Abstract
High-precision forecasting of short-term wind power (WP) is integral for wind farms, the safe dispatch of power systems, and the stable operation of the power grid. Currently, the data related to the operation and maintenance of wind farms mainly comes from the Supervisory Control and Data Acquisition (SCADA) systems, with certain information about the operating characteristics of wind turbines being readable in the SCADA data. In short-term WP forecasting, Long Short-Term Memory (LSTM) is a commonly used in-depth learning method. In the present study, an optimized LSTM based on the modified bald eagle search (MBES) algorithm was established to construct an MBES-LSTM model, a short-term WP forecasting model to make predictions, so as to address the problem that the selection of LSTM hyperparameters may affect the forecasting results. After preprocessing the WP data acquired by SCADA, the MBES-LSTM model was used to forecast the WP. The experimental results reveal that, compared with the PSO-RBF, PSO-SVM, LSTM, PSO-LSTM, and BES-LSTM forecasting models, the MBES-LSTM model could effectively improve the accuracy of WP forecasting for wind farms.
1. Introduction
The development of renewable energy can effectively reduce the deficiency of global energy and reduce environmental pollution [1]. Notably, wind energy has become one of the fastest-growing renewable energy sources [2], serving as an environmentally friendly and clean energy source that can meet the requirements of human sustainable development [3]. According to statistics related to WT (wind turbine) released by the World Wind Energy Association (WWEA) in early 2021, the total installed capacity of global WT in 2020 reached 744 GW [4].
Despite the extensive promotion of WP, bringing about significant economic benefits, wind farms are also facing several challenges. Since the wind farms’ output power can be volatile and uncertain, after the wind farm is connected to the grid, there will be certain disturbances to the safe operation of the power system [5]. To overcome such problems, accurate forecasting of the wind farm output power is necessary. Through forecasting, WP fluctuations can be determined in advance. As such, corresponding countermeasures can also be prepared in advance, and a reasonable power generation plan can be arranged, which not only ensures the safety of the grid, but also improves its reliability [6].
In recent years, researchers have conducted extensive research on WP forecasting using numerous mainstream models, including physical models [7], statistical models [8,9], and artificial intelligence (AI) models [10,11], among which AI models are the most widely studied.
AI models usually establish a high-dimensional nonlinear function to fit WP by minimizing training errors [12]. The more widely used methods are mainly machine learning (ML) methods and artificial neural network (ANN) methods. ML methods mainly include Support Vector Regression (SVR), Least Square Support Vector Machine (LSSVM), and Extreme Learning Machine (ELM) networks [13]. Kuilin Chen et al. [14] used an unscented Kalman filter (UKF) for integration with SVR to establish an SVR-UKF forecasting model, which improved the forecasting accuracy of the SVR model. The ANN acts as a parallel processor with the ability of efficiently storing and figuring out experimental knowledge; it is suitable for solving complex nonlinear problems [15]. D. Huang et al. [16] used GA and BP neural networks to forecast the WP of a wind farm. This GA-BP model was beneficial in improving the correctness of WP forecasting. P. Guo et al. [17] used GA to optimize the hyper-parameters of RBF and to predict the WP of a wind farm. As the theories and technology of neural networks have gradually developed and matured, more researchers have applied deep neural networks (DNN), such as convolutional neural networks (CNN) [18], deep belief networks (DBN) [19], and RNN [20] to predict the WP of wind farms.
LSTM as a form of RNN, has been demonstrated to be suitable for analyzing long series data, and there have been an increasing number of studies on the forecasting of WP based on LSTM networks. In order to construct an LSTM network model that meets the requirements, it is necessary to adjust the relevant hyperparameters, and researchers often set the parameters according to their actual experience and priori knowledge. For different problems, it may be necessary to repeatedly manually tune the relevant parameters.
To address such issues, the parameters of LSTM are optimized using the MEBS algorithm; thus, constructing the MBES-LSTM forecasting model. The experimental results reveal that the optimized forecasting model can better predict the trend of WP and provide technical support for the refinement of wind farm management. The main contributions are highlighted as follows:
- (1)
- The original BES algorithm was improved, and the improved BES algorithm was tested.
- (2)
- The wind farm data collected by the SCADA system was cleaned and filtered to form a sample set and processed by means of an empirical mode decomposition (EMD) method.
- (3)
- The parameters of the LSTM such as iteration number , learning rate , number of the first layer , number of the second layer , were optimized by the MBES algorithm, and the MBES-LSTM forecasting model was subsequently constructed.
- (4)
- The processed WP data was used as the test sample with the PSO-RBF, PSO-SVM, LSTM, PSO-LSTM, BES-LSTM, and MBES-LSTM models to predict and compare performance.
The balance of this paper is organized as follows: Section 2 describes the LSTM, BES, and MBES algorithm. Evaluation index, MBES-LSTM forecasting model, SCADA data preprocess, and relevant parameter settings are introduced in Section 3. Section 4 provides some graphical results, along with analysis. Finally, Section 5 concludes this paper.
2. Description of LSTM, BES, and MBES
2.1. LSTM
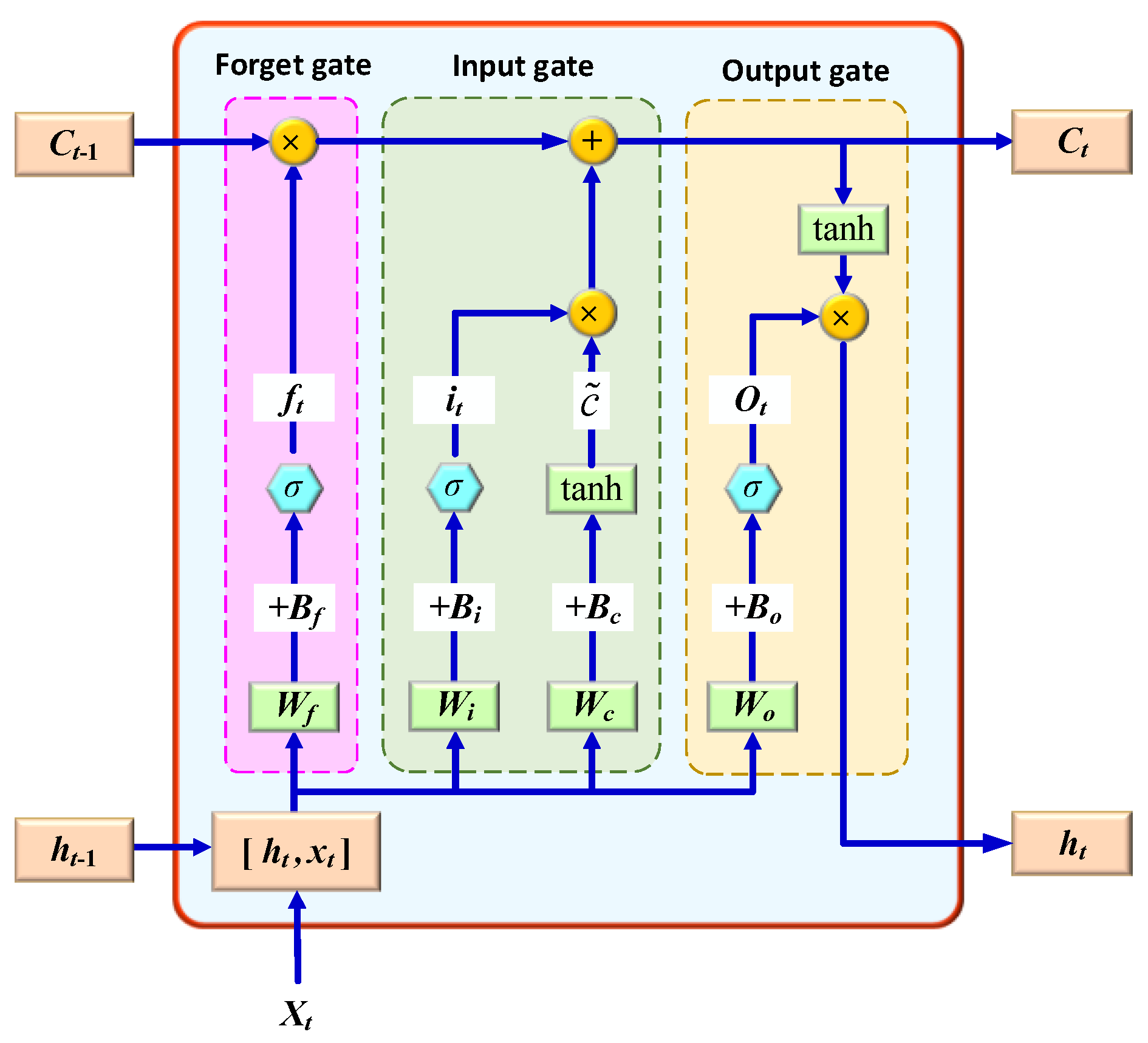
LSTM is a special type of RNN, of which the hidden layer is composed of one or more memory cells, and each memory cell includes a forget gate, an input gate, and an output gate [21]; its structure is shown in Figure 1.
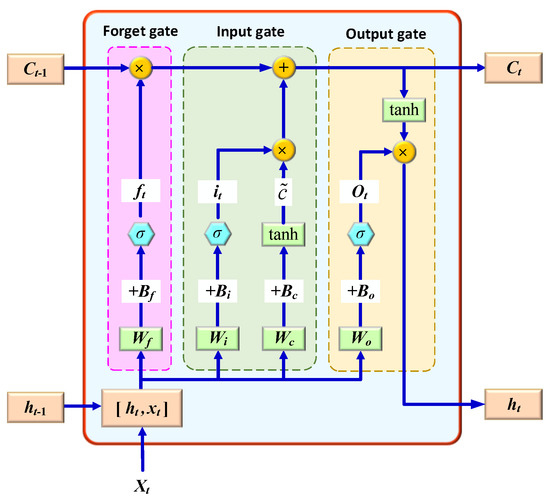
Figure 1.
Structure of LSTM.
(1) Forget gate: The forget gate is responsible for controlling whether the long-term state continues to be preserved, and is jointly determined by the input of the current moment and the output of the previous moment . The relevant formula is as follows:
where represents the weight matrix of the forget gate; represents the bias term; and represents the sigmoid function.
(2) Input gate: The function of the input gate is to establish a new unit state , perform related processing therein, and control how much information is added. The calculation formula is as follows:
where is the input gate result; represents the weight matrix of the input gate; represents the bias of the input gate; represents the current input cell state; represents the weight matrix; and represents the bias of the cell state. The matrix is composed of two vectors, the output at the previous moment and the input at the current moment . is the sigmoid activation function and is a double tangent function.
(3) Output gate: In the output gate, the output of the previous moment and the input of the current moment are used to output through a sigmoid function , namely:
where represents the weight matrix of the output gate; and represents the bias term of the output gate.
In the LSTM structure, due to the unique three-gate structure and the existence of the hidden state with storage function, LSTM can better reveal long-term historical data, thereby solving the issue of long-term dependence. First, the hidden state of the current moment uses the forget gate to control which information in the hidden state of the last moment needs to be discarded, and which information can continue to be retained. Second, the structure discards certain information in the hidden state and the forget gate, and learns new information through the input gate. Third, after a series of calculations, the cell state is updated. Here, LSTM uses the output gate, cell state , and a tanh layer to determine the final output value .
2.2. BES Algorithm
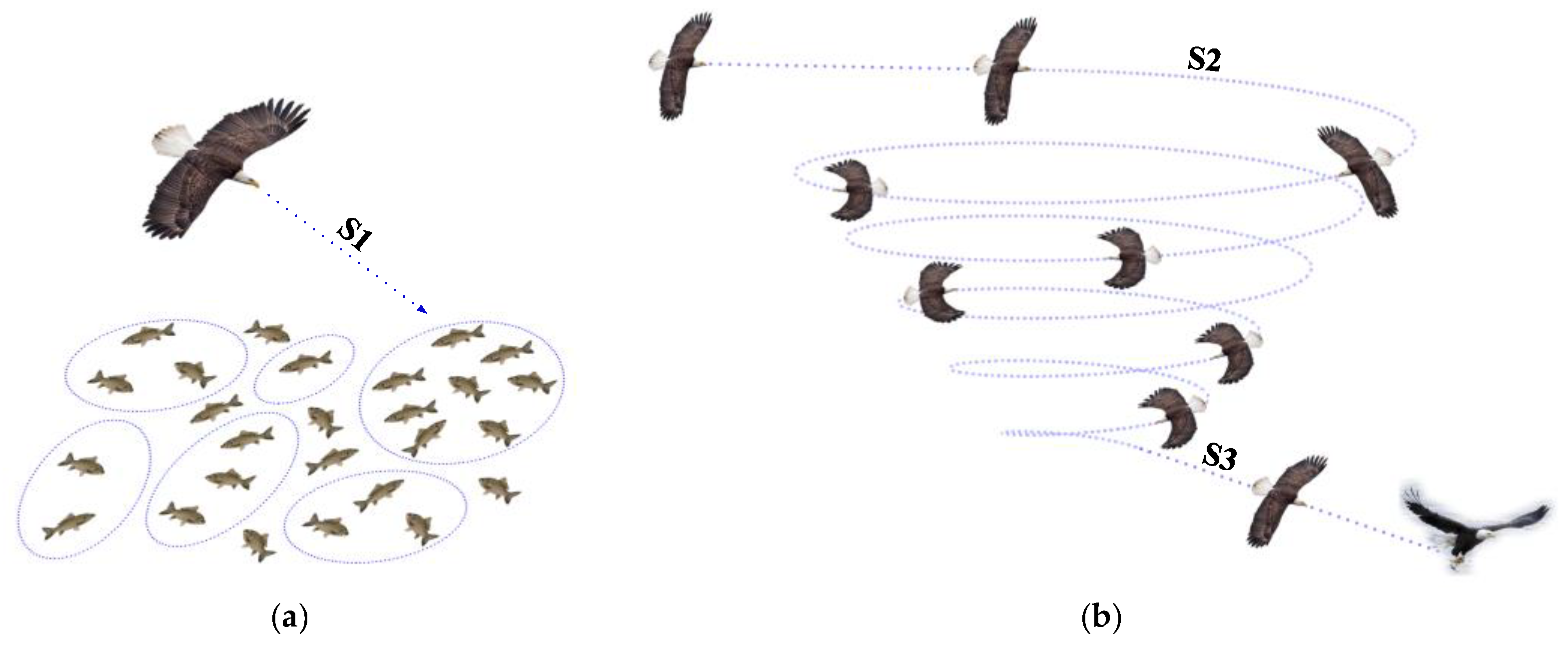
The BES is a new meta-heuristic optimization algorithm established in 2020 by H. A. Alsattar, who was inspired by the hunting behavior of bald eagles [22]. Bald eagles are found throughout North America and have sharp eyesight and significantly high observation ability during flight [23]. Taking salmon predation as an example, the bald eagle will first select a search space based on the distribution density of individuals and populations to salmon and fly towards a specific area; next, the bald eagle will search the water surface in the selected search space until a suitable prey is found; finally, the bald eagle will gradually change the flying altitude, dive down quickly, and successfully catch salmon and other prey from the water. The BES algorithm simulates the prey-preying behavior of this condor and divides it into three stages: select stage, search stage, and swooping stage, as shown in Figure 2.
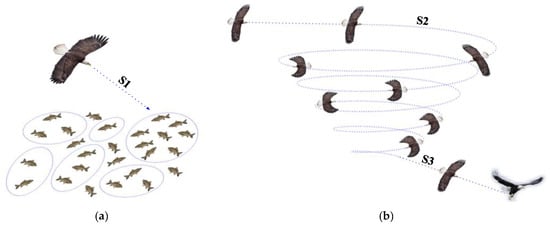
Figure 2.
Diagram of the BES for the three main phases of hunting (S1—selecting phase; S2—searching phase; S3—swooping phase). (a) Selecting phase; (b) Search and swooping phase.
(1) Selecting phase: In the selecting phase, the search area is randomly selected by the bald eagle looking for the area with the most prey. The updated description of the bald eagle’s position at this phase is:
where, represents the latest location of the i-th bald eagle, and is the current optimal position; represents the location of the i-th bald eagle; is the evenly distributed bald eagle’s position after the previous search; is the parameter which controls the positions change; and is an arbitrary number
(2) Searching phase: In the searching phase, the bald eagle flies in a conical spiral in the selected search space, looking for prey. In the conical spiral space, the bald eagle moves in a different course to accelerate its searching speed and find the best dive capture location. The updated description of the spiral flight position of the bald eagle is:
where is the polar angle of the spiral equation; is the polar diameter of the spiral equation; and are the parameters that control the spiral trajectory; and represent the bald eagle’s location in polar coordinates, with both values being (−1, 1). The bald eagle’s position is updated as follows:
where is the next updated location of the i-th bald eagle.
(3) Swooping phase: After the bald eagle locks onto a target, it quickly dives from the best position and flies towards the target. The movement state of this phase is still used, and the polar coordinate equation can be denoted as follows:
where, and represents best position and center position, respectively.
2.3. MBES Algorithm
The MBES algorithm is an improved version of the original BES algorithm. In the selection phase, the parameter in Formula (7) was optimized to no longer be a fixed value between [1.5, 2], which can be expressed by the following formula:
where is the bald eagle’s position change control parameter; represents the current iteration number; is the maximum iteration number.
The MBES algorithm was tested and evaluated using different benchmark functions; the parameters of all compared algorithms, such as particle swarm optimization (PSO), grey wolf optimizer (GWO), whale optimization algorithm (WOA), BES, and MBES are shown in Table 1. Table 2 presents the name and parameter settings of the benchmark functions.

Table 1.
Parameter value of PSO, GWO, WOA, BES, and MBES.
Table 2.
Parameter settings of test functions.
The relevant statistical experiment results of selecting each algorithm to run 20 times independently in the benchmark function are shown in Table 3 (unimodal benchmark functions), Table 4 (multimodal benchmark functions), and Table 5 (composite benchmark functions).
Table 3.
Results for unimodal benchmark functions.
Table 4.
Results for multimodal benchmark functions.
Table 5.
Results for composite benchmark functions.
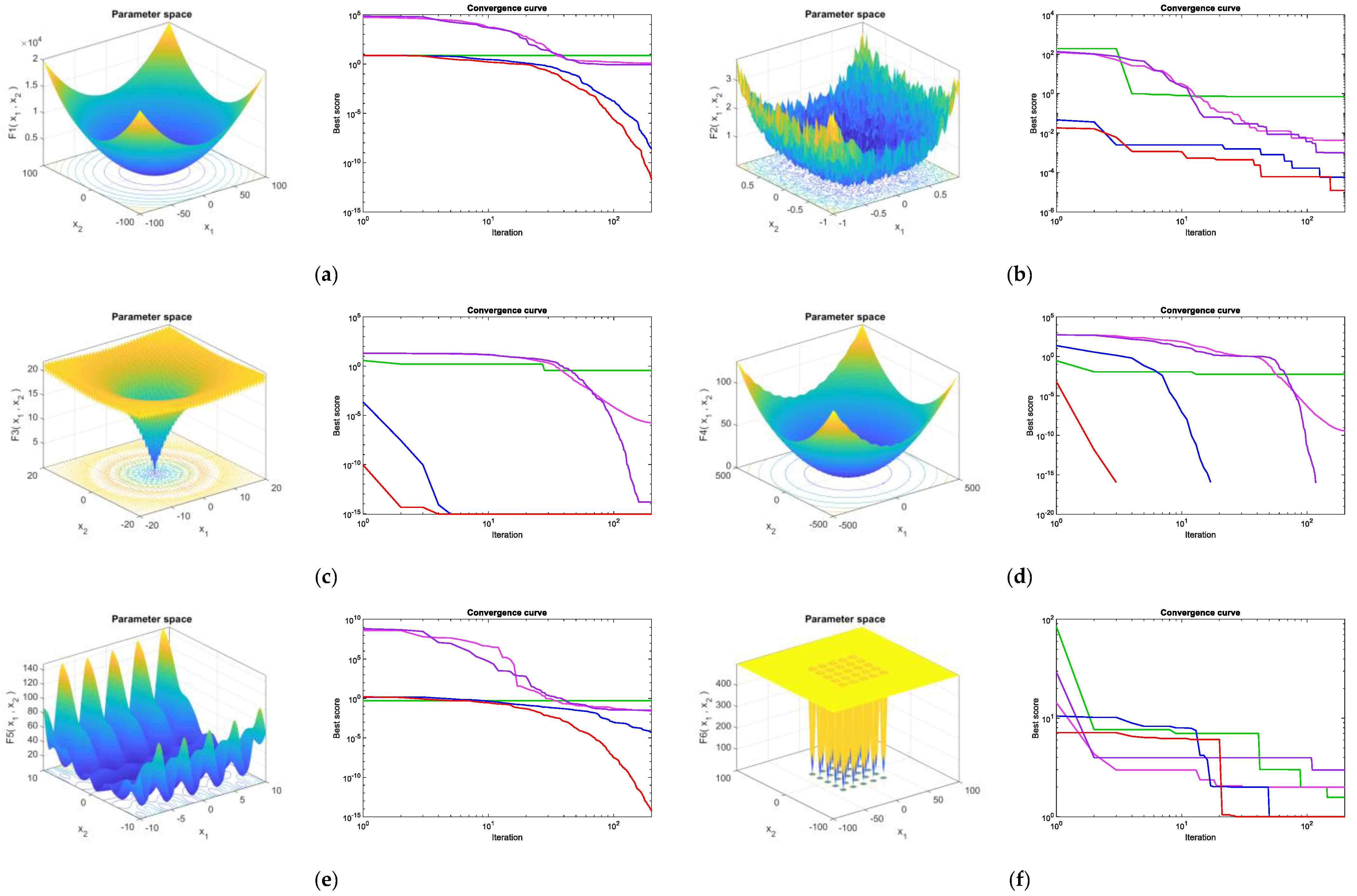
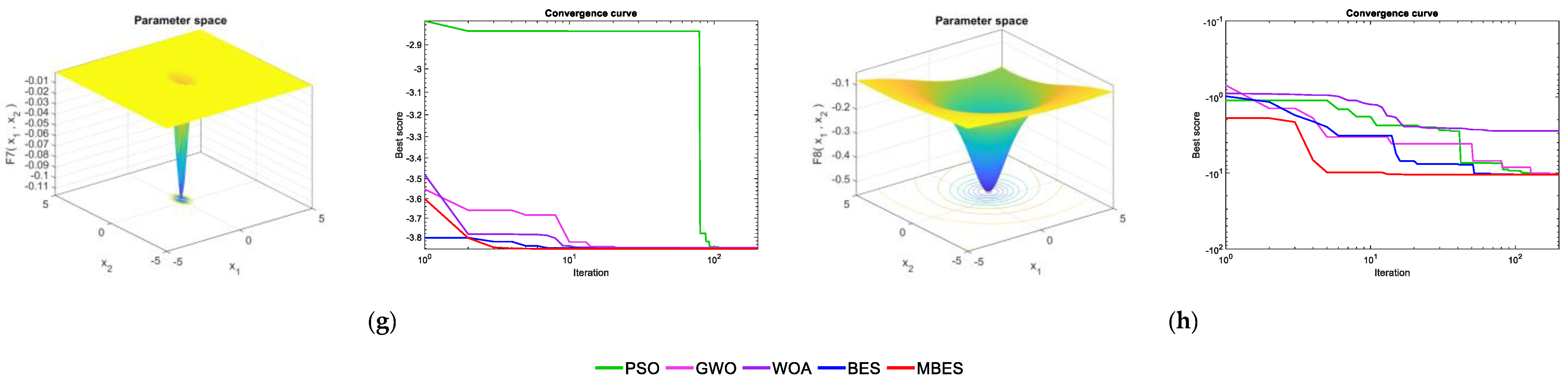
Figure 3 presents the qualitative metrics for the F1–F8 functions, including 2D views of the functions and convergence curves. For the convergence curves in Figure 3, the red line represents the MBES and the blue line represents the BES. As can be seen, the MBES’s speed of convergence is faster than the others.
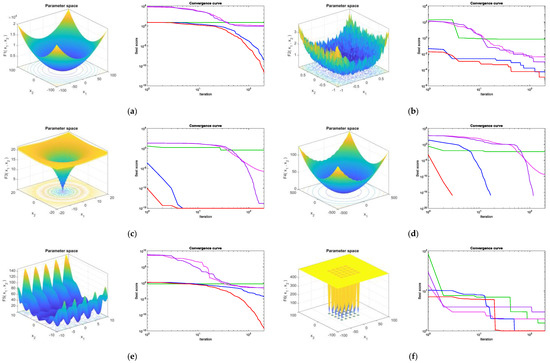
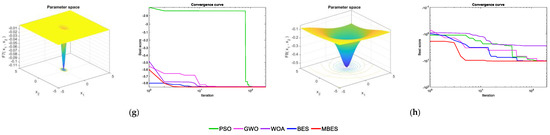
Figure 3.
Qualitative metrics for the benchmark functions: 2D views and convergence curves of the functions. (a) F1; (b) F2; (c) F3; (d) F4; (e) F5; (f) F6; (g) F7; (h) F8.
3. WP Forecast
3.1. MBES-LSTM Forecasting Model
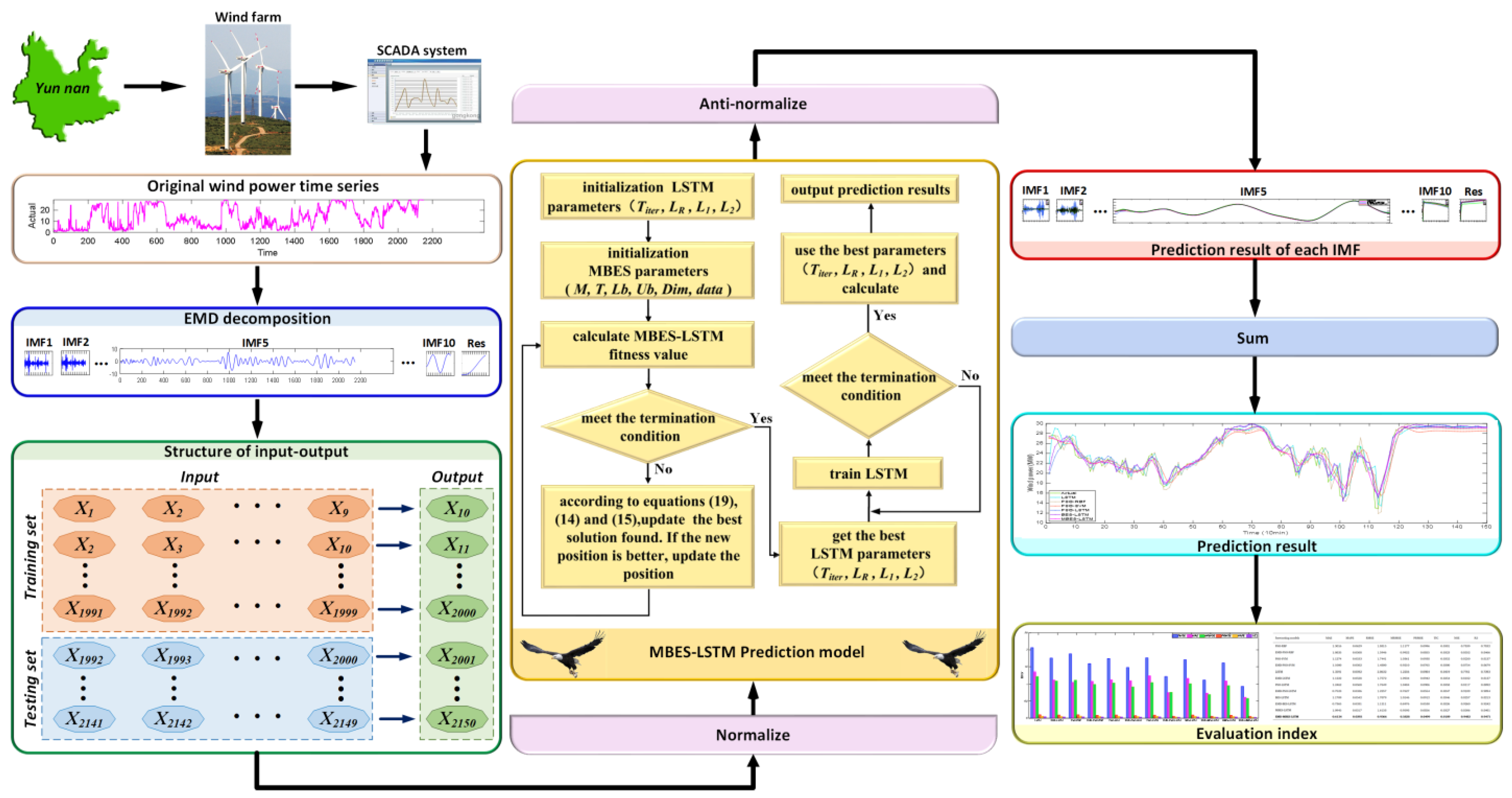
To reduce forecasting errors, SCADA data is decomposed using the EMD method after preprocessing. The flow chart of the MBES-LSTM WP forecasting model based on the EMD is shown in Figure 4, and the specific steps were as follows:
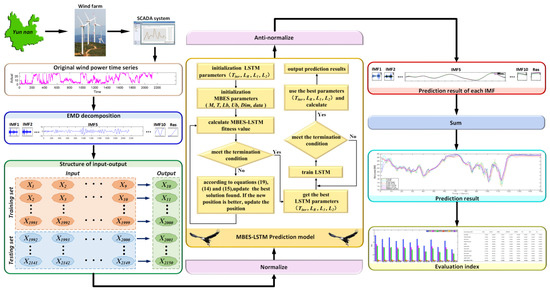
Figure 4.
Forecasting process of the proposed model.
Step 1: The EMD method was used to decompose the pre-processed WP time series data and to decompose the data into the intrinsic mode function (IMF).
Step 2: The data of each IMF was divided into a training set and a test set.
Step 3: The decomposition data from each IMF was normalized.
Step 4: The MBES-LSTM model was used for training and forecasting, respectively, and in this step:
- (1)
- The LSTM parameter and the MBES algorithm parameters, including the bald eagle population , the maximum iterations , the upper limit of argument , the lower limit of argument , the dimension , and the sample data were initialized.
- (2)
- The data of the fitness value was calculated. The mean square error obtained by training the LSTM network was used as the fitness value, and the value was updated in real-time as the bald eagle continued to operate; within the iteration range, Formulas (14), (15), and (19) were used to calculate the position of the bald eagle. If the current new position was better, the old position was updated.
- (3)
- According to the optimal parameter combination, the LSTM network was trained, and testing samples were used to forecast and save the result of each IMF.
Step 5: The results of each IMF from Step 4 were anti-normalized.
Step 6: By linearly superimposing the forecasting results of each IMF, the final forecasting result was obtained.
Step 7: The relevant evaluation metrics were calculated.
3.2. Data Preprocessing and EMD Decomposition
In the present study, the actual operational SCADA data of a wind farm in Yunnan, China, from 1 August 2018 to 31 August 2018, was selected for the analysis of the calculation examples. The time resolution of the data was ten minutes. After data cleaning, the first 2150 groups were taken as experimental samples. The relevant features of the samples are shown in Table 6.
Table 6.
Attributes of training set and test set samples.
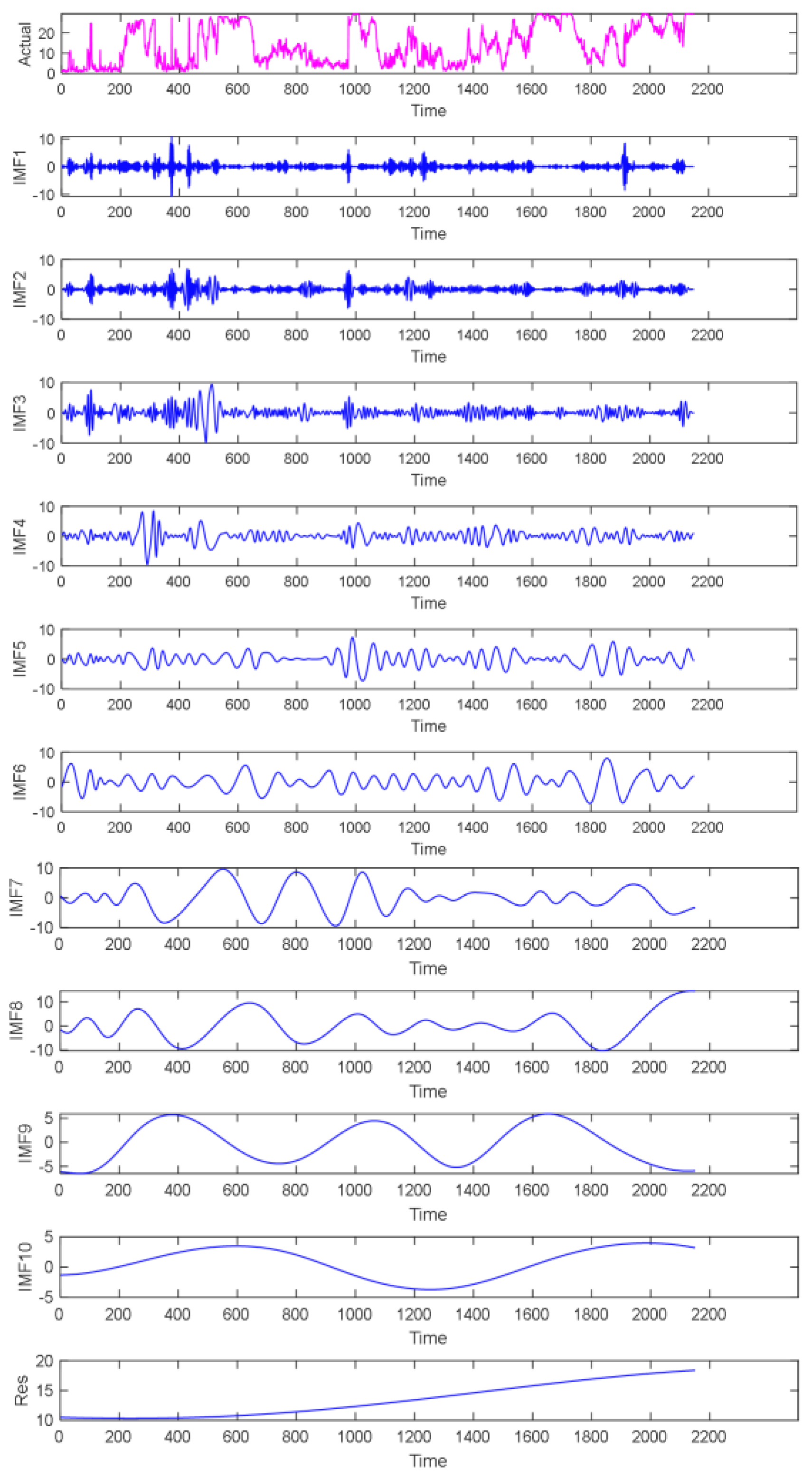
To further reduce the nonlinearity and strong volatility characteristics of the WP signal and enhance the forecasting precision, the EMD algorithm was first used to decompose the preprocessed SCADA data and then perform related calculations. The EMD decomposition results of the original WP data are shown in Figure 5. A total of 10 IMF components and 1 remaining component were decomposed, and they are plotted in blue. Figure 5 shows that the time characteristic scale of the eigenmode function component increased from IMF1 to IMF10, and the frequency changed from high to low.
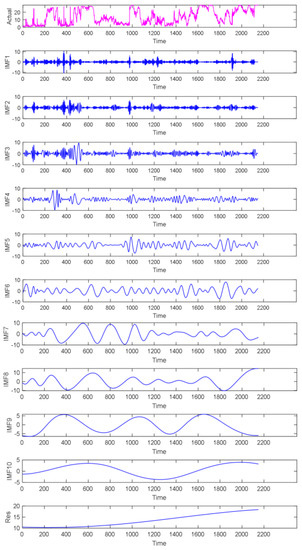
Figure 5.
Diagram of original WP data and its EMD decomposition.
3.3. Parameters Setting
In the present study, PSO-RBF and PSO-SVM models were established, and algorithms such as PSO, BES, and MBES were used to optimize the hyper-parameters of the LSTM. The relevant parameter values are shown in Table 7.
Table 7.
The parameter values of PSO-RBF, PSO-SVM, PSO-LSTM, BES-LSTM, and MBES-LSTM.
3.4. Evaluation Indicators
To better assess the performance of the MBES-LSTM forecasting model, RMSE, MAE, MAPE, COV, CC, TIC, EC, and r2 were used in the present study. The specific expressions are as follows:
(1) The root mean square error (RMSE) indicates the deviation between the predicted and actual values.
(2) The mean absolute error (MAE) reflects the actual situation of the errors, and this value also becomes larger when the error is large.
(3) The mean absolute percentile error (MAPE) is used to the measure forecast accuracy. Smaller MAPE values indicate that the model is more accurate in predicting
(4) The coefficient of variance (COV) [24] reflects the degree of discretization of the data, with a larger value indicating a higher degree of data scattering.
(5) The correlation coefficient (CC) represents the relationship between the actual and predicted values. This value is close to 1 when the actual data is strongly correlated with the predicted data.
(6) The Theil’s inequality coefficient (TIC) [25], with a value range between [0, 1]. The smaller the TIC value, the better the prediction accuracy of the model.
(7) The efficiency coefficient (EC) [26] is generally used to verify the goodness of fit of the model’s prediction results, and if the EC is close to 1, the prediction quality of the model is good.
(8) The coefficient of determination r2 (r2) estimates the combined dispersion against the single dispersion of the observed and predicted series.
where represents the WP observation value at time t; is the WP forecast value at time t; is the average WP observation; is the average WP forecast; and N is the number of samples in the sequence.
4. Experimental Results and Discussion
In WP forecasting, the setting of related parameters directly affects the forecasting precision of the LSTM network. In the present study, the PSO, BES, and MBES algorithms were used to optimize the hyper-parameters such as , , , and . The LSTM-related parameter values and calculated errors in each IMF decomposition are shown in Table 8.
Table 8.
The LSTM hyper-parameters value and errors based on PSO, BES, and MBES.
Table 9 indicates the Loss and RMSE of the LSTM, PSO-LSTM, BES-LSTM, and MBES-LSTM models in the training set and the testing set. An observation can be made that the MBES-LSTM model trends towards small Loss and RMSE value in the training set and the testing set.
Table 9.
Forecasting errors of LSTM, PSO-LSTM, BES-LSTM, and MBES-LSTM models.
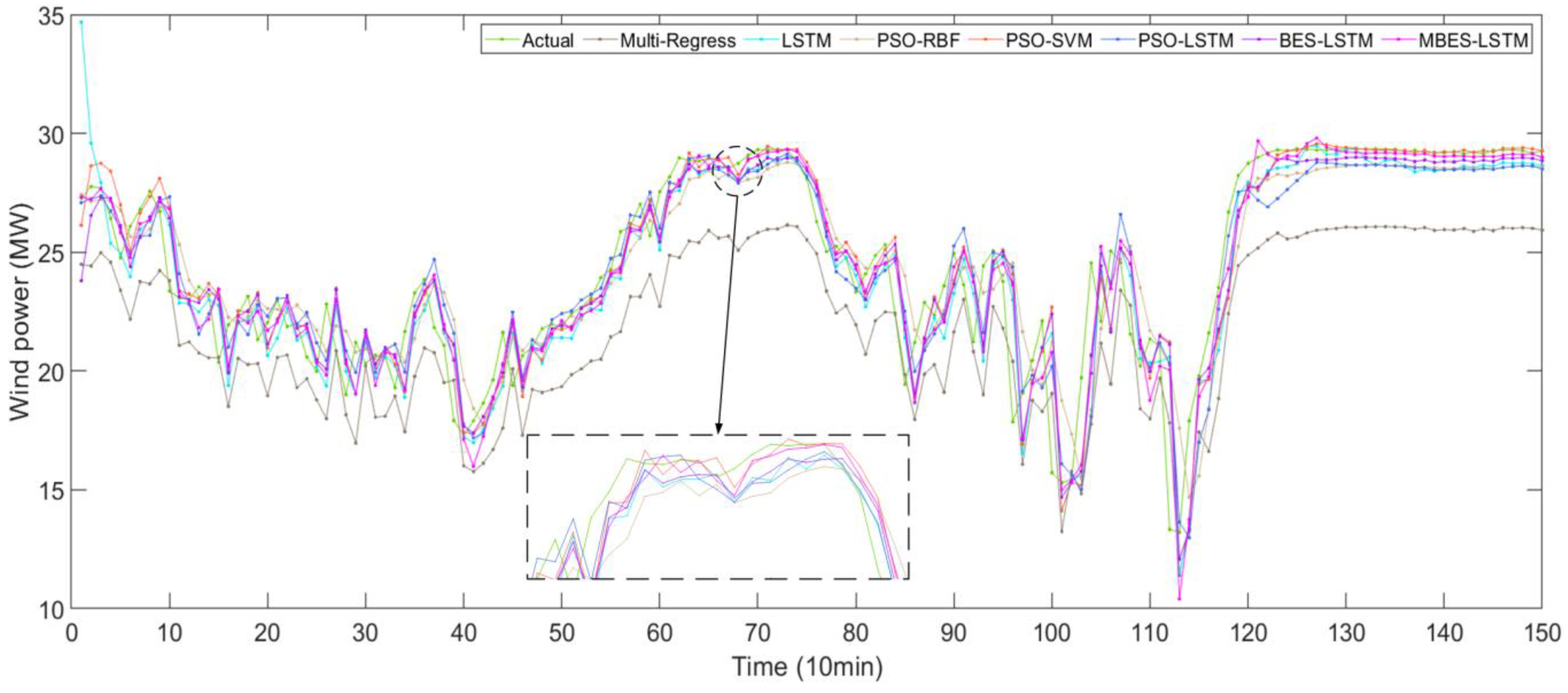
To further reflect the advantages of the MBES-LSTM forecasting model, some models were contrasted with other models such as the Multi-Regress, LSTM, PSO-RBF, PSO-SVM, PSO-LSTM, and BES-LSTM models. Figure 6 shows a comparison diagram of the direct forecasting results of the models. It can be noted from Figure 6 that the prediction line of the multi-regress model was far away from the actual line, indicating that the prediction results were poor, while the prediction lines of other models were near the actual lines.
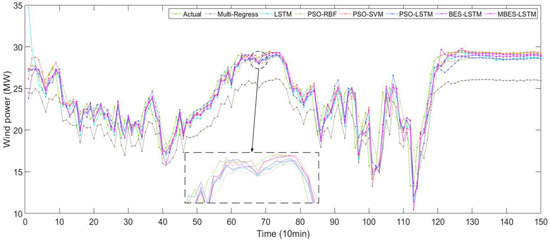
Figure 6.
The forecasting results of different models.
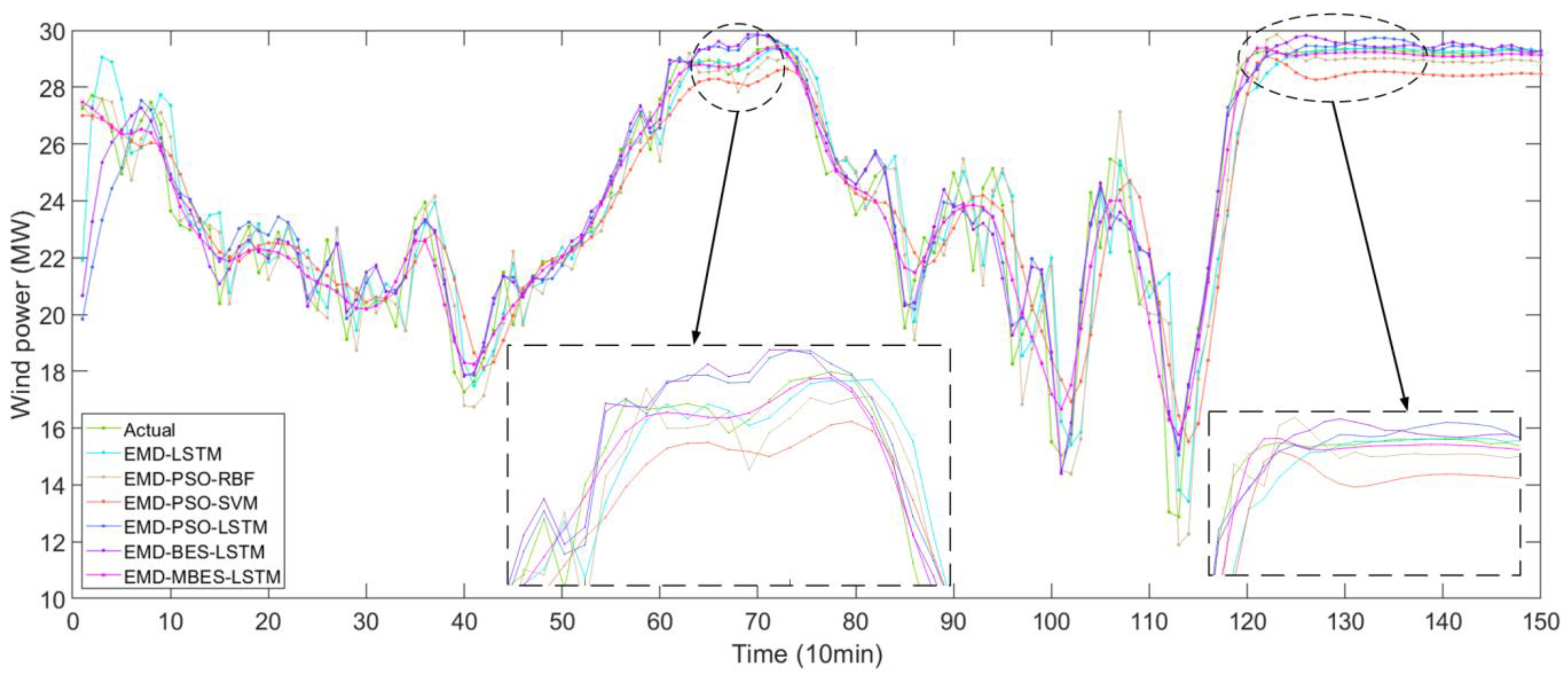
Figure 7 shows the forecasting results of different models based on the EMD algorithm.
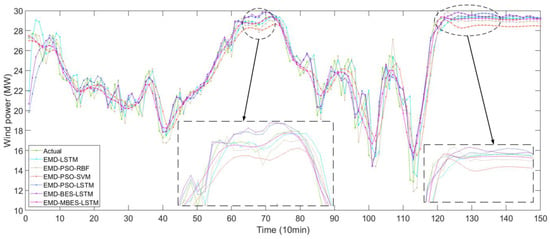
Figure 7.
The forecasting results of different models based on EMD.
In Figure 6 and Figure 7, the solid green line represent the actual values, while the remaining six colored lines represent the forecasted values. The closer their location to the green line, the higher the forecasting accuracy of the models. An observation can be made that the forecasting value line of the MBES-LSTM model was closer to the green line, which indicates that the forecasting precision of MBES-LSTM was the highest.
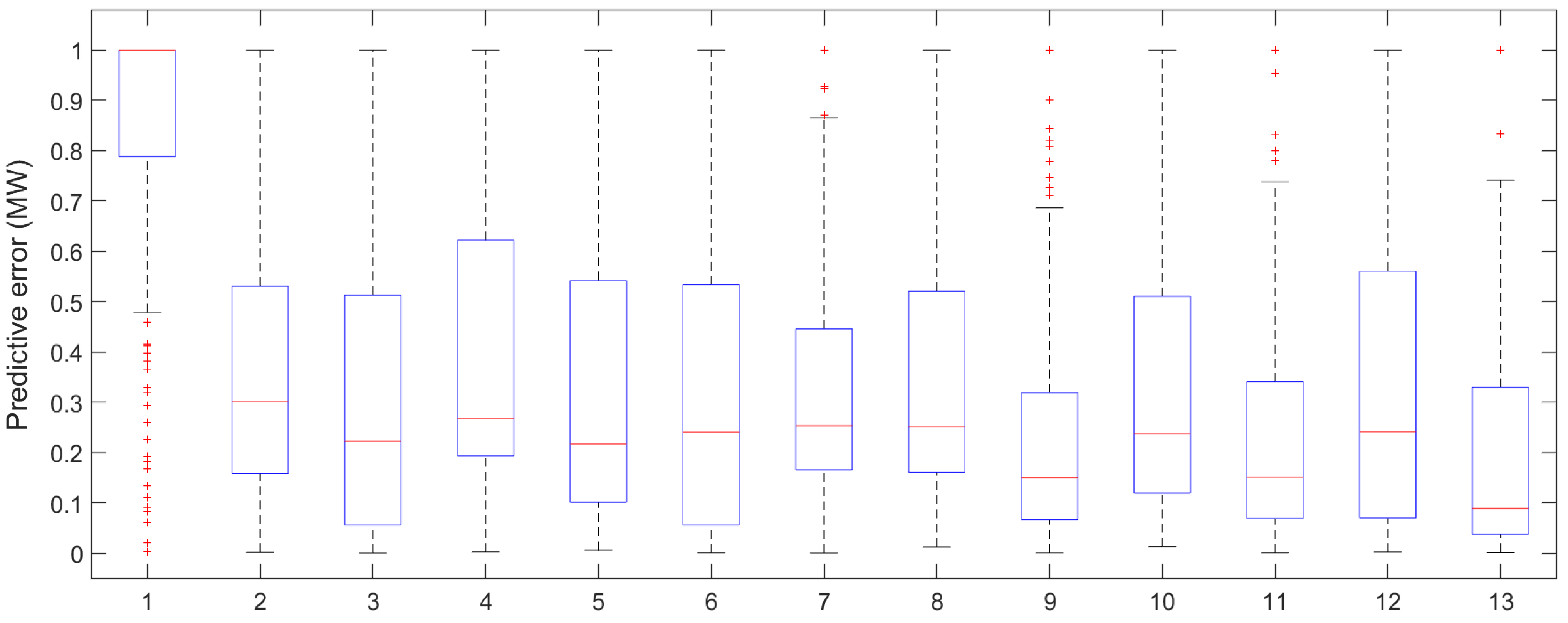
In order to more intuitively reflect the size of the forecasting error, a box-plot was drawn to graphically present the forecasting error, as shown in Figure 8. According to the box-plot, the MBES-LSTM model based on EMD showed less errors.
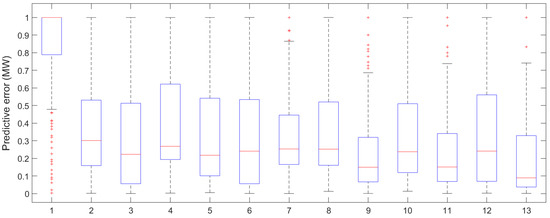
Figure 8.
The box-plot of forecasting errors of the different models (1, Multi-Regress; 2, LSTM; 3, EMD-LSTM; 4, PSO-RBF; 5, EMD-PSO-RBF; 6, PSO-SVM; 7, EMD-PSO-SVM; 8, PSO-LSTM; 9, EMD-PSO-LSTM; 10, BES-LSTM; 11, EMD-BES-LSTM; 12, MBES-LSTM; 13, EMD-MBES-LSTM).
Formulas (20)–(27) were used to calculate the relevant evaluation indicators of each forecasting model. The calculation results are shown in Table 10, according to which proposed EMD-MBES-LSTM model had the optimal forecasting performance, exhibiting the highest performance indexes.
Table 10.
Comparison of evaluation metrics.
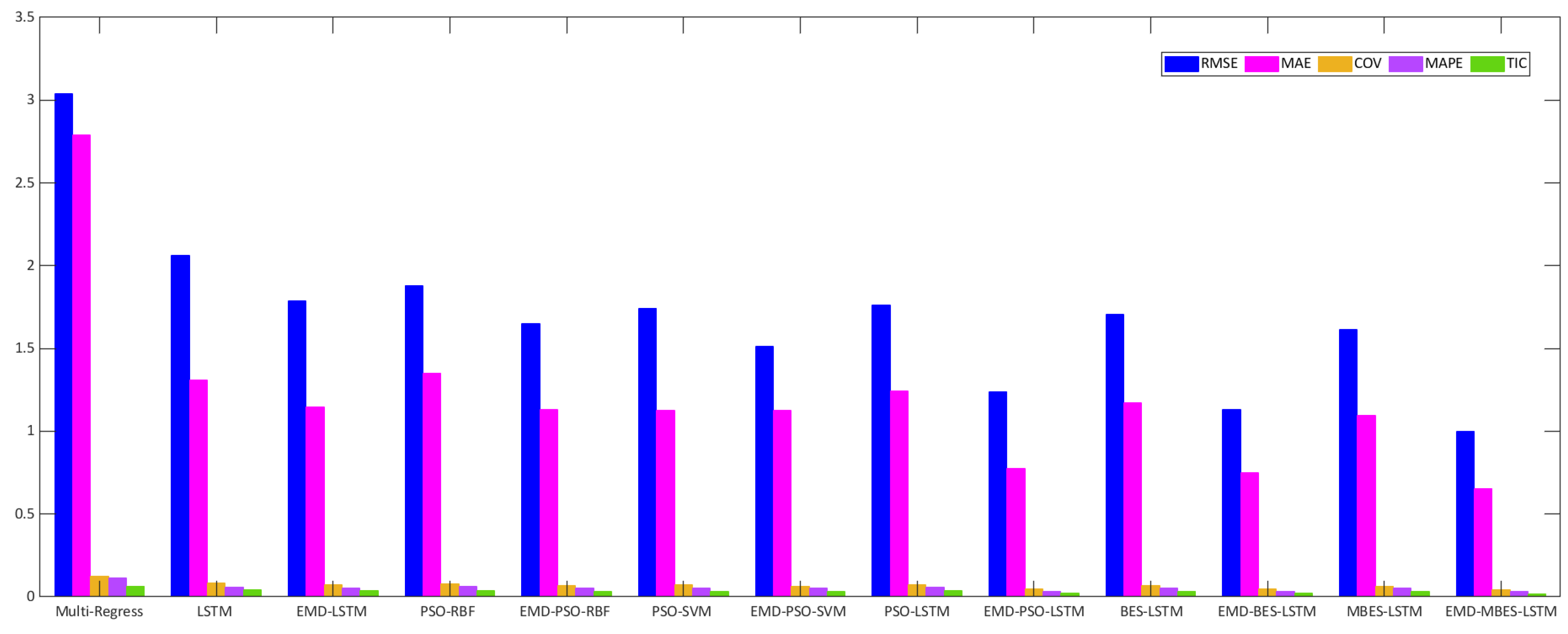
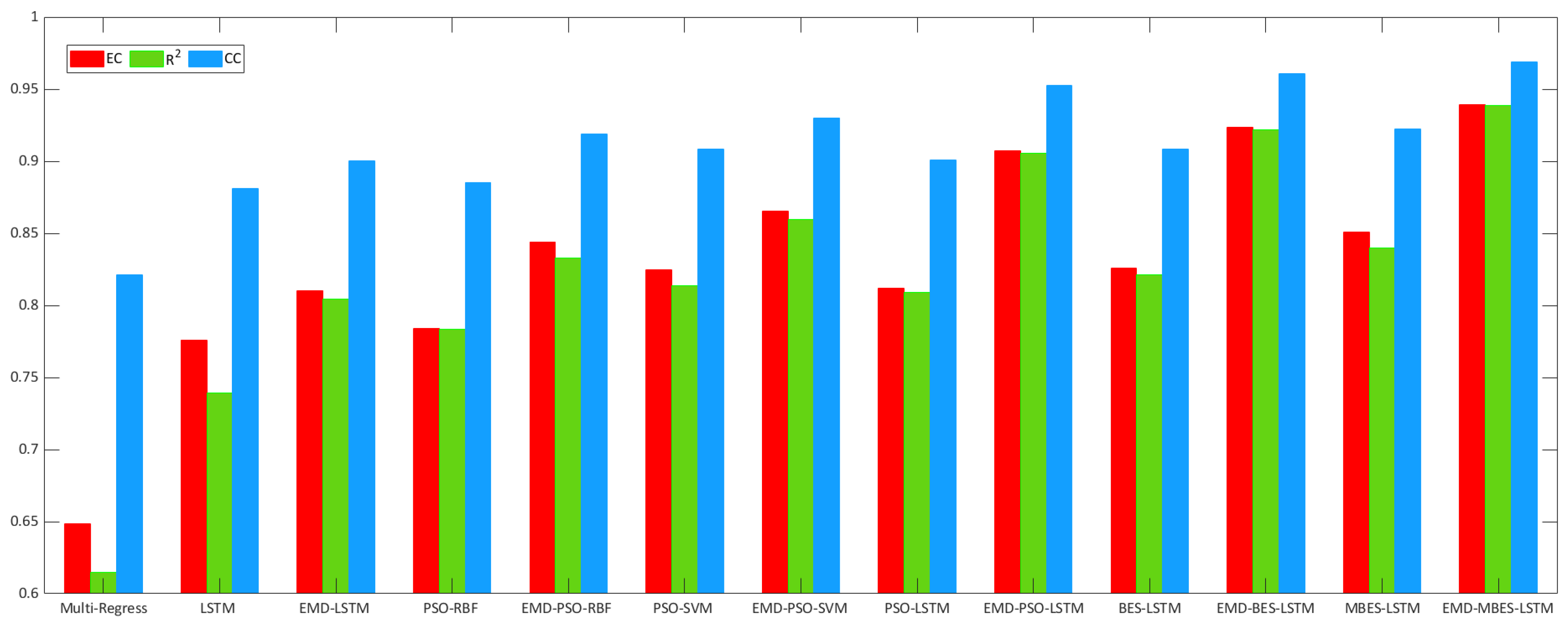
Figure 9 and Figure 10 describe the relevant evaluation index histograms. In Figure 9, the height of the blue column represents the RMSE of the Multi-Regress, LSTM, PSO-RBF, PSO-SVM, PSO-LSTM, BES-LSTM, and MBES-LSTM forecasting models; the height of the magenta column represents the MAE of every model; the height of the green column represents the TIC. In Figure 10, the height of the red column represents the EC, and the height of the green column represents the r2 of each model. From Figure 9 and Figure 10, an observation can be made that the MBES-LSTM model described in the present study showed the minimum evaluation error and highest evaluation coefficient, regardless of which evaluation standard was used.
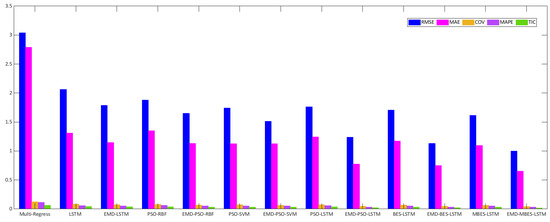
Figure 9.
Evaluation error of different forecasting models.
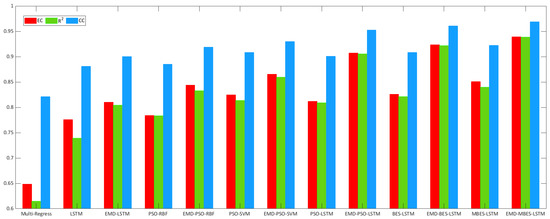
Figure 10.
Evaluation coefficient results of different forecasting models.
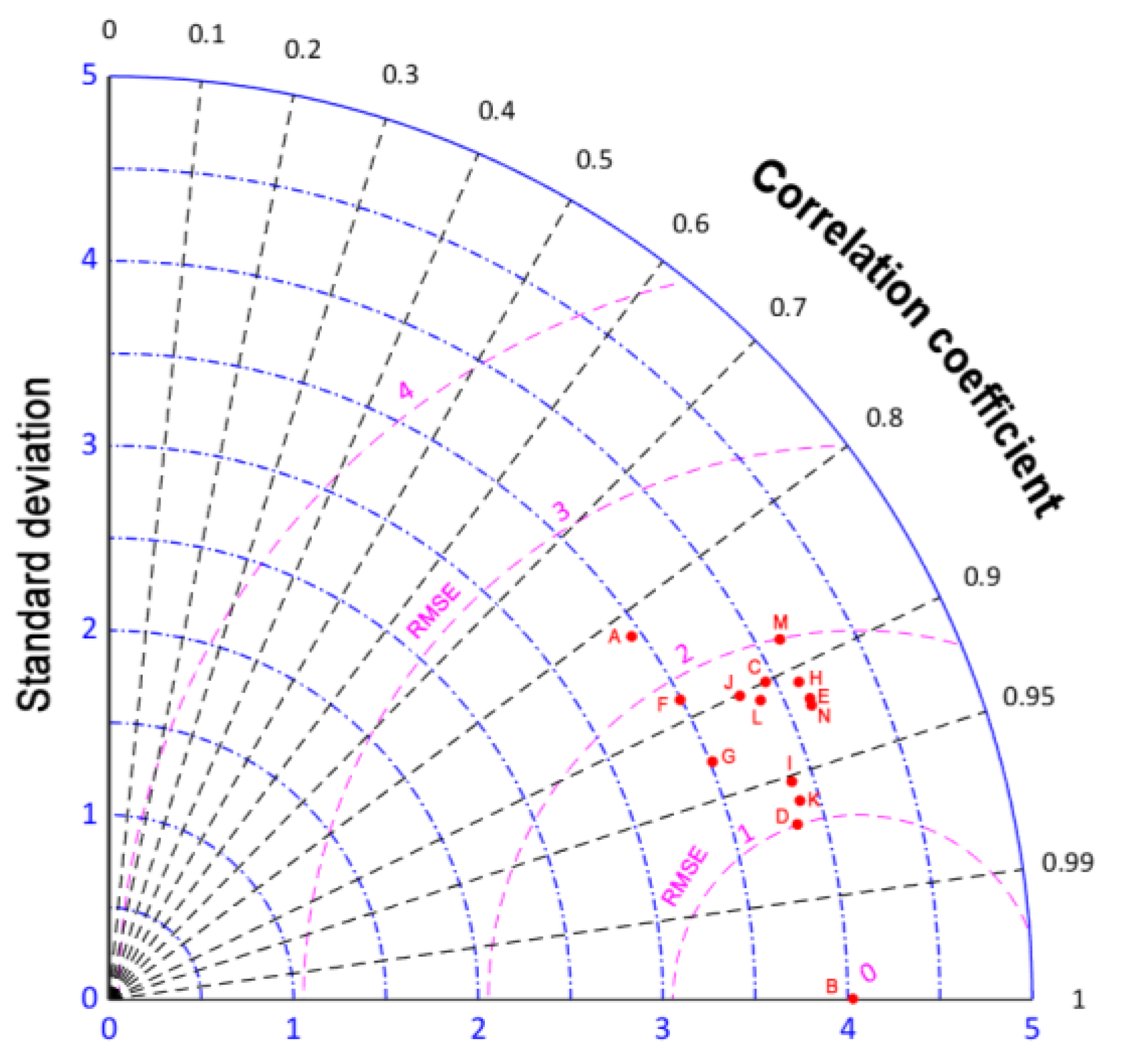
A Taylor diagram of the forecasting models is shown in Figure 11. In Figure 11, point D is closest to point B, indicating that point D had the best performance metrics. Specifically, the MBES-LSTM model based on EMD had the optimal predictive performance.
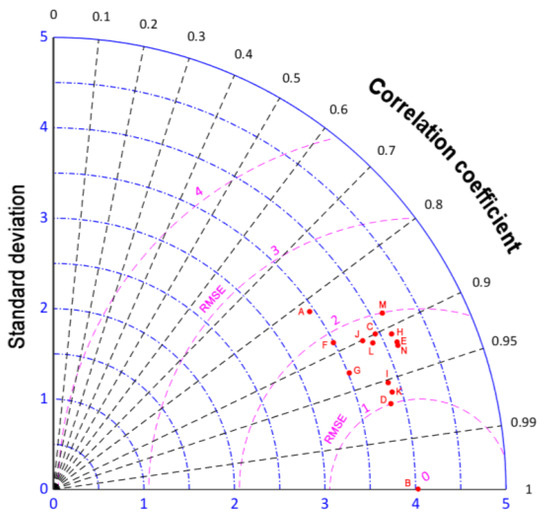
Figure 11.
The Taylor diagram of the forecasting results (A: Multi-Regress; B: Actual; C: EMD-LSTM; D: EMD-MBES-LSTM; E: EMD-PSO-RBFF; F: PSO-RB; G: EMD-PSO-SVM; H: PSO-SVM; I: EMD-PSO-LSTM; J: PSO-LSTM; K: EMD-BES-LSTM; L: BES-LSTM; M: LSTM; N: MBES-LSTM).
The MBES-LSTM model based on EMD has many advantages. Compared with the other models, there was a significant improvement in the forecasting accuracy in terms of WP forecasting. The MBES-LSTM model can be summarized as follows:
(1) The EMD algorithm was a significant factor in data preprocessing, and it significantly improved the forecasting accuracy. As can be seen from Figure 6 and Figure 7 and Table 10, after EMD decomposition on LSTM, RMSE decreased by about 0.2751, MAE decreased by about 0.1607, and r2 increased by about 0.0649.
(2) The proposed algorithm was evaluated through several different benchmark functions and was applied in the parameter estimation of LSTM. As can be seen from Table 9 and Table 10, compared with the standard bald eagle algorithm, the modified bald eagle algorithm had a positive effect on LSTM hyper-parameter optimization. After optimizing the related parameters of LSTM with the modified bald eagle algorithm, RMSE decreased by about 0.0922, MAE decreased by about 0.0764, and r2 increased by about 0.0188.
5. Conclusions
Accurate forecasting of WP is integral for the safe dispatch of power systems and the operation management of wind farms. In the field of WP forecasting, LSTM is a commonly used in-depth learning algorithm. With the aim of solving the problem that the improper selection of LSTM related parameters may adversely affect the forecasting results of the LSTM, an MBES-LSTM WP short-term forecasting model was established in the present study.
(1) In the selection phase, the improvement of parameters is based on creating varied values for the learning parameter in each iteration, which helps to enhance the exploration of the MBES algorithm.
(2) The MBES algorithm was adopted to optimize the relevant parameters of the LSTM to form the MBES-LSTM model. In the WP forecasting test on the wind farm, the forecasting accuracy rate was better than that of the PSO-RBF, PSO-SVM, LSTM, PSO-LSTM, and BES-LSTM models.
Only historical WP data are used in the MBES-LSTM forecasting model. The WP is constantly affected by external factors, such as the wind direction, landforms, humidity, air temperature, and atmospheric pressure. Such factors will lead to rapidness, high nonlinearity, and uncertainty of WP changes, and thus, should be considered reasonable when establishing a multi-input forecasting model. In this way, the accuracy of WP forecasting can be further improved, which is also indicated for future study.
Author Contributions
Data curation, H.G., N.Z., Y.G.; methodology, C.X.; resources, L.G.; Investigation and writing, W.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology of the Peoples Republic of China (Grant No. 2019YFE0104800), the Special Training Plan for Minority Science and Technology Talents, the Natural Science Foundation of the Xinjiang Uyghur Autonomous Region (Grant No. 2020D03004), the National Natural Science Foundation of China (Grant No. U1865101), the Fundamental Research Funds for the Central Universities, and the Postgraduate Research and Practice Innovation Program of the Jiangsu Province (Grant No. B210201018).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support this manuscript are available from Chang Xu upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gu, B.; Zhang, T.; Meng, H.; Zhang, J. Short-term forecasting and uncertainty analysis of wind power based on long short-term memory, cloud model and non-parametric kernel density estimation. Renew. Energy 2021, 164, 687–708. [Google Scholar] [CrossRef]
- Xue, F.; Duan, H.; Xu, C.; Han, X.; Shangguan, Y.; Li, T.; Fen, Z. Research on the Power Capture and Wake Characteristics of a Wind Turbine Based on a Modified Actuator Line Model. Energies 2022, 15, 282. [Google Scholar] [CrossRef]
- Gu, C.; Li, H. Review on Deep Learning Research and Applications in Wind and Wave Energy. Energies 2022, 15, 1510. [Google Scholar] [CrossRef]
- WWEA. Worldwide Wind Capacity Reaches 744 Gigawatts–An Unprecedented 93 Gigawatts Added in 2020. Available online: https://wwindea.org/worldwide-wind-capacity-reaches-744-gigawatts/ (accessed on 24 March 2021).
- Donadio, L.; Fang, J.; Porté-Agel, F. Numerical Weather Prediction and Artificial Neural Network Coupling for Wind Energy Forecast. Energies 2021, 14, 338. [Google Scholar] [CrossRef]
- Pichault, M.; Vincent, C.; Skidmore, G.; Monty, J. Short-Term Wind Power Forecasting at the Wind Farm Scale Using Long-Range Doppler LiDAR. Energies 2021, 14, 2663. [Google Scholar] [CrossRef]
- Landberg, L. A mathematical look at a physical power prediction model. Wind Energy 1998, 1, 23–28. [Google Scholar] [CrossRef]
- Lydia, M.; Kumar, S.S.; Selvakumar, A.I.; Kumar, G.E.P. Linear and non-linear autoregressive models for short-term wind speed forecasting. Energy Convers. Manag. 2016, 112, 115–124. [Google Scholar] [CrossRef]
- Han, Q.; Meng, F.; Hu, T.; Chu, F. Non-parametric hybrid models for wind speed forecasting. Energy Convers. Manag. 2017, 148, 554–568. [Google Scholar] [CrossRef]
- Lodge, A.; Yu, X.H. Short Term Wind Speed Prediction Using Artificial Neural Networks. In Proceedings of the 2014 4th IEEE International Conference on Information Science and Technology, Shenzhen, China, 26–28 April 2014; pp. 539–542. [Google Scholar] [CrossRef]
- Kalogirou, S.; Neocleous, C.; Pashiardis, S.; Schizas, C.N. Wind speed prediction using artificial neural networks. In Proceedings of the European Symposium on Intelligent Techniques, Crete, Greece, 3–4 June 1999. [Google Scholar]
- Lorenzo, J.; Mendez, J.; Castrillon, M.; Hernandez, D. Short-Term Wind Power Forecast Based on Cluster Analysis and Artificial Neural Networks. In Proceedings of the 11th International Work-Conference on Artificial Neural Networks (Advances in Computational Intelligence, IWANN 2011, Pt I), Torremolinos-Málaga, Spain, 8–10 June 2011; Cabestany, J., Rojas, I., Joya, G., Eds.; Springer: Berlin/Heidelberg, Germany; Volume 6691, pp. 191–198. [Google Scholar]
- An, G.; Jiang, Z.; Cao, X.; Liang, Y.; Zhao, Y.; Li, Z.; Dong, W.; Sun, H. Short-Term Wind Power Prediction Based on Particle Swarm Optimization-Extreme Learning Machine Model Combined with Adaboost Algorithm. IEEE Access 2021, 9, 94040–94052. [Google Scholar] [CrossRef]
- Hur, S. Short-term wind speed prediction using Extended Kalman filter and machine learning. Energy Rep. 2021, 7, 1046–1054. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Sharshir, S.W.; Abd Elaziz, M.; Kabeel, A.E.; Guilan, W.; Haiou, Z. Modeling of solar energy systems using artificial neural network: A comprehensive review. Sol. Energy 2019, 180, 622–639. [Google Scholar] [CrossRef]
- Huang, D.; Gong, R.; Gong, S. Prediction of Wind Power by Chaos and BP Artificial Neural Networks Approach Based on Genetic Algorithm. J. Electr. Eng. Technol. 2015, 10, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Guo, P.; Qi, Z.; Huang, W. Short-term wind power prediction based on genetic algorithm to optimize RBF neural network. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 1220–1223. [Google Scholar]
- Peng, X.; Li, Y.; Dong, L.; Cheng, K.; Wang, H.; Xu, Q.; Wang, B.; Liu, C.; Che, J.; Yang, F.; et al. Short-Term Wind Power Prediction Based on Wavelet Feature Arrangement and Convolutional Neural Networks Deep Learning. IEEE Trans. Ind. Appl. 2021, 57, 6375–6384. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, X.; Collu, M. Wind power prediction based on high-frequency SCADA data along with isolation forest and deep learning neural networks. Int. J. Electr. Power Energy Syst. 2020, 118, 105835. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, X.; Dong, M.; Huang, L.; Guo, Y.; He, S. Deep Learning-Based Prediction of Wind Power for Multi-turbines in a Wind Farm. Front. Energy Res. 2021, 9, 403. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Alsattar, H.A.; Zaidan, A.A.; Zaidan, B.B. Novel meta-heuristic bald eagle search optimisation algorithm. Artif. Intell. Rev. 2020, 53, 2237–2264. [Google Scholar] [CrossRef]
- Hansen, A.J. Fighting Behavior in Bald Eagles: A Test of Game Theory. Ecology 1986, 67, 787–797. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Panchal, H.; Ahmadein, M.; Mosleh, A.O.; Sadasivuni, K.K.; Alsaleh, N.A. Productivity forecasting of solar distiller integrated with evacuated tubes and external condenser using artificial intelligence model and moth-flame optimizer. Case Stud. Therm. Eng. 2021, 28, 101671. [Google Scholar] [CrossRef]
- Tian, Z.; Chen, H. A novel decomposition-ensemble prediction model for ultra-short-term wind speed. Energy Convers. Manag. 2021, 248, 114775. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Katekar, V.P.; Muskens, O.L.; Deshmukh, S.S.; Elaziz, M.A.; Dabour, S.M. Utilization of LSTM neural network for water production forecasting of a stepped solar still with a corrugated absorber plate. Process Saf. Environ. Prot. 2021, 148, 273–282. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).