1. Introduction
To cope with the growing severity of environmental challenges and climate change, in 2020, the Chinese government announced a new target toward a carbon dioxide emission peak by 2030. The country aims to strengthen regulations and take measures in order to attain carbon neutrality by 2060 [
1]. One critical component of achieving a low-carbon future is expanding the usage of clean energy sources such as solar and wind [
2]. However, in the case of an unstable clean energy supply and immature large-scale energy storage technologies, coal, China’s most abundant fossil fuel, is an essential source of energy security.
Due to the low safety and lower production efficiency challenges associated with underground mining, China’s open-pit coal mining capacity has increased year by year, from less than 5% of total coal output in 2000 to 10% in 2010 and 21% in 2016. At present, the proportion of open-pit mining also continues to grow [
3]. However, open-pit mining brings a number of environmental problems and health issues [
4,
5], owing to the fact that green and climate-smart mining practices are not yet well implemented in China [
6].
In relative terms, surface mining leads to more environmental degradation and air pollution than underground mining, with particulate matter pollution being one source of pollution [
7,
8], especially in northwest China, where rainfall is low, and water resources are scarce [
9]. The high soil content and low rock hardness of the material stripped from open-pit coal mines make road dust a serious problem [
10], especially in winter when air pressure is low [
11]. As a result, significant watering is required to reduce the concentration of dust [
12]. Therefore, as an indispensable component of green and climate-smart mining [
13], the effective utilization of water resources has become an essential aspect of open-pit dust concentration control. The accurate prediction and estimation of dust concentrations are critical in this respect for optimizing water consumption rates.
Establishing monitoring stations is a highly practical method of obtaining environmental data, such as dust concentrations in open-pit mines [
14]. Estimating dust concentrations based on measured data can effectively provide critical information that aids dust management in the area surrounding the monitoring locations. Researchers around the world have attempted to study dust concentration estimations. For instance, Tartakovsky, et al. [
15] used the atmospheric dispersion models AERMOD and CALPUFF to estimate TSP in a quarry. The results showed that the estimations of AERMOD exhibited better agreement with the measurements than those of CALPUFF, while the estimations showed that on-site meteorological data proved to be the key to reliable dispersion calculations in complex terrain. Wanjun and Qingxiang [
16] used a fluent model to simulate the transport pattern of dust concentration in an open-cast coal mine and analyzed the variation of dust concentration with the wind flow. Qi, et al. [
17] used the particle swarm optimization method to optimize the random forest (RF) hyperparameters to improve dust concentration estimation accuracy. Lu, et al. [
18] used a gradient boosting machine to predict dust concentration in an open-pit mine. Li, et al. [
19] used long short-term memory (LSTM) to predict dust concentration in open-pit mines.
The literature demonstrates that, among the different tools and techniques available, machine learning—a multidisciplinary field method involving probability theory, statistics, and a range of other disciplines—is widely applicable and highly effective at predicting and estimating [
20,
21,
22]. Previously, the research team had used the random forest-particle swarm optimization (RF-PSO) model to estimate dust concentrations in open-pit coal mines and achieved good results, with Pearson correlation coefficients of 0.91, RMSE of 6.97, and MAE of 3.95 for PM2.5 [
17]. However, a serious problem was identified in subsequent studies. The problem is that the intensity of mining often changes during ongoing production due to a variety of factors, such as geological conditions, production schedules, and climate change, making it necessary to update the model frequently and over a relatively long period, while the expertise to update the model is lacking in Chinese open-pit coal mines. The direct cause of dust pollution and mining intensity can be added to the model inputs to reduce the frequency of updates. However, mining intensity is challenging to quantify, so a model with a low update time and low update difficulty is more suitable for field applications, as well as for existing mine personnel to learn and maintain the model.
This study, therefore, proposes the application of the random forest-Markov chain (RF-MC) model to dust concentration estimation, as it treats the transition of errors in the time-ordered dust concentration estimates as a Markov process and uses Markov chains to correct the estimations obtained through the RF model to improve the estimation accuracy. The core of this model update operation is the update of the MC model through historical data statistics, which allows for simple and fast model updates with the possibility of automatic updates through programming, making it more suitable for field applications. At the same time, this study is more concerned with the effect of Markov chains on the correction of random forests, especially for RF models with relatively poor estimation accuracy, which will affect the frequency of the RF model updates in the RF-MC model.
3. Results and Discussion
3.1. Random Forest Estimation
From the above analysis, it is clear that the RF-MC model involves a total of three datasets: a training set for training the random forest model, a test set for testing the model, which, along with the test results, is an important dataset for establishing the transition matrix, and a correction set for testing the Markov correction performance.
Random forest model training requires a large number of datasets as a training base to ensure the applicability of the model. Moreover, data outside the model establishment process is needed as a test set for testing the performance of the model and as the base data for Markov correction. Therefore, the study must ensure that there is sufficient training data for the random forest model, as well as data for establishing the transfer matrix. As a result, 70% of the measurement data is selected as the training set and 30% as the test set. In other words, the first 7 days of the 10 days of data collected were used as the training set (29,176 data) and the last 3 days as the test set (11,905 data). The test set should normally be 12,205 data, but the study kept the last 300 data as a correction set for the Markov correction.
Hyperparameters have an important influence on the training results of random forest models, and general machine learning research also focuses on how to determine better hyperparameters. However, the focus of this study is to analyze the ability of Markov chains to correct machine learning estimations, especially for models with poor estimation accuracy.
Therefore, The hyperparameters in this study were chosen directly from the past training results [
17]. Compared to the previous random forest model, the input for this study has no wind direction or noise and adds atmospheric pressure. As expected, a random forest model with poor estimation accuracy was obtained. The hyperparameters of RF were chosen, as shown in
Table 2.
The Pearson correlation coefficient (R), mean absolute error (MAE), and root mean squared error (RMSE) were chosen as the evaluation index for the estimation results and are calculated as follows.
R reflects the linear relationship between the estimated and measured values. The better the estimate, the closer the R is to 1. The closer it is to 0, the worse the estimate is. RMSE and MAE can directly reflect the average error between the true value xr and the estimated value xe, which is more conducive to field personnel visually judging the estimation results.
In the test set, PM2.5, PM10, and TSP were estimated, respectively, and the estimation results are shown in
Table 3. Compared to the
R values of around 0.9 obtained in a previous study, this random forest model performs poorly and has relatively large errors in the
RMSE and
MAE.
3.2. Markov Chain Correction
3.2.1. Error Statistics and Transition Matrix Acquisition
Among the 12,205 data points, 11,905 estimated values were used as the training set for the Markov chain correction, and the remaining 300 retained data were used as the correction set. The error
e is calculated according to the following formula.
Figure 5 shows the estimation error distribution for 11,905 estimated values.
The PM2.5, PM10, and TSP errors are mainly distributed between −1 and 1. The middle of the range of error status is used as the correction parameter
c, so the greater the number of statuses, the smaller the maximum possible correction error when the status estimate is accurate. In this study, the error
e was divided into 16 levels, as shown in
Table 4.
The following equation is the formula for the Markov chain correction for the corrected data
xmc.
The error status was divided for all data in the training and correction sets. The transition status of the training set data was determined according to the transition step
n = 1, 2, 3, respectively.
Table 5 shows the status transition of some of the data for PM2.5. The transition statuses derived from the different transition steps for PM2.5, PM10, and TSP were then counted separately.
Table 6 shows the one-step transition matrix for PM2.5. After obtaining the transition matrix for the different transition steps, the RF was applied to the 300 corrections set data. Afterwards, each estimated data was corrected in time order.
3.2.2. Result Correction of RF Estimation
The
RMSE comparison of the estimated values, before and after the Markov chain correction for the 300 data, is shown in
Table 7. The estimated values after the Markov correction are significantly better than those before the correction, with the one-step transition correction being the best, indicating that the estimated data status is the most relevant to the previously estimated data error.
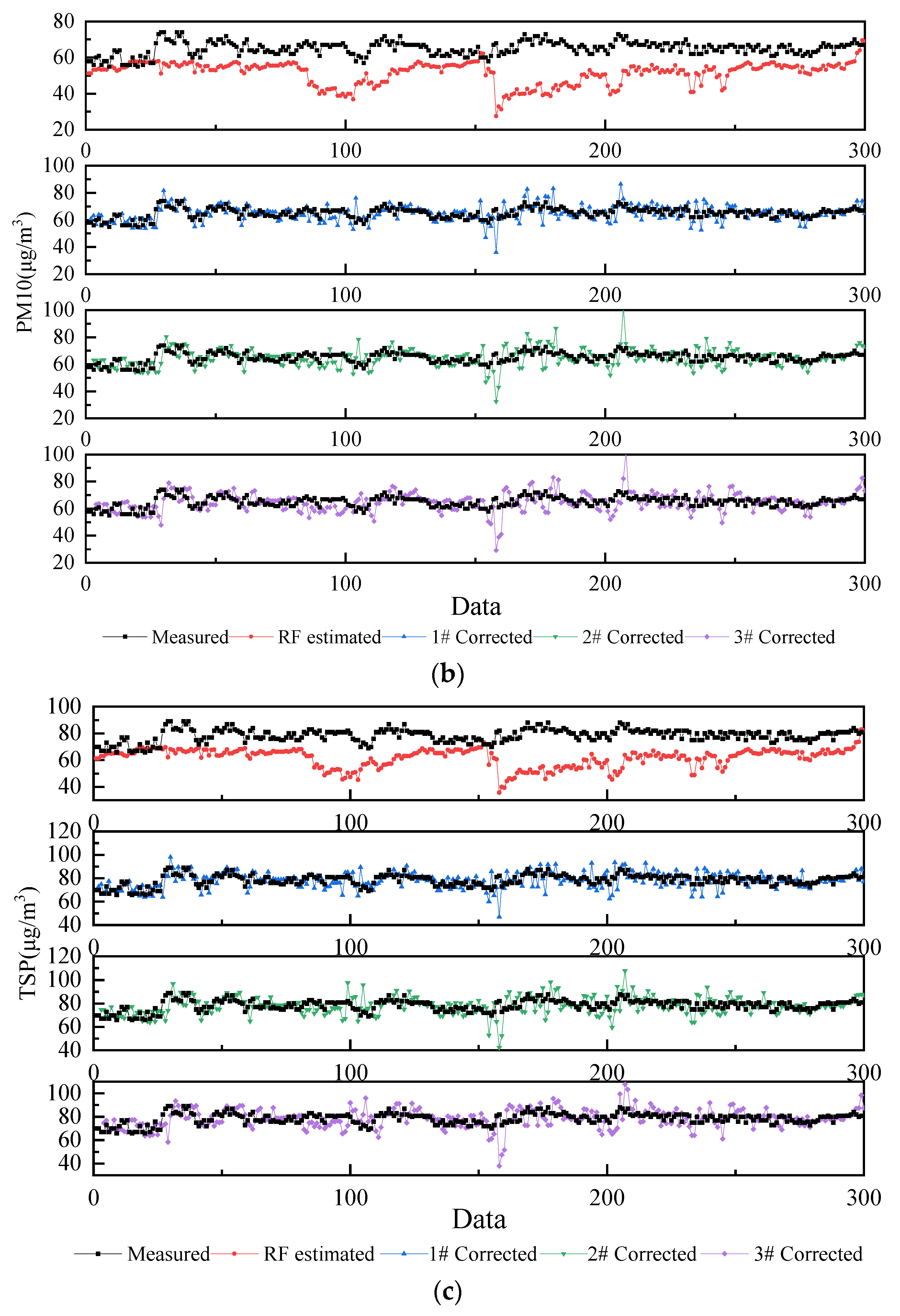
The measured values from the field, the estimated values by RF, and the corrected values by Markov chain are shown in
Figure 6, where 1#, 2#, and 3# represent a one-step transition, two-step transition, and three-step transition, respectively. The fold line shows some error between the measured data and the estimated data, with the estimated data being small overall. The
RMSE and
MAE of the corrected data are significantly smaller. The corrected curve is overall near the measured data curve. However, there are fluctuations caused by over-correction or under-correction, and this fluctuation is also reflected in the R-value. The possible reasons for this may be that the noise of the measured data affects the transition probability, that the number of status divisions is insufficient, or both.
As seen in
Figure 7, in the previous study, the R in the PM2.5 performance evaluation reached 0.91, far better than the 0.45 performance in this study. Although the RMSE was reduced from 6.97 to 2.56 and the
MAE from 3.95 to 2.44, the inconsistency in the range of dust concentrations between the two studies makes it difficult to compare the
RMSE and
MAE.
Although the corrected R is still not good enough, the performance of RMSE and MAE is more important for field applications. The 1st level limits of the daily average for PM2.5, PM10, and TSP required in China are 0–35, 0–50, and 0–120, respectively, while the RMSE and MAE for TSP are only 6.27 and 4.28. The accuracy of the estimates in this study will not cause a large bias in determining dust concentrations in the field. Similar conclusions were drawn for PM2.5 and PM10. In addition, it can also be found that the larger the dust particle size, the worse the estimation. Future research on PM10 and TSP may need to consider more features or different approaches in order to further improve the estimation effect. Overall, Markov chains can simply and significantly improve the estimation accuracy of random forest models with poor accuracy to a level that can be applied in the field.
3.3. Discussion of the Feasibility of Application in Chinese Open-Pit Coal Mines
The essence of the RF-PSO model is that RF updates the model, while PSO improves the speed with which the RF model is updated. Due to the excellent correction effect of the MC model, the RF-MC model update is mainly an update of the MC model. The RF model update frequency can be very low as long as the estimation accuracy after MC correction can meet the field requirements. At the same time, MC model updates are statistically more easily and quickly performed than those for the RF-PSO model, and they also have the potential for automation. This makes learning and maintaining estimation models easier for open-pit mine managers. A schematic comparison of the two models is shown in
Figure 8, where a specific update interval is assumed for the model.
For input parameter acquisition, estimation models require parameters such as temperature and humidity as inputs. Although these inputs need to be estimated, new energy policies in China in recent years have opened the possibility of obtaining these inputs for open-cast coal mines [
30]. To ensure a stable supply of electricity and a higher proportion of new energy, the Chinese government has in recent years been promoting the construction of energy bases, i.e., thermal power plants near coal mines, to ensure the supply of coal. At the same time, photovoltaic power stations are being built in the dumps of open-pit coal mines, and wind power plants are being built nearby, where meteorological conditions permit. In order to ensure that the proportion of electricity generated by different energy sources is regulated adequately at different times, the local meteorological authorities are required to provide detailed weather forecasts to the energy bases or to set up small weather forecasting stations at the energy bases, which provide reliable input data—such as temperature and humidity—needed to estimate dust concentrations.
Regarding sprinkler dispatch, there are two main levels. The first is to estimate the overall daily dust concentration and prepare the number of sprinklers needed to be deployed in advance. Second, it takes approximately one hour for the mine’s sprinklers to prepare to start sprinkling at the designated location, so estimating every hour of the day means that the sprinklers can be scheduled consistently, while parameters such as temperature and humidity are announced by the meteorological office at one-hour intervals.
Concerning the overall open-pit coal mine application, there are inconsistencies in dust pollution levels in different production areas due to different production intensities, meaning that the model built based on data from one monitoring point may not be suitable for estimating other monitoring point areas. Therefore, the adaptability of different monitoring areas to a single model should also be tested in future studies or field applications. Potentially, multiple estimation models may be needed to satisfy the demands different areas. Moreover, model reliability during seasonal transitions is being tested to determine whether there is an impact on model accuracy when large changes in climate occur.
In addition, this study is also an essential contribution to green and climate-smart mining. In China, the concept of green mining started in 2003 [
31] and has been strongly endorsed by the government and society [
32]. It remains the development objective of the Chinese coal industry [
33]. Green mining utilizes green technologies to improve environmental efficiency and maintain the mining industry’s competitiveness over a mine’s entire life cycle. It is particularly crucial for supplying minerals in a way that is economically feasible, socially advantageous, and environmentally responsible [
34]. As an integral component of green open-pit mining, dust management is critical for reducing the environmental pollution in and around mines to protect human health and operation safety [
35]. For example,
Table 8 showing China’s National Ambient Air Quality Standards (GB3095-2012), in conjunction with
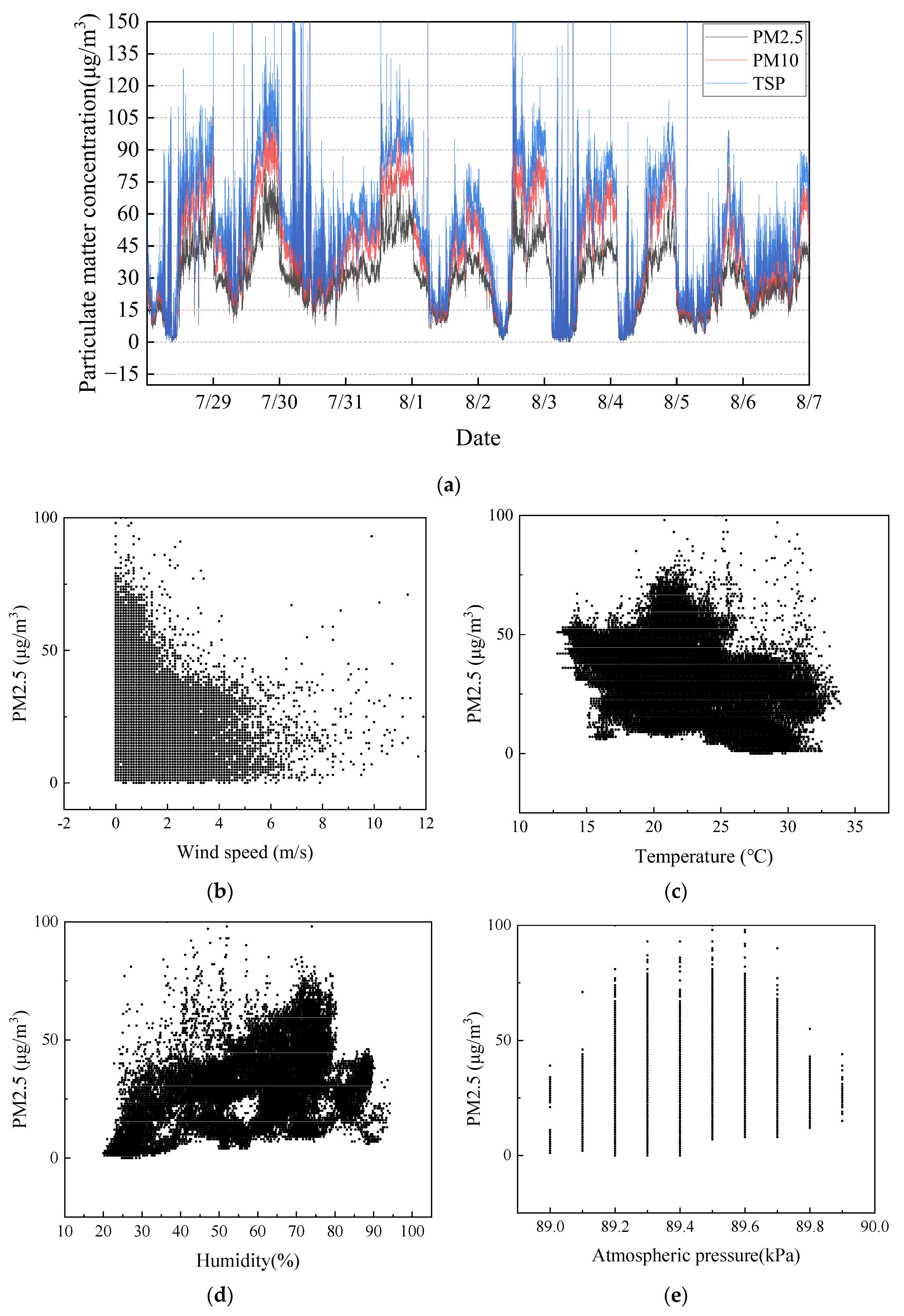
Figure 2a, indicates that the PM2.5 and PM10 concentrations are at the 2nd level for several time intervals, causing health and safety problems, environmental penalties, and loss of production. The accurate estimation of dust concentration not only provides technical support for road dust management, but also offers directions for managing dust in other operations, such as drilling, blasting, and crushing station unloading. By accurately estimating dust concentrations, our proposed approach assists inherently dust-producing open-pit mining operations in ensuring the sustainable development of mine operations and realizing green and climate-smart mining.
4. Conclusions
Dust management in open-pit mines is critical to ensuring miners’ health, the safety of production operations, and the reduction of environmental pollution, which are key components of China’s green mining development. This study proposes an RF-MC model to estimate dust concentrations in open-pit coal mines with an RMSE of only 2.56 (PM2.5), 5.28 (PM10), and 6.27 (TSP), which meets the requirements of estimation accuracy and field application, while also providing technical support for the rational utilization of water resources and dust management in mines. The findings showed that the correction process of the Markov chain is relatively simple. It mainly involves error statistics, status classification, and status transfer statistics. It is faster and simpler than training random forests, making it more suitable for application in open-pit coal mines. Meanwhile, relying on Markov chains can improve the accuracy of random forest models with poor accuracy. After the one-step transition matrix correction, the RMSE of PM2.5 reduced from 7.40 to 2.56, of PM10 from 15.73 to 5.28, and of TSP from 18.99 to 6.27. In comparison, the two and three-step transition matrix corrections are slightly less effective, but still noticeable. The improved machine learning method proposed in the study uses Markov chain correction as its core. In the first RF-MC model application, the training is mainly for RF. Each time the model accuracy decreases afterwards, a rapid error correction is performed, using only MC, to update the model accuracy and bring it back into use.
In future research, the influence of time and space on the accuracy of the dust estimation model will be one of the study directions in order to ensure the performance of the estimation model for its application over the whole open-pit coal mine.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}