2024, 1722, 464863. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Liu, Y.; Han, B.; Wang, M.; Wang, Q.; Zhang, Y.-n. Fiber optic volatile organic compound gas sensors: A review. Coord. Chem. Rev. 2023, 493, 215297. [Google Scholar] [CrossRef]
- Bing, Y.; Zhang, F.; Han, J.; Zhou, T.; Mei, H.; Zhang, T. A method of ultra-low power consumption implementation for MEMS gas sensors. Chemosensors 2023, 11, 236. [Google Scholar] [CrossRef]
- Chen, H.; Huo, D.; Zhang, J. Gas Recognition in E-Nose System: A Review. IEEE Trans. Biomed. Circuits Syst. 2022, 16, 169–184. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhao, H.; Wang, Y.; Zhou, Y. Approaches for selectivity improvement of conductometric gas sensors: An overview. Sens. Diagn. 2024, 3, 336–353. [Google Scholar] [CrossRef]
- Yin, X.-T.; Dastan, D.; Gity, F.; Li, J.; Shi, Z.; Alharbi, N.D.; Liu, Y.; Tan, X.-M.; Gao, X.-C.; Ma, X.-G.; et al. Gas sensing selectivity of SnO2-xNiO sensors for homogeneous gases and its selectivity mechanism: Experimental and theoretical studies. Sens. Actuators A Phys. 2023, 354, 114273. [Google Scholar] [CrossRef]
- Panda, S.; Mehlawat, S.; Dhariwal, N.; Kumar, A.; Sanger, A. Comprehensive review on gas sensors: Unveiling recent developments and addressing challenges. Mater. Sci. Eng. B 2024, 308, 117616. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; He, X.; Yan, R.; Li, Z.; Jiang, Y.; Li, X. Improved deep bidirectional recurrent neural network for learning the cross-sensitivity rules of gas sensor array. Sens. Actuators B Chem. 2024, 401, 134996. [Google Scholar] [CrossRef]
- Pan, X.; Chen, J.; Wen, X.; Hao, J.; Xu, W.; Ye, W.; Zhao, X. A comprehensive gas recognition algorithm with label-free drift compensation based on domain adversarial network. Sens. Actuators B Chem. 2023, 387, 133709. [Google Scholar] [CrossRef]
- Wei, G.; Xu, Y.; Lv, X.; Jiao, S.; He, A. An adaptive drift compensation method based on integrated dual-channel feature fusion for electronic noses. IEEE Sens. J. 2024, 24, 26814–26824. [Google Scholar] [CrossRef]
- Yao, Y.; Chen, B.; Liu, C.; Qu, C. Investigation on the combined model of sensor drift compensation and open-set gas recognition based on electronic nose datasets. Chemom. Intell. Lab. Syst. 2023, 242, 105003. [Google Scholar] [CrossRef]
- Laref, R.; Losson, E.; Sava, A.; Adjallah, K.; Siadat, M. A comparison between SVM and PLS for E-nose based gas concentration monitoring. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018; pp. 1335–1339. [Google Scholar]
- Xu, W.; Tang, J.; Xia, H.; Sun, Z. Prediction method of dioxin emission concentration based on PCA and deep forest regression. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 1212–1217. [Google Scholar]
- Xia, W.; Song, T.; Yan, Z.; Song, K.; Chen, D.; Chen, Y. A method for recognition of mixed gas composition based on PCA and KNN. In Proceedings of the 2021 19th International Conference on Optical Communications and Networks (ICOCN), Qufu, China, 23–27 August 2021; pp. 1–3. [Google Scholar]
- Li, K.; Yang, G.; Wang, K.; Lu, B.; Jia, J.; Sun, T. Prediction of dissolved gases concentration in transformer oil based on VMD and ELM. In Proceedings of the 2023 IEEE 7th Conference on Energy Internet and Energy System Integration (EI2), Hangzhou, China, 15–18 December 2023; pp. 3749–3753. [Google Scholar]
- Martono, N.P.; Kuramaru, S.; Igarashi, Y.; Yokobori, S.; Ohwada, H. Blood alcohol concentration screening at emergency room: Designing a classification model using machine learning. In Proceedings of the 2023 14th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 4–5 October 2023; pp. 255–260. [Google Scholar]
- Zhu, R.; Gao, J.; Li, M.; Gao, Q.; Wu, X.; Zhang, Y. A ppb-level online detection system for gas concentrations in CS2/SO2 mixtures based on UV-DOAS combined with VMD-CNN-TL model. Sens. Actuators B Chem. 2023, 394, 134440. [Google Scholar] [CrossRef]
- Mao, G.; Zhang, Y.; Xu, Y.; Li, X.; Xu, M.; Zhang, Y.; Jia, P. An electronic nose for harmful gas early detection based on a hybrid deep learning method H-CRNN. Microchem. J. 2023, 195, 109464. [Google Scholar] [CrossRef]
- Chu, J.; Li, W.; Yang, X.; Wu, Y.; Wang, D.; Yang, A.; Yuan, H.; Wang, X.; Li, Y.; Rong, M. Identification of gas mixtures via sensor array combining with neural networks. Sens. Actuators B Chem. 2021, 329, 129090. [Google Scholar] [CrossRef]
- Song, S.; Chen, J.; Ma, L.; Zhang, L.; He, S.; Du, G.; Wang, J. Research on a working face gas concentration prediction model based on LASSO-RNN time series data. Heliyon 2023, 9, e14864. [Google Scholar] [CrossRef]
- Zeng, L.; Xu, Y.; Ni, S.; Xu, M.; Jia, P. A mixed gas concentration regression prediction method for electronic nose based on two-channel TCN. Sens. Actuators B Chem. 2023, 382, 133528. [Google Scholar] [CrossRef]
- Li, X.; Guo, J.; Xu, W.; Cao, J. Optimization of the mixed gas detection method based on neural network algorithm. ACS Sens. 2023, 8, 822–828. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, H.; Wu, Y.; Jiang, W.; Chen, X.; Zeng, M.; Yang, J.; Su, Y.; Hu, N.; Yang, Z. Target discrimination, Concentration prediction of binary mixed gases based on random forest algorithm in the electronic nose system mixed gases, and status judgment of electronic nose system based on large-scale measurement and multi-task deep learning. Sens. Actuators B Chem. 2022, 351, 130915. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, W.; Ma, R.; Zhuo, J.; Zeng, Y.; Wu, P.; Chu, J. A novel high accuracy fast gas detection algorithm based on multi-task learning. Measurement 2024, 228, 114383. [Google Scholar] [CrossRef]
- Fu, C.; Zhang, K.; Guan, H.; Deng, S.; Sun, Y.; Ding, Y.; Wang, J.; Liu, J. Progressive prediction algorithm by multi-interval data sampling in multi-task learning for real-time gas identification. Sens. Actuators B Chem. 2024, 418, 136271. [Google Scholar] [CrossRef]
- Kang, M.; Cho, I.; Park, J.; Jeong, J.; Lee, K.; Lee, B.; Del Orbe Henriquez, D.; Yoon, K.; Park, I. High accuracy real-time multi-gas identification by a batch-uniform gas sensor array and deep learning algorithm. ACS Sens. 2022, 7, 430–440. [Google Scholar] [PubMed]
- Zhang, S.; Cheng, Y.; Luo, D.; He, J.; Wong, A.K.Y.; Hung, K. Channel attention convolutional neural network for chinese baijiu detection with E-Nose. IEEE Sens. J. 2021, 21, 16170–16182. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Number | Response Gas |
|---|---|
| MQ-2 | Liquefied Gas, C3H8, H2 |
| MQ-3 | C2H5OH |
| MQ-4 | CH4 |
| MQ-5 | C4H10, C3H8, CH4 |
| MQ-6 | C3H8, C4H10 |
| MQ-7 | CO |
| MQ-8 | H2 |
| MQ-9 | CO |
| Gas Type | Single n-Propanol | Single Ethanol | n-Propanol and Ethanol |
|---|---|---|---|
| Label | 01 | 10 | 11 |
| Layer | Configuration | Input Shape |
|---|---|---|
| 1st Convolutional | Map: 16, K: 3, S: 1, P: 2 | |
| CA Module | / | |
| BN, Activation | / | |
| 2.1st–2.2st Convolutional | Map: 32, K: 3, S: 1, P: 2 | / |
| BN, Activation | ||
| FC1 | , 128 | / |
| FC2 | 128, 64 | 128 |
| FC3 | 64, 3 (TA) || 2 (TB) | 64 |
| Output | TA: 5 × 3, TB: 5 × 2 | / |
| Accuracy | Std. | F1 | Std. | MAE | Std. | R2 | Std. |
|---|---|---|---|---|---|---|---|
| 94.86% | 0.03 | 0.94 | 0.03 | 5.40 | 1.26 | 0.95 | 0.03 |
| Algo. | MAE | R2 | Accuracy | F1 |
|---|---|---|---|---|
| KNN | 6.8000 | 0.8164 | 0.9257 | 0.8975 |
| SVM | 27.3700 | 0.0914 | 0.7143 | 0.2778 |
| RF | 10.4900 | 0.8263 | 0.8971 | 0.8249 |
| RNN | 20.8944 | 0.4151 | 0.8400 | 0.8463 |
| LSTM | 20.6333 | 0.4397 | 0.8171 | 0.8086 |
| CNN | 8.1681 | 0.8712 | 0.9200 | 0.9092 |
| ResNet | 7.3927 | 0.8882 | 0.8914 | 0.8984 |
| MRCA | 5.3961 | 0.9471 | 0.9486 | 0.9449 |
| Algo. | MAE | R2 | Accuracy | F1 |
|---|---|---|---|---|
| MRCA-C | / | / | 0.9142 | 0.9068 |
| MRCA-R | 6.7737 | 0.9182 | / | / |
| MRCA | 5.3961 | 0.9471 | 0.9486 | 0.9449 |
| Algo. | MAE | R2 | Accuracy | F1 |
|---|---|---|---|---|
| MRCA-1 | 5.3961 | 0.9471 | 0.9486 | 0.9449 |
| MRCA-2 | 5.7812 | 0.9445 | 0.9486 | 0.9456 |
| MRCA-3 | 7.2567 | 0.8953 | 0.9014 | 0.9011 |
| NO Attention | 7.3411 | 0.9017 | 0.9029 | 0.9009 |
| NO Cross | 6.7503 | 0.9179 | 0.9371 | 0.9378 |
| BaseLine | 7.3927 | 0.8882 | 0.8914 | 0.8984 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, H.; Yang, R.; Peng, J.; Meng, K.; Wang, T.; Wang, L. Research on Binary Mixed VOCs Gas Identification Method Based on Multi-Task Learning. Sensors 2025, 25, 2355. https://doi.org/10.3390/s25082355
Mei H, Yang R, Peng J, Meng K, Wang T, Wang L. Research on Binary Mixed VOCs Gas Identification Method Based on Multi-Task Learning. Sensors. 2025; 25(8):2355. https://doi.org/10.3390/s25082355
Chicago/Turabian StyleMei, Haixia, Ruiming Yang, Jingyi Peng, Keyu Meng, Tao Wang, and Lijie Wang. 2025. "Research on Binary Mixed VOCs Gas Identification Method Based on Multi-Task Learning" Sensors 25, no. 8: 2355. https://doi.org/10.3390/s25082355
APA StyleMei, H., Yang, R., Peng, J., Meng, K., Wang, T., & Wang, L. (2025). Research on Binary Mixed VOCs Gas Identification Method Based on Multi-Task Learning. Sensors, 25(8), 2355. https://doi.org/10.3390/s25082355