
Towards Predictive Crude Oil Purchase: A Case Study in the USA and Europe



Abstract
:1. Introduction
2. Statistical Background
2.1. Autoregressive Integrated Moving Average (ARIMA) Model
2.2. Seasonal Autoregressive Integrated Moving Average (SARIMA) Model
2.3. Accuracy Measurement
2.4. Min–Max Normalization
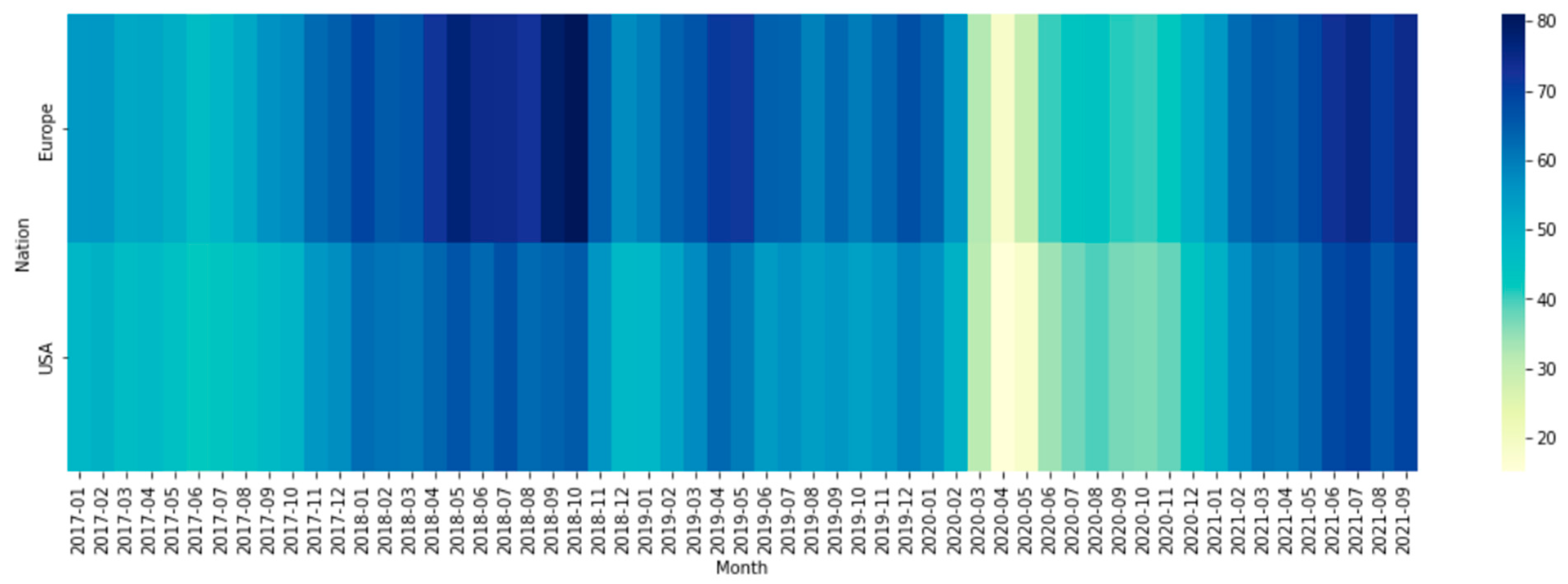
3. Data Collection
4. Result
4.1. Descriptive Statistics
4.2. Application
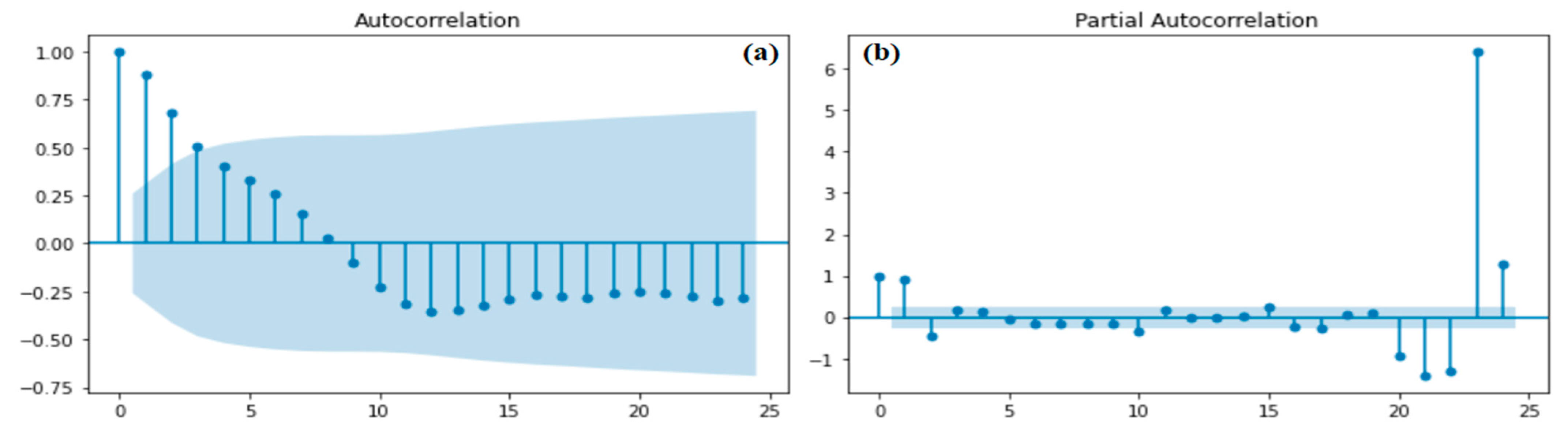
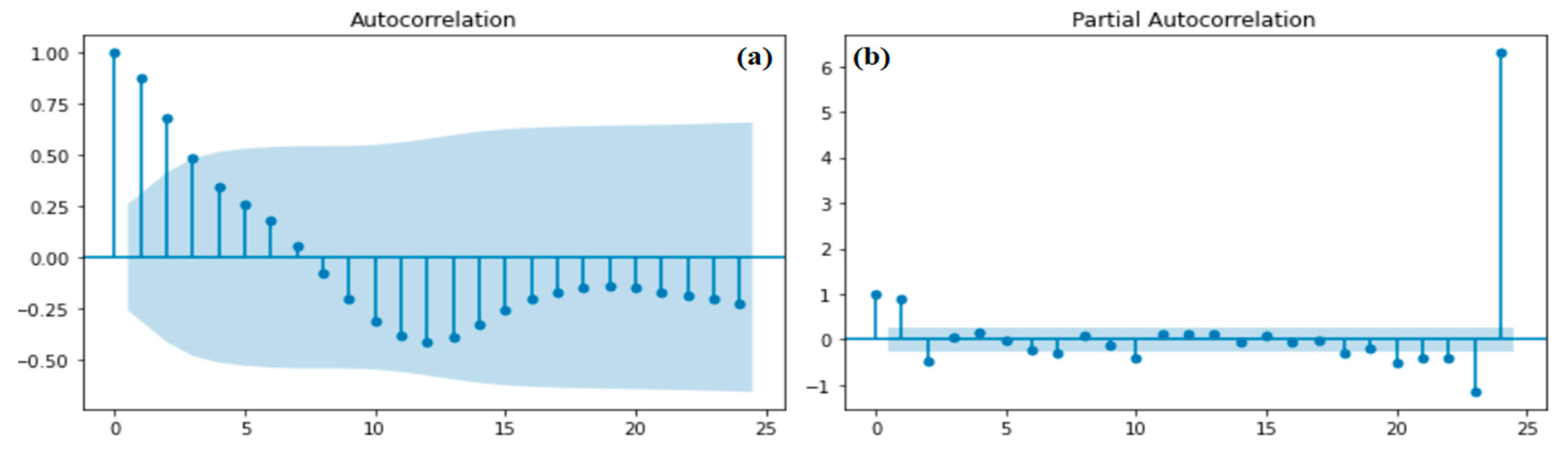
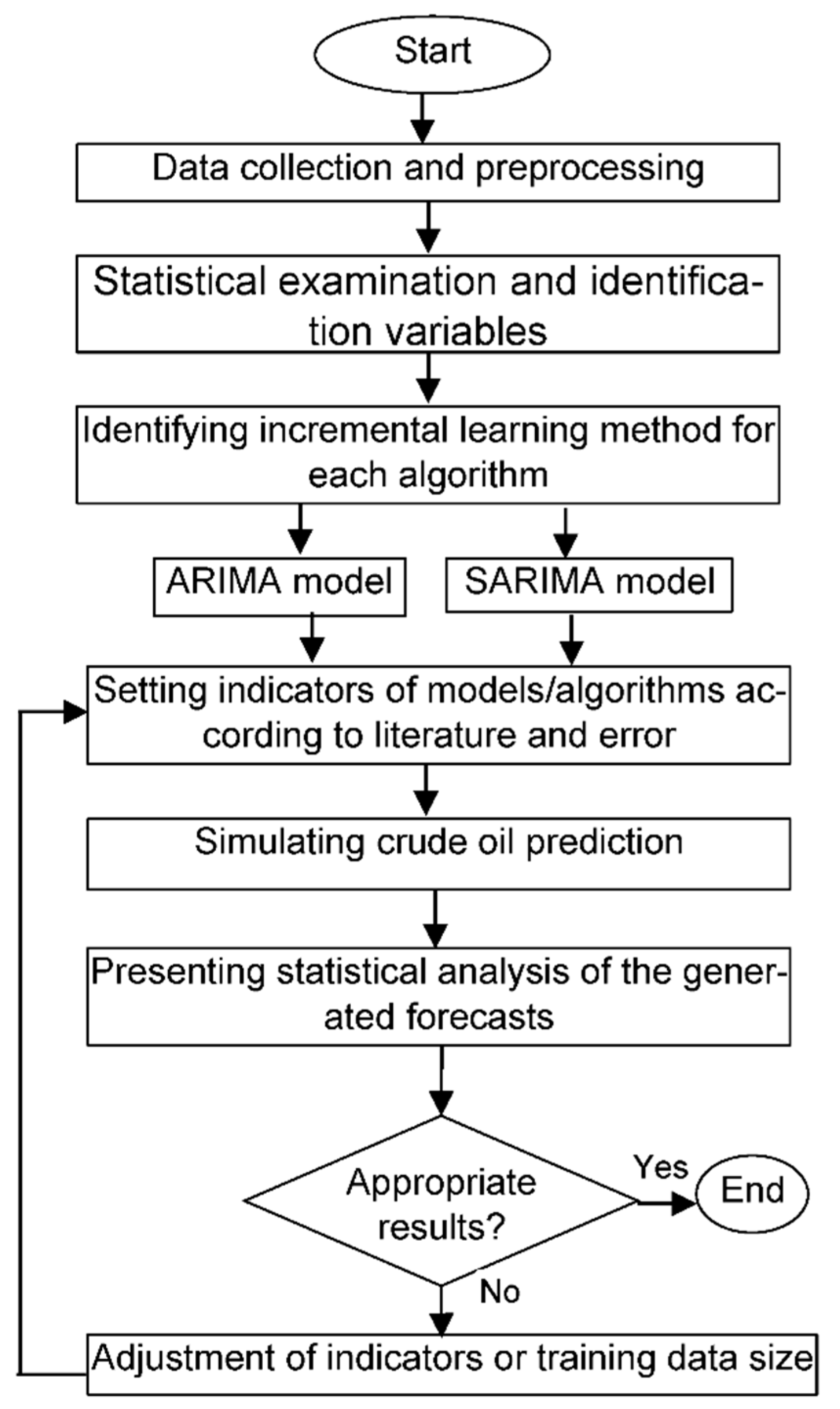
4.2.1. The Five Steps for This Experiment Determine the Optimal Predictive Models
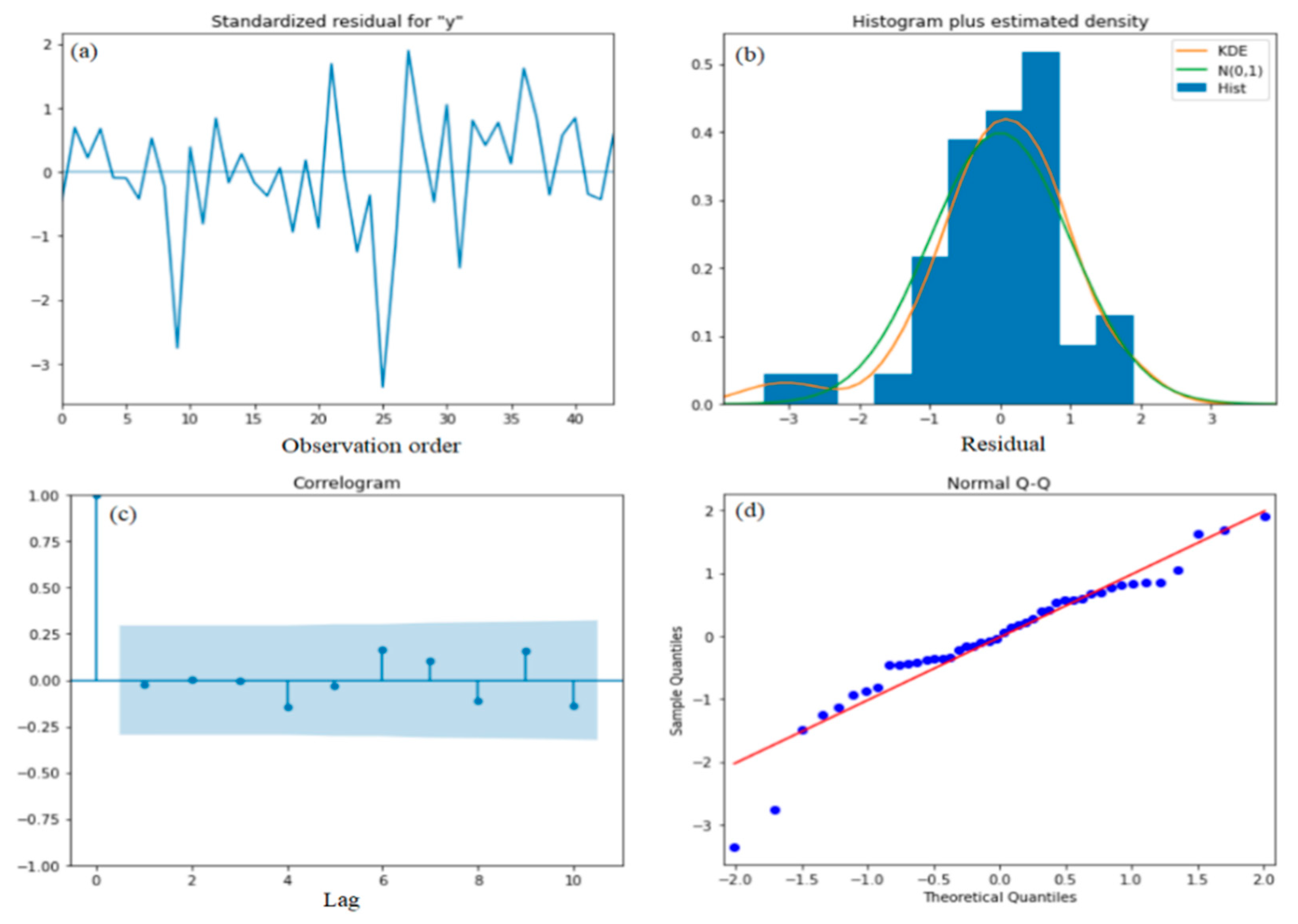
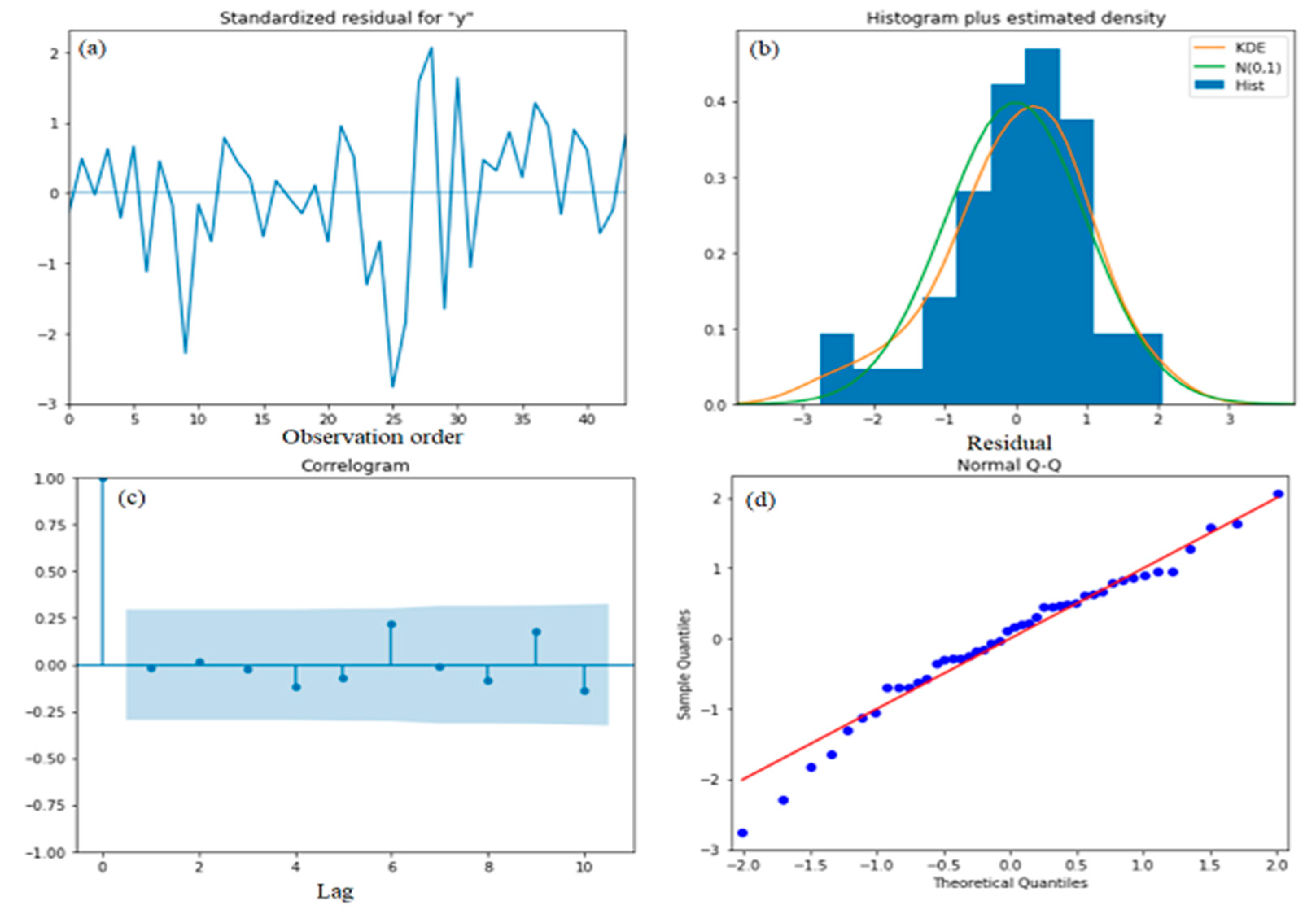
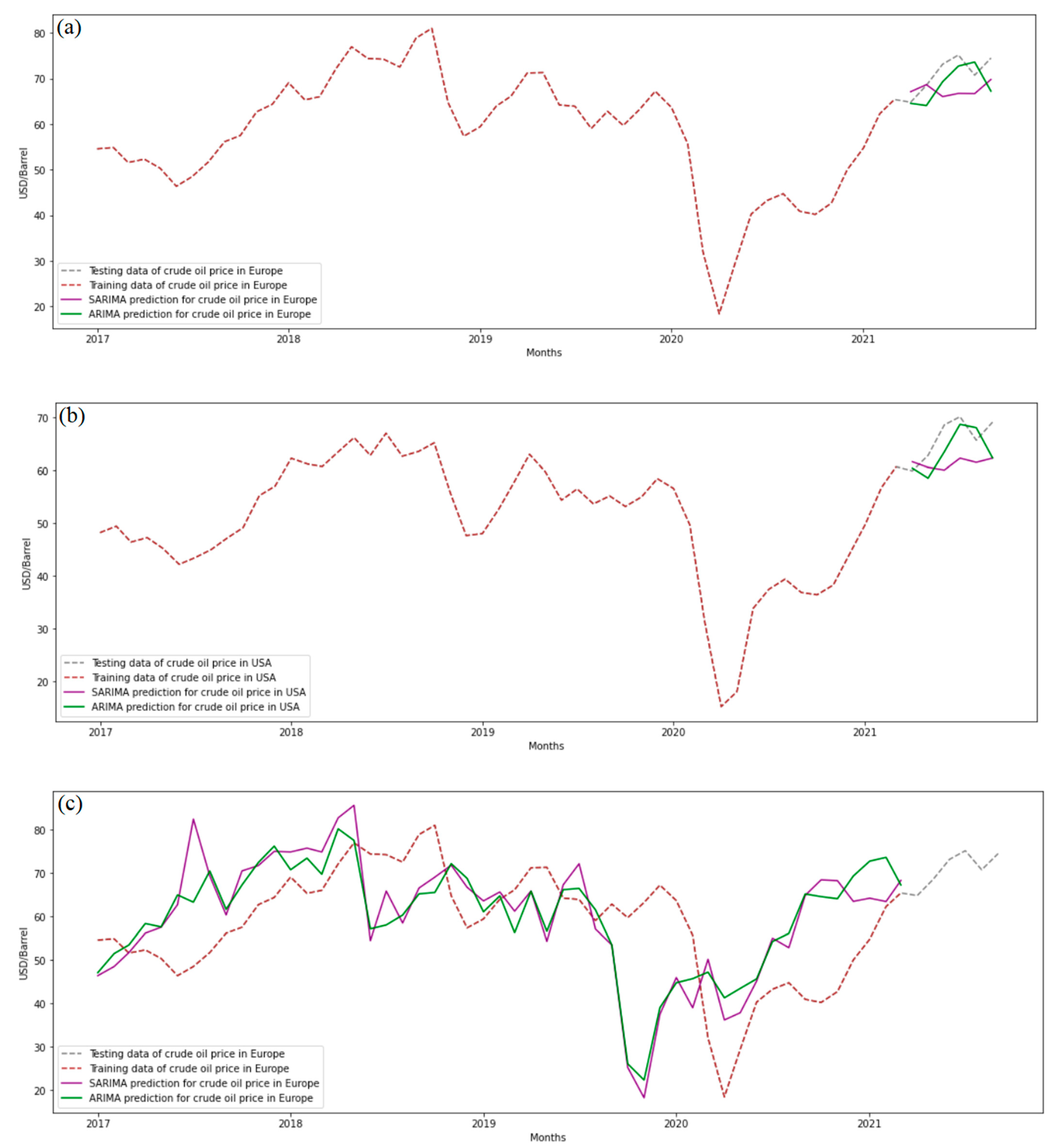
4.2.2. The Forecasting Crude Oil Price of the ARIMA and SARIMA Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Alekhina, V.; Yoshino, N. Impact of World Oil Prices on an Energy Exporting Economy Including Monetary Policy; ADBI Working Paper No. 828; Asian Development Bank Institute (ADBI): Tokyo, Japan, 2018. [Google Scholar]
- Erb, C.B.; Harvey, C.R. The strategic and tactical value of commodity futures. Financ. Anal. J. 2006, 62, 69–97. [Google Scholar] [CrossRef]
- Shafiee, S.; Topal, E. When will fossil fuel reserves be diminished? Energy Policy 2009, 37, 181–189. [Google Scholar] [CrossRef]
- Mensi, W.; Hammoudeh, S.; Shahzad, S.J.H.; Shahbaz, M. Modeling systemic risk and dependence structure between oil and stock markets using a variational mode decomposition-based copula method. J. Bank. Financ. 2017, 75, 258–279. [Google Scholar] [CrossRef]
- Squalli, J. Electricity consumption and economic growth: Bounds and causality analyses of OPEC members. Energy Econ. 2007, 29, 1192–1205. [Google Scholar] [CrossRef]
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine learning in energy economics and finance: A review. Energy Econ. 2019, 81, 709–727. [Google Scholar] [CrossRef]
- Ekechukwu, G.K.; Falode, O.; Orodu, O.D. Improved method for the estimation of minimum miscibility pressure for pure and impure co2–crude oil systems using Gaussian process machine learning approach. J. Energy Resour. Technol. 2020, 142, 123003. [Google Scholar] [CrossRef]
- Abdullah, S.N.B. Machine Learning Approach for Crude Oil Price Prediction. Ph.D. Thesis, The University of Manchester, Manchester, UK, 2014. [Google Scholar]
- Herrera, G.P.; Constantino, M.; Tabak, B.M.; Pistori, H.; Su, J.-J.; Naranpanawa, A. Data on forecasting energy prices using machine learning. Data Brief 2019, 25, 104122. [Google Scholar] [CrossRef]
- James, S.C.; Zhang, Y.; O’Donncha, F. A machine learning framework to forecast wave conditions. Coast. Eng. 2018, 137, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Lei, Y. A new approach for crude oil price prediction based on stream learning. Geosci. Front. 2017, 8, 183–187. [Google Scholar] [CrossRef] [Green Version]
- Lippi, M.; Bertini, M.; Frasconi, P. Short-term traffic flow forecasting: An experimental comparison of time-series analysis and supervised learning. IEEE Trans. Intell. Transp. Syst. 2013, 14, 871–882. [Google Scholar] [CrossRef]
- Ryoo, B.; Ashtab, M. Predictive capabilities of supervised learning models compare with time series models in forecasting construction hiring. EPiC Ser. Built Environ. 2021, 2, 117–126. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Kelleher, J.D.; Mac Namee, B.; D’arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Mohammadi, H.; Su, L. International evidence on crude oil price dynamics: Applications of ARIMA-GARCH models. Energy Econ. 2010, 32, 1001–1008. [Google Scholar] [CrossRef]
- Nochai, R.; Nochai, T. ARIMA model for forecasting oil palm price. In Proceedings of the 2nd IMT-GT Regional Conference on Mathematics, Statistics and Applications, Penang, Malaysia, 13–15 June 2006; pp. 13–15. [Google Scholar]
- Ahmed, R.A.; Shabri, A.B. Daily crude oil price forecasting model using ARIMA, generalized autoregressive conditional heteroscedastic and support vector machines. Am. J. Appl. Sci. 2014, 11, 425. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, C.; Yang, L. Oil price shocks and agricultural commodity prices. Energy Econ. 2014, 44, 22–35. [Google Scholar] [CrossRef]
- Tayib, S.A.M.; Nor, S.R.M.; Norrulashikin, S.M. Forecasting on the crude palm oil production in Malaysia using SARIMA Model. J. Phys. Conf. Ser. 2021, 1988, 012106. [Google Scholar] [CrossRef]
- Etuk, E.H.; Amadi, E.H. Multiplicative SARIMA modelling of Nigerian monthly crude oil domestic production. J. Appl. Math. Bioinform. 2013, 3, 103. [Google Scholar]
- Ahmad, S.; Latif, H.A. Forecasting on the crude palm oil and kernel palm production: Seasonal ARIMA approach. In Proceedings of the 2011 IEEE Colloquium on Humanities, Science and Engineering, Penang, Malaysia, 5–6 December 2011; pp. 939–944. [Google Scholar] [CrossRef]
- Luo, H.; Liu, X.; Wang, S. Based on SARIMA-BP hybrid model and SSVM model of international crude oil price prediction research. ANZIAM J. 2016, 58, E143. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Wachtmeister, H.; Henke, P.; Höök, M. Oil projections in retrospect: Revisions, accuracy and current uncertainty. Appl. Energy 2018, 220, 138–153. [Google Scholar] [CrossRef]
- Baumeister, C.; Kilian, L. Forty years of oil price fluctuations: Why the price of oil may still surprise us. J. Econ. Perspect. 2016, 30, 139–160. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Khanarsa, P.; Sinapiromsaran, K. Automatic SARIMA order identification convolutional neural network. Int. J. Mach. Learn. Comput. 2020, 10, 662–668. [Google Scholar] [CrossRef]
- Aburto, L.; Weber, R. Improved supply chain management based on hybrid demand forecasts. Appl. Soft. Comput. 2007, 7, 136–144. [Google Scholar] [CrossRef]
- Cools, M.; Moons, E.; Wets, G. Investigating the variability in daily traffic counts through use of ARIMAX and SARIMAX models: Assessing the effect of holidays on two site locations. Transp. Res. Rec. 2009, 2136, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Farsi, M.; Hosahalli, D.; Manjunatha, B.R.; Gad, I.; Atlam, E.-S.; Ahmed, A.; Elmarhomy, G.; Elmarhoumy, M.; Ghoneim, O.A. Parallel genetic algorithms for optimizing the SARIMA model for better forecasting of the NCDC weather data. Alex. Eng. J. 2021, 60, 1299–1316. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S.; Stoffer, D.S. Time Series Analysis and Its Applications; Springer: New York, NY, USA, 2000; Volume 3. [Google Scholar]
- Puthran, D.; Shivaprasad, H.C.; Kumar, K.K.; Manjunath, M. Comparing SARIMA and Holt-Winters’ forecasting accuracy with respect to Indian motorcycle industry. Trans. Eng. Sci. 2014, 2, 25–28. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Obite, C.P.; Chukwu, A.; Bartholomew, D.C.; Nwosu, U.I.; Esiaba, G.E. Classical and machine learning modeling of crude oil production in Nigeria: Identification of an eminent model for application. Energy Rep. 2021, 7, 3497–3505. [Google Scholar] [CrossRef]
- Ajumi, O.; Kaushik, A. Exchange rates prediction via deep learning and machine learning: A literature survey on currency forecasting. Int. J. Sci. Res. 2017, 7, ART20193849. [Google Scholar]
- Lewis, C. International and Business Forecasting Methods; Butterworths: London, UK, 1982. [Google Scholar]
- Chatfield, C. The Analysis of Time Series: An Introduction; Chapman and Hall/CRC: Boca Raton, FL, USA, 2003. [Google Scholar]
- Sahu, S.K.; Dey, D.K.; Branco, M.D. A new class of multivariate skew distributions with applications to Bayesian regression models. Can. J. Stat. 2003, 31, 129–150. [Google Scholar] [CrossRef] [Green Version]
- Brys, G.; Hubert, M.; Struyf, A. A robust measure of skewness. J. Comput. Graph. Stat. 2004, 13, 996–1017. [Google Scholar] [CrossRef]
- Aiello, M.; Yang, Y.; Zou, Y.; Zhang, L.J. (Eds.) Artificial Intelligence and Mobile Services—AIMS; Springer International Publishing: New York, NY, USA, 2018. [Google Scholar]
- Manigandan, P.; Alam, M.D.S.; Alharthi, M.; Khan, U.; Alagirisamy, K.; Pachiyappan, D.; Rehman, A. Forecasting natural gas production and consumption in United States-Evidence from SARIMA and SARIMAX models. Energies 2021, 14, 6021. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Milo, A.; Sánchez, R.; Barrio, I. Short-term office building elevator energy consumption forecast using SARIMA. J. Build. Perform. Simul. 2019, 13, 69–78. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Y.; Li, X.; Wu, J.; He, T. Forecasting daily crude oil prices using improved CEEMDAN and ridge regression-based predictors. Energies 2019, 12, 3603. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Ji, L.; Wu, C.W.D.; Tso, K.F.G. Using SARIMA–CNN–LSTM approach to forecast daily tourism demand. J. Hosp. Tour. Manag. 2021, 49, 25–33. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | USA | Europe |
|---|---|---|
| Mean | 52.28 | 59.41 |
| Standard Deviation | 11.86 | 13.03 |
| Min | 15.18 | 18.38 |
| Max | 70.12 | 81.03 |
| Kurtosis | 1.22 | 0.76 |
| Skewness | −0.99 | −0.86 |
| Results of Dickey–Fuller Test | ||
| Test Statistic | −1.79 | −1.78 |
| p-value | 0.38 | 0.39 |
| Critical Value (1%) | −3.56 | −3.56 |
| Critical Value (5%) | −2.92 | −2.92 |
| Critical Value (10%) | −2.60 | −2.60 |
| Europe | USA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARIMA | AIC | MAPE | SARIMA | AIC | MAPE | ARIMA | AIC | MAPE | SARIMA | AIC | MAPE |
| (2,0,0) | −103.04 | 0.24 | (2,1,0) × (0,1,1,12) | −63.55 | 0.24 | (2,0,0) | −97.67 | 0.28 | (2,1,0) × (0,1,1,12) | −56.06 | 0.33 |
| (1,0,1) | −106.69 | 0.23 | (0,1,1) × (0,1,1,12) | −63.28 | 0.25 | (1,0,1) | −100.58 | 0.27 | (0,1,1) × (0,1,1,12) | −55.91 | 0.34 |
| (2,0,1) | −104.69 | 0.24 | (2,1,0) × (2,1,0,12) | −62.59 | 0.24 | (2,0,1) | −98.93 | 0.29 | (0,1,2) × (0,1,1,12) | −54.61 | 0.33 |
| (0,1,1) | −110.53 | 0.63 | (2,1,0) × (0,1,2,12) | −62.53 | 0.23 | (0,1,1) | −104.73 | 1.97 | (2,1,1) × (0,1,1,12) | −54.59 | 0.30 |
| (1,1,1) | −108.53 | 0.64 | (2,1,0) × (1,1,1,12) | −62.45 | 0.24 | (1,1,1) | −103.02 | 1.94 | (0,1,2) × (0,1,1,12) | −54.43 | 0.39 |
| Parameter | ARIMA_Europe | SARIMA_Europe | ARIMA_USA | SARIMA_USA | ||||
|---|---|---|---|---|---|---|---|---|
| Testing | Training | Testing | Training | Testing | Training | Testing | Training | |
| MAPE | 0.05 | 0.24 | 0.06 | 0.24 | 0.05 | 0.27 | 0.09 | 0.30 |
| MAE ($) | 3.51 | 11.99 | 4.46 | 12.38 | 3.41 | 11.13 | 5.23 | 10.57 |
| RMSE ($) | 4.11 | 14.77 | 5.25 | 15.51 | 4.04 | 13.98 | 5.86 | 14.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-Y.; Nguyen, T.-T.; Nguyen, H.-G.; Lee, J.-Y. Towards Predictive Crude Oil Purchase: A Case Study in the USA and Europe. Energies 2022, 15, 4003. https://doi.org/10.3390/en15114003
Lee J-Y, Nguyen T-T, Nguyen H-G, Lee J-Y. Towards Predictive Crude Oil Purchase: A Case Study in the USA and Europe. Energies. 2022; 15(11):4003. https://doi.org/10.3390/en15114003
Chicago/Turabian StyleLee, Jen-Yu, Tien-Thinh Nguyen, Hong-Giang Nguyen, and Jen-Yao Lee. 2022. "Towards Predictive Crude Oil Purchase: A Case Study in the USA and Europe" Energies 15, no. 11: 4003. https://doi.org/10.3390/en15114003