
Grid Distribution Fault Occurrence and Remedial Measures Prediction/Forecasting through Different Deep Learning Neural Networks by Using Real Time Data from Tabuk City Power Grid


Abstract
:1. Introduction
2. Case Study
2.1. Data Classification
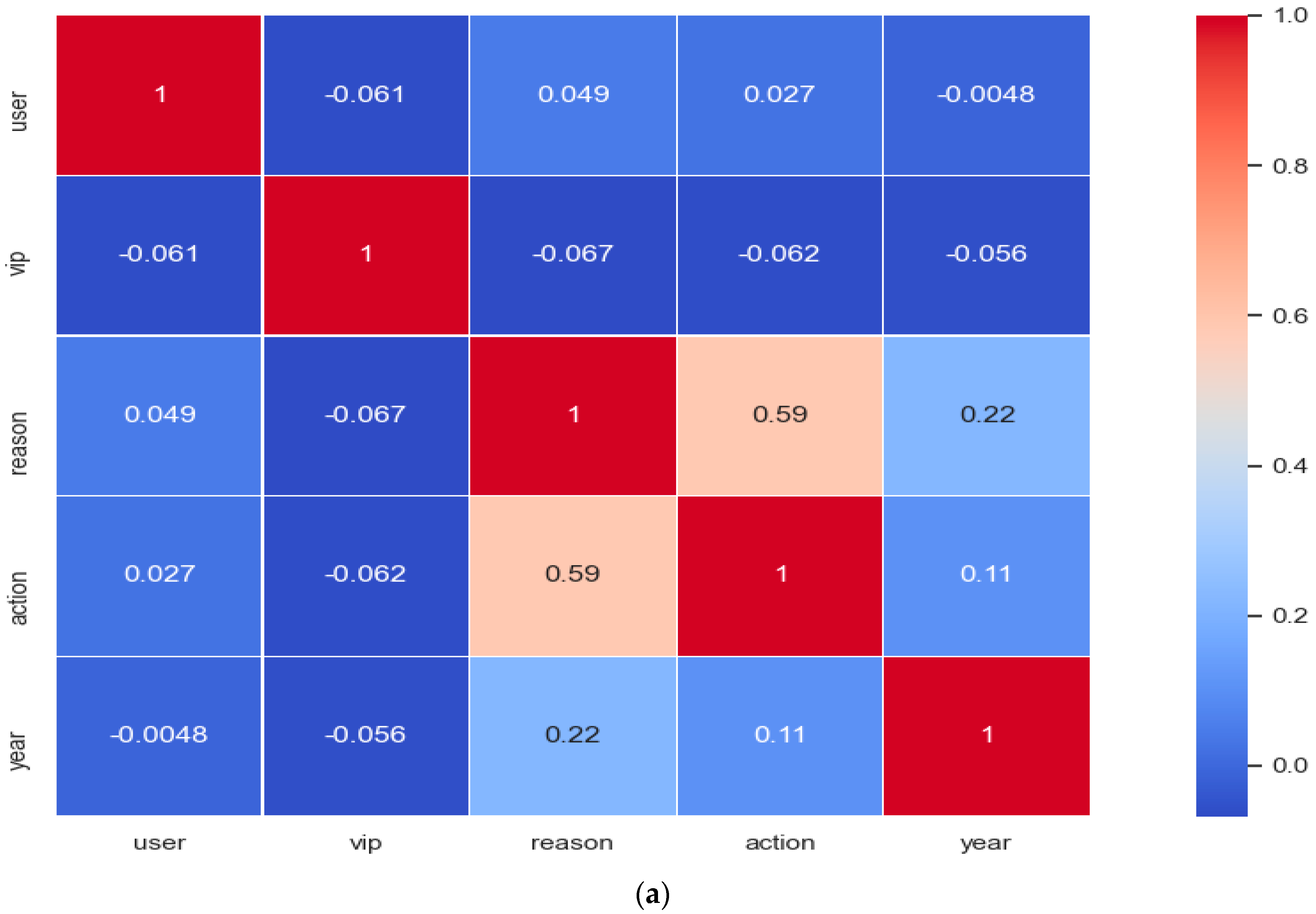
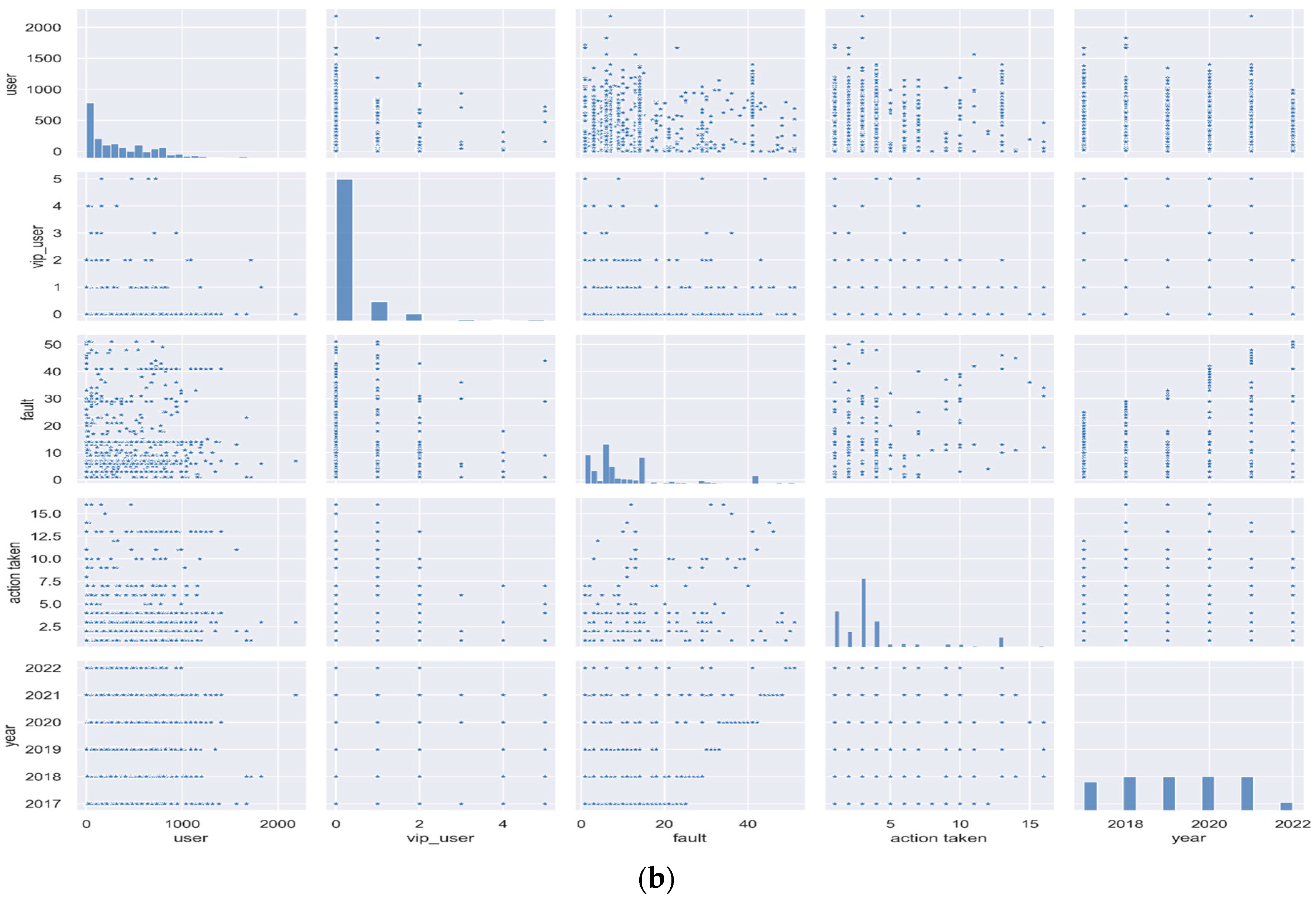
2.2. Data Analysis
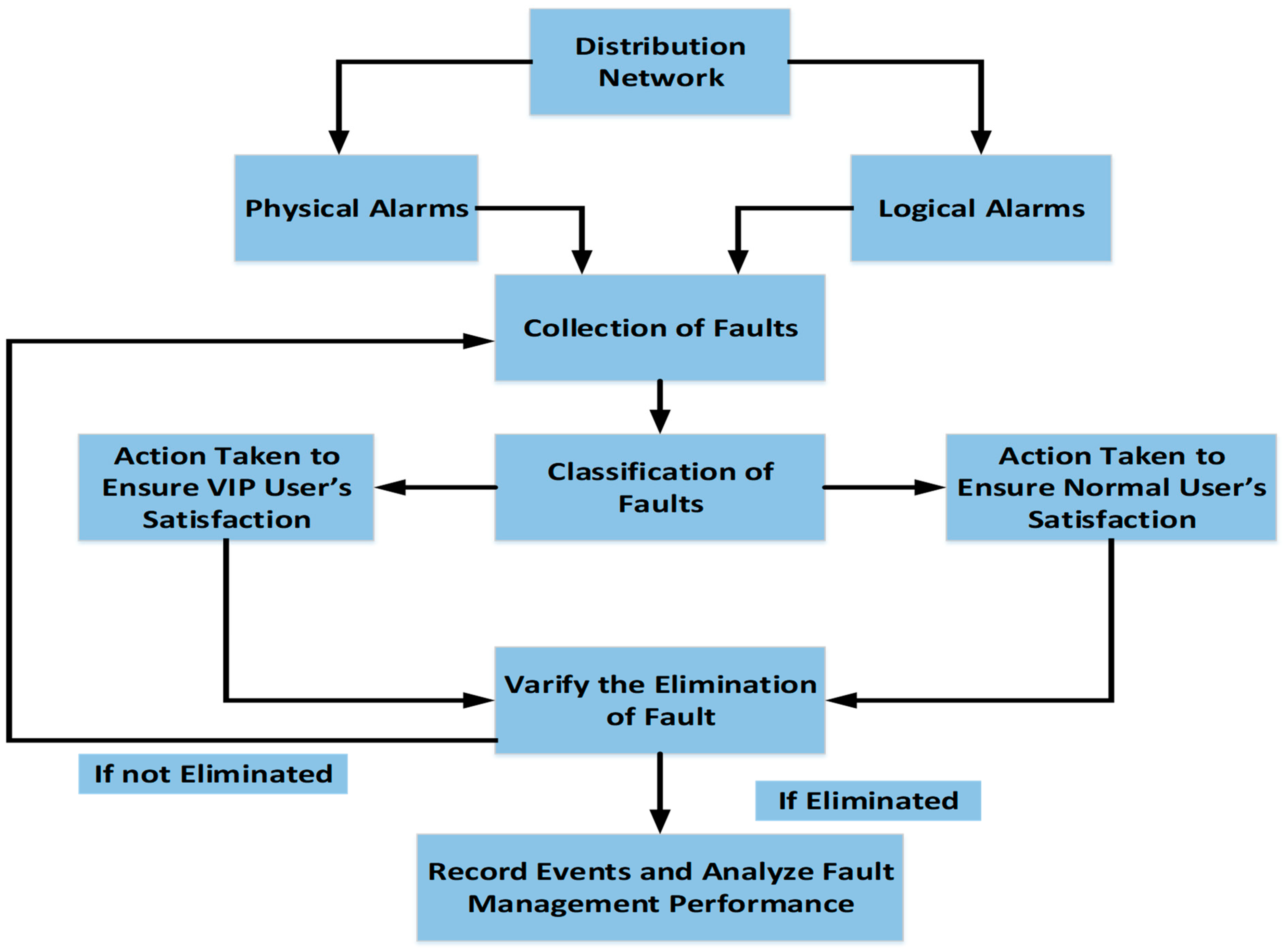
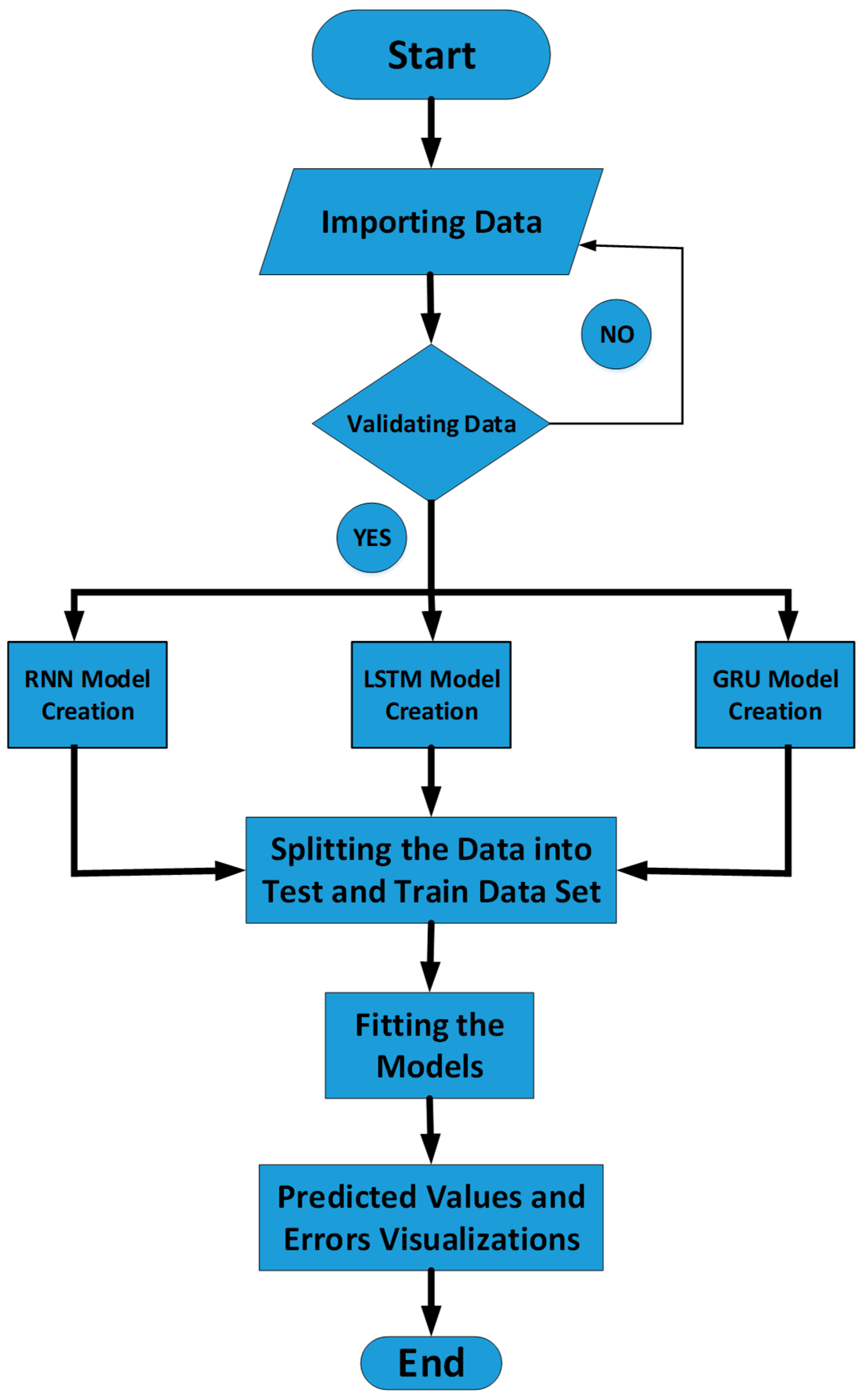
3. Framework with Fault Management
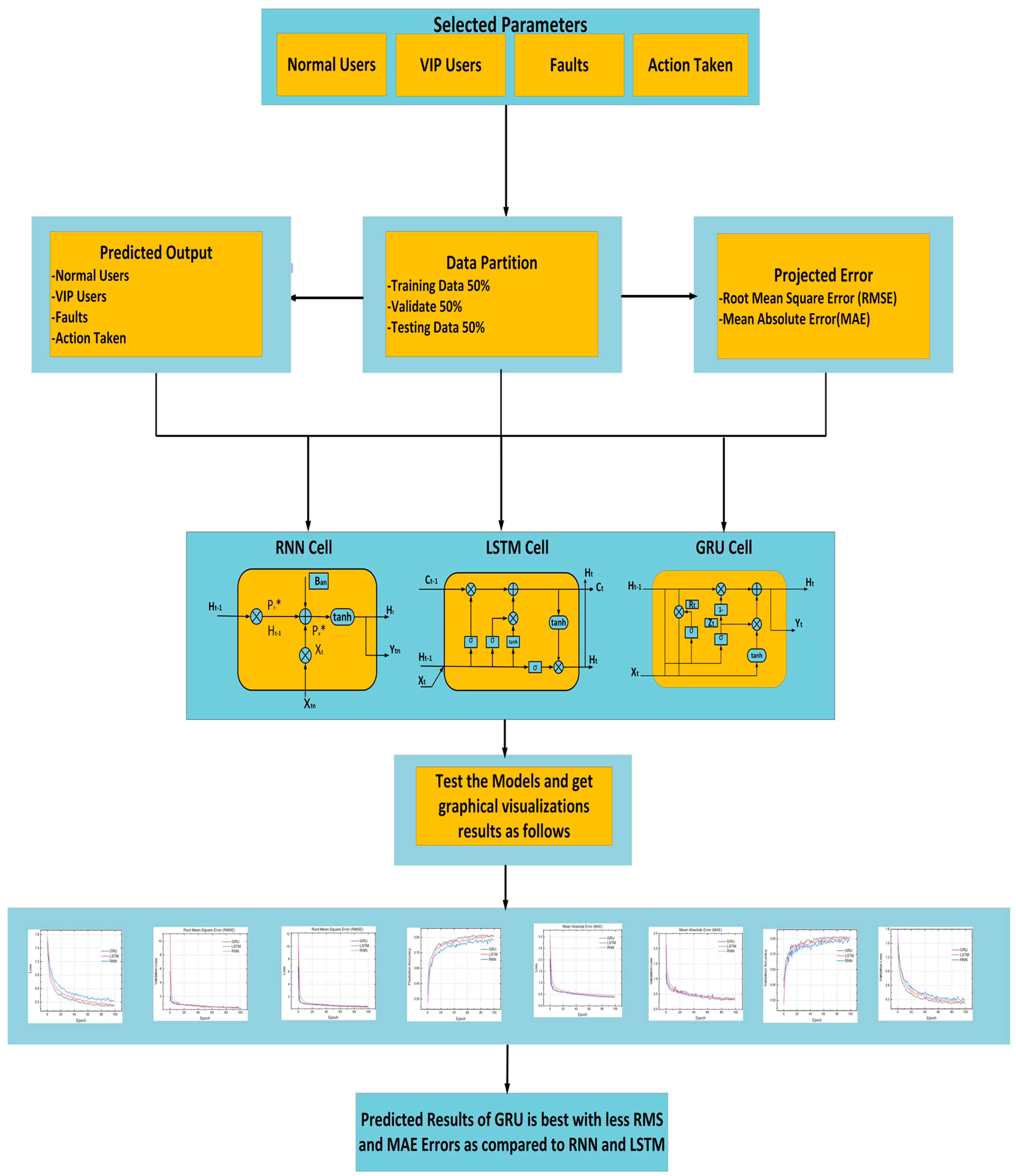
3.1. Mathematical Expressions and Functional Process of RNN, LSTM and GRU
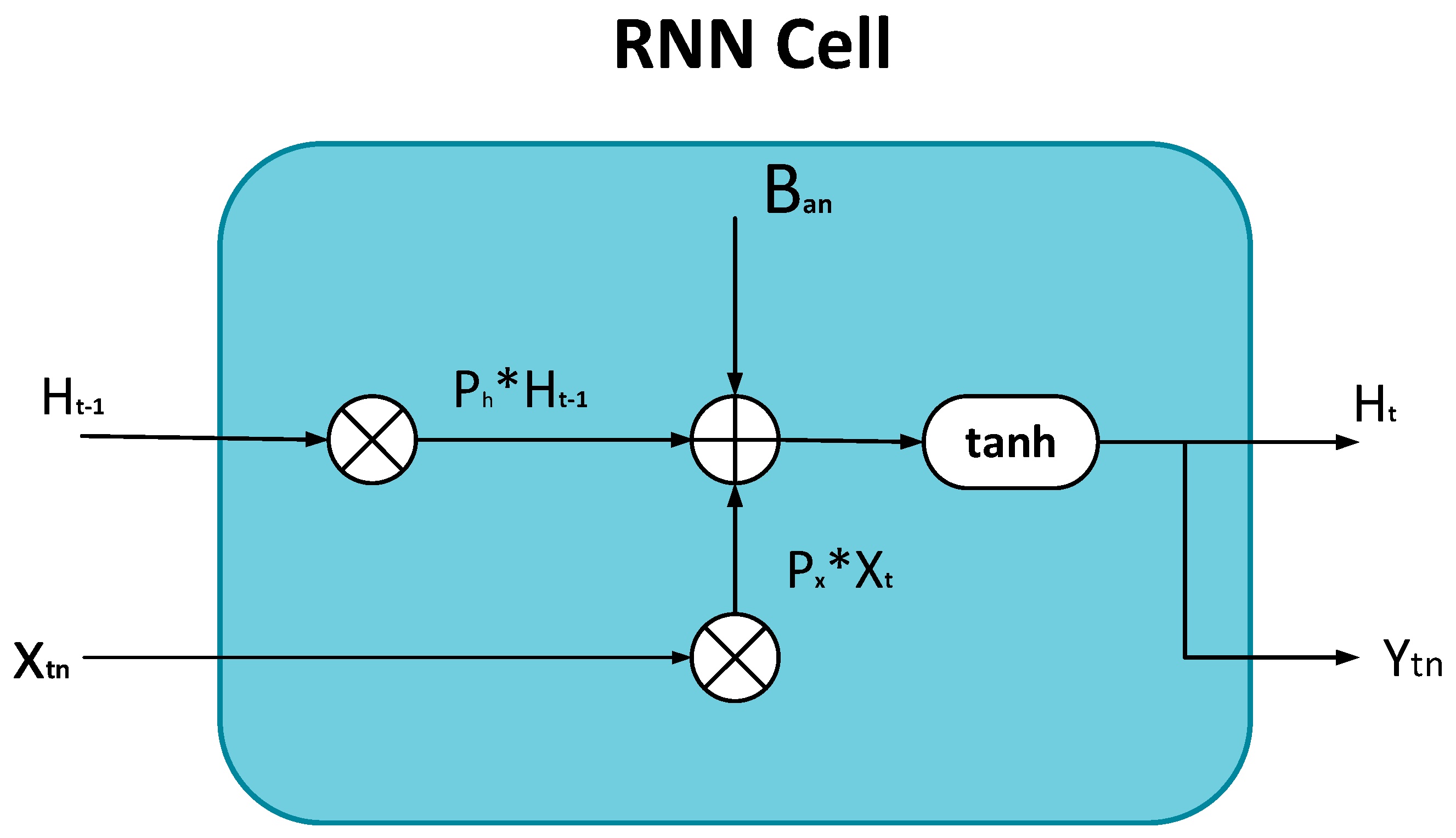
3.1.1. Simple Recurrent Neural Network (RNN)
3.1.2. GRU Explanation
3.1.3. LSTM Explanation
3.1.4. Experimental Setup Used
- CPU: Intel(R) Core (TM) i7-10875H [email protected] 2.30 GHz
- Graphics Card: NVIDIA GeForce RTX 2060
- RAM: 16.0 GB, 6 GB GUP Memory
- OS: 64-bit Windows operating system
- Software: Python 3.7, Keras, TensorFlow version 2.3.1
- TP: True positive rate is the number of fault classifications samples that were successfully identified as malignant.
- TN: True negative rate is the number of benign samples that were successfully identified as benign.
- FP: False positive rate is the number of benign samples that were wrongly identified as malignant.
- FN: False negative rate is the number of malignant samples that were wrongly identified as benign.
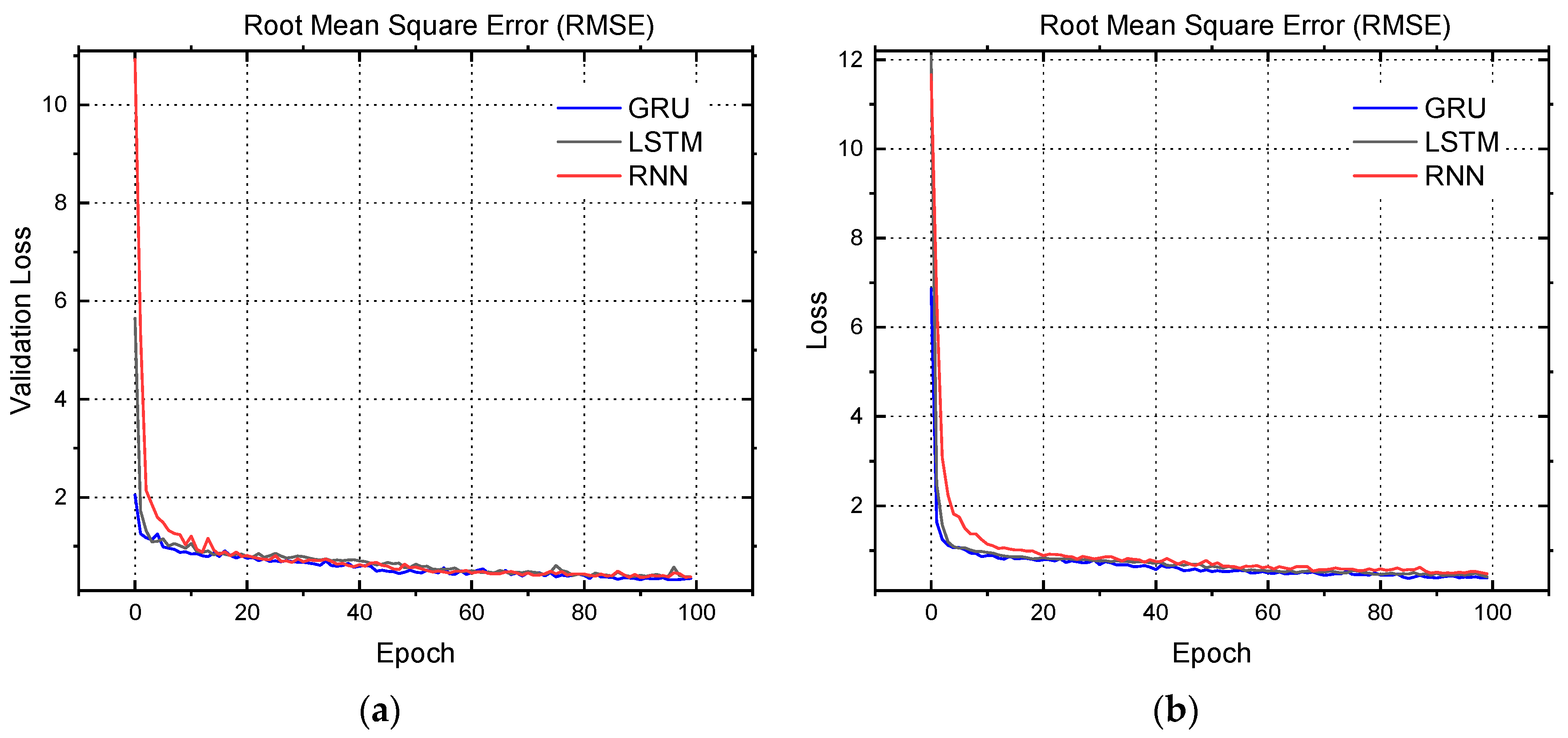
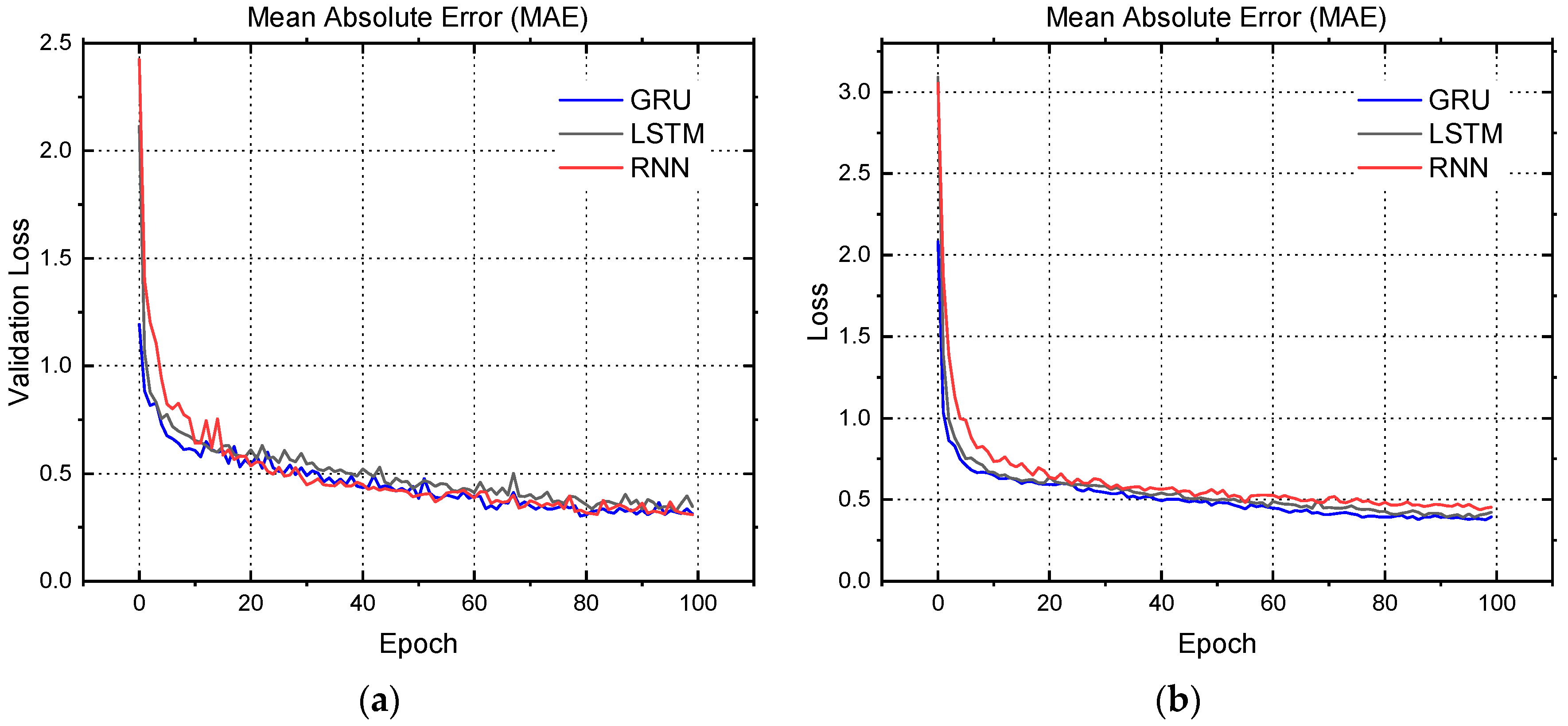
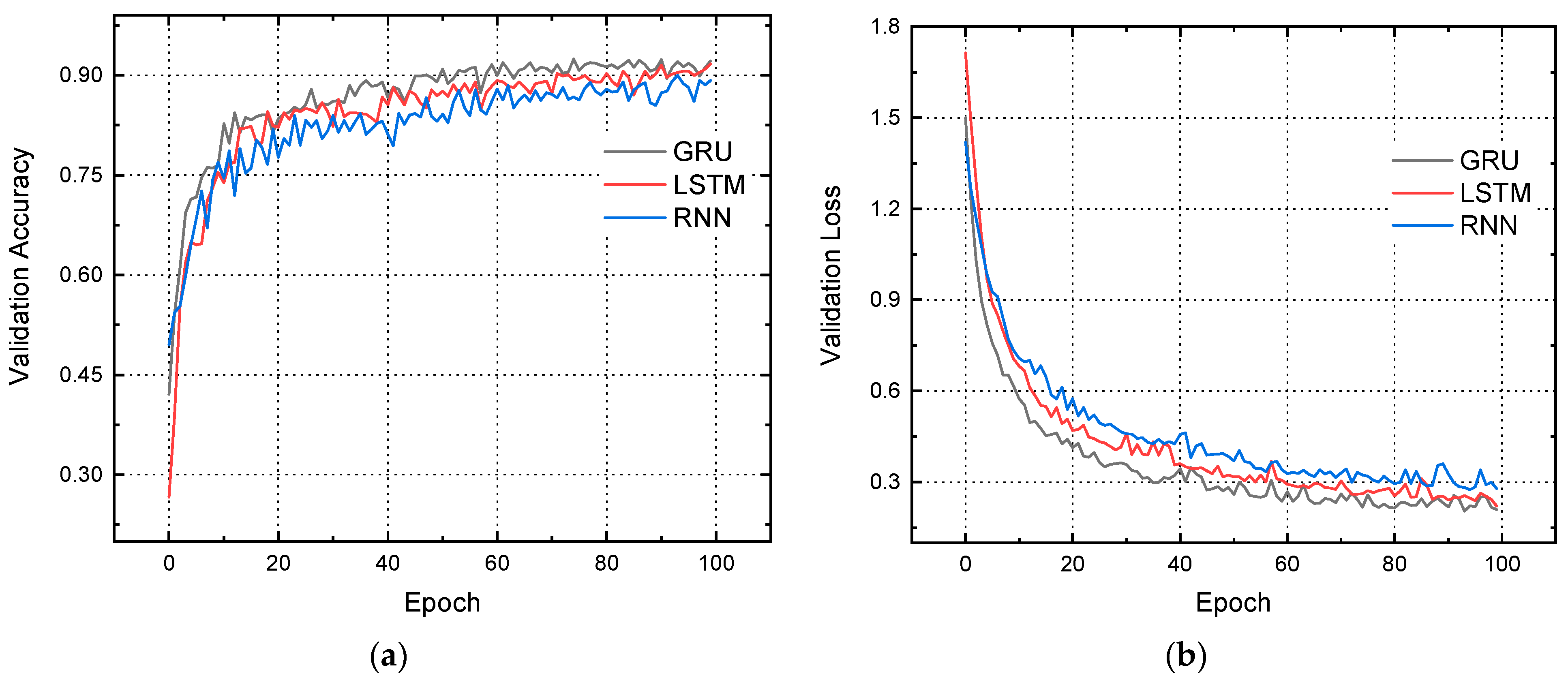
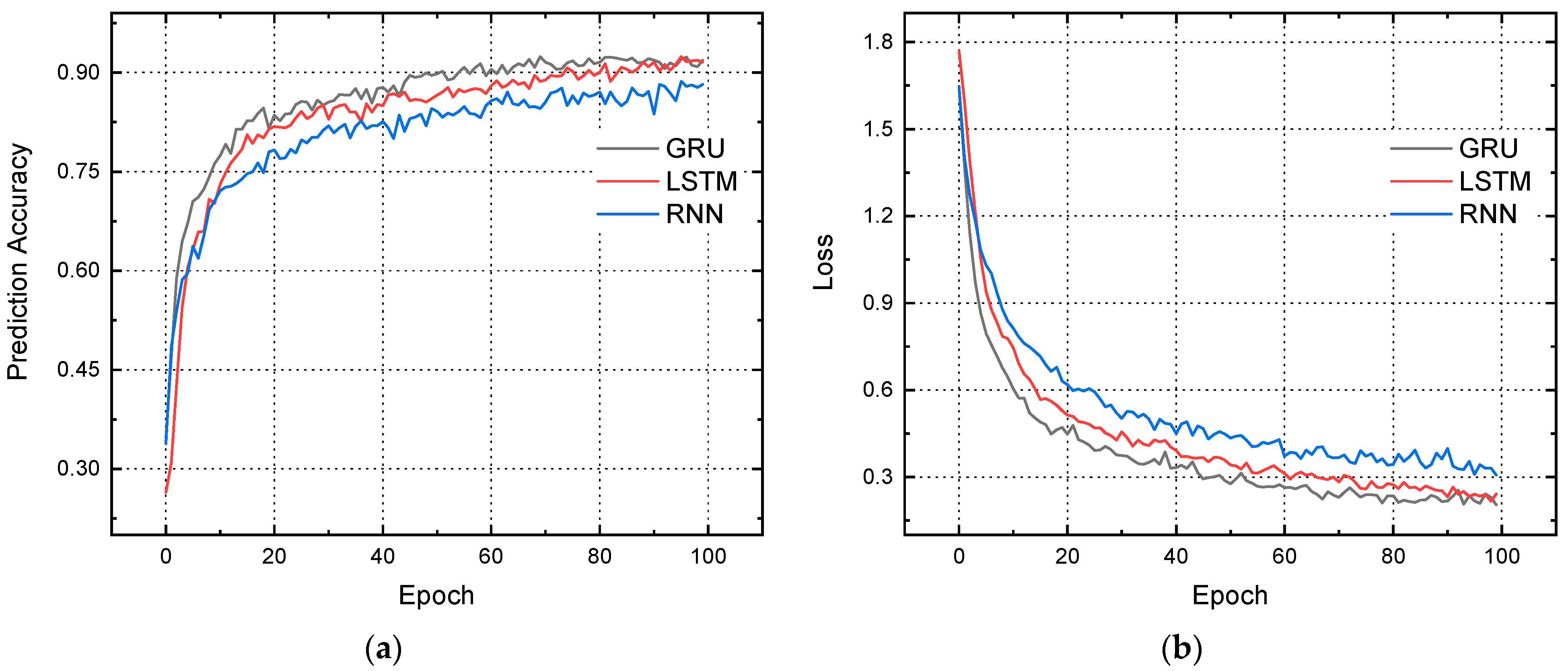
4. Results and Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- US DOE. Enabling modernization of the electric power system. In Quadrennial Technology Review; US DOE: Washington, DC, USA, 2015; Volume 22. [Google Scholar]
- Abubakar, M.; Che, Y.; Ivascu, L.; Almasoudi, F.M.; Jamil, I. Performance Analysis of Energy Production of Large-Scale Solar Plants Based on Artificial Intelligence (Machine Learning) Technique. Processes 2022, 10, 1843. [Google Scholar] [CrossRef]
- Sarfraz, M.; Naseem, S.; Mohsin, M.; Bhutta, M.S.; Jaffri, Z.U.A.; Chen, C.; Zhang, Z.; Wei, L.; Qiu, Y.; Xu, W.; et al. Recent analytical tools to mitigate carbon-based pollution: New insights by using wavelet coherence for a sustainable environment. Environ. Res. 2022, 212, 113074. [Google Scholar] [CrossRef]
- Sarfraz, M.; Iqbal, K.; Wang, Y.; Bhutta, M.S.; Jaffri, Z.U.A. Role of agricultural resource sector in environmental emissions and its explicit relationship with sustainable development: Evidence from agri-food system in China. Resour. Policy 2023, 80, 103191. [Google Scholar] [CrossRef]
- Bhutta, M.S.; Sarfraz, M.; Ivascu, L.; Li, H.; Rasool, G.; Jaffri, Z.U.A.; Farooq, U.; Shaikh, J.A.; Nazir, M.S. Voltage Stability Index Using New Single-Port Equivalent Based on Component Peculiarity and Sensitivity Persistence. Processes 2021, 9, 1849. [Google Scholar] [CrossRef]
- Chen, W.; Liu, B.; Nazir, M.S.; Abdalla, A.N.; Mohamed, M.A.; Ding, Z.; Bhutta, M.S.; Gul, M. An Energy Storage Assessment: Using Frequency Modulation Approach to Capture Optimal Coordination. Sustainability 2022, 14, 8510. [Google Scholar] [CrossRef]
- Nazir, M.S.; Abdalla, A.N.; Zhao, H.; Chu, Z.; Nazir, H.M.J.; Bhutta, M.S.; Javed, M.S.; Sanjeevikumar, P. Optimized economic operation of energy storage integration using improved gravitational search algorithm and dual stage optimization. J. Energy Storage 2022, 50, 104591. [Google Scholar] [CrossRef]
- Mnyanghwalo, D.; Kawambwa, S.; Mwifunyi, R.; Gilbert, G.M.; Makota, D.; Mvungi, N. Fault Detection and Monitoring in Secondary Electric Distribution Network Based on Distributed Processing. In Proceedings of the 2018 Twentieth International Middle East Power Systems Conference (MEPCON), Cairo, Egypt, 18–20 December 2018; pp. 84–89. [Google Scholar] [CrossRef]
- Jamil, M.; Sharma, S.K.; Singh, R. Fault detection and classification in electrical power transmission system using artificial neural network. SpringerPlus 2015, 4, 334. [Google Scholar] [CrossRef] [Green Version]
- Kaur, K.; Kaur, R. Energy management system using PLC and SCADA. Int. J. Eng. Res. Technol. 2014, 3, 528–531. [Google Scholar]
- Gou, B.; Kavasseri, R.G. Unified PMU Placement for Observability and Bad Data Detection in State Estimation. IEEE Trans. Power Syst. 2014, 29, 2573–2580. [Google Scholar] [CrossRef]
- Shahriar, M.S.; Habiballah, I.O.; Hussein, H. Optimization of Phasor Measurement Unit (PMU) Placement in Supervisory Control and Data Acquisition (SCADA)-Based Power System for Better State-Estimation Performance. Energies 2018, 11, 570. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Mohammadrezaei, M.; Hunt, J.; Zakeri, B. Internet of Things (IoT) and the Energy Sector. Energies 2020, 13, 494. [Google Scholar] [CrossRef] [Green Version]
- Wani, S.A.; Rana, A.S.; Sohail, S.; Rahman, O.; Parveen, S.; Khan, S.A. Advances in DGA based condition monitoring of transformers: A review. Renew. Sustain. Energy Rev. 2021, 149, 111347. [Google Scholar] [CrossRef]
- Duan, H.; Liu, D. Application of improved Elman neural network based on fuzzy input for fault diagnosis in oil-filled power transformers. In Proceedings of the 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011; pp. 28–31. [Google Scholar]
- Wang, F.; Bi, J.; Zhang, B.; Yuan, S. Research of Transformer Intelligent Evaluation and Diagnosis Method Based on DGA. MATEC Web Conf. 2016, 77, 01002. [Google Scholar] [CrossRef] [Green Version]
- Qi, B.; Wang, Y.; Zhang, P.; Li, C.; Wang, H. A Novel Deep Recurrent Belief Network Model for Trend Prediction of Transformer DGA Data. IEEE Access 2019, 7, 80069–80078. [Google Scholar] [CrossRef]
- Yan, C.; Li, M.; Liu, W. Transformer Fault Diagnosis Based on BP-Adaboost and PNN Series Connection. Math. Probl. Eng. 2019, 2019, 1019845. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Chen, W.; Li, A.; Yang, C.; Xie, Z.; Dong, H. BA-PNN-based methods for power transformer fault diagnosis. Adv. Eng. Inform. 2019, 39, 178–185. [Google Scholar] [CrossRef]
- Yang, X.; Chen, W.; Li, A.; Yang, C. A Hybrid machine-learning method for oil-immersed power transformer fault diagnosis. IEEJ Trans. Electr. Electron. Eng. 2019, 15, 501–507. [Google Scholar] [CrossRef]
- Luo, Z.; Zhang, Z.; Yan, X.; Qin, J.; Zhu, Z.; Wang, H.; Gao, Z. Dissolved Gas Analysis of Insulating Oil in Electric Power Transformers: A Case Study Using SDAE-LSTM. Math. Probl. Eng. 2020, 2020, 2420456. [Google Scholar] [CrossRef]
- Velásquez, R.M.A.; Lara, J.V.M. Root cause analysis improved with machine learning for failure analysis in power transformers. Eng. Fail. Anal. 2020, 115, 104684. [Google Scholar] [CrossRef]
- Mi, X.; Subramani, G.; Chan, M. The Application of RBF Neural Network Optimized by K-means and Genetic-backpropagation in Fault Diagnosis of Power Transformer. E3S Web Conf. 2021, 242, 03002. [Google Scholar] [CrossRef]
- Taha, I.B.M.; Ibrahim, S.; Mansour, D.-E.A. Power Transformer Fault Diagnosis Based on DGA Using a Convolutional Neural Network with Noise in Measurements. IEEE Access 2021, 9, 111162–111170. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Tao, L.; Yang, L. Transformer Fault Diagnosis Model Based on Improved Gray Wolf Optimizer and Probabilistic Neural Network. Energies 2021, 14, 3029. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L. A Combined Fault Diagnosis Method for Power Transformer in Big Data Environment. Math. Probl. Eng. 2017, 2017, 9670290. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Zheng, H.; Liu, J.; Zhao, J.; Zhang, Y.; Wang, K. A Transformer Fault Diagnosis Model Using an Optimal Hybrid Dissolved Gas Analysis Features Subset with Improved Social Group Optimization-Support Vector Machine Classifier. Energies 2018, 11, 1922. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, Y.; Liu, J.; Zheng, H.; Wang, K. A Novel Fault Diagnosis System on Polymer Insulation of Power Transformers Based on 3-stage GA–SA–SVM OFC Selection and ABC–SVM Classifier. Polymers 2018, 10, 1096. [Google Scholar] [CrossRef] [Green Version]
- Illias, H.A.; Liang, W.Z. Identification of transformer fault based on dissolved gas analysis using hybrid support vector machine-modified evolutionary particle swarm optimisation. PLoS ONE 2018, 13, e0191366. [Google Scholar] [CrossRef] [Green Version]
- Kari, T.; Gao, W.; Zhao, D.; Abiderexiti, K.; Mo, W.; Wang, Y.; Luan, L. Hybrid feature selection approach for power transformer fault diagnosis based on support vector machine and genetic algorithm. IET Gener. Transm. Distrib. 2018, 12, 5672–5680. [Google Scholar] [CrossRef]
- Kim, Y.; Park, T.; Kim, S.; Kwak, N.; Kweon, D. Artificial Intelligent Fault Diagnostic Method for Power Transformers using a New Classification System of Faults. J. Electr. Eng. Technol. 2019, 14, 825–831. [Google Scholar] [CrossRef]
- Zeng, B.; Guo, J.; Zhu, W.; Xiao, Z.; Yuan, F.; Huang, S. A Transformer Fault Diagnosis Model Based on Hybrid Grey Wolf Optimizer and LS-SVM. Energies 2019, 12, 4170. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, X.; Zheng, H.; Yao, H.; Liu, J.; Zhang, C.; Peng, H.; Jiao, J. A Fault Diagnosis Model of Power Transformers Based on Dissolved Gas Analysis Features Selection and Improved Krill Herd Algorithm Optimized Support Vector Machine. IEEE Access 2019, 7, 102803–102811. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Fan, X.; Zhang, W.; Zhuo, R.; Hao, J.; Shi, Z. An Integrated Model for Transformer Fault Diagnosis to Improve Sample Classification near Decision Boundary of Support Vector Machine. Energies 2020, 13, 6678. [Google Scholar] [CrossRef]
- Benmahamed, Y.; Kherif, O.; Teguar, M.; Boubakeur, A.; Ghoneim, S. Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier. Energies 2021, 14, 2970. [Google Scholar] [CrossRef]
- Islam, M.; Lee, G.; Hettiwatte, S.N. A nearest neighbour clustering approach for incipient fault diagnosis of power transformers. Electr. Eng. 2017, 99, 1109–1119. [Google Scholar] [CrossRef]
- Li, E.; Wang, L.; Song, B.; Jian, S. Improved Fuzzy C-Means Clustering for Transformer Fault Diagnosis Using Dissolved Gas Analysis Data. Energies 2018, 11, 2344. [Google Scholar] [CrossRef] [Green Version]
- Misbahulmunir, S.; Ramachandaramurthy, V.K.; Thayoob, Y.H.M. Improved Self-Organizing Map Clustering of Power Transformer Dissolved Gas Analysis Using Inputs Pre-Processing. IEEE Access 2020, 8, 71798–71811. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Sharshir, S.W.; Elaziz, M.A.; Kabeel, A.; Guilan, W.; Haiou, Z. Modeling of solar energy systems using artificial neural network: A comprehensive review. Sol. Energy 2019, 180, 622–639. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Saba, A.I.; Panchal, H.; Shanmugan, S.; Alsaleh, N.A.; Ahmadein, M. Artificial Intelligence for Forecasting the Prevalence of COVID-19 Pandemic: An Overview. Healthcare 2021, 9, 1614. [Google Scholar] [CrossRef]
- Elsheikh, A. Bistable Morphing Composites for Energy-Harvesting Applications. Polymers 2022, 14, 1893. [Google Scholar] [CrossRef]
- Moustafa, E.B.; Elsheikh, A. Predicting Characteristics of Dissimilar Laser Welded Polymeric Joints Using a Multi-Layer Perceptrons Model Coupled with Archimedes Optimizer. Polymers 2023, 15, 233. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Elaziz, M.A.; Vendan, A. Modeling ultrasonic welding of polymers using an optimized artificial intelligence model using a gradient-based optimizer. Weld. World 2021, 66, 27–44. [Google Scholar] [CrossRef]
- AbuShanab, W.S.; Elaziz, M.A.; Ghandourah, E.I.; Moustafa, E.B.; Elsheikh, A.H. A new fine-tuned random vector functional link model using Hunger games search optimizer for modeling friction stir welding process of polymeric materials. J. Mater. Res. Technol. 2021, 14, 1482–1493. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Elaziz, M.A.; Das, S.R.; Muthuramalingam, T.; Lu, S. A new optimized predictive model based on political optimizer for eco-friendly MQL-turning of AISI 4340 alloy with nano-lubricants. J. Manuf. Process. 2021, 67, 562–578. [Google Scholar] [CrossRef]
- Moustafa, E.B.; Hammad, A.H.; Elsheikh, A.H. A new optimized artificial neural network model to predict thermal efficiency and water yield of tubular solar still. Case Stud. Therm. Eng. 2021, 30, 101750. [Google Scholar] [CrossRef]
- Khoshaim, A.B.; Moustafa, E.B.; Bafakeeh, O.T.; Elsheikh, A.H. An Optimized Multilayer Perceptrons Model Using Grey Wolf Optimizer to Predict Mechanical and Microstructural Properties of Friction Stir Processed Aluminum Alloy Reinforced by Nanoparticles. Coatings 2021, 11, 1476. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Katekar, V.P.; Muskens, O.L.; Deshmukh, S.S.; Elaziz, M.A.; Dabour, S.M. Utilization of LSTM neural network for water production forecasting of a stepped solar still with a corrugated absorber plate. Process Saf. Environ. Prot. 2020, 148, 273–282. [Google Scholar] [CrossRef]
- DiPietro, R.; Hager, G.D. Chapter 21—Deep learning: RNNs and LSTM. In Handbook of Medical Image Computing and Computer Assisted Intervention; Zhou, S.K., Rueckert, D., Fichtinger, G., Eds.; The Elsevier and MICCAI Society Book Series; Academic Press: Cambridge, MA, USA, 2020; pp. 503–519. ISBN 9780128161760. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Outage Reason |
|---|---|
| 1 | Breakdown-Failure |
| 2 | Contact with conductors (birds/animals) |
| 3 | End connection combustion (to-ring/ crank unit) |
| 4 | Shaft / tensioner / bracket damaged by an external factor |
| 5 | Power cut due to (sandstorm/wind) |
| 6 | Straightening/T-joint failure |
| 7 | Cable failure caused by an external factor |
| 8 | Power cut due to (rain/thunderstorm) |
| 9 | Force majeure (disasters, floods, earthquakes) |
| 10 | Separation due to transmission protection |
| 11 | Disconnection of the feeder due to a fault in the subscriber’s network |
| 12 | broken insulation |
| 13 | Emergency separation |
| 14 | Cable failure due to (longevity/insulation defect) |
| 15 | power restored to the feeder with a fault that has not been isolated |
| 16 | Blowout / air breaker switch (LBS) failure |
| 17 | Throw wires and metal pieces at the connectors |
| 18 | contact with conductors (trees) |
| 19 | Wrong operation of the protection devices |
| 20 | antenna transducer failure |
| 21 | Failure of the cable connection with the antenna connector |
| 22 | Detachable / burning jumper |
| 23 | A pillar fell due to the wind |
| 24 | Feeder breaker end combustion |
| 25 | Separation of the feeder at the request of the Civil Defense Department |
| 26 | Disconnection of the circuit breaker for the senior subscribers’ switching unit due to a fault in the subscriber’s network |
| 27 | Distribution substation transformer failure (compact / unit / building) |
| 28 | Damage to the splicing unit (annular/expandable) by an external factor |
| 29 | Transformer end connection combustion |
| 30 | Internal failure of the toroidal wrench |
| 31 | Earth transformer failure without toroidal unit |
| 32 | Ground transformer combustion without toroidal unit |
| 33 | Part/or the entire main distribution station is out of service |
| 34 | Distribution substation transformer combustion (compact/unit/building) |
| 35 | Failure of the lightning rod |
| 36 | Failure due to feeder overload |
| 37 | Internal combustion of the VIP subscribers switch unit |
| 38 | Emergency break for overhead jumper repair |
| 39 | Cut / rupture of the antenna connector |
| 40 | Emergency disconnection at the request of the civil defense / government agency |
| 41 | Failure due to transmission network |
| 42 | Emergency disconnection for operational operations (transfer or reload/ failure isolation/ change (N.O) |
| 43 | Key failure caused by an animal |
| 44 | one of the phases touches another phase |
| 45 | Emergency disconnection at the request of the subscriber |
| 46 | Emergency disconnection at the request of other activities (transmission – power plant) |
| 47 | Transformer damage by external factor |
| 48 | Failure of the GIS circuit breaker end connection |
| 49 | Failure of the protection system |
| 50 | A main distribution station breaker failure due to a fault in the trip setting values |
| No. | Action Taken |
|---|---|
| 1 | Turned on and back to normal |
| 2 | Isolated and restarted from alternate source |
| 3 | Isolated and gradual restart |
| 4 | Isolated and restarted |
| 5 | Replaced and restarted |
| 6 | Restarted after passing the overhead line |
| 7 | Eliminated and restarted |
| 8 | Isolated and waiting for the subscriber to fix the fault |
| 9 | The subscriber has been isolated and restarted |
| 10 | Repaired and restarted |
| 11 | The isolation point has been changed and restarted |
| 12 | After checking, the switch was turned off and restarted |
| 13 | After approval from the transmission network, it was restarted |
| 14 | Restarted after the subscriber fixed the failure |
| 15 | Loads reduced and restarted |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| gru (GRU) | (None, None, 256) | 199,680 |
| dropout (Dropout) | (None, None, 256) | 0 |
| gru_1 (GRU) | (None, None, 128) | 148,224 |
| dropout_1 (Dropout) | (None, None, 128) | 0 |
| gru_2 (GRU) | (None, None, 64) | 37,248 |
| dropout_2 (Dropout) | (None, None, 64) | 0 |
| gru_3 (GRU) | (None, 32) | 9408 |
| dropout_3 (Dropout) | (None, 32) | 0 |
| dense (Dense) | (None, 6) | 198 |
| activation (Activation) | (None, 6) | 0 |
| Total params | 394,758 | |
| Trainable params | 394,758 | |
| Non-trainable params | 0 | |
| Performance of GRU | ||
| Loss: 0.21, Accuracy: 92.13% |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| lstm (LSTM) | (None, None, 256) | 265,216 |
| dropout (Dropout) | (None, None, 256) | 0 |
| lstm_1 (LSTM) | (None, None, 128) | 197,120 |
| dropout_1 (Dropout) | (None, None, 128) | 0 |
| lstm_2 (LSTM) | (None, None, 64) | 49,408 |
| dropout_2 (Dropout) | (None, None, 64) | 0 |
| lstm_3 (LSTM) | (None, 32) | 12,416 |
| dropout_3 (Dropout) | (None, 32) | 0 |
| dense (Dense) | (None, 6) | 198 |
| activation (Activation) | (None, 6) | 0 |
| Total params | 524,358 | |
| Trainable params | 524,358 | |
| Non-trainable params | 0 | |
| Performance of LSTM | ||
| Loss: 0.22, Accuracy:91.69% |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| simple_rnn (SimpleRNN) | (None, None, 256) | 66304 |
| dropout (Dropout) | (None, None, 256) | 0 |
| simple_rnn_1 (SimpleRNN) | (None, None, 128) | 49280 |
| dropout_1 (Dropout) | (None, None, 128) | 0 |
| simple_rnn_2 (SimpleRNN) | (None, None, 64) | 12352 |
| dropout_2 (Dropout) | (None, None, 64) | 0 |
| simple_rnn_3 (SimpleRNN) | (None, 32) | 3104 |
| dropout_3 (Dropout) | (None, 32) | 0 |
| dense (Dense) | (None, 6) | 198 |
| activation (Activation) | (None, 6) | 0 |
| Total params | 131,238 | |
| Trainable params | 131,238 | |
| Non-trainable params | 0 | |
| Performance of Simple RNN | ||
| Loss: 0.28, Accuracy: 89.21% |
| Model of Neural Network Prediction | Losses | Accuracy (%) | MAE Loss | RMSE Loss |
|---|---|---|---|---|
| Recurrent Neural Network (RNN) | 0.28 | 89.21 | 0.45 | 0.47 |
| Long-Short Term Memory (LSTM) | 0.22 | 91.69 | 0.42 | 0.40 |
| Gated Recurrent Unit (GRU) | 0.21 | 92.13 | 0.37 | 0.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almasoudi, F.M. Grid Distribution Fault Occurrence and Remedial Measures Prediction/Forecasting through Different Deep Learning Neural Networks by Using Real Time Data from Tabuk City Power Grid. Energies 2023, 16, 1026. https://doi.org/10.3390/en16031026
Almasoudi FM. Grid Distribution Fault Occurrence and Remedial Measures Prediction/Forecasting through Different Deep Learning Neural Networks by Using Real Time Data from Tabuk City Power Grid. Energies. 2023; 16(3):1026. https://doi.org/10.3390/en16031026
Chicago/Turabian StyleAlmasoudi, Fahad M. 2023. "Grid Distribution Fault Occurrence and Remedial Measures Prediction/Forecasting through Different Deep Learning Neural Networks by Using Real Time Data from Tabuk City Power Grid" Energies 16, no. 3: 1026. https://doi.org/10.3390/en16031026