
A Review of Reinforcement Learning-Based Powertrain Controllers: Effects of Agent Selection for Mixed-Continuity Control and Reward Formulation

Abstract
:1. Introduction
- Are highly complex nonlinear systems. This makes representative powertrain models difficult to derive and computationally heavy.
- Contain a mixture of continuous and discrete actuators. Simultaneous operation in both continuity domains is difficult for many techniques.
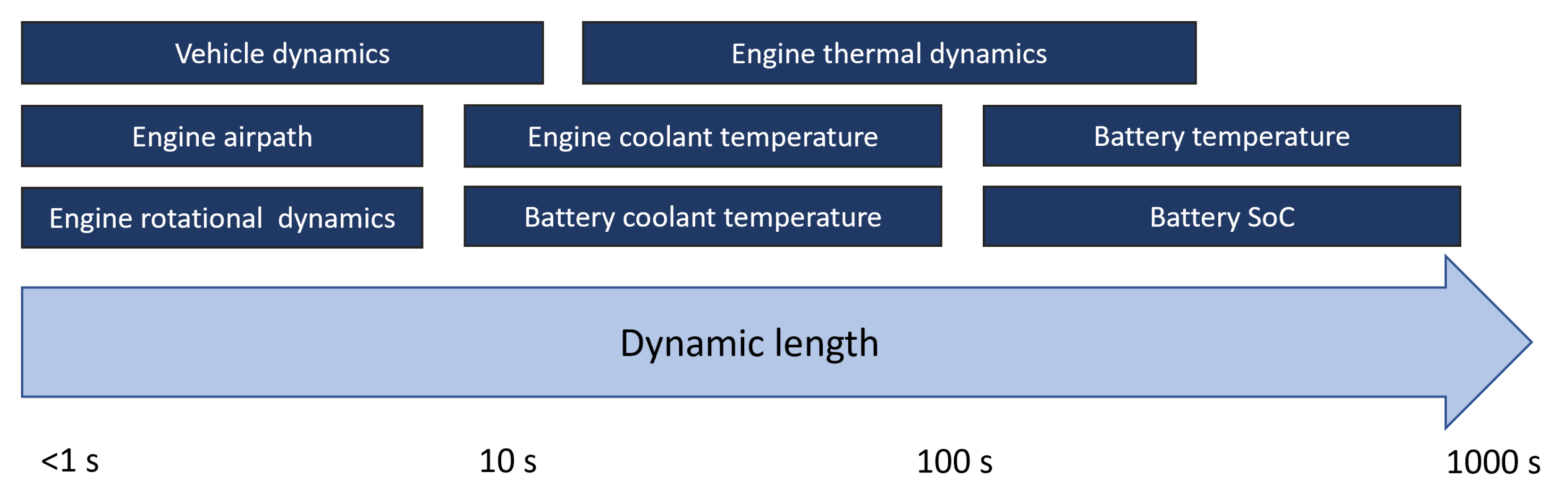
- Have dynamics with timescales orders of magnitudes apart. Controlling a system with mixed timescales requires a small time step and long optimization horizon.
- Performance goals often conflict with regulatory requirements. Defining the control problem mathematically can be difficult.
2. Reinforcement Learning Algorithm Selection
2.1. Control of Continuous Actuator(s) with Discrete Action Output(s)
2.2. Control of Continuous Actuator(s) with Continuous Action Output(s)
2.3. Combined Control of Continuous and Discrete Actuators
2.4. Comparisons between Reinforcement Learning Algorithms
3. Reinforcement Learning Reward Formulation
3.1. Single Objective Optimization Studies
3.1.1. Minimize Fuel Consumption
3.1.2. Minimize Power Consumption
3.1.3. Minimize Losses/Maximize Extracted Power
3.1.4. Minimize Cost to Operate Vehicle
3.1.5. Minimize Tracking Error
3.2. Multi-Objective Optimization Studies
3.3. Comparisons between Reward Functions
4. Conclusions and Future Research Directions
4.1. RL Algorithm Selection and Action Continuity
4.2. Reward Function Formulation Studies
4.3. Future Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| RL | reinforcement learning |
| ICE | internal combustion engine |
| BEV | battery electric vehicle |
| FCV | fuel cell vehicle |
| HEV | hybrid electric vehicle |
| DoE | design of experiments |
| NN | neural network |
| MPC | model predictive control |
| ECMS | equivalent consumption minimization strategy |
| DP | dynamic programming |
| EMS | energy management strategy |
| SoC | state of charge |
| PHEV | plug-in hybrid electric vehicle |
| TC | terminal condition |
| UC | ultracapacitor |
| ORC | organic Rankine cycle |
| WHR | waste-heat recovery |
| PID | proportional-integral-derivative |
| EV | electric vehicle |
| FC | fuel cell |
| HyAR | hybrid action representation |
| PMP | Pontryagin’s maximum principle |
| EM | electric machine |
| DC | direct current |
| DDPG | deep deterministic policy gradient |
| PILCO | probabilistic inference for learning control |
| REINFORCE | reward increment = non-negative factor × offset reinforcement × characteristic eligibility |
| PPO | proximal policy optimization |
| MPO | maximum a posteriori policy optimization |
| EA | evolutionary algorithm |
| CEM | cross entropy method |
| TRPO | trust region policy optimization |
| DQN | deep Q-network |
| CPO | constrained policy optimization |
| TD3 | twin delayed deep deterministic policy gradient |
| SARSA | state, action, reward, [next] state, [next] action |
| A3C | Asynchronous advantage actor-critc |
| The following symbols are used in this manuscript: | |
| k | an iterable |
| V | value, or cost-to-go, or a state |
| u | control input, a.k.a. action |
| x | system state |
| r | reward, given from a cost/reward function |
| s | system state |
| probability | |
| discount factor | |
| N | number of steps |
| Q | value, or cost-to-go, of a state-action pair |
| change in value between the previous and current time step | |
| P | power |
| torque | |
| n | selection of a discrete actuator |
| rotational velocity | |
| i | current |
| m | mass |
| position of a continuous actuator | |
| v | velocity |
| terminal condition | |
| difference between the present value of a signal and a user-defined reference value | |
| Power loss | |
| w | weighting coefficient |
| c | constant |
| efficiency | |
| E | energy |
| Q | heat generation |
| T | temperature |
| f | function |
| t | time |
| The following superscripts and subscripts are used in this manuscript: | |
| * | optimal |
| 0 | initial |
| battery | |
| consumption of the electric system in fuel equivalent units | |
| − | min(0, value) |
| + | max(0, value) |
References
- Atkinson, C. Fuel Efficiency Optimization Using Rapid Transient Engine Calibration; SAE Technical Paper No. 2014-01-2359; SAE International: Warrendale, PA, USA, 2014; p. 1. [Google Scholar]
- Kianifar, M.R.; Campean, L.F.; Richardson, D. Sequential DoE framework for steady state model based calibration. SAE Int. J. Engines 2013, 6, 843–855. [Google Scholar] [CrossRef]
- Gurel, C.; Ozmen, E.; Yilmaz, M.; Aydin, D.; Koprubasi, K. Multi-objective optimization of transient air-fuel ratio limitation of a diesel engine using DoE based Pareto-optimal approach. SAE Int. J. Commer. Veh. 2017, 10, 299–308. [Google Scholar] [CrossRef]
- Powell, W.B. Approximate Dynamic Programming: Solving the Curses of Dimensionality; John Wiley & Sons: Hoboken, NJ, USA, 2007; Volume 703. [Google Scholar]
- Onori, S.; Serrao, L.; Rizzoni, G. Dynamic Programming; Springer: Berlin/Heidelberg, Germany, 2016; pp. 41–49. [Google Scholar]
- FEV. TOPEXPERT Suite. Model-Based Calibration. Available online: https://www.fev-sts.com/fileadmin/user_upload/TOPEXPERT-Kleine_Aufl%C3%B6sung_Doppelseiten.pdf (accessed on 15 February 2023).
- AVL CAMEO 4™. Available online: https://www.avl.com/documents/10138/2699442/AVL+CAMEO+4%E2%84%A2+Solution+Brochure (accessed on 15 February 2023).
- Wu, B.; Filipi, Z.; Assanis, D.; Kramer, D.M.; Ohl, G.L.; Prucka, M.J.; DiValentin, E. Using artificial neural networks for representing the air flow rate through a 2.4 liter VVT engine. SAE Trans. 2004, 113, 1676–1686. [Google Scholar]
- Nüesch, T.; Wang, M.; Isenegger, P.; Onder, C.H.; Steiner, R.; Macri-Lassus, P.; Guzzella, L. Optimal energy management for a diesel hybrid electric vehicle considering transient PM and quasi-static NOx emissions. Control Eng. Pract. 2014, 29, 266–276. [Google Scholar] [CrossRef]
- Bertsekas, D. 6.231 Dynamic Programming Fall 2015 Lecture 8: Suboptimal Control, Cost Approximation Methods: Classification, Certainty Equivalent Control, Limited Lookahead Policies, Performance Bounds, Problem Approximation Approach, Parametric Cost-To-Go Approximation. Available online: https://ocw.mit.edu/courses/6-231-dynamic-programming-and-stochastic-control-fall-2015/resources/mit6_231f15_lec8/ (accessed on 15 February 2023).
- Bemporad, A.; Bernardini, D.; Long, R.; Verdejo, J. Model Predictive Control of Turbocharged Gasoline Engines for Mass Production; SAE International: Warrendale, PA, USA, 2018. [Google Scholar] [CrossRef]
- Norouzi, A.; Shahpouri, S.; Gordon, D.; Winkler, A.; Nuss, E.; Abel, D.; Andert, J.; Shahbakhti, M.; Koch, C.R. Deep Learning based Model Predictive Control for Compression Ignition Engines. Control. Eng. Pract. 2022, 127, 105299. [Google Scholar] [CrossRef]
- Koli, R.V. Model Predictive Control of Modern High-Degree-of-Freedom Turbocharged Spark Ignited Engines with External Cooled Egr. Ph.D. Thesis, Clemson University, Clemson, SC, USA, 2018. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Powell, W. What you should know about approximate dynamic programming. Nav. Res. Logist. (NRL) 2009, 56, 239–249. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, J.; Pi, D.; Lin, X.; Grzesiak, L.M.; Hu, X. Battery Health-Aware and Deep Reinforcement Learning-Based Energy Management for Naturalistic Data-Driven Driving Scenarios. IEEE Trans. Transp. Electrif. 2022, 8, 948–964. [Google Scholar] [CrossRef]
- Ye, Y.; Xu, B.; Zhang, J.; Lawler, B.; Ayalew, B. Reinforcement Learning-Based Energy Management System Enhancement Using Digital Twin for Electric Vehicles. In Proceedings of the 2022 IEEE Vehicle Power and Propulsion Conference (VPPC), Merced, CA, USA, 1–4 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, X.; Bogdan, P.; Chang, N.; Pedram, M. Machine learning-based energy management in a hybrid electric vehicle to minimize total operating cost. In Proceedings of the 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 627–634. [Google Scholar] [CrossRef]
- Ganesh, A.H.; Xu, B. A review of reinforcement learning based energy management systems for electrified powertrains: Progress, challenge, and potential solution. Renew. Sustain. Energy Rev. 2022, 154, 111833. [Google Scholar] [CrossRef]
- Hu, X.; Liu, T.; Qi, X.; Barth, M. Reinforcement Learning for Hybrid and Plug-In Hybrid Electric Vehicle Energy Management: Recent Advances and Prospects. IEEE Ind. Electron. Mag. 2019, 13, 16–25. [Google Scholar] [CrossRef] [Green Version]
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef] [Green Version]
- Moos, J.; Hansel, K.; Abdulsamad, H.; Stark, S.; Clever, D.; Peters, J. Robust Reinforcement Learning: A Review of Foundations and Recent Advances. Mach. Learn. Knowl. Extr. 2022, 4, 276–315. [Google Scholar] [CrossRef]
- ElDahshan, K.A.; Farouk, H.; Mofreh, E. Deep Reinforcement Learning based Video Games: A Review. In Proceedings of the 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 302–309. [Google Scholar] [CrossRef]
- Levine, S.; Kumar, A.; Tucker, G.; Fu, J. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv 2020, arXiv:2005.01643. [Google Scholar]
- Liu, W.; Hua, M.; Deng, Z.G.; Huang, Y.; Hu, C.; Song, S.; Gao, L.; Liu, C.; Xiong, L.; Xia, X. A Systematic Survey of Control Techniques and Applications: From Autonomous Vehicles to Connected and Automated Vehicles. arXiv 2023, arXiv:2303.05665. [Google Scholar]
- Jazayeri, F.; Shahidinejad, A.; Ghobaei-Arani, M. Autonomous computation offloading and auto-scaling the in the mobile fog computing: A deep reinforcement learning-based approach. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 8265–8284. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Sumanth, U.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Enhanced Behavioral Cloning-Based Self-driving Car Using Transfer Learning. In Proceedings of the Data Management, Analytics and Innovation, Online, 14–16 January 2022; Sharma, N., Chakrabarti, A., Balas, V.E., Bruckstein, A.M., Eds.; Springer: Singapore, 2022; pp. 185–198. [Google Scholar]
- Lian, R.; Tan, H.; Peng, J.; Li, Q.; Wu, Y. Cross-Type Transfer for Deep Reinforcement Learning Based Hybrid Electric Vehicle Energy Management. IEEE Trans. Veh. Technol. 2020, 69, 8367–8380. [Google Scholar] [CrossRef]
- Hieu, N.Q.; Hoang, D.T.; Niyato, D.; Wang, P.; Kim, D.I.; Yuen, C. Transferable Deep Reinforcement Learning Framework for Autonomous Vehicles With Joint Radar-Data Communications. IEEE Trans. Commun. 2022, 70, 5164–5180. [Google Scholar] [CrossRef]
- Tang, X.; Chen, J.; Liu, T.; Qin, Y.; Cao, D. Distributed Deep Reinforcement Learning-Based Energy and Emission Management Strategy for Hybrid Electric Vehicles. IEEE Trans. Veh. Technol. 2021, 70, 9922–9934. [Google Scholar] [CrossRef]
- Qu, X.; Yu, Y.; Zhou, M.; Lin, C.T.; Wang, X. Jointly dampening traffic oscillations and improving energy consumption with electric, connected and automated vehicles: A reinforcement learning based approach. Appl. Energy 2020, 257, 114030. [Google Scholar] [CrossRef]
- Li, G.; Li, S.; Li, S.; Qin, Y.; Cao, D.; Qu, X.; Cheng, B. Deep reinforcement learning enabled decision-making for autonomous driving at intersections. Automot. Innov. 2020, 3, 374–385. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge: Cambridge, UK, 1994. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Abdolmaleki, A.; Springenberg, J.T.; Tassa, Y.; Munos, R.; Heess, N.; Riedmiller, M. Maximum a Posteriori Policy Optimisation. arXiv 2018, arXiv:1806.06920. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained Policy Optimization. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 22–31. [Google Scholar]
- Lin, X.; Wang, Y.; Bogdan, P.; Chang, N.; Pedram, M. Reinforcement learning based power management for hybrid electric vehicles. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 3–6 November 2014; pp. 33–38. [Google Scholar] [CrossRef]
- Sun, M.; Zhao, P.; Lin, X. Power management in hybrid electric vehicles using deep recurrent reinforcement learning. Electr. Eng. 2021, 104, 1459–1471. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, Y.; Chang, N.; Zhu, Q.; Lin, X. A deep reinforcement learning framework for optimizing fuel economy of hybrid electric vehicles. In Proceedings of the 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018; pp. 196–202. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, H.; Wu, Y.; Xiao, R.; Shen, J.; Liu, Y. Energy Management for a Power-Split Plug-In Hybrid Electric Vehicle Based on Reinforcement Learning. Appl. Sci. 2018, 8, 2494. [Google Scholar] [CrossRef] [Green Version]
- Liessner., R.; Schmitt., J.; Dietermann., A.; Bäker., B. Hyperparameter Optimization for Deep Reinforcement Learning in Vehicle Energy Management. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 19–21 February 2019; pp. 134–144. [Google Scholar] [CrossRef]
- Liessner, R.; Lorenz, A.; Schmitt, J.; Dietermann, A.M.; Baker, B. Simultaneous Electric Powertrain Hardware and Energy Management Optimization of a Hybrid Electric Vehicle Using Deep Reinforcement Learning and Bayesian Optimization. In Proceedings of the IEEE Vehicle Power and Propulsion Conference (VPPC), Hanoi, Vietnam, 14–17 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, B.; Rathod, D.; Zhang, D.; Yebi, A.; Zhang, X.; Li, X.; Filipi, Z. Parametric study on reinforcement learning optimized energy management strategy for a hybrid electric vehicle. Appl. Energy 2020, 259, 114200. [Google Scholar] [CrossRef]
- Xu, B.; Hou, J.; Shi, J.; Li, H.; Rathod, D.; Wang, Z.; Filipi, Z. Learning Time Reduction Using Warm-Start Methods for a Reinforcement Learning-Based Supervisory Control in Hybrid Electric Vehicle Applications. IEEE Trans. Transp. Electrif. 2021, 7, 626–635. [Google Scholar] [CrossRef]
- Xu, B.; Rathod, D.; Yebi, A.; Filipi, Z. Real-time realization of Dynamic Programming using machine learning methods for IC engine waste heat recovery system power optimization. Appl. Energy 2020, 262, 114514. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Liu, Y.; Gao, G.; Liang, S.; Ma, H. Reinforcement learning-based intelligent energy management architecture for hybrid construction machinery. Appl. Energy 2020, 275, 115401. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Hu, W.; Zou, Y. A Heuristic Planning Reinforcement Learning-Based Energy Management for Power-Split Plug-in Hybrid Electric Vehicles. IEEE Trans. Ind. Inf. 2019, 15, 6436–6445. [Google Scholar] [CrossRef]
- Fang, Y.; Song, C.; Xia, B.; Song, Q. An energy management strategy for hybrid electric bus based on reinforcement learning. In Proceedings of the Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4973–4977. [Google Scholar]
- Han, X.; He, H.; Wu, J.; Peng, J.; Li, Y. Energy management based on reinforcement learning with double deep Q-learning for a hybrid electric tracked vehicle. Appl. Energy 2019, 254, 113708. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Kong, Z.; Wu, J.; He, D. Intelligent energy management for hybrid electric tracked vehicles using online reinforcement learning. Appl. Energy 2019, 251, 113388. [Google Scholar] [CrossRef]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement learning of adaptive energy management with transition probability for a hybrid electric tracked vehicle. IEEE Trans. Ind. Electron. 2015, 62, 7837–7846. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, T.; Liu, D.; Sun, F. Reinforcement learning-based real-time energy management for a hybrid tracked vehicle. Appl. Energy 2016, 171, 372–382. [Google Scholar] [CrossRef]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement Learning–Based Energy Management Strategy for a Hybrid Electric Tracked Vehicle. Energies 2015, 8, 7243–7260. [Google Scholar] [CrossRef] [Green Version]
- Yang, N.; Han, L.; Xiang, C.; Liu, H.; Hou, X. Energy management for a hybrid electric vehicle based on blended reinforcement learning with backward focusing and prioritized sweeping. IEEE Trans. Veh. Technol. 2021, 70, 3136–3148. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Guo, L.; Guo, N. Heuristic Energy Management Strategy of Hybrid Electric Vehicle Based on Deep Reinforcement Learning with Accelerated Gradient Optimization. IEEE Trans. Transp. Electrif. 2021, 7, 2194–2208. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Guo, L.; Guo, N. Energy management for a hybrid electric vehicle based on prioritized deep reinforcement learning framework. Energy 2022, 241, 122523. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Khajepour, A.; Wang, H.; Peng, J. Energy management for a power-split hybrid electric bus via deep reinforcement learning with terrain information. Appl. Energy 2019, 255, 113762. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, H.; Wu, Y.; Peng, J. Hybrid electric vehicle energy management with computer vision and deep reinforcement learning. IEEE Trans. Ind. Informat. 2020, 17, 3857–3868. [Google Scholar] [CrossRef]
- Biswas, A.; Anselma, P.G.; Emadi, A. Real-time optimal energy management of electrified powertrains with reinforcement learning. In Proceedings of the IEEE Transportation Electrification Conference and Expo (ITEC), Detroit, MI, USA, 19–21 June 2019; pp. 1–6. [Google Scholar]
- Liu, T.; Hu, X. A Bi-Level Control for Energy Efficiency Improvement of a Hybrid Tracked Vehicle. IEEE Trans. Ind. Informat. 2018, 14, 1616–1625. [Google Scholar] [CrossRef] [Green Version]
- Biswas, A.; Wang, Y.; Emadi, A. Effect of immediate reward function on the performance of reinforcement learning-based energy management system. In Proceedings of the IEEE Transportation Electrification Conference & Expo (ITEC), Haining, China, 28–31 October 2022; pp. 1021–1026. [Google Scholar] [CrossRef]
- Liu, T.; Wang, B.; Yang, C. Online Markov Chain-based energy management for a hybrid tracked vehicle with speedy Q-learning. Energy 2018, 160, 544–555. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Li, S.E.; Cao, D. Reinforcement Learning Optimized Look-Ahead Energy Management of a Parallel Hybrid Electric Vehicle. IEEE/ASME Trans. Mechatron. 2017, 22, 1497–1507. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, H.; Wu, Y.; Zhang, Y.; Li, G.; Liu, Y. Stochastic model predictive control for energy management of power-split plug-in hybrid electric vehicles based on reinforcement learning. Energy 2020, 211, 118931. [Google Scholar] [CrossRef]
- Zhou, J.; Xue, S.; Xue, Y.; Liao, Y.; Liu, J.; Zhao, W. A novel energy management strategy of hybrid electric vehicle via an improved TD3 deep reinforcement learning. Energy 2021, 224, 120118. [Google Scholar] [CrossRef]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Yao, Z.; Olson, J.; Yoon, H.S. Sensitivity Analysis of Reinforcement Learning-Based Hybrid Electric Vehicle Powertrain Control. SAE Int. J. Commer. Veh. 2021, 14, 409–419. [Google Scholar] [CrossRef]
- Yao, Z.; Yoon, H.S. Hybrid Electric Vehicle Powertrain Control Based on Reinforcement Learning. SAE Int. J. Electrified Veh. 2021, 11, 165–176. [Google Scholar] [CrossRef]
- Xu, B.; Tang, X.; Hu, X.; Lin, X.; Li, H.; Rathod, D.; Wang, Z. Q-Learning-Based Supervisory Control Adaptability Investigation for Hybrid Electric Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6797–6806. [Google Scholar] [CrossRef]
- Xu, B.; Hu, X.; Tang, X.; Lin, X.; Li, H.; Rathod, D.; Filipi, Z. Ensemble Reinforcement Learning-Based Supervisory Control of Hybrid Electric Vehicle for Fuel Economy Improvement. IEEE Trans. Transp. Electrif. 2020, 6, 717–727. [Google Scholar] [CrossRef]
- Mittal, N.; Bhagat, A.P.; Bhide, S.; Acharya, B.; Xu, B.; Paredis, C. Optimization of Energy Management Strategy for Range-Extended Electric Vehicle Using Reinforcement Learning and Neural Network. SAE Tech. Pap. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Peng, J.; Wang, H. Deep reinforcement learning-based energy management for a series hybrid electric vehicle enabled by history cumulative trip information. IEEE Trans. Veh. Technol. 2019, 68, 7416–7430. [Google Scholar] [CrossRef]
- Tang, X.; Chen, J.; Pu, H.; Liu, T.; Khajepour, A. Double deep reinforcement learning-based energy management for a parallel hybrid electric vehicle with engine start-stop strategy. IEEE Trans. Transp. Electrif. 2021, 8, 1376–1388. [Google Scholar] [CrossRef]
- Lee, H.; Song, C.; Kim, N.; Cha, S.W. Comparative analysis of energy management strategies for HEV: Dynamic programming and reinforcement learning. IEEE Access 2020, 8, 67112–67123. [Google Scholar] [CrossRef]
- Lee, H.; Kang, C.; Park, Y.I.; Kim, N.; Cha, S.W. Online data-driven energy management of a hybrid electric vehicle using model-based Q-learning. IEEE Access 2020, 8, 84444–84454. [Google Scholar] [CrossRef]
- Jin, L.; Tian, D.; Zhang, Q.; Wang, J. Optimal Torque Distribution Control of Multi-Axle Electric Vehicles with In-wheel Motors Based on DDPG Algorithm. Energies 2020, 13, 1331. [Google Scholar] [CrossRef] [Green Version]
- Yue, S.; Wang, Y.; Xie, Q.; Zhu, D.; Pedram, M.; Chang, N. Model-free learning-based online management of hybrid electrical energy storage systems in electric vehicles. In Proceedings of the IECON 2014—40th Annual Conference of the IEEE Industrial Electronics Society, Dallas, TX, USA, 29 October–1 November 2014; pp. 3142–3148. [Google Scholar] [CrossRef]
- Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.J. A Novel Blended Real-Time Energy Management Strategy for Plug-in Hybrid Electric Vehicle Commute Trips. In Proceedings of the IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 1002–1007. [Google Scholar] [CrossRef]
- Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.J.; Gonder, J. Data-Driven Reinforcement Learning–Based Real-Time Energy Management System for Plug-In Hybrid Electric Vehicles. Transp. Res. Rec. 2016, 2572, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M.J. Deep reinforcement learning-based vehicle energy efficiency autonomous learning system. In Proceedings of the IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 1228–1233. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M. Deep reinforcement learning enabled self-learning control for energy efficient driving. Transp. Res. Part C Emerg. Technol. 2019, 99, 67–81. [Google Scholar] [CrossRef]
- Liessner, R.; Schroer, C.; Dietermann, A.; Bäker, B. Deep Reinforcement Learning for Advanced Energy Management of Hybrid Electric Vehicles. In Proceedings of the 10th International Conference on Agents and Artificial Intelligence, Funchal, Portugal, 16–18 January 2018; pp. 61–72. [Google Scholar] [CrossRef]
- Liessner, R.; Dietermann, A.M.; Baker, B. Safe Deep Reinforcement Learning Hybrid Electric Vehicle Energy Management; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 161–181. [Google Scholar]
- Wang, X.; Wang, R.; Shu, G.; Tian, H.; Zhang, X. Energy management strategy for hybrid electric vehicle integrated with waste heat recovery system based on deep reinforcement learning. Sci. China Technol. Sci. 2022, 65, 713–725. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, J.; Shuai, B.; Williams, H.; He, Y.; Li, Z.; Xu, H.; Yan, F. Multi-step reinforcement learning for model-free predictive energy management of an electrified off-highway vehicle. Appl. Energy 2019, 255, 113755. [Google Scholar] [CrossRef]
- Shuai, B.; Zhou, Q.; Li, J.; He, Y.; Li, Z.; Williams, H.; Xu, H.; Shuai, S. Heuristic action execution for energy efficient charge-sustaining control of connected hybrid vehicles with model-free double Q-learning. Appl. Energy 2020, 267, 114900. [Google Scholar] [CrossRef]
- Xiong, R.; Duan, Y.; Cao, J.; Yu, Q. Battery and ultracapacitor in-the-loop approach to validate a real-time power management method for an all-climate electric vehicle. Appl. Energy 2018, 217, 153–165. [Google Scholar] [CrossRef]
- Xiong, R.; Cao, J.; Yu, Q. Reinforcement learning-based real-time power management for hybrid energy storage system in the plug-in hybrid electric vehicle. Appl. Energy 2018, 211, 538–548. [Google Scholar] [CrossRef]
- Xu, B.; Li, X. A Q-learning based transient power optimization method for organic Rankine cycle waste heat recovery system in heavy duty diesel engine applications. Appl. Energy 2021, 286, 116532. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, H.; Peng, J.; Jiang, Z.; Wu, Y. Energy management of hybrid electric bus based on deep reinforcement learning in continuous state and action space. Energy Convers. Manag. 2019, 195, 548–560. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Peng, J.; Zhang, H. Power Management for a Plug-in Hybrid Electric Vehicle Based on Reinforcement Learning with Continuous State and Action Spaces. Energy Procedia 2017, 142, 2270–2275. [Google Scholar] [CrossRef]
- Zou, R.; Fan, L.; Dong, Y.; Zheng, S.; Hu, C. DQL energy management: An online-updated algorithm and its application in fix-line hybrid electric vehicle. Energy 2021, 225, 120174. [Google Scholar] [CrossRef]
- Li, H.; Wan, Z.; He, H. Constrained EV Charging Scheduling Based on Safe Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 2427–2439. [Google Scholar] [CrossRef]
- Wan, Z.; Li, H.; He, H.; Prokhorov, D. Model-Free Real-Time EV Charging Scheduling Based on Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 10, 5246–5257. [Google Scholar] [CrossRef]
- Wang, X.; Wang, R.; Jin, M.; Shu, G.; Tian, H.; Pan, J. Control of superheat of organic Rankine cycle under transient heat source based on deep reinforcement learning. Appl. Energy 2020, 278, 115637. [Google Scholar] [CrossRef]
- Hsu, R.C.; Liu, C.T.; Chan, D.Y. A reinforcement-learning-based assisted power management with QoR provisioning for human-electric hybrid bicycle. IEEE Trans. Ind. Electron. 2012, 59, 3350–3359. [Google Scholar] [CrossRef]
- Reddy, N.P.; Pasdeloup, D.; Zadeh, M.K.; Skjetne, R. An intelligent power and energy management system for fuel cell/battery hybrid electric vehicle using reinforcement learning. In Proceedings of the IEEE Transportation Electrification Conference and Expo (ITEC), Detroit, MI, USA, 19–21 June 2019; pp. 1–6. [Google Scholar]
- Liu, C.; Murphey, Y.L. Power management for Plug-in Hybrid Electric Vehicles using Reinforcement Learning with trip information. In Proceedings of the IEEE Transportation Electrification Conference and Expo (ITEC), Beijing, China, 31 August–3 September 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Yuan, J.; Yang, L.; Chen, Q. Intelligent energy management strategy based on hierarchical approximate global optimization for plug-in fuel cell hybrid electric vehicles. Int. J. Hydrogen Energy 2018, 43, 8063–8078. [Google Scholar] [CrossRef]
- Zhou, J.; Zhao, J.; Wang, L. An Energy Management Strategy of Power-Split Hybrid Electric Vehicles Using Reinforcement Learning. Mob. Inf. Syst. 2022, 2022, 9731828. [Google Scholar] [CrossRef]
- Hsu, R.C.; Chen, S.M.; Chen, W.Y.; Liu, C.T. A Reinforcement Learning Based Dynamic Power Management for Fuel Cell Hybrid Electric Vehicle. In Proceedings of the 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems and 2016 17th International Symposium on Advanced Intelligent Systems (SCIS-ISIS 2016), Sapporo, Japan, 25–28 August 2016; pp. 460–464. [Google Scholar] [CrossRef]
- Sun, H.; Fu, Z.; Tao, F.; Zhu, L.; Si, P. Data-driven reinforcement-learning-based hierarchical energy management strategy for fuel cell/battery/ultracapacitor hybrid electric vehicles. J. Power Sources 2020, 455, 227964. [Google Scholar] [CrossRef]
- Zhou, Y.F.; Huang, L.J.; Sun, X.X.; Li, L.H.; Lian, J. A Long-term Energy Management Strategy for Fuel Cell Electric Vehicles Using Reinforcement Learning. Fuel Cells 2020, 20, 753–761. [Google Scholar] [CrossRef]
- Lee, H.; Kim, N.; Cha, S.W. Model-Based Reinforcement Learning for Eco-Driving Control of Electric Vehicles. IEEE Access 2020, 8, 202886–202896. [Google Scholar] [CrossRef]
- Chiş, A.; Lundén, J.; Koivunen, V. Reinforcement learning-based plug-in electric vehicle charging with forecasted price. IEEE Trans. Veh. Technol. 2017, 66, 3674–3684. [Google Scholar] [CrossRef]
- Li, W.; Cui, H.; Nemeth, T.; Jansen, J.; Ünlübayir, C.; Wei, Z.; Zhang, L.; Wang, Z.; Ruan, J.; Dai, H.; et al. Deep reinforcement learning-based energy management of hybrid battery systems in electric vehicles. J. Energy Storage 2021, 36, 102355. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy management strategy for a hybrid electric vehicle based on deep reinforcement learning. Appl. Sci. 2018, 8, 187. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Lee, H.; Kim, K.; Cha, S.W. A Power Management Strategy for Parallel PHEV Using Deep Q-Networks. In Proceedings of the IEEE Vehicle Power and Propulsion Conference (VPPC), Chicago, IL, USA, 27–30 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, C.; Murphey, Y.L. Optimal power management based on Q-learning and neuro-dynamic programming for plug-in hybrid electric vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1942–1954. [Google Scholar] [CrossRef] [PubMed]
- Choi, W.; Kim, J.W.; Ahn, C.; Gim, J. Reinforcement Learning-based Controller for Thermal Management System of Electric Vehicles. In Proceedings of the 2022 IEEE Vehicle Power and Propulsion Conference (VPPC), Merced, CA, USA, 1–4 November 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, P.; Partridge, J.; Bucknall, R. Cost-effective reinforcement learning energy management for plug-in hybrid fuel cell and battery ships. Appl. Energy 2020, 275, 115258. [Google Scholar] [CrossRef]
- Wei, Z.; Jiang, Y.; Liao, X.; Qi, X.; Wang, Z.; Wu, G.; Hao, P.; Barth, M. End-to-end vision-based adaptive cruise control (ACC) using deep reinforcement learning. arXiv 2020, arXiv:2001.09181. [Google Scholar]
- Fechert, R.; Lorenz, A.; Liessner, R.; Bäker, B. Using Deep Reinforcement Learning for Hybrid Electric Vehicle Energy Management under Consideration of Dynamic Emission Models; SAE International: Warrendale, PA, USA, 2020. [Google Scholar] [CrossRef]
- Yan, F.; Wang, J.; Du, C.; Hua, M. Multi-Objective Energy Management Strategy for Hybrid Electric Vehicles Based on TD3 with Non-Parametric Reward Function. Energies 2023, 16, 74. [Google Scholar] [CrossRef]
- Puccetti, L.; Köpf, F.; Rathgeber, C.; Hohmann, S. Speed Tracking Control using Online Reinforcement Learning in a Real Car. In Proceedings of the 6th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 20–23 April 2020; pp. 392–399. [Google Scholar] [CrossRef]
- Xu, Z.; Pan, L.; Shen, T. Model-free reinforcement learning approach to optimal speed control of combustion engines in start-up mode. Control. Eng. Pract. 2021, 111, 104791. [Google Scholar] [CrossRef]
- Johri, R.; Salvi, A.; Filipi, Z. Optimal Energy Management for a Hybrid Vehicle Using Neuro-Dynamic Programming to Consider Transient Engine Operation. Dyn. Syst. Control. Conf. 2011, 54761, 279–286. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Görges, D. Ecological adaptive cruise control for vehicles with step-gear transmission based on reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4895–4905. [Google Scholar] [CrossRef]
- Zhu, Z.; Gupta, S.; Gupta, A.; Canova, M. A Deep Reinforcement Learning Framework for Eco-driving in Connected and Automated Hybrid Electric Vehicles. arXiv 2021, arXiv:2101.05372. [Google Scholar]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Degris, T.; White, M.; Sutton, R.S. Off-Policy Actor-Critic. arXiv 2012, arXiv:1205.4839. [Google Scholar]
- Musardo, C.; Rizzoni, G.; Guezennec, Y.; Staccia, B. A-ECMS: An Adaptive Algorithm for Hybrid Electric Vehicle Energy Management. Eur. J. Control 2005, 11, 509–524. [Google Scholar] [CrossRef]
- Jinquan, G.; Hongwen, H.; Jiankun, P.; Nana, Z. A novel MPC-based adaptive energy management strategy in plug-in hybrid electric vehicles. Energy 2019, 175, 378–392. [Google Scholar] [CrossRef]
- Chang, F.; Chen, T.; Su, W.; Alsafasfeh, Q. Charging Control of an Electric Vehicle Battery Based on Reinforcement Learning. In Proceedings of the 10th International Renewable Energy Congress (IREC 2019), Sousse, Tunisia, 26–28 March 2019. [Google Scholar] [CrossRef]
- Ramadass, P.; Haran, B.; Gomadam, P.M.; White, R.; Popov, B.N. Development of First Principles Capacity Fade Model for Li-Ion Cells. J. Electrochem. Soc. 2004, 151, A196. [Google Scholar] [CrossRef]
- Subramanya, R.; Sierla, S.A.; Vyatkin, V. Exploiting Battery Storages With Reinforcement Learning: A Review for Energy Professionals. IEEE Access 2022, 10, 54484–54506. [Google Scholar] [CrossRef]
- Masson, W.; Ranchod, P.; Konidaris, G. Reinforcement Learning with Parameterized Actions. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. StarCraft II: A New Challenge for Reinforcement Learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Li, B.; Tang, H.; Zheng, Y.; Hao, J.; Li, P.; Wang, Z.; Meng, Z.; Wang, L. HyAR: Addressing Discrete-Continuous Action Reinforcement Learning via Hybrid Action Representation. arXiv 2021, arXiv:2109.05490. [Google Scholar]
- Neunert, M.; Abdolmaleki, A.; Wulfmeier, M.; Lampe, T.; Springenberg, J.T.; Hafner, R.; Romano, F.; Buchli, J.; Heess, N.; Riedmiller, M. Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics. arXiv 2020, arXiv:2001.00449. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.B.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. arXiv 2017, arXiv:1706.03741. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for inverse reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML 2000), Stanford, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Arora, S.; Doshi, P. A survey of inverse reinforcement learning: Challenges, methods and progress. Artif. Intell. 2021, 297, 103500. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm/Agent | Action Space Continuity |
|---|---|
| Q-learning (table-based) [34] | discrete |
| Deep Q-network (DQN) [35] | discrete |
| SARSA [36] | discrete |
| Policy gradient [37] | discrete or continuous |
| Proximal policy optimization (PPO) [38] | discrete or continuous |
| Deep deterministic policy gradient (DDPG) [39] | continuous |
| Twin delayed DDPG (TD3) [40] | continuous |
| Maximum a posteriori policy optimization (MPO) [41] | discrete, continuous, or both |
| Constrained policy optimization (CPO) [42] | discrete, continuous |
| Continuous Powertrain Actuators | Discrete Powertrain Actuators |
|---|---|
| Optimization Goal | Instantaneous Reward Function | Constraint(s) in Reward Function | System Controlled |
|---|---|---|---|
| minimize fuel consumption | parallel [43,44,45], power-split [46] HEV | ||
| parallel HEV [47,48] | |||
| parallel [49,50,51], series [52], power-split [53] HEV | |||
| parallel HEV [54] | |||
| series HEV [55] | |||
| series [56,57,58,59,60,61,62], power-split [63,64,65] HEV | |||
| power-split [66], series [67] HEV | |||
| power-split HEV [68] | |||
| series [69], parallel [70], power-split [71] HEV | |||
| parallel [72], power-split [73] HEV | |||
| parallel HEV [74,75] | |||
| parallel HEV [76,77] | |||
| series HEV [78] | |||
| series HEV [79] | |||
| parallel HEV [80] | |||
| parallel HEV [81,82] | |||
| minimize power consumption | 8 × 8 EV [83] | ||
| EV with UC and battery [84] | |||
| power-split PHEV [85,86,87,88] | |||
| parallel HEV [89,90] | |||
| parallel HEV with ORC-WHR [91] | |||
| minimize losses | series HEV [92,93] | ||
| EV with UC and battery [94,95] | |||
| maximize extracted power | ORC-WHR [96] | ||
| minimize cost to operate vehicle | power-split PHEV [97,98,99] | ||
| series PHEV [100] | |||
| EV [101] | |||
| EV [102] | |||
| parallel HEV [18] | |||
| minimize tracking error | ORC-WHR [103] | ||
| bicycle with electric motor [104] |
| RL Algorithm(s) | Study | System Controlled | Control Action(s) | Action Continuity | Actuator Continuity |
|---|---|---|---|---|---|
| Value estimation | [106] | parallel PHEV | discrete | combined | |
| SARSA | [107] | FC PHEV | , weight of penalty on | discrete | continuous |
| Q-learning (table-based) | [49,50,51,70,76,77,81,82] | parallel HEV | discrete | continuous | |
| [46,71,85,86,108,109] | power-split HEV | ||||
| [66] | power-split HEV | ||||
| [52,56,57,58,59,67,69,78,92] | series HEV | ||||
| [84,94,95] | battery-UC EV | ||||
| [17] | battery-UC EV | ||||
| [105] | FC HEV | ||||
| [110] | FC-battery-UC HEV | ||||
| [111] | FC HEV | ||||
| [112] | EV | ||||
| [96] | ORC-WHR | ||||
| [18,43] | parallel HEV | discrete | combined | ||
| Dyna-Q | [52,59,60] | series HEV | discrete | continuous | |
| [53] | power-split PHEV | ||||
| Q-learning (approximate) | [54] | parallel HEV | discrete | continuous | |
| [113] | EV | overnight | |||
| Q-learning vs. DQN | [114] | EV with two batteries | discrete | continuous | |
| DQN | [72,91,115,116] | parallel HEV | discrete | continuous | |
| [63,73,87] | power-split HEV | ||||
| [117] | power-split PHEV | ||||
| [61,100] | series HEV | ||||
| [102] | EV | ||||
| [118] | EV thermal management | ||||
| [44,45] | parallel HEV | discrete | combined | ||
| Double-DQN | [55,62,93,119] | FC series HEV | discrete | continuous | |
| [120] | vehicle | ||||
| Dueling-DQN | [88] | power-split PHEV | discrete | continuous | |
| Double-DQN and DDPG | [80] | parallel HEV | combined | combined | |
| DDPG | [72,75,89,121] | parallel HEV | continuous | continuous | |
| [47,48,90] | parallel HEV | ||||
| [79] | series HEV | ||||
| [65] | power-split HEV | ||||
| [103] | ORC-WHR | ||||
| [83] | 8 × 8 EV | ||||
| [73,97] | power-split HEV | ||||
| [64] | power-split HEV | continuous | combined | ||
| TD3 | [72,74,75] | parallel HEV | continuous | continuous | |
| [122] | parallel HEV | ||||
| actor-critic | [99] | power-split PHEV | continuous | continuous | |
| [123] | vehicle | ||||
| [124] | SI engine | ||||
| [98] | power-split PHEV | combined | combined | ||
| actor-critic (two actors) | [125] | series hydraulic hybrid | continuous | continuous | |
| [126] | vehicle | (discrete), (continuous) | combined | combined | |
| PPO | [127] | parallel HEV | continuous | continuous | |
| CPO | [101] | EV | discrete | continuous | |
| A3C | [68] | power-split HEV | either | continuous |
| Optimization Goals | Instantaneous Reward Function | Constraint(s) in Reward Function | System Controlled |
|---|---|---|---|
| (1) maintain desired velocity (2) minimize acceleration | vehicle [123] | ||
| (1) minimize fuel consumption (2) maintain distance to lead vehicle | vehicle with geared transmission [126] | ||
| (1) maintain distance to lead vehicle (2) minimize acceleration | ICE vehicle or EV [120] | ||
| (1) minimize fuel consumption (2) minimize emissions | series hydraulic hybrid [125] | ||
| parallel HEV [121] | |||
| (1) minimize energy loss (2) maximize electrical and thermal safety | EV with two batteries [114] | ||
| (1) improve battery lifetime (2) maximize system efficiency | FC HEV [105] | ||
| (1) minimize fuel consumption (2) minimize travel time | parallel HEV [127] | ||
| (1) minimize charge time (2) minimize charge cost | EV [132] | ||
| (1) minimize energy consumption (2) minimize travel time | v | EV [112] | |
| (1) maximize FC lifetime (2) maximize battery lifetime | FC HEV [111] | ||
| (1) minimize fuel and battery degradation cost (2) maintain charge margin | parallel HEV [122] | ||
| (1) minimize energy consumption (2) minimize cabin temperature error | EV thermal management [118] | ||
| (1) minimize energy consumption (2) minimize battery degradation | battery UC EV [17] | ||
| (1) minimize fuel consumption (2) minimize battery degradation | power-split HEV [16] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Egan, D.; Zhu, Q.; Prucka, R. A Review of Reinforcement Learning-Based Powertrain Controllers: Effects of Agent Selection for Mixed-Continuity Control and Reward Formulation. Energies 2023, 16, 3450. https://doi.org/10.3390/en16083450
Egan D, Zhu Q, Prucka R. A Review of Reinforcement Learning-Based Powertrain Controllers: Effects of Agent Selection for Mixed-Continuity Control and Reward Formulation. Energies. 2023; 16(8):3450. https://doi.org/10.3390/en16083450
Chicago/Turabian StyleEgan, Daniel, Qilun Zhu, and Robert Prucka. 2023. "A Review of Reinforcement Learning-Based Powertrain Controllers: Effects of Agent Selection for Mixed-Continuity Control and Reward Formulation" Energies 16, no. 8: 3450. https://doi.org/10.3390/en16083450