Abstract
Low-light RAW image enhancement (LRIE) has attracted increased attention in recent years due to the demand for practical applications. Various deep learning-based methods have been proposed for dealing with this task, among which the fusion-based ones achieve state-of-the-art performance. However, current fusion-based methods do not sufficiently explore the physical correlations between source images and thus fail to sufficiently exploit the complementary information delivered by different sources. To alleviate this issue, we propose a Guided Filter-inspired Network (GFNet) for the LRIE task. The proposed GFNet is designed to fuse sources in a guided filter (GF)-like manner, with the coefficients inferred by the network, within both the image and feature domains. Inheriting the advantages of GF, the proposed method is able to capture more intrinsic correlations between source images and thus better fuse the contextual and textual information extracted from them, facilitating better detail preservation and noise reduction for LRIE. Experiments on benchmark LRIE datasets demonstrate the superiority of the proposed method. Furthermore, the extended applications of GFNet to guided low-light image enhancement tasks indicate its broad applicability.
1. Introduction
Images captured in low-light environments often suffer from severe noise and color distortion, which can significantly degrade user experience and impair the performance of downstream vision tasks. To mitigate these challenges, low-light image enhancement (LIE) has garnered increasing attention in recent years [1,2,3,4,5,6]. Traditionally, LIE was mainly carried out in the sRGB domain. However, sRGB images, which are often produced by camera image signal processing (ISP) from RAW format ones, can lose valuable metadata for post-processing. As a result, direct LIE on RAW images has emerged as a new trend in recent years, following pioneering work by Chen et al. [7]. In that work, a real paired low-light RAW image dataset, See-in-the-Dark (SID), was created, and a deep learning-based pipeline was proposed to perform low-light RAW image enhancement (LRIE). This pipeline employs a deep neural network to directly map dark, noisy RAW images to bright, clean sRGB ones, simultaneously removing noise and enhancing details.
Since the introduction of this end-to-end LRIE pipeline, multiple deep learning methods [8,9,10,11,12] have been developed and demonstrated promising results. Among them, the methods that use a fusion-based approach to enhance low-light RAW images with auxiliary images, mostly self-generated from the RAW images [11,12], have achieved state-of-the-art performance. These methodologies achieve performance superiority by effectively leveraging cross-modal complementary features, particularly in preserving spatial context and high-frequency textural patterns, all of which are crucial for restoring images with high visual quality in the LRIE task. However, it is worth noting that these methods usually employ feature domain fusion, which involves directly feeding aggregated features (e.g., concatenation or average) extracted from different source images into subsequent network modules, without fully exploring the physical correlations between sources. Here, physical correlations refer to the inherent and explicit relationships between source inputs, such as consistent or complementary spatial structures, due to their derivation from the same RAW source. As a result, the complementary information from different sources may not be utilized effectively, leading to limited performance, particularly in detail preservation and noise reduction.
The spatially variant linear representation model (SVLRM) represents a significant advancement in image fusion by integrating the guided filter [13,14] with Convolutional Neural Networks (CNNs) [15]. SVLRM leverages the learnable parameters of the guided filter within the image domain to achieve effective image fusion, outperforming traditional human-designed filters. By combining the edge-preserving properties of the guided filter with the feature extraction capabilities of CNNs, SVLRM successfully addresses challenges related to detail preservation and noise reduction. However, its scope is primarily confined to the image domain, limiting its ability to fully exploit the potential of guided filtering in more abstract feature representations. To overcome this limitation, we propose a novel deep neural network, termed the Guided Filter-Inspired Network (GFNet), which extends the concept of learnable guided filtering into the feature domain. Unlike SVLRM, GFNet integrates guided filtering principles into the hierarchical feature spaces of CNNs, enabling more robust detail preservation and enhanced noise suppression through guided filtering.
The proposed GFNet primarily comprises two key modules: the Image-Guided Fusion (ImGF) module and the Feature-Guided Fusion (FeGF) module. The ImGF module enhances detail preservation by fusing two source images derived from the low-light RAW image in the image domain. While inspired by SVLRM [16], this module adheres more strictly to the original principles of the guided filter [13]. The FeGF module extends the GF-like fusion mechanism to the feature domain, enabling more effective fusion of complementary information from features extracted from different sources. This extension results in improved noise removal and overall enhancement performance.
To summarize, our main contributions are as follows:
- From the perspective of decomposing and fusing contextual and textural information, we propose a novel approach for the LRIE task. The proposed method incorporates the guided filtering mechanism into the network structure, leading to a more reasonable and effective fusion for this task.
- To better preserve details, we propose an ImGF network module to fuse input source images in the image domain, emphasizing contextual and textural information related to the low-light RAW image, respectively. In addition, we introduce an FeGF module that extends the GF-like operation to the feature domain, allowing for a more effective fusion of multi-scale features extracted from input sources, thus leading to better noise reduction. Together, these modules promote more effective fusion by better utilizing complementary information from the source images.
- By combining the ImGF and FeGF modules, along with a multi-scale feature extraction module, we construct the GFNet for the LRIE task, achieving state-of-the-art performance on the SID benchmark.
2. Related Work
LIE for sRGB images. The LIE problem was originally raised for sRGB images. The early work mainly focused on value mapping, such as histogram equalization [17,18] and gamma correction [19,20]. Later, Retinex theory [21] became more popular and was adopted as the base model in many methods [1,2,3]. Recently, deep learning-based methods for this task have achieved superior performance [4,5,22,23,24,25,26,27].
LIE for RAW images. As mentioned in Introduction, since RAW images can provide more useful information for post-processing, the LRIE problem has attracted increased attention in recent years. The pioneering work was conducted by Chen et al. [7], who built the SID dataset, which consists of noisy low-light RAW images captured by DSLR in extremely low-light indoor/nighttime situations and their corresponding clean normal-light ones. Additionally, the authors proposed a deep ISP pipeline with U-Net [28] to enhance noisy low-light RAW images and directly output clean normal-light sRGB ones in an end-to-end manner. On the basis of the SID dataset and the proposed pipeline, multiple deep learning methods for LRIE have been developed and have achieved distinguished performance. For example, Gu et al. [8] adopted a top–down self-guidance architecture to better exploit multi-scale features; Xu et al. [9] proposed a frequency-based decomposition and enhancement structure for sufficient noise removal; Zhu et al. [11] generated multi-exposure frames from raw sensor images in order to fuse them for higher contrast and utilized a pre-trained edge detection network for better detail preservation. Jin et al. [29] proposed a decoupled feedback framework with RAW and sRGB feature interaction to address domain ambiguity and information loss. Huang et al. [30] applied HDR reconstruction with diverse CRFs to generate multi-exposure frames from a low-light RAW image and fused them to produce high-quality sRGB images. Wang et al. [31] proposed a multi-scale feature fusion network to to fully capture and enhance global details in low-light images. Among these methods, a major clue for network design is to fuse multi-modal source images generated from the original RAW image.
Guided Filter. The guided filter (GF) [13,14] is a computationally efficient edge-preserving filter that leverages a guidance image to maintain structural details during smoothing, widely used in denoising and image fusion. Subsequent extensions enhance its adaptability: Li et al. [32] proposed a weighted GF with a dynamic range-aware mechanism for improved detail preservation; Zhang et al. [33] designed the Rolling Guidance Filter to iteratively separate texture and structure; Ham et al. [34] introduced non-convex potentials to enhance noise compression while preserving edges. Recent efforts integrate GF with deep learning for enhanced flexibility. Lv et al. [23] developed a Fast GF enabling end-to-end CNN joint optimization, while Dong et al. [16] proposed a CNN-driven spatially variant linear model (SVLRM) to transfer structural guidance effectively. These methods excel in enhancement, denoising, and fusion tasks. However, existing approaches remain limited by partial integration of GF principles and image-domain restrictions, underscoring the need for frameworks unifying GF’s theoretical strengths with deep learning’s representational power.
3. Guided Filter-Inspired Network
In this section, we first provide a brief review of the guided filter (GF) [13,14] and then introduce the detailed modules of our proposed GF-inspired network for the low-light RAW image enhancement task.
3.1. Preliminary and Motivation
The guided filter (GF) [13] is a versatile image processing tool designed to filter an input image using a guidance image , effectively fusing two source images. It has demonstrated significant effectiveness in various tasks, including image enhancement [14], image fusion [35,36], and image segmentation [37,38,39]. The core principle of GF is based on the assumption that the filtering output is a linear transform of the guidance image within a local window centered at pixel k. Specifically, for each pixel j in the window , the output is expressed as follows:
where and are linear coefficients computed as follows:
Here, and are the mean and variance of in the window , is the mean of in , and denotes the covariance between and in . The final filtering output is obtained by averaging the contributions from all overlapping windows that contain pixel j:
where and are the averaged coefficients. In matrix form, the process is represented as follows:
where and are matrices composed of the averaged coefficients, and ∘ denotes element-wise multiplication. This formulation highlights the efficiency and simplicity of GF in achieving edge-preserving smoothing and image fusion.
The use of GF for LRIE is motivated by its inherent ability to preserve structural and textural information while effectively suppressing noise—key attributes for the task. As detailed in the Introduction, fusion-based methods have achieved remarkable performance in LRIE by leveraging complementary information from different sources while showing limitations in fully exploring the physical correlations between sources. Since self-generated source images typically share consistent spatial properties, GF offers a natural framework for explicitly modeling the local correlations between these source images.
Recent advances in deep learning have enabled learnable guided filtering networks [16,23], which incorporate trainable parameters to enhance flexibility and achieve improved performance in tasks like image restoration and fusion. However, these methods often partially integrate the theoretical principles of GF, such as oversimplifying the learning process of and and ignoring the correlation between these feature maps. In addition, they are restricted to the image domain, limiting their ability to fully exploit structural guidance across modalities. To address these limitations, our work adopts a learnable GF framework while explicitly unifying its edge-preserving mechanism in both image and feature domains, enabling better detail preservation and noise compression performance.
3.2. Overall Network Structure and Workflow
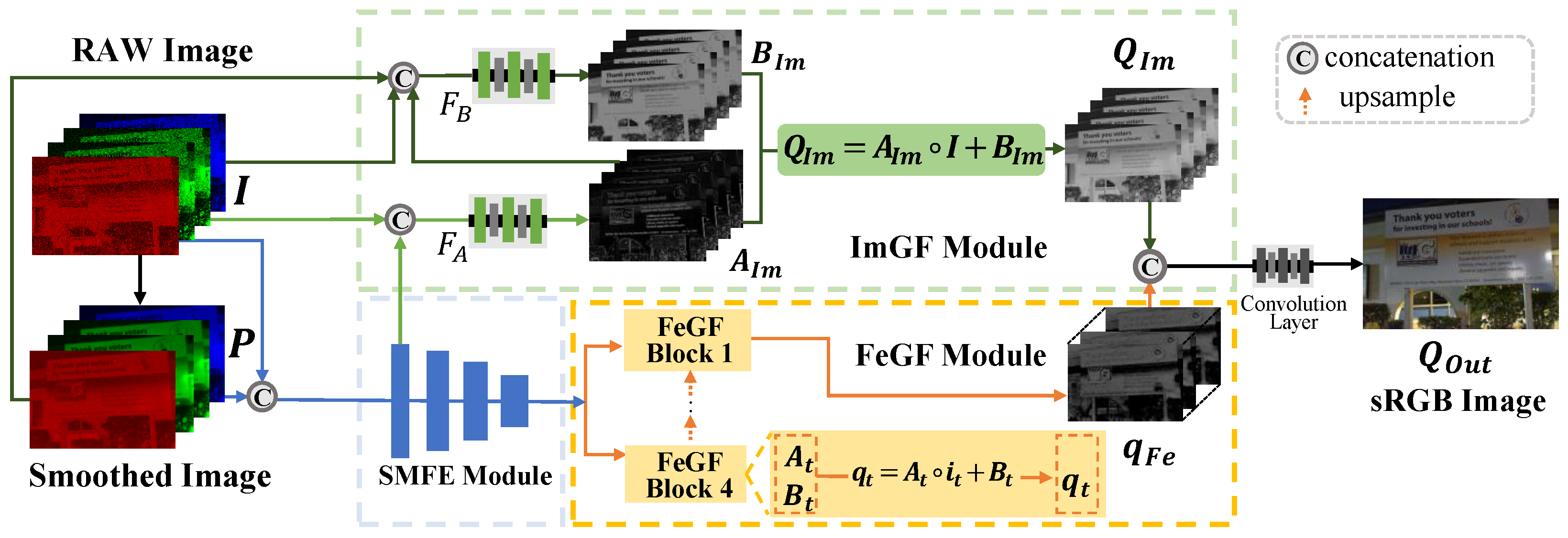
Our proposed GFNet comprises three key modules: a Semi-coupled Multi-scale Feature Extraction (SMFE) module for extracting multi-scale features, an Image-Guided Fusion (ImGF) module for image-domain fusion, and a Feature-Guided Fusion (FeGF) module for feature-domain fusion. In particular, the ImGF module is mainly designed to preserve image details better, while the FeGF module mainly contributes to better removing noise, as demonstrated in Section 4.2. The overall network structure is shown in Figure 1.
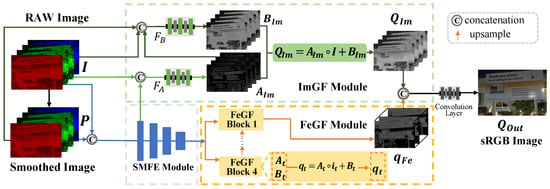
Figure 1.
The overview of GFNet. The SMFE, ImGF, and FeGF modules are introduced in Section 3.3.1, Section 3.3.2, and Section 3.3.3, respectively. and are convolutional layers to infer and , whose details are in Appendix A.
Fusion inputs. Building upon the property of GF, we anticipate that the guidance image will reflect more textual information, while the filtering input will provide more contextual information. Therefore, though noisy, we treat the low-light RAW image as the guidance, since it contains entire image details, as illustrated in Figure A1. As for the filtering input, we generate it by applying the bilateral filter (BF) [40] to the given RAW image, as BF provides a filtered result with reduced noise and enhanced contextual information. This choice is based on a balance between performance and simplicity, and more information and justification about it can be found in Section 4.2.
Workflow of GFNet. First, the low-light RAW image is packed to an N-channel tensor with a size of , and we also denote it as for convenience. Here, the number of input channels N is determined according to the pattern of the color filter array (CFA), e.g., for the Bayer pattern. The bilateral filtered result of is denoted as . Then, and are input to the SMFE module to jointly extract their multi-scale features. The extracted features are then passed to the ImGF and FeGF modules for subsequent processing. In the ImGF module, the extracted features, together with the input source images, are used to infer and for the guided fusion result in the image domain. In the FeGF module, the extracted multi-scale features are first fused by FeGF blocks in a GF-like way at each scale and then aggregated by upsample blocks to obtain the final feature , where C refers to the number of channels. Finally, and are concatenated and input to a small network with attention and convolutional layers (details are provided in Appendix A) to obtain the enhanced result with the sRGB format. The loss between and the ground truth is adopted for network training.
3.3. Architecture Details
In this subsection, following the workflow, we discuss the three key modules of GFNet: the SMFE module for multi-scale feature extraction, the ImGF module for image-domain fusion, and the FeGF module for feature-domain fusion. More detailed structures about GFNet are provided in Appendix A.
3.3.1. SMFE Module for Multi-Scale Feature Extraction
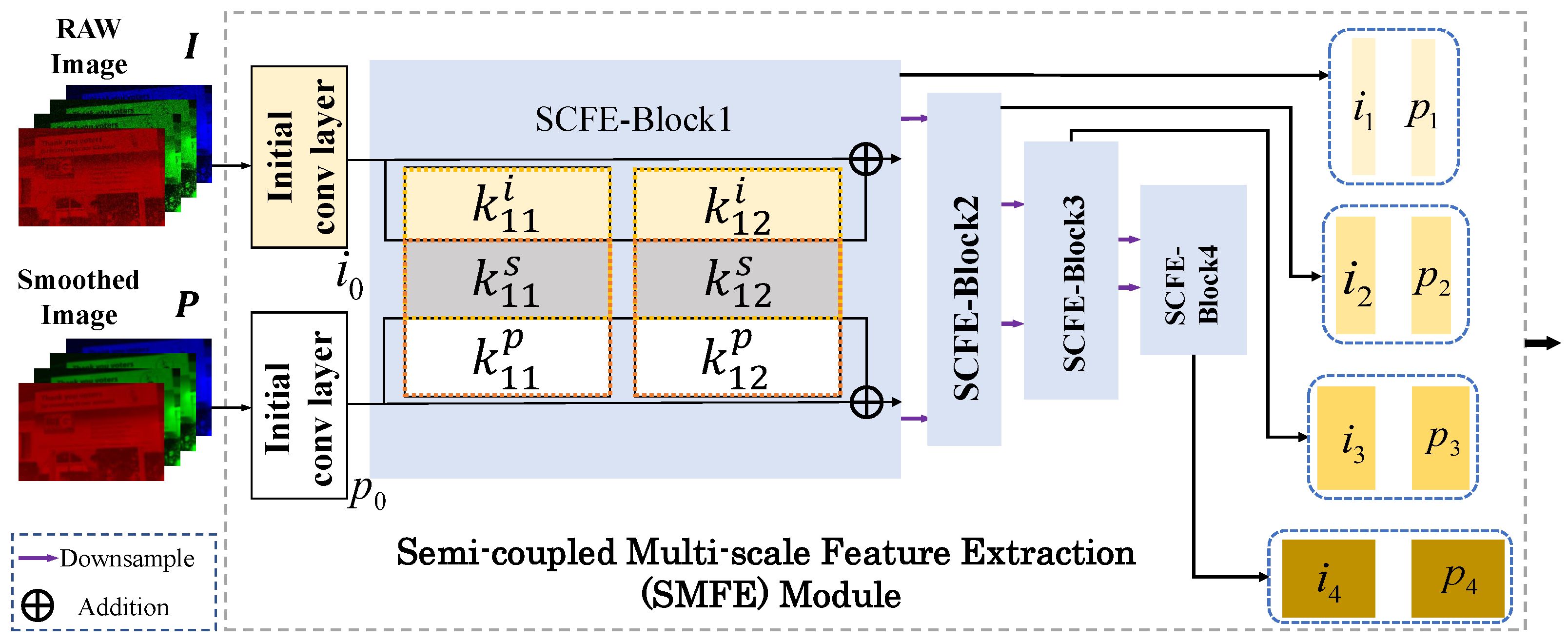
GFNet first needs to extract features from the packed RAW image and the bilateral filtered result . Rather than using two separate subnetworks, we introduce the semi-coupled feature extraction (SCFE) module [41] to jointly extract features from and , considering their high correlation, as illustrated in SCFE-Block 1 of Figure 2. With this design, the feature extractor can extract shared and private informative features effectively from input image pairs.
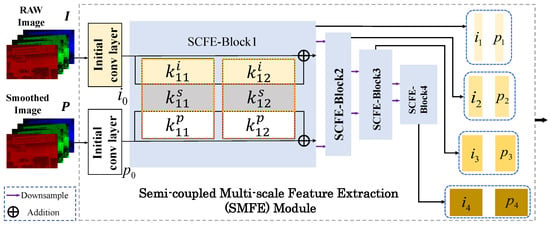
Figure 2.
The detailed architecture of the SMFE module. and refer to the private convolutional kernel to extract features of and in the 1st SCFE block, and refers to the shared convolutional kernel. Please refer to [41] for details of the SCFE block.
Also, considering the success of using multi-scale features, e.g., [28], we extend SCFE to a multi-scale version, called the SMFE module. The structure of the SMFE module is illustrated in Figure 2. Specifically, we cascade four SCFE blocks, each of which (except the first one) takes the downsampled output (obtained by max pooling and convolution operations, whose detailed architecture is presented in Appendix A) of the previous block as its input. Then, the output pairs of all SCFE blocks are retained as multi-scale features, which are denoted as . Each pair has half the spatial width and height, and twice the number of channels compared with .
3.3.2. ImGF Module for Image-Domain Fusion
The ImGF module is designed to fuse and in a guided filtering way for better detail preservation. Specifically, it produces the fusion result by
where and should be inferred using networks with the information of and . This is expected to retain the textual information of as much as possible according to the physical model of GF discussed in Section 3.1.
As discussed before, should characterize the intrinsic correlations between and , and thus it is natural to use the features extracted from them as the input of the inference network. In addition, according to Equation (2), the statistics of guidance , i.e., variance, is adopted to normalize A in GF, and therefore it is reasonable to also treat as input for inferring . Combining these two observations, we can use a small convolutional network to infer :
where is the inference network parameterized by , and denotes features output by the first SCFE block in the SMFE module. Note that we only use the features with the same spatial size as and here, which makes the concatenation operation simpler.
According to Equation (3), the calculation for B in GF is based on A, , and . Therefore, we can use and , as well as , as the input to the inference network of :
where is a small convolutional network parameterized by .
With the designing mechanism discussed above, the learnable guided fusion in the image domain can be achieved by ImGF.
3.3.3. FeGF Module for Feature-Domain Fusion
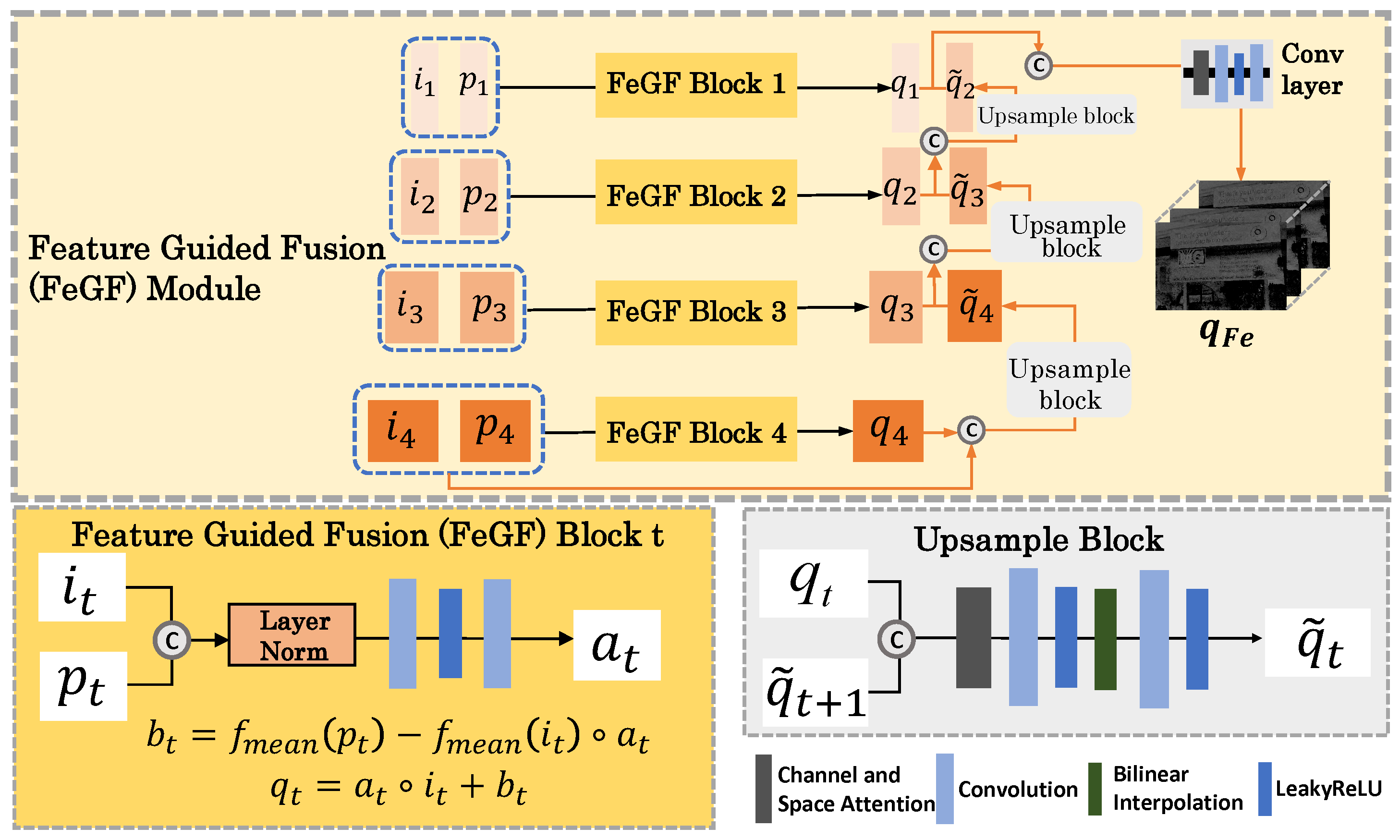
The FeGF module extends the GF-like operation to the feature domain, aiming at a more effective fusion of the features extracted from and by SMFE. Specifically, at each scale , and are fused according to
Here, is calculated by
where is a small convolutional network parameterized by , and refers to layer normalization. Here, we apply layer normalization before input to , because its importance in low-level vision has recently been emphasized by [42]. For , we directly calculate it using the following equation:
where denotes the mean filter. Note that we do not infer using a learnable network as is carried out in the image domain. Instead, we adopt the original guided filter formulation. This design is motivated by two considerations: (1) After processing through the SMFE module, the feature pair already contains sufficiently rich private and shared information jointly extracted from and , making further abstraction in the feature space less necessary. (2) The use of a fixed mean filter significantly reduces both the number of parameters and computational cost. Combining Equations (9)–(11), we construct one FeGF block at the feature scale, which is depicted in Figure 3.
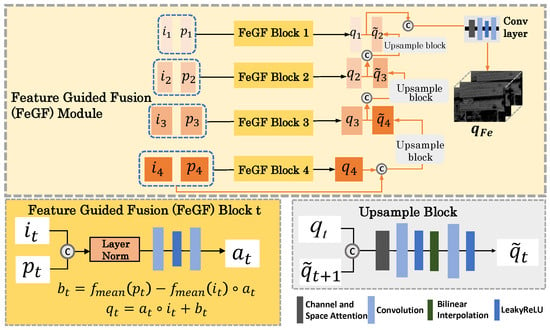
Figure 3.
The detailed architecture of the FeGF module.
After the scale-wise fused features, , are calculated, we aggregate them with upsampling and attention-based concatenation as follows:
Here, refers to the concatenation operation with a channel and space attention layer, is a small convolutional network, and denotes the upsample block illustrated in Figure 3. In addition, we define as the supplement to upsample . Then, the final output of the whole FeGF module is .
4. Experiments
In this section, we conduct experiments to verify the effectiveness of GFNet. We first evaluate the performance of GFNet on the LRIE task, with ablation studies on model ingredients. To further evaluate the generalization and transferability of our method, we also conduct tests on additional real-world scenarios.
4.1. Experiments on the LRIE Task
4.1.1. Settings
Datasets. We conduct experiments on the Low-Resolution Image Enhancement (LRIE) task using the Sony and Fujifilm datasets from the SID dataset [7], which comprises extremely low-light RAW images. The Sony dataset contains images captured by the Sony 7S II Bayer sensor with a resolution of , while the Fujifilm dataset includes images captured by the Fujifilm X-Trans sensor with a resolution of . Due to their distinct Color Filter Array (CFA) patterns, the raw Bayer images in the Sony dataset are packed into 4 channels, and the raw X-Trans images in the Fujifilm dataset are packed into 9 channels before being fed into the network. We adhere to the post-processing and dataset splitting protocols described in [7,11,12] for training and testing. For the Sony dataset, we use 185 paired images for training and 50 paired images for testing. For the Fujifilm dataset, we use 193 paired images for training and 41 paired images for testing. While we report results on both datasets, we place greater emphasis on the Sony dataset, as the Bayer pattern is more prevalent in consumer devices [11,12,43]. In addition, we calculated the illumination levels for the SID dataset test set with the mean grayscale value (normalized to a 0—1 scale) of the image. It spans a broad range of 0.0002 to 0.003, reflecting diverse low-light conditions.
Competing Methods. We compare our approach with eight representative methods, including the original guided filter (GF) [13,14], its trainable variant Fast Guided Filter (FGF) [44], and state-of-the-art methods for the LRIE task: SID [7], EEMEFN [11], SGN [8], RED [43], LRDE [9], and DBLE [12]. For the Sony dataset, SID [7], DBLE [12], RED [43], and EEMEFN [11] are evaluated using their provided pre-trained models, while the remaining methods are retrained under our experimental settings. For the Fujifilm dataset, only EEMEFN [11] is evaluated using its provided pre-trained model, with the others are retrained under our experimental settings.
Evaluation metrics. Four metrics, including PSNR, SSIM, LPIPS [45], and Delta E () [46], are adopted for quantitative evaluation. Among these metrics, PSNR and SSIM are widely used in image restoration tasks for performance evaluation; LPIPS is a deep feature-based metric aiming at assessing the perceptual quality of an image with a reference image; is a metric for color distortion. In addition, the number of model parameters and FLOPs on the Sony dataset is also reported.
Implementation details. All experiments are implemented by PyTorch 3.7 using an NVIDIA V100 GPU. For the SID dataset, including both the Sony and Fujifilm datasets, the initial learning rate of GFNet is set to and adjusted to after 4000 epochs. The batch size is set to 1 and the patch size is set to . For other deep learning methods, we retrain the models following the recommendations of the original work, or directly test using the author-released models.
4.1.2. Results
In this section, we present both qualitative and quantitative results of the compared methods on the benchmark datasets. To facilitate a comprehensive comparison, additional visual results are provided in Appendix B.
Results on the Sony dataset. The quantitative and visual results are shown in Table 1 and Figure 4, respectively. It can be seen from Table 1 that our GFNet outperforms other competing LRIE methods with respect to all the quantitative metrics. Specifically, our method outperforms all the competing methods in both PSNR and SSIM, indicating its superiority in restoring high-quality images. In addition, achieving the lowest LPIPS value indicates that our method can also produce images that are perceptually very close to the ground truth. Moreover, our GFNet also achieves the best performance with respect to the metric, a widely used metric to measure the color difference between two images, which evidently demonstrates its effectiveness in accurately recovering the color information against other methods. In addition to the superior average performance, the statistical indicators further demonstrate the robustness and consistency of our method. Specifically, the relatively narrow 95% confidence intervals (CIs) and small standard deviations (Stds) across all metrics indicate that GFNet produces stable results across different test samples. At the same time, in terms of model size, our method remains not too large, possessing only about one-ninth the number of parameters compared to EEMEFN, which ranks second on most evaluation metrics. In terms of computational cost and efficiency, measured by FLOPs and inference time, our method also achieves lower values than the state-of-the-art approaches DBLE [12] and EEMEFN [11], highlighting its favorable trade-off between performance and efficiency.

Table 1.
Quantitative results on Sony dataset with statistical metrics (95% confidence intervals). The best and second-best results are highlighted in bold and underlined, respectively.

Figure 4.
Visual results of all competing methods on the Sony dataset. The level of low-light illusion of the input image is 0.0008. The red box and magnified area in the picture mark the details that need attention. For detailed analysis, please refer to Section 4.1.2.
As for visual quality, the performance of our method is also promising. Specifically, as can be seen from Figure 4, most of the compared methods, including GF, FGF, SID, and DBLE, suffer from unexpected artifacts and uneven surfaces. While LRDE, SGN, and EEMEFN have smoother visuals, they are noticeably over-smoothed and lose important details. In comparison, our method provides a more faithful recovery with reference to the ground truth.
Results on the Fujifilm dataset. We present the quantitative and visual results in Table 2 and Figure 5, respectively. Compared with the Sony dataset, the Fujifilm one is more challenging due to its more complex sensor pattern. Nevertheless, our GFNet still shows its superiority. Specifically, GFNet outperforms the most competitive EEMEFN method in most adopted metrics, except for LPIPS. Considering the huge gap in the model size between the two methods, the effectiveness of the designing mechanism underlying our GFNet can be substantiated. Beyond the average values, the statistical indicators further confirm the robustness of GFNet.
Table 2.
Quantitative results on Fujifilm dataset with statistical metrics (95% confidence intervals). The best and second-best results are highlighted in bold and underlined, respectively.

Figure 5.
Visual results of all competing methods on the Fujifilm dataset. The level of low-light illusion of the input image is 0.0009. The red and green boxes and the magnified area in the picture mark the details that need attention. For detailed analysis, please refer to Section 4.1.2.
Visual results in Figure 5 demonstrate that GFNet can effectively restore both textural and contextual information from the degraded input. In contrast, other competing methods either suffer from color distortion or fail to recover details with less noise, or both. For example, SID, SGN, and EEMEFN suffer from severe color bias despite producing promising structural reconstruction. Interestingly, we find that FGF and our GFNet perform visually better in color recovery, indicating that the introduction of the GF model may help to alleviate the color distortion issue.
4.2. Ablation Study
In this subsection, we conduct experiments on the Sony dataset to verify the necessity and effectiveness of key modules in the proposed GFNet. The overall results are summarized in Table 3 and shown in Figure 6, whose full-size version is provided in Appendix B.
Table 3.
Quantitative results of ablation study on the Sony dataset.

Figure 6.
Visualization of ablation study on the Sony dataset. The order of subfigures follows Table 3.
Ablation on the inputs. As discussed in Section 3.2, applying BF is a simple yet effective strategy for generating the filtering input. Therefore, we conduct experiments here to verify its validity.
We first replace the bilateral filtered image with the original RAW input, which results in somewhat of a self-guided fusion procedure. Not surprisingly, the quantitative result in Line (a) of Table 3 is not as promising as that with BF, which is also confirmed by the visual result in Figure 6a. Then, we replace the bilateral filter with a Gaussian filter, which can also suppress noise to some degree. The obtained result, though better than that without filtering, is still significantly worse compared with that of using BF, as can be observed from Line (b) of Table 3 and Figure 6b. We also replace BF with a simple UNet. At the expense of extra parameters, the results in Line (c) of Table 3 and Figure 6c are very close to that of using BF. In summary, these results demonstrate the balance between the effectiveness and simplicity of BF in our framework.
Ablation on the fusion modules. We conduct experiments to verify the necessity of the two key modules, ImGF and FeGF, in our GFNet. These two modules are responsible for fusion in image and feature domains, respectively, and we show that both of them play important roles.
We first replace the ImGF and FeGF modules with ordinary convolutional layers with a similar number of parameters. The results are shown in (d) and (e) of Table 3 and Figure 6. Unsurprisingly, the performance in terms of all metrics becomes worse, as can be seen from Lines (d) and (e) of Table 3. In addition, visual artifacts can be clearly observed in Figure 6d,e, especially for replacing the FeGF module.
We then experiment by replacing both ImGF and FeGF modules with convolutional layers, and the results are shown in (e) of Table 3 and Figure 6. Together with the separate ablations, two observations can be summarized. First, the performance significantly becomes worse than that of GFNet and also worse than that of replacing any of the two modules. This suggests that both modules are important to the final results. Second, ImGF and FeGF play complementary roles in the whole framework. Specifically, the visual result in Figure 6f is smoother than that in Figure 6e, indicating the denoising ability of FeGF; on the other hand, the visual result in Figure 6f has sharper edges, compared with that in Figure 6e, suggesting the detail preservation ability of ImGF.
4.3. Test in Real-World Scenarios
For further comparison, we evaluate our model on real-world low-light images from [10], and the corresponding results are shown in Figure 7. The proposed method demonstrates robust enhancement performance. However, it still faces limitations under extremely challenging conditions and cross-sensor generalization challenges. For example, in the left input image, which was captured under very low illumination, the result exhibits local color biases and loss of details because of extremely heavy noise despite the overall enhancement quality.

Figure 7.
Test results of real-world scenarios.
5. Conclusions
In this paper, we propose a Guided Fusion Network (GFNet), inspired by guided filtering, for the low-light RAW image enhancement (LRIE) task. The proposed GFNet fuses contextual and textural information from RAW inputs through a dual-domain (image and feature) guided filtering mechanism, explicitly leveraging physical correlations such as exposure-dependent brightness complementarity, noise continuity, and spectral consistency across input sources. Extensive experiments validate the method’s superiority over state-of-the-art approaches, and extended applications in guided low-light enhancement tasks demonstrate its generalization potential for broader image fusion scenarios, such as guided depth map super-resolution [41], multi-focus image fusion [47], and 3D imaging [48]. However, as a supervised learning framework, GFNet requires paired training data with domain-specific ground truth, which may limit its adaptability to unseen sensor configurations or extremely low-light conditions beyond the training distribution. Future work could explore unsupervised or self-supervised paradigms to reduce dependence on meticulously aligned datasets while retaining physics-guided fusion principles. Additionally, current LRIE methods, including ours, are generally designed for specific sensor types and data formats (e.g., Bayer or xTrans). There is potential for further research to develop more generalizable approaches, or even an all-in-one method, capable of handling a wider range of sensor types and formats. Moreover, for practical deployment, especially on devices with limited computational resources, model efficiency becomes a crucial consideration. In such resource-constrained scenarios, the computational burden of GFNet can be alleviated through model compression techniques such as knowledge distillation or by reducing channel dimensions, enabling a better balance between performance and efficiency.
Author Contributions
Conceptualization, X.L. and Q.Z.; methodology, X.L. and Q.Z.; software, X.L.; validation, X.L.; formal analysis, X.L.; investigation, X.L.; writing—original draft preparation, X.L.; writing—review and editing, Q.Z.; visualization, X.L.; supervision, Q.Z.; project administration, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 12471485 and 62331028.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are publicly available data (sources stated in the citations). Please contact the corresponding author regarding data availability.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Guided Fusion Network
In this section, we will present additional details of our network in Figure A1.
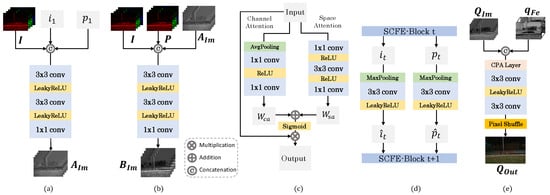
Figure A1.
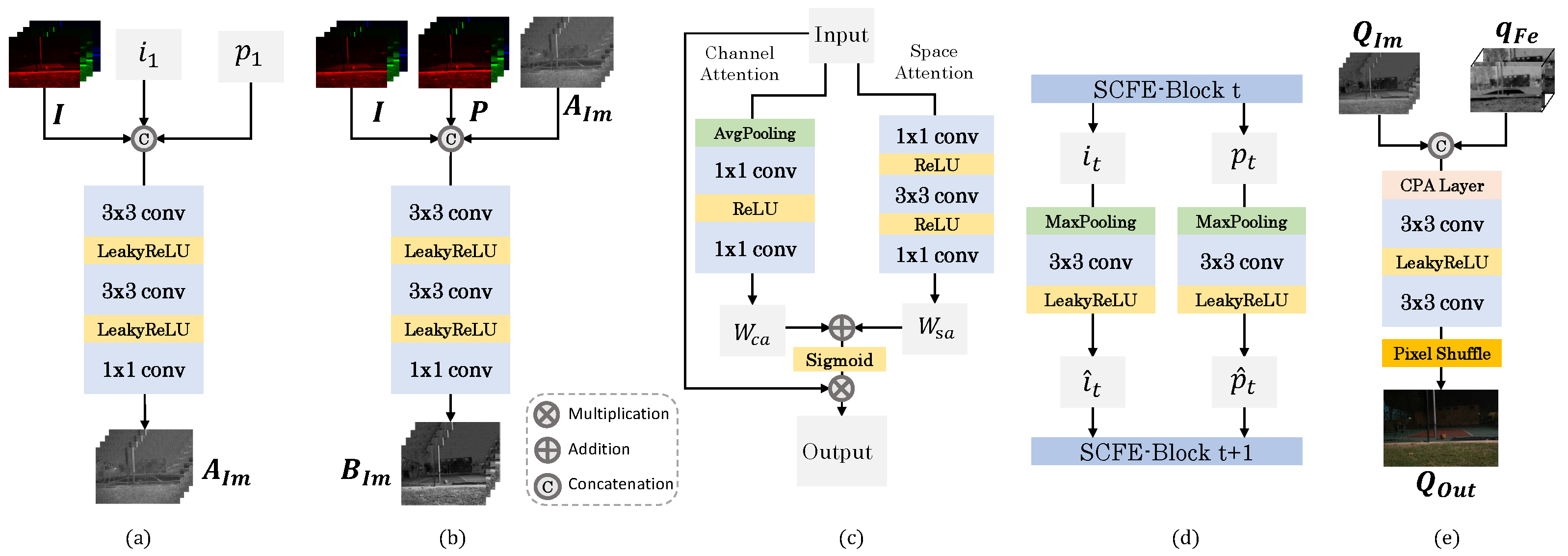
Detailed network blocks. (a) is the convolutional block to infer the map in the ImGF module, as described in Equation (7). and are the abstracted features from input and P; (b) is the convolutional block to infer the map in the ImGF module, as described in Equation (8); (c) is the detailed architecture of the channel and space attention (CPA) block, as shown in Equation (12), refers to the channel attention module, and refers to the spatial attention module; (d) is the downsampling and channel expansion operations between SCFE blocks in the SMFE module, as shown in Section 3.3.1; (e) is the convolution layer for the combination of and .
Figure A1.
Detailed network blocks. (a) is the convolutional block to infer the map in the ImGF module, as described in Equation (7). and are the abstracted features from input and P; (b) is the convolutional block to infer the map in the ImGF module, as described in Equation (8); (c) is the detailed architecture of the channel and space attention (CPA) block, as shown in Equation (12), refers to the channel attention module, and refers to the spatial attention module; (d) is the downsampling and channel expansion operations between SCFE blocks in the SMFE module, as shown in Section 3.3.1; (e) is the convolution layer for the combination of and .
Appendix B. Additional Evaluation Results
Complementary visualization results of Sony and Fujifilm datasets are shown in Figure A2 and Figure A3 and Figure A4 and Figure A5, respectively.

Figure A2.
Visual comparison of SOTA methods on the Sony Dataset.
Figure A2.
Visual comparison of SOTA methods on the Sony Dataset.


Figure A3.
Visual comparison of SOTA methods on the Sony dataset.
Figure A3.
Visual comparison of SOTA methods on the Sony dataset.


Figure A4.
Visual comparison of SOTA methods on the Fujifilm dataset.
Figure A4.
Visual comparison of SOTA methods on the Fujifilm dataset.


Figure A5.
Visual comparison of SOTA methods on the Fujifilm dataset.
Figure A5.
Visual comparison of SOTA methods on the Fujifilm dataset.

References
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A Weighted Variational Model for Simultaneous Reflectance and Illumination Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. LR3M: Robust Low-Light Enhancement via Low-Rank Regularized Retinex Model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Liu, X.; Xie, Q.; Zhao, Q.; Wang, H.; Meng, D. Low-light Image Enhancement by Retinex Based Algorithm Unrolling and Adjustment. arXiv 2022, arXiv:2202.05972. [Google Scholar] [CrossRef]
- Hamza, A.B.; Krim, H. A Variational Approach to Maximum a Posteriori Estimation for Image Denoising. In Proceedings of the Energy Minimization Methods in Computer Vision and Pattern Recognition, Sophia Antipolis, France, 3–5 September 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 19–34. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Gu, S.; Li, Y.; Gool, L.V.; Timofte, R. Self-guided network for fast image denoising. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2511–2520. [Google Scholar]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W. Learning to restore low-light images via decomposition-and-enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2281–2290. [Google Scholar]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A physics-based noise formation model for extreme low-light raw denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2758–2767. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13106–13113. [Google Scholar]
- Dong, X.; Xu, W.; Miao, Z.; Ma, L.; Zhang, C.; Yang, J.; Jin, Z.; Teoh, A.B.J.; Shen, J. Abandoning the Bayer-Filter To See in the Dark. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17431–17440. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- Dong, J.; Pan, J.; Ren, J.S.; Lin, L.; Tang, J.; Yang, M.H. Learning Spatially Variant Linear Representation Models for Joint Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8355–8370. [Google Scholar] [CrossRef] [PubMed]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef]
- Guan, X.; Jian, S.; Hongda, P.; Zhiguo, Z.; Haibin, G. An image enhancement method based on gamma correction. In Proceedings of the 2009 Second International Symposium on Computational Intelligence and Design, Changsha, China, 12–14 December 2009; IEEE: Piscataway, NJ, USA, 2009; Volume 1, pp. 60–63. [Google Scholar]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Lv, F.; Liu, B.; Lu, F. Fast enhancement for non-uniform illumination images using light-weight CNNs. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1450–1458. [Google Scholar]
- MacPhee, C.; Jalali, B. Vision enhancement via virtual diffraction and coherent detection (VEViD): A physics-inspired low-light enhancement algorithm. In Proceedings of the AI and Optical Data Sciences IV, San Francisco, CA, USA, 28 January–3 February 2023; SPIE: Bellingham, WA, USA, 2023; p. PC124380P. [Google Scholar]
- Yang, S.; Zhang, X.; Wang, Y.; Yu, J.; Wang, Y.; Zhang, J. DiffLLE: Diffusion-based Domain Calibration for Weak Supervised Low-light Image Enhancement. Int. J. Comput. Vis. 2025, 133, 2527–2546. [Google Scholar] [CrossRef]
- Sharif, S.M.A.; Myrzabekov, A.; Khudjaev, N.; Tsoy, R.; Kim, S.; Lee, J. Learning optimized low-light image enhancement for edge vision tasks. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 6373–6383. [Google Scholar]
- Bai, J.; Yin, Y.; He, Q.; Li, Y.; Zhang, X. Retinexmamba: Retinex-based mamba for low-light image enhancement. arXiv 2024, arXiv:2405.03349. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Jin, X.; Han, L.H.; Li, Z.; Guo, C.L.; Chai, Z.; Li, C. DNF: Decouple and Feedback Network for Seeing in the Dark. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18135–18144. [Google Scholar]
- Huang, Y.; Zhu, X.; Yuan, F.; Shi, J.; Kintak, U.; Fu, J.; Peng, Y.; Deng, C. A two-stage HDR reconstruction pipeline for extreme dark-light RGGB images. Sci. Rep. 2025, 15, 2847. [Google Scholar] [CrossRef]
- Wang, W.; Song, B. Multi-Scale Feature Fusion for Low-light Image Enhancement in the RAW Domain. In Proceedings of the 2024 10th International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2024; pp. 615–619. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Zhu, Z.; Yao, W.; Wu, S. Weighted guided image filtering. IEEE Trans. Image Process. 2014, 24, 120–129. [Google Scholar] [PubMed]
- Zhang, Q.; Shen, X.; Xu, L.; Jia, J. Rolling guidance filter. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 815–830. [Google Scholar]
- Ham, B.; Cho, M.; Ponce, J. Robust guided image filtering using nonconvex potentials. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1576–1590. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image Fusion With Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Kollu, V.; Gang, X.; Dhuli, R. Fusion of MRI and CT images using guided image filter and image statistics. Int. J. Imaging Syst. Technol. 2017, 27, 227–237. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, W.; Zhang, W.; Peng, J.; Fan, J. Guided Filter Network for Semantic Image Segmentation. IEEE Trans. Image Process. 2022, 31, 2695–2709. [Google Scholar] [CrossRef]
- Abid, M.; Shahid, M. Tumor Detection in MRI Data using Deep Learning Techniques for Image Classification and Semantic Segmentation. Sustain. Mach. Intell. J. 2024, 9, 1–13. [Google Scholar] [CrossRef]
- Ullah, W.; Naveed, H.; Ali, S. Deep Learning for Precise MRI Segmentation of Lower-Grade Gliomas. Sustain. Mach. Intell. J. 2025, 10, 23–36. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 839–846. [Google Scholar]
- Zhao, Z.; Zhang, J.; Xu, S.; Lin, Z.; Pfister, H. Discrete cosine transform network for guided depth map super-resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5697–5707. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. arXiv 2022, arXiv:2204.04676. [Google Scholar]
- Lamba, M.; Mitra, K. Restoring extremely dark images in real time. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3487–3497. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1838–1847. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Backhaus, W.G.; Kliegl, R.; Werner, J.S. Color Vision: Perspectives from Different Disciplines; Walter de Gruyter: Berlin, Germany, 2011. [Google Scholar]
- Zhang, X. Deep learning-based multi-focus image fusion: A survey and a comparative study. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4819–4838. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Chen, W.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Single-shot super-resolved fringe projection profilometry (SSSR-FPP): 100,000 frames-per-second 3D imaging with deep learning. Light. Sci. Appl. 2025, 14, 70. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).