
Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function


Abstract
:1. Introduction
2. Vehicle Modeling and Energy Management Formulation
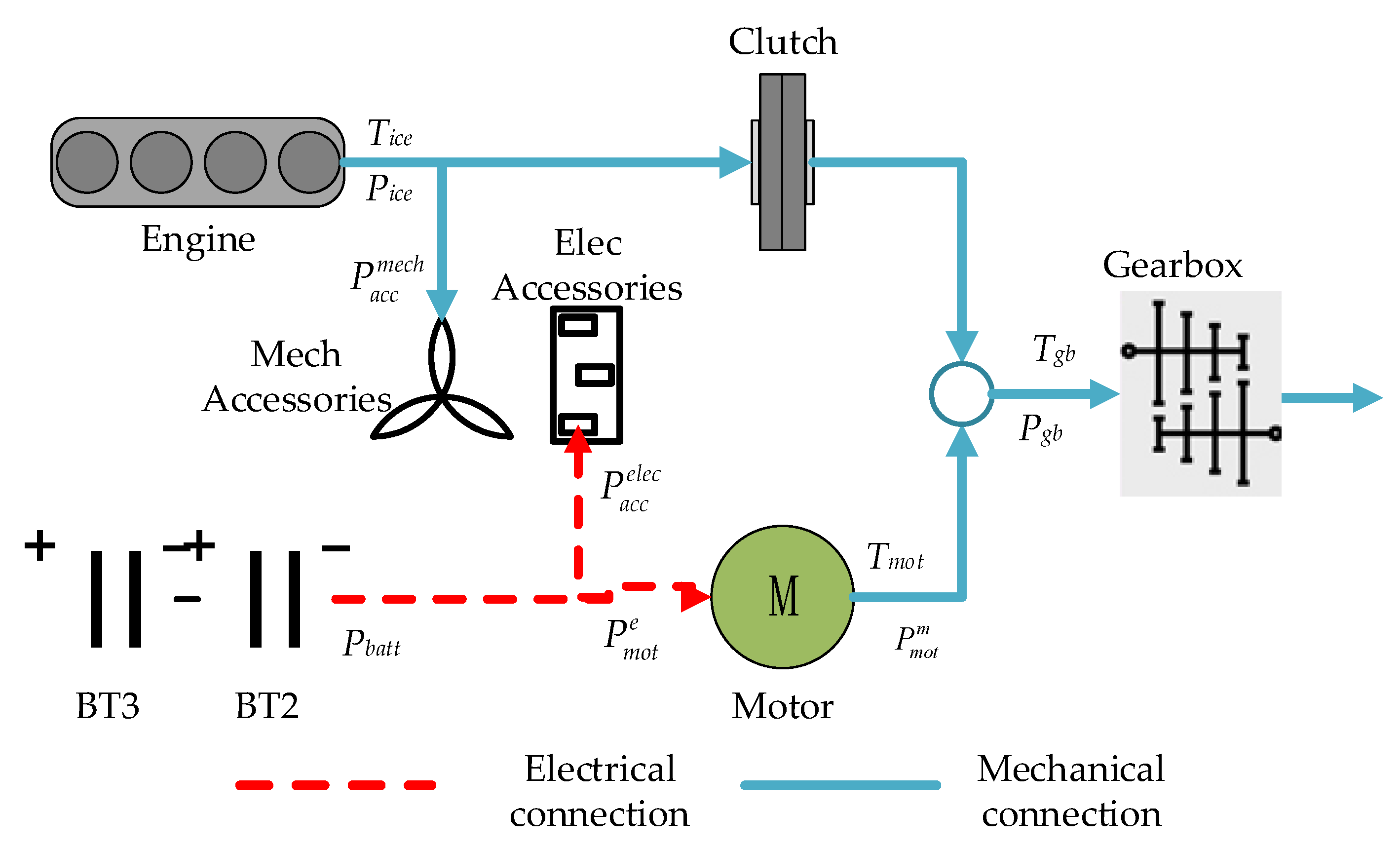
2.1. Vehicle Structure
2.2. Battery Thermal and Health Model
3. Energy Management System
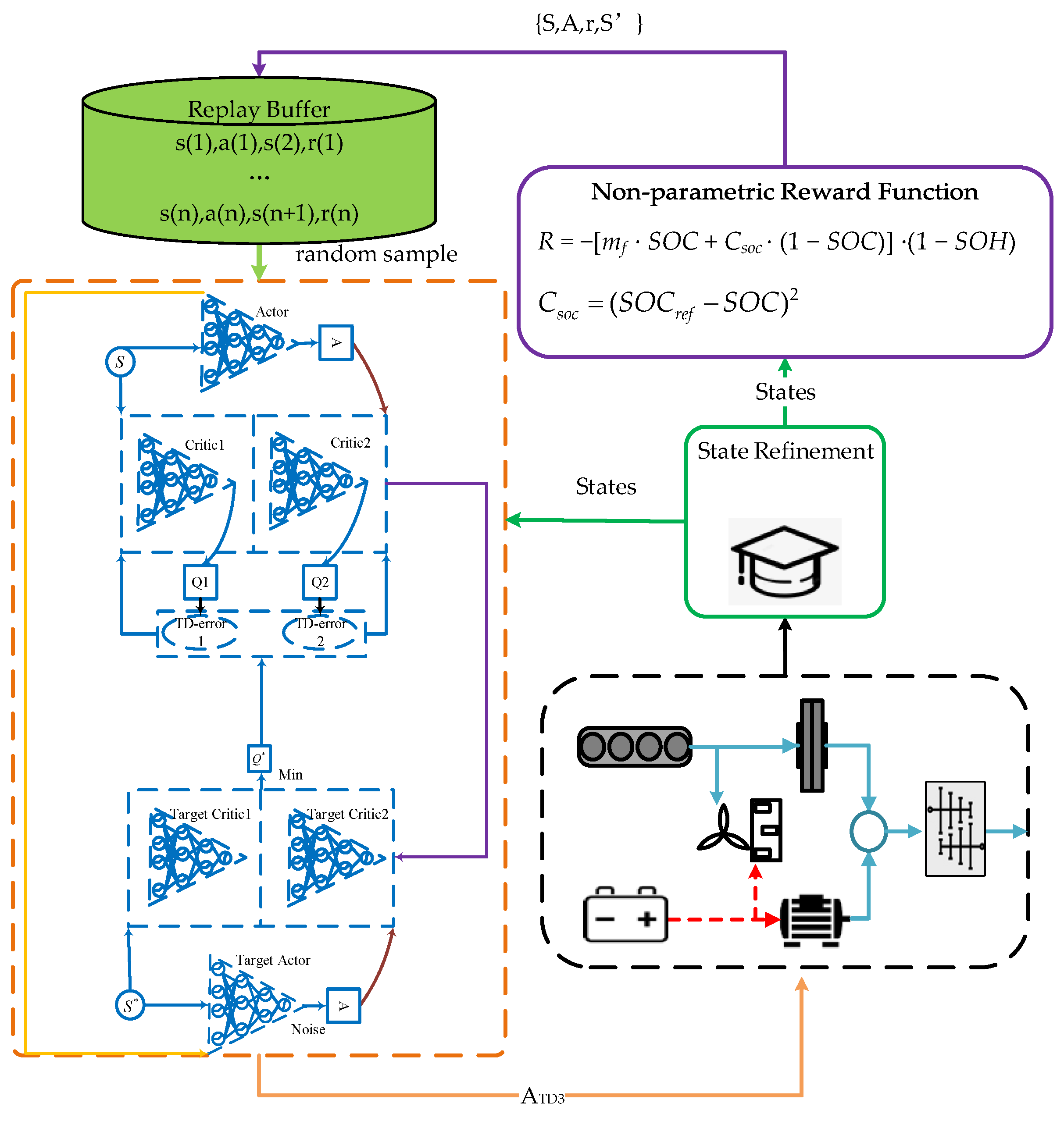
3.1. Fundamentals of TD3 Algorithm
3.2. State Space Refinement Techniques
3.3. Non-Parametric Reward Function
4. Results and Discussion
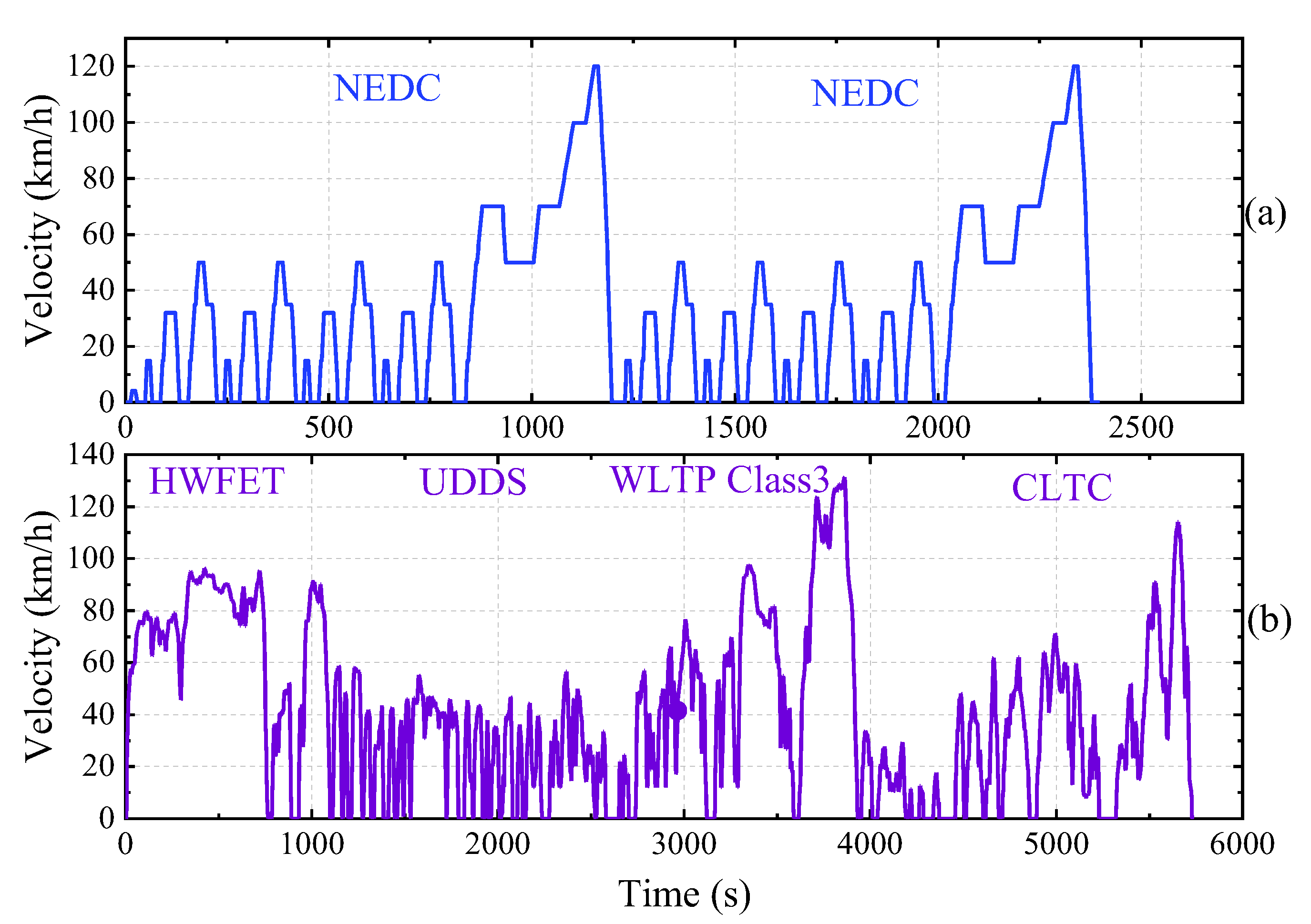
4.1. Validation Condition and Method Comparison
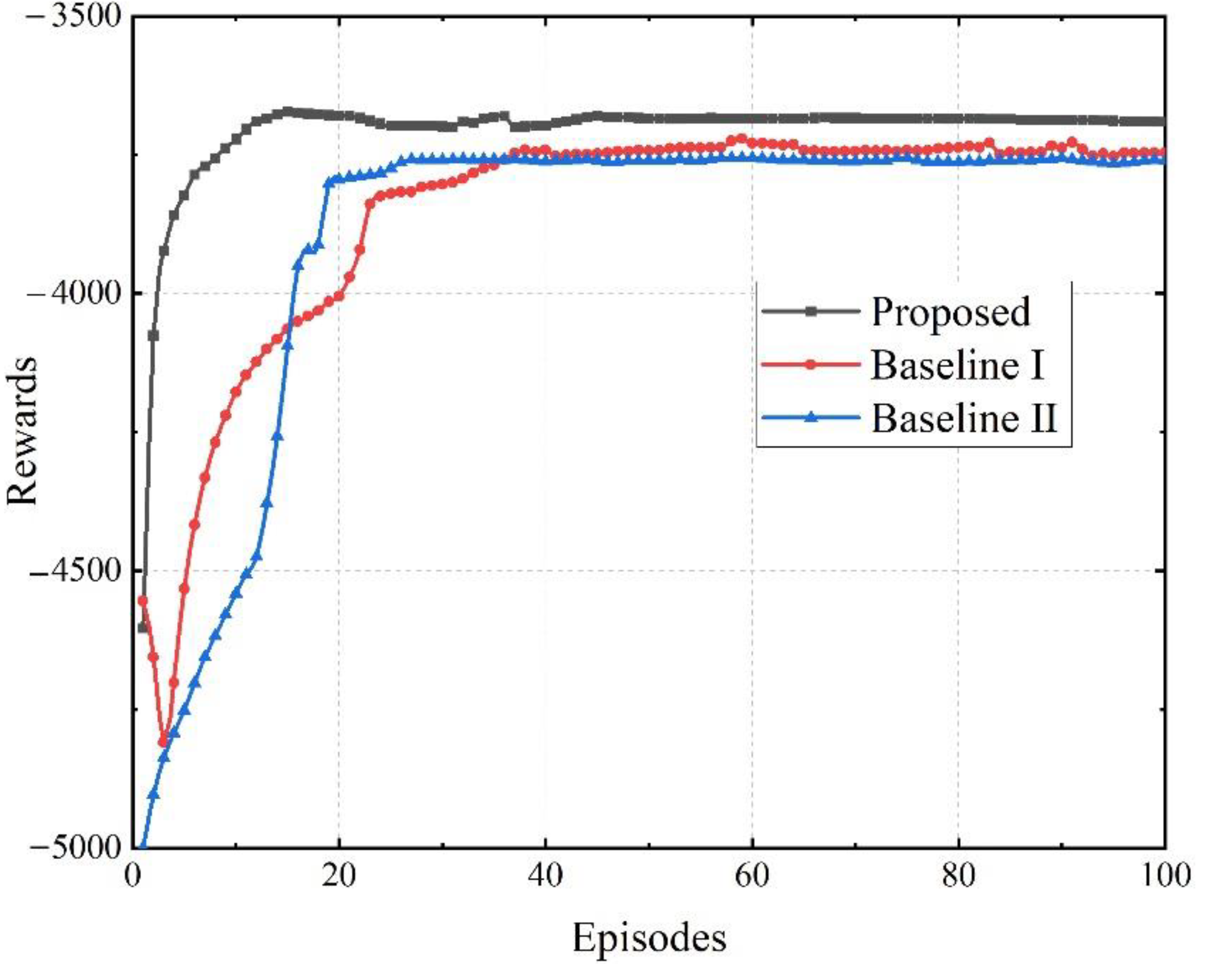
4.2. Results of Training
4.3. Validation of Energy Efficiency and Degradation
5. Conclusions
- (1)
- State redundancy is a major roadblock to the real-time implementation of DRL strategies, and state refinement techniques are a very promising approach to improve the learning efficiency of DRL strategies. In addition, the state space must be designed in accordance with the reward function.
- (2)
- The non-parametric reward function is able to cope with rapidly changing scenarios, which improves the optimality and adaptability of the proposed strategy by 12.25% compared with the parametric counterpart.
- (3)
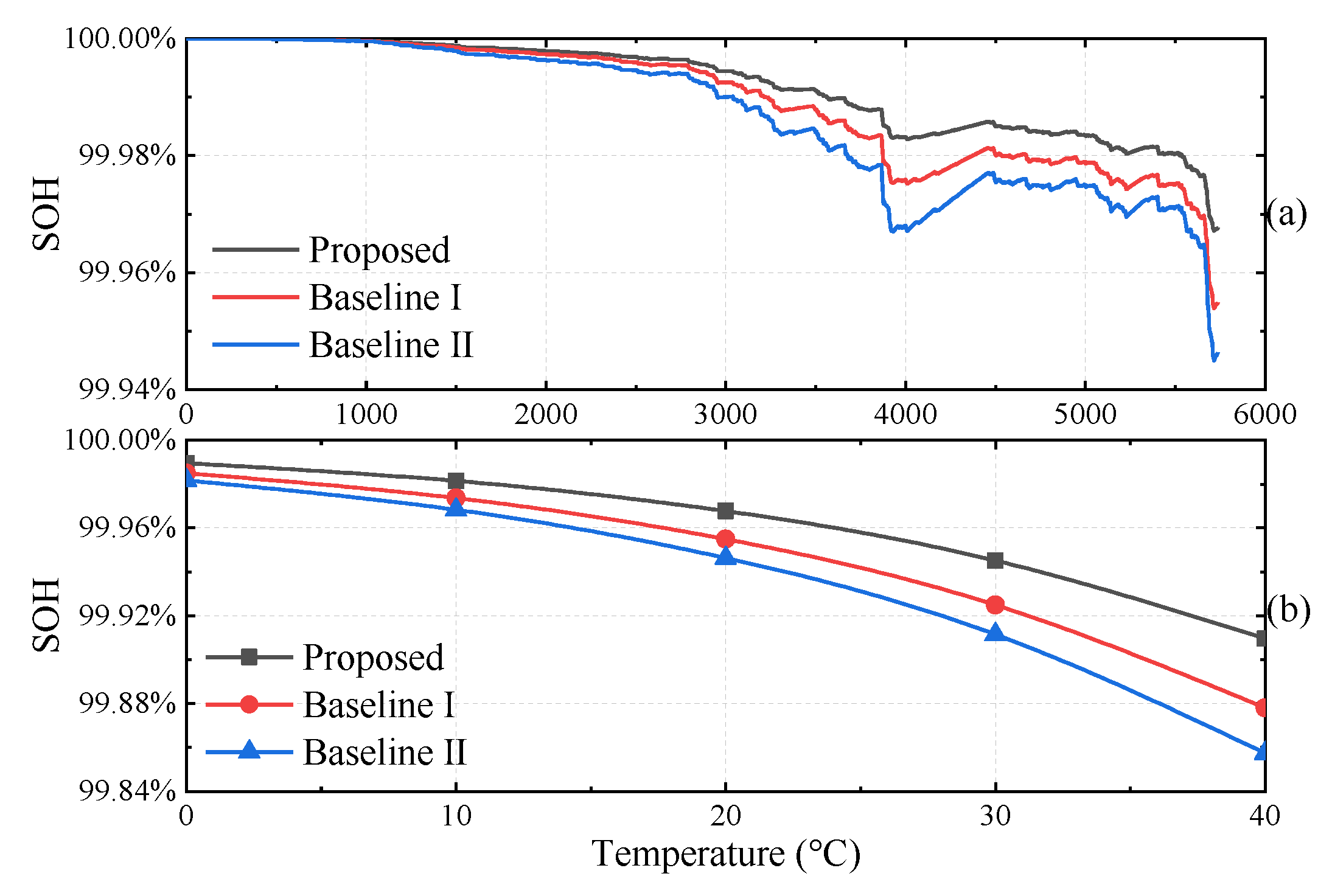
- The proposed strategy compresses the degradation rate of battery SOH to about 50% of the degradation rate of Baseline II strategy.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hannan, M.A.; Azidin, F.A.; Mohamed, A. Hybrid electric vehicles and their challenges: A review. Renew. Sustain. Energy Rev. 2014, 29, 135–150. [Google Scholar] [CrossRef]
- Wang, H.; Huang, Y.; He, H.; Lv, C.; Liu, W.; Khajepour, A. Energy management of hybrid electric vehicles. Model. Dyn. Control. Electrified Veh. 2018, 2018, 159–206. [Google Scholar] [CrossRef]
- Tie, S.F.; Tan, C.W. A review of energy sources and energy management system in electric vehicles. Renew. Sustain. Energy Rev. 2013, 20, 82–102. [Google Scholar] [CrossRef]
- Li, J.; Zhou, Q.; Williams, H.; Xu, H. Back-to-Back Competitive Learning Mechanism for Fuzzy Logic Based Supervisory Control System of Hybrid Electric Vehicles. IEEE Trans. Ind. Electron. 2020, 67, 8900–8909. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Zhan, J.; Shang, F. Heuristic Dynamic Programming Based Online Energy Management Strategy for Plug-In Hybrid Electric Vehicles. IEEE Trans. Veh. Technol. 2019, 68, 4479–4493. [Google Scholar] [CrossRef]
- Peng, J.; He, H.; Xiong, R. Rule based energy management strategy for a series–parallel plug-in hybrid electric bus optimized by dynamic programming. Appl. Energy 2017, 185, 1633–1643. [Google Scholar] [CrossRef]
- Liu, T.; Yu, H.; Guo, H.; Qin, Y.; Zou, Y. Online Energy Management for Multimode Plug-In Hybrid Electric Vehicles. IEEE Trans. Ind. Inform. 2019, 15, 4352–4361. [Google Scholar] [CrossRef]
- Panday, A.; Bansal, H.O. Energy management strategy for hybrid electric vehicles using genetic algorithm. J. Renew. Sustain. Energy 2016, 8, 15701. [Google Scholar] [CrossRef]
- Zhou, Q.; He, Y.; Zhao, D.; Li, J.; Li, Y.; Williams, H.; Xu, H. Modified Particle Swarm Optimization with Chaotic Attraction Strategy for Modular Design of Hybrid Powertrains. IEEE Trans. Transp. Electrif. 2021, 7, 616–625. [Google Scholar] [CrossRef]
- Zhou, Q.; Guo, S.; Xu, L.; Guo, X.; Williams, H.; Xu, H.; Yan, F. Global Optimization of the Hydraulic-Electromagnetic Energy-Harvesting Shock Absorber for Road Vehicles with Human-Knowledge-Integrated Particle Swarm Optimization Scheme. IEEE/ASME Trans. Mechatron. 2021, 26, 1225–1235. [Google Scholar] [CrossRef]
- Kim, N.; Cha, S.; Peng, H. Optimal Control of Hybrid Electric Vehicles Based on Pontryagin’s Minimum Principle. IEEE Trans. Control Syst. Technol. 2011, 19, 1279–1287. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Wu, Z. Research on the Energy Management Strategy of Hybrid Vehicle Based on Pontryagin’s Minimum Principle. In Proceedings of the 2018 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 25–26 August 2018; IEEE: New York, NY, USA, 2018; pp. 356–361. [Google Scholar]
- Wang, H.; Xie, Z.; Pu, L.; Ren, Z.; Zhang, Y.; Tan, Z. Energy management strategy of hybrid energy storage based on Pareto optimality. Appl. Energy 2022, 327, 120095. [Google Scholar] [CrossRef]
- Li, Y.; Chen, B. Development of integrated rule-based control and equivalent consumption minimization strategy for HEV energy management. In Proceedings of the 2016 12th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Auckland, New Zealand, 29–31 August 2016; IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Guan, J.; Chen, B. Adaptive Power Management Strategy Based on Equivalent Fuel Consumption Minimization Strategy for a Mild Hybrid Electric Vehicle. In Proceedings of the 2019 IEEE Vehicle Power and Propulsion Conference (VPPC), Hanoi, Vietnam, 14–17 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar]
- Huang, Y.; Wang, H.; Khajepour, A.; He, H.; Ji, J. Model predictive control power management strategies for HEVs: A review. J. Power Sources 2017, 341, 91–106. [Google Scholar] [CrossRef]
- Wang, J.; Hou, X.; Du, C.; Xu, H.; Zhou, Q. A Moment-of-Inertia-Driven Engine Start-Up Method Based on Adaptive Model Predictive Control for Hybrid Electric Vehicles with Drivability Optimization. IEEE Access 2020, 8, 133063–133075. [Google Scholar] [CrossRef]
- Hu, X.; Wang, H.; Tang, X. Cyber-Physical Control for Energy-Saving Vehicle Following with Connectivity. IEEE Trans. Ind. Electron. 2017, 64, 8578–8587. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, Y.; Li, Z.; Li, J.; Xu, H.; Olatunbosun, O. Cyber-Physical Energy-Saving Control for Hybrid Aircraft-Towing Tractor Based on Online Swarm Intelligent Programming. IEEE Trans. Ind. Inform. 2018, 14, 4149–4158. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Liu, T.; Qi, X.; Barth, M. Reinforcement Learning for Hybrid and Plug-In Hybrid Electric Vehicle Energy Management: Recent Advances and Prospects. IEEE Ind. Electron. Mag. 2019, 13, 16–25. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement Learning of Adaptive Energy Management with Transition Probability for a Hybrid Electric Tracked Vehicle. IEEE Trans. Ind. Electron. 2015, 62, 7837–7846. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, T.; Liu, D.; Sun, F. Reinforcement learning-based real-time energy management for a hybrid tracked vehicle. Appl. Energy 2016, 171, 372–382. [Google Scholar] [CrossRef]
- Shuai, B.; Zhou, Q.; Li, J.; He, Y.; Li, Z.; Williams, H.; Xu, H.; Shuai, S. Heuristic action execution for energy efficient charge-sustaining control of connected hybrid vehicles with model-free double Q-learning. Appl. Energy 2020, 267, 114900. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971v6. [Google Scholar]
- Wu, J.; Wei, Z.; Liu, K.; Quan, Z.; Li, Y. Battery-Involved Energy Management for Hybrid Electric Bus Based on Expert-Assistance Deep Deterministic Policy Gradient Algorithm. IEEE Trans. Veh. Technol. 2020, 69, 12786–12796. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, J.; Shuai, B.; Williams, H.; He, Y.; Li, Z.; Xu, H.; Yan, F. Multi-step reinforcement learning for model-free predictive energy management of an electrified off-highway vehicle. Appl. Energy 2019, 255, 113755. [Google Scholar] [CrossRef]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Ganesh, A.H.; Xu, B. A review of reinforcement learning based energy management systems for electrified powertrains: Progress, challenge, and potential solution. Renew. Sustain. Energy Rev. 2022, 154, 111833. [Google Scholar] [CrossRef]
- Zhu, J.G.; Sun, Z.C.; Wei, X.Z.; Dai, H.F. A new lithium-ion battery internal temperature on-line estimate method based on electrochemical impedance spectroscopy measurement. J. Power Sources 2015, 274, 990–1004. [Google Scholar] [CrossRef]
- Liu, K.; Li, Y.; Hu, X.; Lucu, M.; Widanage, W.D. Gaussian Process Regression with Automatic Relevance Determination Kernel for Calendar Aging Prediction of Lithium-Ion Batteries. IEEE Trans. Ind. Inform. 2020, 16, 3767–3777. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Wang, C.; Zhou, Q.; Xu, H. Sensitivity Study of Battery Thermal Response to Cell Thermophysical Parameters (No. 2021-01-0751). In Proceedings of the SAE WCX Digital Summit, Virtual, 12–15 April 2021. SAE Technical Paper. [Google Scholar]
- Lin, X.; Perez, H.E.; Mohan, S.; Siegel, J.B.; Stefanopoulou, A.G.; Ding, Y.; Castanier, M.P. A lumped-parameter electro-thermal model for cylindrical batteries. J. Power Sources 2014, 257, 1–11. [Google Scholar] [CrossRef]
- Mura, R.; Utkin, V.; Onori, S. Energy Management Design in Hybrid Electric Vehicles: A Novel Optimality and Stability Framework. IEEE Trans. Control Syst. Technol. 2015, 23, 1307–1322. [Google Scholar] [CrossRef]
- Ebbesen, S.; Elbert, P.; Guzzella, L. Battery State-of-Health Perceptive Energy Management for Hybrid Electric Vehicles. IEEE Trans. Veh. Technol. 2012, 61, 2893–2900. [Google Scholar] [CrossRef]
- Sanghi, N. Deep Reinforcement Learning with Python: With PyTorch, TensorFlow and OpenAI Gym; Apress: Berkeley, CA, USA, 2021. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Wiewiora, E.; Cottrell, G.W.; Elkan, C. Principled Methods for Advising Reinforcement Learning Agents. In Proceedings of the 20th International Conference, Washington, DC, USA, 21–24 April 2003; pp. 792e–799e. [Google Scholar]
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, N.; Liang, J.; Ai, Q.; Zhao, W.; Huang, T.; Zhang, Y. Deep reinforcement learning based direct torque control strategy for distributed drive electric vehicles considering active safety and energy saving performance. Energy 2022, 238, 121725. [Google Scholar] [CrossRef]
- Zhou, J.; Xue, S.; Xue, Y.; Liao, Y.; Liu, J.; Zhao, W. A novel energy management strategy of hybrid electric vehicle via an improved TD3 deep reinforcement learning. Energy 2021, 224, 120118. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Value |
|---|---|
| Vehicle mass | 1730 kg |
| Engine power | 70 kW |
| Motor power | 112 kW |
| Battery energy capacity | 12 kWh |
| Frontal area | 2.2 m2 |
| Gear ratio | [2.725 1.5 1 0.71] |
| Final drive ratio | 3.27 |
| Wheel radius | 0.275 m |
| cr | 0.5 | 2 | 6 | 10 |
|---|---|---|---|---|
| B(cr) | 31,630 | 21,681 | 12,934 | 15,512 |
| Strategy | State Space | Reward Function |
|---|---|---|
| Proposed strategy | Non-parametric RF | |
| Baseline I | Non-parametric RF | |
| Baseline II | Parametric RF |
| Strategy | Convergence Episodes | Average Reward | Fuel (g) |
|---|---|---|---|
| Proposed | 16 | −3691.17 | 525.43 |
| Baseline I | 38 | −3746.75 | 545.41 |
| Baseline II | 28 | −3760.86 | 574.74 |
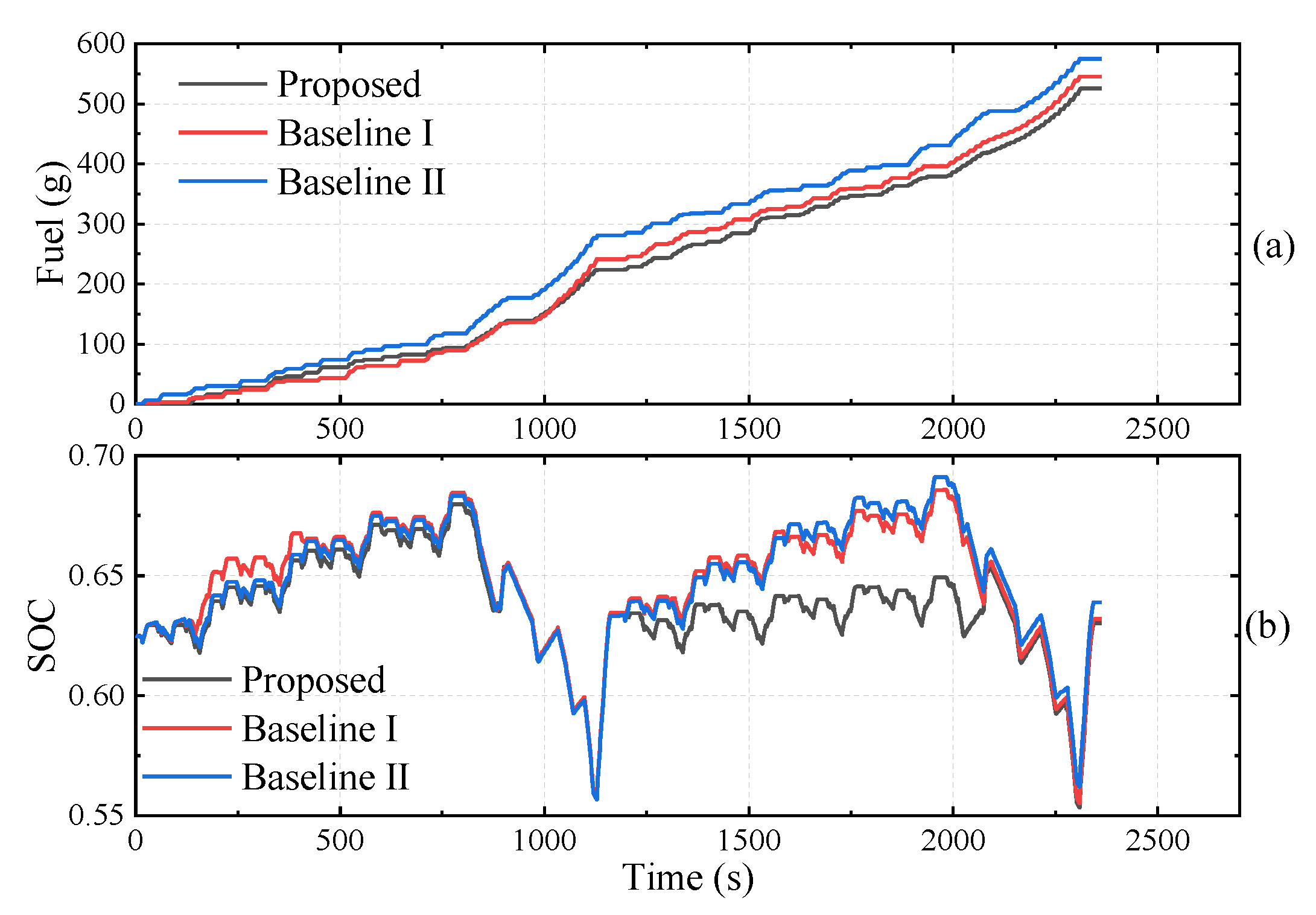
| EMS | Fuel (g) | Terminal SOC (%) |
|---|---|---|
| Proposed | 525.43 | 63.03 |
| Baseline I | 545.41 | 63.21 |
| Baseline II | 574.74 | 63.90 |
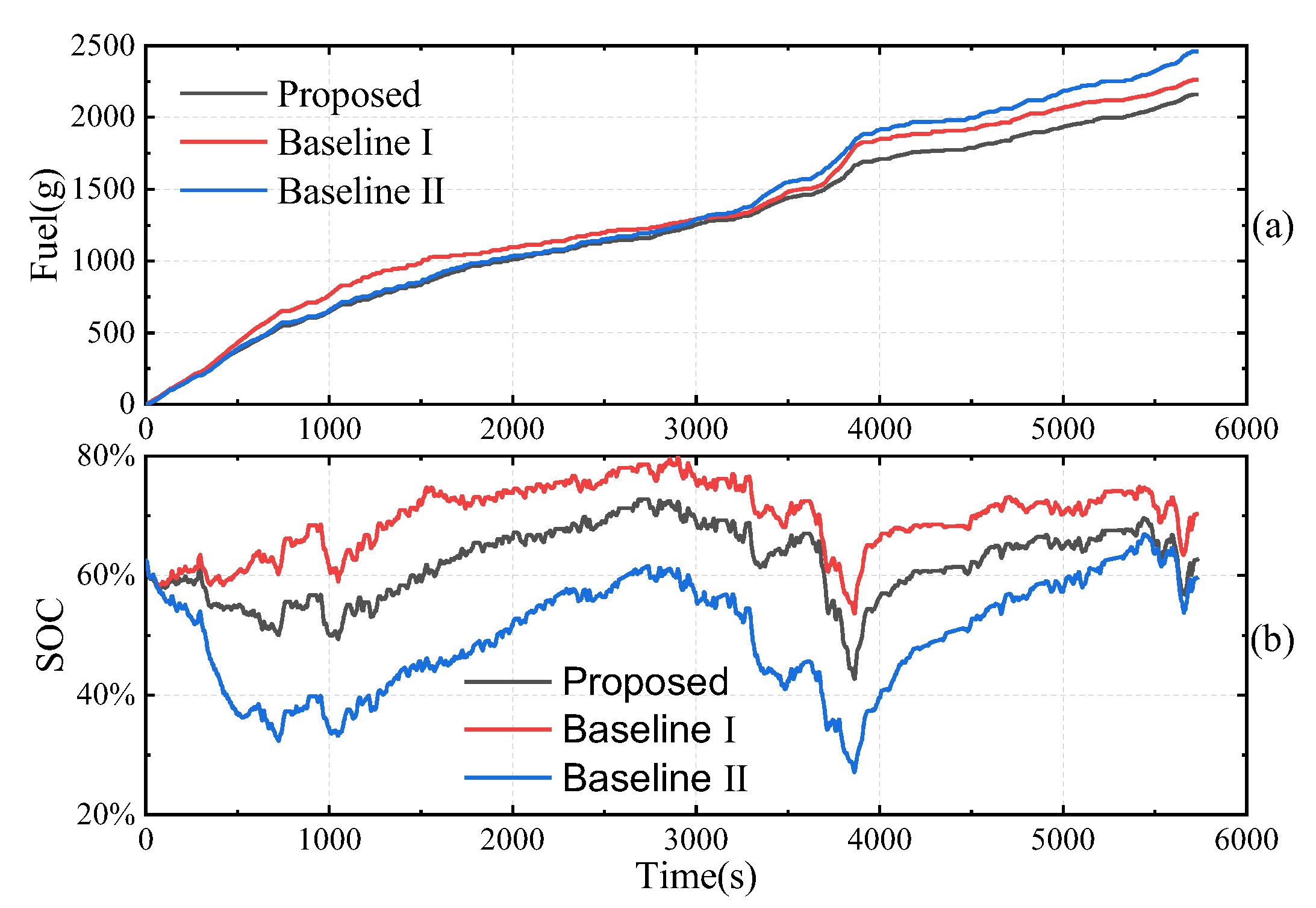
| EMS | Fuel (g) | Terminal SOC (%) |
|---|---|---|
| Proposed | 2158.60 | 62.69 |
| Baseline I | 2263.28 | 70.30 |
| Baseline II | 2459.85 | 59.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, F.; Wang, J.; Du, C.; Hua, M. Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function. Energies 2023, 16, 74. https://doi.org/10.3390/en16010074
Yan F, Wang J, Du C, Hua M. Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function. Energies. 2023; 16(1):74. https://doi.org/10.3390/en16010074
Chicago/Turabian StyleYan, Fuwu, Jinhai Wang, Changqing Du, and Min Hua. 2023. "Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function" Energies 16, no. 1: 74. https://doi.org/10.3390/en16010074
APA StyleYan, F., Wang, J., Du, C., & Hua, M. (2023). Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function. Energies, 16(1), 74. https://doi.org/10.3390/en16010074