3.1. Research Methodology and Overall Process
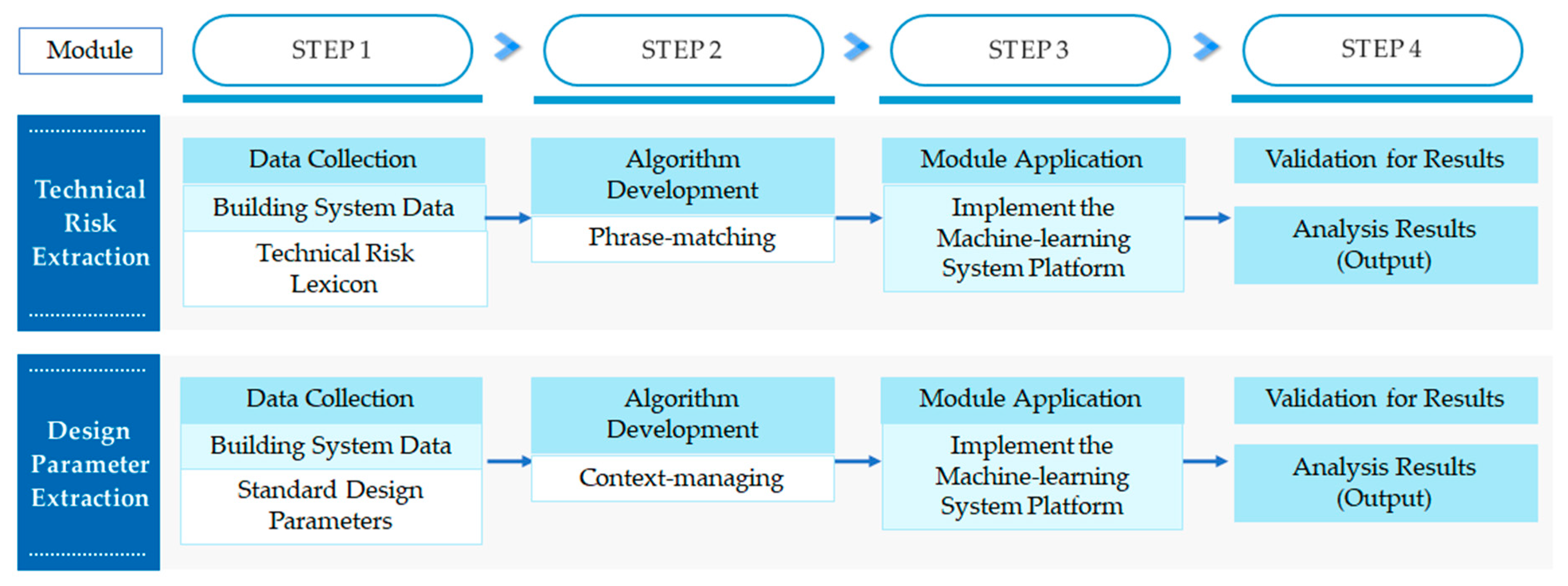
The process of this study was carried out in four steps as follows: (1) database construction for algorithm analysis; (2) algorithm development; (3) system application; (4) the verification of analysis results and the analysis of results. The detailed explanation of each step is described in
Section 3.3 and
Section 3.4, and this section provides a brief introduction to understand the overall research flow.
The first step is the data collection and application stage, suitable for the two algorithm modules (TRE and DPE). The data lexicon was built by collecting design risk keywords from the TRE module, and it was collectively called the technical risk lexicon (TRL). When analyzing technical specifications, the database derives a score calculated from the frequency of risk keywords and presents the results in order of risk severity. The process for building the TRL is introduced in detail in
Section 3.3. Next, in the DPE module, two types of data were required. The first was basic data to establish the engineering standard for the equipment or structure, such as the vessel and instruments to be analyzed, that is, the SDP. The process for building the SDP is introduced in detail in
Section 3.4. It is displayed in a table format and includes parameters and information about the corresponding equipment. The second required data were collectively called the synonym dictionary of SDP, synonyms for the first basic data. It played a role in enabling the detection and extraction of synonymous words and similar words.
As the second algorithm development stage, the logic construction suitable for the two module characteristics and the ML technology were used accordingly. By applying the phrase matcher technique [
46] of NLP to the TRE algorithm, it was possible to analyze the results according to the severity of risk through the grouping of keywords and scoring based on frequency. The risk sentence was extracted by matching the risk keyword with the phrase in the technical specifications through the phrase matcher technology. In the DPE module, an algorithm that derives the result by comparing the standard with the design standard of the corresponding technical specifications was applied through the context manager technique developed in this research project. Context manager means the process of learning the parameters of SDP in the context and reducing the influence score as the relevance of SDP decreases, or learning new parameters of SDP. The SDP of the equipment selected by the user can be learned, which serves to provide the data of the desired information at high speed.
In the third system application stage, the analysis result was visualized by implementing the algorithm in a dashboard on the ML platform. In other words, the module user could view the two modules (TRE and DPE) after selecting the technical specification analysis module. After uploading the selected technical specification document files and performing the analysis, the results were visually confirmed, and quantitative analysis was performed on the screen. The detailed description of the system configuration of each module is discussed in
Section 3.3 and
Section 3.4, respectively.
In the last step, a pilot test was performed to verify the system performance of the implemented two modules. The performance results are presented in
Section 4. Two EPC engineers (verification subjects) participated as a comparison test group with the module in the pilot test. The third-party verification method was adopted for the verification of the pilot test results. Two subject matter experts (SMEs) with over 15 years of experience participated as verification evaluators, and the SMEs who participated in the verification had experience in performing many projects. First, for the pilot test, one EPC project technical specification was selected separately from 25 technical specifications. The review process was conducted individually by each expert so that independent verification was carried out. The risk analysis detection rate of the system module and EPC engineer was calculated, and the analysis time was measured. Based on the verification results, it was prepared in the form of a table of results for each module, and the final result was displayed as a Detection Performance Comparison Index (DCPI).
Figure 1 shows the research steps and process methodology of this study.
3.3. Technical Risk Extraction (TRE) Module
The TRE module presents an algorithm that automatically extracts design risk clauses by analyzing technical specifications. Using the phrase matcher technique in NLP, the risk keywords in the technical specifications were automatically extracted, the extracted sentences were presented, and the evaluation factor and histogram were presented through the analysis results in a step-by-step manner.
The analysis process and algorithm of the TRE module were described in the activity sequence. As metadata consisting of tokens in sentence units was required to analyze PDF files, the definition of the analysis target in the technical specifications input file and the database embedded in the algorithm were compared in the TRE module.
3.3.1. PDF Data Pre-Processing—Sentence Tokenization
Data Pre-Processing refers to the process of converting unstructured data into structured data. This process must be preceded in order to perform the TRE and DPE modules because all documents must be classified in a language that the computer can parse. First, text data were loaded from a PDF using Tika Package [
47]. Tika is the library of the programming language (Python) and is used as a function to load (extract) the text of a PDF file [
48]. The loaded data were classified through the Sentence Tokenizer method. When the unit of a token was a sentence, this task classified sentences in a corpus, which is sometimes called sentence segmentation [
49]. A corpus is a collection of language samples used to study a natural language. A token is a grammatically indivisible language element. Text tokenization refers to the operation of separating tokens from the corpus.
When the analysis was performed by applying sentence tokenization by the period of the sentence as in the usual Sentence Tokenizer method, as shown in
Figure 5, the period already appeared several times before the end of the sentence. It was not suitable for the classification of sentences in technical specifications that contained periods to express belonging to sentences, such as “5.1.5”.
The rules were directly defined according to the sentence format of the technical specifications among ITB documents or how special characters are used within the corpus. Through the ITB Sentence Tokenizer, sentences were divided into units that indicated the affiliation of the device. A binary classifier was used to handle exceptions in which a period appeared multiple times. When a period was a part of a word, as in “5.1.5”, and when a period played the role of dividing an actual sentence, it was divided into two classes and the ML algorithm was trained. The separated sentences were saved as standardized data in the comma-separated values (CSV) format. As shown in
Figure 5, “5.2 Design Pressure”, it was confirmed that the affiliation (number) of the sentence was distinguished. Based on the following results, the items of technical specifications were classified and applied to both modules.
Figure 6 shows the results of the PDF standardization module.
3.3.2. Definition of Input File
The document to be analyzed was the technical specification, one of the bid documents obtained from the project owners at the bidding stage. The technical specifications for most EPC projects describe the engineering requirements for major equipment and parts required for the project.
3.3.3. Definition of Database—TRL Construction
Based on the project’s technical specifications collected from EPC contractors, documents were analyzed, and necessary data were collected. For this study, 25 technical specifications for various EPC projects such as construction and plant fields were collected, with case-based design risk keyword extraction from the collected technical specification documents, the participation of experts (SMEs) with more than 15 years of experience in EPC project execution and a review to establish the TRL. TRL requires a continuous update in connection with the number of technical specifications for EPC projects continuously accumulating. Since documents for analysis mainly consist of unstructured data, converting them into structured data that a computer can recognize is required. Next, we look at the database formation process included in the algorithm based on the collected technical specification documents.
Lexicon terms means embedded data in the form of a database within the algorithm. This TRE module is configured in the form of a lexicon, that is, a lexicon for risk terms for design risk keyword extraction. TRL has the structure shown in
Table 1.
In the 25 technical specifications, about 450 technical risk vocabularies were collected for each type of work, such as machinery, electricity, instrumentation, civil engineering, architecture, firefighting, HVAC and plumbing. As for the risk vocabulary, the advisory team was formed of three experts with over 15 years of experience in EPC projects, and they selected risk sentences that could affect the project by comprehensively judging the upstream and downstream engineering process. Additionally, the severity was classified into three groups based on the risk keyword. The classification method described in Dumbravă et al. [
50] was utilized as the evaluation method of the Impact Matrix.
Based on the review of five SMEs, they were classified into three severity groups and scored, and the classification criteria are as follows. The HH (High Impact/High Probability) group had the keywords that SMEs experts judged have a high probability of risk occurrence and significant impact. The HM (High Impact/Medium Probability) group was classified as the keywords that have a high risk or can have a significant impact but have a relatively lower risk occurrence than the HH group. Finally, the MM (Medium Impact/Medium Probability) group was classified into the factors with a degree of risk but relatively little impact. The H/H group had a risk score of 3 points, the H/M group had a risk score of 2 points, and the M/M group had a risk score of 1 point. As a risk classification criterion, the Impact Matrix was referred to, as shown in
Figure 7. The keywords included in group A were the H/H group, the keywords included in group B were the H/M group, and the keywords included in group C were defined as the M/M group.
In the TRE module, the evaluation factor of the EPC project is presented in the summary results output as an evaluation index, and it is presented to users as an index to evaluate the project’s risk level. The evaluation factor is the value obtained by dividing the “total risk score” by the “total number of extracted clauses” and it is the core information of the summary results output.
The range designation of the evaluation factor was performed through the normalization process. As shown in
Table 2, the range was specified through discussion by five SMEs based on the average values of the evaluation factors analyzed from 25 technical specifications. The average and standard deviation of the evaluation factors were 0.822 and 0.375 for the 23 technical specifications after excluding the minimum (0.26) and the maximum (2.71) values from the 25 technical specifications based on the trimmed average law. The five SMEs reviewed the 23 evaluation factors and determined the ranges. If the evaluation factor exceeded 1.0, it was high risk, a value between 0.6 and 1.0 was defined as medium risk, and a value less than 0.6 was defined as low risk.
3.3.4. TRL Terms
First, in the TRE module, the TRL was embedded in the system. It is composed of a list of keywords called terms in coding and of groups A, B, and C according to the degree of risk. The input file to be analyzed in correspondence with the corresponding terms was a PDF standardized technical specifications file. It is composed of a CSV file and is broken down into sentences. Breaking sentence by sentence is called sentence tokenization, and in the next step, keywords were matched through tokenization of words or phrases.
3.3.5. Word Tokenization—Count Vectorizer
In this case, the count vectorizer function of the feature-extraction sub-package of Scikit-learn was used to tokenize the sentence and divide it into words or phrases. This process is called word tokenization. Since the concept of this module is to automatically extract the risk clause through the frequency and severity score of the technical risk keywords, expressing the frequency as a vector value is necessary. This process is called word counting. Count vectorizer is used to generate count vectors, a Python class that converts documents into the Token Count Matrix [
5]. The concept diagram of the TRE module shows the process of the word counting by count vectorizer and group counting, scoring, and sorting by phrase matcher in
Figure 8.
3.3.6. Word Dictionary—Count Vectorizer
Count vectorizer learns all the words in the corpus and creates a count vector by matching each word to the number of times it appears in each sentence. The generated vectors are derived as a dictionaried result, as shown in
Figure 9. The dictionary is a data structure that can store key-value type values. Through this process, the keywords of each sentence are converted into a dictionary and can be used for analysis.
3.3.7. Grouping—Phrase Matcher
Phrase matcher is a spaCy technique that learns matching patterns and creates rule-based matches. Using the phrase matcher technique efficiently matches many keywords. An input file, that is, the data list loaded by default from a code is transformed into tokenized texts. Some languages, including English selected in this study, consist of both lowercase and uppercase letters. By designating the lowercase property in this transforming process, the phrase matcher technique can match without distinction between lowercase and uppercase letters. The group counting step extracts word frequencies from count vectors and grouping them into groups. The number of keywords for each sentence is calculated from the count-vectorizing result, and the keyword frequency is calculated by grouping the keywords into groups. Phrase matcher refers to counting the number of occurrences by matching the TRL Terms stored in the system to each sentence of the technical specification documents. Match results are derived, for example, A (1), B (3), C (2), depending on the sentence.
3.3.8. Score Calculation and Sorting—Phrase Matcher
In the scoring and sorting step, the total score of the sentence was determined by the score of each group. Then, the ranking was given and sorted according to the score. As for the score for each group, according to the TRL as mentioned above, group A (HH) was given 3 points, group B (HM) 2 points, and group C (MM) 1 point. For example, in the case of sentences resulting from a grouping of A(1), B(3), and C(2), the total score was A-related 3 points, B-related 6 points, and C-related 2 points, resulting in a total risk score of 11 points.
3.3.9. Analysis Result Output—Output
The sorted sentences were calculated as the following four data frames. The TRE analysis module provides a summary table for four analysis results (main result, summary result, histogram data, and histogram image).
As for the output of the TRE module, the analysis result was derived as an Excel file. Based on the following results, the severity of the risk sentence was scored and displayed, and the risk sentence according to the ranking, the affiliation of the sentence, and the frequency of keywords could be checked. As the next output, the summarized result was presented as an Excel file, and the total number of sentences, the number of extracted risk sentences, and the evaluation factor were calculated from the result. In addition, a histogram of the analysis result was created in the form of an image, and the information of the histogram was also output and could be checked. The analysis result table among the total four outputs was implemented as an analysis result screen, as shown in
Figure 10. The remaining three outputs are displayed on one screen. The summary table, histogram, and histogram information are displayed on the result summary screen, as shown in
Figure 11.
3.4. Design Parameter Extraction (DPE) Module
The DPE module analyzes the requirements and ranges of each equipment parameter by comparing the SDP of the technical specifications embedded in the system with the design standards of the object to be compared and presents the comparison results. Through the function of detecting design errors for numerical requirements in the technical specifications, it was confirmed whether the selected equipment met the minimum requirements. The comparison results present TRUE if the analysis result falls within the standard specification and its category, and FALSE if the result of the specification does not apply or deviates from the standard specification. This not only shortens the comparison time but also allows a user to identify various engineering requirements that may be omitted. In addition, by providing the ability to edit SDP data according to the characteristics of a user’s demand, the purpose of this was to prevent the design risk of contractors in advance and to establish a project-specific DB.
The basic data of the DPE module analysis algorithm were constructed in two ways (SDP or synonym dictionary). The first data were the SDP for equipment used in the EPC project. SDP are the standard data for comparative analysis and are composed of a data table format, as shown in
Table 3.
Table 3 shows pressure vessel equipment among plant equipment, and
Table 4 shows SDP for instrument equipment, respectively. Parameter (PRM) consists of three steps and is defined in order of importance. PRM1 stands for Definition. Basic input data required for analysis include “design temperature,” “minimum thickness,” and “design pressure.” PRM2 can be a component of equipment. Like “Shell” or “Head”, it means each part of the pressure vessel. PRM3 is a sub-element to additional input information such as environment and status. Next, the attribute to designate the range of values and the range of technical specifications are presented, and finally, the unit for the number is input.
After the process of analysis and review by experts for each type of work, a hierarchy for a total of 10 types of equipment was constructed, as shown in
Figure 12. The prepared thesaurus is shown in
Table 5. SDP parameters are sometimes expressed differently in technical specifications of projects. Although the meaning is the same, they are sometimes used in various expressions. A synonym dictionary was built to secure the accuracy and reliability of the analysis. The two embedded data (SDP and synonym dictionary) were used for context manager analysis.
In the DPE algorithm, the user can select the equipment so that SDP data can be managed through the Database (DB). Data management through the DB shortens the analysis time of the selected equipment and facilitates management when data are converted or added later by the user through the SDP editing function [
30]. The DB is provided through the Database Management System (DBMS) management system built through the open source of MySQL [
51]. MySQL is the world’s most widely used relational DB management system. The digitized data are stored in the cloud using the MySQL DB service. DB construction for the DPE module created one database and two lower tables (SDP and synonym dictionary). As shown in
Figure 13, the conditions for each table column are specified differently depending on the property.
PK: Primary Key. Is it a property that can distinguish each row?
NN: Not Null. Should it not be blank?
UN: Unsigned type. Is it unsigned data?
AI: Auto Increment. When checked, a larger value of 1 is automatically set for each row.
The data of each table were applied by loading the CSV files of SDP and synonym dictionary. It was confirmed that the SDP data were activated as a DB table and applied, as shown in
Figure 14.
In order to utilize the above SDP and synonym data for analysis, the analysis code must access the server and receive data. A database server and a client communicate in a language called SQL (Structured Query Language). When a client sends a query (request), the server can create, modify, delete, and print data accordingly.
Since data must be received from the server, the corresponding SELECT statement is sent as a query. For the user account function, only the row whose USER_ID column value is the same as the current user ID is selected and loaded. The user account function is a function that allows users to modify the DB as a function to improve the usability of future platform users. Through this, it became possible to build a customized DBMS according to user demand.
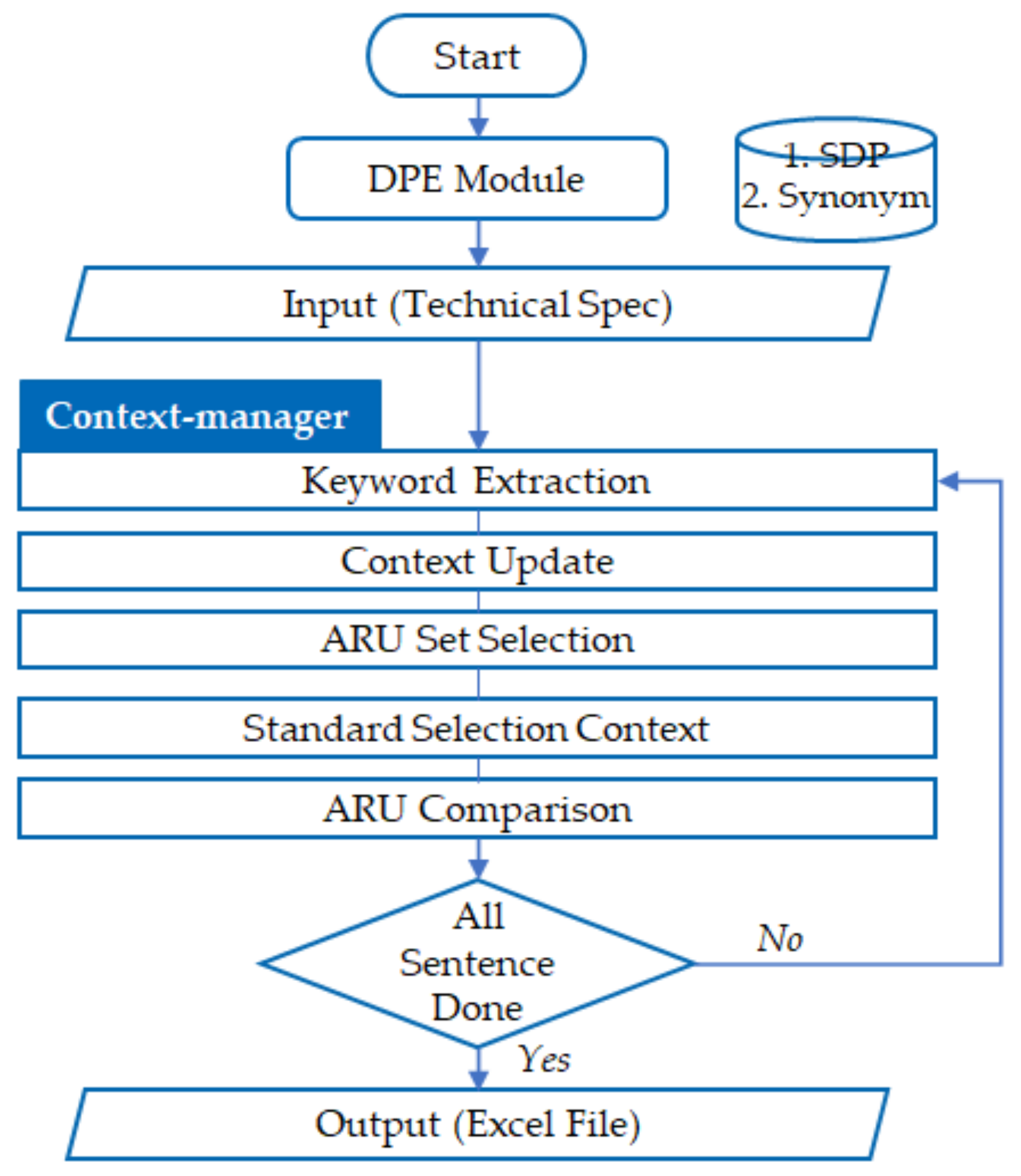
Figure 15 shows the algorithm concept diagram of the DPE module. The SDP and synonym dictionary construction process was previously described, and the description of the context manager applied as the analysis method of this module is described below.
In order to select SDP as the internal data clarification process of the DPE module, it is necessary to only leave the data corresponding to the work type and equipment specified in the checklist. Next, SDP and part of synonym data are reprocessed using the internal dictionary among the data types of the programming language (Python). Through this, the execution time can be shortened when searching for keywords or synonyms in sentences. The plural form of parameter was added as a synonym in the dictionary. Furthermore, sentence pre-processing, the step of generating an N-gram that views a phrase in which
n tokens are bundled as a unit through the tokenization process, was performed.
Section 3.3.1 to
Section 3.3.2 are the same pre-processing steps described in
Section 3.3.
3.4.1. Keyword Extraction
In the keyword extraction stage, keywords include parameter, attribute, range, and unit. Range is extracted with Python’s regular expression, and the rest are extracted using N-gram and Dictionary. The extracted keywords were used for the following algorithm analysis.
3.4.2. Context Update
In the context update stage, analysis time could be reduced because only the SDP data related to the sentence were selectively analyzed. The relevant DPE data were selected using the parameter context data. The context analysis algorithm was improved so that sentence analysis and comparison was possible even if there were no parameters in one sentence. Sentences containing keywords of SDP were converted into context scores and expressed according to their influence on the relevant paragraph. In calculating the context score, parameters 1, 2, and 3 were learned as context keywords and applied when calculating the context score of a paragraph. Up to three parameters were trained for each parameter type. The context analysis algorithm was designed so that the influence of the parameter could be extended to several sentences beyond one sentence. Therefore, even if all parameters in the sentence are not included, it is possible to perform a comparative analysis with SDP by checking the context.
In the context updating process, if the SDP keyword of the context is duplicated or if the keyword of the SDP of the same device is detected, the SDP extraction score of the corresponding context is increased. When the SDP keyword is detected in the sentence, it is added to the context keyword data, and a score is given to the paragraph. This score decreases each time the sentence is changed, and when the score reaches 0, the corresponding SDP keyword is deleted from the context data. Once the SDP keyword appears, the influence of the SDP keyword is maintained for several sentences after that. This context data were used to compare and analyze the attribute, range, and unit (ARU) of the embedded SDP parameters in the subsequent process.
3.4.3. ARU Set Selection
Each of several attributes, ranges, and units included in the sentence are grouped in the ARU Set Selection stage. The range may be two. For example, if there was a sentence “The length is greater than 1 m, and the weight is 5 kg maximum.” they were grouped into “greater than, 1 m” and “maximum, 5 kg”, respectively.
3.4.4. Standard Selection Context
In the Standard Selection Context step, SDP criteria are selected. The row containing the parameter stored in the context data in the embedded SDP Table is found. As one of the sentence conditions, if even one definition of range or unit for numerical requirements is omitted in the sentence, the analysis is performed except for the sentence. It has the advantage of increasing the analysis accuracy and speeding up the analysis.
3.4.5. Context Manager
The context manager technology developed in this module is applied from keyword extraction to the Standard Selection Context process. Only relevant SDP data were selected and analyzed through the context manager, and analysis was not performed if certain conditions were not met. Through this, it was possible to remove unnecessary extraction results during comparative analysis and shorten the extraction time. The context manager technique was developed based on the concept of supervised learning in this study. Context manager sets the standard design parameters with fixed numerical values or ranges and uses them as standards to compare the input variables extracted from the target technical specifications in the DPE module. For example, in the clause, “pressure vessel’s pressure is 150 MPa”, context manager sets “150 MPa” as the fixed value of the standard design parameter “pressure” in the model training process. When the DPE module extracts design parameters and their values from the target technical specifications, context manager will compare the values in the design parameters with the fixed values of the SDP in the model and generates a result report. If context manager finds a value higher than “150 MPa” as the SDP, “pressure” in a target technical specification, context manager considers the clause to contain the design risk and includes it in a result report.
3.4.6. ARU Comparison
In the ARU Comparison step, a criterion to be automatically extracted from the sentence and compared with the selected the ARU set was selected from the embedded SDP Table. It included the context data or the position of the parameter in the sentence. The result value was derived by comparing the criteria selected in the ARU Set Selection step and the Standard Selection Context step with each other. It shows TRUE if the extracted range is included in the standard range, otherwise FALSE. It repeats the process from Keyword Extraction to ARU Comparison until the analysis is complete for all sentences in the technical specification. After analysis, the data frame is formed as the output. The data frame is displayed as an SDP comparison table in an Excel format. A list of equipment for each type of work is constructed. It can be confirmed that the parameters of the corresponding equipment are shown, and the standard ARU and the ARU of the analysis target are shown in turn. The corresponding output is shown on the analysis result screen, as shown in
Figure 16.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}