1. Introduction
The power sector is experiencing a very favorable moment for innovation and incorporation of new technologies. Motivated by environmental concerns, such as greenhouse gas (GHG) emissions, discharges of local pollutants, and water consumption (economic aspects), industrial policy, and technological development, the sector seeks for alternatives to fossil fuels to meet its increasing demand for electricity [
1].
According to the International Renewable Energy Agency (IRENA), between 2009 and 2018, 413 GW of wind energy and 463 GW of solar energy were installed throughout the world. Both sources represent more than 72% of the additional renewable capacity installed worldwide in the last 10 years [
2]. Brazil faces the same scenario. Government expansion plans and internationally signed commitments point to a prosperous future for these nondispatchable sources of electricity generation. According to Brazil’s commitment to fight climate change, by the end of 2030, the country is expected to generate 105 TWh by onshore wind farms and 35 TWh in centralized and distributed solar plants [
3]. In the Brazilian Ten-Year Energy Expansion Plan 2027 (PDE2027), the Energy Research Company (EPE) expects the installation of 17.4 GW of photovoltaic solar energy and 34 GW of onshore wind energy [
4] in the coming years.
In this context, the photovoltaic solar source plays a relevant role due to its accelerated expansion capacity by decentralized residential and commercial panels. This perspective integrates many generation and consumption agents in the electrical system, in different locations, affected by adverse meteorological events and with an extremely variable character, feeding the sector with extensive data for decision-making [
5].
From the perspective of the operation of the electrical system, the ability to predict the behavior of these thousands of new agents frequently entering the system is essential, whether it be for purposes of planning, control, or adequacy of operating logics [
6]. New solutions are therefore required in every electricity mix aiming at the intensive connection of photovoltaic generation systems intelligently to the grids, reducing the impacts of natural variability in the solar resource. These solutions must be fast and sufficiently integrated to contemplate the interaction of multiple system agents, a factor multiplied exponentially by the expansion of distributed generation [
7].
Machine learning (ML) algorithms attempt to predict incident solar radiation and bring intelligence to the management of energy resources using historical series of locally measured meteorological parameters as input data. Studies show the existing correlation between radiation and other meteorological variables for decision-making in the electricity sector [
8].
The literature presents ML algorithms in a variety of applications to minimize the impacts of solar variability. Studies range from solar trackers, which seek to direct the panels in an intelligent way, to the maximum of solar radiation incident on the site, to storage solutions [
9,
10,
11].
Increasing the predictability of electricity generation is an interesting alternative, as it brings more information to energy planning and reduces the total generation costs to meet the demand. ML algorithms have helped to make more accurate and earlier predictions in planning [
12,
13,
14].
Based on the Systematic Literature Review (SLR) methodology proposed by [
15], a SLR was conducted by Viscondi et al. [
16] to understand the ML algorithms most used worldwide to predict solar radiation based on different modeling approaches. As a result, Support Vector Machine (SVM), Artificial Neural Networks (ANN), and Extreme Learning Machines (ELM) are the most frequently used algorithms, and datasets most of the time rely on meteorological parameters as features to predict solar radiation [
16].
For instance, in [
17], the authors presented an application of Support Vector Machine (SVM) to predict daily and mean monthly global solar radiation in an arid climate. Measured local temperatures were the parameters used to train multiple models and predict solar radiation daily. Models showed an increased performance by introducing calculated sunshine duration and extraterrestrial solar radiation. In the best models, the statistical tests show that the Normalized Root-Mean-Square Error (NRMSE) ranges from 13.163% to 13.305% and the Pearson correlation coefficient (R) varies from 0.894 to 0.896 (
p < 0.001). Predicting solar radiation monthly requires fewer parameters to train the best predicting models. Considering only minimum local temperature and calculated extraterrestrial solar radiation inputs, the best models achieved a NRMSE of 7.442% and R close to 0.986 (
p < 0.001).
Multiple research papers propose the use of Artificial Neural Networks (ANN) algorithms to predict solar radiation and power as it is consistently a great prediction algorithm [
18,
19,
20]. The authors in [
21] predicted hourly solar irradiance by comparing the performance of the Similarity Method (SIM), SVM, and ANN-based models. The models were trained considering the previous hours of the predicting day and the days having the same number of sunshine hours in the dataset. ANN presented the lowest NRMSE among the models implemented.
The authors in [
22] selected Extreme Learning Machines (ELM) as the ML algorithm for solar photovoltaic power predictions. ELM is a neural network-based learning algorithm consisting of a single hidden layer feedforward network, which has earned increasing interest recently considering its simplicity, fast-pace computational processing, and generalization capability [
23]. The paper concludes that due to the characteristics cited previously, ELM provides a slightly more accurate 24-hour-ahead solar power prediction when compared to ANN models. Monthly, from January to September, the Root-Mean-Square Error (RMSE) for solar power predictions ranges from 1.42 to 30.74 for ANN models while for the same months, ELM RMSE ranges from 0.99 to 29.39.
Even though the algorithm plays a significant role in the prediction performance, the location in which the study is conducted is considerably important to fine tune the models. Since models are mainly trained by meteorological parameters, the environmental particularities of the location are very important, suggesting a local analysis of the best suited algorithm.
Several papers also propose comparing the performance of different ML models to predict solar radiation on a specific site, understanding the best suitable model for each location. The authors in [
24] compared the performance of six different ML algorithms in the context of the United States of America (USA): Distributed Random Forest (DRF), Extremely Randomized Trees (XRT), stacked ensemble build, Gradient Boosting Machine (GBM), and Deep Learning and Generalized Linear Model (GLM). DRF presented the fewest errors (MAE and RMSE) on a first test and was therefore implemented to predict solar radiation in 12 different locations in the USA. The algorithm presented a different performance in each location, emphasizing the need to choose the locally best and most suitable algorithm [
24].
This work proposes an extensive comparison of the three ML algorithms most used worldwide for forecasting solar radiation based on meteorological parameters measured in situ in a case study scenario for São Paulo, Brazil. The São Paulo metropolitan area is the most populous region in Brazil and a strong candidate to a fast deployment of distributed solar panels due to its economic prosperity. In this specific location, there is no known record in the literature on solar radiation forecasting using ML algorithms; therefore, one of the objectives of this paper is to evaluate the algorithm with the highest accuracy for the location.
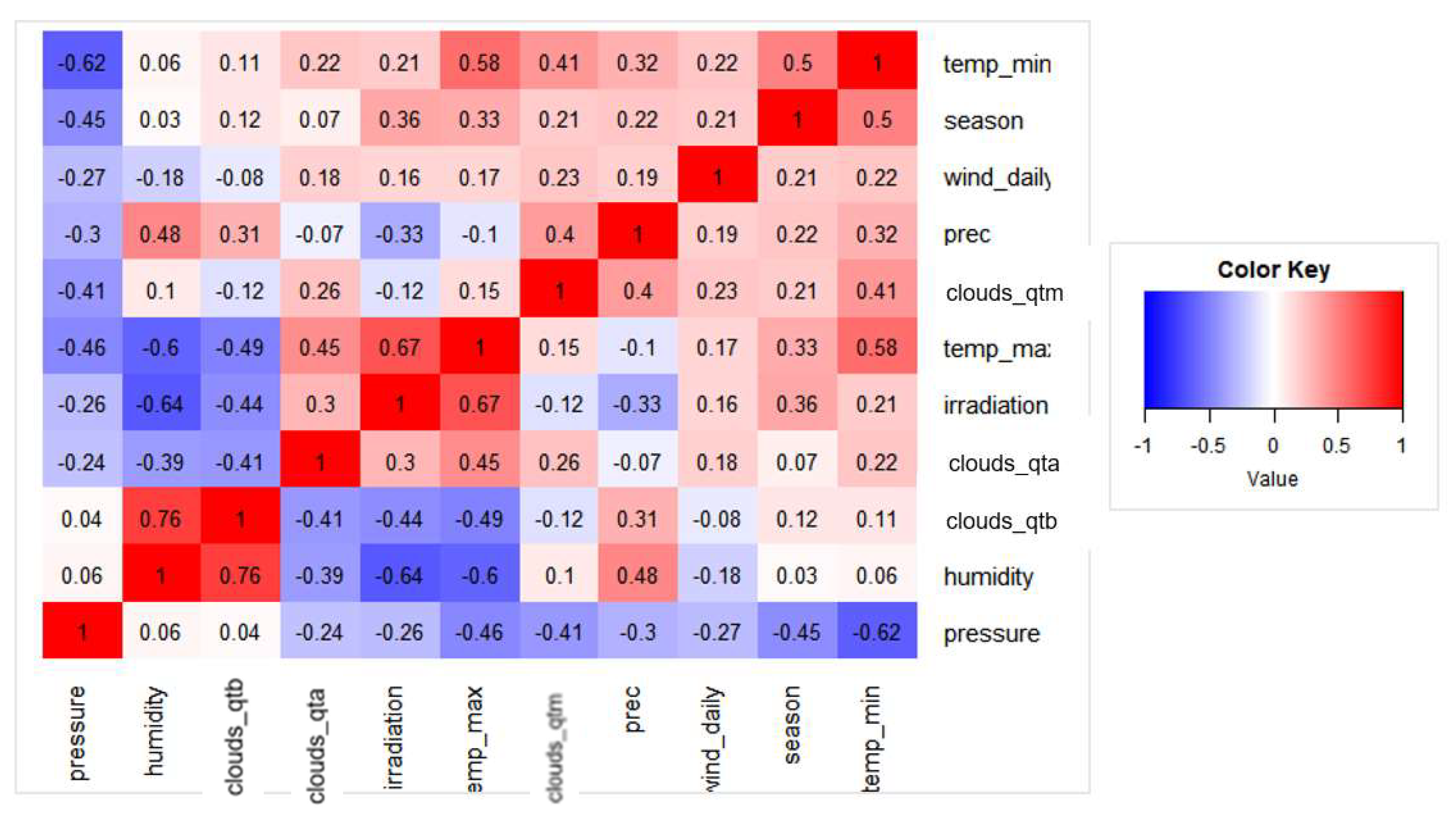
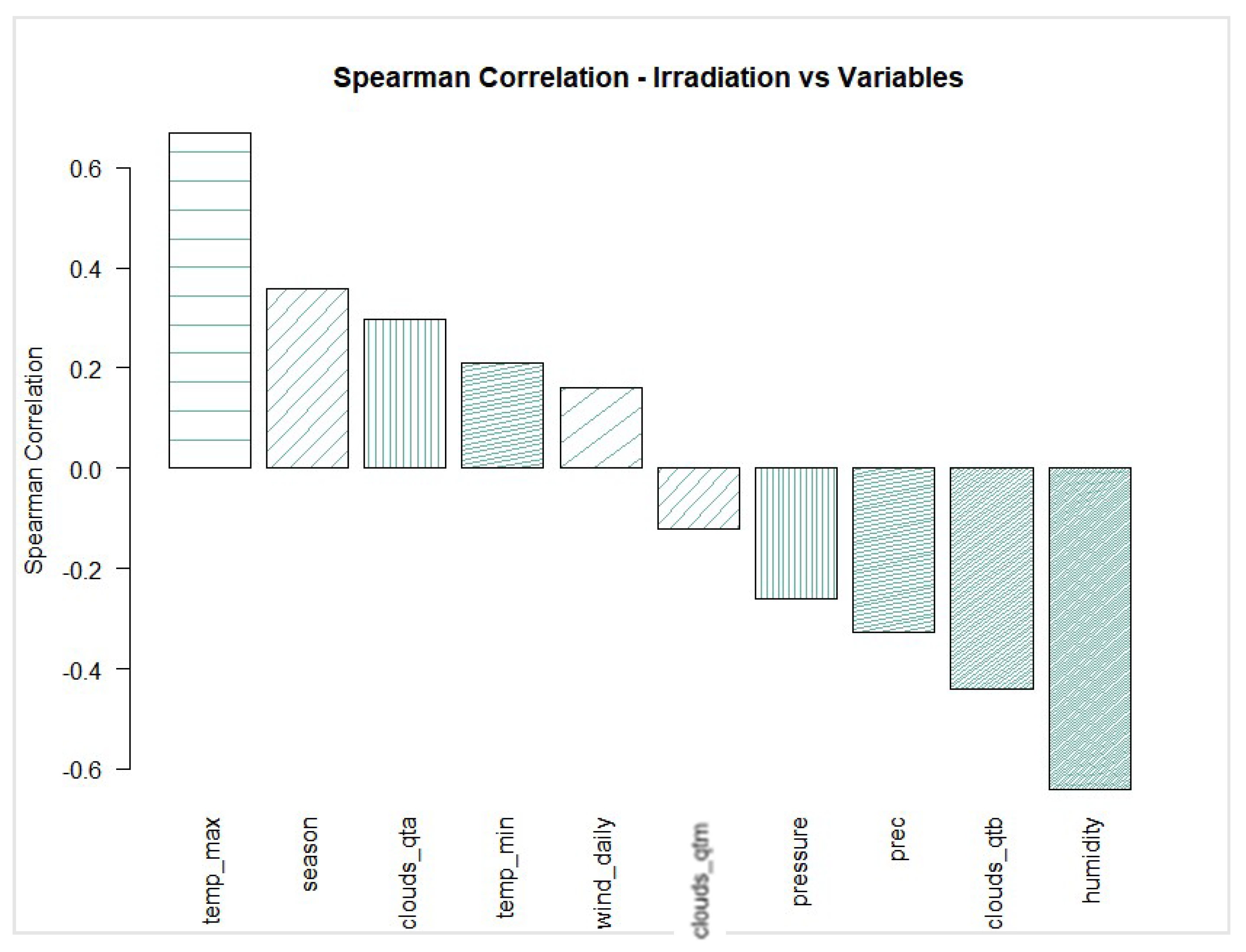
As a complementary objective, it is important to validate the capacity of a dataset to meet the needs of statistically representing the characteristics of the location, enabling good forecasting results. A dataset from the meteorological station at the University of São Paulo (USP) was used, consisting of 10 meteorological parameters measured from 1962 to 2014. The SVM, ANN, and ELM algorithms were trained, comparing their efficiency to predict solar radiation locally.
This paper is organized as follows: a brief explanation of ML algorithms and the theory of SVM, ANN, and ELM are presented in
Section 2. Site, database description, and methodology to implement the algorithms are reported in
Section 3.
Section 4 presents the results and a discussion on the predictions. Finally,
Section 5 provides the conclusions and future perspectives of the work.
5. Conclusions and Future Work
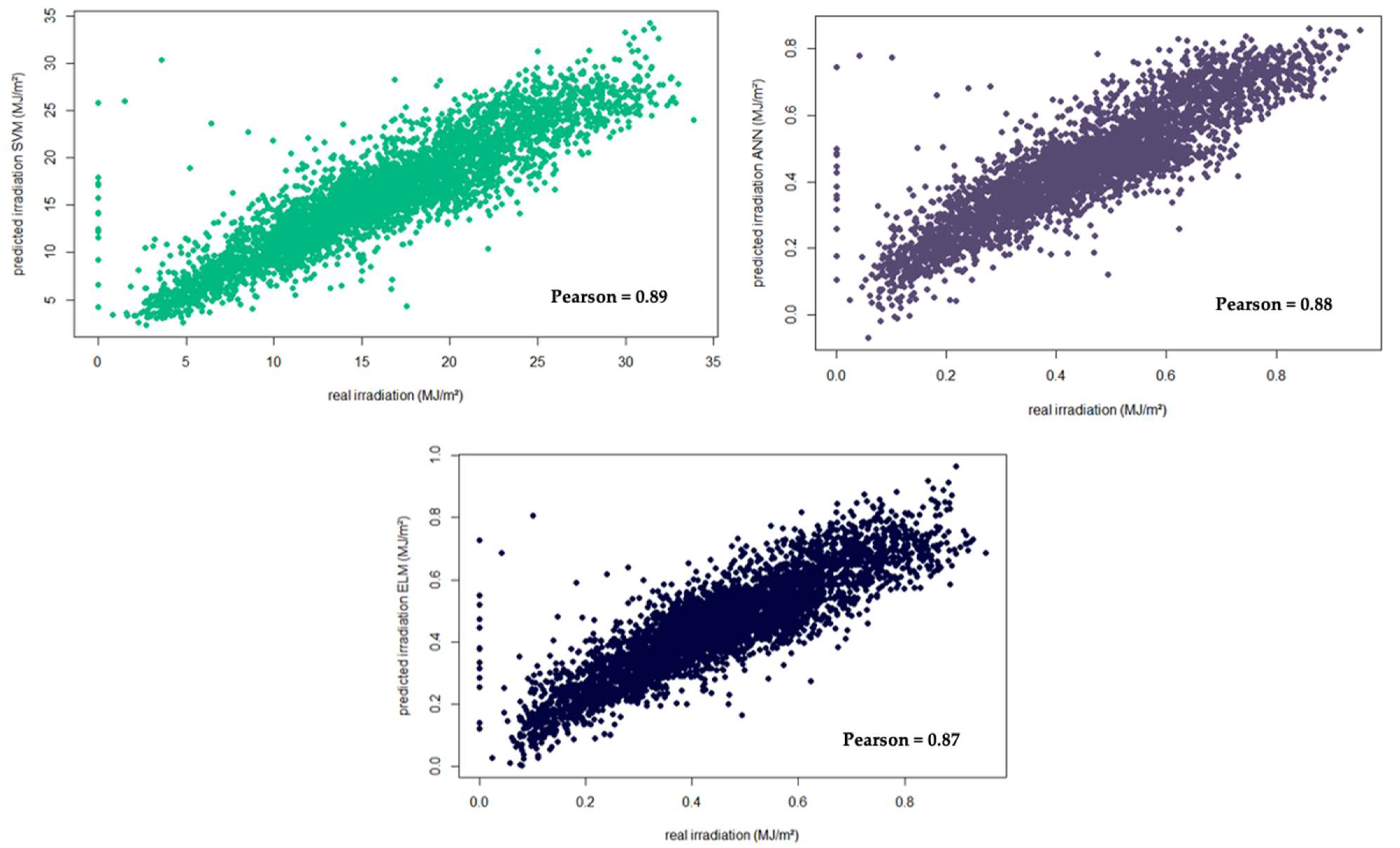
All the algorithms used presented good results when trained with all the meteorological parameters; however, when exploring their performance in an actual case study for the city of São Paulo, Brazil, SVM produced the lowest RMSE and ELM the fastest training rate.
Even though the performance of SVM, ANN, and ELM were similar, SVM presents the best results with no considerable increase in training time. For solar electricity generating capacity planning purposes, the algorithms most frequently used in the literature presented a similar performance when trained with data for the city of São Paulo.
The literature also suggests that ELM is expected to play a significant role on solar forecasting due to its fast-training ability and ease of implementation. The results presented herein for the city of São Paulo show ELM can reduce the average training time by 94.3% compared to SVM, and 93.8% compared to ANN training rates. However, the RMSE rises to 3.3% and 11.1% when compared to ANN and SVM, respectively.
As the number of training parameters increases, so do the accuracy of the models. The best predicting models for all three algorithms are trained with all the data available for the site, there being 10 available meteorological parameters responsible for the improvement in results.
It can also be concluded that the extensive dataset from the University of São Paulo played a good role in providing data for training a ML forecasting model. Therefore, for local and regional deployment of solar photovoltaic generating facilities, this public dataset can play a significant role in reducing the uncertainties of solar resource natural variability.
Future Research Directions
As the number of meteorological parameters plays a significant role in the forecasting accuracy, there is an opportunity to further evaluate the impact of adding other parameters to the models as they become available by the meteorological measuring station.
In Brazil, the energy planning exercise is conducted at a national level, considering local specificities, such as resource availability, electricity demand, and social/environmental impact. Therefore, there is similarly an opportunity to assess the performance of the same models in other sites for the country to integrate the forecasting exercise and to maximize the performance of the models.
Finally, quality of data is also a major concern when these models are trained and operated for decision-making. There is an opportunity for considering the impact of data quality on the performance of the models. Further steps of this work contemplate understanding data quality dimensions, such as completeness, uniqueness, validity, accuracy, consistency, and timeliness, besides their relationship with forecasting solar radiation for solar photovoltaic electricity generation.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}