Optimization Techniques for Mining Power Quality Data and Processing Unbalanced Datasets in Machine Learning Applications


Abstract
:1. Introduction
1.1. Disturbance Detection in Power System Datasets
1.2. Contributions
1.3. Article Organization
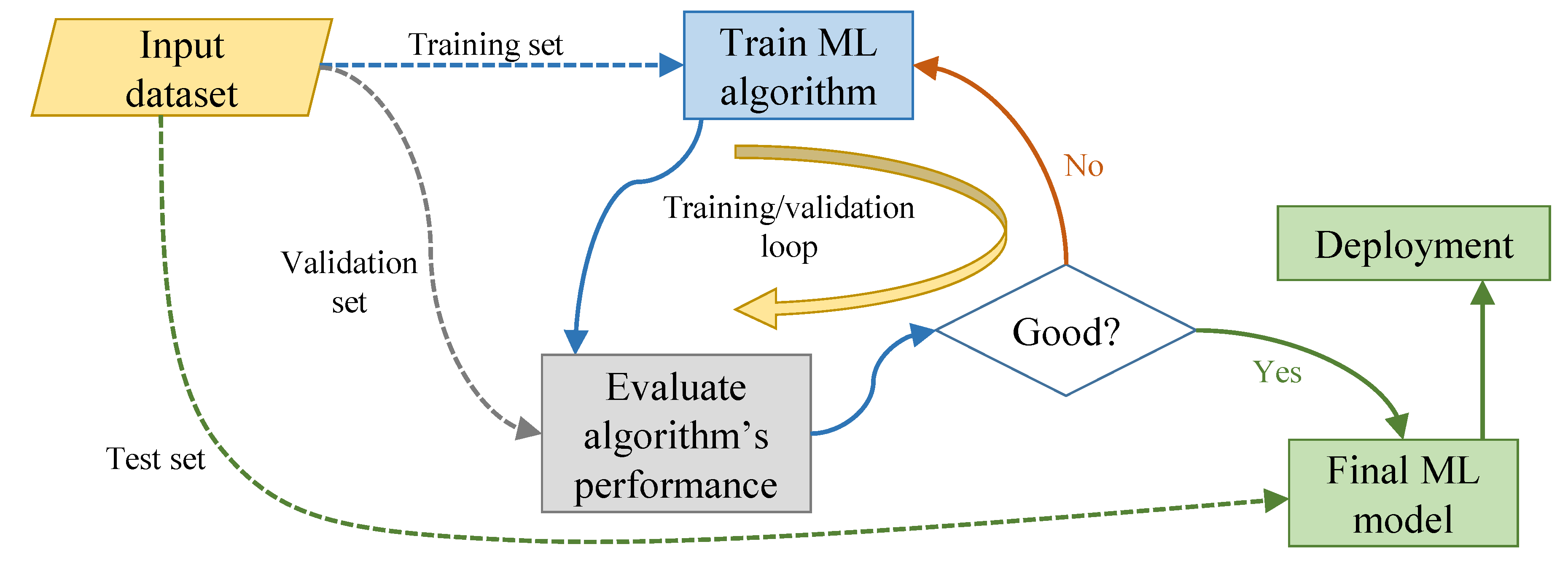
2. The Problem of Unbalanced Datasets in Machine Learning Training
- Computational finance, for credit scoring and algorithmic trading;
- Image processing and computer vision, for face recognition, motion detection and object detection;
- Computational biology, for tumor detection, drug discovery and DNA sequencing;
- Energy production, for price and load forecasting;
- Automotive, aerospace and manufacturing, for predictive maintenance;
- Natural language processing.
- Collect more data;
- Explore alternative performance metrics, such as the confusion matrix, precision, recall, F-score, Cohen’s kappa and receiver operating characteristic (ROC) curves [30];
- Resample the dataset (either through under-sampling or over-sampling, depending on the dataset’s initial size);
- Generate synthetic observations;
- Investigate penalized models, where additional costs are imposed on the misclassification of the minority class during training and a higher cost of prediction is associated with rarity [31];
- Reconstruct the training dataset, where the minority observations are identified through anomaly or change detection.
- (1)
- Partition the input profile into multiple equal-length segments and determine which contain significant changes in the RMS voltage levels; a significant change is defined as an RMS voltage step change greater than a pre-specified threshold, which will be introduced in later sections. Each one of these selected segments corresponds to one observation of the minority class (event) in the training dataset—let denote the number of such observations;
- (2)
- Among the segments without a significant change in the RMS voltage level (non-event), randomly select segments to form the majority class (non-event) in the training dataset.
3. The State-of-the-Art
3.1. The RMS Voltage Gradient Profile Detection Approach
- Voltage regulators are devices that adjust the voltage level by changing the tap positions in an autotransformer. In general, they provide a −10% to +10% regulation range with 32 steps, where each step represents ±0.625% of the nominal voltage [32].
3.2. Alternative Standard Detector
- 1
- Compute the arithmetic mean of the immediately preceding RMS voltage values:where f is the system frequency (either 50 or 60 Hz).
- 2
- Flag a new RMS voltage value as part of an RVC if it deviates from by more than a given threshold :
3.3. RMS Voltage Profile Filtering
- Noise introduced by the measurement device;
- Small load variations, which create intermittent variations in the RMS voltage profile and have the potential to hinder the detection of the events of interest.
4. Methodology
4.1. Problem Setup
4.1.1. Data
- Signal 1: The voltage level in a distribution system was in a quasi-stationary condition at 0.996 pu for 1 second. At that time instant, a capacitor bank was energized, instantaneously increasing the RMS voltage to 1.0 pu. After another 1 second had elapsed, the capacitor bank was de-energized and the RMS voltage level returned to 0.996 pu.
- Signal 2: The voltage level in a distribution system was in a quasi-stationary condition at 1.0 pu for 1 second. At that time instant, the load size connected to the system increased gradually over 1 second, causing the RMS voltage to drop linearly to 0.996 pu. This voltage drop triggered the energizing of a capacitor bank, instantaneously increasing the voltage level back to 1.0 pu. Note: this is the scenario in which median filtering was unable to track the original signal, as mentioned in Section 3.3.
4.1.2. RMS Profile Computation
4.1.3. Vector Norms
4.2. Proposed Approach
4.3. Data Filtering
- : there is no penalty associated with the roughness of the output signal; thus, no smoothing is performed and . This scenario corresponds to the endpoint at the left in the Pareto curve, and it represents the smallest possible value of without any consideration of .
- : a stronger emphasis is placed on the smoothness of the output signal, at the expense of disregarding the similarity between the corrupted and estimated signals; for a sufficiently large , becomes a constant signal. This scenario corresponds to the endpoint at the right in the Pareto curve, and it represents the smallest possible value of without any consideration of .
4.3.1. Quadratic Smoothing
- (under-filtering): the weight associated with the output signal roughness is too small; although the steep edges in the signal are preserved, there is almost no reduction in the signal noise.
- (optimal): this scenario represents the optimal trade-off between corrupted and estimated signals similarity and noise reduction; however, the noise level in the filtered signal is still quite high.
- (over-filtering): an excessive weight is placed on the signal smoothness, resulting in over-filtering; the similarity between the corrupted and estimated signals is rather low.
4.3.2. Total Variation Smoothing
- (under-filtering): the weight associated with the output signal roughness is too small, meaning that there is almost no reduction in the signal noise.
- (optimal): this scenario represents the optimal trade-off between corrupted and estimated signal similarity and noise reduction.
- (over-filtering): an excessive weight is placed on the signal smoothness, resulting in over-filtering; due to the large penalty associated with variations in the signal, the magnitude of the step change in the filtered signal is much smaller than the magnitude of the true step change.
4.3.3. Quadratic vs. Total Variation Smoothing
- -norm penalty: has many non-zero small entries and relatively few larger ones;
- -norm penalty: has many zero or very small entries and more larger ones.
5. Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AR | Autoregressive |
| ML | Machine learning |
| PQM | Power quality monitor |
| pu | Per unit |
| RMS | Root-mean-square |
| ROC | Receiver operating characteristic |
| RVC | Rapid voltage change |
References
- Mosavi, A.; Salimi, M.; Ardabili, S.F.; Rabczuk, T.; Shamshirband, S.; Varkonyi-Koczy, A.R. State of the art of machine learning models in energy systems: A systematic review. Energies 2019, 12, 1301. [Google Scholar] [CrossRef] [Green Version]
- Kumar, N.M.; Chand, A.A.; Malvoni, M.; Prasad, K.A.; Mamun, K.A.; Islam, F.R.; Chopra, S.S. Distributed energy resources and the application of AI, IoT, and blockchain in smart grids. Energies 2020, 13, 5739. [Google Scholar] [CrossRef]
- Perez-Ortiz, M.; Jimenez-Fernandez, S.; Gutierrez, P.A.; Alexandre, E.; Hervas-Martinez, C.; Salcedo-Sanz, S. A review of classification problems and algorithms in renewable energy applications. Energies 2016, 9, 607. [Google Scholar] [CrossRef]
- Bastos, A.F.; Santoso, S. Condition monitoring of circuit-switchers for shunt capacitor banks through power quality data. IEEE Trans. Power Deliv. 2019, 34, 1499–1507. [Google Scholar] [CrossRef]
- Ananthan, S.N.; Bastos, A.F.; Santoso, S.; Chirapongsananurak, P. Model-based approach integrated with fault circuit indicators for fault location in distribution systems. In Proceedings of the IEEE Power and Energy Society General Meeting, Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar]
- Ananthan, S.N.; Bastos, A.F.; Santoso, S. Novel system model-based fault location approach using dynamic search technique. IET Gener. Transm. Distrib. 2021. [Google Scholar] [CrossRef]
- Bastos, A.F.; Santoso, S.; Freitas, W.; Xu, W. SynchroWaveform measurement units and applications. In Proceedings of the IEEE Power and Energy Society General Meeting, Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar]
- Bastos, A.F.; Lao, K.W.; Todeschini, G.; Santoso, S. Novel moving average filter for detecting rms voltage step changes in triggerless PQ data. IEEE Trans. Power Deliv. 2018, 33, 2920–2929. [Google Scholar] [CrossRef] [Green Version]
- Xu, W. Experiences on Using Gapless Waveform Data and Synchronized Harmonic Phasors. In Panel Session in IEEE Power and Energy Society General Meeting; Technical Report; IEEE Power & Energy Society: Piscataway, NJ, USA, 2015. [Google Scholar]
- Silva, L.; Kapisch, E.; Martins, C.; Filho, L.; Cerqueira, A.; Duque, C.; Ribeiro, P. Gapless power-quality disturbance recorder. IEEE Trans. Power Deliv. 2017, 32, 862–871. [Google Scholar] [CrossRef]
- Li, B.; Jing, Y.; Xu, W. A generic waveform abnormality detection method for utility equipment condition monitoring. IEEE Trans. Power Deliv. 2017, 32, 162–171. [Google Scholar] [CrossRef]
- Bastos, A.F.; Freitas, W.; Todeschini, G.; Santoso, S. Detection of inconspicuous power quality disturbances through step changes in rms voltage profile. IET Gener. Transm. Distrib. 2019, 13, 2226–2235. [Google Scholar] [CrossRef]
- Bollen, M.; Gu, I. Signal Processing of Power Quality Disturbances; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- IEC. IEC Electromagnetic Compatibility: Testing and Measurements Techniques—Power Quality Measurement Methods; IEC: London, UK, 2015; Standard 61000-4-30. [Google Scholar]
- Bastos, A.F.; Santoso, S. Universal waveshape-based disturbance detection in power quality data using similarity metrics. IEEE Trans. Power Deliv. 2020, 35, 1779–1787. [Google Scholar] [CrossRef]
- Santoso, S.; Powers, E.J.; Grady, W.M.; Parsons, A.C. Power quality disturbance waveform recognition using wavelet-based neural classifier—Part 1: Theoretical foundation. IEEE Trans. Power Deliv. 2000, 15, 222–228. [Google Scholar] [CrossRef]
- Bastos, A.F.; Lao, K.W.; Todeschini, G.; Santoso, S. Accurate identification of point-on-wave inception and recovery instants of voltage sags and swells. IEEE Trans. Power Deliv. 2019, 34, 551–560. [Google Scholar] [CrossRef] [Green Version]
- Bastos, A.F.; Santoso, S.; Todeschini, G. Comparison of methods for determining inception and recovery points of voltage variation events. In Proceedings of the IEEE Power and Energy Society General Meeting, Portland, OR, USA, 5–10 August 2018; pp. 1–5. [Google Scholar]
- Bastos, A.F.; Santoso, S. Identifying switched capacitor relative locations and energizing operations. In Proceedings of the IEEE Power and Energy Society General Meeting, Boston, MA, USA, 17–21 July 2016; pp. 1–5. [Google Scholar]
- Hart, W.E.; Laird, C.D.; Watson, J.P.; Woodruff, D.L.; Hackebeil, G.A.; Nicholson, B.L.; Siirola, J.D. Pyomo—Optimization Modeling in Python, 2nd ed.; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2017; Volume 67. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2000. [Google Scholar]
- Gron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 1st ed.; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Torgo, L.; Ribeiro, R.P. Precision and Recall for Regression; Discovery Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 332–346. [Google Scholar]
- Bastos, A.F.; Santoso, S.; Krishnan, V.; Zhang, Y. Machine learning-based prediction of distribution network voltage and sensor allocation. In Proceedings of the IEEE Power and Energy Society General Meeting, Montreal, QC, Canada, 2–6 August 2020; pp. 1–5. [Google Scholar]
- Brownlee, J. 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset. 2015. Available online: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/ (accessed on 20 December 2020).
- Chawla, N.V. Data Mining for Imbalanced Datasets: An Overview. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 853–867. [Google Scholar]
- Tamayo, S.C.; Luna, J.M.F.; Huete, J.F. On the use of weighted mean absolute error in recommender systems. In Proceedings of the Workshop on Recommendation Utility Evaluation, Dublin, Ireland, 9 September 2012; pp. 24–26. [Google Scholar]
- Torgo, L.; Ribeiro, R.P.; Pfahringer, B.; Branco, P. SMOTE for Regression. In Lecture Notes in Computer Science, Proceedings of the Progress in Artificial Intelligence, Azores, Portugal, 9–12 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 378–389. [Google Scholar]
- Short, T.A. Electric Power Distribution Handbook; CRC Press: Boca Raton, RL, USA, 2003. [Google Scholar]
- IEEE. IEEE Guide for Application of Shunt Power Capacitors; Standard 1036; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Bastos, A.F.; Biyikli, L.; Santoso, S. Analysis of power factor over correction in a distribution feeder. In Proceedings of the IEEE Power and Energy Society Transmission and Distribution Conference and Exposition, Dallas, TX, USA, 3–5 May 2016; pp. 1–5. [Google Scholar]
- Gustafsson, F. Adaptive Filtering and Change Detection; John Wiley & Sons: Hoboken, NJ, USA, 2000. [Google Scholar]
- Bastos, A.F.; Santoso, S. Root-mean-square profiles under varying power frequency: Computation and applications. In Proceedings of the IEEE Power and Energy Society General Meeting, Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar]
- Bastos, A.F.; Kim, T.; Santoso, S.; Grady, W.M.; Gravois, P.; Miller, M.; Kadel, N.; Schmall, J.; Huang, S.H.; Blevins, B. Frequency retrieval from PMU data corrupted with pseudo-oscillations during off-nominal operation. In Proceedings of the North American Power Symposium, Tempe, AZ, USA, 11–14 April 2021; pp. 1–6. [Google Scholar]
- Smith, S. The Scientist and Engineer Guide to Digital Signal Processing; California Tech. Pub.: San Diego, CA, USA, 1997. [Google Scholar]
- Castro, E.A.; Donoho, D.L. Does median filtering truly preserve edges better than linear filtering? Ann. Stat. 2009, 37, 1172–1206. [Google Scholar] [CrossRef] [Green Version]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- IEEE. IEEE Guide for Voltage Sag Indices; Standard 1564; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization, 7th ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Bertsimas, D.; Tsitsiklis, J.N. Introduction to Linear Optimization, 1st ed.; Athena Scientific: Belmont, MA, USA, 1997. [Google Scholar]
- Selesnick, I.W.; Bayram, I. Total Variation Filtering. 2010. Available online: https://eeweb.engineering.nyu.edu/iselesni/lecture_notes/TV_filtering.pdf (accessed on 20 December 2020).
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Little, M.A.; Jones, N.S. Sparse Bayesian step-filtering for high-throughput analysis of molecular machine dynamics. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4162–4165. [Google Scholar]
- Chambolle, A. An algorithm for total variation minimization and applications. J. Math. Imaging Vis. 2004, 20, 89–97. [Google Scholar]
- Strong, D.; Chan, T. Edge-preserving and scale-dependent properties of total variation regularization. Inverse Probl. 2003, 19, S165–S187. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before Rebalancing | After Rebalancing | |
|---|---|---|
| Majority class (Event) | 1672 (99.52%) | 8 (50%) |
| Minority class (Non-Event) | 8 (0.48%) | 8 (50%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furlani Bastos, A.; Santoso, S. Optimization Techniques for Mining Power Quality Data and Processing Unbalanced Datasets in Machine Learning Applications. Energies 2021, 14, 463. https://doi.org/10.3390/en14020463
Furlani Bastos A, Santoso S. Optimization Techniques for Mining Power Quality Data and Processing Unbalanced Datasets in Machine Learning Applications. Energies. 2021; 14(2):463. https://doi.org/10.3390/en14020463
Chicago/Turabian StyleFurlani Bastos, Alvaro, and Surya Santoso. 2021. "Optimization Techniques for Mining Power Quality Data and Processing Unbalanced Datasets in Machine Learning Applications" Energies 14, no. 2: 463. https://doi.org/10.3390/en14020463