1. Introduction
Climate change has induced a surge in extreme weather events worldwide, including heatwaves, cold waves, typhoons, floods, and droughts [
1]. Heatwaves have become increasingly frequent in Europe, Australia, and South Korea, primarily due to the compounding effects of global warming and urbanization [
2,
3]. Numerous regions of South Korea have experienced unprecedented temperature spikes since 2018, marking a significant departure from historical meteorological records [
4].
The adverse health effects of heat waves have been extensively documented in various countries. For instance, in 2003, approximately 72,210 deaths were attributed to heatwaves across 15 European nations [
5]. Similarly, the UK reported 892 excess deaths during a heatwave in 2019, while [
6], Portugal and Spain experienced 1,063 and 679 excess deaths, respectively, during heatwaves in June and July 2022 [
7]. South Korea also faced a grim toll, with an estimated 800–900 excess deaths attributed to heatwaves in 2018 [
8,
9].
Future projections indicate that climate change and urbanization will exacerbate the intensity, frequency, and duration of heatwaves [
1]. Given the profound implications of heatwaves on human health, understanding the regions susceptible to heatwaves is of paramount importance for public health and safety. Effective response strategies and protective measures hinge on the accurate identification of vulnerable areas.
Heat vulnerability maps serve as invaluable tools for identifying regions vulnerable to heat waves. By visually highlighting areas with heightened vulnerability, these maps can assist policymakers in devising targeted intervention measures. Additionally, they raise awareness of health-related issues and aid public health organizations in formulating appropriate response strategies. Moreover, heat vulnerability maps can be used to anticipate spatial pattern changes in vulnerability, rendering them indispensable for urban planning and sustainable development.
Previous studies on heat vulnerability maps have predominantly focused on analyzing regional vulnerability using socioeconomic variables. Various methodologies, such as principal component (PC) analysis and equal weighting assumptions, have been employed for variable selection and weighting [
10,
11,
12,
13,
14,
15]. Research on the uncertainty of heat vulnerability maps is of great interest to researchers. Some studies have shown that caution is required when relying solely on heat vulnerability maps constructed using a single method compared to those constructed using different methods [
16,
17].
However, there remains a dearth of studies exploring the uncertainty surrounding the explanatory power of health outcomes in heat vulnerability maps. Health outcomes characterize heat-related outpatient visits as a mild impact, and emergency room admissions and mortality as a severe impact [
18]. Several studies have compared the explanatory power of health outcomes and heat vulnerability maps but only used mortality as an indicator [
17,
19]. Most other studies have not attempted to compare health outcomes and heat vulnerability maps. Therefore, little is known about the relationship between heat vulnerability maps and health outcomes. For instance, it is difficult to determine which heat impact indicator’s spatial distribution is better explained by heat vulnerability maps and whether the same variables can be used to construct vulnerability maps for mild and severe health outcomes. Understanding the relationship between health outcomes and heat vulnerability maps is essential for identifying vulnerability factors and developing policies. Differences in socioeconomic vulnerability factors, depending on the impact indicator, could provide critical information for policy development.
Previous studies have assumed a linear relationship between independent variables and health outcomes and constructed heat vulnerability maps through a combination of independent variables. However, the possibility of a nonlinear expression of the influence of specific variables due to interactions between independent variables and the existence of thresholds in the influence of independent variables on dependent variables has been overlooked.
Additionally, the impact of heatwaves varies depending on socioeconomic conditions such as age, occupation, and income, with older adults being well known as a group vulnerable to heatwaves [
20,
21,
22]. Limited mobility and chronic illnesses (e.g., cardiovascular diseases) of the elderly may affect their ability to adequately protect themselves and respond promptly to extreme weather [
23]. Furthermore, their acquisition and utilization of information related to heatwaves are limited [
24,
25].
The increasing number of elderly people vulnerable to heatwaves could exacerbate the societal and economic risks of heatwaves, leading to significant social problems. South Korea is one of the countries experiencing rapid aging globally, with the proportion of the elderly population increasing from 7.2% in 2000 to 16.6% in 2021 [
26]. Sim et al. calculated the exposure risk of the population to heatwaves based on future scenarios of heatwave days and national population estimates, forecasting that rapid aging would be a significant factor in increasing the exposure risk to heatwaves [
27]. An increase in the elderly population in the future is expected to escalate the scale of heatwave damage alongside an increase in extreme weather phenomena [
28]. Therefore, despite several studies, continued interest and research on the elderly are needed.
The HVI (Heat Vulnerability Index) mapping can be used as a proxy measure for potential health impacts when comprehensive health data is not available. Furthermore, it provides various insights that are difficult to identify from simple health impact indicators, offering advantages in policy development and future risk prediction. HVI mapping takes a multifaceted approach by integrating demographic, socioeconomic, and climate variables instead of relying on a single indicator or variable. This allows for a more comprehensive assessment of heat vulnerability in specific regions, enabling the analysis of key factors contributing to regional vulnerability. This approach offers a more holistic understanding compared to analyzing individual health outcomes alone. It provides policymakers with the information necessary for developing tailored policies and effectively allocating resources to address socioeconomic weaknesses in specific regions. Additionally, while direct health impact indicators show the current state or past impacts, HVI can help predict potential future risks. This plays a crucial role in minimizing health impacts through preventive measures. Therefore, the approach to improving HVI mapping proposed in this study will play a vital role in predicting future risks, developing tailored policies, and enhancing preventive measures.
The objective of this study was to enhance the understanding of the uncertainties that need to be considered when constructing heat vulnerability maps. First, we aimed to examine the relationship between heat vulnerability outcomes and health outcomes, proposing a method for combining heat vulnerability outcomes based on linear and nonlinear relationships. Furthermore, this study aimed to construct heat vulnerability maps based on the nonlinear relationship between heat vulnerability and health outcomes. Finally, we aimed to investigate differences in socioeconomic vulnerability factors associated with various health outcomes of heatwaves, thereby providing critical insights for policy development.
2. Materials and Methods
2.1. Data
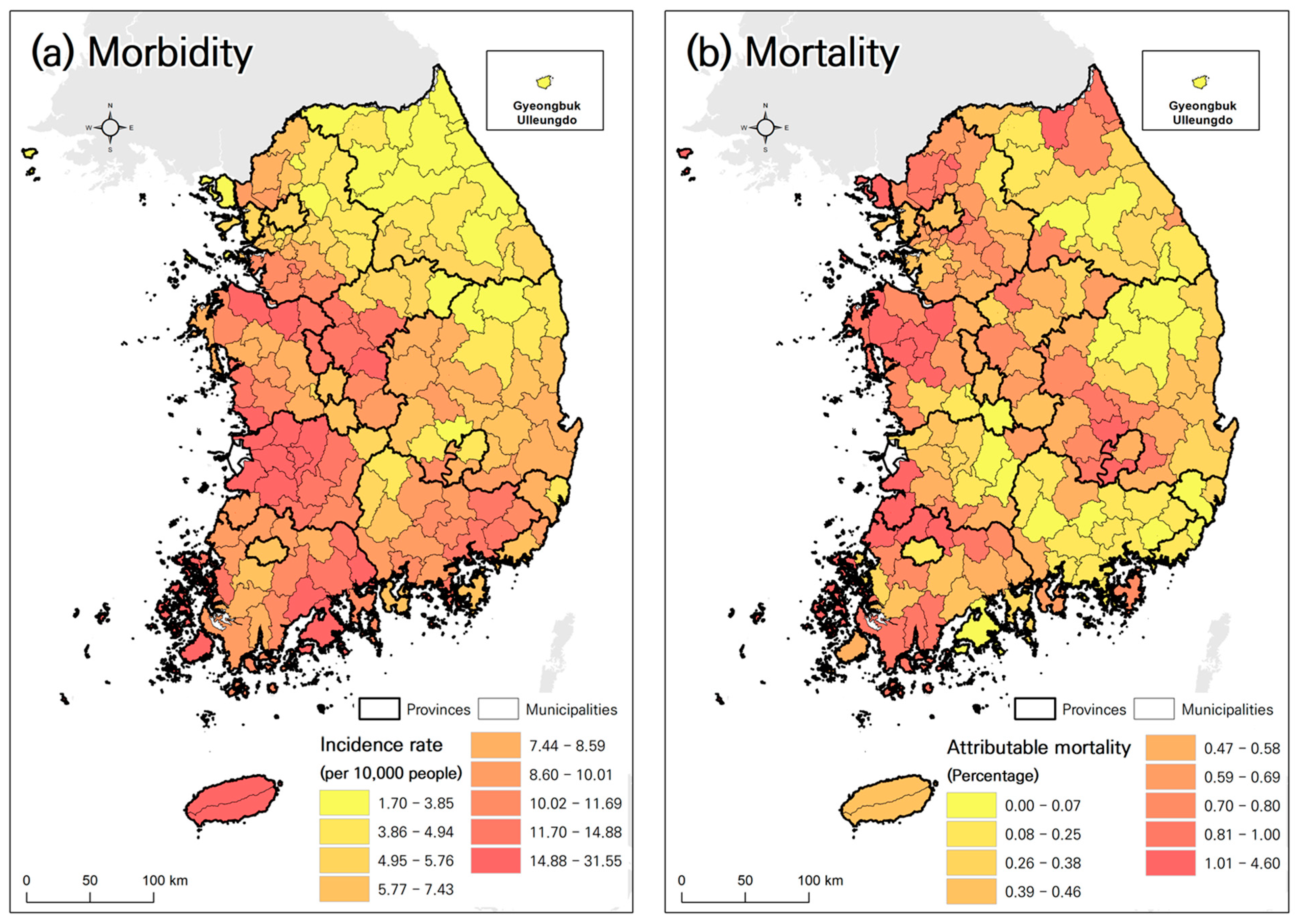
The spatial scope of this study encompassed 167 municipalities in South Korea (
Figure 1). The analysis covered the period from 2007 to 2020, spanning 14 years. Two negative health outcomes of for heatwaves were considered: morbidity, representing a mild impact, and mortality, representing a severe impact. Morbidity was measured using the incidence rate of heat-related illnesses during the summer months (June–August), whereas mortality was assessed using the proportion of excess deaths attributable to heatwaves.
Data on outpatient visits for heat-related illnesses were obtained from the National Health Insurance Service of South Korea, utilizing healthcare big data. Heat-related illnesses (HRI) were defined using the T67 code from the 10th Revision of the International Classification of Diseases (ICD-10). Mortality data were acquired from Statistics Korea’s cause-of-death statistics, including all deaths from external and other causes, and extracted using ICD-10 codes A-R. In this study, older adults were defined as individuals aged 65 and above. The number of outpatient visits for heat-related illnesses among older adults during the summer months was 70,685, and the total number of older adult deaths over the entire period was 4,006,289.
A total of 11 socioeconomic variables were used to create the heat vulnerability map. A list of variables and a map for each variable can be seen in
Table 1 and
Figure 1, respectively. Population variables include factors related to the elderly population, occupation, and household structure. The variables included the proportion of the population aged 65 or older (pop_65), the proportion of the population in rural areas (agri_65), and the proportion of the population living alone (single_65).
Economic variables include factors that reflect the income level of the elderly population and social infrastructure. The income level of the elderly population (income_65) was calculated as the ratio of low-income households among the population aged 65 or older. For low-income households, data from the lower insurance premium class (bottom 20%) were used. Financial independence refers to the ratio of self-revenue, which is the basis of a local government’s independent financial capacity, to its budget size. It is an indicator showing the degree of self-reliance based on each local government’s internal revenue, and the higher the ratio, the better the self-reliant basis of the local government.
For climate variables, temperature and humidity data from each region from 2007 to 2020 (14 years) were used to explain exposure to heat waves. The 90th percentile temperature (t90) of each region represents the level of high temperature throughout the year. The number of days exceeding the 95th percentile (tmax95) indicates the number of days when the daily maximum temperature in summer was above the 95th percentile, reflecting the intensity and frequency of heat waves. The daily average temperature (tag) in summer for each region reflects the average summer temperature.
Summers in Korea tend to have high humidity, which is closely related to the occurrence of heat-related illnesses. Therefore, we included humidity data in our analysis. The number of days (rhav80) with relative humidity above the 80th percentile in summer for each region indicates the intensity and frequency of high humidity. Additionally, the average summer relative humidity (rhav_avg) of each region was included as a variable.
We adopted the daily maximum temperature for our study. Although some existing studies have used average temperature [
29], those analyses included the influence of winter. In contrast, this study focuses solely on the summer period. Several studies in Korea have demonstrated the health effects of the daily maximum temperature, and the heatwave warning system has long been based on this metric [
18,
22]. Therefore, our analysis was performed using the daily maximum temperature.
Furthermore, the ratio of forest to total area was used as a proxy variable for assessing the impact of green space on alleviating the thermal environment.
Temperature and humidity data, consisting of climate variables, were obtained from the Automated Synoptic Observation System of the Korea Meteorological Administration. Area average data for each region were assigned using the Thiessen polygon method. Commonly used interpolation methods for meteorological applications include nearest-station assignment, inverse-distance weighting, inverse-distance-square weighting, Thiessen polygon method, orthogonal-polynomial approximation, Lagrange method, interpolation by splines, kriging, and interpolation by empirical orthogonal functions. Each method has its merits and is applicable based on the temporal scale, spatial scale, stationarity, and variability of the field under consideration [
30].
The Thiessen polygon approach determines the average weather by considering only the representative area of a station, which is determined by the bisector between each pair of stations. Although this method has limitations, such as not accounting for topographic effects, it is useful for producing long-term regional average weather data [
31].
2.2. Ethical Approval
The study protocol underwent thorough review and approval by the Institutional Review Board (IRB) of Kongju National University (Confirmation No. 2022-46). Given the observational nature of this study and the use of anonymized statistical data, the IRB committee waived the requirement for informed consent. All methodologies adhered to the guidelines stipulated by the Korean government for health and medical data usage.
2.3. Methodology for Impact Indicator Calculation
The attributable mortality rate of excess deaths was calculated based on the statistical relationship between the daily maximum temperature and mortality. Initially, the relationship between the daily maximum temperature and mortality was analyzed regionally. The Distributed Lag Non-Linear model (DLNM) was adopted for this purpose. The DLNM, known for its ability to account for the lag effects of independent variables, has been widely utilized in recent epidemiological research [
22]. The model was formulated as shown in Equation (1), and analysis was conducted using R version 4.3.0 with the dlnm package.
where
Yij represents the number of deaths recorded in region
j on day
i.
Tmax denotes the daily maximum temperature, and
l represents the lag effect. Considering the tendency for the impact of heatwaves to be strongest on the same day and rapidly decrease within a short period [
32,
33,
34], we set the lag period to three days. Here, Rhavg refers to the average daily humidity,
doy represents the day of the year in terms of Julian days, and
sn denotes the serial number. The degree of freedom for this variable was set to 6 and multiplied by 14 years (the duration of the study data). Weekdays indicate the days of the week. Natural cubic splines (
NS) were used to examine the non-linear relationship between the dependent and independent variables. Based on the relative risk of death calculated from temperature using the aforementioned method, excess deaths for each region were calculated using Equation (2) [
8].
where
i and
j represent the variables for the date and region, respectively,
Yij denotes the number of excess deaths that occurred in region
j on day
i.
D represents the daily deaths, and
β indicates the slope of the relative risk above the threshold temperature. The threshold temperature for region
j was determined by observing the non-linear relationship between the temperature and deaths mentioned above. Δ
T represents the difference between the threshold and the temperature for each day. If the temperature in region
j on day
i exceeded the threshold temperature,
H was 1; otherwise, it was 0.
The contribution rate of excess deaths for each region was calculated by averaging the percentage of excess deaths compared to the total number of deaths per year. The heat-related illness incidence rate was calculated by averaging the number of heat-related illness cases per ten thousand elderly population per year.
Throughout all stages of the analysis, including the calculation of excess death contribution rates, heat-related illness incidence rates, and socioeconomic variables, data for seven metro cities (Seoul, Busan, Daegu, Incheon, Gwangju, Daejeon, and Ulsan) were exclusively used for each city. However, for other cities and rural areas, data were integrated from adjacent regions because the sample size for these areas was sometimes inadequate due to low variability and limited data availability to establish statistical models. Therefore, to ensure an adequate sample size for the analysis, data from adjacent regions were integrated. Consequently, the interpretation of the results considered these areas from a regional perspective, rather than focusing on individual cities outside metro areas.
2.4. Methodology for Analysis of Relationships between Variables
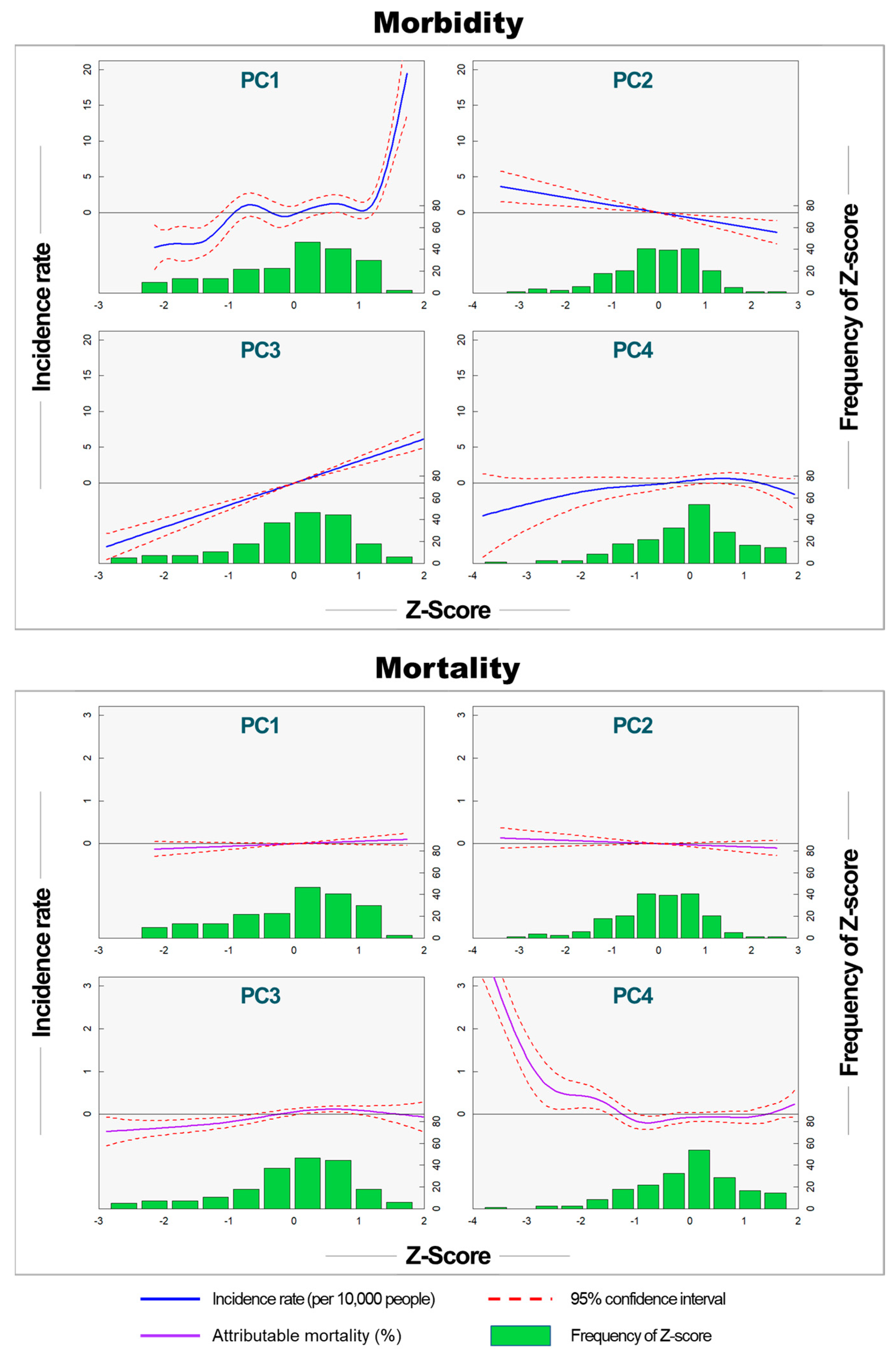
The analysis of the relationships between health outcomes and socioeconomic variables proceeded as follows: Firstly, the socioeconomic variables were transformed into components without multicollinearity issues using a PC analysis. Subsequently, these components were utilized as independent variables, while the relative risks of morbidity and mortality were employed as dependent variables to analyze their relationships. Both linear and nonlinear models, represented by Equations (3) and (4) respectively, were used in this analysis.
where Y represents the dependent variable, which can be either the incidence rate of heat-related illnesses or the attributable mortality rate. β
0 denotes the intercept of the model, while X
1–X
n represents the independent variables. β
1–β
n are the coefficients for each independent variable. f
1–f
n represents the smoothing functions for each independent variable to account for nonlinearity. For linear and nonlinear models, we used R’s linear model (LM) and the generalized additive model (GAM), respectively.
2.5. Methodology for Generating Heat Vulnerability Maps
Heat vulnerability maps were constructed using two approaches. The first was based on the results of a linear model. Utilizing the linear relationship analysis mentioned earlier, vulnerability maps were created using PCs that exhibited statistically significant relationships (p < 0.05) with health outcomes (incidence rate of heat-related illnesses and attributable mortality rate) at a 95% confidence level. The PC values were assigned to nine risk levels, with the direction of risk allocation determined based on the relationship (negative or positive) between the PCs and the health outcomes. The final heat vulnerability map was constructed by averaging the maps assigned to the PCs. In this study, we refer to this method as the Heat Vulnerability Index based on the Linear Model (HVI-LM).
The second approach was based on the results of a nonlinear model (NLM). This map was created based on previously analyzed nonlinear relationships. Firstly, we identified the thresholds in the nonlinear relationship between the health outcomes and PCs. The changes observed above these thresholds were used to assign the values of the PCs to the nine risk levels. We refer to this method as the Heat Vulnerability Index based on the Nonlinear Model (HVI-NLM).
4. Discussion
This study demonstrated significant differences in heat vulnerability maps based on health outcomes and statistical models. The results revealed notable variations in socioeconomic variables that were statistically significant for morbidity and mortality risks. For morbidity, PC1 (size of the elderly population and socioeconomic conditions) and PC3 (temperature and the effect of green space) showed statistically significant explanatory power. In contrast, PC2 (climate conditions) and PC4 (income of the elderly and temperature) demonstrated statistically significant explanatory power for mortality. These differences contributed to variations in the heat vulnerability maps for morbidity and mortality.
Furthermore, this study identified nonlinear relationships between socioeconomic variables and health outcomes. Several existing studies that have constructed heat vulnerability maps [
13,
14,
15,
16,
17] have assumed a linear relationship between socioeconomic variables and vulnerability, assigning vulnerability based on changes in socioeconomic variables. However, our study indicates that NLMs better explain the relationship between socioeconomic variables and health outcomes than LMs. Heat vulnerability maps based on nonlinear relationships matched the spatial patterns of impacts better than those using linear models.
The implications of these findings underscore the importance of considering health outcomes and statistical modeling factors when constructing heat vulnerability maps. Given the utilization of heat vulnerability maps as a tool for formulating heat response policies, differences in health outcomes have significant implications. A heat vulnerability map that does not specifically identify heat-related health risks may have limitations when utilized in policymaking. Regions with high morbidity risks may require education and preventive measures to raise awareness about heat-related illnesses, whereas regions with high mortality risks may require strengthening of healthcare facilities, emergency services, and support for vulnerable populations, such as low-income individuals and the disabled. Therefore, ensuring clarity in health outcomes when developing heat vulnerability maps can enhance policy utility.
Previous studies have not addressed the various types of damages that can be identified using heat vulnerability maps. According to prior research, because the temperature thresholds for morbidity and mortality differ, different response policies are required in terms of timing and risk communication. Since morbidity tends to precede mortality, studies have indicated challenges in providing adequate warnings for a large number of morbidity cases when heat warning systems are primarily designed to address mortality [
18,
35]. Similarly, the distinct distribution of heat vulnerability for morbidity and mortality, along with differences in the PCs associated with mortality and morbidity, implies the need for tailored response policies for each region. Therefore, constructing separate heat vulnerability maps for morbidity and mortality could assist in formulating customized policies for each region.
However, this study has certain limitations that highlight the need for further investigation. First, additional research is required to enhance the explanatory power of the spatial distribution of heat-related damage. The explanatory power for morbidity and mortality in this study was 55.7% and 52.5%, respectively, indicating that there is room for improvement. This could involve exploring dynamic data that reflect societal activities. In an existing case targeting a single city, the coefficient of determination between the heat vulnerability index and heat-related disease deaths was 0.58 using an improved method and 0.32 using the existing method [
16]. This suggests that it is challenging to accurately reproduce actual impacts with the heat vulnerability index. The selection of different variables can lead to significantly different results on heat vulnerability maps. Therefore, efforts to develop variables and find appropriate combinations are crucial [
36].
For example, there is a need to develop variables for social ties [
37], effective heat wave warning systems [
24,
38,
39] and the quality and accessibility of medical services [
40]. Additionally, variables representing the operational and activity levels of social and cultural facilities should be considered. Cultural facilities not only serve as shelters from heat but also provide gathering spaces and activities. In Seoul, for example, cultural facilities extend their operating hours during the summer and offer various programs. The operations of cultural facilities encompass structural (installation, development, and maintenance), nonstructural (investment, support, and monitoring), and social (collaboration, education, promotion, and guidelines) measures. Quantifying regional differences in such dynamic variables can be incorporated into the construction of heat vulnerability maps.
Additionally, in terms of modeling, it is necessary to apply the NLMs identified in this study while determining the extent to which variables should be minimized or maximized to enhance the model’s explanatory power. Finding the appropriate balance is crucial. Although the integration of factor analysis and DLNM used in this study was essential for minimizing variables and identifying statistically significant causal relationships, the DLNM model, which reduces the variance of model estimates in a nonlinear fashion, poses challenges in interpreting the results. Future research is required to enhance the overall reliability of DLNM and select significant factors that can differentiate between urban and non-urban areas.
Secondly, when using NLMs, it is necessary to establish a more systematic process for assigning heat vulnerabilities. The finding that NLMs yield better results than LMs is significant. However, in NLMs, the assignment of vulnerability values based on researcher observations introduces the potential for subjective judgment, which can hinder the construction of heat vulnerability maps based on NLMs. To address this issue, it is necessary to accumulate various research cases based on NLMs and establish a systematic assignment process.
Despite these challenges, this study identified the impact variables associated with heat-related morbidity and mortality and revealed the spatial patterns of heat vulnerability for morbidity and mortality at the municipal level. Addressing the limitations and conducting further research will contribute to the refinement and effectiveness of heat vulnerability mapping.
5. Conclusions
This study highlights the differences in heat vulnerability maps based on health outcomes and statistical models, underscoring the significant impact of socioeconomic variables on morbidity and mortality risks. Our findings indicate that the variables significantly associated with morbidity and mortality differed. Additionally, non-linear models offered a more accurate representation of the relationship between socioeconomic variables and health outcomes compared to linear models. These results emphasize the importance of selecting appropriate statistical models to enhance the accuracy of heat vulnerability maps and the need to configure variables differently depending on the specific health outcomes.
Several limitations were identified in the heat vulnerability mapping process. Firstly, there is the issue of low explanatory power. Addressing this challenge requires efforts to develop various variables beyond those proposed in this study. Variables such as social cohesion, effective heat warning systems, and the quality and accessibility of healthcare may be crucial. Furthermore, research is needed to minimize subjective judgment when using nonlinear models. To enhance model reliability, establishing a systematic process for assigning the results of nonlinear models to heat vulnerability is essential.
In conclusion, our study underscores the importance of considering both health outcomes and statistical modeling factors in constructing heat vulnerability maps. These maps serve as crucial tools to inform heat response policies and facilitate targeted interventions based on specific regional vulnerabilities. Insights from this study can assist national and local governments in prioritizing areas for heat response and management. Additionally, our findings offer valuable guidance for researchers developing heat vulnerability maps and advocate for the integration of advanced statistical modeling techniques with health outcomes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}