Abstract
The classification of drilling conditions is a crucial task in the drilling process, playing a vital role in improving drilling efficiency and reducing costs. In this study, we propose an improved stacking ensemble learning algorithm with the objective of enhancing the performance of drilling conditions classification. Additionally, this algorithm aims to have a positive impact on automated drilling time estimation and the continuous improvement of efficiency. In our experimental setup, we employed various base learners, such as random forests, support vector machine, and the K-nearest neighbors algorithm, as initial models for the task of drilling conditions classification. To improve the model’s expressive power and feature relevance specifically for this task, we enhanced the meta-model component of the stacking algorithm by incorporating feature engineering techniques. The experimental results show that the improved ensemble learning algorithm achieves an accuracy and recall rate of 97% and 98%, respectively. Through continuous improvement in drilling operations, the average sliding time is reduced by 21.1%, and the average Rate of Penetration (ROP) is increased by 15.65%. This research holds significant importance for engineering practice in the drilling industry, providing robust support for optimizing and enhancing the drilling process.
1. Introduction
Numerous academics have conducted study on the use of big data and artificial intelligence techniques in drilling engineering as a result of the quick growth of artificial intelligence and big data technologies. A significant and intricate system of engineering is found in drilling engineering. Drilling efficiency and costs can be successfully increased and decreased by automatically identifying various working situations.
Golitsyna et al. [1] proposed an automatic anomaly detection method during drilling, based on machine learning, which used drilling parameters to improve the intelligent detection effect of abnormal conditions in drilling.
YIN Qishuai et al. [2] proposed a program based on working condition recognition method, which effectively eliminated the influence of personnel on drilling condition recognition. This method, however, did not take into account the relationship between the data before and after or the potential fluctuation of drilling data because it was based on programming language.
Eric van Oort and Ed Taylor et al. [3] proposed an automatic drilling condition identification method that could not only record the learning curve in batch drilling but could also check the source of invisible lost time and solve these problems by communicating with drilling personnel to shorten the invisible lost time.
Eric Maidla and William Maidla [4] proposed methods for data quality control and automatic identification of drilling conditions in the drilling process and successfully drilled a series of wells onshore using these methods. By ensuring the accuracy of drilling condition identification, training, and implementation of new drilling workflows, 31% to 43% of drilling time was saved.
Sun Ting et al. [5] established a real-time drilling condition recognition model with a support vector machine model and achieved certain application effects, reducing the invisible lost time in the drilling process and improving the drilling efficiency. The kernel function and support vector machine parameters are selected by a cross-validation method. Six different drilling conditions, including rotary drilling, drilling, tubing running, single connection, backrow, and plug drilling, can be recognized by the model. The model offers excellent generalizability and great accuracy.
Ben (2019) et al. [6] pointed out that it is difficult to classify the two drilling conditions of “rotary drilling” and “sliding drilling” based on the surface rotary speed alone, because of top-drive vibration. To achieve the desired classification accuracy, three machine learning models for identifying “rotary drilling” and “sliding drilling” were evaluated, namely random forest (RF), convolutional neural network (CNN), and recurrent neural network (RNN) models, finding that machine learning models are far superior to rule-based models.
Gabriel L. Dioliveira et al. [7] found the invisible lost time in the drilling process by establishing an automatic drilling condition identification method and calculating key performance indicators of drilling time, such as drilling start and trip time. This method was used to evaluate drilling data over three years, and it revealed more than 700 days of non-visible lost time, showing that drilling efficiency has a great deal of opportunity to grow.
Coley [8] developed a key component of an internal system to report key performance indicators of invisible lost time across drilling operations and developed a classification engine for common drilling conditions based on supervised machine learning.
Qiao Ying et al. [9] proposed a convolutional neural network (CNN) and bidirectional gated recurrent unit neural network (GRU) parallel hybrid network (CNN–BiGRU) for intelligent identification of drilling conditions. The accuracy percentage was 94% overall. Experiments demonstrate the model’s great accuracy and efficiency as well as its capacity to intelligently recognize drilling circumstances.
In addition, we have summarized some research on traditional stacking and improved stacking algorithms, as shown in Table 1.

Table 1.
The research on stacking algorithms.
The drilling condition identification method used in current research methods rarely takes knowledge of drilling engineering mechanisms into account. As a result, the model’s interpretability is poor, and it is challenging for people to comprehend the model’s internal working principles and decision-making process. The model may have trouble adjusting to new circumstances and domains if it only generates predictions by identifying patterns in the training data, rather than simulating the mechanics of the issue. As a result, the integrated learning algorithm that determines stacking conditions based on knowledge of the fusion mechanism is proposed to be improved upon in this study. The importance of integrating mechanistic information in feature building lies in the fact that it can enhance the model’s performance in terms of generalization, interpretability, and dependability.
The drilling process can be monitored and managed in real time by segmenting the drilling process into particular drilling conditions and establishing the key performance indicators (KPIs) of these drilling conditions. Additionally, the drilling process can be made more efficient and the well construction cycle can be shortened by identifying the invisible lost time brought on by redundant operating procedures.
Through fine monitoring and analysis of the drilling process, the invisible lost time in the drilling process can be found, which has important practical significance for improving drilling efficiency, shortening the well construction cycle, and saving drilling costs. The purpose of this study is to effectively identify drilling conditions, further record the duration of various conditions, and uncover hidden time losses. Ultimately, this can significantly improve drilling efficiency and reduce drilling costs.
2. Methodology
2.1. Data Processing
2.1.1. Dataset Description
The data used in this research are sourced from a specific well in Xinjiang Oilfield. The data are derived from a well log with multiple logging parameters at depths between 3000 and 6000 m. The data include five operating conditions, including rotary drilling, sliding drilling, circulation, empty well, and other operating conditions. Drilling site specialists analyze data outliers after annotating the data using the criteria of data validity, empirical relevance, and expert experience. Finally, more than 1.5 million data points were chosen for the model’s testing and training. Table 2 displays a summary of the data related to the five drilling conditions.
Table 2.
The data volume for five drilling conditions.
2.1.2. Feature Selection
In the process of drilling, the identification of drilling conditions is affected by many factors. Through correlation analysis and mechanistic knowledge, parameters that have a greater impact on drilling conditions are selected, parameters that have less impact or are irrelevant are removed, the dimension of input parameters is reduced, and two or more parameters with high similarity are avoided at the same time. The Spearman correlation coefficient [16] is selected for analysis in this paper, and the calculation formula is shown in Equation (1). The specific calculation formula is as follows,
where represents the Spearman’s rank correlation coefficient, di represents the difference between the ranks of two variables, and represents the number of observations.
When there is a nonlinear relationship between the variables, Spearman correlation coefficients can be employed because they are comparatively unaffected by outliers. The range of the Spearman correlation coefficient is −1 to 1. The two variables are completely positively correlated when the Spearman correlation coefficient is 1, which is the highest possible value. A value of −1 indicates a perfect negative connection. A linear correlation between the two variables does not exist when the Spearman correlation value is 0.
The parameters whose correlation coefficient is greater than 0.5 are selected through calculation, and 18 parameters are selected as the input of the intelligent model combined with mechanistic knowledge. The output is the type of drilling condition, as shown in Table 3.
Table 3.
Input and output parameters of models.
2.1.3. Evaluation Indicators
Model evaluation indexes of multi-classification tasks are used to measure the performance of classification models in multiple categories. Confusion matrices comprise a common model evaluation tool that show what a model predicts in each category, as shown in Table 4. The confusion matrix contains four indicators: true positive (TP), false positive (FP), true negative (TN), and false negative (FN), which can be used to calculate other evaluation indicators [17].
Table 4.
Confusion matrix.
Based on the confusion matrix in Table 3, four important evaluation indexes of anomaly detection methods can be calculated, namely accuracy, recall, precision, and f1 score, which can be calculated by the following formulas:
Accuracy—the proportion of all correct predictions in the total sample:
Recall—the proportion of predicted positive samples to the actual positive samples:
Precision—the proportion of true-positive samples among all the samples predicted as positive by the model:
F1Score—harmonic mean of recall and precision.
2.2. Model Building
2.2.1. Multi-Layer Perceptron
Multi-layer perceptron (MLP) is a machine learning model based on feedforward neural networks [18]. It consists of one or more hidden layers, with each hidden layer containing multiple neurons. The input layer of the MLP receives input data, which is then passed through the hidden layers, and the final prediction is generated through the output layer. In each neuron, the inputs are weighted and then undergo a nonlinear transformation through an activation function. Each connection is associated with a weight, which is adjusted during the training process using a backpropagation algorithm to minimize the model’s prediction error. The hidden layers of the MLP enable the model to learn higher-level feature representations, capturing complex patterns and relationships in the input data. Commonly used activation functions include Sigmoid, ReLU, and Tanh.
2.2.2. Random Forest
Random forests (RF) are often used for classification and regression problems [19]. They are made up of several decision trees, each of which is developed using a randomly chosen subset of features. The random forest training procedure is as follows: We first create a new training set, referred to as the self-sampling set; a portion of the sample is first randomly chosen from the original dataset (with sampling back). After that, a decision tree is built for each batch of self-sampling data. To choose the optimal segmentation feature, a feature subset is randomly chosen on each node as the tree is being built. Further decision trees are built by repeating the procedure above.
Random forests have the following qualities: (1) they can process high-dimensional data without feature selection; (2) they have good robustness to outliers and noise; (3) they enable estimation of how important a given feature is; and (4) they can handle large-scale datasets and compute faster.
2.2.3. K-Nearest Neighbors
The K-nearest neighbors (KNN) algorithm is an instance-based classification algorithm [20]. It determines the separation between the samples that need to be categorized and the samples in the training set, chooses the K neighbors with the shortest separation, casts votes based on the categories of the K neighbors, and assigns the samples to the category that received the most votes. The KNN model’s training procedure is relatively straightforward: the model is not actually trained; it merely saves the training sample. The KNN model measures the separation between each sample in the training set and the sample being classified during classification. The Euclidean distance and the Manhattan distance are two commonly used distance measurement techniques. The categories of the samples to be classified are then decided by voting in accordance with the categories of the K neighbors, starting with the K samples that are nearest to one another.
2.2.4. Support Vector Machine
Support vector machine (SVM) is a commonly used classification algorithm that can effectively deal with linear and nonlinear classification problems [21]. Finding the best hyperplane to divide samples into distinct classes while maximizing the distance between sample points nearest to the hyperplane is the aim of SVM. SVM has the following benefits: (1) it can handle high-dimensional data; (2) it has good generalization capabilities for small sample data; and (3) it can solve nonlinear problems by using kernel functions. The following are some shortcomings of SVM: (1) long training times for large datasets; (2) it is easily impacted by increased data noise.
2.2.5. Stacking Ensemble Learning (SEL)
Stacking is a commonly used model ensemble method, initially proposed by Wolpert [22,23]. It consists of two components: base learners and a strong learner. Stacking utilizes cross-validation to train base learners and obtain predictions for the entire training dataset. These predictions are then used as input features for the strong learner, which produces the final prediction. To implement stacking, the dataset is first divided into a training set and a test set according to a specified ratio. The training set is used to train the base learners, and their output results are combined into a feature matrix that serves as input for the second-level strong learner [24]. The final prediction of the model can be obtained from the trained meta-learner. The algorithmic process is illustrated in Figure 1.
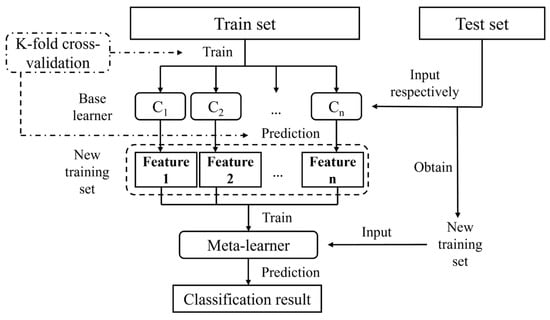
Figure 1.
The process of ensemble learning algorithm.
2.2.6. Improved Stacking Ensemble Learning (ISEL)
In the traditional stacking model, the number of input features for the meta-learner is determined by the base learners and is typically limited to the output results of each base learner, resulting in a relatively small quantity of features [25]. Having fewer features can lead to the model’s inability to capture complex relationships in the data, resulting in underfitting issues and potential loss of information. This can impact the model’s understanding and modeling capabilities, thereby affecting its accuracy and generalization performance. Feature augmentation, such as feature cross-combinations, can be employed to address this limitation. Incorporating domain knowledge into the process of feature engineering is significant as it can enhance the model’s interpretability, reliability, and generalization performance. The process of generating a new training set in the improved stacking algorithm is illustrated in Figure 2.
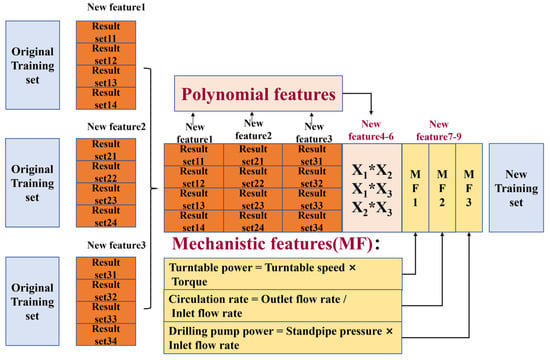
Figure 2.
The process of generating a new training set using the improved Stacking algorithm.
This paper proposes two improvement measures for the generalization capability and prediction accuracy of the stacking model:
- (1)
- Feature construction using polynomial cross-combination;
- (2)
- Feature construction based on the integration of mechanistic knowledge.
- (1)
- Feature construction using polynomial cross-combination
In traditional models, as the data volume is much larger than the number of features, the data often cannot be linearly separated. Therefore, by performing a polynomial cross-combination transformation on the original data, more cross-terms between features can be obtained. Through a multidimensional linkage mechanism, the generalization capability of the model can be enhanced. The output features of the base learners are increased from the original three features to six features by introducing additional features as shown in Figure 2: new features 4–6.
- (2)
- Feature construction based on the integration of mechanistic knowledge
Integrating mechanistic knowledge can assist in better understanding the relationship between the data and the model, thereby improving the model’s interpretability. It can reduce the risk of overfitting, enhancing the model’s reliability. Moreover, it helps in designing more representative features, thus improving the model’s transfer and generalization performance.
Domain knowledge: Turntable power = Turntable speed × Torque, Circulation rate = Outlet flow rate/Inlet flow rate, Drilling pump power = Standpipe pressure × Inlet flow rate.
In the improved model, the number of features has been increased from the original three features output by the traditional three base learners to nine features. Among them, three features are based on the integration of mechanistic knowledge, represented as new features 7–9 in Figure 2.
2.3. Model Parameter
In this study, we first selected MLP to classify drilling conditions. Then, we further selected random forest, K-nearest neighbors (KNN), and support vector machine (SVM) machine learning models to effectively classify drilling conditions. To improve the accuracy of the model, we used these three models as base learners and logistic regression as the meta-learner in a stacking ensemble learning model. In the base learner ensemble of the stacking model, we used models with significant differences as base learner models. This is because different models based on different methods essentially observe the data from different perspectives in the feature space and establish corresponding models based on the algorithm’s observation and its own algorithm principles. Therefore, selecting algorithms with significant principal differences can maximize the diversity of algorithms and reduce the correlation of output labels from the base learning layer. Lastly, to improve the model’s transferability and generalization capability, mechanistic knowledge was embedded into the stacking ensemble learning model through feature engineering. The parameters of different models are shown in Table 5.
Table 5.
Parameters of model.
3. Results and Discussion
Using Python programming, we conducted an experiment on a drilling dataset. First, we divided the dataset into training and testing sets. Then, following the algorithm flow, we input the data into the models and calculated the four evaluation metrics for each model. In this section, we compared and analyzed the performance of different drilling condition segmentation models, identified the strengths of different models, and ultimately selected the best-performing model. The comparative analysis results are shown in Table 6.
Table 6.
Experimental evaluation results.
The improved ensemble learning model performed the best in terms of accuracy, precision, recall, and F1 score. It can fully leverage the advantages of multiple base learners, improving the predictive performance and generalization ability of the model.
Random forest and KNN models also achieved good results, with high levels of accuracy, precision, recall, and F1 score. They are based on the concepts of decision trees and instance distance, enabling them to handle complex feature relationships and classification problems.
The MLP and support vector machine (SVM) models showed slightly lower accuracy and F1 score. The MLP may require more training and parameter tuning to improve performance, while SVM may benefit from better feature selection and adjustment of the kernel function to optimize classification results.
The ensemble learning model performed well in terms of accuracy and F1 score but had slightly lower precision and recall compared to the improved ensemble learning model. It makes decisions by combining the predictions of multiple base learners, effectively reducing the risk of overfitting and improving the model’s robustness.
The improved ensemble learning algorithm has the following advantages:
- Strong feature combination capability: The embedded mechanism model can automatically learn and discover complex relationships and interactions between features. By embedding mechanisms such as nonlinear transformations, cross-features, and high-order feature combinations in the model, it enhances the modeling capability for complex data patterns;
- Strong adaptability: The embedded mechanism model can automatically adjust the model’s complexity and flexibility based on the characteristics of the data. It can select appropriate feature embedding methods and parameter settings automatically, thereby improving the model’s adaptability and performance;
- Strong interpretability: Compared to some black-box models, the embedded mechanism model often has better interpretability. Due to its explicit feature embedding process and model parameters, it becomes easier to understand how the model processes input features, thus providing better explanations for the model’s predictions;
- Strong generalization capability: The embedded mechanism model learns and extracts the intrinsic feature representation of the data, enabling it to capture the underlying patterns and distribution characteristics of the data, resulting in strong generalization ability. It can effectively handle new unseen samples and maintain good performance across different datasets.
4. Drilling Time Efficiency Statistics and Enhancement
4.1. Invisible Lost Time
The division of drilling time is illustrated in Figure 3, where the actual drilling cycle consists of productive time (PT) and non-productive time (NPT). PT is composed of technical limits time (TLT) and invisible lost time (ILT) [26]. Within the productive time, there exists a portion of time lost due to low operational efficiency, known as invisible lost time (ILT). ILT is invisible because it does not appear in any daily conventional drilling reports, whereas non-productive time is often recorded in daily drilling reports.
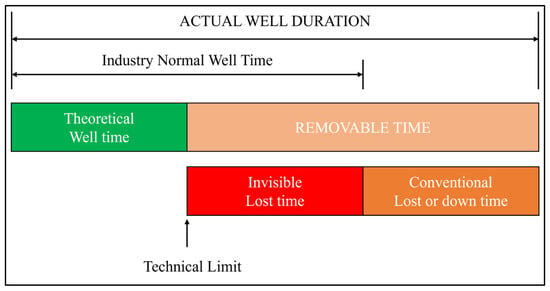
Figure 3.
Composition and division of drilling time.
4.2. Drilling Time Efficiency Statistics
The drilling time efficiency automatic statistics module is a tool used to automatically analyze and calculate the start time, end time, and duration of various drilling operations in drilling activities. Its working principle is based on the automatic drilling conditions recognition method, which obtains identification codes for each drilling state and encapsulates them along with the corresponding time data in the format of wellsite data transmission, which is then sent to the drilling time efficiency automatic statistics module.
In the automatic drilling conditions recognition method, drilling conditions data are labeled and classified, and each state is assigned a unique identification code. The purpose of these codes is to differentiate between different conditions, allowing the statistics module to accurately identify and calculate the time for each operation. Once the identification codes and time data are encapsulated and sent to the drilling time efficiency automatic statistics module, the module starts analyzing the data.
The module parses the received data, extracts the start time and end time for each operation, and calculates the duration of each operation. Through these calculations, the drilling time efficiency automatic statistics module can achieve automatic statistics of dynamic drilling operation times.
Drilling time efficiency analysis is performed based on the recognition of drilling conditions. Its objective is to measure and calculate the proportion of time occupied by different drilling operations during the entire drilling process. By analyzing the duration of each operation, the statistics module can calculate the time proportion of each operation in the overall drilling process. This enables drilling operation managers to understand the impact of each operation on the total drilling time and make appropriate optimizations and adjustments.
4.3. Enhancing Drilling Efficiency
Step 1: Based on the results of the drilling time efficiency automatic statistics module, the time spent on each drilling operation by different drilling teams can be analyzed and calculated. To visually depict the time distribution of each drilling operation for each team, charts and graphs can be used for statistical and visual representation.
Step 2: Through comprehensive analysis of historical neighboring well data, geological conditions, drilling conditions, and other factors, it is possible to engage experts to determine key performance indicators (KPIs) for each drilling state. These KPIs serve as important metrics for evaluating drilling efficiency and quality. The expertise and knowledge of the experts assist in identifying suitable KPIs for specific situations, enabling better assessment of drilling performance.
Step 3: For drilling workers who fail to meet the set KPIs, training and guidance can be provided to standardize the drilling operation process. Through training and guidance, drilling workers can learn and master standardized procedural operations and understand and adhere to best practices in drilling operations. This helps improve operational efficiency and quality, thereby reducing the duration of drilling operations. Regular training and continuous supervision ensure that drilling workers maintain a proficient level of operation and continuously enhance the overall efficiency of drilling operations [27].
In conclusion, through measures such as automatic statistics of drilling time efficiency, KPI determination, and standardized training, it is possible to comprehensively analyze and optimize the time distribution and efficiency of drilling operations, thereby improving the overall performance of drilling activities. This integrated analysis and improvement process can assist drilling teams in continuously enhancing the quality and efficiency of drilling operations in practice. The time of different drilling conditions is shown in Figure 4.
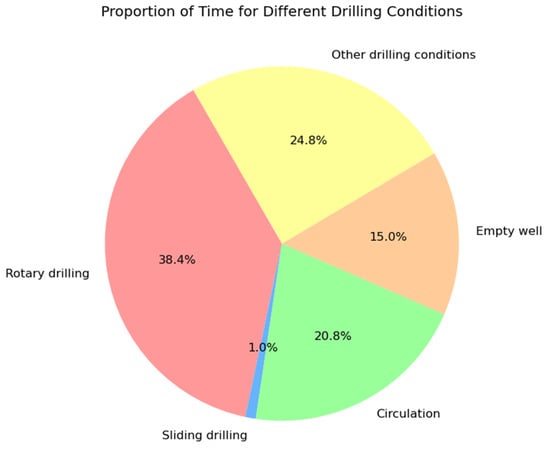
Figure 4.
Time proportion of different drilling conditions.
4.4. Engineering Applications
In terms of sliding drilling, certain inclined wellbore sections are selected, and positive displacement motors are used for sliding drilling. The sliding time is an important indicator to evaluate sliding drilling operations. As shown in Figure 5, the overall sliding time is reduced, leading to an improvement in sliding drilling efficiency. The average sliding time for the first batch of wells is 82 min, while the average sliding time for the second batch of three wells is 64.7 min, resulting in an average sliding time reduction of 21.1%.
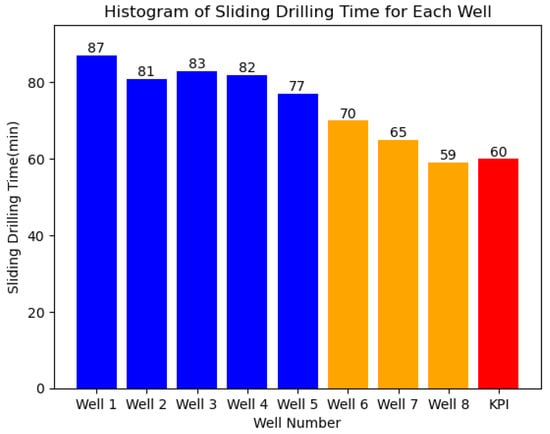
Figure 5.
Histogram of Sliding Drilling Time for Each Well.
In terms of rotary drilling, as shown in Figure 6, the average Rate of Penetration (ROP) for the first batch of five wells is 44.1 m/h, while the average ROP for the second batch of three wells is 51 m/h, resulting in an average ROP increase of 15.65%. Although there is a relative increase in ROP, the improvement margin is limited. The drilling team should maintain the current operational status.
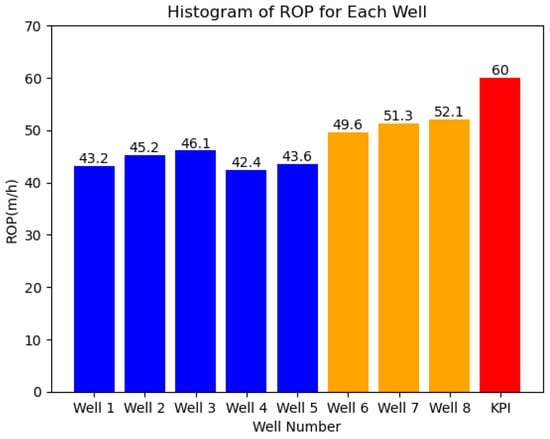
Figure 6.
Histogram of ROP for Each Well.
5. Conclusions
This article compares various models for drilling conditions classification and ultimately selects an improved stacking ensemble learning algorithm for drilling conditions classification. The chosen model enhances the performance by incorporating polynomial interactions and incorporating domain knowledge for feature engineering. The accuracy of this model has reached 97%. The effective classification of drilling operating conditions lays the foundation for the next step of time statistics.
The goal of continuously improving drilling efficiency is to set key performance indicators (KPIs) for drilling conditions and operate based on standardized procedures aligned with those KPIs. By automating time tracking and monitoring drilling operation times in real time, wasteful time segments can be promptly identified and corrected. Through the establishment of KPIs and continuous improvement efforts, the drilling process can be optimized, leading to enhanced drilling efficiency. Through engineering applications, it can be observed that the average sliding time is reduced by 21.1%, and the average Rate of Penetration (ROP) is increased by 15.65%. These measures contribute to reducing non-productive time, improving drilling efficiency, and achieving cost-effectiveness.
Author Contributions
Conceptualization, X.Y.; methodology, X.Y. and Y.Z.; software, D.Z.; validation, X.Y. and Y.Z.; formal analysis, X.Y.; investigation, X.Y.; resources, Y.J. and X.S.; data curation, Y.Y. and D.L.; writing—original draft preparation, Y.J. and Z.L.; writing—review and editing, X.Y., D.Z. and Z.Z.; visualization, D.Z., Y.Z. and Z.W.; supervision, X.S.; project administration, Z.Z.; funding acquisition, X.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Project, grant number 2019YFA0708300X, Strategic Cooperation Technology Projects of CNPC and CUPB, grant number ZLZX2020-03, and the Distinguished Young Foundation of the National Natural Science Foundation of China, grant number 52125401.
Data Availability Statement
The data are not publicly available due to the involvement of information related to Chinese oil fields and their need to be kept confidential.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Golitsyna, M.; Semenikhin, A.; Chebuniaev, I.; Vasilyev, V.; Koryabkin, V.; Makarov, V.; Simon, I.; Baybolov, T.; Osmonalieva, O. Automatic Method for Anomaly Detection while Drilling. In Proceedings of the First EAGE Digitalization Conference and Exhibition, Vienna, Austria, 30 November–3 December 2020; EAGE Publications BV: Bunnik, The Netherlands, 2020; pp. 1–5. [Google Scholar]
- Yin, Q.; Yang, J.; Zhou, B.; Jiang, M.; Chen, X.; Fu, C.; Yan, L.; Li, L.; Li, Y.; Liu, Z. Improve the Drilling Operations Efficiency by the Big Data Mining of Real-Time Logging. In Proceedings of the SPE/IADC Middle East Drilling Technology Conference and Exhibition, Abu Dhabi, United Arab Emirates, 29–31 January 2018; OnePetro: Richardson, TX, USA, 2018. [Google Scholar]
- van Oort, E.; Taylor, E.; Thonhauser, G.; Maidla, E. Real-time rig-activity detection helps identify and minimize invisible lost time: Drilling technology. World Oil 2008, 229, 39–47. [Google Scholar]
- Maidla, E.; Maidla, W. Rigorous Drilling Nonproductive-Time Determination and Elimination of Invisible Lost Time: Theory and Case Histories. In Proceedings of the SPE Latin American and Caribbean Petroleum Engineering Conference, Lima, Peru, 1–3 December 2010. [Google Scholar]
- Sun, T.; Zhao, Y.; Yang, J.; Yin, Q.; Wang, W.; Chen, Y. Real-Time Intelligent Identification Method under Drilling Conditions Based on Support Vector Machine. Pet. Drill. Tech. 2019, 47, 28–33. [Google Scholar]
- Ben, Y.; James, C.; Cao, D. Development and application of a real-time drilling state classification algorithm with machine learning. In Proceedings of the Unconventional Resources Technology Conference, Unconventional Resources Technology Conference (URTeC), Denver, CO, USA, 22–24 July 2019; pp. 3053–3066. [Google Scholar]
- de Oliveira, G.L.; Zank, C.A.; Costa, A.F.; Mendes, H.M.; Henriques, L.F.; Mocelin, M.R.; de Oliveira Neto, J. Offshore Drilling Improvement through Automating the Rig State Detection Process-Implementation Process History and Proven Success. In Proceedings of the IADC/SPE Drilling Conference and Exhibition, Forth Worth, TX, USA, 1–3 March 2016; OnePetro: Richardson, TX, USA, 2016. [Google Scholar]
- Coley, C. Building a Rig State Classifier Using Supervised Machine Learning to Support Invisible Lost Time Analysis. In Proceedings of the SPE/IADC International Drilling Conference and Exhibition, Hague, The Netherlands, 5–7 March 2019; OnePetro: Richardson, TX, USA, 2019. [Google Scholar]
- Qiao, Y.; Lin, H.; Zhou, W. Intelligent identification of drilling conditions based on CNN-BiGRU parallel hybrid network. In Proceedings of the 5th Petroleum and Petrochemical Artificial Intelligence High-End Forum and the 8th Intelligent Digital Oilfield Open Forum, Beijing, China, 15 September 2022. [Google Scholar]
- Wang, Z.; Wang, Z.; Ning, A. Research on Blockchain Anomaly Transaction Detection Technology Based on Stacking Ensemble Learning. J. Inf. Secur. Res. 2023, 9, 98–108. [Google Scholar]
- Su, F.; Luo, H. A fingerprint recognition algorithm based on improved Stacking ensemble learning. Comput. Eng. Sci. 2022, 44, 2153–2161. [Google Scholar]
- Shao, W. Heart Disease Diagnosis Method Based on Stacking Ensemble Learning. Mod. Informationn Technol. 2022, 6, 97–99, 103. [Google Scholar]
- Cao, M.; Gong, W.; Gao, Z. Research on Lithology Identification Based on Stacking Integrated Learning. Comput. Technol. Dev. 2022, 32, 161–166. [Google Scholar]
- Pu, Y.; Liu, X. Application of Stacking Integrated Learning in Sales Volume Forecasting. Softw. Guide 2022, 21, 103–108. [Google Scholar]
- Li, Y.; Zhou, X.; Gao, W.; Bo, Z.; Geng, N. Emergency Patient Arrival Forecast Based on Stacking Ensemble Learning. Ind. Eng. Manag. 2019, 6, 16–22. [Google Scholar]
- Myers, L.; Sirois, M.J. Spearman correlation coefficients, differences between. Encycl. Stat. Sci. 2004, 12, 7901. [Google Scholar] [CrossRef]
- Ruuska, S.; Hämäläinen, W.; Kajava, S.; Mughal, M.; Matilainen, P.; Mononen, J. Evaluation of the confusion matrix method in the validation of an automated system for measuring feeding behaviour of cattle. Behav. Process. 2018, 148, 56–62. [Google Scholar] [CrossRef] [PubMed]
- Taud, H.; Mas, J.F. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Cham, Switzerland, 2018; pp. 451–455. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Suthaharan, S.; Suthaharan, S. Support vector machine. Machine learning models and algorithms for big data classification: Thinking with examples for effective learning. Integr. Ser. Inf. Syst. 2016, 36, 207–235. [Google Scholar]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.; Wang, S.; Cao, Z. An ensemble classifier based on stacked generalization for predicting membrane protein types. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–6. [Google Scholar]
- Anguita, D.; Ghelardoni, L.; Ghio, A.; Oneto, L.; Ridella, S. The ‘K’ in K-Fold Cross Validation; ESANN: Bruges, Belgium, 2012; pp. 441–446. [Google Scholar]
- Li, C.; Miu, J.; Shen, B. Operational Effectiveness Prediction of Equipment System based on improved Stacking-Ensemble-Learning Method. Acta Armamentarii 2022. [Google Scholar] [CrossRef]
- de Wardt, J.P.; Rushmore, P.H.; Scott, P.W. True Lies: Measuring Drilling and Completion Efficiency. In Proceedings of the IADC/SPE Drilling Conference and Exhibition, Fort Worth, Texas, USA, 1–3 March 2016; OnePetro: Richardson, TX, USA, 2016. [Google Scholar]
- Hou, X. The State Recognition and the Time-Dependent Analysis Based on Mud Logging Data in Drilling Operations; China University of Petroleum: Dongying, China, 2020. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).