1. Introduction
The essential part of modern bioinformatics is related to the quantitative analysis and visualization of quasi-random symbolic series obtained in the course of the DNA-sequencing procedure [
1,
2]. The explosive development of bioinformatics, which can perform essential simulations, in recent decades has given rise to an abundance of various approaches to the representation and analysis of linear nucleotide-based sequences in 2D, 3D, and higher-order spaces. The general idea of such representations is based on the creation of four-point bases and the step-by-step recurrent transformation of the analyzed linear symbolic (A, C, T, and G) sequence into an ensemble of mapping points in a higher-order space. Each point of the created basis is associated with one of the four basic nucleotides (adenine (A), cytosine (C), thymine (T), and guanine (G)).
A number of approaches to the visualization of DNA-associated (A, C, T, and G) sequences developed in the last two decades involve a recurrent synthesis of the representing polylines in two or three dimensions, such as the H-line [
3], C-line [
4,
5], Z-line [
6], RY-, MR-, and WS-lines [
7], etc. In these procedures, an appropriate choice of the basic configuration (namely, the establishment of certain associations between the base nucleotides and opposite points of the basis) makes it possible to additionally reveal some biochemical features of the analyzed DNA fragments. These features are the predominance of the keto groups over amino groups (or vice versa, the RY basis), purines over pyrimidines (or vice versa, the MK basis), and strong hydrogen bonds over weak bonds (or vice versa, the WS basis) in the sequences. They can be identified by analyzing the polyline projections onto the corresponding coordinate axes of the chosen basis [
7].
An alternative approach to the polyline representation of nucleotide sequences, to a certain extent, is their two-dimensional display as dot sets on a plane region (usually square in shape). The most popular method using this dot-based displaying technique is the chaos game representation (CGR), introduced into bioinformatics by H.J. Jeffrey in 1990 [
8]. Since that time, the CGR technique has been successfully used to analyze and visualize various nucleotide sequences many times (see, e.g., [
9,
10,
11,
12,
13]). It should be noted that the general problem when using polyline and dot-based displaying techniques (including the CGR technique) for nucleotide sequences is the low level of their representations of relatively short fragments of nucleotide sequences (those with several hundred to several thousand bases). In this case, the emerging relatively low volume or surface density of the displayed line segments or dots does not allow, in particular, the confident identification of the presence of fractal properties in the displayed nucleotide structures, which is associated with existence of large-scale correlations of base positions in the sequences. From the point of view of the convenience of analyzing the resulting representations with relatively small lengths of displayed sequences, it is proper to fragment the display space onto a set of voxels and count the number of display elements in each voxel. In the case of chaos game representation, this concept is implemented via the so-called frequency chaos game representation technique (FCGR) [
14,
15,
16,
17].
As a specific approach to the two-dimensional representation of nucleotide sequences of a finite length, the polarization imaging technique [
18,
19] should also be noted. This technique is based on modeling the reading of a DNA-associated two-dimensional phase object (quasi-random phase screen) using a coherent light beam with a given polarization state and the subsequent analysis of the local polarization structure of the readout beam in the far diffraction zone. The DNA-associated quasi-random phase screen is a 2N × 2N matrix, where N
2 is the number of nucleotide triplets in the displayed fragment of the nucleotide sequence. Accordingly, each triplet is associated with a certain 2 × 2 submatrix in the total 2N × 2N matrix, and positions of the submatrix elements are associated with four basic nucleotides (e.g., the first element of the first row of a submatrix is associated with adenine and the second one with cytosine, the first element of the second row corresponds to thymine, and the last element of the submatrix is associated with guanine). The submatrix elements can take one of four values (0, 1, 2, or 3), with the value determined by the content of the corresponding nucleotide in the triplet coded by the submatrix; accordingly, the sum of all elements of any submatrix is always equal to 3. The values of the elements determine the phase modulation depth for the x- and y-polarized components of the readout coherent beam. In accordance with the phase modulation scheme proposed in [
19], the values of the phase shifts for orthogonally polarized components of the readout beam passing through various elements of the 2N × 2N phase screen can vary in the range of 0 to 3π/2, with a step of π/2. The polarization states with the phase shifts of 0 and 2π are identical. This type of phase modulation leads to a high probability of the occurrence of close-to-circular local polarization states of the readout light field in the far diffraction zone. In turn, recovery of the spatial distributions of these extreme states, which exceed the specified level of discrimination, makes it possible to create a 2D binary structure, which in fact is a unique identifier (“fingerprint”) of the analyzed nucleotide sequence. Such uniqueness follows from a rather rigid condition for the formation of a local circular polarization state in the far diffraction zone (equality of amplitudes of the superposing x- and y-polarized components of the diffracted readout beam and the phase shift between them, exactly equal to π/2 or 3π/2). In particular, a pilot verification of this methodology using model data and nucleotide sequences for three strains of the SARS-CoV-2 virus showed the high sensitivity of the synthesized binary maps to single-nucleotide substitutions in the analyzed sequences relative to the reference ones [
19]. It should be noted that synthesis of 2D binary maps of extreme polarization states, in contrast to a vast majority of popular representation techniques, directly leads to the formation of identification matrices of 2N × 2N size, and does not require the additional fragmentation of the representation space and the counting of the imaging elements in individual voxels. This is a direct consequence of the inherent properties of the discrete Fourier transform underlying the polarization mapping technique.
From a biological point of view, the described computational methods may be applicable in the analysis of and discrimination between different strains of microorganisms that vary in terms of the number of substituted nucleotides, which circulate in certain populations. This task is of great importance for disease outbreak handling, for example, in farm animals, where the rapid differentiation of the circulating strains in vaccinated herds is critical at the beginning of the outbreak, especially in the case of attenuated vaccines, where a live pathogen replicates, stimulating the immune system of the host. For this reason, a genetic variant of “differentiate immunized from vaccinated animals” (DIVA) strategy may be employed [
20]. Initially, the DIVA strategy proposed by J.T. van Oirschot in the early 1990s [
21] implied the use of marker vaccines based on deletion mutants of wild-type microorganisms depleted of some immunogenic components and the subsequent implementation of accompanying serological tests to determine the antibody response against the antigens lacking in the vaccine strain. This approach enables a differentiation between the vaccine-induced and post-infection immune responses [
22]. However, the classical DIVA strategy requires time for antibody accumulation, and is not very useful when the elicited specific humoral immune response is not pronounced. In contrast, DIVA PCR-based tests detect genetic differences between the vaccine and wild type field strains.
Listeriosis is a severe infectious disease of humans and wild and farm animals with a high mortality rate of 30–50%, depending on the clinical form of the disease. The major causative agent is
Listeria monocytogenes, a facultative intracellular bacterium capable of switching from a saprophyte to a parasitic lifestyle.
L. monocytogenes is widespread in different ecological niches, and can successfully replicate in food products, which are the main source of infection for humans. Large foodborne outbreaks of listeriosis in humans often have parallels to outbreaks in animals [
23]. Therefore, control of the infection in herds is one of the ways to control the human infection.
A number of vaccines against listeriosis are being developed for the prevention of the disease. Among them, live attenuated vaccines are considered as more potent because of they mimic natural infection and elicit the cell-mediated protective immune response needed against intracellular pathogens [
24], while inactivated vaccines require adjuvants or special processing to induce a cellular response [
25,
26,
27,
28]. Natural or artificial attenuation is commonly due to the lack of mutations or mutations in the target genes coding the pathogen’s virulence factors. Listeriolysin (LLO), a pore-forming toxin, is a major virulence determinant of
Listeria which plays a crucial role in the intracellular lifestyle of pathogenic
Listeria spp. LLO enables bacteria to escape from phagosomes and participates in cell-to-cell spread [
29,
30]. Substitution mutations in the structural
hly gene coding LLO lead to a significant reduction in the virulence of mutated strains, providing a basis for the development of attenuated listeria vaccines [
31]. LLO is also a highly immunogenic molecule, and induces innate and adaptive immune responses in different animal models and in humans [
29,
32,
33]. LLO acts as a vaccine target, and immunization with a non-pore-forming LLO variant supplemented with the choler toxin as an adjuvant elicits protective T-cellular and humoral response in mice [
34].
The purpose of this work is a comparative analysis of two approaches to the two-dimensional binary mapping of nucleotide sequences in terms of a unique correspondence between the structure of the synthesized maps and structure of the sequences (testing the “fingerprinting efficiency”). The first approach is based on the consideration of 2D binary maps of extreme local polarization states. Accordingly, as the impact parameters, the discrimination threshold of local polarization states and the transformation scale of the DNA-associated phase screen into the analyzed polarization-dependent diffraction field are considered. The second approach is based on the use of a FCGR technique with assessment of the affect in the choice of RY-, MK- and WS-basis and degree of fragmentation (the voxel size) on the “fingerprinting efficiency”). Symbol series corresponding to nucleotide sequences of the hly gene of the vaccine and wild type L. monocytogenes strains differing in the number of mutationally substituted nucleotides were used as the model objects of analysis. In order to analyze the efficiency of the proposed approaches for nucleotide sequences with small numbers of substitutions, the modification of the original target sequences of the L. monocytogenes strains was carried out. This modification was performed using the procedure of the reverse translation of protein sequences, and the artificially generated sequences with reduced numbers of substitutions were also used for the analysis.
2. Materials and Methods
2.1. Analyzed Nucleotide Sequences
Nucleotide sequences of the hly gene encoded LLO in the L. monocytogenes strains, which were isolated from farm animals with the complete whole genome status and were accessed from the NCBI GenBank and used for the polarization- and FCGR-based binary mapping (“fingerprinting”). The list of the L. monocytogenes strains included the following:
As was shown in the previous study [
19], the polarization-based binary mapping approach displays a high sensitivity to a small number of substitutions (less than 10) in the structure of a pair of nucleotide sequences. The sensitivity decreases with an increasing number of differences. Thus, two sets of model data were used in this work to consider the fingerprinting techniques in a wide range (from ten to several tens) of substitutions. The first dataset (dataset # 1) is referenced above. The second model set with reduced numbers of substitutions includes the artificial sequences generated on the base of the first set using the EMBOSS Backtranseq tool (
https://www.ebi.ac.uk/Tools/st/emboss_backtranseq/ (accessed on 25 September 2023)). The generation procedure is based on reverse translation of protein sequences as the input data, and results in the artificial nucleic acid sequences, which represent the most likely non-degenerate coding sequences. Thus, the “simplistic”
hly gene sequences (the dataset # 2) with a reduced number of substitutions regarding the reference AUF sequence # 1 (6–11 SNPs vs. 44–56 SNPs in the case of dataset # 1) were obtained. Note that the artificial sequences are one triplet shorter than the original sequences (1587 vs. 1590 base nucleotides) due to loss of the terminate codon. A comparison of the used datasets # 1 and # 2 is given in the
Supplementary Materials, including the multiple sequence alignments of the original and artificial sequences (see
Figure S1a,b and Tables S1 and S2).
With regard to polarization-based binary mapping for all eight model strains from the datasets ## 1 and 2, the relevant sequence fragments containing 1587 base nucleotides (with 529 triplets) were carefully considered. A preliminary frequency analysis of the combinations of basic nucleotides (adenine (A), thymine (T), cytosine (C), and guanine (G)) in the arbitrarily chosen triplets showed the significant inhomogeneity of the relative frequencies of their combinations. For example,
Table 1 displays relative frequencies for the AUF artificial reference sequence from the dataset # 2. Note that the “n elements” designation determines the content of a given nucleotide in a triplet; accordingly, the last column in
Table 1 gives the probabilities of finding triplets such as AAA, TTT, CCC, and GGG (these probabilities occur zero-equal for the finite-length sequence, except for the case of CCC).
Table 2 displays the differences in the triplets between the A, C, T, and G sequences for dataset # 2; it can be seen that the maximal difference in the triplets occurs for the strains 1 and 2, and 8.
2.2. Methodology of Polarization-Based Encoding and Recovery of the Binary Maps of Extreme Polarization States
In accordance with [
19], the following stages of polarization-based encoding and mapping can be outlined:
- -
Synthesis of the virtual 2N × 2N DNA-associated quasi-random phase screen;
- -
Simulation of the polarization-dependent far-zone diffraction pattern formation due to reading out the synthesized phase screen by a coherent collimated beam with a given polarization state;
- -
Selection of close-to-circular local polarization states in the simulated diffraction pattern (the latter procedure is carried out using the discrimination procedure for a spatial distribution of the fourth component of Stokes vector).
Each triplet in the displayed DNA-associated nucleotide sequence is encoded by a four-element squared matrix
(submatrix) in accordance with the following rule:
(note that establishment of the correspondences between the submatrix elements and basic nucleotides is arbitrary). The value of the corresponding element determines the content of the given nucleotide in the triplet. For the above correspondence rule, the encoding examples are as follows:
After representation of the nucleotide triplets by a set of submatrices, the main phase-modulating matrix (the virtual phase screen) is synthesized through a line-by-line assembling of the submatrices in accordance with the order of triplets in the analyzed sequence. The size of the analyzed sequence fragment must be equal to .
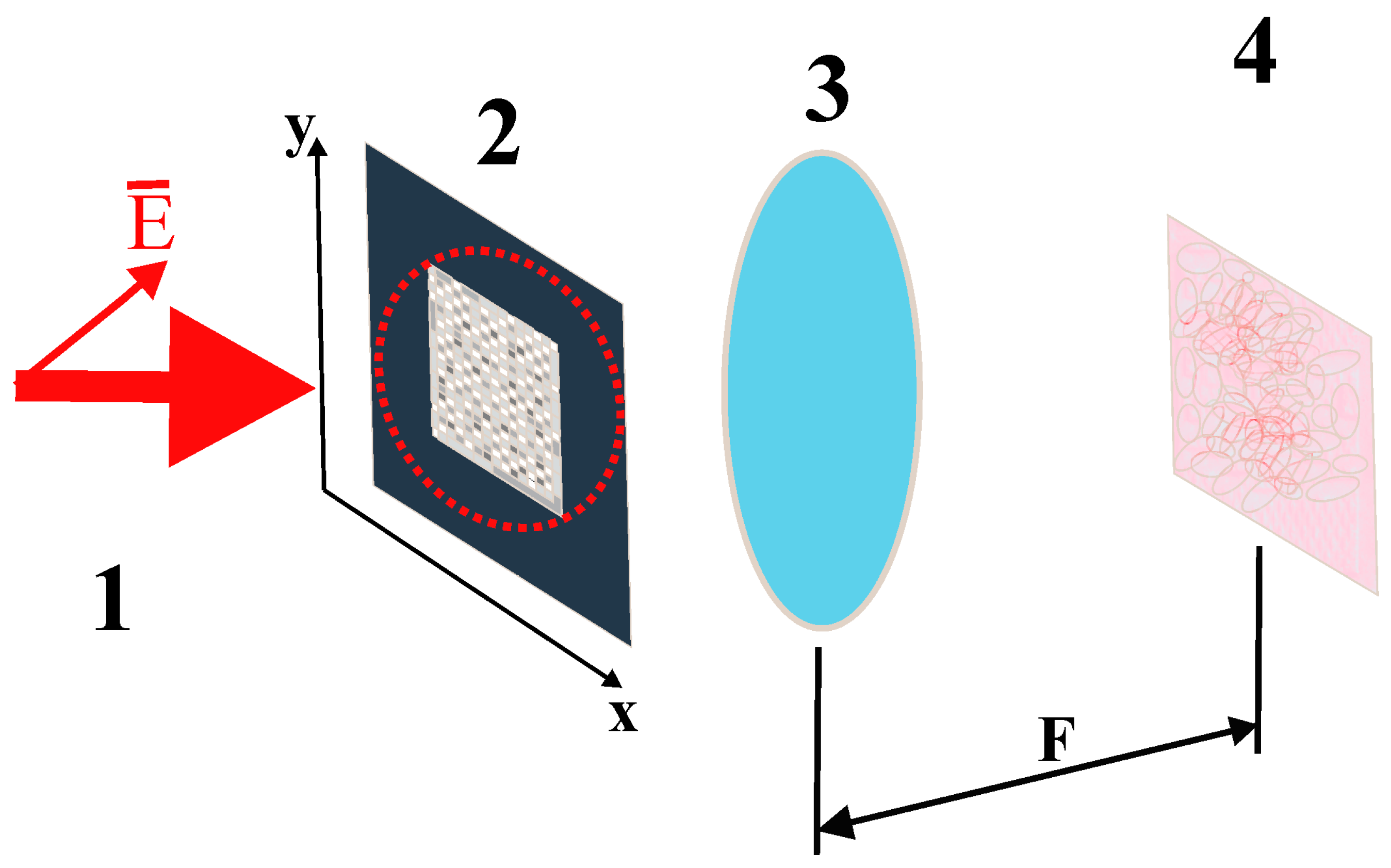
Let us assume that the synthesized phase screen is read by a collimated linearly polarized light beam, with the polarization plane forming a 45° angle with the sides of the screen (
Figure 1).
The phase modulation of the x- and y-polarized beam components is carried out in accordance with the following rule:
The amplitude distribution of orthogonally polarized components of the diffracted readout beam in the far diffraction zone can be described by the following expression (see, e.g., [
42]):
where
is the imaginary unit and
is the scale factor that determines the size of the analyzed area within the far diffraction zone. Indices
determine positions of the displayed elements of the phase screen, and indices
correspond to positions of the analyzed points in the far diffraction zone. Expression (3) essentially describes the two-dimensional discrete Fourier transform of the transmission function of the synthesized phase screen. In the case of instrumental implementation of the considered technique, the far diffraction zone is realized in the rear focal plane of the Fourier transforming lens (see
Figure 1). The scale factor
is determined by the following relationship between the focal length
of the lens, the wavelength
of the readout beam, the linear size
of the phase screen elements, and the pixel size
in the readout plane:
Increasing the scale factor results in a finer-scale (“panoramic”) display of the diffraction pattern from the DNA-associated phase screen in the far diffraction zone. Note that in the case of modeling the diffraction mapping using a two-dimensional discrete Fourier transform (3), the maximum allowable value of the scale factor is 0.5. Large values lead to the manifestation of the aliasing effect [
43] in the synthesized diffraction patterns.
In the framework of the considered technique, the polarization structure of the synthesized diffraction patterns can be analyzed and displayed in terms of the local values of the Stokes vector elements [
44]. These local values are introduced as
The local value of the first element defines the total intensity of the diffraction pattern at the (k, m) point; characterizes the difference in intensities of the x- and y-components of diffracted light for this point. The third element is similar to the second element, but it is introduced for the coordinate system rotated at the angle of 45° with respect to the basic (x, y) coordinate system. Finally, the fourth element defines the intensity difference for the right- and left-circular polarized components of the diffracted light at the chosen point.
For further analysis, it is convenient to use the normalized local values based on the fundamental relation for the Stokes vector elements of the polarized light Note that the normalized local values vary from −1 to 1. The proximity of the values to ±1 indicates the occurrence of an extreme polarization state at a given point, which is characterized by significant dominance of either a linear or a circular component.
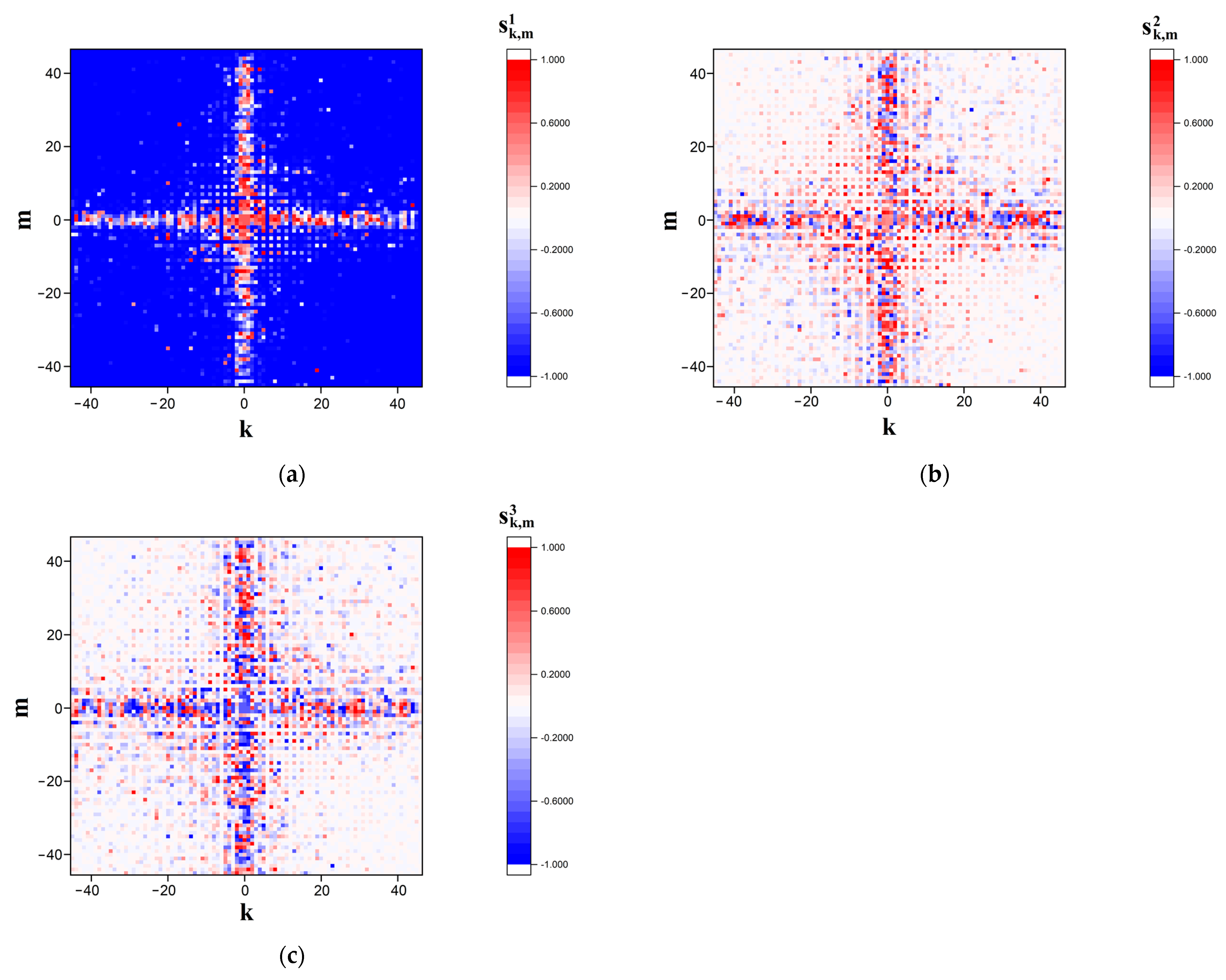
Figure 2 and
Figure 3 display the examples of the modeled
distributions in the far diffraction zone in the case of polarization-based representation of the symbolic sequence corresponding to sequence # 1 from dataset # 2.
Figure 2 corresponds to the case of the finest-scale (panoramic mapping,
= 0.5) representation, whereas
Figure 3 displays sufficiently more detailed images of modeled distributions in the near-axis area of the diffraction zone (detailed mapping,
= 0.1).
Within the framework of the considered polarization encoding of nucleotide sequences, fingerprinting of a given sequence can be carried out by synthesizing a binary map of the local states of a close-to-circular polarization. For a given cutoff threshold
, the synthesis algorithm has the following form:
where
is the weight of the (
) pixel in the synthesized fingerprinting map; case
in the first formula corresponds to the mapping of extreme states close to the right-circular polarization, and the opposite case allows the selection of extreme local states with
values approaching the left circular state.
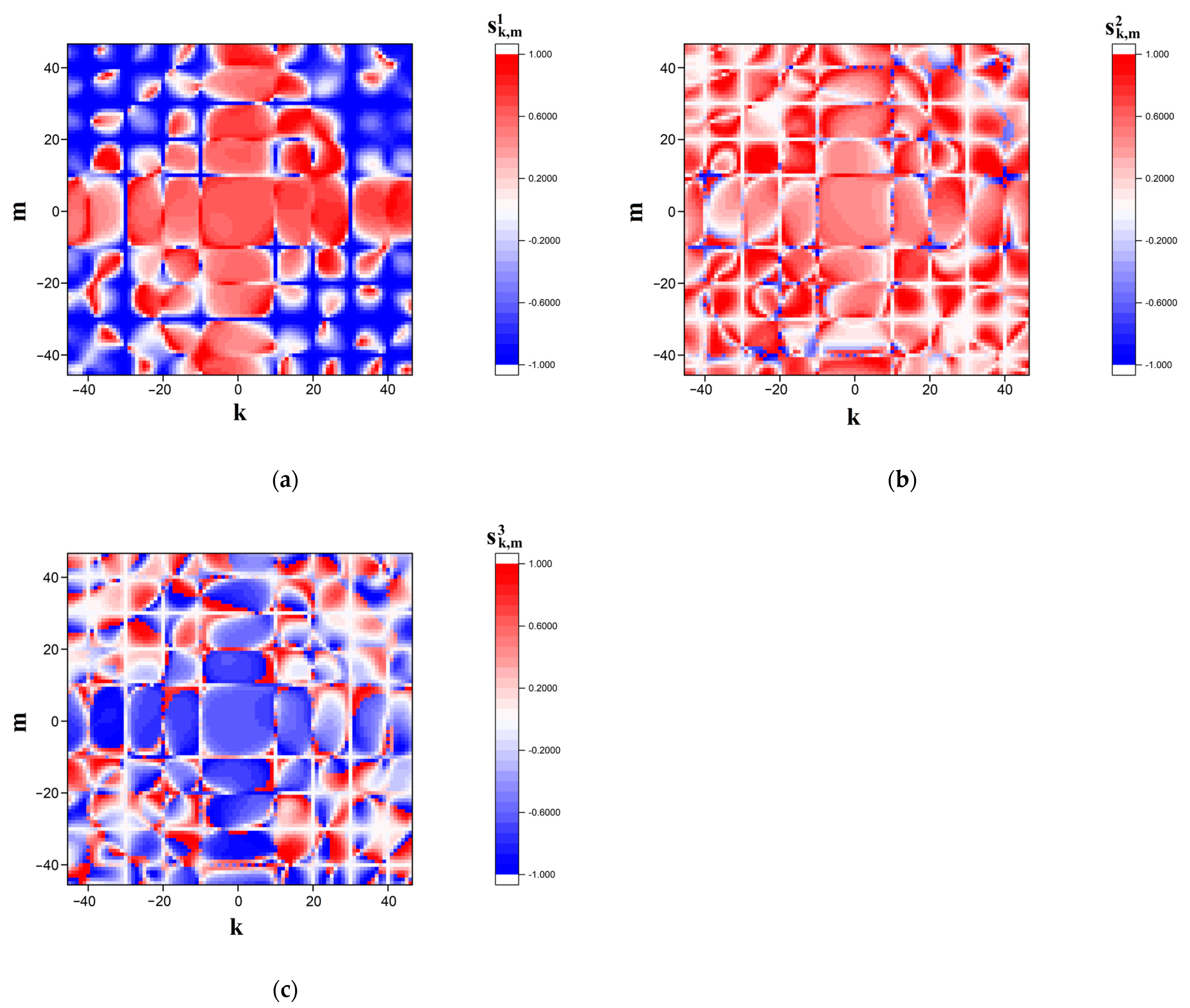
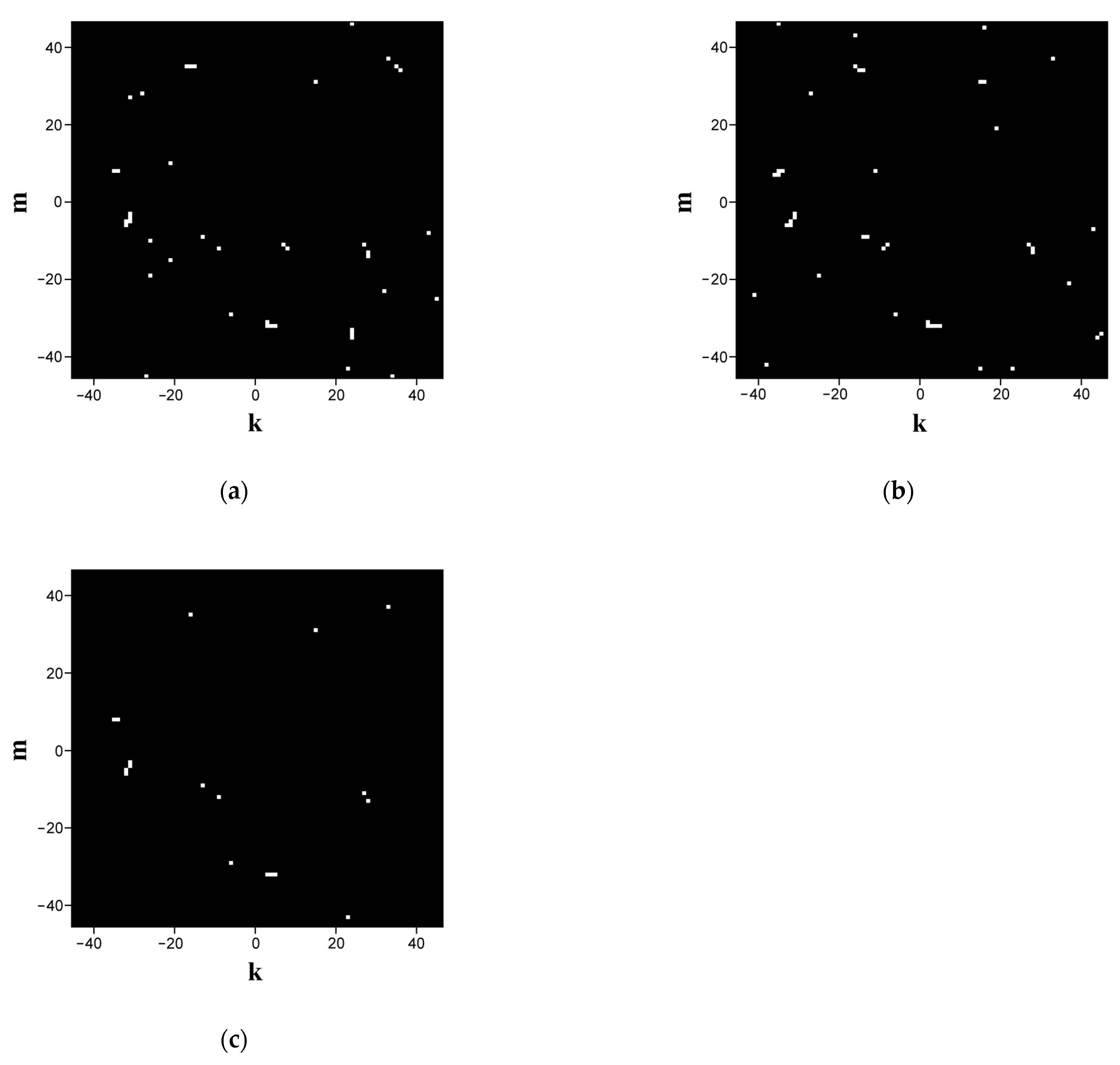
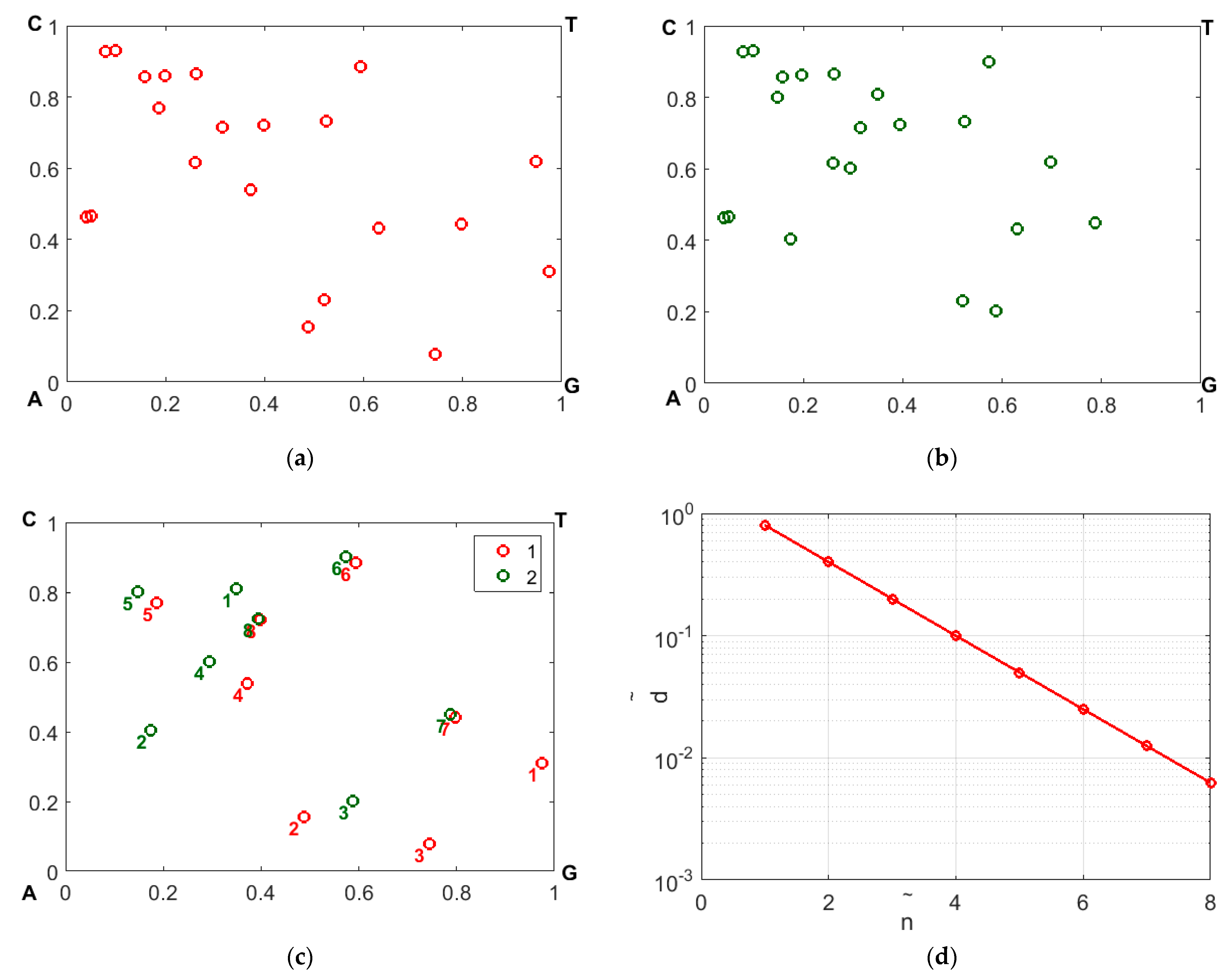
Figure 4a,b displays the fingerprints synthesized in this way for sequences ## 1 and 2 from dataset # 2 with a cutoff level of −0.98 (i.e., close-to-left circular states are displayed). The scale factor
is equal to 0.1 (the detailed imaging). High specificity of the synthesized binary maps is confirmed through their pixel-by-pixel logical multiplication (
Figure 4c); note that when the number of unit pixels in the images a and b is 42, the number of the matching items is 18, indicating an appropriately high level of specificity. A more detailed analysis of the quantitative indicators of the specificity is presented in
Section 3.
2.3. CGR-Based Fingerprinting of Nucleotide Sequences: Basic Principles
Taking into account CGR mapping methodology (see, e.g., [
8]), we can write the following set of expressions for the x- and y-coordinates of the imaging points corresponding to certain nucleotides in the displayed sequence. At the first step,
where
denote the x- and y-coordinates of the base node, corresponding to the first nucleotide in the sequence. The upper index denotes the position of the displayed nucleotide in the sequence. Positions of the base nodes (“nucleotide vertices”, [
8]) are given by the coordinate pairs
,
,
, and
. Regardless of the used basis (RY, MK, or WS), the A-node is always at the position
. This offset of the starting point makes it possible to obtain more compact recurrence relations for the coordinates of the imaging points. For example, when using the WS base for the CGR mapping, the node coordinates are as follows:
. The RY base is characterized by the following associations:
, and the MK base corresponds to
.
At the second step of the CGR map synthesis,
Accordingly, at the n-the step we obtain
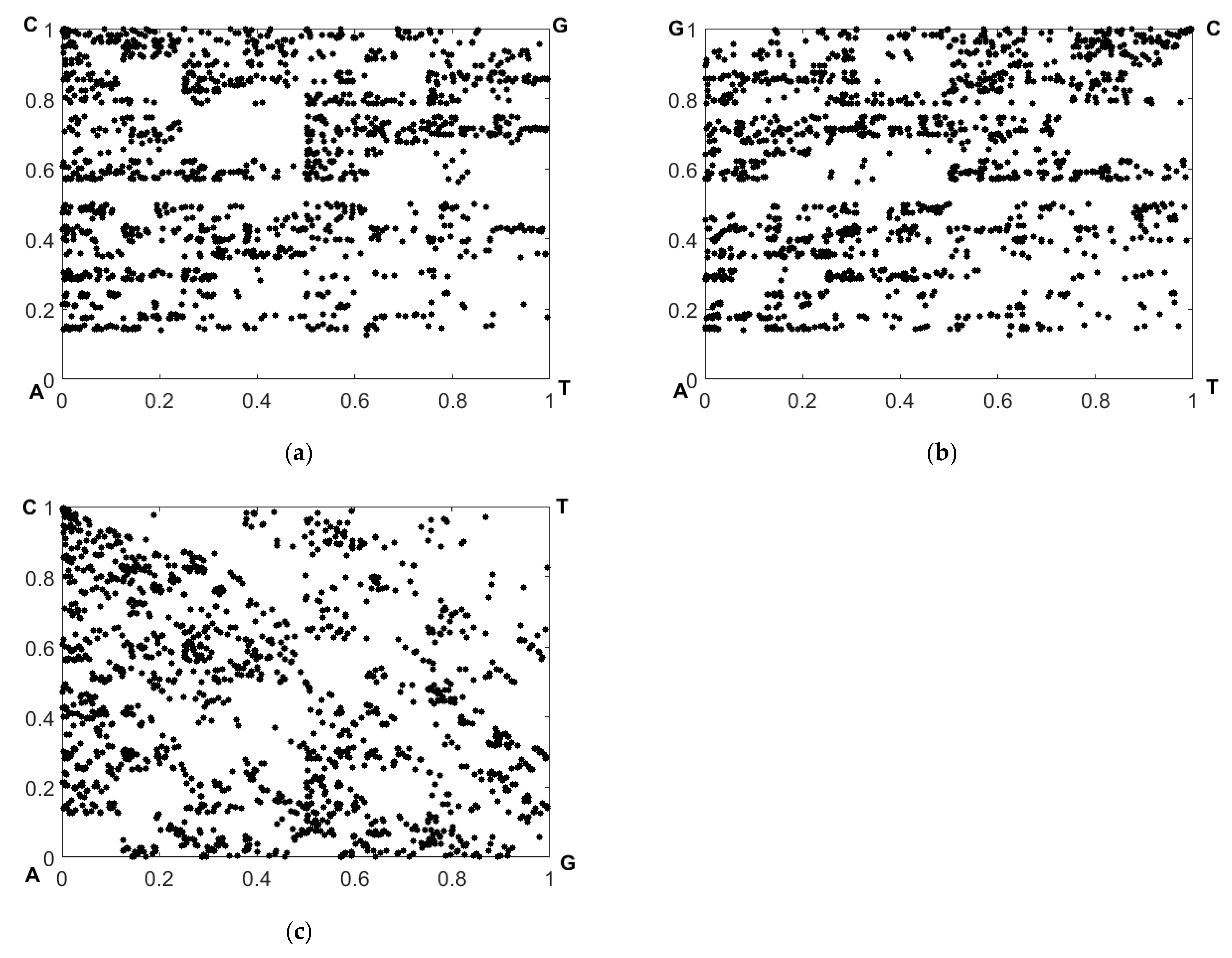
Figure 5 displays the recovered CGR maps in the RY, MK, and WS bases for the nucleotide sequence corresponding to sample # 1 from the dataset # 2.
The expressions (9) allow us to consider the decorrelation effect of the mutual positions of the imaging points in two CGR maps (reference and analyzed) resulting from a mutational substitution of one nucleotide in the sequence. The maximum differences in the coordinates
occur for the imaging point corresponding to the substituted nucleotide, and gradually decay with the increase in the number
(here,
is the current position of the mapped nucleotide in the sequence, and
is the position of the substituted nucleotide). It can be shown that this decay obeys the negative exponential law
.
Figure 6 illustrates a gradual decay in
, with an increasing displacement of the representing nucleotides along the sequences with respect to the substitution position. The panels a and b display the CGR maps in the WS base for samples 1 and 2; panel c illustrates the effect of mismatching in the representing points due to occurrence of nucleotide replacement in sequence # 2 with respect to sequence # 1.
The mismatched representative points are labeled by the values of . Panel d displays the distance between the mismatched points in panel d depending on ; the above-mentioned exponential decay is clearly seen.
The imaging points corresponding to certain nucleotides in the synthesized CGR maps are characterized by the real values of x and y coordinates in the (0.0; 1.0) intervals (i.e., their set is infinite). For numerical analysis of the correlation between the CGR maps of the reference sequence and the sequence with several substituted nucleotides, it is necessary to convert them to a matrix form, thereby reducing cardinality of the set of coordinate values of the representing points. Within the framework of this concept, the GCR map should be divided into
sub-areas, and the presence and absence of imaging points in these sub-areas can be characterized by binary factors 1 and 0. Thus, finding a correlation between two similarly binarized CGR maps is reduced to an element-wise logical multiplication of two synthesized binary matrices, summation of the products dividing the result by the sum of the elements in the reference matrix. It is obvious that the level of fragmentation (“granulation”) of the CGR map area, which makes it possible to minimize redundancy (more than one imaging point in a sub-area), is determined not only by the number of nucleotides in the analyzed fragment of the nucleotide sequence. Another key factor is existence of large-scale correlations of nucleotide positions in the analyzed sequences. These correlations are a manifestation of their fractal properties and, accordingly, are displayed in a significant heterogeneity of spatial distributions of the representing points in the CGR maps. A detailed analysis of this point is carried out in
Section 3.
3. Results and Discussion
A quantitative comparison of the synthesized polarization- or CGR-based binary maps for the analyzed and reference symbol sequences can be carried out by calculating the correlation coefficients between them in accordance with the following expression:
where the designations
and
refer to the elements of the analyzed and reference maps that have the values 0 or 1. Thus, the numerator of the expression (10) determines the number of matching non-zero elements in the analyzed and reference maps, and the denominator determines the number of non-zero elements in the reference map.
3.1. Polarization-Based Fingerprinting
The correlation coefficients (10) between the polarization-based binary maps corresponding to the artificially generated symbol sequences from dataset # 2 are collected in
Table 3. The synthesized maps correspond to spatial distributions of the normalized fourth component of the Stokes vector
, and the threshold level
was chosen as −0.95 (the extreme states close to the left circular polarization were selected). The scale factor
, equal to 0.1 (the detailed mapping), was applied.
The main diagonal in the matrix of correlation coefficients is highlighted in grey, and the cells with the unit correlation coefficients for different strains indicating identity of the symbol sequences are colored green. The following feature of the set of correlation coefficients should be mentioned, such as the distribution asymmetry of non-unit correlation coefficients relative to the main diagonal (for example, ). This feature is due to the differences in the number of unit elements in the synthesized binary maps for various strains.
3.2. CGR-Based Fingerprinting
When transforming a CGR map into a finite-dimensional matrix by dividing the map area into
equal-sized square fragments, the ideal case is that only one representative point hits (or misses) each fragment. Let us consider the estimate of the “admissible” degree of fragmentation, or the required number
in the case of using the CGR map for the substitution-reduced sequences ## 1–8 (the dataset # 2). The “admissibility” criterion can be introduced based on the numerical analysis of the average redundancy indicators of the filling fragments with representative points. In particular, the ratio of the number of the
cells with several points to the total number of nucleotides in the sequence (
1587) can be estimated depending on the
ratio.
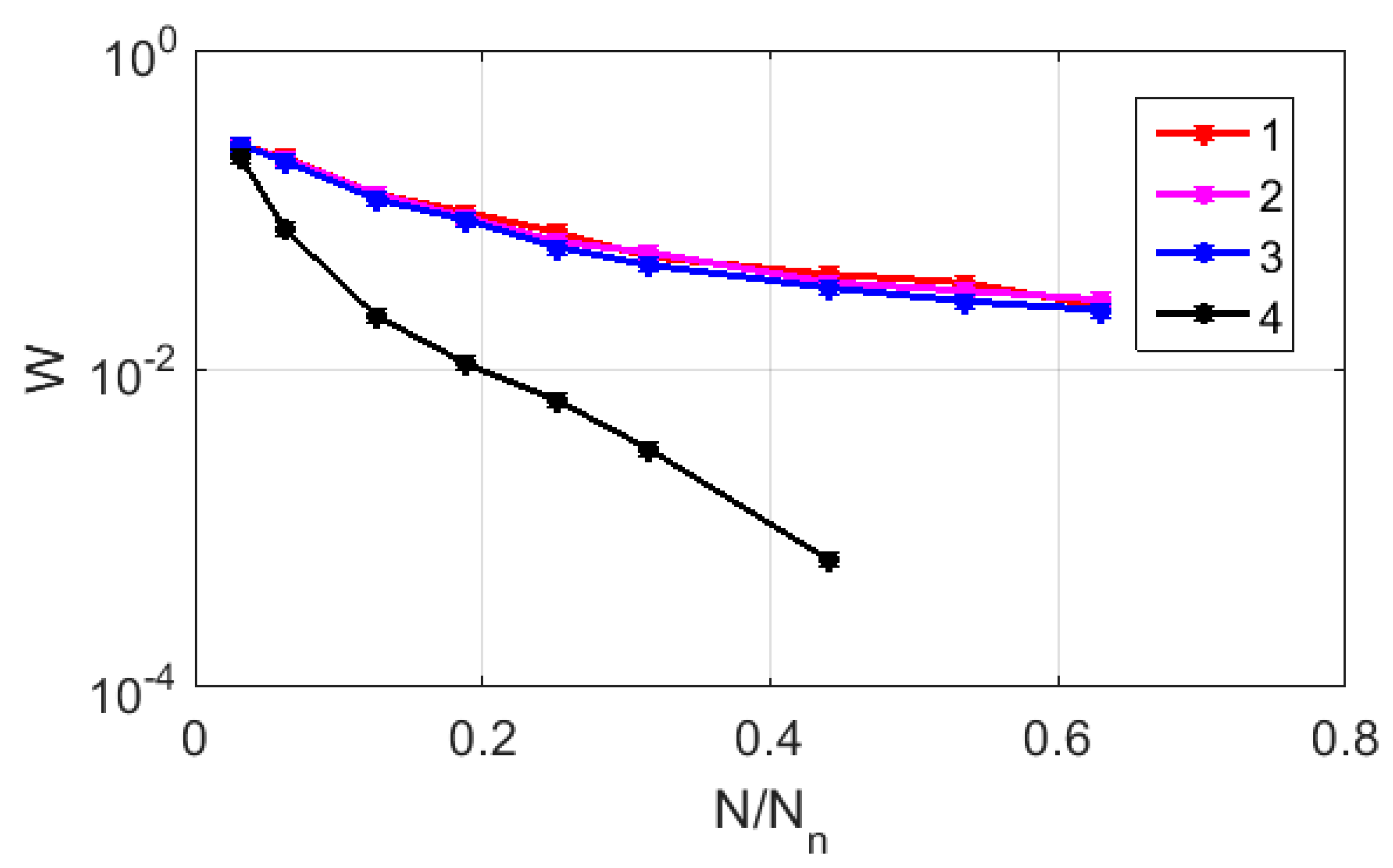
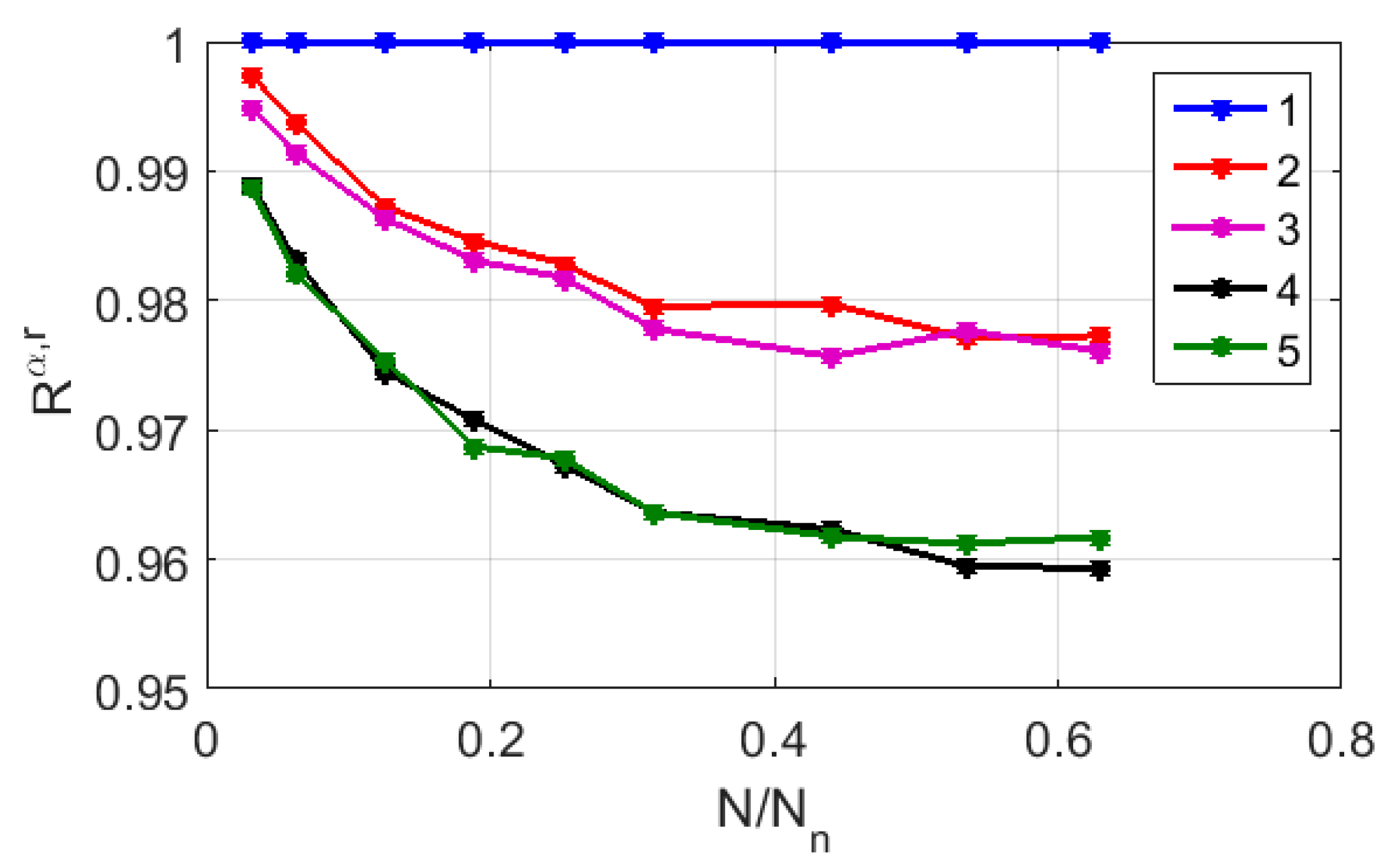
Figure 7 displays the relationship between
and
in logarithmic coordinates for the CGR maps of sample # 2, which are recovered using RY, MK, and WS bases (markers 1–3). For comparison, a similar relationship was considered for the case of the uniform filling of the map area with 1588 points (marker # 4). The red and green lines serve as guides for the eye and indicate the trends in the decay of
, which are close to the power law in all the cases if
> 0.1. However, in the case of a uniform filling, the exponent approximates the expected value of 2, while for the RY, MK, and WS maps, its value is close to 1. This feature is due to the fractal nature of the distribution of representative points over the CGR maps, which leads to significantly non-uniform distributions of the local density points.
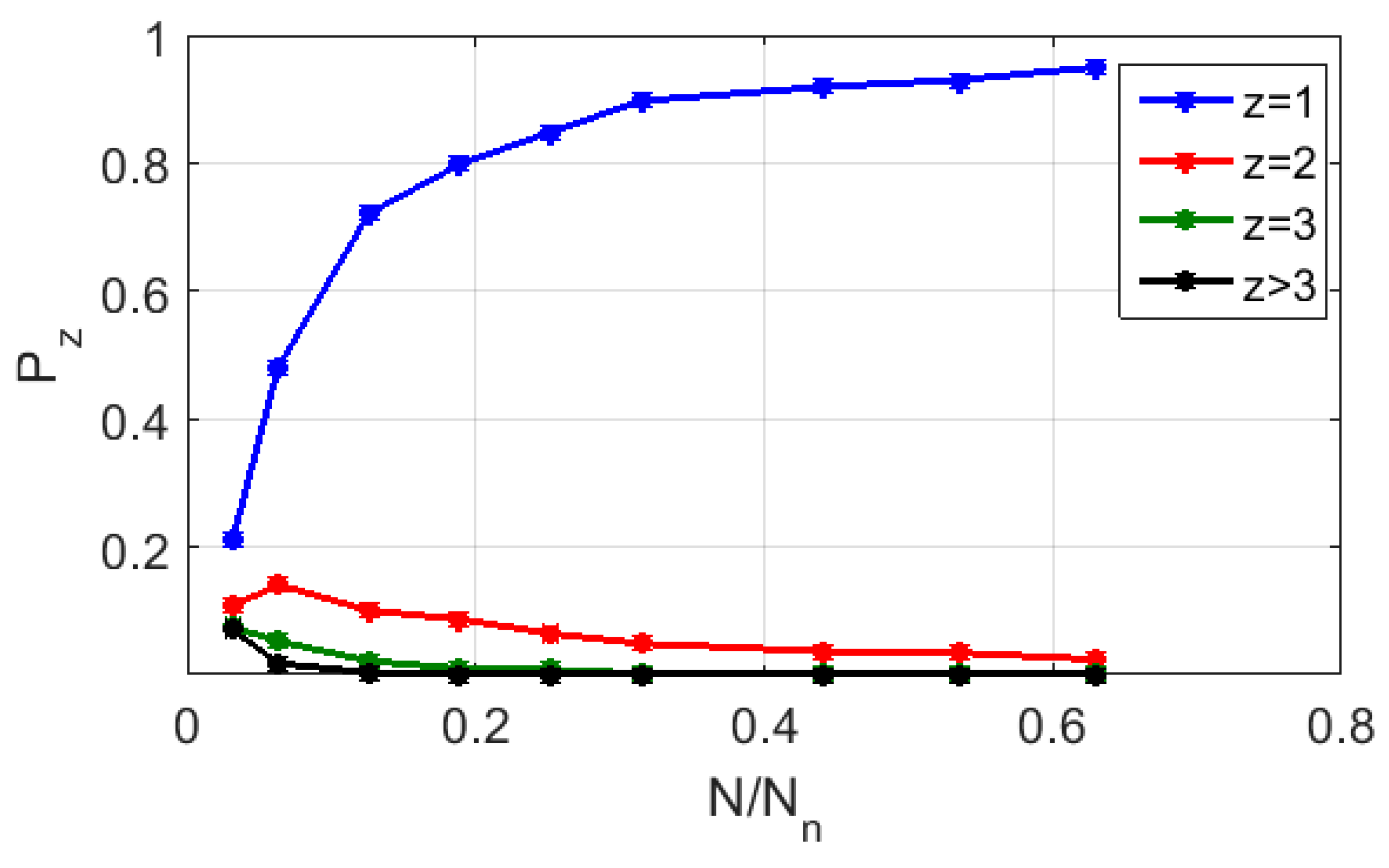
Figure 8 displays the calculated probability values
of random finding of cells with various numbers of representing points (from z = 1 to z > 3) depending on the level of the CGR map (RY base) fragmentation for the symbol sequence corresponding to strain #2. As in
Figure 7, the fragmentation level is given by the ratio
. Setting
0.95 as the “admissibility” criterion, we admit that this ratio must be at least equal to ≈0.64 (i.e., the minimum number of elements in a binarized CGR map must be at least ≈10
6 or more). Note that this value is many times greater than the similar value for the polarization-based binary maps synthesized for the same sequences (≈8.5 × 10
3).
The analysis of the values of the correlation coefficients
between the CGR-based binary maps for the sequences ## 1–8 with the reduced numbers of substitutions (the dataset # 2), depending on
, shows their rather weak dependence on the number of substitutions in the nucleotide sequences relative to the reference sequence. As an example,
Figure 9 presents the values of the correlation coefficients against
for the strain-associated CGR-based binary maps in the RY base. Note that the dependences
in the case of the MR and WS bases exhibit a similar behavior, shown by the close-to-unit values of even the criterion which is above the introduced “admissibility” and by the relatively large numbers of nucleotide substitutions. For comparison, the correlation coefficients of the polarization-based binary maps show a significantly higher sensitivity to the changes in the structure of nucleotide sequences (see
Table 3).
3.3. Robustness of Estimates for Polarization-Based Binary Identifiers
Due to the quasi-random nature and variety of possible types of substitutions in the analyzed symbol sequences, the values will differ for different sequences with the same number of substitutions relative to the reference sequence. Regarding the polarization encoding of DNA-associated symbol sequences and synthesis of polarization-based binary identifiers , the effect of the variety of substitution types can be analyzed in terms of the transformation of a submatrix associated with the changed triplet. The following scenarios of transformation can be considered (note that the content and positions of symbols in the changed triplets are presented for illustrative purposes only).
- (i)
or or
- (ii)
or or etc.;
- (iii)
or
- (iv)
- (v)
- (vi)
or or
In the case of a single substitution to the reference sequence, the correlation coefficients
of the corresponding binary identifiers will significantly differ from each other depending on the transformation scenario (i–vi).
Table 4 presents the results of statistical modeling of the decorrelation between the binary identifiers of the reference and changed sequences in the case of a single substitution. The symbol sequence # 1 from the dataset # 2 was chosen as the reference object. The polarization-based binary identifiers
were synthesized according to the procedure described above, with the following parameters:
= 0.1;
= −0.95. For the cases (i–vi), single replacements of symbols were repeatedly made in the corresponding triplets, selected in a random manner, and sets of 10 statistically independent
values were accumulated in each case. The table displays the average values of the correlation coefficient with confidence intervals corresponding to a significance level of 0.9. It can be seen that the maximum decorrelation of binary identifiers with random single substitutions occurs in case v, while single substitutions in accordance with scenarios i and iv lead to minimal differences between the reference and analyzed identifiers.
Note that substitutions corresponding to scenarios i and iv are associated only with permutations of the submatrix elements, while scenarios leading to maximum decorrelations under single substitutions are also associated with changes in the relationships between elements.
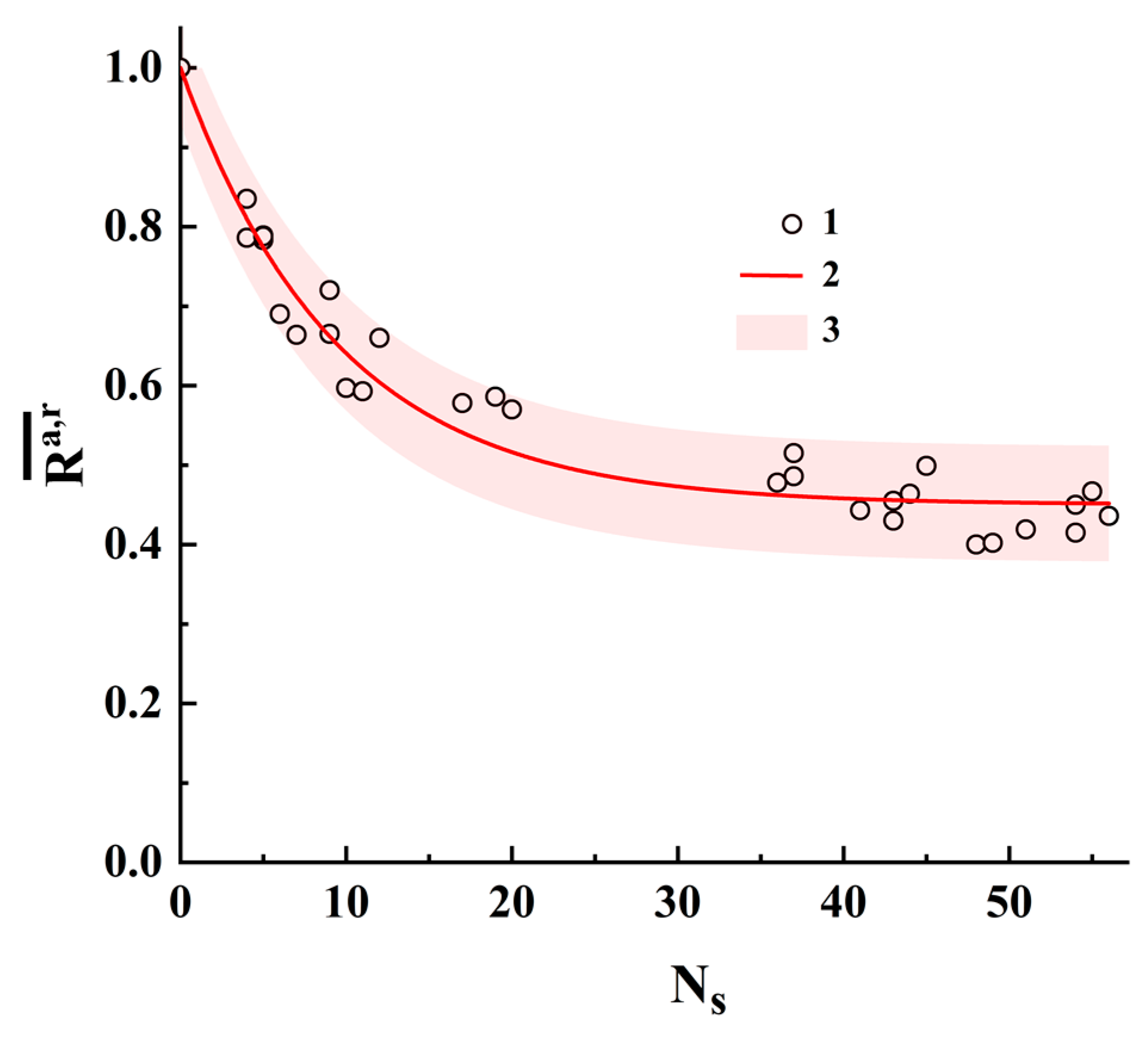
Figure 10 displays the pairwise-averaged correlation coefficients
against the number of substitutions
for both analyzed sets of sequences # 1 and # 2. The reason for using
is because the binary identifiers “a” and “r” can differ from each other in terms of the numbers of single states
(up to 10%), and averaging allows the influence of this factor to be reduced to a certain extent. The corresponding pairwise differences between the basic sequences (dataset # 1) and the artificially generated sequences (dataset # 2) are presented in the
Supplementary Materials (Tables S3 and S4). Note that the number of plotted data items in
Figure 10 is less than the number of sequence pairs due to the coincidence of some
values for the equal
values.
The solid red line corresponds to the fitting dependence (regression model):
with
0.550 ± 0.010 and
0.106 ± 0.005. The fitting procedure was performed using OriginPro 2021 version 9.8.0.200 software. The adjusted R-squared value for this fitting is ≈0.949; accordingly, we can conclude that the quality of the regression model (11) is acceptable. The pink-colored area corresponds to the 95% prediction band.
Note that the interpolated value at = 1 calculated using the regression model (11) is approximately equal to 0.944 ± 0.032, which is very close to the model values for the transformation scenarios i and iv. We can assume that these types of substitutions in nucleotide sequences are more likely to occur than other types. However, this assumption requires a more in-depth analysis and is considered an object for further research.
It is also interesting to consider the behavior of the regression model at large values of , when the structures of the compared binary identifiers are almost uncorrelated. In this case where 0.45, this value is determined by random coincidences of the positions of unit elements in two uncorrelated binary structures. The results of the performed analysis also confirm the previously made conclusion about the remarkably larger sensitivity of polarization-based binary identifiers to structural changes in the displayed sequences compared with CGR-based identifiers.
3.4. Potential Application of the Findings
A list of molecular DIVA assays has been proposed for a number of infectious animal diseases [
45,
46,
47,
48,
49,
50,
51,
52]. Although PCR (especially real-time PCR) is a rapid and sensitive technology with high specificity, providing good perspectives for the DIVA strategy, in some cases it does not suffice for the exact differentiation between vaccine and field strains. The example illustrating such problem is the PCR DIVA tests used for LSDV (lumpy skin disease virus), which could not properly assign recombinant vaccine-like viruses as either a field or vaccine virus due to the variability in the target gene sequences [
53]. Instead, sequence analysis of the whole genome or target genes may serve as a more accurate alternative for PCR tests. The subsequent sequence comparison may be performed with the use of both gene and genome sequence mapping technologies. For instance, this group of methods was applicable in phylogeny studies and genome similarity analysis [
10,
54,
55,
56,
57,
58,
59]. The vast majority of them is based on CGR transform and shares common characteristics. When comparing the pair of sequences, the distance matrix of their complete CGR graphs must be calculated [
55]. The CGR-based approaches have been successfully used even for interspecific discrimination of different bacterial and viral species including those that could not be classified by the traditional multiple sequence alignment methods based on the whole genome nucleotide sequences [
60], particularly, when only incomplete genomic sequences are available [
13]. However, a single-target gene analysis with smaller numbers of mismatches may be less fortunate.
Here, we consider another application of sequence visualization methods—with a perspective for DIVA strategy. In particular, two approaches to the two-dimensional binary mapping were used for the representation of the target gene nucleotide changes and differences between the vaccine and wild type bacterial strains on the model of L. monocytogenes, an important human and animal pathogen.
A comparative analysis of the sensitivity of polarization-encoded- and CGR-based binary maps to small deviations in the structure of the analyzed nucleotide sequences from the reference samples shows certain advantages of the polarization encoding approach. One of these advantages is associated with a significantly smaller size of a synthesized matrix of extreme polarization states compared to the binarized CGR map for the analyzed sequence. The small sizes of polarization-based binary identifiers are due to the essential properties of the discrete Fourier transform used in their synthesis.
Another advantage of the polarization encoding of DNA-associated symbol sequences is the significantly higher sensitivity of polarization-based “fingerprints” to the changes in the structure of the analyzed sequences due to the substitution of small numbers of nucleotides relative to the reference sequence. In fact, the obtained data proved that polarization-encoded binary map representation of the target artificially generated sequence dataset is comparable in accuracy to the classic, widely used alignment-based methods of sequence comparison [
61]. Since this approach is more sensitive to single sequence mismatches, it can be used for pathogen interspecies discrimination in a more accurate way. It should be expected that a rather low sensitivity of binary representations to the structural changes is typical, not only in the case of the CGR-based approach, but also for other forms of representations based on the principle of iterative mapping in the four-point (A, C, T, and G) bases (in particular, 2D and 3D polylines).
The possibilities of the polarization encoding of nucleotide sequences are not limited to only the synthesis of their unique binary identifiers (“fingerprints”), and also include, for instance, the frequency analysis of the content of nucleotides in the sequences (the results of a pilot attempt of this kind of frequency analysis in relation to the SARS-CoV-2 virus are presented in [
19]). In particular, we can consider the principle of constructing the triplet-associated submatrices in the RY, MR, and WS bases with a subsequent comparative analysis of the synthesized 2D binary maps as one of the possible directions for the further development of this technique. These feasible directions are a subject for further research activity.
The promising application of this strategy additionally to challenges in a general phylogeny, including phylogenetic and cluster analysis and evolutionary and global biodiversity research could be extended to a development of high-precision new generation point-of care diagnostic devices resulting in rapid and precise identification/differentiation of model Listeria and other pathogens and non-pathogens as well.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}