
A Unified Graph Formulation for Spatio-Temporal Wind Forecasting


Abstract
:1. Introduction
- An investigation into a unified graph formulation for wind forecasting, where spatial and temporal dependencies are considered simultaneously by a GNN.
- Only a GNN was required for the proposed formulation, alleviating the need for additional temporal networks. As a result, inputs did not have to be aligned and the framework naturally allowed for missing input information, irregular time series and different sampling frequencies.
- Since the proposed graph formulation removed the need for the imputation or removal of samples with missing information, it should not impose additional bias or distribution shifts on the available data.
- The proposed spatio-temporal unified graph network (STUGN) was compared against a range of different baselines for the task of spatio-temporal wind speed forecasting in the North Sea under different amounts of missing input information.
2. Related Works
3. Materials and Methods
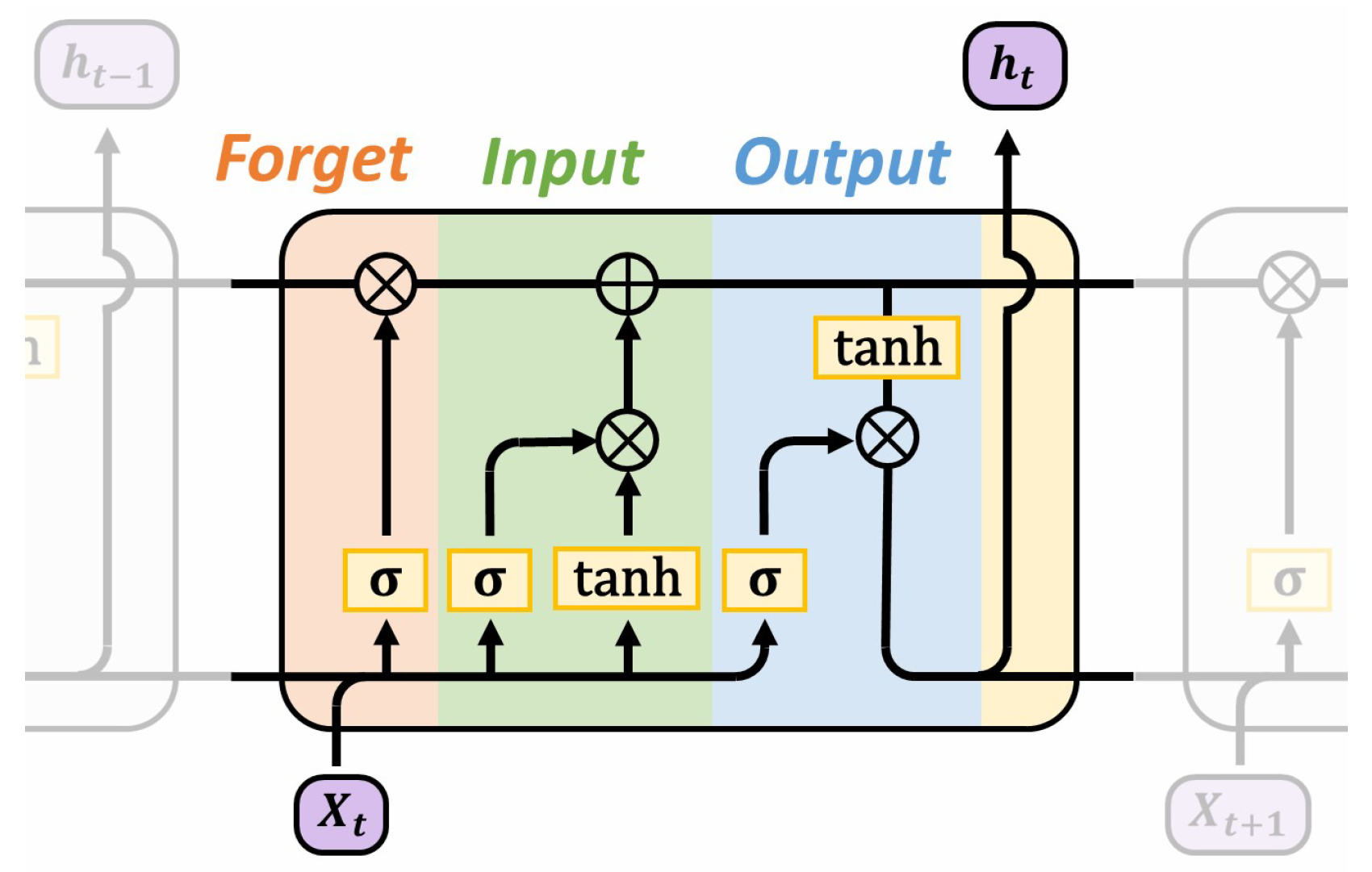
3.1. Long Short-Term Memory
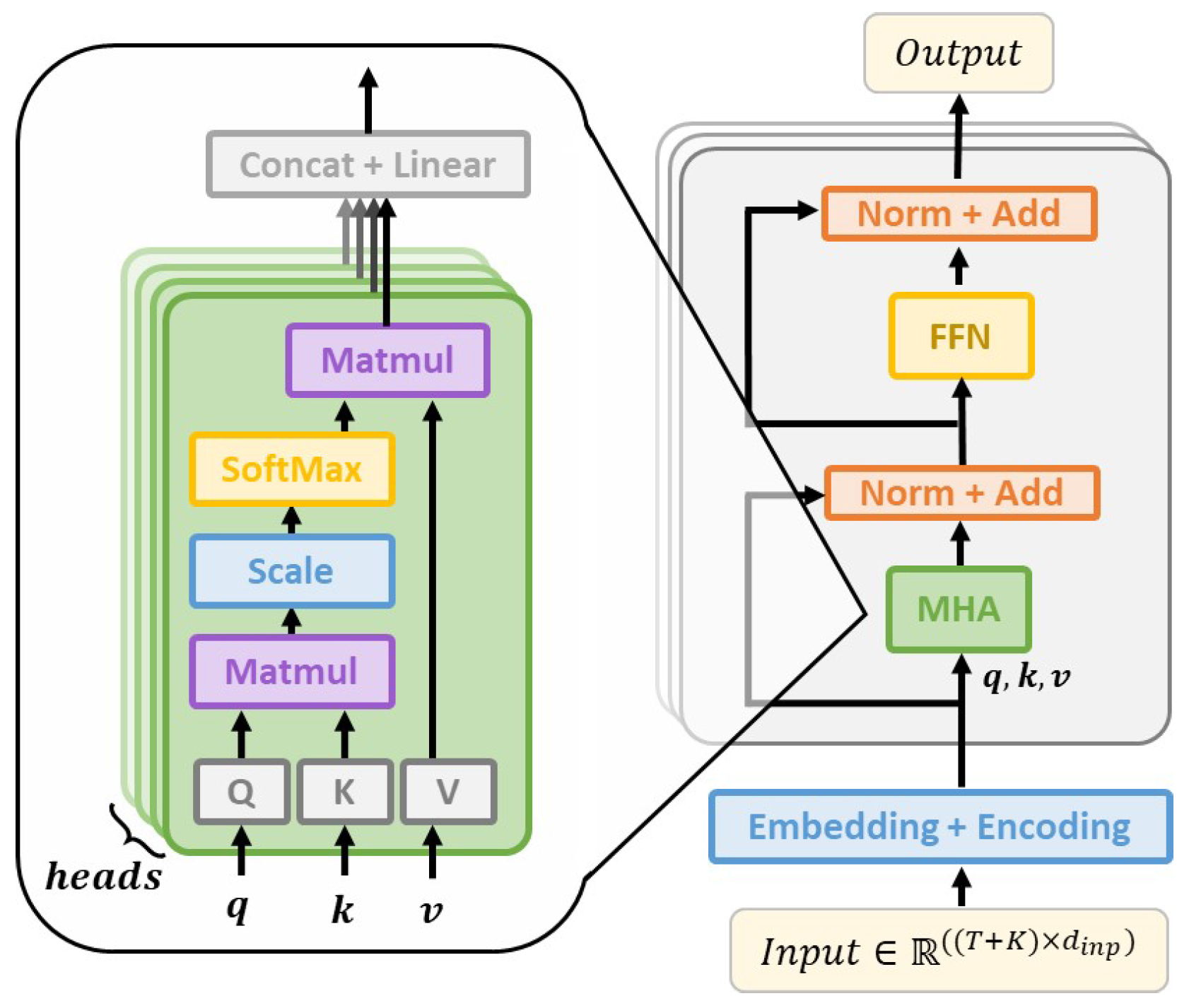
3.2. Transformer
3.3. Traditional Spatio-Temporal Problem Formulation
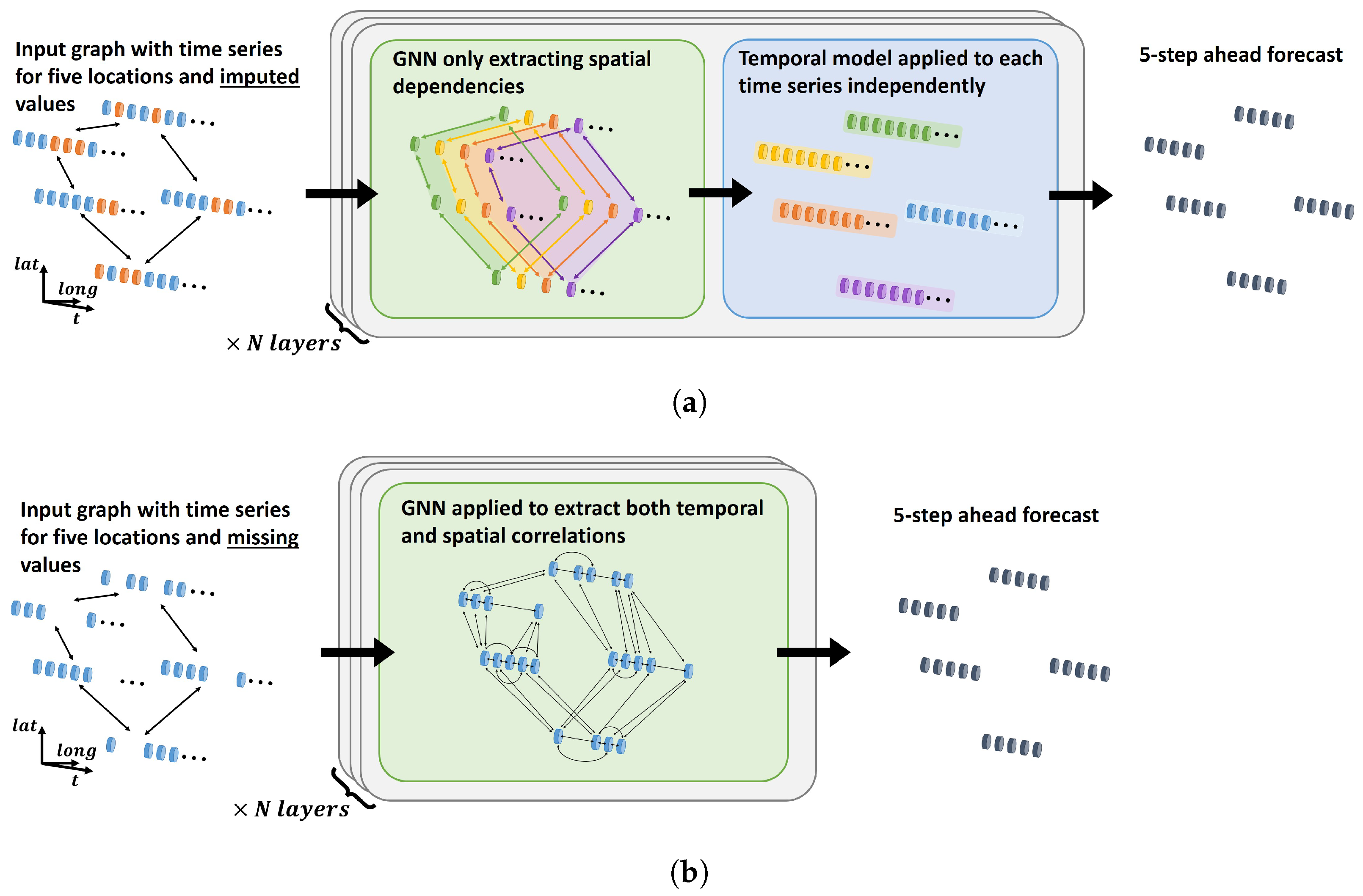
3.4. Traditional Spatio-Temporal Architecture Using GNNs
4. Proposed Framework
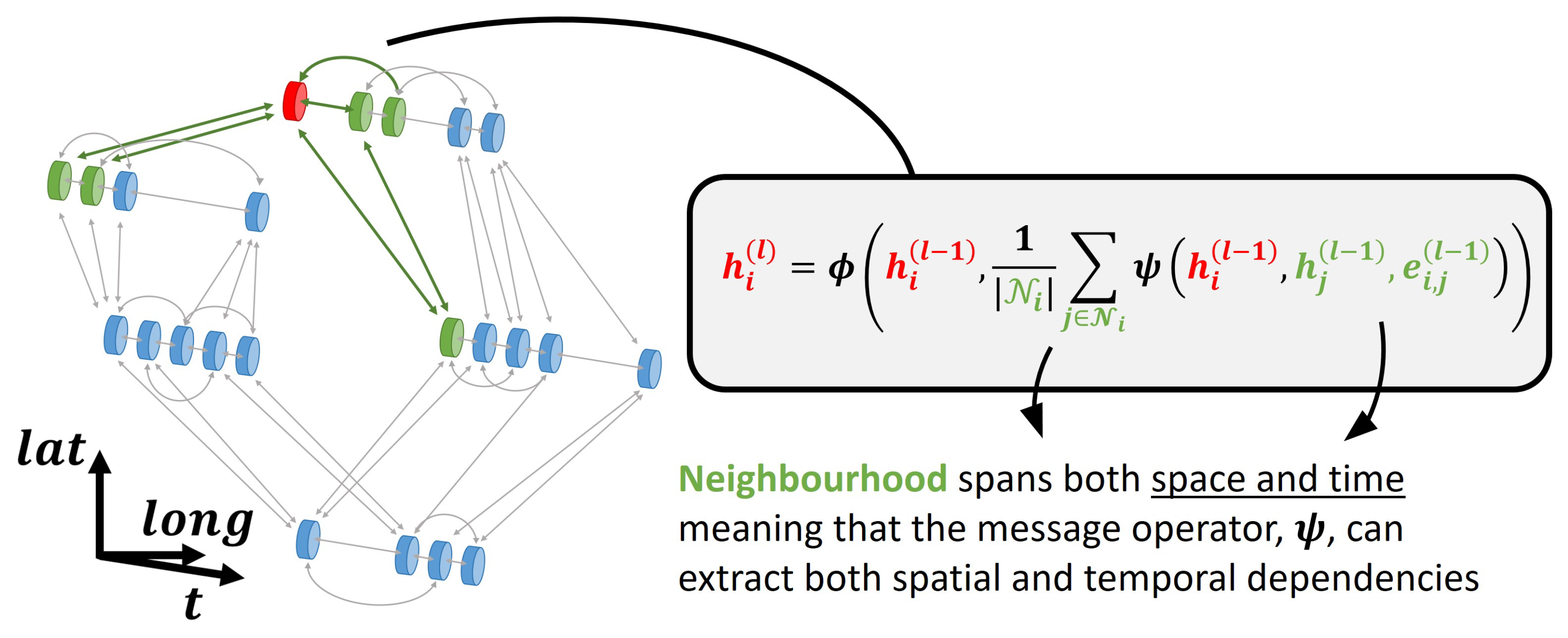
4.1. Unified Graph Formulation
- Since the framework allows for sparse inputs in both space and time, missing values can simply be omitted from the inputs.
- Spatial and temporal information are encoded in a similar manner, enabling a GNN to learn both spatial and temporal dependencies simultaneously.
- With a large number of sensors, different meteorological variables might be sampled at different frequencies. For instance, wind speeds might be recorded every ten minutes and precipitation every hour. Other features, such as component failures or control instructions, typically occur at irregular intervals. The proposed architecture naturally allows for different and irregular sampling since it does not require aligned inputs along the spatial or temporal dimensions. This might be a particularly desirable feature in order to incorporate all potentially relevant information to produce accurate forecasts.
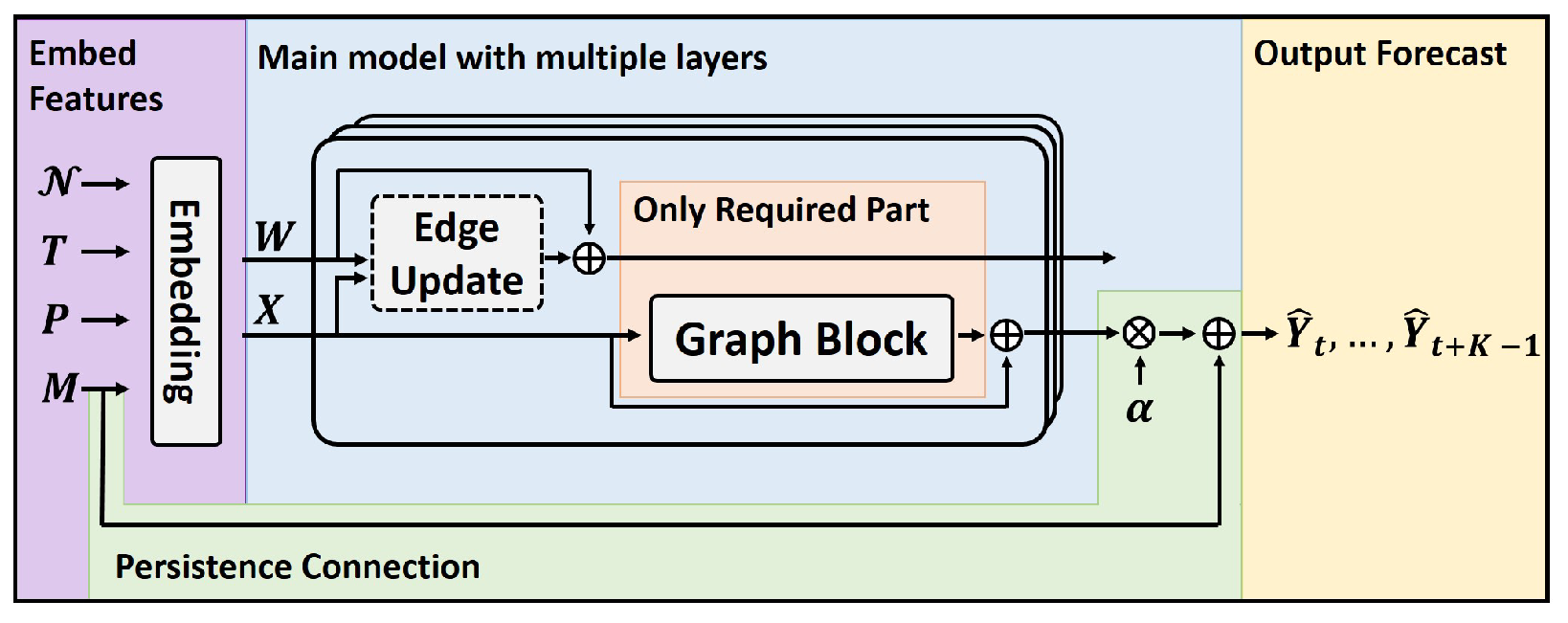
4.2. Network Architecture
5. Experiments
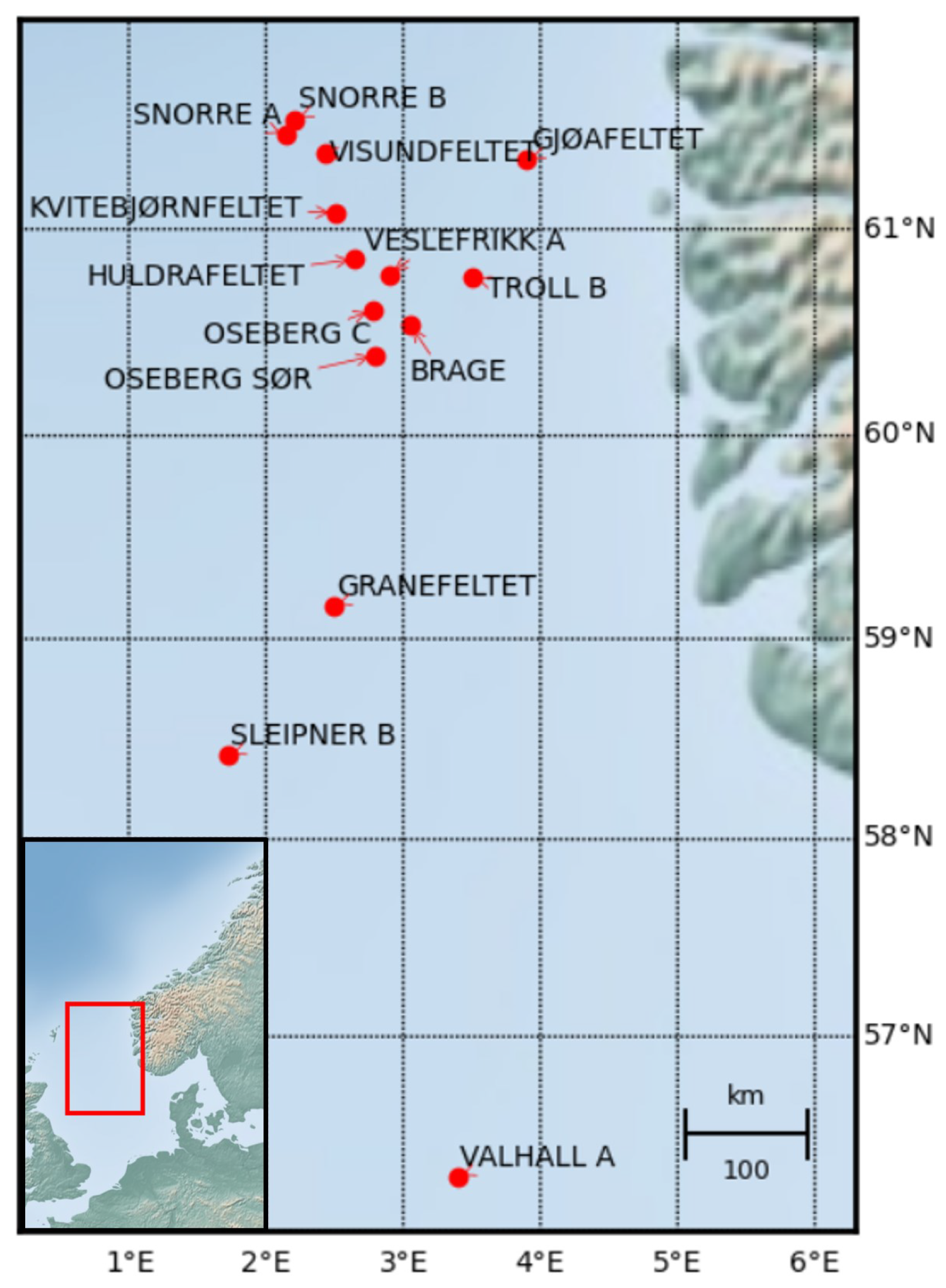
5.1. Dataset
5.2. Baseline Methods for Comparison
5.3. Experimental Set-Up
6. Results and Discussion
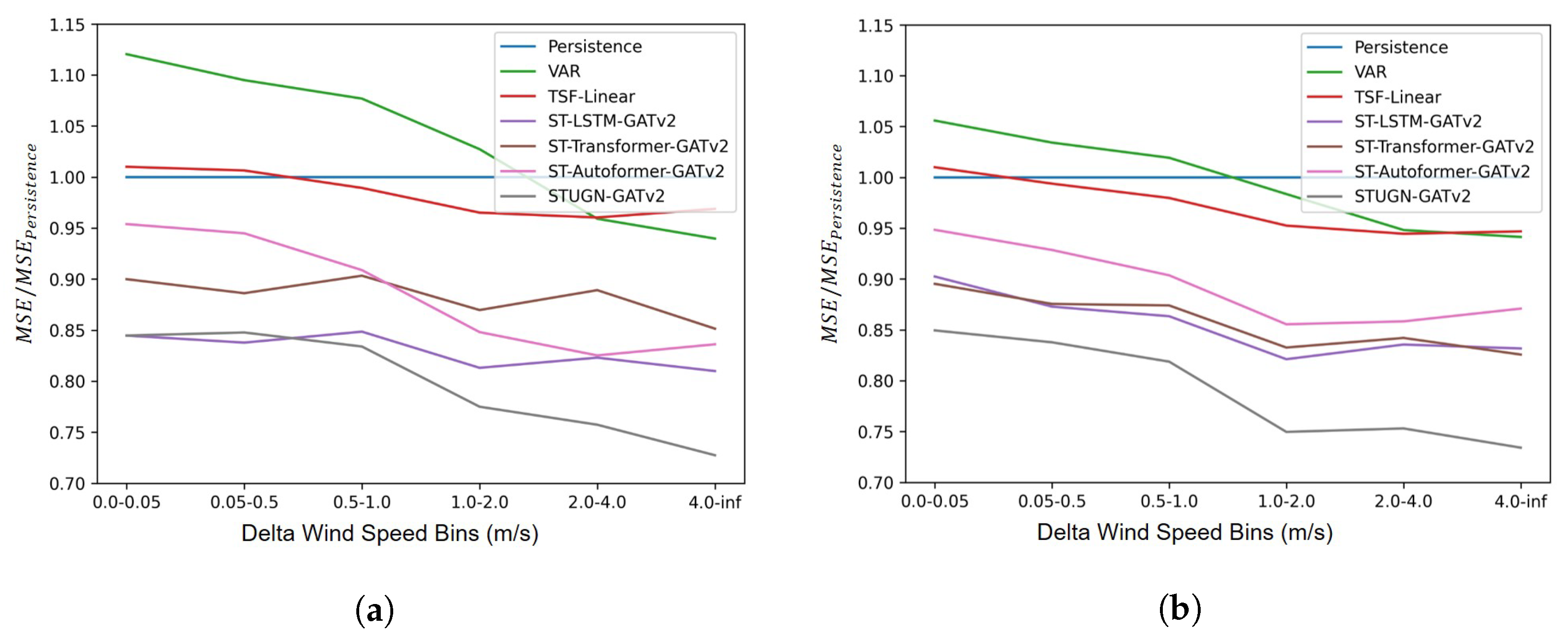
6.1. Prediction Accuracy
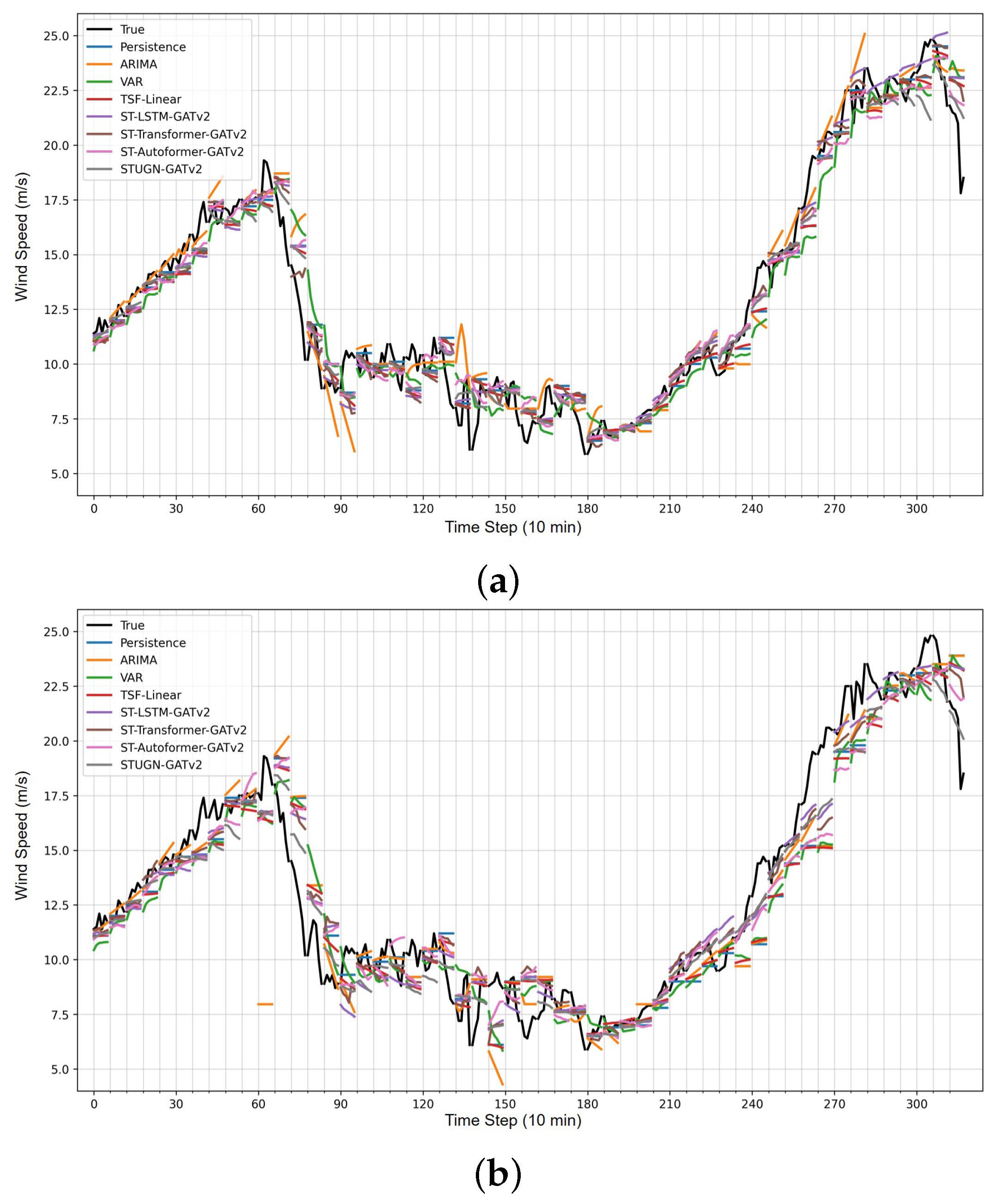
6.2. Prediction Examples
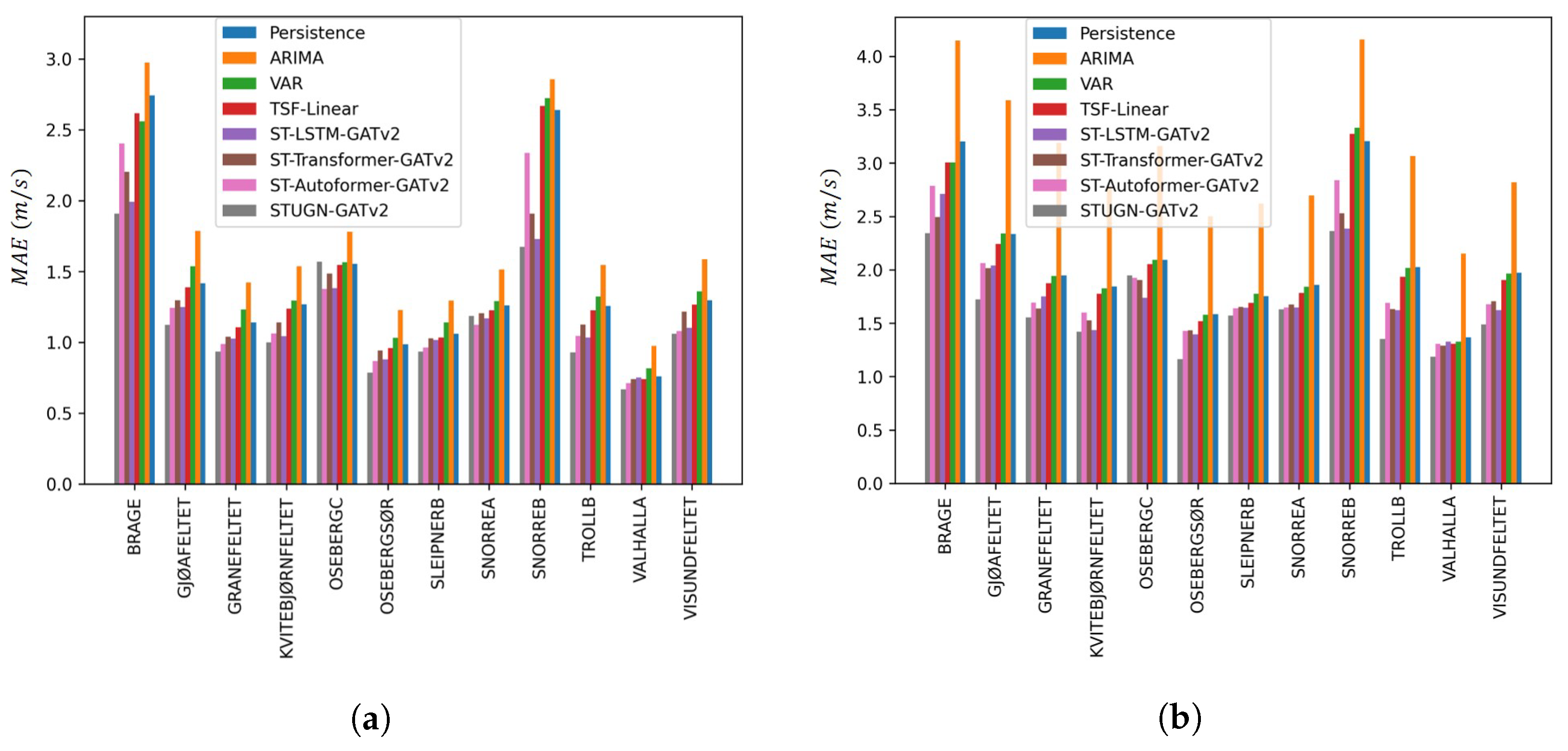
6.3. Station-Specific Accuracy
6.4. Power-Saving Performance
6.5. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3634–3640. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Qi, Y.; Li, C.; Deng, H.; Cai, M.; Qi, Y.; Deng, Y. A deep neural framework for sales forecasting in e-commerce. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 299–308. [Google Scholar]
- Smyl, S.; Hua, N.G. Machine learning methods for GEFCom2017 probabilistic load forecasting. Int. J. Forecast. 2019, 35, 1424–1431. [Google Scholar] [CrossRef]
- Li, X.; Shang, W.; Wang, S. Text-based crude oil price forecasting: A deep learning approach. Int. J. Forecast. 2019, 35, 1548–1560. [Google Scholar] [CrossRef]
- Ghaderi, A.; Sanandaji, B.M.; Ghaderi, F. Deep Forecast: Deep Learning-based Spatio-Temporal Forecasting. In Proceedings of the ICML 2017 Time Series Workshop, Sydney, Australia, 11–15 August 2017. [Google Scholar]
- Sønderby, C.K.; Espeholt, L.; Heek, J.; Dehghani, M.; Oliver, A.; Salimans, T.; Agrawal, S.; Hickey, J.; Kalchbrenner, N. Metnet: A neural weather model for precipitation forecasting. arXiv 2020, arXiv:2003.12140. [Google Scholar]
- Okumus, I.; Dinler, A. Current status of wind energy forecasting and a hybrid method for hourly predictions. Energy Convers. Manag. 2016, 123, 362–371. [Google Scholar] [CrossRef]
- GWEC. Global Wind Report. 2022. Available online: https://gwec.net/global-wind-report-2022/ (accessed on 4 September 2023).
- Zhou, J.; Lu, X.; Xiao, Y.; Su, J.; Lyu, J.; Ma, Y.; Dou, D. Sdwpf: A dataset for spatial dynamic wind power forecasting challenge at kdd cup 2022. arXiv 2022, arXiv:2208.04360. [Google Scholar]
- An, E. Strategy to Harness the Potential of Offshore Renewable Energy for a Climate Neutral Future; European Commission: Brussels, Belgium, 2020. [Google Scholar]
- European Commision. Member States Agree New Ambition for Expanding Offshore Renewable Energy. 2023. Available online: https://energy.ec.europa.eu/news/member-states-agree-new-ambition-expanding-offshore-renewable-energy-2023-01-19_en (accessed on 11 August 2023).
- Yang, B.; Zhong, L.; Wang, J.; Shu, H.; Zhang, X.; Yu, T.; Sun, L. State-of-the-art one-stop handbook on wind forecasting technologies: An overview of classifications, methodologies, and analysis. J. Clean. Prod. 2021, 283, 124628. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C.; Lee, S.J.; Park, N. Machine learning based hybrid system for imputation and efficient energy demand forecasting. Energies 2020, 13, 2681. [Google Scholar]
- Elsaraiti, M.; Merabet, A. A comparative analysis of the arima and lstm predictive models and their effectiveness for predicting wind speed. Energies 2021, 14, 6782. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Singh, S.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Jørgensen, K.L.; Shaker, H.R. Wind power forecasting using machine learning: State of the art, trends and challenges. In Proceedings of the 2020 IEEE 8th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2020; pp. 44–50. [Google Scholar]
- Sfetsos, A. A novel approach for the forecasting of mean hourly wind speed time series. Renew. Energy 2002, 27, 163–174. [Google Scholar] [CrossRef]
- Guo, Z.h.; Wu, J.; Lu, H.y.; Wang, J.z. A case study on a hybrid wind speed forecasting method using BP neural network. Knowl.-Based Syst. 2011, 24, 1048–1056. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, H.; Xu, Y.; Jiang, W. A hybrid framework for short term multi-step wind speed forecasting based on variational model decomposition and convolutional neural network. Energies 2018, 11, 2292. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Dong, X.; Sun, Y.; Li, Y.; Wang, X.; Pu, T. Spatio-temporal convolutional network based power forecasting of multiple wind farms. J. Mod. Power Syst. Clean Energy 2021, 10, 388–398. [Google Scholar] [CrossRef]
- Shivam, K.; Tzou, J.C.; Wu, S.C. Multi-step short-term wind speed prediction using a residual dilated causal convolutional network with nonlinear attention. Energies 2020, 13, 1772. [Google Scholar] [CrossRef]
- Yamak, P.T.; Yujian, L.; Gadosey, P.K. A comparison between arima, lstm, and gru for time series forecasting. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 49–55. [Google Scholar]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Sun, Y.; Wang, X.; Yang, J. Modified particle swarm optimization with attention-based LSTM for wind power prediction. Energies 2022, 15, 4334. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Pan, X.; Wang, L.; Wang, Z.; Huang, C. Short-term wind speed forecasting based on spatial-temporal graph transformer networks. Energy 2022, 253, 124095. [Google Scholar] [CrossRef]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-temporal transformer networks for traffic flow forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Huang, X.; Jiang, A. Wind Power Generation Forecast Based on Multi-Step Informer Network. Energies 2022, 15, 6642. [Google Scholar] [CrossRef]
- Bentsen, L.Ø.; Warakagoda, N.D.; Stenbro, R.; Engelstad, P. Spatio-temporal wind speed forecasting using graph networks and novel Transformer architectures. Appl. Energy 2023, 333, 120565. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32, 5243–5253. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? arXiv 2022, arXiv:2205.13504. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, G.; Luo, J.; He, J.; Sun, H. A multi-location short-term wind speed prediction model based on spatiotemporal joint learning. Renew. Energy 2022, 183, 148–159. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Pei, S.; Jiang, Z.; Feng, Z.; Zhou, J. Probabilistic spatiotemporal wind speed forecasting based on a variational Bayesian deep learning model. Appl. Energy 2020, 260, 114259. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Cao, D.; Wang, Y.; Duan, J.; Zhang, C.; Zhu, X.; Huang, C.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; et al. Spectral temporal graph neural network for multivariate time-series forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17766–17778. [Google Scholar]
- Zhang, X.; Zeman, M.; Tsiligkaridis, T.; Zitnik, M. Graph-Guided Network for Irregularly Sampled Multivariate Time Series. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Horn, M.; Moor, M.; Bock, C.; Rieck, B.; Borgwardt, K. Set functions for time series. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 4353–4363. [Google Scholar]
- Tawn, R.; Browell, J.; Dinwoodie, I. Missing data in wind farm time series: Properties and effect on forecasts. Electr. Power Syst. Res. 2020, 189, 106640. [Google Scholar] [CrossRef]
- Wen, H.; Pinson, P.; Gu, J.; Jin, Z. Wind energy forecasting with missing values within a fully conditional specification framework. Int. J. Forecast. 2023, in press. [Google Scholar] [CrossRef]
- Rao, A.R.; Wang, Q.; Wang, H.; Khorasgani, H.; Gupta, C. Spatio-temporal functional neural networks. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 81–89. [Google Scholar]
- You, J.; Ma, X.; Ding, Y.; Kochenderfer, M.J.; Leskovec, J. Handling missing data with graph representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19075–19087. [Google Scholar]
- Huang, Z.; Sun, Y.; Wang, W. Coupled graph ode for learning interacting system dynamics. In Proceedings of the 27th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD), Virtual, 14–18 August 2021. [Google Scholar]
- Roy, A.; Roy, K.K.; Ahsan Ali, A.; Amin, M.A.; Rahman, A.M. SST-GNN: Simplified spatio-temporal traffic forecasting model using graph neural network. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, 11–14 May 2021, Proceedings, Part III; Springer: Cham, Switzerland, 2021; pp. 90–102. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Veličković, P. Everything is Connected: Graph Neural Networks. arXiv 2023, arXiv:2301.08210. [Google Scholar] [CrossRef] [PubMed]
- Haugsdal, E.; Aune, E.; Ruocco, M. Persistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting. arXiv 2022, arXiv:2208.14236. [Google Scholar] [CrossRef]
- Bachlechner, T.; Majumder, B.P.; Mao, H.; Cottrell, G.; McAuley, J. Rezero is all you need: Fast convergence at large depth. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, PMLR, Online, 27–30 July 2021; pp. 1352–1361. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How Attentive are Graph Attention Networks? In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. In Proceedings of the ICLR Workshop on Representation Learning on Graphs and Manifolds, New Orleans, LA, USA, 6 May 2019. [Google Scholar]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T. On layer normalization in the transformer architecture. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 10524–10533. [Google Scholar]
- Jonkman, J.; Butterfield, S.; Musial, W.; Scott, G. Definition of a 5-MW Reference Wind Turbine for Offshore System Development; Technical Report; National Renewable Energy Lab (NREL): Golden, CO, USA, 2009. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Percentage Missing | 0% | 10% | 20% | 30% | 50% | 80% |
|---|---|---|---|---|---|---|
| Persistence | 1.448 ± 0.000 | 1.448 ± 0.000 | 1.455 ± 0.000 | 1.487 ± 0.000 | 1.585 ± 0.000 | 2.098 ± 0.000 |
| ARIMA | 1.707 ± 0.000 | 1.707 ± 0.000 | 1.716 ± 0.000 | 1.740 ± 0.000 | 1.821 ± 0.000 | 3.073 ± 0.000 |
| VAR | 1.488 ± 0.001 | 1.488 ± 0.001 | 1.496 ± 0.001 | 1.518 ± 0.001 | 1.601 ± 0.001 | 2.084 ± 0.001 |
| TSF-Linear | 1.418 ± 0.000 | 1.418 ± 0.001 | 1.424 ± 0.000 | 1.454 ± 0.000 | 1.545 ± 0.001 | 2.029 ± 0.000 |
| ST-LSTM-MPNN | 1.197 ± 0.002 | 1.198 ± 0.002 | 1.206 ± 0.003 | 1.236 ± 0.008 | 1.322 ± 0.006 | 1.773 ± 0.004 |
| ST-LSTM-GATv2 | 1.185 ± 0.010 | 1.187 ± 0.006 | 1.195 ± 0.008 | 1.227 ± 0.009 | 1.310 ± 0.011 | 1.767 ± 0.012 |
| ST-LSTM-TGAT | 1.208 ± 0.007 | 1.207 ± 0.006 | 1.213 ± 0.006 | 1.243 ± 0.009 | 1.327 ± 0.010 | 1.753 ± 0.009 |
| ST-Transformer-MPNN | 1.233 ± 0.012 | 1.233 ± 0.012 | 1.239 ± 0.012 | 1.264 ± 0.007 | 1.344 ± 0.008 | 1.786 ± 0.009 |
| ST-Transformer-GATv2 | 1.268 ± 0.014 | 1.279 ± 0.006 | 1.267 ± 0.022 | 1.305 ± 0.009 | 1.380 ± 0.006 | 1.771 ± 0.017 |
| ST-Transformer-TGAT | 1.283 ± 0.010 | 1.286 ± 0.011 | 1.289 ± 0.005 | 1.319 ± 0.009 | 1.381 ± 0.007 | 1.782 ± 0.006 |
| ST-Autoformer-MPNN | 1.293 ± 0.022 | 1.292 ± 0.012 | 1.292 ± 0.011 | 1.310 ± 0.009 | 1.401 ± 0.008 | 1.866 ± 0.016 |
| ST-Autoformer-GATv2 | 1.273 ± 0.006 | 1.275 ± 0.011 | 1.282 ± 0.005 | 1.313 ± 0.009 | 1.412 ± 0.012 | 1.876 ± 0.019 |
| ST-Autoformer-TGAT | 1.288 ± 0.007 | 1.287 ± 0.008 | 1.294 ± 0.010 | 1.331 ± 0.011 | 1.423 ± 0.004 | 1.891 ± 0.014 |
| STUGN-MPNN | 1.192 ± 0.016 | 1.193 ± 0.014 | 1.201 ± 0.006 | 1.221 ± 0.006 | 1.312 ± 0.019 | 1.668 ± 0.019 |
| STUGN-GATv2 | 1.160 ± 0.015 | 1.160 ± 0.016 | 1.165 ± 0.018 | 1.193 ± 0.013 | 1.277 ± 0.015 | 1.636 ± 0.008 |
| STUGN-TGAT | 1.153 ± 0.010 | 1.155 ± 0.013 | 1.164 ± 0.006 | 1.190 ± 0.011 | 1.264 ± 0.014 | 1.642 ± 0.022 |
| Percentage Missing | 0% | 10% | 20% | 30% | 50% | 80% |
|---|---|---|---|---|---|---|
| Persistence | 0.810 ± 0.000 | 0.810 ± 0.000 | 0.813 ± 0.000 | 0.823 ± 0.000 | 0.855 ± 0.000 | 0.997 ± 0.000 |
| ARIMA | 0.882 ± 0.000 | 0.882 ± 0.000 | 0.885 ± 0.000 | 0.891 ± 0.000 | 0.915 ± 0.000 | 1.147 ± 0.000 |
| VAR | 0.846 ± 0.000 | 0.846 ± 0.000 | 0.849 ± 0.000 | 0.856 ± 0.000 | 0.882 ± 0.000 | 1.015 ± 0.000 |
| TSF-Linear | 0.803 ± 0.000 | 0.803 ± 0.000 | 0.806 ± 0.000 | 0.817 ± 0.000 | 0.848 ± 0.000 | 0.987 ± 0.000 |
| ST-LSTM-MPNN | 0.749 ± 0.001 | 0.750 ± 0.001 | 0.753 ± 0.001 | 0.764 ± 0.003 | 0.795 ± 0.002 | 0.933 ± 0.001 |
| ST-LSTM-GATv2 | 0.748 ± 0.003 | 0.748 ± 0.003 | 0.751 ± 0.003 | 0.763 ± 0.003 | 0.794 ± 0.004 | 0.931 ± 0.003 |
| ST-LSTM-TGAT | 0.755 ± 0.003 | 0.756 ± 0.003 | 0.758 ± 0.003 | 0.769 ± 0.003 | 0.799 ± 0.002 | 0.928 ± 0.002 |
| ST-Transformer-MPNN | 0.761 ± 0.004 | 0.760 ± 0.004 | 0.762 ± 0.004 | 0.772 ± 0.002 | 0.802 ± 0.002 | 0.937 ± 0.002 |
| ST-Transformer-GATv2 | 0.767 ± 0.003 | 0.770 ± 0.003 | 0.769 ± 0.005 | 0.781 ± 0.002 | 0.809 ± 0.001 | 0.931 ± 0.004 |
| ST-Transformer-TGAT | 0.772 ± 0.003 | 0.773 ± 0.003 | 0.775 ± 0.001 | 0.786 ± 0.003 | 0.810 ± 0.002 | 0.935 ± 0.002 |
| ST-Autoformer-MPNN | 0.776 ± 0.007 | 0.776 ± 0.006 | 0.776 ± 0.002 | 0.784 ± 0.004 | 0.815 ± 0.003 | 0.954 ± 0.006 |
| ST-Autoformer-GATv2 | 0.771 ± 0.003 | 0.772 ± 0.004 | 0.774 ± 0.003 | 0.785 ± 0.004 | 0.820 ± 0.005 | 0.958 ± 0.005 |
| ST-Autoformer-TGAT | 0.775 ± 0.003 | 0.774 ± 0.004 | 0.778 ± 0.003 | 0.791 ± 0.002 | 0.824 ± 0.001 | 0.964 ± 0.004 |
| STUGN-MPNN | 0.748 ± 0.005 | 0.749 ± 0.005 | 0.753 ± 0.002 | 0.760 ± 0.002 | 0.793 ± 0.005 | 0.908 ± 0.005 |
| STUGN-GATv2 | 0.737 ± 0.005 | 0.738 ± 0.005 | 0.740 ± 0.006 | 0.751 ± 0.004 | 0.782 ± 0.004 | 0.898 ± 0.003 |
| STUGN-TGAT | 0.735 ± 0.004 | 0.736 ± 0.004 | 0.740 ± 0.002 | 0.750 ± 0.002 | 0.778 ± 0.003 | 0.901 ± 0.006 |
| Percentage Missing | 0% | 10% | 20% | 30% | 50% | 80% |
|---|---|---|---|---|---|---|
| Persistence | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ARIMA | ||||||
| VAR | 0.0 | −0.1 | 0.1 | 0.8 | 1.5 | 2.5 |
| TSF-Linear | 4.1 | 4.1 | 4.1 | 4.3 | 4.9 | 6.4 |
| ST-LSTM-MPNN | 30.0 | 29.6 | 29.9 | 30.9 | 30.6 | 28.4 |
| ST-LSTM-GATv2 | 28.8 | 28.4 | 28.9 | 28.8 | 27.2 | 28.5 |
| ST-LSTM-TGAT | 24.9 | 24.0 | 24.4 | 26.4 | 26.5 | 30.6 |
| ST-Transformer-MPNN | 20.9 | 23.4 | 22.8 | 24.6 | 24.7 | 26.6 |
| ST-Transformer-GATv2 | 19.3 | 18.8 | 20.2 | 20.5 | 22.4 | 29.1 |
| ST-Transformer-TGAT | 18.0 | 17.7 | 18.3 | 19.1 | 20.7 | 29.0 |
| ST-Autoformer-MPNN | 22.3 | 22.5 | 21.3 | 22.2 | 22.5 | 19.3 |
| ST-Autoformer-GATv2 | 21.4 | 20.2 | 21.0 | 21.9 | 21.7 | 21.4 |
| ST-Autoformer-TGAT | 19.8 | 17.8 | 20.2 | 17.8 | 17.5 | 13.9 |
| STUGN-MPNN | 28.5 | 26.8 | 29.0 | 29.8 | 29.9 | 37.8 |
| STUGN-GATv2 | 36.5 | 37.0 | 37.3 | 36.2 | 35.1 | 42.5 |
| STUGN-TGAT | 36.8 | 36.9 | 36.7 | 33.8 | 34.6 | 42.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bentsen, L.Ø.; Warakagoda, N.D.; Stenbro, R.; Engelstad, P. A Unified Graph Formulation for Spatio-Temporal Wind Forecasting. Energies 2023, 16, 7179. https://doi.org/10.3390/en16207179
Bentsen LØ, Warakagoda ND, Stenbro R, Engelstad P. A Unified Graph Formulation for Spatio-Temporal Wind Forecasting. Energies. 2023; 16(20):7179. https://doi.org/10.3390/en16207179
Chicago/Turabian StyleBentsen, Lars Ødegaard, Narada Dilp Warakagoda, Roy Stenbro, and Paal Engelstad. 2023. "A Unified Graph Formulation for Spatio-Temporal Wind Forecasting" Energies 16, no. 20: 7179. https://doi.org/10.3390/en16207179
APA StyleBentsen, L. Ø., Warakagoda, N. D., Stenbro, R., & Engelstad, P. (2023). A Unified Graph Formulation for Spatio-Temporal Wind Forecasting. Energies, 16(20), 7179. https://doi.org/10.3390/en16207179