1. Introduction
As global temperatures warm and environmental issues become more prominent, how to reduce emissions has become the focus of the world’s attention. The Paris Agreement established the goal of controlling the global average temperature to a level well below 2 °C and working towards a 1.5 °C temperature control target. Under the premise of setting mandatory carbon emission control targets and allowing carbon emission quota trading, the carbon market optimizes the allocation of carbon emission space resources through market mechanisms to provide economic incentives for emission entities to reduce carbon emissions. It is a greenhouse gas reduction measure based on market mechanisms. Compared with emission reduction measures, such as administrative orders and economic subsidies, the carbon emission trading mechanism is a low-cost and sustainable carbon emission reduction policy tool. It is of great significance. First, it is a major institutional innovation to address climate change and reduce greenhouse gas emissions by market mechanisms. Second, it is an important means to help incentive entities to achieve carbon reduction targets at low cost and to achieve total greenhouse gas emissions control. Third, it helps to channel technology and funding to low-carbon development. After years of practice, the carbon market has been certified to be an efficacious tool to address climate change and a chronic mechanism to solve environmental issues; people can effectively reduce carbon dioxide emissions by buying and selling carbon emission quotas.
As the carbon trading market at home and abroad matures, the focus on carbon prices is increasing. According to the efficient markets hypothesis (EMH) proposed in 1970 by Eugene Fama, a famous professor at the University of Chicago in the United States, in a stock market with sound laws, good functions, high transparency and full competition, all valuable information is reflected in the stock price trend, which is timely, accurate, and sufficient. Therefore, the carbon price is the core factor for evaluating the effectiveness of the carbon market system. It is not only an important tool for regulating supply and demand but also a key factor in the development of carbon financial derivatives. Accurately predicting carbon prices is critical for policymakers to establish effective and stable carbon pricing mechanisms, which is also important for market participants to avoid investment risks. Carbon price prediction, as one of the issues closely concerned and need to be solved, has become a hot topic of academic circles. Therefore, it is of practical significance to explore and develop a carbon price prediction method with high accuracy. This article is devoted to proposing a new hybrid prediction model based on multi-resolution singular value decomposition (MRSVD) and the extreme learning machine (ELM) optimized by moth–flame optimization (MFO) considering both internal factors (historical carbon price data) and external factors (energy and economic factors) for the analysis and prediction of carbon price. Compared with traditional statistical models, it has superior learning ability, which can grasp the non-linear characteristics of the carbon price series. Compared with the classical intelligent algorithm, it can avoid the defects of a single algorithm and predict the future change in carbon price with more accurate fitting. Therefore, the research in this paper has certain academic significance and application value.
Carbon prices have always been a hot spot in carbon market research. At present, the study of carbon prices can be separated into two types. One focuses on the factors analysis affecting the carbon prices, while the other focuses on carbon price forecasts.
Numerous studies have analyzed the influencing factors of the carbon price. Reference [
1] proved that the ideal predictor to predict carbon price is coal. Reference [
2] studied the relationship between the prices of fuel and European emission allowances (EUA) during phase 3 of European Union emissions trading scheme (EU ETS), and found that the forward prices of EUA, coal, gas, and Brent oil are jointly determined in equilibrium; EUA prices are driven by the dynamics of fuel prices. Reference [
3] studied the determining factors of EUA prices in the third phase of the EU ETS. The results show that EUA prices have a causal effect on electricity and natural gas prices. Second, all variables, including coal prices, oil prices, gas prices, electricity prices, industrial production, economic confidence, bank loans, maximum temperature, precipitation, and certification emission reduction (CER) prices, are positively correlated with EUA prices. Reference [
4] discover that there is a strong relationship between German electricity prices and gas and coal prices to the price of EUA, and the EUA forward price depends on the price of electricity as well as on the gas–coal difference. Reference [
5] examines the impact of currency exchange rates on the carbon market, and found that a shock in the Euro/USD exchange rate can be transmitted through the channel of energy substitution between coal and natural gas, and influence the carbon credit market. Reference [
6] found that only variations in economic activity and the growth of wind and solar electricity production are robustly explaining EUA price dynamics. Reference [
7] showing that EUA spot prices react not only to energy prices with forecast errors but also to unanticipated temperatures changes during colder events. Reference [
8] investigate the link between carbon prices and macro risks in China’s cap and trade pilot schemeempirically.
Carbon price forecasts could be broadly divided into two main categories: traditional statistical models and artificial intelligence (AI) technologies. Traditional statistical models primarily include the autoregressive integral moving average (ARIMA) model [
9,
10], the generalized autoregressive conditional heteroskedasticity (GARCH) model [
11,
12], the gray model [
13], nonparametric modeling [
14], and so on. A disadvantage of traditional statistical models is that objects must satisfy certain statistical assumptions (such as data stability tests) before building such statistical models. But carbon price time series are typical of unstable and nonlinear series, and traditional statistical models may not be suitable for carbon price prediction.
As a parallel predictive model, AI technology does not need to meet statistical assumptions and presents clear superiority in nonlinear fitting ability, robustness, and self-learning ability. They are already utilized in lots of prediction areas. Backpropagation neural networks (BPNN) [
15,
16] and least squares support vector machines (LSSVM) [
17] are used to predict carbon price sequences. However, when the data set is not sufficient, BPNN’s neural network is likely to result in bad fitness. Different types of core functions and core parameters greatly influence the fitting precision and generalization function of LSSVM. Huang G.B. et al. proposed the extreme learning machine (ELM) model; it owns better generalization precision and faster convergence speed compared with above models, that is, using ELM to predict the unknown data, the generalization error obtained is smaller and the time taken is shorter [
18]. In addition, in the gradient-based learning approach, many problems are prevented, such as suspending criteria and learning cycles. Therefore, since its introduction, it has been widely used in different fields of forecasting, such as load forecasting [
19], wind speed forecasting [
20], electricity price forecasting [
21], and carbon emission forecasting [
22]. The experimental results show that the ELM model performs best in the comparison model. Therefore, this paper intends to use ELM as a carbon price prediction model.
Furthermore, the input weight matrix and hidden layer bias of ELM, which is stochastically allocated, may affect the generalization ability of the ELM. Hence, for the purpose of getting the input layer’s weight and the deviation of the hidden layer, an optimization algorithm is highly needed. Given moth-like spiral motion, Mirjalili, S. proposed moth–fire optimization (MFO) [
23]. Unlike algorithms that rely solely on equations to update proxy locations, the ability to reduce the risk of falling into the local optimum of solution space by smoothly balancing exploration and exploitation in runtime is considered a strength of MFO when comparing with the genetic algorithm (GA) and particle swarm optimization (PSO). Consequently, MFO has been widely used in some optimization problems [
24,
25]. Thus, this paper intends to use MFO as an optimization model for ELM parameters.
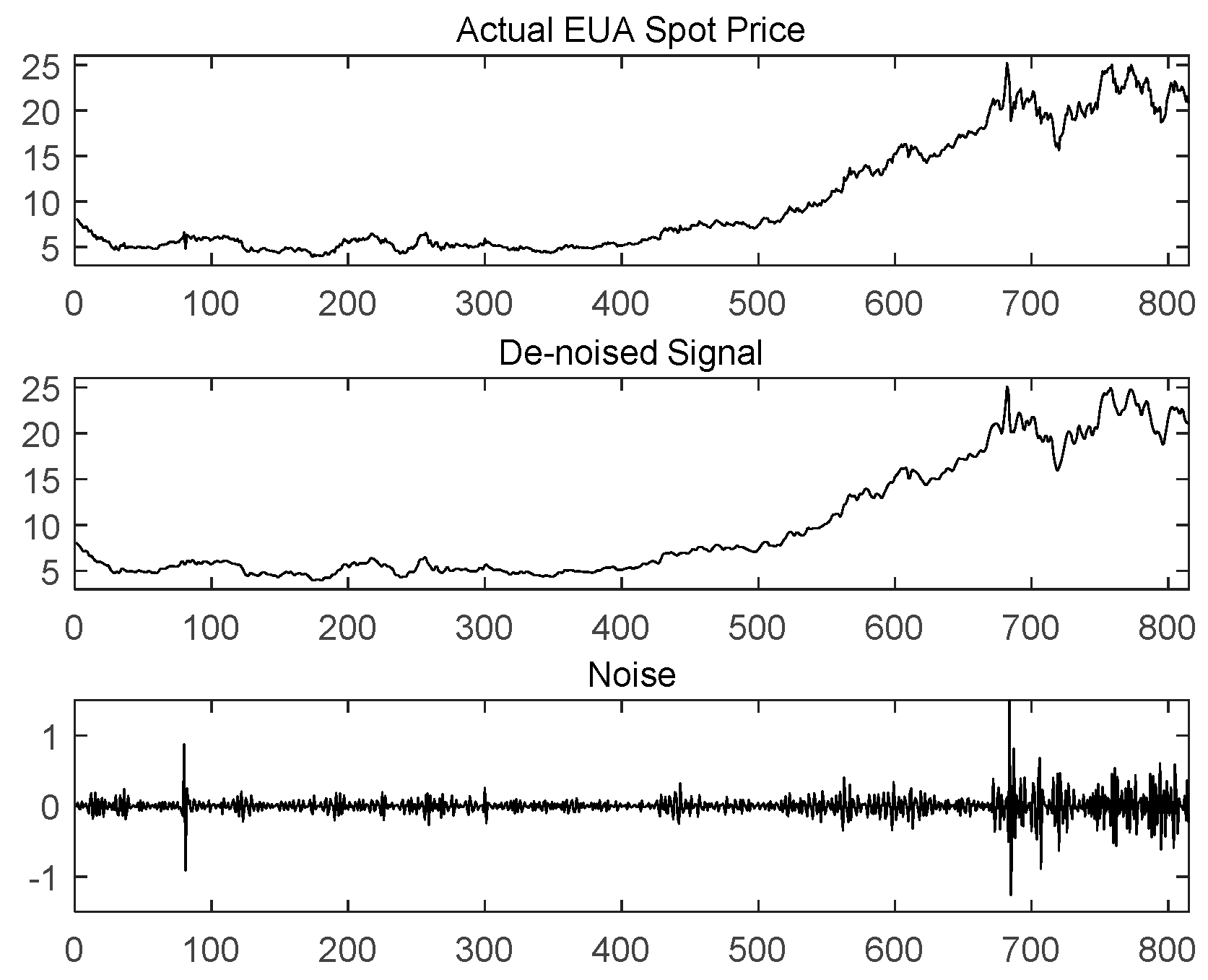
Given the chaotic nature and inherent complexity of carbon prices, direct prediction of carbon prices without data pre-processing may be inappropriate. At present, wavelet transform (WT) [
26,
27] and empirical mode decomposition (EMD) [
28,
29] are regarded as common data pre-processing methods for decomposing initial sequences and eliminating stochastic volatility. However, EMD decomposes the time series into several intrinsic mode functions (IMFs), which significantly increases the difficulty of prediction. The high redundancy of WT is an inherent defect, and the selection of a wavelet basis is also one of the difficulties of WT. In addition to the disintegration approaches mentioned, singular value decomposition (SVD) is also a de-noising method with the strength of a naught phase shift and less waveform distortion [
30]. To solve the problem of determining the phase space matrix form and dimension in SVD, a new decomposition method—multi-resolution singular value decomposition (MRSVD), which puts the basis on the dichotomy and matrix recursive generation, is put forward. MRSVD is similar to WT, and its basic idea is to replace the filtering with singular value decomposition (SVD) on each layer of the smoothing component [
31]. This paper chooses MRSVD as the decomposition model of carbon price sequences.
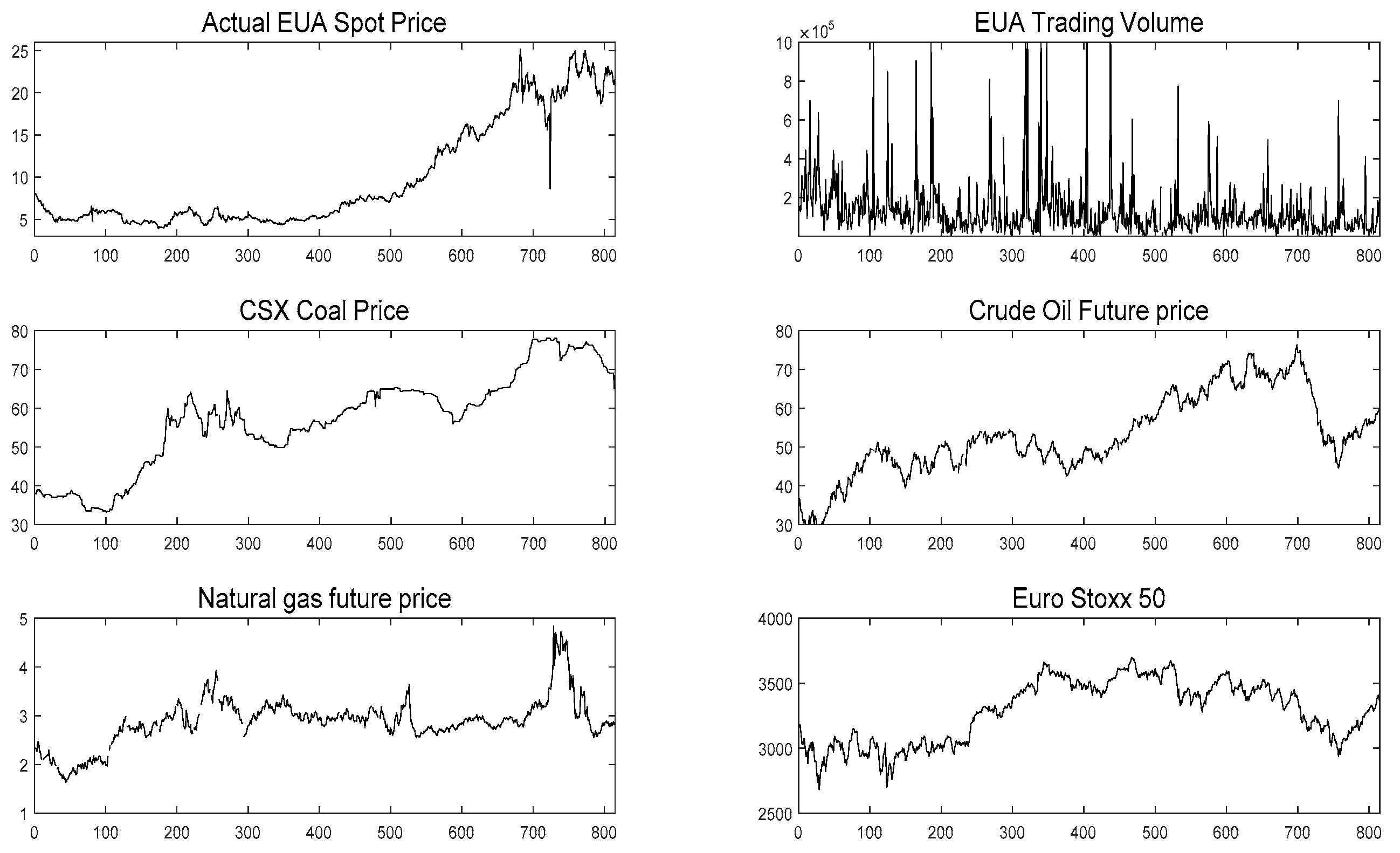
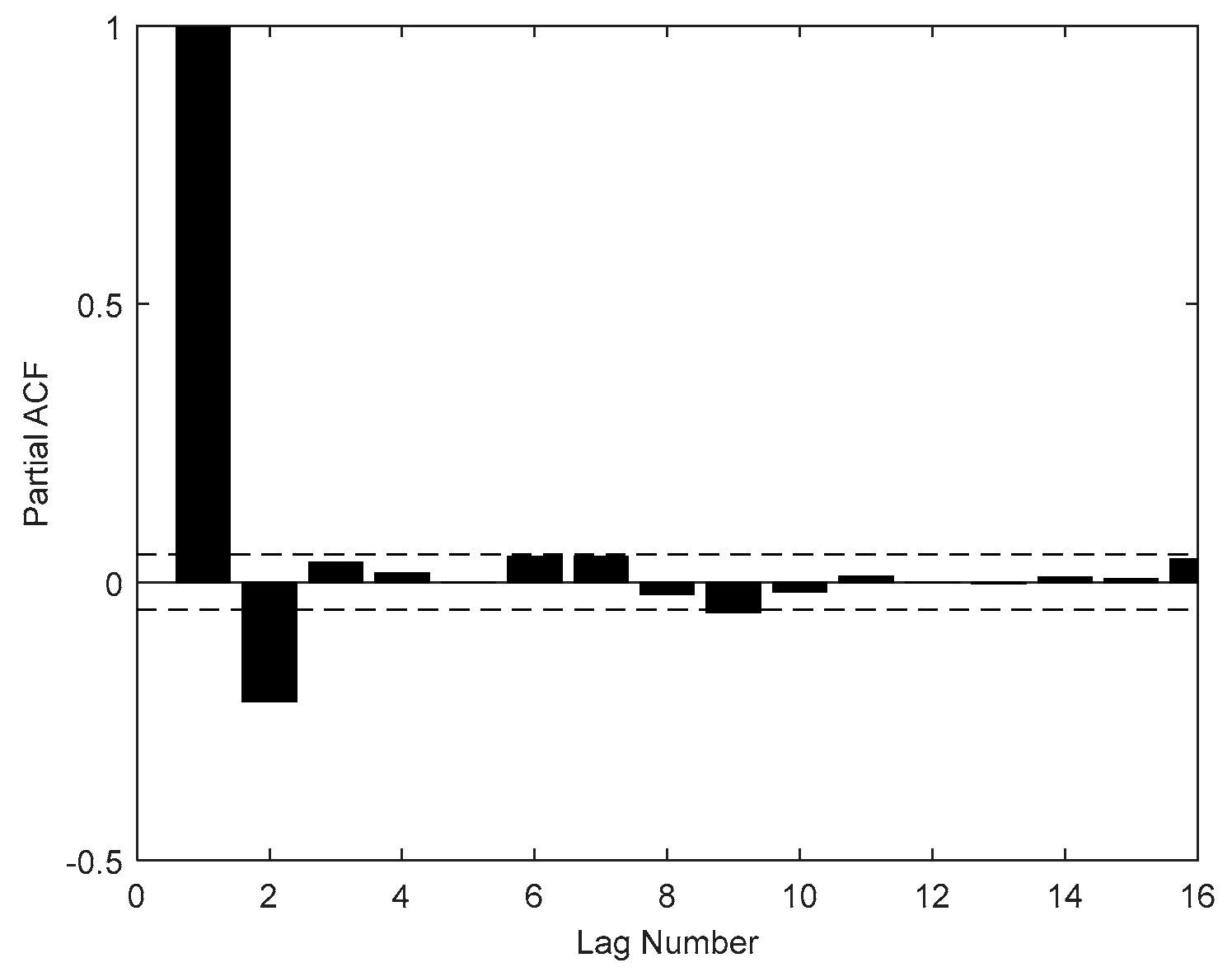
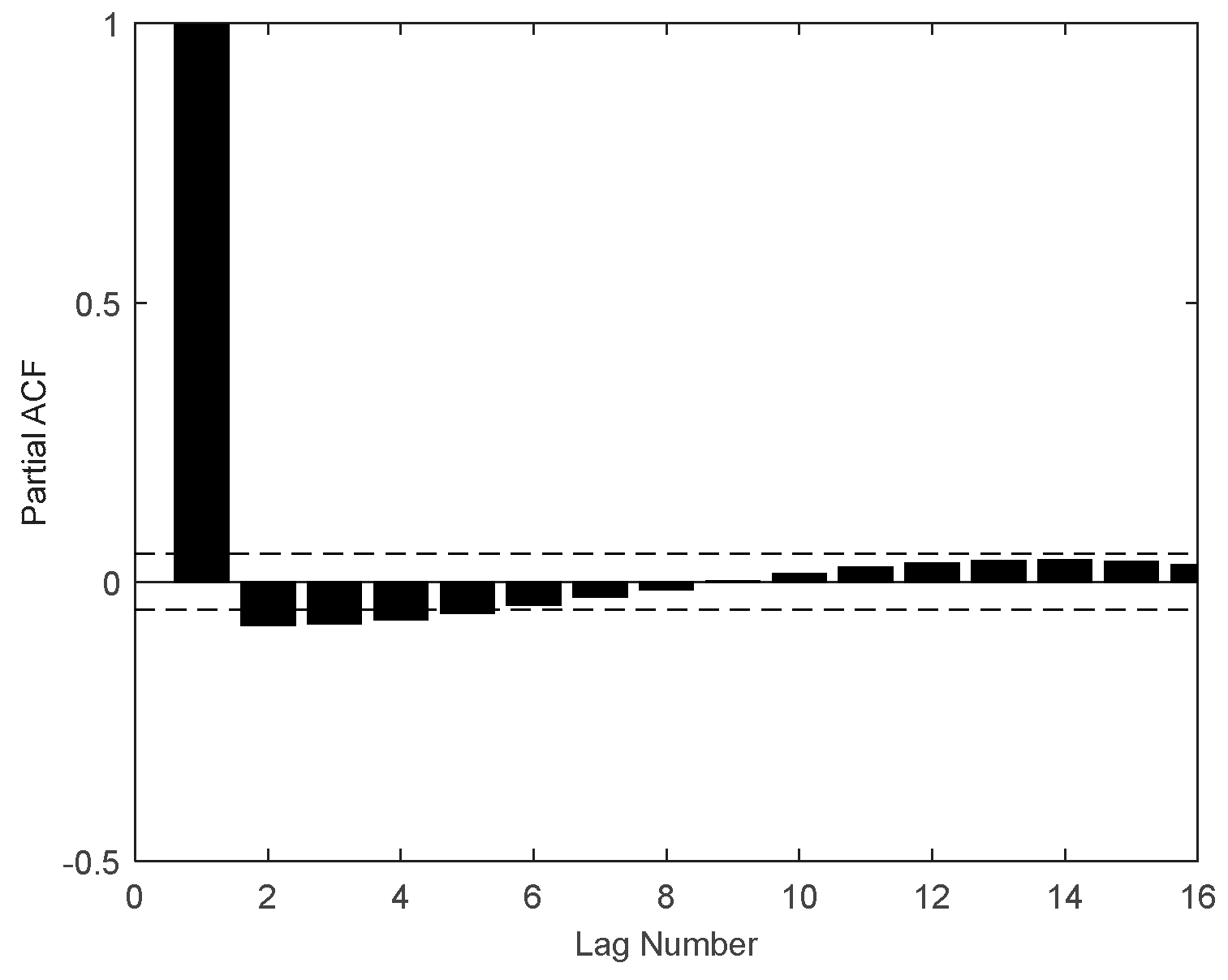
At present, there are few literatures on carbon price prediction considering both internal factors (carbon price historical data) and external factors (the influencing indicators of the carbon price, such as energy price, economic index, and so on). Most of the literature only predicts carbon prices based on historical data or only studies the relationship between carbon prices and their influencing factors. Therefore, historical data determined by partial autocorrelation function (PACF) and influencing indicators selected by the augmented Dickey–Fuller (ADF) test, cointegration test, and granger causality test are both used to predict carbon prices at the same time in this paper.
In addition, the data selected in the empirical research part of most of the literature come from one market, such as the EU emissions trading scheme (EU ETS) or China ETS. To verify the versatility of the model built in this paper, the empirical part of this paper will select both EU ETS and China ETS to study. The main contributions of this article are as follows:
The carbon price forecast not only considers internal factors (historical carbon price data) but also considers external factors, including energy prices and economic factors, which makes the forecast more comprehensive and accurate.
The MFO-optimized ELM, called MFO-ELM, was selected as the predictive model. The MFO-ELM model has the ability to maximize the global search ability of the MFO and the learning speed of the ELM and solve the intrinsic instability of the ELM by optimizing its parameters.
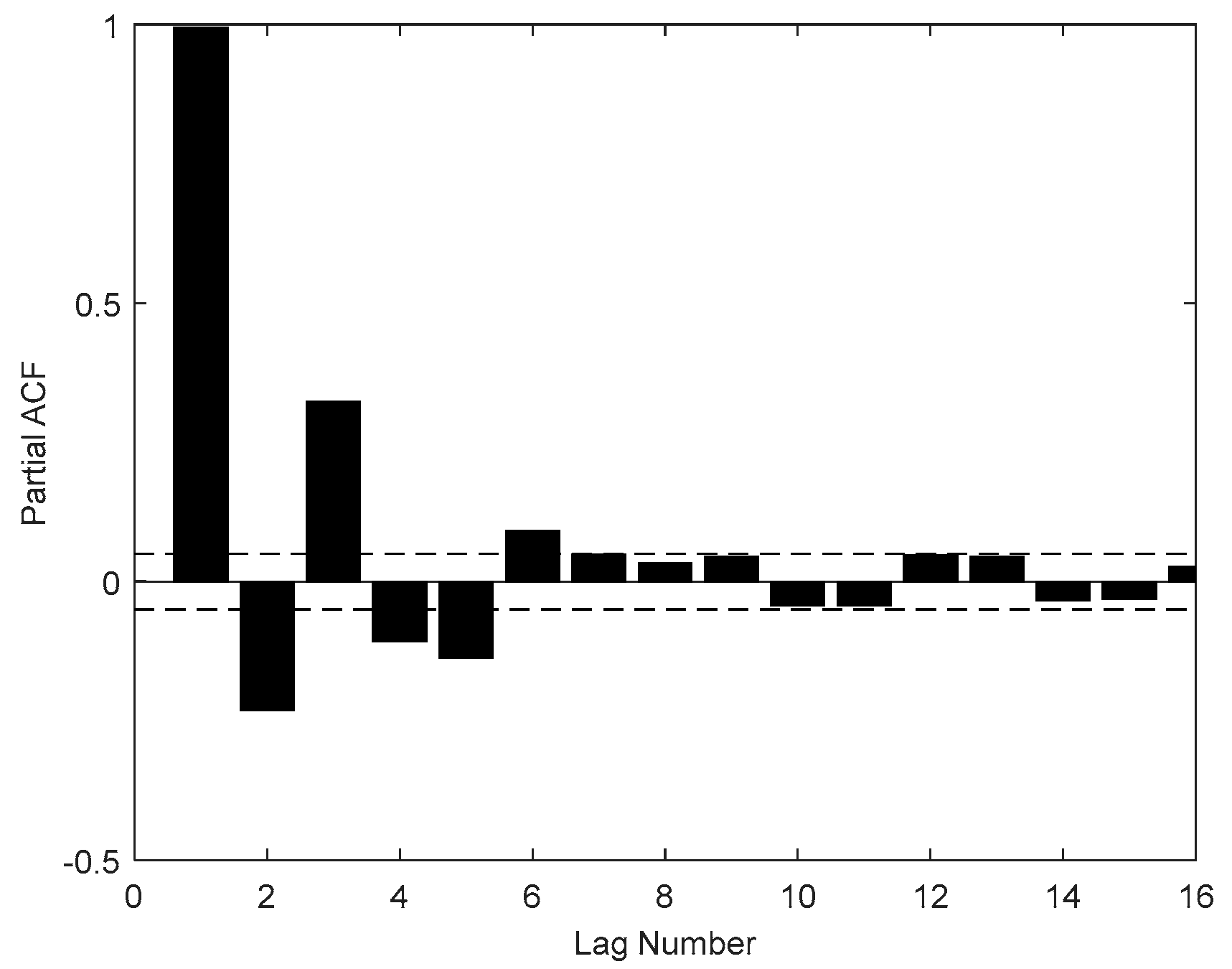
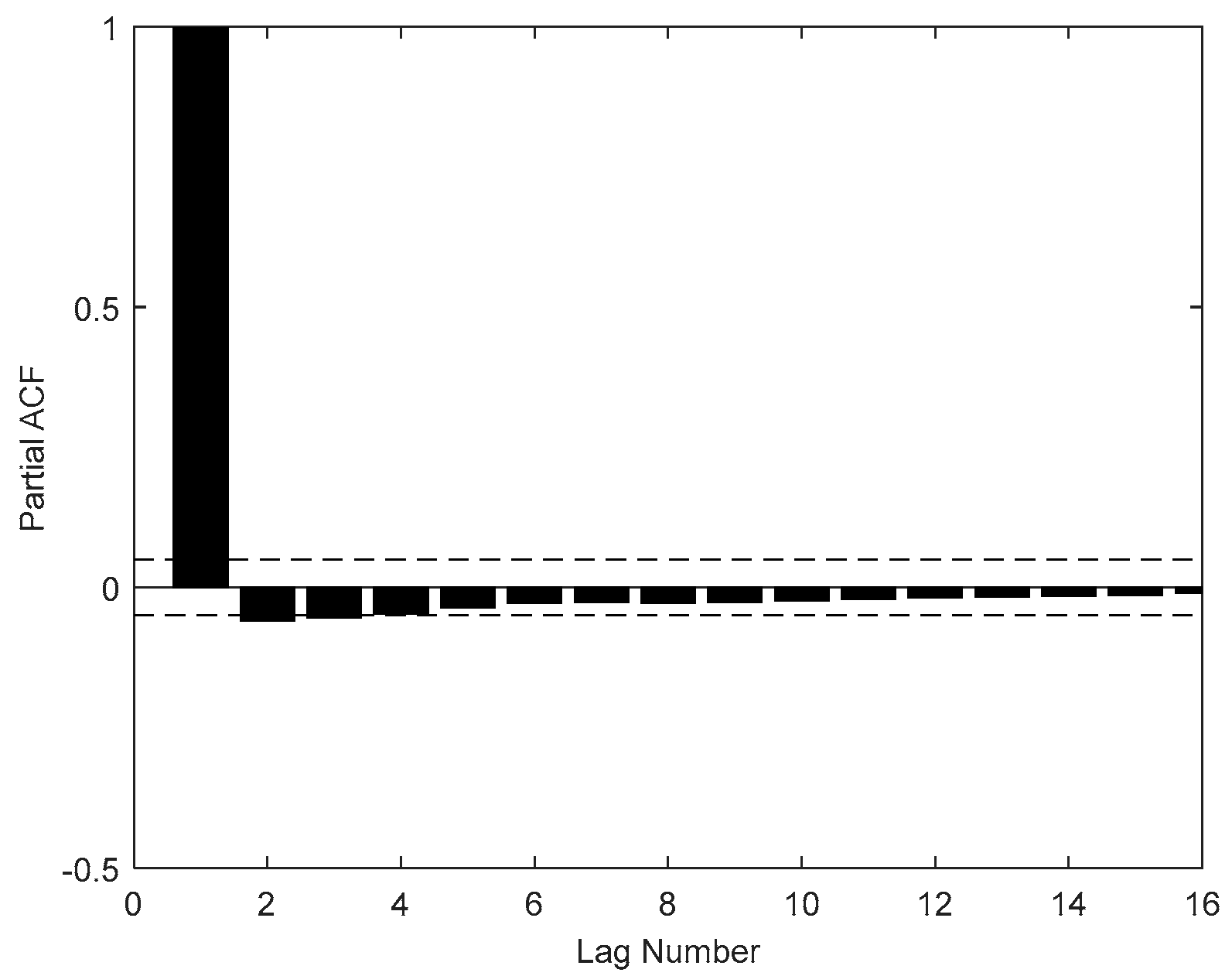
Using MRSVD to decompose the historical carbon price sequences and selecting partial autocorrelation function (PACF), we can determine the lag data as internal factors, which are a part of the MFO-ELM input.
Combining ADF testing, cointegration testing, Granger causality testing, we can select external factors; this is another part of the MFO-ELM input.
The carbon price dates of the EU ETS and the China ETS were both collected and predicted with the intention of testing the universality of the proposed model.
This paper’s framework is as below:
Section 2 shows methods and models employed in this paper, which includes MRSVD, MFO, and ELM. The entire framework of the proposed model (MRSVD-MFO-ELM) is then detailed in
Section 3.
Section 4 presents empirical studies, including data collection, external and internal input selection, parameter settings, prediction results, and error analysis for EU ETS and China ETS. Conclusions in view of the results are shown in
Section 5.
2. Methodology
This section highlights a brief introduction to the methods used in this article. Therefore, a brief review of the theory involved, namely the ADF test, cointegration test, and Granger causality test, MRSVD, PACF, MFO, and ELM, is shown below, respectively.
2.1. ADF Test
If a time series meets the following conditions: (1) Mean is a constant independent of time t. (2) Variance is a constant independent of time t. (3) Covariance is a constant only related to time interval k, independent of time t, then, the time series is stationary.
The ADF test is a way to determine whether a sequence is stable. For the regression . If = 1 is found, the random variable has a unit root, then the sequence is not stable; otherwise, there is no unit root, and the sequence is stable.
2.2. Cointegration Test
If a non-stationary time series becomes smooth after 1-differential , the original sequence is called integrated of 1, which is denoted as I(1). Generally, if one non-stationary time series becomes smooth after d-differential, the original sequence is called integrated of d, which is denoted as I(d).
For two non-stationary time series and , if and are both sequences, and there is a linear combination making a stationary sequence, then there is a cointegration relationship between and .
2.3. Granger Causality Test
If variable X does not help predict another variable Y, then X is not the cause of Y. Instead, if X is the cause of Y, two conditions must be met: (1) X should help predict Y. That is to say, adding the past value of X as an independent variable should significantly increase the explanatory power of the regression; (2) Y should not help predict X, because if X helps predict Y, Y also helps in predicting X, there is likely to be one or several other variables, which are both the cause of the X and Y. This causal relationship, defined from the perspective of prediction, is generally referred to as Granger causality.
Estimate two regression equations:
Unconstrained regression model (
u)
Constrained regression model (
r)
represents a constant term,
are the maximum lag periods of
Y and
X, respectively.
is white noise.
Then use the residual squared sum (
) of the two regression models to construct the F statistic.
where n is the sample size:
Test null hypothesis : X is not the Granger cause of Y (: )
If , then is not zero significantly. The null hypothesis should be rejected; otherwise, cannot be rejected.
Akaike information criterion (
AIC) is used for judging lag orders in the Granger causality test.
AIC is defined as
where
is the number of model parameters, representing the complexity of the model, and
is the likelihood function, representing the fitting degree of the model. The goal is to select the model with the minimum
AIC.
AIC should not only improve the model fitting degree but also introduce a penalty term to make the model parameters as little as possible, which helps to reduce the possibility of overfitting.
2.4. MRSVD
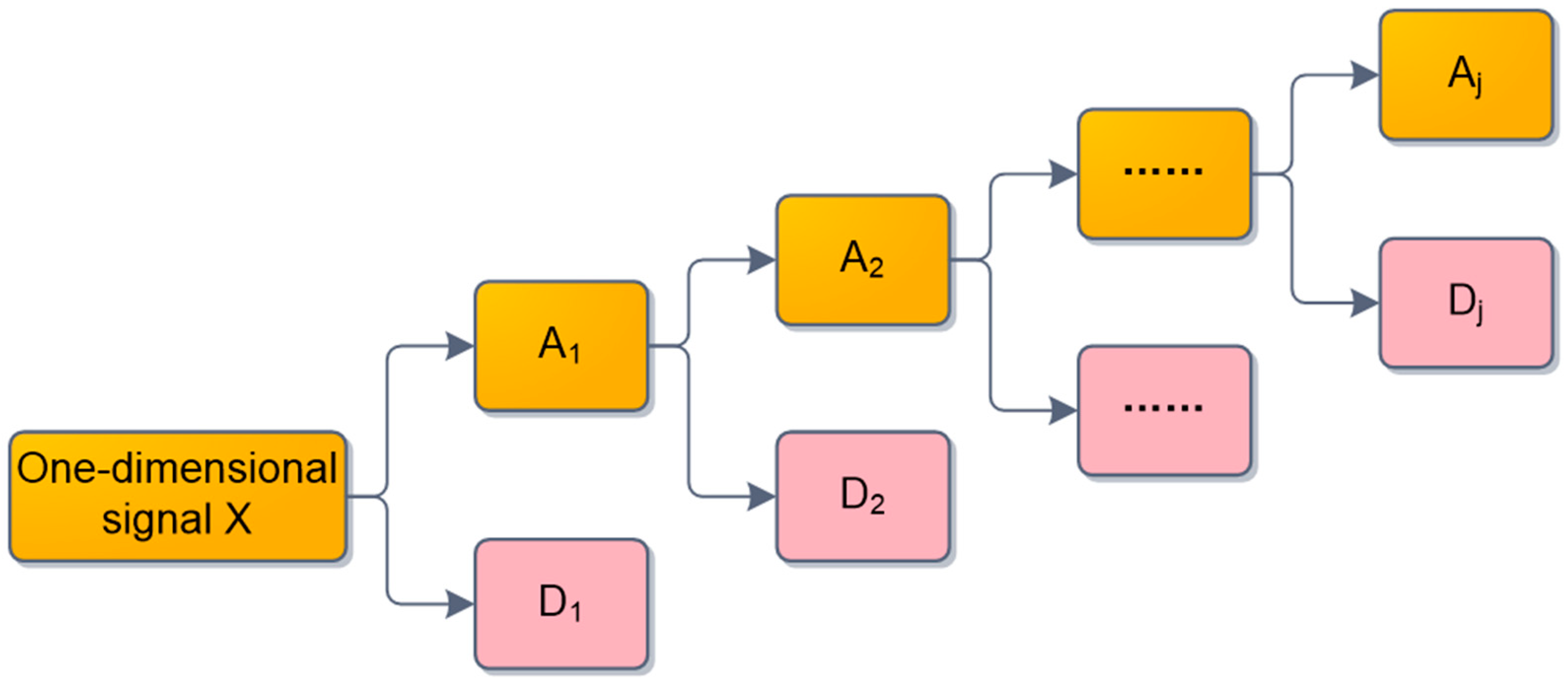
Based on SVD, MRSVD draws on the idea of wavelet multi-resolution [
32] and uses the two-way recursive idea to construct the Hankel matrix to analyze the signal [
33], which realizes a decomposition of complex signals into sub-spaces of different levels. The core idea of MRSVD is to first decompose the original signal
X into the detail signal (D1) and with less correlation with the original signal and the approximation signal (A1) with more correlation with the original signal, and then decompose A1 by SVD recursively. Finally, the original signal is decomposed into a series of detail signals and approximation signals with different resolutions [
34]. Specific steps are as follows:
First, construct a Hankel matrix for one-dimensional signal
.
Then perform SVD on the matrix
H to obtain:
Among them,
and
are singular values obtained by decomposition,
,
are, respectively, column vectors obtained after SVD decomposition;
,
, corresponds to the large singular value, reflecting the approximation component of
H;
, corresponds to the small singular, reflecting the detailed component of
H.; Continue to perform SVD on
, and the decomposition process is shown in
Figure 1 [
35].
MRSVD for one-dimensional discrete signals shows that there is a certain difference between MRSVD and WT. The number of decomposition layers of WT is limited, and MRSVD is not limited by the number of decomposition layers. Multi-level multi-resolution of the original signals can be performed by MRSVD. To prevent the energy loss of the signal, the number of components in the signal decomposition process is two. According to the above steps, the original signal can reflect the detail signal and the approximate signal through multiple levels, and finally, the inverse of the extracted signal is performed. The structure can realize the noise reduction and feature extraction of the original signal.
2.5. PACF
The partial autocorrelation function (PACF) is a commonly used method that describes the structural characteristics of a stochastic process, which gives the partial correlation of a time series with its own lagged values, controlling for the values of the time series at all shorter lags.
Given a time series , the partial autocorrelation of lag , is the autocorrelation between and that is not accounted for by lags 1 to k − 1. Described in mathematical language is as follows:
Suppose that the k-order autoregressive model can be expressed as
where
represents the
-th regression coefficient in the
-th order autoregressive expression, and
is the last coefficient.
2.6. Moth–Flame Optimization Algorithm
The MFO algorithm is a cluster intelligent optimization algorithm based on the behavior of moths flying close to the flame in the dark night. The algorithm uses the moth population M and the flame population F to represent the solution to be optimized. The role of the moth is to constantly update the movement and finally find the optimal position, while the role of the flame is to preserve the optimal position found by the current moth. The moths are in one-to-one correspondence with the flames, and each moth searches for the surrounding flame according to the spiral function. If a better position is found, the current optimal position saved in the flame is replaced. When the iterative termination condition is satisfied, the optimal moth position saved in the output flame is the optimal solution for the optimization problem [
36].
In the MFO algorithm, the moth is assumed to be a candidate solution. The variable of the problem is the position of the moth in space. The position matrix of the moth can be expressed as
M, and the vector storing its fitness value is
.
where n is the number of moths; d is the number of variables.
Another important component of the MFO algorithm is the flame. Its position matrix can be expressed as F, and the matrices M and F have the same dimension. The vector storing the flame adaptation value is
:
The
algorithm is a three-dimensional method for solving the global optimal solution of nonlinear programming problems, which can be defined as
where
I is a function that can generate random moths and corresponding fitness values. The mathematical model of the function I can be expressed as
The function
is the main function, which can freely move the position of the moth in the search space. The function
records the final position of the moth through the update of the matrix
.
The function
T is the termination function. If the function
T satisfies the termination condition, ‘true’ will be returned, and the procedure will be stopped; otherwise, ‘false’ will be returned, and the function
P will continue to search.
The general framework for describing MFO algorithms using I, P, and T is defined as follows:
M = I();
while T(M) is equal to false
M = P(M);
End
After function
I is initialized, function
P iterates until function
T returns true. To accurately simulate the behavior of the moth, Equation (14) is used to update the position of each moth relative to the flame:
Here
denotes the
i-th moth,
denotes the
j-th flame, and
S denotes a logarithmic spiral function.
represents the distance between the
i-th moth and the
j-th flame,
b is a constant defining the shape of the logarithmic spiral, and
t is a random number between [−1,1].
is calculated by the Equation (15):
Additionally, another problem here is that location updates of moths relative to
n different locations in the search space may reduce the exploitation of the best promising solutions. With this in mind, an adaptive mechanism capable of adaptively reducing the number of flames in the iterative process is proposed to ensure fast convergence speed. Use the following equation in this regard:
where
is the current number of iterations,
N is the maximum number of flames, and
T is the maximum number of iterations [
37].
2.7. Extreme Learning Machine
ELM is a single hidden layer feedforward neural network (Single-hidden layer feedforward neural network). Its main feature is that the connection weights between the input layer and hidden layer w (the hidden layer neuron threshold) are randomly initialized, the network converting the training problem of the network into a solution to directly find a linear system. Unlike the traditional gradient learning algorithm, which requires multiple iterations to adjust the weight parameters, ELM has the advantages of short training time and small calculation [
38].
The ELM consists of an input layer x1 … xn, a hidden layer, and an output layer y1 … yn, where the input layer neuron number is n, the hidden layer neuron number is L, and the output layer neuron number is m.
The connection weights between the input layer and the hidden layer are , and the connection weights between the hidden layer and the output layer are .
Make the training set input matrix with
Q samples to be
output matrix to be
the hidden layer neuron threshold is
the hidden layer activation function is
The expected output of the network is
[
39]. Therefore, ELM can be illustrated as
However, random parameter settings not only improve the learning speed of ELM but also increase the risk of getting expected results simultaneously. Therefore, this paper uses MFO to search for the best optimal parameters, including the input weight and the bias in the hidden layer, to improve the training process and avoid over-fitting.
3. The Whole Framework of the Proposed Model
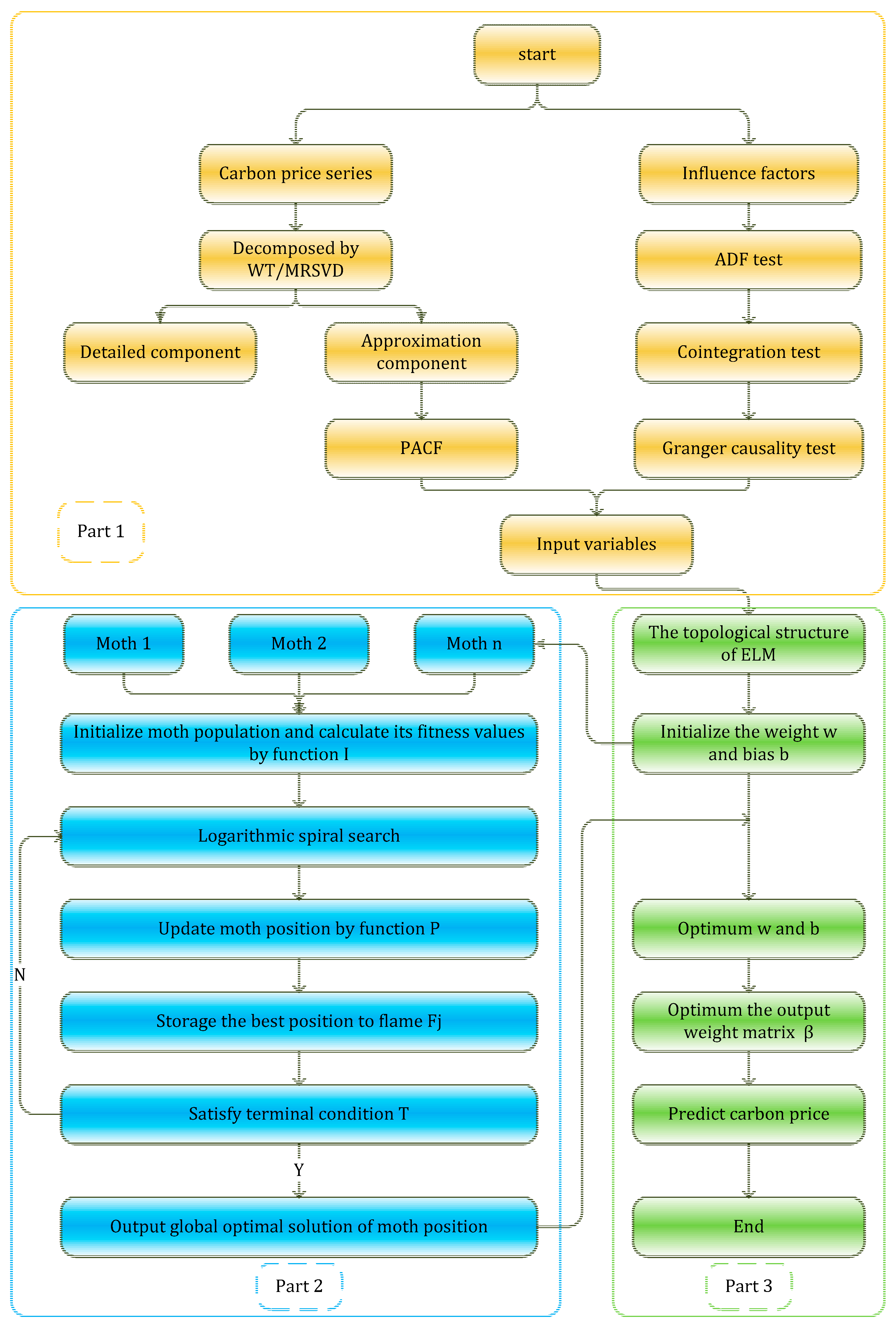
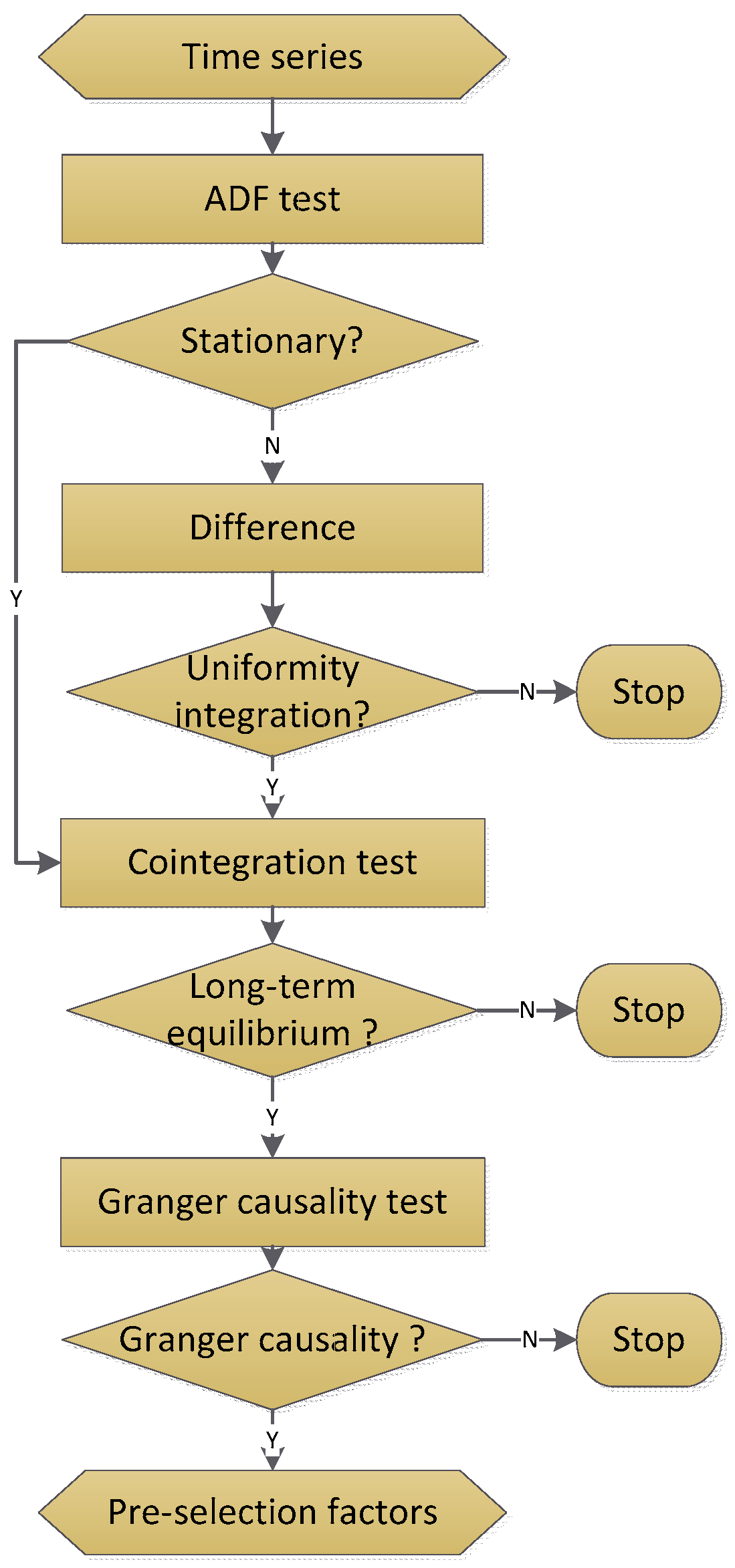
Figure 2 introduces the overall idea and frame of the article. There are three parts with different colors yellow, green, and blue.
Part 1 describes the input indicator selection procedure. The input variables used in ELM include two parts, external factors analyzed by the ADF test, cointegration test and Granger causality test, internal factors, and internal factors of the carbon price decomposed by WT and MRSVD, respectively, whose lags are determined by the PACF.
Part 2 mainly introduces the process of MFO. The purpose of this part is optimizing the parameter weight w and bias b of the ELM.
Part 3 is the ELM’s training procedure, whose set data can be obtained in Part 1, and Part 2 optimizes the parameters of the ELM. Thus, the carbon price prediction result can be obtained by the optimized ELM model.
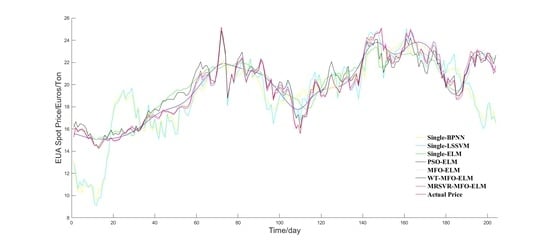
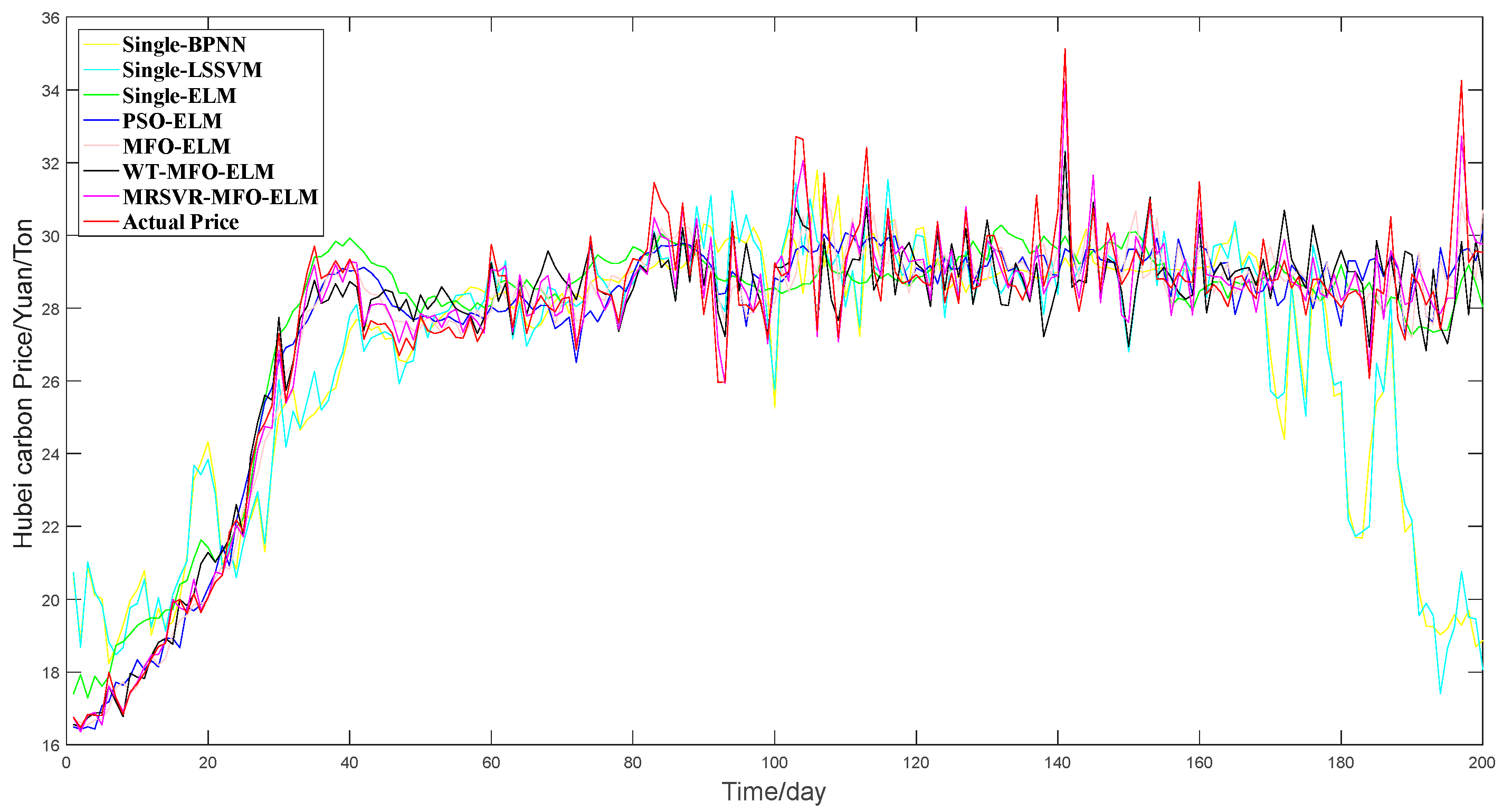
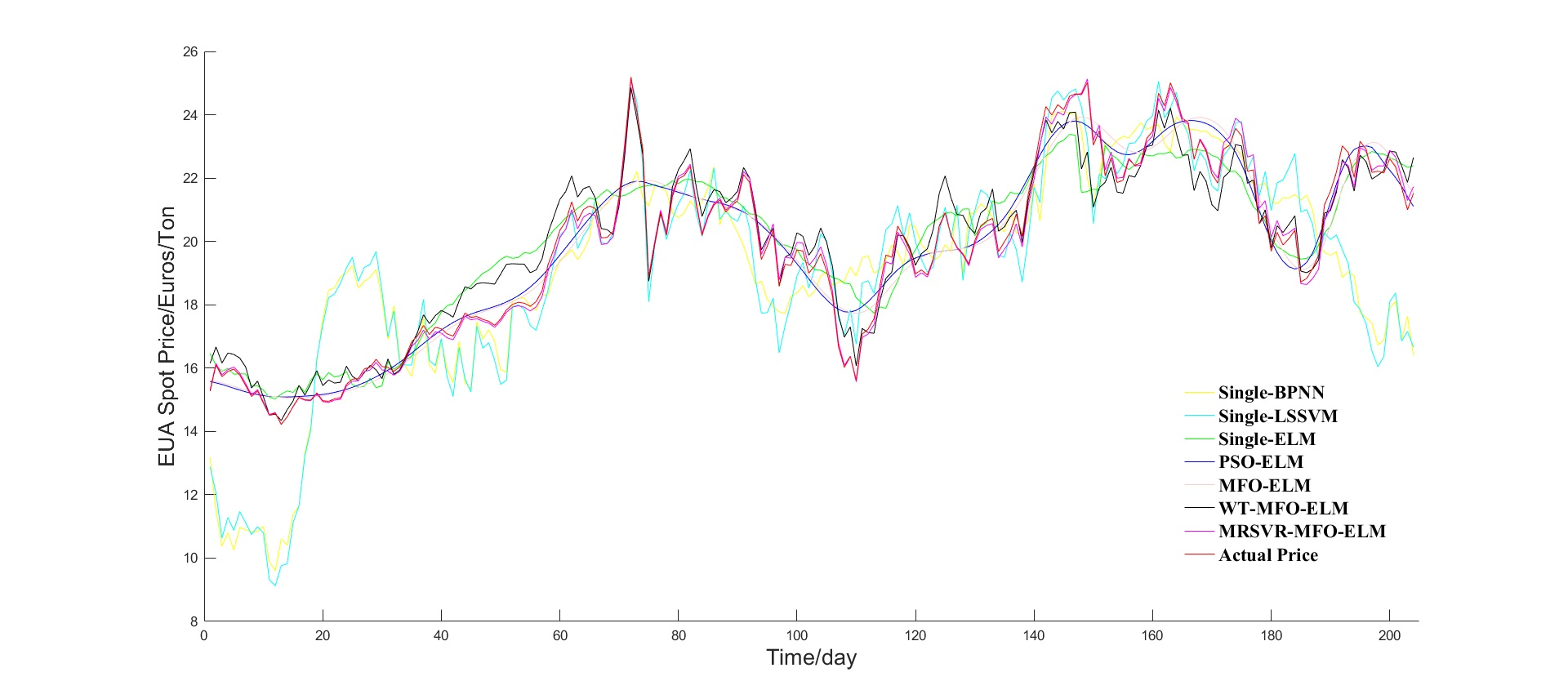
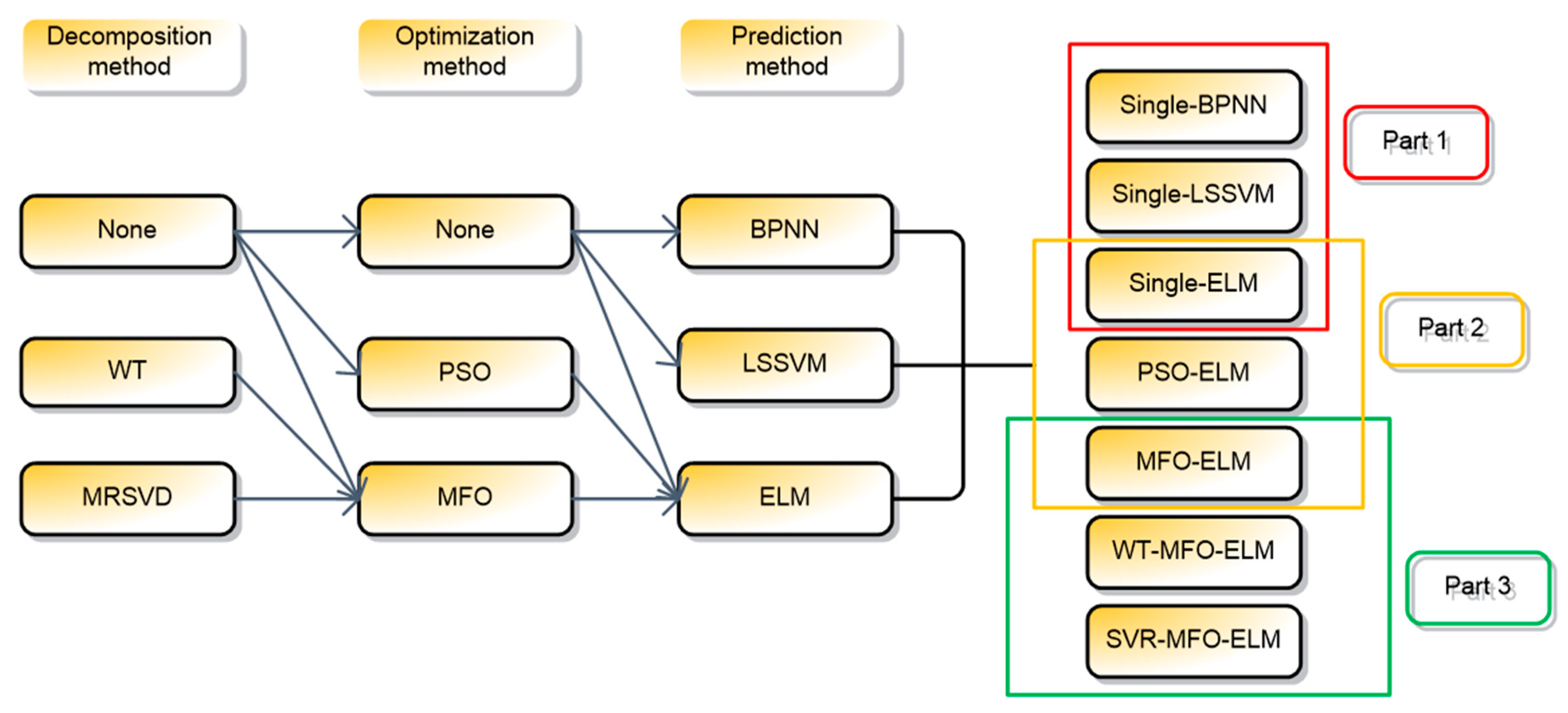
To verify the superiority of the proposed model, a comparison framework is shown in
Figure 3, which includes three sections.
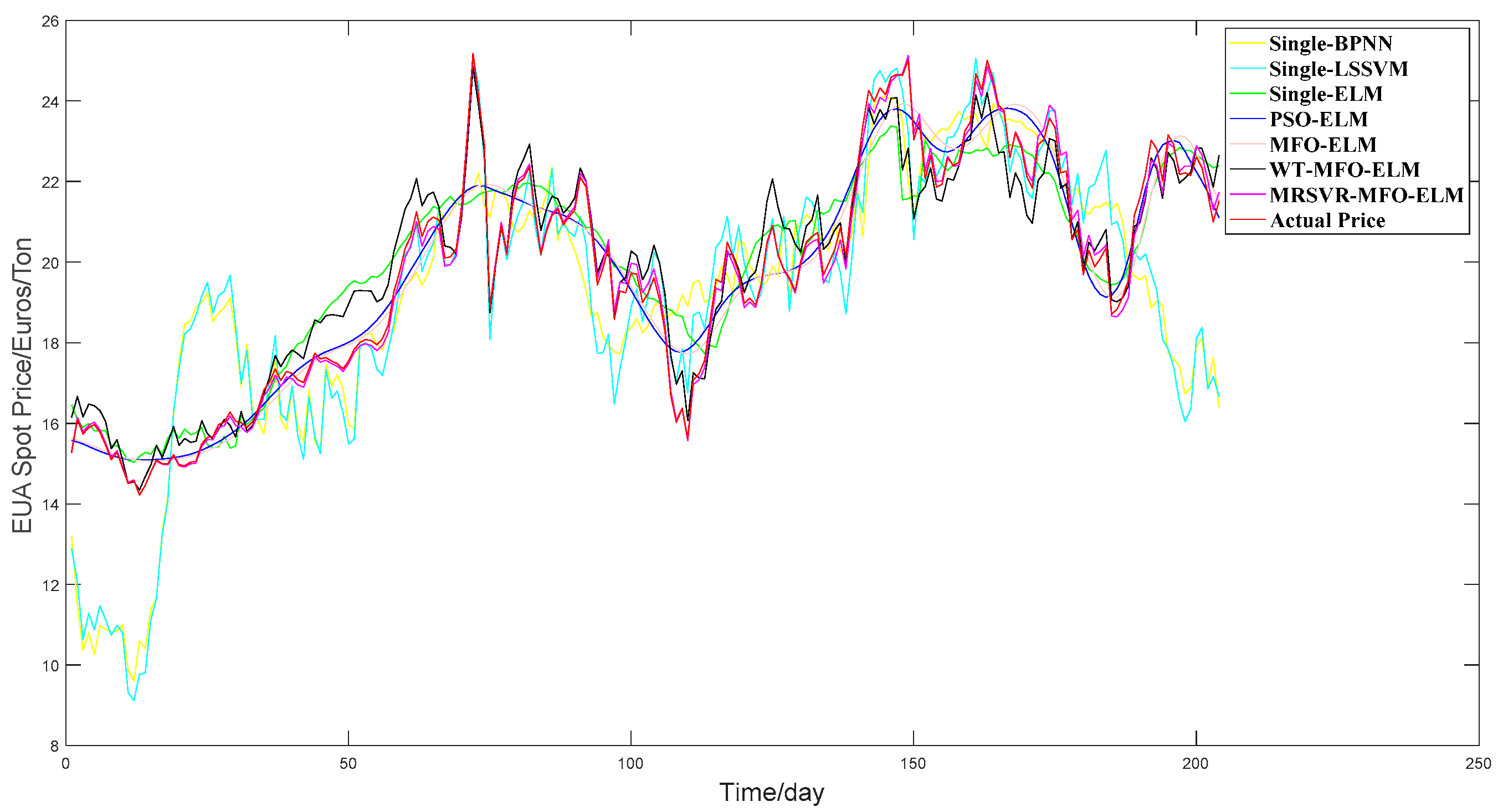
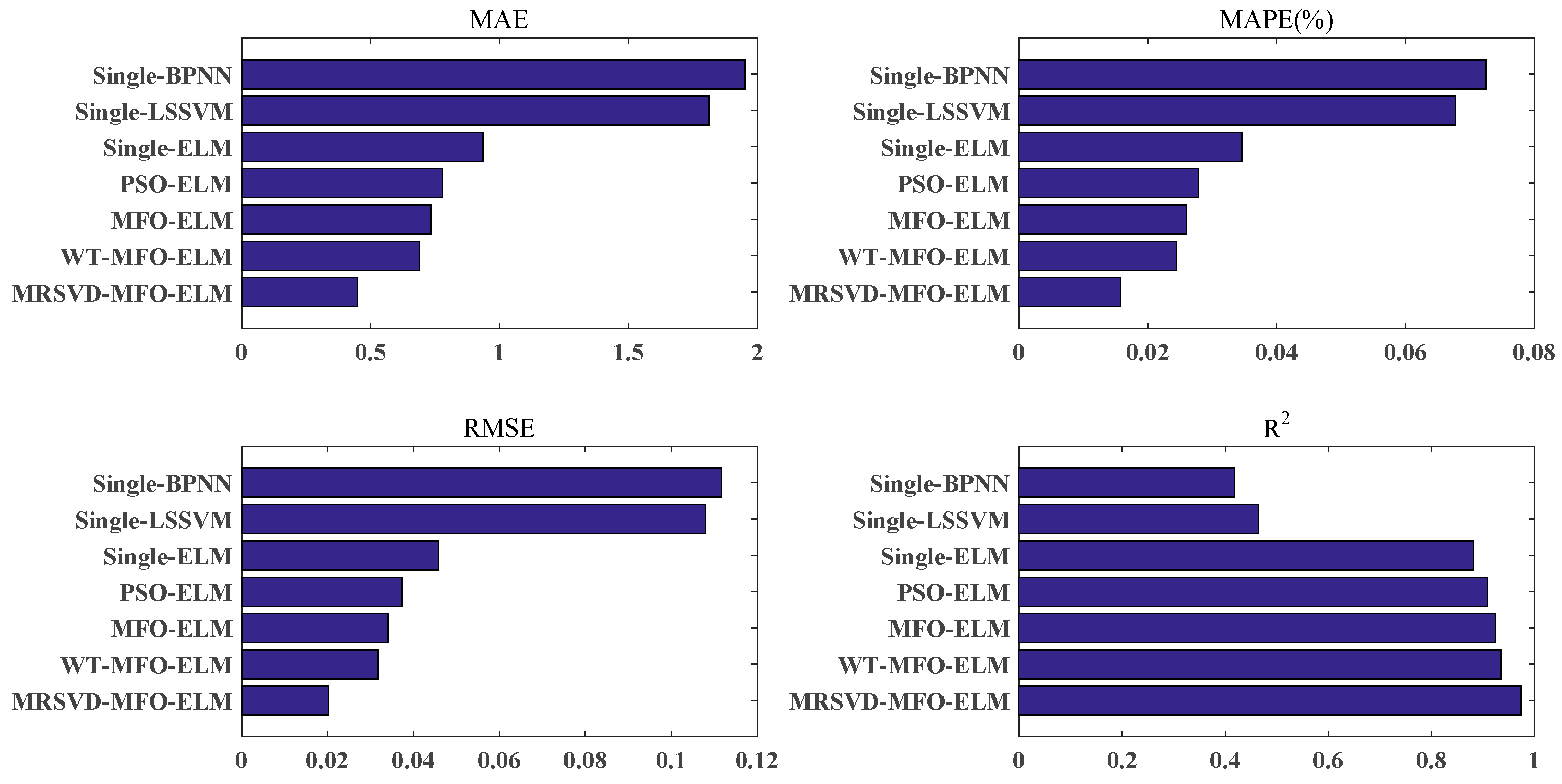
In section 1, single BPNN, single LSSVM, and single-ELM were congregated to present the predictive performance of three neural network models and verify the advantages of single ELM.
In section 2, single-ELM, PSO-ELM, and MFO-ELM were collected to demonstrate the necessity of optimizing the parameter of ELM, and verify the advantages of MFO compared with PSO.
In section 3, MFO-ELM, WT-MFO-ELM, MRSVD-MFO-ELM were used to demonstrate the effectiveness of the carbon price decomposition process and the advantage of MRSVD.
5. Conclusions
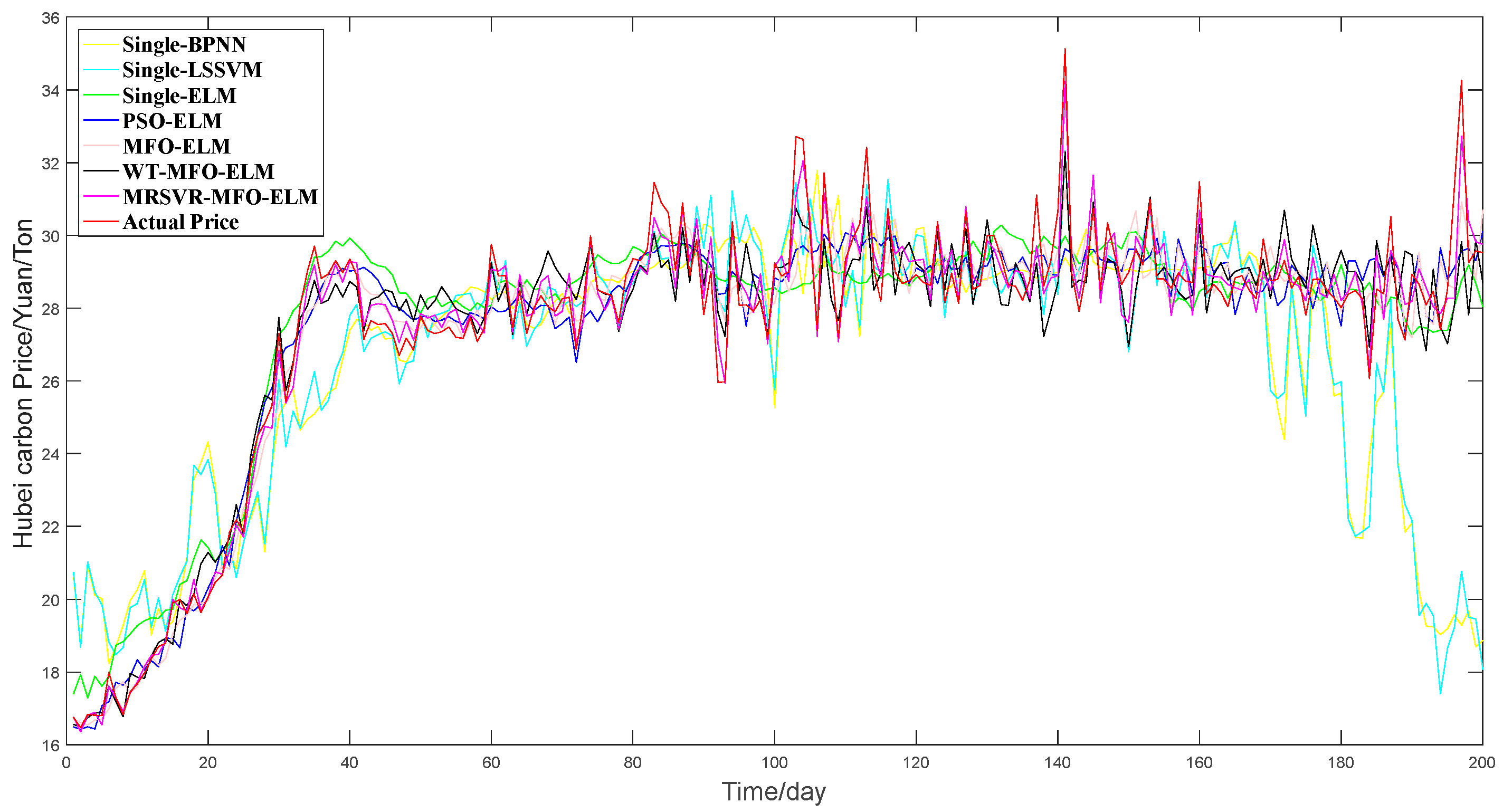
In this paper, a new hybrid model in view of MRSVD and ELM optimized by MFO for carbon price forecasting is proposed. First, through the ADF test, cointegration test, and Granger causality test, the external factors of the carbon price are selected in turn. To choose the internal factors of the carbon price, the carbon price sequences were decomposed by MRSVD, and the lags were decided by PACF. And then, MFO was used for the optimization of the parameters of the ELM; both the external factors and internal factors were inputted into the MFO-ELM model. Finally, the ability and effectiveness of the MRSVD-MFO-ELM were tested using a variety of models and carbon series. Overall, based on the carbon price forecast results of the EU ETS and China ETS, the following conclusions can be drawn:
(a) Coal prices, oil prices, gas prices, and EuroStoxx 50 are the Granger cause for the EUA spot price, while EUA spot trading volume is not. Coal prices, oil prices, gas prices, and the Shanghai Composite Index are the Granger cause for Hubei’s carbon price.
(b) Compared with WT-MFO-ELM, MFO-ELM, PSO-ELM, single ELM, single LSSVM, and single BPNN, the MRSVD-MFO-ELM model shows a clear strength in carbon price prediction results.
(c) ELM is a prediction model that is more suitable for carbon price forecasting than LSSVN and BPNN.
(d) ELM with an optimization algorithm is able to achieve better results than the ELM without optimization algorithms, and MFO performs better than the PSO in the optimization of ELM parameters.
(e) Decomposition methods help to improve prediction accuracy, and MRSVD presents superiority to WT in decomposing the carbon price.
This paper proposes a carbon price prediction model with high accuracy, to provide a scientific decision-making tool for carbon emission trading investors to comprehensively evaluate the value of carbon assets, avoid carbon market risks caused by carbon price changes and promote the stable and healthy development of carbon market.
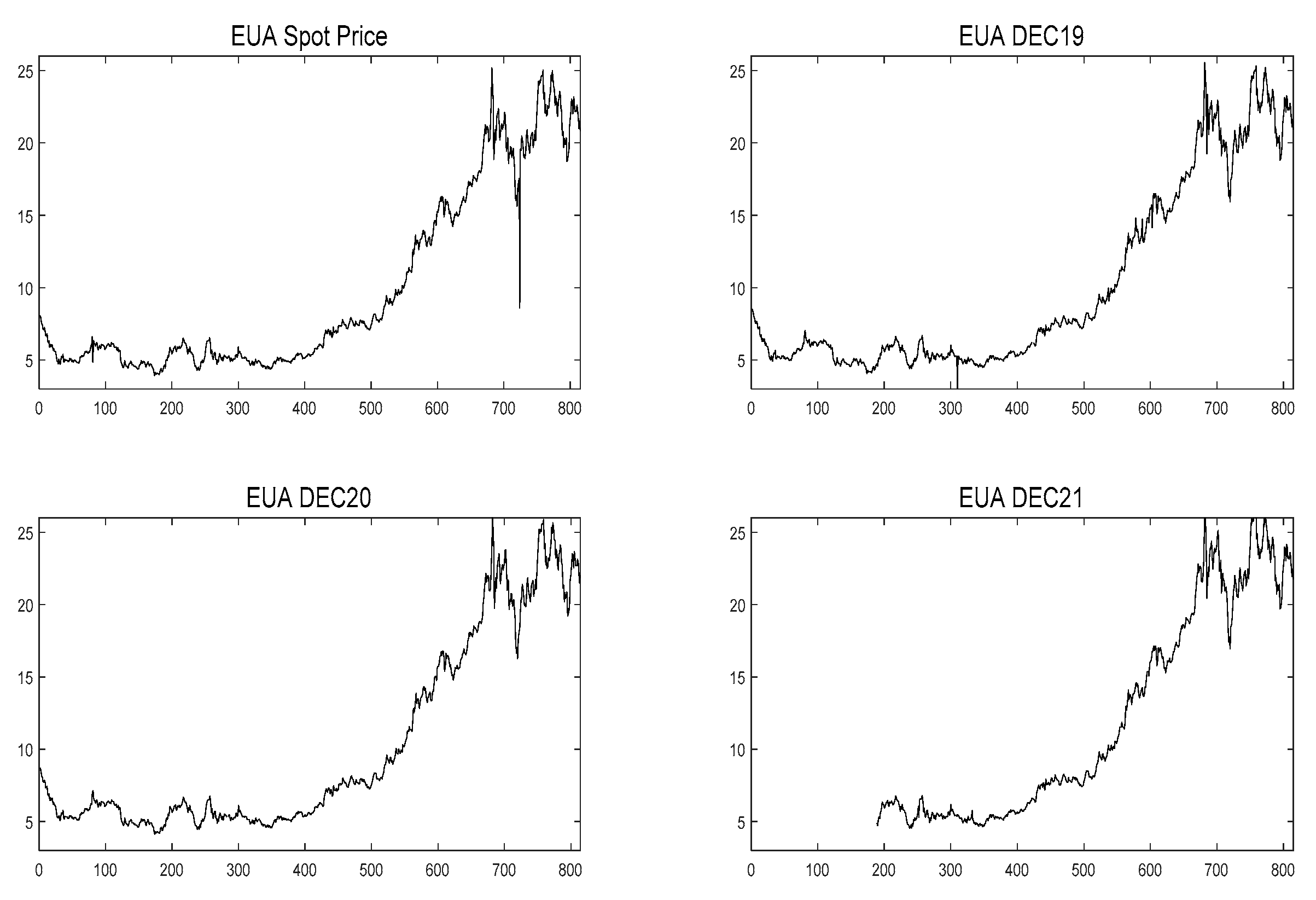
By comparing the carbon prices of EU ETS and China ETS from 20 March 2018 to 20 March 2019, we find that the average value of the EUA spot price was 18.61 Euros per ton. However, the HUBEI carbon price was only 24.32 Yuan per ton, which was much lower than the EUA spot price. Therefore, China’s carbon market should take corresponding measures to reasonably price carbon assets. On the one hand, a reasonable carbon price can force enterprises to carry out low-carbon transformation more actively; on the other hand, it can attract more social capital to enter the carbon market and increase the market’s activity.
This paper primarily studied carbon price prediction, which takes consideration of energy price indicators, economic indicators, and historical carbon price sequences. In addition, there are many factors affecting carbon prices, such as policy, climate, carbon supply, and carbon market-related product prices. Therefore, there are still several directions to be studied.













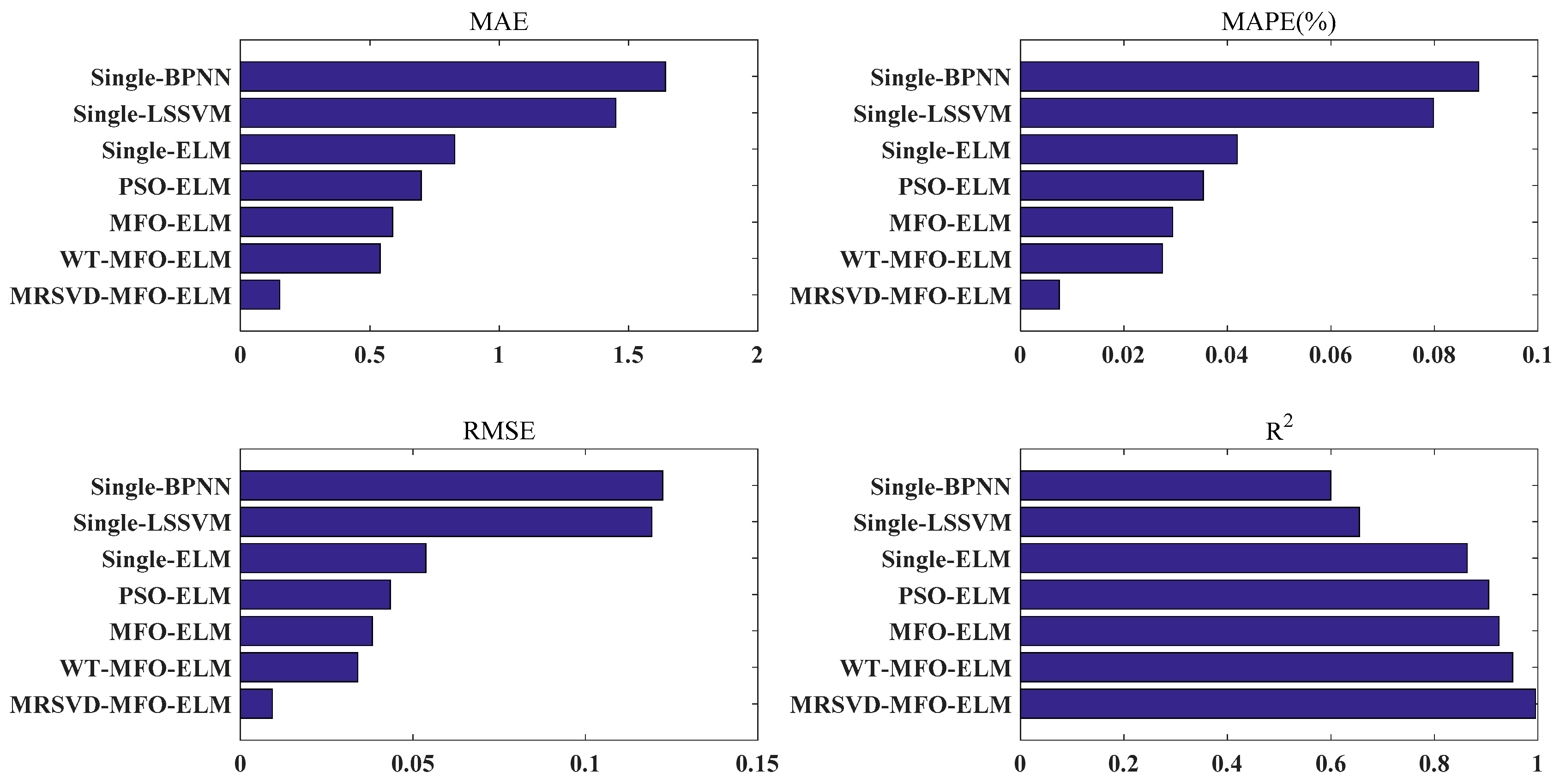




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
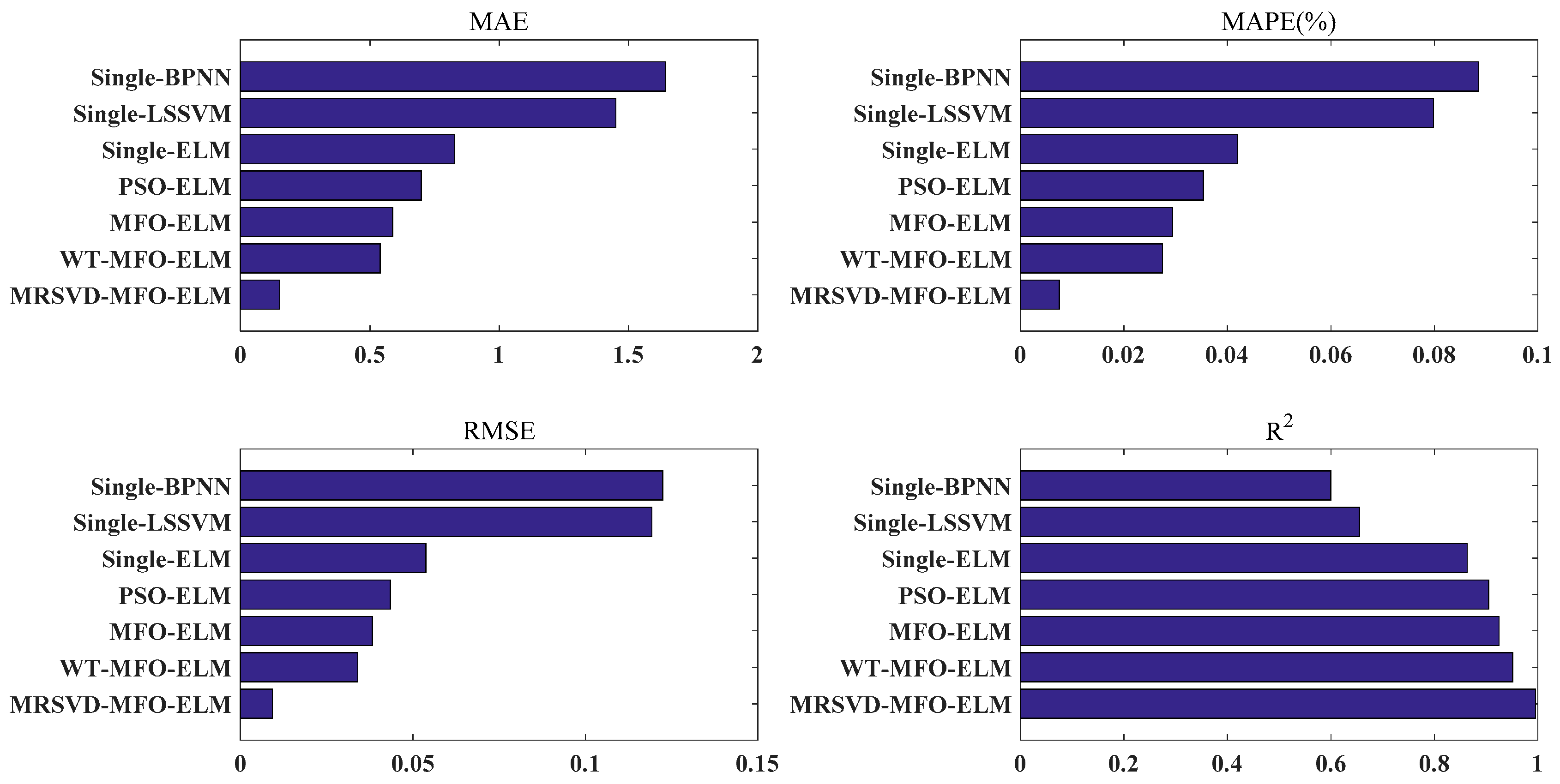{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}