1. Introduction
The majority of the global energy supply is generated by the burning of fossil fuels. Progress and global economic growth have been accompanied by an increase in the consumption of fossil fuels, resulting in climate change and global warming. Importantly, fossil fuels are distributed unequally across the global geography, creating challenges related to access in unstable and conflict zones. This has resulted in a shift towards the use of renewable energy sources (RES), with the intention of reducing dependency on fossil fuels and the challenges associated with the use of fossil fuels. Renewable energy is locally available, clean, sustainable and eco-friendly and therefore offers an attractive alternative to fossil fuels. Consequently, researchers and policy makers have shown an increased interest in greener sources of energy. According to data [
1] available from the International Energy Agency (IEA), the share of electricity generation from renewable sources in overall energy production in 2018 has exceeded 25% and is constantly growing. This is evident in the increased production numbers of renewable energy over the three preceding decades (see
Figure 1). During recent decades, the share of energy from wind and solar photovoltaic (PV) in total production of renewable energy has increased significantly.
Many countries have decided to promote renewable energy and to reduce dependence on fossil fuels and to do so, have established mandatory renewable energy targets. Such measures form part of respective governments’ legislated plans that require electricity retailers to source specific proportions of total electricity sales from RES within a fixed time frame. For example, the People’s Republic of China and India have a target level of 50% and 40% of total electric power generation from non-fossil energy sources, respectively. Renewable energies have been incorporated leading source of non-fossil energy. Specifically, the People’s Republic of China has established targets of 723 GW from RES by 2020. The underlying targets include increasing wind power capacity to 210 GW and solar energy to 110 GW [
2]. In turn, the government of India set a target of achieving 175 GW from RES by 2022 which mainly consists of energy from solar (100 GW) and wind (60 GW) [
3]. Moreover, Turkey, Thailand and Chinese Taipei have established RES targets as part of their total electric power generation. Turkey has set a target share of RES at 30% by 2030. Thailand has set a target level of 20% by 2036 and Chinese Taipei has a target of 8% by 2025 (see
Figure 2). According to data provided by the IEA, none of the countries with set targets have achieved their targets, aside from Turkey which achieved its target in 2015.
Achieving these targets necessitates an increase in installed electric power generation capacity. Thus, the demand for manufactured solar modules, solar cells, solar silicon rods, solar wafers, solar power, solar photovoltaic products and equipment is increasing. This increase in demand is further compounded by the incentives offered by governments to promote investment in the PV industry and RES energy in general. For example, the Chinese government has set up national science and technology plans to support the research and development (R&D) into PV technology, the setting up of key laboratories that promote R&D in the industry and the promotion of demonstration projects in rural areas. Also, a feed-in tariff policy was implemented and exemptions from import tariffs were offered for imported equipment for domestic and foreign PV investment projects. The Chinese government also offered tax incentives for PV related enterprises in the form of R&D cost rebates, rebates for the purchases of special equipment and the amortization of costs for intangible assets and tax policies to promote PV power generation, high-tech enterprises in the PV sector and investment in R&D and PV production processes [
7,
8] provides an overview of the measures applied to promote investment in PV capacity within the EU-27 countries. The most popular measure to promote PV is the use of feed-in tariffs, which guarantee the price at which electricity is purchased. This is then followed by subsidies which are part of specific national programmes although subsidies are decreasing. Then, tax incentives are offered in almost half of the EU-27 countries. Broadly, these include tax credits, exemptions and reduced tax rates. For example, in Bulgaria, value added tax (VAT) for PV revenues is 10% as opposed to the normal rate of 15%. Tax deductions or tax credits are applied in Belgium, Denmark, France, Germany, Ireland and the Netherlands, reducing the amount of taxable income or the amount of tax due respectively. A number of countries have implemented tradable green certificates. For example, Belgium implemented a green certificate trading system for electricity, providing renumeration per certificate coming from a grid operator. Finally, soft loans have also been offered by a small number of EU countries. Solangi et al. [
9] outline measures used to promote solar energy deployment in the US and Canada. In the US, incentives were formulated as early as 1978, with investment tax credits being offered for renewable energy technologies initially. Residential tax credits of 30% and business tax credits for investment in renewable energy, including solar energy, of 15% were offered respectively. Later on, residential and business investment tax credits were raised to 30% and extended, resulting in a doubling of installed PV capacity. In Canada, feed-in tariffs were implemented in 18 provinces, with the feed-in tariff implemented in Ontario credited with stimulating manufacturing and the growth of the Ontario PV industry. The Canadian government also provided loan guarantees, tax holidays and subsidies to support PV manufacturing. Sachu [
10] outlines policies applied in the top 10 RES producing countries, including Germany. To promote the use of renewable energy, the German government mandated the purchase of renewable energy and offered large subsidies to renewable energy producers. A target was set to reach a specified level of solar PV capacity and feed-in tariffs were established. Sachu [
10] notes that the policies applied in Germany have had a significant impact on reducing soft costs associated with solar installation, such as permitting, inspections, interconnection, financing and customer acquisition.
All these policies, which include targets and incentives, require that investment in RES companies increases. This can readily take place happen if RES related companies, specifically those that produce photovoltaic components, offer an attractive alternative to other companies that belong to the semiconductor and related device manufacturing sector and are lucrative overall. We contribute to the literature on RES by focusing on a class of companies that operate within the renewable energy value chain. These are companies that manufacture semiconductors and related solid state devices. We divide these companies into two groups. The green group comprises companies that manufacture solar modules, solar cells, solar silicon rods, solar wafers, solar power, solar photovoltaic products and related equipment for RES companies. This group is the focus of this paper. The red group comprises the remainder of companies that are not associated with RES companies).
We seek to identify ratios (i.e., indicators), which discriminate between companies within the manufacturing sector that produce PV components and those that do not. Once we have identified such ratios, we can analyze these ratios to answer the question as to whether these companies show strong financial performance, that is, offer an attractive investment alternative. In the literature, there is great interest in evaluating returns for the energy sector, especially for companies that produce renewable energy. Relationships between returns on renewable energy stocks, changes in the oil price, equity indices, carbon prices and carbon pass-through rates, for example, Trück and Weron [
11] examine convenience yields and risk premiums in the EU-wide CO
2 emissions trading scheme during the first Kyoto commitment period. They report that during their sample period, the EUA market has shifted from a period of backwardation to a period of contango with negative convenience yields. Bohl et al. [
12] investigate the common factors driving the performance of German renewable energy stocks. They find that renewable energy stocks mirror ambiguity related to the future economic outlook faced by the industry. Henriques and Sadorsky [
13] investigate the relationship between alternative energy stock prices, technology stock prices, oil prices and interest rates. Stock prices for alternative energy companies are found to be impacted by shocks to technology stock prices but shocks to oil prices do not have an impact on alternative energy companies. Inchauspe et al. [
14] investigate the impact of energy prices and stock market indices on private investments in renewable energy, finding that these have shown substantial growth attributable to government policies, oil prices and evolving market liquidity. Kumar et al. [
15] analyze the relationship between oil prices and alternate energy prices, finding that oil prices, stock prices for high technology firms and interest rates impact clean stocks. Managi and Okimoto [
16] analyze the relationships between oil prices, clean energy stocks prices and technology stock prices. The impact of legislation on electricity future contracts in examined by Reference [
17]. Studies also investigate the financial performance of firms operating in the energy sector [
18,
19,
20,
21,
22]. For example, Capece et al. [
18] focus on changes in the performance of the natural gas retail markets and analyze the financial statements of 105 companies by performing cluster analysis. They report that most companies in the sector perform well, with best performers belonging to existing business groups. Capece et al. [
19] analyze the combined effect of regulatory measures and of the economic crisis on the performance of Italian gas companies. The observe that average measures of profitability rose until 2009 and then declined in 2009. This is attributed to the financial crisis and regulatory policies.
A number of studies, similarly to ours, evaluate the financial performance of firms that operate within the renewable energy sector using financial ratios. For example, Halkos and Tzeremes [
20] evaluate the financial performance of renewable energy firms. They apply a data envelopment analysis and construct financial ratios to assess performance. Performance is found to be positively related to high levels of returns on assets and equity and by lower levels of debt. They also undertake a within sector analysis, finding that firms producing wind energy outperform firms generating hydropower. The dataset is limited to the Greek renewable energy sector and considers a limited number of ratios in the analysis of RES firm performance. Paun [
21] analyzes the sustainability of the renewable energy sector in Romania. Their sample encompasses 91 major energy producers for the years 2012 to 2015. To analyze performance, they consider profitability ratios, measures of return on equity and measures of return on assets but do not consider key measures in the form of return on investment and the current ratio, given limitations in the data. They find that companies that produce fossil fuels perform better relatively to companies that produce green energy. They also report deteriorating performance, after 2013 and relatively low returns on equity for RES firms after 2014, suggesting that RES firms underperform other sectors. Also, returns on assets are found to decrease after 2013, this being attributed to changes in government and delays in issuing green certificates, leading to decreases in investment. Based upon ratio analysis, Paun [
21] concludes that RES companies are close to financial distress. Tomczak [
22] investigates whether powerplants that produce electricity using renewable energy sources are in a better financial position than those that rely upon traditional (fossil fuel) energy sources using a sample of companies in Baltic and Central European countries, comprising a total sample of 37 companies. In order to assess financial performance, he considers a total of 16 ratios indicative of four aspects, namely liquidity, profitability, turnover and debt—ratios that are used in bankruptcy prediction. An analysis of ratios shows RES companies have lower return on assets and return on equity ratios than fossil fuel energy producers, which translates into lower interest from potential investors. Also, fossil fuel companies were found to be characterized by higher profitability but lower turnover ratios. Tomczak [
22] concludes that investing in RES companies is not profitable business. Our study is similar to these studies; we also consider financial ratios, through the use of DTs, we identify and then analyze financial ratios to gain an insight into the performance of green companies.
Another strand of literature considers the relationship between corporate environmental performance and financial performance, with performance again measured by ratios, demonstrating the value of ratio analysis [
23,
24,
25,
26]. Clarkson et al. [
23] investigate the factors that impact firms’ decisions to engage in a proactive environmental strategy. The study is carried out using a sample of firms belonging to the four most polluting firms in the US, namely the pulp and paper, chemical, oil and gas and metals and mining industries. They consider how changes in environmental strategy impact profitability, liquidity and leverage. Analysis shows that becoming green leads to improved firm performance and that improved firm performance subsequently improves relative environmental performance. This is reflected by increasing return on assets, rising cashflows (profitability) and a decreases in leverage. Ruggiero and Lehkonen [
24] show that there is a negative relationship between renewable energy production by electricity producers and short- and long-term financial performance. To measure financial performance, they use the return on equity and the return on assets and a firm’s market value relative to total assets and regress these onto the volume of renewable energy produced, as a main variable of interest. Granger-causality is also tested. They find a negative relationship between measures of financial performance and the amount of renewable energy produced, attributing this to higher capital costs. Sueyoshi and Goto [
25] examine the impact of environmental regulations in the US. Similarly to Ruggiero and Lehkonen [
24], they use the return on assets as a measure of financial performance. They regress the return on assets for a 167 US electric utilities onto measures of environmental protection. Results indicate that environmental protection expenditure by US electric utilities has resulted in decreased financial performance. Sueyoshi and Goto [
25] conclude that that both the positive and negative aspects of environmental policies should be considered, given that emphasis is usually placed upon the positive aspects and negative aspects. Telle [
26] challenges the methods applied in previous studies to conclude that firms that go green benefit financially. They note that one of the issues in studies that seek to relate financial performance to environmental performance is the presence of omitted variables. The omission of variables may result in an (erroneous) positive relationship between financial performance and environmental performance. Telle [
26] shows that when the return on sales for Norwegian plants are regressed onto observable firm characteristics and omitted unobserved variables are controlled form, the positive impact of good environmental performance disappears. The study’s significance lies in challenging findings of a positive impact of environmental performance on financial performance. The question of going green—and analogously—of producing components for the RES industry remains unanswered. Within the context of our present study, such findings suggest that green firms—and those related to RES—may not be characterized by improved financial performance relative to firms that are not green.
Finally, a number studies consider further aspects of the financial performance of firms that operate within the energy sector. For example, Pätäri et al. [
27] investigate whether corporate social responsibility investments have an impact on corporate performance within the energy industry, finding that different aspects of corporate social responsibility impact either both profitability and/or market value. Arslan-Ayaydin and Thewissen [
28] compare the financial performance of energy sector firms with different environmental scores, finding that those with good scores outperform financially those with poor scores. Sueyoshi and Goto [
29] investigate the efficiency of national oil companies and aim to establish whether companies that are under public ownership outperform those under international ownership, showing that companies under national ownership outperform international oil companies under international private ownership in terms of efficiency.
None of these studies seek to investigate whether investing in companies manufacturing solar components is a lucrative business by classifying companies on the basis of ratios and then analyzing these ratios. To answer to this question, we apply a decision tree based analysis. We frame our analysis within the theoretical basis provided by literature on corporate failure and financial distress, which relies upon the classification of firms, as we do in this study [
30,
31]. The genesis of bankruptcy prediction models, is attributed to Beaver (1966) who uses 30 grouped ratios and information for failed and non-failed industrial firms to identify five ratios predictive of bankruptcy. His noteworthy conclusion is that ratios for distressed firms differ from those of healthy firms, making it possible to predict financial distress by discriminating between healthy and distressed firms. Altman [
32] builds upon Beaver’s [
33] work and applies multiple discriminant analysis (MDA) to estimate a five-factor model predictive of bankruptcy for a sample of manufacturing firms. The joint consideration of ratios in Altman (1968) removes the ambiguity and confusion associated with interpreting individual ratios. Ohlson [
34] proposes the use of logit analysis (logistic regression) to estimate an O-score model that combines financial ratios and indicators, yielding a probability of bankruptcy bounded between 0 and 1. The model provides a more precise and readily understood indication of the likelihood of bankruptcy and permits a greater range of outcomes than Altman’s (1968) model. Frydman, Altman and Kao [
35] propose a non-parametric solution in the form of decision trees (DTs) to classify distressed and non-distressed firms. DTs require no distributional assumptions or transformed variables. They can handle missing values and qualitative data, are readily understood and can incorporate misclassification costs. They apply these to manufacturing and retailing companies, finding that DTs are more accurate and minimize misclassification costs. Koh and Low [
36] show that DTs outperform logit analysis and artificial neural networks in predicting bankruptcies. Similarly, Li, Sun and Wu [
37] assess the performance of algorithmic implementations of decision trees for companies on the Shenzen and Shanghai Stock Exchange, finding that these outperform other classifications methods—notably methods used in bankruptcy prediction. Gepp, Kumar and Bhattacharya [
38] take a similar approach, showing that DT implementations are superior classifiers and predictors of bankruptcy for retailing and manufacturing companies. Fedorova, Gilenko and Dovzhenko [
39] extend the application of bankruptcy prediction models to the Russian manufacturing sector by combining statistical methods with artificial intelligence techniques.
We build upon bankruptcy prediction literature that applies DTs to classify bankrupt firms and to predict bankruptcy. We apply DTs in a novel manner. While we do not aim to predict bankruptcy on the basis of financial ratios, we set out to determine whether companies that manufacture solar modules, solar cells, solar silicon rods, solar wafers, solar power, solar photovoltaic products and related equipment (green companies) can be differentiated from other enterprises in the sector that are not associated with RES companies (red companies) on the basis of financial ratios and whether these companies are in a better financial state. Based upon our analysis, the most critical ratios can be identified from a total of 62 ratios. It is hoped that using these ratios will give managers and investors the ability to undertake a broader and more detailed assessment of companies in the sector, without only focusing on profitability ratios.
2. Data and Methodology
Our methodology comprises a number of steps. First, we collect data from financial reports for companies in the semiconductor and related device manufacturing sector. Financial reports are downloaded from the Emerging Markets Information Service (EMIS) database, a Euromoney Institutional Investor Company (
www.emis.com). The initial sample consists of 2345 companies operating in China (1742), Chinese Taipei (272), South Korea (114), Thailand (48), Singapore (37), India (33), Vietnam (24), Hong Kong (21), Malaysia (20), Russia (10), Turkey (6), Ukraine (4), Ecuador (3) and two companies each from the Czech Republic, Indonesia, Iran, Philippines as well as one each from Bulgaria, El Salvador and Romania. To determine whether investing in companies that manufacture RES components pays off, we divide companies in the sector into two groups. The first group comprises enterprises that manufacture solar modules, solar cells, solar silicon rods, solar wafers, solar power, solar photovoltaic products and related equipment. We define companies within this group as green companies. The second group comprises companies that are not associated with RES companies. We defined these companies as red companies. The number of companies in our samples is unbalanced that means the number of green companies is much lower than the number of red companies. There are 528 companies in the green group while 1817 companies in the red group. All data are for 2017.
The second step is to construct financial ratios for the companies in our sample using financial reports. Consequently, we consider 62 indicators. Most of these have also been considered in Reference [
40]. The ratios considered characterize different aspects of financial performance, namely liquidity, profitability, efficiency, solvency and other aspects (see
Table 1). Such variables have been widely used in the analysis of the financial status of companies for the purposes of bankruptcy prediction.
The final step is to apply a decision tree (DT) analysis. We take a similar approach as in bankruptcy prediction models and the principle remains the same; we identify ratios that discriminate between green and red companies. We however do not apply commonly used techniques in bankruptcy prediction. Therefore, we do not use multiple discriminant analysis (MDA) as this technique requires a multivariate normal distribution and equal dispersion matrices. Also, we do not use logit analysis as this method is highly sensitive to multicollinearity and relies upon the assumption of homogenous variation in the data and is highly sensitive to outliers, missing values and extreme non-normality [
37,
41,
42]. Instead, we apply DTs to differentiate between companies associated with the RES manufacturing sector and companies belonging to the general semiconductor and related device manufacturing sector. DT methods have numerous advantages. They require no distributional assumptions or transformed variables. They can handle missing values and qualitative data, are readily understood and can incorporate misclassification costs. Splitting rules are univariate, permitting an easy identification of significant variables. DTs however require the probabilities of successful and failed businesses as inputs. DT algorithms generate a set of tree based classification rules and assign observations to either a successful or failing group, within the context of bankruptcy prediction models. The process begins with a root node, followed by non-leaf nodes which reflect splitting rules—financial ratios. These are then connected to leaf nodes, which represent success or failure. The process of constructing a DT begins with a search for an independent variable that divides observations in a sample in such a way that the difference in the dependent variable is greatest between subgroups. In the next stage, each subgroup is subdivided further by again searching for an independent variable that divides the subgroup so that the difference in the dependent variable is greatest between the subdivided groups. DT algorithms determine the best splitting rule at each non-leaf node. The process continues until splitting no longer produces statistically significant differences in subgroups or subgroups are too small for further division. To simplify the process, some nodes may be removed (pruned), while maintaining a small error rate. DTs differ from logit analysis and MDA in that they identify the relative significance of variables, unlike the latter two approaches which only identify significant variables. DTs nevertheless have predictive power by setting out a sequence of nodes that leads to a classification [
36,
38,
42].
To obtain robustness of results, the database is divided into six samples that consist of different numbers of companies and ratios, detailed information can be found in
Tables S1–S6 (Supplementary Materials). From the onset, we consider all 62 indicators and then proceed to reduce this number to 38 and finally to 8 variables. The criterion for removing indicators from our database is a lack of sufficient data for companies comprising a database. The research samples used in the construction of DTs consider a number of companies. Samples with a low number of variables comprise a larger number of companies. The more ratios in a sample, the lower the number of companies it has. The number of enterprises is also lower for samples in which the number of green and red companies is balanced. By reducing the number of indicators, we increase the number of enterprises in the sample. The list of all samples considered in the study together with number of ratios and companies is reported in
Table 2.
We view DTs as being well suited for the task at hand. DTs are appropriate for large datasets with a relatively short history. Furthermore, our aim is to build a tree with a minimum number of nodes. Consequently, DT rules are simpler and easier to interpret. The general algorithm comprises the following steps:
With a set of K-records, determine that they belong to the same class. If so, end the algorithm.
Otherwise, consider all possible classifications of the overall set K into subsets K1, K2, …, Kn so that they are as homogeneous as possible.
Assess each of the classifications according to adopted criteria and select the best one.
Divide the set K according to the adopted criteria.
Perform steps 1–4 recursively for each subset.
The subject of division is an N-element set of objects. Here, these are companies that are characterized by
M + 1 ratios (e.g., retained earnings to total assets ratio, (gross profit + extraordinary items + financial expenses) to total assets ratio) which indicate their financial standing. Therefore, the vector [
y, x] together with the respective financial ratios can be defined as follows:
where:
are financial variables.
y is the dependent variable, defined a C for red companies and Z for green companies.
Once indicators are defined (data from the Equation (1)), a relationship between
y and the variables
can be established on the basis of the predictors that determine the value of y as follows:
For this purpose, a recursive split methodology is used to obtain an approximation of the following specification:
where:
—disjoint groups in multidimensional space (red,green),
—model parameters, determined upon the basis of:
where:
—probability that an element of the R_k group belongs to class l.
The multidimensional space of independent variables (
) is divided into groups. The model is created by submitting models built in each of
K disjoint groups. For quantitative variables, as used in this study, the model can be stated as follows:
where:
—upper limit of the segment in the m-th dimension of space,
—lower limit of the segment in the m-th dimension of space,
The DT is a diagrammatic representation of specification (3). The DT algorithm first identifies ratios according to which companies. We term this the training set. It then uses these values to test data set. The model is constructed recursively [
43].
We apply three algorithms to construct DTs, namely the Chi-squared Automatic Interaction Detector (CHAID), Classification and Regression Trees (CRT) and Quick, Unbiased, Efficient Statistical Tree (QUEST) algorithms. The CHAID algorithm is an effective algorithm for building DTs developed by Reference [
44]. It is mainly used in the segmentation or extension of a DT. The algorithm is appropriate for both quantitative and qualitative variables. It is not a binary method as it can produce more than two categories at any given node. Therefore, this method has the potential to produce a larger DT relative to binary methods. At each step, the CHAID algorithm selects an independent (predictor) variable that has the strongest interaction with the dependent variable. Categories of each predictor are merged if they do not significantly differ in relation to the dependent variable.
The CRT algorithm was developed by Breiman, Firedman, Olshen and Stone in 1984 [
45]. Unlike the CHAID algorithm, it is a binary decision algorithm. It is robust to outliers, making it different from other classical methods. It functions in a recurrent manner which means that data is divided into two subsets so that records in each subset are more homogeneous than in the previous sub-set. Both subsets are then again divided until the criterion of homogeneity and other retention criteria are met. The ultimate objective is to maximize homogeneity within sample sub-groups. We apply the Gini index to determine the optimal sub-set division:
The QUEST algorithm is a relatively new DT algorithm for binary classifications. It is most often used to classify and explore data [
46] and is similar to the CRT algorithm. The difference lies in that the QUEST algorithm is time efficient and unburdened. It does not lose its predictive quality while being efficient and decreases complexity and thereby minimizes DT size [
47].
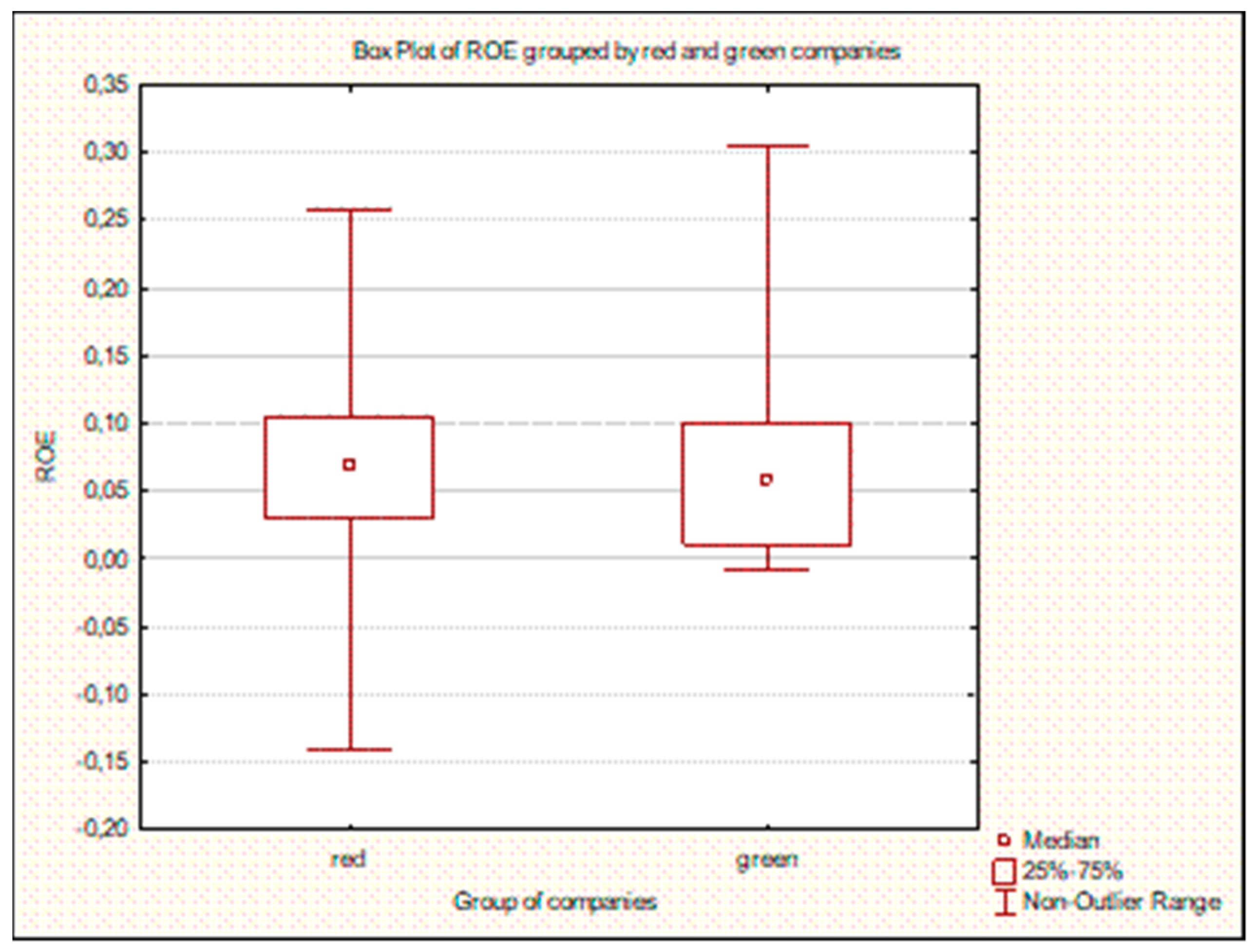
To confirm the accuracy of the resultant classifications, we examined accuracy with various settings for training parameters and apply the 25-fold cross-validation methodology. The calculated risk of cross verification in the output is the risk averaging for 25 test samples. Subsampling DTs are not shown for n-fold cross verification. Only the DT constructed on the full sample is reported. Similarly, only the full sample classification table is reported. Finally, we also investigate whether based upon the results obtained and the analysis of profitability ratios, green companies exhibit superior performance relative to the remainder of the sector. We point out the most critical indicators occurring in the tree and we test the statistical significance of differences in the selected indicators between groups of companies using the Student’s t-test.
4. Conclusions
Our study investigates whether investing in the solar technology manufacturers’ components is a lucrative business by analysing the semiconductor and related device manufacturing sector. To do so, we apply a novel approach for the sector, namely DTs. We consider 62 financial ratios and our initial database comprises 2345 companies, mostly operating in China. The companies in the sector are classified into two groups, green companies which are those for which production is related to renewable energy and red companies which are those for which production is not related to renewable energy. We define six samples, both balanced and unbalanced samples and comprising large and small samples of companies and 25-fold cross-validation, which does not significantly improve the results. The literature reports on RES companies, with most of the existing literature related to power plants [
21,
22], electric utilities [
24] or energy companies [
30]. Our results are similar to other studies of RES companies. On the basis of certain financial ratios, we find that green companies underperform red companies [
21,
22]. Our contribution lies in addressing the lack of studies that assess the relative financial performance of companies that provide equipment needed for renewable energy production. Moreover, we apply DTs for the purposes of identifying classifying ratios.
The decision tree based analysis identifies the most important indicators for evaluating enterprises, especially for those operating in China. This provides a broader overview of the financial standing of groups of companies to managers and investors. Our results indicate that investing in companies that manufacture RES components may not be a lucrative business. For managers, this is important information that indicates that RES companies are not profitable or as financially sound relative to companies in the general semiconductor and solid state device manufacturing sector. For investors potentially interested in investing in RES associated companies, our findings demonstrate a need for caution. This should be viewed within the context of achieving RES targets in total energy production. Given government targets for renewable energy, the demand for components for renewable energy production will increase. However, it remains to be seen whether this increase in demand will accompany profits.
The topic chosen by us for analysis is difficult and multi-threaded but it is worth making a foundation for further research. Our research provides a solid basis for further exploration of this data. With this foundation in place, we can continue research in the directions indicated by the reviewer. The authors are aware that all factors, both fundamental and economic, may impact the profitability of doing business.
Our analysis, however, focuses on financial ratios and is a good basis for further research. Specifically, we focus on companies within the semiconductor and related device manufacturing sector. The purpose of our work is not to compare which industry is more profitable for the investor but to determine whether selected financial indicators will indicate differences between enterprises related to the production of semi-finished products for renewable energy production and conventional energy.
Given the importance of renewable energy sources for investors, information on the profitability of not only these enterprises themselves but also enterprises in the entire production chain is crucial. Our research is significant and fills the gap in the analysed area regarding the analysis of financial indicators for enterprises from the semiconductor and related device manufacturing sector.
We recognize some of the limitations of our study. First, the research period only encompasses 2017. This may influence results. We are faced with this limitation owing to missing data for the years 2008-2016. Second, three-quarters of analysed enterprises in our sample are from China. Third, we only rely upon financial ratios in our study. Finally, we limit ourselves to applying only DTs in this study. Other approaches, such as neural network (NN) can also be used for classification purposes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}