1. Introduction
Worldwide domestic energy consumption has doubled since 1982 [
1]. In developed countries, the energy that is consumed in buildings represents over 40% of total energy use [
2]. In developing countries, buildings have already become the largest source of energy consumption and CO
2 emissions, which are predicted to increase in the future [
3]. Accurate daily demand prediction is important for understanding future use of energy and it can be used to reduce building energy costs and emissions. For example, the building operator can choose to preheat or precool in different seasons according to the prediction results. While accurate and reliable demand predictions can improve building energy performance, the predictions are a complex problem that strongly depends on the specific building. Many factors affect heat and electricity consumption, directly or indirectly, for example, outdoor temperature, equipment efficiency, and occupancy [
4]. For thermal loads, increasing numbers of new and refurbished commercial buildings use building management systems (BMS) to regulate the heat consumption, typically using measurements of indoor and outside temperature difference and assumptions regarding the thermal efficiency of the building itself [
5]. For electrical load, occupancy is seen as a major driver with temperature contributing to a lesser extent [
6]. Numerous load modelling approaches are based on these factors, which fall into two broad categories: physical and data-driven methods [
4], with their respective advantages being documented in published studies.
Physical models capture interactions between the building efficiency, lighting, heating, ventilation, occupancy, and air conditioning (HVAC) system and weather to predict consumption. It uses physical equations to describe different factors and calculate demand and takes a wide range of mechanisms into account, including conduction, ventilation, and so on [
7]. A range of software tools integrating these complex physical principles have been developed, e.g., TRNSYS, EnergyPlus, and ESP-r. Nan et al. [
8] applied ESP-r to model demand in a modern domestic dwelling that is based on the weather, building information, and some other social components. Muhammad et al. [
9] demonstrated the potential for energy savings on electricity and heating for households in Thailand through modelling in EnergyPlus. Lizana et al. [
10] developed a low carbon heating technology for flexible energy building modelling in TRNSYS.
The main limitation of the physical method is that the model requires a deep level of detail regarding building geometry, material properties, and heating and ventilation systems to calculate reliable results. Unfortunately, this information might not always be available or reliable, particularly for older buildings that have been refurbished one or more times [
11]. Data-driven tools, by contrast, have the power to generate models from recorded or proxy data, and these have been used in building simulations and energy performance predictions. Multiple regression and Artificial Neural Networks (ANN) represent two commonly used techniques [
12].
Regression models are widely used due to the interpretability and ease of use of model parameters. For heat demand modelling, Rosa et al. [
13] proposed a simple dynamic degree-day model for predicting the heating/cooling demand for residential buildings. Catalina et al. [
14] built a multiple regression model that was based on the building global heat loss coefficient, the south-facing equivalent surface, and the temperature difference to determine the heating demand. Jaffal et al. [
15] utilized an alternative evaluation regression model to model the UK annual heat demand according to dynamic simulation results. Regression models have also been used for electricity modelling. Newsham and Birt [
16] put special emphasis on the influence of occupancy, which can increase the model accuracy. Fan et al. [
17] used a multiple linear regression model along with eight other models to predict the electricity load of the tallest commercial building in Hong-Kong. Renaldi et al. [
18] developed a synthetic linear heat demand model that was based on an “energy signature method”. Irrespective of the approach, they can only determine one specific potential relationship between the selected variables. For example, the relationship between outdoor temperature and electricity demand varies in different seasons, which cannot use the same model to express both winter and summer scenarios. Commonly, researchers tend to do classification processing and manually build a series of seasonal or calendar models to reduce the uncertainty [
19]. The method works well, although it can be time and computationally expensive.
Machine learning (ML) algorithms, such as support vector machine (SVM), have become new tools for researchers in demand modelling. Apart from the fast calculation speed, the main advantages of these methods over traditional ones are the capability of discovering patterns and automatically capturing the non-numerical information from a large number of datasets. Samuel et al. [
20] used four ML techniques to forecast the heat demand in a district heating system with the inputs of outdoor temperature, historical heat loads, and time factor variables; SVM performed the best among all ML algorithms used. Jang et al. [
21] optimized a ML model for predicting the thermal energy consumption of buildings by extracting major variables through feature selection. In modelling building electricity use, Nizami and Garni [
22] used a simple feed-forward ANN to relate the electrical demand to the number of occupants and weather data. Similarly, Kampelis et al. [
23] proposed an ANN power prediction for day-ahead energy management at the building and district levels. Wong et al. [
24] used an ANN to predict energy consumption for office buildings with day-lighting controls in subtropical climates; the outputs of the model include daily electricity usage for cooling, heating, and lighting. Some data-driven models employ lagged variables, e.g., actual historic consumption in previous time steps, within the demand prediction, leading to significantly improved results [
25,
26].
Which variables or features to include in the models are usually chosen by expert knowledge or previous experience and not through a formalized procedure that is based on the model characteristics, leading to a gap between the prediction and actual value [
27]. Feature selection processes can be used to find the most important features from a ‘feature pool’ in a formalized and reproducible way. Feature selection approaches are categorized as filter, embedded, and wrapper methods [
28]. Filter methods rank features based on statistical properties that ignore the processing of different features by the algorithm itself, such that there is no way to ensure the accuracy of feature selection [
28]. The embedded methods incorporate feature selection into the model training process [
29], and they are typically used in regression models, e.g., step-wise regression (LMSR) or classification trees. The wrapper method finds the best feature sets according to the model performance with the selection results varying with the algorithm. Wrapper methods are widely used in feature selection [
29] and they view it as an optimization procedure; the methods applied include Particle Swarm Optimization and the well-known Genetic Algorithms (GA) [
30,
31].
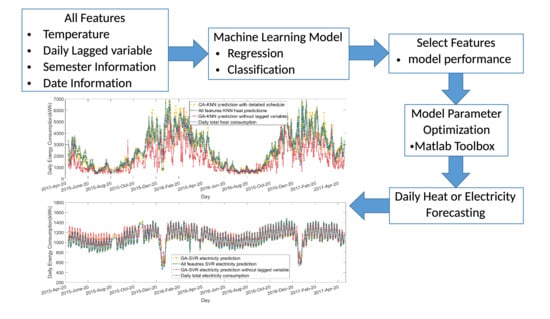
While it is clear that many papers use machine learning technologies with different features as inputs to predict heat and electricity demand, there are still gaps in existing studies that need to be overcome. Most of the work in the literature has tended to regard consumption as a continuous numerical variable utilizing regression models for prediction; however, each daily consumption level can be conceivably described by a discrete class in its own right, lending itself to the application of classification models. Second, the use of classifiers for specific types of day (e.g., weekday/weekend) is well established in demand modelling, as individuals tend to follow established routines and groups of individuals tend to behave similarly. Universities are unusual entities with a wide range of discrete cohorts of users and a complex pattern of activities that take place throughout the year. Given that there are distinct cohorts of occupants, this work regards the agent behaviour as activities that are aggregated across cohorts, which are considered to be determined by schedule. Open source information, such as semester and holiday schedules and timetabling, acts as a proxy for people’s behaviour. The hypothesis is that classification of different types of days will reflect different activities with associated energy consumption. The term ‘agent schedules’ is employed to describe these behaviours, but it should be noted that this is explicitly not a form of agent-based modelling (of which there are many examples in the literature) and avoids the complex data collection and modelling process required.
This paper examines the scope for different types of data-driven prediction of daily electricity and heat energy consumption in a complex, large, mixed-use university building. A GA feature selection approach is used to find the best feature set for both heat and electricity demand prediction. The main contributions are (1) a detailed comparison of the performance of sample classification and regression ML algorithms in modelling daily heat and demand profiles, (2) the examination of the value of feature selection in enhancing model performance, and (3) an examination of the value of daily historical measured energy data.
The paper is laid out, as follows.
Section 2 describes the methodology covering the data requirements and ML techniques applied.
Section 3 presents the case study, while the final section discusses the findings and concludes.
4. Discussion and Conclusions
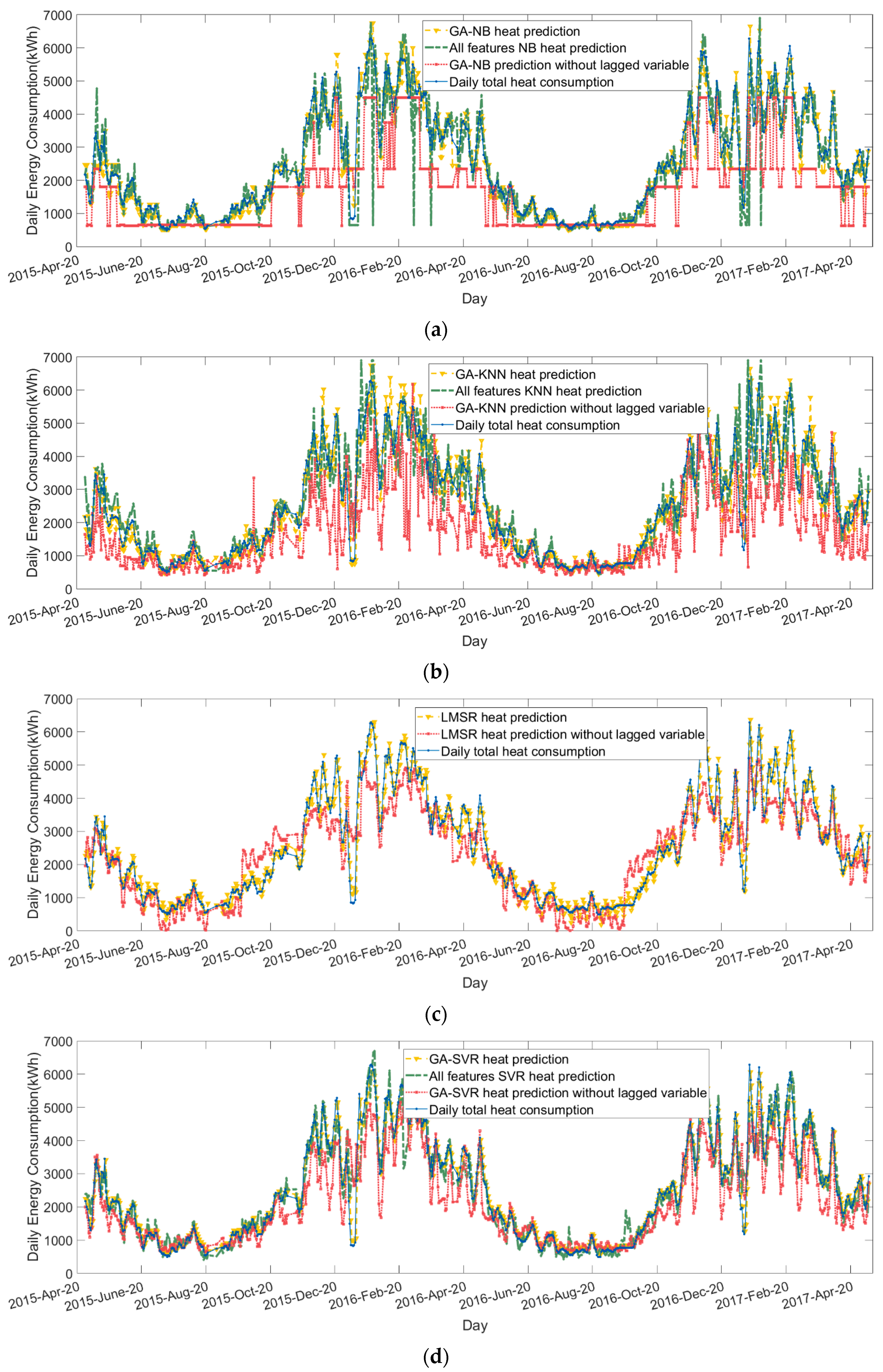
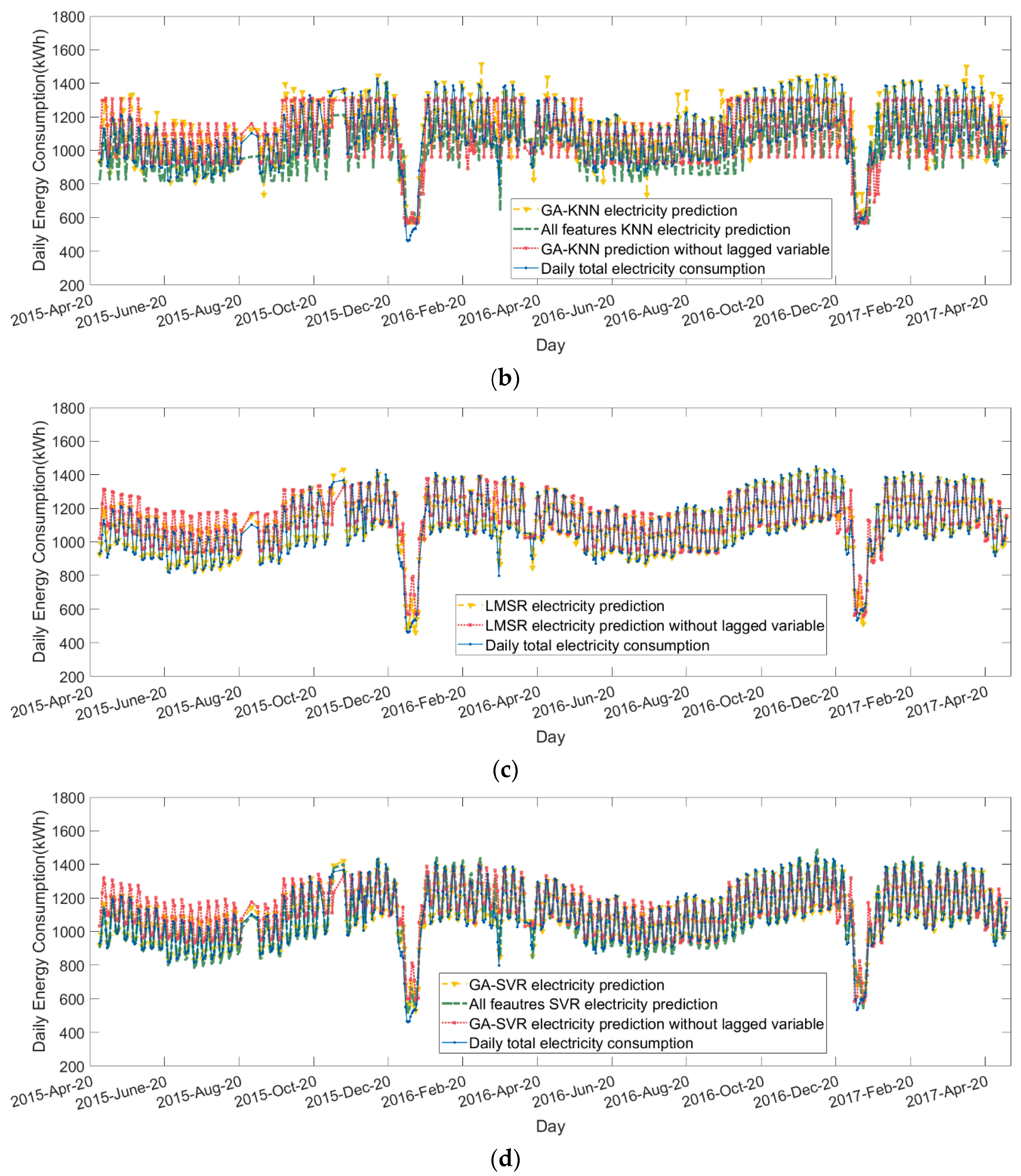
Previous work has studied ML applied to electricity and heat demand. However, these studies have either used regression models only or have not integrated ‘feature selection’ from large datasets, including daily historical electricity and heat consumption within the analysis. Here, four different algorithms, different scenarios regarding information on users, and the incorporation of other energy data allowed for a wide analysis of the benefits and limitations of the data-driven approach. Broadly, regression models perform better across the board and look fit for purpose in modelling daily electricity and heat demand.
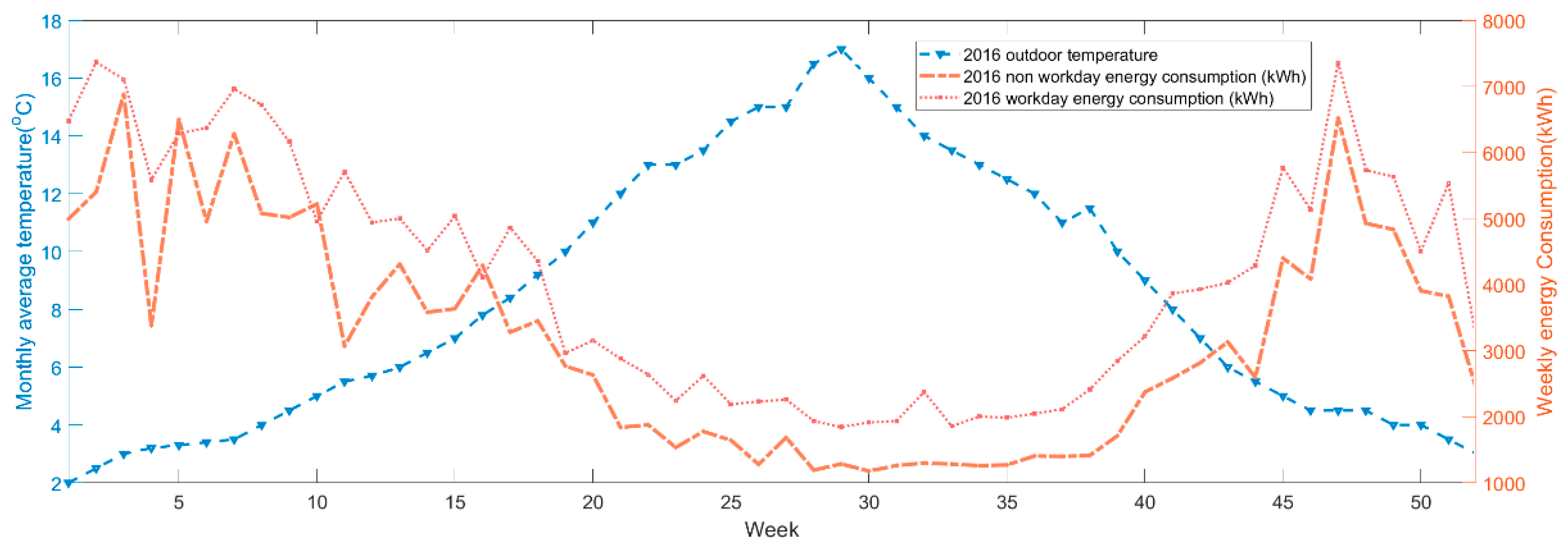
The use of feature selection on demand prediction improved performance in modelling both electricity and heat demand for all models. Without feature selection, the classification models offer poorer performance overall, although specific algorithms and cases are closer to that of regression models for heat modelling. This suggests that thermal loads are more easily classified than electrical loads, which may be due to the BMS that cannot respond directly to heat that is associated with electrical load or human activity, or more likely, that external temperature has a much more dominant role in heat demand.
On the other hand, the results from optimal feature selection indicate that the heat and electricity demand predictions need different information to achieve good performance. Temperature and some key schedule information that describes the occupancy rate along with the lagged demand variables are important for enhancing the model accuracy. Two results from the case study support this conclusion. First, all of the optimal feature sets contain the lagged variable and the results are the best among all features; secondly, removing the lagged variable from the optimal set degrades the accuracy of both electricity and heat models. The feature selection results show that the incorporation of historical heat demand information in the electricity modelling and vice versa was unhelpful in ensuring adequate modelling performance; this reflects the relative disconnect between the drivers of heating and electrical demand in this building. Clearly, this distinction will reduce in cases where heat is provided by electrical means. The ‘agent schedule’ approach that is used in this analysis is not what many would recognise as ‘true’ ABM; however, the value of providing information that reflects the behaviour of cohorts of users is clearly demonstrated.
The effectiveness of the data-driven approach has been demonstrated for the Chrystal Macmillan Building. Built 70 years ago and recently refurbished, the building is reasonably representative of a large number of buildings in the UK that are, or will, be refurbished. It is of significance to study the data-driven model for this kind of building: due to the continuous updating of historical buildings, the construction of physical models require the estimation of material properties, which involves great uncertainty and is difficult to achieve [
54]. The results illustrate that the data-driven models can simulate the energy consumption, despite no knowledge of the building’s physical condition.
There are a number of unresolved questions that arise from this work. First, as far as heat load is concerned, it seems that the ML model performs well; further work could consider whether introducing a hybrid model—incorporating building physical parameters in the data-driven model, e.g., BMS parameters or U-value—improves the predictive capability. Secondly, it is worth discussing whether the performance of the electrical demand classification model can be improved by introducing more detailed schedule and power equipment information. Answers to these questions may allow for the framework to be developed into a more complete toolkit in the future.
Finally, the proposed approach can be used to estimate other buildings’ energy consumption by transformation. For example, the demand model developed here will be applied to other University of Edinburgh buildings with similar uses and building controls to develop models of campus level energy use. This would enable the forecasting of day-ahead electricity and heat consumption to assist with efforts to reduce operational energy costs and CO2 emissions. Similarly, this enables a more accurate load curve incorporating realistic schedule information to be applied in simulating the effects of interventions in building fabric and energy supply options in long term planning exercises.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







