1. Introduction
Decarbonisation of transportation is a major activity worldwide towards “securing global net zero by mid-century and keeping 1.5 degrees within reach” [
1]. Transportation was responsible for 27% of the United Kingdom (UK)’s carbon dioxide (
) emissions in 2019, of which over 90%, or 111 Mega-tonnes (Mt), of
were a product of road transport vehicles. Cars, including taxis, have played a major role in these emissions as, combined, they produced 68 Mt of
, corresponding to 61% of the road transport vehicle emissions or a staggering 15% of UK’s annuals emissions [
2]. As transportation is an essential part of our daily activities, and therefore cannot easily be reduced, electric vehicles (EVs) are a promising solution to tackle this challenge. The short- to medium-term aim is to replace vehicles that run with internal combustion engines with electric ones, especially if the electricity is produced by renewable energy sources.
Driven by global climate change goals, and transition to net-zero economies, many governments world-wide have provided attractive incentives to EV users leading to a tremendous boom in EV purchase for domestic and business use. Indeed, according to the International Energy Agency [
3], the share of EVs on roads in 2020 has exceeded the 10 million mark—a jump from 7 million in 2019 [
4].
With the increasing penetration of EVs in the market, power grids face great challenges regarding the ability to supply, transfer and distribute power. Indeed, the exponential increase of electric car sales—both plug-in hybrid and fuel cell, which are fuelled from the grid—requires major changes in the energy markets and grid infrastructure as electrification of transportation poses numerous challenges for the existing power networks. In particular, modelling shows that large-scale residential charging of EVs could result in overloading of distribution networks during peak hours if infrastructure upgrades and smart grid management are not implemented [
5,
6].
Understanding where and when EVs are charging is important for uptake modelling, supply planning, and grid infrastructure reinforcement [
7]. Knowledge of EV charging patterns is also required for smart grid solutions such as Demand Response (DR) [
8] and Vehicle-to-Grid (V2G) [
9]. Future energy polices and transport planning would also benefit from accurate information on EV charging patterns. In addition, information about household consumption as a result of EV charging could be useful for customers to manage running costs of EVs in a similar manner to fuel costs for petrol and diesel cars. Awareness of the financial and carbon footprint implications of EV charging at home may incentivise customers to charge at public points and places of work, or opt-in to DR-based tariffs and V2G programmes, alleviating the overloading of distribution systems during peak hours as a result and maximising charging from solar feed-in.
There are two options for monitoring the presence of EV charging on power networks. The first is Intrusive Load Monitoring, a popular approach which sub-meters the EV charger at charge point, requiring additional hardware installation and maintenance costs; while this may benefit the end user and car manufacturer who have access to the EV’s charging consumption statistics, the data are often not readily available to utilities, grid operators and network operators for infrastructure planning and grid demand management. A preferred alternative is Non-Intrusive Load Monitoring (NILM), from which energy consumption and time-of-use of the EV chargers is obtained via advanced signal information processing of aggregate power data, collected at a single point of measurement, e.g., a smart meter. The aim of NILM estimation of consumption—a regression problem—and time of use—a classification problem—algorithms is to match the equivalent submetered readings, therefore acting as a virtual sub-meter.
NILM has been an active area of study for over 30 years, but with the ongoing roll-out of millions of smart electricity meters globally, the deployment of large-scale residential NILM systems is emerging. Early work in the area often assumed the availability of mid- to-high frequency power measurements in the region of 1 Hz and above, as well as current and voltage measurements. However, due to storage limitations and potential privacy concerns, current real-world smart meter readings are only available at 15 to 60 min intervals, and providing only aggregate consumed power. The Smart Meter Equipment Technical Specifications Version:2 (SMETS2) framework in the UK, for example, permits regular smart meter readings to be taken at a 30 min resolution [
10]. This motivates the need for for low- (1–60 s) to very low-resolution (15–60 min) NILM algorithms operating on power measurements only [
11]. Recent years have seen an explosion of low-frequency NILM approaches, mostly based on Deep Neural Networks (DNNs). Indeed, according to [
12], which provides a thorough literature review of DNN approaches for NILM, there were 87 DNN-NILM publications in the period 2018 to 2020. However, these DNN-NILM approaches focus primarily on typical household appliances, excluding EVs, and do not report results with meaningful performance metrics to truly evaluate consumption estimation. This is partly because of the limited availability of EV charging consumption datasets and generic, non-application-specific regression and classification metrics for evaluating DNN approaches for benchmarking.
Besides DNN approaches, the low-frequency NILM problem has also been tackled via other supervised and unsupervised approaches over the years, the former requiring training on labelled data unlike the latter—an up-to-date review can also be found in [
13]. Examples of supervised NILM approaches are Graph Signal Processing (GSP) approaches [
14], Support Vector Machines (SVM) [
15], Decision Trees (DTs) [
16] and k-Nearest Neighbour (kNN) [
17]. Some unsupervised approaches include Combinational Optimisation, unsupervised GSP [
11], Hidden Markov Models (HMM) [
18,
19] and Dynamic Time Warping [
16]. Unsupervised methods have the advantage of not being limited by appliances available in training data, but achieving good performance is challenging. Supervised approaches could equally be viable for practical large-scale deployment as long as sufficient labelled training data are available, and generalisability to similar unseen data and cross-domain transferability to other data can be demonstrated [
20]. Most supervised approaches have mainly focused on NILM on seen houses and, more recently, unseen houses on the same dataset, and even fewer on cross-domain transferability [
12,
13].
The most popular electrical measurements’ datasets on which NILM approaches are generally validated in the literature are REDD [
21], UK-DALE [
22], REFIT [
23] and Pecan Street Dataport [
24]—see [
13] for some other examples of commonly used datasets, none of which include EVs. Only Dataport includes EV sub-metering and aggregate meter readings for multiple houses for a few months. A thorough review of available EV load datasets including charging point locations, historical and real-time charging sessions which refer to the period of time an EV is charged, traffic counts, travel surveys and registered vehicles, is presented in [
25] in order to improve EV load modelling. However, none of the vehicle-centric data contain actual consumption readings from charging points, but rather spatial and temporal EV charging sessions to artificially reconstruct synthetic house-level and aggregated load consumption. This is not used in this study since synthetic loads do not reflect true consumption from the grid, and are not integrated into the household overall mains metering with other interfering loads and prosumers.
While NILM models have been developed for disaggregation of most conventional household appliances, NILM techniques for the disaggregation of EV loads is still an emerging area of study. Although, at first glance, EV load disaggregation may seem a relatively simple problem due to its high power level and being a single state load, houses nowadays use many electric devices with complex electrical signals and high energy consumption that make the separation of the EV signal a challenge. These include households with electric heaters, heat pumps, electric showers, Air Conditioning (AC) and Heating, Ventilation and Air Conditioning (HVAC) units, or prosumers, i.e., consumers that also produce electricity through solar panels and/or other renewable energy sources—tend to have quite complex load signals.
In this article, a detailed and robust methodology for large-scale robust evaluation of EV load disaggregation from household smart meter data are presented, leveraging on prior NILM algorithms that have been shown to have excellent classification performance, namely the Random Decision Forest (RF) classifier as used for EV load classification in [
26], and the sequence-to-subsequence DNN of [
27], which was shortlisted in [
12]’s review paper to have one of the best regression performance on standard household appliances. Sequence-to-sequence and sequence-to-point DNN are used to perform a sequence transformation and therefore are appropriate for identifying electrical load signatures. The sequence-to-subsequence network was chosen as a trade-off between convergence speed of sequence-to-sequence, and computational load of sequence-to-point, as the proposed methodology should be both accurate and computationally efficient for scalability. The main contributions of this paper are:
A critical review of the emerging literature on disaggregation of EV loads using supervised and unsupervised NILM;
Implementation of RF bagging—based on [
26]—and a suite of boosting-based ensemble algorithms, namely AdaBoost (ADA), XGBoost (XGB), Light Gradient-Boosting Machine (LGBM) and CatBoot, for binary classification of EV charging load;
Novel, low-complexity post-processing steps for mitigating false positives arising due to high load interference, and for accurately estimating the EV load based on RF classification output, using time information;
Adapting sequence-to-subsequence DNN-based NILM from [
27] to EV load estimation, providing full details to enable reproducibility of the work including hyper-parameter tuning and post-processing steps;
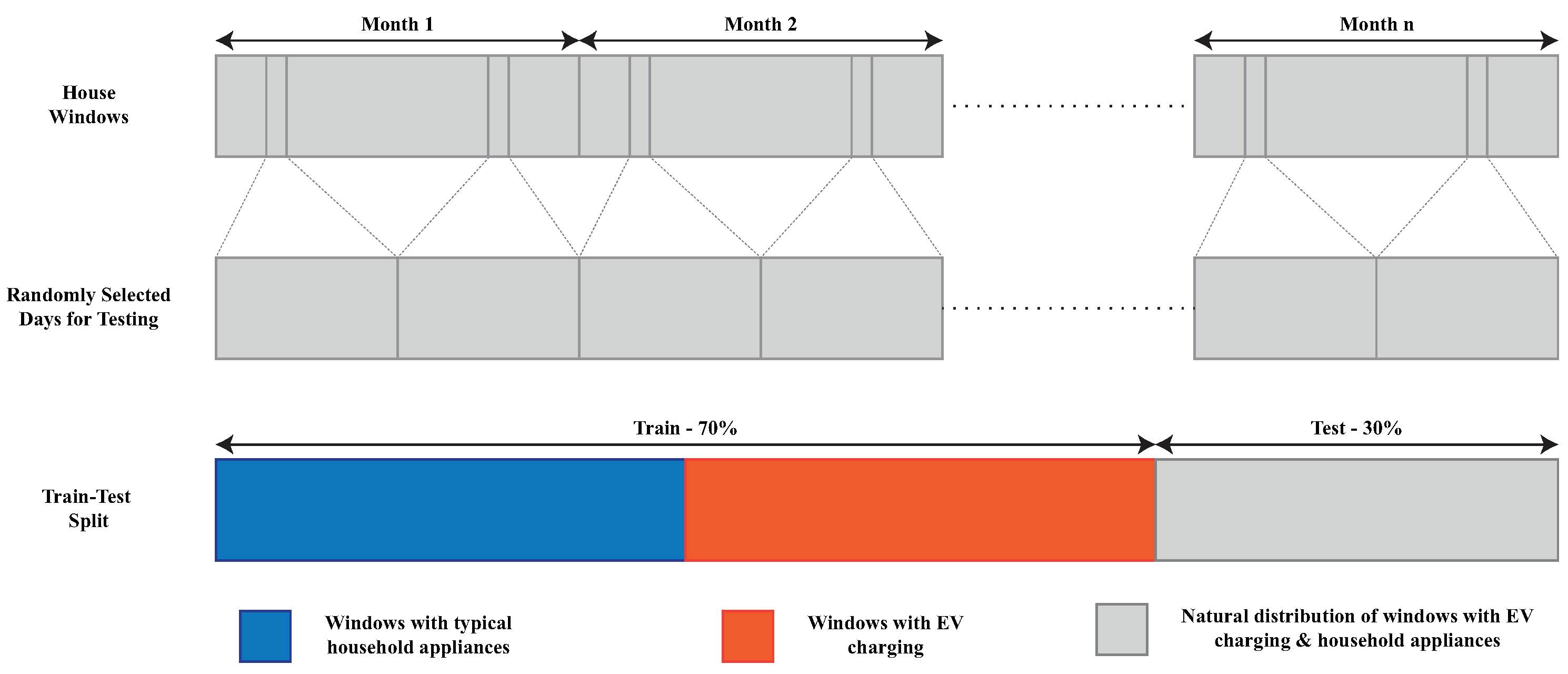
Evaluation on 15 real houses from two geographical regions in the USA from the Dataport dataset, with 1 and 15 min resolution data containing high power interference from AC and different EV load profiles, where the EV charging power, duration of EV charging events, sparsity of charging events, and the relative noise or interference from unknown loads that could negatively affect disaggregation performance, are calculated and reported for each house;
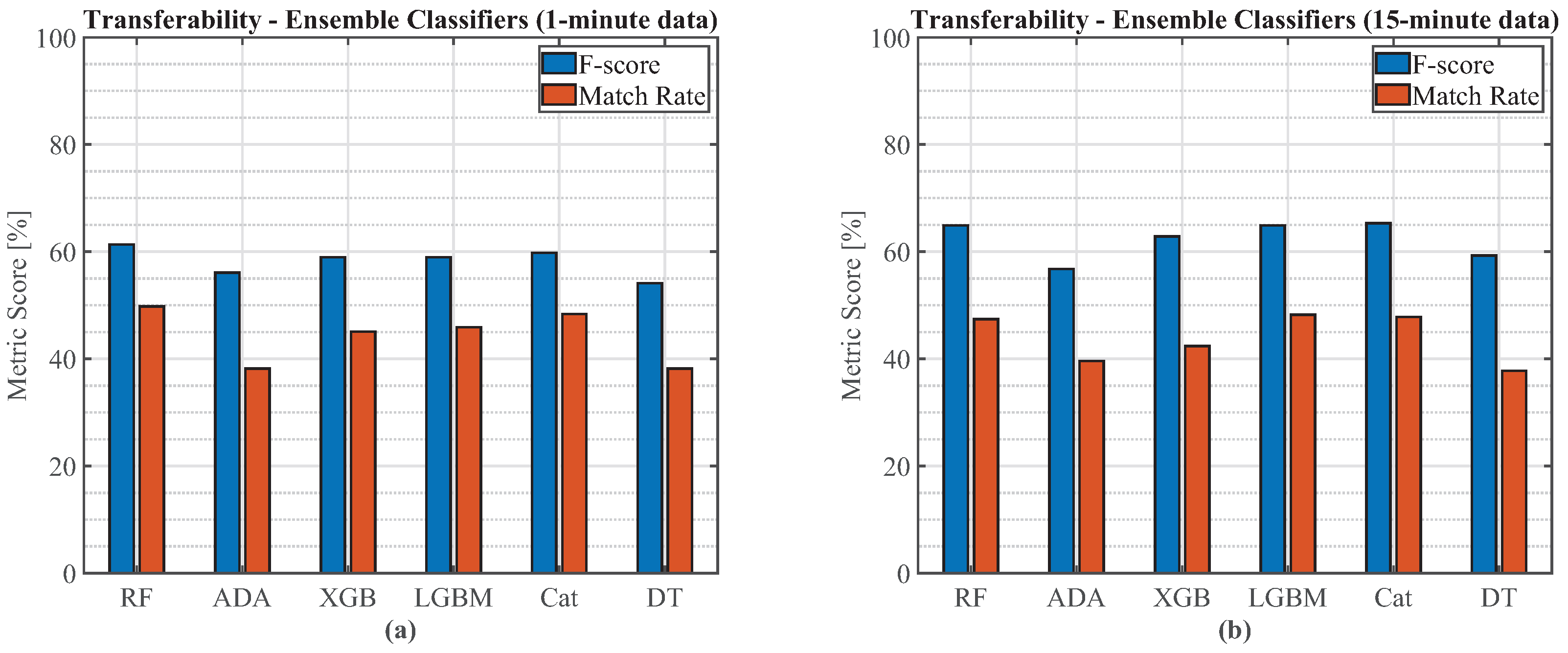
Rigorous evaluation of the above NILM approaches, with a focus on creating realistic test scenarios including generalisability on unseen households with EVs with similar EV load profile from Austin, Texas and cross-domain transferability evaluation on unseen houses with a different EV load profile from New York;
Quantifying generalisability and cross-domain transferability of the proposed methods by adapting metrics of [
28,
29];
Evaluation of meaningfulness of standard and NILM-specific metrics and recommendations for EV load disaggregation for network operators.
For NILM evaluation, the most popular metrics include the standard
for classification and the standard Mean Square Error (MSE) or Mean Absolute Error (MAE) for regression, as well as more meaningful NILM specific metrics such as Accuracy (
) and Match Rate (MR). These and other NILM metrics are reviewed in [
30]. The choice of the dataset and how challenging it is to disaggregate loads of interest can be measured through the noisiness of the dataset metric of [
28]. Additional metrics to calculate the generalisation loss that occurs when testing a NILM model on unseen houses is described in [
29]. Given the potential impact of residential EV charging on the smart grid and the benefits of NILM for EV charging consumption and time-of-use for network operators and energy consumers, this paper will present and discuss results using all the above metrics.
The rest of the paper is organised as follows. In
Section 2, supervised and unsupervised NILM approaches that are specifically designed for EVs are reviewed. In
Section 3, a rigorous approach to evaluate the generalisability and transferability of ensemble methods and a sequence-to-subsequence DNN for classification of time of use of EVs and consumption estimation is proposed. In
Section 4, the proposed methodology is evaluated using generic classification and regression metrics, as well as NILM specific consumption metrics. This is followed by
Section 5, where observations are discussed in detail in relation to EV load estimation to inform grid demand. Lastly, conclusions are summarised in
Section 6.
5. Discussion
During data processing and algorithm tuning, it was observed that, in the presence of houses with solar panels, it was better to extract EV load charge events without solar generation. EV load signatures have a distinctly high power levels, and therefore the drop in amplitude caused by solar generation is insufficient to completely obfuscate the EV signal. In the Dataport [
24] houses considered in the study, EVs were connected to the grid in the evening and night hours, when solar generation is either very low or non-existent. This pattern agrees with the daily routines, as people tend to use their vehicles to commute to work during morning and afternoon—when solar generation is at its peak. It is therefore worth exploring the possibility of storage of energy produced during the daytime and use that energy later so as to charge EVs and help reducing grid peaks that usually occur in the late afternoon/evening.
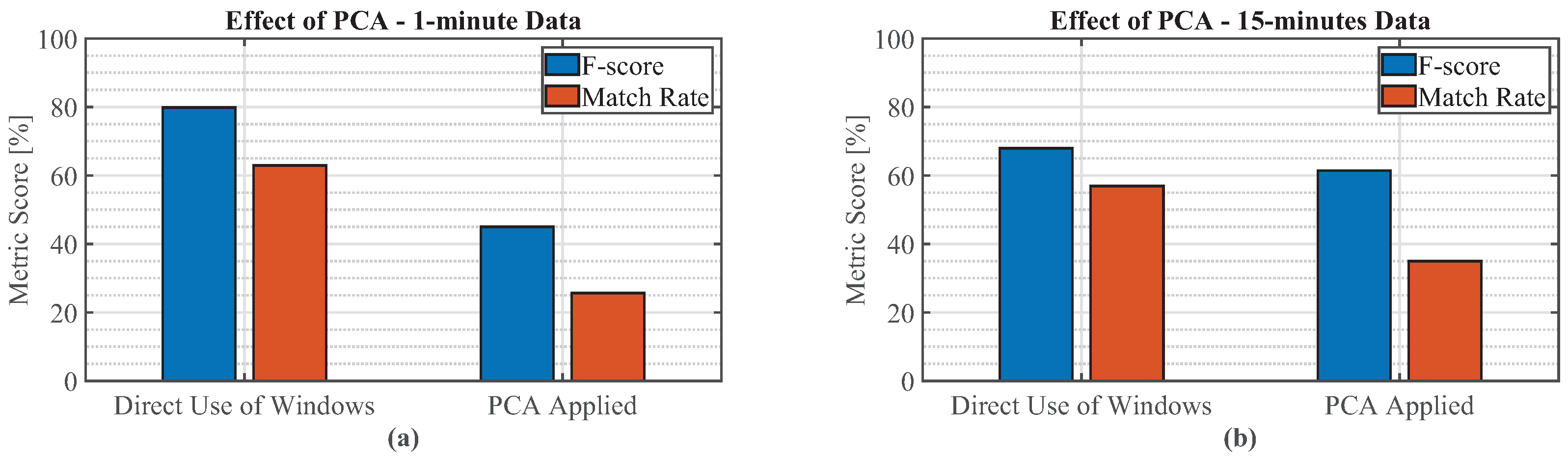
is more suitable to evaluate how accurately EV charging events are detected compared to metrics like , especially for realistic, unbalanced testing datasets. Complementary metrics for measuring the accuracy in estimating the load consumption of the EV charging events are and MR, whilst MAE and SAE can explain the performance of regression networks. Similarly, generalisation loss as a metric based on , and MAE, provide a good representation of performance loss of these measures due changes in granularity of the meter readings, as well as due to generalisability to unseen houses in a similar geographic area and with similar EV charging loads, and transferability to unseen houses in different geographic areas and with different EV charging loads.
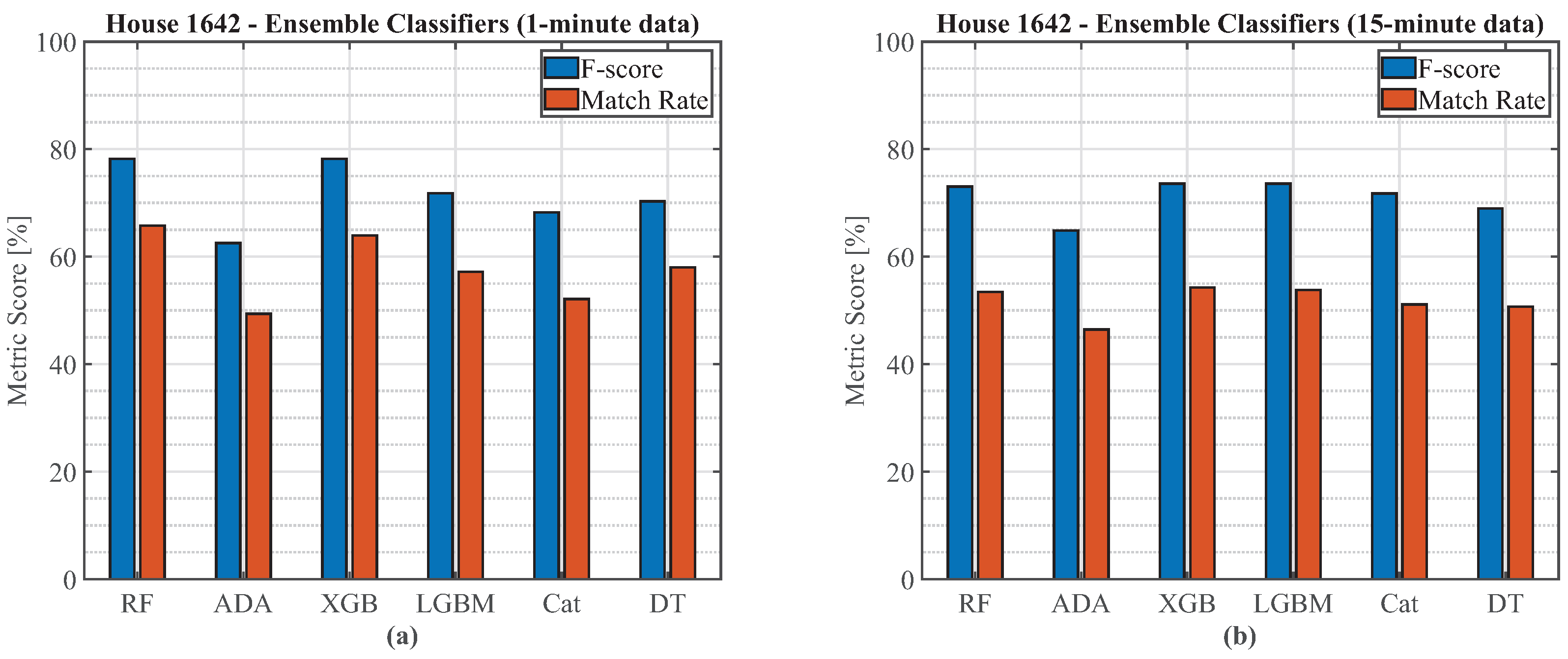
The ensemble classification models were more robust to insufficient EV charging events for training than the DNN-based regression models. That is, the sequence-to-subsequence DNN is especially sensitive to the amount of training samples, which takes precedence over the noisiness level of the house due to interfering loads. Otherwise, it was observed that both ensemble-based classification and regression models accurately performed EV load estimation on the same house the models were trained on, as well as showed excellent generalisability performance when tested on unseen houses for similar EV charging levels in different geographic areas. During generalisability and transferability experiments, it was observed that the regression network is less affected by lower granularity readings than the RF classification and load reconstruction approach. The proposed final recommendation for EV charging event detection, as well as accurate energy consumption for each charging event, is therefore a sequence-to-subsequence DNN, when plenty of training data are available in a mixed mode approach, with data from different geographic areas, and especially with a balanced number of EV charging load levels to avoid bias towards a particular EV charging level.








{kind=link}
{kind=link}
{kind=link}
{kind=link}