
Chiller Optimization Using Data Mining Based on Prediction Model, Clustering and Association Rule Mining


Abstract
:1. Introduction
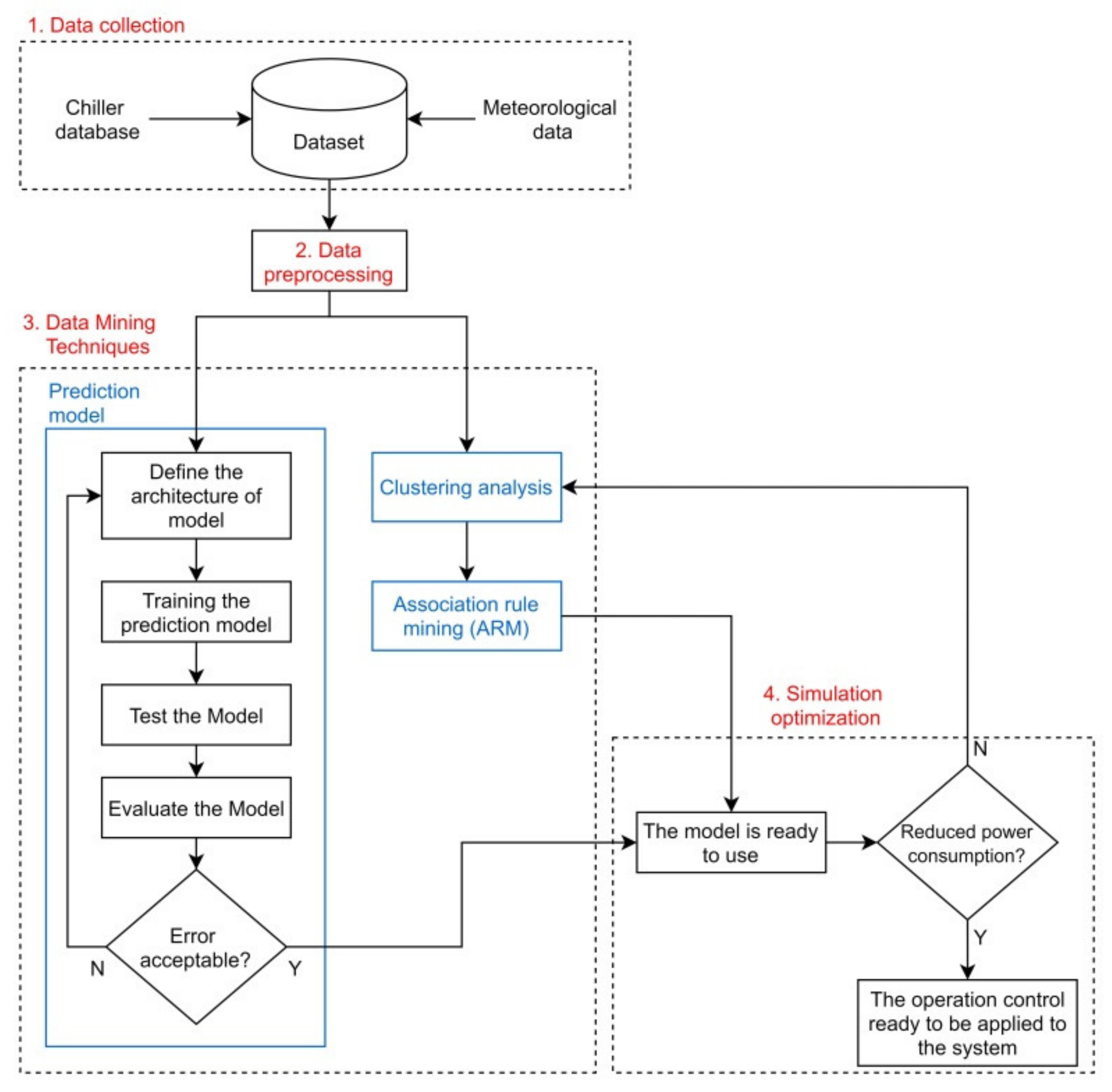
2. Methodology
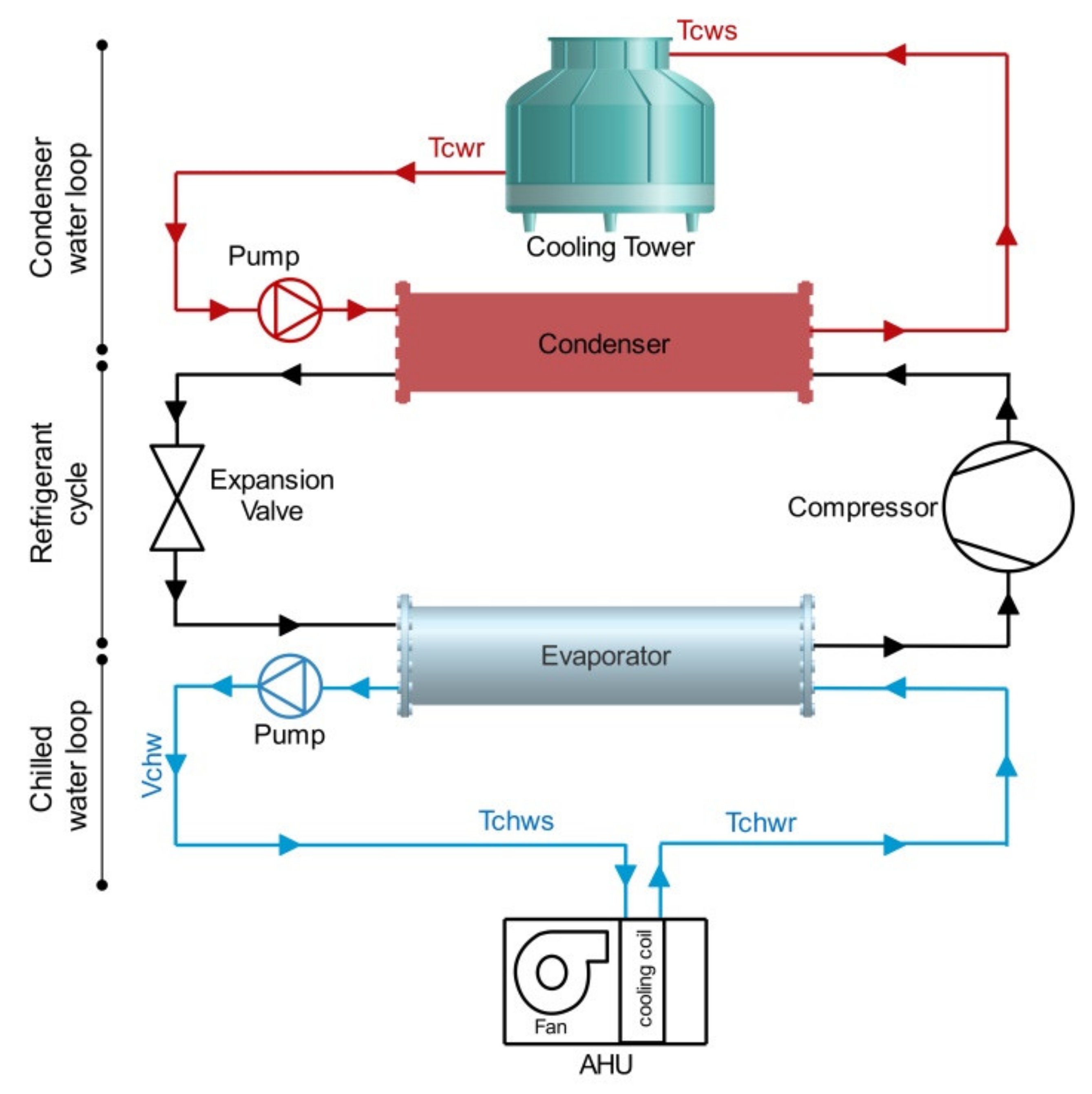
2.1. Data Collection
2.2. Data Preprocessing
2.2.1. Data Cleaning
2.2.2. Data Splitting
2.2.3. Data Scaling
2.3. Data Mining Techniques
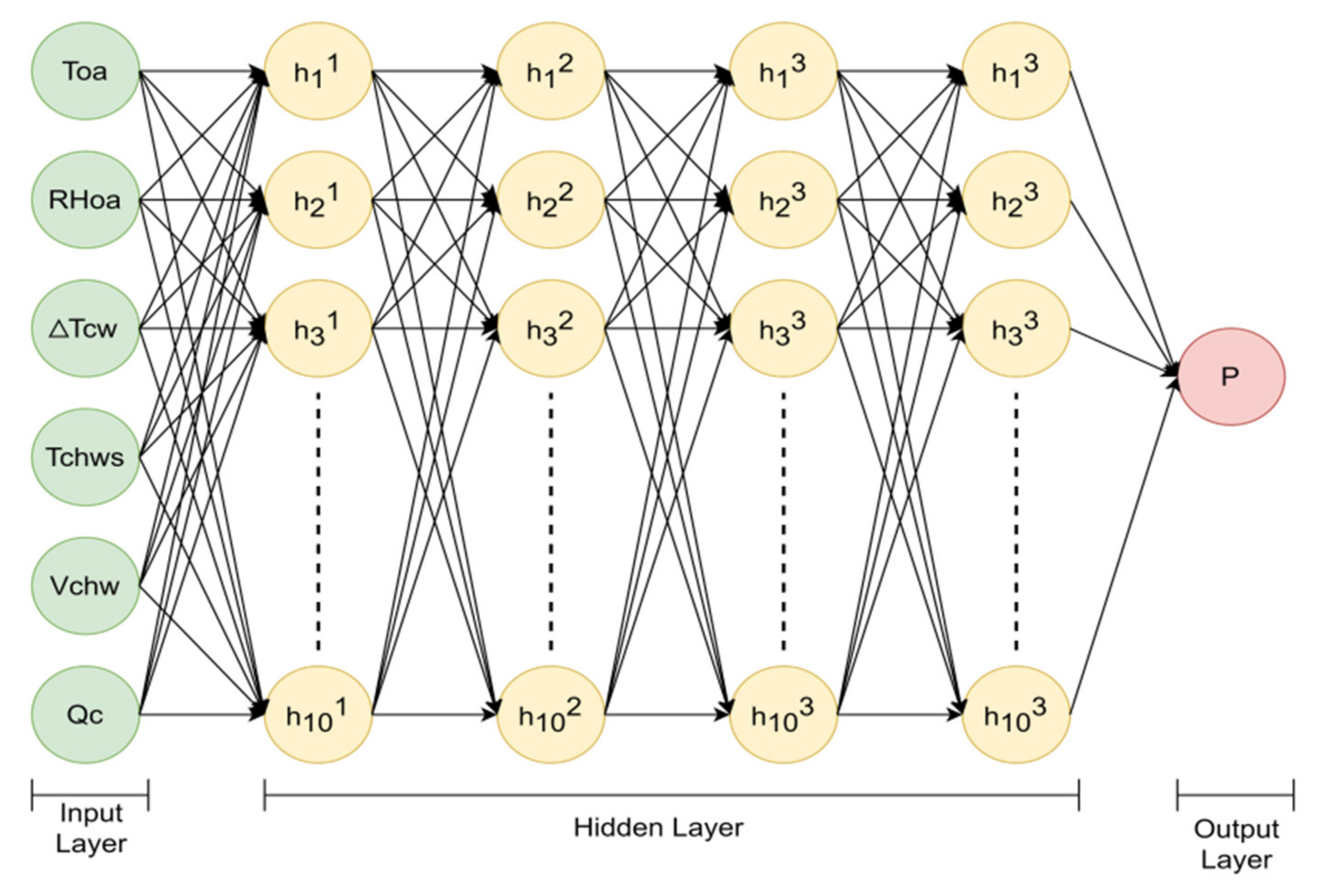
2.3.1. Prediction Model
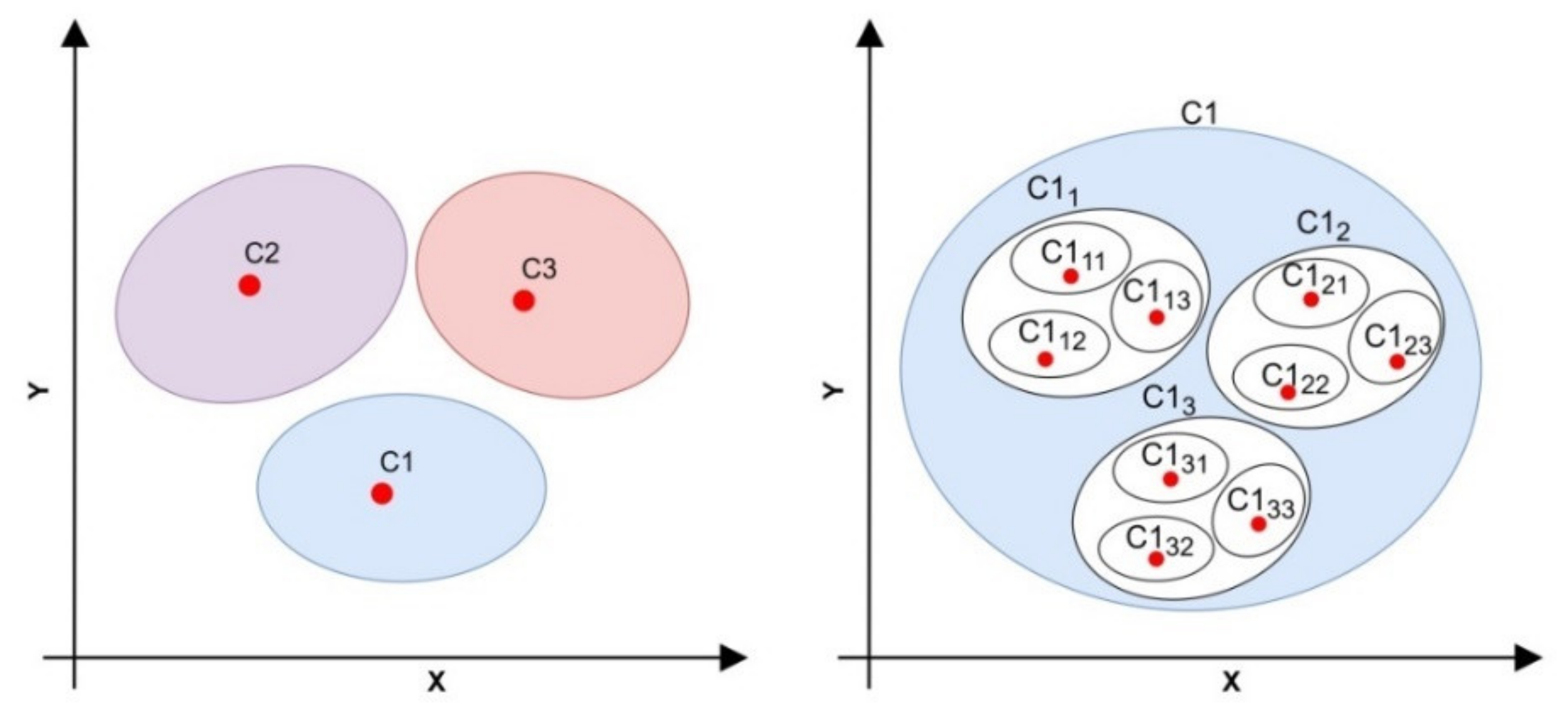
2.3.2. Clustering Analysis
2.3.3. Association Rules Mining (ARM) Analysis
2.4. Simulation Optimization
3. Result and Discussion
3.1. Software and Hardware
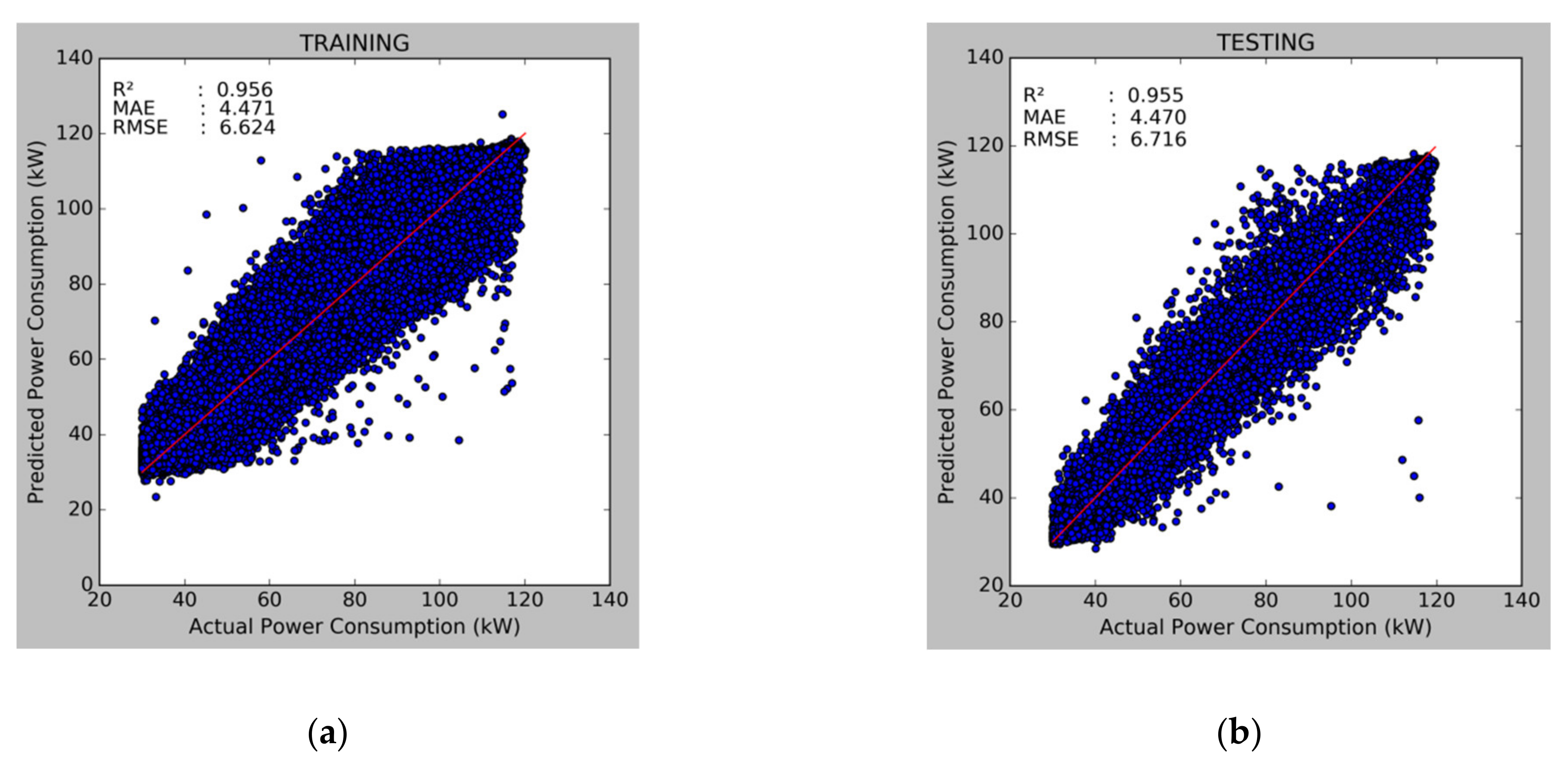
3.2. Prediction Model
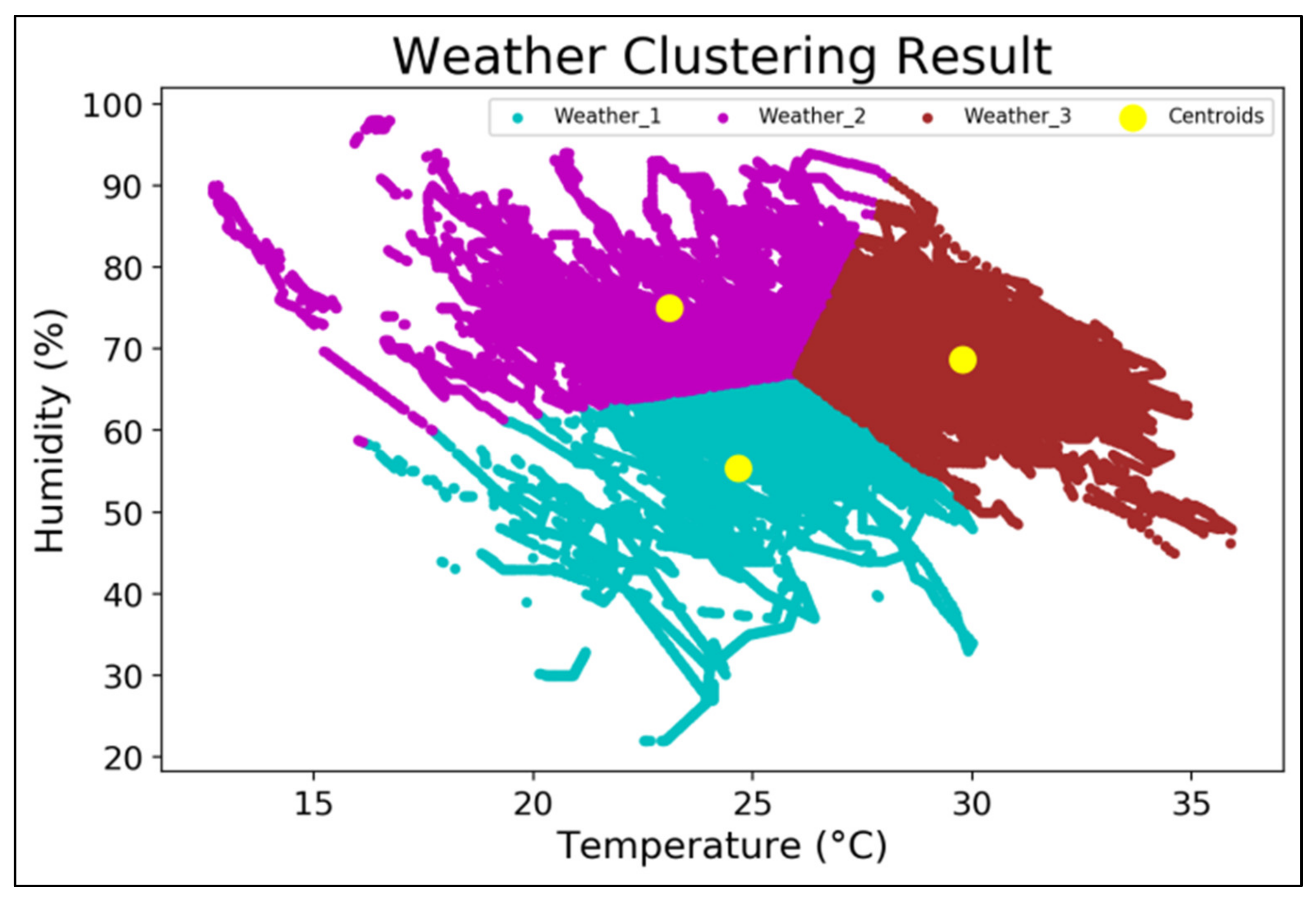
3.3. Clustering Analysis
3.4. Association Rules Mining (ARM) Analysis
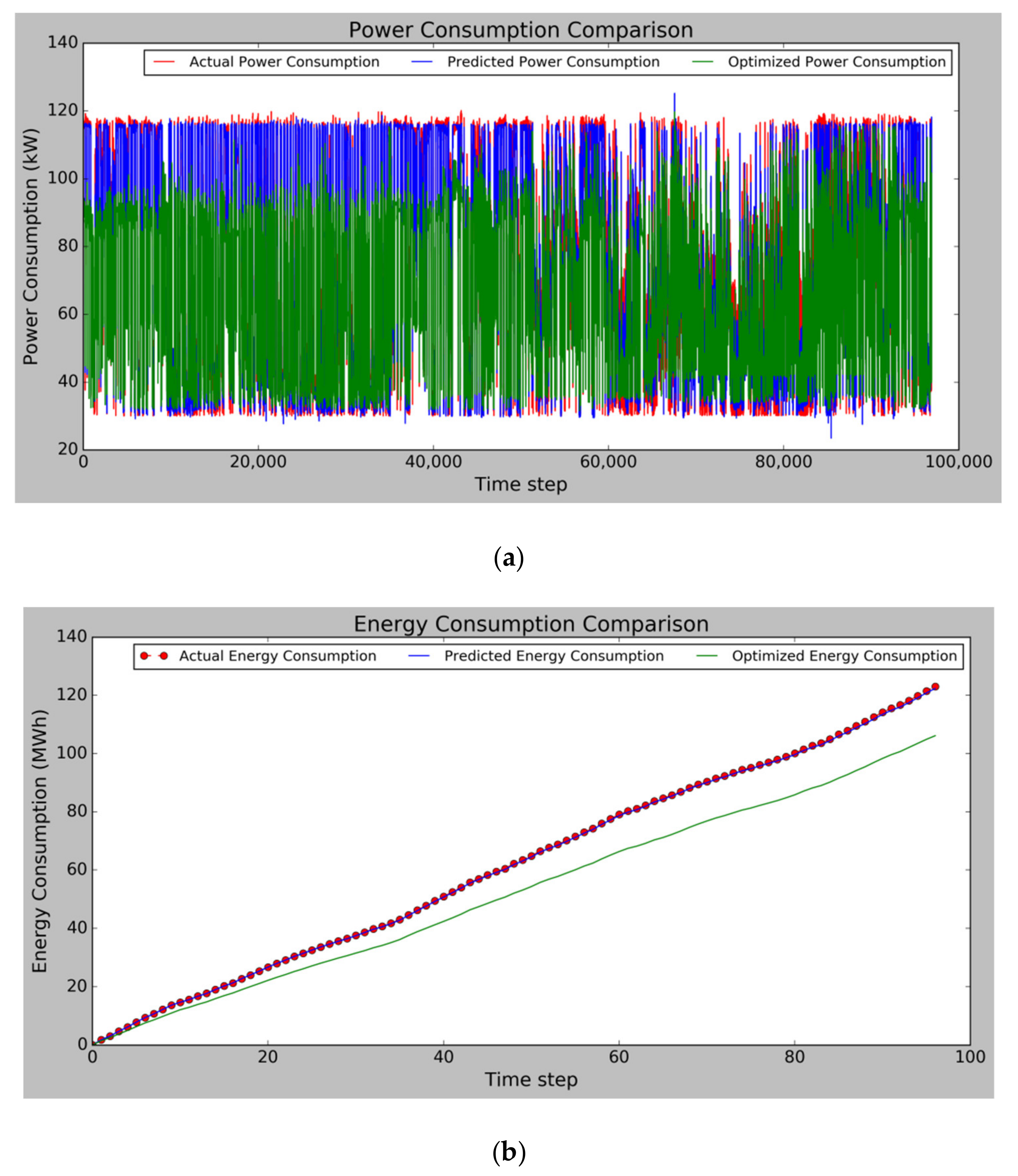
3.5. Simulation Optimization
3.6. Discussion
4. Conclusions and Future Work
- The power consumption prediction model was built using the DNN algorithm. There are six inputs: , , , , , and . The model performance evaluations are 0.955 of , 4.470 of MAE, and 6.716 of RMSE.
- The clustering analysis used the k-means algorithm to cluster the data into nine conditions based on weather and cooling capacity. The COP and the operational parameters (, , and ) were also clustered into three: high, medium, and low. The clustering analysis results are applied to the ARM analysis.
- The ARM analysis was performed using the Apriori algorithm. The nine conditions identify the operational parameters that have strong association rules with high COP. The minimum support, confidence and lift are set to 0.001, 0.1, and 1.0.
- The operational parameters from ARM were simulated using the prediction model. The simulation result shows that the operational parameters from ARM consume 100.68 MWh in a year. The actual operational parameters were also simulated by the prediction model. It consumes 123.04 MWh in a year. This simulation revealed that the operational parameters from ARM can successfully save energy consumption by 22.36 MWh or 18.17% in a year.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, J.-T.; Chang, Y.-C.; Ho, C.-Y. The Optimization of Chiller Loading by Adaptive Neuro-Fuzzy Inference System and Genetic Algorithms. Math. Probl. Eng. 2015, 2015, e306401. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Xu, C.; Guo, Y.; Chen, H. A Novel Deep Reinforcement Learning Based Methodology for Short-Term HVAC System Energy Consumption Prediction. Int. J. Refrig. 2019, 107, 39–51. [Google Scholar] [CrossRef]
- Sala-Cardoso, E.; Delgado-Prieto, M.; Kampouropoulos, K.; Romeral, L. Predictive Chiller Operation: A Data-Driven Loading and Scheduling Approach. Energy Build. 2020, 208, 109639. [Google Scholar] [CrossRef]
- Chaerun Nisa, E.; Kuan, Y.-D. Comparative Assessment to Predict and Forecast Water-Cooled Chiller Power Consumption Using Machine Learning and Deep Learning Algorithms. Sustainability 2021, 13, 744. [Google Scholar] [CrossRef]
- Yu, J.; Liu, Q.; Zhao, A.; Qian, X.; Zhang, R. Optimal Chiller Loading in HVAC System Using a Novel Algorithm Based on the Distributed Framework. J. Build. Eng. 2020, 28, 101044. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, B.; Liang, L.; Yan, J.; Pan, D. An Operational Parameter Optimization Method Based on Association Rules Mining for Chiller Plant. J. Build. Eng. 2019, 26, 100870. [Google Scholar] [CrossRef]
- Wang, Y.; Li, K.; Gan, S.; Cameron, C. Analysis of Energy Saving Potentials in Intelligent Manufacturing: A Case Study of Bakery Plants. Energy 2019, 172, 477–486. [Google Scholar] [CrossRef]
- Li, G.; Hu, Y.; Chen, H.; Li, H.; Hu, M.; Guo, Y.; Liu, J.; Sun, S.; Sun, M. Data Partitioning and Association Mining for Identifying VRF Energy Consumption Patterns under Various Part Loads and Refrigerant Charge Conditions. Appl. Energy 2017, 185, 846–861. [Google Scholar] [CrossRef]
- Xu, Y.; Yan, C.; Shi, J.; Lu, Z.; Niu, X.; Jiang, Y.; Zhu, F. An Anomaly Detection and Dynamic Energy Performance Evaluation Method for HVAC Systems Based on Data Mining. Sustain. Energy Technol. Assess. 2021, 44, 101092. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F. Assessment of Building Operational Performance Using Data Mining Techniques: A Case Study. Energy Procedia 2017, 111, 1070–1078. [Google Scholar] [CrossRef]
- Zhang, C.; Xue, X.; Zhao, Y.; Zhang, X.; Li, T. An Improved Association Rule Mining-Based Method for Revealing Operational Problems of Building Heating, Ventilation and Air Conditioning (HVAC) Systems. Appl. Energy 2019, 253, 113492. [Google Scholar] [CrossRef]
- Jayasri, N.P.; Aruna, R. Big Data Analytics in Health Care by Data Mining and Classification Techniques. ICT Express 2021, S2405959521000849. [Google Scholar] [CrossRef]
- Dietler, D.; Loss, G.; Farnham, A.; de Hoogh, K.; Fink, G.; Utzinger, J.; Winkler, M.S. Housing Conditions and Respiratory Health in Children in Mining Communities: An Analysis of Data from 27 Countries in Sub-Saharan Africa. Environ. Impact Assess. Rev. 2021, 89, 106591. [Google Scholar] [CrossRef]
- Chen, S.; Li, X.; Liu, R.; Zeng, S. Extension Data Mining Method for Improving Product Manufacturing Quality. Procedia Comput. Sci. 2019, 162, 146–155. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine Learning and Data Mining in Manufacturing. Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, N.; Xu, Z.-Y.; Wu, K. The Internet of Things-Based Decision Support System for Information Processing in Intelligent Manufacturing Using Data Mining Technology. Mech. Syst. Signal. Process. 2020, 142, 106630. [Google Scholar] [CrossRef]
- Al-Hashedi, K.G.; Magalingam, P. Financial Fraud Detection Applying Data Mining Techniques: A Comprehensive Review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Kim, M. A Data Mining Framework for Financial Prediction. Expert Syst. Appl. 2021, 173, 114651. [Google Scholar] [CrossRef]
- Farvaresh, H.; Sepehri, M.M. A Data Mining Framework for Detecting Subscription Fraud in Telecommunication. Eng. Appl. Artif. Intell. 2011, 24, 182–194. [Google Scholar] [CrossRef]
- Keramati, A.; Jafari-Marandi, R.; Aliannejadi, M.; Ahmadian, I.; Mozaffari, M.; Abbasi, U. Improved Churn Prediction in Telecommunication Industry Using Data Mining Techniques. Appl. Soft Comput. 2014, 24, 994–1012. [Google Scholar] [CrossRef]
- Xiao, F.; Fan, C. Data Mining in Building Automation System for Improving Building Operational Performance. Energy Build. 2014, 75, 109–118. [Google Scholar] [CrossRef]
- Caruso, G.; Gattone, S.A.; Balzanella, A.; Di Battista, T. Cluster Analysis: An Application to a Real Mixed-Type Data Set. In Models and Theories in Social Systems. Studies in Systems, Decision and Control; Flaut, C., Hošková-Mayerová, Š., Flaut, D., Eds.; Springer: Cham, Switzerland, 2019; Volume 179, ISBN 9783030000837. [Google Scholar]
- Wang, J.; Hou, J.; Chen, J.; Fu, Q.; Huang, G. Data Mining Approach for Improving the Optimal Control of HVAC Systems: An Event-Driven Strategy. J. Build. Eng. 2021, 39, 102246. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Z.; Chen, H.; Zhang, J.; Liu, Q.; Wu, J.; Shen, L. Research on Diagnostic Strategy for Faults in VRF Air Conditioning System Using Hybrid Data Mining Methods. Energy Build. 2021, 247, 111144. [Google Scholar] [CrossRef]
- Mirnaghi, M.S.; Haghighat, F. Fault Detection and Diagnosis of Large-Scale HVAC Systems in Buildings Using Data-Driven Methods: A Comprehensive Review. Energy Build. 2020, 229, 110492. [Google Scholar] [CrossRef]
- Awan, M.B.; Li, K.; Li, Z.; Ma, Z. A Data Driven Performance Assessment Strategy for Centralized Chiller Systems Using Data Mining Techniques and Domain Knowledge. J. Build. Eng. 2021, 41, 102751. [Google Scholar] [CrossRef]
- Guo, Y.; Li, G.; Chen, H.; Wang, J.; Guo, M.; Sun, S.; Hu, W. Optimized Neural Network-Based Fault Diagnosis Strategy for VRF System in Heating Mode Using Data Mining. Appl. Therm. Eng. 2017, 125, 1402–1413. [Google Scholar] [CrossRef]
- Sha, H.; Xu, P.; Hu, C.; Li, Z.; Chen, Y.; Chen, Z. A Simplified HVAC Energy Prediction Method Based on Degree-Day. Sustain. Cities Soc. 2019, 51, 101698. [Google Scholar] [CrossRef]
- Alizadeh, R.; Jia, L.; Nellippallil, A.B.; Wang, G.; Hao, J.; Allen, J.K.; Mistree, F. Ensemble of Surrogates and Cross-Validation for Rapid and Accurate Predictions Using Small Data Sets. AIEDAM 2019, 33, 484–501. [Google Scholar] [CrossRef]
- Awan-Ur-Rahman What Is Data Cleaning? How to Process Data for Analytics and Machine Learning Modeling? Available online: https://towardsdatascience.com/what-is-data-cleaning-how-to-process-data-for-analytics-and-machine-learning-modeling-c2afcf4fbf45 (accessed on 23 August 2021).
- Kim, M.; Jung, S.; Kang, J. Artificial Neural Network-Based Residential Energy Consumption Prediction Models Considering Residential Building Information and User Features in South Korea. Sustainability 2019, 12, 109. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y. Convolutional Neural Network Based Malignancy Detection of Pulmonary Nodule on Computer Tomography. Ph.D. Thesis, University of Saskatchewan, Saskatoon, SK, Canada, 2018. [Google Scholar] [CrossRef]
- Chen, C.-W.; Li, C.-C.; Lin, C.-Y. Combine Clustering and Machine Learning for Enhancing the Efficiency of Energy Baseline of Chiller System. Energies 2020, 13, 4368. [Google Scholar] [CrossRef]
- Yu, S.-S.; Chu, S.-W.; Wang, C.-M.; Chan, Y.-K.; Chang, T.-C. Two Improved K-Means Algorithms. Appl. Soft Comput. 2018, 68, 747–755. [Google Scholar] [CrossRef]
- Yu, X.; Ergan, S.; Dedemen, G. A Data-Driven Approach to Extract Operational Signatures of HVAC Systems and Analyze Impact on Electricity Consumption. Appl. Energy 2019, 253, 113497. [Google Scholar] [CrossRef]
- Yan, L.; Qian, F.; Li, W. Research on Key Parameters Operation Range of Central Air Conditioning Based on Binary K-Means and Apriori Algorithm. Energies 2018, 12, 102. [Google Scholar] [CrossRef] [Green Version]
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 23 August 2021).
- Scikit-Learn: Machine Learning in Python—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 23 August 2021).
- Apriori—Mlxtend. Available online: http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/ (accessed on 23 August 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Antecedent | Consequent | Assessments | ||||||
|---|---|---|---|---|---|---|---|---|
| Weather ID | COP | Support (%) | Confidence (%) | Lift | ||||
| 1 (24.67 °C, 55.33%) | <498 | 10.7 | 14.9 | 3.3 | 115 | 6.67 | 16.86 | 2.06 |
| 498–707 | 12.5 | 13.9 | 3.1 | 115 | 3.29 | 18.47 | 1.89 | |
| >707 | 11.3 | 13.7 | 5.1 | 115 | 9.27 | 21.73 | 1.70 | |
| 2 (23.10 °C, 75.04%) | <453 | 11.3 | 17.1 | 2.1 | 114 | 4.56 | 14.08 | 2.92 |
| 453–673 | 13.9 | 16.2 | 3.4 | 117 | 9.32 | 19.05 | 1.65 | |
| >673 | 1.5 | 13.9 | 4.3 | 115 | 4.24 | 22.73 | 4.44 | |
| 3 (29.77 °C, 68.68%) | <415 | 8.5 | 11.9 | 2.0 | 100 | 21.00 | 24.63 | 1.12 |
| 415–664 | 12.9 | 18.1 | 3.9 | 117 | 0.30 | 11.61 | 6.09 | |
| >664 | 9.4 | 17.3 | 4.8 | 118 | 2.91 | 24.26 | 3.71 | |
| Sample Data | Total Data | Energy Consumption (MWh) | Energy Saving (%) | ||
|---|---|---|---|---|---|
| Actual | Predicted | Optimized | |||
| Weather_1 | 17,476 | 22.50 | 22.37 | 21.59 | 3.49 |
| Weather_2 | 32,407 | 37.65 | 37.36 | 32.76 | 12.31 |
| Weather_3 | 47,005 | 63.52 | 63.31 | 52.43 | 17.19 |
| All Weather | 96,888 | 123.68 | 123.04 | 100.68 | 18.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nisa, E.C.; Kuan, Y.-D.; Lai, C.-C. Chiller Optimization Using Data Mining Based on Prediction Model, Clustering and Association Rule Mining. Energies 2021, 14, 6494. https://doi.org/10.3390/en14206494
Nisa EC, Kuan Y-D, Lai C-C. Chiller Optimization Using Data Mining Based on Prediction Model, Clustering and Association Rule Mining. Energies. 2021; 14(20):6494. https://doi.org/10.3390/en14206494
Chicago/Turabian StyleNisa, Elsa Chaerun, Yean-Der Kuan, and Chin-Chang Lai. 2021. "Chiller Optimization Using Data Mining Based on Prediction Model, Clustering and Association Rule Mining" Energies 14, no. 20: 6494. https://doi.org/10.3390/en14206494
APA StyleNisa, E. C., Kuan, Y.-D., & Lai, C.-C. (2021). Chiller Optimization Using Data Mining Based on Prediction Model, Clustering and Association Rule Mining. Energies, 14(20), 6494. https://doi.org/10.3390/en14206494