2.1. Data
The following analysis is based on data obtained from
https://www.coingecko.com/. CoinGecko tracks market data of over 13,000 cryptocurrencies and provides fundamental analysis, such as on-chain metrics and coverage of major events.
Haq et al. (
2021) found that 37% of research published between 2017 and 2021 relied on market data by
https://coinmarketcap.com/, while only four percent retrieved data from CoinGecko. Coinmarketcap.com is therefore the most-referenced price-tracking website for cryptocurrencies in academic literature. We remark that Coinmarketcap has been acquired by the cryptocurrency exchange Binance.com in April 2020. Binance runs its own blockchain network BNB Smart Chain (formerly Binance Smart Chain) and the corresponding ERC-20 token “BNB”, as well as “Binance USD” (
Binance 2022). To ensure the highest quality of data and avoid any possible bias, this article relies on data obtained from CoinGecko.
In the following, the 100 largest cryptocurrencies, in terms of market capitalisation, have been analysed. The date of observation was 22 April 2022. The authors found that the 56 largest cryptocurrencies represent more than 90% of the total market capitalisation.
Table 1 shows the respective coins, their market cap in US Dollars (USD) and their relative market share.
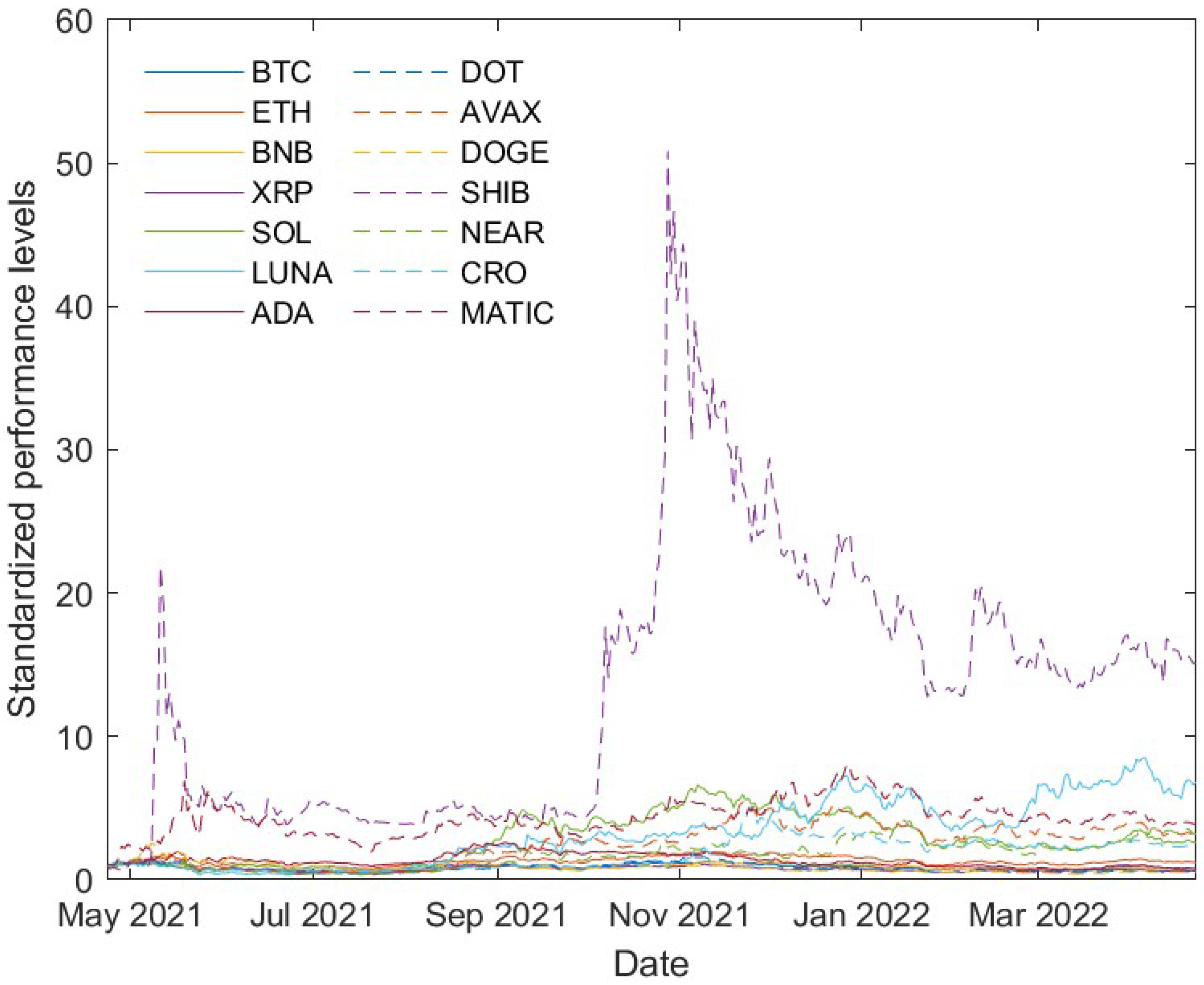
It is noteworthy that two cryptocurrencies, namely Bitcoin and Ethereum, jointly amount to around 57% of the total market. This allows us to make statements about a large proportion of the market by analysing only these two assets, as has been achieved in many previous studies. Prior to the year 2017, when the cryptocurrency prices appreciated substantially, Bitcoin and Ethereum combined had represented around 90% of the market. Subsequently, other cryptocurrencies have proportionally outgrown Bitcoin and its relative market cap has decreased to the level depicted in
Table 1. Thus, it is no longer possible to determine the properties of the total cryptocurrency market and derive statements relevant to investors by analysing only the two aforementioned cryptocurrencies. This article, therefore, provides a broad analysis of the 20 largest cryptocurrencies, representing 82.1% of the total cryptocurrency market.
Many previous articles used a specified minimum number of available data as a selection criterion for the cryptocurrencies to be analysed, in order to ensure a reliable outcome of their research. This is appropriate to show the goodness-of-fit or transferability of models or research topics to the asset class of cryptocurrencies. For investors, this approach limits the relevance of the analysis. Chosen cryptocurrencies might be abandoned (either by the community or developers) or no longer relevant in terms of market cap or current market trends.
To overcome this problem, this article analyses the daily prices of different individual observation periods for each of the selected cryptocurrencies, starting from the earliest data available on CoinGecko up to 22 April 2022.
Table 2 shows the selected time periods for each cryptoasset and the amount of available prices during that period. To cope with missing prices, the Last Observation Carried Forward approach, as in
Schmitz and Hoffmann (
2020);
Trimborn et al. (
2020), and
Börner et al. (
2021) has been utilised.
Six cryptocurrencies are excluded from further analysis (Tether, USD Coin, Terra USD, Binance USD, Wrapped Bitcoin, and Lido Staked Ether). These represent so-called stablecoins or synthetic tokens. Stablecoins try to peg their value to another less volatile asset, most commonly the USD. This peg can be sustained either by collateralisation, i.e., backing by USD in a fixed ratio or by algorithmic modifications to equilibrate demand and supply to stabilise prices around a defined level (
Fatás 2019). Wrapped Bitcoin or Lido staked Ether are synthetic tokens that represent the underlying cryptocurrencies (Bitcoin or staked Ether) (
BitGo 2018). This enables the liquid usage of the otherwise unusable cryptocurrencies, i.e., Bitcoin on the Ethereum blockchain. As their prices try to artificially mimic the value of other assets and do not necessarily correspond to the pricing of capital markets, they are to be excluded from further analysis but might be of interest for future research.
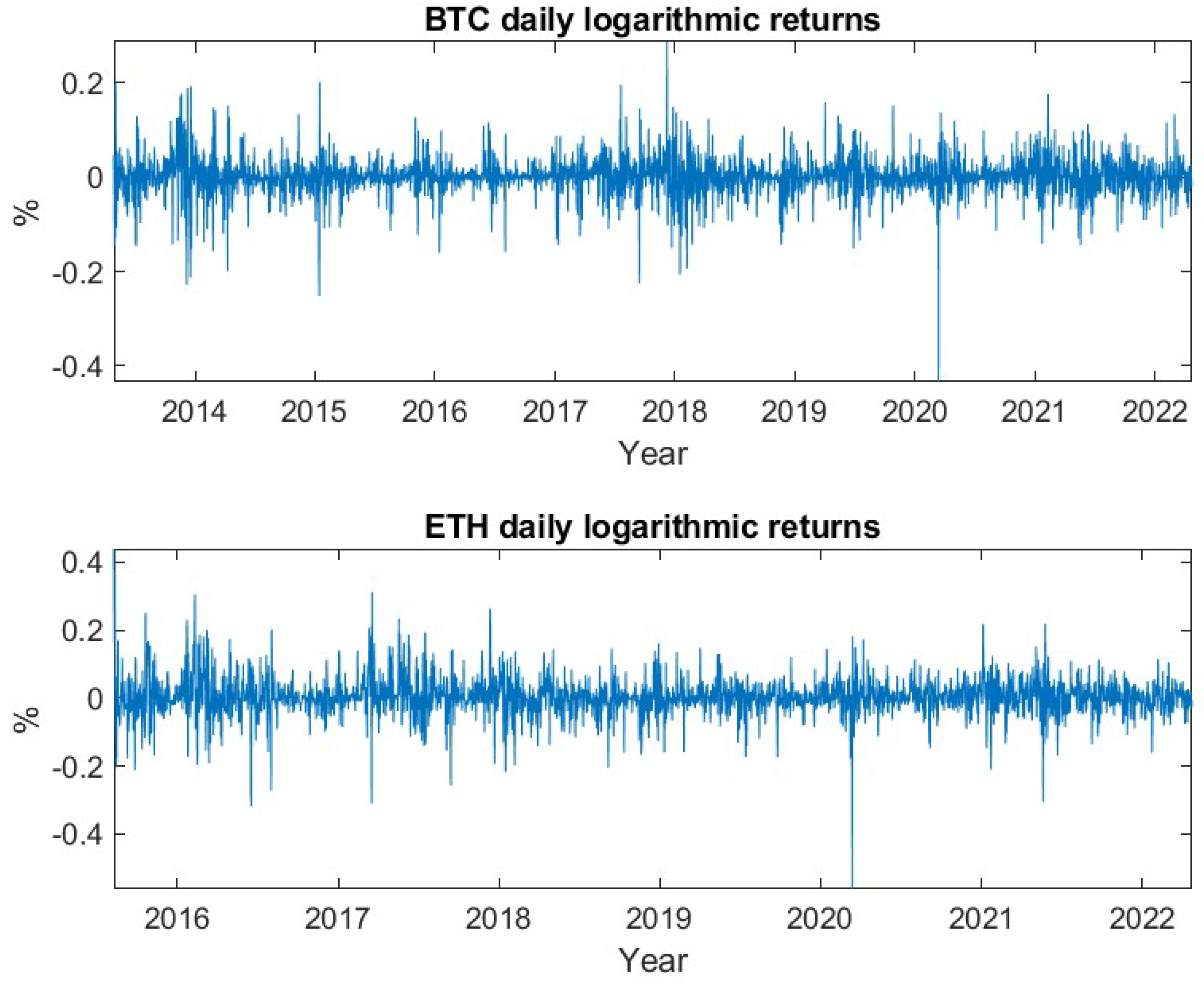
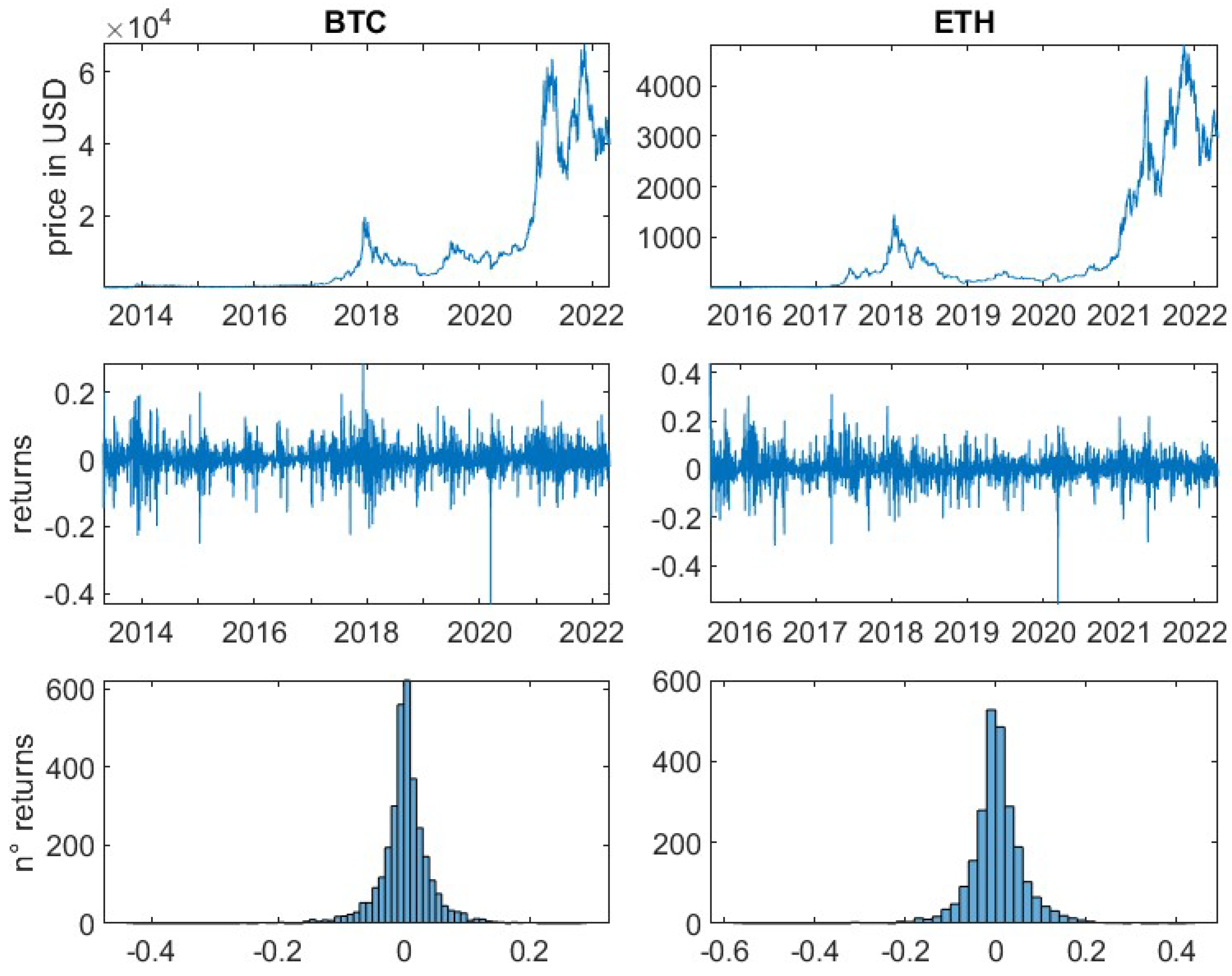
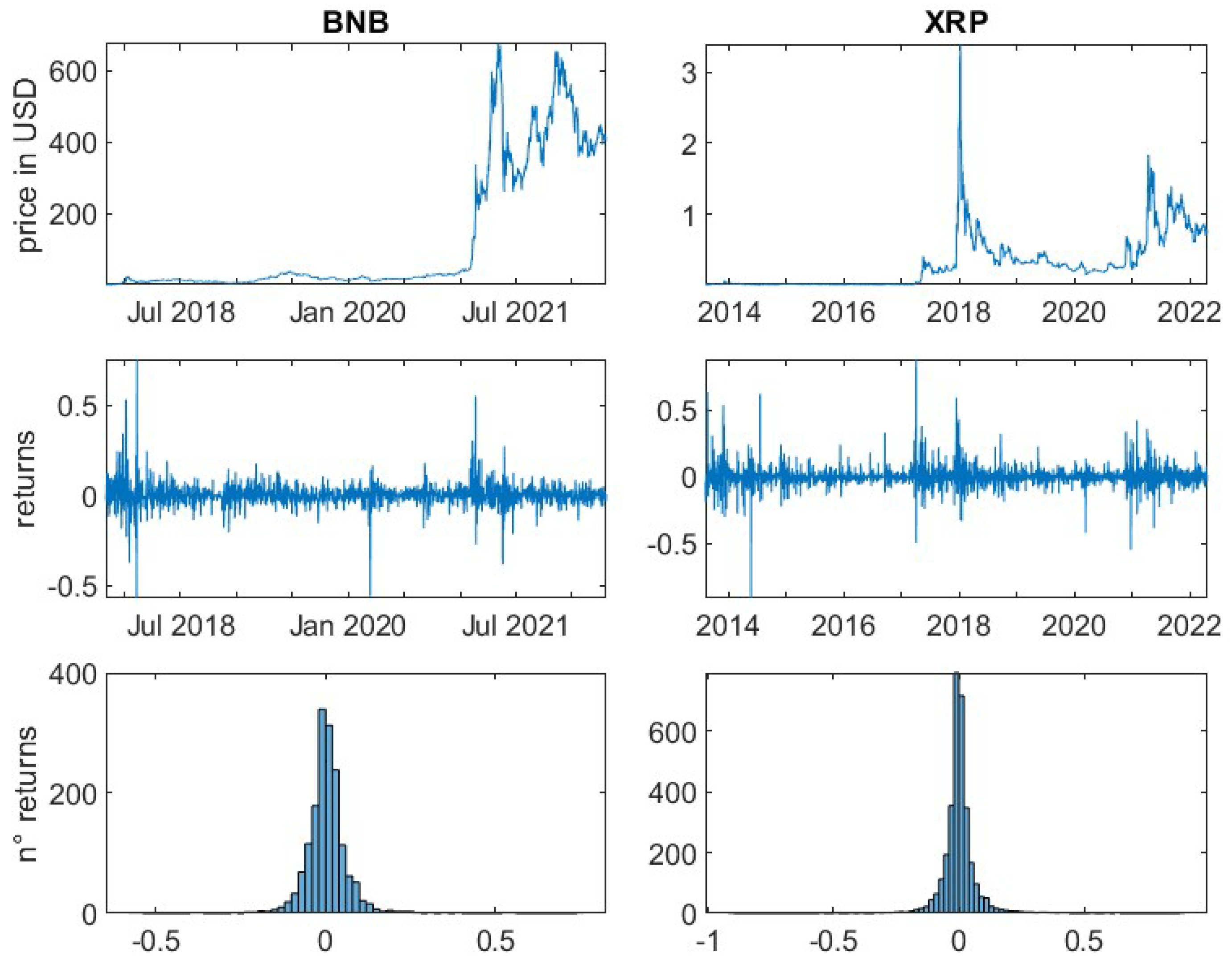
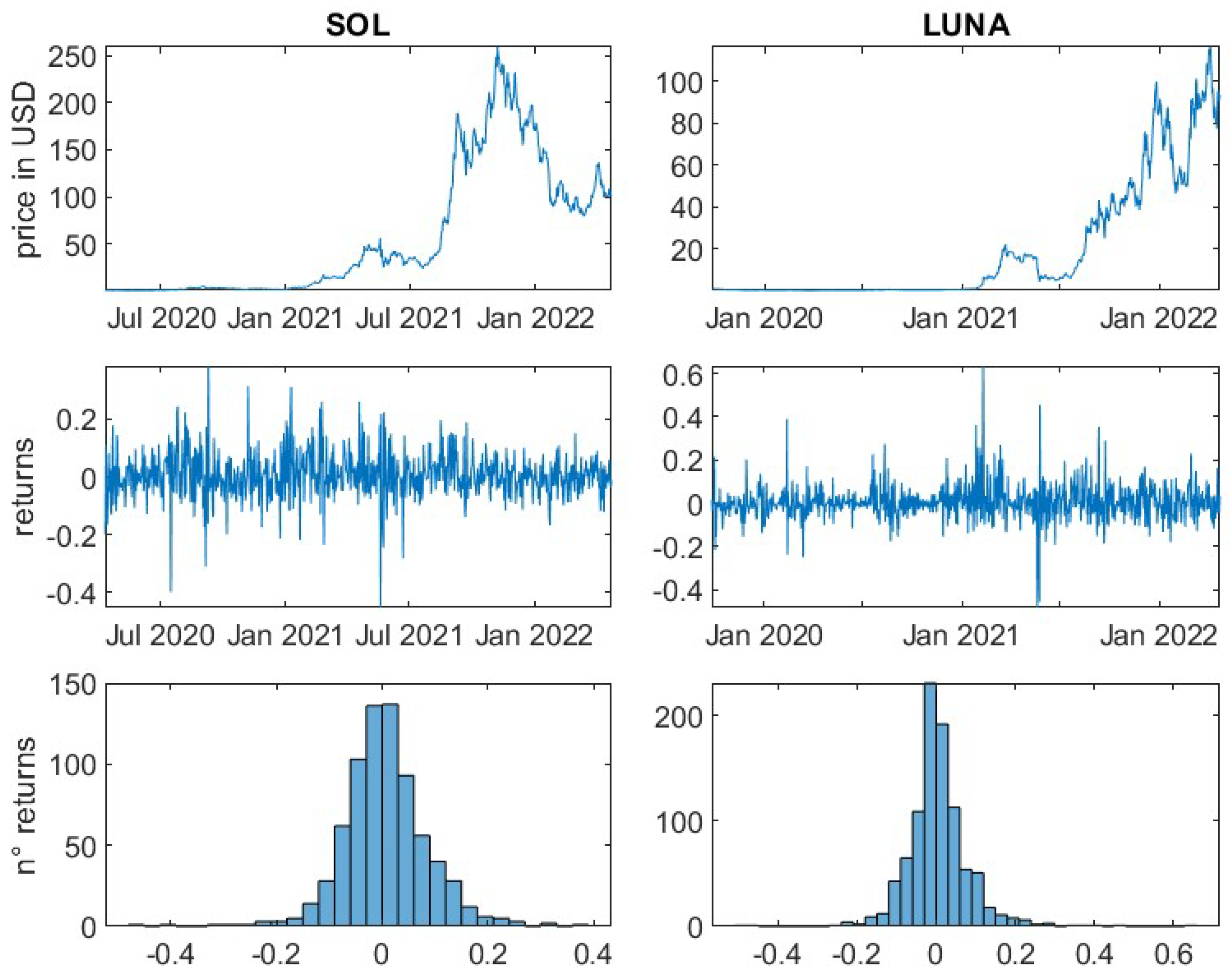
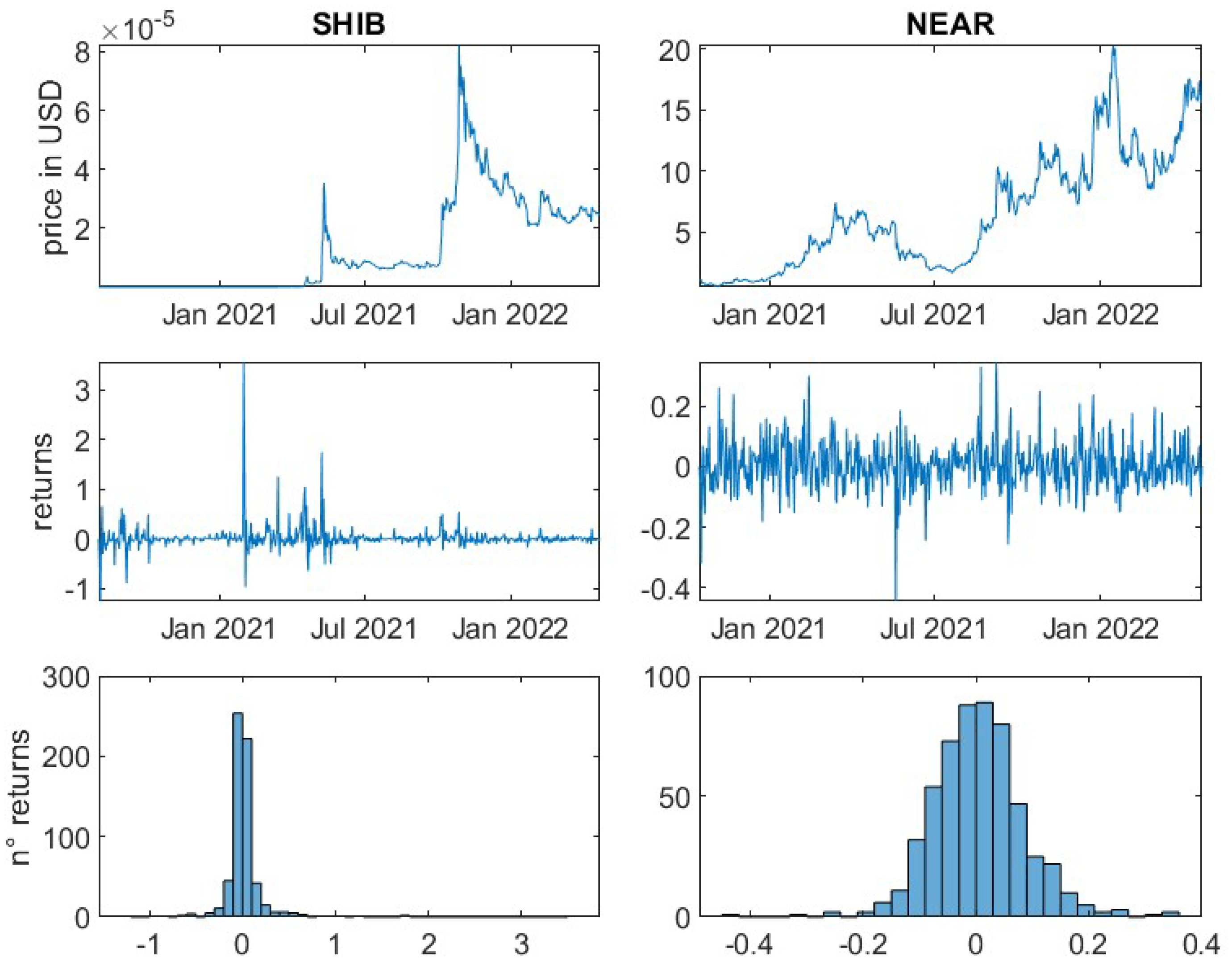
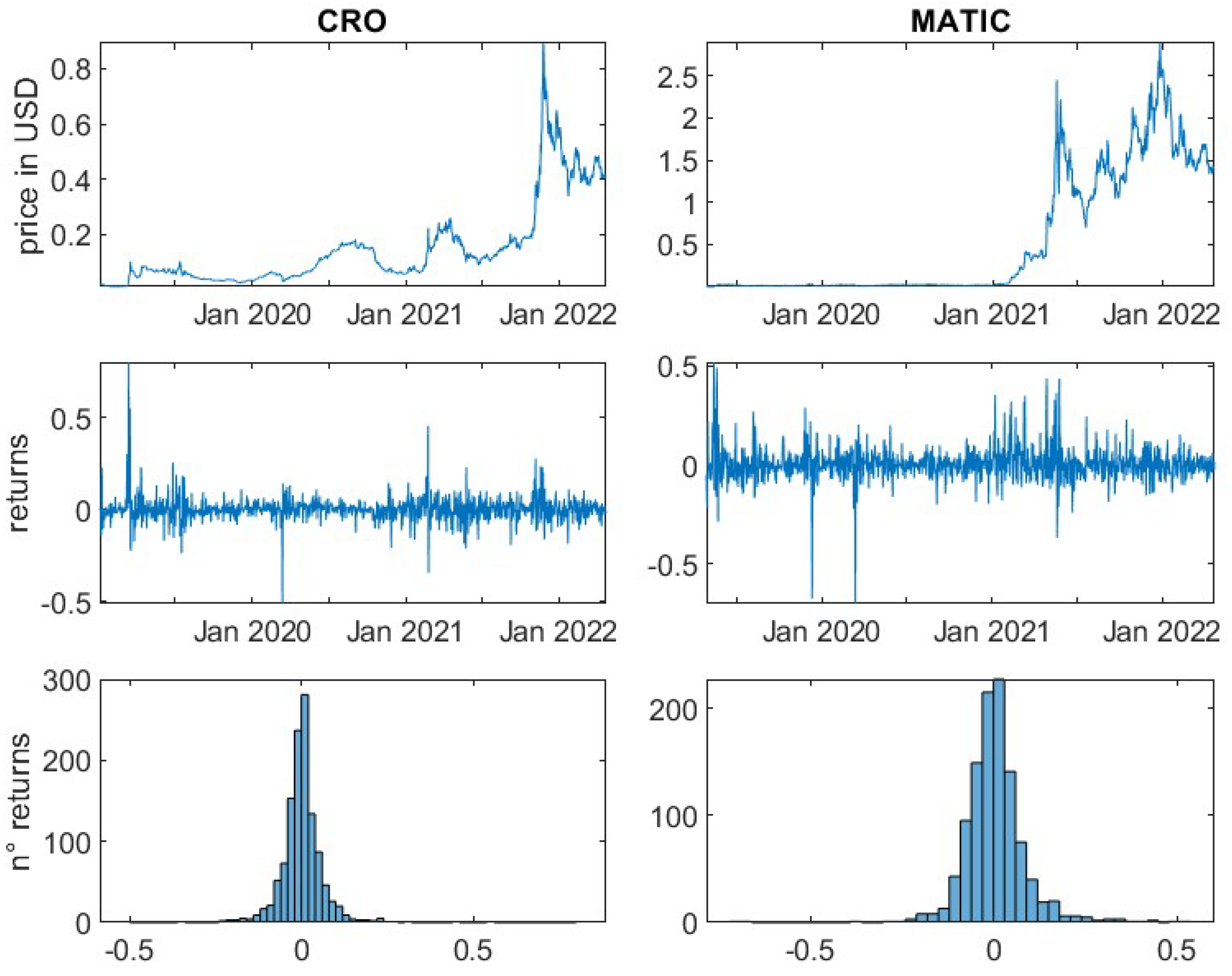
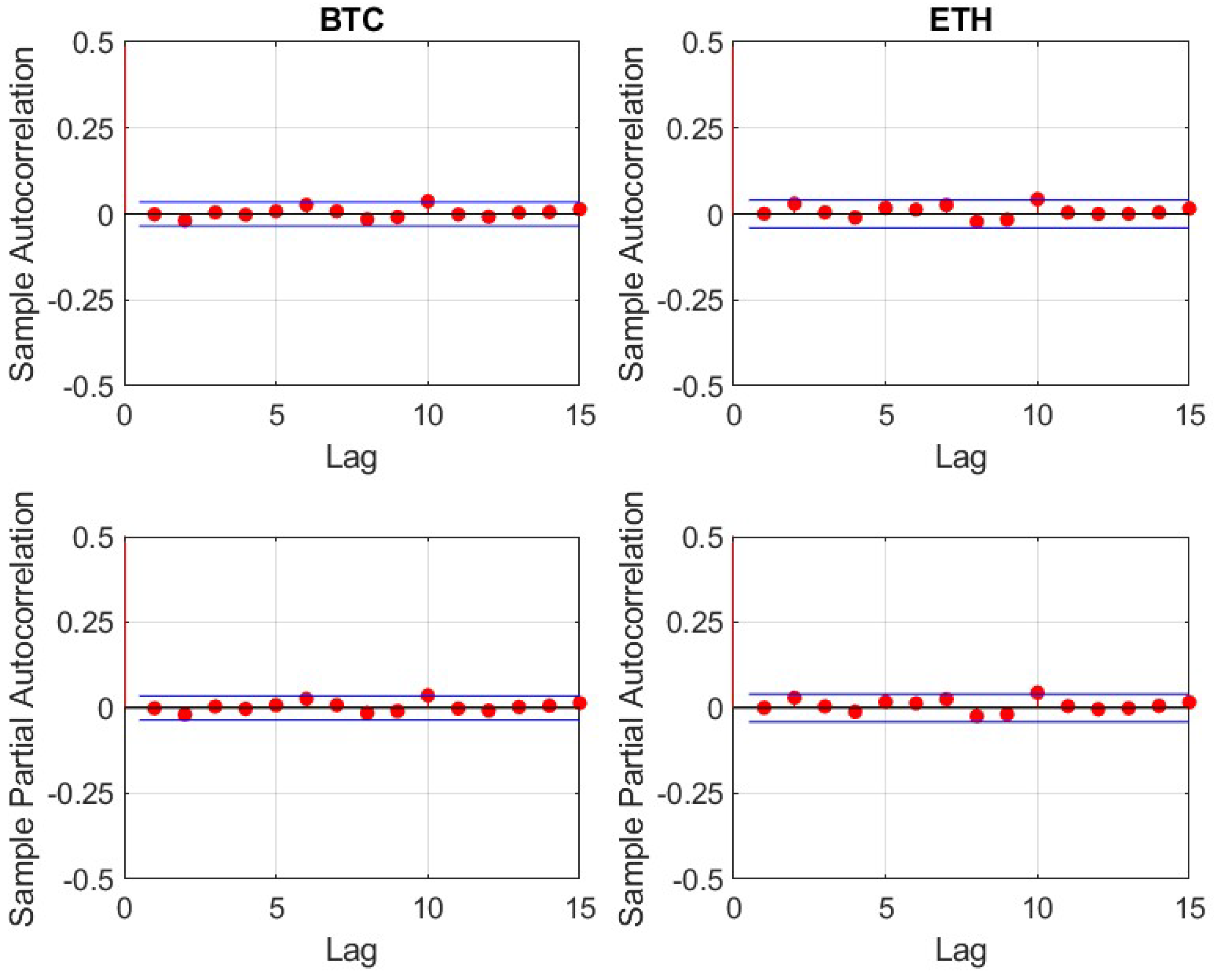
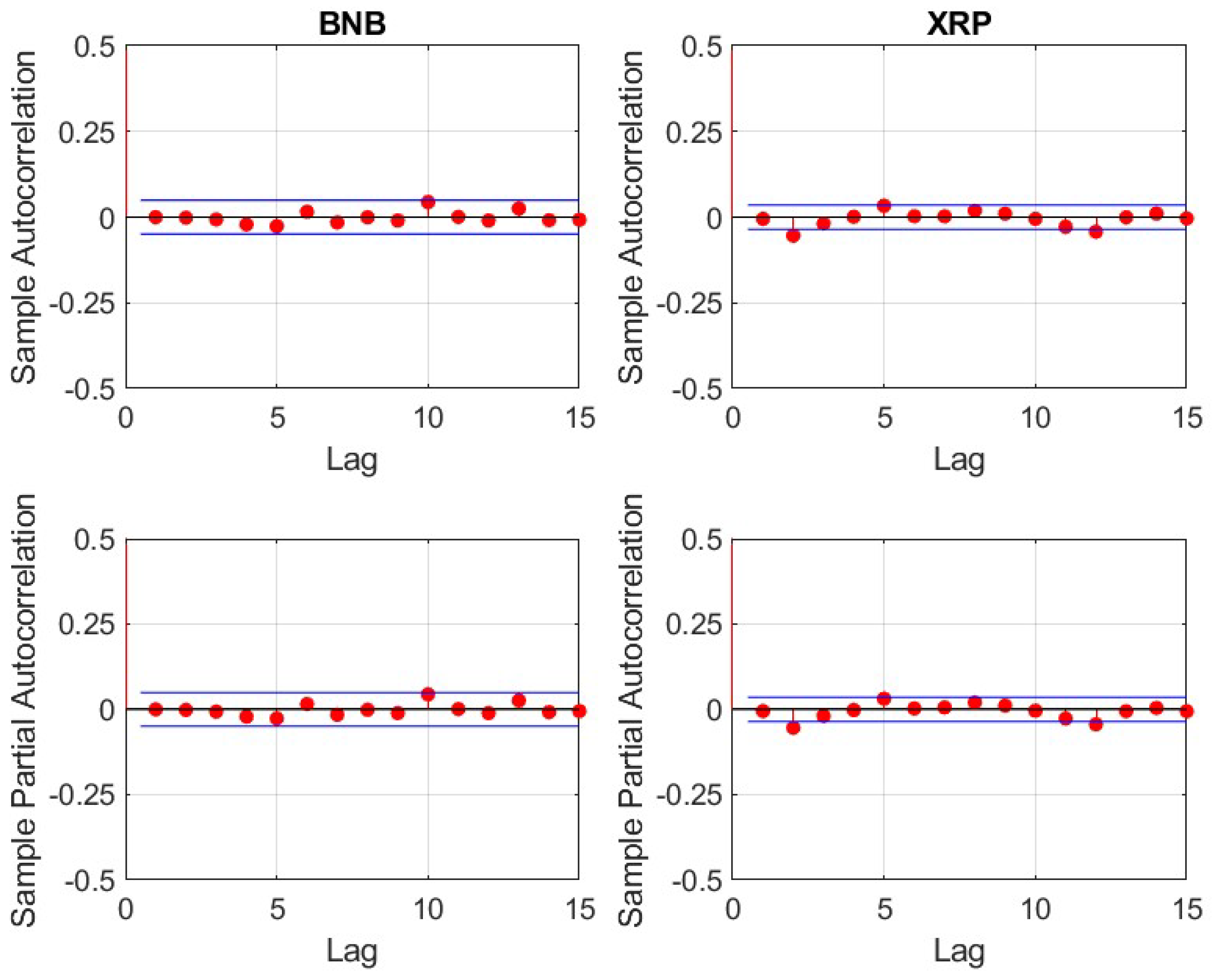
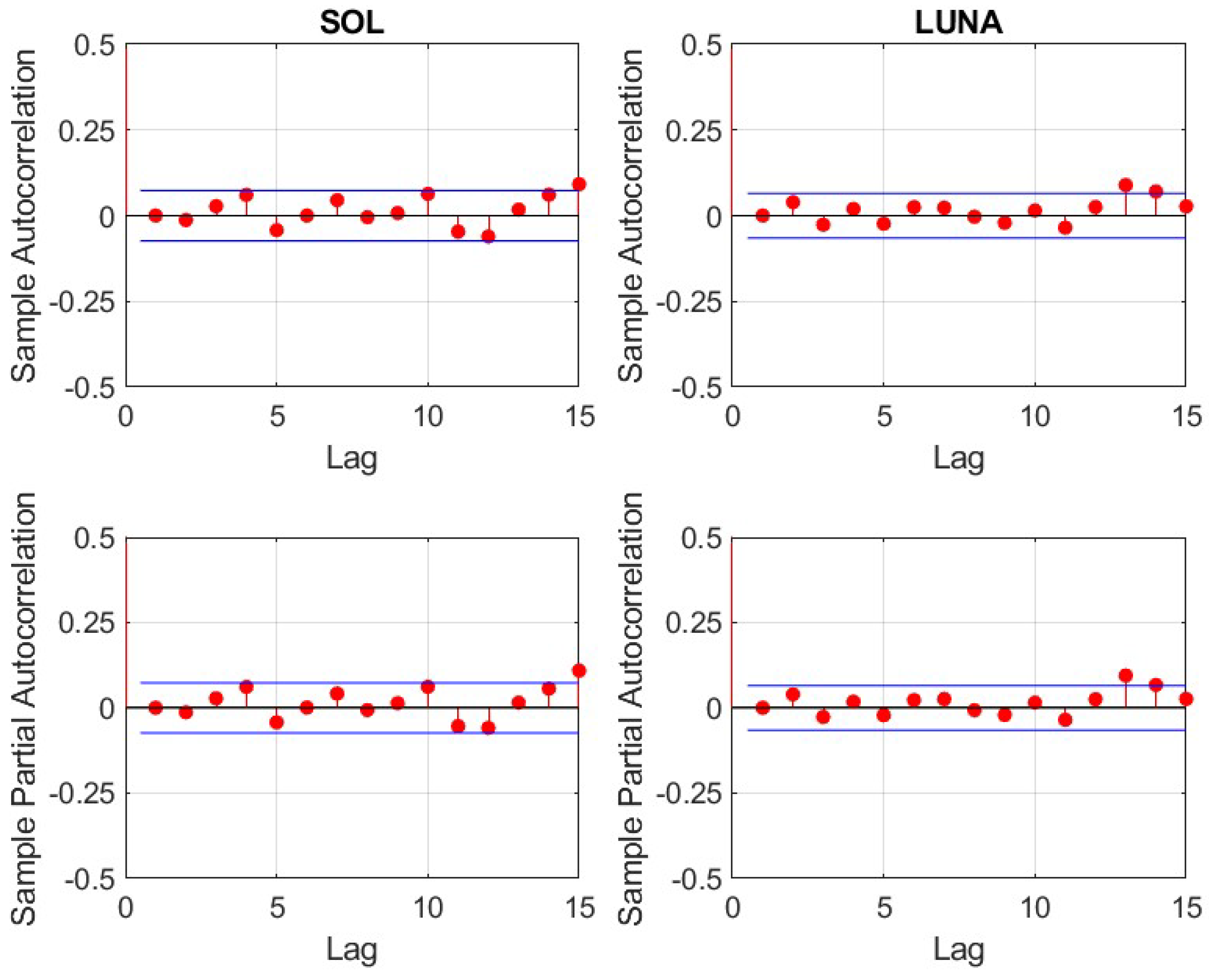
For the remaining 14 cryptocurrencies, logarithmic returns have been calculated based on daily prices. It is important to note, that in contrast to traditional financial markets, cryptocurrency markets are open 24 h for seven days a week. Therefore, seven, instead of five subsequent daily prices (returns) equate to one trading week. All underlying daily prices have been derived at 00:00 UTC.
2.2. Methodology
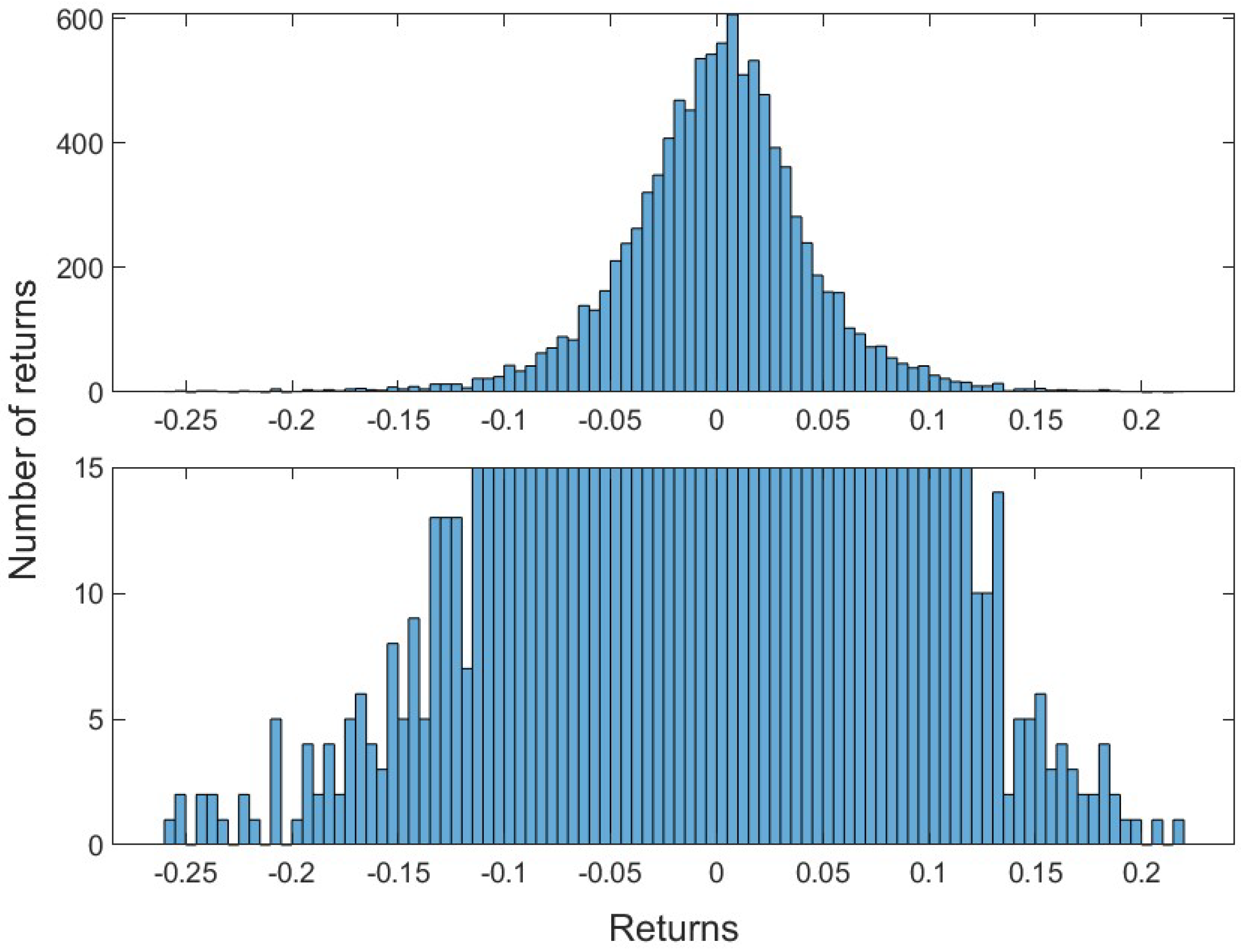
This article is divided into two parts. First, a general analysis of the crypto market is performed. For all selected cryptocurrencies the mean, the variance and the standard deviation of the daily logarithmic returns are determined to give the reader insights into their general risk characteristics. Furthermore, the kurtosis and the skewness of the empirical return distributions are computed. The skewness measures the asymmetry of data around the mean. Negative skewness indicates a longer left tail, while a positive skewness represents a spread of data to the right of the mean. The kurtosis measures if a distribution is heavier-tailed or lighter-tailed as compared to a standard normal distribution. A kurtosis of less than three, indicates a less outlier-prone distribution, while greater than three indicates a heavier-tailed behaviour in relation to the standard normal distribution.
In addition, the practitioner’s important risk measures, Value-at-Risk and Expected-Shortfall, for the confidence levels 95% and 99% are computed. They represent, respectively, the loss within a certain period, i.e., one day, that will not be exceeded with a probability represented by the confidence level and the expected loss if the Value-at-Risk is exceeded. Note that risk indicators should generally be positive. Accordingly, the losses are represented by positive values, which contrasts with the previous steps.
As aforementioned, Bitcoin and Ethereum represent around 57% of the overall cryptocurrency market. To demonstrate how the remaining market reacts to changes in their prices, we determine the Pearson correlation coefficients. They measure the linear dependence of two random variables. The possible values range from −1, indicating a strong negative relationship, to +1, implying a strong positive relationship. Values around 0 represent a weak to no linear relationship.
The second part of this article consists of the application of Extreme Value Theory to estimate the extreme tail risks. EVT is a part of the probability theory with the aim of mathematically describing extreme events and their corresponding distribution functions. It allows us to make statements about extreme quantiles of a distribution, for which only very limited data is available and can provide the basis to derive additional risk measures, such as the Value-at-Risk or Expected-Shortfall (
Zeder 2007). In finance, the Extreme Value Theory is often applied to predict future extreme returns of investable assets, such as equities, commodities, or new asset classes, namely cryptocurrencies. Extreme positive returns are usually regarded as an additional profit and are therefore no reason for concern. Extreme negative returns, on the contrary, can lead to undercutting minimum capital requirements, default or the failure to uphold the minimum portfolio volumes (
Hoffmann 2015). Therefore, the Extreme Value Theory in the financial industry is usually applied to describe and predict extreme negative events and hence, acts as an important risk management tool.
It is important to note that the EVT is not a crystal ball that allows us to predict the future or the occurrence of such extreme events with high certainty. However, it is rather a mathematical theory to describe the extremes of a distribution (
Zeder 2007). To estimate a distribution function of extreme values of a univariate dataset, the EVT offers multiple methods. Whereby, the Peaks-over-Threshold Method (POTM) based on the Generalised Pareto Distribution (GPD) for the tail, is the most frequently applied method by banks (
BCBS 2009).
The Peaks-over-Threshold Method measures the exceedances of data
over a high threshold
u. The exceedance is denoted as
. The distribution function of the excesses is given by:
Theorem 1 (Pickands-Balkema-de-Haan Theorem).
For a large class of underlying distribution functions, the conditional excess distribution function , for a sufficiently large u, converges to a Generalised Pareto Distribution:with and . is the shape parameter and
is the scale parameter of the distribution function. For
the GPD follows a re-parameterised version of the usual Pareto distribution, for
an exponential distribution and for
a type II Pareto distribution (
Embrechts et al. 1997).
As the approximated GPD describes the distribution of the exceedances
Y over a large threshold
u, the determination of an optimal threshold
u is crucial. A too large
u limits the number of exceedances and leads to a high variance in the estimated parameters. A too small
u leads to biasedness and a not fully achieved GPD convergence. The selection of the threshold
u is not only a statistical problem but also related to the risk aversity of the involved parties. Hence, no consensus on an optimal
u has been reached so far (
McNeil and Frey 2000).
Schuhmacher and Auer (
2015) note that often
u is set so that 10% of the sample is included.
Embrechts et al. (
1997) recommend the use of plots, estimating over a variety of thresholds and the use of common sense.
This article follows a novel approach described by
Hoffmann and Börner (
2020a,
2020b,
2021) to automatically determine the optimal threshold for the tail of an unknown parent distribution. We denote negative returns as positive values as this analysis aims to describe extreme negative events (returns). Hence, a coordinate transformation must be performed to apply this process to estimate the left tail of a loss distribution.
The automated approach estimates the parameters
and
of the GPD for each of the
n observed losses
, sorted in descending order. At each step
the next smaller loss is added and the GPD is re-parameterised. Furthermore, for each
k the corresponding probability
for
and the deviation measure
is calculated.
represents the upper tail statistics and is the weighted Mean Squared Error between the empirical and Monte Carlo simulated data, with weights
for the lower tail and
for the upper tail. It is therefore focusing only on one side of the distribution function. The
goes back to
Ahmad et al. (
1988) and is given by:
This process results in a time series of the deviation measures
for
. The minimal deviation at any point of the time series
, indicates the best fit for the tail model and the corresponding loss
the optimal threshold
. The goodness-of-fit is determined by the confidence levels of
, the Cramér-von Mises, and the Anderson–Darling test. The Cramér-von Mises and Anderson-Darling statistics are both Mean Squared Error measurements between the empirical and the modelled distribution. The respective weights are
and
for the Cramér-von Mises statistics and
and
for the Anderson–Darling statistics. By calculating the confidence levels (
p-values) the quality of the model can be measured. The
p-value measures the probability of being mistaken, if the estimated GPD as the tail model is rejected, and should be close to 100% (
Hoffmann and Börner 2020a).
Based on the approximated GPD on the optimal threshold and the estimated parameters, high quantiles required for risk assessment can be computed. To compare the results to the first part of the analysis, the Value-at-Risk and Expected-Shortfall for the confidence levels 95% and 99% are calculated. By estimating the tail model of the unknown parent distribution, we can additionally compute the VaR for the confidence level of 99.9%.
The Value-at-Risk of the GPD is defined as:
with the optimal threshold
, the estimated GPD parameters
and
, the number of observations in the tail
N and the number of excesses
.
While the Expected-Shortfall can be calculated by using the mean excess function of the estimated GPD:
where the threshold
u is set equal to the Value-at-Risk of the corresponding confidence level
Embrechts et al. (
1997). This automated approach is applied in Matlab via the FindTheTail algorithm (
Bruhn 2022).
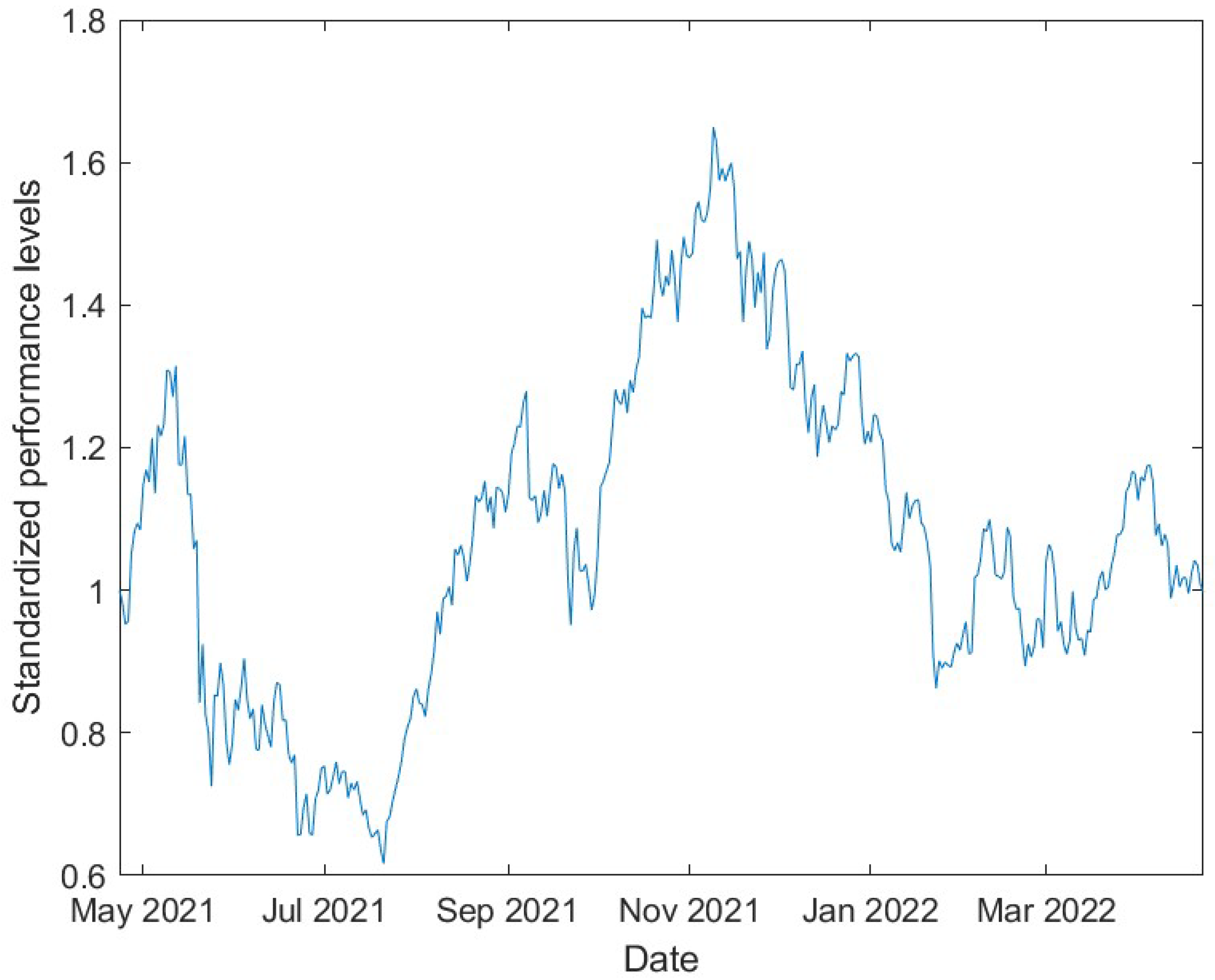
We further examine the properties and the possible diversification benefits of a portfolio of the 14 cryptocurrencies, weighted based on their respective market share. For simplicity, we apply the current market share and, retrospectively, calculate the returns and the properties for the last 365 trading days. Diversification effects may arise due to offsetting risk characteristics of the individual portfolio positions. To aggregate the individual risks and calculate their joint probability distribution we use Copulas. Copulas are joint probability distributions that describe the dependence structure between random variables. They are applied in risk management to have an integrated view of a company’s risk positions (
Zeder 2007). Copulas go back to
Sklar (
1959).
Theorem 2 (Sklar’s Theorem).
Let H denote a joint distribution function with its marginal distribution functions . Then, there exists an n-Copula C such that for all x in ,If are all continuous, then C is unique. Conversely, if C is an n-Copula and are distribution functions, then the function H defined above is an n-dimensional distribution function with margins (Embrechts et al. 2003). There exist multiple classes of Copula functions such as Elliptical Copulas, Archimedean Copulas or Extreme Value Copulas. We join
Luu Duc Huynh (
2019) in applying a t-Student Copula, an Elliptical Copula, to model the joint distribution and dependencies amongst the 14 cryptocurrencies, comprising our market portfolio. Huynh showed that cryptocurrencies have a strong dependence structure at the tail. t-Student Copulas are well suited to capture tail dependencies. An investigation of the goodness-of-fit of different Copula models to cryptocurrency portfolios might be a subject for future research. The Student-t Copula
can be written as
with
degrees of freedom, the Pearson’s correlation coefficient
r and the inverse of the Student cumulative distribution function
(
Ly et al. 2019).
By modelling the joint probability distribution of all 14 portfolio positions via a t-Student Copula, we aggregate all individual risks and describe the dependencies of the portfolio positions. To determine the risk properties of the market portfolio, we then compute the empirical VaR and the empirical ES for different confidence levels. The basis for these calculations is 10,000 daily portfolio returns, generated by a Monte-Carlo-Simulation on the previously determined joint probability distribution. Conclusively, we determine the diversification effect from the difference between the expected daily return of the market portfolio with aggregated risks and the portfolio with the sum of all individual risks. Hence, a positive diversification effect indicates that the portfolio of aggregated risks is expected to have higher daily returns or lower daily losses.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}