Robustness of Short-Term Wind Power Forecasting against False Data Injection Attacks


Abstract
:1. Introduction
- A false data injection attack approach against wind power forecasting is first developed where the attacker can inject any amount of malicious data into wind data without being detected by the least-squares-based anomaly detection tool.
- The Monte Carlo simulation framework is established to simulate false data injection attacks on wind power data and meteorological data. The Monte Carlo simulation framework can be utilized to evaluate the robustness of any wind power forecasting models.
- It benchmarks the accuracy of six representative wind power forecasting approaches (including three deterministic ones and three probabilistic ones) under different attack intensities and different attack targets (including wind power data and meteorological data).
2. Cyber Attack Scenarios on Wind Energy Management System
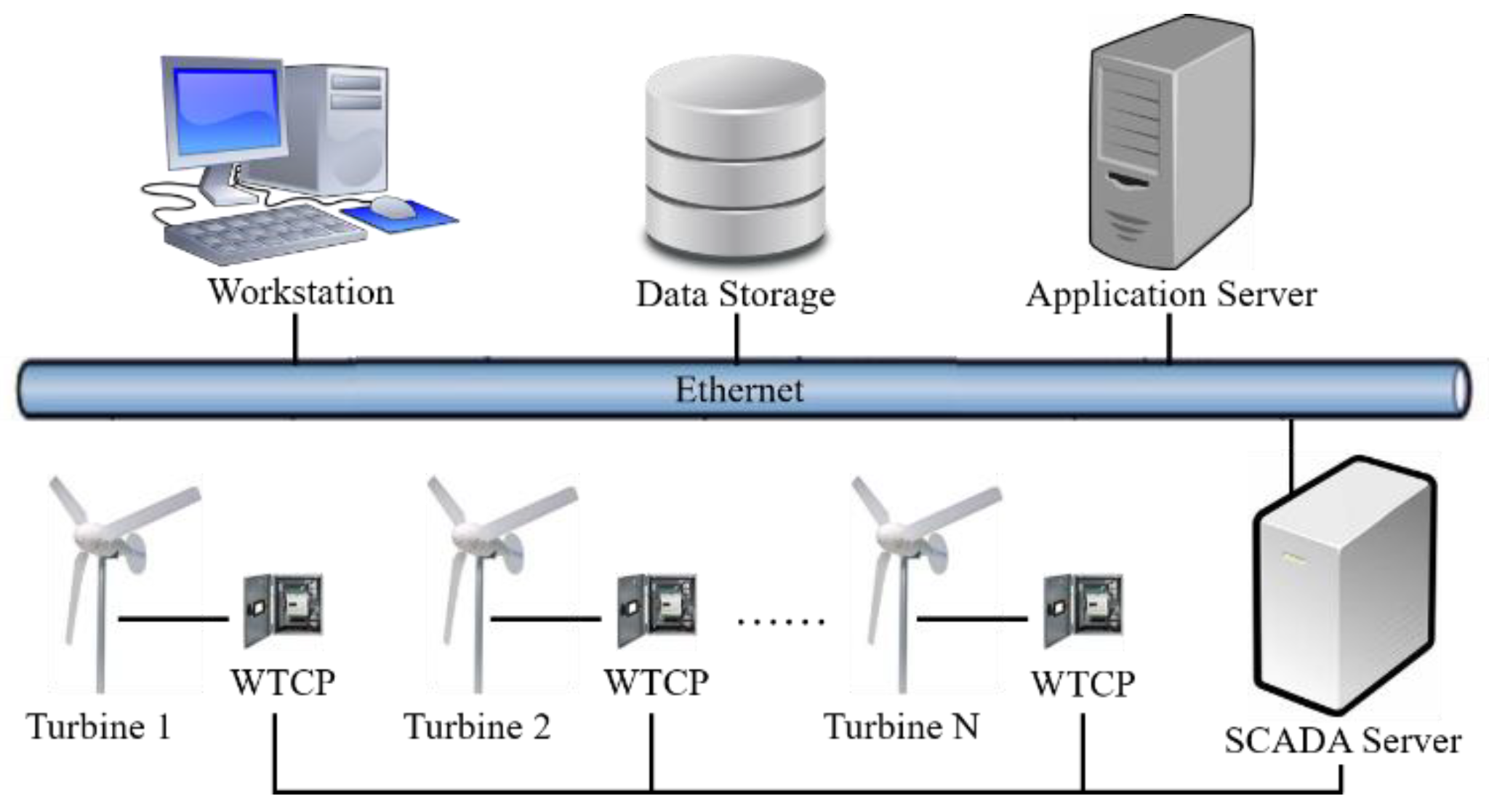
2.1. Architecture of Wind Farm SCADA/EMS System
2.2. Credible False Data Attack Scenarios
2.2.1. Scenario I: Attack on WTCP
2.2.2. Scenario II: Attack on Optical Fiber Cables
2.2.3. Scenario III: Attack on SCADA/EMS Servers
3. False Data Injection Attack against Wind Power Forecasting
3.1. Least-Squares-Based Anomaly Detection Technique
3.2. False Data Injection Attack Approach
- for (the attacker cannot inject errors into elements that cannot be accessed).
- ( is a linear combination of column vectors of ).
3.3. False Data Attack on Wind Power Data
3.4. False Data Attack on Meteorological Data
4. Wind Power Forecasting Models
4.1. Deterministic Forecasting Models
4.1.1. Multiple Nonlinear Regression (MNR)
4.1.2. Artificial Neural Network (ANN)
4.1.3. Support Vector Machine (SVM)
4.2. Probabilistic Forecasting Models
4.2.1. Quantile Regression (QR)
4.2.2. Quantile Regression Neural Network (QRNN)
4.2.3. K-Nearest Neighbors (KNN) and Kernel Density Estimator (KDE)
5. Robustness Assessment Framework of Wind Power Forecasting Model
5.1. Accuracy Evaluation of Wind Power Forecasting
5.2. Robustness Assessment Framework
- Step 1.a:
- Given all training samples , construct the design matrix and the design vector . Then, calculate according to Theorem 2.
- Step 1.b:
- Initialize the iteration counter, . Set the tolerance . Suppose that the attacker injects malicious data into % of the original data (). The number of the attacked data is .
- Step 2.a:
- Update the iteration counter . Randomly select elements (from elements) as the attack target. Their indexes are .
- Step 2.b:
- Construct a -by- matrix . Randomly generate a -dimensional non-zero vector . Then, calculate .
- Step 2.c:
- Construct the attack vector by filling the element of into the corresponding position of (i.e.,) and filling 0 into the remaining position of .
- Step 2.d:
- Inject the attack vector into the training dataset and then obtain the malicious data .
- Step 2.e:
- Use the training dataset ( and ) to train one of six wind power forecasting models (MNR, ANN, SVM, QR, QRNN, or KNN-KDE).
- Step 2.f:
- Evaluate the forecasting model and tune the model hyperparameters on the validation dataset. Then, we can obtain the final forecasting model.
- Step 3.a:
- Evaluate the forecast error (RMSE or QS) on the test dataset.
- Step 3.b:
- Collect all forecast errors up to the current iteration (), calculate the variance coefficient :
- Step 3.c:
- If , then terminate with the final forecast error being the average error of all iterations, i.e., . Otherwise, return to Step 2.
6. Data and Model Setup
6.1. GEFCom2014 Data
6.2. Setup of Deterministic Forecasting Models
6.3. Setup of Probabilistic Forecasting Models
- “DAY”, the day of a year (0, 1, …, 364);
- “HOUR”, the time of a day (0, 1, …, 23);
- “WS100”, wind speed prediction at 100m from NWP;
- “WP”, wind power prediction from MNR.
7. Numerical Results
7.1. Results of Deterministic Forecasting
7.1.1. Case I: Varying the Percentage of Injected False Data
7.1.2. Case II: False Data Attacks on Input Variable “WS100”
7.1.3. Case III: Varying the Number of Training Samples
7.2. Results of Probabilistic Forecasting
7.2.1. Case I: Varying the Percentage of Injected False Data
7.2.2. Case II: False Data Attacks on Input Variable “WS100”
7.2.3. Case III: Varying the Number of Training Samples
8. Conclusions
- Among three deterministic forecasting approaches, SVM and ANN demonstrate stronger robustness than MNR. Among three probabilistic forecasting models, KNN-KDE is the most robust one followed by QRNN and QR.
- None of six representative approaches are robust enough to provide accurate wind power forecasting (either deterministic or probabilistic results) under very strong false data attacks.
- Compared with attacking meteorological data, attacking wind power data can make greater influence on the accuracy of either deterministic or probabilistic forecasting. Therefore, it is imperative to protect wind power data for improving the cyber security of wind power forecasting.
- Increasing the number of training samples may be one of the easiest ways to improve the robustness of wind power forecasting models. In such way, the proportion of false data to normal data decreases and thus it will be much difficult for attackers to affect the accuracy of wind power forecasting models.
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Sridhar, S.; Hahn, A.; Govindarasu, M. Cyber–physical system security for the electric power grid. Proc. IEEE 2011, 100, 210–224. [Google Scholar] [CrossRef]
- Liang, G.; Weller, S.R.; Zhao, J.; Luo, F.; Dong, Z.Y. The 2015 ukraine blackout: Implications for false data injection attacks. IEEE Trans. Power Syst. 2016, 32, 3317–3318. [Google Scholar] [CrossRef]
- Ten, C.W.; Liu, C.C.; Manimaran, G. Vulnerability assessment of cybersecurity for SCADA systems. IEEE Trans. Power Syst. 2008, 23, 1836–1846. [Google Scholar] [CrossRef]
- Xie, L.; Gu, Y.; Zhu, X.; Genton, M.G. Short-term spatio-temporal wind power forecast in robust look-ahead power system dispatch. IEEE Trans. Smart Grid 2013, 5, 511–520. [Google Scholar] [CrossRef]
- Pinson, P.; Chevallier, C.; Kariniotakis, G.N. Trading wind generation from short-term probabilistic forecasts of wind power. IEEE Trans. Power Syst. 2007, 22, 1148–1156. [Google Scholar] [CrossRef] [Green Version]
- Matos, M.A.; Bessa, R.J. Setting the operating reserve using probabilistic wind power forecasts. IEEE Trans. Power Syst. 2010, 26, 594–603. [Google Scholar] [CrossRef]
- Luo, J.; Hong, T.; Fang, S.-C. Benchmarking robustness of load forecasting models under data integrity attacks. Int. J. Forecast. 2018, 34, 89–104. [Google Scholar] [CrossRef]
- Luo, J.; Hong, T.; Yue, M. Real-time anomaly detection for very short-term load forecasting. J. Mod. Power Syst. Clean Energy 2018, 6, 235–243. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.; Hong, T.; Fang, S. Robust regression models for load forecasting. IEEE Trans. Smart Grid 2019, 10, 5397–5404. [Google Scholar] [CrossRef]
- Cui, M.; Wang, J.; Yue, M. Machine learning based anomaly detection for load forecasting under cyberattacks. IEEE Trans. Smart Grid 2019, 10, 5724–5734. [Google Scholar] [CrossRef]
- Yue, M.; Hong, T.; Wang, J. Descriptive analytics based anomaly detection for cybersecure load forecasting. IEEE Trans. Smart Grid 2019, 10, 5964–5974. [Google Scholar] [CrossRef]
- Zheng, R.; Gu, J.; Jin, Z.; Peng, H.; Zhu, Y. Load forecasting under data corruption based on anomaly detection and combined robust regression. Int. Trans. Electr. Energy Syst. 2019. [Google Scholar] [CrossRef]
- Chen, Y.; Tan, Y.; Zhang, B. Exploiting vulnerabilities of load forecasting through adversarial attacks. In Proceedings of the 2019 ACM International Conference on Future Energy Systems, Phoenix, AZ, USA, 25–28 June 2019; pp. 1–11. [Google Scholar]
- Ma, L.; Luan, S.Y.; Jiang, C.W.; Liu, H.L.; Zhang, Y. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar]
- Foley, A.M.; Leahy, P.G.; Marvuglia, A.; McKeogh, E.J. Current methods and advances in forecasting of wind power generation. Renew. Energy 2012, 37, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Potter, C.W.; Negnevitsky, M. Very short-term wind forecasting for Tasmanian power generation. IEEE Trans. Power Syst. 2006, 21, 965–972. [Google Scholar] [CrossRef]
- Costa, A.; Crespo, A.; Navarro, J.; Lizcano, G.; Madsen, H.; Feitosa, E. A review on the young history of the wind power short-term prediction. Renew. Sustain. Energy Rev. 2008, 12, 1725–1744. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.Z.; Qin, S.S.; Zhou, Q.P.; Jiang, H.Y. Medium-term wind speeds forecasting utilizing hybrid models for three different sites in Xinjiang, China. Renew. Energy 2015, 76, 91–101. [Google Scholar] [CrossRef]
- Bludszuweit, H.; Dominguez-Navarro, J.A.; Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Cassola, F.; Burlando, M. Wind speed and wind energy forecast through Kalman filtering of Numerical Weather Prediction model output. Appl. Energy 2012, 99, 154–166. [Google Scholar] [CrossRef]
- Sideratos, G.; Hatziargyriou, N.D. An advanced statistical method for wind power forecasting. IEEE Trans. Power Syst. 2007, 22, 258–265. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Torres, J.L.; Garcia, A.; de Blas, M.; de Francisco, A. Forecast of hourly average wind speed with ARMA models in Navarre (Spain). Sol. Energy 2005, 79, 65–77. [Google Scholar] [CrossRef]
- Kariniotakis, G.; Stavrakakis, G.; Nogaret, E. Wind power forecasting using advanced neural networks models. IEEE Trans. Energy Convers. 1996, 11, 762–767. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]
- Liu, Y.; Shi, J.; Yang, Y.; Lee, W.-J. Short-term wind-power prediction based on wavelet transform–support vector machine and statistic-characteristics analysis. IEEE Trans. Ind. Appl. 2012, 48, 1136–1141. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.Y.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Convers. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Uzunoglu, M. A review of combined approaches for prediction of short-term wind speed and power. Renew. Sustain. Energy Rev. 2014, 34, 243–254. [Google Scholar] [CrossRef]
- Bremnes, J.B. Probabilistic wind power forecasts using local quantile regression. Wind Energy 2004, 7, 47–54. [Google Scholar] [CrossRef]
- Bessa, R.J.; Miranda, V.; Botterud, A.; Zhou, Z.; Wang, J. Time-adaptive quantile-copula for wind power probabilistic forecasting. Renew. Energy 2012, 40, 29–39. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J. K-nearest neighbors and a kernel density estimator for GEFCom2014 probabilistic wind power forecasting. Int. J. Forecast. 2016, 32, 1074–1080. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, W.; Liu, C.; Wang, Z.; Hou, Y. Probabilistic forecast for multiple wind farms based on regular vine copulas. IEEE Trans. Power Syst. 2017, 33, 578–589. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, M.; Wan, C.; Wang, J.; Song, Y. A multi-model combination approach for probabilistic wind power forecasting. IEEE Trans. Sustain. Energy 2018, 10, 226–237. [Google Scholar] [CrossRef]
- Yan, J.; Zhang, H.; Liu, Y.; Han, S.; Li, L.; Lu, Z. Forecasting the high penetration of wind power on multiple scales using multi-to-multi mapping. IEEE Trans. Power Syst. 2018, 33, 3276–3284. [Google Scholar] [CrossRef]
- Khorramdel, B.; Chung, C.Y.; Safari, N.; Price, G.C.D. A Fuzzy Adaptive Probabilistic Wind Power Prediction Framework Using Diffusion Kernel Density Estimators. IEEE Trans. Power Syst. 2019, 33, 7109–7121. [Google Scholar] [CrossRef]
- Bulbul, R.; Sapkota, P.; Ten, C.; Wang, L.; Ginter, A. Intrusion Evaluation of Communication Network Architectures for Power Substations. IEEE Trans. Power Deliv. 2015, 30, 1372–1382. [Google Scholar] [CrossRef]
- Wang, C.; Ten, C.; Hou, Y. Inference of Compromised Synchrophasor Units Within Substation Control Networks. IEEE Trans. Smart Grid 2018, 9, 5831–5842. [Google Scholar] [CrossRef]
- Yan, J.; Liu, C.; Govindarasu, M. Cyber intrusion of wind farm SCADA system and its impact analysis. In Proceedings of the 2011 IEEE/PES Power Systems Conference and Exposition, Phoenix, AZ, USA, 20–23 March 2011; pp. 1–6. [Google Scholar]
- Zhang, Y.; Xiang, Y.; Wang, L. Power System Reliability Assessment Incorporating Cyber Attacks Against Wind Farm Energy Management Systems. IEEE Trans. Smart Grid 2017, 8, 2343–2357. [Google Scholar] [CrossRef]
- Zabetian-Hosseini, A.; Mehrizi-Sani, A.; Liu, C. Cyberattack to Cyber-Physical Model of Wind Farm SCADA. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 4929–4934. [Google Scholar]
- Wang, C.; Hou, Y.; Ten, C. Determination of Nash Equilibrium Based on Plausible Attack-Defense Dynamics. IEEE Trans. Power Syst. 2017, 32, 3670–3680. [Google Scholar] [CrossRef]
- Brier, E.; Naccache, D.; Paillier, P. Chemical Combinatorial Attacks on Keyboards; IACR Cryptology ePrint Archive: Las Vegas, NV, USA, 2003. [Google Scholar]
- Iqbal, M.Z.; Fathallah, H.; Belhadj, N. Optical fiber tapping: Methods and precautions. In Proceedings of the 8th International Conference on High-capacity Optical Networks and Emerging Technologies, Riyadh, Saudi Arabia, 19–21 December 2011; pp. 164–168. [Google Scholar]
- Wang, Y.; Infield, D.G.; Stephen, B.; Galloway, S.J. Copula-based model for wind turbine power curve outlier rejection. Wind Energy 2014, 17, 1677–1688. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.; Lu, Z.; Qiao, Y.; Min, Y.; O’Malley, M. Identification and correction of outliers in wind farm time series power data. IEEE Trans. Power Syst. 2016, 31, 4197–4205. [Google Scholar] [CrossRef]
- Long, H.; Sang, L.; Wu, Z.; Gu, W. Image-based Abnormal Data Detection and Cleaning Algorithm via Wind Power Curve. IEEE Trans. Sustain. Energy 2019. [Google Scholar] [CrossRef]
- Wan, Y.; Milligan, M.; Parsons, B. Output power correlation between adjacent wind power plants. J. Sol. Energy Eng. 2003, 125, 551–555. [Google Scholar] [CrossRef]
- Zhao, Y.; Ye, L.; Wang, W.; Sun, H.; Ju, Y.; Tang, Y. Data-driven correction approach to refine power curve of wind farm under wind curtailment. IEEE Trans. Sustain. Energy 2017, 9, 95–105. [Google Scholar] [CrossRef]
- Chen, J.; Li, W.; Lau, A.; Cao, J.; Wang, K. Automated load curve data cleansing in power systems. IEEE Trans. Smart Grid 2010, 1, 213–221. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Li, W.; Lau, A.; Inga-Rojas, T.; Wang, K. Detecting X-outliers in load curve data in power systems. IEEE Trans. Power Syst. 2011, 27, 875–884. [Google Scholar] [CrossRef]
- Akouemo, H.N.; Povinelli, R.J. Probabilistic anomaly detection in natural gas time series data. Int. J. Forecast. 2016, 32, 948–956. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Hong, T. GEFCom2014 probabilistic electric load forecasting: An integrated solution with forecast combination and residual simulation. Int. J. Forecast. 2016, 32, 1012–1016. [Google Scholar] [CrossRef]
- Liu, Y.; Ning, P.; Reiter, M.K. False data injection attacks against state estimation in electric power grids. ACM Trans. Inf. Syst. Secur. 2011, 14, 13–33. [Google Scholar] [CrossRef]
- Meyer, C.D. Matrix Analysis and Applied Linear Algebra; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar]
- Koenker, R.; Hallock, K.F. Quantile regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Wei, J.; Zhang, Y.; Wang, J.; Cao, X.; Khan, M.A. Multi-period planning of multi-energy microgrid with multi-type uncertainties using chance constrained information gap decision method. Appl. Energy 2020, 260, 114188. [Google Scholar] [CrossRef]
- Li, Q.; Wang, J.; Zhang, Y.; Fan, Y.; Bao, G.; Wang, X. Multi-period generation expansion planning for sustainable power systems to maximize the utilization of renewable energy source. Sustainability 2020, 12, 1083. [Google Scholar] [CrossRef] [Green Version]
- Taylor, J.W. A quantile regression neural network approach to estimating the conditional density of multiperiod returns. J. Forecast. 2000, 19, 299–311. [Google Scholar] [CrossRef]
- Rubinstein, R.Y.; Kroese, D.P. Simulation and the Monte Carlo Method; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE (Deterministic Forecasts) | QS (Probabilistic Forecasts) | |||||
|---|---|---|---|---|---|---|
| MNR | ANN | SVM | QR | QRNN | KNN-KDE | |
| 01 | 19.563 | 17.671 | 17.533 | 5.598 | 3.647 | 3.653 |
| 02 | 15.566 | 14.586 | 14.354 | 4.516 | 3.883 | 4.036 |
| 03 | 16.946 | 14.746 | 13.795 | 5.015 | 4.004 | 4.012 |
| 04 | 16.725 | 16.034 | 16.276 | 4.486 | 4.203 | 4.065 |
| 05 | 16.512 | 16.386 | 16.133 | 4.586 | 4.190 | 4.203 |
| 06 | 18.743 | 18.569 | 17.308 | 5.105 | 4.451 | 4.430 |
| 07 | 14.355 | 14.136 | 13.345 | 4.054 | 3.863 | 3.795 |
| 08 | 17.774 | 17.444 | 16.895 | 4.863 | 4.481 | 4.557 |
| 09 | 15.680 | 16.483 | 15.807 | 4.505 | 4.124 | 3.997 |
| 10 | 19.878 | 19.055 | 19.315 | 5.605 | 5.262 | 5.057 |
| Avg. | 17.174 | 16.511 | 16.076 | 4.833 | 4.211 | 4.180 |
| 18 Months | 14 Months | 10 Months | 6 Months | |
|---|---|---|---|---|
| 0% | 16.588 | 16.491 (0.58%) | 16.649 (−0.96%) | 17.426 (−4.67%) |
| 20% | 16.835 | 16.827 (0.05%) | 16.891 (−0.38%) | 17.947 (−6.25%) |
| 40% | 17.443 | 17.425 (0.10%) | 17.543 (−0.68%) | 19.255 (−9.76%) |
| 60% | 18.523 | 18.520 (0.02%) | 18.683 (−0.88%) | 21.467 (−14.9%) |
| 80% | 19.691 | 19.656 (0.18%) | 19.823 (−0.85%) | 23.413 (−18.1%) |
| 100% | 20.755 | 20.748 (0.03%) | 20.897 (−0.72%) | 25.241 (−20.8%) |
| 25% | 50% | 75% | 100% | |
|---|---|---|---|---|
| QR | 4.941 | 5.186 | 5.619 | 6.116 |
| QRNN | 4.330 | 4.609 | 5.196 | 5.850 |
| KNN-KDE | 4.293 | 4.557 | 5.047 | 5.533 |
| 0% | 25% | 50% | 75% | 100% | |
|---|---|---|---|---|---|
| QR | 4.833 | 4.841 (0.16%) | 4.862 (0.60%) | 4.900 (1.39%) | 4.959 (2.61%) |
| QRNN | 4.208 | 4.216 (0.20%) | 4.215 (0.14%) | 4.218 (0.24%) | 4.224 (0.38%) |
| KNN-KDE | 4.185 | 4.185 (0.00%) | 4.186 (0.02%) | 4.189 (0.10%) | 4.193 (0.19%) |
| QR | QRNN | KNN-KDE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 18M | 6M | ROC | 18M | 6M | ROC | 18M | 6M | ROC | |
| 100% | 6.119 | 7.795 | −27.39% | 5.859 | 7.696 | −31.35% | 5.541 | 6.489 | −17.11% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lin, F.; Wang, K. Robustness of Short-Term Wind Power Forecasting against False Data Injection Attacks. Energies 2020, 13, 3780. https://doi.org/10.3390/en13153780
Zhang Y, Lin F, Wang K. Robustness of Short-Term Wind Power Forecasting against False Data Injection Attacks. Energies. 2020; 13(15):3780. https://doi.org/10.3390/en13153780
Chicago/Turabian StyleZhang, Yao, Fan Lin, and Ke Wang. 2020. "Robustness of Short-Term Wind Power Forecasting against False Data Injection Attacks" Energies 13, no. 15: 3780. https://doi.org/10.3390/en13153780