
Crypto Exchanges and Credit Risk: Modeling and Forecasting the Probability of Closure



Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Credit Scoring Models
3.2. Machine Learning Techniques
3.3. Model Evaluation
4. Results
4.1. Data
- CoinGecko5: it is a platform that aggregates information from different crypto exchanges and has a free application programming interface (API) with access to its database;
- Cybersecurity Ranking and Certification platform6: it is an organization performing security reviews and assessments of crypto exchanges;
- Cryptowisser7: it is a site specialized in comparison of different crypto exchanges, including those closed and bankrupt;
- Mozilla Observatory8: it is a service allowing users to test the security of a particular website.
- Server security. This category consists of testing cryptographic protocols, such as the Transport Security Layer (TLS), the Secure Sockets Layer (SSL), the Web Application Firewall (WAF) in combination with a Content Delivery Network (CDN), the Domain Name System Security Extensions (DNSSEC), Sender Policy Framework (SPF), and many others.
- User security. This category assesses the implementation of security measures related to the user experience, such as the two-factor authentication, CAPTCHA, password requirements, device management, anti-phishing code, withdrawal whitelist, and previous hack cases.
- Penetration test (or ethical hacking test). This kind of test looks for vulnerabilities of the exchange security and how fraudsters may use them.
- Bug bounty program. The program aims at stimulating hackers and cybersecurity specialists to find bugs or errors in the crypto exchange software in exchange for a reward.
- ISO 27001. The test verifies compliance with the standard published by the International Organization of Standardization (ISO) and the International Electrotechnical Commission (IEC) that regulates information security management systems.
- Fund insurance. It verifies that the crypto exchange has identifiable wallets and minimum funding.
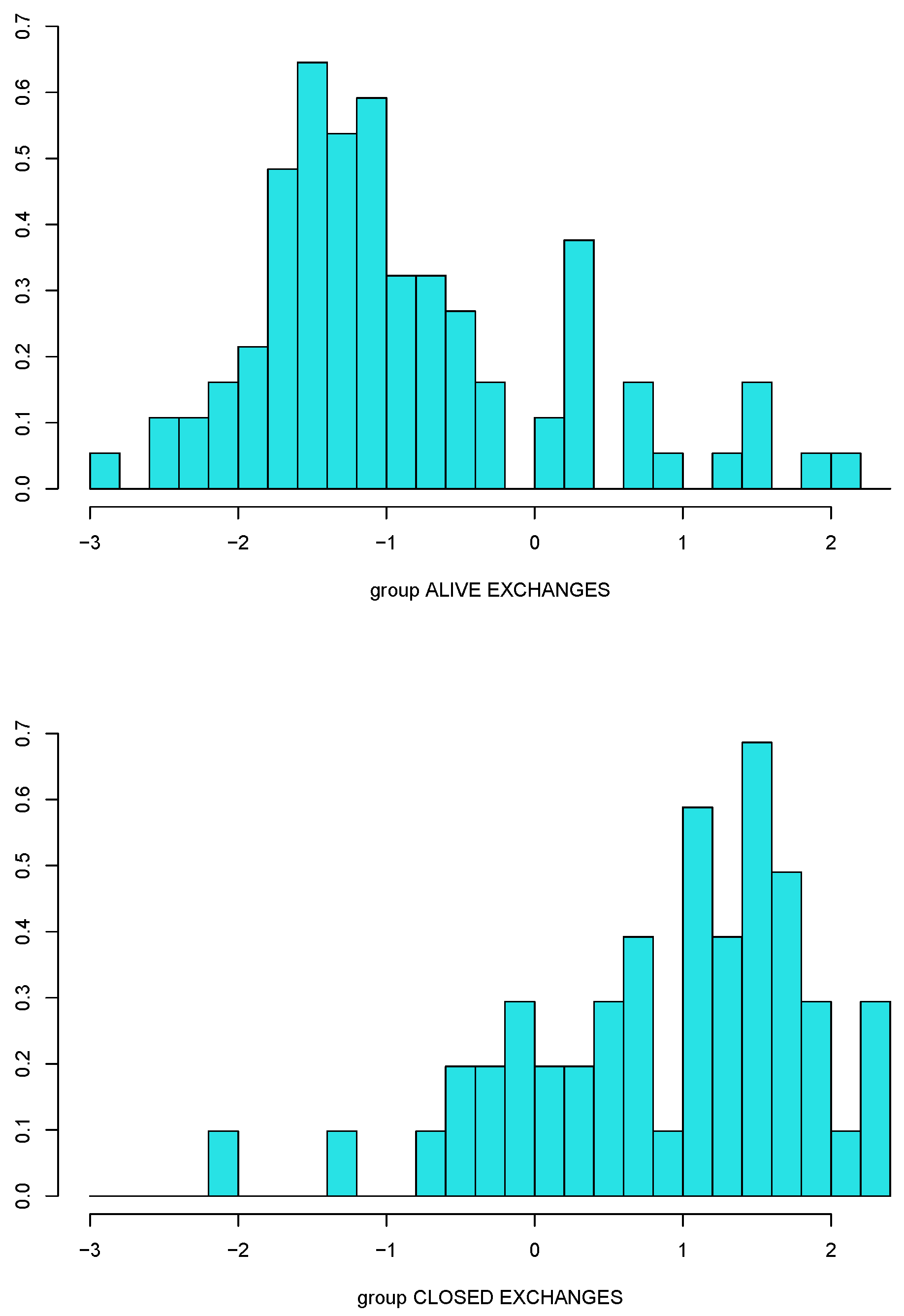
4.2. In-Sample Analysis
- 51% of exchanges (=73 exchanges) had a public team and an age bigger than 2.5 years (68 remained alive and 5 closed, 93% and 7%, respectively);
- 11% of exchanges (=16 exchanges) had a public team and an age smaller than 2.5 years (7 remained alive and 9 closed, 44% and 56%, respectively);
- 11% of exchanges (=16 exchanges) did not have a public team and they had a number of tradable assets bigger than 35 (11 remained alive and 5 closed, 69% and 31%, respectively);
- 27% of exchanges (=39 exchanges) did not have a public team and they had a number of tradable assets smaller than 35 (7 remained alive and 32 closed, 18% and 82%, respectively).
4.3. Out-of-Sample Analysis
5. Robustness Checks
5.1. Centralized or Decentralized Exchanges: Does It Matter?
5.2. Country of Registration: Does It Matter?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A. Exchanges Names

{kind=link}
{kind=link}
{kind=link}
| 3xbit | BTSE | FTX | NLexch |
| 6X | Bybit | Gate.io | Oceanex |
| Aax | C-Cex | Femini | Okcoin |
| Alterdice | Chainrift | Gopax | Okex |
| Altilly | Chilebit | HB.top | Otcbtc |
| Altsbit | Cobinhood | Hbtc | Paribu |
| Ascend | Coinegg | HBUS | Phemex |
| B2Bx | Coinbene | Hitbtc | Poloniex |
| Bancor | Coinchangex | Hoo | Poloni dex |
| Bankera | Coincheck | Hotbit | Probit |
| Bibox | Coindeal | Huobi | Purcow |
| Bigone | Coinex | Ice3x | Shortex |
| Biki | Coinfalcon | ICOCryptex | Sistemkoin |
| Bilaxy | Coinfloor | Indodax | Sparkdex |
| Binance | Coinhub | Instant Bitex | Stex |
| Bitbank | Coinlim | IQFinex | Stormgain |
| Bitbay | Coinmetro | Itbit | The PIT |
| Bitbox | Coinnest | Koineks | TheRockTrading |
| Bitfinex | Coinone | Korbit | Tidex |
| Bitflyer | Coinrate | Kraken | TokensNet |
| Bitforex | Coinsbit | Kucoin | TopBTC |
| Bitget | Coinsuper | Kuna | Trade Satoshi |
| Bithumb | Cointiger | Lakebtc | Tux exchange |
| Bitkub | CPDAX | Latoken | Unichange |
| Bitlish | Credox | Lbank | Upbit |
| Bitmart | Crypto Bridge | LEOxChange | Vbitex |
| Bitmesh | Crypto Dao | Liquid | VeBitcoin |
| Bitmex | CryTrEx | Livecoin | VirWox |
| Bitopro | Dcoin | Lukki | Wazirx |
| Bitpanda | Deribit | luno | Whitebit |
| Bitstamp | Dflow | Mercado Bitcoin | Yobit |
| Bittrex | Digifinex | Mercatox | Zaif |
| Bleutrade | Exmo | Narkasa | ZB.com |
| BTCbear | Fcoin | Neraex | ZBG |
| BTCturk | Fisco | Nicehash | ZG.top |
| Wire transfer | 1.36 |
| Credit card | 1.08 |
| Age | 1.27 |
| Number of tradable assets | 1.24 |
| Public team | 1.42 |
| CER cyber security grade | 1.46 |
| Mozilla security grade | 1.26 |
| Hacked | 1.09 |
| Wire Transfer | Credit Card | Age | Number of Tradable Assets | Public Team | CER Cyber Security Grade | Mozilla Security Grade | Hacked | |
|---|---|---|---|---|---|---|---|---|
| Wire transfer | 1 | 0.22 | 0.38 | −0.14 | 0.27 | 0.09 | 0.18 | −0.15 |
| Credit card | 0.22 | 1 | 0.19 | 0.05 | 0.14 | 0.02 | 0.12 | 0.04 |
| Age | 0.38 | 0.19 | 1 | 0.10 | 0.26 | 0.03 | 0.13 | −0.03 |
| Number of tradable assets | −0.14 | 0.05 | 0.10 | 1 | 0.10 | 0.31 | 0.24 | 0.14 |
| Public team | 0.27 | 0.14 | 0.26 | 0.10 | 1 | 0.41 | 0.30 | 0.11 |
| CER cyber security grade | 0.09 | 0.02 | 0.03 | 0.31 | 0.41 | 1 | 0.37 | −0.04 |
| Mozilla security grade | 0.18 | 0.12 | 0.13 | 0.24 | 0.30 | 0.37 | 1 | 0.04 |
| Hacked | −0.15 | 0.04 | −0.03 | 0.14 | 0.11 | −0.04 | 0.04 | 1 |
| 1 | This is a general definition of cryptocurrency that is based on the current practices among both financial and IT professionals, see, for example, the official technical report by the Association of Chartered Certified Accountants (ACCA (2021)), as well as the formal definition of cryptocurrency proposed by Lansky (2018), which is considered the most precise by IT specialists, and which was later adopted by Fantazzini and Zimin (2020) to formally define credit risk for cryptocurrencies. Antonopoulos (2014) and Narayanan et al. (2016) to provide a larger discussion at the textbook level. |
| 2 | https://coinmarketcap.com/charts/ (accessed on 1 August 2021). CoinMarketCap is the main aggregator of cryptocurrency market data, and it has been owned by the crypto exchange Binance since April 2020, see https://crypto.marketswiki.com/index.php?title=CoinMarketCap (accessed on 1 August 2021) for more details. Website accessed on June 15, 2021. |
| 3 | We will use the terms ‘probability of closure’ and ‘probability of default’ interchangeably. |
| 4 | This type of risk was originally defined by Fantazzini and Zimin (2020), pp. 24–26, as “the gains and losses on the value of a position of a cryptocurrency that is abandoned and considered dead according to professional and/or academic criteria, but which can be potentially revived and revamped”. |
| 5 | https://www.coingecko.com (accessed on 1 August 2021). |
| 6 | https://cer.live (accessed on 1 August 2021). |
| 7 | https://www.cryptowisser.com (accessed on 1 August 2021). |
| 8 | https://observatory.mozilla.org (accessed on 1 August 2021). |
| 9 | https://github.com/mozilla/http-observatory/blob/master/httpobs/docs/scoring.md (accessed on 1 August 2021). |
| 10 | The dates of crypto exchange foundations were taken from CoinGecko, while the dates of closure (if any) from Cryptowisser. |
| 11 | The information about security breaches was collected manually from websites, blogs, and official Twitter accounts of the exchanges. |
| 12 | Cryptowisser reports how many cryptocurrencies are traded on each exchange. |
| 13 | Information about the exchanges’ developer team is available at CoinGecko. |
| 14 | The names of these exchanges are reported in Table A1 in the Appendix A. |
| 15 | The variance inflation factors (VIF) are used to measure the degree of collinearity among the regressors in an equation. They can be computed by dividing the variance of a coefficient estimate with all the other regressors included by the variance of the same coefficient estimated from an equation with only that regressor and a constant. Classical “rules of thumbs” to get rid of collinearity are to eliminate those variables with a VIF higher than 10 or to eliminate one of the two variables with a correlation higher than 0.7–0.8 (in absolute value). |
| 16 | Wash trading is a process whereby a trader buys and sells an asset to feed misleading information to the market. It is illegal in most regulated markets, see James Chen (2021) and references therein for more details. However, there is recent evidence that up to 30% of all traded tokens on two of the first popular decentralized exchanges on the Ethereum blockchain (IDEX and EtherDelta) were subject to wash trading activity, see Victor and Weintraud (2021) for more details. |
| 17 | The “know your customer” or “know your client” check is the process of identifying and verifying the client’s identity when opening a financial account, see https://en.wikipedia.org/wiki/Know_your_customer (accessed on 1 August 2021) and references therein for more details. |
| 18 | https://trends.google.ru/trends/explore?date=all&q=decentralized%20exchanges (accessed on 1 August 2021). |
References
- ACCA. 2021. Accounting for Cryptocurrencies. London: Association of Chartered Certified Accountants. [Google Scholar]
- Alexander, Carol, and Daniel F. Heck. 2020. Price discovery in Bitcoin: The impact of unregulated markets. Journal of Financial Stability 50: 100776. [Google Scholar] [CrossRef]
- Alkurd, Ibrahim. 2021. The Rise of Decentralized Cryptocurrency Exchanges; Forbes. Available online: https://www.forbes.com/sites/theyec/2020/12/01/the-rise-of-decentralized-cryptocurrency-exchanges/ (accessed on 1 August 2021).
- Altman, Edward. 1968. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance 23: 589–609. [Google Scholar] [CrossRef]
- Altman, Edward, and Gabriele Sabato. 2007. Modelling credit risk for SMEs: Evidence from the US market. Abacus 43: 332–57. [Google Scholar] [CrossRef]
- Antonopoulos, Andreas. 2014. Mastering Bitcoin: Unlocking Digital Cryptocurrencies. Sevastopol: O’Reilly Media, Inc. [Google Scholar]
- Baek, Chung, and Matt Elbeck. 2015. Bitcoins as an investment or speculative vehicle? a first look. Applied Economics Letters 22: 30–34. [Google Scholar] [CrossRef]
- Baesens, Bart, and Tony Van Gestel. 2009. Credit Risk Management: Basic Concepts. Oxford: Oxford University Press. [Google Scholar]
- Bamber, Donald. 1975. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. Journal of Mathematical Psychology 12: 387–415. [Google Scholar] [CrossRef]
- Barboza, Flavio, Herbert Kimura, and Edward Altman. 2017. Machine learning models and bankruptcy prediction. Expert Systems with Applications 83: 405–17. [Google Scholar] [CrossRef]
- Baur, Dirk G., Kihoon Hong, and Adrian D. Lee. 2018. Bitcoin: Medium of exchange or speculative assets? Journal of International Financial Markets, Institutions and Money 54: 177–89. [Google Scholar] [CrossRef]
- Biais, Bruno, Christophe Bisiere, Matthieu Bouvard, Catherine Casamatta, and Albert J. Menkveld. 2020. Equilibrium Bitcoin Pricing. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3261063 (accessed on 1 August 2021).
- Bilder, Christopher, and Thomas Loughin. 2014. Analysis of Categorical Data with R. Boca Raton: CRC Press. [Google Scholar]
- Borges, Tome Almeida, and Rui Ferreira Neves. 2020. Ensemble of machine learning algorithms for cryptocurrency investment with different data resampling methods. Applied Soft Computing 90: 106187. [Google Scholar] [CrossRef]
- Boser, Bernhard E., Isabelle M. Guyon, and Vladimir N. Vapnik. 1992. A training algorithm for optimal margin classifiers. Paper presented at the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, July 27–29; pp. 144–52. [Google Scholar]
- Brier, Glenn. 1950. Verification of forecasts expressed in terms of probability. Monthly Weather Review 78: 1–3. [Google Scholar] [CrossRef]
- Brummer, Chris. 2019. Cryptoassets: Legal, Regulatory, and Monetary Perspectives. Oxford: Oxford University Press. [Google Scholar]
- Burniske, Chris, and Jack Tatar. 2018. Cryptoassets: The Innovative Investor’s Guide to Bitcoin and Beyond. New York: McGraw-Hill. [Google Scholar]
- Chen, Weili, Jun Wu, Zibin Zheng, Chuan Chen, and Yuren Zhou. 2019. Market manipulation of Bitcoin: Evidence from mining the Mt. Gox transaction network.Paper presented at the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, April 29–May 2; pp. 964–972. [Google Scholar]
- Chen, Yi-Hsuan, and Dmitri Vinogradov. 2021. Coins with Benefits: On Existence, Pricing Kernel and Risk Premium of Cryptocurrencies. Technical Report. Berlin: Humboldt University of Berlin, International Research Training Group 1792, Discussion Paper No. 2021-006. [Google Scholar]
- Cortes, Corinna, and Vladimir Vapnik. 1995. Support-vector networks. Machine Learning 20: 273–97. [Google Scholar] [CrossRef]
- Daian, Philip, Steven Goldfeder, Tyler Kell, Yunqi Li, Xueyuan Zhao, Iddo Bentov, Lorenz Breidenbach, and Ari Juels. 2020. Flash boys 2.0: Frontrunning in decentralized exchanges, miner extractable value, and consensus instability. Paper presented at the 2020 IEEE Symposium on Security and Privacy (SP), Francisco, CA, USA, May 17–21; pp. 910–927. [Google Scholar]
- De Prado, Marcos Lopez. 2018. Advances in Financial Machine Learning. New York: John Wiley & Sons. [Google Scholar]
- DeLong, Elizabeth, David DeLong, and Daniel Clarke-Pearson. 1988. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 44: 837–45. [Google Scholar] [CrossRef] [PubMed]
- Digiconomist. 2016. Introducing the Fraud Assessment Tool. Available online: https://digiconomist.net/introducing-fat (accessed on 1 August 2021).
- Dixon, Matthew F., Igor Halperin, and Paul Bilokon. 2020. Machine Learning in Finance. New York: Springer. [Google Scholar]
- Federation des Experts Comptables Europeens. 2005. How SMEs Can Reduce the Risk of Fraud. Bruxelles: European Federation of Accountants (FEE). [Google Scholar]
- Fama, Marco, Andrea Fumagalli, and Stefano Lucarelli. 2019. Cryptocurrencies, monetary policy, and new forms of monetary sovereignty. International Journal of Political Economy 48: 174–94. [Google Scholar] [CrossRef]
- Fantazzini, Dean. 2019. Quantitative Finance with R and Cryptocurrencies. Seattle: Amazon KDP, ISBN-13: 978-1090685315. [Google Scholar]
- Fantazzini, Dean, and Silvia Figini. 2008. Default forecasting for small-medium enterprises: Does heterogeneity matter? International Journal of Risk Assessment and Management 11: 138–63. [Google Scholar] [CrossRef]
- Fantazzini, Dean, and Silvia Figini. 2009. Random survival forests models for sme credit risk measurement. Methodology and Computing in Applied Probability 11: 29–45. [Google Scholar] [CrossRef]
- Fantazzini, Dean, and Nikita Kolodin. 2020. Does the hashrate affect the Bitcoin price? Journal of Risk and Financial Management 13: 263. [Google Scholar] [CrossRef]
- Fantazzini, Dean, and Mario Maggi. 2015. Proposed coal power plants and coal-to-liquids plants in the us: Which ones survive and why? Energy Strategy Reviews 7: 9–17. [Google Scholar] [CrossRef]
- Fantazzini, Dean, and Stephan Zimin. 2020. A multivariate approach for the simultaneous modelling of market risk and credit risk for cryptocurrencies. Journal of Industrial and Business Economics 47: 19–69. [Google Scholar] [CrossRef] [Green Version]
- Feder, Amir, Neil Gandal, J. T. Hamrick, and Tyler Moore. 2017. The impact of DDoS and other security shocks on Bitcoin currency exchanges: Evidence from Mt. Gox. Journal of Cybersecurity 3: 137–44. [Google Scholar] [CrossRef]
- Fisher, Ronald A. 1936. The use of multiple measurements in taxonomic problems. Annals of Eugenics 7: 179–88. [Google Scholar] [CrossRef]
- Fuertes, Ana-Maria, and Elena Kalotychou. 2006. Early warning systems for sovereign debt crises: The role of heterogeneity. Computational Statistics and Data Analysis 51: 1420–41. [Google Scholar] [CrossRef]
- Gandal, Neil, J. T. Hamrick, Tyler Moore, and Tali Oberman. 2018. Price manipulation in the Bitcoin ecosystem. Journal of Monetary Economics 95: 86–96. [Google Scholar] [CrossRef]
- Giudici, Giancarlo, Alistair Milne, and Dmitri Vinogradov. 2020. Cryptocurrencies: Market analysis and perspectives. Journal of Industrial and Business Economics 47: 1–18. [Google Scholar] [CrossRef] [Green Version]
- Giudici, Paolo, and Silvia Figini. 2009. Applied Data Mining for Business and INDUSTRY. New York: Wiley Online Library. [Google Scholar]
- Glaser, Florian, Kai Zimmermann, Martin Haferkorn, Moritz Christian Weber, and Michael Siering. 2014. Bitcoin-asset or currency? revealing users’ hidden intentions. Revealing Users’ Hidden Intentions (15 April 2014). ECIS. Available online: https://ssrn.com/abstract=2425247 (accessed on 1 August 2021).
- Hacken Cybersecurity Services. 2021. Cryptocurrency Exchange Security Assessment Methodology. Available online: https://hacken.io/researches-and-investigations/cryptocurrency-exchange-security-assessment-methodology/ (accessed on 1 August 2021).
- Hand, David J. 2006. Classifier technology and the illusion of progress. Statistical Science 21: 1–14. [Google Scholar] [CrossRef] [Green Version]
- Hanley, James, and Barbara McNeil. 1982. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 143: 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hansen, Peter, Asger Lunde, and James Nason. 2011. The model confidence set. Econometrica 79: 453–97. [Google Scholar] [CrossRef] [Green Version]
- Harney, Alexandra, and Steve Stecklow. 2017. Twice burned—How Mt. Gox’s Bitcoin customers could lose again. Reuters, November 30. [Google Scholar]
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer. [Google Scholar]
- Hopwood, William, Jay Leiner, and George Young. 2012. Forensic Accounting and Fraud Examination. New York: McGraw-Hill. [Google Scholar]
- Hosmer, David, and Stanley Lemesbow. 1980. Goodness of fit tests for the multiple logistic regression model. Communications in Statistics-Theory and Methods 9: 1043–69. [Google Scholar] [CrossRef]
- James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning. New York: Springer, Volume 112. [Google Scholar]
- James Chen. 2021. Wash TRADING. Available online: https://www.investopedia.com/terms/w/washtrading.asp (accessed on 1 August 2021).
- Johnson, Kristin N. 2021. Decentralized finance: Regulating cryptocurrency exchanges. William & Mary Law Review 62: 1911. [Google Scholar]
- Joseph, Ciby. 2013. Advanced Credit Risk Analysis and Management. New York: John Wiley & Sons. [Google Scholar]
- Ketz, Edward. 2003. Hidden Financial Risk: Understanding Off-Balance Sheet Accounting. New York: John Wiley & Sons. [Google Scholar]
- Krzanowski, Wojtek, and David Hand. 2009. ROC Curves for Continuous Data. Boca Raton: CRC Press. [Google Scholar]
- Lansky, Jan. 2018. Possible state approaches to cryptocurrencies. Journal of Systems Integration 9: 19–31. [Google Scholar] [CrossRef]
- Leising, Matthew. 2021. CoinLab Cuts Deal With Mt. Gox Trustee Over Bitcoin Claims. Bloomberg, January 15. [Google Scholar]
- Lin, Lindsay X., Eric Budish, Lin William Cong, Zhiguo He, Jonatan H. Bergquist, Mohit Singh Panesir, Jack Kelly, Michelle Lauer, Ryan Prinster, Stephenie Zhang, and et al. 2019. Deconstructing decentralized exchanges. Stanford Journal of Blockchain Law & Policy 2: 58–77. [Google Scholar]
- Maimon, Oded, and Lior Rokach. 2014. Data Mining with Decision Trees: Theory and Applications. London: World Scientific, Volume 81. [Google Scholar]
- McClish, Donna. 1989. Analyzing a portion of the roc curve. Medical Decision Making 9: 190–5. [Google Scholar] [CrossRef] [PubMed]
- McCullagh, Peter, and John A. Nelder. 1989. Generalized Linear Model. London: Chapman Hall. [Google Scholar]
- McFadden, Daniel. 1974. Conditional logit analysis of qualitative choice behavior. Frontiers in Econometrics, 105–42. [Google Scholar]
- Metz, Charles. 1978. Basic principles of ROC analysis. In Seminars in Nuclear Medicine. Amsterdam: Elsevier, Volume 8, pp. 283–98. [Google Scholar]
- Metz, Charles, and Helen Kronman. 1980. Statistical significance tests for binormal ROC curves. Journal of Mathematical Psychology 22: 218–43. [Google Scholar] [CrossRef]
- Moore, Tyler, and Nicolas Christin. 2013. Beware the middleman: Empirical analysis of Bitcoin-exchange risk. In International Conference on Financial Cryptography and Data Security. New York: Springer, pp. 25–33. [Google Scholar]
- Moore, Tyler, Nicolas Christin, and Janos Szurdi. 2018. Revisiting the risks of Bitcoin currency exchange closure. ACM Transactions on Internet Technology 18: 1–18. [Google Scholar] [CrossRef]
- Moore, Tyler, Jie Han, and Richard Clayton. 2012. The postmodern ponzi scheme: Empirical analysis of high-yield investment programs. In International Conference on Financial Cryptography and Data Security. New York: Springer, pp. 41–56. [Google Scholar]
- Moscatelli, Mirko, Fabio Parlapiano, Simone Narizzano, and Gianluca Viggiano. 2020. Corporate default forecasting with machine learning. Expert Systems with Applications 161: 113567. [Google Scholar] [CrossRef]
- Narayanan, Arvind, Joseph Bonneau, Edward Felten, Andrew Miller, and Steven Goldfeder. 2016. Bitcoin and Cryptocurrency Technologies: A Comprehensive Introduction. Princeton: Princeton University Press. [Google Scholar]
- Osius, Gerhard, and Dieter Rojek. 1992. Normal goodness-of-fit tests for multinomial models with large degrees of freedom. Journal of the American Statistical Association 87: 1145–52. [Google Scholar] [CrossRef]
- Provost, Foster, and R. Kohavi. 1998. Glossary of terms. Journal of Machine Learning 30: 271–74. [Google Scholar] [CrossRef]
- Reiff, Nathan. 2020. How to Identify Cryptocurrency and ICO Scams. Investopedia. Available online: https://www.investopedia.com/tech/how-identify-cryptocurrency-and-ico-scams/ (accessed on 1 August 2021).
- Reurink, Arjan. 2018. Financial fraud: A literature review. Journal of Economic Surveys 32: 1292–325. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, Arnulfo, and Pedro N. Rodriguez. 2006. Understanding and predicting sovereign debt rescheduling: A comparison of the areas under receiver operating characteristic curves. Journal of Forecasting 25: 459–79. [Google Scholar] [CrossRef]
- Sammut, Claude, and Geoffrey Webb. 2011. Encyclopedia of Machine Learning. New York: Springer. [Google Scholar]
- Schar, Fabian, and Aleksander Berentsen. 2020. Bitcoin, Blockchain, and Cryptoassets: A Comprehensive Introduction. Cambridge: MIT Press. [Google Scholar]
- Schilling, Linda, and Harald Uhlig. 2019. Some simple Bitcoin economics. Journal of Monetary Economics 106: 16–26. [Google Scholar] [CrossRef]
- Sebastião, Helder, and Pedro Godinho. 2021. Forecasting and trading cryptocurrencies with machine learning under changing market conditions. Financial Innovation 7: 1–30. [Google Scholar] [CrossRef]
- Shimko, David. 2004. Credit Risk Models and Management. London: Risk Books. [Google Scholar]
- Smith, Chris, and Mark Koning. 2017. Decision Trees and Random Forests: A Visual Introduction for Beginners. Blue Windmill Media. [Google Scholar]
- Steinwart, Ingo, and Andreas Christmann. 2008. Support Vector Machines. New York: Springer Science & Business Media. [Google Scholar]
- Strobl, Carolin, Anne-Laure Boulesteix, Thomas Kneib, Thomas Augustin, and Achim Zeileis. 2008. Conditional variable importance for random forests. BMC Bioinformatics 9: 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strobl, Carolin, Anne-Laure Boulesteix, Achim Zeileis, and Torsten Hothorn. 2007. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinformatics 8: 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strobl, Carolin, Torsten Hothorn, and Achim Zeileis. 2009. Party on! A new, conditional variable importance measure available in the party package. The R Journal 2: 14–17. [Google Scholar] [CrossRef]
- Stukel, Thérèse. 1988. Generalized logistic models. Journal of the American Statistical Association 83: 426–31. [Google Scholar] [CrossRef]
- Sze, Jin. 2020. Coingecko Trust Score Explained; Coingecko. Available online: https://blog.coingecko.com/trust-score-team-presence-incidents-update (accessed on 1 August 2021).
- Twomey, David, and Andrew Mann. 2020. Fraud and manipulation within cryptocurrency markets. In Corruption and Fraud in Financial Markets: Malpractice, Misconduct and Manipulation. New York: Wiley, pp. 205–50. [Google Scholar]
- Victor, Friedhelm, and Andrea Marie Weintraud. 2021. Detecting and quantifying wash trading on decentralized cryptocurrency exchanges. In Proceedings of the Web Conference 2021. Ljubljana: International World Wide Web Conference Committee, pp. 23–32. [Google Scholar]
- Votipka, Daniel, Rock Stevens, Elissa Redmiles, Jeremy Hu, and Michelle Mazurek. 2018. Hackers vs. testers: A comparison of software vulnerability discovery processes. Paper presented at 2018 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, May 21–23; pp. 374–391. [Google Scholar]
- White, Reilly, Yorgos Marinakis, Nazrul Islam, and Steven Walsh. 2020. Is Bitcoin a currency, a technology-based product, or something else? Technological Forecasting and Social Change 151: 119877. [Google Scholar] [CrossRef]
- Yepes, Concepcion Verdugo. 2011. Compliance with the AML/CFT International Standard: Lessons from a Cross-Country Analysis. Technical Report. Washington: International Monetary Fund. [Google Scholar]


| Observed/Predicted | Closed Exchange | Alive |
|---|---|---|
| Closed Exchange | a | b |
| Alive | c | d |
| Scoring Range | Grade |
|---|---|
| 100+ | A+ |
| 90–99 | A |
| 85–89 | A− |
| 80–84 | B+ |
| 70–79 | B |
| 65–69 | B− |
| 60–64 | C+ |
| 50–59 | C |
| 45–49 | C− |
| 40–44 | D+ |
| 30–39 | D |
| 25–29 | D− |
| 0–24 | F |
| Variable | Description | Source |
|---|---|---|
| Closed (dep. variable) | Binary variable that is 1 if the exchange is closed and zero otherwise | CoinGecko/Cryptowisser |
| Wire transfer | Binary variable that is 1 if the exchange supports wire transfers and zero otherwise | Data from exchanges |
| Credit card | Binary variable that is 1 if the exchange supports credit card transfers and zero otherwise | Data from exchanges |
| Age | Age of the exchange in years | CoinGecko/Cryptowisser |
| Number of tradable assets | Number of cryptocurrencies traded on the exchange | Cryptowisser |
| Public team | Binary variable that is 1 if the exchange’s developer team is public and zero otherwise | CoinGecko |
| CER Cyber security grade | Security grade of the exchange assigned by the CER platform. It ranges between 0 and 10 | Cybersecurity Ranking and CERtification Platform |
| Mozilla security grade | Security grade of the exchange assigned by the Mozilla Observatory. It ranges between 0 and 100 | Mozilla Observatory |
| Hacked | Binary variable that is 1 if the exchange experienced a security breach and zero otherwise | Data collected manually from websites, blogs, and official Twitter accounts of the exchanges |
| Variable | Estimate | Std. Error | z-Statistic | Pr(>|z|) |
|---|---|---|---|---|
| (Intercept) | 3.51 | 0.82 | 4.30 | 0.00 |
| Wire transfer | −0.98 | 0.54 | −1.83 | 0.07 |
| Credit card | −0.56 | 0.54 | −1.03 | 0.30 |
| Age | −0.22 | 0.13 | −1.63 | 0.10 |
| Number of tradable assets | −0.01 | 0.01 | −1.32 | 0.19 |
| Public team | −1.79 | 0.52 | −3.48 | 0.00 |
| CER Cyber security grade | −0.37 | 0.16 | −2.34 | 0.02 |
| Mozilla security grade | −0.00 | 0.01 | −0.36 | 0.72 |
| Hacked | 0.97 | 0.59 | 1.65 | 0.10 |
| McFadden R-squared: | 0.38 | |||
| Hosmer-Lemeshow statistic | p-value: | 0.14 | ||
| Osius-Rojek statistic | p-value: | 0.01 | ||
| Stukel statistic | p-value: | 0.17 |
| Variable | Coefficients |
|---|---|
| Wire transfer | −0.72 |
| Credit card | −0.30 |
| Age | −0.11 |
| Number of tradable assets | −0.00 |
| Public team | −1.37 |
| CER cyber security grade | −0.20 |
| Mozilla security grade | −0.00 |
| Hacked | 0.51 |
| Model | AUC | [AUC 95% Conf. Interval] | Brier Score | MCS | |
|---|---|---|---|---|---|
| LOGIT | 0.89 | 0.83 | 0.95 | 0.12 | not included |
| LDA | 0.89 | 0.83 | 0.94 | 0.13 | not included |
| Decision Tree | 0.87 | 0.81 | 0.93 | 0.12 | not included |
| Random Forest | 0.99 | 0.98 | 1.00 | 0.02 | included |
| Conditional R.F. | 0.95 | 0.92 | 0.98 | 0.11 | not included |
| SVM | 0.97 | 0.94 | 0.99 | 0.07 | not included |
| : AUC(LOGIT) = AUC(LDA) = AUC(Decision Tree) = | ||
|---|---|---|
| = AUC(Random Forest) = AUC(Conditional R.F.) = AUC(SVM) | ||
| Test statistics | 25.73 | |
| p-value | 0.00 | |
| Excluded Variable | LOGIT | LDA | Decision Tree | Random Forest | Conditional R.F. | SVM |
|---|---|---|---|---|---|---|
| Wire transfer | −0.90% | −1.26% | 0.00% | 0.00% | −0.45% | −2.26% |
| Credit card | −0.40% | −0.34% | 0.00% | 0.00% | −0.65% | −0.61% |
| Age | −0.85% | −0.45% | −2.35% | −0.06% | −0.60% | −1.81% |
| Number of tradable assets | −0.64% | −0.24% | 2.17% | −0.04% | −0.54% | −2.68% |
| Public team | −3.25% | −3.43% | −0.79% | 0.00% | −0.63% | −2.42% |
| CER Cyber security grade | −1.66% | −0.98% | 0.00% | 0.00% | −0.67% | −1.48% |
| Mozilla security grade | −0.27% | −0.08% | 0.00% | 0.00% | −0.83% | −1.00% |
| Hacked | −0.79% | −0.62% | 0.00% | 0.00% | −0.69% | −1.79% |
| Model | AUC | [AUC 95% Conf. Interval] | Brier Score | MCS | |
|---|---|---|---|---|---|
| LOGIT | 0.85 | 0.78 | 0.92 | 0.14 | not included |
| LDA | 0.85 | 0.78 | 0.92 | 0.15 | not included |
| Decision Tree | 0.67 | 0.54 | 0.79 | 0.18 | not included |
| Random Forest | 0.90 | 0.85 | 0.95 | 0.12 | included |
| Conditional R.F. | 0.90 | 0.85 | 0.95 | 0.14 | not included |
| SVM | 0.89 | 0.84 | 0.94 | 0.13 | included |
| : AUC(LOGIT) = AUC(LDA) = AUC(Decision Tree) = | ||
|---|---|---|
| = AUC(Random Forest) = AUC(Conditional R.F.) = AUC(SVM) | ||
| Test statistics | 21.75 | |
| p-value | 0.00 | |
| Excluded Variable | LOGIT | LDA | Decision Tree | Random Forest | Conditional R.F. | SVM |
|---|---|---|---|---|---|---|
| Wire transfer | −0.47% | −0.89% | 0.00% | −0.46% | −1.62% | −2.32% |
| Credit card | 0.05% | 0.22% | 0.00% | −0.36% | −0.35% | 0.88% |
| Age | 0.02% | −0.65% | 0.00% | −3.71% | −2.72% | 0.50% |
| Number of tradable assets | −0.57% | 0.00% | 2.27% | −2.37% | −1.67% | −4.93% |
| Public team | −3.89% | −4.36% | −17.73% | −5.83% | −4.93% | −4.98% |
| CER Cyber security grade | −2.16% | −1.66% | 5.88% | −0.80% | −0.70% | −1.52% |
| Mozilla security grade | 0.77% | 0.44% | 0.00% | 0.49% | 0.66% | 0.95% |
| Hacked | 0.32% | 0.12% | 0.00% | −0.35% | −0.33% | −0.97% |
| Model | AUC | [AUC 95% Conf. Interval] | Brier Score | MCS | |
|---|---|---|---|---|---|
| LOGIT | 0.85 | 0.78 | 0.92 | 0.15 | included |
| LDA | 0.85 | 0.78 | 0.92 | 0.15 | included |
| Decision Tree | 0.67 | 0.54 | 0.79 | 0.18 | not included |
| Random Forest | 0.90 | 0.85 | 0.95 | 0.13 | included |
| Conditional R.F. | 0.90 | 0.85 | 0.95 | 0.14 | included |
| SVM | 0.88 | 0.82 | 0.94 | 0.14 | included |
| : AUC(LOGIT) = AUC(LDA) = AUC(Decision Tree) = | ||
|---|---|---|
| = AUC(Random Forest) = AUC(Conditional R.F.) = AUC(SVM) | ||
| Test statistics | 20.05 | |
| p-value | 0.00 | |
| Excluded Variable | LOGIT | LDA | Decision Tree | Random Forest | Conditional R.F. | SVM |
|---|---|---|---|---|---|---|
| Wire transfer | −0.50% | −0.84% | 0.00% | −1.32% | −1.72% | −1.99% |
| Credit card | 0.15% | 0.17% | 0.00% | −0.15% | 0.05% | 1.05% |
| Age | −0.12% | −0.62% | 0.00% | −4.11% | −2.40% | −0.74% |
| Number of tradable assets | −0.42% | −0.20% | 2.27% | −2.01% | −0.96% | −5.13% |
| Public team | −4.20% | −4.51% | −13.52% | −5.40% | −5.18% | −5.25% |
| CER Cyber security grade | −2.39% | −1.79% | 5.88% | −0.67% | −0.24% | −1.53% |
| Mozilla security grade | 0.72% | 0.42% | 0.00% | 0.59% | 1.01% | 0.91% |
| Hacked | 0.47% | 0.30% | 0.00% | −0.05% | 0.16% | −0.60% |
| Decentralized | 0.17% | 0.15% | 0.00% | 0.20% | 0.24% | 1.61% |
| Model | AUC | [AUC 95% Conf. Interval] | Brier Score | MCS | |
|---|---|---|---|---|---|
| LOGIT | 0.85 | 0.78 | 0.92 | 0.15 | not included |
| LDA | 0.85 | 0.78 | 0.92 | 0.15 | not included |
| Decision Tree | 0.67 | 0.54 | 0.79 | 0.18 | not included |
| Random Forest | 0.90 | 0.85 | 0.95 | 0.12 | included |
| Conditional R.F. | 0.90 | 0.84 | 0.95 | 0.14 | not included |
| SVM | 0.89 | 0.83 | 0.94 | 0.13 | included |
| : AUC(LOGIT) = AUC(LDA) = AUC(Decision Tree) = | ||
|---|---|---|
| = AUC(Random Forest) = AUC(Conditional R.F.) = AUC(SVM) | ||
| Test statistics | 21.95 | |
| p-value | 0.00 | |
| Excluded Variable | LOGIT | LDA | Decision Tree | Random Forest | Conditional R.F. | SVM |
|---|---|---|---|---|---|---|
| Wire transfer | −0.35% | −1.11% | 0.00% | −1.36% | −1.20% | −2.04% |
| Credit card | 0.57% | 0.17% | 0.00% | −0.37% | 0.35% | 0.50% |
| Age | −0.07% | −0.84% | 0.00% | −2.79% | −3.04% | −0.40% |
| Number of tradable assets | −0.65% | −0.25% | 2.27% | −1.22% | −1.08% | −4.58% |
| Public team | −4.03% | −4.80% | −13.52% | −5.47% | −4.66% | −5.55% |
| CER Cyber security grade | −2.12% | −1.63% | 5.88% | −1.76% | −0.73% | −1.61% |
| Mozilla security grade | 0.67% | 0.35% | 0.00% | 0.64% | 1.01% | −0.19% |
| Hacked | 0.10% | 0.07% | 0.00% | −0.21% | 0.00% | 0.69% |
| AML−CFT | 0.37% | 0.02% | 0.00% | 0.20% | 0.28% | 0.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fantazzini, D.; Calabrese, R. Crypto Exchanges and Credit Risk: Modeling and Forecasting the Probability of Closure. J. Risk Financial Manag. 2021, 14, 516. https://doi.org/10.3390/jrfm14110516
Fantazzini D, Calabrese R. Crypto Exchanges and Credit Risk: Modeling and Forecasting the Probability of Closure. Journal of Risk and Financial Management. 2021; 14(11):516. https://doi.org/10.3390/jrfm14110516
Chicago/Turabian StyleFantazzini, Dean, and Raffaella Calabrese. 2021. "Crypto Exchanges and Credit Risk: Modeling and Forecasting the Probability of Closure" Journal of Risk and Financial Management 14, no. 11: 516. https://doi.org/10.3390/jrfm14110516