4.1. Autoencoder
We next construct a model that expresses the yield curve of the Japanese government bond market using an autoencoder, an algorithm for dimension compression using neural networks (
Hinton and Salakhutdinov 2006). Principal component analysis is an example of a linear dimension compression. With autoencoders, the same training data is learned through the input and output layers of a neural network. By increasing the number of nodes in a hidden layer, more complex yield curve shapes can be expressed. In this research, we construct neural network models with 2, 3, and 4 nodes in the hidden layer for comparison.
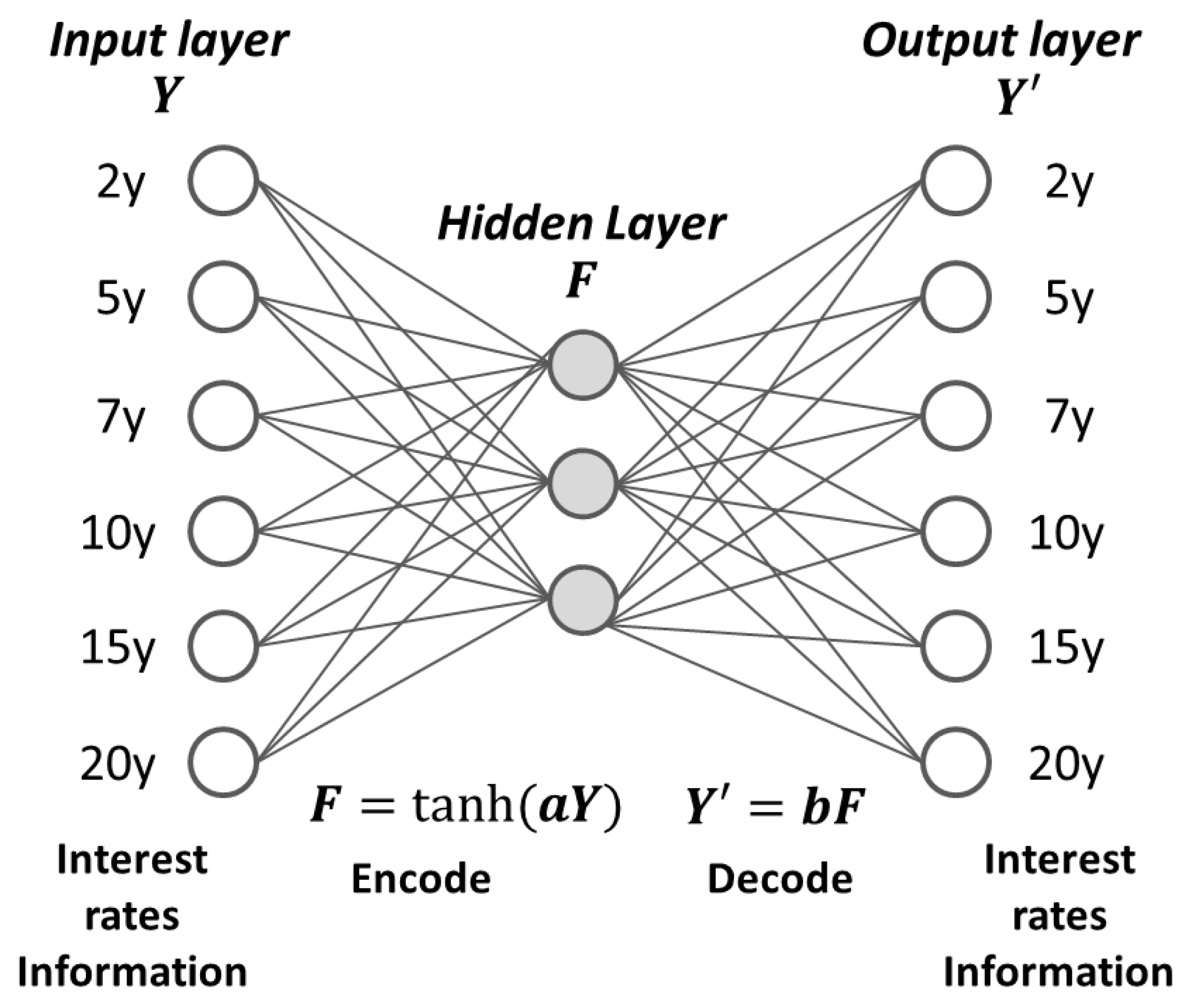
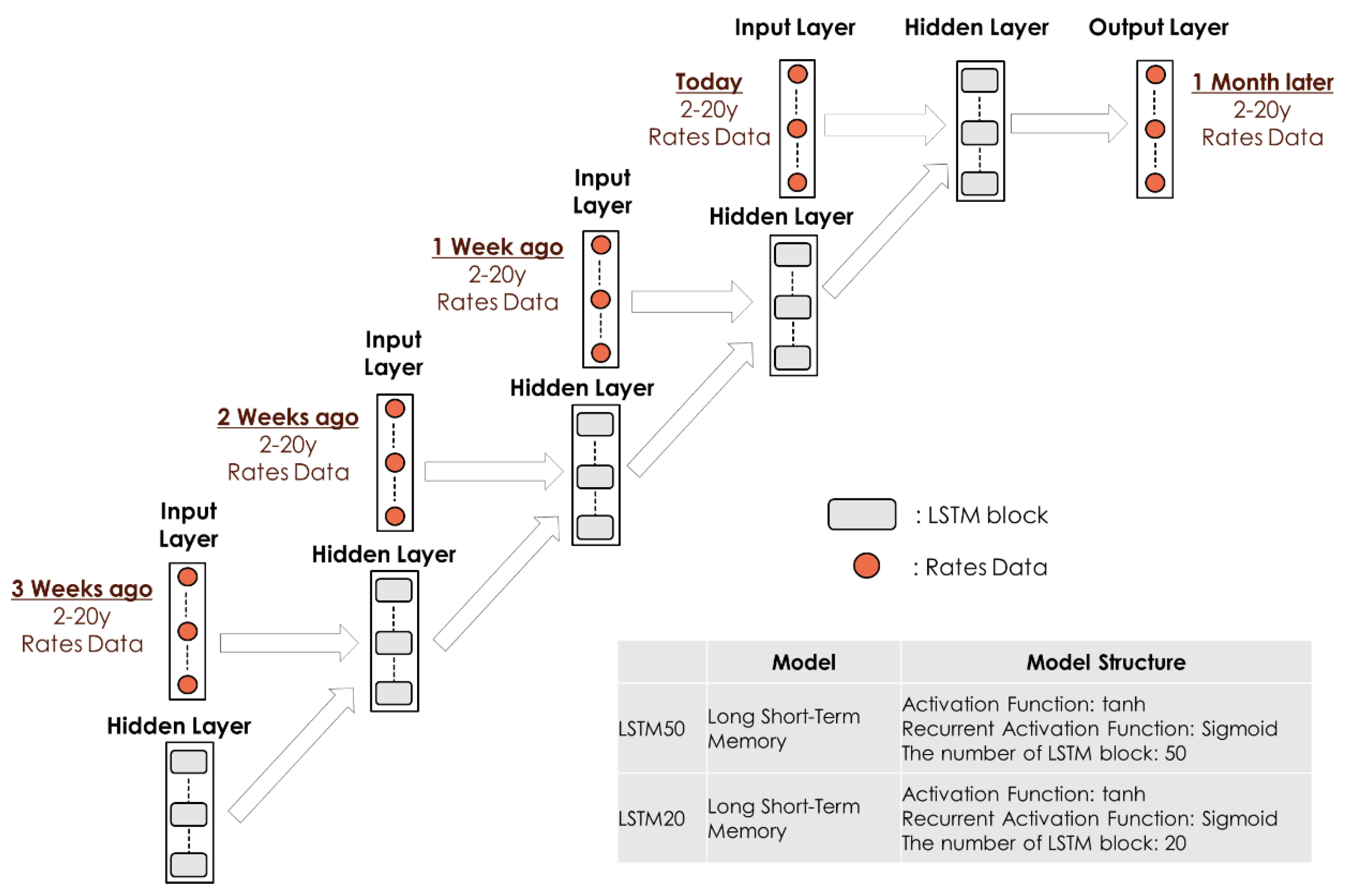
Figure 6 illustrates how we incorporate 2-, 5-, 7-, 10-, 15-, and 20-year interest rate data into a learning model. In this autoencoder model,
Y is the vector of the input information, 2-, 5-, 7-, 10-, 15-, and 20-year interest rate data and the activation function to the hidden layer is hyperbolic tangent. The output information of the model is
Y′. We estimate the model parameters
b and
a so that the input information
Y and the output information
Y′ matches. we use weekly data from July 1992 to July 2019 to estimate the model. We interpret each node of the hidden layer in the self-encoder by assigning a linear function to represent the path to the output layer and consider the function’s coefficient.
First, we analyze the model with a hidden layer comprised of three nodes.
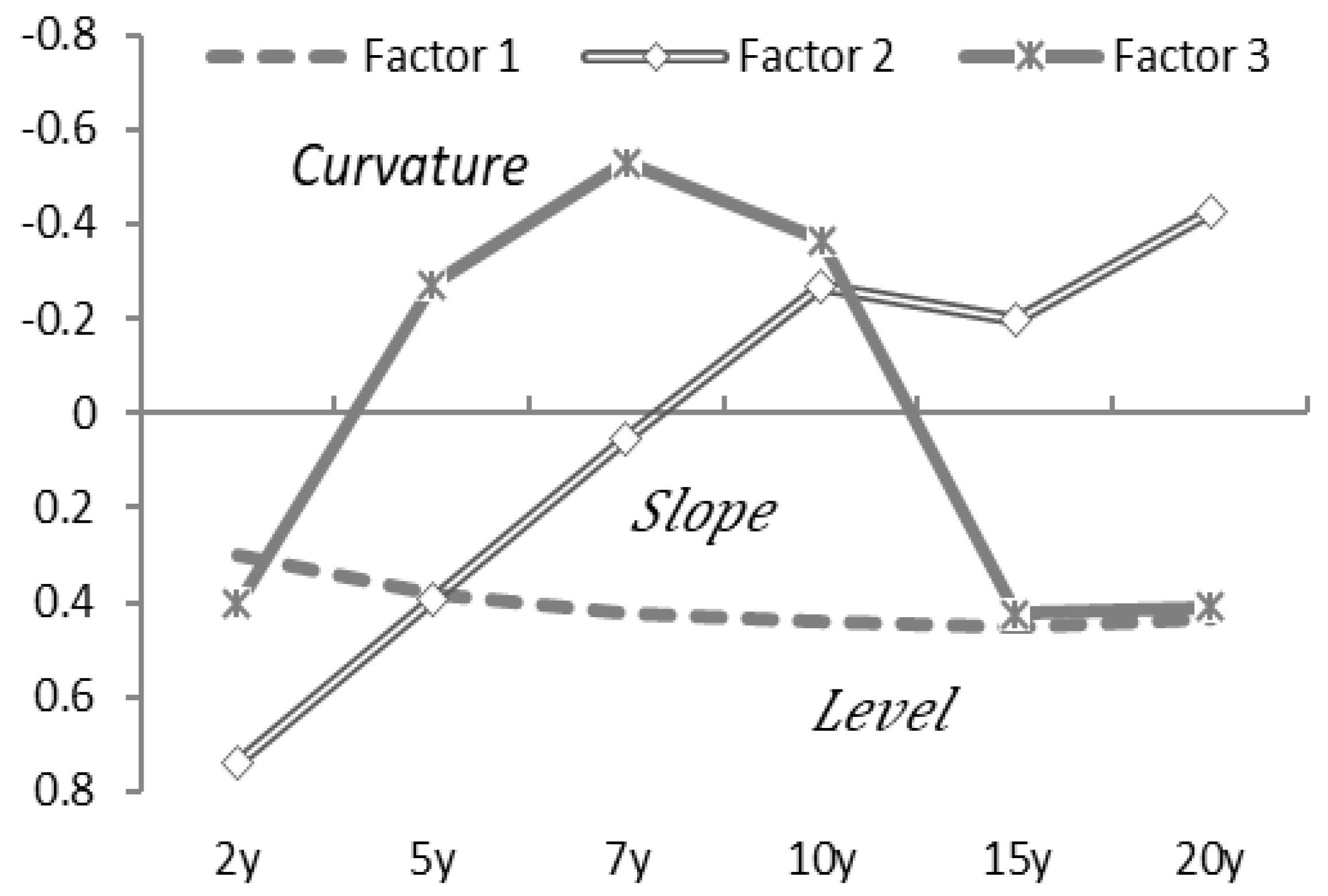
Figure 7 shows the coefficient
b of the linear function representing the output from the hidden layer, which provides the correspondence between the hidden layer’s nodes and the output layer’s nodes. Each node in the hidden layer can be interpreted as the level, slope, and curvature of the yield curve.
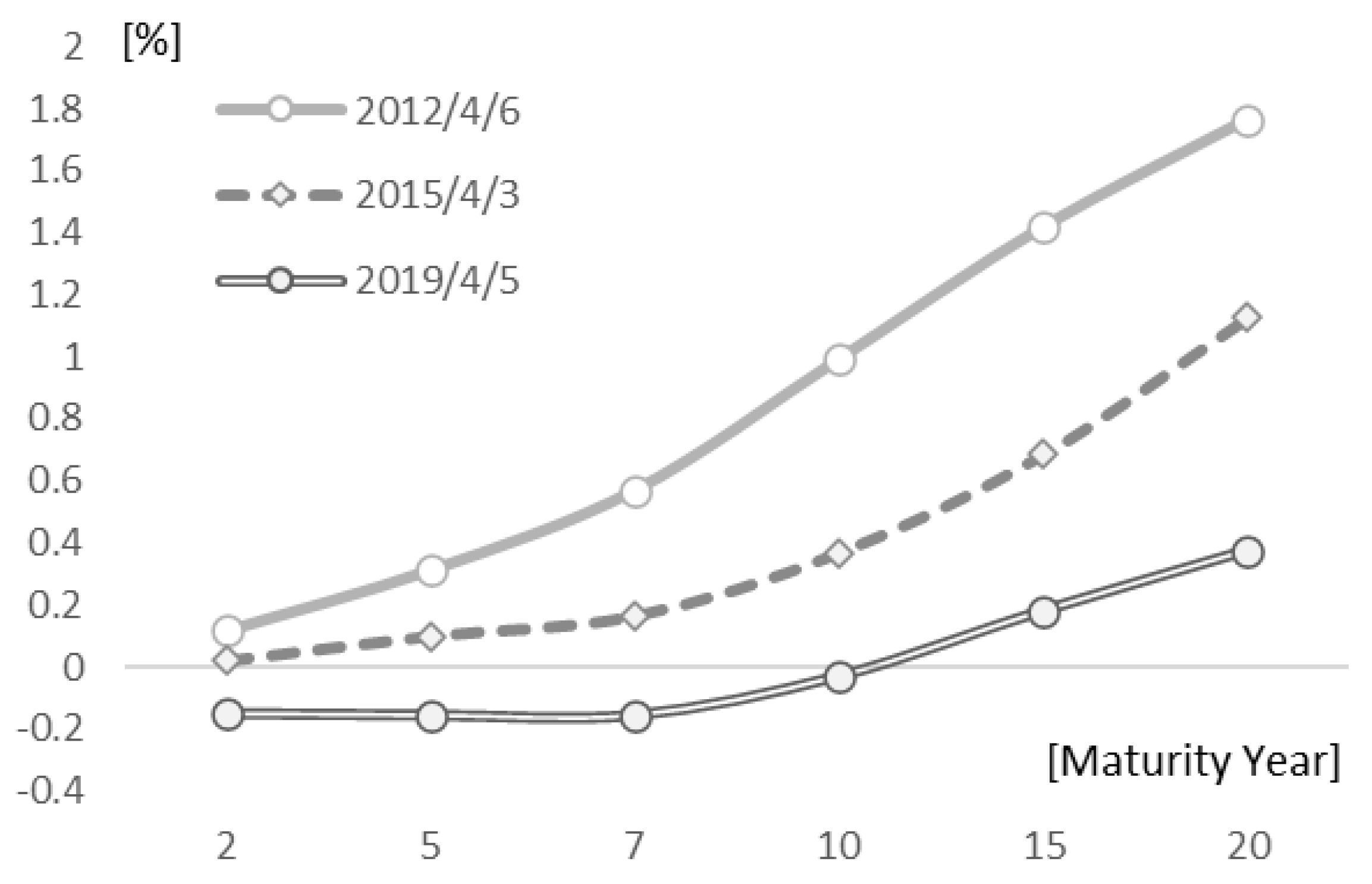
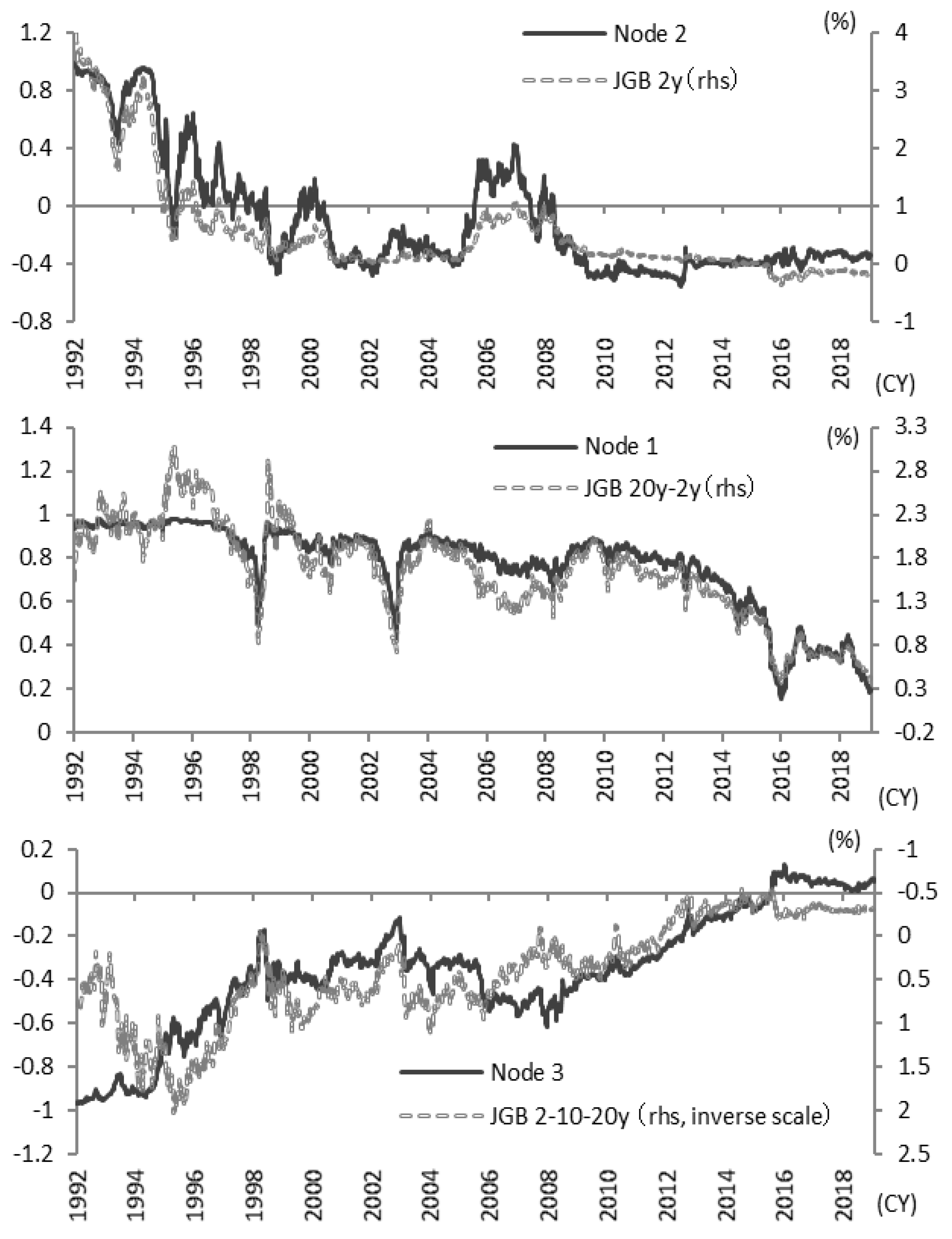
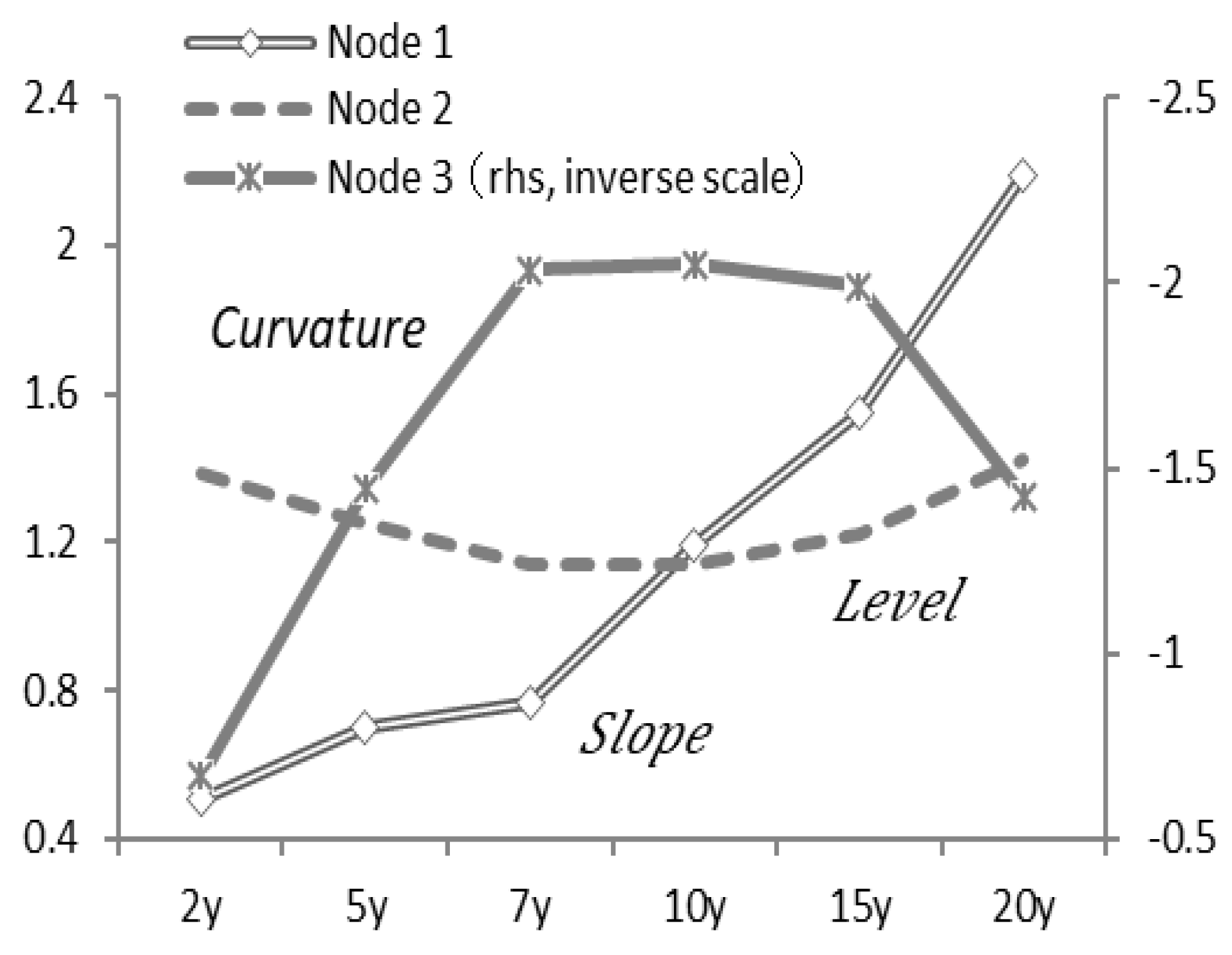
Based on these results,
Figure 8 compares the value of each node with the actual interest rate level and interest rate spread (i.e., the interest rate difference). For example, comparing Node 2, representing a level, with a two-year interest rate near the start of the yield curve, the two are approximately linked. Comparing Node 1, interpreted as the slope, with the 2–20-year interest rate spread (i.e., 20-year yield - 2-year yield), both move similarly. Node 3, interpreted as the curvature of the yield curve centered on long-term interest rates, compared with the 2-10-20 year butterfly spread (i.e., 2 × 10-year yield - 10-year yield - 20-year yield), also moves similarly in
Figure 8.
Next, we review the results with only two nodes in the hidden layer.
Figure 9 plots the coefficients of the linear function representing the hidden layer for each node to the output layer. With only two hidden layers, the nodes are interpreted as the curvature of the yield curve and the combined slope and level of the yield curve.
Figure 10 plots comparisons between the value of each node in the hidden layer with the actual interest rate spread. Node 1, interpreted as the slope, moves similarly to the 2-20-year interest rate spread (i.e., 20-year yield - 2-year yield). Node 2, interpreted as a curvature of the yield curve centered on the long-term interest rate, is approximately linked to the 2-7-20 year butterfly spread (i.e., 2 × 10-year yield - 7-year yield - 20-year yield).
Finally, we analyze the model with four nodes in the hidden layer. According to the coefficients of the linear function representing the output from the hidden layer, as shown in
Figure 11, Node 1 represents the level, Node 3 represents the curvature, and Node 2 and Node 4 represent the slope. However, according to the shape of each coefficient vector, Node 1, Node 2, and Node 4 also include a curvature element. So, with four nodes in the hidden layer, the interpretation of each is not as straightforward as the models with two or three nodes. In the principal component analysis (PCA) described in
Section 3, the cumulative contribution to the shape of the yield curve when using the third principal component factor was about 99%. So, as suggested by these results, the autoencoder can best represent the shape of the yield curve with three nodes in the hidden layer.
In this research, we proposed a yield curve model using an autoencoder. Like the Nelson–Siegel model (
Nelson and Siegel 1987), and other known factor models (
Svensson 1995) (
Dai and Singleton 2000), the proposed model can express the shape of the yield curve by combining the three factors, curvature, level, and slope. The factor models, such as the Nelson–Siegel model and the Svensson model etc., that we mention above need to explicitly set a function form that expresses the shapes of the yield curve. However, the autoencoder-based model or neural network-based model have high flexibility for the expression of the yield curve because these models can set the function forms flexibly. With significant changes in monetary policy and other factors, the fluctuation characteristics of the yield curve also change, so a flexible functional form is required for the yield curve modeling. When using autoencoder-based model or neural network-based model, not only the model parameters but also hyperparameters and the number of nodes can be changed to increase the flexibility of the model function that express the shape of the yield curve.
Furthermore, when using PCA for the yield curve modeling and specifying the number of principal component factors, we cannot cover the contribution of the other PCA factors. However, when using an autoencoder for the modeling, all input information can be used via the network model. These points are advantages of the autoencoder-based model as a yield curve factor model compared to other factor models.
4.2. Autoencoder-Based Yield Curve Model and Trading Strategy
From the viewpoint of asset price evaluation and investment strategies for government bonds, we propose using an autoencoder that models the shape of the yield curve. The interest rate output by the trained autoencoder is calculated based on the relative relationship with the interest rates of the other maturities. So, in this section, we apply the trained autoencoder as a discriminator for overvalued or undervalued government bonds compared to other maturities. We also construct a long–short strategy for government bonds based on these overvalued and undervalued evaluations to verify its performance.
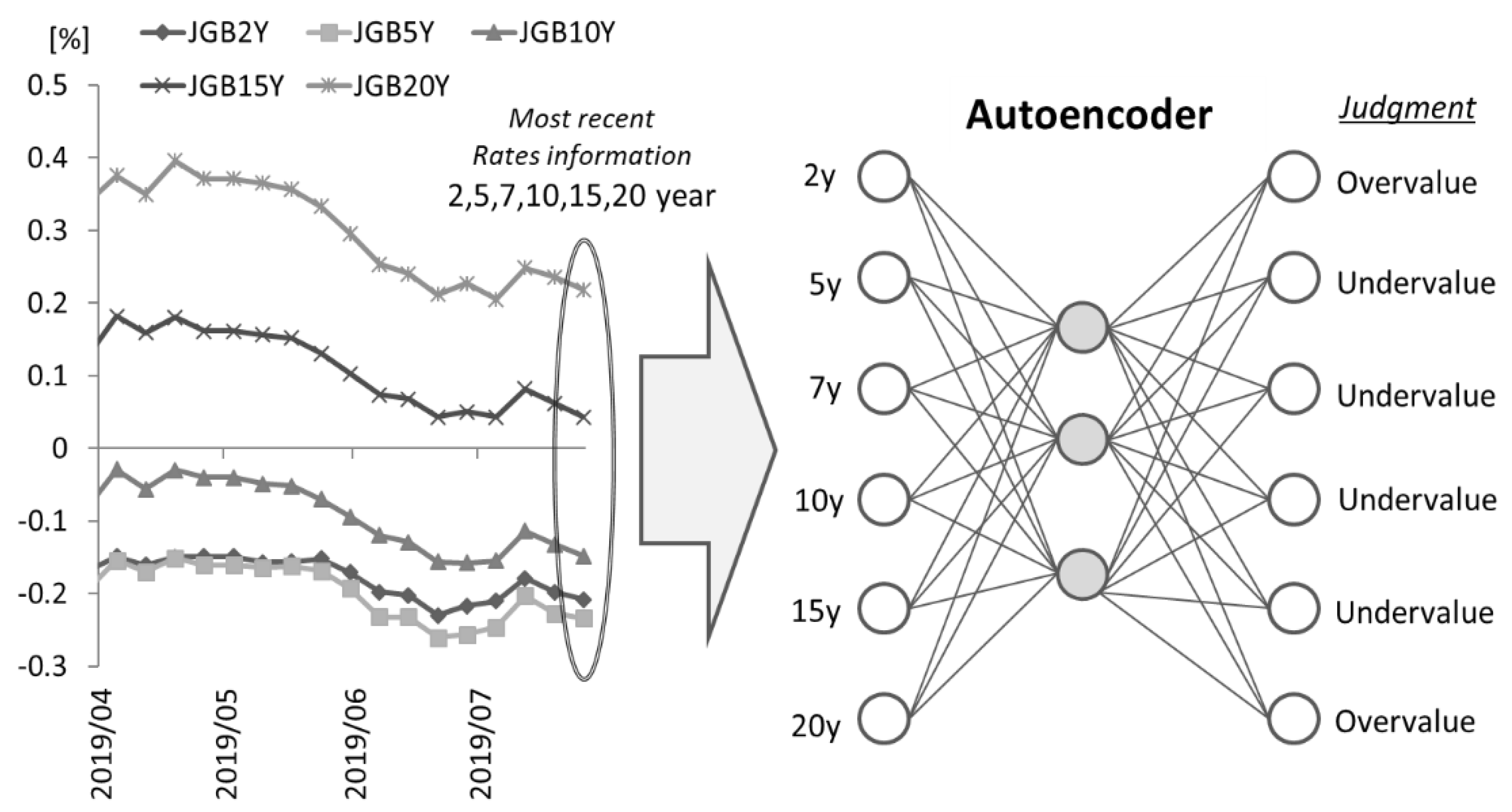
The interest rate data for each maturity at the time of investment is input to the learned autoencoder, and we define the output interest rate as the reference interest rate. For each maturity, if the interest rate at the time of investment is higher than the reference interest rate, we judge the government bond as undervalued as shown in
Figure 12, so we long (buy) the bond. On the other hand, if the interest rate is lower than the base interest rate, we short (sell) the bond. The investment period for each position is one or three months. For training the autoencoder, we include data from the previous 2, 5, and 10 years, excluding data at the time of the model update, and update the models annually. Weekly interest rate data from July 1992 to July 2019 is used for the investment simulation.
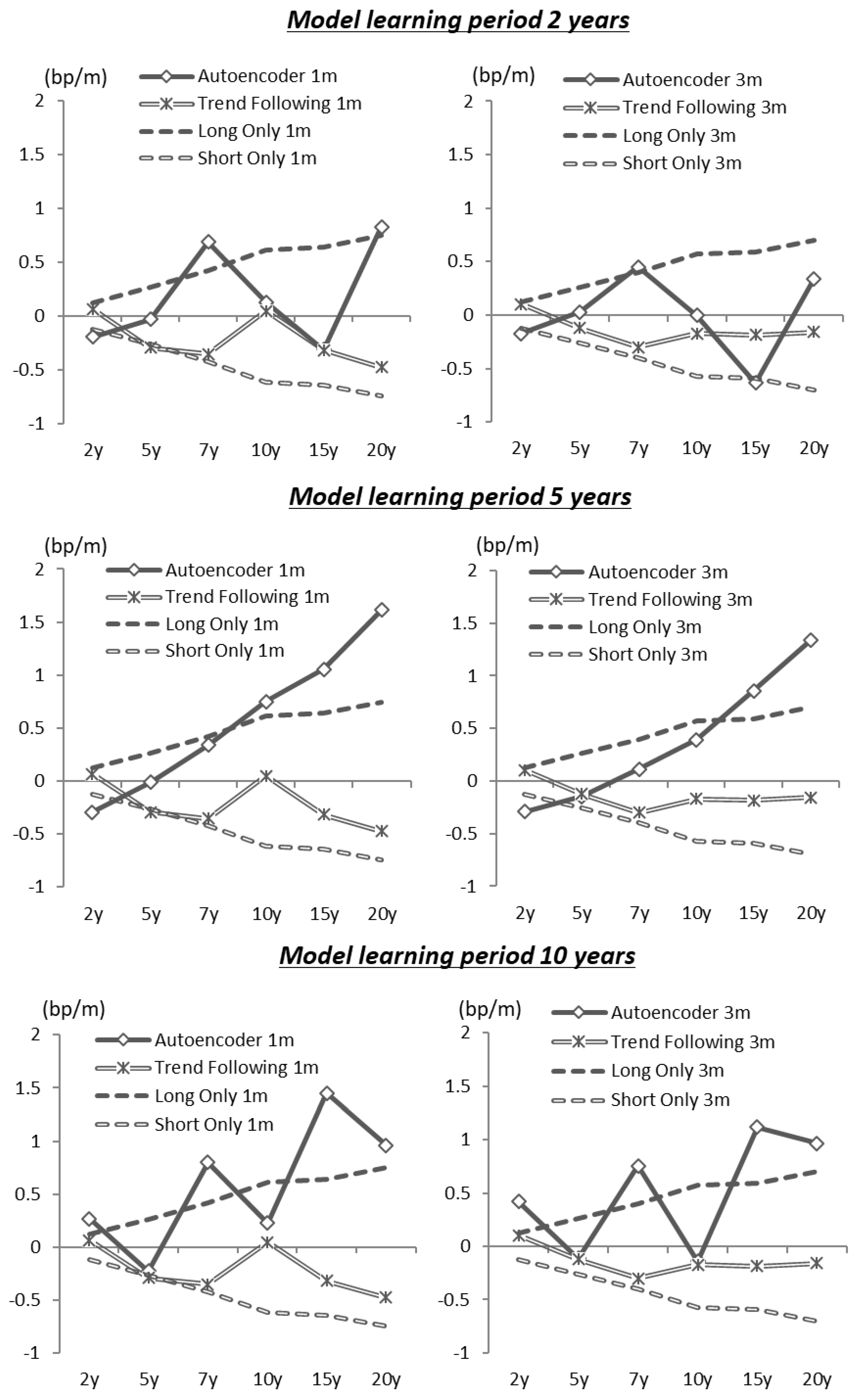
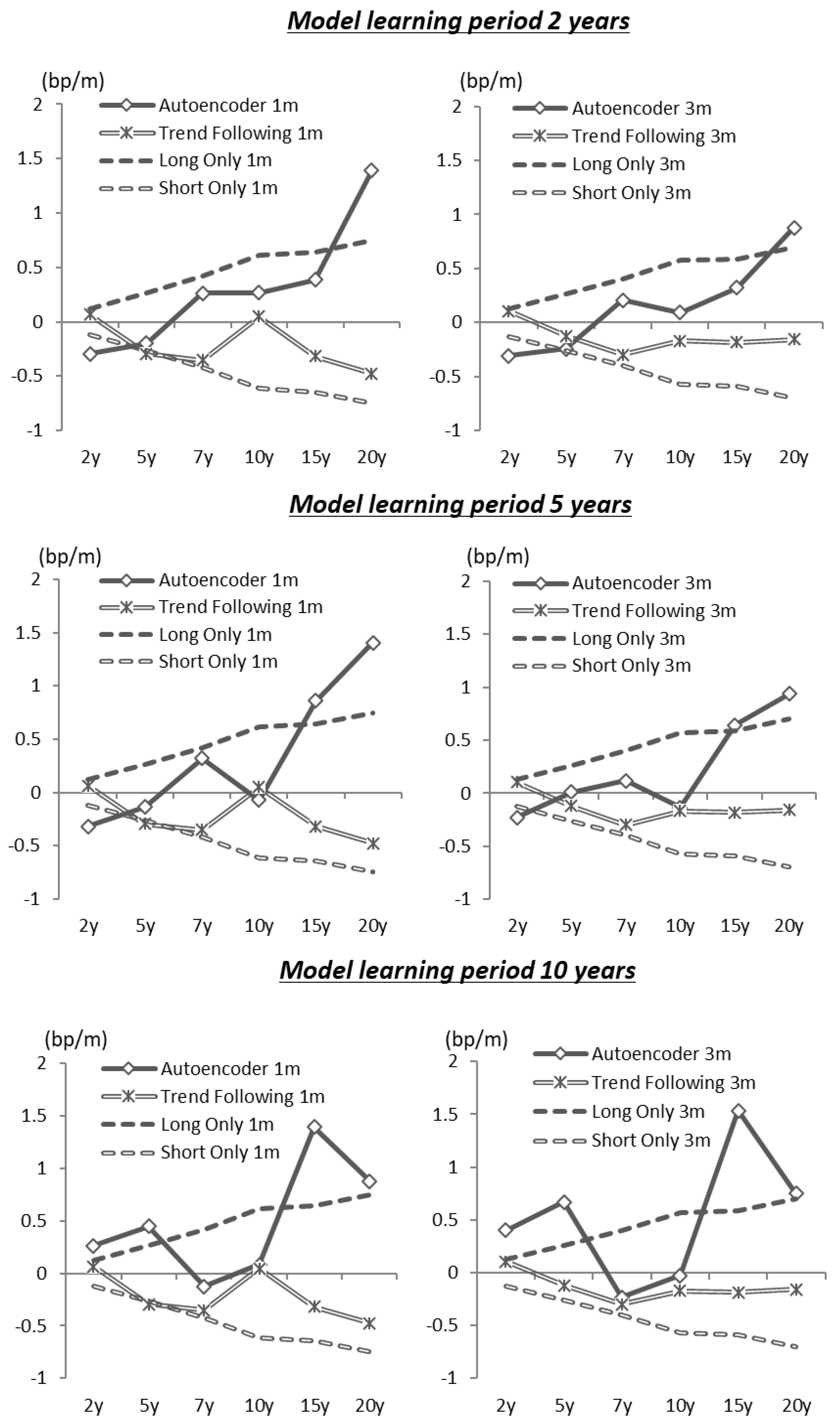
Figure 13 shows the simulation results for the autoencoder with three hidden layer nodes modeling the average capital gain over one month for each long–short strategy. The unit of the capital gain is bp (0.01%). For the long position, the decrease in interest rates during the investment period is the capital gain, and, for the short position, the increase in interest rates is the capital gain. To verify the accuracy of the interest rate forecasting by the model, we do not consider the effects of carry and rolldown and repo cost when making a short position. For the comparison of this trading strategy, we present the results of a trend-follow investment strategy (i.e., long if the interest rate declines from the previous week at each investment period, and short if interest rates rise) along with the results of investment strategies that are always a long (short) position.
The performance of the investment simulation depends on the number of nodes in the hidden layer, the learning period of the model, and the maturity of the government bonds to be invested.
Figure 13 shows the result of the proposed strategy with the three-node model with a learning period of about 5 years and an investment period of 1 month. For the 10-year and 20-year government bonds’ investment strategies, these results suggest that the proposed model has a higher investment return than the trend-follow investment strategy.
The results from the models with two or four nodes in the hidden layer are included in
Appendix A. For both cases, the performances are similar to the model with three hidden layer nodes. However, for the one-month investment strategy of 10-year and 20-year government bonds using 5 years for the learning period, the performance of the three-node case is better.
In this strategy, the trained autoencoder calculates the base interest rate from the relationships with the other maturities’ interest rates. If the interest rate of the target maturity is distorted compared to the other rates, there is merit in that the autoencoder’s judgment can automatically construct the investment position for correcting the distortion. However, such interest rate distortions between maturities are corrected in a relatively short period, so the one-month investment period is better than three months, as shown in these results of the investment performance.
The performance of the model is good when the learning period is approximately 5 years, which is likely due to the frequency of monetary policy changes that significantly affect the characteristics of the interest rate market. Based on the
Yu-cho Foundation (
2018),
Figure 14 shows the timing of recent major Japanese monetary policy changes and illustrates that the monetary policy framework changes every two to five years. Considering this frequency of change, if the model learning period is 10 years, it is difficult to respond to these changes in the market characteristics. On the other hand, if the model learning period is 2 years, the number of data samples for learning is too small in the form of weekly granular data. From these observations, a learning period of 5 years is presumed to offer the best performance.
In summary, we confirmed the relative effectiveness of the performance of the 10-year and 20-year government bonds strategies with a learning period of 5 years and an investment period of 1 month.
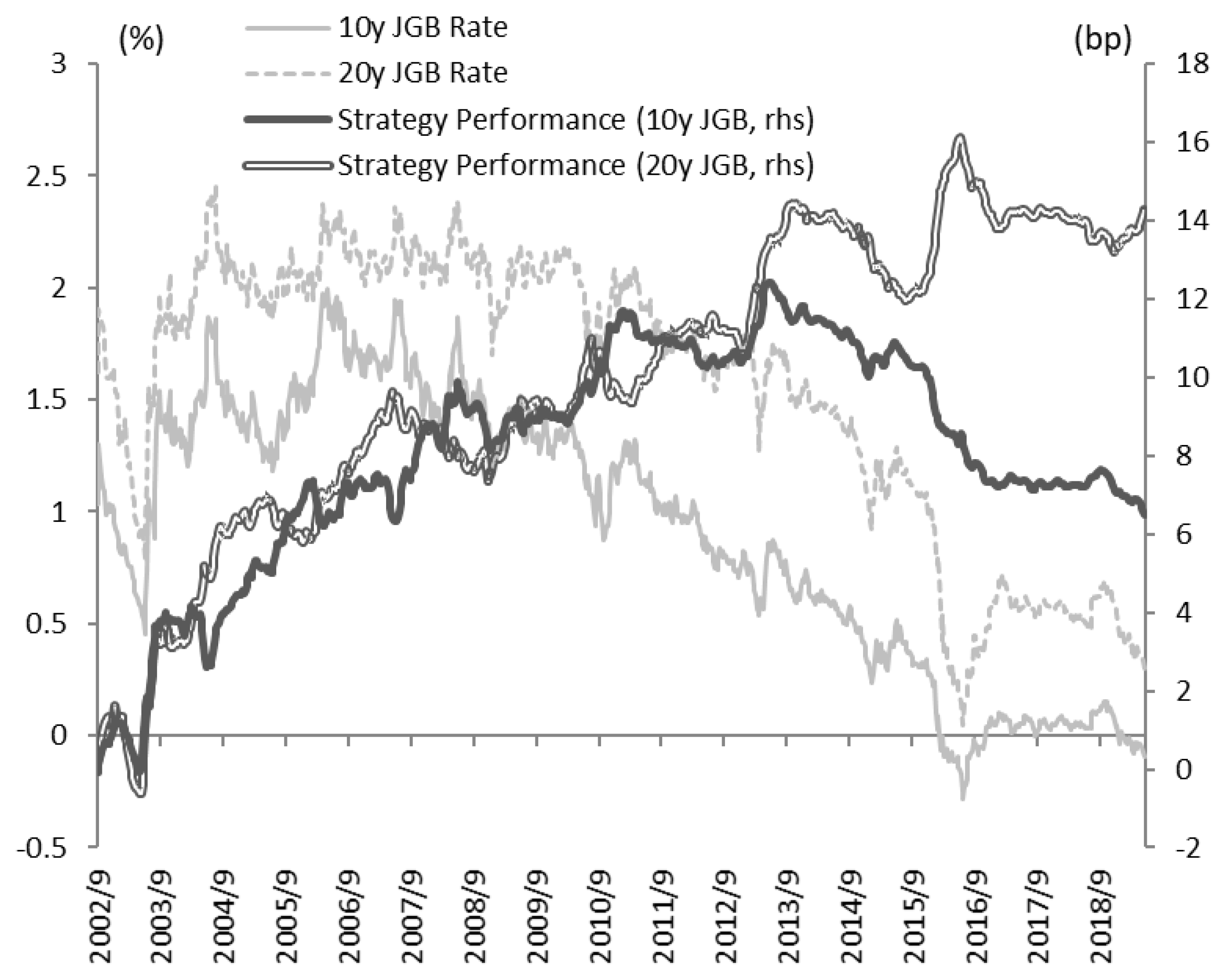
Figure 15 shows the cumulative performance of this strategy that verifies the positive cumulative returns for both strategies. However, in the 10-year government bonds strategy, the cumulative returns decline significantly after the beginning of 2016.
Figure 15 also includes the 10-year and 20-year bond yields, showing that the 10-year bond yield fell nearly to 0% since the introduction of the “Quantitative and Qualitative Monetary Easing with a Negative Interest Rate” policy in January 2016. Furthermore, after the introduction of the “Quantitative and Qualitative Monetary Easing with Yield Curve Control” policy in September 2016, the 10-year bond yield remains strictly around 0%. Therefore, we see that such rigidity in market interest rates can cause the sluggish performance of the long–short strategies for 10-year government bonds.
4.3. Comparison with Other Strategy Models
In the previous section, we confirmed the performance of the investment strategies that use the autoencoder as a discriminator to judge overvaluation or undervaluation for each maturities’ government bonds. In this strategy, as shown in
Figure 16, the investment decision is based on the interest rate data at the time of the investment, without directly using the historical data before the investment day. Nevertheless, a relatively stable return is obtained.
On the other hand, this investment strategy is ancillary as it was devised during the development of the autoencoder for the yield curve factor model. Typically, when making an investment strategy for government bonds, the historical data of the interest rates would be incorporated. For example,
Suimon (
2018), and
Suimon et al. (
2019b), proposed an investment strategy based on a neural network model that learned with historical time series data of interest rates. These studies demonstrated the usefulness of an LSTM (Long Short-Term Memory) (
Hochreiter and Schmidhuber 1997) model that also learned to make predictions based on interest rate time series data. In addition, VAR (Vector autoregression)-based strategies (
Estrella and Mishkin 1997;
Ang and Piazzesi 2003;
Afonso and Martins 2012) are also known as investment strategies for the government bonds market by using the historical interest rates data. Based on these past studies, we next implement an investment strategy using the LSTM and VAR model trained on interest rate historical data to compare its investment performance with that of the autoencoder model.
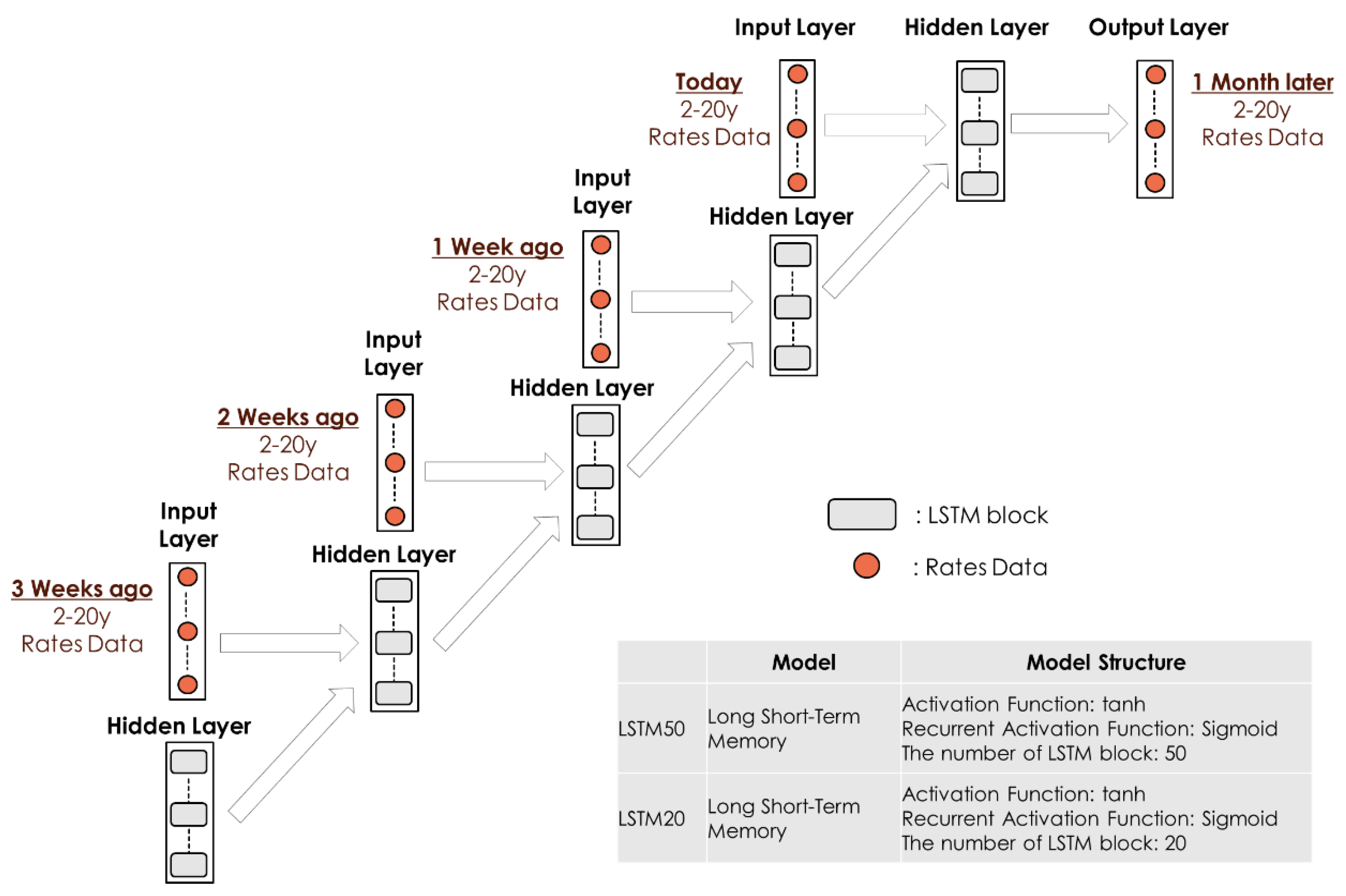
The LSTM model is a type of Recurrent Neural Network (RNN) model that inputs past time series information sequentially.
Figure 17 illustrates the relationship between the input and output information of the interest rate data for the LSTM model we implement here. The structure of the LSTM block in
Figure 17 is as shown in
Figure 18. As shown in
Figure 16, in addition to the interest rate data at the time of investment, the interest rate data of the previous weeks are used as input information for the model. Then, the LSTM model learns the correspondence between these past interest rates and future interest rates.
Furthermore, as with LSTM, we implement a VAR model which use the interest rate information of the past few weeks as the input information and which use the interest rate information of one month ahead as the output information. Here, let
be the interest rate of one month ahead and
be the weekly interest rate of the past three weeks including the time of investment.
and
are the model parameters.
Using the LSTM model and VAR model, we predict the interest rate one month later and decide to buy or sell the government bonds for each maturity based on the relationship between the actual interest rate at the time of investment and the forecasted future interest rate. For example, if the predicted interest rate one month ahead according to the model is higher than the interest rate at the time of investment, we expect the interest rate will rise, so we short (sell) the government bond. On the other hand, if the predicted interest rate is lower than the current interest rate, we expect the interest rate will fall, and we long (buy) the government bond.
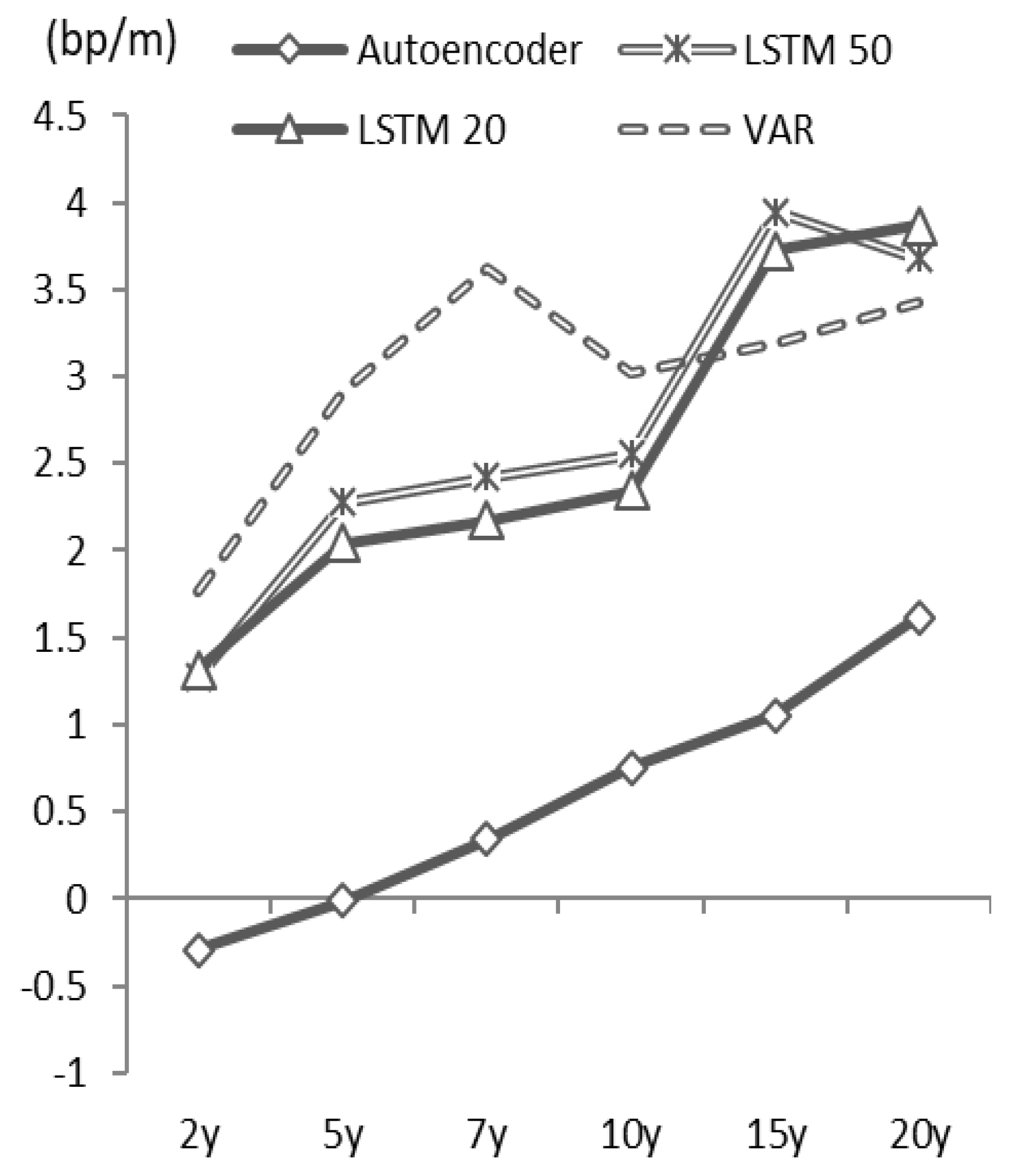
Figure 19 shows the results of our investment simulation. Similar to the strategy using the autoencoder, the learning period of the LSTM and VAR model is 5 years, and we relearn the model every year. As a result, the investment strategy using these models demonstrates relatively high investment performance compared to that of the strategy using the autoencoder.
Considering the cumulative returns presented in
Figure 20, the LSTM and VAR model utilizing the historical time series information provides stable forecasting of the returns. On the other hand, the strategy using the autoencoder that does not use time series information of past interest rates as the input data is inferior in terms of trading performance.
However, based on the yield curve shape information at the time of investment, the autoencoder determines if the government bonds are overpriced or underpriced, enabling a decision to sell or buy based on its valuation. The cumulative return of the autoencoder strategy is stably positive. So, the evaluation of overpricing or underpricing for each bond at the time of investment is reasonable. Therefore, the proposed model using an autoencoder is effective from the viewpoint of the asset evaluation of government bonds relative to the market environment.
In addition, from the viewpoint of interpretability, we have merit to use the autoencoder-based model that we propose in this research. The autoencoder-based model expresses the yield curve by three factors, which are interpreted as the level, slope, and curvature of the yield curve. In the trading strategy, as we proposed, we decide to sell or buy based on its valuation of the yield curve shape information at the time of investment based on the autoencoder. So, the proposed strategy is to construct a trading position to the direction in which the deviation between the actual curve and the theoretical curve by autoencoder is corrected. Therefore, we can clearly interpret what we are betting on in the proposed strategy. On the other hand, the investment strategy based on LSTM and VAR shown in the paper predicts the future interest rate directly based on historical interest rate information at the time of investment and decide to sell or buy based on prediction. Therefore, it is difficult to interpret whether the trading position by LSTM or VAR is betting on the pattern of interest rate change from the past or betting on correcting the distortion of the yield curve at the time of investment. As described above, the merit of the proposed model based on the autoencoder is the interpretability of the model and the interpretability of what we are betting on.
Finally, I would like to supplement the analysis/simulation programming method used in this research. The programming language used throughout this research is Python, and the Python library TensorFlow was used to implement the neural network (the proposed autoencoder-based yield curve model, LSTM model), and scikit-learn was used to implement PCA.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}