
Implementation of a C Library of Kalman Filters for Application on Embedded Systems



Abstract
:1. Introduction
1.1. Application Fields of Kalman Filtering
1.2. Embedded Implementation of Kalman Filter Algorithms
1.3. Contribution of This Work
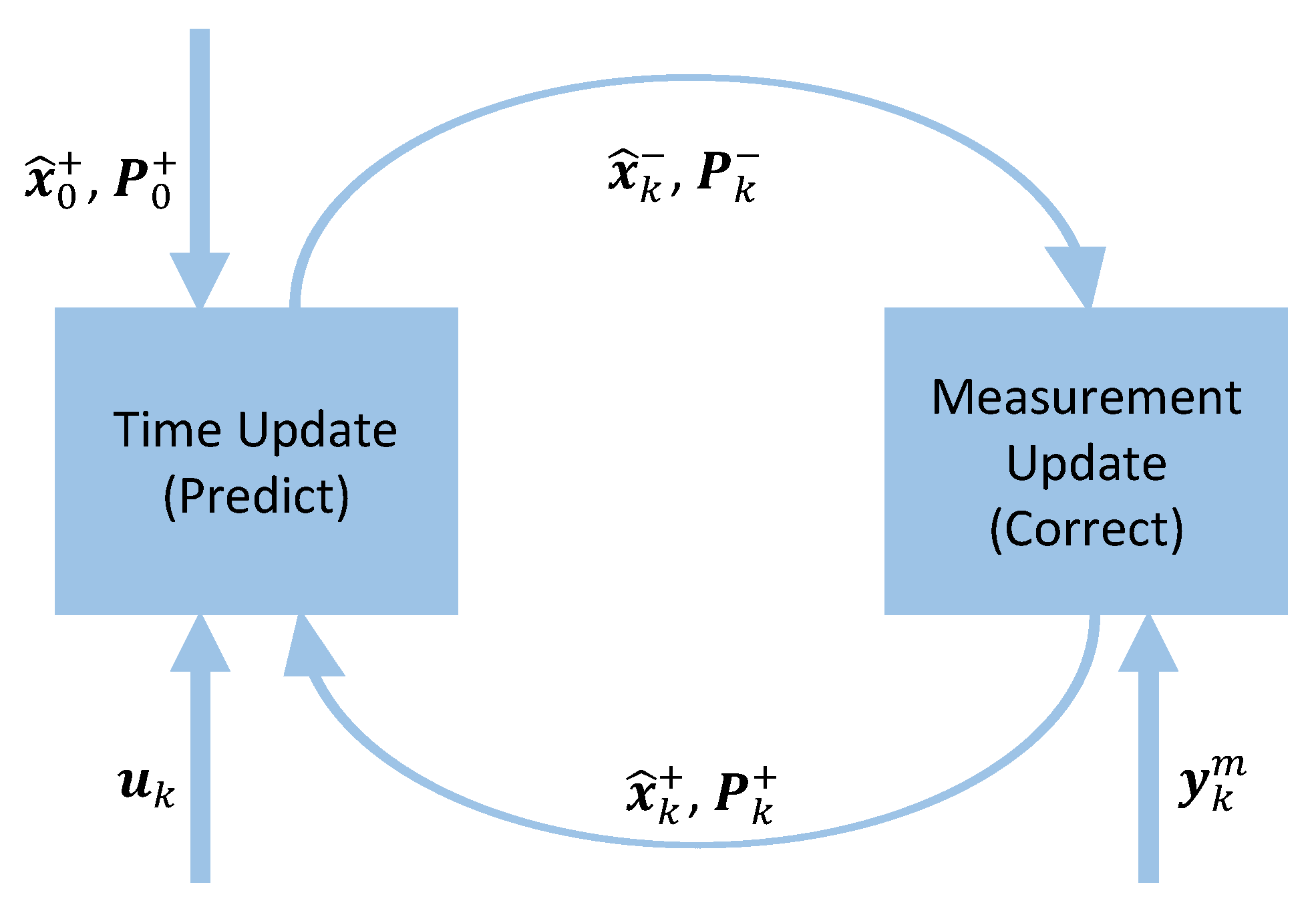
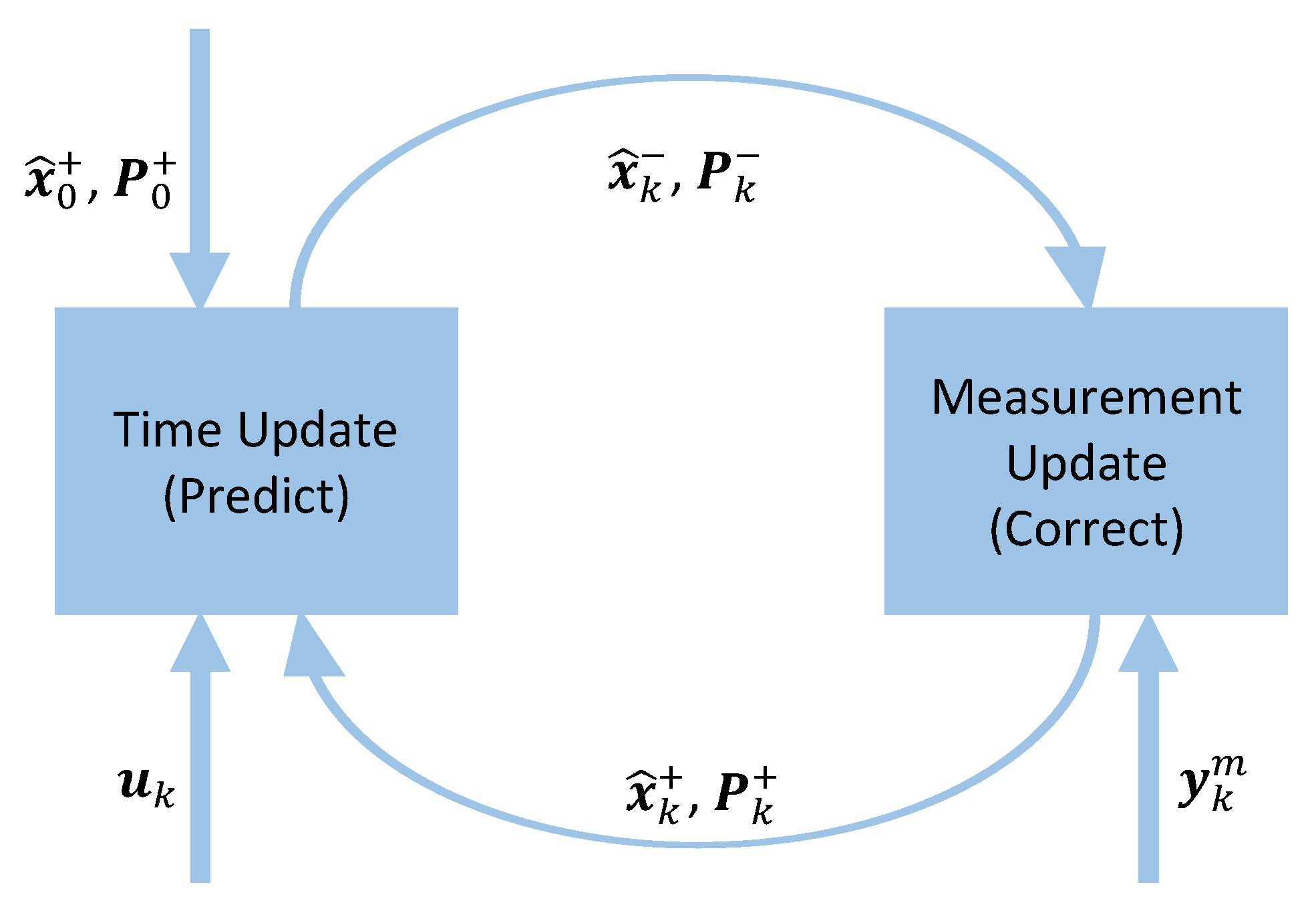
2. General Theory on Kalman Filters
2.1. Nonlinear Kalman Filter Variants
2.2. Incorporation of State Constraints
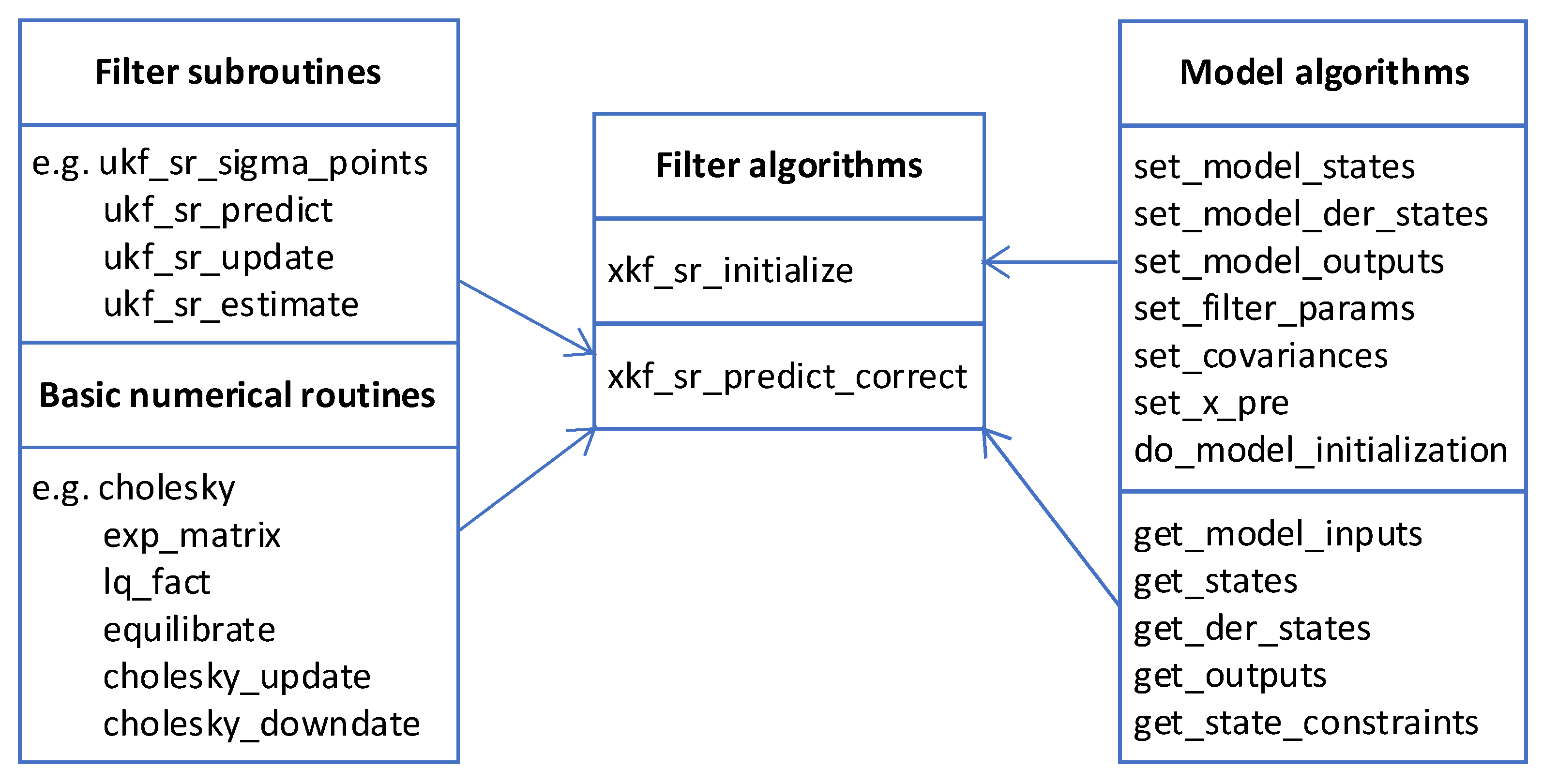
3. Implementation of the Embedded Kalman Filter Library
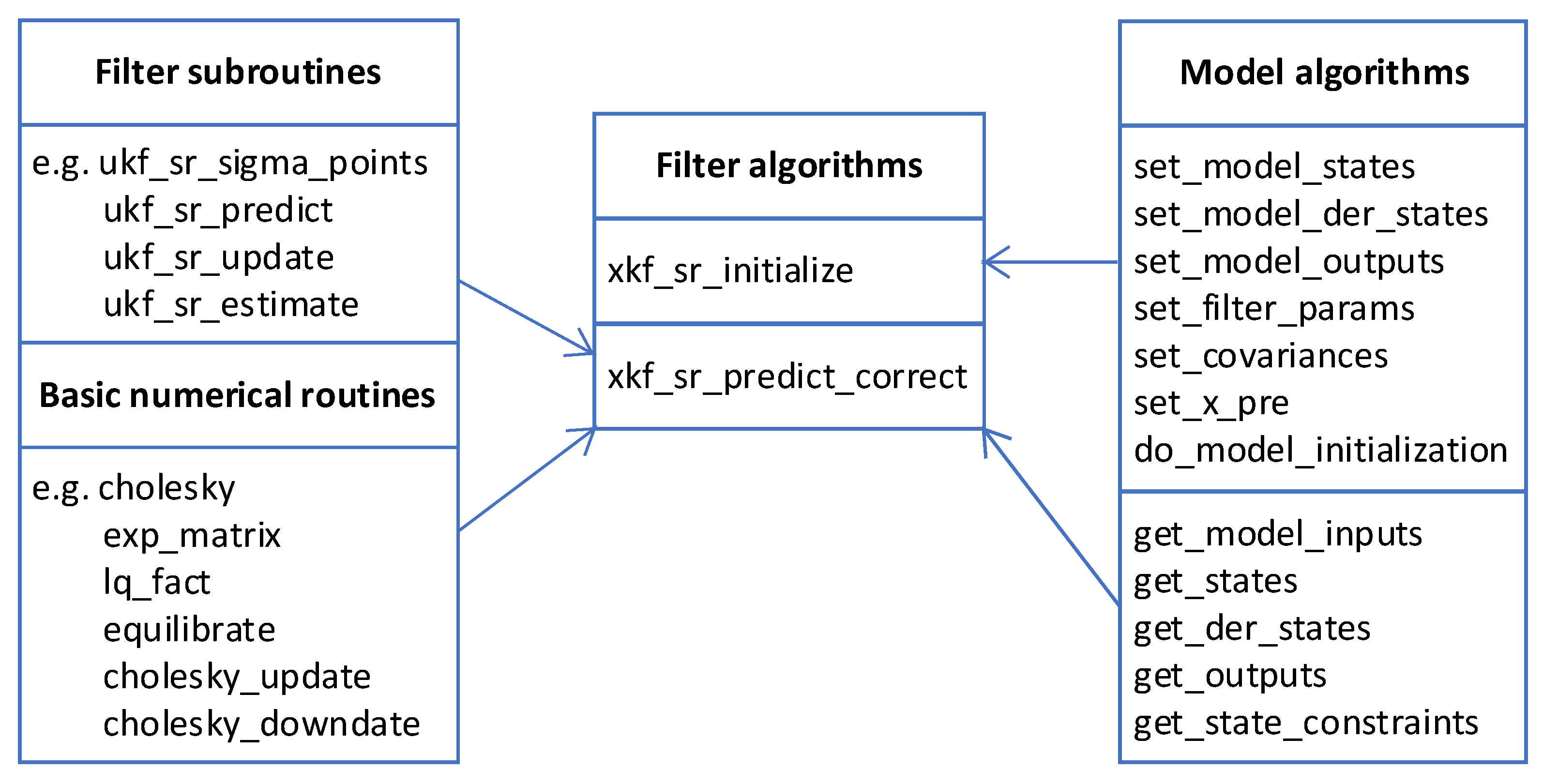
3.1. Structure of the Embedded Kalman Filter Library
- to provide prediction model-specific functions using the given interfaces of the library (right part of Figure 2), see Section 3.2 for more details on these functions,
- to call the function xkf_sr_initialize once in the initialization phase,
- to call the function xkf_sr_predict_correct in each sample time step of the environment, and
- to provide variables for the inputs , and the outputs of the function xkf_sr_predict_correct.
- void xkf_sr_initialize (void)
- void xkf_sr_predict_correct (real_t * ptr_u, real_t * ptr_y_meas, real_t * ptr_out)
3.2. Incorporation of User-Defined Prediction Models
- void set_model_states(real_t * states[NX])
- void set_model_der_states(real_t * der_states[NX]) (only needed for the EKF-SR)
- void set_model_outputs(real_t * outputs[NY])
- void set_x_pre(real_t xpre[NX])
- void set_filter_params(real_t *alpha, real_t *beta, real_t *kappa) (only needed for the UKF-SR)
- void set_covariances(real_t CfPpre[NX*NX], real_t CfQ[NX*NX], real_t CfR[NY*NY])
- void do_model_initialization(void)
- void get_model_inputs(real_t *ptr_u)
- void get_der_states(void) (only needed for the EKF-SR)
- void get_outputs(void)
- void get_states(void)
- void get_state_constraints (int state_constr_ind[NX_CONSTR], real_t constrVecLow[NX_CONSTR], real_t constrVecUp[NX_CONSTR]) (optional)
3.3. Basic Routines Employed in the Library
- Cholesky factorization (cholesky):, where is a symmetric and positive definite matrix and is a lower triangular matrix with positive diagonal entries.is called the Cholesky factor. The algorithm is described in [24]. It is possible to organize the calculations in such a way that the matrix is overwritten. Thus, no additional memory is required. The algorithm returns the lower triangle, with the remaining matrix completed with zeros. This factorization is used to obtain the matrix square-roots of the covariance matrices, see e.g., Section A.3.
- Matrix exponential (exp_matrix):, with a real matrix , the identiy matrix and a scalar which is the sampling time here. The computation is performed by means of a Taylor series expansion. The implementation, which is employed in Equation (A3), is based on the algorithm used in the Modelica Standard Library (“Modelica.Math.Matrices.exp”) [25]. It includes balancing of the matrix , i.e., a transformation to get a matrix with a smaller condition number. Due to the particular design of the algorithm, where the calculations are carried out by using multiples of two, no roundoff errors are generated. More information about the matrix exponential can also be found in [24].
- LQ factorization (lq_fact):
- , where is a real matrix, is a lower triangular matrix and is an orthogonal matrix. The implementation is based on the corresponding LAPACK routine sgelqf [26]. The algorithm returns the matrix on the lower triangle of , while the matrix is only implicitly available. Several other methods for basic matrix operations are included in this routine. It is used in Equations (A22) and (A23).
- Equilibration (equilibrate):This algorithm can be employed directly preceding the LQ factorization to equilibrate the corresponding matrix that is to be decomposed. The use of this routine is optional. It applies a different methodology than the balancing mentioned above. Its goal is to reduce the condition number of a matrix by computing row and column scaling. Thereby, roundoff errors can be minimized. The algorithm is based on the LAPACK routine sgeequ [26].
- Low-rank Cholesky updating and downdating (cholesky_update, cholesky_downdate):
3.4. Consideration of Coding Guidelines
4. Application on Embedded Systems
4.1. Application of the EKF-SR in a Small-Scale Production Series ECU
4.2. Application of the UKF-SR on a Rapid Prototyping System
4.2.1. Vehicle Prediction Model
4.2.2. Integration of the Model Code in the Embedded Kalman Filter Library
- the export of the Modelica model to eFMI GALEC code [29] by a Dymola prototype implementation,
- manual modifications of the generated GALEC code to provide all necessary features and function interfaces for state estimation, and
- the generation of eFMI production C code based on the modified GALEC code by an CATIA ESP prototype implementation. CATIA ESP is a newly developed production code generator not yet released by Dassault Systèmes.
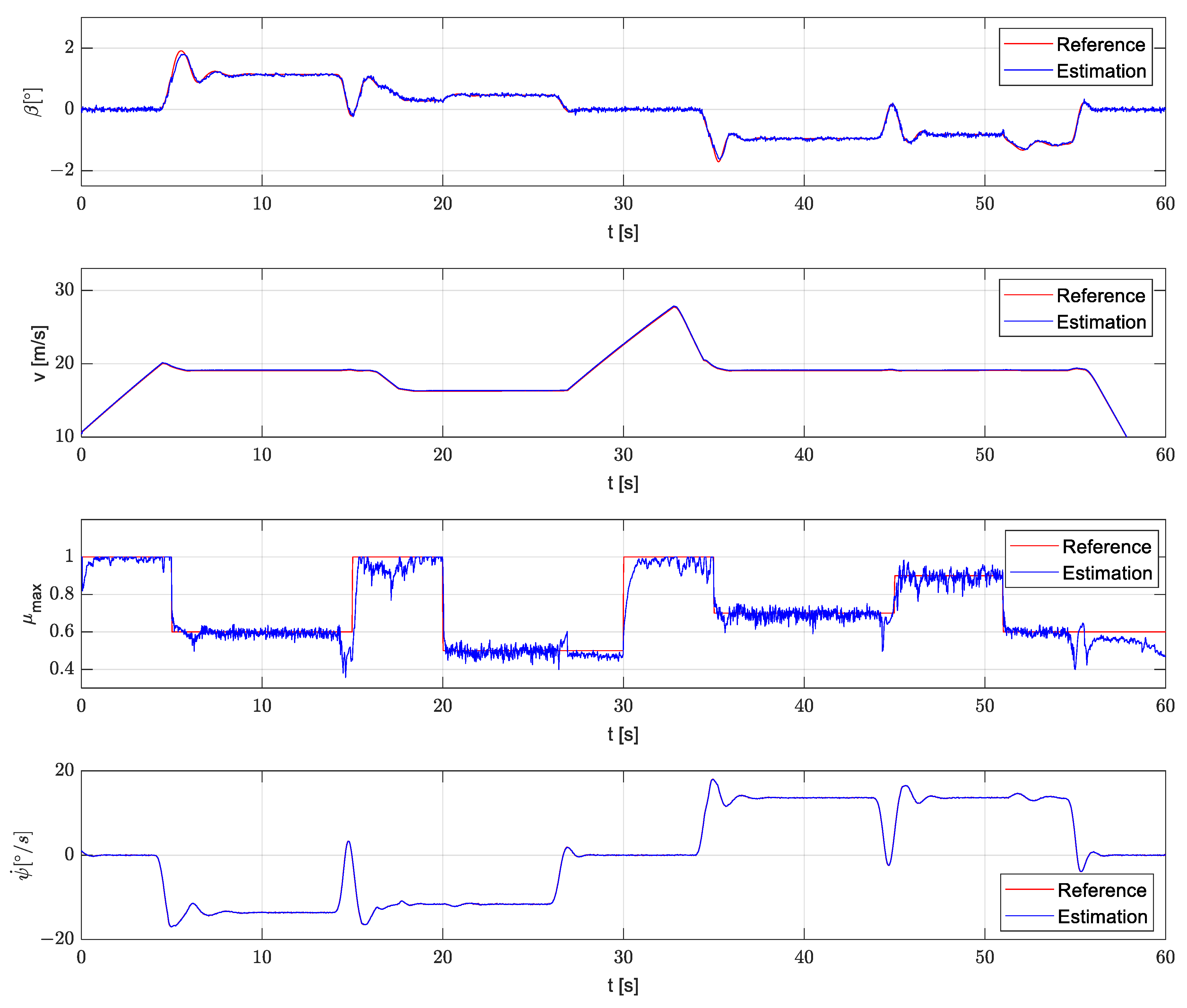
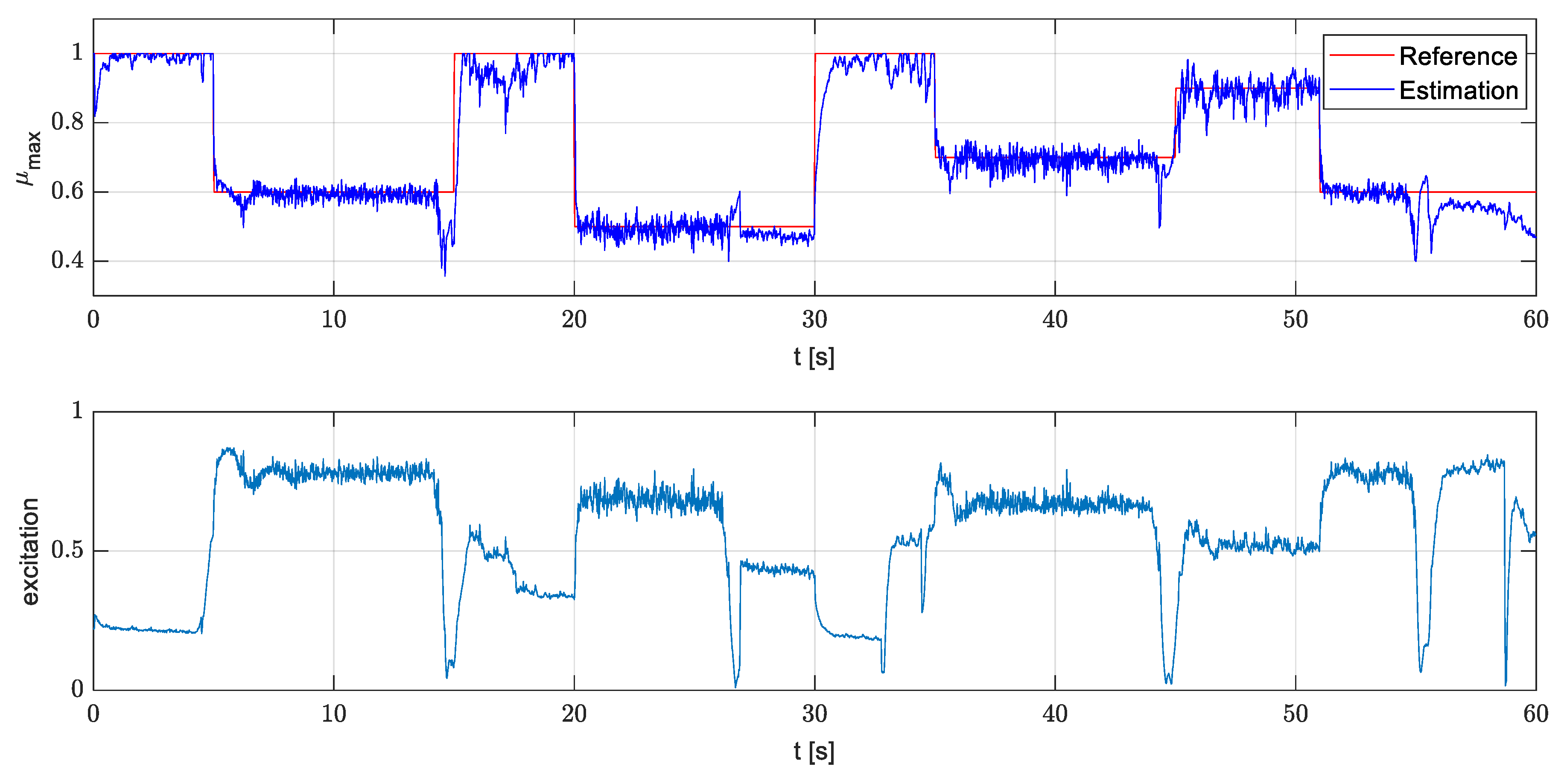
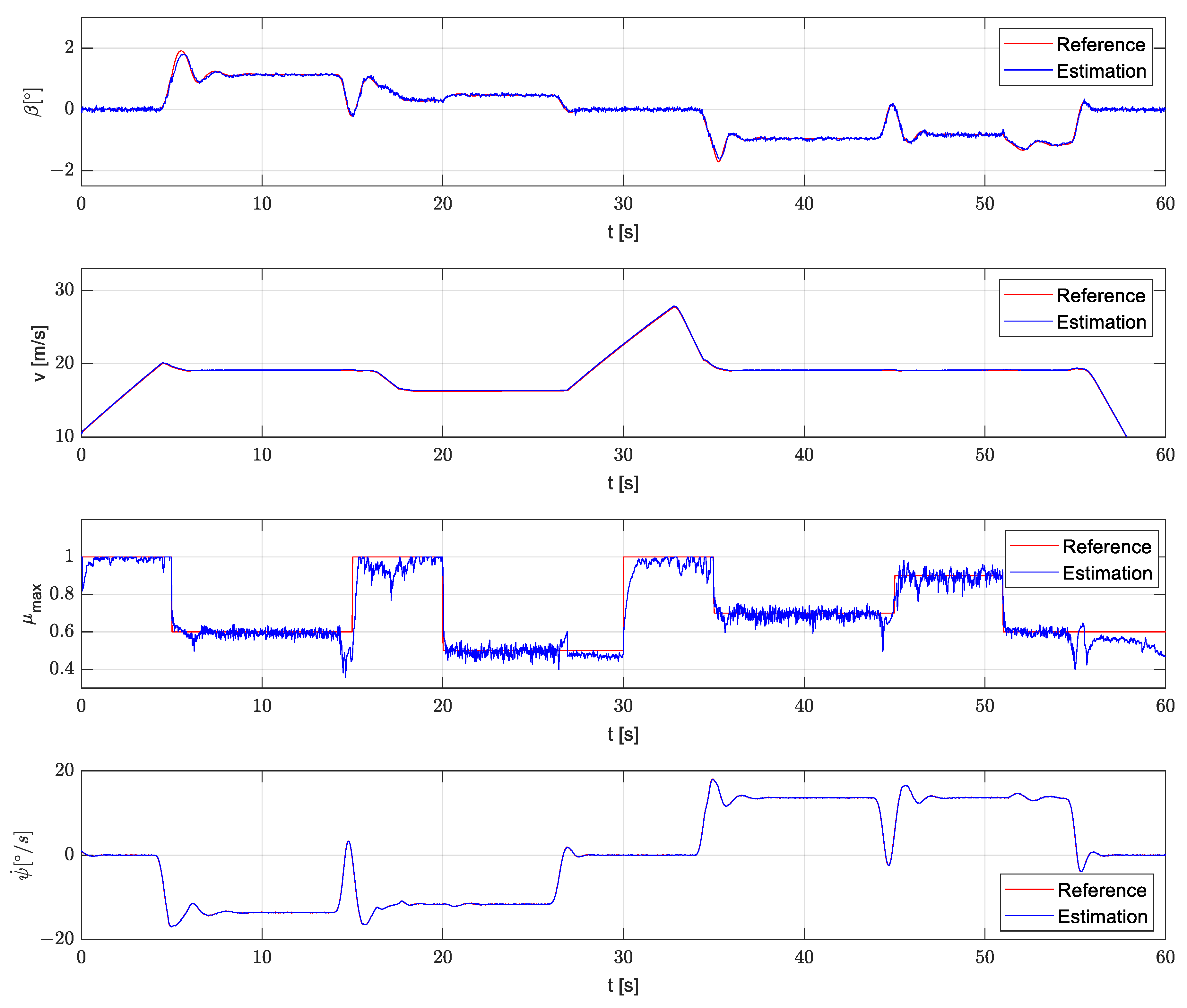
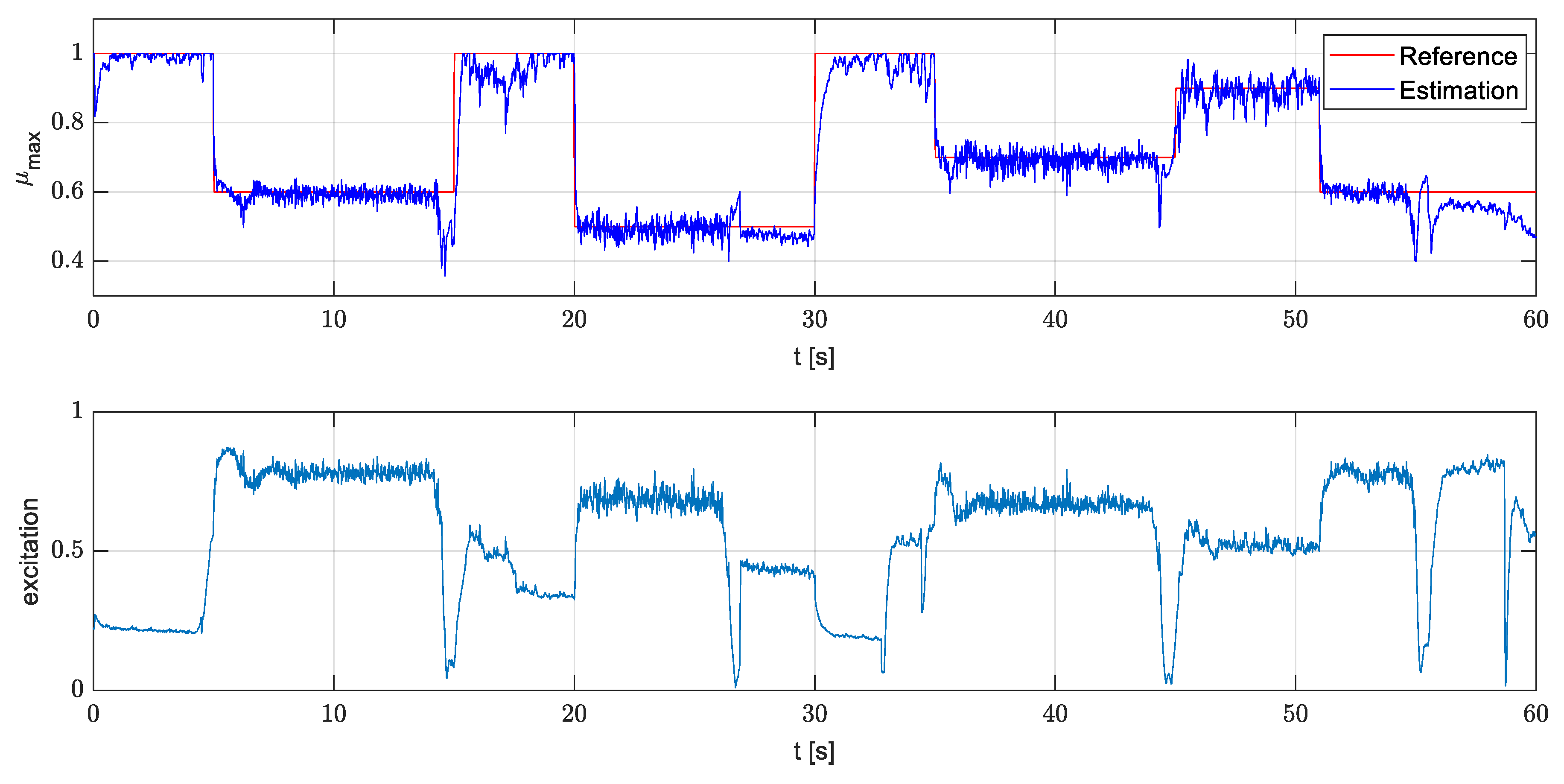
4.2.3. Simulation in Simulink
4.2.4. Execution on the Rapid Prototyping Platform
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Kalman Filter Algorithms
Appendix A.1. Extended Kalman Filter (EKF)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initialization: | |
| | (A1) |
| Predict: | |
| (A2) | |
| with | (A3) |
| Correct: | |
| with | (A4) |
| (A5) | |
| (A6) |
Appendix A.2. Extended Kalman Filter with Square-Rooting (EKF-SR)
Appendix A.3. Unscented Kalman Filter (UKF)
| Parameter | Description |
|---|---|
| Spread of the sigma points around the current mean | |
| Characteristic of the stochastic distribution | |
| Scaling kurtosis of the sigma points |
| Weight | Description |
|---|---|
| Scaling parameter | |
| Scaling parameter | |
| Weight of unmodified mean prediction | |
| Weight of unmodified output mean prediction | |
| Weight of sigma points of states and outputs |
| Initialization: | |
| | (A9) |
| Predict: | |
| (A10) | |
| (A11) | |
| (A12) | |
| (A13) | |
| (A14) | |
| (A15) | |
| (A16) | |
| Correct: | |
| (A17) | |
| (A18) | |
| (A19) | |
| (A20) | |
| (A21) |
Appendix A.4. Unscented Kalman Filter with Square-Rooting (UKF-SR)
References
- Haykin, S. Kalman Filtering and Neural Networks; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Karamta, M.R.; Jamnani, J.G. Implementation of extended kalman filter based dynamic state estimation on SMIB system incorporating UPFC dynamics. Energy Procedia 2016, 100, 315–324. [Google Scholar] [CrossRef] [Green Version]
- Li, J.-M.; Chen, C.W.; Cheng, T.-H. Estimation and Tracking of a Moving Target by Unmanned Aerial Vehicles. In Proceedings of the American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019. [Google Scholar]
- Wutke, M.; Heinrich, F.; Das, P.P.; Lange, A.; Gentz, M.; Traulsen, I.; Warns, F.K.; Schmitt, A.O.; Gültas, M. Detecting animal contacts—A deep learning-based pig detection and tracking approach for the quantification of social contacts. Sensors 2021, 21, 7512. [Google Scholar] [CrossRef] [PubMed]
- Al Khatib, E.I.; Jaradat, M.A.; Abdel-Hafez, M.; Roigari, M. Multiple Sensor Fusion for Mobile Robot Localization and Navigation Using the Extended Kalman Filter. In Proceedings of the 10th International Symposium on Mechatronics and Its Applications (ISMA), Sharjah, United Arab Emirates, 8–10 December 2015. [Google Scholar]
- Ullah, I.; Su, X.; Zhang, X.; Choi, D. Simultaneous localization and mapping based on Kalman filter and extended Kalman filter. Wirel. Commun. Mob. Comput. 2020, 2020, 2138643. [Google Scholar] [CrossRef]
- Fossen, S.; Fossen, T.I. Five-state extended Kalman filter for estimation of Speed over Ground (SOG), Course over Ground (COG) and Course Rate of Unmanned Surface Vehicles (USVs): Experimental results. Sensors 2021, 21, 7910. [Google Scholar] [CrossRef] [PubMed]
- Vergori, E.; Mocera, F.; Somà, A. Battery modelling and simulation using a programmable testing equipment. Computers 2018, 7, 20. [Google Scholar] [CrossRef] [Green Version]
- Colonnier, F.; della Vedova, L.; Orchard, G. ESPEE: Event-based sensor pose estimation using an extended Kalman filter. Sensors 2021, 21, 7840. [Google Scholar] [CrossRef] [PubMed]
- Ponte, S.; Ariante, G.; Papa, U.; del Core, G. An embedded platform for positioning and obstacle detection for small unmanned aerial vehicles. Electronics 2020, 9, 1175. [Google Scholar] [CrossRef]
- Fico, V.M.; Arribas, C.P.; Soaje, Á.R.; Prats, M.Á.M.; Utrera, S.R.; Vázquez, A.L.R.; Casquet, L.M.P. Implementing the Unscented Kalman Filter on an Embedded System: A Lesson Learnt. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015. [Google Scholar]
- EEKF—Embedded Extended Kalman Filter. 2015. Available online: https://github.com/dr-duplo/eekf (accessed on 4 October 2022).
- Valade, A.; Acco, P.; Grabolosa, P.; Fourniols, J.-Y. A study about Kalman filters applied to embedded sensors. Sensors 2017, 17, 2810. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasmussen, T.B.; Yang, G.; Nielsen, A.H.; Dong, Z.Y. Implementation of a Simplified State Estimator for Wind Turbine Monitoring on an Embedded System. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems, Prague, Czech Republic, 3–6 September 2017; pp. 1167–1175. [Google Scholar]
- Motor Industry Software Reliability Association. MISRA-C:2012. 2012. Available online: https://www.misra.org.uk/ (accessed on 4 October 2022).
- Bagnara, R.; Bagnara, A.; Hill, P.M. The MISRA C Coding Standard and Its Role in the Development and Analysis of Safety- and Security-Critical Embedded Software. In Proceedings of the Static Analysis: The 25th International Symposium (SAS 2018), Freiburg, Germany, 29–31 August 2018. [Google Scholar]
- Anderson, E.; Bai, Z.; Bischof, C.; Blackford, L.S.; Demmel, J.; Dongarra, J.; Croz, J.D.; Greenbaum, A.; Hammarling, S.; McKenney, A.; et al. LAPACK Users’ Guide, 3rd ed.; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1999. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches; John Wiley & Sons, Inc.: Cleveland, OH, USA, 2006. [Google Scholar]
- van der Merwe, R.; Wan, E.A. The Square-Root Unscented Kalman Filter for State and Parameter-Estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001. [Google Scholar]
- Brembeck, J. Model Based Energy Management and State Estimation for the Robotic Electric Vehicle ROboMObil. Ph.D. Thesis, Technische Universität München, Munich, Germany, 2018. [Google Scholar]
- Kandepu, R.; Imsland, L.; Foss, B.A. Constrained State Estimation Using the Unscented Kalman Filter. In Proceedings of the 16th Mediterranean Conference on Control and Automation, Ajaccio, France, 25–27 June 2008; pp. 1453–1458. [Google Scholar]
- Brembeck, J. A physical model-based observer framework for nonlinear constrained state estimation applied to battery state estimation. Sensors 2019, 19, 4402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brembeck, J. Nonlinear constrained moving horizon estimation applied to vehicle position estimation. Sensors 2019, 19, 2276. [Google Scholar] [CrossRef] [PubMed]
- Golub, G.H.; Van Loan, C.F. Matrix Computations, 4th ed.; The Johns Hopkins University Press: Baltimore, MA, USA, 2013. [Google Scholar]
- Modelica Association. Modelica Standard Library v4.0.0. 2020. Available online: https://github.com/modelica/ModelicaStandardLibrary/releases/tag/v4.0.0 (accessed on 21 September 2022).
- Netlib. LAPACK Documentation. 2022. Available online: http://www.netlib.org/lapack/explore-html/ (accessed on 4 October 2022).
- Seeger, M. Low Rank Updates for the Cholesky Decomposition; Department of EECS, University of California at Berkeley: Berkeley, CA, USA, 2008. [Google Scholar]
- Ultsch, J.; Ruggaber, J.; Pfeiffer, A.; Schreppel, C.; Tobolář, J.; Brembeck, J.; Baumgartner, D. Advanced controller development based on eFMI with applications to automotive vertical dynamics control. Actuators 2021, 10, 301. [Google Scholar] [CrossRef]
- Lenord, O.; Otter, M.; Bürger, C.; Hussmann, M.; le Bihan, P.; Niere, J.; Pfeiffer, A.; Reicherdt, R.; Werther, K. eFMI: An Open Standard for Physical Models in Embedded Software. In Proceedings of the 14th International Modelica Conference, Linköping, Sweden, 20–24 September 2021. [Google Scholar]
- Modelica Association. Modelica Language Specification 3.5. 2021. Available online: https://modelica.org/documents/MLS.pdf (accessed on 23 September 2022).
- dSPACE GmbH. TargetLink. 2022. Available online: https://www.dspace.com/en/pub/home/products/sw/pcgs/targetlink.cfm (accessed on 6 September 2022).
- Brembeck, J.; Ho, L.M.; Schaub, A.; Satzger, C.; Tobolar, J.; Bals, J.; Hirzinger, G. ROMO—The Robotic Electric Vehicle. In Proceedings of the 22nd IAVSD International Symposium on Dynamics of Vehicle on Roads and Tracks, Manchester, UK, 11–14 August 2011. [Google Scholar]
- Ruggaber, J.; Brembeck, J. A novel Kalman filter design and analysis method considering observability and dominance properties of measurands applied to vehicle state estimation. Sensors 2021, 21, 4750. [Google Scholar] [CrossRef] [PubMed]
- Joos, H.-D.; Bals, J.; Looye, G.; Schnepper, K.; Varga, A. A Multi-Objective Optimisation-Based Software Environment for Control Systems Design. In Proceedings of the IEEE International Conference on Control Applications and International Symposium on Computer Aided Control Systems Design, Glasgow, UK, 18–20 September 2002. [Google Scholar]
- The MathWorks, Inc. Write Level-2 MATLAB S-Functions. 2022. Available online: https://de.mathworks.com/help/simulink/sfg/writing-level-2-matlab-s-functions.html (accessed on 4 October 2022).
- The MathWorks, Inc. Simulink. 2022. Available online: https://www.mathworks.com/products/simulink.html?s_tid=hp_ff_p_simulink (accessed on 6 September 2022).
- dSPACE GmbH. MicroAutoBox II. 2022. Available online: https://www.dspace.com/en/inc/home/products/hw/micautob/microautobox2.cfm (accessed on 4 October 2022).
- dSPACE GmbH. Real-Time Interface (RTI). 2022. Available online: https://www.dspace.com/en/inc/home/products/sw/impsw/real-time-interface.cfm (accessed on 6 September 2022).
- dSPACE GmbH. ControlDesk. 2022. Available online: https://www.dspace.com/en/pub/home/products/sw/experimentandvisualization/controldesk.cfm (accessed on 6 September 2022).
- Wan, E.A.; van der Merwe, R. The Unscented Kalman Filter for Nonlinear Estimation. In Proceedings of the IEEE Symposium on Adaptive Systems for Signal Processing, Communications, and Control, Lake Louise, AB, Canada, 4 October 2000. [Google Scholar]

| #define single_precision #ifdef double_precision typedef double real_t; #define ukf_sr_fabs fabs #define ONE 1.0 #elif defined single_precision typedef float real_t; #define ukf_sr_fabs fabsf #define ONE 1.0f #endif |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schreppel, C.; Pfeiffer, A.; Ruggaber, J.; Brembeck, J. Implementation of a C Library of Kalman Filters for Application on Embedded Systems. Computers 2022, 11, 165. https://doi.org/10.3390/computers11110165
Schreppel C, Pfeiffer A, Ruggaber J, Brembeck J. Implementation of a C Library of Kalman Filters for Application on Embedded Systems. Computers. 2022; 11(11):165. https://doi.org/10.3390/computers11110165
Chicago/Turabian StyleSchreppel, Christina, Andreas Pfeiffer, Julian Ruggaber, and Jonathan Brembeck. 2022. "Implementation of a C Library of Kalman Filters for Application on Embedded Systems" Computers 11, no. 11: 165. https://doi.org/10.3390/computers11110165
APA StyleSchreppel, C., Pfeiffer, A., Ruggaber, J., & Brembeck, J. (2022). Implementation of a C Library of Kalman Filters for Application on Embedded Systems. Computers, 11(11), 165. https://doi.org/10.3390/computers11110165