
Neighborhood Deprivation, Indoor Chemical Concentrations, and Spatial Risk for Childhood Leukemia


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Data
2.2. Neighborhood Data
2.3. Statistical Models
2.4. Selection Bias Sensitivity Analysis
3. Results
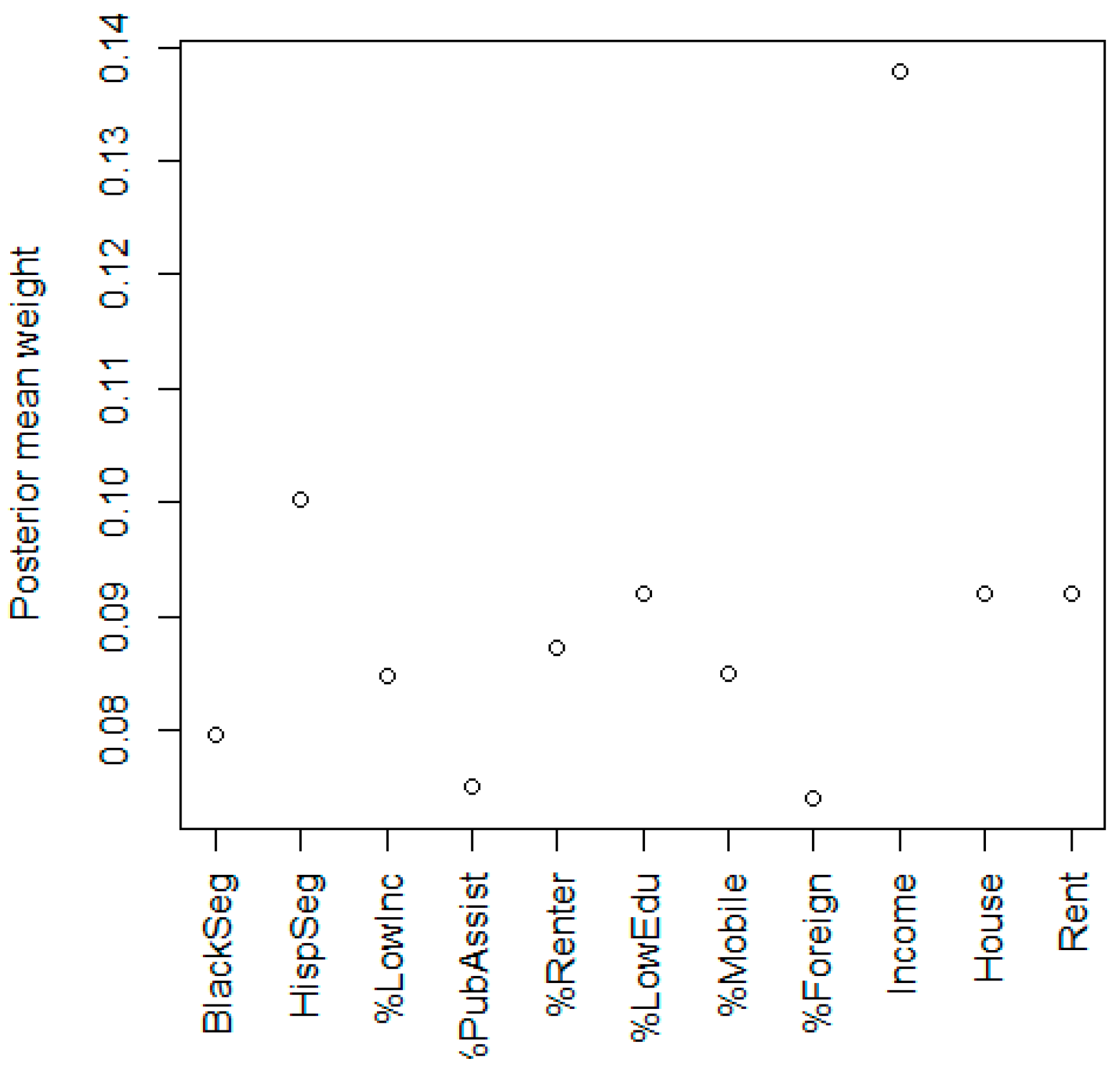
3.1. Neighborhood Deprivation
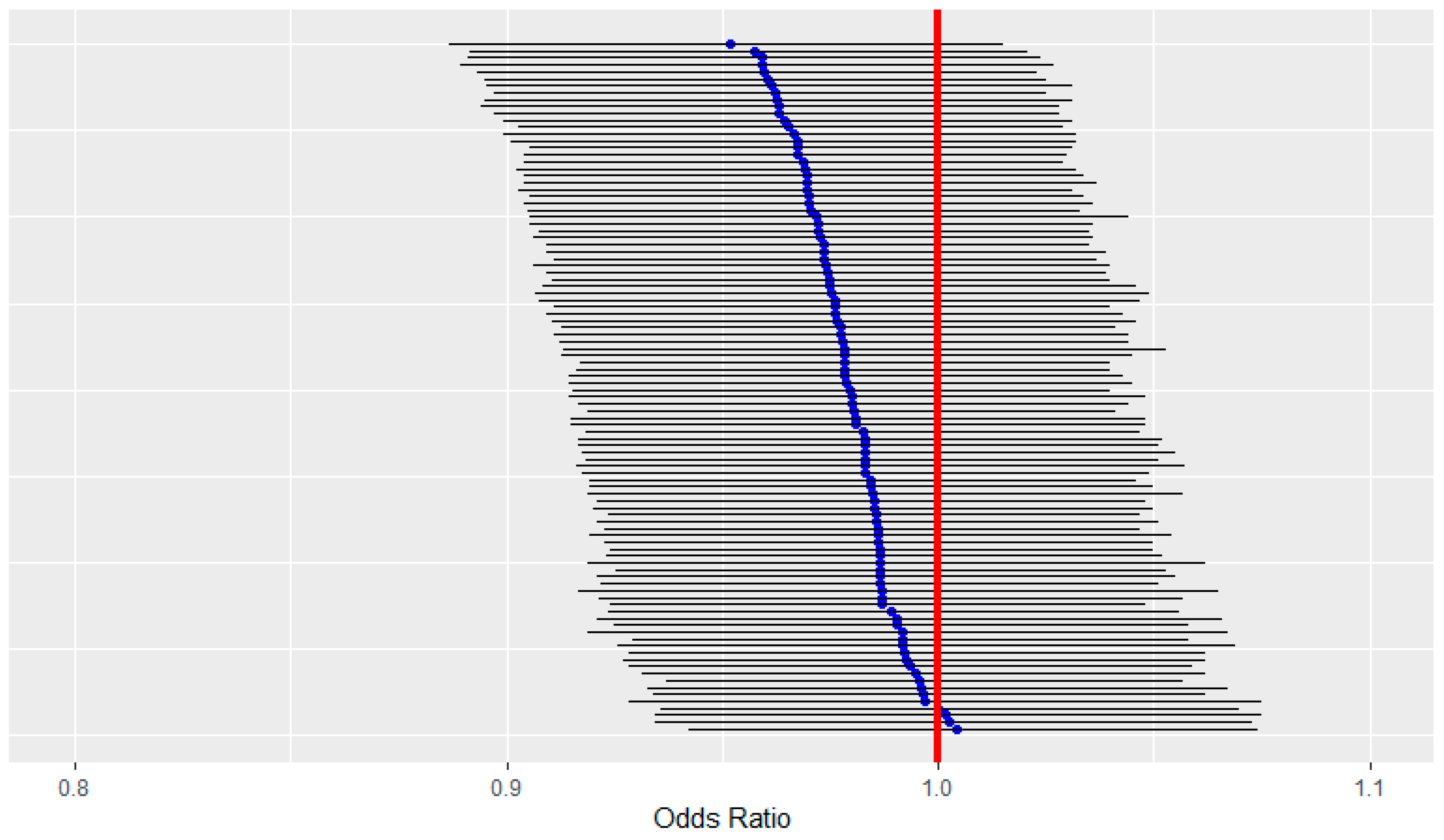
3.2. Selection Bias Sensitivity Analysis for Neighborhood Deprivation
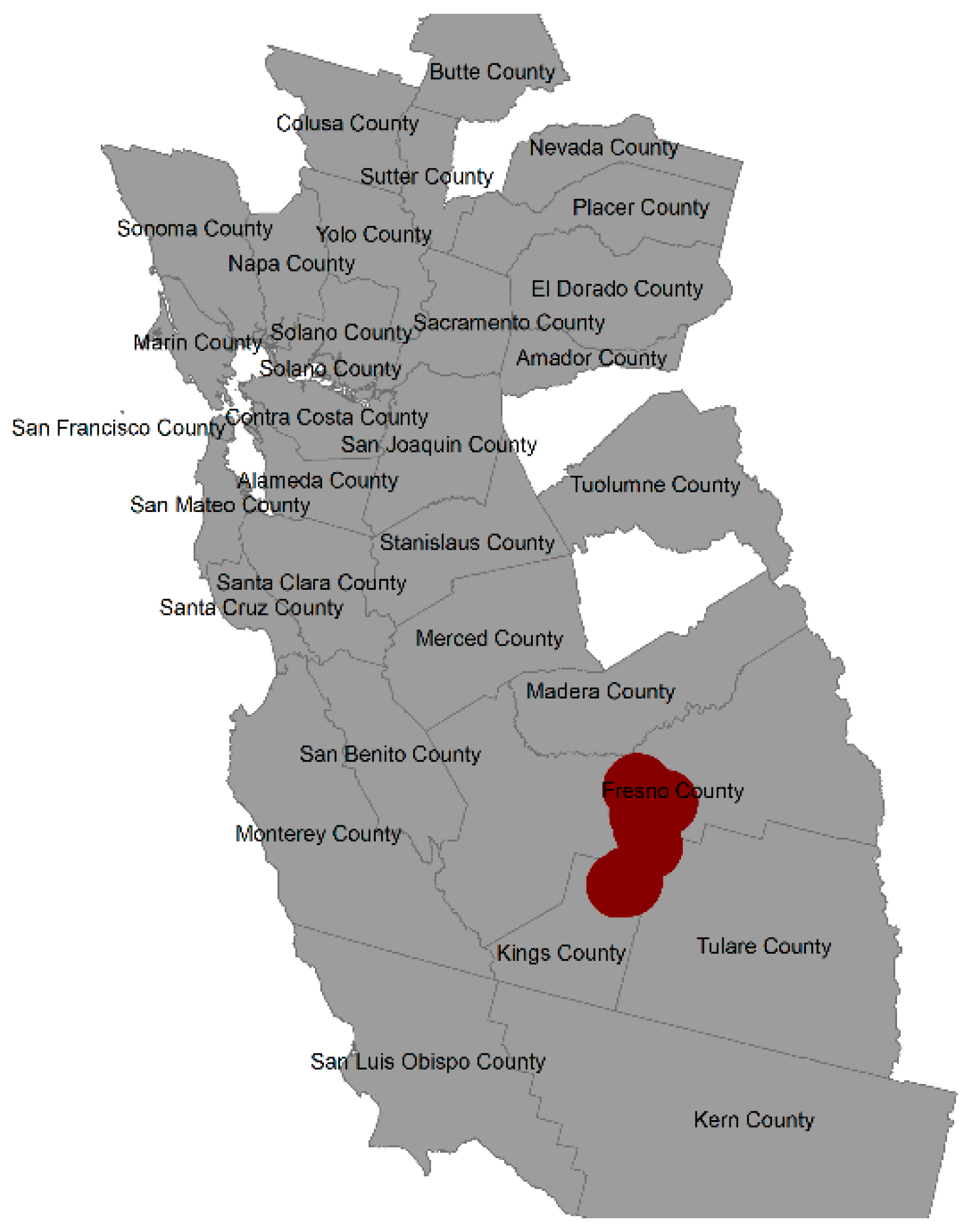
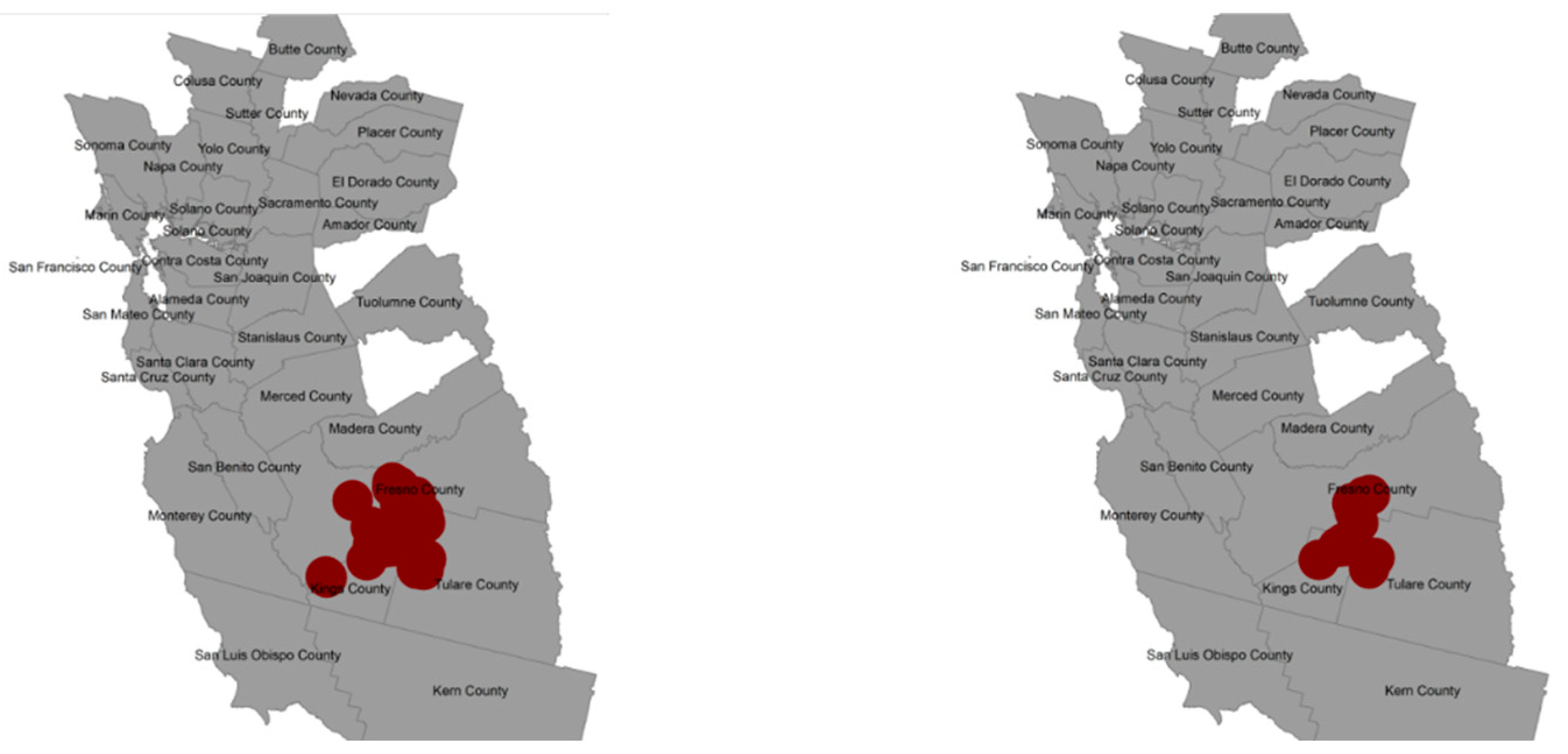
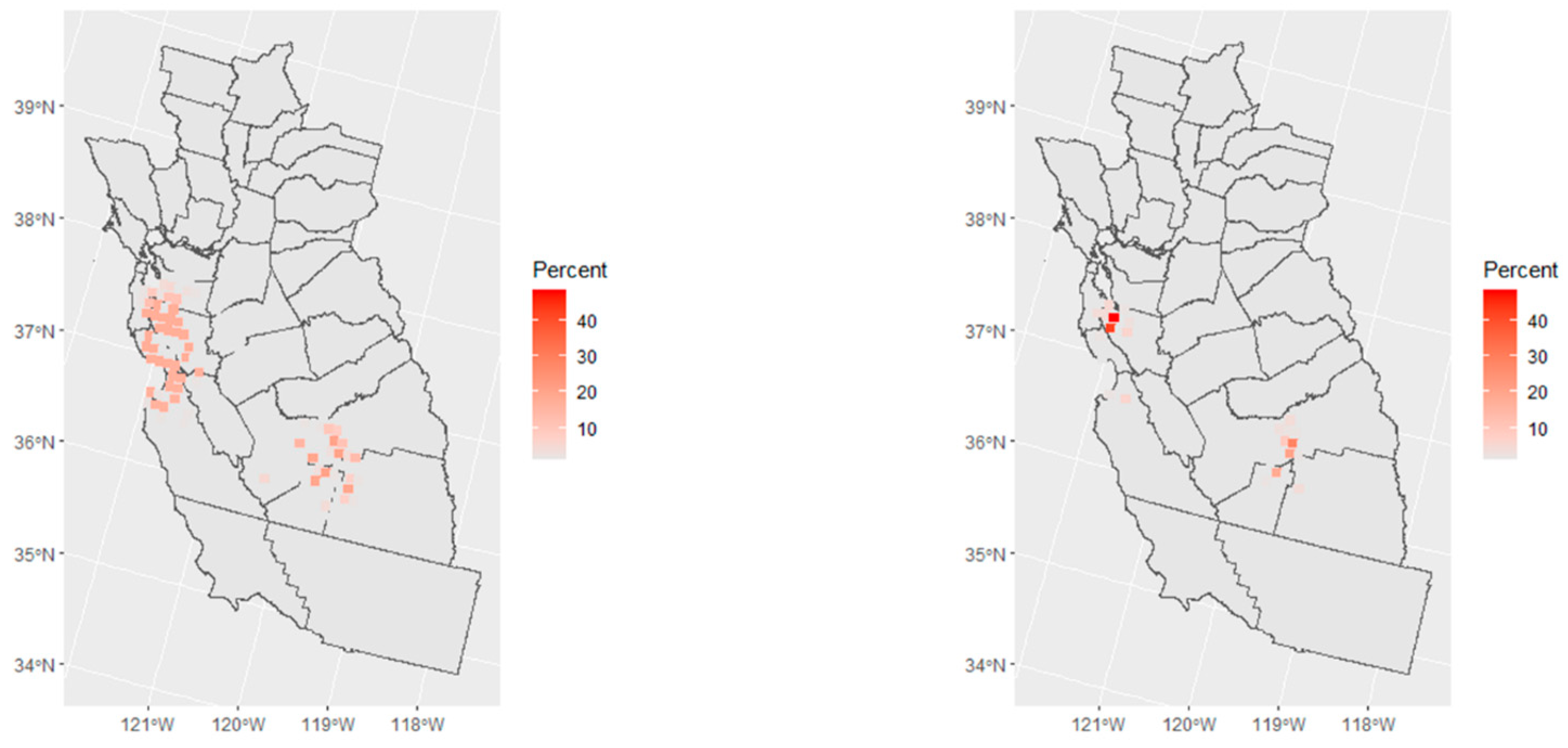
3.3. Spatial Risk
3.4. Selection Bias Sensitivity Analysis for Spatial Risk
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Whitehead, T.P.; Metayer, C.; Wiemels, J.L.; Singer, A.W.; Miller, M.D. Childhood Leukemia and Primary Prevention. Curr. Probl. Pediatr. Adolesc. Health Care 2016, 46, 317–352. [Google Scholar] [CrossRef] [Green Version]
- Onyije, F.M.; Olsson, A.; Baaken, D.; Erdmann, F.; Stanulla, M.; Wollschläger, D.; Schüz, J. Environmental Risk Factors for Childhood Acute Lymphoblastic Leukemia: An Umbrella Review. Cancers 2022, 14, 382. [Google Scholar] [CrossRef] [PubMed]
- Dalmasso, P.; Pastore, G.; Zuccolo, L.; Maule, M.M.; Pearce, N.; Merletti, F.; Magnani, C. Temporal trends in the incidence of childhood leukemia, lymphomas and solid tumors in north-west Italy, 1967–2001. A report of the Childhood Cancer Registry of Piedmont. Haematologica 2005, 90, 1197–1204. [Google Scholar] [PubMed]
- Kroll, M.; Draper, G.; Stiller, C.; Murphy, M. Childhood leukemia incidence in Britain, 1974–2000: Time trends and possible relation to influenza epidemics. J. Natl. Cancer Inst. 2006, 98, 417–420. [Google Scholar] [CrossRef] [Green Version]
- Ries, L.; Melbert, D.; Krapcho, M.; Mariotto, A.; Miller, B.; Freuer, E.; Clegg, L.X.; Eisner, M.P.; Horner, M.J.; Howlader, N.; et al. SEER Cancer Statistics Review: 1975–2004. Available online: https://seer.cancer.gov/csr/1975_2004 (accessed on 14 February 2023).
- Nishi, M.; Miyake, H.; Takeda, T.; Shimada, M. Epidemiology of childhood leukemia in Hokkaido, Japan. Int. J. Cancer 1996, 67, 323–326. [Google Scholar] [CrossRef]
- Giddings, B.M.; Whitehead, T.P.; Metayer, C.; Miller, M.D. Childhood leukemia incidence in California: High and rising in the Hispanic population. Cancer 2016, 122, 2867–2875. [Google Scholar] [CrossRef] [Green Version]
- Barrington-Trimis, J.L.; Cockburn, M.; Metayer, C.; Gauderman, W.J.; Wiemels, J.; McKean-Cowdin, R. Trends in childhood leukemia incidence over two decades from 1992 to 2013. Int. J. Cancer 2017, 140, 1000–1008. [Google Scholar] [CrossRef] [Green Version]
- Steliarova-Foucher, E.; Fidler, M.M.; Colombet, M.; Lacour, B.; Kaatsch, P.; Piñeros, M.; Soerjomataram, I.; Bray, F.; Coebergh, J.W.; Peris-Bonet, R.; et al. Changing geographical patterns and trends in cancer incidence in children and adolescents in Europe, 1991–2010 (Automated Childhood Cancer Information System): A population-based study. Lancet Oncol. 2018, 19, 1159–1169. [Google Scholar] [CrossRef] [Green Version]
- Steliarova-Foucher, E.; Colombet, M.; Ries, L.A.G.; Moreno, F.; Dolya, A.; Bray, F.; Hesseling, P.; Shin, H.Y.; Stiller, C.A.; IICC-3 Contributors. International incidence of childhood cancer, 2001–2010: A population-based registry study. Lancet Oncol. 2017, 18, 719–731. [Google Scholar] [CrossRef]
- Ward, M.; Colt, J.; Metayer, C.; Gunier, R.; Lubin, J.; Crouse, V.; Nishioka, M.G.; Reynolds, P.; Buffler, P.A. Residential exposure to polychlorinated biphenyls and organochlorine pesticides and risk of childhood leukemia. Environ. Health Perspect. 2009, 117, 1007–1013. [Google Scholar] [CrossRef] [Green Version]
- Ward, M.H.; Colt, J.S.; Deziel, N.C.; Whitehead, T.P.; Reynolds, P.; Gunier, R.B.; Nishioka, M.; Dahl, G.V.; Rappaport, S.M.; Buffler, P.A.; et al. Residential levels of polybrominated diphenyl ethers and risk of childhood acute lymphoblastic leukemia in California. Environ. Health Perspect. 2014, 122, 1110–1116. [Google Scholar] [CrossRef]
- Metayer, C.; Colt, J.S.; Buffler, P.A.; Reed, H.D.; Selvin, S.; Crouse, V.; Ward, M.H. Exposure to herbicides in house dust and risk of childhood acute lymphoblastic leukemia. J. Expo. Sci. Environ. Epidemiol. 2013, 23, 363–370. [Google Scholar] [CrossRef] [PubMed]
- Deziel, N.C.; Rull, R.P.; Colt, J.S.; Reynolds, P.; Whitehead, T.P.; Gunier, R.B.; Month, S.R.; Taggart, D.R.; Buffler, P.; Ward, M.H.; et al. Polycyclic aromatic hydrocarbons in residential dust and risk of childhood acute lymphoblastic leukemia. Environ. Res. 2014, 133, 388–395. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carli, M.; Ward, M.; Metayer, C.; Wheeler, D. Imputation of below detection limit missing data in chemical mixture analysis with Bayesian group index regression. Int. J. Environ. Res. Public Health 2022, 19, 1369. [Google Scholar] [CrossRef]
- Wheeler, D.; Rustom, S.; Carli, M.; Whitehead, T.; Ward, M.H.; Metayer, C. Bayesian group index regression for modeling chemical mixtures and cancer risk. Int. J. Environ. Res. Public Health 2021, 18, 3486. [Google Scholar] [CrossRef] [PubMed]
- Kehm, R.D.; Spector, L.G.; Poynter, J.N.; Vock, D.M.; Osypuk, T.L. Socioeconomic Status and Childhood Cancer Incidence: A Population-Based Multilevel Analysis. Am. J. Epidemiol. 2018, 187, 982–991. [Google Scholar] [CrossRef] [PubMed]
- Kroll, M.E.; Stiller, C.A.; Murphy, M.F.; Carpenter, L.M. Childhood leukaemia and socioeconomic status in England and Wales 1976–2005: Evidence of higher incidence in relatively affluent communities persists over time. Br. J. Cancer 2011, 105, 1783–1787. [Google Scholar] [CrossRef] [Green Version]
- Erdmann, F.; Hvidtfeldt, U.A.; Feychting, M.; Sørensen, M.; Raaschou-Nielsen, O. Is the risk of childhood leukaemia associated with socioeconomic measures in Denmark? A nationwide register-based case-control study. Int. J. Cancer 2021, 148, 2227–2240. [Google Scholar] [CrossRef]
- Adam, M.; Kuehni, C.E.; Spoerri, A.; Schmidlin, K.; Gumy-Pause, F.; Brazzola, P.; Probst-Hensch, N.; Zwahlen, M. Socioeconomic Status and Childhood Leukemia Incidence in Switzerland. Front. Oncol. 2015, 5, 139. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, K.B.; Buffler, P.A.; Metayer, C. Socioeconomic status and childhood acute lymphocytic leukemia incidence in São Paulo, Brazil. Int. J. Cancer 2008, 123, 1907–1912. [Google Scholar] [CrossRef]
- Smith, A.; Roman, E.; Simpson, J.; Ansell, P.; Fear, N.T.; Eden, T. Childhood leukaemia and socioeconomic status: Fact or artefact? A report from the United Kingdom childhood cancer study (UKCCS). Int. J. Epidemiol. 2006, 35, 1504–1513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wheeler, D.; Czarnota, J.; Jones, R. Estimating an areal-level socioeconomic status index and its association with colonoscopy screening adherence. PLoS ONE 2017, 12, e0179272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wheeler, D.; Jones, R.; Schootman, M.; Nelson, E. Explaining variation in elevated blood lead levels among children in Minnesota using neighborhood socioeconomic variables. Sci. Total Environ. 2019, 650 Pt 1, 970–977. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, D.; Boyle, J.; Barsell, J.; Maguire, R.; Dahman, B.; Murphy, S.; Hoyo, C.; Zhang, J.; Oliver, J.; McClernon, J.; et al. Neighborhood deprivation is associated with increased risk of prenatal smoke exposure. Prev. Sci. 2022, 23, 1078–1089. [Google Scholar] [CrossRef]
- Colt, J.S.; Gunier, R.B.; Metayer, C.; Nishioka, M.G.; Bell, E.M.; Reynolds, P.; Buffler, P.A.; Ward, M.H. Household vacuum cleaners vs. the high-volume surface sampler for collection of carpet dust samples in epidemiologic studies of children. Environ. Health 2008, 7, 6. [Google Scholar] [CrossRef] [Green Version]
- Firth, D. Bias reduction of maximum likelihood estimates. Biometrika 1993, 80, 27–38. [Google Scholar] [CrossRef]
- Heinze, G.; Schemper, M. A solution to the problem of separation in logistic regression. Stat. Med. 2002, 21, 2409–2419. [Google Scholar] [CrossRef]
- Slusky, D.A.; Does, M.; Metayer, C.; Mezei, G.; Selvin, S.; Buffler, P.A. Potential role of selection bias in the association between childhood leukemia and residential magnetic fields exposure: A population-based assessment. Cancer Epidemiol. 2014, 38, 307–313. [Google Scholar] [CrossRef] [Green Version]
- Bartley, K.; Metayer, C.; Selvin, S.; Ducore, J.; Buffler, P. Diagnostic X-rays and risk of childhood leukaemia. Int. J. Epidemiol. 2010, 39, 1628–1637. [Google Scholar] [CrossRef] [Green Version]
- Francis, S.S.; Enders, C.; Hyde, R.; Gao, X.; Wang, R.; Ma, X.; Wiemels, J.L.; Selvin, S.; Metayer, C. Spatial-Temporal Cluster Analysis of Childhood Cancer in California. Epidemiology 2020, 31, 214–223. [Google Scholar] [CrossRef]
- Slusky, D.; Mezei, G.; Metayer, C.; Selvin, S.; Von Behren, J.; Buffler, P. Comparison of racial differences in childhood cancer risk in case-control studies and population-based cancer registries. Cancer Epidemiol. 2012, 36, 36–44. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.; Priest, N.; Anderson, N. Understanding associations among race, socioeconomic status, and health: Patterns and prospects. Health Psychol. 2016, 35, 407–411. [Google Scholar] [CrossRef] [PubMed]
- Chiu, D.; Green, D.; Abidin, N.; Hughes, J.; Odudu, A.; Sinha, S.; Kalra, P. Non-recruitment to and selection bias in studies using echocardiography in haemodialysis patients. Nephrology 2017, 22, 864–871. [Google Scholar] [CrossRef]
- Sritharan, J.; Luo, Y.; Harris, M.A. Trends in participation rates in case–control studies of occupational risk factors 1991–2017. Occup. Environ. Med. 2020, 77, 659–665. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, D.; De Roos, A.; Cerhan, J.; Morton, L.; Severson, R.; Cozen, W.; Ward, M. Spatial-temporal analysis of non-Hodgkin lymphoma in the NCI-SEER NHL case-control study. Environ. Health 2011, 10, 63. [Google Scholar] [CrossRef] [Green Version]
- Wheeler, D. A comparison of spatial clustering and cluster detection techniques for childhood leukemia incidence in Ohio, 1996–2003. Int. J. Health Geogr. 2007, 6, 13. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Odds Ratio | 2.5% CI | 97.5% CI |
|---|---|---|---|
| NDI | 0.97 | 0.87 | 1.07 |
| Child’s age | 1.00 | 0.91 | 1.11 |
| Female | 1.00 | 0.73 | 1.37 |
| Child’s ethnicity | |||
| Hispanic | 1.30 | 0.86 | 2.08 |
| Non-Hispanic | 1.46 | 0.96 | 2.27 |
| Household income | |||
| $15,000–$29,999 | 1.04 | 0.53 | 2.06 |
| $30,000–$44,999 | 0.90 | 0.46 | 1.70 |
| $45,000–$59,999 | 0.87 | 0.42 | 1.70 |
| $60,000–$74,999 | 0.52 | 0.22 | 1.10 |
| $75,000 or more | 0.44 | 0.22 | 0.88 |
| Income missing | 0.67 | 0.22 | 1.69 |
| Mother’s education | |||
| High school | 1.12 | 0.62 | 2.29 |
| Some college | 1.09 | 0.59 | 2.20 |
| Bachelor’s or higher | 1.25 | 0.67 | 2.62 |
| Mother’s age | 1.01 | 0.98 | 1.04 |
| Residence since birth | 0.72 | 0.50 | 1.02 |
| Variable | Odds Ratio | 2.5% CI | 97.5% CI |
|---|---|---|---|
| PCBs | 1.19 | 0.91 | 1.52 |
| Insecticides | 0.58 | 0.35 | 0.94 |
| Herbicides | 1.22 | 0.84 | 1.80 |
| Metals | 0.79 | 0.59 | 1.06 |
| PAHs | 1.21 | 0.98 | 1.52 |
| Tobacco | 0.84 | 0.67 | 1.04 |
| PBDEs | 1.25 | 0.82 | 1.86 |
| NDI | 0.95 | 0.85 | 1.07 |
| Child’s age | 1.01 | 0.91 | 1.11 |
| Female | 0.97 | 0.68 | 1.36 |
| Child’s ethnicity | |||
| Hispanic | 1.32 | 0.83 | 2.18 |
| Non-Hispanic | 1.42 | 0.90 | 2.29 |
| Household income | |||
| $15,000–$29,999 | 1.02 | 0.46 | 2.20 |
| $30,000–$44,999 | 0.73 | 0.32 | 1.50 |
| $45,000–$59,999 | 0.74 | 0.31 | 1.60 |
| $60,000–$74,999 | 0.41 | 0.15 | 1.01 |
| $75,000 or more | 0.32 | 0.13 | 0.70 |
| Income missing | 0.51 | 0.15 | 1.50 |
| Mother’s education | |||
| High school | 1.33 | 0.64 | 3.14 |
| Some college | 1.31 | 0.62 | 3.22 |
| Bachelor’s or higher | 1.34 | 0.61 | 3.44 |
| Mother’s age | 1.01 | 0.98 | 1.05 |
| Residence since birth | 0.68 | 0.46 | 1.00 |
| Method | Local Spatial Scan | Besag–York–Mollie | ||
|---|---|---|---|---|
| Weights | Equal | SES | Equal | SES |
| % with Cluster | 37.0 | 30.0 | 55.0 | 41.0 |
| Size | 0 (0, 5586) | 0 (0, 4813) | 0 (0, 7373) | 0 (0, 8918) |
| Overlap | 0 (0, 100.0) | 0 (0, 92.0) | 0 (0, 64.0) | 0 (0, 30.0) |
| % with Overlap | 20.0 | 12.0 | 23.0 | 12.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wheeler, D.C.; Boyle, J.; Carli, M.; Ward, M.H.; Metayer, C. Neighborhood Deprivation, Indoor Chemical Concentrations, and Spatial Risk for Childhood Leukemia. Int. J. Environ. Res. Public Health 2023, 20, 3582. https://doi.org/10.3390/ijerph20043582
Wheeler DC, Boyle J, Carli M, Ward MH, Metayer C. Neighborhood Deprivation, Indoor Chemical Concentrations, and Spatial Risk for Childhood Leukemia. International Journal of Environmental Research and Public Health. 2023; 20(4):3582. https://doi.org/10.3390/ijerph20043582
Chicago/Turabian StyleWheeler, David C., Joseph Boyle, Matt Carli, Mary H. Ward, and Catherine Metayer. 2023. "Neighborhood Deprivation, Indoor Chemical Concentrations, and Spatial Risk for Childhood Leukemia" International Journal of Environmental Research and Public Health 20, no. 4: 3582. https://doi.org/10.3390/ijerph20043582