1. Introduction
In the field of aerodynamics, complex steady flows are simulated by computational fluid dynamics (CFD) daily in the industry since CFD tools have already reached an acceptable level of maturity. These simulations are usually performed over full-aircraft configurations or several aircraft components where meshes of hundreds of million points are required in order to provide precise features of the flow. In addition, simulations are performed for different parameters to properly explore the design space. This implies a high computational cost that may be, in certain situations, even infeasible nowadays. To overcome this limitation, the CFD solver could be replaced by a surrogate model which produces a fast prediction of the aerodynamic features, based on previous simulations or wind-tunnel data. Machine learning techniques commonly used in the area of artificial intelligence (AI) and data mining (DM) can represent a valuable support to reduce the computational cost required for aerodynamic analysis.
The objective of this paper is to research in the application of machine learning and data-driven approaches for aerodynamic analysis. While these techniques have been broadly used in other sectors such as finances or risk analysis, the application in the aeronautical sector is still in its infancy. The novelty of this paper is to research on the feasibility and potential benefits of applying these techniques for aerodynamic analysis of aeronautical configurations. Application test cases have been selected amongst those commonly used in the literature for validation purpose, in order to be able to quickly generate the required databases for testing the methods, and to provide comparable results. For the abovementioned purpose, this paper covers all the required aspects in any machine learning project, such as data analysis, feature scaling, model construction, and accuracy measurement.
The main motivation for this research is to analyze the potential of data mining and machine learning techniques for a fast aerodynamic features prediction based on previous and existing aerodynamic data. These techniques may have a huge impact in the aerodynamic design process for achieving novel aeronautical configurations, since they would allow the evaluation of different promising shapes in a quick manner, therefore reducing the associated cost of the overall design stage.
The paper is structured as follows:
Section 2 presents a review of the state-of-the-art methods in the technical fields involved in this research, focusing on machine learning and data-driven approaches for aerodynamic analysis.
Section 3 describes the followed methodology for data analysis and model construction and validation, together with the numerical results and finally,
Section 4 presents the conclusions. As annexed at the end of this paper, the complete databases information is provided to allow other researchers to further exploit the data with other techniques.
2. Brief Review of the State of the Art
This section will review the state of the art in the technical fields involved in this research, namely machine learning and data-driven approaches for aerodynamic analysis.
In the five last years, there has been an increasing interest in the development of techniques to handle aerodynamic data, coming from different sources, such as CFD simulations, wind tunnel experiments or even flight test data. The ability of handling this vast amount of data of a heterogeneous nature is a crucial factor in order to enable machine learning methods to be applied in the aeronautic industry.
In the following
Table 1, the most recent state-of-the-art studies in the scientific literature are reviewed:
In summary, from the last 5 years, it can be observed that machine learning techniques have been used to predict the aerodynamic features, to accelerate or improve the precision of turbulence models, to speed-up the shape design optimization process and to quantify manage uncertainties in the flow fields, amongst others.
All the papers found, however, focus more on the application, and do not provide an overall view of all the requires steps and requirements to properly handle and prepare the data for machine learning techniques. This paper aims to fill in this gap and provides, through simple examples, an overall scheme of all the steps needed to obtain proper models by machine learning.
3. Methodology and Results
The
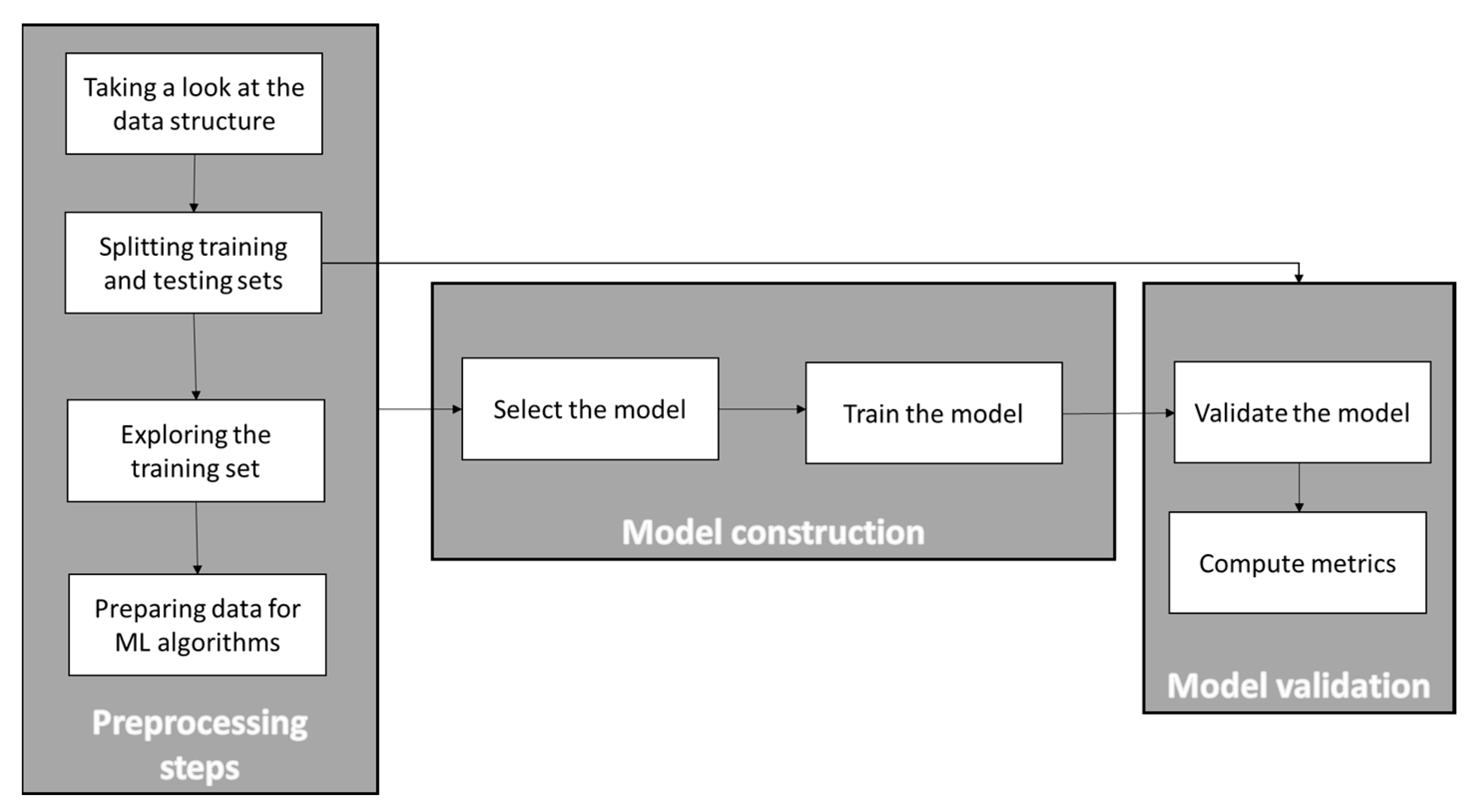
Figure 1 shows the main steps of a typical machine learning process:
In this section, each of the steps in the figure above will be explained and applied to the selected aerodynamic databases. It is important to mention that all the research performed in this paper used Scikit-learn 0.22.1, pandas 1.0.1, matplotlib 3.1.3, and python 3.8.2 libraries, all included in the Anaconda distribution. CFD computations for the databases generation were performed with the DLR TAU code (release 2019.1.0, Spalart–Allmaras turbulence model, convergence criteria based on minimum residuals).
In order to allow other researchers to perform experiments on existing aerodynamic databases and avoid the repetition of the CFD simulations required to build such databases,
Appendix A provides all the required data for free use within the research community
3.1. Data Polishing and Statistical Analysis
The first step was to quickly explore what the databases looked like. As mentioned previously, the complete databases for all the tested performed in this paper can be found in the annexes.
One of the important issues in databases for machine learning is that there are no empty values because, in case they exist, they should be substituted by the average, by zero or other values, depending on the specific case, in order to not affect the surrogate model performance. Therefore, it was checked if there were empty values for any of the variables and the result, as can be observed in the following
Table 2, was that there were no empty values in the databases.
As can be observed in the previous table, all three databases are composed of 4 columns (corresponding to the Mach, AoA, lift coefficient and drag coefficient). The data size varies depending on the configuration, the NACA0012 database has 185 rows (it means CFD computations), the RAE2822 database has 122 samples, and the DPW databases includes 100 samples.
Then, it is possible to have a look at some statistics of the aerodynamic data in the databases
Table 3,
Table 4 and
Table 5:
In the table above, the rows labeled “count”, “mean”, “min”, and “max” correspond to the number of samples, mean value of the parameter, minimum and maximum values, respectively. The row labeled “std” shows the standard deviation of the values for this particular parameter. Rows labeled as 25%, 50%, and 75% show the percentiles, which reflect the value below which a given percentage of observations in a certain group of observations falls.
From these statistics, there is one important aspect to consider. The AoA values have a high standard deviation and this will have to be considered further when deciding how to scale the training data to not affect the model performance.
It is also possible to plot the histograms of each of the considered parameters, to better understand the type of data to deal with. The following
Figure 2,
Figure 3 and
Figure 4 show the histograms of each variable in the database for the three cases considered:
As can be deduced from the pictures above, all the three database were generated with a Latin Hypercube Sampling (LHS) method in parameters AoA and Mach, this is why the histograms show the same bars altitude except for those cases where the CFD solver did not converge (those with highest angles of attack which did not achieve the minimum residual convergence criteria) and were eliminated from the database.
In the case of Cd, the histogram shows a strong concentration of values near to 0, and the Cl histogram shows the main concentration for values between 0.7 and 1.25, especially in the two airfoil databases.
3.2. Splitting Training and Test Sets
The next step was to split the database between train and test sets. In this example, the split was done with a pure random sampling method and considering 80% of the initial samples for the train set and the other 20% for the test set. This step could be improved by using other splitting methods (such as cross-fold validation for instances as the work performed in [
21]), but since the purpose of this paper is to give a general overview of the machine learning process for aerodynamic analysis, this random sampling technique was considered.
3.3. Exploring the Training Set
Now, the kind of data that will be used to build the model is explored more in detail, as can be observed in
Figure 5:
In addition, since the datasets are of a manageable size, it is also possible to compute the Pearson’s coefficient
for every pair of variables, as are displayed in the following
Table 6,
Table 7 and
Table 8:
In addition, one can also plot every numerical variable against any other numerical variable. In this case, since there are 4 attributes, 42 plots are obtained for each database, as can be observed in the following
Figure 6,
Figure 7 and
Figure 8:
Since the main diagonal of these plots would be full of straight lines, instead of showing them, it is displayed as a histogram of each attribute (remember that these histograms look different with respect to the ones showed previously, since now only the training dataset is considered).
From these pictures, it can be observed that, for predicting the lift coefficient, the AoA has a very strong importance, while the Mach number is less important. However, for the prediction of the Cd, both parameters have almost the same importance, especially in the 2D cases. This aspect is less clear in the DPW test case, where the Mach number seems to be less important than the AoA for Cd prediction.
3.4. Preparing the Data for Machine Learning Algorithms
The first step here would be to handle the missing values in the database, but as it was mentioned before, the databases do not have missing values, since all the cases without solver convergence were not incorporated in the database.
Now, it is necessary to apply one of the most important transformations to the data, which is feature scaling. Machine learning algorithms do not behave well when the parameters have different ranges, and this is the case here since the scales of the AoA and the Cd for instance are very different, as it was also mentioned previously. In this research, a standard normally distributed scaling method [
22] for each column in the training database (0 mean and unit variance) was used. The selected scaling method does not have a relevant impact on the results; what is really crucial is that all features are scaled in order to help machine learning methods to provide efficient predictions.
3.5. Model Construction
Until now, the problem has been stablished, the data have been obtained and examined, the training set and a test set have been sampled, and feature scaling has been performed to adapt the data for machine learning algorithms. In this subsection, a machine learning model is going to be selected and trained.
Since this paper aims to provide a global overview of the machine learning process, it is not in the scope to provide a deep evaluation of different models and tune the model parameters. Instead, only two regression models are selected and used with the default variables defined in the Scikit-learn packages:
Support vector regression (gamma = “scale”, C = 1.0, epsilon = 0.1 for Cl prediction, 0.01 for Cd prediction)) [
24].
3.6. Model Validation
Once the model is trained, the final step is to use it for predicting new values and validate its performance.
First, the linear regression model was tested.
Table 9 shows the typical regression metrics for model comparison.
Figure 9 shows the comparison between true vs. predicted coefficient values with linear regression method.
Then, the support vector regression model was tested. The following
Table 10 shows the typical regression metrics for model comparison.
Figure 10 shows the comparison between true vs. predicted coefficient values with SVR method.
As can be observed in the figures above, the SVR model behaves better than the linear regression model, as was expected. The R2 metrics show reasonable accuracy values for the constructed model. Of course, a more robust cross-validation strategy, as well as the optimization of the SVR hyper parameters could have been performed, but the objective of this paper was only to give an overall view of the whole machine learning process for analysis of aerodynamic databases and prediction of aerodynamic coefficients.
4. Conclusions
This paper focuses on exploring the benefits that machine learning and data mining techniques can offer to aerodynamicists in order to extract knowledge from the CFD data and to make quick predictions of aerodynamic coefficients. The main objective of this paper has been to introduce all the steps in a typical machine learning process and apply these steps to aerodynamic databases. For this purpose, three aerodynamic databases (NACA0012 airfoil, RAE2822 airfoil and 3D DPW wing) have been used and results have demonstrated the feasibility and potential benefits of applying machine learning and data-driven techniques for aerodynamic analysis of aeronautical configurations.
As the future work, there is still further potential to be exploited: a clever generation of the samples in the initial dataset (not LHS), the use of more robust model validation strategies, such as cross-fold validation, the combination of multi-fidelity data within the aerodynamic database (e.g., CFD, wind tunnel, flight testing data, etc.), the comparison of different regression models and tuning these parameters, etc. In addition, the use of these models for uncertainty quantification is another future research topic to face.
Finally, it is important to mention that all databases used in this paper are freely available for the scientific community.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}