
Machine Learning in Futures Markets


Abstract
:1. Introduction
2. Data and Software
2.1. Data
2.2. Software
3. Methodology
3.1. Study Periods and Training–Trading Sets
3.2. Generation of Features and Targets
3.2.1. Volume-Weighted Average Prices
3.2.2. Features
3.2.3. Targets
3.3. Models
3.3.1. Logistic Regression
3.3.2. Random Forest
3.3.3. Gradient-Boosting Classifier
3.4. Signal Generation and Backtesting Framework
4. Results
4.1. Baseline Results
4.1.1. Model Performance
4.1.2. Feature Importance
4.2. Varying Portfolio Size
4.3. Varying Holding Period
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DTN | DTN IQFeed |
| VWAP | Volume-weighted average price |
| EST | Eastern Standard Time |
| LR | Logistic regression |
| RF | Random forest |
| GBC | Gradient-boosting classifier |
| MKT | General market |
| VaR | Value at risk |
References
- Ang, Andrew, Sergiy Gorovyy, and Gregory B. Van Inwegen. 2011. Hedge fund leverage. Journal of Financial Economics 102: 102–26. [Google Scholar] [CrossRef]
- Berkowitz, A. Stephen, E. Dennis Logue, and A. Eugene Noser. 1988. The total cost of transactions on the NYSE. The Journal of Finance 43: 97–112. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef] [Green Version]
- Dare, Wale. 2017. Statistical Arbitrage in the U.S. Treasury Futures Market. Economics Working Paper Series; St. Gallen: University of St. Gallen, vol. 1716. [Google Scholar]
- Dixon, Matthew, Diego Klabjan, and Jin Bang. 2017. Classification-based financial market prediction using deep neural networks. Algorithmic Finance 6: 67–77. [Google Scholar] [CrossRef] [Green Version]
- Enke, David, and Suraphan Thawornwong. 2005. The use of data mining and neural networks for forecasting stock market returns. Expert Systems with Applications 29: 927–40. [Google Scholar] [CrossRef]
- Fama, Eugene F. 1970. Efficient capital markets: A review of theory and empirical work. The Journal of Finance 25: 383–417. [Google Scholar] [CrossRef]
- Fischer, Thomas, and Christopher Krauss. 2018. Deep learning with long short-term memory networks for financial market predictions. European Journal of Operational Research 270: 654–69. [Google Scholar] [CrossRef] [Green Version]
- Fischer, Thomas, Christopher Krauss, and Alexander Deinert. 2019. Statistical arbitrage in cryptocurrency markets. Journal of Risk and Financial Management 12: 31. [Google Scholar] [CrossRef] [Green Version]
- Focardi, Sergio, Frank Fabozzi, and Mitov Ivan. 2016. A new approach to statistical arbitrage: Strategies based on dynamic factor models of prices and their performance. Journal of Banking & Finance 65: 134–55. [Google Scholar]
- Girma, Paul Berhanu, and Albert S. Paulson. 1999. Risk arbitrage opportunities in petroleum futures spreads. Journal of Futures Markets 19: 931–55. [Google Scholar] [CrossRef]
- Harris, Charles R., K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, and et al. 2020. Array programming with NumPy. Nature 585: 357–62. [Google Scholar] [CrossRef]
- Henrique, Bruno Miranda, Vinicius Amorim Sobreiro, and Herbert Kimura. 2019. Literature review: Machine learning techniques applied to financial market prediction. Expert Systems with Applications 124: 226–51. [Google Scholar] [CrossRef]
- Ho, Tin Kam. 1995. Random decision forests. Proceedings of 3rd International Conference on Document Analysis and Recognition 1: 278–282. [Google Scholar]
- Huck, Nicolas. 2009. Pairs selection and outranking: An application to the S&P 100 index. European Journal of Operational Research 196: 819–25. [Google Scholar]
- Huck, Nicolas. 2019. Large data sets and machine learning: Applications to statistical arbitrage. European Journal of Operational Research 278: 330–42. [Google Scholar] [CrossRef]
- iqfeed.net. 2019. DTN Prosper in a Dynamic World. Available online: https://www.dtn.com (accessed on 29 December 2020).
- Jegadeesh, Narasimhan. 1990. Evidence of predictable behavior of security returns. The Journal of Finance 45: 881–98. [Google Scholar] [CrossRef]
- Ke, Guolin, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A highly efficient gradient boosting decision tree. Proceedings of the 31st International Conference on Neural Information Processing Systems 30: 3149–57. [Google Scholar]
- Kleinbaum, David, and Mitchel Klein. 2010. Logistic Regression: A Self-Learning Text. New York: Springer. [Google Scholar]
- Krauss, Christopher. 2017. Statistical arbitrage pairs trading strategies: Review and outlook. Journal of Economic Surveys 31: 513–45. [Google Scholar] [CrossRef]
- Krauss, Christopher, Xuan Anh Do, and Nicolas Huck. 2017. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500. European Journal of Operational Research 259: 689–702. [Google Scholar]
- Lehmann, Bruce N. 1990. Fads, martingales, and market efficiency. The Quarterly Journal of Economics 105: 1–28. [Google Scholar] [CrossRef]
- Leung, Mark T., Hazem Daouk, and An-Sing Chen. 2020. Forecasting stock indices: A comparison of classification and level estimation models. International Journal of Forecasting 16: 173–90. [Google Scholar] [CrossRef]
- Lo, Andrew W., and A. Craig MacKinlay. 2015. When are contrarian profits due to stock market overreaction? The Review of Financial Studies 3: 175–205. [Google Scholar] [CrossRef]
- Masteika, Saulius, Rutkauskas V. Aleksandras, and Janes Andrea Aleksandra. 2012. Continuous futures data series for back testing and technical analysis. Conference Proceedings, 3rd International Conference on Financial Theory and Engineering 29: 265–69. [Google Scholar]
- McKinney, Wes. 2010. Data structures for statistical computing in Python. Paper presented at the 9th Python in Science Conference, Austin, TX, USA, June 28–July 3; vol. 445, pp. 56–61. [Google Scholar]
- Nakajima, Tadahiro. 2019. Expectations for statistical arbitrage in energy futures markets. Journal of Risk and Financial Management 12: 14. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, Fabian, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Python Software Foundation. 2018. Python 3.7.1 Documentation. Available online: https://www.python.org/downloads/release/python-371/ (accessed on 29 December 2019).
- Quantopian Inc. 2016. Empyrical: Common Financial Risk Metrics. Available online: https://github.com/quantopian/empyrical (accessed on 29 December 2019).
- Schnaubelt, Matthias. 2019. A comparison of machine learning model validation schemes for non-stationary time series data. FAU Discussion Papers in Economics 11. [Google Scholar]
- Schnaubelt, Matthias, Thomas Fischer, and Christopher Krauss. 2020. Separating the signal from the noise—Financial machine learning for Twitter. Journal of Economic Dynamics and Control 114: 103895. [Google Scholar] [CrossRef] [Green Version]
- Seabold, Skipper, and Josef Perktold. 2010. Statsmodels: Econometric and statistical modeling with Python. Paper presented at the 9th Python in Science Conference, Austin, TX, USA, June 28–July 3. [Google Scholar]
- Sezer, Omer Berat, Mehmet Ugur Gudelek, and Ahmet Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Applied Soft Computing 90: 106181. [Google Scholar] [CrossRef] [Green Version]
- Simon, David P. 1999. The soybean crush spread: Empirical evidence and trading strategies. Journal of Futures Markets 19: 271–89. [Google Scholar] [CrossRef]
- Stevens Analytics. 2019. Continuous Futures. Available online: https://www.quandl.com/databases/SCF/documentation (accessed on 29 December 2020).
- Takeuchi, Lawrence, and Yu-Ying Albert Lee. 2013. Applying Deep Learning to Enhance Momentum Trading Strategies in Stocks. Working Paper. Stanford: Stanford University. [Google Scholar]
- Vojtko, Radovan, and Matus Padysak. 2020. Continuous Futures Contracts Methodology for Backtesting. Available online: https://ssrn.com/abstract=3517736 or https://dx.doi.org/10.2139/ssrn.3517736 (accessed on 15 January 2021).
- Zuckerman, Gregory. 2019. The Man Who Solved the Market. London: Penguin Books Limited. [Google Scholar]
| 1 | |
| 2 | By not including the trading set, we only consider information that is available up to the time of predicting out of sample. |



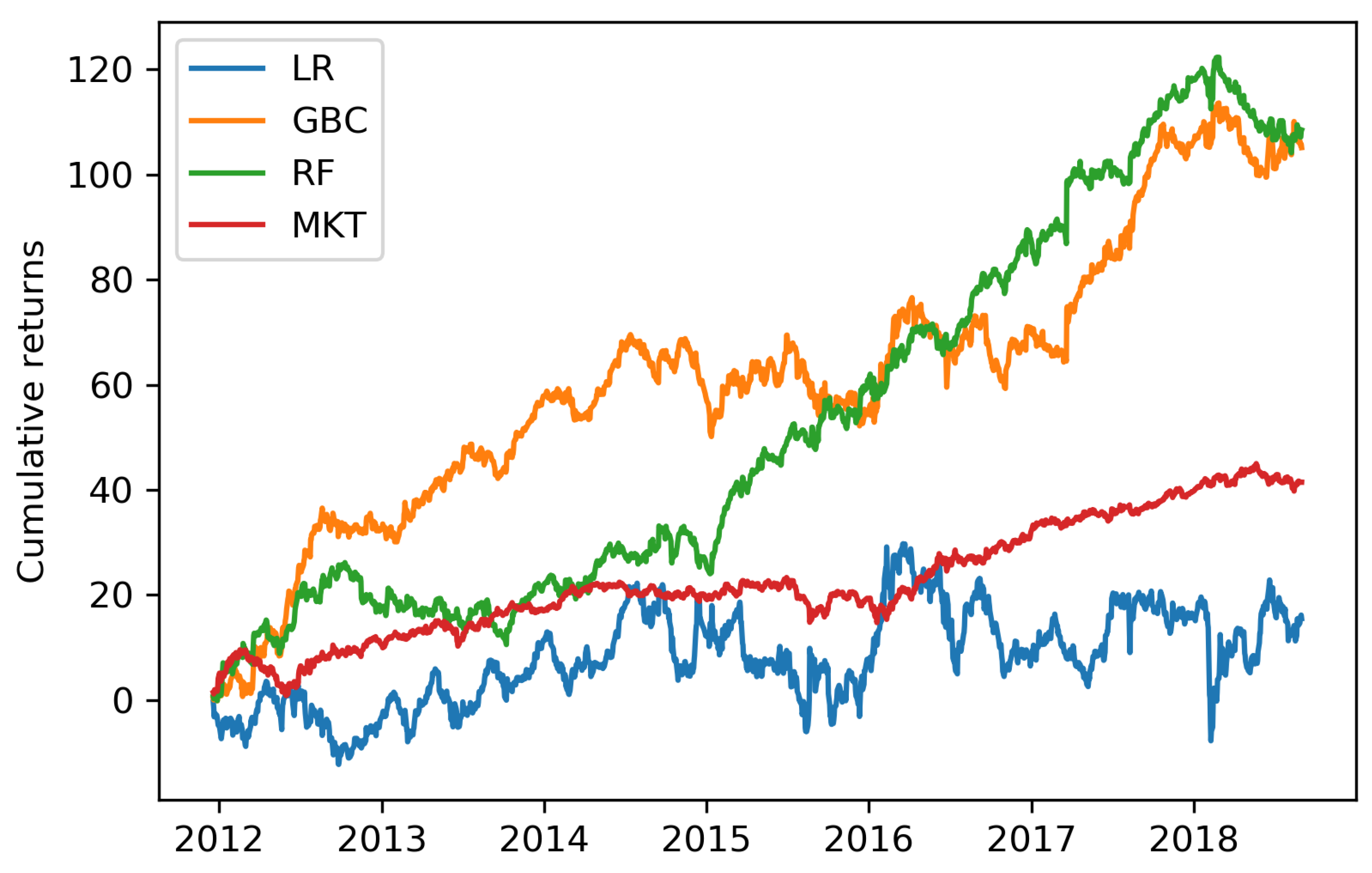{kind=link}
{kind=link}
| LR | GBC | RFC | MKT | ||
|---|---|---|---|---|---|
| A | Break-even transaction cost | 0.00009 | 0.00061 | 0.00063 | 0.00024 |
| Break-even transaction cost (long) | 0.00052 | 0.00109 | 0.00118 | - | |
| Break-even transaction cost (short) | −0.00015 | 0.00013 | 0.00007 | - | |
| t-Statistic (NW) | 0.30579 | 2.62765 | 3.11186 | 2.52548 | |
| Minimum | −0.12808 | −0.04298 | −0.04027 | −0.02482 | |
| Quartile 1 | −0.00590 | −0.00459 | −0.00330 | −0.00214 | |
| Median | 0.00028 | 0.00029 | 0.00016 | 0.00033 | |
| Quartile 3 | 0.00590 | 0.00524 | 0.00421 | 0.00252 | |
| Maximum | 0.09844 | 0.09933 | 0.11678 | 0.01877 | |
| Standard deviation | 0.01224 | 0.00965 | 0.00841 | 0.00396 | |
| Skewness | −0.32935 | 0.87212 | 2.09778 | −0.03325 | |
| Kurtosis | 11.56410 | 9.18384 | 25.57640 | 2.55999 | |
| Share > 0 | 0.50874 | 0.51573 | 0.51573 | 0.53555 | |
| B | VaR | −0.02439 | −0.01871 | −0.01620 | −0.00768 |
| Maximum drawdown | −0.34114 | −0.18039 | −0.16953 | −0.08429 | |
| C | Annualized return | 0.00383 | 0.15331 | 0.16232 | 0.06067 |
| Calmar ratio | 0.01124 | 0.84986 | 0.95750 | 0.71971 | |
| Sharpe ratio | 0.11715 | 1.00666 | 1.19216 | 0.96752 | |
| Sortino ratio | 0.16416 | 1.58896 | 2.00973 | 1.43528 |
| Top/Flop One | Top/Flop Two | Top/Flop Three | Top/Flop Five | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GBC | RF | GBC | RF | GBC | RF | GBC | RF | ||
| A | Break-even transaction cost | 0.00132 | 0.00131 | 0.00090 | 0.00083 | 0.00061 | 0.00063 | 0.00037 | 0.00046 |
| Break-even transaction cost (long) | 0.00180 | 0.00192 | 0.00153 | 0.00156 | 0.00109 | 0.00118 | 0.00076 | 0.00092 | |
| Break-even transaction cost (short) | 0.00085 | 0.00069 | 0.00027 | 0.00010 | 0.00013 | 0.00007 | −0.00001 | 0.00000 | |
| t-Statistic (NW) | 2.76110 | 3.11080 | 2.93075 | 3.15662 | 2.62764 | 3.11186 | 2.25589 | 3.07501 | |
| Minimum | −0.10135 | −0.10135 | −0.05926 | −0.05835 | −0.04299 | −0.04027 | −0.03273 | −0.02740 | |
| Quartile 1 | −0.00740 | −0.00496 | −0.00543 | −0.00383 | 0.00460 | −0.00330 | −0.00344 | −0.00271 | |
| Median | 0.00047 | 0.00045 | 0.00028 | 0.00034 | 0.00029 | 0.00016 | 0.00024 | 0.00014 | |
| Quartile 3 | 0.00867 | 0.00622 | 0.00615 | 0.00496 | 0.00524 | 0.00421 | 0.00378 | 0.00335 | |
| Maximum | 0.27963 | 0.35127 | 0.14794 | 0.17182 | 0.09933 | 0.11678 | 0.05810 | 0.07125 | |
| Standard deviation | 0.01994 | 0.01738 | 0.01280 | 0.01095 | 0.00965 | 0.00841 | 0.00690 | 0.00620 | |
| Skewness | 2.35936 | 5.99524 | 1.20400 | 2.89764 | 0.87212 | 2.09778 | 0.44085 | 1.33217 | |
| Kurtosis | 28.13396 | 106.51918 | 13.53247 | 40.63920 | 9.18384 | 25.57640 | 5.58418 | 12.04839 | |
| Share > 0 | 0.51457 | 0.52448 | 0.51457 | 0.52098 | 0.51573 | 0.51573 | 0.51981 | 0.51807 | |
| B | VaR | −0.03856 | −0.03348 | −0.02471 | −0.02109 | −0.01870 | −0.01620 | −0.01344 | −0.01195 |
| Maximum drawdown | −0.36443 | −0.29841 | −0.22777 | −0.21107 | −0.18039 | −0.16953 | −0.16371 | −0.10751 | |
| C | Annualized return | 0.33113 | 0.34041 | 0.23095 | 0.21592 | 0.15330 | 0.16232 | 0.09286 | 0.11760 |
| Calmar ratio | 0.90862 | 1.14075 | 1.01394 | 1.02302 | 0.84985 | 0.95749 | 0.56721 | 1.09389 | |
| Sharpe ratio | 1.05778 | 1.19175 | 1.12278 | 1.20931 | 1.00665 | 1.19216 | 0.86424 | 1.17804 | |
| Sortino ratio | 1.81288 | 2.32253 | 1.81317 | 2.09544 | 1.58895 | 2.00973 | 1.31664 | 1.92731 | |
| One Day | Two Days | Three Days | |||||
|---|---|---|---|---|---|---|---|
| GBC | RF | GBC | RF | GBC | RF | ||
| A | Break-even transaction cost | 0.00061 | 0.00063 | 0.00078 | 0.00104 | 0.00242 | 0.00186 |
| Break-even transaction cost (long) | 0.00109 | 0.00156 | 0.00157 | 0.00160 | 0.00313 | 0.00237 | |
| Break-even transaction cost (short) | 0.00013 | 0.00010 | 0.00000 | 0.00050 | 0.00172 | 0.00134 | |
| t-Statistic (NW) | 2.62764 | 3.11186 | 2.11017 | 3.51750 | 5.49028 | 5.02821 | |
| B | Mean return | 0.00061 | 0.00063 | 0.00038 | 0.00052 | 0.00080 | 0.00062 |
| Minimum | −0.04299 | −0.04027 | −0.08987 | −0.06418 | −0.04005 | −0.03910 | |
| Quartile 1 | −0.00460 | −0.00330 | −0.00332 | −0.00248 | −0.00252 | −0.00212 | |
| Median | 0.00029 | 0.00016 | 0.00034 | 0.00026 | 0.00043 | 0.00030 | |
| Quartile 3 | 0.00524 | 0.00421 | 0.00398 | 0.00330 | 0.00373 | 0.00283 | |
| Maximum | 0.09933 | 0.11678 | 0.06045 | 0.05670 | 0.04081 | 0.04362 | |
| Standard deviation | 0.00965 | 0.00841 | 0.00761 | 0.00615 | 0.00609 | 0.00511 | |
| Skewness | 0.87212 | 2.09778 | −1.08371 | −0.13586 | 0.69039 | 0.99260 | |
| Kurtosis | 9.18384 | 25.57640 | 18.22652 | 14.86417 | 6.46430 | 12.39674 | |
| Share > 0 | 0.51573 | 0.51573 | 0.52273 | 0.52389 | 0.53438 | 0.53846 | |
| C | Annualized return | 0.15330 | 0.16232 | 0.09462 | 0.13518 | 0.21999 | 0.16559 |
| VaR | −0.01870 | −0.01620 | −0.01485 | −0.01178 | −0.01138 | −0.00961 | |
| Maximum drawdown | −0.18039 | −0.16953 | −0.26101 | −0.12467 | −0.11512 | −0.11325 | |
| Calmar ratio | 0.84985 | 0.95749 | 0.36252 | 1.08426 | 1.91081 | 1.46219 | |
| Sharpe ratio | 1.00665 | 1.19216 | 0.80841 | 1.34756 | 2.10334 | 1.92632 | |
| Sortino ratio | 1.58895 | 2.00973 | 1.14286 | 2.06169 | 3.56316 | 3.28521 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waldow, F.; Schnaubelt, M.; Krauss, C.; Fischer, T.G. Machine Learning in Futures Markets. J. Risk Financial Manag. 2021, 14, 119. https://doi.org/10.3390/jrfm14030119
Waldow F, Schnaubelt M, Krauss C, Fischer TG. Machine Learning in Futures Markets. Journal of Risk and Financial Management. 2021; 14(3):119. https://doi.org/10.3390/jrfm14030119
Chicago/Turabian StyleWaldow, Fabian, Matthias Schnaubelt, Christopher Krauss, and Thomas Günter Fischer. 2021. "Machine Learning in Futures Markets" Journal of Risk and Financial Management 14, no. 3: 119. https://doi.org/10.3390/jrfm14030119
APA StyleWaldow, F., Schnaubelt, M., Krauss, C., & Fischer, T. G. (2021). Machine Learning in Futures Markets. Journal of Risk and Financial Management, 14(3), 119. https://doi.org/10.3390/jrfm14030119