
Spatially-Explicit Prediction of Capacity Density Advances Geographic Characterization of Wind Power Technical Potential


Abstract
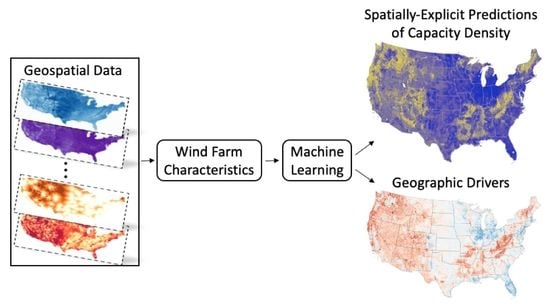
:
1. Introduction
1.1. Problem Overview
1.2. Aim and Contributions
2. Background
2.1. Terminology and Derivation of Capacity Density
2.2. Role of Capacity Density in Technical Potential Modeling
2.3. Approaches to Representing Capacity Density

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach for Representing Capacity Density | Description | Application | Assumed Capacity Density 1 (MW/km2) | Reference |
|---|---|---|---|---|
| Average wind turbine installation density methodology | Relies on empirically-derived estimates of capacity density based on project-level information on wind farm footprint and installed capacity. Resulting capacity densities are considered to be spatially uniform (i.e., they do not vary geographically). | U.S. | 5 | [27] |
| Global; land suitability factors combined with fixed capacity density to adjust local geographic potential | 4 | [39] | ||
| Global | 5; range of 2–9 MW/km2 evaluated for sensitivity analysis | [36,45] | ||
| U.S. | 3 | [13] | ||
| India | 9 | [26] | ||
| Europe U.S. China | 19.8 21.7 48 | [16] 2 | ||
| Turbine spacing methodology | Estimates turbine-specific capacity density using rule of thumb minimum spacing requirements based on rotor diameter (D). Resulting densities are implemented as spatially uniform. | Global; turbine spacing computed using 4D × 7D | 9 | [38] |
| Finland; turbine spacing computed using 5D × 7D | 5.3–10.6 | [44] | ||
| Global; turbine spacing computed using 4D × 7D | 8.9 | [43] | ||
| Global; turbine spacing computed using 5D × 10D; local geographic potential adjusted following Hoogwijk et al. [39] | 6.5 | [40] | ||
| Europe; turbine spacing computed using 4.375D × 4.375D based on Enevoldsen and Valentine [46] | 11.1 | [19] | ||
| Saudi Arabia; turbine spacing computed using 5D × 7D | 4.9–7.9 | [47] |
2.4. Spatial Drivers of Capacity Density
3. Materials and Methods
3.1. Wind Farm Data
3.2. Wind Farm Area Estimation
3.3. Capacity Density Characterization
3.4. Spatial Sampling of Wind Farm Characteristics
3.5. Geospatial Data
3.6. Machine Learning Using Boosted Regression Trees
Model Building
4. Results
4.1. Validation
4.2. Model Interpretation
4.3. Spatially-Explicit Predictions of Capacity Density
4.4. Mechanisms Driving Capacity Density Predictions
5. Discussion
5.1. Comparison with Other Findings
5.2. Model Evaluation
6. Applications and Conclusions
6.1. Applications
6.2. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DOE | United States Department of Energy |
| EERE | Office of Energy Efficiency and Renewable Energy |
| RPS | Renewable Portfolio Standards |
| R&D | Research and Development |
| D | Rotor Diameter |
| MW | Megawatt |
| W | Watt |
| KM | Kilometer |
| M | Meter |
| U.S. | United States |
| MSE | Mean Squared Error |
| TFBT | TensorFlow Boosted Trees |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| R2 | r-squared |
| DFC | Directional Feature Contribution |
| CONUS | Conterminous United States |
| USWTDB | U.S. Wind Turbine Database |
| GAP | Gap Analysis Project |
| ACC | Urban accessibility measured through travel time to nearest urban center (minutes) |
| BUI | Built-up intensity of residential and commercial buildings (m2) |
| CLF | Fractional areal extent of cliff landform (unitless) |
| CON | Landscape metric describing contagion (i.e., the spatial “clumpiness” of unsuitable lands; wind exclusions) |
| CRG | Fraction of pixel containing ridge landform (unitless) |
| DIV | Fractional areal extent of divide landform (unitless) |
| GAP | GAP 1&2 status protected lands (%) |
| HUD | Housing unit density (units/km2) |
| LBL | Wind regions defined by Lawrence Berkeley National Laboratory |
| LC1 | Fractional areal extent of water land cover class (unitless) |
| LC2 | Fractional areal extent of developed land cover class (unitless) |
| LC3 | Fractional areal extent of barren land cover class (unitless) |
| LC4 | Fractional areal extent of forest land cover class (unitless) |
| LC5 | Fractional areal extent of shrubland cover class (unitless) |
| LC7 | Fractional areal extent of herbaceous land cover class (unitless) |
| LC8 | Fractional areal extent of planted/cultivated land cover class (unitless) |
| LC9 | Fractional areal extent of wetlands land cover class (unitless) |
| LFR | Landform regions |
| LSP | Fractional areal extent of lower slope landform (unitless) |
| LU1 | Land use class (level I) |
| MWS | Mean long-term wind speed at 80 m hub height (m/s) |
| POP | Population density (persons/km2) |
| RDG | Fractional areal extent of ridge landform (unitless) |
| RIX | Fractional areal extent exceeding critical slope threshold (unitless) |
| SLF | Fractional areal extent of suitable landforms (i.e., not cliff or valley; unitless) |
| TRC | Fractional areal extent of tree cover |
| USP | Fractional areal extent of upper slope landform (unitless) |
| VLY | Fractional areal extent of valley landform (unitless) |
| WEQ | Power equitability metric describing the evenness of wind energy contributions at 100 m hub height across compass directions |
| WEX | Fractional areal extent of wind exclusions |
| WND | Dimensionless wind energy at 100-m hub height (unitless) |
References
- Beiter, P.; Cooperman, A.; Lantz, E.; Stehly, T.; Shields, M.; Wiser, R.; Telsnig, T.; Kitzing, L.; Berkhout, V.; Kikuchi, Y. Wind power costs driven by innovation and experience with further reductions on the horizon. Wiley Interdiscip. Rev. Energy Environ. 2021, e398. [Google Scholar] [CrossRef]
- U.S. Department of Energy (DOE). 2017 Wind Technologies Market Report; Office of Energy Efficiency and Renewable Energy (EERE): Washington, DC, USA, 2018.
- Wiser, R.; Rand, J.; Seel, J.; Beiter, P.; Baker, E.; Lantz, E.; Gilman, P. Expert elicitation survey predicts 37% to 49% declines in wind energy costs by 2050. Nat. Energy 2021, 6, 555–565. [Google Scholar] [CrossRef]
- Barbose, G.L. US Renewables Portfolio Standards: 2019 Annual Status Update; Lawrence Berkeley National Laboratory (LBNL): Berkeley, CA, USA, 2019.
- Williams, J.H.; Jones, R.A.; Haley, B.; Kwok, G.; Hargreaves, J.; Farbes, J.; Torn, M.S. Carbon-neutral pathways for the United States. AGU Adv. 2021, 2, e2020AV000284. [Google Scholar] [CrossRef]
- Larson, E.; Greig, C.; Jenkins, J.; Mayfield, E.; Pascale, A.; Zhang, C.; Drossman, J.; Williams, R.; Pacala, S.; Socolow, R.; et al. Net-Zero America: Potential Pathways, Infrastructure, and Impacts—Interim Report; Princeton University: Princeton, NJ, USA, 2020. [Google Scholar]
- Lopez, A.; Mai, T.; Lantz, E.; Harrison-Atlas, D.; Williams, T.; Maclaurin, G. Land use and turbine technology influences on wind potential in the United States. Energy 2021, 223, 120044. [Google Scholar] [CrossRef]
- Mai, T.; Lopez, A.; Mowers, M.; Lantz, E. Interactions of wind energy project siting, wind resource potential, and the evolution of the U.S. power system. Energy 2021, 223, 119998. [Google Scholar] [CrossRef]
- Mai, T.; Wiser, R.; Sandor, D.; Brinkman, G.; Heath, G.; Denholm, P.; Hostick, D.; Darghouth, N.; Schlosser, A.; Strzepek, K. Electricity Futures Study. Exploration of High-Penetration Renewable Electricity Futures; Office of Scientific and Technical Information (OSTI): Golden, CO, USA, 2012; Volume 1.
- IEA. World Energy Outlook 2018. 2018. Available online: https://www.iea.org/reports/world-energy-outlook-2018 (accessed on 22 March 2020).
- Bridge, G.; Bouzarovski, S.; Bradshaw, M.; Eyre, N. Geographies of energy transition: Space, place and the low-carbon economy. Energy Policy 2013, 53, 331–340. [Google Scholar] [CrossRef]
- Wu, G.C.; Torn, M.S.; Williams, J.H. Incorporating land-use requirements and environmental constraints in low-carbon electricity planning for California. Environ. Sci. Technol. 2015, 49, 2013–2021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mai, T.T.; Lantz, E.J.; Mowers, M.; Wiser, R. The Value of Wind Technology Innovation: Implications for the U.S. Power System, Wind Industry, Electricity Consumers, and Environment; Office of Scientific and Technical Information (OSTI): Golden, CO, USA, 2017.
- Smil, V. Energy in Nature and Society: General Energetics of Complex Systems; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Jordaan, S.M.; Heath, G.A.; Macknick, J.; Bush, B.W.; Mohammadi, E.; Ben-Horin, D.; Urrea, V.; Marceau, D. Understanding the life cycle surface land requirements of natural gas-fired electricity. Nat. Energy 2017, 2, 804–812. [Google Scholar] [CrossRef]
- Enevoldsen, P.; Jacobson, M.Z. Data investigation of installed and output power densities of onshore and offshore wind turbines worldwide. Energy Sustain. Dev. 2021, 60, 40–51. [Google Scholar] [CrossRef]
- Zhang, J.; Draxl, C.; Hopson, T.; Monache, L.D.; Vanvyve, E.; Hodge, B.-M. Comparison of numerical weather prediction based deterministic and probabilistic wind resource assessment methods. Appl. Energy 2015, 156, 528–541. [Google Scholar] [CrossRef] [Green Version]
- Herbert-Acero, J.F.; Probst, O.; Réthoré, P.-E.; Larsen, G.C.; Castillo-Villar, K.K. A review of methodological approaches for the design and optimization of wind farms. Energies 2014, 7, 6930–7016. [Google Scholar] [CrossRef]
- Enevoldsen, P.; Permien, F.-H.; Bakhtaoui, I.; von Krauland, A.-K.; Jacobson, M.Z.; Xydis, G.; Sovacool, B.K.; Valentine, S.V.; Luecht, D.; Oxley, G. How much wind power potential does europe have? Examining european wind power potential with an enhanced socio-technical atlas. Energy Policy 2019, 132, 1092–1100. [Google Scholar] [CrossRef]
- Wu, G.C.; Leslie, E.; Sawyerr, O.; Cameron, D.R.; Brand, E.; Cohen, B.; Allen, D.; Ochoa, M.; Olson, A. Low-impact land use pathways to deep decarbonization of electricity. Environ. Res. Lett. 2020, 15, 074044. [Google Scholar] [CrossRef]
- Van Zalk, J.; Behrens, P. The spatial extent of renewable and non-renewable power generation: A review and meta-analysis of power densities and their application in the U.S. Energy Policy 2018, 123, 83–91. [Google Scholar] [CrossRef]
- Miller, L.M.; Keith, D.W. Observation-based solar and wind power capacity factors and power densities. Environ. Res. Lett. 2018, 13, 104008. [Google Scholar] [CrossRef] [Green Version]
- Denholm, P.; Hand, M.; Jackson, M.; Ong, S. Land-Use Requirements of Modern Wind Power Plants in the United States; (NREL/TP-6A2-45834); National Renewable Energy Lab. (NREL): Golden, CO, USA, 2009.
- Jacobson, M.Z.; Delucchi, M.A.; Bauer, Z.A.; Goodman, S.C.; Chapman, W.E.; Cameron, M.A.; Bozonnat, C.; Chobadi, L.; Clonts, H.A.; Enevoldsen, P.; et al. 100% clean and renewable wind, water, and sunlight all-sector energy roadmaps for 139 countries of the world. Joule 2017, 1, 108–121. [Google Scholar] [CrossRef] [Green Version]
- Lantz, E.; Mai, T.; Wiser, R.H.; Krishnan, V. Long-term implications of sustained wind power growth in the United States: Direct electric system impacts and costs. Appl. Energy 2016, 179, 832–846. [Google Scholar] [CrossRef] [Green Version]
- Deshmukh, R.; Wu, G.C.; Callaway, D.S.; Phadke, A. Geospatial and techno-economic analysis of wind and solar resources in India. Renew. Energy 2019, 134, 947–960. [Google Scholar] [CrossRef] [Green Version]
- Lopez, A.; Roberts, B.; Heimiller, D.; Blair, N.; Porro, G. U.S. Renewable Energy Technical Potentials: A GIS-Based Analysis; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2012.
- U.S. Department of Energy (DOE). Report to Congress on Renewable Energy Resource Assessment Information for the United States; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2006.
- Smil, V. Power Density Primer: Understanding the Spatial Dimension of the Unfolding Transition to Renewable Electricity Generation (Part IV—New Renewables Electricity Generation). 2010. Available online: http://www.vaclavsmil.com/wp-content/uploads/docs/smil-article-power-density-primer.pdf (accessed on 2 November 2020).
- Kalmikov, A. Wind power fundamentals. In Wind Energy Engineering; Elsevier: Amsterdam, The Netherlands, 2017; pp. 17–24. [Google Scholar]
- Mohammadi, K.; Alavi, O.; Mostafaeipour, A.; Goudarzi, N.; Jalilvand, M. Assessing different parameters estimation methods of Weibull distribution to compute wind power density. Energy Convers. Manag. 2016, 108, 322–335. [Google Scholar] [CrossRef]
- Maclaurin, G.J.; Grue, N.W.; Lopez, A.J.; Heimiller, D.M. The Renewable Energy Potential (reV) Model: A Geospatial Platform for Technical Potential and Supply Curve Modeling; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2019.
- Cole, W.J.; Frazier, A.; Donohoo-Vallett, P.; Mai, T.T.; Das, P. 2018 Standard Scenarios Report: A US Electricity Sector Outlook; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2018.
- Eliasson, B. Renewable energy: Status and prospects. In Energy and Global Change; ABB Corporate Research Ltd.: Baden, Switzerland, 1998. [Google Scholar]
- Elliott, D.; Wendell, L.; Gower, G. An Assessment of the Available Windy Land Area and Wind Energy Potential in the Contiguous United States; Pacific Northwest Lab.: Richland, WA, USA, 1991. [Google Scholar]
- Zhou, Y.; Luckow, P.; Smith, S.J.; Clarke, L. Evaluation of global onshore wind energy potential and generation costs. Environ. Sci. Technol. 2012, 46, 7857–7864. [Google Scholar] [CrossRef]
- Kline, D.; Heimiller, D.; Cowlin, S. GIS Method for Developing Wind Supply Curves; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2008.
- Archer, C.L. Evaluation of global wind power. J. Geophys. Res. Space Phys. 2005, 110. [Google Scholar] [CrossRef] [Green Version]
- Hoogwijk, M.; de Vries, B.; Turkenburg, W. Assessment of the global and regional geographical, technical and economic potential of onshore wind energy. Energy Econ. 2004, 26, 889–919. [Google Scholar] [CrossRef]
- Bosch, J.; Staffell, I.; Hawkes, A.D. Temporally-explicit and spatially-resolved global onshore wind energy potentials. Energy 2017, 131, 207–217. [Google Scholar] [CrossRef]
- Grubb, M.J.; Meyer, N.I. Wind energy: Resources, systems and regional strategies. In Renewable Energy: Sources for Fuels and Electricity; Johansson, T.B., Kelly, H., Reddy, A.K.N., Williams, R.H., Eds.; Island Press: Washington, DC, USA, 1993; pp. 157–212. [Google Scholar]
- U.S. Department of Energy (DOE). 20% Wind Energy by 2030: Increasing Wind Energy’s Contribution to U.S. Electricity Supply; (NREL/TP-500-41869); National Renewable Energy Lab. (NREL): Golden, CO, USA, 2008.
- Lu, X.; McElroy, M.B.; Kiviluoma, J. Global potential for wind-generated electricity. Proc. Natl. Acad. Sci. USA 2009, 106, 10933–10938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rinne, E.; Holttinen, H.; Kiviluoma, J.; Rissanen, S. Effects of turbine technology and land use on wind power resource potential. Nat. Energy 2018, 3, 494–500. [Google Scholar] [CrossRef]
- Herran, D.S.; Dai, H.; Fujimori, S.; Masui, T. Global assessment of onshore wind power resources considering the distance to urban areas. Energy Policy 2016, 91, 75–86. [Google Scholar] [CrossRef]
- Enevoldsen, P.; Valentine, S.V. Do onshore and offshore wind farm development patterns differ? Energy Sustain. Dev. 2016, 35, 41–51. [Google Scholar] [CrossRef]
- Giani, P.; Tagle, F.; Genton, M.G.; Castruccio, S.; Crippa, P. Closing the gap between wind energy targets and implementation for emerging countries. Appl. Energy 2020, 269, 115085. [Google Scholar] [CrossRef]
- Diffendorfer, J.E.; Compton, R.W. Land cover and topography affect the land transformation caused by wind facilities. PLoS ONE 2014, 9, e88914. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.-C.; Jung, H.-S.; Lee, M.J.; Lee, S. Spatial prediction of flood susceptibility using random-forest and boosted-tree models in Seoul metropolitan city, Korea. Geomat. Nat. Hazards Risk 2017, 8, 1185–1203. [Google Scholar] [CrossRef] [Green Version]
- Hoen, B.D.; Diffendorfer, J.E.; Rand, J.T.; Kramer, L.A.; Garrity, C.P.; Hunt, H.E. United States Wind Turbine Database. USWTDB V1.3. 2018. Available online: https://eerscmap.usgs.gov/uswtdb (accessed on 2 November 2020).
- Levenshtein, A. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Trainor, A.M.; McDonald, R.I.; Fargione, J. Energy sprawl is the largest driver of land use change in United States. PLoS ONE 2016, 11, e0162269. [Google Scholar] [CrossRef]
- Aydin, N.Y.; Kentel, E.; Duzgun, S. GIS-based environmental assessment of wind energy systems for spatial planning: A case study from Western Turkey. Renew. Sustain. Energy Rev. 2010, 14, 364–373. [Google Scholar] [CrossRef]
- Clark, A.T.; Ye, H.; Isbell, F.; Deyle, E.R.; Cowles, J.; Tilman, G.D.; Sugihara, G. Spatial convergent cross mapping to detect causal relationships from short time series. Ecology 2015, 96, 1174–1181. [Google Scholar] [CrossRef]
- Hurlbert, S.H. Pseudoreplication and the design of ecological field experiments. Ecol. Monogr. 1984, 54, 187–211. [Google Scholar] [CrossRef] [Green Version]
- Draxl, C.; Clifton, A.; Hodge, B.-M.; McCaa, J. The Wind Integration National Dataset (WIND) toolkit. Appl. Energy 2015, 151, 355–366. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Weiss, D.J.; Nelson, A.; Gibson, H.; Temperley, W.; Peedell, S.; Lieber, A.; Hancher, M.; Poyart, E.; Belchior, S.; Fullman, N.; et al. A global map of travel time to cities to assess inequalities in accessibility in 2015. Nat. Cell Biol. 2018, 553, 333–336. [Google Scholar] [CrossRef]
- Leyk, S.; Uhl, J.H. HISDAC-US, historical settlement data compilation for the conterminous United States over 200 years. Sci. Data 2018, 5, 180175. [Google Scholar] [CrossRef]
- Theobald, D.M.; Harrison-Atlas, D.; Monahan, W.B.; Albano, C.M. Ecologically-relevant maps of landforms and physiographic diversity for climate adaptation planning. PLoS ONE 2015, 10, e0143619. [Google Scholar] [CrossRef] [Green Version]
- U.S. Geological Survey (USGS). Protected areas database of the United States (PAD-US). 2019. Available online: https://www.sciencebase.gov/catalog/item/5b030c7ae4b0da30c1c1d6de (accessed on 2 November 2020).
- Center for International Earth Science Information Network (CIESIN). Columbia University. 2017. U.S. Census Grids (Summary File 1), 2010. NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA. Available online: https://sedac.ciesin.columbia.edu/data/set/usgrid-summary-file1-2010 (accessed on 2 November 2020).
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 national land cover database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote. Sens. 2015, 81, 345–354. [Google Scholar]
- Karagulle, D.; Frye, C.; Sayre, R.; Breyer, S.; Aniello, P.; Vaughan, R.; Wright, D. Modeling global Hammond landform regions from 250 m elevation data. Trans. GIS 2017, 21, 1040–1060. [Google Scholar] [CrossRef]
- Theobald, D.M. Development and applications of a comprehensive land use classification and map for the US. PLoS ONE 2014, 9, e94628. [Google Scholar] [CrossRef] [Green Version]
- Pesaresi, M.; Freire, S. GHS Settlement Grid Following the REGIO Model 2014 in Application to GHSL Landsat and CIESIN GPW v4-Multitemporal (1975–1990–2000–2015); European Commission Joint Research Center: Geel, Belgium, 2016. [Google Scholar]
- Gesch, D.; Oimoen, M.; Greenlee, S.; Nelson, C.; Steuck, M.; Tyler, D. The national elevation dataset. Photogramshanm. Eng. Remote Sens. 2002, 68, 5–32. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Palczewska, A.; Palczewski, J.; Robinson, R.M.; Neagu, D. Interpreting random forest classification models using a feature contribution method. In Integration of Reusable Systems; Springer: Cham, Switzerland, 2014; pp. 193–218. [Google Scholar]
- Liu, S.; Xiao, J.; Liu, J.; Wang, X.; Wu, J.; Zhu, J. Visual diagnosis of tree boosting methods. IEEE Trans. Vis. Comput. Graph. 2018, 24, 163–173. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De’Ath, G. Boosted Trees for ecological modeling and prediction. Ecology 2007, 88, 243–251. [Google Scholar] [CrossRef]
- Ponomareva, N.; Radpour, S.; Hendry, G.; Haykal, S.; Colthurst, T.; Mitrichev, P.; Grushetsky, A. TF boosted trees: A scalable tensorflow based framework for gradient boosting. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; Springer: Berlin, Germany, 2017; pp. 423–427. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Zheng, X. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Python Core Team. Python: A Dynamic, Open Source Programming Language; Python Software Foundation: Wilmington, DE, USA, 2019. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Saabas, A. Interpreting Random Forests. 2014. Available online: http://blog.datadive.net/interpreting-random-forests/ (accessed on 2 November 2020).
- Rawles, C.; Ponomareva, N.; Tan, Z. How to Train Boosted Trees Models in TensorFlow. 2019. Available online: https://medium.com/tensorflow/how-to-train-boosted-trees-models-in-tensorflow-ca8466a53127 (accessed on 2 November 2020).
- Lorenz, E.N. Available potential energy and the maintenance of the general circulation. Tellus 1955, 7, 157–167. [Google Scholar] [CrossRef] [Green Version]
- Marvel, K.; Kravitz, B.; Caldeira, K. Geophysical limits to global wind power. Nat. Clim. Chang. 2013, 3, 118–121. [Google Scholar] [CrossRef]
- Harrison-Atlas, D.; King, R.N.; Glaws, A. A scalable surrogate model for national assessment of wind technology innovation. Wind Energy 2021. under review. [Google Scholar]
- Jones, N.F.; Pejchar, L. Comparing the ecological impacts of wind and oil and gas development: A landscape scale assessment. PLoS ONE 2013, 8, e81391. [Google Scholar] [CrossRef]
- Wiser, R.; Bolinger, M.; Heath, G.; Keyser, D.; Lantz, E.; Macknick, J.; Mai, T.; Millstein, D. Long-term implications of sustained wind power growth in the United States: Potential benefits and secondary impacts. Appl. Energy 2016, 179, 146–158. [Google Scholar] [CrossRef] [Green Version]
- International Energy Association (IEA). Energy Technology Perspectives 2016. 2017. Available online: https://www.iea.org/reports/energy-technology-perspectives-2016 (accessed on 2 November 2020).










| Variable | Description | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|---|
| ACC * | Urban accessibility measured through travel time to nearest urban center (minutes); [58] | 0 | 9.45 × 102 | 1.21 × 102 | 93.2 |
| BUI | Built-up intensity of residential and commercial buildings (m2); derived from [59] | 0 | 1.1 × 107 | 2.65 × 103 | 3.27 × 104 |
| CLF | Fractional areal extent of cliff landform (unitless); derived from [60] | 0 | 38 | 4.91 × 10−2 | 0.64 |
| CON * | Landscape metric describing contagion (i.e., the spatial “clumpiness” of unsuitable lands; wind exclusions); derived from [7] | 5 | 1.00 × 102 | 71.3 | 23.3 |
| CRG | Fraction of pixel containing ridge landform (unitless); derived from [60] | 0 | 1 | 32.1 | 0.47 |
| DIV | Fractional areal extent of divide landform (unitless); derived from [60] | 0 | 27 | 6.19 × 10−2 | 0.72 |
| GAP | GAP 1&2 status protected lands (%); derived from [61] | 0 | 1 | 6.85 × 10−2 | 0.023 |
| HUD * | Housing unit density (units/km2) [62] | 0 | 1.58 × 104 | 17.2 | 1.08 × 102 |
| LBL | Wind regions defined by Lawrence Berkeley National Laboratory [2] | N/A | N/A | N/A | N/A |
| LC1 * | Fractional areal extent of water land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 1.84 | 9.98 |
| LC2 | Fractional areal extent of developed land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 5.45 | 12.9 |
| LC3 | Fractional areal extent of barren land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 1.16 | 7.67 |
| LC4 * | Fractional areal extent of forest land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 24.9 | 31.2 |
| LC5 | Fractional areal extent of shrubland cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 22.1 | 33.0 |
| LC7 | Fractional areal extent of herbaceous land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 14.7 | 25.7 |
| LC8 * | Fractional areal extent of planted/cultivated land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 22.7 | 31.2 |
| LC9 | Fractional areal extent of wetlands land cover class (unitless); derived from [63] | 0 | 1.00 × 102 | 5.02 | 13.8 |
| LFR | Landform regions; derived from [64] | N/A | N/A | N/A | N/A |
| LSP | Fractional areal extent of lower slope landform (unitless); derived from [60] | 0 | 1.00 × 102 | 39.3 | 15.7 |
| LU1 | Land use class (level I); derived from [65] | N/A | N/A | N/A | N/A |
| MWS | Mean long-term wind speed at 80 m hub height (m/s); derived from [56] | 1.35 | 14 | 6.26 | 1.08 |
| POP | Population density (persons/km2); derived from [66] | 0 | 3.18 × 104 | 41.3 | 2.58 × 102 |
| RDG * | Fractional areal extent of ridge landform (unitless); derived from [60] | 0 | 36 | 1.59 | 3.77 |
| RIX | Fractional areal extent exceeding critical slope threshold (unitless); derived from [67] | 0 | 1 | 6.30∙10−2 | 0.17 |
| SLF | Fractional areal extent of suitable landforms (i.e., not cliff or valley; unitless); derived from [60] | 1.90 | 1.00 × 102 | 86.2 | 10.8 |
| TRC | Fractional areal extent of tree cover); derived from [60] | 0 | 1.00 × 102 | 26.0 | 28.2 |
| USP | Fractional areal extent of upper slope landform (unitless); derived from [60] | 0 | 1.00 × 102 | 43.3 | 15.2 |
| VLY | Fractional areal extent of valley landform (unitless); derived from [60] | 0 | 70 | 13.0 | 9.47 |
| WEQ * | Power equitability metric describing the evenness of wind energy contributions at 100 m hub height across compass directions; derived from [56] | 0 | 99 | 90.7 | 8.46 |
| WEX | Fractional areal extent of wind exclusions; derived from [7] | 1 | 1 | 1 | 0 |
| WND * | Dimensionless wind energy at 100 m hub height (unitless); derived from [56] | 0 | 1.94 × 102 | 96.4 | 25.0 |
| Number of Trees | Maximum Depth | Learning Rate | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| 200 | 10 | 0.005 | 1.02 MW/km2 | 1.25 MW/km2 | 0.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harrison-Atlas, D.; Maclaurin, G.; Lantz, E. Spatially-Explicit Prediction of Capacity Density Advances Geographic Characterization of Wind Power Technical Potential. Energies 2021, 14, 3609. https://doi.org/10.3390/en14123609
Harrison-Atlas D, Maclaurin G, Lantz E. Spatially-Explicit Prediction of Capacity Density Advances Geographic Characterization of Wind Power Technical Potential. Energies. 2021; 14(12):3609. https://doi.org/10.3390/en14123609
Chicago/Turabian StyleHarrison-Atlas, Dylan, Galen Maclaurin, and Eric Lantz. 2021. "Spatially-Explicit Prediction of Capacity Density Advances Geographic Characterization of Wind Power Technical Potential" Energies 14, no. 12: 3609. https://doi.org/10.3390/en14123609