1. Introduction
Through the increase of renewable energy sources (RES) in the electrical grid, the load flow in the grid changes. Even with a known amount of installed power plants, RES and electrical loads in the grid, the load flow is still uncertain as the generated and consumed electrical energy depends on uncertainties. The produced energy results from the actual demand and RES production. In turn, the production of RES results from weather conditions and, finally, the conventional power plants need to balance the residual load. The whole interdependencies and characteristics of these uncertainties need to be considered, for instance, for transmission expansion planning.
Nowadays, a great number of approaches in the field of transmission expansion planning exist. They vary, amongst others, regarding their solving method, time horizon, and the consideration of uncertainties. The transmission expansion plan can be optimized by different mathematical and heuristic methods, e.g. Benders decomposition, exemplarily used in [
1], or evolutionary algorithms, as exemplarily applied in [
2] and [
3]. When considering the time horizon, they can be distinguished between static and dynamic planning. Static planning only considers one year, e.g. seen in [
2] and [
3], while the dynamic planning considers various years, e.g. exerted in [
1]. Dynamic planning leads to a large and time-consuming problem [
4]. Nowadays, in many research projects and case studies dealing with power system planning or grid operation, the uncertainties are neglected as seen, e.g. in [
1] and [
2]. Some use scenarios to consider uncertainties e.g. in [
3,
5,
6] and [
7]. This is often done by using one historic weather year and the corresponding electric load data of the same year. With the assumption of same weather conditions and energy demands in the future, the energy production of the conventional power plants are determined, and, e.g., bottlenecks in the transmission grid are analysed. The greater the installed power and, thereby, the produced energy by RES, the greater is the influence of assumed weather conditions on the final outcome. On the one hand, this approach requires a high calculation effort. On the other hand, it is known that one year is not representative for future years, especially as the weather conditions can vary widely from year-to-year.
As real grids are often large, they also depend on the installed, generated, and consumed energy in different regional or Transmission System Operator (TSO) areas. For example, the German transmission grid is embedded in the Continental European transmission grid and it cannot be separately regarded. In existing approaches, e.g. [
5], the problem is solved by considering the complete Continental European transmission grid in detail or as an aggregated version. This results in a high computational burden, even though e.g. the TSO of Germany is mainly interested in the expected load flows on the German transmission lines.
A few papers have started to analyse the distributions and dependencies of RES and electrical load feed-ins. In [
3], all of the uncertainties are represented by beta-distributions and correlations are neglected. Some represent wind speeds by Weibull distributions and they determine the Pearson correlation coefficient to capture the linear correlation, e.g. presented in [
8] and [
9]. Others use copulas. Copulas are statistical functions that allow for building a joint probability distribution by separately modelling the marginal distribution function and the dependence structure. It was introduced by Sklar in 1959 [
10]. In contrast to the correlation coefficient, the copula can model linear and nonlinear dependencies. It was introduced to uncertainty modelling in power systems in recent years. Existing works mainly use bivariate copulas that take the dependence of only two locations [
11,
12,
13], and [
14] into account. These papers differ by the selected copula model (Gaussian, Gumbel, etc.) and by the considered uncertainties (wind/wind, wind/load, etc.). In [
15], a 15-dimensional Gaussian copula is built. However, the Gaussian copula is quite inflexible. A more flexible tool are vine copulas [
16], which have been applied, e.g. in [
17] to represent the dependencies of wind speed in a small dimension or in [
18], to model the spatial dependence of wind power forecast errors. In past works, copulas have proved to be useful in risk analysis of power systems. However, the typical copula models become inflexible and face difficulties in becoming extended to higher dimensions. For real test cases, high dimensional copulas are necessary, as every station implies one dimension for each uncertainty. Moreover, the presented models focus only on some uncertainties, e.g. wind power, but neglect the necessity to implement one full model when considering a wide range of uncertainties to use it for real problem solutions.
Therefore, this paper proposes a new model for dealing with uncertainties. The uncertainties are modelled by a joint distribution model. It includes the interdependencies of wind speed, solar irradiance, electrical load, and the energy exchange between connected TSOs. Interconnected TSO exchange energy via cross boarder lines. Considering the cross boarder flows (CBF) in the joint distribution function enables grid reduction, as the import and export of energy is captured by the CBF. These flows are restricted by the network transfer capacities (NTC) and they depend on the developments of the installed power in all of the connected countries and the actual generation and load. Exemplarily, data for Germany as part of the Continental European transmission grid are used.
In
Section 2, the copula concept with a special focus on pair-copulas is introduced, in
Section 3 the joint probability model for Germany is presented and the copula is used to determine the probability for rare events.
Section 4 presents the probabilistic load flow model. A case study is presented in order to analyse the load on the transmission grid of 2030.
Section 5 concludes.
2. Probabilistic Approach
The proposed approach determines the load flow on the transmission lines when considering uncertainties. It consists of a joint distribution model to generate samples as an input for a MCS and a MCS. First, the modelling of the joint probability distribution function using copula is shown, and then the probabilistic load flow approach is presented.
2.1. Copula
This section gives an overview of copula constructions. Further information can be found in [
10] and [
16]. Copulas are used to model a joint probability distribution for which the marginal probability distribution of each variable is uniform. A bivariate copula function
is a distribution on
with uniform marginals. Sklar provides the central theorem of copulas. Equation (2) shows the connection of the bivariate distribution functions and their univariate margins.
C is called the copula; it describes the dependence between two variables and with distribution functions F and G. H is called joint distribution. The equation can be extended from the bivariate case to a multivariate one. The main advantages of copulas are the possibility to separately model marginal distributions and the joint dependence structure. In addition, it is not restricted to specific parametric models such as the multivariate normal distribution. It can be distinguished between different copula classes, which, in turn, consist of different families. The most common classes are the Archimedean copulas and the elliptical copulas.
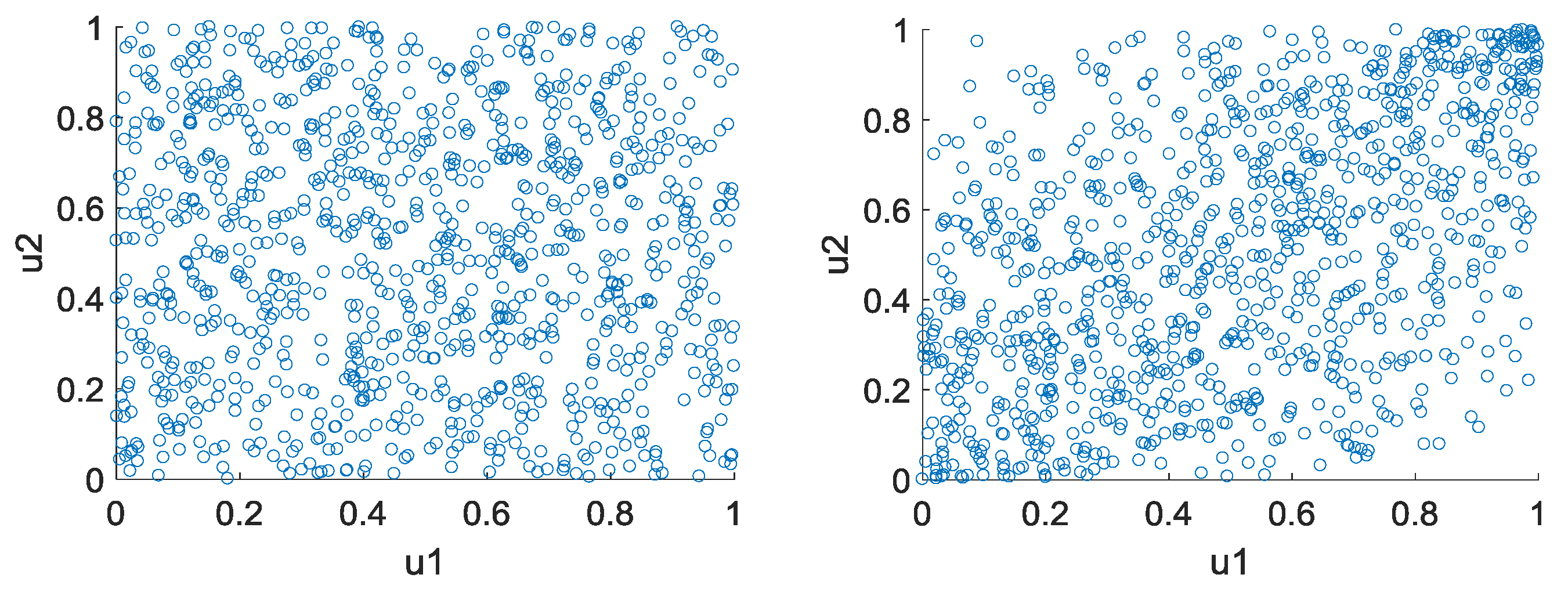
Figure 1 shows examples of bivariate Gaussian copulas.
Different classes and families can express different dependence structures. Elliptical copulas have radial symmetries, resulting in the same upper and lower tail dependence. Their application is restricted to cases without different tail behaviour. In contrast, the Archimedean copulas allow for a greater range of dependence structures. E.g., the Gumbel family represents upper tail dependence, while the Clayton family represents lower tail dependence [
10]. The Archimedean are mainly used for bivariate copulas, as they are not practical for higher dimensions and entail one-parametric Archimedean copulas, two-parametric Archimedean copulas, and rotated versions of the Archimedean used for negative dependencies [
19]. The joint probability model is determined in two steps: First, marginal probability distribution functions are determined and, second, the copula captures the dependence structure.
2.1.1. Marginal Distributions
Marginal distributions are determined while using a parametric or a non-parametric estimation. The parametric estimation assumes a particular form for the underlying distribution function first, while the non-parametric avoids any classification to parametric families, e.g. Normal or Weibull distribution [
20]. Distributions can be unimodal or multimodal.
A multimodal distribution is a PDF with more than one (local) maximum, which results in various modes. Often multimodal distributions are mixtures of two or more different unimodal distributions. The contemporaneous consideration of different groups might lead to multimodal distributions.
The histogram is a basic and well known probability density estimator. Its main disadvantages are the resulting noncontinuous density functions and the lack of rule for estimating, e.g., the bin width. The Kernel estimator is a more flexible method for non-parametric estimation. The Kernel density estimator for estimating the density of a random sample (
) is defined by
The value
describes the bandwidth and it is also called the smoothing parameter. The Kernel function
K must satisfy (4)
Normally, known density functions, e.g., the Normal distribution, are selected for the Kernel function [
20].
2.1.2. Dependence Modelling Using Pair-Copula Constructions
The pair-copula construction was introduced in [
16] to allow or flexible constructions and to be suitable for higher dimensions. They can handle high dimensions with heterogeneous dependencies. The multivariate copula is decomposed into various bivariate copulas, so they allow for different dependence structures between pairs of variables. The copula is built up by products of marginal densities and bivariate copula densities. For high-dimensional distributions, a great variety of possible pair-constructions can be determined, i.e. the decomposition is not unique. The graphical models—Regular-vines (R-vine), Canonical vines (C-vines), and Drawable vines (D-vines)—can be used to organize them [
19]. With
d variables
pair-copulas arise. Equation (5) shows the connection of pair-copula densities and marginal densities for the C-vine approach
where
denotes the marginal densities and
,
Z is defined, as
and
presents the bivariate copula densities with their parameter(s)
.
Copulas can be fitted e.g. by a method of moments inversion of Kendall’s or by the maximum likelihood estimation. With the Akaike Information Criteria (AIC) or the Bayesian Information Criteria (BIC), the copula family is chosen.
2.2. Joint Probability Model For Wind Speed, Solar Irradiance, Electrical Load and Cross Boarder Flows
A joint probability model is established. Exemplarily, data for Germany are used to analyse the load flow in the German transmission grid as an example for an interconnected TSO. This model includes the uncertainties due to weather characteristics, the electrical load, and the export/import to neighboring countries. The interdependencies are nonlinear, the distributions are non-normal, and, due to the great amount of considered uncertainties, the structure becomes high-dimensional. The problem is modelled with a C-vine copula, which can cope with the mentioned characteristics. A great amount of data is needed to develop the joint probability distribution. As the copula models the marginal distributions and the dependence structure separately, the data are used to estimate, on the one hand, the marginal distributions and, on the other hand, the dependence structure. The latter requires contemporaneous available data. In this section, the marginal distribution functions are presented, followed by the description of the copula. In the last part, the copula is used to determine the probability of extreme events. For the analysis, software R and the package CDVine is used.
2.2.1. Marginal Distribution Functions
Weather Characteristics
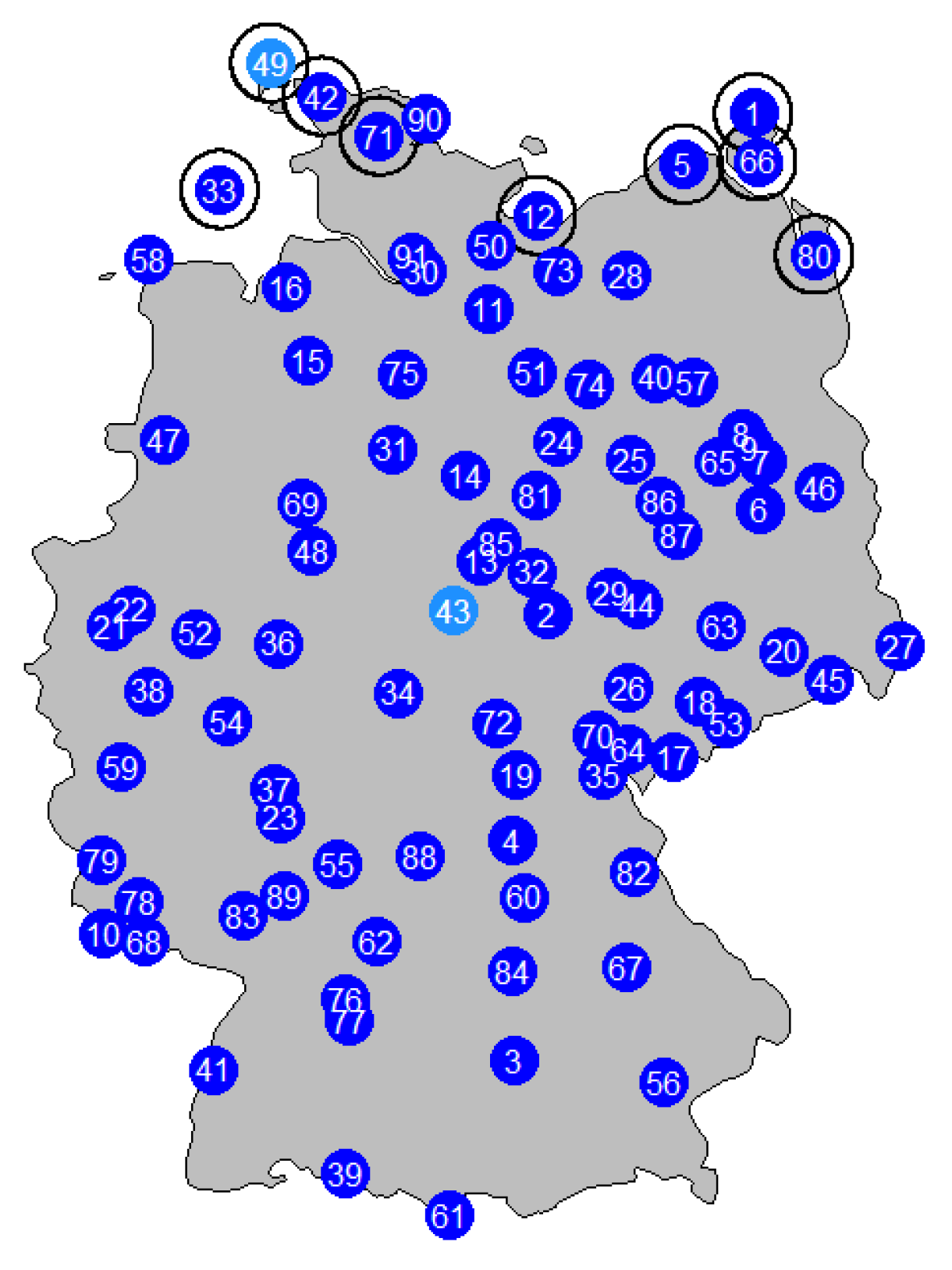
As RES depend on weather characteristics, these are modelled in a first step. Wind speed data are taken from the database of the German Weather Forecast Service (DWD). They comprise the measured hourly mean wind speed data. Datasets can entail missing data points due to e.g. defective measurement equipment or false data classification. When considering 20 years (1995 to 2014), 91 out of 410 German measurement stations are selected. They are chosen when considering simultaneous availability of data and measurement consistency, e.g. no change of station height etc. during the measurement time. Their locations are shown in
Figure 2.
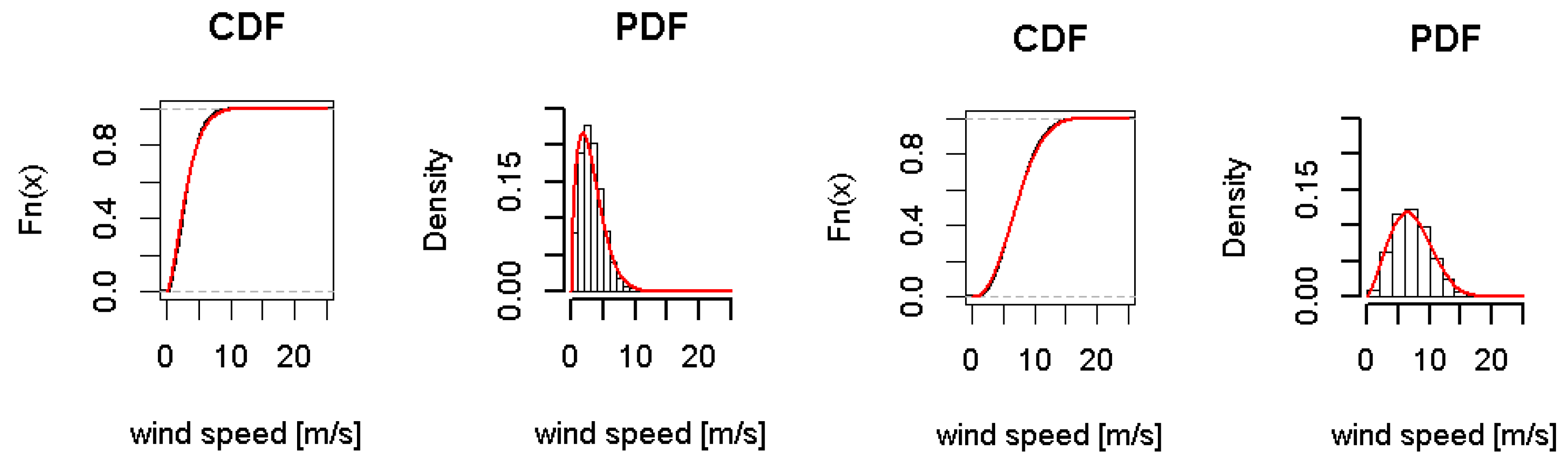
The wind speeds at each station are approximated by a Weibull distribution. The parameters are estimated by maximum likelihood. The fitting is based on around 70,000 observations for each station. The
-test is used to confirm the fitting, which requires statistically independent observations. This is achieved by selecting observations with time distance when considering their autocorrelation function [
21].
As an example,
Figure 3 shows two approximated Weibull distributions for station 43, in the Middle of Germany, and station 49, in the North of Germany. The stations are marked in a light blue in
Figure 2.
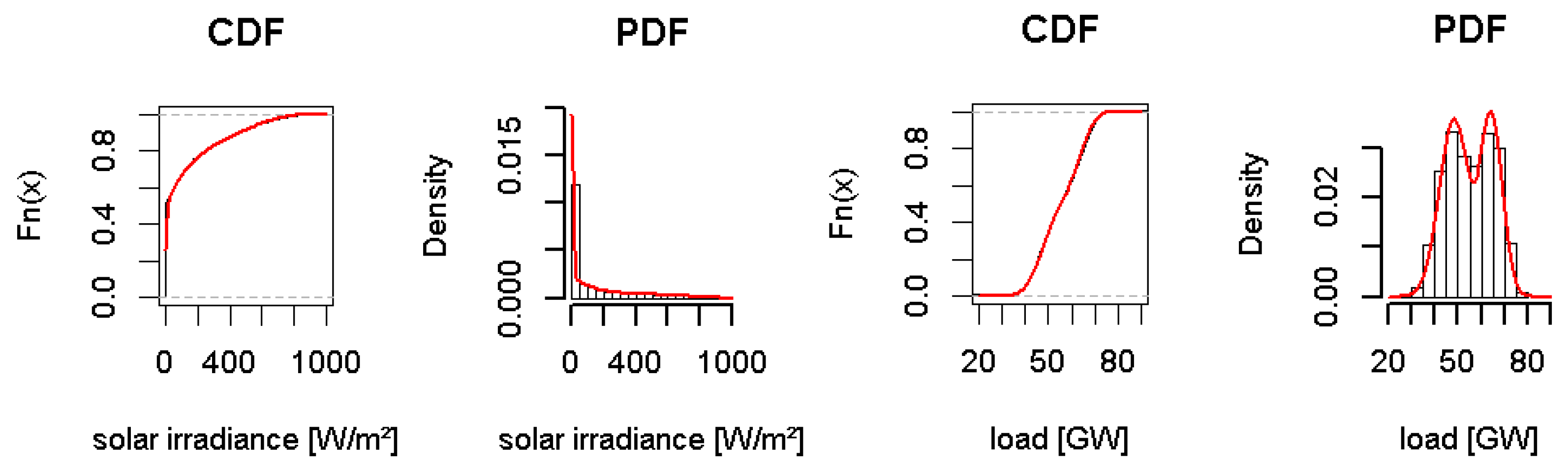
The measured solar irradiance data that were published by the DWD are not sufficient for developing a joint probability distribution model. Therefore, modelled data from EUMETSAT’s Satellite Application Facility on Climate Monitoring (CM SAF) are used. The data are hourly modelled values that are based on satellite information of Meteosat satellites. They are available for a 0.05 × 0.05 degree grid [
22]. The closest available values for the locations (
Figure 2) are used to synchronize these data with the wind speed data. In a detailed analysis, the data of the same period as the wind speed data (1995 to 2014) are investigated. For this time period, around 150,000 contemporaneous observations for each station are available. As an example, the fitting for the station 43 is shown (5). They cannot be categorized while using any parametric families. Instead, the non-parametric kernel estimator is used to estimate the PDF of the data. The bandwith is estimated by cross-validation likelihood.
Electrical Load
For the German electrical load, the hourly total load data that were published by ENTSO-E are used. They consist of measurements for the years 2006 to 2014. The total amount of available data are nearly 80,000 observations. The histograms show a multimodal characteristic and are estimated by a bimodal distribution, consisting of two Normal distributions, as seen in
Figure 4. Industrial electrical load strongly influences the whole electrical load. It peaks during weekdays and daytime, but gets small at weekends and during the night. This results in two groups with mean values of about 48 GW and 65 GW.
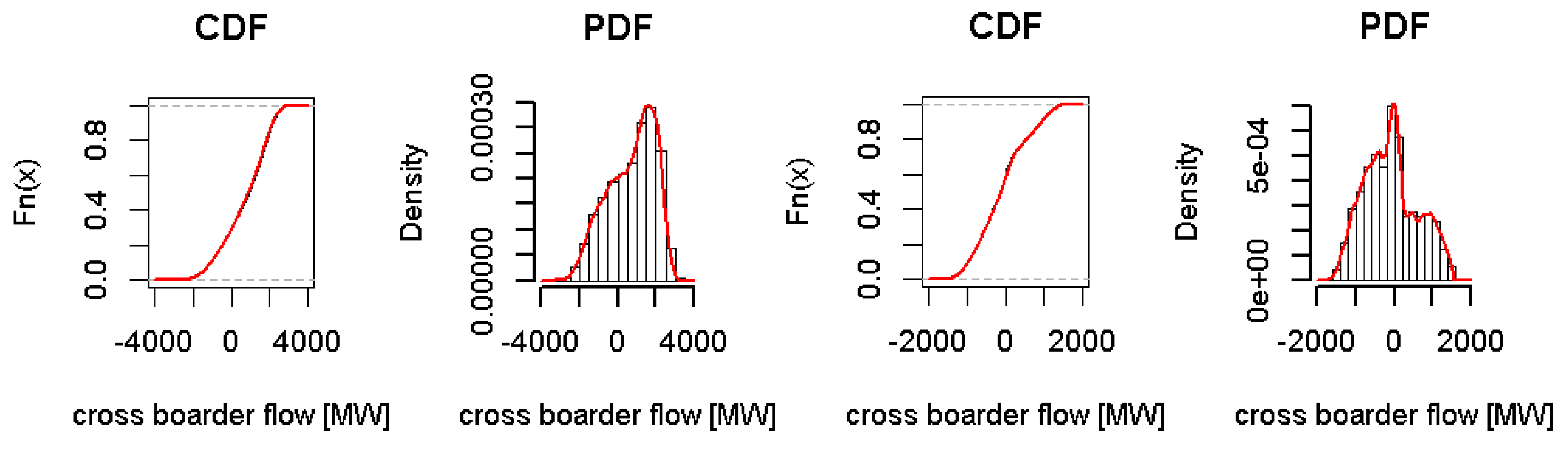
Cross Boarder Flows
Interconnected TSOs exchange energy with neighbouring TSOs. Germany, as part of the Continental European grid, is influenced due to physical CBF. The ENTSO-E publishes hourly values for CBF. In the analysis the data for the years 2012 to 2014 are taken. The data consist of around 25,000 data. Similar to the solar irradiance distribution, no categorization into one-parametric family is possible. The kernel density estimator estimates the CBF. The bandwith is estimated by cross-validation likelihood. Nowadays, Germany (DE) exchanges energy with Austria (AT), Switzerland (CH), Czech Republic (CZ), Western Denmark (DK1), Eastern Denmark (DK2), France (FR), Luxembourg (LU), Netherlands (NL), Poland (PL), and Sweden (SE). In
Figure 5, the CBF between DE and CH and between DE and DK1 are presented.
2.2.2. C-Vine-Copula
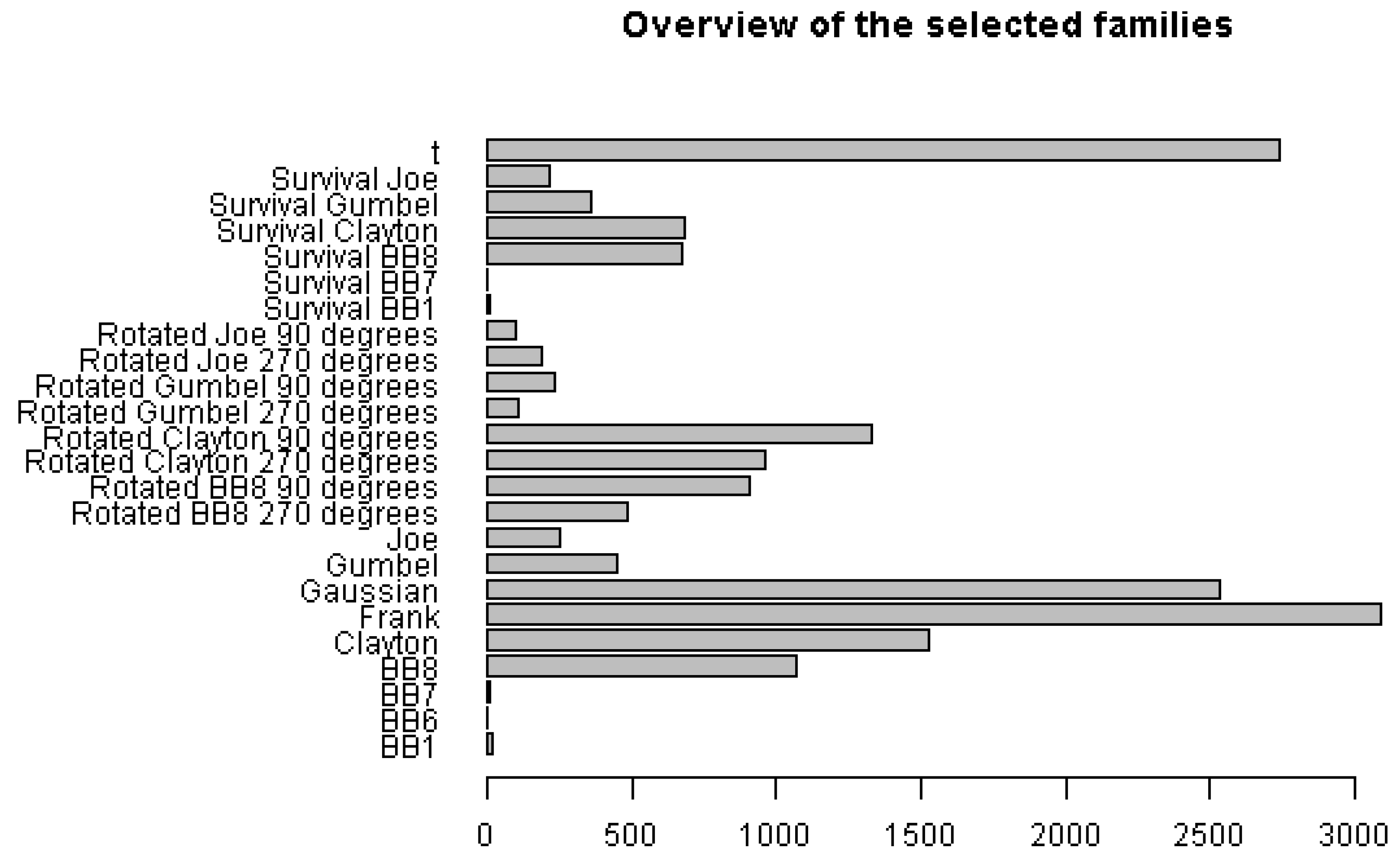
The C-vine copula approach establishes the joint distribution model. The bivariate copulas are selected with the AIC from 33 different copula families listed in [
23]. They include elliptical and Archimedean copulas and as subclasses, the one-parametric, two-parametric and rotated Archimedean copulas. The maximum likelihood estimation is used for the fitting and, based on the AIC, the copula family is selected. With an amount of 190 variables, 17,955 copula families were selected. The variables consist of 91 wind speed measurements, 91 solar irradiance model based data, the measured total electrical load, and the measured CBF to seven neighboring countries. The published data for the exchange between DE and CZ, between DE and NL and between DE and LU, are lacking. Accordingly, they are not integrated in the copula as contemporaneous data are necessary for the determination of the dependence structure. The dependence structure is determined with 10,500 contemporaneous observations. In
Figure 6, an overview of the chosen families is given. It can be seen, that one-third of all the selected families are t-copula and Gaussian copula, which have radial symmetries. All others belong to the Archimedean class, which express asymmetric and/or nonlinear dependence. Nearly one-third of all copulas are rotated copulas expressing negative dependence. The results of the classes depend on the decomposition.
Determination of the probability for certain events
The defined copula can be used to estimate the probability of certain events. These events could be extreme or rare events, e.g. low electrical load, but high wind speeds and high solar irradiance for whole Germany or a certain area. Simulating a high number of samples and extracting the samples that meet predetermined criteria for these events can estimate the probability of these events.
For this paper, 5,000,000 samples were generated and probabilities for specific events were calculated. The samples are generated while using the copula with the algorithm presented in [
24]. The model is verified by the comparison of the determined probability using the copula and the probability of the real observations.
As an example, four events are examined and the results are presented. By choosing the events, it has to be taken into account that the joint probability model is based on raw data, i.e. wind speeds on measurements heights. The Hellmann exponential law (Equation (6)) and a typical power curve are taken into account for selecting the wind speed values for certain events.
The Hellmann exponential law relates the wind speed on measurement heights to the one on hubs height [
25].
The parameter is called friction coefficient or Hellmann exponent. It describes the surface roughness that depends on the topography at a specific site. The measured wind speed on height is described by , the wind speed on hub’s height is .
Two cases are considered for the presented events: no power generation, i.e. less than on the hub´s height, and power generation of more than 0.65 p.u., i.e. more than on the hub´s height.
No thresholds are defined for the presented events. In the examination, two groups of stations are considered: (i) all 91 and the defined criteria should be true for at least 90% of all stations and (ii) only the stations in the North of Germany (NG), 1, 5, 12, 33, 42, 49, 66, 71, 80, should meet the predetermined criteria.
Table 1 shows the events and the corresponding determined probabilities.
Event 1 describes the case, that at 90% of all stations the wind speeds on hub´s height are higher than , while the load is less than 55 GW. The model determines its probability with 0.01%. The probability is reduced to 0.0005%, if the solar irradiances should exceed at 90% of all stations (event 2). The probability of more than at the defined stations in NG are 0.39% (event 3). Event 4 describes the probability for rather high load (>65 GW) and low RES production (wind speed less than 3 m/s and solar irradiance less than ). Its probability is 0.064%.
2.3. Probabilistic Load Flow Approach
The joint probability model is integrated in a probabilistic load flow approach that is based on a MCS. A MCS with random samples provides precise results, if a sufficient number of simulations are carried out. The copula can provide the needed high amount of samples. The approach analyses the German transmission grid for a scenario in 2025. The approach is presented after a description of the used data and assumptions.
2.3.1. Data and Assumptions
For the considered scenario of 2025, the developed scenarios in [
26] are used. A detailed description can be found in [
27].
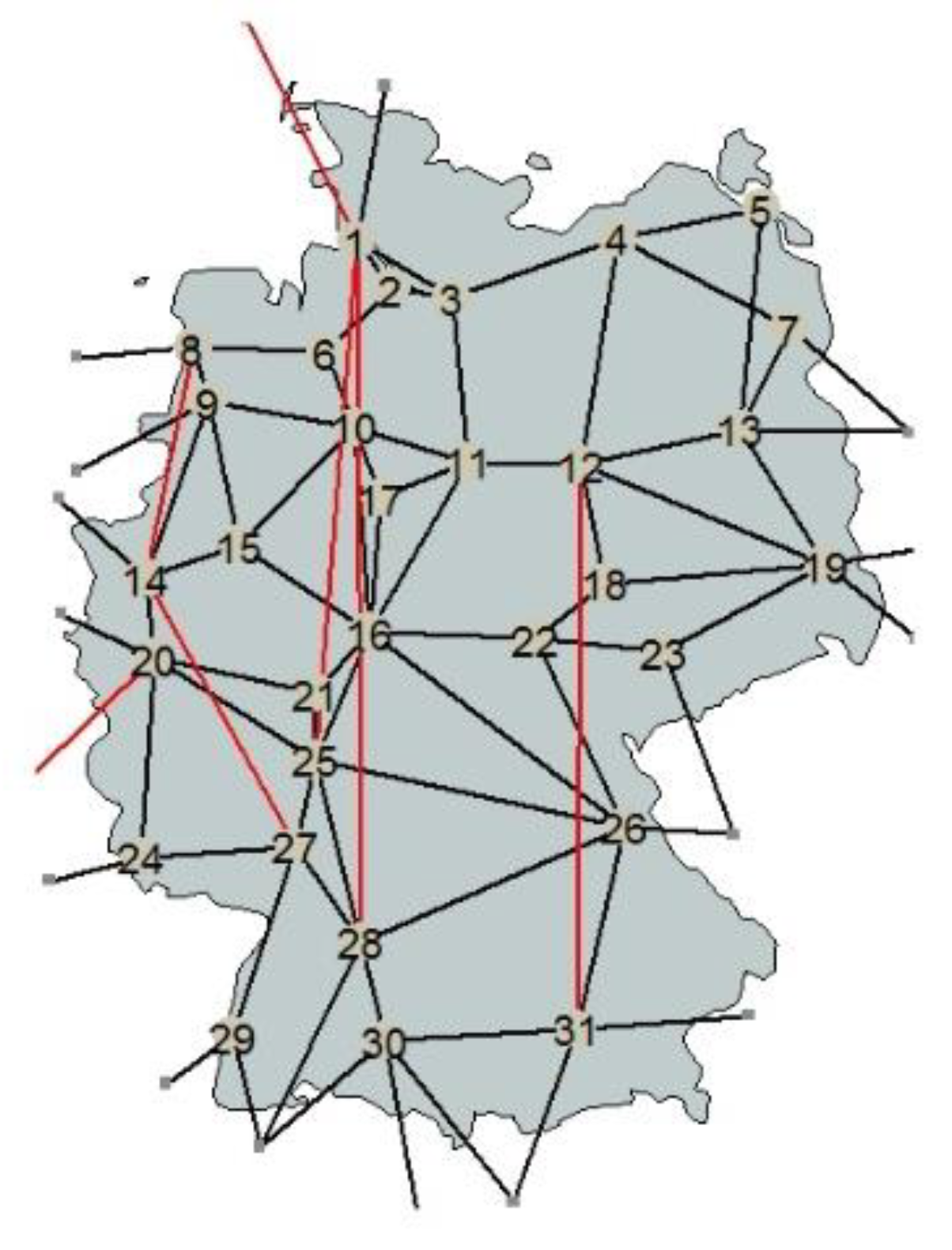
An aggregated model of the European Transmission System consisting of 200 nodes [
28] is used. From these 200 nodes, 31 nodes are located in Germany. The aggregated grid model of Germany can be seen in
Figure 7 and it is described in [
28]. It is a cutout of the whole ENTSO-E aggregated model. For the year 2025, the grid expansion measures described in NEP 2013, 2nd edition, are added [
5]. Only lines and cross-border lines (AC and HVDC) that are situated in Germany or connected to German grid nodes are considered.
Figure 7 shows the used grid nodes and lines. The considered weather stations (
Figure 2) are collated to these grid nodes.
In this scenario, it is assumed that the dependence structure that is captured by the joint probability model and based on the historical data is not changed. They were not incorporated in the copula bcause of the small amount of available data for the exchanges between DE/NL as well as DE/CZ. Nevertheless, the available data are fitted by the non-parametric kernel estimator and samples are generated. For the energy exchange between DE/LU no data exists, neither for the planned cross-border lines between DE and Norway (NO) and DE and Belgium (BE). For these, random samples are generated being limited by the NTC values. Due to the expectation of higher NTC values according to [
1], the marginal density functions for the CBFs for all countries are scaled. The energy exchanges between DE/NL, DE/CZ, DE/BE, and DE/LU are assumed to be independent of all other parameters. The exchanges between DE/NO are stated to be negatively correlated to the wind power production in Germany. This results, in an export to NO during high wind power generation in DE and vice versa. The model is used for the base case, i.e. no (n-1)-calculations are executed. The model is implemented in Matlab and it uses the toolbox Matpower.
2.3.2. Description of the Probabilistic Load Flow Model
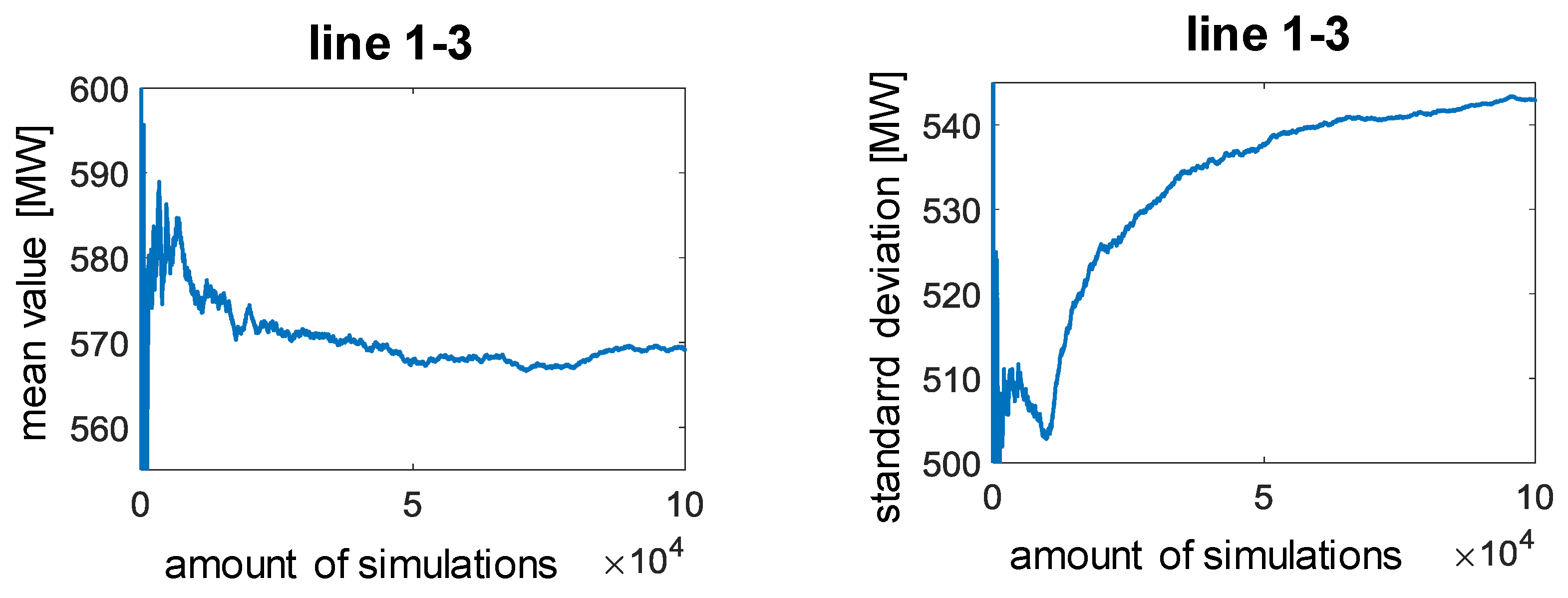
The required number of simulations must be checked using suitable convergence criteria, as the MCS provides precise results if a sufficient number of simulations are carried out. For this purpose, the mean values and standard deviations of the output variables after each additional simulation run are considered in this work. There are large standard deviations at many network nodes as well as input variables that are not normally distributed, so that a large number of simulation runs is required due to the wide range of uncertain input variables.
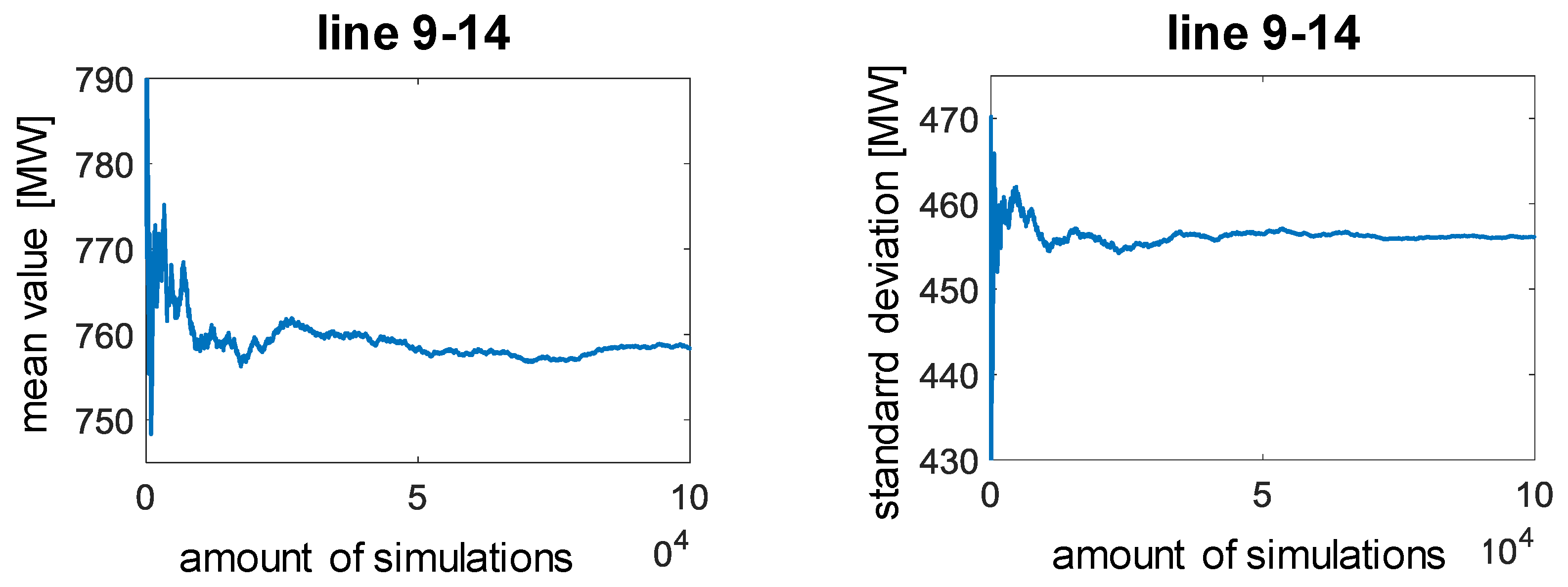
It can be seen that with the specified maximum number of 100,000 simulations, the fluctuations in mean values and standard deviations have largely subsided. The greatest fluctuations can be seen on line 1–3.
Figure 8 and
Figure 9 show the development of the mean values and standard deviation depending on the number of simulations for line 1–3 and line 9–14. In the following, the MCS with 100,000 simulation runs is used. The samples are generated using the copula with the algorithm that is presented in [
24]. As a result, samples for wind speeds, solar irradiance, the total electric load, and values for CBF arise. Two models are developed to determine the wind power and solar power generation at each grid node. The wind generation model determines the wind speed on hub´s height first. Then, it calculates the wind power by applying aggregated power curves based on power curves for common on- and offshore wind generators. The PV model computes the power curve of an aggregated PV module depending on the solar irradiance. The inverter is assumed to be able to keep the PV module in its maximum power point (MPP). The samples for CBF define the import to DE and export from DE, respectively. They are distributed to the corresponding foreign grid nodes. With more than one grid node in each country, the sampled CBF are equally distributed.
Conventional power plants need to balance the resulting residual load. A merit order approach determines the dispatch of the power plants. As a final result, there is at each grid node a distribution function describing the generated and needed power. These data are then used for load flow calculations.
3. Results
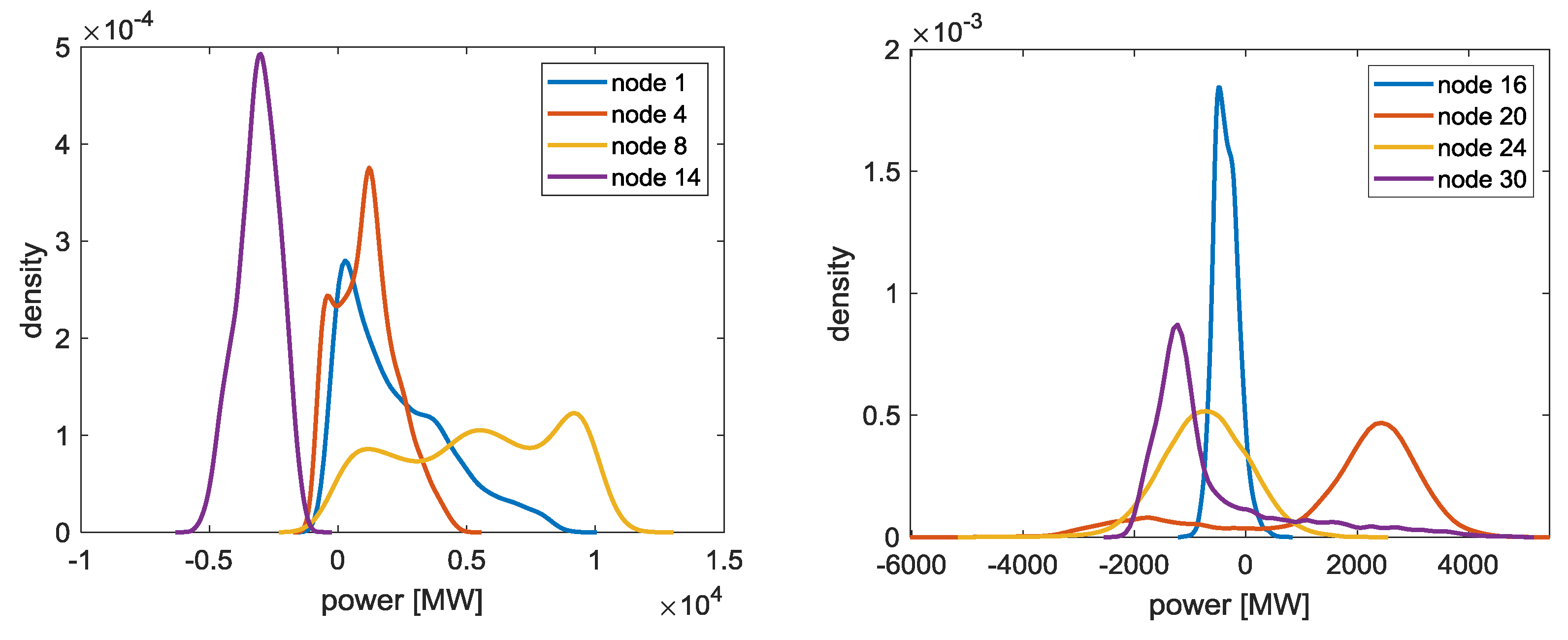
In order to analyse the German transmission grid, 100,000 load flow simulations are executed using the distribution functions as described before. Exemplarily, in
Figure 10 the density functions at nodes 1, 4, 8, 14, 16, 20, 24, and 30 are shown. Positive power means generation and negative power means load demand. Throughout the year, a grid node can function as a producer or consumer. The density functions are used as an input for the probabilistic load flow calculation. First, the simulation run is determined without HVDC lines. Subsequently, in a second run, the HVDC lines are included. The dispatch of the HVDC-lines are determined with an optimization to avoid overloads on AC-lines.
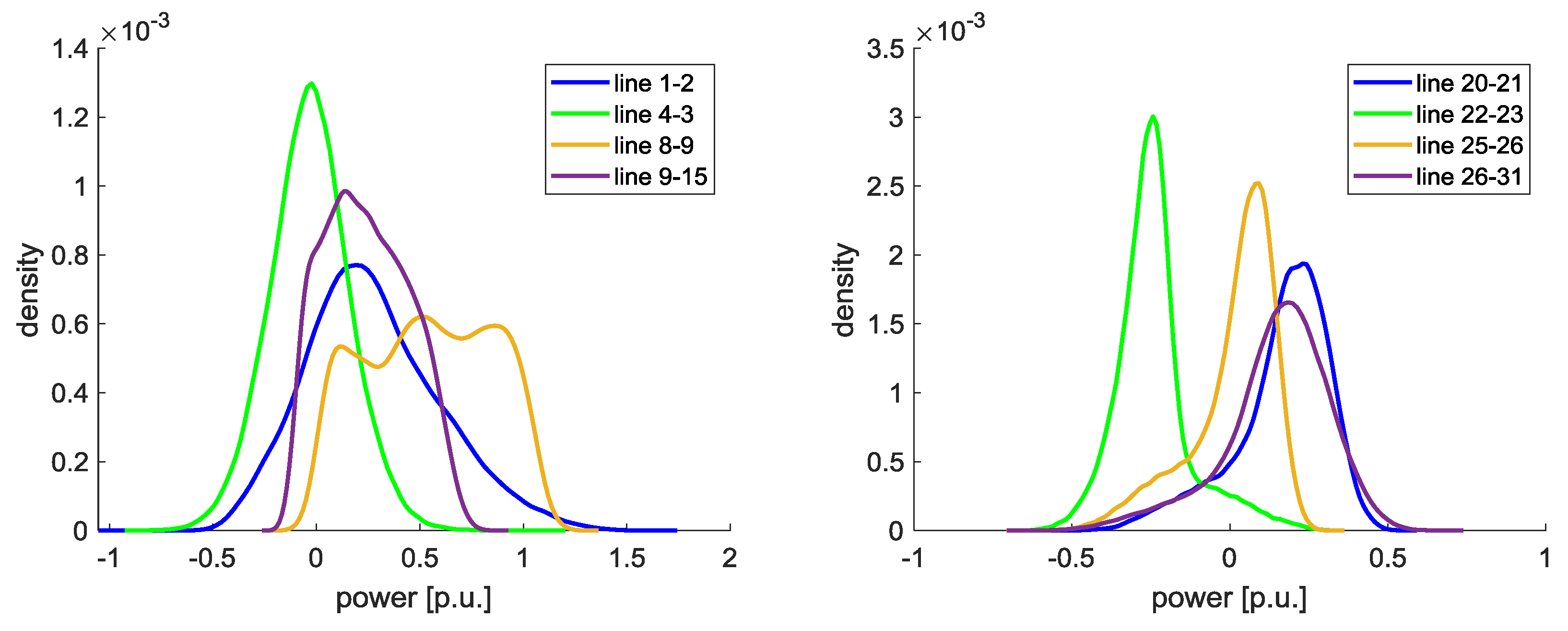
For all 100,000 samples load flow calculations are executed. Exemplarily, in
Figure 11, the load flow between the lines 1–2, 4–3, 8–9, and 9–15 (left), and between the lines 20–21, 22–23, 25–26, and 26–31 (right) are shown. Here, the HVDC lines are neglected. It can be seen that line 1–2 and line 8–9 are partly overloaded. The probability that line 1–2 exceeds 1 p.u. is 2.32% and that line 8–9 exceeds 1 p.u. is 5.82%.
The results are independent of a specific weather year, but are instead based on the general weather characteristics. In addition, the TSOs can predefine events to consider or exclude from the transmission expansion planning and determine their probability of appearance.
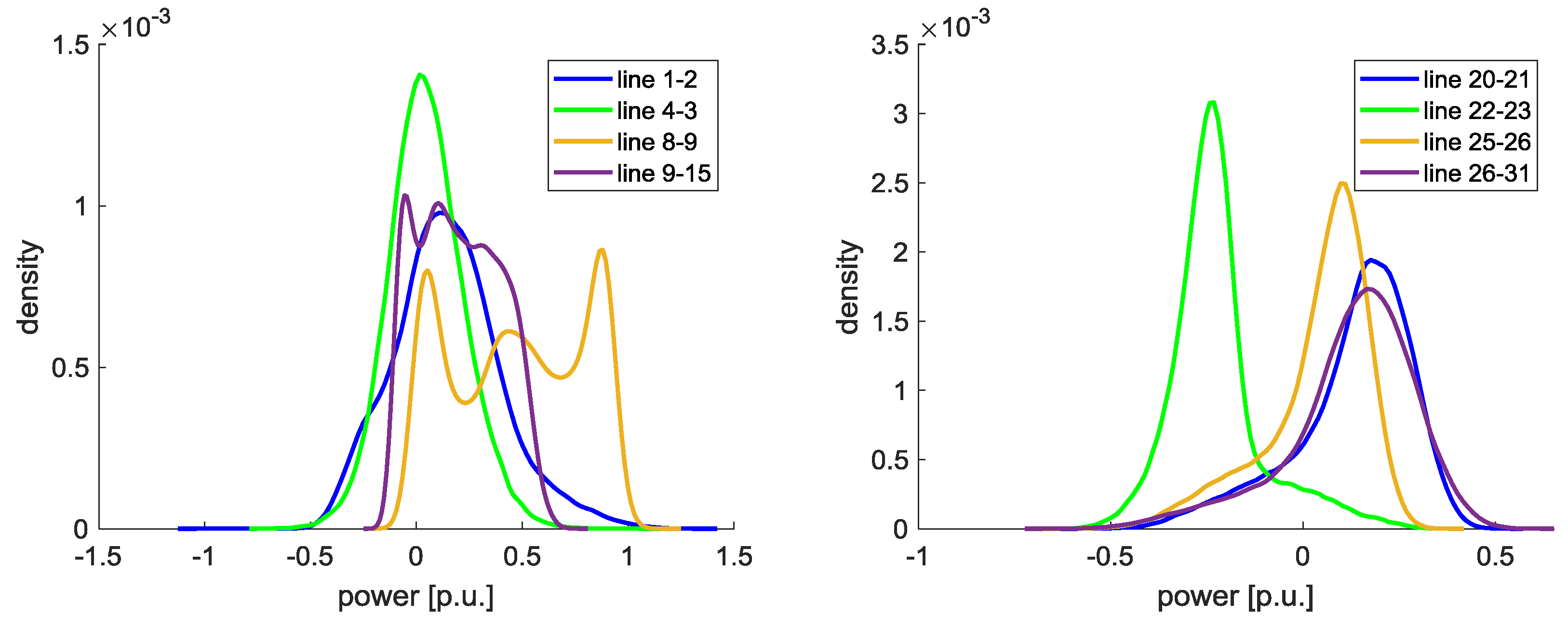
Now, HVDC lines are considered. The same lines are shown in
Figure 12. It can be seen that the load flow on the lines 1–2 and 8–9 is reduced. The probability of overload decreases to 0.25% on line 1–2 and to 0.1% on line 8–9.
4. Discussion
The modeled C-vine Copula is based on historical data of the uncertain input variables. The model is used to provide the input variables for the probabilistic load flow calculation with the assumption that the historical data are representative of a future scenario. Therefore, in the following it is discussed, which uncertain factors influence the modeled variables.
The developed model represents the properties and relationships for the actual state of the weather conditions (wind speeds and solar irradiance), the cross border load flows (import and export), and the total load in Germany. However, different influencing variables can change the characteristics of the modeled variables in a future scenario.
1. Weather Characteristics
The weather characteristics are simulated based on twenty years, so that they are considered to representative for the medium-term period. Developments in climate change and other meteorological changes must be analyzed and, if necessary, integrated into the model to consider a long-term period (>30 years). By regularly expanding the database, climate changes can be automatically anticipated.
2. Energy consumption and generation
Little data are available on energy consumption. The load consists of a domestic and a foreign share, which is expressed by the export. Consumption is composed of the needs within the different sectors: business, commerce and services, transport, private households and industry. It also fluctuates seasonally, depending on the day of the week and the time of day. Various factors influence the overall demand. This includes socio-economic, economic, and technological developments, as well as legal frameworks in inland and abroad, such as the implementation of demand side management, sector change through population increase/decrease, industrial increase/decrease, industrial change or sector coupling in heating and traffic area through the use of heat pumps or electric cars. This influences the energy consumption in inland and abroad and, therefore, also the border coupling power flows.
Energy production is also affected by socio-economic, economic, and technological developments, as well as legal framework conditions in inland and abroad. Exemplary changes can be price developments for raw materials. These also have an impact on the modeled cross border load flows.
For the medium-term period, it is assumed that the historical load profiles and cross-border coupling flows are representative with regard to their characteristics and dependencies. This assumption is permissible if the influences on the sectors as well as the sector composition and temporal relationships are minor. Large changes have an impact on the marginal distributions of the load and/or on the dependencies to the energy generation. For example, a large number of new load components with individual load behavior come into the energy system due to an increase in sector coupling like in the heating sector, which change both the marginal distribution and the dependencies.
3. Cross border load flows
Cross border load flows are limited by the respective interconnectors. The distribution functions developed are scaled to the new limits since information is available on the expansion of interconnectors in the medium term in accordance with the NEP [
5]. Political, economic, or technical changes in Germany and abroad can change both the shape of the marginal distributions and the correlation relationships. No further change is assumed due to the medium-term horizon. In a next step, the influence of changing distribution function of e.g. CBF could be analyzed.
5. Conclusions
The main uncertain influencing values in the future energy system are wind speeds, solar irradiance, electrical load, and import/export of energy. The dependences are captured by a C-vine copula model consisting of 190 dimensions. To model the marginal density functions different distributions are used:
wind speed can be modelled by Weibull distribution;
load can be modelled by multimodal distributions;
solar irradiation can be modelled by non-parametric distributions; and,
cross boarder load flow can be modelled by non-parametric distributions.
The correlation between the uncertain variables is captured by different copula families. The results of the classes depend on the decomposition:
one-third of all selected families are t-copula and Gaussian copula with radial symmetries;
two-third belong to the Archimedean class with asymmetric and/or nonlinear dependence; and,
nearly one-third of all copulas are rotated copulas with negative dependence.
Even though the uncertainties are diverse, it was shown that they could all be modelled together in one model. The plurality of these different modelling approaches allows a precise fitting of all participants. The model can be used in diverse applications. Exemplary, two applications are shown: First, the model enables to determine the probability for certain events. The probability for rather high load (>65 GW) and low RES production with wind speed less than 3 m/s and solar irradiance less than at 90% of all stations is e.g., 0.064%.
Second, the model can be integrated in a probabilistic load flow approach that is based on a MCS. As the MCS needs a high amount of samples to converge, consistent samples are needed that can be provided by the copula. Assuming e.g., a development of the installed capacity of wind generators in a future scenario, the resulting probability density functions of the line´s load can be determined. Instead of regarding the complete Intercontinental European transmission grid, it can only be reduced to the German transmission grid. This is achieved by using the dependence structure of the energy exchange captured by the copula. The calculation time can be reduced drastically due to the reduction of only the German transmission grid.
In a case study for the German transmission grid, the ability of the approach is demonstrated. For a scenario of 2025, the load flows in the grid are evaluated. The influence of the planned HVDC lines is shown. Without the consideration of HVDC lines several AC lines are highly overloaded. The HVDC lines significantly reduce the load on the AC lines.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}