3.2. Data
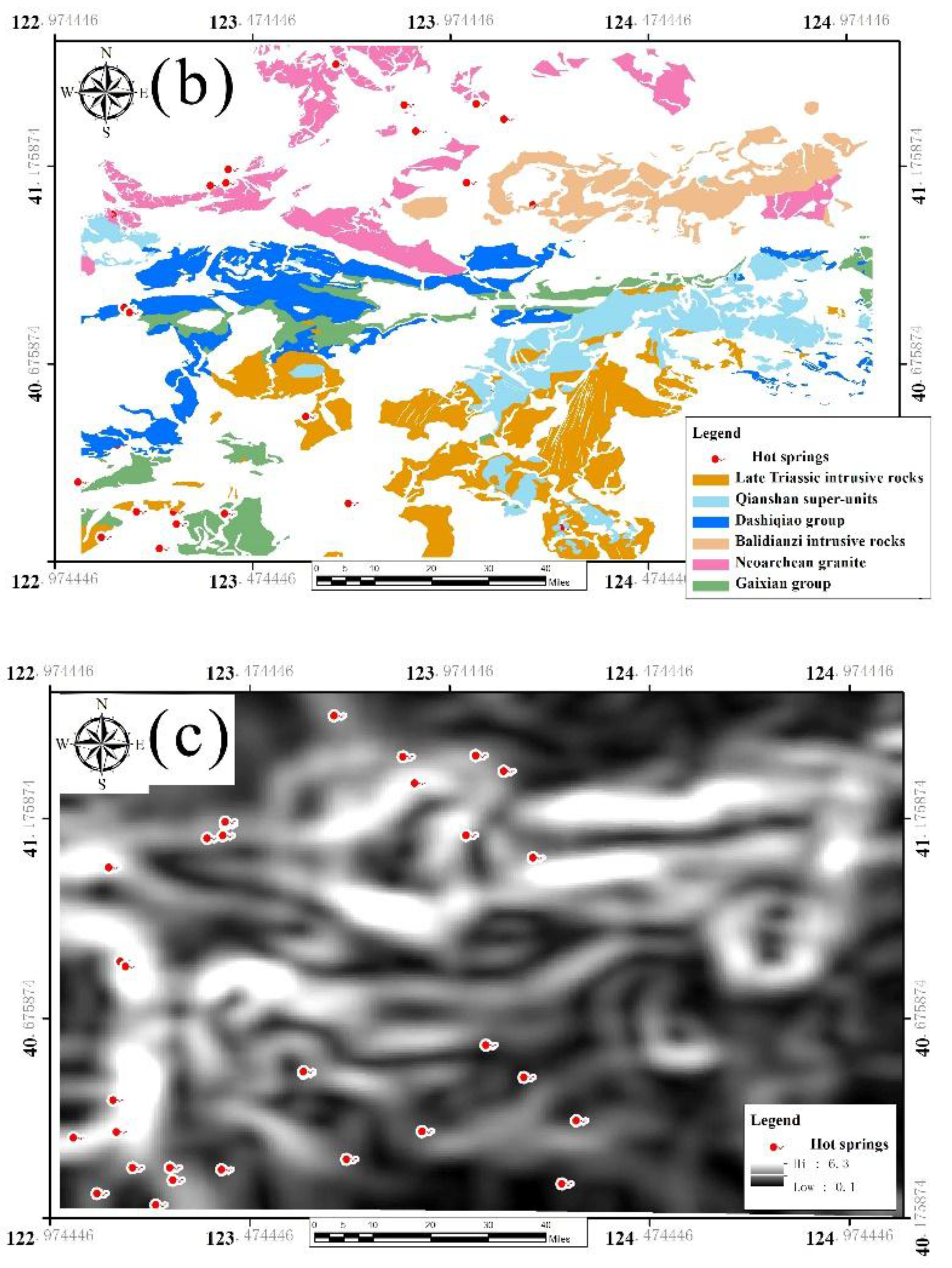
The improvement of the fault treatment method is the main characteristic of the Fry-WofE method. The analysis of the fault factor shows special importance because the fault in the Liaoning region has a great influence on the development of geothermal energy. In this paper, ArcGIS (The best commercial GIS tool of the world) and SPSS (The first statistical analysis software of the world) tools are selected for spatial analysis and statistical analysis, and the preprocessing of original data needs to be done. Then we can get hot spring point data, river network data, lithologic data, Bouguer gravity data, and fault data after remote sensing interpretation processing.
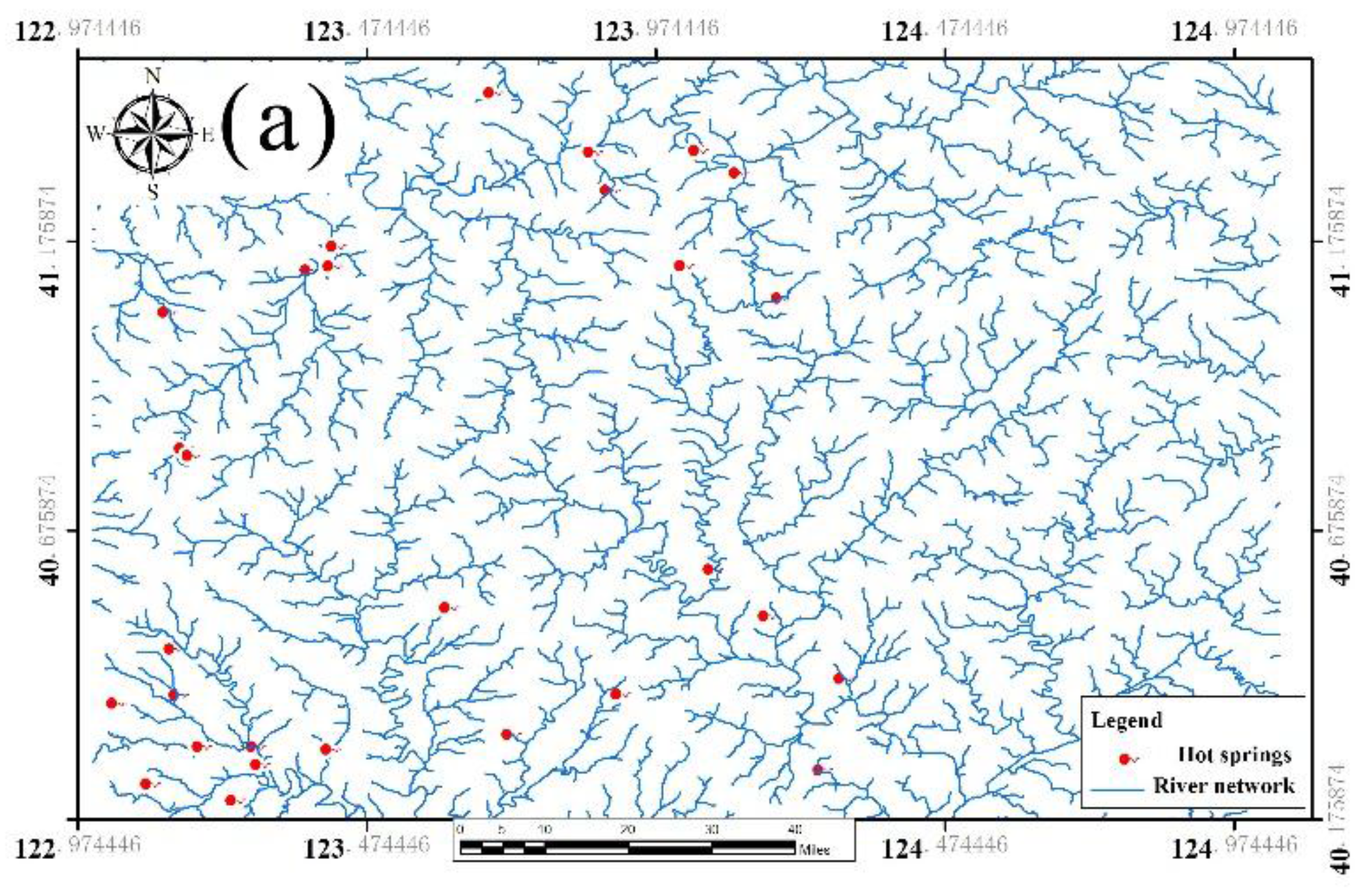
The total number of hot springs in the study area is 33, among which 24 were obtained by digitizing historical data, three were found by field survey, and six is were obtained by searching the Internet. Among them, there are 28 artesian springs and five artificial mining hot springs.
The geological unit data we used comes from a 1:250,000 geological map, which was drawn by the Research Institute of Geology and a survey of the mineral resources of Liaoning province and Jilin Province, and it has been revised and supplemented by the project named “Deep geological survey of Linjiang and Benxi” by the China Geological Survey.
This study uses four Landsat8 remote sensing images; the map numbers are LC81180312016090LGN00, LC81180322014276LGN00, LC81180312016138LGN00, and LC81190322016241LGN00. They are suitable for visual interpretation as they have less cloud cover and false color composition (red-green-blue false color: 752) is adopted to improve the recognition of surface features. The interpretation results are classified into fracture data after comparison with a geological map.
The application of a digital elevation model (DEM) is increasingly extensive (I. D. Moore, 1991). The DEM data used in this study is ASTER GDEM (global digital elevation model) data, the mesh accuracy of which is 30 m and the elevation accuracy of which is 7 m. Valley data are derived from DEM data after hydrological treatment. The vector data of the river network have been obtained after filling and analyzing the flow direction with the DEM data, computing flow accumulation data, and extracting the grid and vectorization. The two data sets above are provided by the Geospatial Data Cloud site of the Computer Network Information Center at the Chinese Academy of Sciences (
http://www.gscloud.cn).
3.3. The Fry-WofE Method
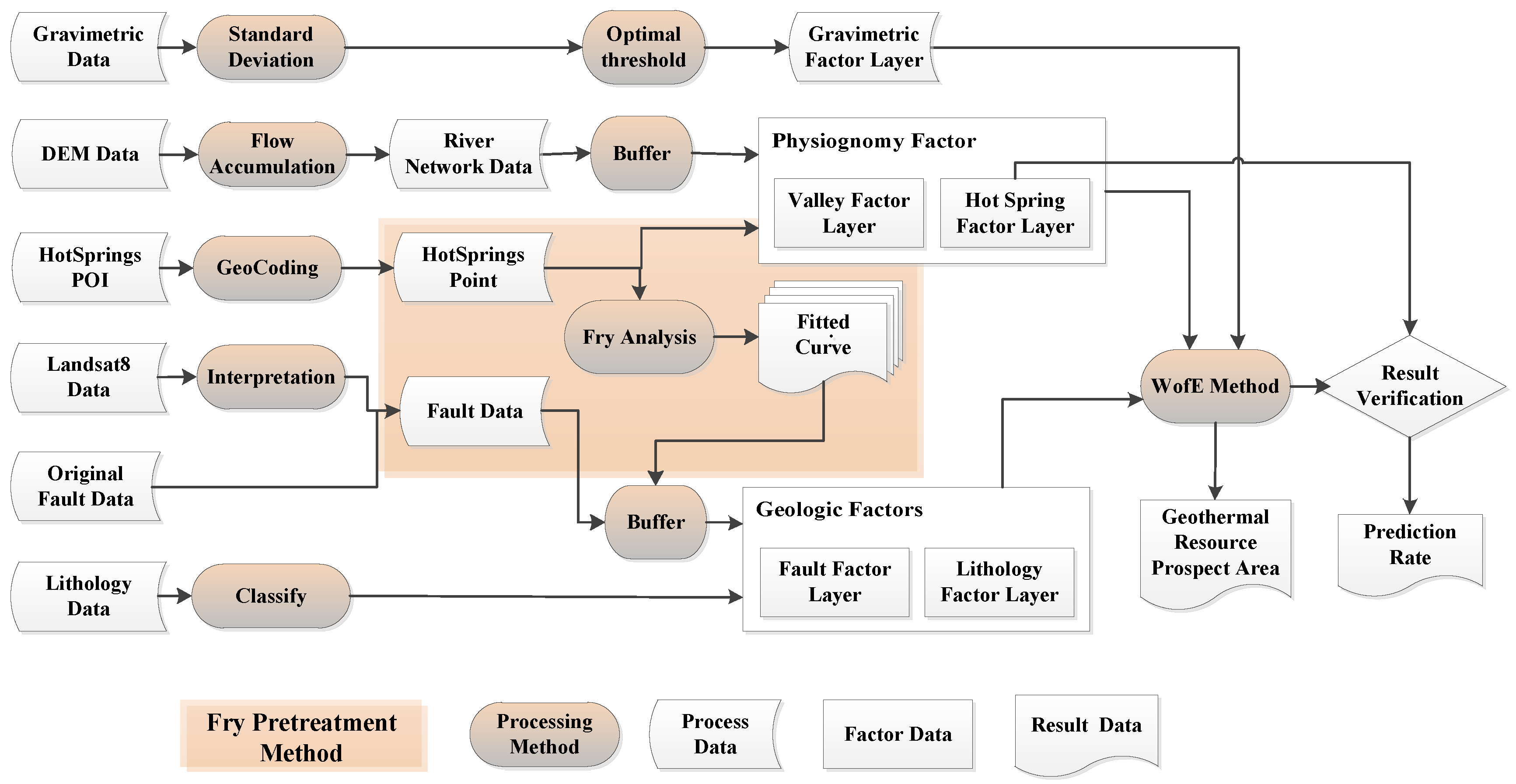
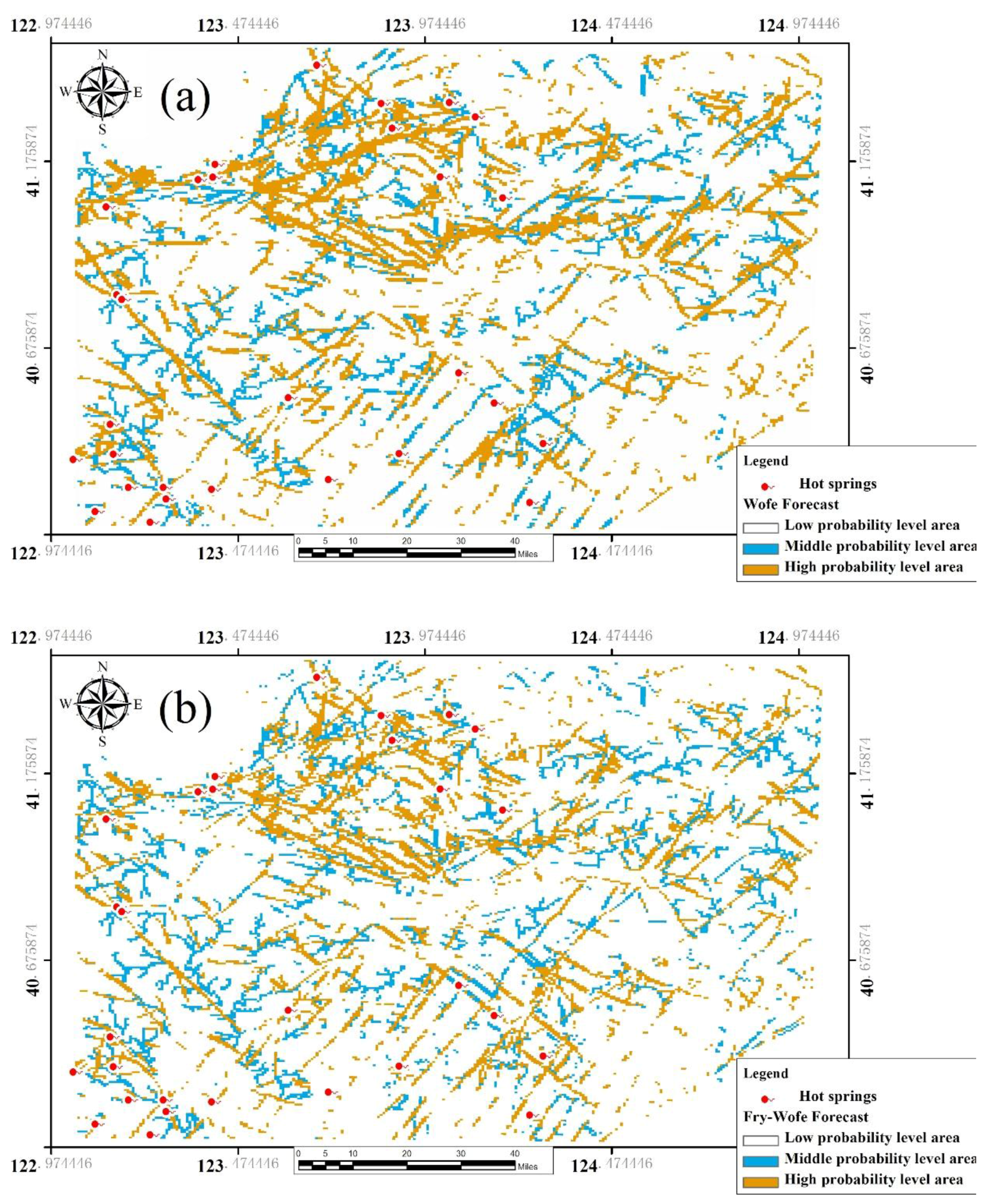
Fry-WofE is based on the WofE method, a data driven model. Before forecasting the prediction probability, the predicted target number or target area should be calculated. When the probability of evidence factors and the prediction appear at the same time, the predicted goal they control will be more important and more accurate. The weighted value of the corresponding weight factor will be larger at the same time. Each weight factor, which is an evidence layer, is superimposed and covered. The expectation map of different levels can be obtained by weighted overlay and coverage synthesis by using the statistical evidence of each grid layer as the prediction target.
Before the calculation of the weights of the evidence model, we should deal with the weight of the layer that will be calculated for binarization. Let the map range equal S, the cell size of the layer be s, and the abnormal value that indicates this be P (the P range is not completely coincident with the actual point set Q of the geothermal anomaly). At this time, the prior probability of the layer is O(P), indicating the probability of a geothermal anomaly occurring in the position region. The weight of each layer is calculated respectively, and finally the comprehensive predictive factor map is obtained under the influence of many layers, the weighted evidence of which is computed by the prior probability of each layer.
According to the traditional evidence weighting model:
The prior probability is:
The weight of evidence is:
where
indicates the significant extent of the geothermal anomaly at the
i section in the evidence layer. The formula is shown as follows:
In the Fry-WofE method, before the weighted calculation of the evidence (take fault layer
L as an example), the parameters for the subdivision layer of the evidence layer should be split. The prior probability of the subdivision layer can be obtained by the Fry model statistics. The formula is as follows:
is the distribution frequency of the
kth small fault in the Fry analysis rose diagram and
n is the number of evidence points.
Then,
, which can fit the fault distribution frequency, can be obtained using:
and type
n should be satisfied:
The should be a small constant, ensuring that the normr value (comparing between and ) won’t change too much. They can converge to in the local scope.
In addition, The StudentC method is used to reflect the significance of the
C value. The formula is as follows:
were the variance of , and C, respectively.
Finally, in the comprehensive analysis of the multivariate data uses the following to calculate the weight
S of the
n layers and the prediction results, respectively:
where
is the
C value of
ith layer and
is the
S value of
ith layer. Then the formula is normalized to make
.
3.4. Hot Spring Data Processing by the Fry Method
Fry analysis, an analysis method first applied in petrology and the structural domain, was proposed by Fry in 1979. Fry analysis can indicate the direction of tectonic stress by locating spots and points and calculating their direction distribution, thus indicating the distribution direction of point or line objects. Later, many scholars expanded the scene of application to spatial distribution analysis [
39,
40] and achieved good results [
6]. Fry analysis [
41] can operate manually by using a sheet of tracing paper on which a series of parallel reference lines (typically north pointing on a map) have been drawn and the location of each data point is recorded. On a second sheet of tracing paper with a center point (or origin), a set of marked parallel lines are kept parallel to those on the first sheet. The origin of the second sheet is placed on one of the data points on the first sheet, and the second sheet is marked with all the positions of points on the first. Then the origin of the second sheet is placed on a different data point on the first, and the positions are again recorded on the second sheet. This is continued, maintaining the same orientation, until all the points on the first sheet have been used as the origin on the second. For
n data points, there are
n2 −
n translations. The resulting Fry plot may be further analyzed by the construction of a rose diagram, recording join frequency versus directional sector. The Fry method provides a better visualization of spatial distribution by redrawing the distribution features that are not visible.
The spatial distribution of hot springs is the reasoning premise of the reverse inference of the extent of the influence of fault lines. Fry analysis [
41] has appeared in scholars’ studies like those by Noorollahi, Moghaddam, and Wibowo [
2,
3,
4], but it was used only to show the distribution trend of objects or as an auxiliary tool for spatial analysis. Since the distribution of hot springs can be determined by the Fry angle rose diagram, the distribution trend of hot springs can also be expressed by the Fry method. The fault consistent with this trend should be given higher weight in later calculations. In this study, the process of applying Fry analysis to hot spring data is shown in
Figure 3.
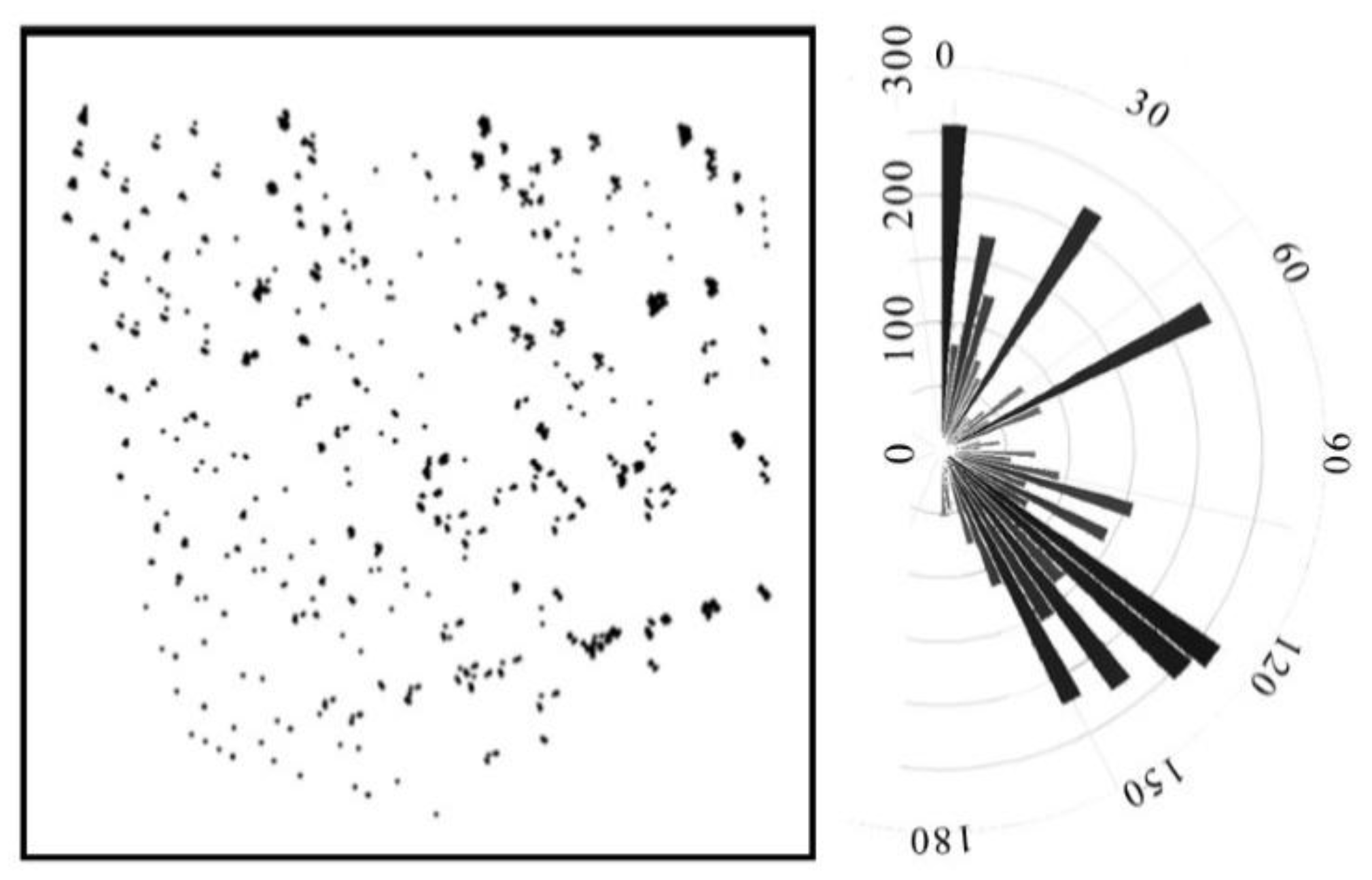
After repeated drawing of the hot springs in the study area by the Fry method, the spatial distribution results are shown as follows. The orientation of the Fry points is concentrated from 120° to 160° and 0° (
Figure 4). It shows that the distribution of hot spring points in eastern Liaoning province is obviously NW and NS trending. This is consistent with studies of our predecessors, which have considered the hot springs to be mainly distributed on both sides of faults in the NW and nearly NNE directions [
24,
42].
The geographical data is discrete but also continuous [
43]. The frequency distribution of faults in all directions is discontinuous. In order to make the different orientations of faults smooth and reduce the ‘cliff intermittent’ of the forecast results, we should use a curve fitting method to fit the Fry points distribution data. In this study, high order curve fitting is adopted, in which the number of fitting numbers is determined by the Fry number and the residual maximum modulus and the degree of discretization of the angular data is reduced by polynomial fitting.
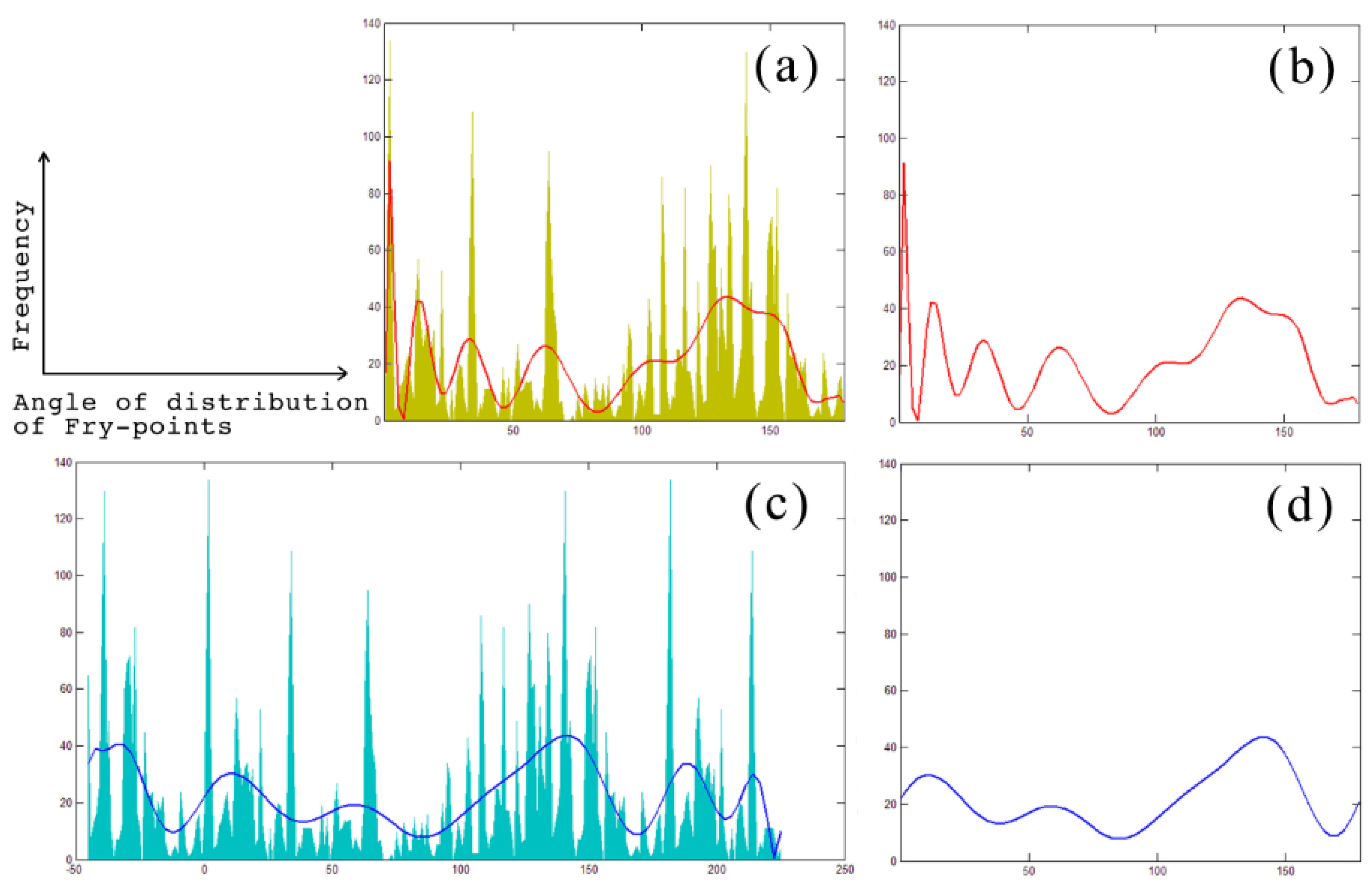
Figure 5a,c is the Cartesian coordinate graph, which plots frequency on the vertical Y-axis against the angle of distribution of the Fry-points on the horizontal x-axis, including orientations from 0° to 359°, where 0° to −179° and 180° to −359° are repeated; we can only adjust for the 0° to −179° range. In order to ensure the fitting accuracy of the two curves, the data should be processed at both ends before fitting the curve. The amount of data in the range of the augmented existing data in two segments of the quarter has a distribution angle of 45°. The fitting range expanded from −45° to −225° to ensure a fitting accuracy between 0° to −179°, making the curve equal the values from 0° to 180°.
Figure 5 shows examples of cases of high-order curve fitting by 20 times. Compared with the original method of
Figure 5b fitting
Figure 5a, the method of
Figure 5d fitting
Figure 5c can obviously obtain better processing results at both ends of the fitting curve without changing the amount of data.
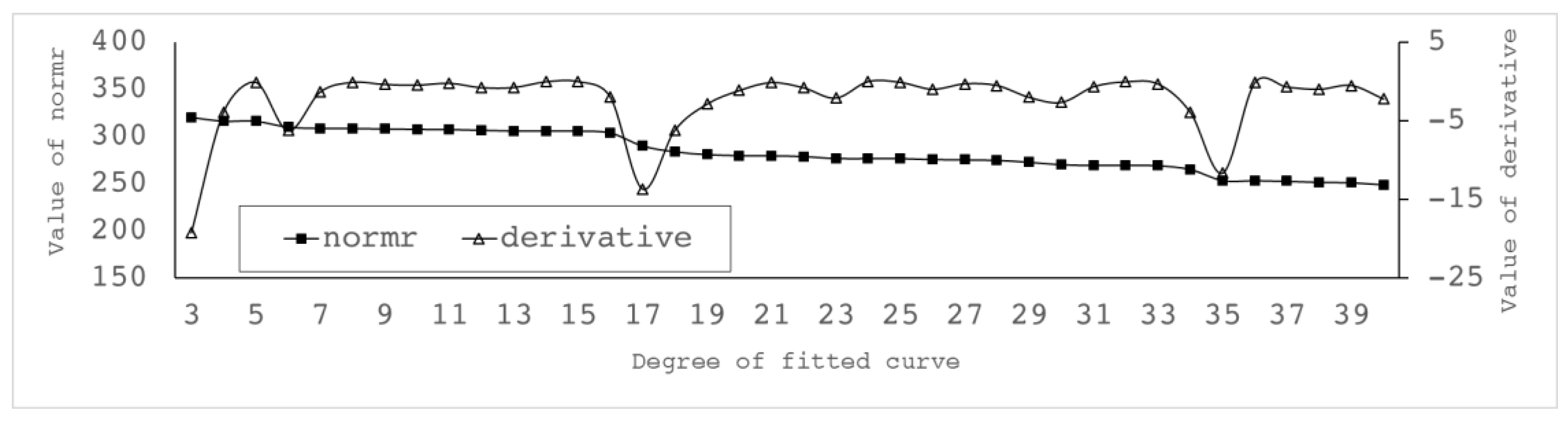
In order to evaluate the effect of curve fitting and determine time of the best fitting curve, the normr value is introduced as the evaluation criterion, and normr is the maximum modulus of the residual. The smaller the value, the better the fitting accuracy of the curve. In the curve fitting of Fry distribution data, if the time of the fitting curve equation is too high, it is easy to over fit. If it is too low, it cannot accurately fit the distribution. There are 33 data points of hot spring spots in this region. The number time of fitting curve equation,
n, should be within 3–33, and n should make the normr value of the curve as small as possible or make the normr value change less obviously at n. By comparing the normr values of the three to 33 curves (
Figure 6), it can be seen that the normr values change little from 20 to 33, that they have almost converged, and that the values are lower than the normr values from three to 19. As you can see from the diagram,
n = 20 is at the earliest stable position after the change of the slope of the curve. Therefore, this experiment chooses 20 as the best parameter of the fitting curve.
In order to establish the relationship between the fitting curve and the weight, we put the fitting curve of the normalized
y values in the range of 0 to 1. We use MatLab, letting
x = 0:0.01:180 from 0 to 180, with 0.01 for each step for the fitting results, to find the lowest and highest point of the function curve through the transformation:
This is used to find the fitting function equation after normalization. The 20th curve equation used in this study is:
x is the fault orientation, and
z is the intermediate value for centering and scaling the
x value. The values of
to
are shown in
Table 1.
We establish the relation between the fault orientation and the frequency distribution of the hot spring by fitting the curve, yet the distribution frequency of hot springs is positively related to the spatial distribution of hot springs. Thus, the relationship between the fault orientation and the geothermal distribution trend has been established.
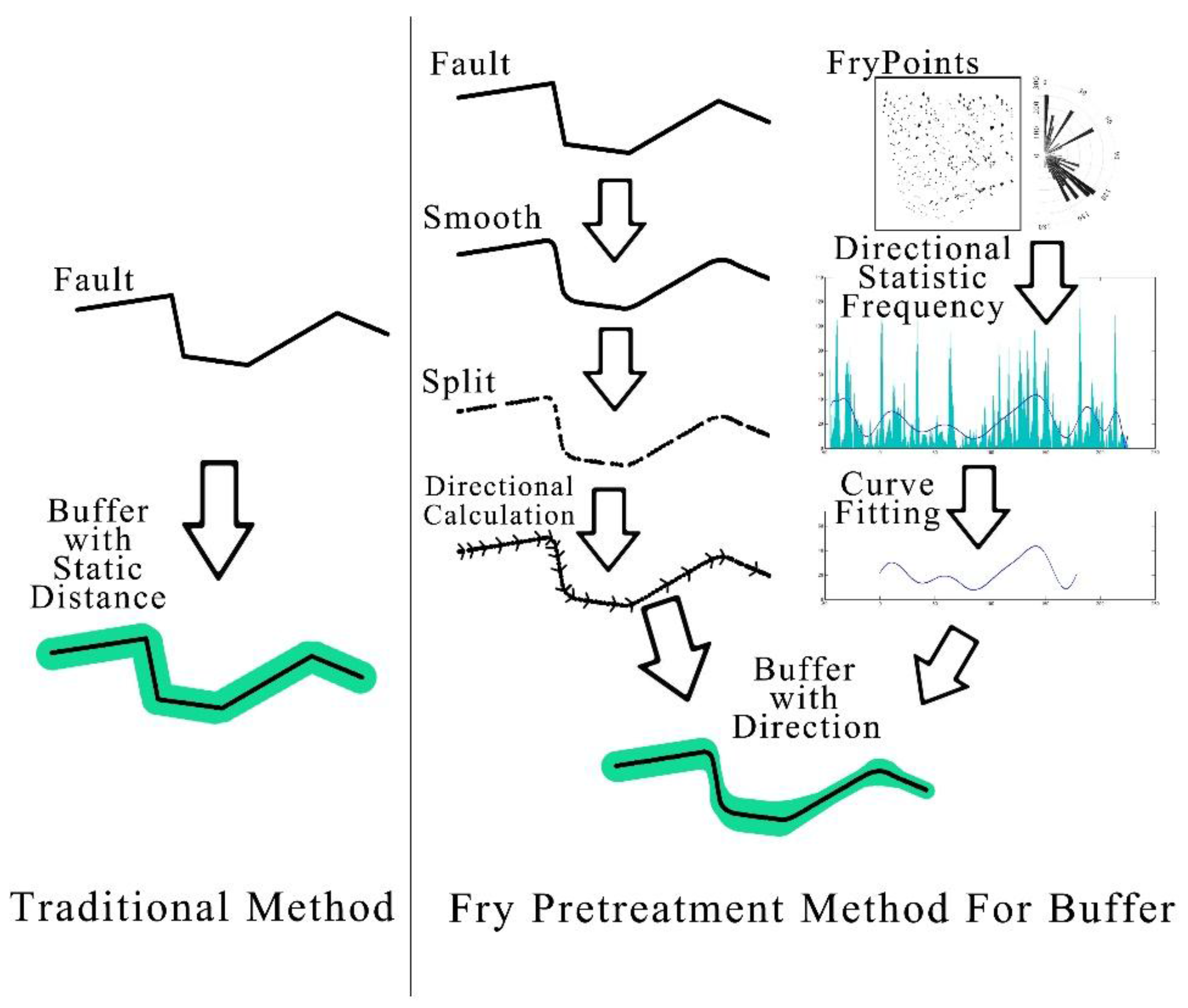
In order to reduce fracture data discontinuities caused by too few data at the reflection points, it is necessary to smooth the fault data without affecting the accuracy, and, after smoothing, the corners become denser. It is convenient to segment the fault data into a large number of small faults and then to obtain the orientation of each minor fault. Combined with the fitting curve obtained before, the buffer distance of the fracture under the orientation weighting correction is obtained.
The λ is the parameter to be determined. We need to use the weights of evidence method to determine its optimum value.
The accuracy of the DEM data used in this study is 90 m, so the buffer step of fault data we used in WofE processing is less than 90 m, which is enough to meet the precision requirements. Experiments show that, when the threshold value is up to 700 m, the buffer area has completely covered all the authentication points. Continuing to increase the threshold does nothing to support the weight of the evidence. Therefore, we take the threshold from 40–2000 m, with 70 m steps into the buffer calculation. The corresponding buffer area is calculated from 474 km
2 to 16,327 km
2, and the weight of the evidence is calculated in the attached table (
Table A1).
When the fault layer is treated as the evidence layer by the Fry method, the buffer distance of the fault is determined by λ. It can be calculated by Formula 12; when
λ has avalue from 5 to 35, it can make the fault buffer area correspond from 1432 km
2 to 9487 km
2 (
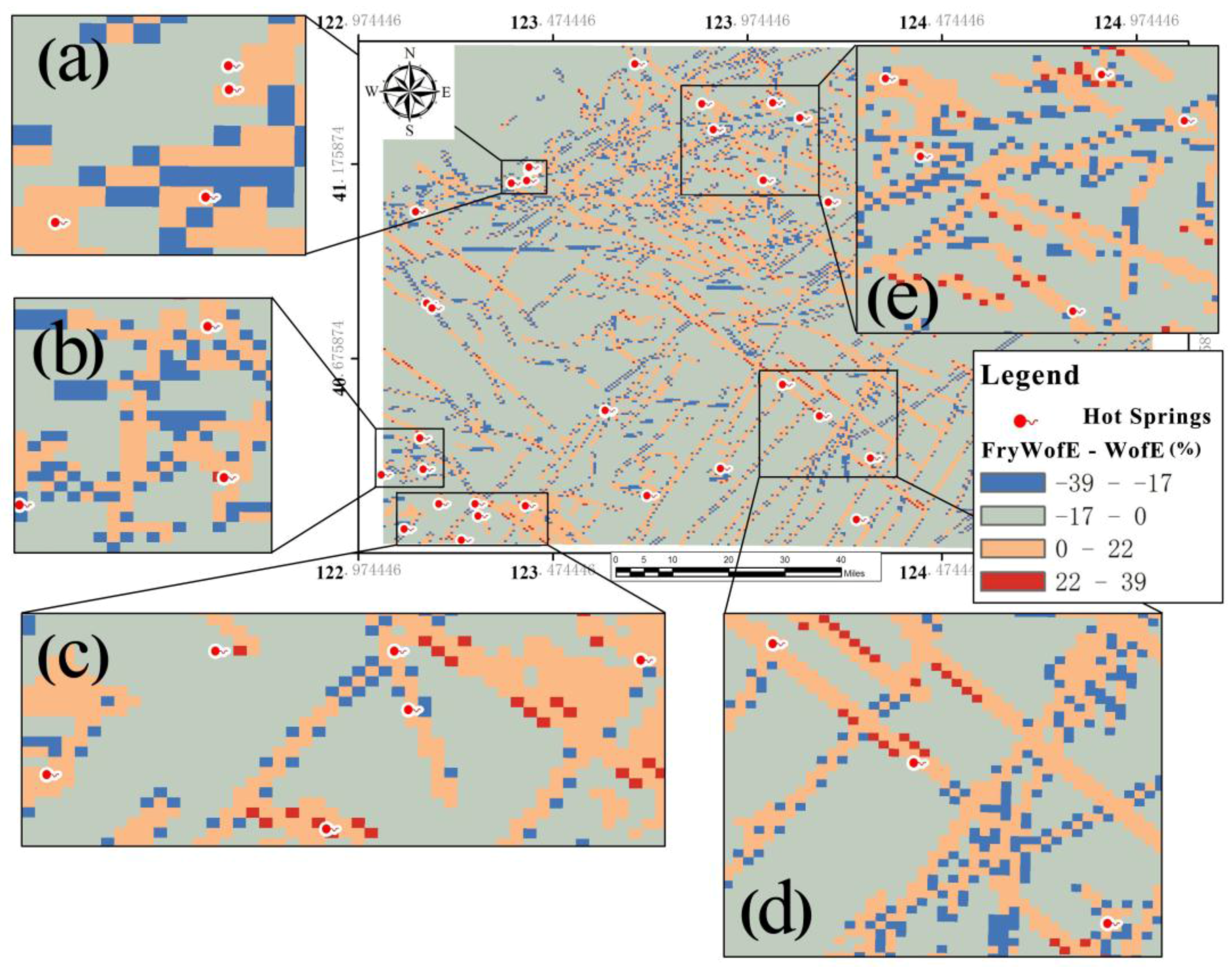
Table A2). It is convenient to compare the effect of the fault layer with the Fry-WofE and WofE methods (
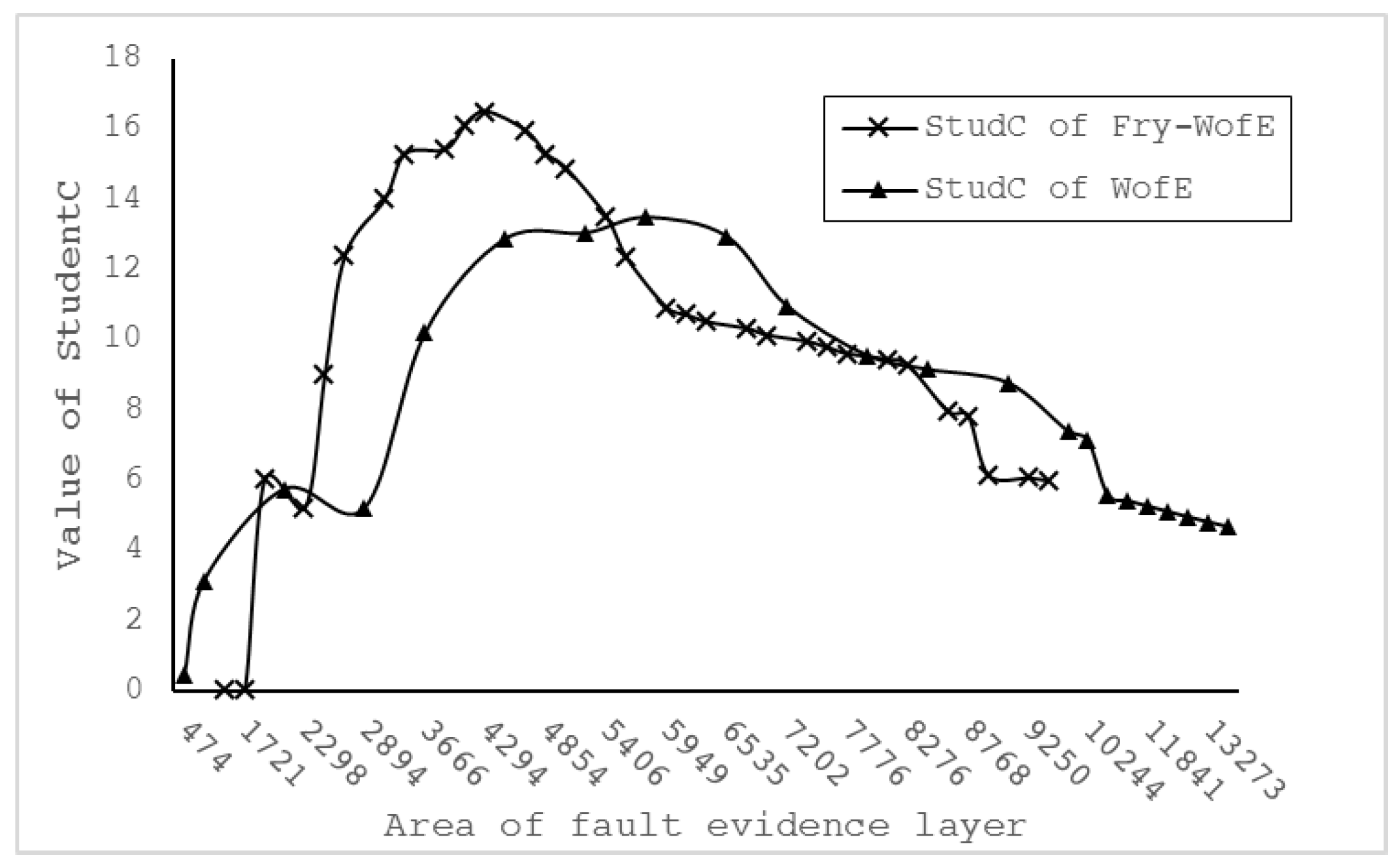
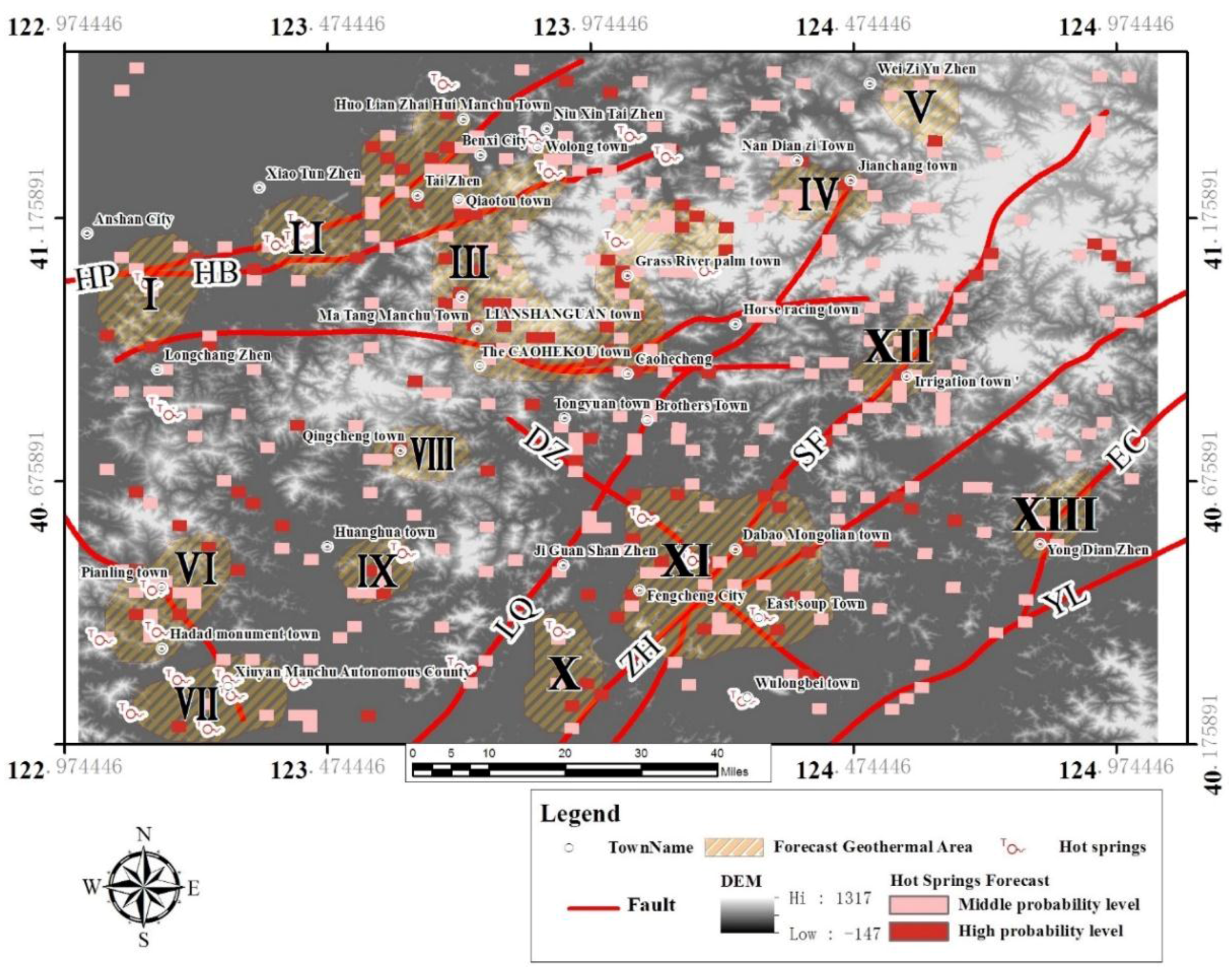
Figure 7). We placed StudC (student C index that the response of the data) and the area of calculation result in one graph, and we can found that the fault layer after Fry analysis in the evidence weighted calculation process has a better StudC response (
Figure 8).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













