
A Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception Method Based on Heterogeneous Sensors

Abstract
:1. Introduction
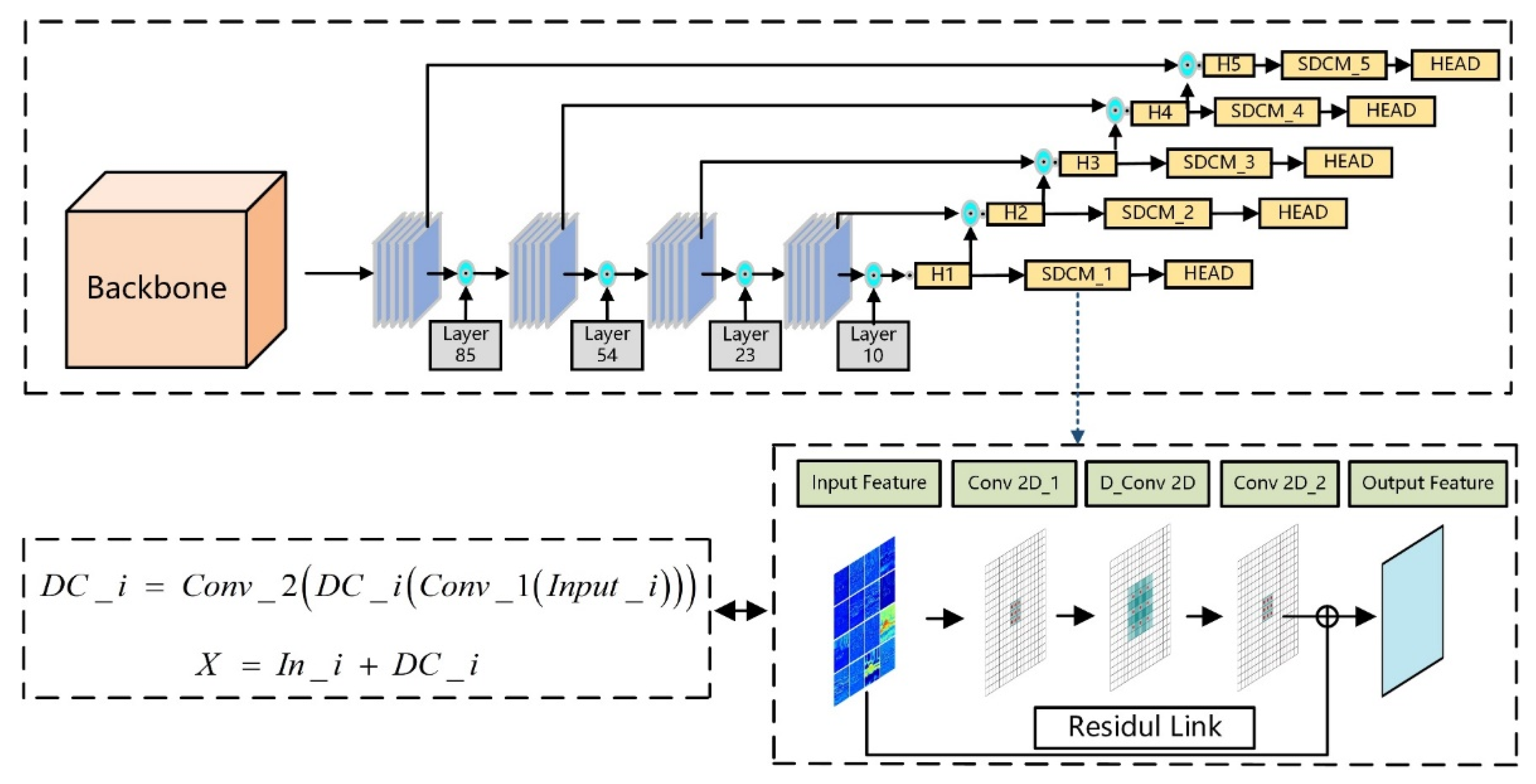
- Proposed a spatial dilated convolution module (SDCM) that uses spatial dilated convolution. It was incorporated into the YOLOv4 algorithm, in order to improve the algorithm’s detection accuracy, without increasing its computational load.
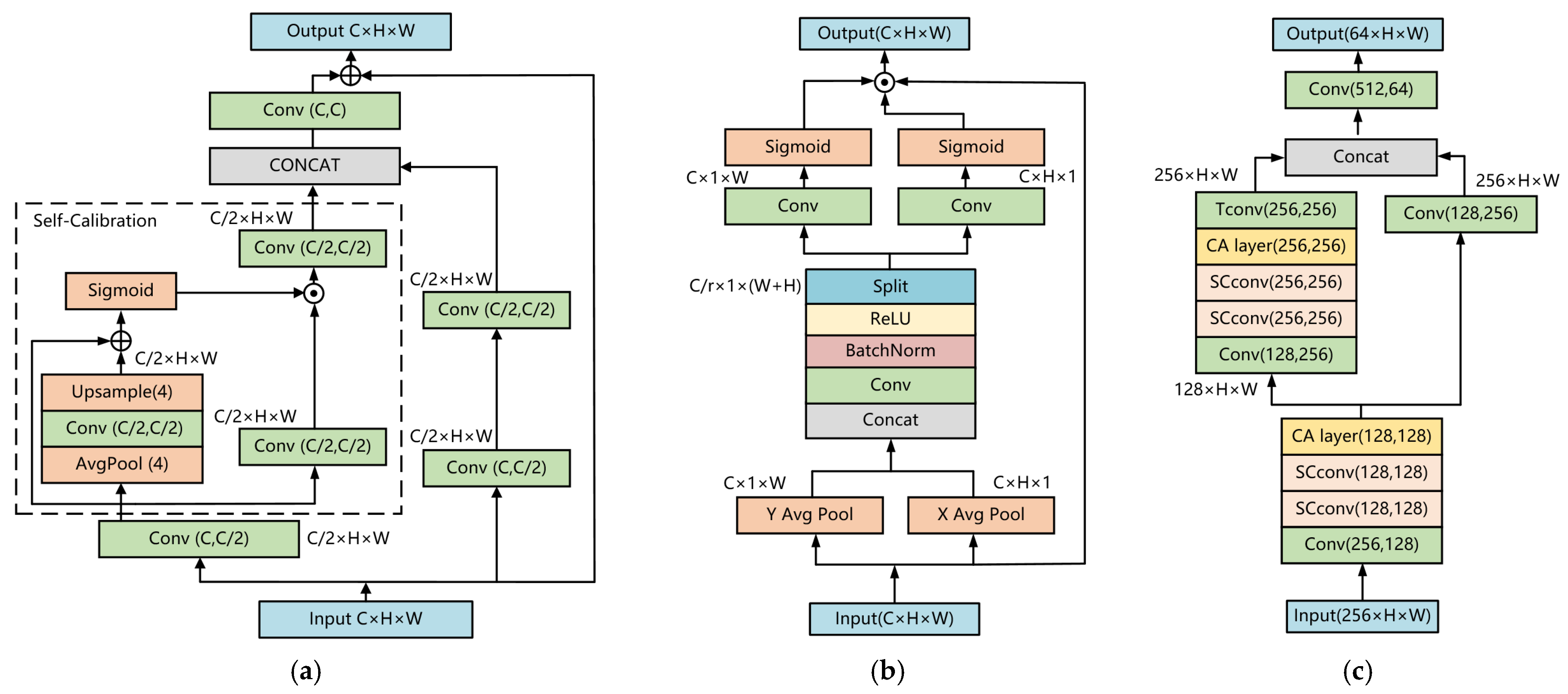
- Based on the CenterPoint network, the backbone was enhanced by substituting the original traditional convolutional layer with a self-calibrated convolutions layer, and by adding coordinate attention and residual structure, which effectively improves the network’s feature extraction capability.
- Proposed and constructed a collaborative sensing platform with high flexibility for road vehicles; set cooperative perception modes and deployed perception algorithm on the basis of various scenes; and selected the intersection to conduct the beyond visual range perception experiment.
2. Related Studies
2.1. Multi-Object Detection Based on Vision
2.2. 3D Multi-Object Detection Based on LiDAR
2.3. Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception
3. Methodology
3.1. 2D Multi-Object Detection Algorithm YOLOv4-SDCM
3.2. 3D Multi-Object Detection Algorithm Centerpoint-FE
3.2.1. 2D Backbone Network Improvement
3.2.2. 3D Backbone Network Improvement
3.3. Algorithm of beyond Visual Range Perception Based on Vehicle-to-Infrastructure
4. Experiments and Results
4.1. 2D Multi-Object Detection Algorithm YOLOv4-SDCM
4.2. 3D Multi-Object Detection Algorithm Centerpoint-FE
4.3. Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception Test
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, H.; Xu, Y.; He, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 2515612. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust Target Recognition and Tracking of Self-Driving Cars With Radar and Camera Information Fusion Under Severe Weather Conditions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6640–6653. [Google Scholar] [CrossRef]
- Luo, T.; Wang, H.; Cai, Y.; Chen, L.; Wang, K.; Yu, Y. Binary Residual Feature Pyramid Network: An Improved Feature Fusion Module Based on Double-Channel Residual Pyramid Structure for Autonomous Detection Algorithm. IET Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-End Learning for Point Cloud Based 3d Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, C.; Zeng, H.; Huang, J.; Hua, X.-S.; Zhang, L. Structure Aware Single-Stage 3d Object Detection from Point Cloud. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-Cnn: Towards High Performance Voxel-Based 3d Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Ge, R.; Ding, Z.; Hu, Y.; Wang, Y.; Chen, S.; Huang, L.; Li, Y. Afdet: Anchor Free One Stage 3d Object Detection. arXiv 2020, arXiv:2006.12671. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-Based 3d Object Detection and Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Dong, C.; Chen, X.; Dong, H.; Yang, K.; Guo, J.; Bai, Y. Research on Intelligent Vehicle Infrastructure Cooperative System Based on Zigbee. In Proceedings of the 2019 5th International Conference on Transportation Information and Safety (ICTIS), Liverpool, UK, 14–17 July 2019; pp. 1337–1343. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling (and a Strong Convolutional Baseline). In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Meng, D.; Li, L.; Liu, X.; Li, Y.; Yang, S.; Zha, Z.-J.; Gao, X.; Wang, S.; Huang, Q. Parsing-Based View-Aware Embedding Network for Vehicle Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7103–7112. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A Deep Learning-Based Approach to Progressive Vehicle Re-Identification for Urban Surveillance; Springer: Berlin/Heidelberg, Germany, 2016; pp. 869–884. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A Strong Baseline and Batch Normalization Neck for Deep Person Re-Identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Jiang, W.; Zhang, X.; Fan, X.; Qian, J.; Zhang, C. AlignedReID++: Dynamically Matching Local Information for Person Re-Identification. Pattern Recognit. 2019, 94, 53–61. [Google Scholar] [CrossRef]
- Wu, C.-W.; Liu, C.-T.; Chiang, C.-E.; Tu, W.-C.; Chien, S.-Y. Vehicle Re-Identification with the Space-Time Prior. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 121–128. [Google Scholar]
- Jiang, N.; Xu, Y.; Zhou, Z.; Wu, W. Multi-Attribute Driven Vehicle Re-Identification with Spatial-Temporal Re-Ranking. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 858–862. [Google Scholar]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative Perception for Connected Autonomous Vehicles Based on 3d Point Clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 514–524. [Google Scholar]
- Vadivelu, N.; Ren, M.; Tu, J.; Wang, J.; Urtasun, R. Learning to Communicate and Correct Pose Errors. arXiv 2020, arXiv:2011.05289. [Google Scholar]
- Wang, T.-H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction; Springer: Berlin/Heidelberg, Germany, 2020; pp. 605–621. [Google Scholar]
- Rauch, A.; Klanner, F.; Rasshofer, R.; Dietmayer, K. Car2x-Based Perception in a High-Level Fusion Architecture for Cooperative Perception Systems. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 270–275. [Google Scholar]
- Rawashdeh, Z.Y.; Wang, Z. Collaborative Automated Driving: A Machine Learning-Based Method to Enhance the Accuracy of Shared Information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3961–3966. [Google Scholar]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A Comparative Study of State-of-the-Art Deep Learning Algorithms for Vehicle Detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z. One Million Scenes for Autonomous Driving: Once Dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map Index | Size | Dilation Ratio |
|---|---|---|
| 0 | 19 × 19 | 4 |
| 1 | 38 × 38 | 3 |
| 2 | 76 × 76 | 2 |
| 3 | 152 × 152 | 1 |
| 4 | 304 × 304 | 1 |
| Faster R-CNN | YOLOv4 | SDCM- YOLOv4 | |
|---|---|---|---|
| Car | 0.8012 | 0.7902 | 0.8036 (+1.34%) |
| Person | 0.6501 | 0.6387 | 0.6422 (+0.35%) |
| Bus | 0.6754 | 0.6525 | 0.6936 (+2.51%) |
| Truck | 0.6589 | 0.6739 | 0.6928 (+1.90%) |
| Traffic light | 0.5628 | 0.5830 | 0.5807 (−0.23%) |
| Traffic sign | 0.7018 | 0.7216 | 0.7218 (+0.02%) |
| Bike | 0.5098 | 0.5128 | 0.5140 (+0.12%) |
| [email protected] | 0.6385 | 0.6590 | 0.6755 (+1.65%) |
| FPS | 10.8 | 52.2 | 50.4 |
| Method | Vehicle | Pedestrian | Cyclist | mAP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Overall | 0–30 m | 30–50 m | 50 m-inf | Overall | 0–30 m | 30–50 m | 50 m-inf | Overall | 0–30 m | 30–50 m | 50 m-inf | ||
| CenterPoint (Org) | 66.79 | 80.10 | 59.55 | 43.39 | 49.90 | 56.24 | 42.61 | 26.27 | 63.45 | 74.28 | 57.94 | 41.48 | 60.05 |
| CenterPoint (Retrain) | 76.11 | 86.81 | 70.44 | 56.62 | 49.01 | 57.81 | 42.73 | 22.55 | 64.93 | 76.54 | 59.95 | 41.60 | 63.35 |
| CenterPoint (ours) | 78.12 | 87.72 | 72.23 | 62.05 | 52.73 | 61.76 | 45.88 | 26.47 | 68.93 | 80.29 | 62.41 | 47.39 | 66.60 |
| Improvement | 2.01 | 0.91 | 1.89 | 5.43 | 3.72 | 3.95 | 3.15 | 3.92 | 4.00 | 3.75 | 2.46 | 5.79 | 3.25 |
| SC Conv | CA Layer | Residual Block | mAP | FPS |
|---|---|---|---|---|
| 63.35 | 27.17 | |||
| ✓ | 64.33 | 23.28 | ||
| ✓ | ✓ | 64.89 | 21.63 | |
| ✓ | ✓ | ✓ | 66.60 | 21.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, T.; Chen, L.; Luan, T.; Li, Y.; Li, Y. A Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception Method Based on Heterogeneous Sensors. Energies 2022, 15, 7956. https://doi.org/10.3390/en15217956
Luo T, Chen L, Luan T, Li Y, Li Y. A Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception Method Based on Heterogeneous Sensors. Energies. 2022; 15(21):7956. https://doi.org/10.3390/en15217956
Chicago/Turabian StyleLuo, Tong, Long Chen, Tianyu Luan, Yang Li, and Yicheng Li. 2022. "A Vehicle-to-Infrastructure beyond Visual Range Cooperative Perception Method Based on Heterogeneous Sensors" Energies 15, no. 21: 7956. https://doi.org/10.3390/en15217956