Research on the Self-Repairing Model of Outliers in Energy Data Based on Regional Convergence


 ,
, 
Abstract
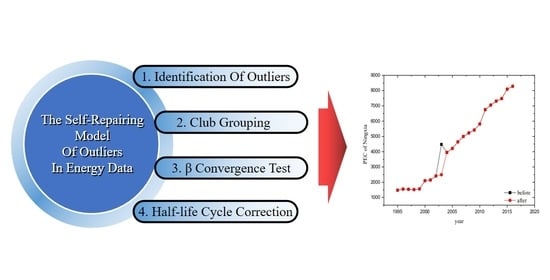
1. Introduction
2. Methodology
2.1. Identification of Outliers
2.1.1. Definition and Classification of Outliers
2.1.2. ARMA Model
2.1.3. Outliers Joint Estimation Method
2.1.4. Outliers Identification Process
2.2. Outlier Correction
2.2.1. Regional Convergence Theory
Unconditional β Convergence
Conditional β Convergence
2.2.2. Club Convergence
Nonlinear Time-Varying Factor Model
Log-T Regression
- (1)
- calculate the cross-sectional variance ratio H1/Ht
- (2)
- regression:
Club Grouping
- (1)
- Form core group: calculate from the section element with the first order, add one element at a time in log-t regression. The calculated value is compared with −1.65 until it is less than −1.65 for the first time. Assuming that k (2 ≤ k< N) cross-section elements fit the bill, the calculation criteria of the number of members k* (k* ≤ k)in the core group are as follows:If k* = N, the convergence club does not exist and the entire panel converges. When k = 2, the constraint condition is not valid, then remove the highest ordered unit and repeat the above steps for the remaining units.
- (2)
- Club members: the cross-section elements outside the core group are added into the core group for log-t regression successively, and the value is calculated. When it is greater than the critical value c (usually 0), the cross-section element is added into the convergence club.
- (3)
- Stop rule: after the first convergence club is formed, perform the log-t-test on the remaining units. If null Hypothesis H0 is not rejected, the remaining units will be another convergence club. When the null hypothesis is rejected, repeat steps (1)–(3) for the remaining units.
2.2.3. Half-Life Cycle
3. Data and Resources
4. Results and Discussion
4.1. Identification of Outliers
4.2. Data Correction
4.2.1. Club Grouping
4.2.2. β Convergence Test
4.2.3. Half-Life Cycle Correction
5. Conclusions
- (1)
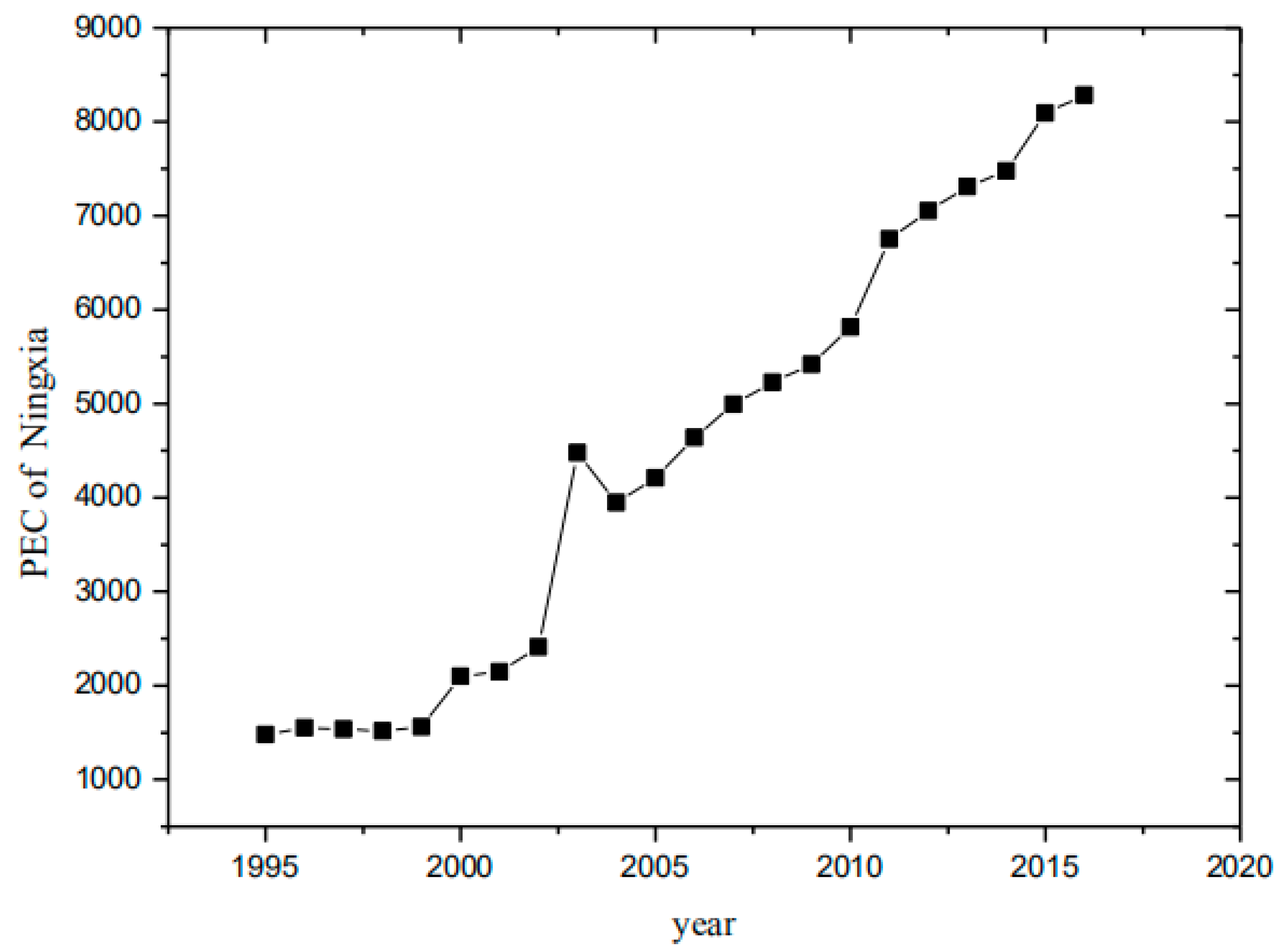
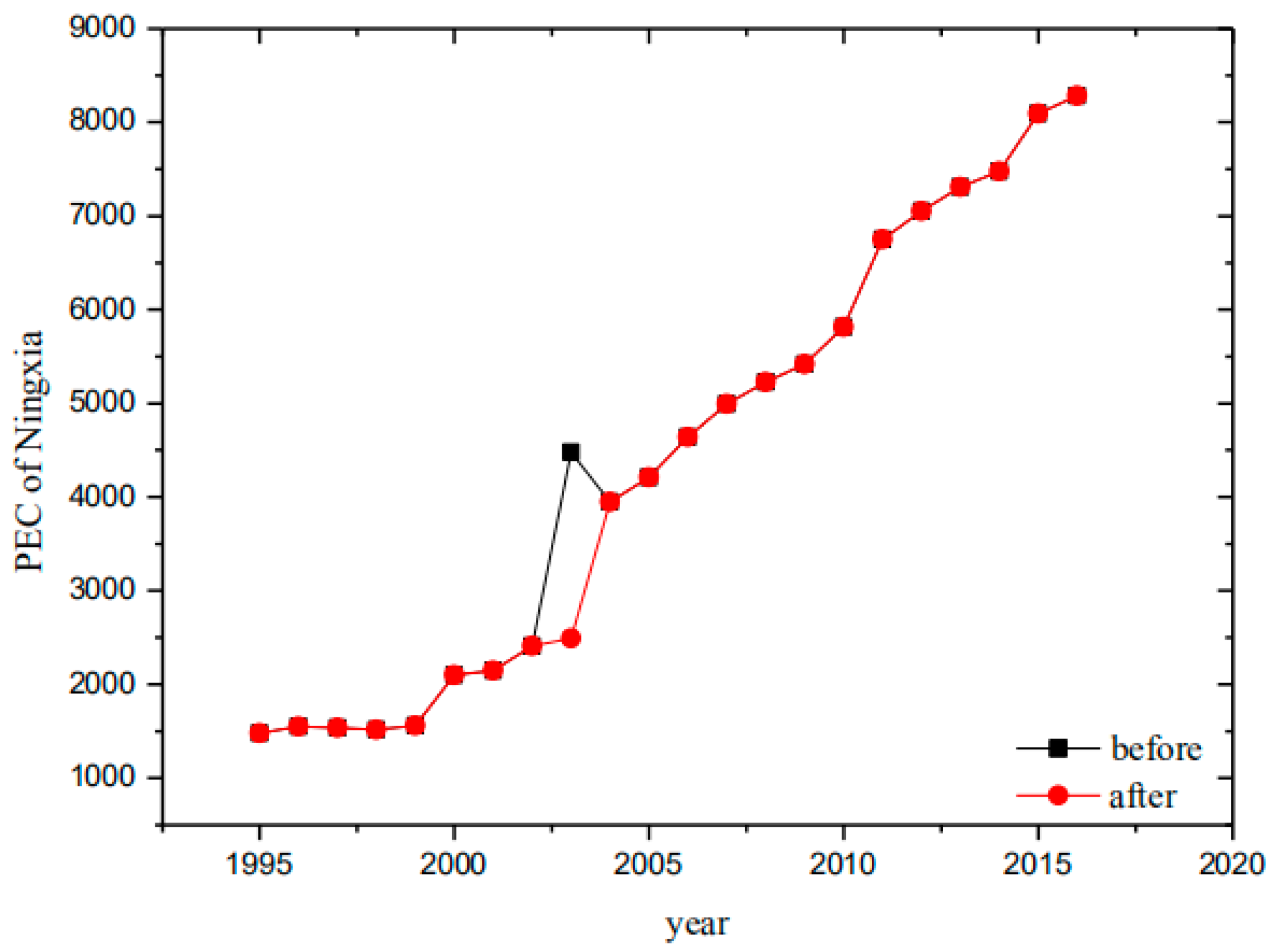
- For the time-series data fitting AR (1) model and through the outlier joint estimation diagnostic method, we calculate the τ value of Ningxia Hui Autonomous Region in 2003 and that is 3.97, which is greater than the critical value and identified as a mutational outlier.
- (2)
- β convergence exists nationwide with a convergence rate of 3.05%. According to the nonlinear time-varying factor model (log-t method), 30 provinces are divided into two convergence clubs. The convergence rate of the first club (high per capita energy consumption) is 4.5%, and that of the second club (low per capita energy consumption) is 6.12%. The convergence rate of the two clubs is higher than that of the whole country.
- (3)
- Based on the half-life cycle model and the convergence rate, the half-life cycle of the first club is 15 years and that of the second club is 11 years. By constructing the half-life cycle model of β convergence theory, the revised data of the Ningxia Hui Autonomous Region represent 2490.53 kce/person.
- (4)
- The outliers identified in the paper are likely to be caused by human error, instrument failure and other errors in the process of data collection. This reminds us to attach importance to data collection, strengthen the supervision of data collection, and take measures such as multiple calculations to make the data real and effective.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Solow, R.M. A Contribution to the Theory of Economic Growth. Q. J. Econ. 1956, 70, 65–94. [Google Scholar] [CrossRef]
- Baumol, W.J. Productivity Growth, Convergence, and Welfare: What the Long-Run Data Show. Am. Econ. Rev. 1986, 76, 1072–1085. [Google Scholar]
- Barro, R.J.; Salaimartin, X. Convergence across States and Regions. Brook. Papers Econ. Act. 1991, 1991, 107–182. [Google Scholar] [CrossRef]
- Roe, T. Determinants of Economic Growth: A Cross-Country Empirical Study. Am. Political Sci. Rev. 2003, 92, 145–477. [Google Scholar] [CrossRef]
- Chambers, D.; Dhongde, S. Convergence in income distributions: Evidence from a panel of countries. Econ. Model. 2016, 59, 262–270. [Google Scholar] [CrossRef]
- Iacovone, L.; Bayardo, L.F.S.; Sharma, S. Regional Productivity Convergence in Peru; Social Science Electronic Publishing: Washington, DC, USA, 2018. [Google Scholar]
- List, J.A. Have air pollutant emissions converged among U.S. regions? Evidence from unit root tests. South. Econ. J. 1999, 66, 144–155. [Google Scholar] [CrossRef]
- Mishra, V.; Smyth, R. Convergence in energy consumption per capita among ASEAN countries. Energy Policy 2014, 73, 180–185. [Google Scholar] [CrossRef]
- Sheng, Y.; Shi, X.; Zhang, D. Economic growth, regional disparities and energy demand in China. Energy Policy 2014, 71, 31–39. [Google Scholar] [CrossRef]
- Apergis, N.; Fontini, F.; Inchauspe, J. Integration of regional electricity markets in Australia: A price convergence assessment. Energy Econ. 2016, 62, 411–418. [Google Scholar] [CrossRef]
- Solarin, S.A.; Gil-Alana, L.A.; Al-Mulali, U. Stochastic convergence of renewable energy consumption in OECD countries: A fractional integration approach. Environ. Sci. Pollut. Res. 2018, 25, 17289–17299. [Google Scholar] [CrossRef]
- Galor, O. Convergence? Inferences from Theoretical Models. Econ. J. 1996, 106, 1056–1069. [Google Scholar] [CrossRef]
- Sul, D. Transition Modeling and Econometric Convergence Tests. Econometrica 2007, 75, 1771–1855. [Google Scholar]
- Phillips, P.; Sui, D. Economic Transition and Growth. J. Appl. Econom. 2010, 24, 1153–1185. [Google Scholar] [CrossRef]
- Kim, Y.S. Electricity Consumption and Economic Development: Are Countries Converging to a Common Trend? Energy Econ. 2015, 49, 192–202. [Google Scholar] [CrossRef]
- Parker, S.; Liddle, B. Economy-wide and manufacturing energy productivity transition paths and club convergence for OECD and non-OECD countries. Energy Econ. 2016, 62, 338–346. [Google Scholar] [CrossRef]
- Mérida, A.L.; Carmona, M.; Congregado, E.; Golpe, A.A. Exploring the regional distribution of tourism and the extent to which there is convergence. Tour. Manag. 2016, 57, 225–233. [Google Scholar] [CrossRef]
- Cuñado, J.; de Gracia, F.P. Real convergence in Africa in the second-half of the 20th century. J. Econ. Bus. 2006, 58, 153–167. [Google Scholar] [CrossRef]
- Cuñado, J.; Gil-Alana, L.A.; de Gracia, F.P. Additional Empirical Evidence on Real Convergence: A Fractionally Integrated Approach. J. Econ. Bus. 2006, 142, 67–91. [Google Scholar]
- Cuñado, J.; De Gracia, F.P. Real convergence in some Central and Eastern European countries. Appl. Econ. 2006, 38, 2433–2441. [Google Scholar] [CrossRef]
- Romer, D. Advanced Macroeconomics, 4th ed.; McGraw-Hill Education: New York, NY, USA, 2001. [Google Scholar]
- Seongman, M. Inter-Region Relative Price Convergence in Korea. East Asian Econ. Rev. 2017, 21, 123–146. [Google Scholar] [CrossRef]
- Bergman, U.M.; Hansen, N.L.; Heeboll, C. Intranational Price Convergence and Price Stickiness: Evidence from Denmark. Scand. J. Econ. 2018, 120, 1229–1259. [Google Scholar] [CrossRef]
- Fox, A.J. Outliers in Time Series. J. R. Stat. Soc. 1972, 34, 350–363. [Google Scholar] [CrossRef]
- Tsay, R. Time Series Model Specification in the Presence of Outliers. Publ. Am. Stat. Assoc. 1986, 81, 132–141. [Google Scholar] [CrossRef]
- Bruce, A.G.; Martin, R.D. Leave-k-out diagnostics for time series. J. R. Stat. Soc. 1989, 51, 363–424. [Google Scholar] [CrossRef]
- Chen, C.; Liu, L.M. Joint Estimation of Model Parameters and Outlier Effects in Time Series. J. Am. Stat. Assoc. 1993, 88, 284–297. [Google Scholar]
- Ping, C.; Jing, Y.; Li, L. Synthetic detection of change point and outliers in bilinear time series models. Int. J. Syst. Sci. 2015, 46, 284–293. [Google Scholar]
- Yan, H.; Yang, B.; Yang, H. Outlier detection in time series data based on heteroscedastic Gaussian processes. J. Comput. Appl. 2018, 76. [Google Scholar] [CrossRef]
- Sathe, S.; Aggarwal, C.C. Subspace histograms for outlier detection in linear time. Knowl. Inf. Syst. 2018, 56. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Data | Year | Data | Year | Data |
|---|---|---|---|---|---|
| 1995 | 1479.65 | 2003 | 4479.31 | 2011 | 6750.07 |
| 1996 | 1552.40 | 2004 | 3948.98 | 2012 | 7049.54 |
| 1997 | 1535.85 | 2005 | 4211.41 | 2013 | 7308.27 |
| 1998 | 1518.40 | 2006 | 4639.07 | 2014 | 7476.64 |
| 1999 | 1561.69 | 2007 | 4995.08 | 2015 | 8092.77 |
| 2000 | 2098.63 | 2008 | 5225.34 | 2016 | 8284.44 |
| 2001 | 2145.83 | 2009 | 5420.25 | ||
| 2002 | 2409.09 | 2010 | 5815.69 |
| Case 1 | Case 2 |
|---|---|
| Model: 1 1 0 Coefficients: AR: 0.974419 *** AIC: −0.239257 | Model: 0 1 1 Coefficients: MA: 0.961220 * AIC: 1.046726 |
| Serial Number | Province | First Club | Second Club | ||
|---|---|---|---|---|---|
| Step 1 | Step 2 | Step 1 | Step 2 | ||
| 1 | Ningxia | benchmark | core | ||
| 2 | Inner Mongolia | −0.1094 | core | ||
| 3 | Qinghai | −1.38054 | core | ||
| 4 | Xinjiang | −1.1309 | core | ||
| 5 | Tianjin | 0.617951 | core | ||
| 6 | Shanxi | −0.17756 | core | ||
| 7 | Shanghai | 2.484757 | core | ||
| 8 | Liaoning | 1.562581 | 1.562581 | ||
| 9 | Hebei | 1.270186 | 2.484757 | ||
| 10 | Shandong | 1.848206 | 2.055578 | ||
| 11 | Jiangsu | 1.786347 | 1.223246 | ||
| 12 | Zhejiang | 0.96617 | −1.00499 | benchmark | |
| 13 | Heilongjiang | −0.57553 | −6.50469 | 1.407396 | |
| 14 | Beijing | −0.17778 | −1.13035 | 6.157279 | |
| 15 | Fujian | 0.619555 | 1.902167 | ||
| 16 | Shaanxi | 1.03126 | 0.447247 | ||
| 17 | Chongqing | 1.394579 | 0.180409 | ||
| 18 | Jilin | 0.763656 | −3.69667 | 5.497718 | |
| 19 | Guizhou | 0.338821 | −3.59548 | 7.292697 | |
| 20 | Hubei | −0.00855 | −2.50695 | 7.092816 | |
| 21 | Guangdong | −0.72039 | −5.46063 | 7.795714 | |
| 22 | Gansu | −1.46008 | −6.52179 | 7.023633 | |
| 23 | Sichuan | −1.38843 | −2.09056 | 7.041624 | |
| 24 | Henan | −1.30784 | −1.77379 | 7.538447 | |
| 25 | Hunan | −0.79085 | −0.53747 | 7.20602 | |
| 26 | Yunnan | −1.3583 | −5.71723 | 6.881611 | |
| 27 | Hainan | −1.56274 | −4.26987 | 6.73345 | |
| 28 | Guangxi | −1.09245 | −1.0436 | 6.628484 | |
| 29 | Anhui | −1.95887 | −8.91176 | 5.915468 | |
| 30 | Jiangxi | −4.79133 | 5.766989 | ||
| Number | Members | The Number of Members | Category |
|---|---|---|---|
| Club 1 | Ningxia, Inner Mongolia, Qinghai, Xinjiang, Tianjin, Shanxi, Shanghai, Liaoning, Hebei, Shandong, Jiangsu, Fujian, Shaanxi, Chongqing | 14 | High energy consumption |
| Club 2 | Zhejiang, Heilongjiang, Beijing, Jilin, Guizhou, Hubei, Guangdong, Gansu, Sichuan, Henan, Hunan, Yunnan, Hainan, Guangxi, Anhui, Jiangxi | 16 | Low energy consumption |
| Test Parameters | Nationwide | First Club | Second Club |
|---|---|---|---|
| α | 0.2211 | 0.2834 | 0.3011 |
| t-Statistic | 5.6626 | 4.4533 | 13.3257 |
| Prob. | 0.0000 | 0.0008 | 0.0000 |
| β | 0.0305 | 0.0450 | 0.0612 |
| t-Statistic | 3.0897 | 2.1954 | 5.7992 |
| Prob. | 0.0045 | 0.0485 | 0.0000 |
| R2 | 0.3849 | 0.5010 | 0.8957 |
| Log likelihood | 83.5074 | 40.1825 | 59.9100 |
| F-statistic | 17.5217 | 12.0503 | 120.2604 |
| Prob (F-statistic) | 0.0003 | 0.0046 | 0.0000 |
| Durbin-Watson stat | 1.2147 | 0.3032 | 1.0712 |
| Club | Club 1 | Club 2 |
|---|---|---|
| β | 4.50% | 6.12% |
| γ | 9.3628 | 8.3233 |
| Half-life cycle (year) | 15 | 11 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Zhao, X.; Mu, H.; Li, Y.; Pang, J.; Jiang, Y.; Jin, X.; Pei, Z. Research on the Self-Repairing Model of Outliers in Energy Data Based on Regional Convergence. Energies 2020, 13, 4909. https://doi.org/10.3390/en13184909
Li N, Zhao X, Mu H, Li Y, Pang J, Jiang Y, Jin X, Pei Z. Research on the Self-Repairing Model of Outliers in Energy Data Based on Regional Convergence. Energies. 2020; 13(18):4909. https://doi.org/10.3390/en13184909
Chicago/Turabian StyleLi, Nan, Xunwen Zhao, Hailin Mu, Yimeng Li, Jingru Pang, Yuqing Jiang, Xin Jin, and Zhenwei Pei. 2020. "Research on the Self-Repairing Model of Outliers in Energy Data Based on Regional Convergence" Energies 13, no. 18: 4909. https://doi.org/10.3390/en13184909
APA StyleLi, N., Zhao, X., Mu, H., Li, Y., Pang, J., Jiang, Y., Jin, X., & Pei, Z. (2020). Research on the Self-Repairing Model of Outliers in Energy Data Based on Regional Convergence. Energies, 13(18), 4909. https://doi.org/10.3390/en13184909