
Evaluating Urban Vitality of Street Blocks Based on Multi-Source Geographic Big Data: A Case Study of Shenzhen
Abstract
:1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data and Data Preprocessing
2.2.1. OpenStreetMap Data
2.2.2. Remote Sensing Data
2.2.3. Geographic Big Data
2.2.4. Urban Vitality Reference Data
3. Methods
3.1. Data Processing and Features Extraction
3.2. Construction of Urban Vitality Index
3.3. Urban Vitality Estimation Model
4. Results
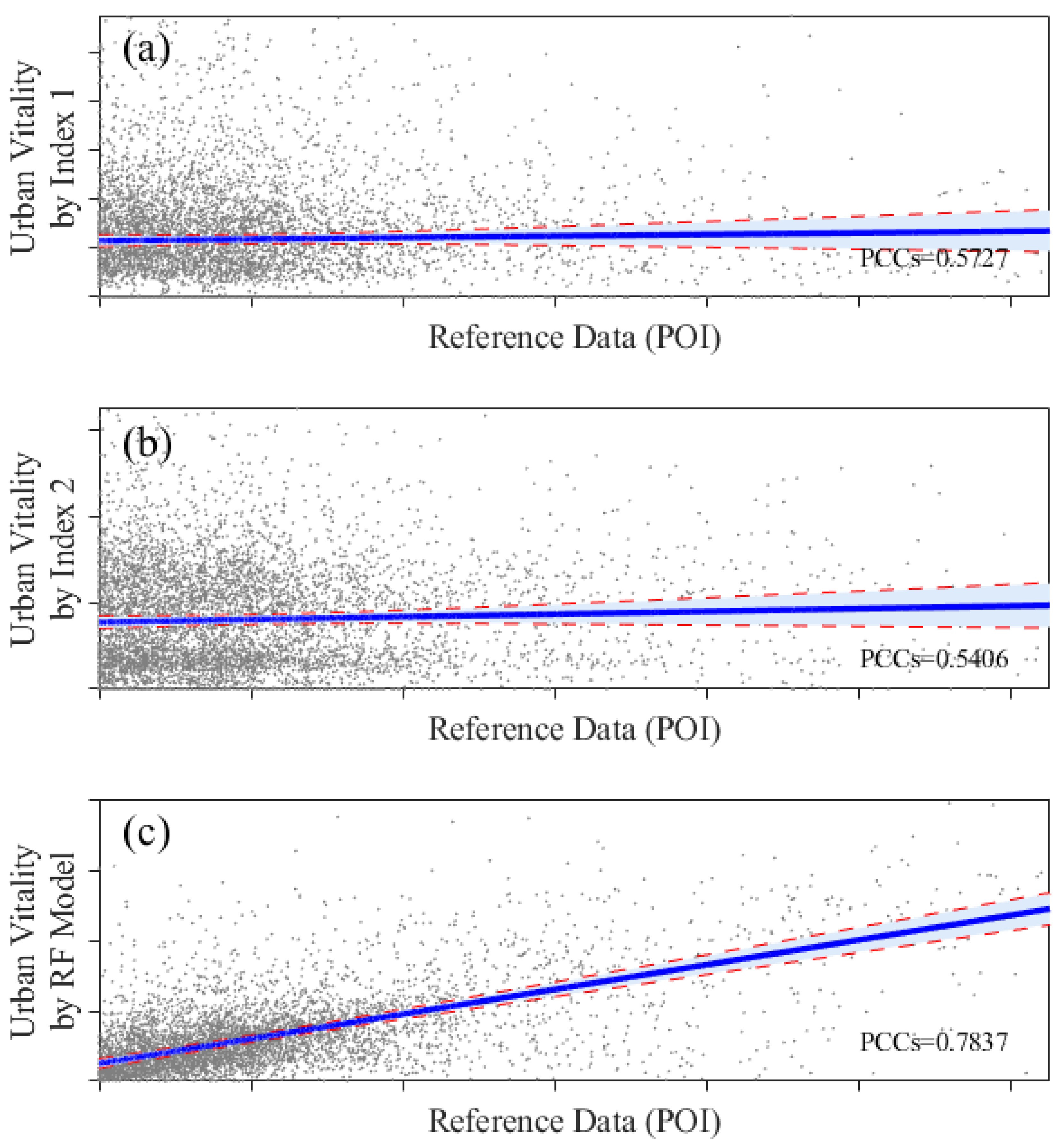
4.1. Evaluation Result of Urban Vitality Index
4.2. Evaluation Result of Urban Vitality Estimation Model
5. Discussion
5.1. Comparison of Urban Vitality Index and Urban Vitality Estimation Model
5.1.1. Estimation Accuracy of and Method Limitation Analysis
5.1.2. Case Analysis on the Difference of Two Methods
5.2. Contribution of the Features to Urban Vitality
5.3. Spatial Pattern of Shenzhen’s Urban Vitality
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, J.I.; Lee, C.M.; Ahn, K.H. Dongdaemun, a traditional market place wearing a modern suit: The importance of the social fabric in physical redevelopments. Habitat. Int. 2004, 28, 143–161. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, C.; Lu, M.Q.; Lu, Y.Q. Assessing the suitability of regional human settlements environment from a different preferences perspective: A case study of Zhejiang Province, China. Habitat. Int. 2017, 70, 1–12. [Google Scholar] [CrossRef]
- Yue, W.Z.; Chen, Y.; Thy, P.T.M.; Fan, P.L.; Liu, Y.; Zhang, W. Identifying urban vitality in metropolitan areas of developing countries from a comparative perspective: Ho Chi Minh City versus Shanghai. Sustain. Cities Soc. 2021, 65, 102609. [Google Scholar] [CrossRef]
- Lin, J.; Zhuang, Y.; Zhao, Y.; Li, H.; He, X.; Lu, S. Measuring the Non-Linear Relationship between Three-Dimensional Built Environment and Urban Vitality Based on a Random Forest Model. Int. J. Environ. Res. Public Health 2020, 20, 734. [Google Scholar] [CrossRef]
- Xia, C.; Yeh, A.G.O.; Zhang, A.Q. Analyzing spatial relationships between urban land use intensity and urban vitality at street block level: A case study of five Chinese megacities. Landsc Urban Plan. 2020, 193, 18. [Google Scholar] [CrossRef]
- Pakoz, M.Z.; Isik, M. Rethinking urban density, vitality and healthy environment in the post-pandemic city: The case of Istanbul. Cities. 2022, 124, 17. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Dong, B.Z.Z.; Pei, Q.; Zhang, Z.H. The impacts of urban vitality and urban density on innovation: Evidence from China’s Greater Bay Area. Habitat. Int. 2022, 119, 102490. [Google Scholar] [CrossRef]
- Xu, G.; Zheng, M.C.; Wang, Y.X.; Li, J. The Urbanization of Population and Land in China: Temporal Trends, Regional Disparities, Size Effect and Comparisons of Measurements. China Land Sci. 2022, 36, 80–90. [Google Scholar]
- Smith, T.; Nelischer, M.; Perkins, N. Quality of an urban community: A framework for understanding the relationship between quality and physical form. Landsc. Urban Plan. 1997, 39, 229–241. [Google Scholar] [CrossRef]
- Lv, G.Y.; Zheng, S.; Hu, W. Exploring the relationship between the built environment and block vitality based on multi-source big data: An analysis in Shenzhen, China. Geomat. Nat. Hazards Risk. 2022, 13, 1593–1613. [Google Scholar] [CrossRef]
- Jacobs, J. The Death and Life of Great American Cities; Random House: London, UK, 1961; pp. 1–458. [Google Scholar]
- Zeng, C.; Song, Y.; He, Q.; Shen, F. Spatially explicit assessment on urban vitality: Case studies in Chicago and Wuhan. Sustain. Cities Soc. 2018, 40, 296–306. [Google Scholar] [CrossRef]
- Zeng, C.; Zhao, Z.; Wen, C.; Yang, J.; Lv, T.Y. Effect of Complex Road Networks on Intensive Land Use in China’s Beijing-Tianjin-Hebei Urban Agglomeration. Land 2020, 9, 19. [Google Scholar] [CrossRef]
- Fang, C.L.; He, S.W.; Wang, L. Spatial Characterization of Urban Vitality and the Association with Various Street Network Metrics from the Multi-Scalar Perspective. Front. Public Health 2021, 9, 13. [Google Scholar] [CrossRef]
- Shi, J.; Miao, W.; Si, H.; Liu, T. Urban Vitality Evaluation and Spatial Correlation Research: A Case Study from Shanghai, China. Land 2021, 10, 1195. [Google Scholar] [CrossRef]
- Jia, C.; Du, Y.Y.; Wang, S.Y.; Bai, T.Y. Measuring the vibrancy of urban neighborhoods using mobile phone data with an improved PageRank algorithm. Trans. GIS 2019, 23, 241–258. [Google Scholar] [CrossRef]
- He, Q.S.; He, W.S.; Song, Y.; Wu, J.Y.; Yin, C.H.; Mou, Y.C. The impact of urban growth patterns on urban vitality in newly built-up areas based on an association rules analysis using geographical ‘big data’. Land Use Policy 2018, 78, 726–738. [Google Scholar] [CrossRef]
- Song, Y.M.; Huang, B.; He, Q.Q.; Chen, B.; Wei, J.; Mahmood, R. Dynamic assessment of PM2.5 exposure and health risk using remote sensing and geo-spatial big data. Environ. Pollut. 2019, 253, 288–296. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhang, Y.; He, T.; Xiao, R. Urban Vitality and its Influencing Factors: Comparative Analysis Based on Taxi Trajectory Data. IEEE J. Sel. 2022, 15, 5102–5114. [Google Scholar] [CrossRef]
- Zikirya, B.; He, X.; Li, M.; Zhou, C.S. Urban Food Takeaway Vitality: A New Technique to Assess Urban Vitality. Int. J. Environ. Res. Public Health 2021, 18, 18. [Google Scholar] [CrossRef]
- Song, Y.; Chen, B.; Ho, H.C.; Kwan, M.-P.; Liu, D.; Wang, F.; Wang, J.; Cai, J.; Li, X.; Xu, Y.; et al. Observed inequality in urban greenspace exposure in China. Environ. Int. 2021, 156, 11. [Google Scholar] [CrossRef]
- Song, Y.M.; Chen, B.; Kwan, M.P. How does urban expansion impact people’s exposure to green environments? A comparative study of 290 Chinese cities. J. Clean. Prod. 2020, 246, 12. [Google Scholar] [CrossRef]
- Li, X.; Li, Y.; Jia, T.; Zhou, L.; Hijazi, I.H. The six dimensions of built environment on urban vitality: Fusion evidence from multi-source data. Cities 2022, 121, 20. [Google Scholar] [CrossRef]
- Ye, Y.; Li, D.; Liu, X.J. How block density and typology affect urban vitality: An exploratory analysis in Shenzhen, China. Urban Geogr. 2018, 39, 631–652. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Lu, H.T.; Zheng, T.C.; Rong, Y.J.; Wang, C.X.; Zhang, W.; Yan, Y.; Tang, L.N. Vitality of Urban Parks and Its Influencing Factors from the Perspective of Recreational Service Supply, Demand, and Spatial Links. Int. J. Environ. Res. Public Health 2020, 17, 17. [Google Scholar] [CrossRef] [Green Version]
- Mushkani, R.A.; Ono, H. The role of land use and vitality in fostering gender equality in urban public parks: The case of Kabul city, Afghanistan. Habitat Int. 2021, 118, 12. [Google Scholar] [CrossRef]
- Gomez-Varo, I.; Delclos-Alio, X.; Miralles-Guasch, C. Jane Jacobs reloaded: A contemporary oper-ationalization of urban vitality in a district in Barcelona. Cities 2022, 123, 15. [Google Scholar] [CrossRef]
- Pei, T.; Liu, Y.X.; Guo, S.H.; Shu, H.; Du, Y.Y.; Ma, T.; Zhou, C.H. Principle of Big Geodata Mining. Acta. Geogr. Sin. 2019, 74, 586–598. [Google Scholar]
- Zhang, J.W.; Liu, X.T.; Tan, X.Y.; Jia, T.; Senousi, A.M.; Huang, J.W.; Yin, L.; Zhang, F. Nighttime Vitality and Its Relationship to Urban Diversity: An Ex-ploratory Analysis in Shenzhen, China. IEEE J. Sel. 2022, 15, 309–322. [Google Scholar] [CrossRef]
- Jiang, Y.H.; Han, Y.; Liu, M.Y.; Ye, Y. Street vitality and built environment features: A data-informed approach from fourteen Chinese cities. Sustain. Cities Soc. 2022, 79, 13. [Google Scholar] [CrossRef]
- Cho, S.E.; Kim, S. Measuring urban diversity of Songjiang New Town: A re-configuration of a Chinese suburb. Habitat Int. 2017, 66, 32–41. [Google Scholar] [CrossRef]
- Sung, H.G.; Go, D.H.; Choi, C.G. Evidence of Jacobs’s street life in the great Seoul city: Identifying the association of physical environment with walking activity on streets. Cities 2013, 35, 164–173. [Google Scholar] [CrossRef]
- Fan, Z.X.; Duan, J.; Luo, M.L.; Zhan, H.R.; Liu, M.R.; Peng, W.C. How Did Built Environment Affect Urban Vitality in Urban Waterfronts? A Case Study in Nanjing Reach of Yangtze River. ISPRS Int. J. Geoinf. 2021, 10, 18. [Google Scholar] [CrossRef]
- Mao, W.S.; Zhong, Y.X. Spatial pattern and influencing factors of urban vitality in the middle reaches of the Yangtze River. World Reg. Stud. 2020, 29, 86–95. [Google Scholar]
- Tang, L.; Xu, H.W.; Ding, Y.W. Comprehensive Vitality Evaluation of Urban Blocks based on Multi-source Geo-graphic Big Data. J. Geogr. Sci. 2021, 24, 1575–1588. [Google Scholar]
- Lan, F.; Gong, X.; Da, H.; Wen, H. How do population inflow and social infrastructure affect urban vitality? Evidence from 35 large- and medium-sized cities in China. Cities 2020, 100, 12. [Google Scholar] [CrossRef]
- Ming, Y.J.; Liu, Y.; Zhou, J.S. Vitality assessment of mountainous cities based on multi-source data: A case of Chongqing Municipality, China. Resour. Sci. 2020, 42, 710–722. [Google Scholar] [CrossRef]
- Yang, Z.S.; Pan, Y.H. Are cities losing their vitality? Exploring human capital in Chinese cities. Habitat Int. 2020, 96, 14. [Google Scholar] [CrossRef]
- Domingos, P. A Few Useful Things to Know About Machine Learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Zhou, B.L.; Liu, L.; Liu, Y.; Fung, H.H.; Lin, H.; Ratti, C. Measuring human perceptions of a large-scale urban region using machine learning. Landsc. Urban Plan. 2018, 180, 148–160. [Google Scholar] [CrossRef]
- Yang, J.C.; Zhang, J.P.; Wang, H.H. Urban Traffic Control in Software Defined Internet of Things via a Multi-Agent Deep Reinforcement Learning Approach. IEEE trans Intell. Transp. Syst. 2021, 22, 3742–3754. [Google Scholar] [CrossRef]
- Caggiano, A.; Zhang, J.J.; Alfieri, V.; Caiazzo, F.; Gao, R.; Teti, R. Machine learning-based image processing for on-line defect recognition in additive manufacturing. CIRP Ann. Manuf. Technol. 2019, 68, 451–454. [Google Scholar] [CrossRef]
- Liu, P.; Choo, K.K.R.; Wang, L.Z.; Huang, F. SVM or deep learning? A comparative study on remote sensing image classification. Soft Comput. 2017, 21, 7053–7065. [Google Scholar] [CrossRef]
- Griffin, M.; Nordstrom, B.W.; Scholes, J.; Joncas, K.; Gordon, P.; Krivenko, E.; Haynes, W.; Higdon, R.; Stewart, E.; Kolker, W.; et al. A Case Study: Analyzing City Vitality with Four Pillars of Activity-Live, Work, Shop, and Play. Big Data 2016, 4, 60–66. [Google Scholar] [CrossRef] [PubMed]
- Qi, Y.; Drolma, S.C.; Zhang, X.; Liang, J.; Jiang, H.B.; Xu, J.G.; Ni, T.H. An investigation of the visual features of urban street vitality using a convolutional neural network. Geo. Spat. Inf. Sci. 2020, 23, 341–351. [Google Scholar] [CrossRef]
- Webb, G.I.; Zhang, Z.J. Multistrategy ensemble learning: Reducing error by combining ensemble learning techniques. IEEE Trans. Knowl. Data Eng. 2004, 16, 980–991. [Google Scholar] [CrossRef] [Green Version]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Zhou, L.; Dang, X.W.; Sun, Q.K.; Wang, S.H. Multi-scenario simulation of urban land change in Shanghai by random forest and CA-Markov model. Sustain. Cities Soc. 2020, 55, 10. [Google Scholar] [CrossRef]
- Bergen, K.J.; Johnson, P.A.; de HOOP, M.V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, 1299. [Google Scholar] [CrossRef]
- Jin, X.B.; Long, Y.; Sun, W.; Lu, Y.Y.; Yang, X.H.; Tang, H.X. Evaluating cities’ vitality and identifying ghost cities in China with emerging geographical data. Cities 2017, 63, 98–109. [Google Scholar] [CrossRef]
- Moeinaddini, M.; Asadi-Shekari, Z.; Sultan, Z.; Shah, M.Z.; Hamzah, A. The relationship between urban street networks and the number of transport fatalities at the city level. Saf. Sci. 2014, 62, 114–120. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Song, C.H.; Band, L.E.; Sun, G.; Li, J.X. Reanalysis of global terrestrial vegetation trends from MODIS products: Browning or greening? Remote Sens. Environ. 2017, 191, 145–155. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Xia, N.; Xu, Y.Y.; Huang, X.F.; Li, M.C. Mapping Population Distribution Based on XGBoost Using Multisource Data. IEEE J. Sel. 2021, 14, 11567–11580. [Google Scholar] [CrossRef]
- Ta, N.; Zeng, Y.T.; Zhu, Q.Y.; Wu, J.Y. Relationship Between Built Environment and Urban Vitality in Shanghai Downtown Area Based on Big Data. Sci. Geol. Sin. 2020, 40, 60–68. [Google Scholar]
- Guo, X.; Chen, H.F.; Yang, X.P. An Evaluation of Street Dynamic Vitality and Its Influential Factors Based on Multi-Source Big Data. ISPRS Int. J. Geoinf. 2021, 10, 19. [Google Scholar] [CrossRef]
- Wang, Y.C.; Huang, C.L.; Zhao, M.Y.; Hou, J.L.; Zhang, Y.; Gu, J. Mapping the Population Density in Mainland China Using NPP/VIIRS and Points-Of-Interest Data Based on a Random Forests Model. Remote Sens. 2020, 12, 22. [Google Scholar] [CrossRef]
- Tan, W.K.; Yang, C.Y. The relationship between narcissism and landmark check-in behaviour on social media. Curr. Issues Tour. 2021, 24, 3489–3507. [Google Scholar] [CrossRef]
- Shi, B.X.; Yang, J.Y. Scale, distribution, and pattern of mixed land use in central districts: A case study of Nanjing, China. Habitat Int. 2015, 46, 166–177. [Google Scholar] [CrossRef]
- Lu, S.W.; Shi, C.Y.; Yang, X.P. Impacts of Built Environment on Urban Vitality: Regression Analyses of Beijing and Chengdu, China. Int. J. Environ. Res. Public Health 2019, 16, 16. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.H.; Yuan, Z.Z.; Xie, H.H.; Cao, S.H.; Wu, X.Y. Analysis on Trips Characteristics of Taxi in Suzhou Based on OD Data. J. Transp. Syst. Eng. Inf. Technol. 2007, 7, 85–89. [Google Scholar]
- Rizwan, M.; Wan, W.G.; Cervantes, O.; Gwiazdzinski, L. Using Location-Based Social Media Data to Observe Check-In Behavior and Gender Difference: Bringing Weibo Data into Play. ISPRS Int. J. Geoinf. 2018, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Xu, G.; Su, J.L.; Xia, C.; Li, X.; Xiao, R. Spatial mismatches between nighttime light intensity and building morphology in Shanghai, China. Sustain. Cities Soc. 2022, 81, 10. [Google Scholar] [CrossRef]
- Kim, Y.L. Data-driven approach to characterize urban vitality: How spatiotemporal context dynamically defines Seoul’s nighttime. Int. J. Geogr. Inf. Sci. 2020, 34, 1235–1256. [Google Scholar] [CrossRef]
- Fan, C.; Myint, S. A comparison of spatial autocorrelation indices and landscape metrics in measuring urban landscape fragmentation. Landsc.Urban Plan. 2014, 121, 117–128. [Google Scholar] [CrossRef]
- Yuan, X.M.; Liu, Y.S.; Huang, Y.H.; Tian, F.C. An approach to quality validation of large-scale data from the Chinese Flash Flood Survey and Evaluation (CFFSE). Nat. Hazards 2017, 89, 693–704. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source & Website | Feature | Description |
|---|---|---|
| Taxi trajectory https://people.cs.rutgers.edu/~dz220/data.html accessed on 30 November 2019 | Taxi_in_mean | Average length of tracks whose end point locates in |
| Taxi_out_mean | Average length of tracks whose start point locates in | |
| Taxi_in_sum | Total length of tracks whose end point locates in | |
| Taxi_out_sum | Total length of tracks whose start point locates in | |
| Taxi_total_mean | Average value of Taxi_in_mean and Taxi_out_mean | |
| Weibo check-in http://m.weibo.cn accessed on 31 August 2019 | Weibo_sum | Sum value of Weibo_day and Weibo_night |
| Weibo_day | Number of Weibo Signing in during 7 a.m. to 6 p.m. | |
| Weibo_night | Number of Weibo Signing in during 6 p.m. to 7 a.m. | |
| Housing rental https://shenzhen.anjuke.com accessed on 31 October 2019 | HR_price_all | Average of all rents |
| HR_pirce_com | Average of commercial rents | |
| HR_price_res | Average of residential rents | |
| Land use www.globallandcover.com accessed on 31 December 2020 | LU_Shannon | Shannon diversity index |
| LU_artificial | Proportion of artificial lands pixels | |
| LU_ecological | Proportion of ecological lands pixels including forest, grass and cultivated lands | |
| LU_water | Proportion of waterbody pixels | |
| OSM road https://www.openstreetmap.org accessed on 30 February 2022 | OSM_all_len | Sum length of all roads |
| OSM_all_den | Road density of all roads | |
| OSM_pri_len | Sum length of primary roads | |
| OSM_pri_den | Road density of primary roads | |
| OSM_sec_len | Sum length of secondary roads | |
| OSM_sec_den | Road density of secondary roads | |
| Nighttime light http://59.175.109.173:8888 accessed on 30 November 2018 | Luojia_mean | Average value of all Luojia pixels |
| Luojia_sum | Sum value of all Luojia pixels | |
| MODIS NDVI/EVI https://ladsweb.nascom.nasa.gov/search accessed on 31 December 2018 | EVI_mean | Average value of all EVI pixels |
| EVI_sum | Sum value of all EVI pixels | |
| NDVI_mean | Average value of all NDVI pixels | |
| NDVI_sum | Average value of all NDVI pixels |
| Parameter | Meaning of Parameters | Range | Footstep |
|---|---|---|---|
| N_estimators | The maximum number of the weak learners obtained from the original dataset | 10–201 | 5 |
| Max_features | The number of features in each decision tree | 1–20 | 1 |
| Max_depth | The maximum depth of a decision tree | 1–20 | 1 |
| Min_samples_split | Minimum number of samples for leaf nodes | 1–50 | 3 |
| Min_samples_leaf | Minimum number of samples for node splitting | 2–50 | 2 |
| Moran’s I | Z Score | |
|---|---|---|
| Urban Vitality Index 1 | 0.2068 | 6.70 |
| Urban Vitality Index 2 | 0.1959 | 5.94 |
| Random Forest Model | 0.4795 | 15.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Xia, N.; Zhao, X.; Gao, X.; Zhuang, S.; Li, M. Evaluating Urban Vitality of Street Blocks Based on Multi-Source Geographic Big Data: A Case Study of Shenzhen. Int. J. Environ. Res. Public Health 2023, 20, 3821. https://doi.org/10.3390/ijerph20053821
Wang Z, Xia N, Zhao X, Gao X, Zhuang S, Li M. Evaluating Urban Vitality of Street Blocks Based on Multi-Source Geographic Big Data: A Case Study of Shenzhen. International Journal of Environmental Research and Public Health. 2023; 20(5):3821. https://doi.org/10.3390/ijerph20053821
Chicago/Turabian StyleWang, Ziyu, Nan Xia, Xin Zhao, Xing Gao, Sudan Zhuang, and Manchun Li. 2023. "Evaluating Urban Vitality of Street Blocks Based on Multi-Source Geographic Big Data: A Case Study of Shenzhen" International Journal of Environmental Research and Public Health 20, no. 5: 3821. https://doi.org/10.3390/ijerph20053821