
Influence of Multi-Modal Warning Interface on Takeover Efficiency of Autonomous High-Speed Train

Abstract
:1. Introduction
- (1)
- Compare and determine the modalities of the automatic driving interface for high-speed trains with the highest takeover performance;
- (2)
- Provide optimization suggestions for the current high-speed train interface to improve the safety of automatic driving of high-speed trains.
2. Related Work
2.1. Application Status of Automatic High-Speed Train Interface
2.2. The Influence of Multi-Modal Interface on Takeover Efficiency
2.2.1. Research on the Impact of Visual Warning Interface on Takeover Performance
2.2.2. Research on the Impact of Auditory Warning Interface on Takeover Performance
2.2.3. The Impact of Tactile Warning Interface on Takeover Performance
2.2.4. The Impact of the Multi-Modal Warning Interface on Takeover Performance
- (1)
- Compare warning interface forms and determine the best multi-modal warning interface form in the situation of the emergency takeover of automatic driving high-speed trains (level 3 warning).
- (2)
- Determine the interface elements and improvement directions that need to be optimized in the existing automatic driving high-speed train visual warning interface (level 1/level 2/level 3), and provide a reference for the optimization design of the high-speed train warning interface.
3. Research Method
3.1. Participants
3.2. Experimental Equipment
3.3. Prototype of Multi-Modal Warning Interface
3.3.1. Visual Interface Prototype
3.3.2. Auditory Interface Prototype
3.3.3. Tactile Interface Prototype
3.3.4. Takeover Information Interface Prototype
3.4. Variables Design
3.4.1. Takeover Time
3.4.2. Fixations
- (a)
- First fixation duration. The first fixation duration was defined as the time elapsed between the sending of a warning message and the time when the participant first gazes at the screen interface (the so-called area of interest, AOI). This information was used to indicate the initial recognition of the target stimulus [37]. The shorter the first fixation duration, the stronger the target’s ability to attract attention [38]. It also showed that the message can be delivered more effectively to the audience.
- (b)
- Total fixation duration. This indicator corresponded to the total fixation duration of the participant in the on-screen interface (AOI) during the takeover process. The total fixation duration can reflect the degree of cognitive difficulty. The longer the total fixation time, the higher the participant’s attention to the area, the greater the difficulty of the corresponding information processing, and the lower the processing efficiency [39].
- (c)
- Fixation count. Fixation count of the participant in the on-screen interface (AOI) during the takeover time. The more fixation points, the more difficult it is to determine the target and extract information [38].
3.4.3. Saccades
- (a)
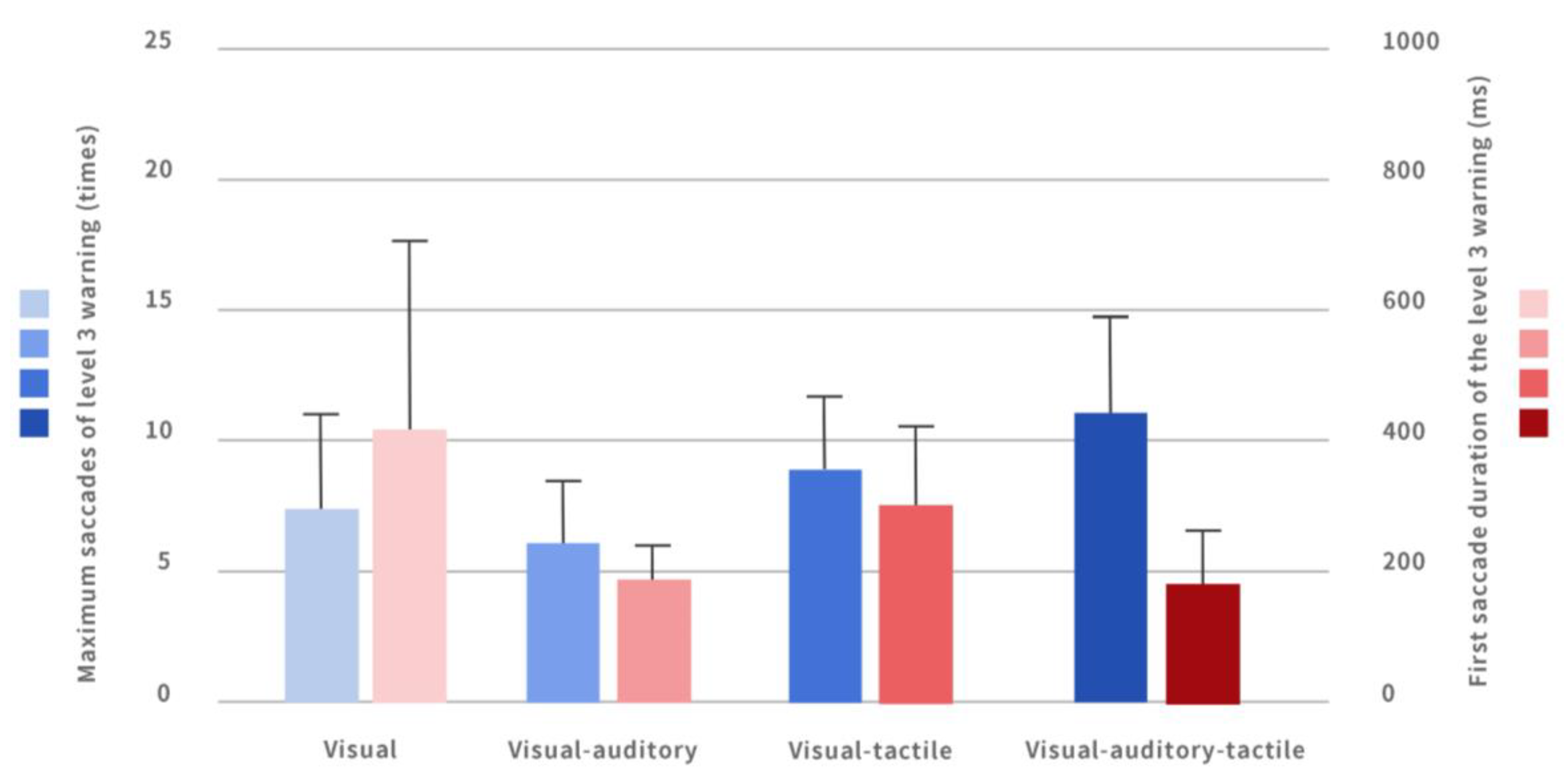
- Saccade count. This indicator reflects the count of visual saccades made during the takeover when receiving the three-level warning. The greater the saccade count, the longer the search process and the inability to determine the target position in time, which affects the takeover efficiency to a certain extent.
- (b)
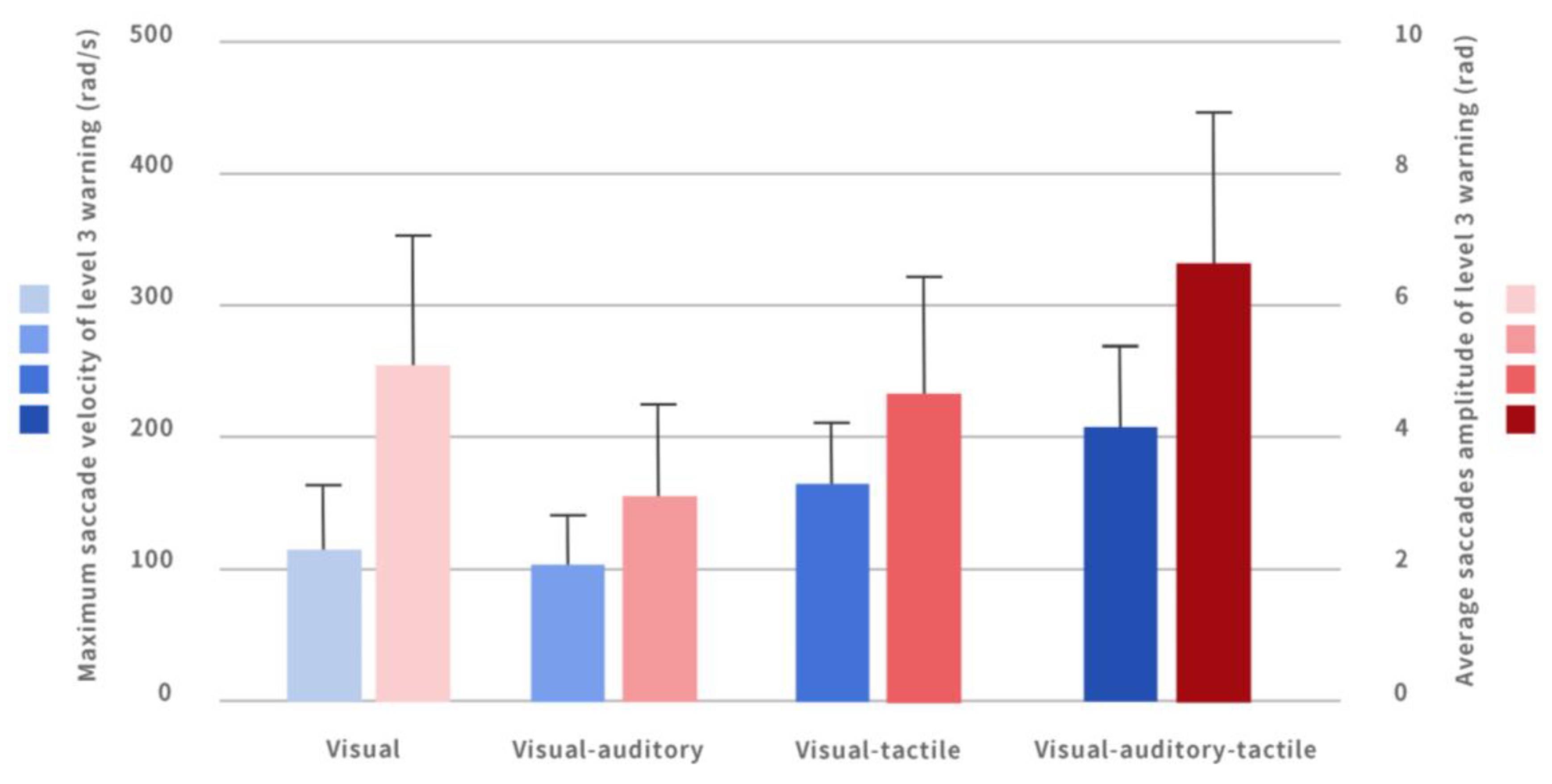
- Average saccade velocity/maximum saccade velocity. These indicators correspond to the average saccade velocity and maximum saccade velocity during the takeover process when the participant receives the level 3 warning. The larger the velocity, the faster the saccade and the more alert the participants.
- (c)
- Average saccade amplitude/maximum saccade amplitude. These indicators reflect the average saccade amplitude and maximum saccade amplitude during the takeover process when the participant receives the level 3 warning. The larger the saccade amplitude, the more meaningful exploration of new areas or locations. When these indicators are large, the subject will also be considered nervous, potentially corresponding to poor recognition of the rail environment [40].
- (d)
- First saccade duration. The duration of the first saccade during the takeover process when the participant received the level 3 warning. The longer the duration of the first saccade, the more difficult it is to process the task and the slower the response speed, resulting in higher takeover time and lower takeover efficiency [2].
3.5. Experiment Design
4. Results
4.1. Takeover Time
4.1.1. Comparison of the Takeover Time of the Visual Warning Interface in Different Levels of Warning
4.1.2. Comparison of the Takeover Time of Each Multi-Modal Warning Interface in the Level 3 Warning
4.2. Fixations
4.2.1. Comparison of the First Fixation Duration of the Visual Warning Interface in Different Levels of Warning
4.2.2. Comparison of the Total Fixation Duration within the AOI of the Visual Warning Interface in Different Levels of Warnings
4.2.3. Comparison of the Number of Fixations Count in the AOI of the Visual Warning Interface in Different Levels of Warning
4.3. Saccades
4.3.1. Comparison of Saccade Count under Different Warnings
4.3.2. Comparison of Average Saccade Velocity/Maximum Saccade Velocity under Different Warnings
4.3.3. Comparison of Average/Maximum Saccade Amplitude under Different Warnings
4.3.4. Comparison of the First Saccade Duration under Different Warnings
5. Discussion
6. Conclusions
Limitations
- None of the participants in the study involved in the experiment were professional drivers with experience in driving high-speed trains. Driving experience may have an effect on learning performance and takeover time, so there are limitations to the experimental results, and professional high-speed train drivers will be introduced for experimental investigation in the subsequent study.
- In the experiment, for the sake of experimental feasibility, the duration of simulated driving was set at 20 min and participants were asked to stay focused during the 20 min. In actual driving, the length of driving is usually one hour and above. The study was limited in its control of driving time and ignored the effect of driving fatigue on the driver taking over the operation.
7. Relevance to Industry
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luke, T.; Brook-Carter, N.; Parkes, A.M.; Grimes, E.; Mills, A. An investigation of train driver visual strategies. Cognit. Technol. Work 2005, 8, 15e29. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y. Brief introduction to the scientific and technological achievements of China Academy of Railway Sciences Group Co., Ltd. in 2018. China Railw. Sci. 2019, 118–128. [Google Scholar]
- Heping, L.; Huting, L. A study on the design of fundamental brake system for high speed train. China Railw. Sci. 2003, 24, 8e13. Available online: http://www.cqvip.com/qk/97928x/200302/7662916.html (accessed on 25 November 2022).
- Li, R.; Chen, Y.V.; Sha, C.; Lu, Z. Effects of interface layout on the usability of in-vehicle information systems and driving safety. Displays 2017, 49, 124–132. [Google Scholar] [CrossRef]
- Naweed, A.; Balakrishnan, G. Understanding the visual skills and strategies of train drivers in the urban rail environment. Work 2014, 47, 339–352. [Google Scholar] [CrossRef]
- Yoon, S.H.; Kim, Y.W.; Ji, Y.G. The effects of takeover request modalities on highly automated car control transitions. Accid. Anal. Prev. 2019, 123, 150–158. [Google Scholar] [CrossRef]
- Zhang, S. Overall Technical Scheme of CTCS-3 Train Control System; China Railway Press: Beijing, China, 2008. [Google Scholar]
- Xu, X.; Yi, H.; Tang, J.; Tang, M. Research on safety and man-machine responsibilities of CTCS2+ATO onboard equipment. Railw. Signal. Commun. Eng. 2017, 14, 4–8. [Google Scholar]
- Zhang, Y.; Qin, Y.; Li, K. Identification method of human-computer interface information of on-board equipment of CTCS-3 Train Control System. China Railw. Sci. 2010, 94–101. [Google Scholar]
- Niu, J.; Zhang, X.; Sun, Y.; Qin, H. Analysis of the driving behavior during the takeover of automatic driving vehicles in dangerous traffic situations. China J. Highw. Transp. 2018, 50, 89–98. [Google Scholar]
- Crundall, E.; Large, D.R.; Burnett, G. A driving simulator study to explore the effects of text size on the visual demand of in-vehicle displays. Displays 2016, 43, 23–29. [Google Scholar] [CrossRef]
- Purucker, C.; Naujoks, F.; Prill, A.; Neukum, A. Evaluating distraction of in-vehicle information systems while driving by predicting total eyes-off-road times with keystroke level modeling. Appl. Ergon. 2017, 58, 543–554. [Google Scholar] [CrossRef] [PubMed]
- Langlois, S.; Soualmi, B. Augmented reality versus classical HUD to take over from automated driving: An aid to smooth reactions and to anticipate maneuvers. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; IEEE: New York, NY, USA, 2016; pp. 1571–1578. [Google Scholar]
- Dettmann, A.; Bullinger, A.C. Spatially distributed visual, auditory and multimodal warning signals—A comparison. In Proceedings of the Human Factors and Ergonomics Society Europe Chapter 2016 Annual Conference, Chemnitz, Germany, 9–13 October 2017; pp. 185–199. [Google Scholar]
- Meng, F.; Spence, C. Tactile warning signals for in-vehicle systems. Accid. Anal. Prev. 2015, 75, 333–346. [Google Scholar] [CrossRef] [PubMed]
- Patterson, R.D. Auditory warning sounds in the work environment. Philosophical transactions of the Royal Society of London. B Biol. Sci. 1990, 327, 485–492. [Google Scholar]
- Nees, M.A.; Walker, B.N. Auditory displays for in-vehicle technologies. Rev. Hum. Factors Ergon. 2011, 7, 58–99. [Google Scholar] [CrossRef] [Green Version]
- Politis, I.; Brewster, S.; Pollick, F. To beep or not to beep? Comparing abstract versus language-based multimodal driver displays. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 3971–3980. [Google Scholar]
- Arrabito, G.R. Effects of talker sex and voice style of verbal cockpit warnings on performance. Hum. Factors 2009, 51, 3–20. [Google Scholar] [CrossRef] [PubMed]
- Jang, P.S. Designing acoustic and non-acoustic parameters of synthesized speech warnings to control perceived urgency. Int. J. Ind. Ergon. 2007, 37, 213–223. [Google Scholar] [CrossRef]
- Large, D.R.; Burnett, G.E. Drivers’ preferences and emotional responses to satellite navigation voices. Int. J. Veh. Noise Vib. 2013, 9, 28–46. [Google Scholar] [CrossRef]
- Gray, R. Looming auditory collision warnings for driving. Hum. Factors 2011, 53, 63–74. [Google Scholar] [CrossRef]
- Jones, L.A.; Sarter, N.B. Tactile displays: Guidance for their design and application. Hum. Factors 2008, 50, 90–111. [Google Scholar] [CrossRef]
- Petermeijer, S.M.; Abbink, D.A.; Mulder, M.; De Winter, J.C. The effect of haptic support systems on driver performance: A literature survey. IEEE Trans. Haptics 2015, 8, 467–479. [Google Scholar] [CrossRef]
- Bazilinskyy, P.; Petermeijer, S.M.; Petrovych, V.; Dodou, D.; de Winter, J.C. Take-over requests in highly automated driving: A crowdsourcing survey on auditory, vibrotactile, and visual displays. Transp. Res. Part F Traffic Psychol. Behav. 2018, 56, 82–98. [Google Scholar] [CrossRef]
- Schwalk, M.; Kalogerakis, N.; Maier, T. Driver support by a vibrotactile seat matrix—Recognition, adequacy and workload of tactile patterns in take-over scenarios during automated driving. Procedia Manuf. 2015, 3, 2466–2473. [Google Scholar] [CrossRef] [Green Version]
- Wickens, C.D.; Hollands, J.G.; Banbury, S.; Banbury, S. Engineering Psychology and Human Performance; Psychology Press: London, UK, 2015. [Google Scholar]
- De Groot, S.; De Winter, J.C.F.; Mulder, M.; Mulder, J.A.; Kuipers, J.; Wieringa, P.A. The effects of route-instruction modality on driving performance in a simulator. In Proceedings of the 9th TRAIL Congress, Rotterdam, The Netherlands, 21 November 2006. [Google Scholar]
- Prewett, M.S.; Elliott, L.R.; Walvoord, A.G.; Coovert, M.D. A meta-analysis of vibrotactile and visual information displays for improving task performance. IEEE Trans. Syst. Man Cybern. Part C 2011, 42, 123–132. [Google Scholar] [CrossRef]
- Bazilinskyy, P.; Kyriakidis, M.; de Winter, J. An international crowdsourcing study into people’s statements on fully automated driving. Procedia Manuf. 2015, 3, 2534–2542. [Google Scholar] [CrossRef] [Green Version]
- Bazilinskyy, P.; De Winter, J.C.F. Analyzing crowdsourced ratings of speech-based take-over requests for automated driving. Appl. Ergon. 2017, 64, 56–64. [Google Scholar] [CrossRef] [Green Version]
- Van Erp, J.B.F.; Toet, A.; Janssen, J.B. Unibi-and tri-modal warning signals: Effects of temporal parameters and sensory modality on perceived urgency. Saf. Sci. 2015, 72, 1–8. [Google Scholar] [CrossRef]
- Gauci, J.; Theuma, K.; Muscat, A.; Zammit-Mangion, D. Evaluation of a multimodal interface for pilot interaction with avionic systems. In Proceedings of the 2018 IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Woodsen, W.E. Human ngineering guide for equipment designer. Technol. Cult. 1964, 7, 124. [Google Scholar]
- Yoon, S.H.; Lee, S.C.; Ji, Y.G. Modeling takeover time based on non-driving-related task attributes in highly automated driving. Appl. Ergon. 2021, 92, 103343. [Google Scholar] [CrossRef]
- Henderson, J.M.; Hayes, T.R.; Rehrig, G.; Ferreira, F. Meaning guides attention during real-world scene description. Sci. Rep. 2018, 8, 13504. [Google Scholar] [CrossRef] [Green Version]
- Henderson, J.M. Visual attention and eye movement control during reading and picture viewing. In Eye Movements and Visual Cognition; Rayner, K., Ed.; Springer: New York, NY, USA, 1992; pp. 260–283. [Google Scholar]
- Tinghu, K.; Hui, Z. Eye movement analysis index in scene perception: Based on gaze and saccade perspective. Psychol. Sci. 2020, 43, 1312–1318. [Google Scholar]
- Goller, J.; Mitrovic, A.; Leder, H. Effects of liking on visual attention in faces and paintings. Acta Psychol. 2019, 197, 115–123. [Google Scholar] [CrossRef] [PubMed]
- Ross, J.; Morrone, M.C.; Goldberg, M.E.; Burr, D.C. Changes in visual perception at the time of saccades. Trends Neurosci. 2001, 24, 113–121. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, J.H.; Kotval, X.P. Computer interface evaluation using eye movements: Methods and constructs. Int. J. Ind. Ergon. 1999, 24, 631–645. [Google Scholar] [CrossRef]
- Yong, M.; Rui, F. Research progress on driver’s visual characteristics and driving safety. Chin. J. Highw. 2015, 6, 82–94. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Automation Level | Name | Definition | Application Status |
|---|---|---|---|
| GOA1 | Manual driving under the supervision of ATP (Automatic Train Protection) | All operations of the train are controlled by the driver, and the driver handles the emergency. | It has been widely used. |
| GOA2 | Automatic driving with driver monitoring | Equipped with automatic driving system. The daily operation is controlled by the system, and a driver is on duty to handle emergency situations. | The high-speed train automatic driving system that is currently being developed and can be realized at present. |
| GOA3 | Manned autonomous driving | Drivers are replaced by automatic driving system and other system functions, and only crew members are arranged to deal with emergencies. | Not yet applied. |
| GOA4 | Unattended autopilot | At present, it is the highest level of train automation system. There are no drivers or crew members, and all functions are automatically managed by the system. | Not yet applied. |
| Warning Level | Urgency Level | Interface Warning Method | Disposal of Drivers |
|---|---|---|---|
| Level 1 | Low | Report warning information in text (Figure 1a). | Needs to be checked immediately, no need to be processed immediately. |
| Level 2 | Medium | A red triangle icon is displayed in the upper-right corner of the screen, including a text report and warning identification (Figure 1b). | Needs to be checked immediately, can be processed immediately, or can be processed after arriving at the station. |
| Level 3 | High | A red triangle icon is displayed in the upper-right corner of the screen, and warning information such as group number, carriage, warning type, fault code, and treatment measures are reported in the form of pop-up window (Figure 1c). | Needs to be checked immediately, needs to be processed immediately. |
| Takeover Time | p | Contrast Item | Adjusted Significance | |
|---|---|---|---|---|
| level 1 | 1.863 (1.585–2.223) | <0.001 | level 2 | 0.368 |
| level 2 | 1.649 (1.468–2.01) | level 3 | <0.001 | |
| level 3 | 2.794 (2.295–3.11) | level 1 | <0.001 | |
| First fixation duration within AOI | p | Contrast item | Adjusted significance | |
| level 1 | 586 (327.5–891.5) | <0.001 | level 2 | 0.118 |
| level 2 | 267.5 (182.25–423.5) | level 3 | <0.001 | |
| level 3 | 368.5 (271–545.75) | level 1 | 0.037 | |
| Total fixation duration in AOI | p | Contrast item | Adjusted significance | |
| level 1 | 392 (322.75–527.5) | <0.001 | level 2 | 0.025 |
| level 2 | 531.5 (422–667.25) | level 3 | 0.435 | |
| level 3 | 600.5 (426.75–854.25) | level 1 | <0.001 | |
| Fixation counts in AOI | p | Contrast item | Adjusted significance | |
| level 1 | 2 (1–2.33) | 0.001 | level 2 | 1.000 |
| level 2 | 2 (2–3) | level 3 | 0.006 | |
| level 3 | 1.67 (1.33–2) | level 1 | 0.002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, C.; Dai, H.; Yao, X.; Du, D.; Yu, K.; Yu, D.; Zhi, J. Influence of Multi-Modal Warning Interface on Takeover Efficiency of Autonomous High-Speed Train. Int. J. Environ. Res. Public Health 2023, 20, 322. https://doi.org/10.3390/ijerph20010322
Jing C, Dai H, Yao X, Du D, Yu K, Yu D, Zhi J. Influence of Multi-Modal Warning Interface on Takeover Efficiency of Autonomous High-Speed Train. International Journal of Environmental Research and Public Health. 2023; 20(1):322. https://doi.org/10.3390/ijerph20010322
Chicago/Turabian StyleJing, Chunhui, Haohong Dai, Xing Yao, Dandan Du, Kaidi Yu, Dongyu Yu, and Jinyi Zhi. 2023. "Influence of Multi-Modal Warning Interface on Takeover Efficiency of Autonomous High-Speed Train" International Journal of Environmental Research and Public Health 20, no. 1: 322. https://doi.org/10.3390/ijerph20010322
APA StyleJing, C., Dai, H., Yao, X., Du, D., Yu, K., Yu, D., & Zhi, J. (2023). Influence of Multi-Modal Warning Interface on Takeover Efficiency of Autonomous High-Speed Train. International Journal of Environmental Research and Public Health, 20(1), 322. https://doi.org/10.3390/ijerph20010322