
Application of Neural Data Processing in Autonomous Model Platform—A Complex Review of Solutions, Design and Implementation



Abstract
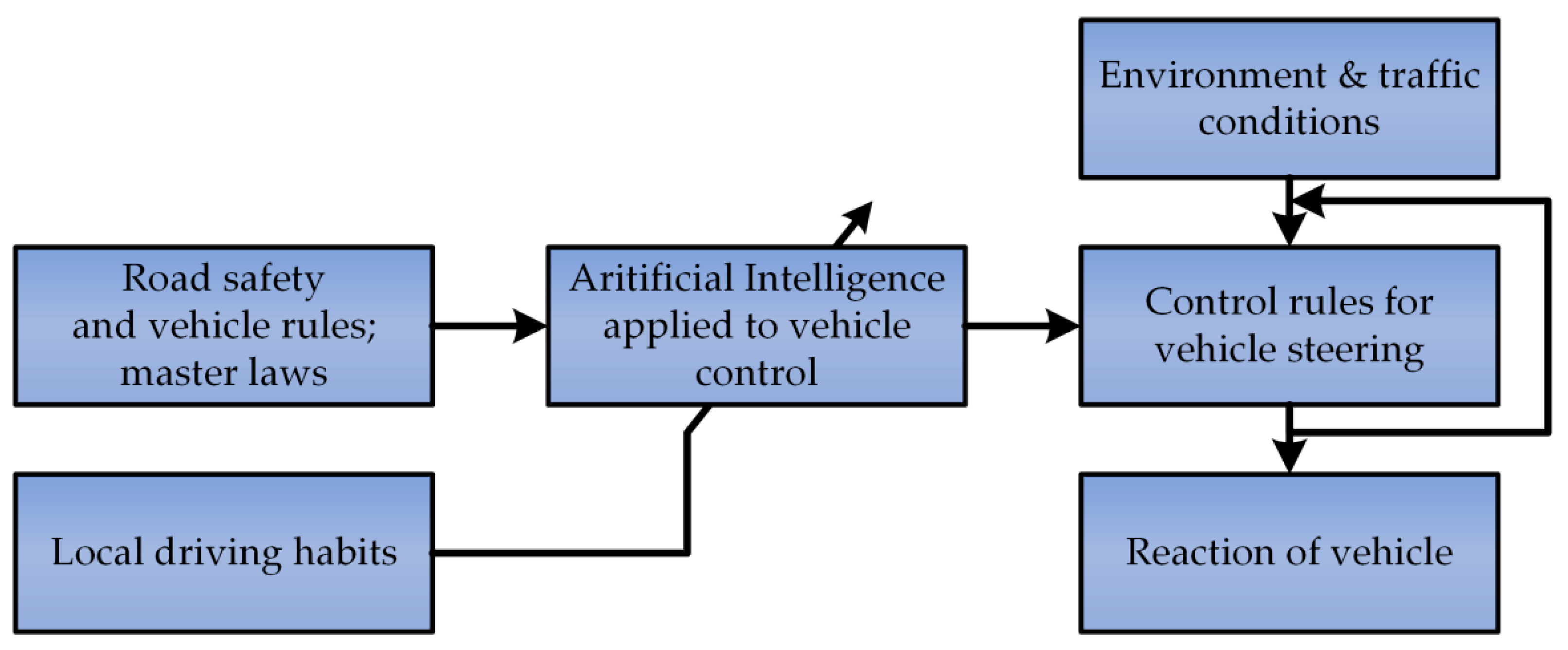
:1. Introduction
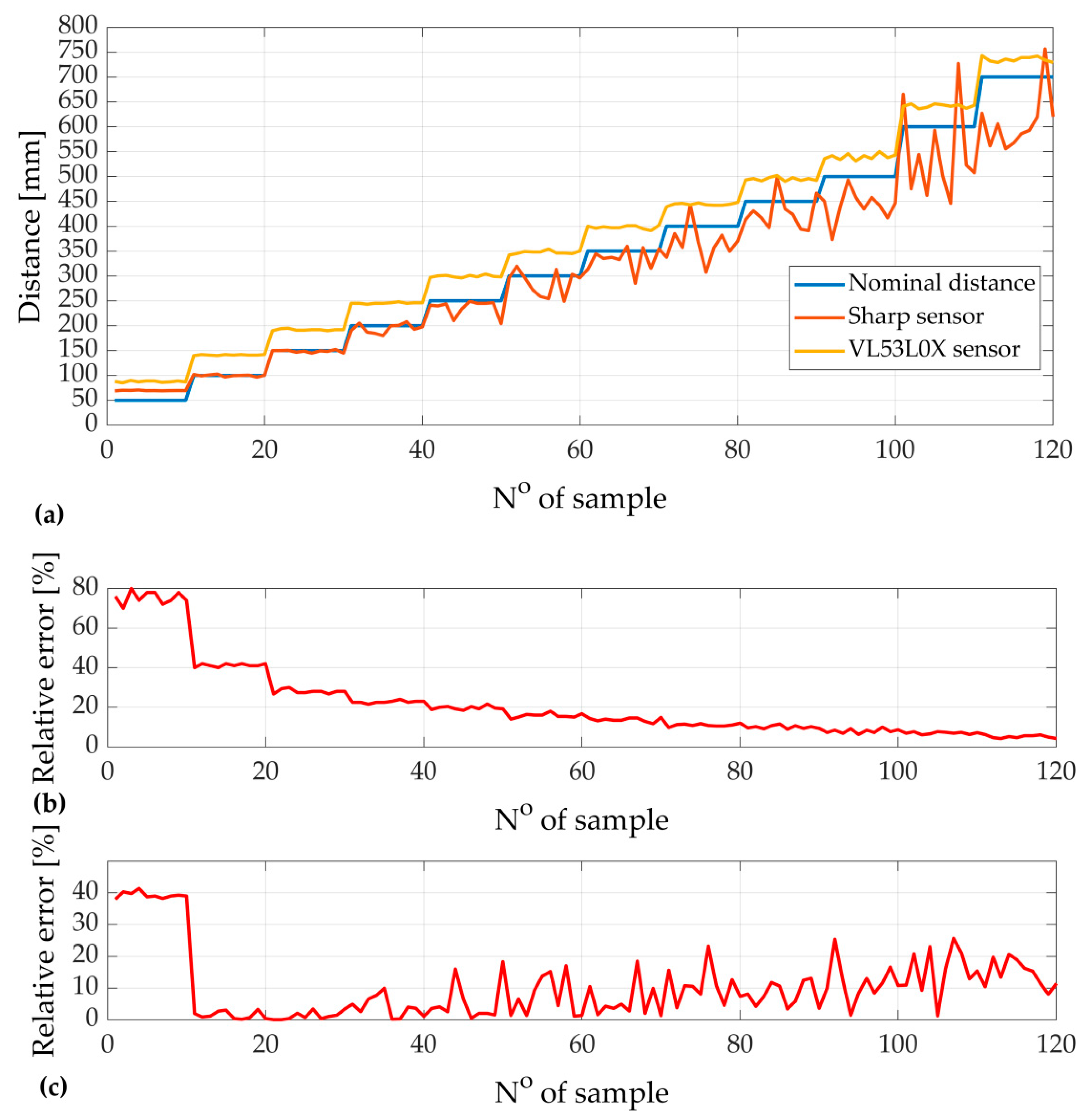
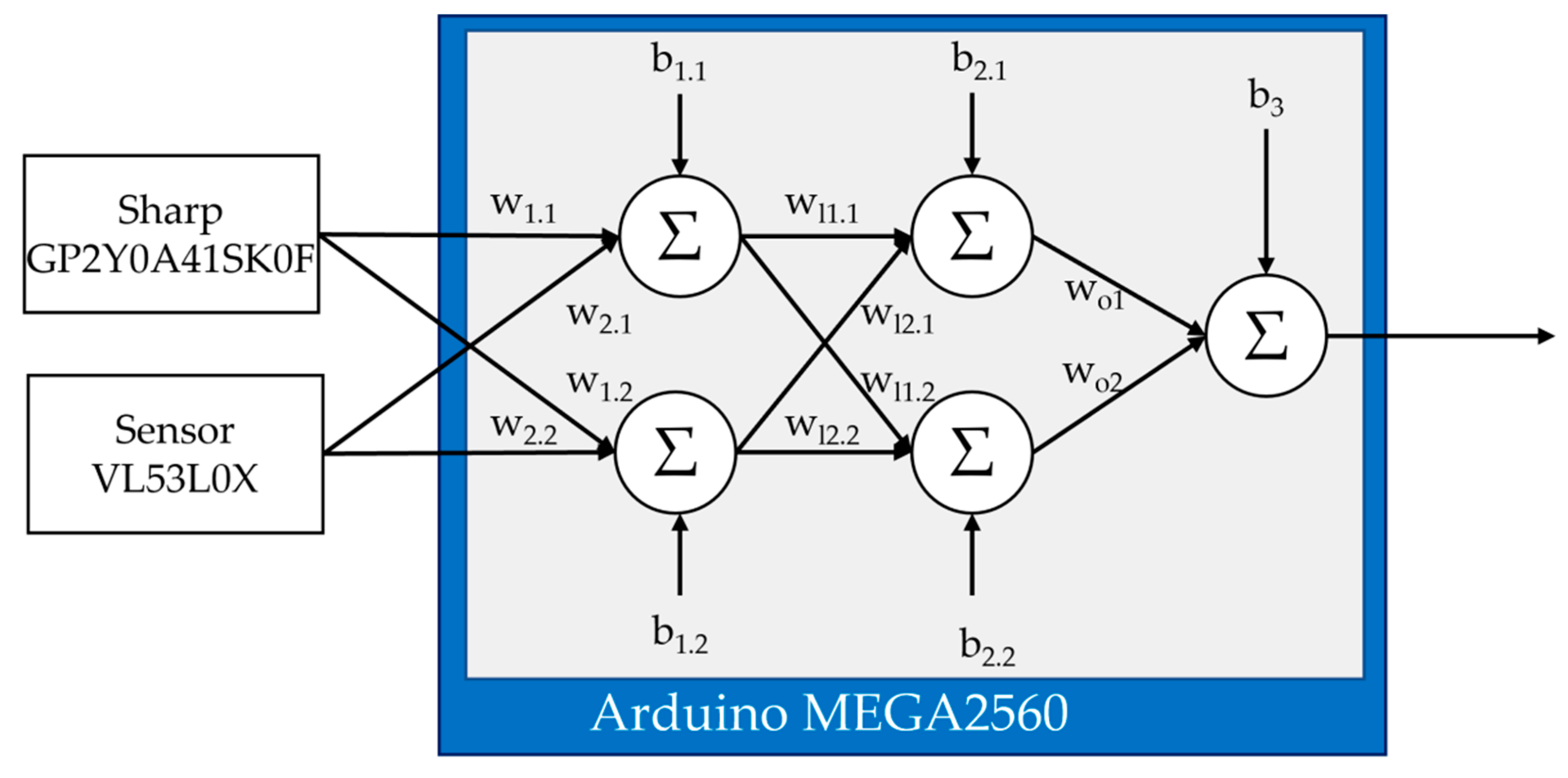
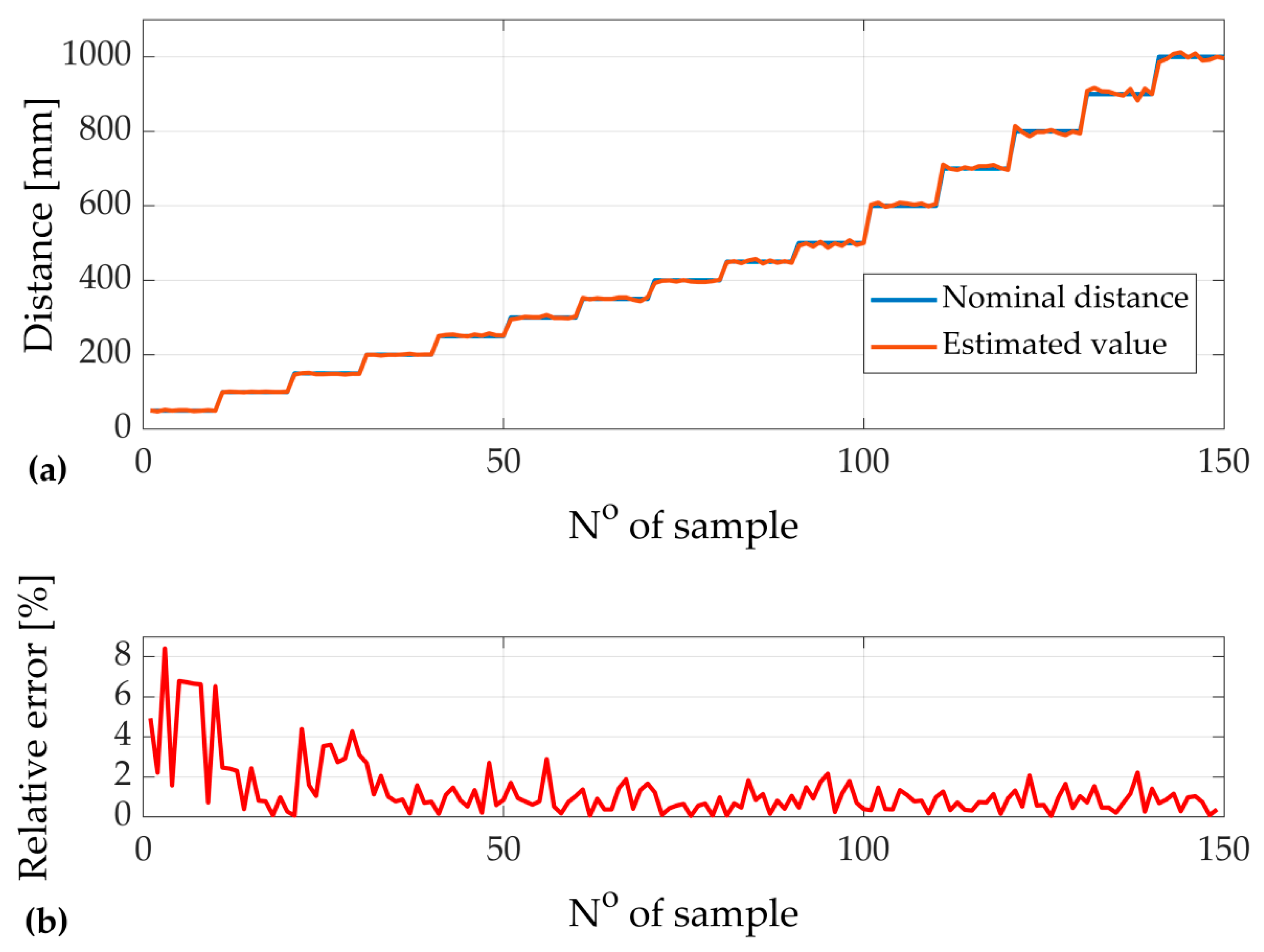
2. Neural Distance Estimator
3. Self-Learning Neural Path Planner Applied to the Platform
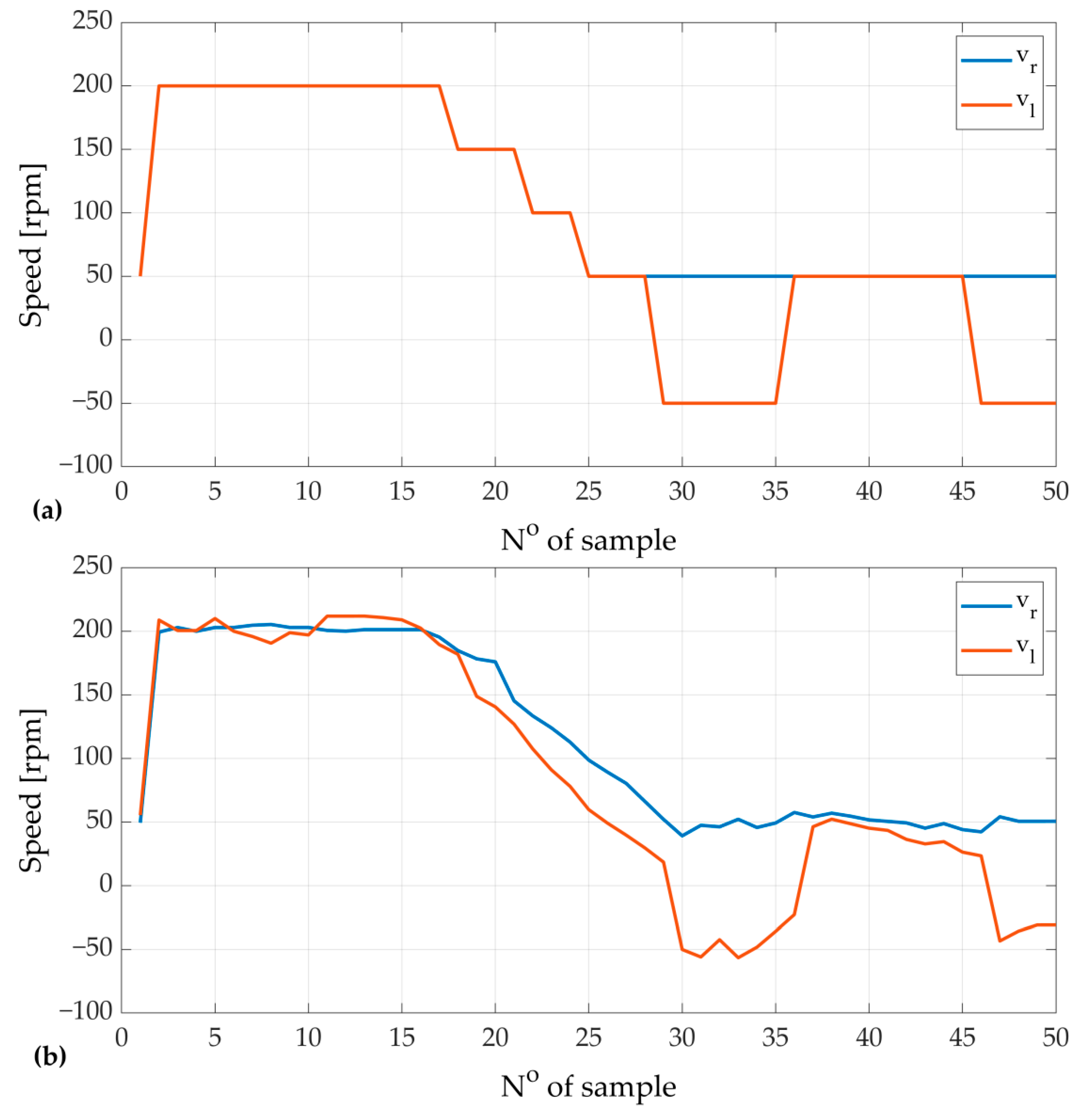
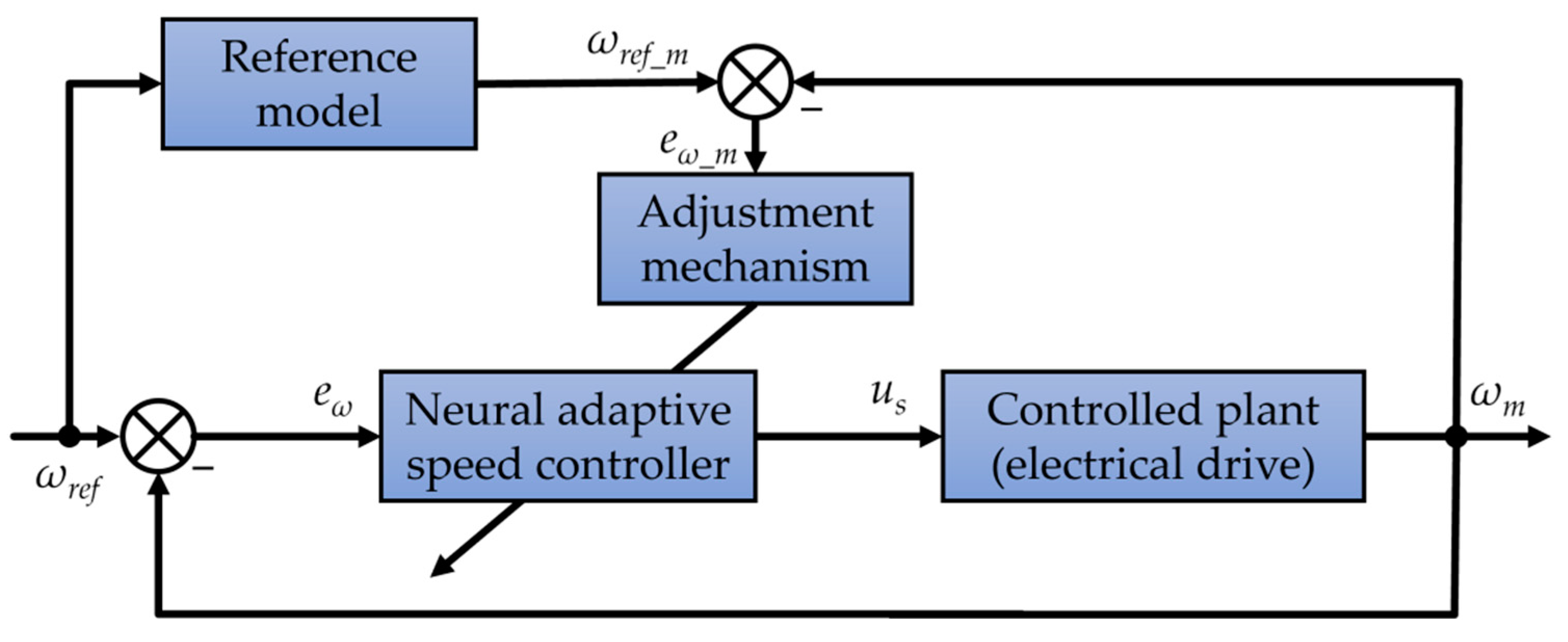
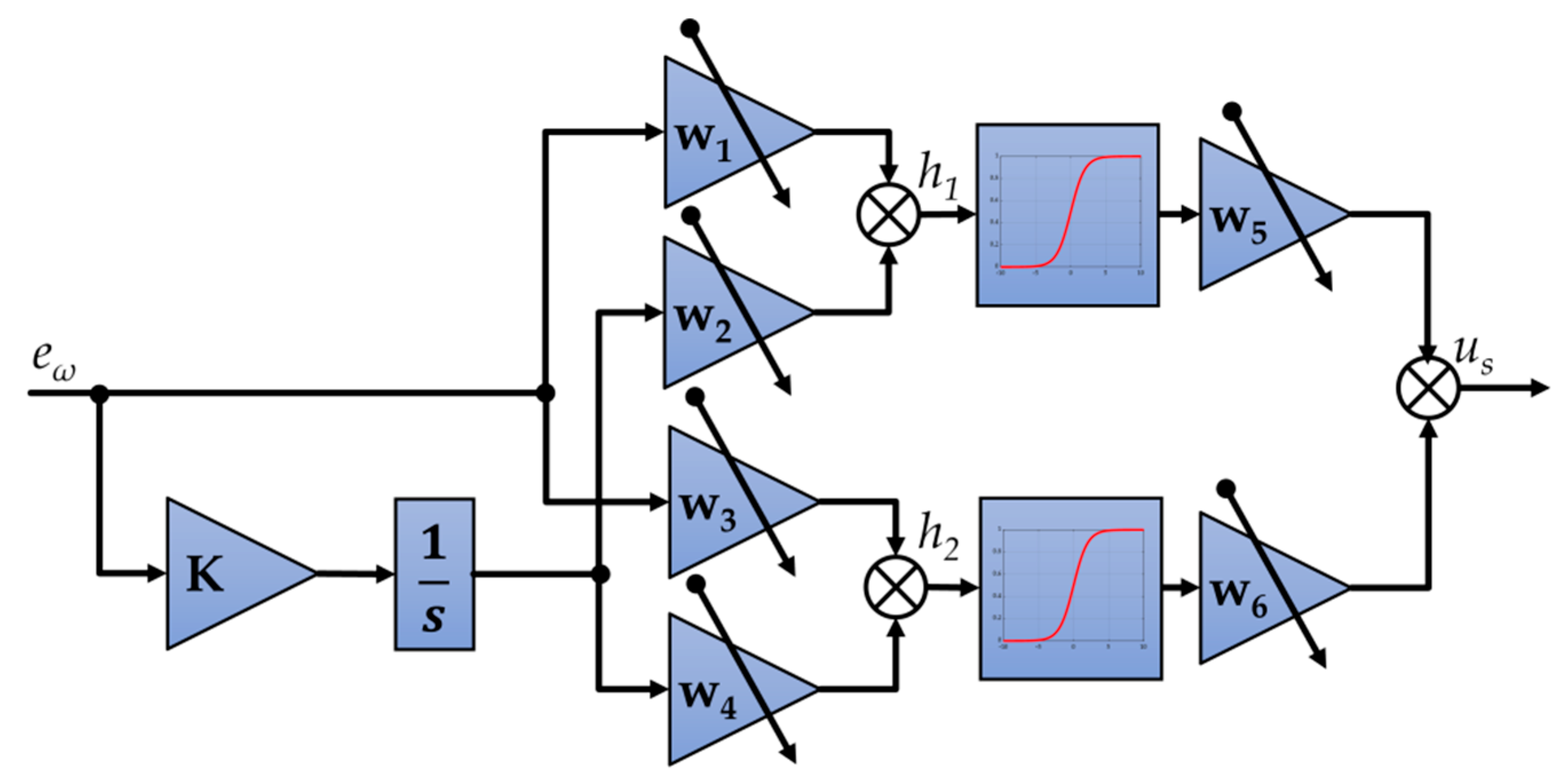
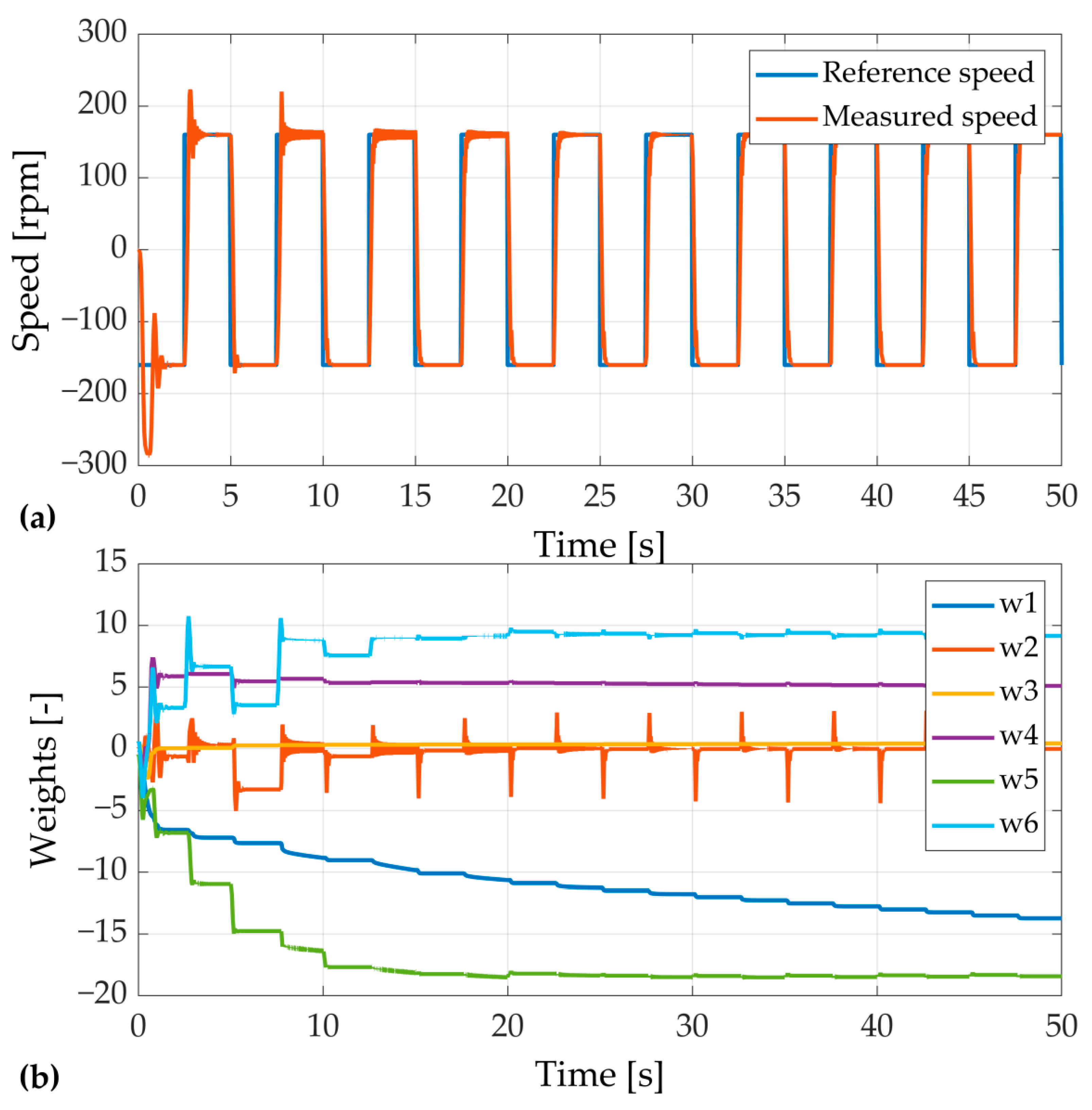
4. Neural Speed Controller
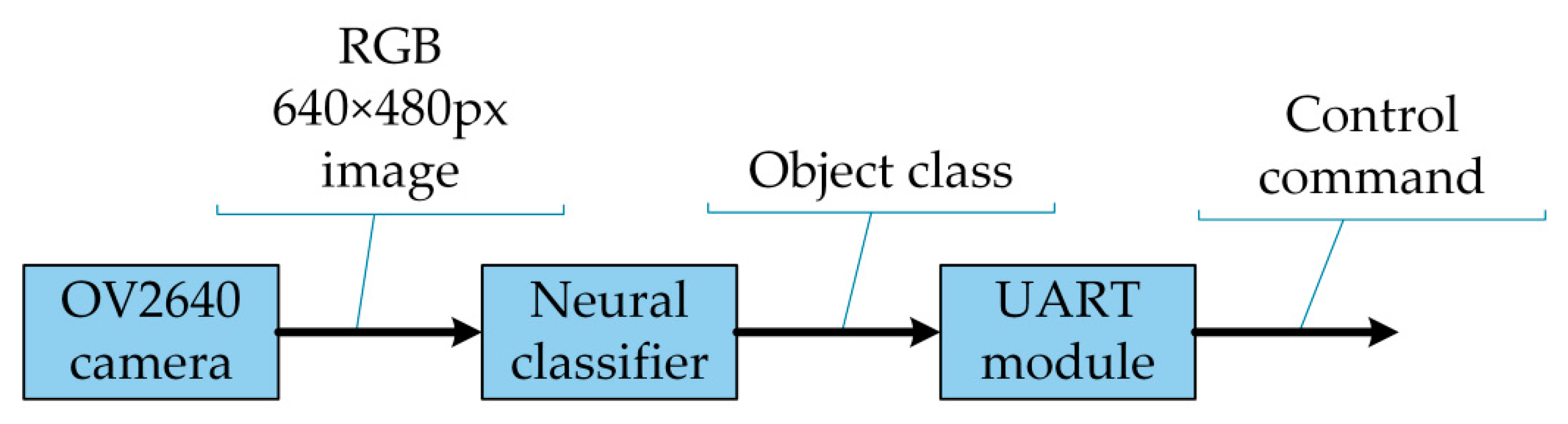
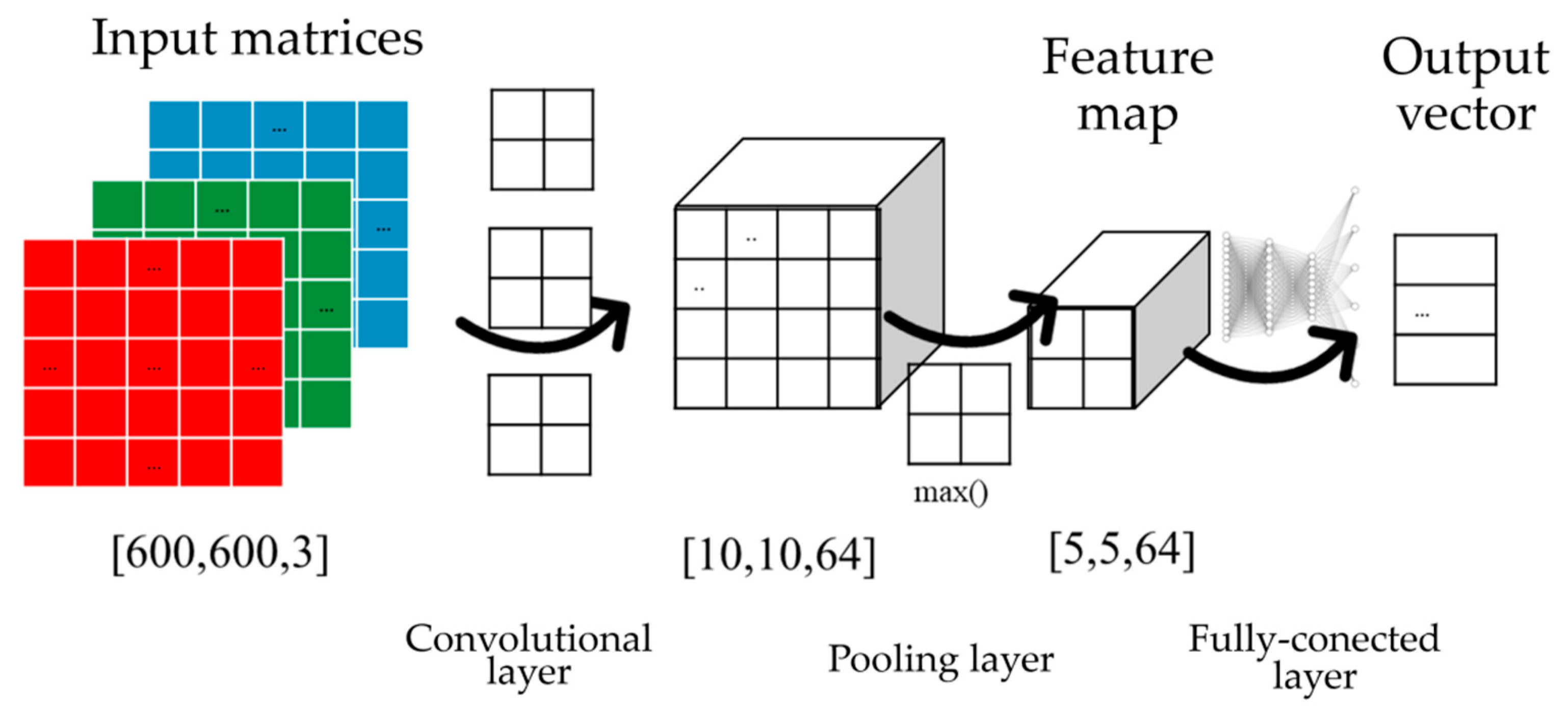
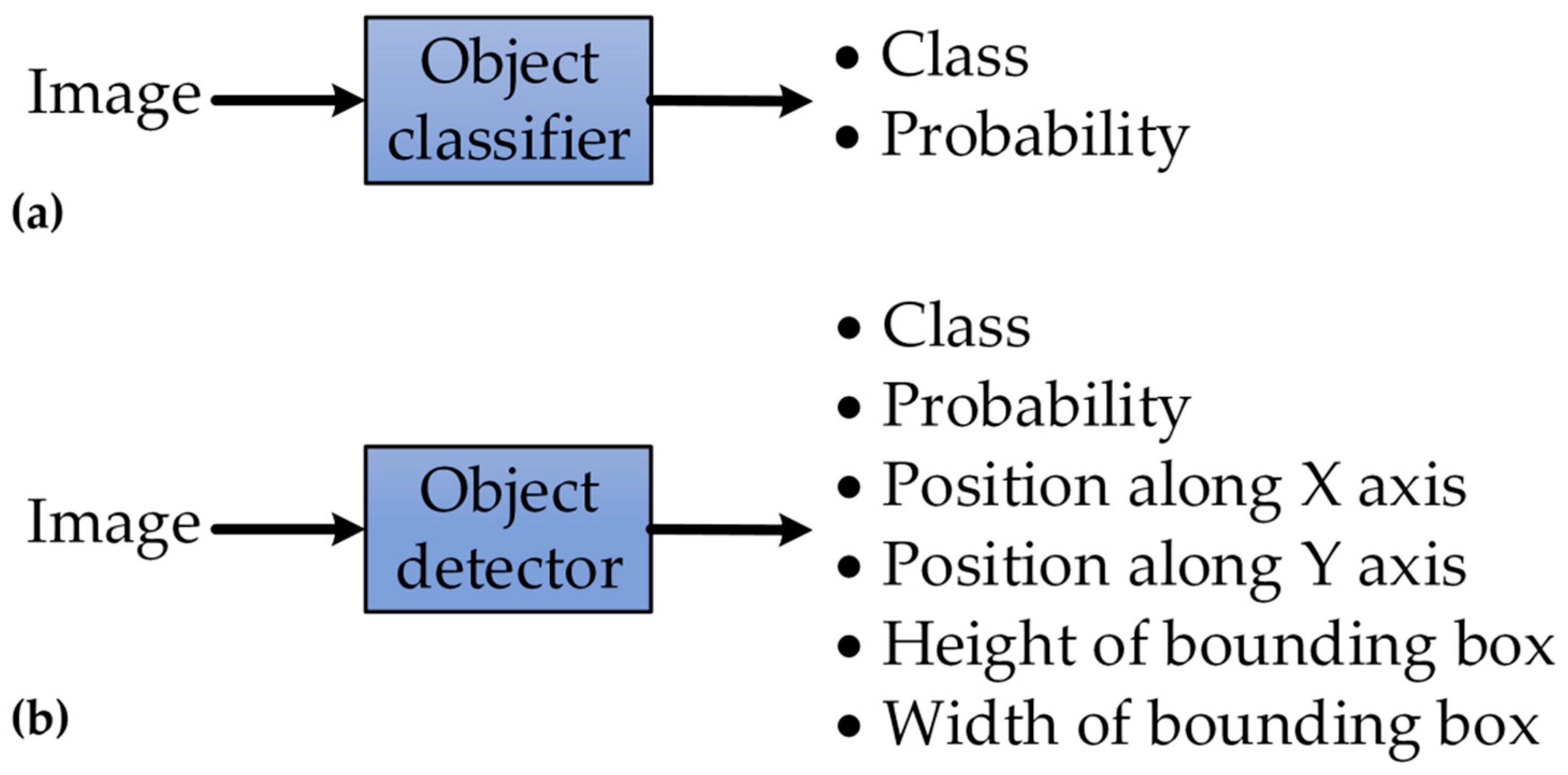
5. Neural Road Sign Classifier
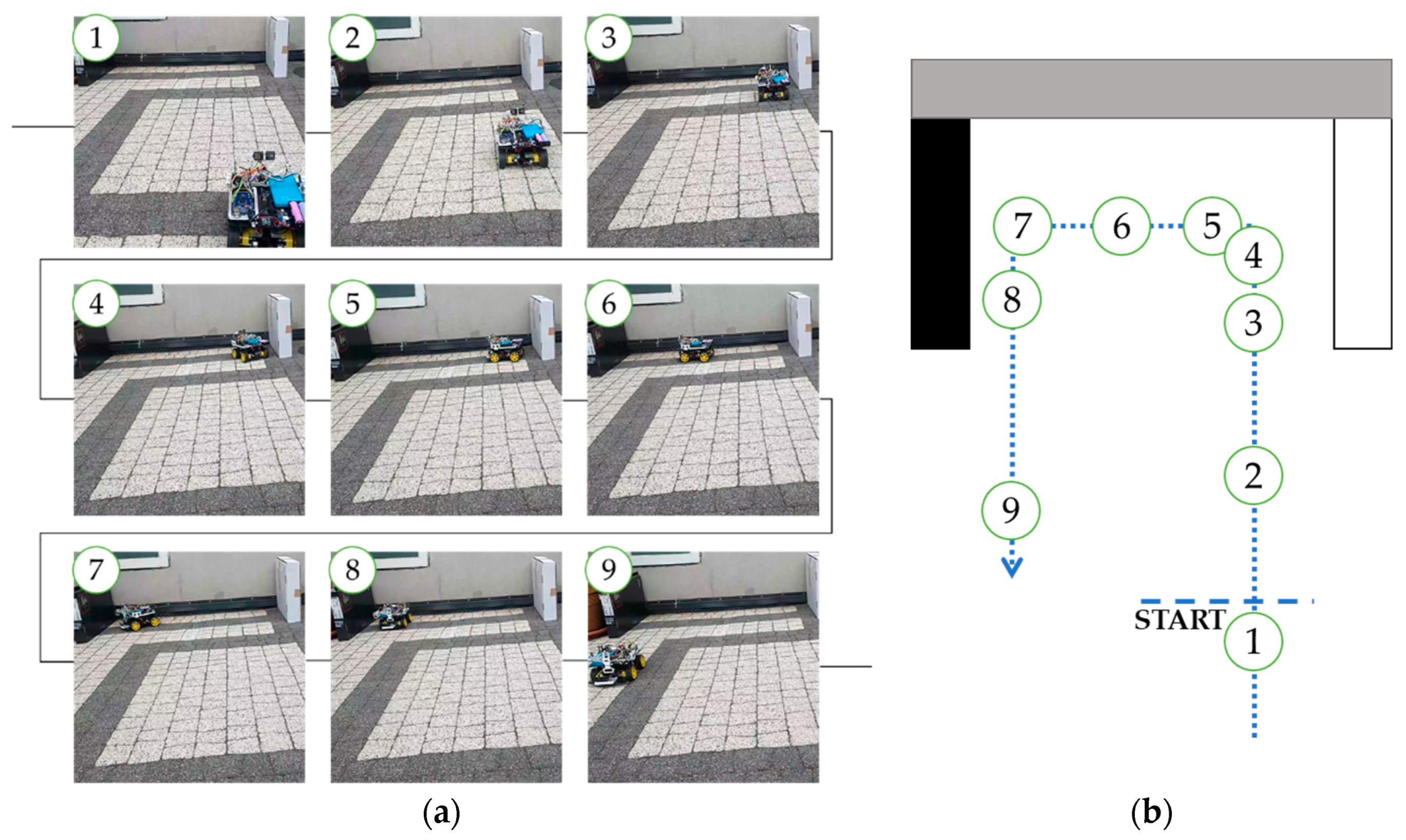
6. Real Platform
7. Conclusions
- Direct mathematical modeling was minimized during the design process of the vehicle. It leads to simplification. However, according to the data representation of the issue (for each analyzed task), the specificity of the object can be taken into account (parameters, nonlinearities, disturbances, etc.).
- Multilayer perceptron neural networks and deep neural networks can be utilized in autonomous vehicles used with low-cost hardware (programmable devices).
- The novel idea of the neural distance estimator allows us to enhance the sensing precision of results. Not only is measurement error minimalized, but computing time is also optimized. That is an advantage in the applications such as autonomous vehicles, where reaction should be immediate. Taking into consideration that the relative error was reduced to only ~1.5% using cheap model sensors, even better results may be obtained utilizing more sophisticated hardware.
- The analyzed structure of neural adaptive speed controller confirms that online tuning of a speed controller is efficient. The main advantage of the control structure is the fact that the transient of speed does not contain overshoots and oscillations after the few adaptation steps. It is worth indicating that the adaptation is an automatized process based on the response of the model.
- Convolutional networks can be easily implemented as neural object classifiers utilizing TensorFlow libraries and additional training features such as aXeleRate libraries. The best classification efficiency for the tested dataset and road sign recognition problem was obtained with a MobileNet neural model.
- A vision system with neural data computing can be implemented with low-cost hardware. A fully working system was achieved with a Sipeed Maix Bit board and OV2640 camera. Because of the variety of supported communication modules, the vision system may be easily connected with most control systems available in the market. The utilized hardware cost can be calculated at about USD 40.
- The design and implementation of this project has proven that low-cost hardware may be used to develop an effective working platform capable of autonomous operation in defined conditions. Such platforms may be implemented in industry as in-plant deliveries. The system may be easily equipped with a wireless transmission module such as Bluetooth or Wi-Fi to send data to a cloud, enabling the smart management of a swarm of platforms.
- Further research will be focused on energy consumption optimization to make the platforms independent of external power sources and to reduce maintenance time required for charging. Alternative renewable energy sources are considered to be added.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADC | Analog to Digital Converter |
| AI | Artificial Intelligence |
| DC | Direct Current |
| FDM | Fused Deposition Modeling |
| FPGA | Field-Programmable Gate Array |
| GPS | Global Positioning System |
| GPU | Graphics Processing Unit |
| I2C | Inter-Integrated Circuit |
| MLP | Multilayer Perceptron |
| SAE | Society of Automotive Engineers |
| UAV | Unmanned Aerial Vehicle |
| UART | Universal Asynchronous Receiver-Transmitter |
| Symbols | |
| distance to obstacle | |
| voltage level measured with ADC | |
| element of target matrix | |
| general symbol of input value | |
| general symbol of matrix of output values | |
| general symbol of matrix of input values | |
| weight of i-th neuron node in j-th layer | |
| lf | distance to an obstacle in front of model |
| lr | distance to an obstacle on right side |
| ll | distance to an obstacle on left side |
| k | number of samples. |
| damping coefficient | |
| resonant frequency | |
| speed error | |
| model reference speed error | |
| reference speed | |
| model reference speed | |
| control signal | |
| measured speed of motor | |
| speed controller input vector | |
| integral gain | |
| bias of i-th neuron node in j-th layer | |
| correction value of weight | |
| general symbol of output value | |
| speed of left wheels | |
| speed of right wheels | |
| input of ReLU function | |
| classification efficiency | |
| number of correctly classified samples | |
| number of samples in dataset |
References
- Chen, Z.; Yang, C.; Fang, S. A Convolutional Neural Network-Based Driving Cycle Prediction Method for Plug-in Hybrid Electric Vehicles with Bus Route. IEEE Access 2019, 8, 3255–3264. [Google Scholar] [CrossRef]
- Caban, J.; Nieoczym, A.; Dudziak, A.; Krajka, T.; Stopková, M. The Planning Process of Transport Tasks for Autonomous Vans—Case Study. Appl. Sci. 2022, 12, 2993. [Google Scholar] [CrossRef]
- Vodovozov, V.; Aksjonov, A.; Petlenkov, E.; Raud, Z. Neural Network-Based Model Reference Control of Braking Electric Vehicles. Energies 2021, 14, 2373. [Google Scholar] [CrossRef]
- Bołoz, L.; Biały, W. Automation and Robotization of Underground Mining in Poland. Appl. Sci. 2020, 10, 7221. [Google Scholar] [CrossRef]
- Rahman, A.; Jin, J.; Cricenti, A.; Rahman, A.; Palaniswami, M.; Luo, T. Cloud-Enhanced Robotic System for Smart City Crowd Control. J. Sens. Actuator Netw. 2016, 5, 20. [Google Scholar] [CrossRef] [Green Version]
- Amicone, D.; Cannas, A.; Marci, A.; Tortora, G. A Smart Capsule Equipped with Artificial Intelligence for Autonomous Delivery of Medical Material through Drones. Appl. Sci. 2021, 11, 7976. [Google Scholar] [CrossRef]
- Iclodean, C.; Cordos, N.; Varga, B.O. Autonomous Shuttle Bus for Public Transportation: A Review. Energies 2020, 13, 2917. [Google Scholar] [CrossRef]
- Fernández-Caramés, T.M.; Blanco-Novoa, O.; Froiz-Míguez, I.; Fraga-Lamas, P. Towards an Autonomous Industry 4.0 Warehouse: A UAV and Blockchain-Based System for Inventory and Traceability Applications in Big Data-Driven Supply Chain Management. Sensors 2019, 19, 2394. [Google Scholar] [CrossRef] [Green Version]
- Barabás, I.; Todoruţ, A.; Cordoş, N.; Molea, A. Current challenges in autonomous driving. IOP Conf. Ser. Mater. Sci. Eng. 2017, 252, 012096. [Google Scholar] [CrossRef]
- Du, L.; Wang, Z.; Wang, L.; Zhao, Z.; Su, F.; Zhuang, B.; Boulgouris, N.V. Adaptive Visual Interaction Based Multi-Target Future State Prediction For Autonomous Driving Vehicles. IEEE Trans. Veh. Technol. 2019, 68, 4249–4261. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Chang, H.; Park, Y.I. Influencing factors on social acceptance of autonomous vehicles and policy implications. In Proceedings of the Portland International Conference on Management of Engineering and Technology (PICMET), Honolulu, HI, USA, 19–23 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wanless, O.C.; Gettel, C.D.; Gates, C.W.; Huggins, J.K.; Peters, D.L. Education and licensure requirements for automated motor vehicles. In Proceedings of the 2019 IEEE International Symposium on Technology and Society (ISTAS), Medford, MA, USA, 15–16 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Koelln, G.; Klicker, M.; Schmidt, S. Comparison of the Results of the System Theoretic Process Analysis for a Vehicle SAE Level four and five. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems, Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Fang, X.; Li, H.; Tettamanti, T.; Eichberger, A.; Fellendorf, M. Effects of Automated Vehicle Models at the Mixed Traffic Situation on a Motorway Scenario. Energies 2022, 15, 2008. [Google Scholar] [CrossRef]
- Kaminski, M. Nature-Inspired Algorithm Implemented for Stable Radial Basis Function Neural Controller of Electric Drive with Induction Motor. Energies 2020, 13, 6541. [Google Scholar] [CrossRef]
- Li, J.; Zhang, D.; Ma, Y.; Liu, Q. Lane Image Detection Based on Convolution Neural Network Multi-Task Learning. Electronics 2021, 10, 2356. [Google Scholar] [CrossRef]
- Rodríguez-Abreo, O.; Velásquez, F.A.C.; de Paz, J.P.Z.; Godoy, J.L.M.; Guendulain, C.G. Sensorless Estimation Based on Neural Networks Trained with the Dynamic Response Points. Sensors 2021, 21, 6719. [Google Scholar] [CrossRef] [PubMed]
- Zawirski, K.; Pajchrowski, T.; Nowopolski, K. Application of adaptive neural controller for drive with elastic shaft and variable moment of inertia. In Proceedings of the 2015 17th European Conference on Power Electronics and Applications (EPE’15 ECCE-Europe), Geneva, Switzerland, 8–10 September 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Zychlewicz, M.; Stanislawski, R.; Kaminski, M. Grey Wolf Optimizer in Design Process of the Recurrent Wavelet Neural Controller Applied for Two-Mass System. Electronics 2022, 11, 177. [Google Scholar] [CrossRef]
- Tarczewski, T.; Niewiara, L.; Grzesiak, L.M. Torque ripple minimization for PMSM using voltage matching circuit and neural network based adaptive state feedback control. In Proceedings of the 2014 16th European Conference on Power Electronics and Applications, Lappeenranta, Finland, 26–28 August 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Orlowska-Kowalska, T.; Szabat, K. Neural-Network Application for Mechanical Variables Estimation of a Two-Mass Drive System. IEEE Ind. Electron. Mag. 2007, 54, 1352–1364. [Google Scholar] [CrossRef]
- Little, C.L.; Perry, E.E.; Fefer, J.P.; Brownlee, M.T.J.; Sharp, R.L. An Interdisciplinary Review of Camera Image Collection and Analysis Techniques, with Considerations for Environmental Conservation Social Science. Data 2020, 5, 51. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Bouguezzi, S.; Ben Fredj, H.; Belabed, T.; Valderrama, C.; Faiedh, H.; Souani, C. An Efficient FPGA-Based Convolutional Neural Network for Classification: Ad-MobileNet. Electronics 2021, 10, 2272. [Google Scholar] [CrossRef]
- Wang, J.; Li, M.; Jiang, W.; Huang, Y.; Lin, R. A Design of FPGA-Based Neural Network PID Controller for Motion Control System. Sensors 2022, 22, 889. [Google Scholar] [CrossRef]
- Barba-Guaman, L.; Naranjo, J.E.; Ortiz, A. Deep Learning Framework for Vehicle and Pedestrian Detection in Rural Roads on an Embedded GPU. Electronics 2020, 9, 589. [Google Scholar] [CrossRef] [Green Version]
- Anderson, M. The road ahead for self-driving cars: The AV industry has had to reset expectations, as it shifts its focus to level 4 autonomy [News]. IEEE Spectr. 2020, 57, 8–9. [Google Scholar] [CrossRef]
- Klimenda, F.; Cizek, R.; Pisarik, M.; Sterba, J. Stopping the Mobile Robotic Vehicle at a Defined Distance from the Obstacle by Means of an Infrared Distance Sensor. Sensors 2021, 21, 5959. [Google Scholar] [CrossRef]
- Li, Z.; Marsh, J.H.; Hou, L. High Precision Laser Ranging Based on STM32 Microcontroller. In Proceedings of the 2020 International Conference on UK-China Emerging Technologies (UCET), Glasgow, UK, 20–21 August 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Lakovic, N.; Brkic, M.; Batinic, B.; Bajic, J.; Rajs, V.; Kulundzic, N. Application of low-cost VL53L0X ToF sensor for robot environment detection. In Proceedings of the 2019 18th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 20–22 March 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Raihana, K.K.; Hossain, S.; Dewan, T.; Zaman, H.U. Auto-Moto Shoes: An Automated Walking Assistance for Arthritis Patients. In Proceedings of the 2018 2nd International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 4–5 May 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Popov, A.V.; Sayarkin, K.S.; Zhilenkov, A.A. The scalable spiking neural network automatic generation in MATLAB focused on the hardware implementation. In Proceedings of the 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Moscow and St. Petersburg, Russia, 29 January–1 February 2018; pp. 962–965. [Google Scholar] [CrossRef]
- Al-Shargabi, A.A.; Almhafdy, A.; Ibrahim, D.M.; Alghieth, M.; Chiclana, F. Tuning Deep Neural Networks for Predicting Energy Consumption in Arid Climate Based on Buildings Characteristics. Sustainability 2021, 13, 12442. [Google Scholar] [CrossRef]
- Demuth, H.; Beale, M.; Hagan, M. Neural Network Toolbox 6. User’s Guide; The MathWorks: Natick, MA, USA, 2008. [Google Scholar]
- Desikan, R.; Burger, D.; Keckler, S.W. Measuring experimental error in microprocessor simulation. In Proceedings of the 28th Annual International Symposium on Computer Architecture, Goteborg, Sweden, 30 June–4 July 2002. [Google Scholar] [CrossRef]
- Balasubramaniam, G. Towards Comprehensible Representation of Controllers using Machine Learning. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019. [Google Scholar] [CrossRef]
- Singh, J.; Chouhan, P.S. A new approach for line following robot using radius of path curvature and differential drive kinematics. In Proceedings of the 2017 6th International Conference on Computer Applications In Electrical Engineering-Recent Advances (CERA), Roorkee, India, 5–7 October 2017; pp. 497–502. [Google Scholar] [CrossRef]
- Derkach, M.; Matiuk, D.; Skarga-Bandurova, I. Obstacle Avoidance Algorithm for Small Autonomous Mobile Robot Equipped with Ultrasonic Sensors. In Proceedings of the IEEE 11th International Conference on Dependable Systems, Services and Technologies (DESSERT), Kyiv, Ukraine, 14–18 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 236–241. [Google Scholar] [CrossRef]
- Bose, B.K. Neural Network Applications in Power Electronics and Motor Drives—An Introduction and Perspective. IEEE Trans. Ind. Electron. 2007, 54, 14–33. [Google Scholar] [CrossRef]
- Kamiński, M.; Szabat, K. Adaptive Control Structure with Neural Data Processing Applied for Electrical Drive with Elastic Shaft. Energies 2021, 14, 3389. [Google Scholar] [CrossRef]
- Kaminski, M. Adaptive Controller with Neural Signal Predictor Applied for Two-Mass System. In Proceedings of the 2018 23rd International Conference on Methods & Models in Automation & Robotics (MMAR), Miedzyzdroje, Poland, 27–30 August 2018; pp. 247–252. [Google Scholar] [CrossRef]
- Shang, Y. Group pinning consensus under fixed and randomly switching topologies with acyclic partition. Networks Heterog. Media 2014, 9, 553–573. [Google Scholar] [CrossRef]
- Kilic, I.; Aydin, G. Traffic Sign Detection and Recognition Using TensorFlow’ s Object Detection API with a New Benchmark Dataset. In Proceedings of the 2020 International Conference on Electrical Engineering (ICEE), Istanbul, Turkey, 25–27 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Swaminathan, V.; Arora, S.; Bansal, R.; Rajalakshmi, R. Autonomous Driving System with Road Sign Recognition using Convolutional Neural Networks. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019. [Google Scholar] [CrossRef]
- Hamdi, S.; Faiedh, H.; Souani, C.; Besbes, K. Road signs classification by ANN for real-time implementation. In Proceedings of the 2017 International Conference on Control, Automation and Diagnosis (ICCAD), Hammamet, Tunisia, 19–21 January 2017; pp. 328–332. [Google Scholar] [CrossRef]
- Hechri, A.; Mtibaa, A. Automatic detection and recognition of road sign for driver assistance system. In Proceedings of the 2012 16th IEEE Mediterranean Electrotechnical Conference, Yasmine Hammamet, Tunisia, 25–28 March 2012; pp. 888–891. [Google Scholar] [CrossRef]
- Arora, D.; Garg, M.; Gupta, M. Diving deep in Deep Convolutional Neural Network. In Proceedings of the 2020 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 18–19 December 2020; pp. 749–751. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ertam, F.; Aydın, G. Data classification with deep learning using Tensorflow. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 755–758. [Google Scholar] [CrossRef]
- Maslov, D. Axelerate Keras-Based Framework for AI on the Edge. MIT. Available online: https://github.com/AIWintermuteAI/aXeleRate (accessed on 20 September 2021).
- Gavai, N.R.; Jakhade, Y.A.; Tribhuvan, S.A.; Bhattad, R. MobileNets for flower classification using TensorFlow. In Proceedings of the 2017 International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 154–158. [Google Scholar] [CrossRef]
- Zhu, X.; Vondrick, C.; Ramanan, D.; Fowlkes, C. Do We Need More Training Data or Better Models for Object Detection? In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, H.; Xie, Q.; Yao, L.; Chen, Q. Research on a Surface Defect Detection Algorithm Based on MobileNet-SSD. Appl. Sci. 2018, 8, 1678. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.G.C.; Huang, C.-W.; Chen, J.-H.; Chen, S.-Y.; Chen, H.-L. AIFood: A Large Scale Food Images Dataset for Ingredient Recognition. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 802–805. [Google Scholar] [CrossRef]
- Stančić, A.; Vyroubal, V.; Slijepčević, V. Classification Efficiency of Pre-Trained Deep CNN Models on Camera Trap Images. J. Imaging 2022, 8, 20. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation (OSDI’16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar] [CrossRef]
- Carneiro, T.; Da Nobrega, R.V.M.; Nepomuceno, T.; Bian, G.-B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Dokic, K.; Martinovic, M.; Mandusic, D. Inference speed and quantisation of neural networks with TensorFlow Lite for Microcontrollers framework. In Proceedings of the 2020 5th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Corfu, Greece, 25–27 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kong, Y.; Han, S.; Li, X.; Lin, Z.; Zhao, Q. Object detection method for industrial scene based on MobileNet. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020; pp. 79–82. [Google Scholar] [CrossRef]
- Rabano, S.L.; Cabatuan, M.K.; Sybingco, E.; Dadios, E.P.; Calilung, E.J. Common Garbage Classification Using MobileNet. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio, Philippines, 29 November–2 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Zhu, F.; Liu, C.; Yang, J.; Wang, S. An Improved MobileNet Network with Wavelet Energy and Global Average Pooling for Rotating Machinery Fault Diagnosis. Sensors 2022, 22, 4427. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calculation Method | Time [µs] |
|---|---|
| Neural estimation | ~550 |
| Equation-based calculation | ~1200 |
| Optical Sharp Sensor | Digital VL53L0X Sensor | Neural Estimator | |
|---|---|---|---|
| Max error value | 42.63% | 79.8% | 8.42% |
| Average error value | 11.28% | 17.7% | 1.23% |
| Road Sign | Command | Description |
|---|---|---|
 | “No entry” | The vehicle stops and reverses |
 | “Give way” | The vehicle slows down for 1 s |
 | “STOP” | The vehicle stops and then accelerates |
 | “Roundabout” | The vehicle rotates 360° |
 | “Turn left” | The vehicle turns left (vl=0) |
 | “Turn right” | The vehicle turns right (vr=0) |
| Neural Model | Classification Efficiency P [%] | Number of Parameters | Number of Trainable Parameters | Training Time [Minutes] | TensorFlow Lite Model Size [MB] |
|---|---|---|---|---|---|
| MobileNet1_0 | 86.7 | 3,479,518 | 2,357,630 | 3 | 13.16 |
| MobileNet5_0 | 100 | 977,790 | 966,846 | 3 | 3.68 |
| MobileNet7_5 | 73.3 | 2,032,430 | 2,016,014 | 3 | 7.67 |
| MobileNet2_5 | 93.3 | 315,598 | 310,126 | 4 | 1.18 |
| Tiny Yolo | 33.3 | 2,372,206 | 2,369,694 | 3 | 9.04 |
| SqueezeNet | 40 | 870,750 | 870,750 | 1 | 3.33 |
| NASNetMobile | 26.7 | 4,526,770 | 4,490,032 | 29 | 17.24 |
| ResNet50 | 46.7 | 24,043,166 | 23,990,046 | 8 | 91.33 |
| Estimated distance range [mm] | 200–270 | 271–350 | 351–450 | 451–550 | 551–650 | 651–750 | 751–850 | 851–950 |
| Width of bounding box [pixels] | 325–240 | 239–175 | 174–125 | 124–105 | 104–85 | 84–72 | 71–62 | 61–54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malarczyk, M.; Tapamo, J.-R.; Kaminski, M. Application of Neural Data Processing in Autonomous Model Platform—A Complex Review of Solutions, Design and Implementation. Energies 2022, 15, 4766. https://doi.org/10.3390/en15134766
Malarczyk M, Tapamo J-R, Kaminski M. Application of Neural Data Processing in Autonomous Model Platform—A Complex Review of Solutions, Design and Implementation. Energies. 2022; 15(13):4766. https://doi.org/10.3390/en15134766
Chicago/Turabian StyleMalarczyk, Mateusz, Jules-Raymond Tapamo, and Marcin Kaminski. 2022. "Application of Neural Data Processing in Autonomous Model Platform—A Complex Review of Solutions, Design and Implementation" Energies 15, no. 13: 4766. https://doi.org/10.3390/en15134766
APA StyleMalarczyk, M., Tapamo, J.-R., & Kaminski, M. (2022). Application of Neural Data Processing in Autonomous Model Platform—A Complex Review of Solutions, Design and Implementation. Energies, 15(13), 4766. https://doi.org/10.3390/en15134766