1. Introduction
The possibility of predicting European Union Allowance (EUA) price level is extremely important, especially from the viewpoint of companies whose production process is inherently related to carbon dioxide (CO2) emissions. As part of the European Union Emission Trading System (EU ETS), these entities are tasked with reducing their CO2 emissions, but in the case of no action being taken against CO2 emitting, they must settle this with purchased or assigned EUA units. This applies to both the energy sector using non-renewable fuels and companies from cement, refinery, coke sectors and many other industry sectors in which emissions occur in the production process. Moreover, this market has become attractive in terms of investment, which has resulted in the accession of many financial entities such as banks and investment funds. This increased the number of participants in the system, which resulted in a greater trading volume and the unpredictability of prices. In recent months, EUA prices have reached over EUR 90 per ton and are already over 150% more expensive than at the beginning of 2021. This has made the CO2 emissions trading system a costly burden, especially for industry and energy which depend on coal. For this reason, the knowledge of the problem of price volatility of CO2 emissions and the possibility of its prediction has become necessary to make profitable decisions by entrepreneurs and, therefore, it is a complex issue that requires a scientific approach.
According to [
1] prediction models for carbon price developed so far are divided into these types:
- -
prediction model using the econometric method;
- -
prediction model based on artificial intelligence algorithms;
- -
combined prediction model.
The traditional statistical and econometric models are widely used for carbon price forecasting. The first group includes IA models for price volatility expanding the scope from models of type Generalized Autoregressive Conditional Heteroskedasticity (GARCH) to models with long-term dependence and regime switches including the class of so-called multifractal models. Ref. [
2] used a non-parametric method to estimate carbon prices and found that the method could reduce the prediction error by almost 15% compared with linear autoregression models. Ref. [
3] applied multivariate GARCH models to estimate the volatility spillover effects amongst the spot and futures allowance markets during the Phase II period. Different GARCH-type models to predict the volatility of carbon futures were explored by [
4]. The conditional variance of carbon emissions prices using various GARCH models was examined by [
5]. Ref. [
6] point out the suitability of applying asymmetric GARCH models for modelling the volatility of carbon allowance prices. Ref. [
7] applied these models to carbon dioxide emission allowance prices from the European Union Emission Trading Scheme and evaluated their performance with up-to-date model comparison tests based on out-of-sample forecasts of future volatility and value at risk. Ref. [
8] developed a combination-MIDAS regression model to perform real-time forecasts for the weekly carbon price, using the latest revealed high-frequency economic and energy data. The authors analyze the forecasting interactions among carbon price, economic and energy variables at the mixed frequencies, and assess the nowcasting performances of the combination-MIDAS regression models by comparing the root mean squared errors (RMSE). Ref. [
9] used asymmetric GARCH processes (EGARCH and GJR-GARCH) to model the asymmetric volatility in emission prices and analyzed how good and bad news impact the EUA market volatility under structural breaks.
The second group of models includes IA a short-term prediction model based on Neural Networks for forecasting carbon prices of the European Union Emissions Trading Scheme in phase III. Ref. [
10] have proposed a Multi-Layer Perceptron (MLP) network model, based on the reconstruction technique of phase space. Ref. [
11] proposed the following computational intelligence techniques: a novel hybrid neuro-fuzzy controller with a closed-loop feedback mechanism (PATSOS); a neural network-based system; and an adaptive neuro-fuzzy inference system (ANFIS). This is the first approach to putting a hybrid neuro-fuzzy controller into forecasting carbon prices. Whereas [
12] proposed, for carbon price forecasting, a novel multiscale nonlinear ensemble leaning paradigm incorporating Empirical Mode Decomposition (EMD) and Least Square Support Vector Machine (LSSVM) with a kernel function prototype. Ref. [
1] developed presented a new carbon price prediction model applied by using a time series complex network analysis technology and an extreme learning machine algorithm (ELM). In that model, the authors’ first stage map of the carbon price data was mapped into a carbon price network (CPN). In the second stage, the effective information of carbon price fluctuations by net-work topology is extracted and the extracted effective information is applied to reconstruct the carbon price sample data.
Ref. [
13] proposed several novel hybrid methodologies that exploit the unique strength of the traditional Autoregressive Integrated Moving Average (ARIMA) and the least squares support vector machine (LSSVM) models in forecasting carbon prices. Additionally, Particle Swarm Optimization (PSO) is used to find the optimal parameters of LSSVM to improve the prediction accuracy. An empirical mode decomposition-based evolutionary least squares support vector regression multiscale ensemble forecasting model for carbon price forecasting was proposed in the study of [
14]. To obtain better estimation results, a hybrid model conjunctive Complete Ensemble Empirical Mode Decomposition (CEEMD), Co-Integration Model (CIM), GARCH and Grey Neural Network (GNN) with Ant Colony Algorithm (ACA) was presented by [
15]. Ref. [
16] developed a hybrid decomposition and integration prediction model using the Hodrick–Prescott filter, an improved grey model and an extreme learning machine.
The EMD–GARCH model that combined integrated empirical mode decomposition (EMD) with generalized autoregressive conditionally heteroskedastic (GARCH) was presented by [
17] to forecast the carbon price of the five pilots (Shenzhen, Shanghai, Beijing, Guangdong and Tianjin) in 2016. The mode decomposition and GARCH model integrated with a Long Short-Term Memory (LSTM) network for carbon price forecasting was proposed in a more recent publication [
18].
Two main trends can be distinguished from the approaches mentioned above: methods in which EUA price prediction is based on time-series data using price-only forecasting (for example [
2,
3,
18]) and methods that use factors influencing the EUA price prediction (for example [
8,
19]).
Ref. [
7] have focused their studies on the significance of energy prices (oil, gas, coal and electricity) and weather (temperatures and radical weather phenomenon) in the influence of carbon prices. Ref. [
20] explored vital factors with an impact on the price of emission allowances in the EU trading system in the years 2005–2007. They analyzed the policy, regulations and market factors: weather and production levels with technical indicators.
Ref. [
19] developed a model to predict daily carbon emissions price changes by taking the analysis rationality of pricing behavior based on weather and non-weather variables. Ref. [
21] proved that energy prices and EUA prices can affect each other. Ref. [
22] identified several macroeconomic drivers of EUA prices and examined the correlation between the return on carbon futures and changes in macroeconomic conditions. Ref. [
23] described a significant correlation between carbon prices and stock prices and the index of industrial production. Ref. [
24] indicated that a shock in the EUR/USD exchange rate has an influence on the carbon credit market. Ref. [
25] applied to the carbon price forecast an artificial neural network (ANN) algorithm based on coal, the S&P clean energy index, the DAX index and other variables. Ref. [
26] applied a semiparametric quantile regression model to explore the effects of energy prices (coal, oil and natural gas prices) and macroeconomic drivers on carbon prices at different quantiles.
Thus, according to the literature, there are many non-weather factors that affect the formation of EUA prices. Most analyses, however, are concerned with select indicators and individual stock exchange contracts representing selected products. The aim of the study is to jointly analyze a wide range of fuel and energy indicators, which are contracts determining EUA price trends, and to find an EUA price prediction methodology that will be best to forecast their daily course based on the analyzed set of factors. To address multiple gaps, the contribution of our paper is:
a. Thanks to a careful analysis of 2021,the first year from 4th EU ETS period, which characterized by very high volatility, the work indicates directions of correlation between EUA prices and the prices of other contracts on the fuel and energy market, what can be used to make additional research studies by researchers or could be directly used by industrial plants involved in emissions trading. This is the latest scope of analyzes concerning the EU ETS system changed after period III, which has not been the subject of research by other scientists so far.
b. Another novelty is the wide input data set for the analysis of the EUA price determinants. The applied mathematical models, thanks to which hundreds of data were analyzed, allowed for a significant narrowing of the set as an input data to prediction models. It was considered in this study, as the most important from the point of view of forecast models’ complexity.
c. Non-price factors, such as the impact of decisions shaping the rules of the EU ETS market, for which we proved that had only a limited, short-term impact on EUA prices, were not investigated in similar research.
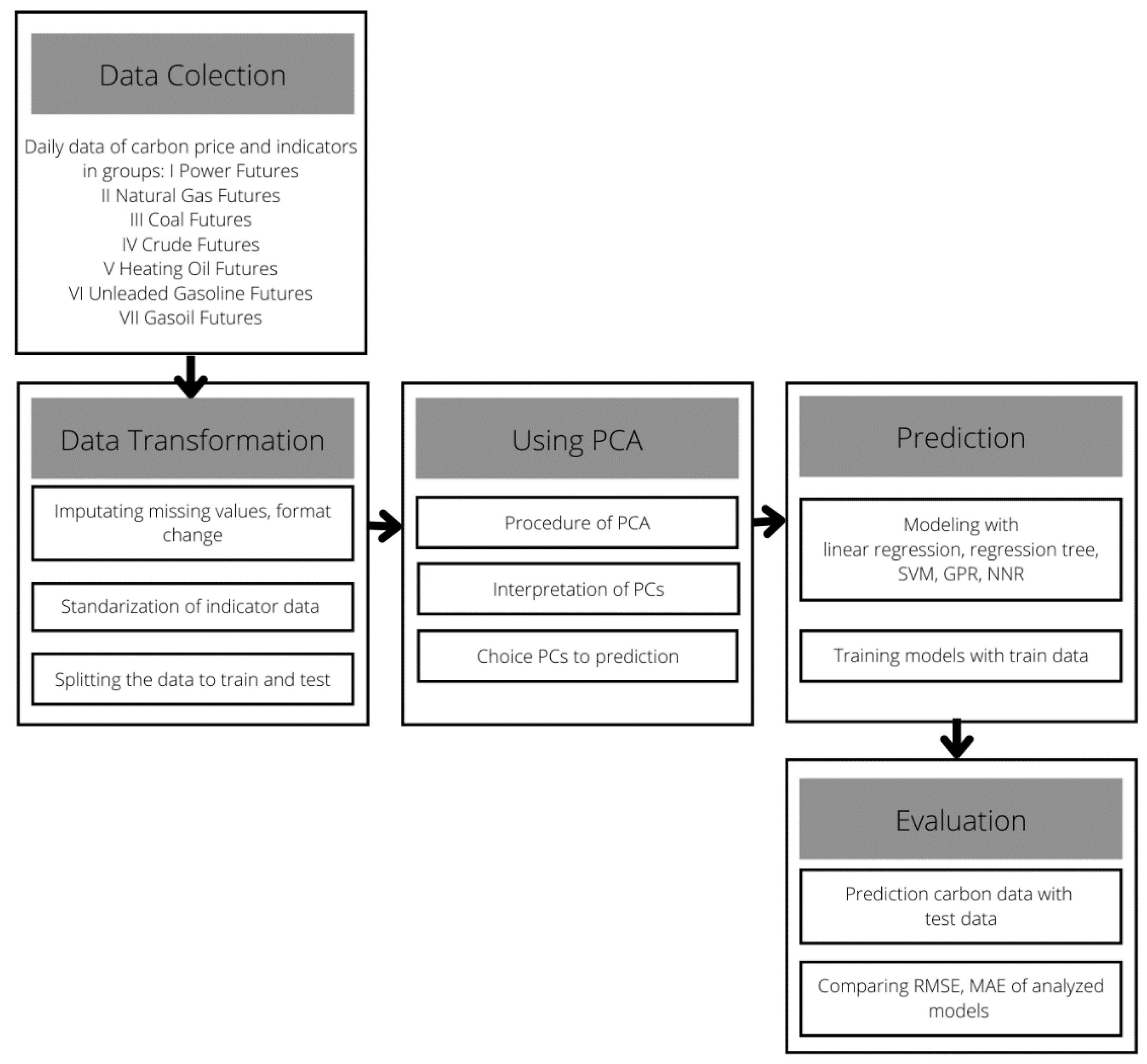
In the proposed approach, by combining the Principal Component Analysis (PCA) method and selected methods of supervised machine learning, the possibilities of predicting the numerical value of the emission price in the period of its rapid growth are explored. The PCA method allows the reduction of the number of variables to the ones used as inputs for predictive models. It also allows this study to list the factors with the decisive value of the variance of the analyzed data space. Among the supervised machine learning methods, these models are compared: regression trees, ensembles of regression trees, Gaussian Process Regression (GPR) models, Support Vector Machines (SVM) models and Neural Network Regression (NNR) models.
There are also studies that use forecasting models in other fields to show the interdisciplinary use of forecasting methods. Ref. [
27] described a functional forecasting method. In particular, a functional autoregressive model of order
P is used to a short-term energy price prediction. The authors propose using a functional final prediction error as a way to selection of the model dimensionality and lag structure. Energy price forecasting is also described in the work of [
28], which proposes a forecasting framework based on big data processing, which selects a small quantity of data to achieve accurate forecasting while reducing the time cost. Price forecasting is difficult due to the specific features of the electricity price series, Ref. [
29] examined the performance of an ensemble-based technique for forecasting short-term electricity spot prices in the Italian electricity market (IPEX). On the other hand, Ref. [
30] proposed a novel interpretable wind speed prediction methodology named VMD-ADE-TFT, which was used to improve the accuracy of forecasts. Ref. [
31], in a further study, described forecasting the U.S oil markets based on social media information during the COVID-19 pandemic. In the studies cited above, it was shown that deep learning can extract textual features from online news automatically. Ref. [
32] performed a comparative analysis for daily peak load forecasting models. They compared the performance of time series, machine learning and hybrid models. The authors proved that hybrid models show significant improvements over the traditional time series model, and single and hybrid LSTM models show no significant performance differences.
The paper is organized as follows:
Section 2 presents works related to the theory of the PCA method. The overall framework of the methodology of the study is demonstrated in
Section 3.
Section 4 analyzes the data used. The experimental results of the proposed approach and discussion about it are presented in
Section 5. The conclusions are reported in the last section.
5. Experimental Results and Discussion
5.1. Principal Component Analysis
For indicators from
Table 1, the PCA method was applied. The variance of data was explained by a relatively small number of PCs (four), which resulted in the selection of four components that should affect the EUA price in 2021. The method reduced the number of input variables for some predictive model to about 10%. The first PC explains over 93% of variance and four first PCs explain together 99.6% of variance (
Figure 6).
Figure 6 presents the results of the PCA method. The details in the table show how much the 15 principal components describe the overall variance of the indicators.
Figure 7 graphically presents the coefficients (contents)
v in formula (4). In the interpretation of the results obtained by use of the PCA, the meaning of each primary indicators in a PC can be determined. The higher the modulus value of an element in the eigenvector, the more important this variable for a PC is.
In PC1, all the coefficients of indicators are positive and not very differentiated; thus, all parameters are positively correlated with the main component that most describes the total variance of the analyzed data. However, these indicators can be identified as having the greatest impact on over 93% of the total variance for the model. These are x1–x16 x18–x25, thus, the products of groups I and II (I Power Futures and II Natural gas Futures).
However, the PC2 with a positive correlation is mainly affected by the variables from the last four groups: IV Crude Futures, V Heating Oil Futures, VI Unleaded Gasoline Futures and VII Gasoil Futures. For the other two groups of indicators, the coefficients are much lower and negative.
The component PC3 mainly represents indicators from the III Coal Futures group and the x17 “NRBNordicPowerFinancialBaseFuture” contract, the values of the remaining indicators negatively affect this input variable, with the largest negative ratio being x9 “FNAFrenchPowerFinancialPeakFuture”.
The indicator “NRBNordicPowerFinancialBaseFuture” is the main factor affecting the value of the fourth surrogate variable (PC4) in prediction models.
To examine which indicators have the greatest impact on the described information, we used the weighted sum of the coefficients for PC1-PC4 modules, where the weights are the percentages of variance described by individual PCs. The results obtained are presented in
Figure 8. The values are very close to each other. The analysis shows that the lowest impact on the described information is due to these indicators: x17 “NRBNordicPowerFinancialBaseFuture”, x26 “AFRRichardsBayCoalFuture”, x28 “GCFglobalCOALRBCoalFuture” and x29 “M42M42IHSMcCloskeyCoalFutures”, hence mainly the indicators from the group III “Coal Futures”.
5.2. Forecasting Day-Ahead Carbon Price by Use of PCA-Based Approach with Supervised Machine Learning
This section presents the use of various predictive data mining methods to explore the possibility of day-ahead predictions of EUA prices based on fuel and energy factors and comparison of methods in this application. The surrogate variables created in the PCA method (constitute inputs for selected prediction methods. The following supervised machine learning techniques are used: regression trees, ensembles of regression trees, Gaussian Process Regression (GPR) models, Support Vector Machines (SVM) models and Neural Network Regression (NNR) models.
To identify the models, daily datasets for carbon price and standardized datasets of 37 indicators (in day-ahead) were randomized into training data and testing data (in 80%/20% ratio). A set of 184 total observations of training data and 46 observations of testing data were obtained. The models were trained using cross-validation with five folds. The cross-validation methodology provides a good estimate of the accuracy of the model prediction after learning with the training dataset. The method uses all data but creates repeated matches. Hence, it is suitable for smaller datasets, like our case. However, multiple matches cause the errors for the training data to be higher than for the model trained once on one dataset, but the predicted accuracy of the model for the testing data is higher because overtraining is avoided. The calculations were made in Matlab and Statistics and Machine Learning Toolbox.
Table 2 presents the results of carbon price predictions with decision tree methods. A decision tree is a hierarchical model composed of decision rules that recursively split independent variables into homogeneous zones [
49]. The literature presents many decision tree applications in real classification and prediction problems. It is a method that requires little memory and training time. The method is also easy to interpret, but due to the large granularity of the output information, it often has a low accuracy of prediction.
Table 2 presents the prediction results for selected simple, medium and complex size decision tree structures and the model fitted with Bayesian optimization to minimize the MSE error function (9). Here, simpler models work better, but their prediction accuracy is not the greatest. Using functional forms of ensemble models such as boosted trees and bagged trees helped slightly. The boosted tree is a model which creates an ensemble of medium decision trees using the LSBoost algorithm. The bagged tree is a bootstrap-aggregated ensemble of complex decision trees [
50]. Among the models, the bagged decision tree has the highest accuracy rate (RMSE 1.6553 for training data and RMSE = 1.7114 for testing data). This model has been adjusted with Bayesian optimization in terms of minimizing the RMSE error by Bag and LSBoost algorithms and these conditions: number of learners: 10–501, learning rate: 0.001–2, minimum leaf size: 1–93 and number of predictors to sample: 1–5. A comparison of the charts of real carbon price and forecasted values and residuals, using optimized medium tree and ensemble tree models, is shown in
Figure 9.
Subsequently, various forms of the SVM method have been used to predict carbon prices. They are SVM with the following kernel functions: quadratic, cubic and Gaussian. Here, the kernel function Fine Gaussian allowed for the best match of the model to the training data (RMSE = 1.8491 for training data and RMSE = 1.9363 for testing data).
In this section, we also used a neural network model. From among the many examined structures, we present the results of analyses for examples with two and three network layers with the ReLu activation function (
Table 3). Neural network of layer size: 11/11/11 turned out to be a better prediction tool compared to the Fine Gaussian SVM because, despite similar errors for the training data, neural networks can better generalize and the RMSE and MAE errors are slightly smaller. A visual comparison of the results can be found in
Figure 10.
Finally, we present an application of the non-parametric, Bayesian machine learning approach. The Gaussian Process Regression model (GPR) works well with small datasets and considers forecast uncertainties. The results of the analyses for the selected model structures are presented in
Table 3. The model was optimized using Bayesian optimization to minimize the MSE error function for the following hyperparameters: various basis functions, kernel functions (isotropic and non-isotropic), kernel scale in the range 0.023975–23.9752 and sigma 0.0001–95.8360. As a result of training, the best GPR model was found to be the model with the following structure: basis function: zero, kernel function: non-isotropic exponential, kernel scale: 0.050335, sigma: 90.5929 and standardize: false. This model seems to be the best solution among the supervised machine learning applications presented above (RMSE = 1.301 for training data and RMSE = 1.349 for testers). The plots of residuals autocorrelation and partial autocorrelation functions for this model are presented in
Figure 11a. The figures show there is a slight dependence on the next residues, which is not significant for evaluating this model. It is worth noting that the GPR model with the isotropic exponential function kernel has the lowest error for the testing data and the residuals are independent of each other (
Figure 11b).
The comparison of the Non-isotropic Exponential GPR model response and the true response for the training data (with cross-validation with 5 folds) is presented in
Figure 12. On average, the observed carbon price values deviate from the forecasts by EUR 1.305/t CO
2 in the train data, which is just over 2.5% of the average carbon price in 2021. For testing data, the average observed carbon price values deviate from the forecasts by EUR 1.339/t CO
2 (slightly above 2.6% of the average carbon price). The variance of the deviation of the predicted values from the real ones for the test data is 1.78, which proves a relatively small dispersion of deviations. The mean absolute percentage error (MAPE) for the train data is 2.16%. Thus, the price prediction for the proposed GPR model can be considered very accurate.
Figure 13 and
Figure 14 show the dependence of the deviations of the actual carbon price from the forecast value in relation to true and predicted values (for train and test data).
Table 4 compares the best PCA-GPR models with the approaches presented in the literature. Based on the mean absolute percentage error (MAPE), which informs us about the average size of forecast errors, we can compare the forecast accuracy of different models. Considering this error for test data as the level prediction ability, our models are better than BPNN model, MOCSCA-KELM model [
51] and VMD-GARCH/LSTM-LSTM model [
18], slightly worse than MLP 3-7-3 model [
10] and significantly worse than Multiple influence factors proposed in [
51]. However, it should be taken into account that the compared models are tested for data from the third and second phase of the EU ETS. This is a period of fairly stabilized emission allowance prices compared to the last fourth phase (started in 2021) where prices are rising drastically and the characteristics of the EU ETS market are unlike anything investors have experienced before 2020.
The largest deviations with the model used in the analyzed period were observed around mid-May, early July, mid-August and October (
Figure 12). They are caused by the influence of other important factors shaping the EUA levels, which determined the direction of the price course. The unnatural increase in the EUA level in 2021, significantly deviating from the direction of the analyzed determinants, was noticeable in May. At that time, record price levels exceeding 55 EUR/EUA were noted. These increases were mainly caused by the new EU targets for reducing CO
2 emissions by 2030. Other important factors were also those of a political nature. Particularly important was the statement of the European Commission official that the decision makers’ top-down stopping of price increases on the EU ETS market was unlikely, which was feared. These concerns resulted from the specific nature of regulating the CO
2 emissions market, which is determined by the EU ETS Directive. Under Article 29a, it is possible to stabilize and regulate EUA prices by placing additional EUAs on the market, but only if several conditions are met. One of those conditions is price increases persisting over a period of over six consecutive months, during which the average EUAs price would over three times exceeded the average for the past two years. This mechanism must not jeopardize the market fundamentals. It was only on May 13 that a correction of the growing EUA trend, caused by a change in market sentiment, was recorded. It resulted in an almost 4% drop in the price level with a trading volume much higher than usual. The reasons for the sudden drop can be found in the general fear of inflation in the US and the declines that occurred in the European markets. In turn, on May 14, after the markets rebounded from inflationary shocks and rising gas prices, the levels of CO
2 emission prices rose again, reaching almost EUR 57/EUA.
Another deviation from the prediction model used occurred for the period falling at the beginning of July. Until the end of June, EUA prices were under the influence of a strong upward trend, mainly due to rising gas prices and the expected reforms in the “Fit for 55” package being introduced. On the last day of June, a doji could be observed on the candlestick charts, which heralded a lack of decisiveness and a possible correction. There was also less interest in purchasing EUAs at government auctions. The direction of EUA prices was reversed, which lasted almost until the end of July. This situation was probably related to the earlier inclusion in the EUA price of the announced “Fit for 55” reforms and a slightly weaker energy and fuel complex.
The deviation from the actual EUA value as of 13 August 2021, as predicted by the mathematical model, resulted from unexpected declines in the gas, coal and electricity markets to which EUA prices reacted after a short time, and the correlation that could be predicted by models was visualized again (
Figure 12).
The last major deviation that appeared during our analyses concerns October 18. It was a time when there was a sudden drop in EUA prices in the real market, which was not shown by the prediction. This decline was probably due to traders’ response to the technical signals seen on the EUA prices charts, predicting further declines after breaking the resistance levels hit that day.
6. Conclusions
This paper proposes a PCA-based approach to day-ahead carbon price predictions based on the wide set of fuel and energy factors. The groups of contracts with the highest degree of correlation with the EUA price levels, representing the most important factors that may affect the EUA price levels, were investigated. In the approach, by combining two methods, the PCA method and selected methods of supervised machine learning, the possibilities of prediction in the period of rapid price increases are shown. The PCA method made it possible to reduce the number of variables from 37 to 4, which are inputs for predictive models. The method also shows that the energy and fuel factors from groups I and II, i.e., Power and Natural Gas Futures, have the greatest impact on over 93% of the total variance of the analyzed data. This proves that EUA prices are the most sensitive to changes caused by energy markets. EUA prices will largely reflect the demand for a type of fuel in this sector. If operating power plants are switched from more expensive gas to cheaper coal (caused by a low gas supply or its excessively high prices), the CO2 emissions will increase and the demand for EUA units will increase. In the case of switch to gaseous fuel in the energy sector, the demand for CO2 emissions will be lower, but electricity prices will be higher due to the use of a more expensive type of fuel.
The paper compares the prediction capabilities using the following supervised machine learning techniques: regression trees, ensembles of regression trees, Gaussian Process Regression (GPR) models, Support Vector Machines (SVM) models and Neural Network Regression (NNR) models. From among the above models, the Gaussian Process Regression model was found to be the most advantageous, whose forecast can be considered very accurate. In this model, the average observed carbon price values deviate from the forecasts by EUR 1.305/t of CO2 in train data (slightly over 2.5% of the average carbon price in 2021) and by EUR 1.339/t of CO2 in the test data (little more than 2.6% of the average carbon price). The use of PCA does not improve prediction errors (they are at a similar level), but it reduces the complexity of the supervised machine learning models, which in turn reduces the training time and prediction speed. For example, for the Non-isotropic exponential PCA-GPR model, the prediction speed is about 2000 obs/s and the training time is 125.79s, while without PCA, the model is learnt 215.01s (increase by 71%) and the prediction speed is more than three times longer (about 6100 obs/s).
The methods applied proved the possibility of determining a precise forecast of EUA prices and using them as a useful tool in the EUA investment decision-making process.
The proposed method also has limitations. Using the PCA method with the selected prediction method reduces the complexity of the model and the time of its training and inference, but, consequently, it does not limit the parameters we use, so to make a prediction, we need data for the entire set of analyzed indicators.
Analyzes conducted for the EU ETS market are characterized by volatility due to different legal grounds relating to trading periods. The current analysis has been prepared for the ongoing IV period; therefore, the obtained results will apply to the coming years (2021–2030). The next period starting after 2030 may be characterized by other factors influencing the further shaping of EUA prices. However, as stated in this paper, it would also be advisable to include in the analysis equally important indicators such as changes in the structure of the EU ETS market, changes caused by political decisions, the ratio of demand and supply in relation to EUAs, the number and type of market participants, including investors participating solely for profits, which will be the subject of further study of the authors.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}