1. Introduction
The Italian law on the protection of workers (D.Leg. 81/2008) includes a system for the registration of occupational cancers based on three activities: The National Mesothelioma Registry (ReNaM) [
1], the Sinonasal Cancer National Registry—ReNaTuns [
2], and a system for the identification of clusters of cancer of occupational origin (Occupational Cancer Monitoring—OCM). ReNaM and ReNaTuns follow the same methodology: In each region, a dedicated operational center identifies the cases in hospitals, interviews them on occupational and environmental exposure, and sends the data to a national center for statistical analyses and reporting.
The methodology for OCM has to be different because OCM targets all cancer types with existing evidence of occupational etiology. It would not be possible to collect individual information on occupational exposure interviewing all subjects: In Italy each year, 371,000 new cases of malignant neoplasm are diagnosed, of which 39,000 are lung cancer [
3]. Therefore, a different operational model was devised for OCM according to the research conducted by Crosignani et al. [
4,
5] for the identification of work-related cancer cases. In extreme synthesis, cancer cases and population controls are linked to the archive of pension contributions held by the Italian National Social Security Institute (INPS). The data for each year include the employing company and its industrial sector but does not provide information on actual exposures. Crosignani et al. developed the methodology to use this information in epidemiological analyses to measure the risk by industry and industrial sector, with the case-control study design [
4,
5]. The record linkage model has the advantage of being applicable on a large scale with very limited resources but has several limits. In particular, the information provided by the record linkage is limited to the identification of the firms where the index subject worked, with no exposure information. Actual exposures have to be estimated using external information, such as JEMs or ‘ad hoc’ investigations carried on by the Occupational Health Departments of the Local Health Authorities.
In the OCM, cancers caused by asbestos exposure are of special interest, given the large use of asbestos materials in Italy, the extent of exposure, and the possibility of compensation for asbestos-related diseases [
6]. According to International Agency for Research on Cancer (IARC), cancers caused by asbestos exposure include cancers of the lung, larynx, ovary, and possibly of the pharynx, stomach, and colon, as well as mesothelioma [
7]. It is extremely important, therefore, to devise a method for preliminary estimation of asbestos exposure applicable in the OCM. The ReNaM data provide a rich database on industries with evidence of asbestos exposure that could be useful for this purpose. Unfortunately, the first attempts in the use of such information showed that the information in the ReNaM database could not be used directly as an additional input to the linkage process because of the lack of standardization of information reported at interview by MM cases.
The present project aims to improve the evaluation of asbestos exposure in the context of the surveillance and discovery of occupational cancers, using the information on asbestos exposure collected in the Italian MM registry—ReNaM and applying it to the evaluation of asbestos exposure of other cancer cases. In this report, we present the design and implementation of the methodological effort aimed at (i) the identification of the firms with possible asbestos exposure and (ii) the application of this list of firms to the cancer cases identified in the OCM monitoring.
2. Materials and Methods
The project was conducted following four steps: (1) MM cases included in the ReNaM database were linked to the INPS database, in order to capture the corresponding firm names and identifiers. (2) The firm names reported for each case in the ReNaM’s interview (reported with possible imprecisions at the interview of MM cases) were associated with the official firm names recorded in the INPS database. (3) Firms with likely exposure to asbestos according to the ReNaM evaluation were listed, identified by INPS firm names and codes, and asbestos exposure rating. (4) The list (thus called ‘dictionary’ in the following) was applied to the occupational histories of the cancer cases from the OCM project for the indication of the firms with possible asbestos exposure. We must remember for understanding step 4 that occupational history for the cancer cases from the OCM project was limited to the information from the INPS database.
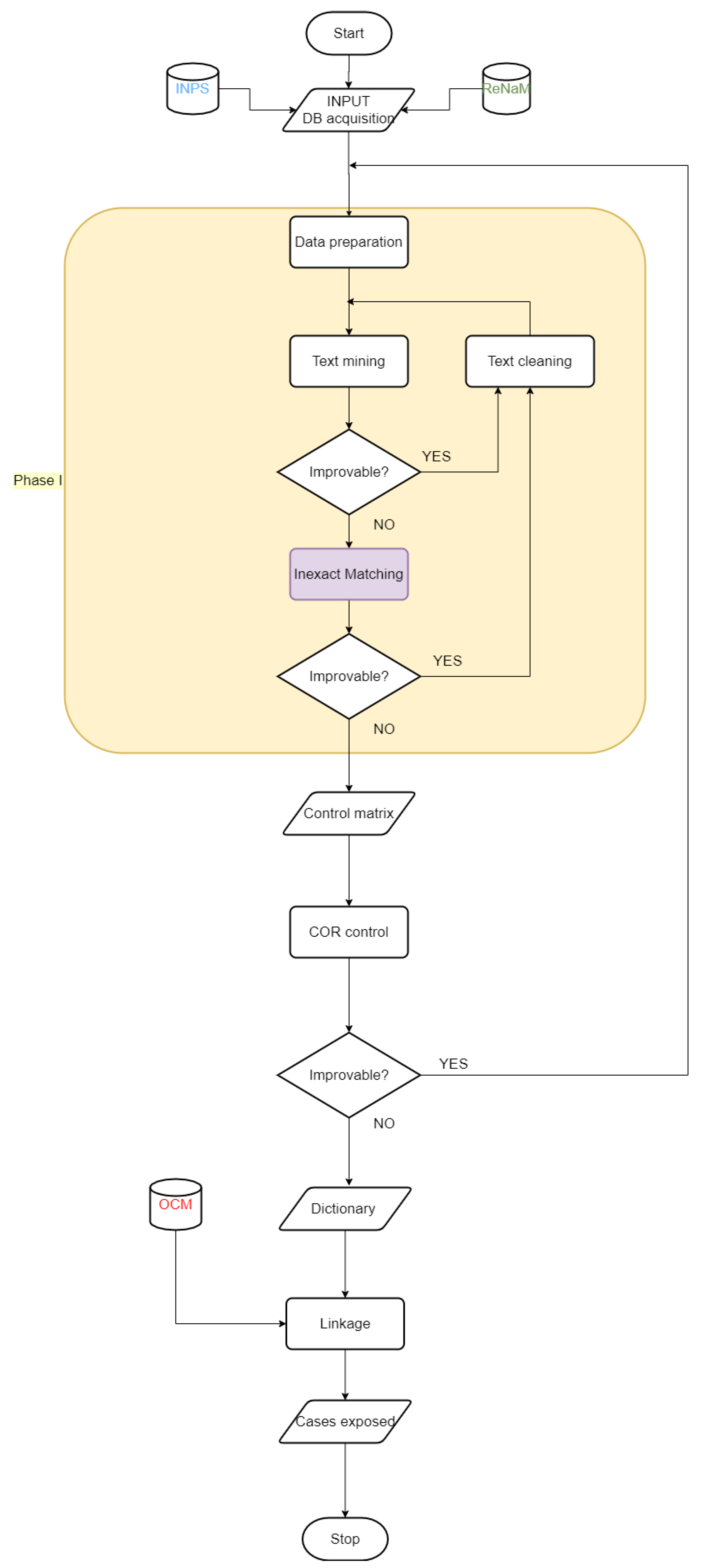
Figure 1 summarizes the flow of different record linkage activities.
2.1. Step 1
The required databases were: The database of the MM cases (ReNaM) and the database of the pension contributions (INPS).
The ReNaM database for this step provided the names and dates of birth of recorded cases.
The INPS database included all pension contributions from private firms from 1974 on. The database included, for each subject and pension contribution, the official registration name and code of the firm. It must be remembered that contributions from the public sector, agriculture, military forces, and self-employed workers were not included in the INPS database.
The linkage was conducted nominally using the MM cases’ names and dates of birth that were linked to the INPS database. In order to reduce the linkage cost, the list of subjects submitted to the linkage was limited to the MM cases with complete demographic data and with evidence of work periods with asbestos exposure according to ReNaM evaluation.
The output from the record linkage in step 1 was the list of firms where the MM cases had worked, according to INPS. It included all firms where a MM case had worked and paid pension contributions, with dates of entry and dismissal. The output record included the official name of the firms and also the address, the Value Added Tax (VAT) code, the economic activity code (coded using both ATECO 91 and ATECO 81), and the job duties of the index subject in broad categories (blue or white-collar).
2.2. Step 2
The data entered in step 2 were the output from step 1 and the records of the job history of MM cases from ReNaM.
The methodology of ReNaM for asbestos exposure assessment was described in detail elsewhere [
1,
8] and was only summarized here for the comprehension of this step of the activity. The ReNaM database included information reported in open words during the interview of MM cases, including the names of the firms where they worked. As always happens in interviews, there were imprecisions in the wording of firm names, often reported differently from their official names. ReNaM occupational hygienists’ rated the level of asbestos exposure for each firm from the job descriptions collected at interview, but kept the firm names as they were reported, with no standardization.
For the purpose of the project, we had to transfer the information on asbestos exposure rated by ReNaM to the official firm names as in the INPS database. The process consisted in the link of the ReNaM database to the output from step 1, by firm names. The linkage cannot be deterministic, due to the different collection of firm identifiers in the ReNaM (interview of MM cases) and in the INPS (official administrative registration) databases. A complex methodology had to be devised and applied to maximize the number of records matched. Our main challenge was the application of approximate string matching or fuzzy name matching to find for each firm name from ReNaM, the corresponding name from the INPS list.
To perform this, we first evaluated and corrected the data, implementing a recursive and iterative pre-processing procedure (text mining and text cleaning [
9]). Second, we linked the databases using different approaches and, third, we sent the results to the different ReNaM regional centers for a check by local experts. This last step was used to evaluate and supervise the performance of our algorithm, examining the linked and non-linked data. We also checked a random sample of records to estimate the percentage of correct matches. The procedure was repeated after receiving the amendments by the regions. Eventually, we prepared the final list of asbestos using firms with their official name and INPS registration code.
The procedure was implemented separately for each region, and the partial-results obtained for each unit were used to increase the capability and competence of the algorithm. The flowchart in
Figure 2 shows the procedure, and further details are provided in the next
Section 2.2.1 and
Section 2.2.2.
2.2.1. Step 2: Text Mining and Text Cleaning
Text mining helped us to understand and discover patterns and anomalies of the firms’ names. The strings with the firms’ names were split into single words in a process called “tokenization”; analyses based on word similarity, term frequency, and word differences were performed with appropriate indices [
9]. The validity of the Zipf [
10] and Heap laws [
11], measures commonly used in quantitative linguistics, was evaluated by studying the relation between the rank of a word and its frequency and between the number of different words and the total number of used words. Terms that tend to co-occur together were also observed using the bi-grams that help to explore pairs of adjacent words [
9].
Text cleaning was performed using the information provided by the text mining. Preprocessing of text data such as removing delimiters, numbers, and converting text to upper case was performed. A list of “stop words”, common terms that were not specific or discriminatory, was defined, and they were deleted from the strings. Data were corrected according to sound-like operators [
12,
13] that studied the inflections, synonyms, and stemming that were the modifications of a word to express different grammatical categories such as tense, case, voice, aspect, person, number, gender, and mood.
After several loop iterations, the 2 datasets were ready for the ‘inexact matching’ linkage procedure.
2.2.2. Step 2: Inexact Matching Linkage
The record linkage between the firm names, as reported at the ReNaM and INPS databases, was used to add the ReNaM evaluation of asbestos exposure to the INPS information.
The linkage algorithm was designed choosing the options that maximized the number of records linked within the regions. The linkage used the single words (tokens) of the firm’s name and not the whole string: For this reason, we used the term “inexact matching”. Before the linkage, records reporting employment in some categories, such as the agricultural sector, the military, and firemen, were excluded from the ReNaM database because these categories were not included in the INPS database (see before for details).
First, we performed an inexact matching within-subject: We considered a correct match when the two datasets shared the cases code and at least one significant word of the firm name.
Second, a full join was performed using the records unmatched in the previous step: All the remaining rows from ReNaM were combined with all records received from INPS. The procedure was time-consuming and, to apply to our big databases, we split the tables into subgroups of 10 rows, selecting only the records that shared at least one word. The remaining records were used and re-controlled in the following step. We decided to consider a successful match when 2 words of the firm name were equal. The choice to use 2 words as a threshold was related to empiric criteria: 1 was too little (excess of sensitivity), and 3 was too big (excess of specificity). In some cases, after the preprocessing phase, the strings were reduced, and they were composed of only one term. In this case, a match was considered successful when the single word present in ReNaM was found in an INPS record.
Third, we searched into the remaining not linked records, the known companies that could be registered with more than one name or with a noun accompanied by other terms. Examples were Enel or Pirelli, big firms with a large number of departments and subgroups. To avoid the possible loss of the records, we forced a list of the company’s names known ‘a priori’.
The ReNaM remaining unmatched records were reorganized into 3 groups: ‘a priori’, ‘generic terms’, and ‘not generic term’ to be controlled by the regional experts. The process was repeated after their input.
Figure 3 presents the record linkage flowchart, expanding the flowchart in
Figure 2.
2.3. Step 3
The result of the merge procedures was a general table (“dictionary”), including all firms with evidence of asbestos exposure. Each firm record included: The official name of the firm as from INPS, its official administrative registration number, the rating of exposure to asbestos (certain, probable, possible) according to ReNaM experts and the firm name as reported at the ReNaM interviews. Duplicates were reduced to a single record, keeping the higher asbestos exposure rating.
The results of the merge procedure were validated by regional experts in each regional unit of the ReNaM.
The firms’ addresses were geocoded [
14,
15], and the latitude and longitude coordinates were used to perform spatial analysis.
2.4. Step 4
The application of the general table (“dictionary”) of asbestos exposing firms to the working histories of cancer cases from the OCM project was conducted for the 2 Italian regions (Lazio and Sicily), according to the OCM data available at the time of the research. All cancer types associated or possibly associated with asbestos according to IARC [
7], were included. The information included for each case were: The diagnosis, the date of diagnosis, and the occupational history as provided by the INPS (firm names and codes). The output was the cases with at least a firm registration number present in the dictionary, i.e., the subjects who worked in a probably asbestos-exposed industry.
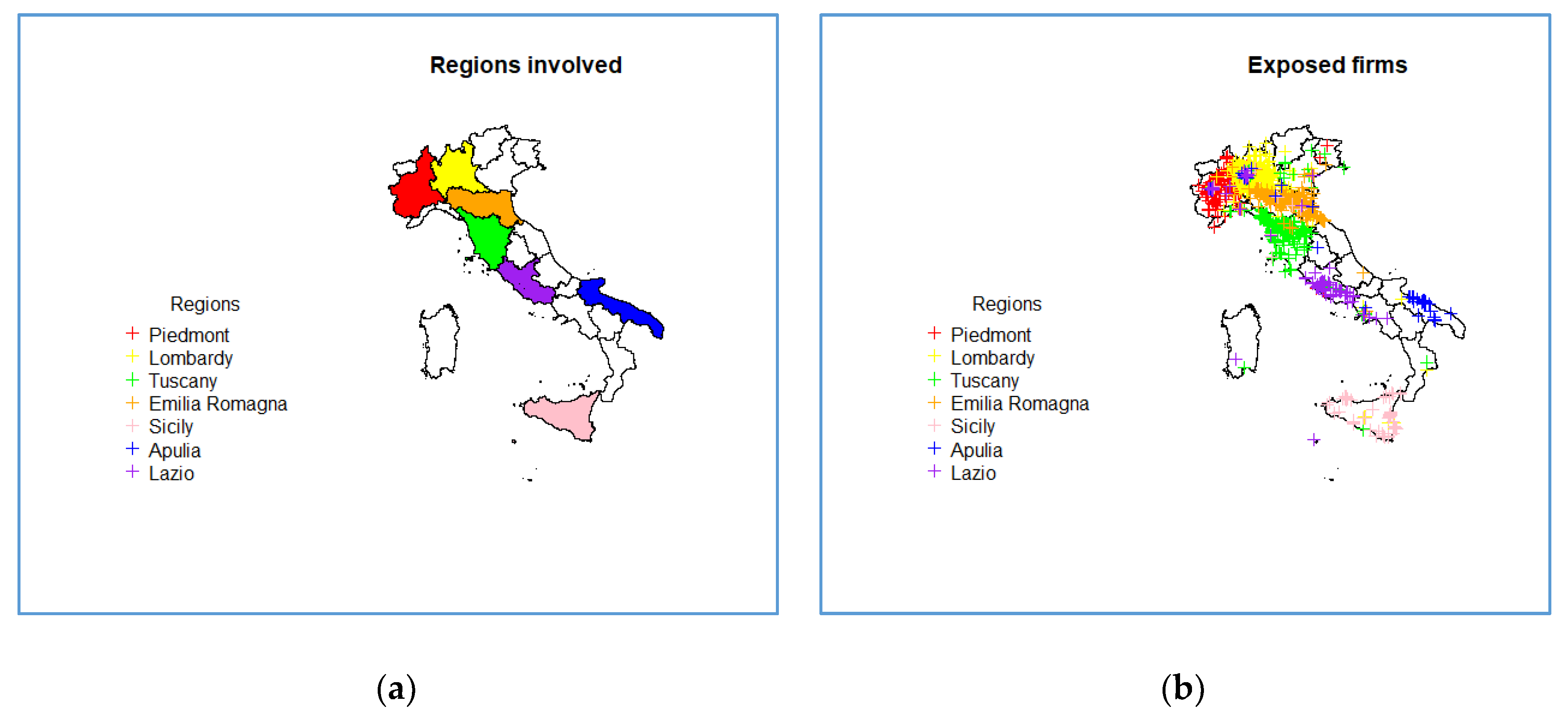
Steps 1 to 3 were conducted using the information on MM cases incident in 1993–2012 in 7 Italian regions separately (Piedmont, Lombardy, Tuscany, Emilia-Romagna, Lazio, Apulia, and Sicily). Step 4 involved only 2 Italian regions corresponding to the extension of the OCM project at the time of our analysis: We used the Lazio’s hospital discharge in the period 2008–2015 and cancer cases in Eastern Sicily in the period 2011–2014.
All analyses were performed using SAS 9.3 (SAS Institute Inc., Cary, NC, USA), R version 3.4.1 (R Core Team, Vienna, Austria), STATA 11 (StataCorp LLC, College Station, TX, USA).
2.5. Ethics
This project did not involve any contact with subjects, and the use of personal information was authorized by the Italian law on the protection of workers (D.Leg. 81/2008), therefore, approval from the Institutional Ethics Committee was not required.
4. Discussion
Exposure to asbestos fibers causes a range of different malignancies, and it is, therefore, highly relevant for any system of detection of occupational cancer. Population health surveillance related to asbestos diseases have different objectives, including: (i) The case detection and notification; (ii) the estimation of reliable epidemiological figures with the identification of outbreaks of disease; (iii) the identification of possible sources of contamination still in place and the prevention of asbestos exposure; (iv) the planning and implementation of public health policies; (v) the support of the effectiveness of insurance systems and the evaluation of the compensation, (vi) the dissemination of results and documentation of the impact of an intervention [
16,
17].
The present project aims at contributing to Italian surveillance on occupational cancer with the identification of asbestos exposing firms and the identification of cancer cases who had worked in asbestos-exposed firms.
The exploration of the asbestos-related etiology of cases requires enormous resources, given the relatively low attributable fraction and the high numbers. The objectives were achieved with record linkage connecting information from ReNaM and from INPS through a complex methodology based on the processing of textual information and probabilistic matching. One of the results was the preparation of a list of firms with possible exposure to asbestos in the past, ready for use as a screening tool in new research projects. This list was applied to the first available data from OCM, the occupational cancer monitoring system that is under preparation.
Research heavily uses record linkage, a procedure that is becoming more and more common in statistical and academic research. Linking records makes it possible to combine data from different sources to answer research questions that are very difficult to answer using data from just one source [
18,
19,
20]. In many situations, record linkage is an efficient way to collect data and it can reduce the inconvenience of asking sensitive questions [
21,
22]. Record linkage is commonly used in Nordic countries to evaluate cancer risk, even in very complex study designs [
23].
The use of surveillance systems of data collected by institutional subjects is both an advantage and a disadvantage. From one side, it reduces the duration and cost of the study and allows a standardized classification of the disease, of the occupational histories, and of exposure estimation. On the other hand, the databases that were not created for scientific or research purposes often lack critical information. In particular, the INPS database does not include enough details on occupational exposure, which is the reason for our research.
The differences in the databases limit the overlap of the two systems we used. The ReNaM database was used only for the cases with certain, probable, and possible occupational exposure as evaluated from the interview data. The INPS database excluded some important occupational categories (agriculture, public employment, armed forces) and self-employees, mainly artisans and shopkeepers. Moreover, it includes only contributions from 1974 onwards [
4].
Data pre-processing was necessary to optimize the information in the administrative databases before the linkage. The application of text mining and text cleaning techniques have been adopted in various successful biomedical applications in recent years. We applied them to extract meaningful information from the firm names written in open words. A great effort was done to prepare the list of “stop words” and to correct and simplify the terms. Different procedures and algorithms were previously available and were routines implemented in the main statistical software, but the majority of them were based on the English language. Therefore, we had to develop algorithms for the Italian setting. These algorithms are available for use in other contexts or with other languages.
The main challenge in our context was the definition of the linkage key between the names of firms reported with different accuracy in the two databases: More loosely in the ReNaM interviews and more strictly in the INPS. We discarded the deterministic linkage methods because they rely on the presence of common uniquely identifying attributes across all sources. We preferred the probabilistic approach using non-unique attributes and calculating similarity indexes for pairwise comparisons. The quality of linkage procedures is difficult to determine, and this constitutes a major issue in record linkage. In the analysis of the process and results of record linkage, both missed links (false negatives) and spurious links (false positives) must be addressed. Missed links are ‘false negatives’, corresponding to the absence of ‘signals’ of asbestos exposure: The corresponding firms will not be included in the list of asbestos exposing firms. As the process is iterative, this error is expected to be reduced with the future extension of the process. Firms indicated by the link but without exposure are the ‘false positive’ signals that can be corrected by the local expert’s revision. Another limitation regards the very large firms with different plants that are not recognized separately by the linkage. For all these reasons, our procedure must be considered only a screening tool with information that must be validated by the local experts evaluating the actual occupational history of the cases [
24].
The algorithm produced a list of firms with potential asbestos exposure that was linked to the occupational histories of cancer cases provided by the OCM system, for the detection of their association to asbestos exposure. Results showed that 18.5% of the firms where the cancer cases other than MM worked had an indication of possible exposure to asbestos.
We provided information extended to the entire country and, therefore, additional to the knowledge of local experts: About 50% of the links referred to firms in regions different from the region of the residence of the case. The graphical distribution of the firm addresses is an effective tool to explore this aspect, which will also be useful for the improvement of interview information in ReNaM.
The process is cost-saving and can be repeated whenever new information is gathered. We are not aware of similar activities using the information from mesothelioma registries for the identification of asbestos exposure of other tumor types. The first extension that can be planned is the nationwide extension of the project, now limited to seven regions, and the evaluation of occupational asbestos exposure for the national OCM system.




 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}