1. Introduction
The goal of energy system modelling is to model and simulate energy systems using different scenarios, as well as analysing their impact and results. This field gained increasing interest due to the integration of renewable energy sources in the energy supply, motivated by environmental, political and economic factors [
1,
2]. Energy system models constitute powerful tools, which help policy- and decision-makers to understand the effects and implication of policies on future energy systems. The insights provided by energy models are the subject of many technical papers, studies and reports, for example dealing with the cost of renewable energy [
3], the stability of the German transmission network [
4] and the Ten-Year Development Plan for the European transmission network [
5].
Despite the importance of energy system modelling, the availability and accessibility of energy-related datasets is an issue, as such data is in general not publicly available [
6]. Reliable data such as generation capacities, electrical loads estimation and locations of renewable energy plants are not available for scientific studies and research activities [
7,
8,
9]. This extends to data of power networks, which are the subject of this publication. In particular cases, non-disclosure agreements can be established between Transmission Network Operators (TSOs) or national network agencies (such as the German Network Agency BNetzA (Bonn, Germany) for research institutions to access power grid models and their corresponding datasets. However, the results obtained using this data are not open for publication, thus transparency, comparability and reproducibility of scientific research is not possible [
10]. The issue of data accessibility is not only important for scientific purposes but also for policy- and decision-makers, as many studies are directly commissioned by different ministries and governmental bodies. Initiatives from the German Federal Ministry for Education (BMBF) and the Federal Ministry of Economic Affairs and Energy (BMWi), which finance projects dealing with open source and open data, are an indicator for the growing interest of decision makers in opening energy models and data.
Such an approach is the Scientific Grid Model (SciGRID) project in which an open source grid model SciGRID (For more information about the SciGRID project visit the project webpage:
www.scigrid.de) [
10,
11] was developed. The SciGRID model uses the OpenStreetMap (OSM) database (OpenStreetMap: the free open source editable map of the world. For more information visit
www.openstreetmap.org) to extract and abstract the power grid. The osmTransmission Grid Model (osmTGmod) (For more information visit:
www.github.com/wupperinst/osmTGmod) model, developed at the Wuppertal Institute for Climate, Environment and Energy in cooperation with Flensburg University of Applied Sciences, also uses OSM as a database, but relies on a broader range of data types. Another example is OpenGridMap platform created by Rivera et al. [
12], which extends the data from OpenStreetMap with information collected by the use of an OpenGridMap mobile app (Version 1.0, Technical University of Munich, Munich, Germany), developed by the authors.
Open source grid models have already been used for power flow calculations, yielding realistic results [
13,
14,
15,
16]. However, those models are not validated yet and differ in their structure. Therefore, it is necessary to first compare them to reference models of grid operators and second to explain the structural differences between the open source models by variations in the derivation processes.
Different approaches have been used to characterise and compare power grid models. Barthelemy [
17] investigates the spatial aspects of networks and classifies power grids as planar networks. Matke et al. [
11] use a graph-theoretical decomposition to characterise the structure of the German power grid. Clusters are identified that may be used in reduced models for optimisation problems addressing system design and operation. Crucitti et al. [
18] conduct a topological analysis of the Italian power grid. Using a model for cascading failures, the authors determine the structural vulnerability of the grid. Cotilla-Sanchez, Hines et al. [
19,
20] describe the structure of the three North American electric power interconnections, from a topological and electrical connectivity perspective. The topology of the analysed networks is compared to those of random [
21], preferential-attachment [
22] and small-world [
23] graphs by calculating mathematical network criteria distributions. For studying the electrical connectivity, the authors propose a new method that uses electrical distances instead of geographic connections.
In this contribution, we compare the open source power grid models SciGRID, GridKit and osmTGmod and address the following research questions. First, we discuss what the general differences in the model derivation processes and the resulting topologies are. Then, we apply a novel multi-criteria approach and combine a mathematical, visual and power-related comparison. Therefore, we investigate how the distributions of the network criteria differ between the models. Next, the grid models are plotted in an interactive grid map and we examine to what extent the topologies are spatially corresponding. The results of the graph-theoretical analysis are added to the map and we check whether this combination can help explaining specific findings in the network criteria distributions. Finally, the power-related completeness of the grid models is compared.
We will use the term power grid models interchangeably to represent models used to derive grid data and also to define the data outputs of power grid models, unless stated otherwise. Power grid models output represent power grids topologies and are defined by the nodes (or vertices) and edges (or links) of their network representation. For transmission networks, which are the subject of the present contribution, the power grid nodes represent electrical substations and the power grid edges represent the transmission lines connecting them.
The remaining part of the paper proceeds as follows.
Section 2 covers the methodology and introduces the open source tool AutoGridComp (AutoGridComp can be downloaded from the code repository,
https://github.com/wheitkoetter/AutoGridComp, or the QGeographic Information System (QGIS) plugin repository,
https://plugins.qgis.org/plugins/AutoGridComp/.) for the automated comparison of power grid models that was developed and applied in this work.
Section 3 is dedicated to results of the multi-criteria comparison of the SciGRID, GridKit and osmTGmod grid models. A conclusion is presented in
Section 4 and
Appendix A and
Appendix B contain further information on the implementation of the power grid comparison tool.
3. Results
This section is dedicated to the results of the qualitative and quantitative comparison of the open source grid models SciGRID, GridKit and osmTGmod. First, we give an overview of general similarities and differences in the derivation processes of the three grid models in
Section 3.1. This allows for an understanding of the structural differences in the resulting grid topologies of these models. Second, in
Section 3.2, the topologies are compared from a visual perspective. In
Section 3.3, a graph theoretical comparison is conducted and the results are added to the map representation of the topologies. Finally,
Section 3.4 deals with the power related completeness of the grid models. For more detailed descriptions of the models, derivation processes and the power-related data available in OSM, please refer to [
10] and the SciGRID model webpage (SciGRID model and project webpage:
http://scigrid.de/), as well as the GridKit (GridKit repository:
https://github.com/bdw/GridKit) and osmTGmod (osmTGmod repository:
https://github.com/wupperinst/osmTGmod) github repositories.
3.1. General Differences in the Grid Model Derivation Approaches and Resulting Topologies
An overview of important features and simplifications used in deriving the three models is given in
Table 1.
Note that the most striking difference between the grid models is the number of nodes and edges in the resulting topologies. This is mainly due to the utilised OSM data types in the different approaches and the methods for creating the edges of the network, as well as the level of abstraction considered by the models. In OSM, power data are represented by the OSM types nodes, ways and relations [
10]. Line-carrying towers and electrical poles are represented by nodes. Ways represent transmission lines, as well as the outlines of substations. Electrical circuits, which comprise, e.g., multiple substations and transmission lines, are represented by the OSM type relation.
The SciGRID grid model is only based on the OSM power relations and does not apply heuristics. This results in a significantly lower number of nodes and edges, as well as a lower complexity than the GridKit and the osmTGmod models. The GridKit model does not make use of power relations but instead derives the edges of the network from the power-tagged OSM nodes and ways using heuristics. This leads to the creation of so-called auxiliary nodes and auxiliary edges by the spatial algorithms used in the model. The osmTGmod approach primarily uses the available power relations to abstract the electrical grid and adds missing information from available power tagged nodes and ways. As a result, the number of nodes and edges and the complexity of the topology is in between the one of the SciGRID and GridKit topologies. In the open_eGo (open_eGo repository:
https://github.com/openego) project, the osmTGmod approach was enhanced by the coverage of the high voltage level (110 kV). When both the high and extra high voltage levels of the German transmission grid are considered, the number of nodes in the osmTGmod grid topology amounts to more than 11,000 [
15] nodes.
In summary, the use of SciGRID can be recommended when a deterministic approach is preferred and no heuristics are desired. If a high completeness of the topology is required, the GridKit and osmTGmod models are advantageous. The quality of OSM data may vary between different countries or regions [
32,
33,
34]. One needs to be careful when deriving power grids for geographical regions where OSM power relation data are not available in sufficient amounts. In this case, the GridKit approach is well-suited because it only relies on OSM nodes and ways data types.
In the next section, it will be shown, how the obtained topologies differ from a graph and a visual perspective due to the differences in the derivation processes and the assumptions used in each model. Since the SciGRID and GridKit approaches differ most, only these two models will be analysed.
3.2. GIS-Based Visual Comparison
In this section we investigate to what extent the SciGRID and GridKit topologies correspond to each other, using the GIS-based representation of the models.
Figure 1 shows the topologies of the two models for the German extra high voltage grid.
In general, the SciGRID and GridKit models show a high accordance. However, the routes of the links are more detailed in the GridKit model due to the introduction of auxiliary vertices and edges. Due to the higher degree of abstraction, the routes are less detailed in the SciGRID model. There are several links that are only contained in the GridKit model, but not in the SciGRID model. This can be explained by the fact that SciGRID only relies on relation information, which is less complete.
3.3. Coupled Mathematical and Visual Comparison
In this section, the results of the graph-theoretical comparison of the SciGRID and GridKit models of the German extra high voltage grid are presented. First, the distributions of the network criteria degree, betweenness centrality and the clustering coefficient are described. Then, the network criteria results are added to the GIS-based representation of the topology to explain specific findings in the distributions.
3.3.1. Degree
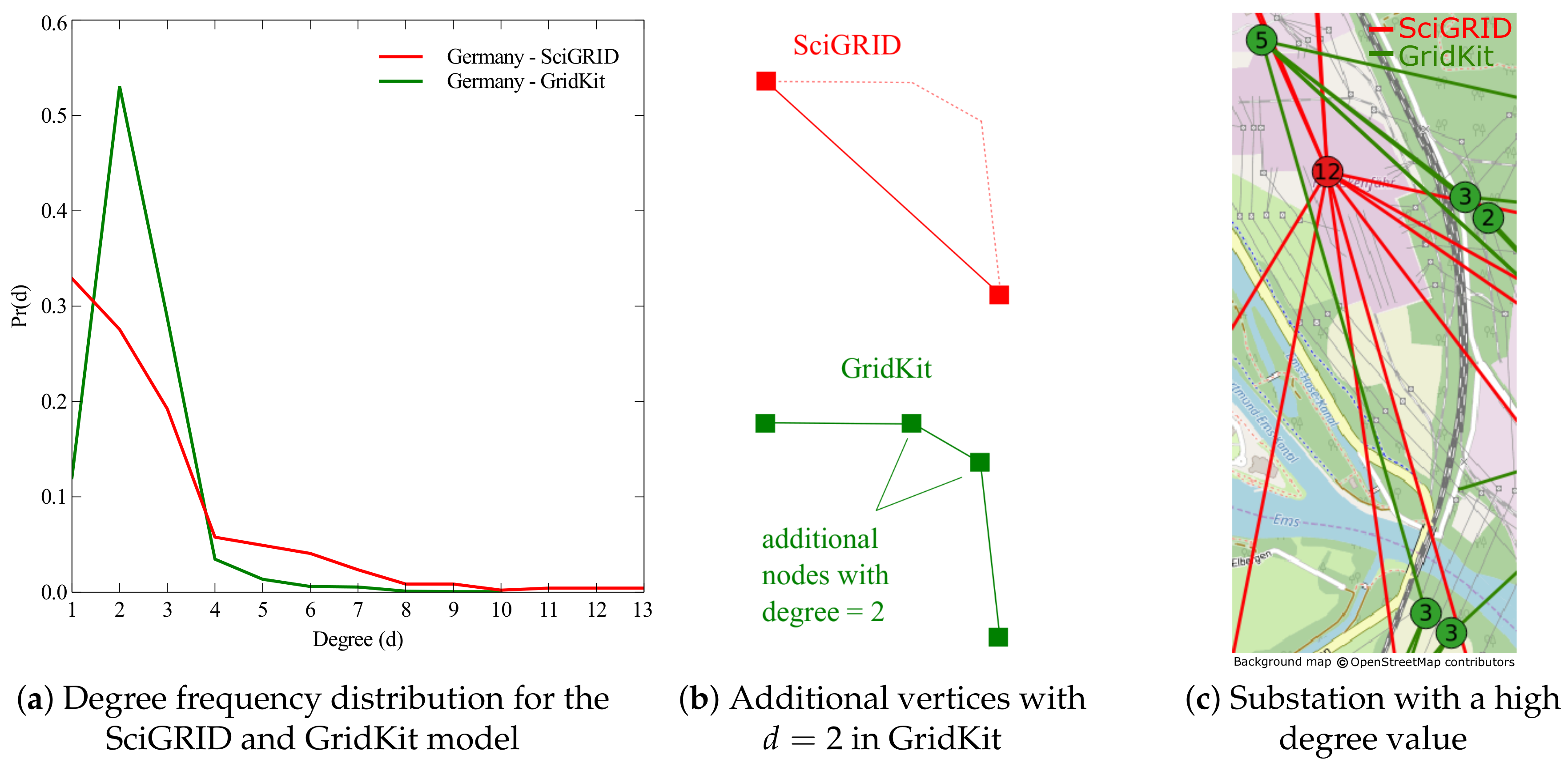
The degree frequency distribution of the vertices in the SciGRID and GridKit model of the Germany transmission grid are shown in
Figure 2a.
The frequency peak for the GridKit model is at a degree value of
, while for the SciGRID model the peak is at
. This difference is caused by the creation of the auxiliary vertices in the GridKit model, which have a degree of two, as depicted in
Figure 2b. The maximum degree value in the GridKit model is 10, whereas there are also vertices with a degree value of
,
and
in the SciGRID model. This difference can be explained by the higher degree of abstraction of the SciGRID model and is demonstrated exemplary in
Figure 2c for the substation at the nuclear power station in the Emsland region in Germany (the degree values are indicated by the numbers in the circles). While the substation is abstracted by one vertex with
in the SciGRID model, it is represented by multiple vertices with lower degree values in the GridKit model.
3.3.2. Edge Betweenness Centrality
Figure 3a shows the cumulative edge betweenness centrality (
bc) distribution for both the SciGRID and GridKit transmission grids for Germany. It can be seen that for
and
the distributions are similar for both models. In the range
, the CDF of the edge betweenness centrality are different in both models. This can be seen as jumps that occur at dissimilar betweenness centrality values for each model. One such jump is marked with a black arrow in
Figure 3a.
To identify the reason for these jumps, the interactive map of the power grid is used. Therein, the links of the grid which have betweenness centrality values corresponding to the jumps are highlighted (see
Figure 4). On the interactive map, it can be seen that all the links with betweenness centrality values corresponding to the jumps (in yellow colour) are part of grid branches situated at the edge of the power grid, hereinafter referred to as outer branches. An example for such a branch is schematically depicted in
Figure 3b for a better understanding. In the GridKit model this outer branch consists of three lines. However, in the SciGRID model and due to the abstraction process, the outer branch is composed of only one line. Using this information, the authors derived an equation (Equation (
4)) to calculate a normalised betweenness centrality value where the total number of vertices
n in the grid, as well as an outer edge index labelled
i, are used. The relationship between the outer edge index (
i) and the betweenness centrality at the jumps is explained for the GridKit and the SciGRID models, as follows:
For the outermost link,
i is set to 1 in Equation (
4). The outer link is part of all shortest paths going from the outermost vertex (labelled outer vertex) to all the remaining vertices in the grid. In Equation (
4), the numerator contains
because self-connection for edges is not considered here. As described above, the denominator contains the total number of shortest paths in the network. The resulting betweenness centrality value matches exactly to the first jump in the curve of the distribution (see
Figure 3a) for GridKit.
The betweenness centrality value for the link, marked with
(the before-last link) in
Figure 3b, is calculated using Equation (
4) and this time setting
. The resulting
in the numerator reflects the fact that the two outermost vertices (one them part of edge
) are both connected to all other vertices of the grid by the shortest path. This means that a value of four 2 × 2 (for the two edges) needs to be subtracted in the numerator, again because self-connecting edges are not considered. In this way, the betweenness centrality value for the second jump in the distribution for GridKit is derived. The value for the third jump in the distribution is calculated using Equation (
4) and setting
i = 3.
It can be noted that the first jump in the distribution for the GridKit model is larger than the second and third jumps. The reason for this is that there exist outer branches containing only one link. This is also the case for most of the outer branches in the SciGRID model. Due to the stronger degree of abstraction in SciGRID, nearly no outer branch consists of more than one link. For that reason, there is a much larger first jump in the betweenness centrality distribution, compared to GridKit and the jumps which follow are significantly smaller.
Furthermore, in
Figure 3a there are links having an even lower betweenness centrality value (blue colour), than the outermost edges. In the GridKit model, those edges account for
of all links and in the SciGRID model they represent
of all edges. These findings somehow contradict the expectation that the outer branches have the lowest betweenness centrality values.
In the following paragraph, a possible explanation for this finding will be given. In
Figure 4, the geo-referenced topology of the German power grid is shown obtained using the SciGRID model. We distinguish between the outer branches and links with a higher or lower betweenness centrality. Most of the links having a lower betweenness centrality than the outer branches are located at the edge of the power grid. However, they are connected to the grid on both ends and do thus differ from outer branches as defined in
Figure 3b. However, on close inspection, some of the links with the lowest betweenness centrality have a central position in the power grid. An example link is marked with a star symbol in
Figure 4. The low betweenness centrality value of this edge can be explained as follows. Firstly, there exist parallel links in the west (left) and east (right) of the considered link, which connect the vertices in the northern part of grid with those in the centre and southern part of the grid. Secondly, the shortest paths, which connect the vertices at the ends of the considered link with the rest of the network, may also head into northern and southern direction, not passing by the considered link which explains the low value of the betweenness centrality of this edge.
3.3.3. Clustering Coefficient
The distribution of the clustering coefficients for the vertices of SciGRID and GridKit grids for Germany is shown in
Figure 5a. It can be seen that most of the vertices in both power grids have a clustering coefficient of zero. Those vertices can be divided into three groups. The first group is formed by the outermost vertices (belonging to the outer branches), as depicted in
Figure 3b and
Figure 5b. These vertices have only one neighbour and thus no pair of adjacent neighbours. The second group consists of the vertices that are on an edge that does not branch and thus have only one pair of neighbours, which is however not connected. The vertices of the third group have multiple pairs of neighbours, but also none of these neighbours is connected.
Furthermore,
Figure 5a shows that the share of vertices with a clustering coefficient of zero is
larger in the GridKit dataset than in the SciGRID dataset. This is due to the lower degree of abstraction of GridKit and the presence of the auxiliary nodes which have a clustering coefficient of zero (belonging to the second group as defined above). Note that in both models, a high share of vertices has a clustering coefficient of
. This is mainly caused by vertices forming triangles inside the network as shown in
Figure 5b. The vertices, which are connected to the triangle and one other branch, have a clustering coefficient of
, because they have three pairs of neighbours, of which one is connected. In the GridKit data the share of vertices with a clustering coefficient of
is about 5 percentage points higher than in the SciGRID grid, because additional triangles are introduced at the intersections of the power lines.
3.4. Power Related Completeness
This subsection deals with the completeness of information on the electrical properties of the grid models. The SciGRID, GridKit and osmTGmod models of the German extra high voltage grid (grid models generated from OSM data downloaded on 15 January 2017) were compared by applying the developed AutoGridComp tool. For more details on the modelling of the electrical properties of the transmission grid using open data, refer to [
10].
Figure 6a shows the power related completeness for the grid vertices, which represent, e.g., the electrical substations. The osmTGmod model has the highest completeness with
for both, the voltage information and the frequency information. The completeness for the SciGRID model is
for the voltage and
for the frequency information. This is due to the fact that in SciGRID missing information from OSM is not added. GridKit has a completeness of
for the voltage and
for the frequency information.
The results for the links are shown in
Figure 6b. For both the information on the voltage and the number of cables per transmission line, SciGRID and GridKit have a higher completeness than osmTGmod. Considering the frequency information, the osmTGmod model is most complete. The completeness of the information on the number of wires per transmission cable is approx.
for SciGRID and GridKit. For osmTGmod, no value is given in
Figure 6b, because the information on the wires was not directly obtained from OSM. Instead, in osmTGmod it is assumed that all 220 kV transmission lines have two wires per cable and all 380 kV lines have four wires per cable [
35]. Links having overall complete information account for
in osmTGmod,
in SciGRID and
in GridKit.
The higher power-related completeness of the osmTGmod and GridKit model in comparison to the SciGRID model can be explained as follows. The osmTGmod and GridKit approaches apply heuristics to complete the missing information, while SciGRID does not use heuristics.
4. Conclusions and Outlook
The qualitative comparison of the open source power grid modelling approaches SciGRID, GridKit and osmTGmod reported in this paper showed that they mainly differ in the OpenStreetMap data types used, as well as the applied heuristics. This leads to different numbers of nodes and edges in the resulting topologies. A novel approach was presented that combines a mathematical, geo-referenced and power-related comparison of power grid models. The results of the graph-theoretical analysis were highlighted in an interactive grid map. For the open source grid models considered in this study, the combined approach allows for sound interpretations of distinctive features, e.g., jumps in network criteria distributions.
These findings can help distinguish between features in the network distributions that are caused by the model derivation process and actual properties of the power grid. Such a primary stage analysis may be followed by a more advanced characterisation of the power grids, e.g., by searching for small-world properties [
23] or community detection [
11]. The results reported here also offer recommendations for improving grid model derivation methods. The GridKit approach creates auxiliary nodes and edges in order to derive the network model. As shown above, this has a strong influence on the network criteria distributions. We recommend that the algorithm be changed in order to avoid this, while maintaining the high degree of information completeness integrated from OpenStreetMap.
The comparison tool, AutoGridComp, which was developed for this study, is provided under an open source license. Thus, it can be used by other researchers in endeavours such as comparing open source power grid models with the official grid models of grid operators. Such a validation is required for assessing the positional accuracy [
36] and completeness [
37] of the OpenStreetMap data.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}