Prediction of Health-Related Leave Days among Workers in the Energy Sector by Means of Genetic Algorithms


 ,
,
Abstract
1. Introduction
2. Materials and Methods
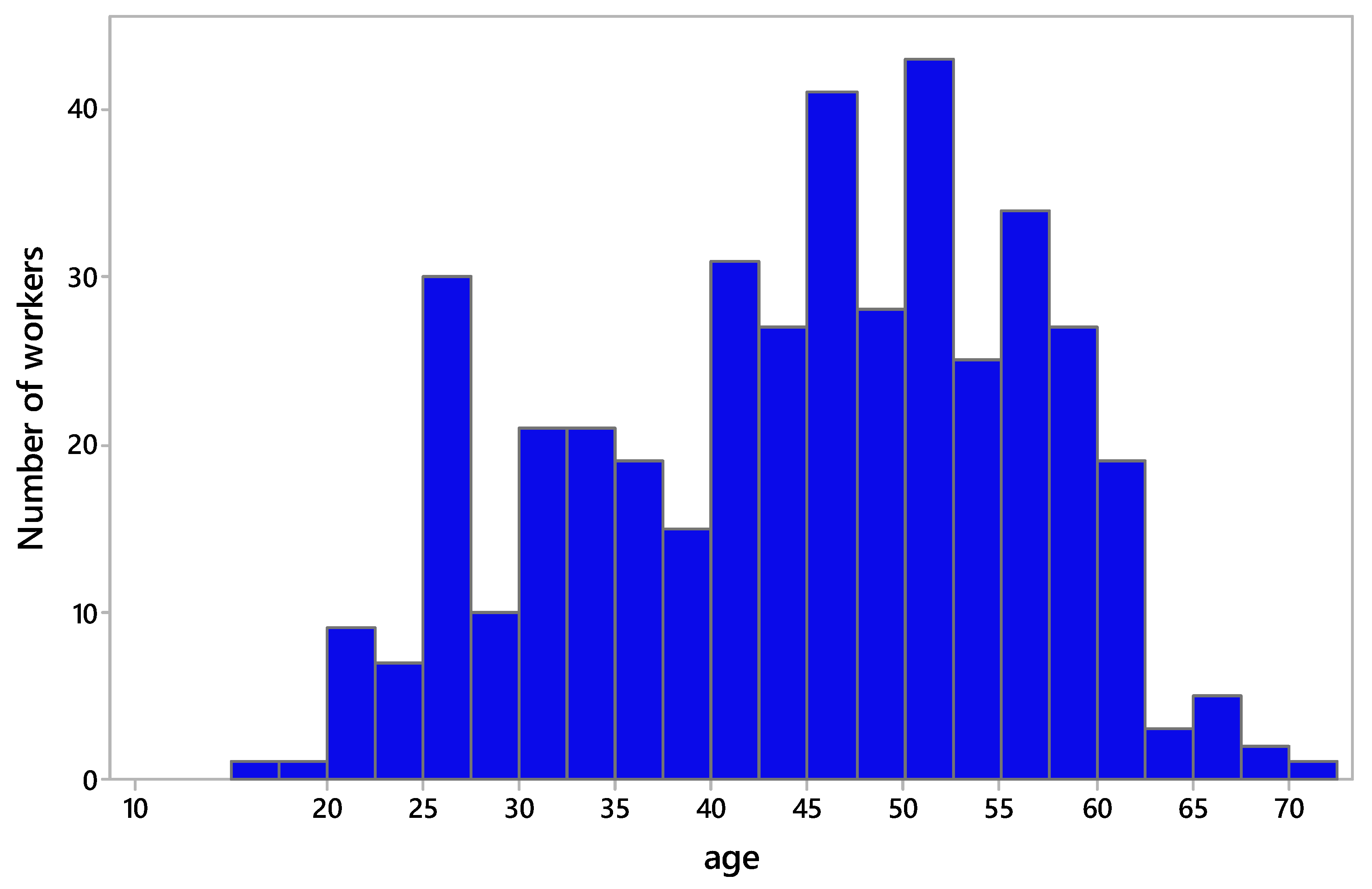
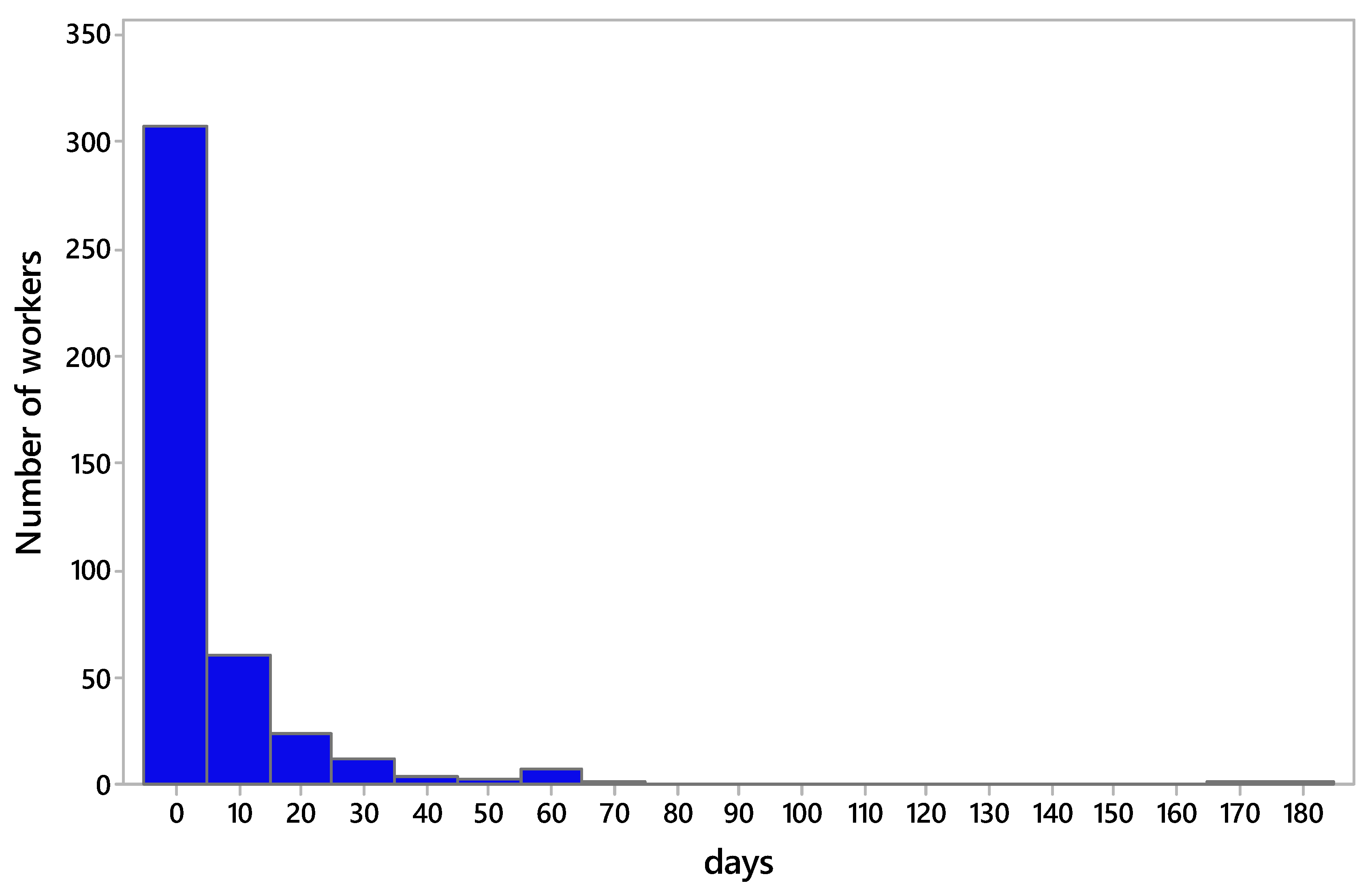
2.1. Dataset
2.2. Multivariate Linear Regression
2.3. Support Vector Machine for Regression
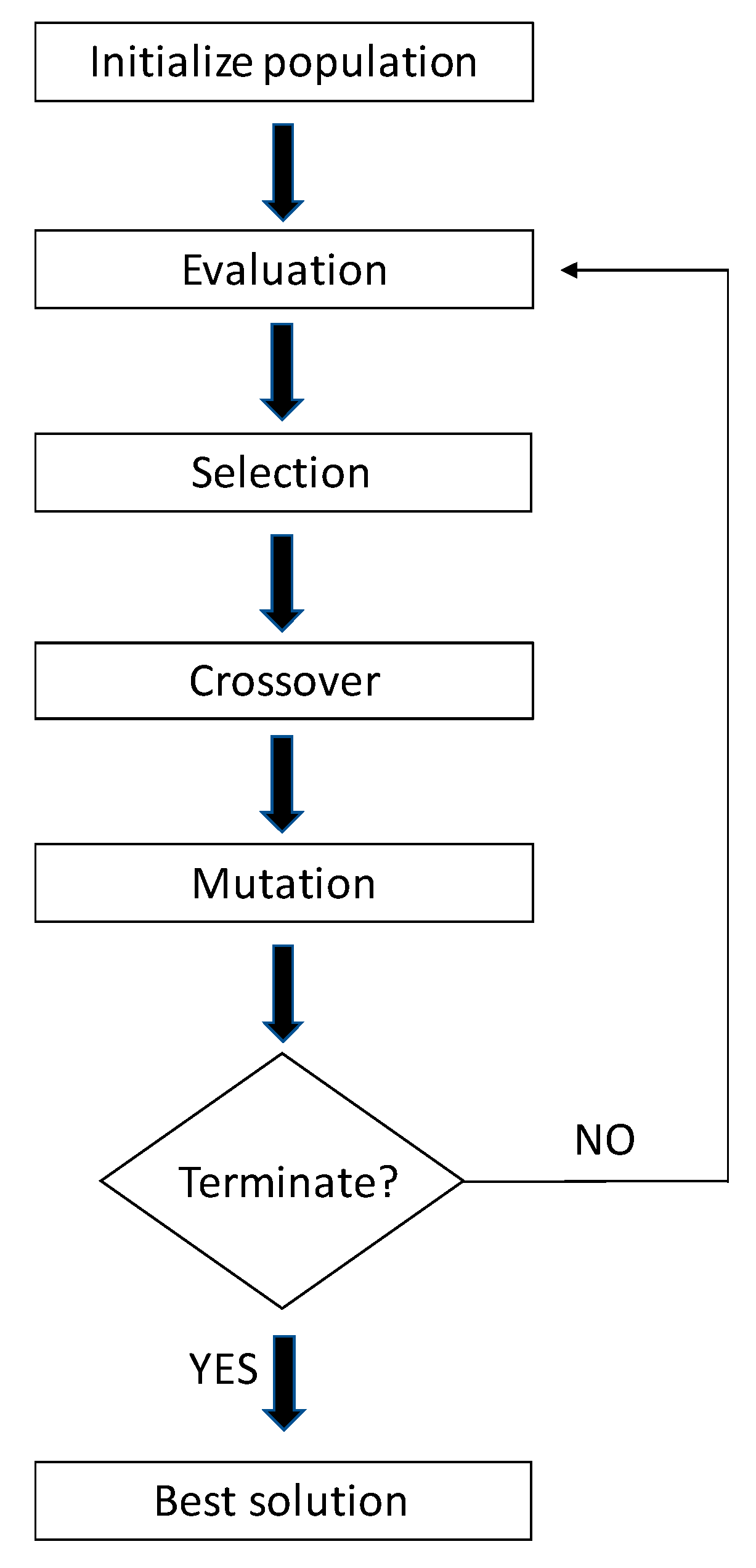
2.4. Genetic Algorithms
- Crossover;
- Mutation;
- Elitism.
2.5. Multivariate Adaptive Regression Splines
- nsubsets: this criterion indicates the number of model subsets that make use of the variable. The larger the number of subsets that include the variable, the more important they will be considered.
- gcv: this criterion calculates the generalized cross-validation (GCV) of the variables, and, taking into account the results, those variables that contribute most to increasing the GCV value are considered the most important.
- rss: this criterion can be considered equivalent to gcv, but making use of the residual sum of squares (RSS) expression.
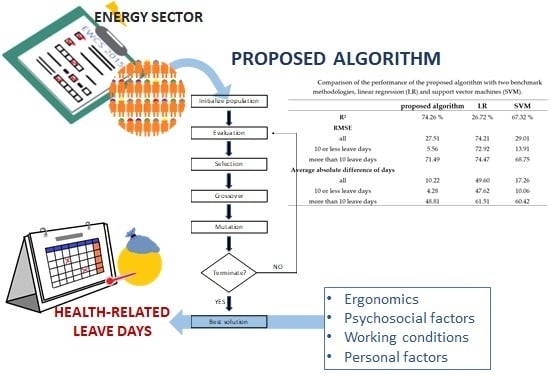
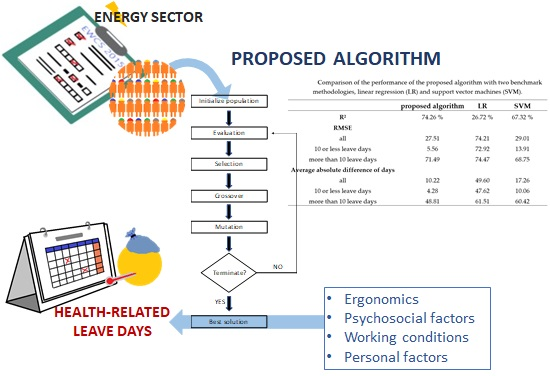
2.6. The Proposed Algorithm
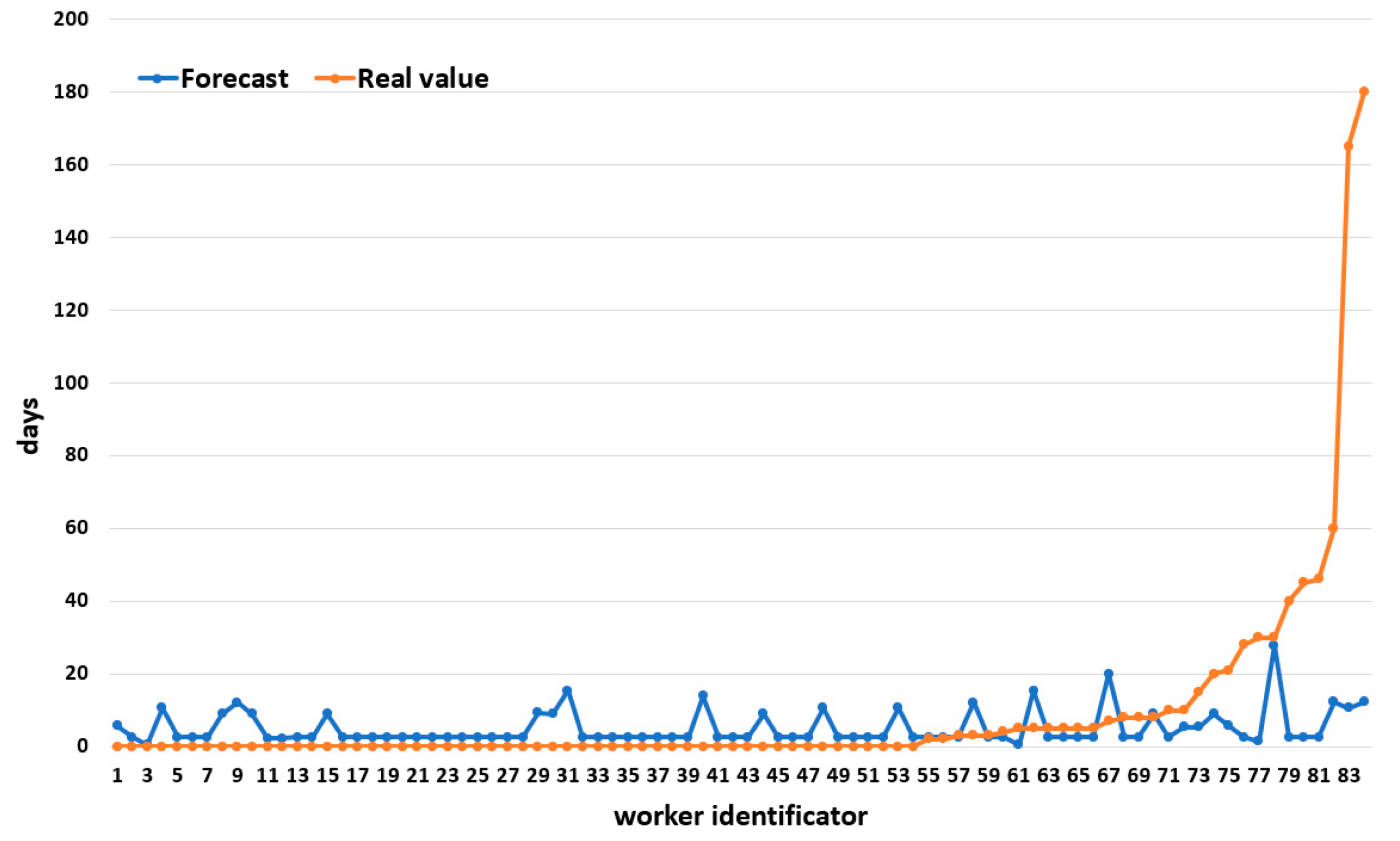
3. Results
4. Discussion
- Ergonomics;
- Psychosocial factors;
- Working conditions;
- Personal data and physiological characteristics.
4.1. Ergonomics
- Doing short repetitive tasks of less than 1 min.
- Doing monotonous tasks.
- Doing short repetitive tasks of less than 10 min.
- Suffering tiring or painful positions.
- Remaining seated for a long time.
4.2. Psychosocial Factors
4.3. Working Conditions
- Being satisfied with working conditions;
- Income;
- Restructuring or reorganization at the workplace;
- Working environment: smoke, fumes, powder and dust;
- Another paid job;
- Work affects health;
- Noise;
- Work hours/week;
- Working environment: low temperatures.
4.4. Personal Data and Physiological Characteristics
- Having headaches and eyestrain;
- Outside work: receiving training or education;
- General health status;
- Suffering a long-lasting illness;
- Age.
5. Conclusions
- Ergonomics;
- Psychosocial factors;
- Working conditions;
- Personal data and physiological characteristics.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Social Protection Statistics—Sickness and Health Care Benefits. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Social_protection_statistics_-_sickness_and_health_care_benefits#Relative_importance_of_expenditure_on_sickness_and_healthcare_benefits (accessed on 3 January 2020).
- European Comission. Sick Pay and Sickness Benefit Scheme in the European Union. Background Report for the Social Protection Committee’s. In-Depth Review on Sickness Benefits. Available online: https://ec.europa.eu/social/BlobServlet?docId=16969&langId=en (accessed on 3 January 2020).
- Oenning, N.; Carvalho, F.M.; Lima, V.M.C. Risk factors for absenteeism due to sick leave in the petroleum industry. Rev. Saúde Pública 2014, 48, 103–112. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Mitchell, R.; Williamson, A.M. Evaluation of an 8 hour versus a 12 hour shift roster on employees at a power station. Appl. Ergon. 2000, 31, 83–93. [Google Scholar] [CrossRef]
- Takahashi, M.; Tanigawa, T.; Tachibana, N.; Mutou, K.; Kage, Y.; Smith, L.; Iso, H. Modifying effects of perceived adaptation to shift work on health, wellbeing, and alertness on the job among nuclear power plant operators. Ind. Health 2005, 43, 171–178. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Murtezani, A.; Hundozi, H.; Orovcanec, N.; Berisha, M.; Meka, V. Low back pain predict sickness absence among power plant workers. Indian J. Occup. Environ. Med. 2010, 14, 49–53. [Google Scholar] [CrossRef]
- Hole, J.; Pande, M. Worker productivity, occupational health, safety and environmental issues in thermal power plant. In Proceedings of the 2009 IEEE International Conference on Industrial Engineering and Engineering Management, Hong Kong, China, 8–11 December 2009; Volume 8, pp. 1082–1086. [Google Scholar] [CrossRef]
- Sánchez, A.S.; Fernández, P.R.; Lasheras, F.S.; Juez, F.D.C.; Nieto, P.G. Prediction of work-related accidents according to working conditions using support vector machines. Appl. Math. Comput. 2011, 218, 3539–3552. [Google Scholar] [CrossRef]
- Krzemień, A. Dynamic fire risk prevention strategy in underground coal gasification processes by means of artificial neural networks. Arch. Min. Sci. 2019, 64, 3–19. [Google Scholar] [CrossRef]
- Krzemień, A. Fire risk prevention in underground coal gasification (UCG) within active mines: Temperature forecast by means of MARS models. Energy 2019, 170, 777–790. [Google Scholar] [CrossRef]
- Asensio-Cuesta, S.; Diego-Mas, J.A.; Alcaide-Marzal, J. Applying generalised feedforward neural networks to classifying industrial jobs in terms of risk of low back disorders. Int. J. Ind. Ergon. 2010, 40, 629–635. [Google Scholar] [CrossRef]
- Sánchez, A.S.; Iglesias-Rodríguez, F.; Fernández, P.R.; Juez, F.D.C. Applying the K-nearest neighbor technique to the classification of workers according to their risk of suffering musculoskeletal disorders. Int. J. Ind. Ergon. 2016, 52, 92–99. [Google Scholar] [CrossRef]
- Serrano, N.M.B.; Nieto, P.J.G.; Sánchez, A.S.; Lasheras, F.S.; Fernández, P.R. A Hybrid Algorithm for the Assessment of the Influence of Risk Factors in the Development of Upper Limb Musculoskeletal Disorders. In Lecture Notes in Computer Science; Springer Science and Business Media LLC: Philadelphia, PA, USA, 2018; pp. 634–646. [Google Scholar]
- Serrano, N.B.; Sánchez, A.S.; Lasheras, F.S.; Iglesias-Rodríguez, F.; Valverde, G.F. Identification of gender differences in the factors influencing shoulders, neck and upper limb MSD by means of multivariate adaptive regression splines (MARS). Appl. Ergon. 2019, 82, 102981. [Google Scholar] [CrossRef]
- Ríos, E.M.A.; Sáchez-Lasheras, F.; Sánchez, A.S.; Iglesias-Rodríguez, F.J.; Crespo, M.D.M.S. Prediction of Computer Vision Syndrome in Health Personnel by Means of Genetic Algorithms and Binary Regression Trees. Sensors 2019, 19, 2800. [Google Scholar] [CrossRef]
- Ríos, E.M.A.; Sánchez, A.S.; Sáchez-Lasheras, F.; Crespo, M.D.M.S. Genetic algorithm based on support vector machines for computer vision syndrome classification in health personnel. Neural Comput. Appl. 2018, 32, 1239–1248. [Google Scholar] [CrossRef]
- Eurofound (European Foundation for the Improvement of Living and Working Conditions). European Working Conditions Survey Integrated Data File, 1991–2015 [Data Collection], 7th ed.; UK Data Service: Colchester, UK, 2018. [Google Scholar]
- UKDS (UK Data Service) Website. Available online: https://www.ukdataservice.ac.uk/ (accessed on 30 March 2020).
- Eurofound. Sixth European Working Conditions Survey—Overview Report; Publications Office of the European Union: Luxembourg, 2016. [Google Scholar]
- Eurofound Website. EWCS 2015—Source Questionnaire. Available online: https://www.eurofound.europa.eu/sites/default/files/page/field_ef_documents/6th_ewcs_2015_final_source_master_questionnaire.pdf (accessed on 24 April 2020).
- Afifi, A.; Clark, V.; May, S. Computer-Aided Multivariate Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Bhattacharyya, H.T.; Kleinbaum, D.G.; Kupper, L.L. Applied Regression Analysis and Other Multivariable Methods. J. Am. Stat. Assoc. 1979, 74, 732. [Google Scholar] [CrossRef]
- Ordóñez, C.; Sáchez-Lasheras, F.; Roca-Pardiñas, J.; Juez, F.J.D.C. A hybrid ARIMA–SVM model for the study of the remaining useful life of aircraft engines. J. Comput. Appl. Math. 2019, 346, 184–191. [Google Scholar] [CrossRef]
- Juez, F.J.D.C.; Sáchez-Lasheras, F.; Roqueni, N.; Osborn, J. An ANN-Based Smart Tomographic Reconstructor in a Dynamic Environment. Sensors 2012, 12, 8895–8911. [Google Scholar] [CrossRef] [PubMed]
- Holland, J.H. Adaptation in Natural and Artificial Systems; MIT Press – Journals: Cambridge, MA, USA, 1992. [Google Scholar]
- Nieto, P.G.; Lasheras, F.S.; Juez, F.D.C.; Alonso-Fernández, J.R. Study of cyanotoxins presence from experimental cyanobacteria concentrations using a new data mining methodology based on multivariate adaptive regression splines in Trasona reservoir (Northern Spain). J. Hazard. Mater. 2011, 195, 414–421. [Google Scholar] [CrossRef]
- De Andrés, J.; Sánchez-Lasheras, F.; Lorca, P.; De Cos Juez, F.J. A hybrid device of Self Organizing Maps (SOM) and Multivariate Adaptive Regression Splines (MARS) for the forecasting of firms’ bankruptcy. Account. Manag. Inf. Syst. Contab. Inform. Gestiune 2011, 10, 351–374. [Google Scholar]
- Alonso-Fernández, J.R.; Muñiz, C.D.; Nieto, P.G.; Juez, F.D.C.; Lasheras, F.S.; Roqueni, N. Forecasting the cyanotoxins presence in fresh waters: A new model based on genetic algorithms combined with the MARS technique. Ecol. Eng. 2013, 53, 68–78. [Google Scholar] [CrossRef]
- Sprent, P.; Draper, N.R.; Smith, H. Applied Regression Analysis. Biomaterials 1981, 37, 863. [Google Scholar] [CrossRef]
- Jakus, D.; Čađenović, R.; Vasilj, J.; Sarajčev, P. Optimal Reconfiguration of Distribution Networks Using Hybrid Heuristic-Genetic Algorithm. Energies 2020, 13, 1544. [Google Scholar] [CrossRef]
- Krzywanski, J. A General Approach in Optimization of Heat Exchangers by Bio-Inspired Artificial Intelligence Methods. Energies 2019, 12, 4441. [Google Scholar] [CrossRef]
- Hallman, D.M.; Holtermann, A.; Björklund, M.; Gupta, N.; Rasmussen, C.D.N. Sick leave due to musculoskeletal pain: Determinants of distinct trajectories over 1 year. Int. Arch. Occup. Environ. Health 2019, 92, 1099–1108. [Google Scholar] [CrossRef] [PubMed]
- Benavides, F.G.; Benach, J.; Moncada, S.; Vahtera, J.; Kivimaki, M. Working conditions and sickness absence: A complex relation. J. Epidemiol. Community Health 2001, 55, 368. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Hellig, T.; Rick, V.; Stranzenbach, R.; Przybysz, P.; Mertens, A.; Brandl, C. Investigation of the Effectiveness of European Assembly Worksheet in Assessing Organizational Measures for MSD Risk Assessment. In Advances in Intelligent Systems and Computing; Springer Science and Business Media LLC: Philadelphia, PA, USA, 2017; Volume 602, pp. 229–235. [Google Scholar]
- Motamedzade, M.; Faghih, M.A.; Golmohammadi, R.; Faradmal, J.; Mohammadi, H. Effects of Physical and Personal Risk Factors on Sick Leave Due to Musculoskeletal Disorders. Int. J. Occup. Saf. Ergon. 2013, 19, 513–521. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Kemmlert, K. Economic impact of ergonomic intervention—Four case studies. J. Occup. Rehab. 1996, 6, 17–32. [Google Scholar] [CrossRef]
- Parenmark, G.; Malmkvist, A.-K.; Örtengren, R. Ergonomic moves in an engineering industry: Effects on sick leave frequency, labor turnover and productivity. Int. J. Ind. Ergon. 1993, 11, 291–300. [Google Scholar] [CrossRef]
- Farhadi, R.; Omidi, L.; Balabandi, S.; Barzegar, S.; Abbasi, A.L.; Poornajaf, A.H.; Karchani, M. Investigation of musculoskeletal disorders and its relevant factors using quick exposure check (QEC) method among Seymareh hydropower plant workers. J. Res. Health 2014, 4, 715–720. [Google Scholar]
- Mohanty, P.; Mohanty, S. Impact of Workplace Bullying on Performance, Psychological Distress and Absenteeism: An Original Review of Healthcare Sector. J. Econ. Perspect. 2017, 11, 1277–1286. [Google Scholar]
- Petrén, V.; Petzäll, K.; Preber, H.; Bergstrom, J. The relationship between working conditions and sick leave in Swedish dental hygienists. Int. J. Dent. Hyg. 2007, 5, 27–35. [Google Scholar] [CrossRef]
- Christmansson, M.; Fridén, J.; Sollerman, C. Task design, psycho-social work climate and upper extremity pain disorders—Effects of an organisational redesign on manual repetitive assembly jobs. Appl. Ergon. 1999, 30, 463–472. [Google Scholar] [CrossRef]
- Lee, L.-K.; Yang, S.-M.; Park, J.; Kim, J. The Effort of Health Management for Workers in Y Combined Cycle Power Plant in Korea. Toxicol. Environ. Health Sci. 2018, 10, 42–48. [Google Scholar] [CrossRef]
- Piha, K.; Laaksonen, M.; Martikainen, P.; Rahkonen, O.; Lahelma, E. Interrelationships between education, occupational class, income and sickness absence. Eur. J. Public Health 2009, 20, 276–280. [Google Scholar] [CrossRef] [PubMed]
- Hansen, A.C.; Selte, H.K. Air Pollution and Sick-leaves. Environ. Resour. Econ. 2000, 16, 31–50. [Google Scholar] [CrossRef]
- Lee, J.; Lee, W.; Choi, W.-J.; Kang, S.-K.; Ham, S. Association between Exposure to Extreme Temperature and Injury at the Workplace. Int. J. Environ. Res. Public Health 2019, 16, 4955. [Google Scholar] [CrossRef]
- Huijs, J.J.J.M.; Koppes, L.L.J.; Taris, T.W.; Blonk, R.W.B. Differences in Predictors of Return to Work Among Long-Term Sick-Listed Employees with Different Self-Reported Reasons for Sick Leave. J. Occup. Rehab. 2012, 22, 301–311. [Google Scholar] [CrossRef]
- Eriksen, W.; Bruusgaard, D. Physical Leisure-Time Activities and Long-Term Sick Leave: A 15-Month Prospective Study of Nurses Aides. J. Occup. Environ. Med. 2002, 44, 530–538. [Google Scholar] [CrossRef]
- Hildebrandt, V.H.; Bongers, P.M.; Dul, J.; Van Dijk, F.J.H.; Kemper, H.C.G. The relationship between leisure time, physical activities and musculoskeletal symptoms and disability in worker populations. Int. Arch. Occup. Environ. Health 2000, 73, 507–518. [Google Scholar] [CrossRef]
- Montano, D. A psychosocial theory of sick leave put to the test in the European Working Conditions Survey 2010–2015. Int. Arch. Occup. Environ. Health 2019, 93, 229–242. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Number of Workers | % |
|---|---|---|
| Norway | 35 | 8.3% |
| Albania | 26 | 6.2% |
| Slovenia | 25 | 6.0% |
| Serbia | 25 | 6.0% |
| Spain | 22 | 5.2% |
| Belgium | 18 | 4.3% |
| United Kingdom | 17 | 4.0% |
| Croatia | 17 | 4.0% |
| Montenegro | 17 | 4.0% |
| Czech Republic | 15 | 3.6% |
| Poland | 14 | 3.3% |
| Bulgaria | 13 | 3.1% |
| Germany | 13 | 3.1% |
| France | 12 | 2.9% |
| Romania | 12 | 2.9% |
| Denmark | 11 | 2.6% |
| Lithuania | 11 | 2.6% |
| Austria | 11 | 2.6% |
| Estonia | 10 | 2.4% |
| Other countries * | 76 | 18.1% |
| Total | 420 |
| Level of Studies (ISCED) | Number of Workers | % |
|---|---|---|
| Early childhood education | 1 | 0.2% |
| Primary education | 1 | 0.2% |
| Lower secondary education | 39 | 9.3% |
| Upper secondary education | 185 | 44.0% |
| Post-secondary non-tertiary education | 23 | 5.5% |
| Short-cycle tertiary education | 54 | 12.9% |
| Bachelor or equivalent | 52 | 12.4% |
| Master or equivalent | 63 | 15.0% |
| Doctorate or equivalent | 2 | 0.5% |
| Total | 420 |
| Is Your Household Able to Make Ends Meet? | Number of Workers | % |
|---|---|---|
| Very easily | 55 | 13.1% |
| Easily | 101 | 24.0% |
| Fairly easily | 121 | 28.8% |
| With some difficulty | 104 | 24.8% |
| With difficulty | 30 | 7.1% |
| With great difficulty | 9 | 2.1% |
| Total | 420 |
| Performance Metric | Proposed Algorithm | LR | SVM |
|---|---|---|---|
| R2 | 74.26% | 26.72% | 67.32% |
| RMSE | |||
| all | 27.51 | 74.21 | 29.01 |
| 10 or less leave days | 5.56 | 72.92 | 13.91 |
| more than 10 leave days | 71.49 | 74.47 | 68.75 |
| Average absolute difference of days | |||
| all | 10.22 | 49.60 | 17.26 |
| 10 or less leave days | 4.28 | 47.62 | 10.06 |
| more than 10 leave days | 48.81 | 61.51 | 60.42 |
| Variable | Nsubsets 1 | gcv 2 | rss 3 | Description |
|---|---|---|---|---|
| y15_Q48a | 30 | 100 | 100 | Short repetitive tasks of less than 1 min |
| y15_Q88 | 30 | 100 | 100 | Satisfied with working conditions |
| y15_Q100 | 30 | 100 | 100 | Income |
| y15_Q20 | 29 | 90.3 | 91.0 | Restructuring or reorganization at the workplace |
| y15_Q53d | 29 | 90.3 | 91.0 | Monotonous tasks |
| y15_Q78f | 29 | 90.3 | 91.0 | Headaches, eyestrain |
| y15_Q95f | 27 | 81.7 | 82.5 | Outside work: taking a training or education |
| y15_Q75 | 24 | 62.6 | 65.2 | General health status |
| y15_Q48b | 19 | 45.6 | 49.4 | Short repetitive tasks of less than 10 min |
| y15_Q30a | 18 | 41.7 | 46.0 | Tiring or painful positions |
| y15_Q30h | 17 | 38.5 | 43.2 | Being in situations that are emotionally disturbing |
| y15_Q76 | 17 | 38.5 | 43.2 | Long-lasting illness |
| y15_Q29e | 15 | 34.8 | 39.3 | Smoke, fumes, powder, dust |
| y15_Q30d | 14 | 30.9 | 36.2 | Sitting |
| y15_Q27_lt | 13 | 27.9 | 33.6 | Other paid job |
| y15_Q74 | 12 | 24.8 | 31.0 | Work affects health |
| y15_Q29b | 9 | 15.9 | 23.9 | Noise |
| y15_Q24 | 8 | 13.9 | 22.0 | Work hours/week |
| y15_Q29d | 5 | 13.4 | 18.2 | Low temperatures |
| y15_Q2b | 4 | 11.2 | 15.9 | Age |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
González Fuentes, A.; Busto Serrano, N.M.; Sánchez Lasheras, F.; Fidalgo Valverde, G.; Suárez Sánchez, A. Prediction of Health-Related Leave Days among Workers in the Energy Sector by Means of Genetic Algorithms. Energies 2020, 13, 2475. https://doi.org/10.3390/en13102475
González Fuentes A, Busto Serrano NM, Sánchez Lasheras F, Fidalgo Valverde G, Suárez Sánchez A. Prediction of Health-Related Leave Days among Workers in the Energy Sector by Means of Genetic Algorithms. Energies. 2020; 13(10):2475. https://doi.org/10.3390/en13102475
Chicago/Turabian StyleGonzález Fuentes, Aroa, Nélida M. Busto Serrano, Fernando Sánchez Lasheras, Gregorio Fidalgo Valverde, and Ana Suárez Sánchez. 2020. "Prediction of Health-Related Leave Days among Workers in the Energy Sector by Means of Genetic Algorithms" Energies 13, no. 10: 2475. https://doi.org/10.3390/en13102475
APA StyleGonzález Fuentes, A., Busto Serrano, N. M., Sánchez Lasheras, F., Fidalgo Valverde, G., & Suárez Sánchez, A. (2020). Prediction of Health-Related Leave Days among Workers in the Energy Sector by Means of Genetic Algorithms. Energies, 13(10), 2475. https://doi.org/10.3390/en13102475