Fault Prognostics for Photovoltaic Inverter Based on Fast Clustering Algorithm and Gaussian Mixture Model



Abstract
:1. Introduction
2. PV Inverter Condition Monitoring
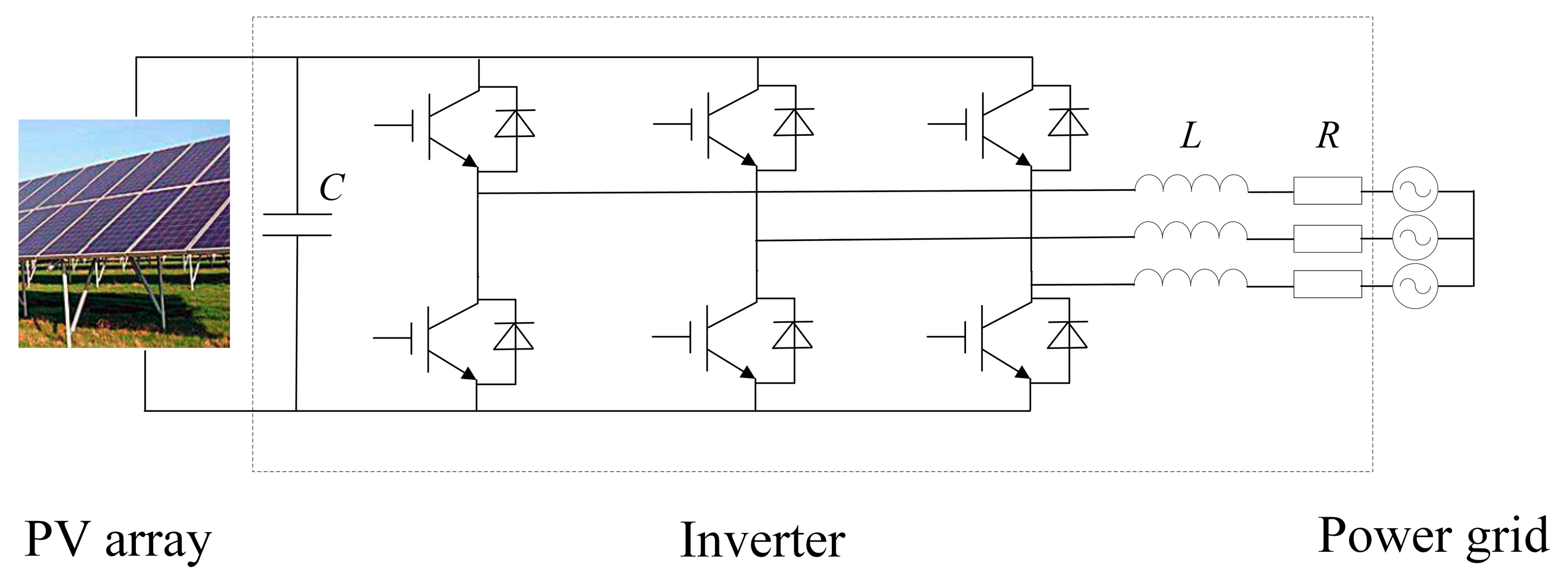
2.1. PV Inverter
2.2. Time-Series Monitoring Data
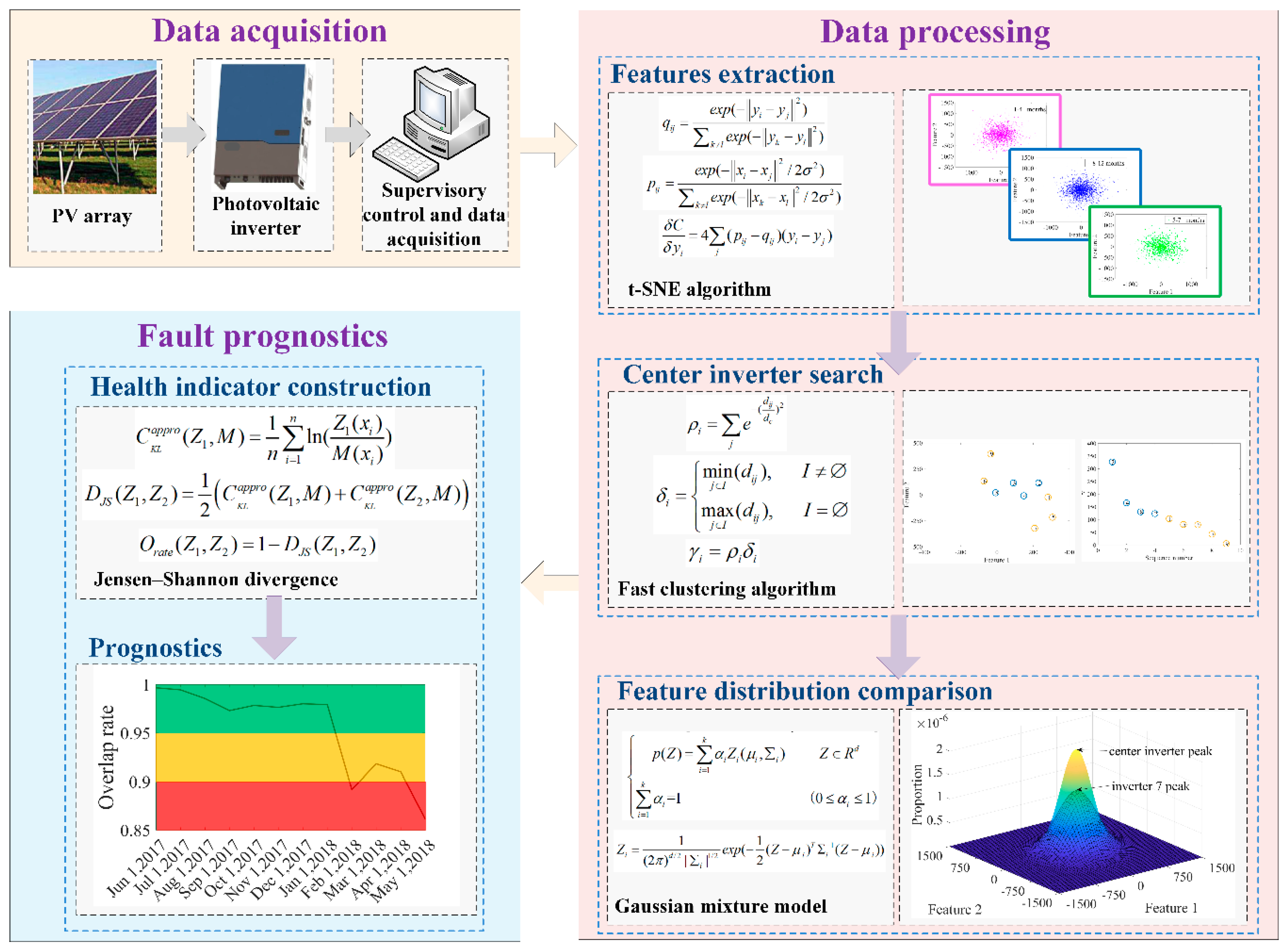
3. Fault Prognostics Method
3.1. t-SNE
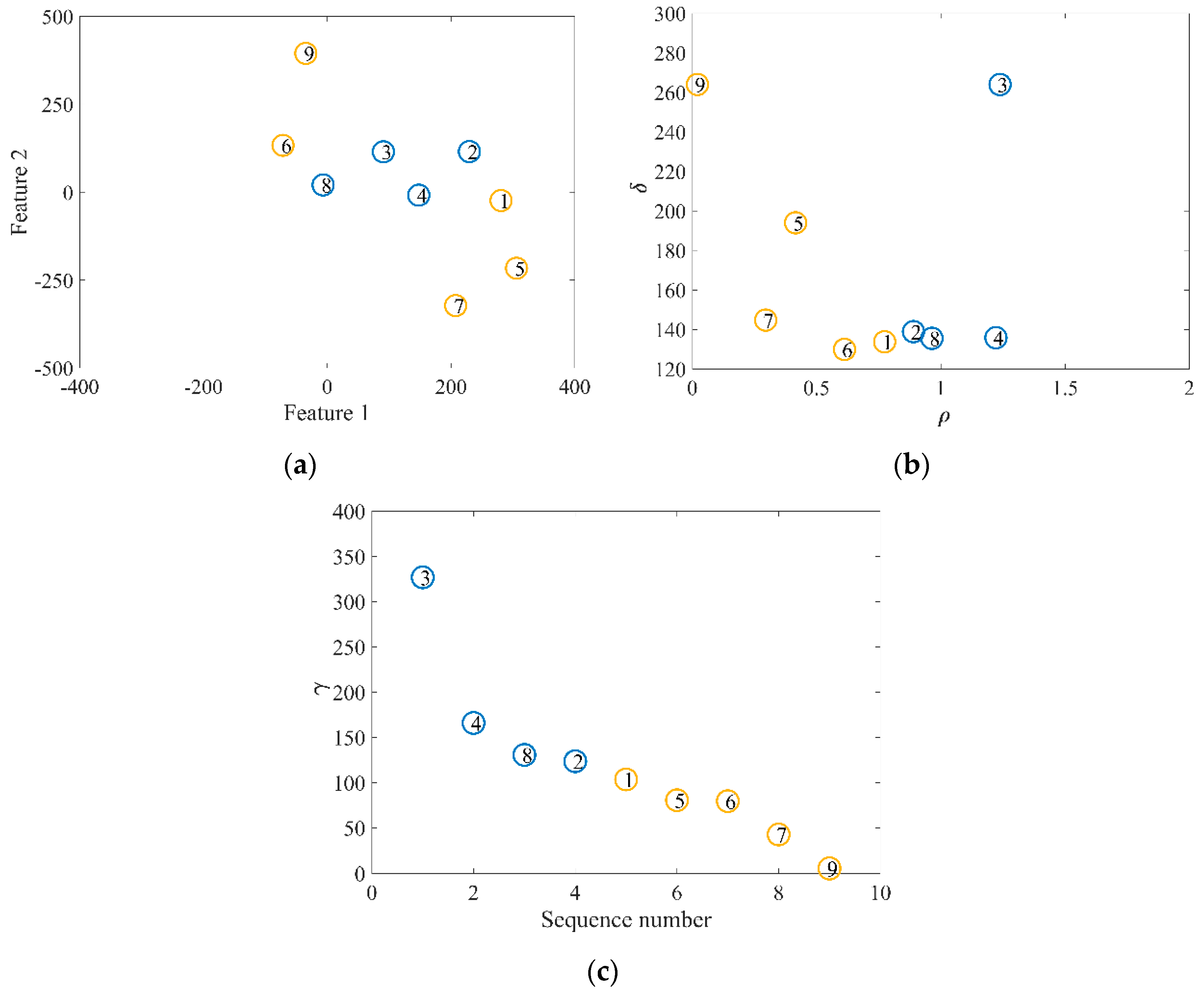
3.2. Fast Clustering Algorithm
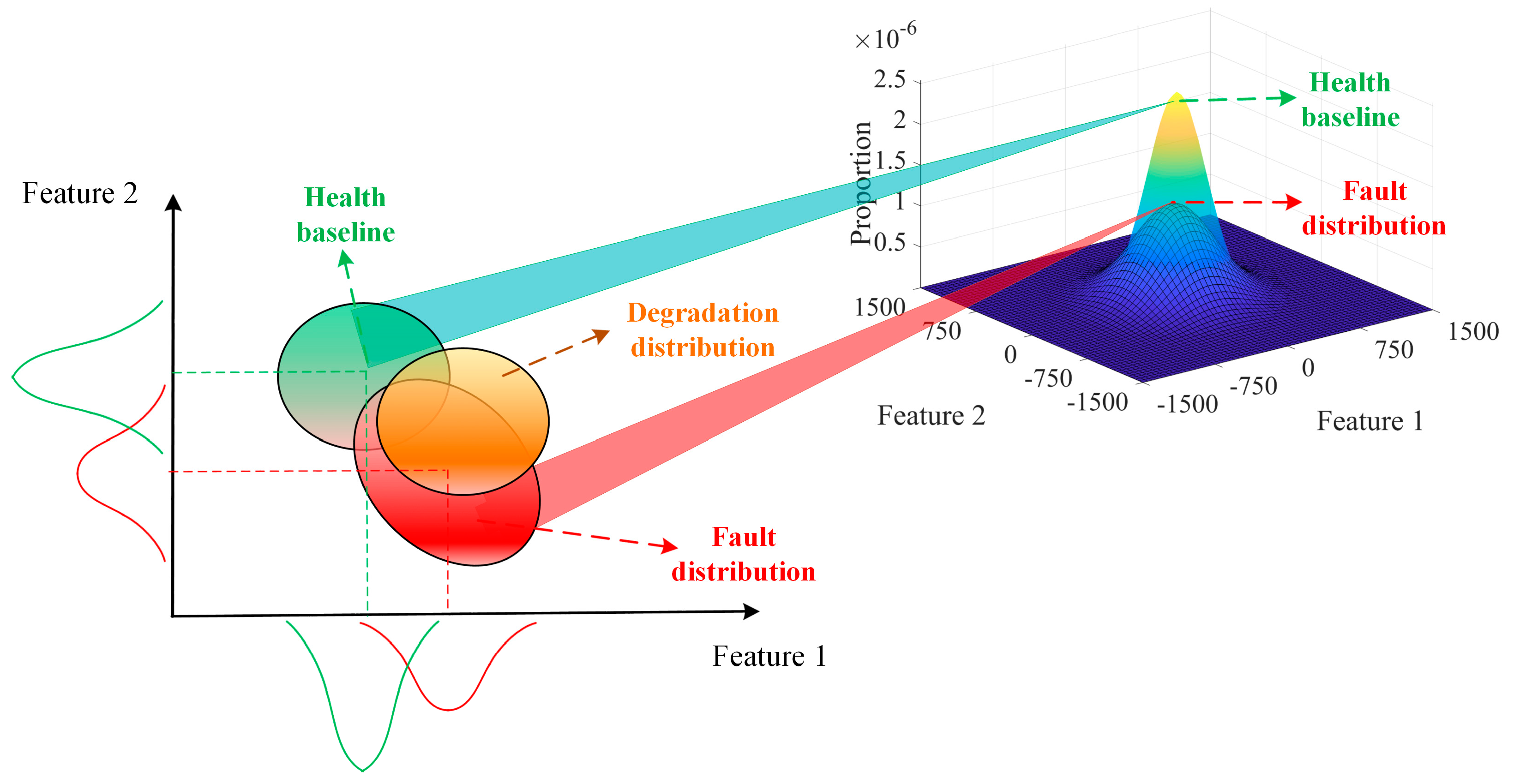
3.3. Gaussian Mixture Model
3.4. Fault Prognostics
4. Experimental Results and Discussion
4.1. Features Extraction
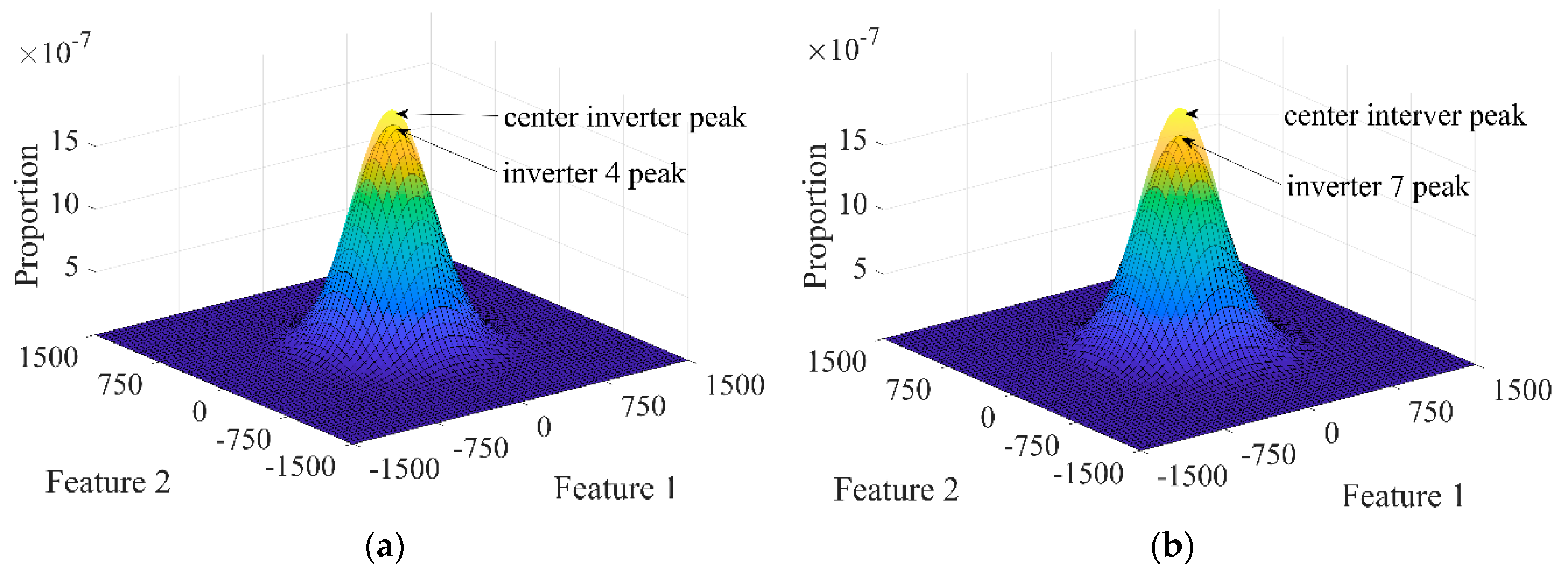
4.2. Center Inverter Search
4.3. Photovoltaic Inverter Fault Prognostics
- (1)
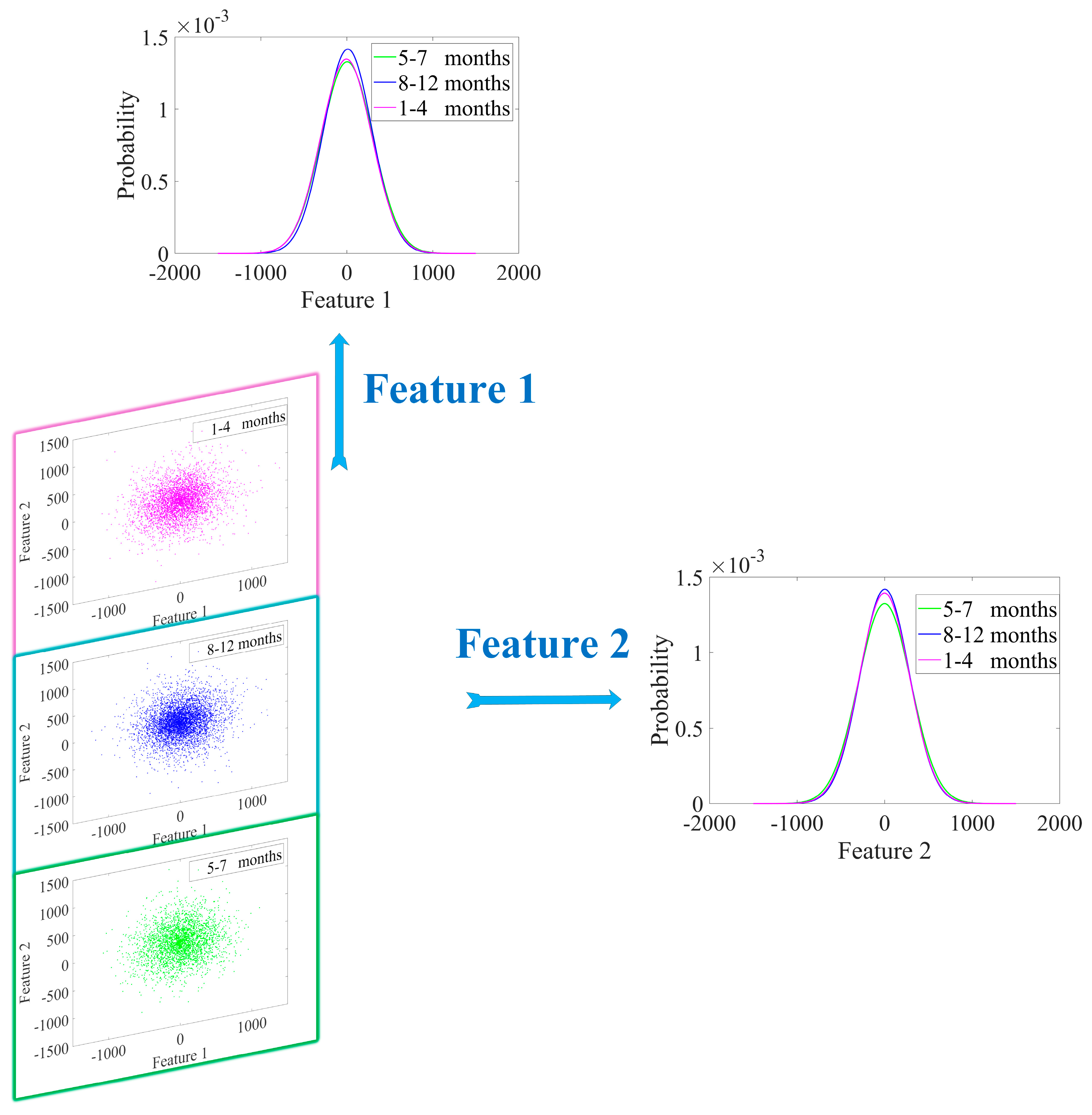
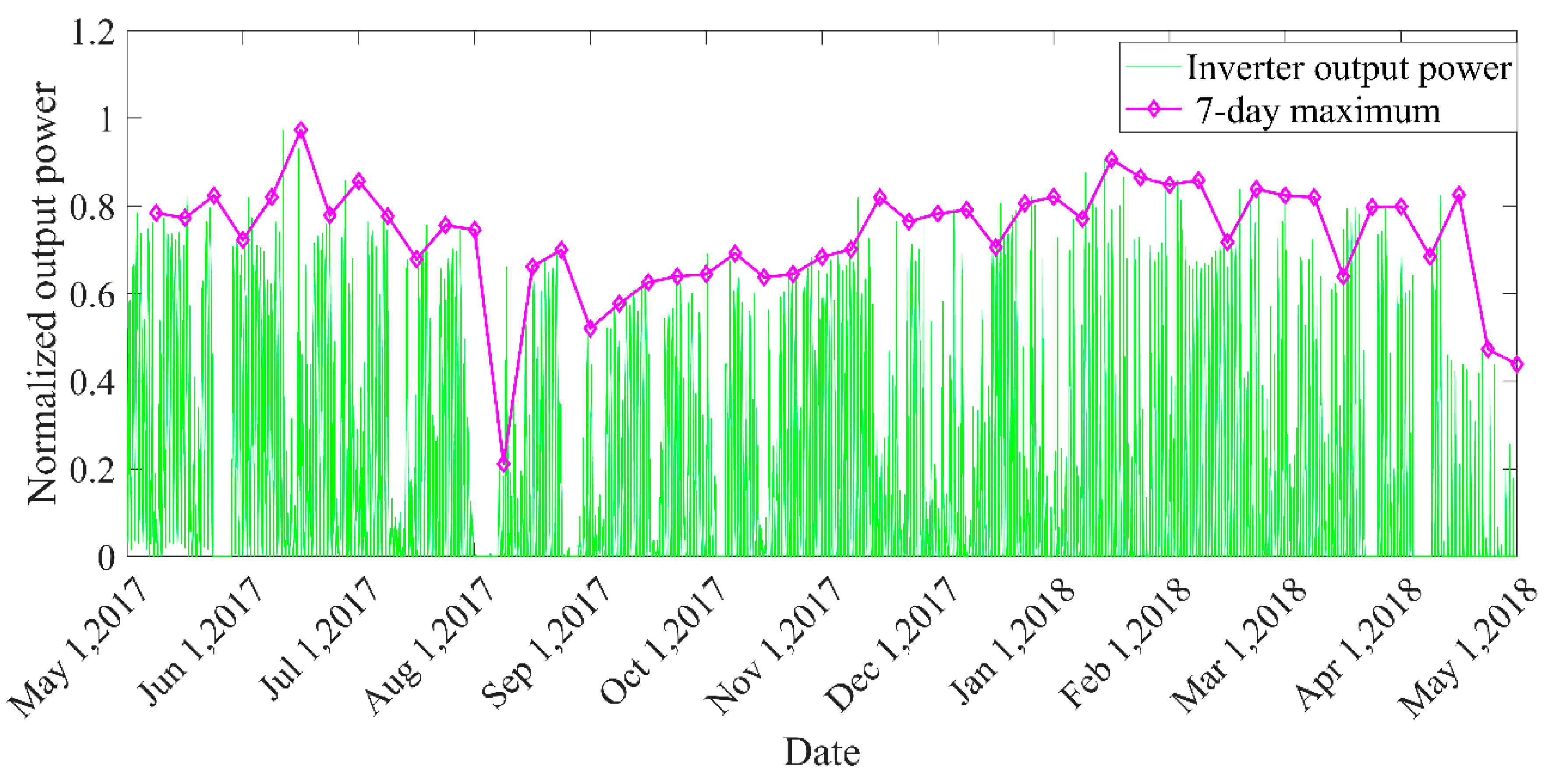
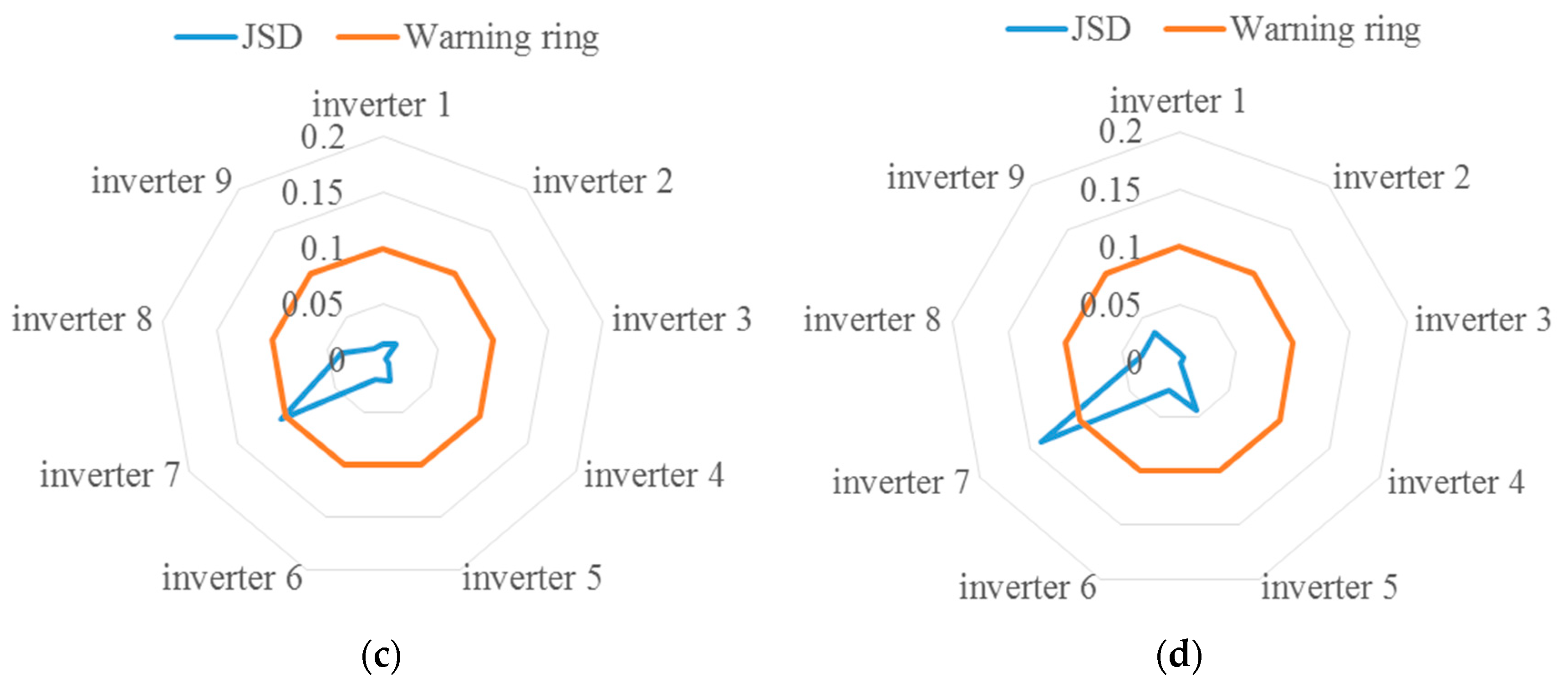
- Robustness. Usually, the health baseline is directly established by the initial state of the equipment [10,11,12,34]. This paper sets up the health baseline based on the inverter group center. It can be seen from Figure 6 that the parameters of PV inverter are easily affected by season, sunshine, and other environmental factors. Observing Figure 7, we can see that for a single inverter, its characteristic distribution interval is also inevitably affected by the season factor. This will eventually lead the health indicator to be affected by the season factor. Observing Figure 10 and Figure 11, the performance degradation (JSD) of each inverter shows a good, gradually increasing trend since the health baseline is established based on the inverter group. It can be seen that the influence of environmental factors is effectively reduced. The reason is that the inverter to be predicted and the central inverter are in the same working condition all the time. In this respect, the method of establishing the health baseline in this paper has good robustness;
- (2)
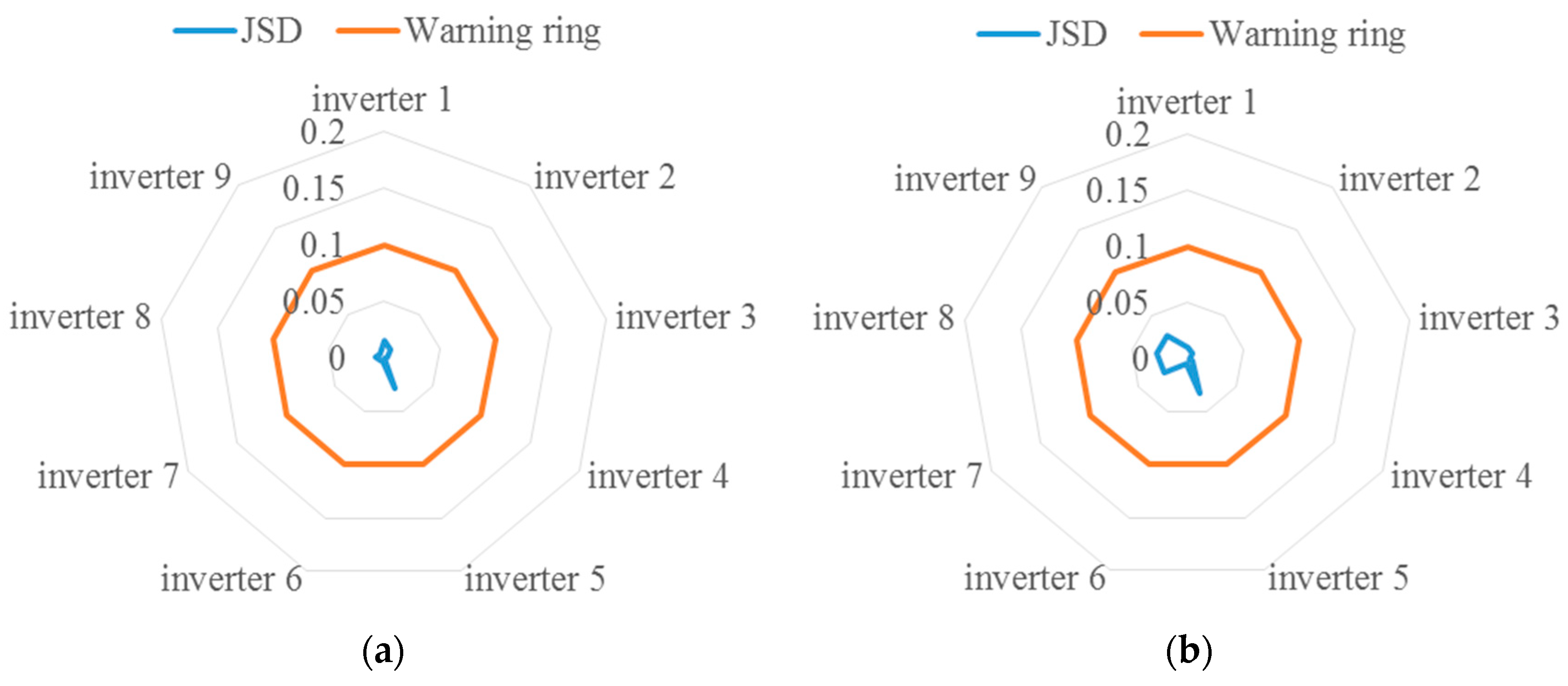
- Quantification. This paper proposed a quantitative health indicator for the inverter. The difference between different feature distributions in the Gaussian mixture model is quantified through JSD, and then the health indicator is calculated. Figure 11 shows that the performance degradation (JSD) of each inverter shows a good, gradually increasing trend. Figure 13 shows that the proposed health indicator (overlap rate) can be effectively used to evaluate the inverter status;
- (3)
- Practicability. The on-site debugging of algorithm parameters is a huge challenge, which leads to poor applicability of algorithms with too many debugging parameters in the field [35]. For the fault prognostics method proposed in this paper, there is only one parameter that needs to be manually set: the early warning line. The value of the early warning line should be combined with the on-site operating conditions and refer to the health indicator range of the entire inverter group. Figure 13 shows that the proposed method accurately realizes the early warning of inverter failure. In brief, the proposed method is of great practicability in the field.
5. Conclusions
- (1)
- The PV inverter’s main monitoring parameters, such as output power, are easily affected by environmental factors. This means that directly using the initial performance of the PV inverter as a health baseline is undesirable. Establishing the health baseline based on the inverter group center can effectively reduce the influence of environmental factors;
- (2)
- By way of searching the center of the PV inverter group, the health baseline can be established and treated as a data cluster of the Gaussian mixture model. Then, the feature probability distribution of the PV inverter to be evaluated forms another data cluster. The change trend of two data clusters’ divergence is consistent with the trend of equipment performance degradation;
- (3)
- To quantify the divergence of the Gaussian mixture model, we can calculate JSD of different data clusters in the Gaussian mixture model. After this, the overlap rate can be deduced from JSD and used for fault prognostics;
- (4)
- The setting of an early warning line is critical for fault prognostics. When there are different types of inverters in the inverter group, it is difficult to judge the abnormal state under all working conditions by setting the early warning line to a fixed value. In the future, we will combine the physical model of the PV system to conduct a more in-depth study on the dynamic setting method of the early warning line.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ghenai, C.; Bettayeb, M. Modelling and performance analysis of a stand-alone hybrid solar PV/Fuel Cell/Diesel Generator power system for university building. Energy 2019, 171, 180–189. [Google Scholar] [CrossRef]
- Mishra, M.K.; Lal, V.N. An improved methodology for reactive power management in grid integrated solar PV system with maximum power point condition. Sol. Energy 2020, 199, 230–245. [Google Scholar] [CrossRef]
- Ghenai, C.; Salameh, T.; Merabet, A. Technico-economic analysis of off grid solar PV/Fuel cell energy system for residential community in desert region. Int. J. Hydrog. Energy 2020, 45, 11460–11470. [Google Scholar] [CrossRef]
- Li, S. A variable-weather-parameter MPPT control strategy based on MPPT constraint conditions of PV system with inverter. Energy Convers. Manag. 2019, 197, 111873. [Google Scholar] [CrossRef]
- Vavilapalli, S.; Umashankar, S.; Sanjeevikumar, P.; Ramachandaramurthy, V.K.; Mihet-Popa, L.; Fedak, V. Three-stage control architecture for cascaded H-Bridge inverters in large-scale PV systems–Real time simulation validation. Appl. Energy 2018, 229, 1111–1127. [Google Scholar] [CrossRef]
- Dogga, R.; Pathak, M.K. Recent trends in solar PV inverter topologies. Sol. Energy 2019, 183, 57–73. [Google Scholar] [CrossRef]
- Ankit; Sahoo, S.K.; Sukchai, S.; Yanine, F.F. Review and comparative study of single-stage inverters for a PV system. Renew. Sustain. Energy Rev. 2018, 91, 962–986. [Google Scholar] [CrossRef]
- Tariq, M.S.; Butt, S.A.; Khan, H.A. Impact of module and inverter failures on the performance of central-, string-, and micro-inverter PV systems. Microelectron. Reliab. 2018, 88, 1042–1046. [Google Scholar] [CrossRef]
- Cupertino, A.F.; Lenz, J.M.; Brito, E.M.; Pereira, H.A.; Pinheiro, J.R.; Seleme Jr, S.I. Impact of the mission profile length on lifetime prediction of PV inverters. Microelectron. Reliab. 2019, 100, 113427. [Google Scholar] [CrossRef]
- Garoudja, E.; Harrou, F.; Sun, Y.; Kara, K.; Chouder, A.; Silvestre, S. Statistical fault detection in photovoltaic systems. Sol. Energy 2017, 150, 485–499. [Google Scholar] [CrossRef]
- Fazai, R.; Abodayeh, K.; Mansouri, M.; Trabelsi, M.; Nounou, H.; Nounou, M.; Georghiou, G.E. Machine learning-based statistical testing hypothesis for fault detection in photovoltaic systems. Sol. Energy 2019, 190, 405–413. [Google Scholar] [CrossRef]
- Yi, Z.; Etemadi, A.H. Line-to-line fault detection for photovoltaic arrays based on multiresolution signal decomposition and two-stage support vector machine. IEEE Trans. Ind. Electron. 2017, 64, 8546–8556. [Google Scholar] [CrossRef]
- Ameur, A.; Berrada, A.; Loudiyi, K.; Aggour, M. Forecast modeling and performance assessment of solar PV systems. J. Clean. Prod. 2020, 267, 122167. [Google Scholar] [CrossRef]
- Basnet, B.; Chun, H.; Bang, J. An Intelligent Fault Detection Model for Fault Detection in Photovoltaic Systems. J. Sens. 2020, 6960328. [Google Scholar] [CrossRef]
- Huang, C.; Wang, L. Simulation study on the degradation process of photovoltaic modules. Energy Convers. Manag. 2018, 165, 236–243. [Google Scholar] [CrossRef]
- Chin, V.J.; Salam, Z.; Ishaque, K. An accurate modelling of the two-diode model of PV module using a hybrid solution based on differential evolution. Energy Convers. Manag. 2016, 124, 42–50. [Google Scholar] [CrossRef]
- Zegaoui, A.; Aillerie, M.; Petit, P.; Charles, J.P. Universal Transistor-based hardware of photovoltaic generators SIMulator for real time simulation. Sol. Energy 2016, 134, 193–201. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Y.; Xie, D.; Zhang, Y. Wind Farm NWP Data Preprocessing Method Based on t-SNE. Energies 2019, 12, 3622. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Jiang, Z.; Pan, H. Sigmoid-based refined composite multiscale fuzzy entropy and t-SNE based fault diagnosis approach for rolling bearing. Measurement 2018, 129, 332–342. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Agis, D.; Pozo, F. A frequency-based approach for the detection and classification of structural changes using t-SNE. Sensors 2019, 19, 5097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, D.; Huang, Y.; Chen, H.; He, Y.; Chen, S. VPPAW penetration monitoring based on fusion of visual and acoustic signals using t-SNE and DBN model. Mater. Des. 2017, 123, 1–14. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, D.; Pang, W.; Miao, C.; Tan, A.H.; Zhou, Y. A Systematic Density-based Clustering Method Using Anchor Points. Neurocomputing 2020, 400, 352–370. [Google Scholar] [CrossRef]
- Gong, C.; Su, Z.G.; Wang, P.H.; Wang, Q. Cumulative belief peaks evidential K-nearest neighbor clustering. Knowl. Based Syst. 2020, 200, 105982. [Google Scholar] [CrossRef]
- Avendano-Valencia, L.D.; Fassois, S.D. Damage/fault diagnosis in an operating wind turbine under uncertainty via a vibration response Gaussian mixture random coefficient model based framework. Mech. Syst. Signal Process. 2017, 91, 326–353. [Google Scholar] [CrossRef]
- Sun, H.; Wang, S. Measuring the component overlapping in the Gaussian mixture model. Data Min. Knowl. Discov. 2011, 23, 479–502. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F.S. Short-term forecasting and uncertainty analysis of wind turbine power based on long short-term memory network and Gaussian mixture model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Gisbrecht, A.; Schulz, A.; Hammer, B. Parametric nonlinear dimensionality reduction using kernel t-SNE. Neurocomputing 2015, 147, 71–82. [Google Scholar] [CrossRef] [Green Version]
- Li, M.A.; Luo, X.Y.; Yang, J.F. Extracting the nonlinear features of motor imagery EEG using parametric t-SNE. Neurocomputing 2016, 218, 371–381. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, D.; Han, T.; Wang, N.; Yang, W.; Yang, Y. Rotating machinery fault diagnosis for imbalanced data based on fast clustering algorithm and support vector machine. J. Sens. 2017, 2017, 8092691. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Lee, G.; Youn, B.D. PHM experimental design for effective state separation using Jensen–Shannon divergence. Reliab. Eng. Syst. Saf. 2019, 190, 106503. [Google Scholar] [CrossRef]
- Zhang, X.; Delpha, C.; Diallo, D. Incipient fault detection and estimation based on Jensen–Shannon divergence in a data-driven approach. Signal Process. 2020, 169, 107410. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.P.; Guo, L.; Li, N.B.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | Cause |
|---|---|
| anomaly of PV string | shielding of PV panel or degradation of PV string |
| anomaly of DC circuit | DC current protection |
| anomaly of inverter circuit | inverter current protection |
| grid connection fault | component damage, etc. |
| communication fault | communication circuit damaged or disturbed |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Zhang, X.; Liu, C.; Han, T. Fault Prognostics for Photovoltaic Inverter Based on Fast Clustering Algorithm and Gaussian Mixture Model. Energies 2020, 13, 4901. https://doi.org/10.3390/en13184901
He Z, Zhang X, Liu C, Han T. Fault Prognostics for Photovoltaic Inverter Based on Fast Clustering Algorithm and Gaussian Mixture Model. Energies. 2020; 13(18):4901. https://doi.org/10.3390/en13184901
Chicago/Turabian StyleHe, Zhenyu, Xiaochen Zhang, Chao Liu, and Te Han. 2020. "Fault Prognostics for Photovoltaic Inverter Based on Fast Clustering Algorithm and Gaussian Mixture Model" Energies 13, no. 18: 4901. https://doi.org/10.3390/en13184901
APA StyleHe, Z., Zhang, X., Liu, C., & Han, T. (2020). Fault Prognostics for Photovoltaic Inverter Based on Fast Clustering Algorithm and Gaussian Mixture Model. Energies, 13(18), 4901. https://doi.org/10.3390/en13184901