
Research on Production Profiling Interpretation Technology Based on Microbial DNA Sequencing Diagnostics of Unconventional Reservoirs

Abstract
:1. Introduction
2. Methods
2.1. Sample Preparation
2.1.1. Sample Pretreatment
2.1.2. DNA Extraction
2.1.3. PCR Amplification
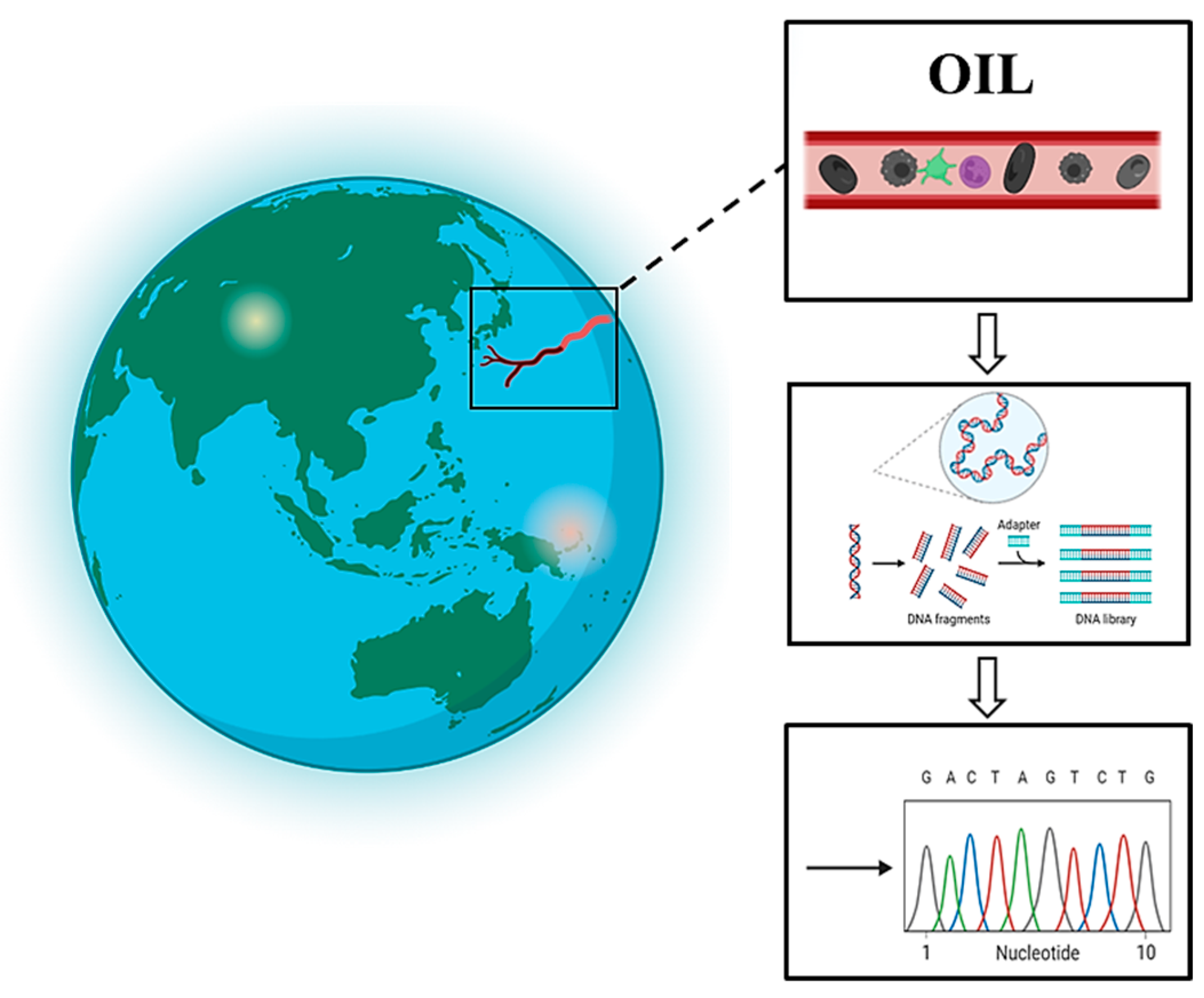
2.2. DNA Sequencing and Data Processing
2.2.1. DNA Sequencing
2.2.2. Downstream Data Filtering
2.3. Traceability of Produced Fluids
2.3.1. Produced Fluids Traceability Model
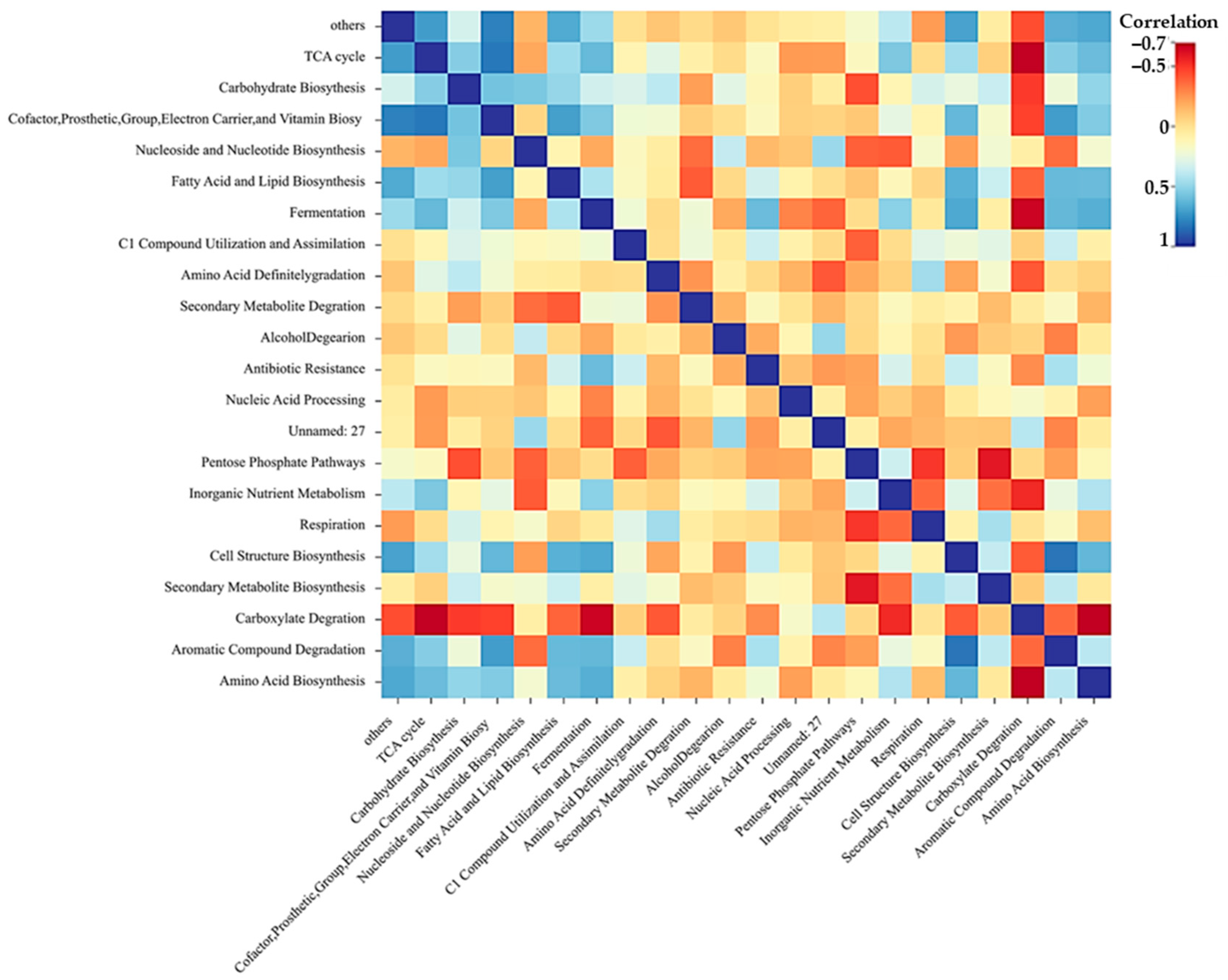
2.3.2. Clustering Method Optimization
- (1)
- Data standardization;
- (2)
- Correlation analysis;
- (3)
- Clustering method selection;
- Naive Bayes classification;
- Random forest classification method;
- Back Propagation classification method;
- (4)
- Production profiling traceability algorithm preferences Method;
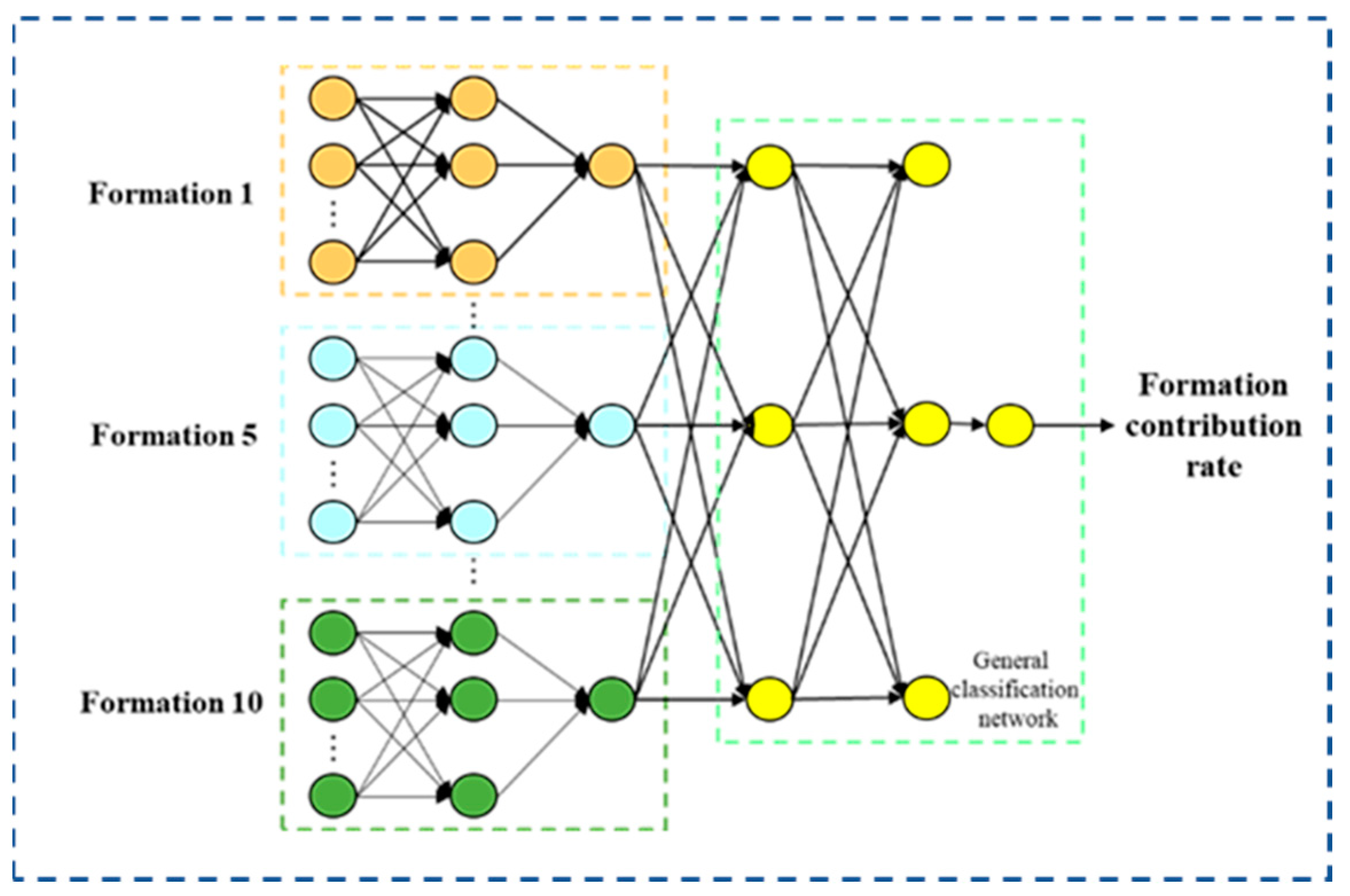
2.3.3. Improvement of Clustering Method
3. Results
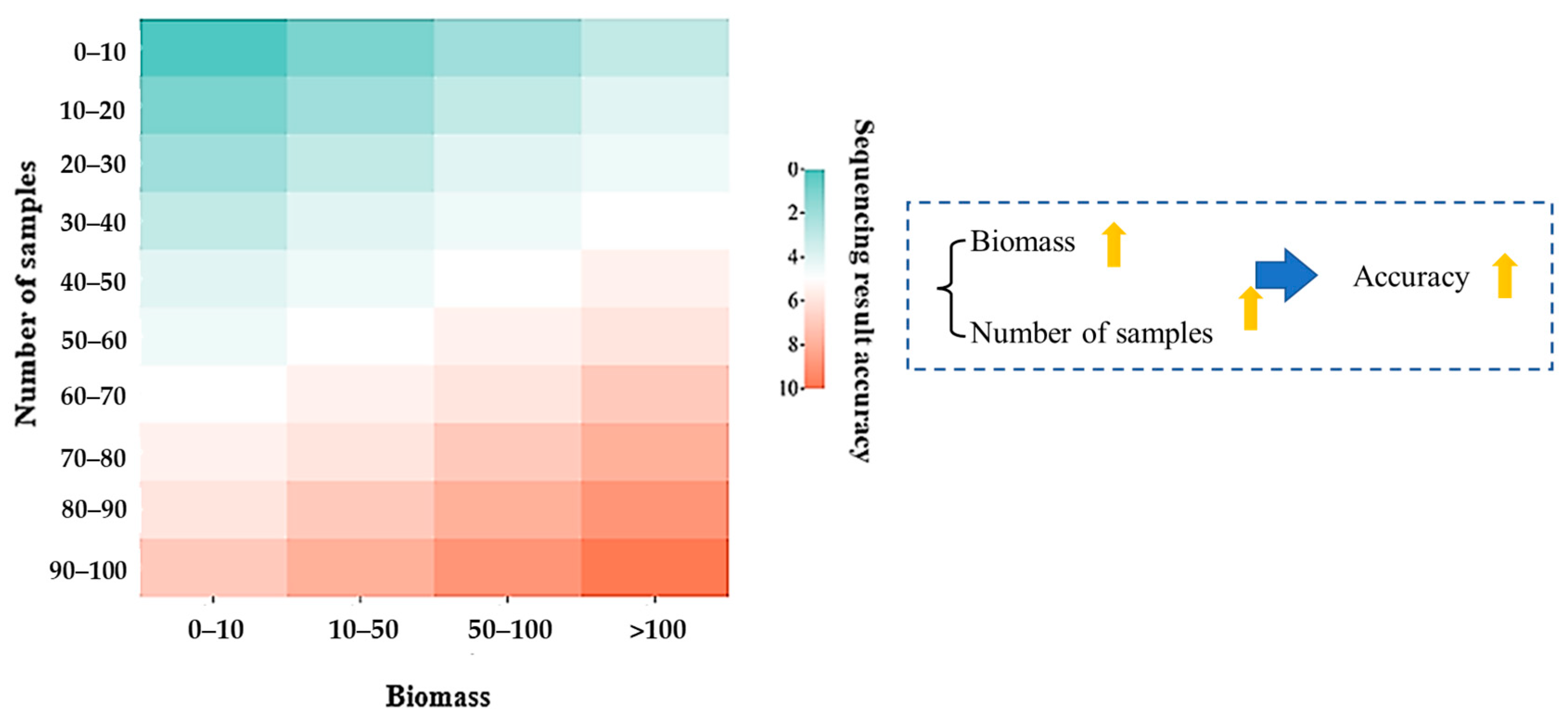
3.1. Establishment of Stratigraphic Baseline
3.2. Traceability Algorithm Preference and Improvement Results
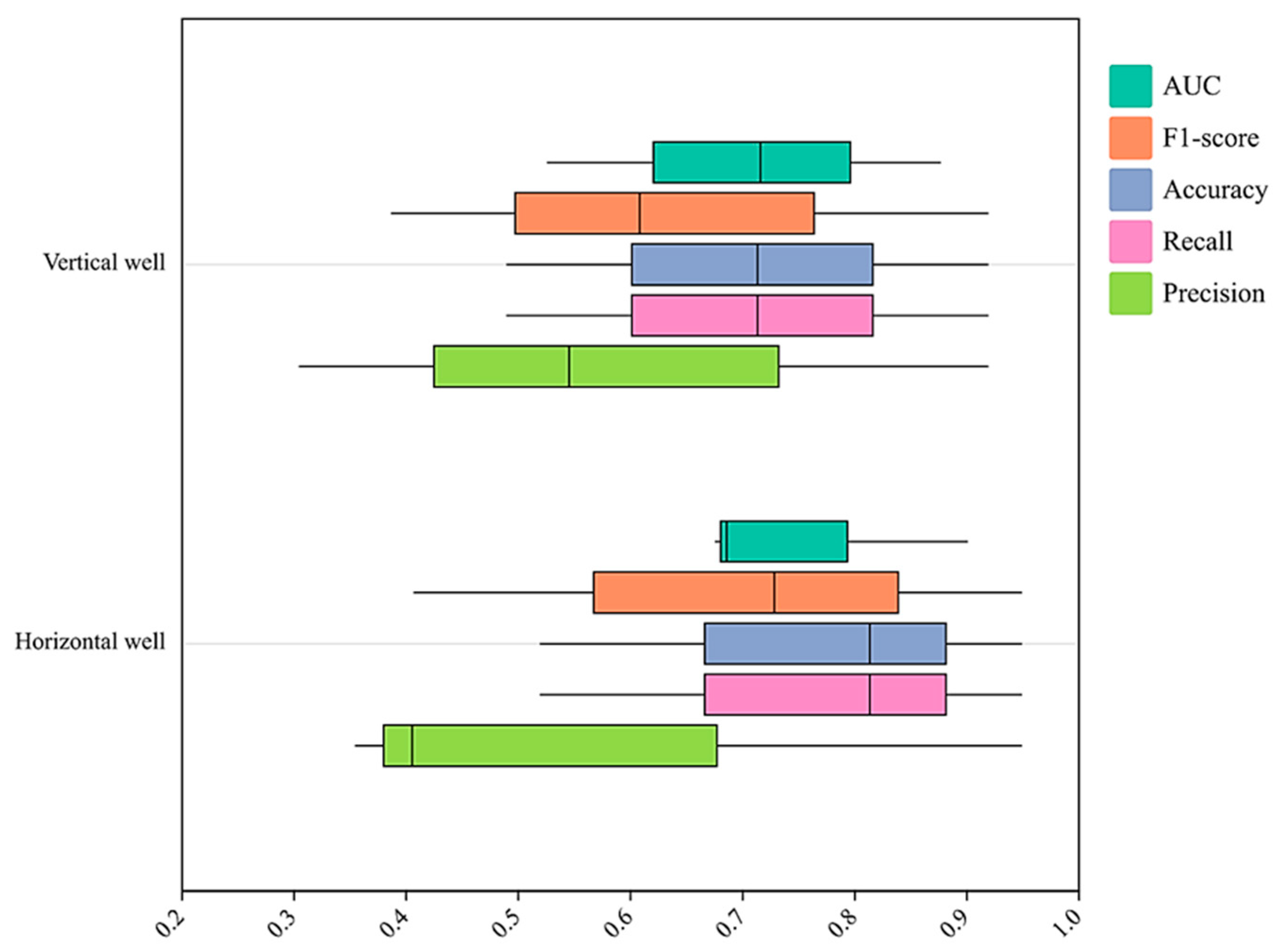
3.2.1. Traceability Algorithm Preference Results
3.2.2. Improvement Results of Traceability Algorithm
- (1)
- Pre-processing the data, the main steps include (a) filling the missing values by the mean fill method, and (b) normalizing the data.
- (2)
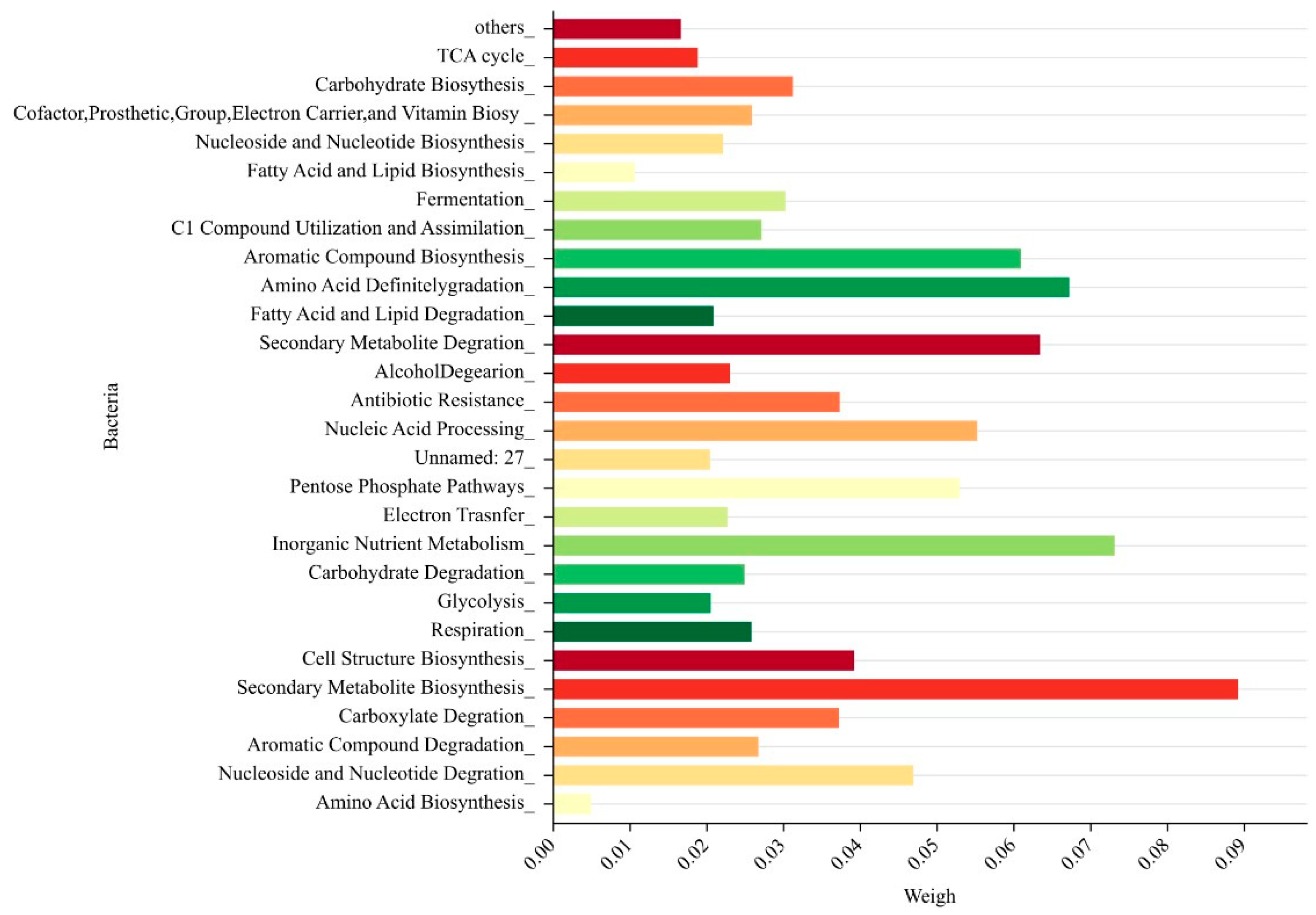
- The 28 bacteria affecting the classification are brought into the random forest algorithm to calculate the feature importance magnitude, and the factors with the lowest importance degree are removed. Importance magnitude and the factors with the lowest degree are removed, and the process is repeatedly cycled until the factor feature importance degree are greater than the set threshold, that is, this stage is ended and the best feature subset was obtained. The importance magnitude of each bacterium is shown in the figure below (Figure 14).
- (3)
- Randomly select 70% as the training set, and the remaining 30% as the test set. The maximum number of iterations is 150. Conduct sample prediction based on PSO random forest method. The confusion matrix is chosen as the evaluation metric for the improved algorithm. Based on the confusion matrix, four core metrics of the model can be derived: accuracy, accuracy, recall, and F1-score value. Accuracy is the ratio of the sum of true positive and true negative values to the total number of samples. The accuracy is also the ratio of the number of samples with the same prediction category and real category to the total number of samples. Accuracy is the sum of true positive values divided by true positive values and false positive values. Recall is the ratio of true positive values to the sum of true positive values and false negative values; F1-score combines two evaluation indexes, precision, and recall, and calculates the magnitude of each index when the true classification effect is the same for the predicted formation and the actual formation, i.e., the mean and weighted mean of each index, respectively. Set the parameters as shown in the following table. When the number of iterations reaches 150, the algorithm stops. The boundary and external conditions of PSO algorithm is shown in Table 3.
3.3. Construction of Fluid-Producing Profiles
4. Discussion
4.1. Advantages Compared with Traditional Production Profiling Technology
4.2. Future Research
5. Conclusions
- (1)
- A complete production profiling process including petroleum microorganism sampling and transportation methods, DNA extraction and PCR amplification methods, and DNA sequencing methods is established. The strategic baseline map is obtained by these methods, which reflects the bacteria species and their abundance in each formation. It illustrates the characteristics of formation bacteria and lays a foundation for the construction of the production profiling.
- (2)
- The random forest algorithm for the production profiling traceability algorithm is preferred by comparing the accuracy, precision, recall, F1-score, and running time of the three clustering methods of Naive Bayes, back propagation, and random forest. The PSO-optimized random forest clustering algorithm is constructed to describe the contribution of each formation to the production fluid. The precision reached 0.97, which improved 0.02 compared with that before optimization.
- (3)
- Previous studies about the present production profiling technologies have a short validity period, which can only reflect the temporary situation. Our laboratory results suggest that it is possible to conduct production profiling interpretation technology based on microbial DNA sequencing diagnostics of unconventional reservoirs in a simple and pollution-free way. By constructing the production profiling of over 5 months, we have confirmed that this method can effectively monitor reservoir production performance for a long time.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- (1)
- Data standardization: In order to avoid the influence of the scale on the variable data, the data should be standardized first.
- (2)
- Correlation analysis.
- (3)
- (4)
- (A)
- Draw the training set from the original sample set. In each round, n training samples are drawn from the original sample set using the Bootstrapping method (with put-back sampling). A total of k rounds are performed to obtain k mutually independent training sets.
- (B)
- One model is obtained using one training set at a time, and a total of k models are obtained for k training sets.
- (C)
- For the classification problem: the k models obtained in the previous step are used to obtain the classification results by voting; for the regression problem, the mean value of the above models is calculated as the final result.
- (5)
- Back propagation: where the input layer of this model is the sequencing data of the stratigraphic baseline, the implicit layer is the new clustering result, and the output layer is the probability that the fluid production originates from each formation, the contribution rate of each formation. The output of the implicit layer is set to Fj, the output of the output layer is set to Ok, the excitation function of the system is set to G, and the learning rate is set to β. Then the mathematical relationship between its three layers is as follows [29].
- (6)
- Accuracy is the percentage of all samples with correct predictions divided by the total sample, and generally speaking the closer to 1 the better. Its meaning is the proportion of predicted and actual categories that are both 1 to the predicted category of 1. For this data set is the total number of samples with the same actual source of fluid production for that formation and the predicted source of fluid production for that formation as a percentage of the predicted source of fluid production for that formation. The formula for this is.
- (7)
- Precision, which indicates the proportion of the number of samples that are actually 1 among the number of samples with a prediction result of 1.
- (8)
- Recall, which indicates the proportion of all samples with true 1 that are correctly predicted by us. A higher recall means that we try to capture as many minority classes as possible, and a lower recall means that we do not capture enough minority classes. For this dataset the meaning is expressed as the proportion of the total number of samples with the same actual source of fluid production as the predicted source of fluid production in the formation to the actual source of the formation. The formula for this is:
- (9)
- In order to balance both precision and recall, we create a summed average of the two numbers as a comprehensive metric to consider the balance between them, called F measure. The F measure is distributed between [0, 1], and the closer to 1, the better. The significance for this dataset is that for a high proportion of the total number of samples where both the actual and predicted sources of fluid production are from that formation to the predicted source of that formation, it will inevitably lead to a decrease in the proportion of the total number of samples where both the actual and predicted formations are from that formation to the actual source of that formation. The ideal F1-score metric is one in which the difference between the accuracy and recall rates is small and both are improved, and the formula is:
- (10)
- The ROC curve, known as receiver operating characteristic curve, reflects the trend of true positive rate (TPR) with false positive rate (FPR), and is a curve plotted with true positive rate (sensitivity) as the vertical coordinate and false positive rate (1-specificity) as the horizontal coordinate. According to the position of the curve, the whole graph is divided into two parts. The area of the lower part of the curve is called AUC (area under curve), which is used to indicate the prediction accuracy, and the higher the AUC value, i.e., the larger the area under the curve, the higher the prediction accuracy. The higher the AUC value, the larger the area under the curve, the higher the prediction accuracy. The closer the curve is to the upper left corner (the smaller the X and the larger the Y), the higher the prediction accuracy.
References
- Lv, Y.; Wang, B.; Huang, W.; Han, E. Integrated technology of horizontal well water detection and testing. Pet. Field Mach. 2011, 40, 93–95. [Google Scholar]
- Di, D.; Guo, X.; He, Z.; Pang, W. Testing Technology of Intelligent Tracer Production Profile. Oil Gas Well Test. 2021, 30, 44–49. [Google Scholar]
- Chang, Q.; Liu, Y.; Lu, W.; Wang, X.; Zhang, H.; Zhang, L. Diagnostic technology of trace substance tracers for shale oil horizontal well pressure drainage. Oil Gas Well Test. 2021, 30, 32–38. [Google Scholar]
- Yue, P. Research on logging technology of liquid production profile. Petrochem. Technol. 2016, 23, 147. [Google Scholar]
- Du, S.; Liu, Q.; Luo, W.; Ma, G. Evaluation and application of liquid production production profiling technology in low permeability reservoirs. Petrochem. Appl. 2018, 37, 87–90. [Google Scholar]
- Cui, H. Research on Comprehensive Interpretation Method of Annular Fluid Production Profile. J. Pet. Nat. Gas 2008, 3, 266–268. [Google Scholar]
- Qin, D.; Gao, Y.; Yu, Y. Evaluation on the adaptability of liquid production production profiling of preset downhole traction horizontal wells. Petrochem. Technol. 2016, 23, 278. [Google Scholar]
- Chen, E.Y.; Chen, R.B. Monitoring Microbial Corrosion in Large Oilfield Water Systems. J. Pet. Technol. 1984, 36, 1171–1176. [Google Scholar] [CrossRef]
- Tang, Y.; Xu, K.; Gu, L.; Yang, F.; Gao, J.; Ren, C.; Wang, G. Research Progress in Theory and Technology of Microbial Exploration for Oil and Gas. Pet. Exp. Geol. 2021, 43, 325–334. [Google Scholar]
- Brown, L.R. Microbial enhanced oil recovery (MEOR). Curr. Opin. Microbiol. 2010, 13, 316–320. [Google Scholar] [CrossRef] [PubMed]
- Sawadogo, J.; Haggertty, M.; Mallory, C.; Huchton, J.; DeAngelis, W.; Price, C. Impact of Completion Design and Interwell Communication on Well Performance in Full Section Development: A STACK Case Study Using DNA Diagnostics. In Proceedings of the SPE Annual Technical Conference & Exhibition, Houston, TX, USA, 12–14 October 2020. SPE-201726-MS. [Google Scholar]
- Ursell, L.; Hale, M.; Menendez, E.; Zimmerman, J.; Dombroski, B.; Hoover, K.; Ishoey, T. High Resolution Fluid Tracking from Verticals and Laterals Using Subsurface DNA Diagnostics in the Permian Basin. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Denver, CO, USA, 22–24 July 2019. [Google Scholar]
- Sawadogo, J.; Ursell, L.; Reeve, N.; Schlecht, M. Mature Fields—Optimizing Waterflood Management Through DNA Based Diagnostics. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 9–12 November 2020. [Google Scholar]
- Percak-Dennett, E.; Liu, J.; Shojaei, H.; Luke, U.; Thomas, I. High Resolution Dynamic Drainage Height Estimations using Subsurface DNA Diagnostics. In Proceedings of the SPE Western Regional Meeting, San Jose, CA, USA, 24 April 2019. [Google Scholar]
- Silva, J.; Ursell, L.; Percak-Dennett, E. Applying Subsurface DNA Diagnostics and Data Science in the Delaware Basin. In Proceedings of the SPE Hydraulic Fracturing Technology Conference and Exhibition, The Woodlands, TX, USA, 23 January 2018. [Google Scholar]
- Zhang, Y.; Dekas, A.E.; Hawkins, A.J.; Parada, A.E.; Gorbatenko, O.; Li, K.; Horne, R.N. Microbial Community Composition in Deep-Subsurface Reservoir Fluids Reveals Natural Interwell Connectivity. Water Resour. Res. 2020, 56, e2019WR025916. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Horne, R.N.; Hawkins, A.J.; Primo, J.C.; Gorbatenko, O.; Dekas, A.E. Geological activity shapes the microbiome in deep-subsurface aquifers by advection. Proc. Natl. Acad. Sci. USA 2022, 119, e2113985119. [Google Scholar] [CrossRef] [PubMed]
- Knights, D.; Kuczynski, J.; Charlson, E.; Zaneveld, J.; Mozer, M.C.; Collman, R.G.; Bushman, F.; Knight, R.; Kelley, S.T. Bayesian community-wide culture-independent microbial source tracking. Nat Methods 2011, 8, 761–763. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shenhav, L.; Thompson, M.; Joseph, T.A.; Briscoe, L.; Furman, O.; Bogumil, D.; Mizrahi, I.; Pe’er, I.; Halperin, E. FEAST: Fast expectation-maximization for microbial source tracking. Nat Methods 2019, 16, 627–632. [Google Scholar] [CrossRef] [PubMed]
- Alberti, L.; Angelotti, A.; Antelmi, M.; La Licata, I. Borehole Heat Exchanger simulations in aquifer: The borehole grout influence in Thermal Response Test modeling. In Proceedings of the 87° Congresso della Società Geologica Italiana, Milan, Italy, 10–12 September 2014. [Google Scholar]
- Bao, Y.J.; Xu, Z.; Li, Y.; Yao, Z.; Sun, J.; Song, H. High-throughput metagenomic analysis of petroleum-contaminated soil microbiome reveals the versatility in xenobiotic aromatics metabolism. J. Environ. Sci. 2017, 56, 25–35. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Wang, Y.; Luo, L.; Pfiffner, S.M.; Li, G.; Dong, Z.; Xu, Z.; Dong, H.; Huang, L. Detection of the deep biosphere in metamorphic rocks from the Chinese continental scientific drilling. Geobiology 2021, 19, 278–291. [Google Scholar] [CrossRef] [PubMed]
- Lasken, R.; McLean, J. Recent advances in genomic DNA sequencing of microbial species from single cells. Nat. Rev. Genet. 2014, 15, 577–584. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Zhang, S. A leaf node weighted Random Forest algorithm based on PSO optimization. Mod. Comput. 2022, 28, 1–4. [Google Scholar]
- Xie, B. Application of Naive Bayesian Classification in Data Mining. J. Gansu Union Univ. Nat. Sci. Ed. 2007, 21, 79–82+91. [Google Scholar]
- Liu, W.; Liang, S.; Wang, C. Naive Bayesian classification method based on weighted kernel principal component. J. Chang. Univ. Technol. China 2022, 43, 610–618. [Google Scholar]
- Adeeyo, Y. Random Forest Ensemble Model for Reservoir Fluid Property Prediction. In Proceedings of the SPE Nigeria Annual International Conference and Exhibition, Lagos, Nigeria, 1–3 August 2022. [Google Scholar]
- Gamal, H.; Alsaihati, A.; Elkatatny, S.; Abdulraheem, A. Sonic Logs Prediction in Real Time by Using Random Forest Technique. In Proceedings of the ARMA/DGS/SEG 2nd International Geomechanics Symposium, Virtual, 1–4 November 2021. [Google Scholar]
- Zhao, H.; Geng, Y.; Liu, Z.; Wang, W.; Zhou, Z.; Kao, J. Study on Fracture-Cavity Instability of Carbonate Rocks Based on Back-Propagation (BP) Back propagation. In Proceedings of the 53rd U.S. Rock Mechanics/Geomechanics Symposium, New York, NY, USA, 23–26 June 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vertical Well | AUC | F1-Score | Accuracy | Recall | Precision |
|---|---|---|---|---|---|
| Random Forest | 0.8775 | 0.92 | 0.92 | 0.92 | 0.92 |
| Back Propagation | 0.7165 | 0.609 | 0.714 | 0.714 | 0.546 |
| Naïve Bayes | 0.5261 | 0.387 | 0.49 | 0.49 | 0.305 |
| Horizontal Well | AUC | F1-Score | Accuracy | Recall | Precision |
|---|---|---|---|---|---|
| Random Forest | 0.9016 | 0.95 | 0.95 | 0.95 | 0.95 |
| Back Propagation | 0.6865 | 0.729 | 0.814 | 0.814 | 0.406 |
| Naïve Bayes | 0.6761 | 0.407 | 0.52 | 0.52 | 0.355 |
| Parameter | Value |
|---|---|
| Maximum Iterations | 150 |
| Inertia weight | 0.9 |
| Individual learning factors | 2 |
| Sociology Department Factor | 2 |
| Maximum iteration speed | 4 |
| Horizontal Well | AUC | F1-Score | Accuracy | Recall | Precision |
|---|---|---|---|---|---|
| Random Forest | 0.9016 | 0.95 | 0.95 | 0.95 | 0.95 |
| Random Forest Based on PSO Optimization | 0.9342 | 0.97 | 0.97 | 0.97 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Wang, L.; Qiang, X.; Ren, Z.; Wang, H.; Wang, Y.; Wang, S. Research on Production Profiling Interpretation Technology Based on Microbial DNA Sequencing Diagnostics of Unconventional Reservoirs. Energies 2023, 16, 358. https://doi.org/10.3390/en16010358
Yang H, Wang L, Qiang X, Ren Z, Wang H, Wang Y, Wang S. Research on Production Profiling Interpretation Technology Based on Microbial DNA Sequencing Diagnostics of Unconventional Reservoirs. Energies. 2023; 16(1):358. https://doi.org/10.3390/en16010358
Chicago/Turabian StyleYang, Haitong, Lei Wang, Xiaolong Qiang, Zhengcheng Ren, Hongbo Wang, Yongbo Wang, and Shuoliang Wang. 2023. "Research on Production Profiling Interpretation Technology Based on Microbial DNA Sequencing Diagnostics of Unconventional Reservoirs" Energies 16, no. 1: 358. https://doi.org/10.3390/en16010358