
Carbon-Responsive Computing: Changing the Nexus between Energy and Computing


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. State of the Art: Foundations for Carbon-Responsive Computing
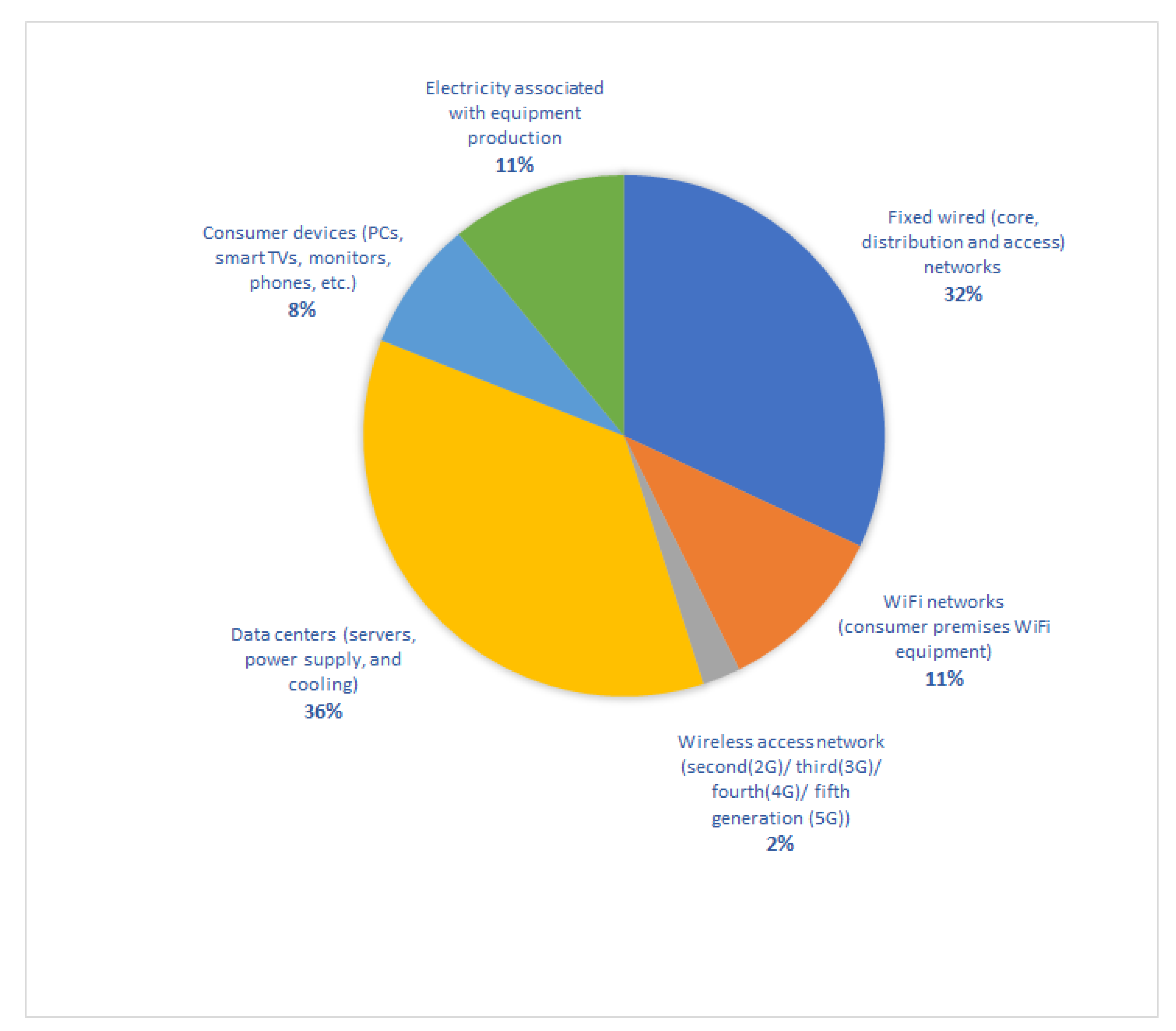
2.1. Data Centers and Carbon-Responsive Computing
2.1.1. Rationale
2.1.2. Optimization Technologies
2.1.3. The Relationship with Smart Grids
2.2. Carbon-Responsiveness beyond Data Centers
2.2.1. Drivers for Expanding CRC
2.2.2. Carbon-Responsiveness at the Edge
2.2.3. Edge Systems and Energy Markets
2.3. The Changing Relationship of Energy and Computing: What Is at Stake for CRC?
2.4. State of the Art of Enabling Data to Support CRC
2.4.1. Available Carbon Intensity Data
2.4.2. Energy Consumption Measurement
3. Framework for Carbon-Responsive Computing in Diverse Contexts
3.1. Carbon-Aware Computing
3.2. Carbon-Responsive Computing
3.3. Carbon-Resilient Computing
3.4. Using the Framework
4. Practical Challenges and Areas for Sociotechnical Research
4.1. The Democracy Gap
4.2. Linked Carbon Intensity Data for Carbon Awareness
4.2.1. Data Granularity
4.2.2. Data Centralization vs. Decentralization
4.2.3. Data Governance
4.2.4. Standardization
4.2.5. Data’s Power to Create Social Realities
4.3. Challenges in Facilitating Energy–Compute Exchange
4.3.1. Market Questions
4.3.2. Complexity and Inclusion
4.4. Real-Time Energy Consumption Data
4.4.1. Improving Transparency
4.4.2. Defining Shiftable Tasks
5. Conclusions
- For quantitative energy researchers: What could the impacts be of coupling edge computing with microgrids in terms of carbon savings? What do emerging qualitative and mixed methods findings about appropriate tasks to time and space shift tell us about the amount of aggregate energy demand that can be decarbonized? Can improved routes for data traffic be predicted based on carbon intensity data currently available, and what does this tell us about requirements for carbon intensity data for the future? What are the geographic and infrastructural factors that influence the ability to make savings?
- For designers and human–computer interaction (HCI) researchers: What constitutes computing “need” and “urgency” in what social situations, with what design strategies? What can be learned in environments that are already constrained by renewable energy availability? What are the best design strategies, of either data systems or ICT products, when matters of controversy arise (what constitutes carbon intensity, the acceptability or not of foregoing a computing task, etc.)? What lessons can be learned from parts of the world with intermittent electricity?
- For computer scientists and the computing industry: In what ways are the tradeoffs in doing carbon responses in edge systems and networks different or similar to those in hyperscale data centers? Under what conditions do the energy-saving strategies in large data centers require adaptation or abandonment in more proximate edge data centers and networks? What algorithms can best recognize and service the time-sensitivity of tasks, or recommend what type of response is best? How much of ICT equipment and its users’ behavior can be predicted and effectively mapped to microgrid renewables surplus? What kind of energy consumption telemetry setup most efficiently characterizes energy on a task basis? What is the most appropriate way to disclose energy consumption data in a standardized manner to the ecosystem and researchers, and to incentivize its use, whilst being mindful of privacy concerns?
- For STS researchers: If “modes of fuelling and modes of governing society can no longer be easily separated” [91] (p. 95), what kinds of energy politiess are forming as ICTs and energy increasingly converge? What actors gain, maintain, or lose social power in that coupling? What sociotechnical interventions are necessary to ensure carbon responses do not merely reproduce business as usual? What kinds of collaborations are necessary to ensure that ethical questions are indeed acknowledged, such as environmental social justice? What actors make for good energy-computing trading partners and poor ones?
- For economists/management studies scholars: Where markets do play a role, what types of markets could be designed, and who are the actors and stakeholders involved? What is the role of pricing, contract structures and business models in maximizing carbon emissions reductions? What algorithms can best match workloads with energy sources, and how might they scale to accommodate federation and peerage of resources within different size regions? How will different regulatory conditions affect the geopolitical dynamics of investment in coupled energy–computing systems?
- For policy researchers: What disincentives are most effective for preventing actors to game or manipulate carbon intensity data, or energy usage data? What policies ensure the best provisioning of electricity as a public good in light of new energy–computing combinations, and across public–private relationships? What role might combined energy–computing systems play in national and international geopolitics, across varied cultural attitudes towards data privacy, and varied histories or electricity provisioning?
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jones, N. How to stop data centres from gobbling up the world’s electricity. Nature 2018, 561, 163–166. [Google Scholar] [CrossRef]
- Lange, S.; Pohl, J.; Santarius, T. Digitalization and energy consumption. Does ICT reduce energy demand? Ecol. Econ. 2020, 176, 106760. [Google Scholar] [CrossRef]
- Koomey, J.; Masanet, E. Does not compute: Avoiding pitfalls assessing the Internet’s energy and carbon impacts. Joule 2021, 5, 1625–1628. [Google Scholar] [CrossRef]
- Freitag, C.; Berners-Lee, M.; Widdicks, K.; Knowles, B.; Blair, G.; Friday, A. The Climate Impact of ICT: A Review of Estimates, Trends and Regulations. 2020. Available online: https://eprints.lancs.ac.uk/id/eprint/158061/ (accessed on 31 August 2021).
- Belkhir, L.; Elmeligi, A. Assessing ICT global emissions footprint: Trends to 2040 & recommendations. J. Clean. Prod. 2018, 177, 448–463. [Google Scholar] [CrossRef]
- Masanet, E.; Shehabi, A.; Lei, N.; Smith, S.; Koomey, J. Recalibrating global data center energy-use estimates. Science 2020, 367, 984–986. [Google Scholar] [CrossRef] [PubMed]
- Manganelli, M.; Soldati, A.; Martirano, L.; Ramakrishna, S. Strategies for improving the sustainability of data centers via energy mix, energy conservation, and circular energy. Sustainability 2021, 13, 6114. [Google Scholar] [CrossRef]
- Usama, M.; Erol-Kantarci, M. A survey on recent trends and open issues in energy efficiency of 5G. Sensors 2019, 19, 3126. [Google Scholar] [CrossRef] [Green Version]
- Chiaraviglio, L.; Mellia, M.; Neri, F. Energy-Aware Backbone Networks: A Case Study. In Proceedings of the 2009 IEEE International Conference on Communications Workshops, Dresden, Germany, 14–18 June 2009; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Akoush, S.; Sohan, R.; Rice, A.; Moore, A.W.; Hopper, A. Free lunch: Exploiting renewable energy for computing. In HotOS; University of Cambridge: Cambridge, UK, 2011; pp. 1–5. [Google Scholar]
- Radovanovic, A. Our Data Centers Now Work Harder When the Sun Shines and Wind Blows. Google. 2020. Available online: https://blog.google/inside-google/infrastructure/data-centers-work-harder-sun-shines-wind-blows/ (accessed on 26 August 2021).
- Lin, L.; Zavala, V.M.; Chien, A.A. Evaluating Coupling Models for Cloud Datacenters and Power Grids. In Proceedings of the Tenth ACM International Conference on Future Energy Systems, Phoenix, AZ, USA, 28 June 2021; pp. 171–184. [Google Scholar] [CrossRef]
- Cioara, T.; Anghel, I.; Salomie, I.; Antal, M.; Pop, C.; Bertoncini, M.; Arnone, D.; Pop, F. Exploiting data centres energy flexibility in smart cities: Business scenarios. Inf. Sci. 2018, 476, 392–412. [Google Scholar] [CrossRef]
- Van der Meulen, R. What Edge Computing Means for Infrastructure and Operations Leaders. 2018. Available online: https://www.gartner.com/smarterwithgartner/what-edge-computing-means-for-infrastructure-and-operations-leaders/ (accessed on 14 July 2021).
- Verified Market Research (VMR) Edge Data Center Market Size, Share, Trends, Opportunities & Forecast. Available online: https://www.verifiedmarketresearch.com/product/edge-data-center-market/ (accessed on 26 July 2021).
- Blaabjerg, F.; Yang, Y.; Yang, D.; Wang, X. Distributed Power-Generation Systems and Protection. Proc. IEEE 2017, 105, 1311–1331. [Google Scholar] [CrossRef] [Green Version]
- Hughes, T.P. Networks of Power: Electrification in Western Society, 1880–1930; Johns Hopkins University Press: Baltimore, MD, USA, 1983; ISBN 0801828732. [Google Scholar]
- Purdie, J. Climate Change Impacts on the New Zealand Energy System. In Proceedings of the Seminar, Centre for Sustainability; University of Otago: Dunedin, New Zealand, 2021. [Google Scholar]
- Wierman, A.; Liu, Z.; Liu, I.; Mohsenian-Rad, H. Opportunities and Challenges for Data Center Demand Response. In Proceedings of the International Green Computing Conference, Dallas, TX, USA, 3–5 November 2015. [Google Scholar] [CrossRef]
- Ghasemi-Gol, M.; Wang, Y.; Pedram, M. An Optimization Framework for Data Centers to Minimize Electric Bill Under Day-Ahead Dynamic Energy Prices While Providing Regulation Services. In Proceedings of the International Green Computing Conference, Dallas, TX, USA, 3–5 November 2014. [Google Scholar] [CrossRef]
- Hogan, M. Data flows and water woes: The Utah Data Center. Big Data Soc. 2015, 2, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Libertson, F.; Velkova, J.; Palm, J. Data-center infrastructure and energy gentrification: Perspectives from Sweden. Sustain. Sci. Pract. Policy 2021, 17, 153–162. [Google Scholar] [CrossRef]
- Brodie, P. Climate extraction and supply chains of data. Media Cult. Soc. 2020, 42, 1095–1114. [Google Scholar] [CrossRef]
- Goiri, Í.; Beauchea, R.; Le, K.; Nguyen, T.D.; Haque, M.E.; Guitart, J.; Torres, J.; Bianchini, R. Greenslot: Scheduling Energy Consumption in Green Datacenters. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seattle, WA, USA, 12–18 November 2011; p. 1. [Google Scholar] [CrossRef]
- Shuja, J.; Gani, A.; Shamshirband, S.; Ahmad, R.W.; Bilal, K. Sustainable Cloud Data Centers: A survey of enabling techniques and technologies. Renew. Sustain. Energy Rev. 2016, 62, 195–214. [Google Scholar] [CrossRef]
- Li, D.; Qu, X.; Wan, J.; Wang, J.; Xia, Y.; Zhuang, X.; Xie, C. Workload Scheduling for Massive Storage Systems with Arbitrary Renewable Supply. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2373–2387. [Google Scholar] [CrossRef]
- Goiri, Í.; Katsak, W.; Le, K.; Nguyen, T.D.; Bianchini, R. Designing and Managing Data Centers Powered by Renewable Energy. IEEE Micro 2014, 34, 8–16. [Google Scholar] [CrossRef]
- Dou, H.; Qi, Y.; Wei, W.; Song, H. Minimizing Electricity Bills for Geographically Distributed Data Centers with Renewable and Cooling Aware Load Balancing. In Proceedings of the 2015 International Conference on Identification, Information, and Knowledge in the Internet of Things (IIKI), Beijing, China, 22–23 October 2016; pp. 210–214. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, M.; Wierman, A.; Low, S.; Andrew, L.L.H. Greening geographical load balancing. ACM Sigmetrics Perform. Eval. Rev. 2011, 39, 193–204. [Google Scholar] [CrossRef] [Green Version]
- St. John, J. Google Tests Load-Shifting at Data Centers to Capture the Grid’s Peak Clean Energy Hours. Available online: https://www.greentechmedia.com/articles/read/google-tests-shifting-data-center-loads-to-capture-grids-clean-energy (accessed on 19 March 2021).
- Klingert, S. DC4Cities—D2.4: Final Market Analysis. Available online: http://www.dc4cities.eu/en/wp-content/uploads/%202016/05/D2.4-Final-Market-Analysis.pdf (accessed on 18 March 2021).
- Cook, G.; Lee, J.; Tsai, T.; Kong, A.; Deans, J.; Johnson, B.; Jardim, E. Clicking Clean: Who Is Winning the Race to Build a Green Internet? 2017. Available online: http://www.clickclean.org/international/en/ (accessed on 17 September 2021).
- Cook, G.; Jardim, E. Clicking Clean Virginia, the Dirty Energy Powering Data Center Alley. 2019. Available online: https://greenpeace.org/usa/wp-content/uploads/2019/02/Greenpeace-Click-Clean-Virginia-2019.pdf?_ga=2.229195804.1861093522.1628839278-976262951.1628839278 (accessed on 17 September 2021).
- Sun, Q.; Ren, S.; Wu, C.; Li, Z. An Online Incentive Mechanism for Emergency Demand Response in Geo-Distributed Colocation Data Centers. In Proceedings of the 17th International Conference on Future Energy Systems, Waterloo, ON, Canada, 21–24 June 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar]
- Bahrami, S.; Wong, V.W.S.; Huang, J. Data Center Demand Response in Deregulated Electricity Markets. IEEE Trans. Smart Grid 2019, 10, 2820–2832. [Google Scholar] [CrossRef]
- Lorincz, J.; Capone, A.; Wu, J. Greener, energy-efficient and sustainable networks: State-of-the-art and new trends. Sensors 2019, 19, 4864. [Google Scholar] [CrossRef] [Green Version]
- Obringer, R.; Rachunok, B.; Maia-Silva, D.; Arbabzadeh, M.; Nateghi, R.; Madani, K. The overlooked environmental footprint of increasing Internet use. Resour. Conserv. Recycl. 2021, 167, 105389. [Google Scholar] [CrossRef]
- Aslan, J.; Mayers, K.; Koomey, J.G.; France, C. Electricity intensity of internet data transmission untangling the estimates. J. Ind. Ecol. 2018, 22, 785–798. [Google Scholar] [CrossRef]
- Jalali, F.; Hinton, K.; Ayre, R.; Alpcan, T.; Tucker, R.S. Fog computing may help to save energy in cloud computing. IEEE J. Sel. Areas Commun. 2016, 34, 1728–1739. [Google Scholar] [CrossRef]
- Gigis, P.; Calder, M.; Manassakis, L.; Nomikos, G.; Kotronis, V.; Dimitropoulos, X.; Katz-Bassett, E.; Smaragdakis, G. Seven Years in the Life of Hypergiants’ off-Nets. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Virtual Event USA, 23–27 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 516–533. [Google Scholar]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive Federated Learning in Resource Constrained Edge Computing Systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef] [Green Version]
- Sapio, A.; Abdelaziz, I.; Aldilaijan, A.; Canini, M.; Kalnis, P. In-Network Computation Is A Dumb Idea Whose Time Has Come. In Proceedings of the 16th ACM Workshop on Hot Topics in Networks, Palo Alto, CA, USA, 30 November–1 December 2017; pp. 150–156. [Google Scholar] [CrossRef] [Green Version]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutorials 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Jiang, C.; Fan, T.; Gao, H.; Shi, W.; Liu, L.; Cérin, C.; Wan, J. Energy aware edge computing: A survey. Comput. Commun. 2020, 151, 556–580. [Google Scholar] [CrossRef]
- Li, W.; Yang, T.; Delicato, F.C.; Pires, P.F.; Tari, Z.; Khan, S.U.; Zomaya, A.Y. On Enabling Sustainable Edge Computing with Renewable Energy Resources. IEEE Commun. Mag. 2018, 56, 94–101. [Google Scholar] [CrossRef]
- Ahvar, E.; Orgerie, A.-C.C.; Lebre, A. Estimating Energy Consumption of Cloud, Fog and Edge Computing Infrastructures. IEEE Trans. Sustain. Comput. 2019, 1, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Mengelkamp, E.; Gärttner, J.; Rock, K.; Kessler, S.; Orsini, L.; Weinhardt, C. Designing microgrid energy markets: A case study: The Brooklyn Microgrid. Appl. Energy 2018, 210, 870–880. [Google Scholar] [CrossRef]
- Vergados, D.J.; Mamounakis, I.; Makris, P.; Varvarigos, E. Prosumer clustering into virtual microgrids for cost reduction in renewable energy trading markets. Sustain. Energy Grids Netw. 2016, 7, 90–103. [Google Scholar] [CrossRef]
- Paladin, A.; Das, R.; Wang, Y.; Ali, Z.; Kotter, R.; Putrus, G.; Turri, R. Micro market based optimisation framework for decentralised management of distributed flexibility assets. Renew. Energy 2021, 163, 1595–1611. [Google Scholar] [CrossRef]
- Ford, R.; Maidment, C.; Vigurs, C.; Fell, M.J.; Morris, M. Smart local energy systems (SLES): A framework for exploring transition, context, and impacts. Technol. Forecast. Soc. Change 2021, 166, 120612. [Google Scholar] [CrossRef]
- Giotitsas, C.; Pazaitis, A.; Kostakis, V. A peer-to-peer approach to energy production. Technol. Soc. 2015, 42, 28–38. [Google Scholar] [CrossRef]
- Schooler, E.M. The Edge-Ification of the Internet: Implications for the Wireless Edge. In Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3 March 2020; p. 2. [Google Scholar] [CrossRef] [Green Version]
- Lally, N.; Kay, K.; Thatcher, J. Computational parasites and hydropower: A political ecology of Bitcoin mining on the Columbia River. Environ. Plan. E Nat. Sp. 2019. [Google Scholar] [CrossRef] [Green Version]
- Mohan, N.; Kangasharju, J. Edge-Fog Cloud: A Distributed Cloud for Internet of Things Computations. In Proceedings of the 2016 Cloudification of the Internet of Things (CIoT), Paris, France, 23–26 November 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Shah-Mansouri, H.; Wong, V.W.S. Hierarchical fog-cloud computing for IoT systems: A computation offloading game. IEEE Internet Things J. 2018, 5, 3246–3257. [Google Scholar] [CrossRef] [Green Version]
- Ku, Y.J.; Sapra, S.; Baidya, S.; Dey, S. State of Energy Prediction in Renewable Energy-Driven Mobile Edge Computing Using CNN-LSTM Networks. In Proceedings of the 2020 IEEE Green Energy and Smart Systems Conference (IGESSC), Long Beach, CA, USA, 2–3 November 2020. [Google Scholar] [CrossRef]
- GSMA. Infrastructure Sharing: An Overview. 2019. Available online: https://www.gsma.com/futurenetworks/wiki/infrastructure-sharing-an-overview (accessed on 31 August 2021).
- Carlini, S. Telco Central Offices are Being Transformed into the Edge to Power the Next Generation of Telco the Early Dilemma with Central Office Transformation—How to Repurpose Transforming the Telco Edge: NGCOs Telco Edge Technology: A Cheat Sheet. 2019. Available online: https://blog.se.com/co-location/2019/02/14/telco-central-offices-transformed-into-edge-power-next-generation-telco/ (accessed on 31 August 2021).
- Tweed, K. Why Cellular Towers in Developing Nations are Making the Move to Solar Power. 2013. Available online: https://www.scientificamerican.com/article/cellular-towers-moving-to-solar-power/ (accessed on 31 August 2021).
- Yang, F.; Chien, A.A. ZCCloud: Exploring Wasted Green Power for High-Performance Computing. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 1051–1060. [Google Scholar] [CrossRef]
- Nurminen, J.K.; Niemi, T.; Strandman, J.; Ruokosuo, K. Sunburn—Using excess energy of small-scale production for distributed computing. Energy Effic. 2018, 11, 97–119. [Google Scholar] [CrossRef]
- Bouzarovski, S.; Frankowski, J.; Tirado Herrero, S. Low-Carbon Gentrification: When Climate Change Encounters Residential Displacement. Int. J. Urban Reg. Res. 2018, 42, 845–863. [Google Scholar] [CrossRef]
- National Grid ESO Carbon Intensity API. Available online: https://carbonintensity.org.uk/ (accessed on 27 August 2021).
- Tomorrow Company ElectricityMap. Available online: www.electricitymap.org (accessed on 27 August 2021).
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models be Too Big? Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, ISBN 9781450383097. [Google Scholar]
- Strubell, E.; Ganesh, A.; & McCallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. preprint. (accessed on 4 October 2021). [Google Scholar]
- Ray, T. AI Industry’s Performance Benchmark, Mlperf, for the First Time Also Measures the Energy That Machine Learning Consumes. 2021. Available online: https://www.zdnet.com/article/ai-industrys-performance-benchmark-mlperf-for-the-first-time-also-measures-the-energy-that-machine-learning-consumes/ (accessed on 27 August 2021).
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Power API. Available online: http://Powerapi.org (accessed on 27 August 2021).
- Fieni, G.; Rouvoy, R.; Seinturier, L. SmartWatts: Self-Calibrating Software-Defined Power Meter for Containers. In Proceedings of the 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, VIC, Australia, 11–14 May 2020; pp. 479–488. [Google Scholar] [CrossRef]
- Nye, D. Electricity and Culture: Conceptualizing the American Case. Ann. Hist. L’électricité 2004, 2, 125. [Google Scholar] [CrossRef]
- Hughes, T.P. Technological Momentum. In Does Technology Drive History: The Dilemma of Technological Determinism; Smith, M.R., Marx, L., Eds.; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Ransan-Cooper, H.; Sturmberg, B.C.P.; Shaw, M.E.; Blackhall, L. Applying responsible algorithm design to neighbourhood-scale batteries in Australia. Nat. Energy 2021, 6, 815–823. [Google Scholar] [CrossRef]
- Miller, C.A.; Iles, A.; Jones, C.F. The Social Dimensions of Energy Transitions. Sci. Cult. 2013, 22, 135–148. [Google Scholar] [CrossRef]
- Bromley, S. American Hegemony and World Oil: The Industry, the State System and the World Economy; Pennsylvania State University Press: University Park, PA, USA, 1991; ISBN 027100746X 9780271007465. [Google Scholar]
- Barry, A. Material Politics: Disputes along the Pipeline; Wiley-Blackwell: New York, NY, USA, 2013. [Google Scholar]
- Callon, M.; Lascoumes, P.; Barthe, Y. Acting in an Uncertain World: An Essay on Technical Democracy; MIT Press: Cambridge, MA, USA, 2009; ISBN 9780262033824. [Google Scholar]
- Makhijani, A.; Saleska, S. The Nuclear Power Deception: US Nuclear Mythology from Electricity “Too Cheap to Meter” to “Inherently Safe” Reactors; The Apex Press: New York, NY, USA, 1999; ISBN 0945257759/9780945257752. [Google Scholar]
- Chung, J.B. Public deliberation on the national nuclear energy policy in Korea—Small successes but bigger challenges. Energy Policy 2020, 145, 111724. [Google Scholar] [CrossRef]
- Kim, P.; Kim, J.; Yim, M.S. How deliberation changes public opinions on nuclear energy: South Korea’s deliberation on closing nuclear reactors. Appl. Energy 2020, 270, 115094. [Google Scholar] [CrossRef]
- Setälä, M.; Grönlund, K.; Herne, K. Citizen deliberation on nuclear power: A comparison of two decision-making methods. Polit. Stud. 2010, 58, 688–714. [Google Scholar] [CrossRef]
- MacArthur, J.L. Challenging public engagement: Participation, deliberation and power in renewable energy policy. J. Environ. Stud. Sci. 2016, 6, 631–640. [Google Scholar] [CrossRef]
- Bergmans, A.; Sundqvist, G.; Kos, D.; Simmons, P. The participatory turn in radioactive waste management: Deliberation and the social-technical divide. J. Risk Res. 2015, 18, 347–363. [Google Scholar] [CrossRef]
- Pschetz, L.; Pothong, K.; Speed, C. Autonomous Distributed Energy Systems: Problematizing the Invisible Through Design, Drama And Deliberation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–14. [Google Scholar] [CrossRef]
- Kerr, S.; Watts, L.; Brennan, R.; Howell, R.; Graziano, M.; O’Hagan, A.M.; van der Horst, D.; Weir, S.; Wright, G.; Wynne, B. Shaping blue growth: Social sciences at the nexus between marine renewables and energy policy. In Advancing Energy Policy. Lessons on the Integration of Social Sciences and Humanities; Ptashnyk, I., Robison, R., Eds.; Palgrave Macmillan: Cham, Switzerland, 2018; pp. 31–46. [Google Scholar]
- Hall, N.L.; Hicks, J.; Lane, T.; Wood, E. Planning to engage the community on renewables: Insights from community engagement plans of the Australian wind industry. Australas. J. Environ. Manag. 2020, 27, 123–136. [Google Scholar] [CrossRef]
- Martinez, N. Resisting renewables: The energy epistemics of social opposition in Mexico. Energy Res. Soc. Sci. 2020, 70, 101632. [Google Scholar] [CrossRef]
- Winthereik, B.R.; Helmreich, S.; O’Doherty, D.; Amador-Jiménez, M.; Marres, N. Five theses on energy polities. In Energy Worlds in Experiment; Maguire, J., Watts, L., Winthereik, B.R., Eds.; Mattering Press: Manchester, UK, 2021; pp. 95–111. [Google Scholar]
- Beer, D. The social power of algorithms. Inf. Commun. Soc. 2017, 20, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Scott, J.C. Seeing Like a State: How Certain Schemes to Improve the Human Condition have Failed; Yale University Press: New Haven, CT, USA, 1998; ISBN 0300070160. [Google Scholar]
- Hossain, M.M.; Georges, J.P.; Rondeau, E.; Divoux, T. Energy, carbon and renewable energy: Candidate metrics for green-aware routing? Sensors (Switzerland) 2019, 19. [Google Scholar] [CrossRef] [Green Version]
- D’Ignazio, C.; Klein, L.F. Data Feminism; MIT Press: Cambridge, MA, USA, 2020; ISBN 9780262358521. [Google Scholar]
- Loukissas, Y.A.; Bowker, G.C. All Data Are Local: Thinking Critically in a Data-Driven Society; MIT Press: Cambridge, MA, USA, 2019; ISBN 9780262039666 0262039664. [Google Scholar]
- Lippert, I. Environment as datascape: Enacting emission realities in corporate carbon accounting. Geoforum 2015, 66, 126–135. [Google Scholar] [CrossRef] [Green Version]
- Power, M. The Audit Society: Rituals of Verification; Oxford University Press: Oxford, UK, 1997; ISBN 0198289472. [Google Scholar]
- Sovacool, B.K. Valuing the greenhouse gas emissions from nuclear power: A critical survey. Energy Policy 2008, 36, 2950–2963. [Google Scholar] [CrossRef]
- Riofrancos, T.N. Resource Radicals: From Petro-Nationalism to Post-Extractivism in Ecuador; Duke University Press: Durham, UK, 2020; ISBN 9781478012122. [Google Scholar]
- Boyer, D. Energopolitics: Wind and Power in the Anthropocene; Duke University Press: Durham, UK, 2019; ISBN 1-4780-0439-8. [Google Scholar]
- Watts, L. Energy at the End of the World: An Orkney Islands Saga; MIT Press: Cambridge, MA, USA, 2018; ISBN 9780262038898. [Google Scholar]
- Buchanan, K.; Russo, R.; Anderson, B. The question of energy reduction: The problem(s) with feedback. Energy Policy 2015, 77, 89–96. [Google Scholar] [CrossRef] [Green Version]
- Mauss, M. The Gift: Forms and Functions of Exchange in Archaic Societies; Cohen & West: London, UK, 1969; ISBN 0710018088. [Google Scholar]
- Graham, S.; Marvin, S. Splintering Urbanism: Networked Infrastructures, Technological Mobilities and the Urban Condition; Routledge: London, UK, 2001; ISBN 0415189640. [Google Scholar]
- Özden-Schilling, C. The infrastructure of markets: From electric power to electronic data. Econ. Anthropol. 2016, 3, 68–80. [Google Scholar] [CrossRef]
- Smale, R.; van Vliet, B.; Spaargaren, G. When social practices meet smart grids: Flexibility, grid management, and domestic consumption in The Netherlands. Energy Res. Soc. Sci. 2017, 34, 132–140. [Google Scholar] [CrossRef]
- Morley, J.; Widdicks, K.; Hazas, M. Digitalisation, energy and data demand: The impact of Internet traffic on overall and peak electricity consumption. Energy Res. Soc. Sci. 2018, 38, 128–137. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nafus, D.; Schooler, E.M.; Burch, K.A. Carbon-Responsive Computing: Changing the Nexus between Energy and Computing. Energies 2021, 14, 6917. https://doi.org/10.3390/en14216917
Nafus D, Schooler EM, Burch KA. Carbon-Responsive Computing: Changing the Nexus between Energy and Computing. Energies. 2021; 14(21):6917. https://doi.org/10.3390/en14216917
Chicago/Turabian StyleNafus, Dawn, Eve M. Schooler, and Karly Ann Burch. 2021. "Carbon-Responsive Computing: Changing the Nexus between Energy and Computing" Energies 14, no. 21: 6917. https://doi.org/10.3390/en14216917