
IvCDS: An End-to-End Driver Simulator for Personal In-Vehicle Conversational Assistant

 ,
,
Abstract
:1. Introduction
Paper Structure
2. Related Work: Task-Oriented Dialogue Systems
2.1. Natural Language Understanding
2.2. Dialog Policy
2.3. Natural Language Generation
3. Methodology
3.1. Data
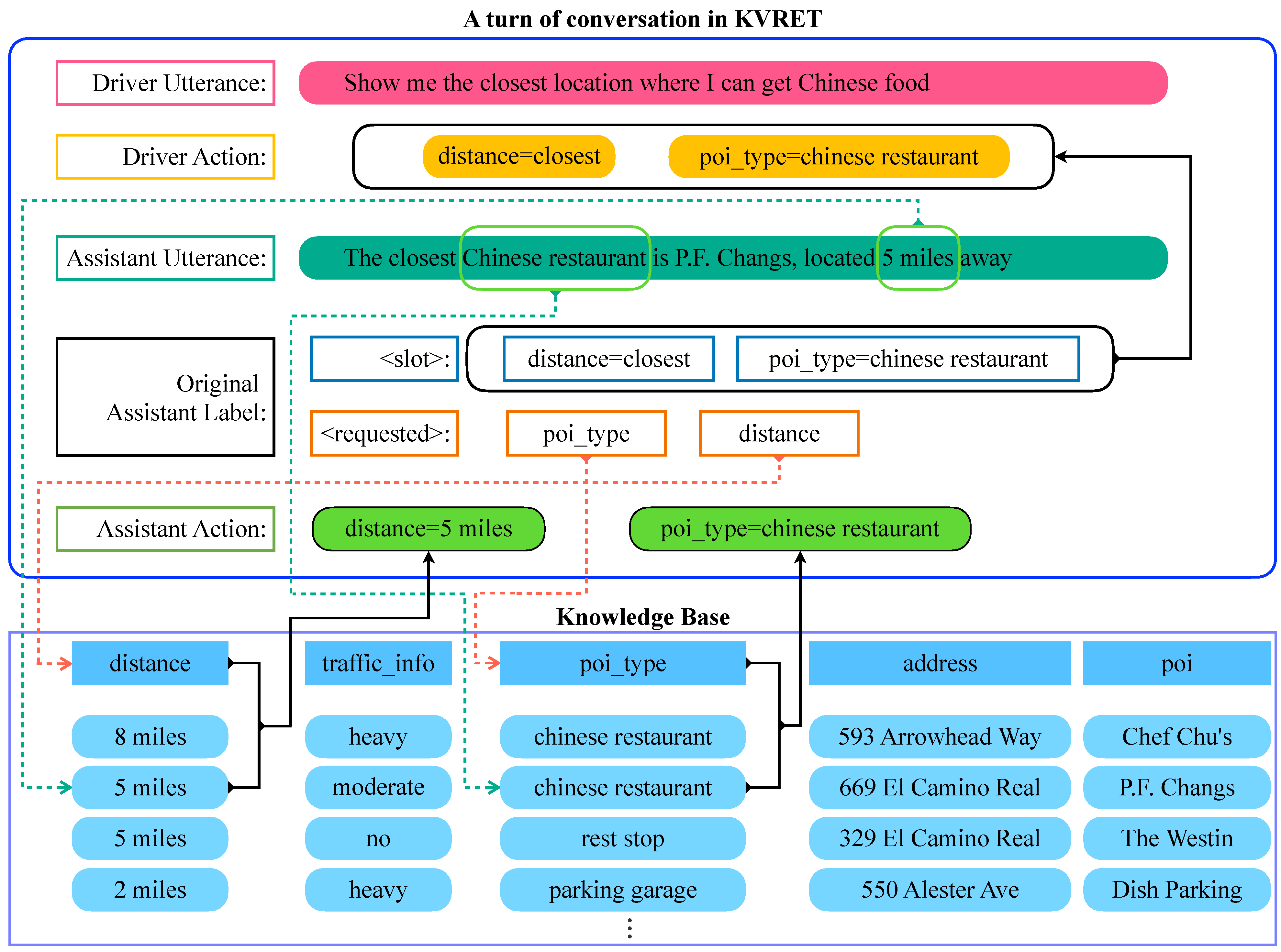
3.1.1. Assistant Actions
| Algorithm 1: The processing step of extracting assistant actions for the weather information retrieval scenario. |
|
3.1.2. Driver Actions
3.1.3. Driver Profile
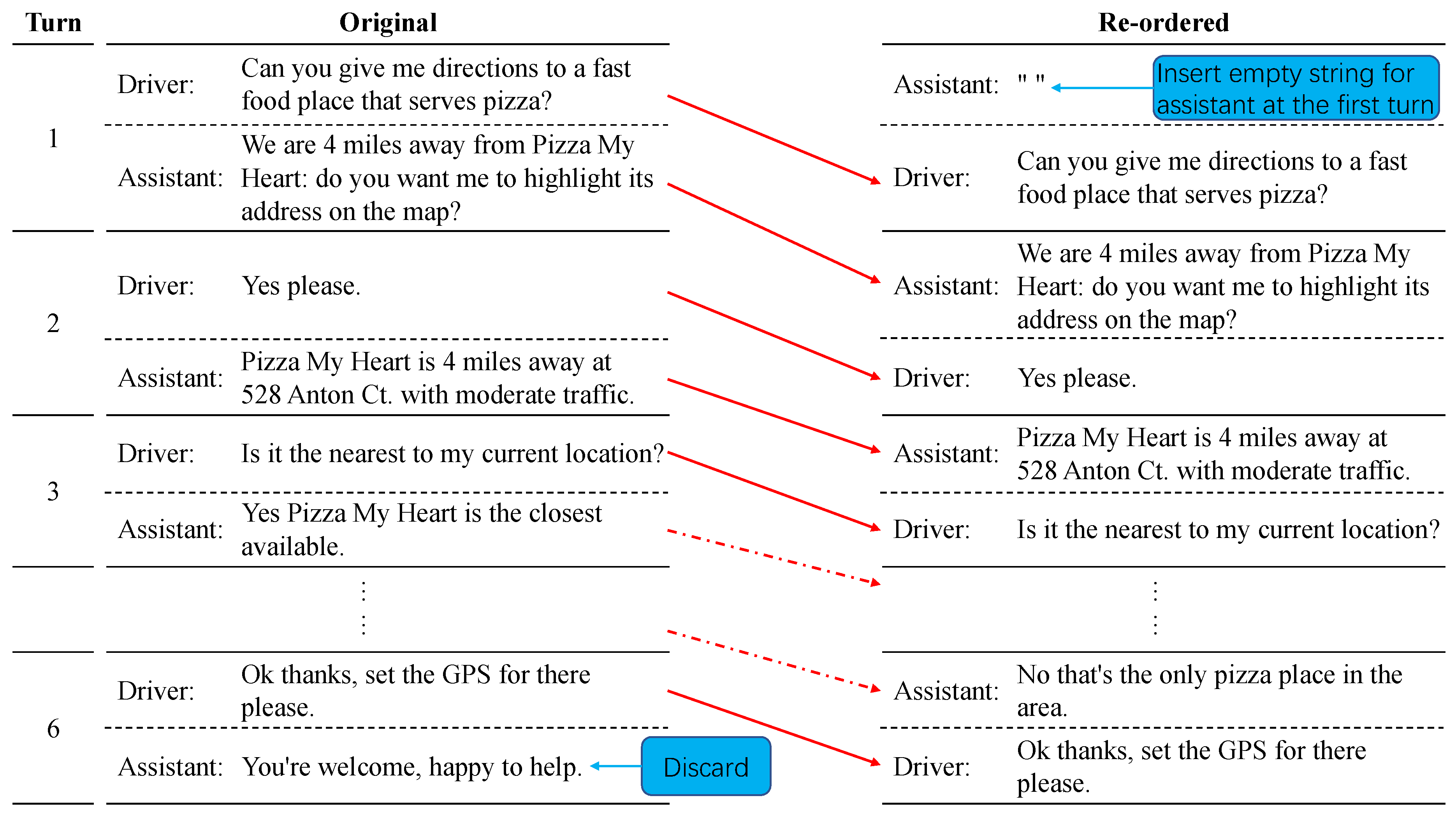
3.1.4. Reordering
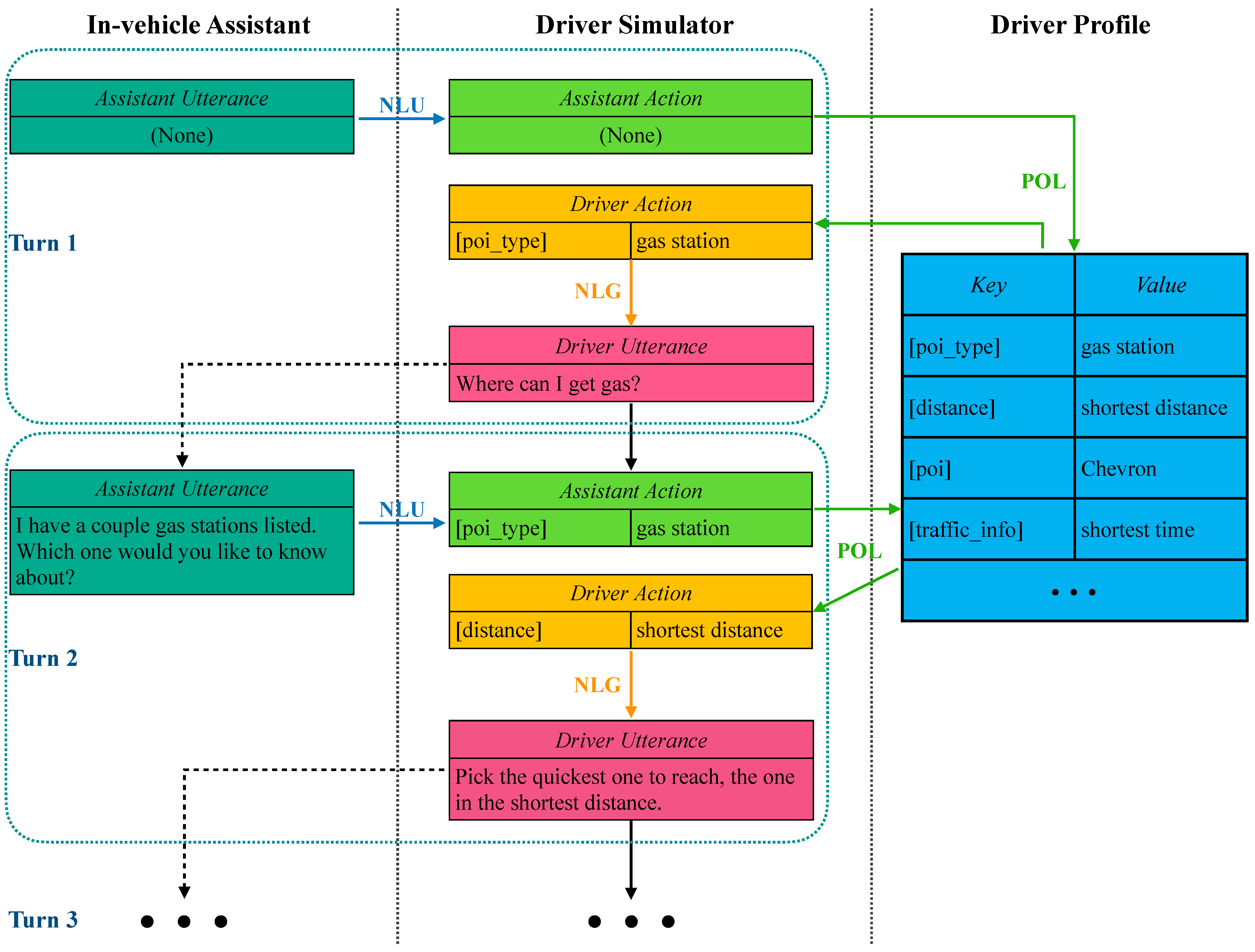
3.2. Model
3.2.1. NLU
3.2.2. Pol
3.2.3. Nlg
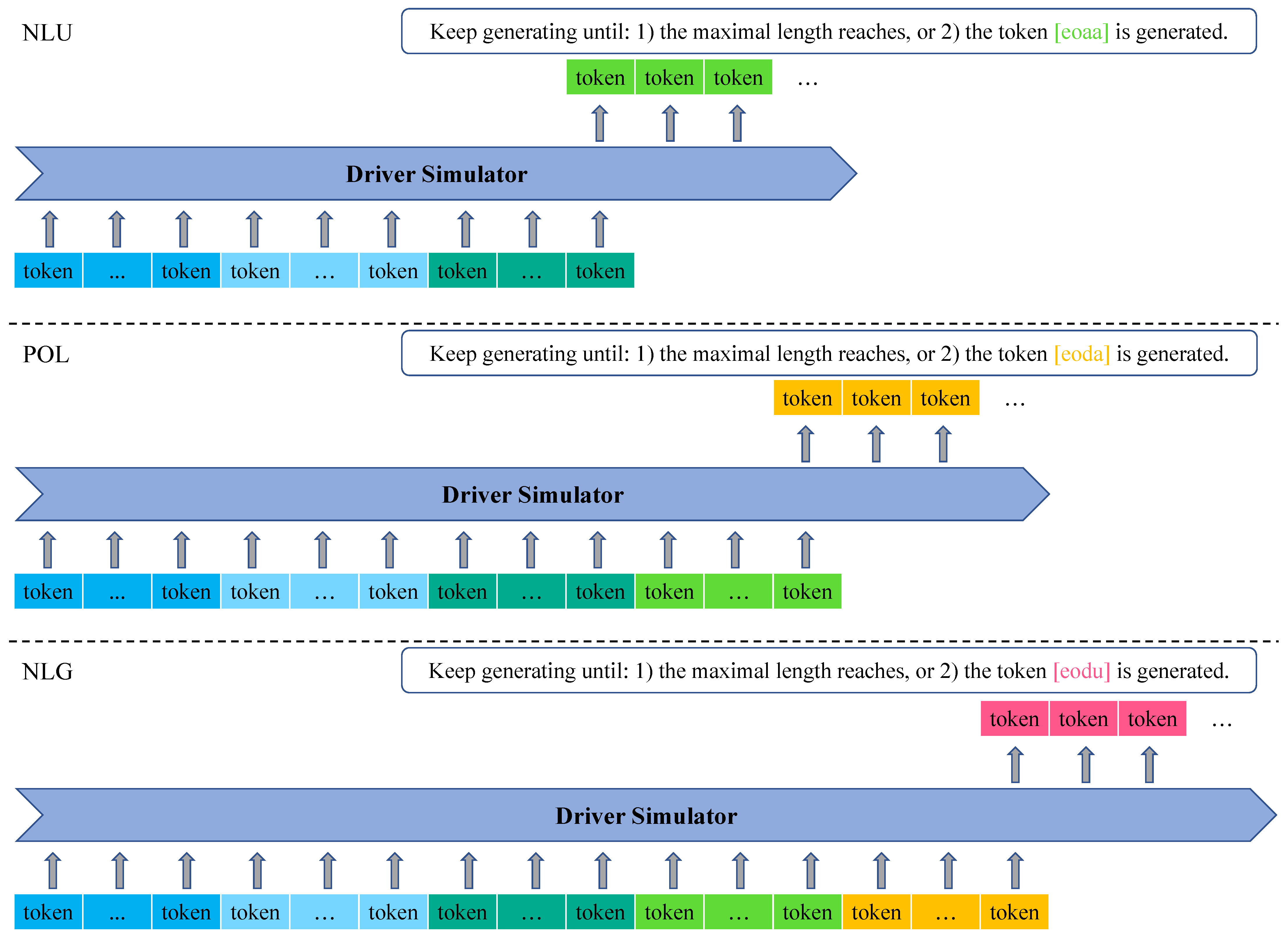
3.2.4. Training and Inference
| driver profile: | [sodp] | and | [eodp] |
| assistant utterance: | [soau] | and | [eoau] |
| assistant action: | [soaa] | and | [eoaa] |
| driver action: | [soda] | and | [eoda] |
| driver utterance: | [sodu] | and | [eodu]. |
4. Experiment
4.1. Experiment Setup
4.1.1. Baseline Models
4.1.2. Evaluation Metrics
- BLEU [76]: The bilingual evaluation understudy (BLEU) is an evaluation metric which assesses the quality of a generated candidate by the precision of the n-grams between it and its corresponding references. In this experiment, we computed the BLEU-4 score, which uses equally weighed 1∼4 grams.
- GLEU [77]: Google-BLEU (GLEU) is a variety of BLEU. Instead of the standalone precision, GLEU computes the precision and recall of n-gram between a candidate and a reference. The minimum between precision and recall is then uses as the GLEU score, and n is typically chosen as 4.
- ROUGE-L [78]: ROUGE-L is the widely applied variant of recall-oriented understudy for gisting evaluation (ROUGE), a recall-adapted version of BLEU, wherein L denotes to the longest common subsequence (LCS). It computes the precision and recall using the LCS between a candidate and a reference, rather than n-gram.
- METEOR [79]: Metric for evaluation of translation with explicit ordering (METEOR) is the evaluation metric that was initially proposed to remedy the known weaknesses of BLEU (e.g., BLEU does not consider recall and performs inaccurately when evaluating at the sentence level). In addition to exact match, METEOR uses other strategies such as synonyms mapping to match the uni-gram between a candidate and a reference, and the METEOR score is computed by the precision and recall.
4.2. System Performances
4.3. Ablation Experiment
4.3.1. Ablated Training & Inference
4.3.2. Sole Ablated Inference
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oviedo-Trespalacios, O.; Truelove, V.; Watson, B.; Hinton, J.A. The impact of road advertising signs on driver behaviour and implications for road safety: A critical systematic review. Transp. Res. Part A Policy Pract. 2019, 122, 85–98. [Google Scholar] [CrossRef]
- Cvahte Ojsteršek, T.; Topolšek, D. Influence of drivers’ visual and cognitive attention on their perception of changes in the traffic environment. Eur. Transp. Res. Rev. 2019, 11, 45. [Google Scholar] [CrossRef]
- Cao, Z.; Ceder, A.A.; Zhang, S. Real-time schedule adjustments for autonomous public transport vehicles. Transp. Res. Part C Emerg. Technol. 2019, 109, 60–78. [Google Scholar] [CrossRef]
- Cao, Z.; Ceder, A.A. Autonomous shuttle bus service timetabling and vehicle scheduling using skip-stop tactic. Transp. Res. Part C Emerg. Technol. 2019, 102, 370–395. [Google Scholar] [CrossRef]
- Hailin, W.; Hanhui, L.; Zhumei, S. Fatigue Driving Detection System Design Based on Driving Behavior. In Proceedings of the 2010 International Conference on Optoelectronics and Image Processing, Washington, DC, USA, 11–12 November 2010; Volume 1, pp. 549–552. [Google Scholar] [CrossRef]
- Stern, H.S.; Blower, D.; Cohen, M.L.; Czeisler, C.A.; Dinges, D.F.; Greenhouse, J.B.; Guo, F.; Hanowski, R.J.; Hartenbaum, N.P.; Krueger, G.P.; et al. Data and methods for studying commercial motor vehicle driver fatigue, highway safety and long-term driver health. Accid. Anal. Prev. 2019, 126, 37–42. [Google Scholar] [CrossRef] [PubMed]
- Fagnant, D.J.; Kockelman, K. Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations. Transp. Res. Part A Policy Pract. 2015, 77, 167–181. [Google Scholar] [CrossRef]
- Cao, Z.; Zhang, S.; Ceder, A.A. Novel coupling–decoupling strategy for scheduling autonomous public transport vehicles in overcrowded corridors. Appl. Math. Model. 2022, 106, 299–324. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Cao, D.; Velenis, E. Multi-scale driver behavior modeling based on deep spatial-temporal representation for intelligent vehicles. Transp. Res. Part C Emerg. Technol. 2021, 130, 103288. [Google Scholar] [CrossRef]
- Hasenjäger, M.; Heckmann, M.; Wersing, H. A Survey of Personalization for Advanced Driver Assistance Systems. IEEE Trans. Intell. Veh. 2020, 5, 335–344. [Google Scholar] [CrossRef]
- Yi, D.; Su, J.; Liu, C.; Quddus, M.; Chen, W.H. A machine learning based personalized system for driving state recognition. Transp. Res. Part C Emerg. Technol. 2019, 105, 241–261. [Google Scholar] [CrossRef]
- Gouribhatla, R.; Pulugurtha, S.S. Drivers’ behavior when driving vehicles with or without advanced driver assistance systems: A driver simulator-based study. Transp. Res. Interdiscip. Perspect. 2022, 13, 100545. [Google Scholar] [CrossRef]
- Feinauer, S.; Schuller, L.; Groh, I.; Huestegge, L.; Petzoldt, T. The potential of gamification for user education in partial and conditional driving automation: A driving simulator study. Transp. Res. Part F Traffic Psychol. Behav. 2022, 90, 252–268. [Google Scholar] [CrossRef]
- Yan, W.; Wong, S.; Loo, B.P.; Wu, C.Y.; Huang, H.; Pei, X.; Meng, F. An assessment of the effect of green signal countdown timers on drivers’ behavior and on road safety at intersections, based on driving simulator experiments and naturalistic observation studies. J. Saf. Res. 2022, 82, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Simović, S.; Ivanišević, T.; Trifunović, A.; Čičević, S.; Taranović, D. What Affects the E-Bicycle Speed Perception in the Era of Eco-Sustainable Mobility: A Driving Simulator Study. Sustainability 2021, 13, 5252. [Google Scholar] [CrossRef]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A survey on dialogue systems: Recent advances and new frontiers. ACM SIGKDD Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Cambria, E. Recent advances in deep learning based dialogue systems: A systematic survey. Artif. Intell. Rev. 2022, 1–101. [Google Scholar] [CrossRef]
- Adewumi, T.; Liwicki, F.; Liwicki, M. State-of-the-Art in Open-Domain Conversational AI: A Survey. Information 2022, 13, 298. [Google Scholar] [CrossRef]
- Kann, K.; Ebrahimi, A.; Koh, J.; Dudy, S.; Roncone, A. Open-domain Dialogue Generation: What We Can Do, Cannot Do, And Should Do Next. In Proceedings of the 4th Workshop on NLP for Conversational AI, Dublin, Ireland, 26 January 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 148–165. [Google Scholar] [CrossRef]
- Ji, T.; Graham, Y.; Jones, G.; Lyu, C.; Liu, Q. Achieving Reliable Human Assessment of Open-Domain Dialogue Systems. In Volume 1: Long Papers, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 6416–6437. [Google Scholar] [CrossRef]
- Louvan, S.; Magnini, B. Recent Neural Methods on Slot Filling and Intent Classification for Task-Oriented Dialogue Systems: A Survey. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 480–496. [Google Scholar]
- Li, C.; Zhang, X.; Chrysostomou, D.; Yang, H. ToD4IR: A Humanised Task-Oriented Dialogue System for Industrial Robots. IEEE Access 2022, 10, 91631–91649. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Z.; Guo, J.; Dai, Y.; Chen, B.; Luo, W. Task-Oriented Dialogue System as Natural Language Generation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2698–2703. [Google Scholar]
- Eric, M.; Krishnan, L.; Charette, F.; Manning, C.D. Key-Value Retrieval Networks for Task-Oriented Dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrücken, Germany, 15–17 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 37–49. [Google Scholar] [CrossRef] [Green Version]
- Budzianowski, P.; Vulić, I. Hello, It’s GPT-2-How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Liu, Q. Dialog state tracking with reinforced data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9474–9481. [Google Scholar]
- Madotto, A.; Lin, Z.; Zhou, Z.; Moon, S.; Crook, P.; Liu, B.; Yu, Z.; Cho, E.; Wang, Z. Continual learning in task-oriented dialogue systems. arXiv 2020, arXiv:2012.15504. [Google Scholar]
- Mi, F.; Wang, Y.; Li, Y. Cins: Comprehensive instruction for few-shot learning in task-oriented dialog systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 11076–11084. [Google Scholar]
- Mi, F.; Li, Y.; Zeng, Y.; Zhou, J.; Wang, Y.; Xu, C.; Shang, L.; Jiang, X.; Zhao, S.; Liu, Q. PANGUBOT: Efficient Generative Dialogue Pre-training from Pre-trained Language Model. arXiv 2022, arXiv:2203.17090. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gašić, M. MultiWOZ—A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 5016–5026. [Google Scholar] [CrossRef] [Green Version]
- Casanueva, I.; Temčinas, T.; Gerz, D.; Henderson, M.; Vulić, I. Efficient Intent Detection with Dual Sentence Encoders. In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Li, X.; Lipton, Z.C.; Dhingra, B.; Li, L.; Gao, J.; Chen, Y.N. A user simulator for task-completion dialogues. arXiv 2016, arXiv:1612.05688. [Google Scholar]
- Tseng, B.H.; Dai, Y.; Kreyssig, F.; Byrne, B. Transferable Dialogue Systems and User Simulators. In Volume 1: Long Papers, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 152–166. [Google Scholar] [CrossRef]
- El Asri, L.; He, J.; Suleman, K. A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems. Interspeech 2016 2016, 1151–1155. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Qian, K.; Wang, X.; Yu, Z. How to Build User Simulators to Train RL-based Dialog Systems. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1990–2000. [Google Scholar] [CrossRef] [Green Version]
- Furlan, R.; Gatti, M.; Menè, R.; Shiffer, D.; Marchiori, C.; Levra, A.G.; Saturnino, V.; Brunetta, E.; Dipaola, F. A natural language processing–based virtual patient simulator and intelligent tutoring system for the clinical diagnostic process: Simulator development and case study. JMIR Med. Inform. 2021, 9, e24073. [Google Scholar] [CrossRef] [PubMed]
- Schatzmann, J.; Thomson, B.; Weilhammer, K.; Ye, H.; Young, S. Agenda-Based User Simulation for Bootstrapping a POMDP Dialogue System. In Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics, Stroudsburg, PA, USA, 23–25 April 2007; Companion Volume, Short Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 149–152. [Google Scholar]
- Lee, H.; Jo, S.; Kim, H.; Jung, S.; Kim, T. SUMBT+LaRL: End-to-end Neural Task-oriented Dialog System with Reinforcement Learning. arXiv 2020, arXiv:2009.10447. [Google Scholar]
- Lipton, Z.; Li, X.; Gao, J.; Li, L.; Ahmed, F.; Deng, L. Bbq-networks: Efficient exploration in deep reinforcement learning for task-oriented dialogue systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Edmonton, AB, Canada, 13–17 November 2018; Volume 32. [Google Scholar]
- Wu, Y.; Li, X.; Liu, J.; Gao, J.; Yang, Y. Switch-based active deep dyna-q: Efficient adaptive planning for task-completion dialogue policy learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hi, USA, 27 January–1 February 2019; Volume 33, pp. 7289–7296. [Google Scholar]
- Li, Y.; Yao, K.; Qin, L.; Che, W.; Li, X.; Liu, T. Slot-consistent NLG for task-oriented dialogue systems with iterative rectification network. In Proceedings of the 58th annual meeting of the association for computational linguistics, Online, 5–10 July 2020; pp. 97–106. [Google Scholar]
- Gao, J.; Galley, M.; Li, L. Neural Approaches to Conversational AI. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2–7. [Google Scholar] [CrossRef]
- Peng, B.; Li, C.; Zhang, Z.; Zhu, C.; Li, J.; Gao, J. RADDLE: An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems. In Volume 1: Long Papers, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4418–4429. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Z.; Fang, Y.; Li, X.; Takanobu, R.; Li, J.; Peng, B.; Gao, J.; Zhu, X.; Huang, M. ConvLab-2: An Open-Source Toolkit for Building, Evaluating, and Diagnosing Dialogue Systems. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 142–149. [Google Scholar] [CrossRef]
- Yao, K.; Zweig, G.; Hwang, M.Y.; Shi, Y.; Yu, D. Recurrent neural networks for language understanding. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 2524–2528. [Google Scholar]
- Chen, Q.; Zhuo, Z.; Wang, W. Bert for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Kreyssig, F.; Casanueva, I.; Budzianowski, P.; Gašić, M. Neural User Simulation for Corpus-based Policy Optimisation of Spoken Dialogue Systems. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, Melbourne, Australia, 12–14 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 60–69. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Li, X.; Gao, J.; Chen, E. Budgeted Policy Learning for Task-Oriented Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3742–3751. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.S.; Hoi, S.C.; Socher, R.; Xiong, C. TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 917–929. [Google Scholar] [CrossRef]
- Mo, K.; Zhang, Y.; Li, S.; Li, J.; Yang, Q. Personalizing a dialogue system with transfer reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Edmonton, AB, Canada, 13–17 November 2018; Volume 32. [Google Scholar]
- Liu, B.; Tur, G.; Hakkani-Tur, D.; Shah, P.; Heck, L. Dialogue learning with human teaching and feedback in end-to-end trainable task-oriented dialogue systems. arXiv 2018, arXiv:1804.06512. [Google Scholar]
- Shah, P.; Hakkani-Tur, D.; Liu, B.; Tür, G. Bootstrapping a neural conversational agent with dialogue self-play, crowdsourcing and on-line reinforcement learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 3, (Industry Papers). pp. 41–51. [Google Scholar]
- Sun, W.; Zhang, S.; Balog, K.; Ren, Z.; Ren, P.; Chen, Z.; de Rijke, M. Simulating user satisfaction for the evaluation of task-oriented dialogue systems. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 2499–2506. [Google Scholar]
- Xu, P.; Hu, Q. An End-to-end Approach for Handling Unknown Slot Values in Dialogue State Tracking. In Volume 1: Long Papers, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1448–1457. [Google Scholar] [CrossRef]
- Peng, B.; Li, C.; Li, J.; Shayandeh, S.; Liden, L.; Gao, J. Soloist: Few-shot task-oriented dialog with a single pretrained auto-regressive model. arXiv 2020, arXiv:2005.05298. [Google Scholar]
- Peng, B.; Zhu, C.; Li, C.; Li, X.; Li, J.; Zeng, M.; Gao, J. Few-shot Natural Language Generation for Task-Oriented Dialog. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 172–182. [Google Scholar] [CrossRef]
- Quan, J.; Zhang, S.; Cao, Q.; Li, Z.; Xiong, D. RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 930–940. [Google Scholar] [CrossRef]
- Wen, T.H.; Vandyke, D.; Mrkšić, N.; Gašić, M.; Rojas-Barahona, L.M.; Su, P.H.; Ultes, S.; Young, S. A Network-based End-to-End Trainable Task-oriented Dialogue System. In Volume 1, Long Papers, Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Online, 19–23 April 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 438–449. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Volume 1 (Long and Short Papers), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Qi, W.; Yan, Y.; Gong, Y.; Liu, D.; Duan, N.; Chen, J.; Zhang, R.; Zhou, M. ProphetNet: Predicting Future N-gram for Sequence-to-SequencePre-training. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2401–2410. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-Training with Extracted Gap-Sentences for Abstractive Summarization. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Lyu, C.; Shang, L.; Graham, Y.; Foster, J.; Jiang, X.; Liu, Q. Improving Unsupervised Question Answering via Summarization-Informed Question Generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 10–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4134–4148. [Google Scholar] [CrossRef]
- Lai, H.; Toral, A.; Nissim, M. Thank you BART! Rewarding Pre-Trained Models Improves Formality Style Transfer. In Volume 2: Short Papers, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 484–494. [Google Scholar] [CrossRef]
- Lyu, C.; Foster, J.; Graham, Y. Extending the Scope of Out-of-Domain: Examining QA models in multiple subdomains. In Proceedings of the Third Workshop on Insights from Negative Results in NLP, Dublin, Ireland, 26 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 24–37. [Google Scholar] [CrossRef]
- Zhou, Y.; Portet, F.; Ringeval, F. Effectiveness of French Language Models on Abstractive Dialogue Summarization Task. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; European Language Resources Association: Paris, France, 2022; pp. 3571–3581. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017), Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, p. 30. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big bird: Transformers for longer sequences. In Proceedings of the Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Roller, S.; Dinan, E.; Goyal, N.; Ju, D.; Williamson, M.; Liu, Y.; Xu, J.; Ott, M.; Smith, E.M.; Boureau, Y.L.; et al. Recipes for Building an Open-Domain Chatbot. In Main Volume, Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Online, 19–23 April 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 300–325. [Google Scholar] [CrossRef]
- Rothe, S.; Narayan, S.; Severyn, A. Leveraging Pre-trained Checkpoints for Sequence Generation Tasks. Trans. Assoc. Comput. Linguist. 2020, 8, 264–280. [Google Scholar] [CrossRef]
- Ji, T.; Lyu, C.; Cao, Z.; Cheng, P. Multi-Hop Question Generation Using Hierarchical Encoding-Decoding and Context Switch Mechanism. Entropy 2021, 23, 1449. [Google Scholar] [CrossRef] [PubMed]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Online, 10–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 85–91. [Google Scholar]
- Meyes, R.; Lu, M.; de Puiseau, C.W.; Meisen, T. Ablation Studies in Artificial Neural Networks. arXiv 2019, arXiv:1901.08644. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Description |
|---|---|
| BART [62] | An approach which utilizes a transformer-based [71] denoising auto-regressive decoder combined with a transformer-based bidirectional encoder to pretrain a seq2seq model. In this experiment, BART-large and BART-base are examined. |
| BigBird [72] | A mechanism which uses sparse attention to enable transformer-based models to handle long sequences. |
| Blenderbot [73] | A transformer-based model trained on large scale data to carry out high-quality conversations. |
| Encoder-Decoder [74] | A framework for constructing a seq2seq model which respectively takes two pretrained models as its encoder and decoder. In this experiment, we examine BERT2BERT, a model using a BERT-based [61] encoder and a BERT-based decoder. |
| PEGASUS [64] | A transformer-based seq2seq model for the abstractive summarization task which is pretrained using extracted gap-sentences on large scale datasets. |
| ProphetNet [63] | A self-supervised model with future n-gram prediction and n-stream self-attention mechanisms that is pretrained on large scale text corpora for both question generation and text summarization tasks. |
| T5 [65] | A large-scale pretrained transformer-based model which utilizes transfer learning techniques to convert text-related language tasks into a text-to-text format. |
| Model | NLU | POL | NLG | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | BLEU-4 | ROUGE-L | METEOR | GLEU | |
| IvCDS | 92.87 | 91.71 | 92.29 | 87.23 | 86.98 | 87.10 | 28.19 | 49.29 | 47.88 | 27.80 |
| ProphetNet | 88.65 | 87.86 | 88.25 | 64.18 | 61.51 | 62.81 | 11.23 | 30.29 | 33.63 | 12.69 |
| BART-large | 76.59 | 86.85 | 81.40 | 66.26 | 89.26 | 76.06 | 20.37 | 40.86 | 49.75 | 22.50 |
| BART-base | 68.18 | 89.38 | 77.35 | 46.83 | 88.01 | 61.14 | 19.53 | 40.04 | 49.45 | 21.77 |
| Pegasus | 41.33 | 88.62 | 56.37 | 72.31 | 84.33 | 77.86 | 6.39 | 26.53 | 37.97 | 7.77 |
| T5-large | 39.19 | 67.13 | 49.49 | 37.09 | 41.97 | 39.38 | 7.80 | 26.55 | 39.35 | 9.39 |
| BigBird | 48.37 | 43.24 | 45.66 | 81.92 | 72.73 | 77.05 | 20.16 | 37.13 | 39.60 | 20.01 |
| Blenderbot | 29.97 | 76.86 | 43.12 | 32.62 | 58.80 | 41.96 | 2.98 | 13.52 | 27.02 | 3.62 |
| BERT2BERT | 19.41 | 87.23 | 31.76 | 21.28 | 68.38 | 32.46 | 4.45 | 21.32 | 29.80 | 5.35 |
| Training | Inference | NLU | POL | NLG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H | H | P | R | F1 | P | R | F1 | BLEU-4 | ROUGE-L | METEOR | GLEU | ||
| 78.23 | 88.09 | 82.87 | 18.34 | 24.00 | 20.79 | 1.43 | 10.13 | 11.67 | 2.63 | ||||
| ✓ | ✓ | 65.24 | 76.79 | 70.54 | 21.43 | 21.55 | 21.49 | 0.93 | 9.27 | 10.55 | 2.14 | ||
| ✓ | ✓ | 61.45 | 83.26 | 70.71 | 27.32 | 39.14 | 32.18 | 1.59 | 13.46 | 15.66 | 2.83 | ||
| ✓ | ✓ | 87.30 | 91.47 | 89.33 | 26.48 | 28.28 | 27.35 | 23.48 | 47.41 | 46.91 | 24.14 | ||
| ✓ | ✓ | ✓ | 92.47 | 91.94 | 92.20 | 28.77 | 31.28 | 29.97 | 26.36 | 48.35 | 47.17 | 26.02 | |
| ✓ | ✓ | ✓ | 88.94 | 91.36 | 90.13 | 73.47 | 79.30 | 76.27 | 27.82 | 48.67 | 48.43 | 27.41 | |
| ✓ | ✓ | ✓ | ✓ | 92.87 | 91.71 | 92.29 | 87.23 | 86.98 | 87.10 | 28.19 | 49.29 | 47.88 | 27.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, T.; Yin, X.; Cheng, P.; Zhou, L.; Liu, S.; Bao, W.; Lyu, C. IvCDS: An End-to-End Driver Simulator for Personal In-Vehicle Conversational Assistant. Int. J. Environ. Res. Public Health 2022, 19, 15493. https://doi.org/10.3390/ijerph192315493
Ji T, Yin X, Cheng P, Zhou L, Liu S, Bao W, Lyu C. IvCDS: An End-to-End Driver Simulator for Personal In-Vehicle Conversational Assistant. International Journal of Environmental Research and Public Health. 2022; 19(23):15493. https://doi.org/10.3390/ijerph192315493
Chicago/Turabian StyleJi, Tianbo, Xuanhua Yin, Peng Cheng, Liting Zhou, Siyou Liu, Wei Bao, and Chenyang Lyu. 2022. "IvCDS: An End-to-End Driver Simulator for Personal In-Vehicle Conversational Assistant" International Journal of Environmental Research and Public Health 19, no. 23: 15493. https://doi.org/10.3390/ijerph192315493
APA StyleJi, T., Yin, X., Cheng, P., Zhou, L., Liu, S., Bao, W., & Lyu, C. (2022). IvCDS: An End-to-End Driver Simulator for Personal In-Vehicle Conversational Assistant. International Journal of Environmental Research and Public Health, 19(23), 15493. https://doi.org/10.3390/ijerph192315493