

A Machine Learning Model to Predict Length of Stay and Mortality among Diabetes and Hypertension Inpatients
 ,
,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
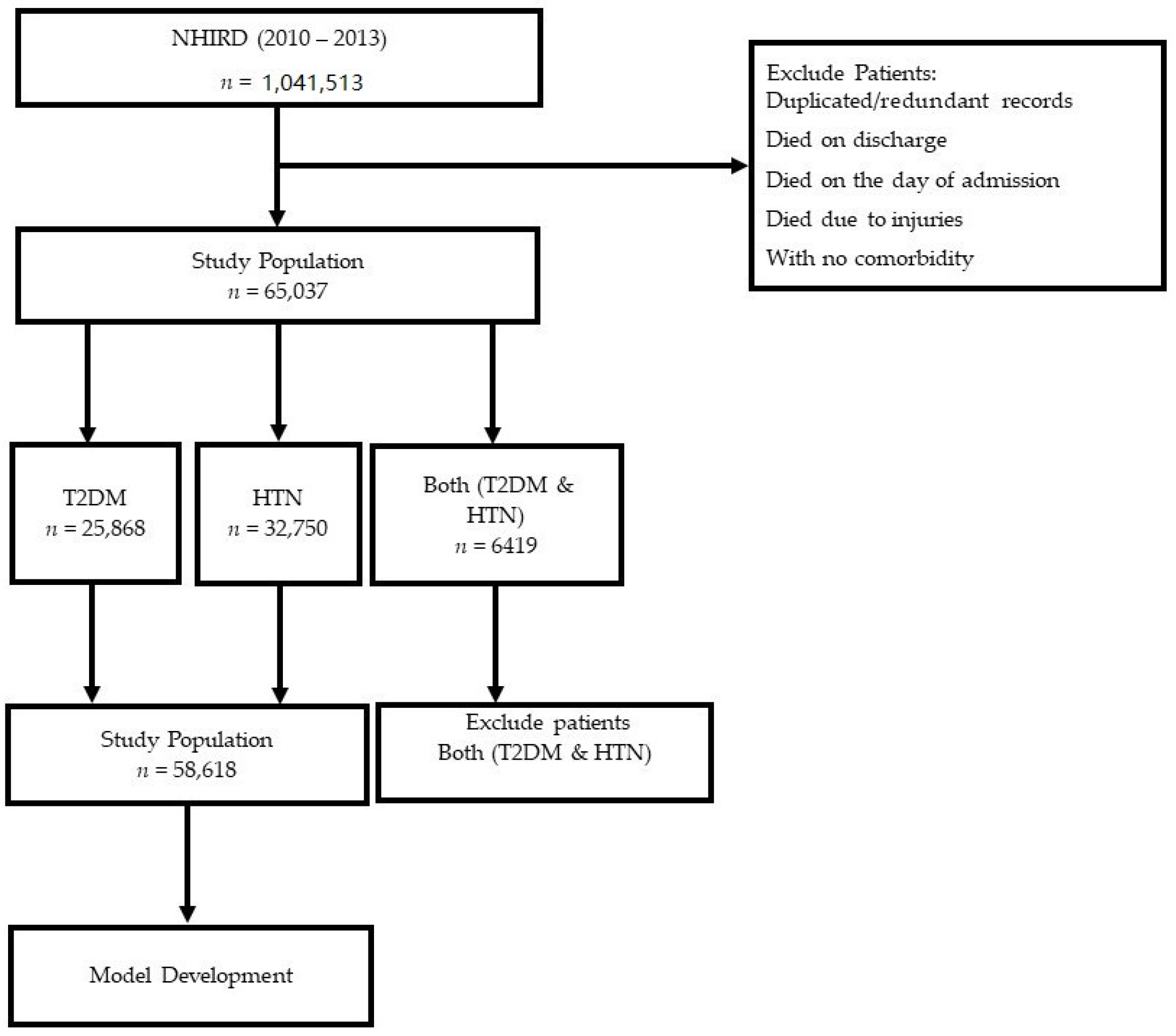
2.1. Data Source
2.2. Inclusion and Exclusion Criteria
2.3. Predictors and Outcomes
2.4. Handling Missing Values
2.5. Features Selection
2.6. Managing Class Imbalance
2.7. Predictive Model Development and Evaluation
2.8. Length of Stay (LoS)
2.9. Mortality
2.10. Document Software and Libraries
3. Results
3.1. Patient Characteristics
3.2. Features Selection
3.3. Comorbidities of T2DM and HTN
3.4. Length of Stay (LoS)
3.5. Feature Importance
3.6. Mortality
3.7. Feature Importance
3.8. The Accuracy and LoS Plots
3.9. The AUC and Precision-Recall Curves
3.10. Calibration
4. Cross–Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Full Form | Abbreviation |
| Linear Regression | LR |
| Logistic Regression | LoR |
| Cross Validation | CV |
| Area Under Curve | AUC |
| Area Under Precision-Recall | AUPR |
| Gradient Boosting Machine | GBM |
| Hypertension | HTN |
| Length of Stay | LoS |
| Machine Learning | ML |
| Mean Absolute Error | MAE |
| National Health Insurance | NHI |
| National Health Insurance Research Database | NHIRD |
| Random Forest | RF |
| Root Mean Square Error | RMSE |
| Receiver Operating Characteristics | ROC |
| Support Vector Machine | SVM |
| Type 2 Diabetes Mellitus | T2DM |
| Extreme Gradient Boosting | XGBoost |
| Exploratory Data Analysis | EDA |
| Interquartile Range | IQR |
| K-Neighbors Classifier | KNN |
| Bagging Classifier | BC |
| Gradient Boosting Classifier | GBC |
References
- Bukhman, G.; Mocumbi, A.O.; Atun, R.; Becker, A.E.; Bhutta, Z.; Binagwaho, A.; Clinton, C.; Coates, M.M.; Dain, K.; Ezzati, M. The Lancet NCDI Poverty Commission: Bridging a gap in universal health coverage for the poorest billion. Lancet 2020, 396, 991–1044. [Google Scholar] [CrossRef]
- World Health Organization. Noncommunicable Diseases. Available online: https://www.who.int/news-room/fact-sheets/detail/noncommunicable-diseases (accessed on 16 September 2022).
- World Health Organization. Global Report on Diabetes; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Chatterjee, S.; Khunti, K.; Davies, M.J. Type 2 diabetes. Lancet 2017, 389, 2239–2251. [Google Scholar] [CrossRef]
- Lin, P.-Y.; Chang, C.-C.; Tung, C.-Y.; Chu, W.-H.; Tong, F.-G. Risk factors of prehypertension and hypertension among workers at public elderly welfare facilities in Taiwan: A cross-sectional survey. Medicine 2021, 100, e24885. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Hypertension. Available online: https://www.who.int/news-room/fact-sheets/detail/hypertension (accessed on 15 September 2022).
- Weder, A.B. Treating acute hypertension in the hospital: A Lacuna in the guidelines. Hypertension 2011, 57, 18–20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Boer, I.H.; Bangalore, S.; Benetos, A.; Davis, A.M.; Michos, E.D.; Muntner, P.; Rossing, P.; Zoungas, S.; Bakris, G. Diabetes and hypertension: A position statement by the American Diabetes Association. Diabetes Care 2017, 40, 1273–1284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lastra, G.; Syed, S.; Kurukulasuriya, L.R.; Manrique, C.; Sowers, J.R. Type 2 diabetes mellitus and hypertension: An update. Endocrinol. Metab. Clin. N. Am. 2014, 43, 103–122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.; Li, X.; Wang, X.; Zhou, J.; Wang, Q.; Rong, X.; Wang, G.; Shao, X. Effect of Hypertension, Waist-to-Height Ratio, and Their Transitions on the Risk of Type 2 Diabetes Mellitus: Analysis from the China Health and Retirement Longitudinal Study. J. Diabetes Res. 2022, 2022, 7311950. [Google Scholar] [CrossRef]
- Huang, X.-B.; Tang, W.-W.; Liu, Y.; Hu, R.; Ouyang, L.-Y.; Liu, J.-X.; Li, X.-J.; Yi, Y.-J.; Wang, T.-D.; Zhao, S.-P. Prevalence of diabetes and unrecognized diabetes in hypertensive patients aged 40 to 79 years in southwest China. PLoS ONE 2017, 12, e0170250. [Google Scholar] [CrossRef] [Green Version]
- Colosia, A.D.; Palencia, R.; Khan, S. Prevalence of hypertension and obesity in patients with type 2 diabetes mellitus in observational studies: A systematic literature review. Diabetes Metab. Syndr. Obes. Targets Ther. 2013, 6, 327. [Google Scholar] [CrossRef] [Green Version]
- Awad, A.; Bader-El-Den, M.; McNicholas, J. Patient length of stay and mortality prediction: A survey. Health Serv. Manag. Res. 2017, 30, 105–120. [Google Scholar] [CrossRef]
- Vincent, J.-L.; Singer, M. Critical care: Advances and future perspectives. Lancet 2010, 376, 1354–1361. [Google Scholar] [CrossRef]
- Lingsma, H.F.; Bottle, A.; Middleton, S.; Kievit, J.; Steyerberg, E.W.; Marang-Van De Mheen, P.J. Evaluation of hospital outcomes: The relation between length-of-stay, readmission, and mortality in a large international administrative database. BMC Health Serv. Res. 2018, 18, 116. [Google Scholar] [CrossRef] [Green Version]
- Sud, M.; Yu, B.; Wijeysundera, H.C.; Austin, P.C.; Ko, D.T.; Braga, J.; Cram, P.; Spertus, J.A.; Domanski, M.; Lee, D.S. Associations between short or long length of stay and 30-day readmission and mortality in hospitalized patients with heart failure. JACC Heart Fail. 2017, 5, 578–588. [Google Scholar] [CrossRef]
- Wu, Y.-C.; Lo, W.-C.; Lu, T.-H.; Chang, S.-S.; Lin, H.-H.; Chan, C.-C. Mortality, morbidity, and risk factors in Taiwan, 1990–2017: Findings from the global burden of disease study 2017. J. Formos. Med. Assoc. 2021, 120, 1340–1349. [Google Scholar] [CrossRef]
- Ministry of Health and Welfare. 2019 Taiwan Health and Welfare Report. Available online: https://www.mohw.gov.tw/cp-137-52878-2.html (accessed on 20 September 2022).
- Hargreaves, C.; Cherie, C. Machine Learning Application to Predict the Length of Stay of type 2 Diabetes Patients in the Intensive Care Unit. Test Eng. Manag. 2020, 82, 6143–6163. [Google Scholar]
- Habehh, H.; Gohel, S. Machine learning in healthcare. Curr. Genom. 2021, 22, 291–300. [Google Scholar] [CrossRef]
- Iwase, S.; Nakada, T.-A.; Shimada, T.; Oami, T.; Shimazui, T.; Takahashi, N.; Yamabe, J.; Yamao, Y.; Kawakami, E. Prediction algorithm for ICU mortality and length of stay using machine learning. Sci. Rep. 2022, 12, 12912. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Su, C.-C.; Shao, S.-C.; Sung, S.-F.; Lin, S.-J.; Yang, Y.-H.K.; Lai, E.C.-C. Taiwan’s national health insurance research database: Past and future. Clin. Epidemiol. 2019, 11, 349. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.-Y.; Warren-Gash, C.; Smeeth, L.; Chen, P.-C. Data resource profile: The national health insurance research database (NHIRD). Epidemiol. Health 2018, 40, e2018062. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Liu, G.; Xu, Y.; Wang, X.; Zhuang, X.; Liang, H.; Xi, Y.; Lin, F.; Pan, L.; Zeng, T.; Li, H. Developing a machine learning system for identification of severe hand, foot, and mouth disease from electronic medical record data. Sci. Rep. 2017, 7, 16341. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N. Data Mining for Imbalanced Datasets: An Overview. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2005. [Google Scholar]
- Kubat, M. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection. In Proceedings of the Fourteenth International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Barsasella, D.; Gupta, S.; Malwade, S.; Aminin; Susanti, Y.; Tirmadi, B.; Mutamakin, A.; Jonnagaddala, J.; Syed-Abdul, S. Predicting length of stay and mortality among hospitalized patients with type 2 diabetes mellitus and hypertension. Int. J. Med. Inform. 2021, 154, 104569. [Google Scholar] [CrossRef] [PubMed]
- Ye, J.; Yao, L.; Shen, J.; Janarthanam, R.; Luo, Y. Predicting mortality in critically ill patients with diabetes using machine learning and clinical notes. BMC Med. Inform. Decis. Mak. 2020, 20, 295. [Google Scholar] [CrossRef] [PubMed]
- Sonar, P.; JayaMalini, K. Diabetes prediction using different machine learning approaches. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 367–371. [Google Scholar]
- Tsai, A.; Liou, J.; Chang, M. Interview to study the determinants of hypertension in older adults in Taiwan: A population based cross-sectional survey. Asia Pac. J. Clin. Nutr. 2007, 16, 338. [Google Scholar]
- Lin, J.; Thompson, T.J.; Cheng, Y.J.; Zhuo, X.; Zhang, P.; Gregg, E.; Rolka, D.B. Projection of the future diabetes burden in the United States through 2060. Popul. Health Metr. 2018, 16, 9. [Google Scholar] [CrossRef] [Green Version]
- Schütt, M.; Fach, E.M.; Seufert, J.; Kerner, W.; Lang, W.; Zeyfang, A.; Welp, R.; Holl, R.; DPV Initiative and the German BMBF Competence Network Diabetes Mellitus. Multiple complications and frequent severe hypoglycaemia in ‘elderly’ and ‘old’ patients with type 1 diabetes. Diabet. Med. 2012, 29, e176–e179. [Google Scholar] [CrossRef]
- Beckman, J.A.; Paneni, F.; Cosentino, F.; Creager, M.A. Diabetes and vascular disease: Pathophysiology, clinical consequences, and medical therapy: Part II. Eur. Heart J. 2013, 34, 2444–2452. [Google Scholar] [CrossRef] [Green Version]
- Low Wang, C.C.; Hess, C.N.; Hiatt, W.R.; Goldfine, A.B. Clinical update: Cardiovascular disease in diabetes mellitus: Atherosclerotic cardiovascular disease and heart failure in type 2 diabetes mellitus–mechanisms, management, and clinical considerations. Circulation 2016, 133, 2459–2502. [Google Scholar] [CrossRef]
- Maulucci, G.; Cordelli, E.; Rizzi, A.; De Leva, F.; Papi, M.; Ciasca, G.; Samengo, D.; Pani, G.; Pitocco, D.; Soda, P. Phase separation of the plasma membrane in human red blood cells as a potential tool for diagnosis and progression monitoring of type 1 diabetes mellitus. PLoS ONE 2017, 12, e0184109. [Google Scholar] [CrossRef] [Green Version]
- Cordelli, E.; Maulucci, G.; De Spirito, M.; Rizzi, A.; Pitocco, D.; Soda, P. A decision support system for type 1 diabetes mellitus diagnostics based on dual channel analysis of red blood cell membrane fluidity. Comput. Methods Programs Biomed. 2018, 162, 263–271. [Google Scholar] [CrossRef]
- Laiteerapong, N.; Karter, A.J.; Liu, J.Y.; Moffet, H.H.; Sudore, R.; Schillinger, D.; John, P.M.; Huang, E.S. Correlates of quality of life in older adults with diabetes: The diabetes & aging study. Diabetes Care 2011, 34, 1749–1753. [Google Scholar]
- Mutowo, M.P.; Lorgelly, P.K.; Laxy, M.; Renzaho, A.M.; Mangwiro, J.C.; Owen, A.J. The Hospitalization Costs of Diabetes and Hypertension Complications in Zimbabwe: Estimations and Correlations. J. Diabetes Res. 2016, 2016, 9754230. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.-L.; Hsiao, F.-Y. Risk of hospitalization and healthcare cost associated with diabetes complication severity index in Taiwan’s national health insurance research database. J. Diabetes Complicat. 2014, 28, 612–616. [Google Scholar] [CrossRef]
- Young, B.A.; Lin, E.; Von Korff, M.; Simon, G.; Ciechanowski, P.; Ludman, E.J.; Everson-Stewart, S.; Kinder, L.; Oliver, M.; Boyko, E.J. Diabetes complications severity index and risk of mortality, hospitalization, and healthcare utilization. Am. J. Manag. Care 2008, 14, 15. [Google Scholar]
- Kuwabara, K.; Imanaka, Y.; Matsuda, S.; Fushimi, K.; Hashimoto, H.; Ishikawa, K.B.; Horiguchi, H.; Hayashida, K.; Fujimori, K. Impact of age and procedure on resource use for patients with ischemic heart disease. Health Policy 2008, 85, 196–206. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Acharya, U.R.; Sudarshan, V.K.; Rong, S.Q.; Tan, Z.; Lim, C.M.; Koh, J.E.; Nayak, S.; Bhandary, S.V. Automated detection of premature delivery using empirical mode and wavelet packet decomposition techniques with uterine electromyogram signals. Comput. Biol. Med. 2017, 85, 33–42. [Google Scholar] [CrossRef]
- Sakellaridis, N. The influence of diabetes mellitus on lumbar intervertebral disk herniation. Surg. Neurol. 2006, 66, 152–154. [Google Scholar] [CrossRef]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Patients with T2DM n = 25,868 | Patients with HTN n = 32,750 | Patients Having Both n = 6419 | Total Patients (T2DM + HTN + Both) n = 65,037 | Total Patients Used for Prediction Model (T2DM or HTN) N = 58,618 | Statistical Significance |
|---|---|---|---|---|---|---|
| Sex | 0.136 | |||||
| Male | 13,138 (50.79) | 16,849 (51.45) | 3070 (47.83) | 33,057 (50.83) | 29,987 (51.16) | |
| Female | 12,730 (49.21) | 15,901 (48.55) | 3349 (52.17) | 31,980 (49.17) | 28,631 (48.84) | |
| Age (years) (mean ± SD) | 75.05 ± 13.41 | 75.19 ± 13.84 | 75.49 ± 11.89 | 75.16 ± 13.49 | 75.12 ± 13.65 | 0.808 |
| <35 | 94 (0.36) | 150 (0.46) | 8 (0.12) | 252 (0.39) | 244 (0.42) | |
| 35–57 | 2408 (9.31) | 3236 (9.89) | 417 (6.50) | 6061 (9.32) | 5644 (9.63) | |
| 58–80 | 13,307 (51.44) | 16,157 (49.33) | 3564 (55.52) | 33,028 (50.78) | 29,464 (50.26) | |
| >80 | 10.059 (38.89) | 13,207 (40.33) | 2430 (37.86) | 25,696 (39.51) | 13,217 (22.55) | |
| Discharge status | 0.001 * | |||||
| Treatment and discharge | 1142 (4.41) | 1953 (5.96) | 325 (5.06) | 3420 (5.26) | 3095 (5.28) | |
| Continue to be hospitalized | 0 | 0 | 0 | 0 | 0 | |
| Change to outpatient treatment | 22,798 (88.13) | 29,422 (89.84) | 5859 (91.28) | 58,079 (89.30) | 22,827 (38.94) | |
| Death | 585 (2.26) | 298 (0.91) | 30 (0.47) | 913 (1.40) | 883 (1.51) | |
| Automatic discharge | 648 (2.51) | 584 (1.78) | 125 (1.95) | 1357 (2.09) | 1232 (2.10) | |
| Transfer | 318 (1.23) | 268 (0.82) | 56 (0.87) | 642 (0.99) | 586 (0.999) | |
| Change of identity | 0 | 0 | 0 | 0 | 0 | |
| Absconding | 3 (0.01) | 2 (0.006) | 0 | 5 (0.01) | 5 (0.009) | |
| Suicide | 1 (0.003) | 0 | 0 | 1 (0.001) | 1 (0.002) | |
| Other | 373 (1.44) | 223 (0.68) | 24 (0.37) | 620 (0.95) | 596 (1.02) | |
| No. of comorbidities | - | |||||
| 0 | 123 (0.48) | 258 (0.79) | 0 (0) | 381 (0.59) | 381 (0.65) | |
| 1 | 2425 (9.37) | 6858 (20.94) | 0 (0) | 9283 (14.27) | 9283 (15.84) | |
| 2 | 11,269 (43.56) | 15,757 (48.11) | 134 (2.09) | 27,160 (41.76) | 27,026 (46.11) | |
| ≥3 | 12,051 (46.59) | 9877 (30.16) | 6285 (97.91) | 28,213 (43.38) | 21,928 (37.41) | |
| Hospital Cost | 0.141 | |||||
| Average Cost(min–max) | 13,208 (0–1,212,764) | 10,449 (0–768,724) | 10,120 (0–768,724) | 11,514 (0–1,212,764) | 11666 (0–1,212,764) | |
| Median (IQR) | 7962 (4470–13,397) | 6852 (3947–11,107) | 6895 (4119–11,084) | 7228 (4298–11,972) | 7228 (4298–12,185) | |
| LoS | 0.031 * | |||||
| Average LoS (min–max) | 8.46 (0–6059) | 6.56 (0–3087) | 6.60 (0–1887) | 7.32 (0–6059) | 6.60 (0–1887) | |
| Median (IQR) | 5.00 (3.00–8.00) | 4.00 (2.00–7.00) | 4.00 (3.00–7.00) | 5.00 (3.00–8.00) | 4.00 (3.00–7.00) |
| Common Comorbidities |
|---|
|
| Model | MSE | RMSE | MAE | R2 |
|---|---|---|---|---|
| SVM | 0.393 | 0.510 | 0.121 | 0.486 |
| LR | 0.570 | 0.755 | 0.065 | 0.172 |
| GBM | 0.584 | 0.755 | 0.004 | 0.397 |
| XGBoost | 0.312 | 0.386 | 0.123 | 0.633 |
| RF | 0.261 | 0.401 | 0.027 | 0.591 |
| Classifier | Accuracy Score | Balanced Accuracy Score | Test Score | Precision | Recall | AUC | AUPR |
|---|---|---|---|---|---|---|---|
| LoR | 0.9779 | 0.9719 | 0.9728 | 0.9432 | 0.9786 | 0.97 | 0.93 |
| RC | 0.9736 | 0.9592 | 0.9692 | 0.9312 | 0.9463 | 0.94 | 0.89 |
| SVM | 0.7899 | 0.7562 | 0.7332 | 0.7599 | 0.6524 | 0.88 | 0.89 |
| Model Name | Precision | Recall | Train Accuracy | Test Accuracy | F1 Score | AUC |
|---|---|---|---|---|---|---|
| Decision Tree | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000000 |
| Random Forest | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.999827 |
| Logistic Regression | 0.94 | 0.98 | 0.97 | 0.97 | 0.96 | 0.971884 |
| Ada Boost | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000000 |
| Bagging | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000000 |
| Gradient Boosting | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000000 |
| XGB | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.000000 |
| SVC | 0.82 | 0.49 | 0.77 | 0.77 | 0.61 | 0.710974 |
| K-Neighbors | 0.85 | 0.95 | 0.95 | 0.92 | 0.90 | 0.926795 |
| Gaussian | 1.00 | 0.98 | 0.99 | 0.99 | 0.99 | 0.992494 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barsasella, D.; Bah, K.; Mishra, P.; Uddin, M.; Dhar, E.; Suryani, D.L.; Setiadi, D.; Masturoh, I.; Sugiarti, I.; Jonnagaddala, J.; et al. A Machine Learning Model to Predict Length of Stay and Mortality among Diabetes and Hypertension Inpatients. Medicina 2022, 58, 1568. https://doi.org/10.3390/medicina58111568
Barsasella D, Bah K, Mishra P, Uddin M, Dhar E, Suryani DL, Setiadi D, Masturoh I, Sugiarti I, Jonnagaddala J, et al. A Machine Learning Model to Predict Length of Stay and Mortality among Diabetes and Hypertension Inpatients. Medicina. 2022; 58(11):1568. https://doi.org/10.3390/medicina58111568
Chicago/Turabian StyleBarsasella, Diana, Karamo Bah, Pratik Mishra, Mohy Uddin, Eshita Dhar, Dewi Lena Suryani, Dedi Setiadi, Imas Masturoh, Ida Sugiarti, Jitendra Jonnagaddala, and et al. 2022. "A Machine Learning Model to Predict Length of Stay and Mortality among Diabetes and Hypertension Inpatients" Medicina 58, no. 11: 1568. https://doi.org/10.3390/medicina58111568
APA StyleBarsasella, D., Bah, K., Mishra, P., Uddin, M., Dhar, E., Suryani, D. L., Setiadi, D., Masturoh, I., Sugiarti, I., Jonnagaddala, J., & Syed-Abdul, S. (2022). A Machine Learning Model to Predict Length of Stay and Mortality among Diabetes and Hypertension Inpatients. Medicina, 58(11), 1568. https://doi.org/10.3390/medicina58111568