
Applied Machine Learning Techniques for Performance Analysis in Large Wind Farms


Abstract
:1. Introduction
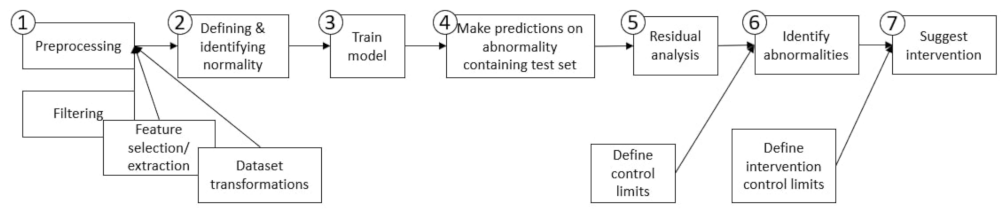
- (1)
- Preprocessing: The first step in NBM flowchart is preprocessing, which prepares data for both training and testing the NBM. It includes the procedures of filtration (see, e.g., in [1]), feature selection (e.g., recursive feature elimination (RFE) as in [2], tree-based out-of-bag permutation importance matrix (OOB) [3], brute-force sensitivity analysis [4] and feature extraction (FE) [5,6]) and transformation of the dataset (e.g., normalisation, standardisation and case-specific selective transformation [7]). These sub-steps clean the dataset of identifiably faulty data, refine the feature set and scale the data such that the different features’ significance on model performance are comparable. In short, this first step refines the dataset so as to yield a set of features and targets clearly possessing the relationships needed for the modelling task.
- (2)
- Defining and Identifying Normality: The second step of the NBM flowchart is to choose specific observations which represent system normality to train the NBM. The methods applied for this step vary the most in wind energy applications throughout the literature. For example, the authors of [8] take advantage of a binary label feature in the considered dataset, which indicates wind turbine “healthy” or “unhealthy” status and is tied to the error flags of different system components. In, e.g., [1,9], normal behaviour is defined considering a period after an act of repair or maintenance, assuming it represents the wind turbine operating at its most normal state. In the absence of labelled data or known periods of assumed normalcy, the act of defining normality becomes less trivial. For such a task, various types of machine learning-based outlier detection algorithms can be used to isolate and filter instances of abnormal observations [5,10].
- (3)
- Train and evaluate model: For the third step in NBM flowchart, two general approaches are typically used: the training of a regression model or of a density model; with the use of the former being far more prevalent than the latter through the literature surveyed. An overview of the machine learning algorithms used for NBM is presented in Table 1. A regression model is trained in order to predict a response variable given explanatory variables. In the case of a regression-based NBM model, if it is trained on a dataset representing purely normal behaviour, then any deviation from a residual of 0 when presented with new test set observations would indicate abnormality.
2. Materials and Methods
2.1. Description of Dataset
2.2. Dataset Formation and Preprocessing
2.3. Defining Normality
2.3.1. Power Curve Regime Partitioning Concept
2.3.2. Per-Wind Turbine Filtration Concept
2.3.3. Application of Abnormality Filtration Sequence
- (1)
- Curtailment filter:In this step, power that is downregulated, or curtailed, is filtered from the dataset.
- (2)
- Cut-in filter:In this step, observations representing power production below the expected minimum production as defined by the OEM nominal specifications are filtered using both the nominal cut-in wind speed (4 m/s) and the power produced at this wind speed (66.66 kW) as filter thresholds. Both were used in tandem as neither fully isolated the power production regime represented by below-cut-in conditions, i.e., only applying a wind speed-based cut-in filter allowed many observations exhibiting power production ≤ to remain in the dataset. As this behaviour is deemed abnormal in this project, such a result was insufficient.
- (3)
- Cut-out filter:In this step, power production above the expected minimum production as defined by the OEM nominal specifications is filtered using only the nominal cut-out wind speed. As aforementioned, when wind speed exceeds the turbine’s cut-out rating, it will attempt to control to a minimal rotor rotational speed for safety purposes in light of the extreme wind conditions. As the rotor speeds and/or resultant power associated with this control situation were unknown and absent from potential inspection within this dataset, it was decided that simply using the cut-out wind speed-based filter was sufficient to isolate this behaviour. Upon inspection of the dataset however, it was observed that only one turbine recorded wind speeds greater than the cut-out wind speed, and that at these wind speeds the power produced was less than 66 kW, and thus captured by the cut-in filter criteria.
- (4)
- Uprated power filtration:It was unknown whether, in fact, the Vestas V80 turbines represented by this dataset were equipped with the power-uprate enhancement described by Vestas as boosting power performance to the tune of an approximate 4% increase in AEP. Further, it is known that the density of power produced in this potentially uprated region is significantly lower than that produced by the distribution centred on and likely belonging to control behaviour. These considerations combined, the decision to define this behaviour as abnormal was made.
- (5)
- LOF applied to threshold 1:This machine learning-based outlier detection was applied to the main body of the each turbine’s power curve using hyperparameters discussed in Section 2.3.
- (6)
- LOF applied to threshold 1 threshold 2This machine learning-based outlier detection was applied to the distribution of the power curve belonging to the wind turbine’s control to . Like in Step 5, LOF n-neighbours = 100 was used, but unlike Step 5, a contamination parameter of 5% was used. This was a decision based on empirical observation of the visual effect of different contamination parameters on this regime, where it was seen that lower contamination parameter levels (e.g., 0.01745 used in Step 5) resulted in an inlying distribution that appeared to include abnormal observations. Further, the fact that the observation counts belonging to this regime and the range of power produced are relatively low compared to the main body of the power curve substantiates the use of such a simple visual-based decision; the implications on overall model performance should be relatively low.
Recombining Filtered Datasets
2.4. NBM Training
- (1)
- The number of wind turbines to draw SCADA from to predict the power of a given turbine. This level is herein referred to as the regression model’s “scale”.
- (2)
- The number of SCADA tags to use per wind turbine selected at the model’s scale.
2.4.1. Model Scale
- (1)
- Wind turbine (WT) —predict power for a given wind turbine using only select SCADA tags for that turbine.
- (2)
- Wind farm local (WFL)—predict power for a given wind turbine using only select SCADA tags from a down-selected number of turbines exhibiting key correlations with the given turbine.
- (3)
- Wind farm (WF)—predict power for a given wind turbine using select SCADA tags from all turbines.
2.4.2. Feature Selection of SCADA Tags
2.4.3. Feature Selection (Turbine Level) for WFL Models
- (1)
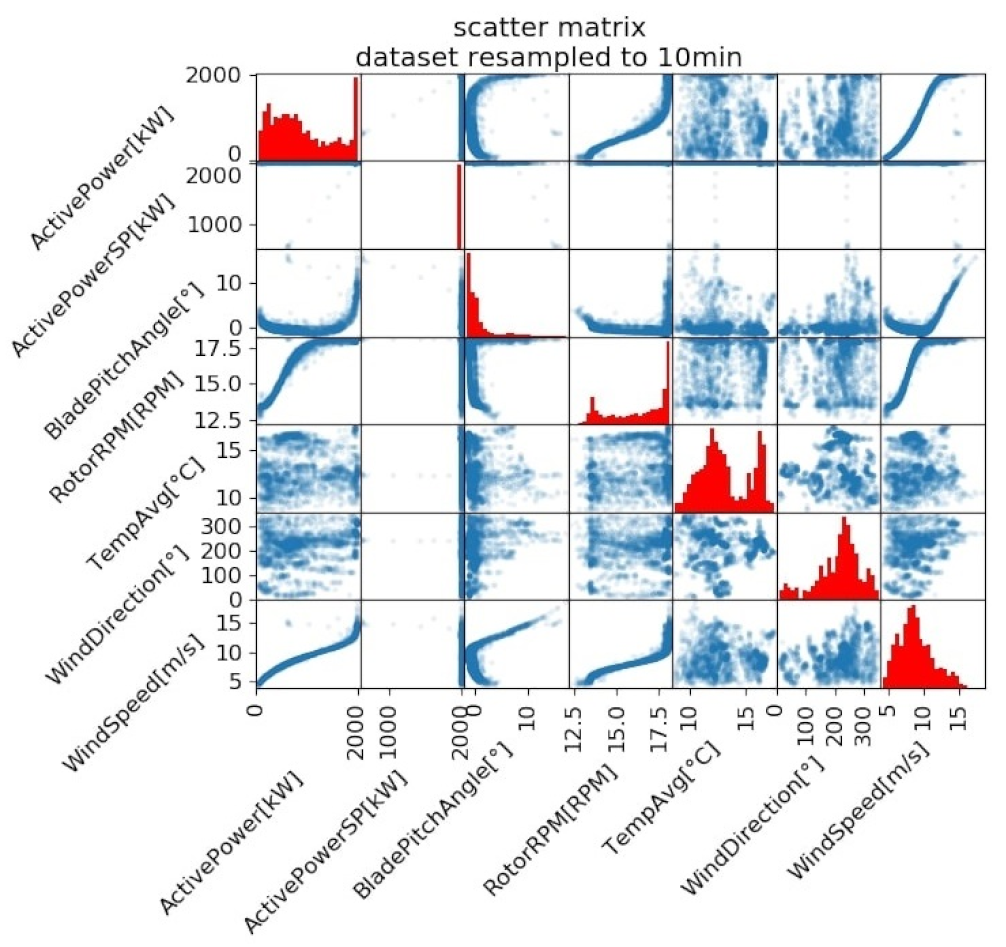
- Cross-validated recursive feature elimination (RFECV):Perform RFECV for each turbine to identify the set of wind turbines that, when used as features for training, yields a model of minimised power prediction error. Briefly mentioned in Section 1, RFE works by iteratively down-selecting features. At each down-selection, a model is trained and the model coefficients corresponding to each feature are stored. The significance of such coefficients used in many regression tasks is that they are indicative of the explanatory power of each feature in regards to the response variable. In the context of this project’s task for example, a highly positive coefficient belonging to a feature would mean that with its increase, an increase in power produced is to be expected. The opposite can be said for a feature possessing a highly negative coefficient: power would be expected to decrease in response to the feature’s increase.Thus, in RFE, the first model iteration is trained using all features. Using the resultant feature’s coefficients, the least important feature is identified and excluded in the feature set used in the next training iteration. This iterative down-selection is repeated recursively until there are no more features to exclude. Though this approach does not promise a globally minimal solution (as not all possible combinations of features are tested) it provides a computationally efficient means of feature down-selection.The RFE used in this task was cross-validated; meaning that at each recursive iteration, 10-fold cross-validation was used to determine which feature was least important and discarded in future iterations. To explain explicitly, at each iteration, the dataset is split into 10 folds. The wind turbine model for which RFECV is being performed is then trained on 9 of these folds, and the coefficients corresponding the the different wind turbines (features) are stored. This is repeated for every possible combination of 9 folds within the 10 total folds. The mean of the coefficients across all these combinations of folds (10 coefficients per feature) is taken. Using these coefficient means, the cross-validated least important feature is identified. This feature is discarded in the next recursive iteration and the 10-fold cross validation is repeated. Thus used, cross-validation serves to offer more robust estimates of a feature’s importance, as it is assessed over varied subsets of observations.The final aspect of the implemented RFECV to be discussed is the regression algorithm used at each recursive elimination to generate the feature coefficients and the choice of data to feed it as input. First, as an ordinary-least squares linear regression model (LR) satisfies the need of RFE for a coefficient-based algorithm as well as offers the simplest and quickest computation, it is selected as the algorithm to use in RFECV. Next, the decision of which feature set to use (wind speed, or wind speed and wind direction) had to be made. As can be observed in Figure 3, wind direction shares a highly nonlinear relationship with power and thus is ill-suited for use in the LR-based RFECV. Accordingly, wind speed was the sole feature chosen for RFECV. Finally, in order to improve the quality of the LR’s fit to the feature’s data, a truncated range of the the power curve of the wind turbine being modelled was used. Specifically, the filtered dataset output from Section 2.3 was only used in the range . This region was selected as it explicitly is more linear than the power curve taken as a whole, and thus presents an input more compatible with the constructed LR-based RFECV.
- (2)
- Entire WF-informed down-selection cut-off:After RFECV is performed for every turbine, curves showing number of features vs. cross-validated power prediction error can be generated. Plotting these curves for every turbine demonstrates that though prediction error decreases with the inclusion of more wind turbines as features as earlier hypothesised, there is a common point among turbine models where the benefit seems to diminish. Thus, to strike a balance between model complexity and performance, a feature cut-off of 15 wind turbines was made. To down-select to 15, the absolute value of the set of coefficients for a given model were sorted by value, and the 15 features (wind turbines) possessing the highest coefficients were taken as the most important. Figure 5 with the following visualisation of these curves was used as reference in determination of this cut-off.
2.4.4. Regression Model Overview
2.5. Model Selection Rationale
2.5.1. Dataset Transformations
2.5.2. Model Tuning
- (1)
- Layer architecture and preliminary lag search:The first exhaustive tuning objective was twofold: identify a preferred layer architecture and sequential-input-defining lag time. Here, in the TensorFlow nomenclature, the lag time is equivalent to the number memory cells per block and a block is equivalent to a neuron.In order to search over both of these hyperparameters, a grid search using a range of lag times 1, 5, 10, 20 and 30 s was implemented for two LSTM-containing ANN architectures:
- (a)
- 2-layer with an LSTM hidden layer
- (b)
- 3-layer with an LSTM hidden layer connected to a fully connected, dense feedforward-style hidden layer.
Though architecture (b) is less common, it was thought worthy to explore given the anecdotal performance improvement of the utilization of 2-hidden layers in the ANN-FF tuning. Further, as demonstrated in [20], such an architecture is particularly capable of learning sequences that are conditional to constraints, such as a power signal conditional to wind turbine operational constraints.From inspection of the validation results between architectures (a) and (b) trained using different lag times, two main observations could be made: First, it appears that the LSTM + Dense network significantly outperforms the single LSTM layer network, scoring a median min RMSE of approximately 150 kW across all turbines, while the single LSTM layer architecture scoring a median min of 350 kW. Second, it was observed that for both architectures, performance improves with added lag time; between 1 to 5 s for LSTM and apparently up to the range max of 30 s for the LSTM + Dense architecture.Based on these results, an extended lag study was performed using the LSTM + Dense architecture for all scales to further investigate a best-suited value for this hyperparameter. - (2)
- Extended lag study using best layer architecture:Here, a range of 1, 5, 10, 20, 30, 45 and 60 s were tested for each model scale, all at the preferred LSTM + Dense architecture.From inspection of this study’s results, a number of observations can be made. First, it was seen that the WT scale model is the primary beneficiary of the extended lag time tested in this search; with performance continuing to significantly improve up until lag = 45 s. Next, it was seen that the WFL scale improves from 1 to 20 s, with no significant change beyond this point (except perhaps an increase in variance between 20 to 60 s). These trends are also exhibited generally by the WF scale. Finally, it was seen that all models achieve similar median min RMSE at their best lag, with the minimum overall median score belonging to the WFL scale using lag = 20 s.Thus, a lag of 20 s was selected as a balance of performance and computational complexity.
- (3)
- Neuron grid search for all scales using best lag time:To check the ANN-FF-tuning-based assumption of 20 neurons being best, a grid search was again performed to search over combinations of neurons for both the LSTM and dense, feedforward layers. As in the ANN-FF grid search, here a 5-fold cross-validation was used. Here, note that corresponds to the number of neurons in the LSTM layer, while corresponds to those in the dense feedforward layer.From inspection of this grid search’s results, a number of observations could be made. First, the WFL was shown to outperform the WF and WT models; a surprising result given the findings of the ANN-FF neuron grid search. Second, for the WT model, a neuron set of = 50, = 50 proved best while = 20, = 20 proved best for WFL and WF models. The fact that these results were monotonically decreasing with lower neuron counts unto the minimum tested in this range motivated a follow-up grid search representing neuron counts of even lower values.
- (4)
- Lower range extended neuron grid search at best model scale (WFL):Here, an extended neuron range of neurons was tested for only the best performing model scale of WFL.From inspection of this extended search, it was seen that a combination of , yielded the best performing model. Thus it is chosen as the neurons-per-layer hyperparameter with which to train the final LSTM-based regression models.
2.5.3. Comparison of Tuned Regression Model Performance
2.6. Trained Model Inspection
2.6.1. Definition of Residual
2.6.2. Residual Inspection
2.6.3. Bias Inspection
2.6.4. Variance Inspection
3. Results and Discussion
3.1. Test Set Power Performance Analysis
3.1.1. Test Set Filtration
- (1)
- False positive here denotes observations that, given the model’s trained definition of normality, would yield high indication of abnormality through high residuals, but yet the nature of which is not of interest in the analysis. Here, instances of downregulation would yield false positives and are thus filtered.
- (2)
- In filtering out observations representing behaviour outside of the nominal bounds of normality, a similar such filter as applied to the training set is considered. However, here conditions are modified slightly in order to preserve observations that, though outside of operational bounds, may indicative of instances of of under or over performance.
3.1.2. Mitigating Test Set Residual Uncertainty
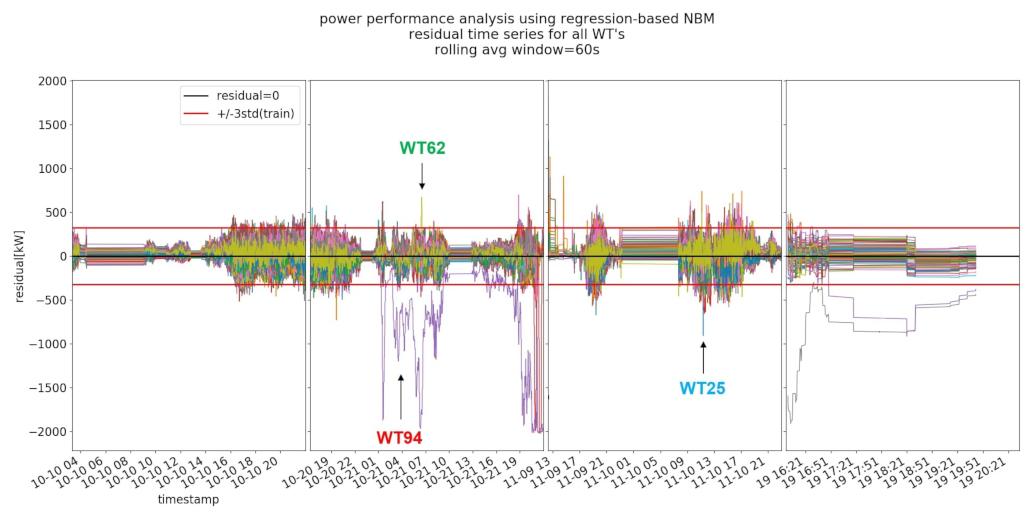
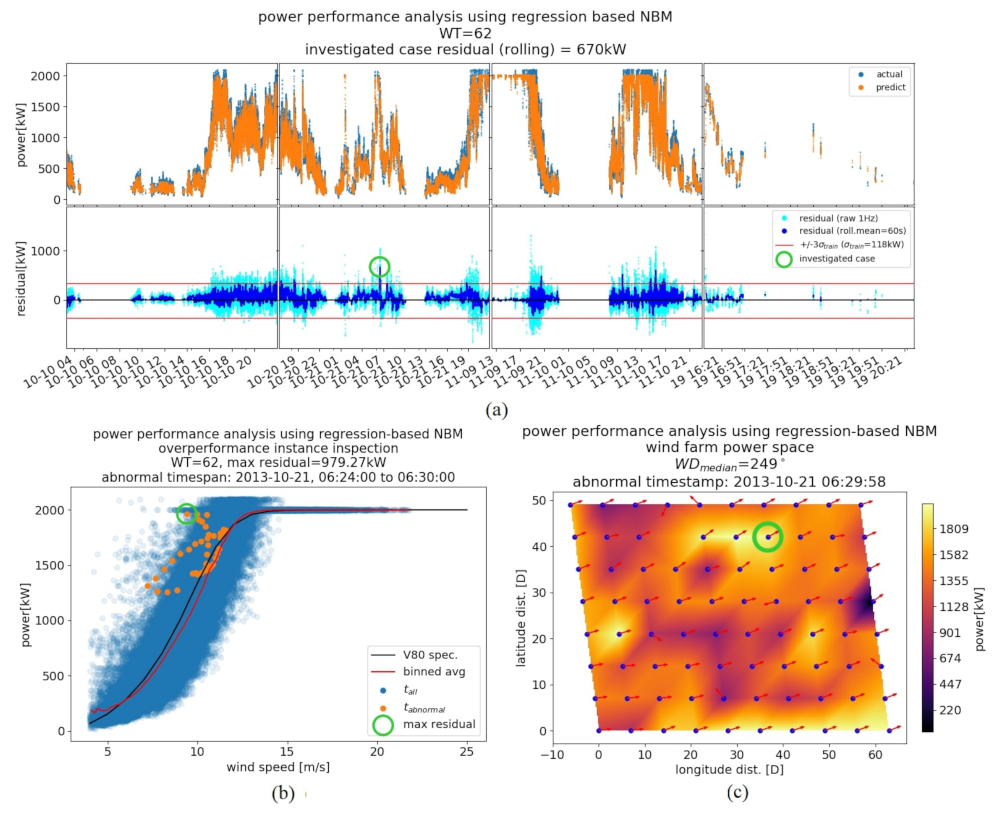
3.1.3. NBM Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SCADA | Supervisory Control and Data Acquisition system |
| NBM | Normal Behaviour Model(ing) |
| ANN | Artificial Neural Network |
| SHM | Structural Health Monitoring |
| CM | Condition Monitoring |
| PM | Performance Monitoring |
| RFE | Recursive Feature Elimination |
| OOB | Out-Of-Bag |
| FE | Feature Extraction |
| FF | Feedforward |
| RFR | Random Forest Regression |
| KNNR | K-nearest Neighbours Regression |
| SVR | Support Vector Regression |
| LR | Linear Regression |
| GP | Gaussian Process |
| LSTM | Long Short-Term Memory |
| GMM | Gaussian Mixture Model |
| LOF | Local Outlier Factor |
| CDF | Cumulative Distribution Function |
| TI | Turbulence Intensity |
| OEM | Original Equipment Manufacturer (Here, the company producing the wind turbine) |
| WT | Wind Turbine |
| WF | Wind Farm |
| WFL | Wind Farm Local (scale) |
| RFECV | Cross-Validated Recursive Feature Elimination |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| MAE | Mean Absolute Error |
References
- Lapira, E.; Brisset, D.; Davari Ardakani, H.; Siegel, D.; Lee, J. Wind turbine performance assessment using multi-regime modeling approach. Renew. Energy 2012, 45, 86–95. [Google Scholar] [CrossRef]
- Colone, L.; Reder, M.; Dimitrov, N.; Straub, D. Assessing the Utility of Early Warning Systems for Detecting Failures in Major Wind Turbine Components. J. Phys. Conf. Ser. 2018, 1037, 032005. [Google Scholar] [CrossRef]
- Gonzalez, E.; Stephen, B.; Infield, D.; Melero, J.J. Using high-frequency SCADA data for wind turbine performance monitoring: A sensitivity study. Renew. Energy 2019, 131, 841–853. [Google Scholar] [CrossRef] [Green Version]
- Colone, L.; Reder, M.; Tautz-Weinert, J.; Melero, J.J.; Natarajan, A.; Watson, S.J. Optimisation of Data Acquisition in Wind Turbines with Data-Driven Conversion Functions for Sensor Measurements. Energy Procedia 2017, 137, 571–578. [Google Scholar] [CrossRef]
- Herp, J.; Pedersen, N.L.; Nadimi, E.S. Wind turbine performance analysis based on multivariate higher order moments and Bayesian classifiers. Control. Eng. Pract. 2016, 49, 204–211. [Google Scholar] [CrossRef]
- Göçmen, T.; Giebel, G. Data-driven Wake Modelling for Reduced Uncertainties in short-term Possible Power Estimation. J. Phys. Conf. Ser. 2018, 1037, 072002. [Google Scholar] [CrossRef]
- Bach-Andersen, M.; Rømer-Odgaard, B.; Winther, O. Flexible non-linear predictive models for large-scale wind turbine diagnostics. Wind Energy 2017, 20, 753–764. [Google Scholar] [CrossRef]
- Papatheou, E.; Dervilis, N.; Maguire, A.E.; Antoniadou, I.; Worden, K. A Performance Monitoring Approach for the Novel Lillgrund Offshore Wind Farm. IEEE Trans. Ind. Electron. 2015, 62, 6636–6644. [Google Scholar] [CrossRef] [Green Version]
- Schlechtingen, M.; Ferreira Santos, I. Comparative analysis of neural network and regression based condition monitoring approaches for wind turbine fault detection. Mech. Syst. Signal Process. 2011, 25, 1849–1875. [Google Scholar] [CrossRef] [Green Version]
- Cardinaux, F.; Brownsell, S.; Hawley, M.; Bradley, D. Modelling of Behavioural Patterns for Abnormality Detection in the Context of Lifestyle Reassurance; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Heidelberg/Berlin, Germany, 2008. [Google Scholar] [CrossRef] [Green Version]
- Japar, F.; Mathew, S.; Narayanaswamy, B.; Lim, C.M.; Hazra, J. Estimating the wake losses in large wind farms: A machine learning approach. In Proceedings of the 2014 IEEE PES Innovative Smart Grid Technologies Conference, ISGT, Washington, DC, USA, 19–22 February 2014. [Google Scholar] [CrossRef]
- Gonzalez, E.; Stephen, B.; Infield, D.; Melero, J.J. On the use of high-frequency SCADA data for improved wind turbine performance monitoring. J. Phys. Conf. Ser. 2017, 926, 012009. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Wind turbine condition monitoring based on SCADA data using normal behavior models. Part 1: System description. Appl. Soft Comput. J. 2013, 13, 259–270. [Google Scholar] [CrossRef]
- Kusiak, A.; Zheng, H.; Song, Z. On-line monitoring of power curves. Renew. Energy 2009, 34, 1487–1493. [Google Scholar] [CrossRef]
- Jia, X.; Jin, C.; Buzza, M.; Wang, W.; Lee, J. Wind turbine performance degradation assessment based on a novel similarity metric for machine performance curves. Renew. Energy 2016, 99, 1191–1201. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breuniq, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000. [Google Scholar] [CrossRef]
- Chollet, F. Keras.Io. In Keras: The Python Deep Learning Library; GitHub: San Francisco, CA, USA, 2015. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Makris, D.; Kaliakatsos-Papakostas, M.; Karydis, I.; Kermanidis, K.L. Combining LSTM and feed forward neural networks for conditional rhythm composition. Commun. Comput. Inf. Sci. 2017, 744, 570–582. [Google Scholar] [CrossRef]
- Huo, Z.; Martínez-García, M.; Zhang, Y.; Yan, R.; Shu, L. Entropy Measures in Machine Fault Diagnosis: Insights and Applications. IEEE Trans. Instrum. Meas. 2020, 69, 2607–2620. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Machine Learning Model | Selected References |
|---|---|---|
| Regression | feedforward artificial neural network (ANN-FF) | [4,8,11] |
| random forest regression (RFR) | [3,4,12] | |
| K-nearest neighbours regression (KNNR) | [13,14] | |
| support vector regression (SVR) | [3,11] | |
| linear regression (LR) | [9,11] | |
| Lasso LR | [2] | |
| Gaussian process (GP) | [8] | |
| long short-term memory ANN (ANN-LSTM) | [6] | |
| [7] | ||
| fuzzy inference systems & logic | [13] | |
| Density | Gaussian mixture model (GMM) | [1,10] |
| Step | Filter Name | Filter Type | Programmatic Filtrate Definitions | Power Curve Regime to Be Filtered |
|---|---|---|---|---|
| 1 | curtail | operational | ActivePowerSP < 2000 kW | entire |
| 2 | cutin | (WindSpeed < 4 m/s) OR (ActivePower < 66.6 kW) | entire | |
| 3 | cutout | WindSpeed > 25 m/s | entire | |
| 4 | uprated | ActivePower ≥ 2010 kW | threshold 1 | |
| 5 | LOF | machine learning outlier detection | hyperparameters: n-neighbours = 100, contamination = 0.0174 | P < threshold 1 |
| 6 | LOF | hyperparameters: n-neighbours = 100, contamination = 0.05 | threshold 1 > P > threshold 2 |
| Layer 1 | Layer 2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Lag [s] | Type | n | Activ. Func. | Type | n | Activ. Func. | Optimizer | Loss | Batch Size | Epochs |
| ANN-FF | NA | dense | 20 | relu | dense | 20 | relu | adam | MSE | 300 | 25 |
| ANN-LSTM | 20 | LSTM | 5 | - | dense | 20 | relu | adam | MSE | 300 | 25 |
| MAE [kW] | RMSE [kW] | Training Time [min] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Feature | WT | WFL | WF | WT | WFL | WF | WT | WFL | WF |
| LR | WS | 173.8 | 155.7 | 165 | 226.7 | 209.5 | 218 | 0.0002 | 0.01 | 0.08 |
| RFR | WS | 115.9 | 88.9 | 85.3 | 166 | 129 | 125.6 | 0.15 | 1.91 | 12 |
| ANN-FF | WS | 117.5 | 94 | 86.8 | 166 | 135.3 | 124.3 | 2.75 | 2.7 | 2.7 |
| ANN-LSTM | WS | 86.8 | 74.4 | 78.3 | 126.2 | 110.8 | 115.5 | 6.8 | 6.6 | 6.3 |
| LR | WS + WD | 175.6 | 152.5 | 153.9 | 227.8 | 203 | 207.6 | 0.02 | 0.09 | 0.4 |
| RFR | WS + WD | 140.7 | 92 | 95.5 | 198.8 | 131.7 | 132.8 | 0.3 | 4.3 | 14.7 |
| ANN-FF | WS + WD | 123.8 | 97.8 | 113.7 | 172.3 | 132.8 | 155.3 | 2.9 | 2.9 | 2.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyons, J.T.; Göçmen, T. Applied Machine Learning Techniques for Performance Analysis in Large Wind Farms. Energies 2021, 14, 3756. https://doi.org/10.3390/en14133756
Lyons JT, Göçmen T. Applied Machine Learning Techniques for Performance Analysis in Large Wind Farms. Energies. 2021; 14(13):3756. https://doi.org/10.3390/en14133756
Chicago/Turabian StyleLyons, John Thomas, and Tuhfe Göçmen. 2021. "Applied Machine Learning Techniques for Performance Analysis in Large Wind Farms" Energies 14, no. 13: 3756. https://doi.org/10.3390/en14133756
APA StyleLyons, J. T., & Göçmen, T. (2021). Applied Machine Learning Techniques for Performance Analysis in Large Wind Farms. Energies, 14(13), 3756. https://doi.org/10.3390/en14133756